
Abstract
Recent advances in technology and devices have caused a data explosion on the Internet and on our home PCs. This data is predominantly obtained in various modalities (text, image, video, etc.) and is essential for e-commerce websites. The products on these websites have both images and descriptions in text form, making them multimodal in nature. Earlier categorization and information retrieval methods focused mostly on a single modality. This study employs multimodal data for classification using neutrosophic fuzzy sets for uncertainty management for information retrieval tasks. This effort utilizes image and text data and, inspired by past techniques of embedding text over an image, attempts to classify the images using neutrosophic classification algorithms. For classification tasks, Neutrosophic Convolutional Neural Networks (NCNNs) are used to learn feature representations of the produced images. We demonstrate how a pipeline based on NCNN can be utilized to learn representations of the innovative fusion method. Traditional convolutional neural networks are vulnerable to unknown noisy conditions in the test phase, and as a result, their performance for the classification of noisy data declines. Comparing our method against individual sources on two large-scale multi-modal categorization datasets yielded good results. In addition, we have compared our method to two well-known multi-modal fusion methodologies, namely early fusion and late fusion.
Keywords
Introduction
Recent years have witnessed the tremendous growth of multimedia content on the web. The new age of web that is Web 2.0, has contributed significantly in this direction. The ever-increasing number of Internet users around the globe has resulted in an increase in the amount of data. This happens because the social media platforms (like Meta, Instagram, Twitter, etc.) have enabled the user to share data/information in various modalities (like text, image, audio, video, etc.) (Fig. 1). Mentioning the data collected by one of the social media platforms, i.e., Instagram makes this point more clear. Instagram has at least 1.452 billion users around the world, and out of those users, 500 million daily active users visit the Instagram app internationally. This number was determined based on the global advertising audience reach of Instagram. [1]. There exists a huge collection of multimodal data with Meta, which claims to be generating 4 petabytes of data per day [2]. With the inclusion of data and descriptions of the multimedia document in the form of metadata, keywords, annotated text, etc., the web now has become completely multimodal in nature. However, the multimodal data is in no way free from uncertainty and indeterminacy. These modalities are much affected by this noise which is incorporated while acquiring, transmitting, and transforming the data. This problem of unwanted noise is referred to as indeterminacy in image. When indeterminacy (uncertainty) in text data is discussed, it is referred to as redundant and unwanted information, such as the information provided on social media by using tags. The indeterminacy in the textual content is also classified as imprecision, which refers to lack of knowledge and accuracy of the present textual data; uncertainty in textual data mainly refers to the irrelevance of text with semantic information available which is directly related to the degree of truth of a piece of information, and incompleteness in textual data refers to the absence of information that is provided using text content such as tags. Uncertain and imprecise information in textual modalities will introduce false positives into users’ search results and thus degrades precision and recall rates in text modality-based applications. In contrast, incomplete textual information will make the related image and video modalities inaccessible. The problems mentioned above with various modalities like image, and text are referred to as indeterminacy and uncertainty in multimodal data.

Concept of multimodal data.
The problem of indeterminacy in data is encountered in various fields of study like image and video processing in the medical domain, object detection, surveillance, etc. Likewise, indeterminacy in text processing is encountered while analysing social media data for various purposes like health care monitoring, pandemic predictions, etc. [3]. This indeterminacy has become a problem while handling data from e-commerce sites [4]. For instance, Fig. 2 depicts four advertisements that are frequently offered on e-commerce websites [6]. These advertisements feature products that appear to have seemingly comparable written descriptions yet appear to have different images.

Images and their corresponding description on e-commerce platforms.
A multi-modal technique could use a scenario like this to its advantage, removing ambiguity and improving classification performance in the process. Numerous tasks, such as modelling semantic relatedness, compositionality, classification, and retrieval, make considerable use of multi-modal approaches that are founded on image and text data [7–10]. In the multimodal method, typical practise involves the use of CNNs to extract visual information. On the other hand, Bag-of-Words models and Log-linear Skip-gram Models [11] are frequently used in the process of generating text features. According to [3, 12], this provides a hurdle when attempting to establish correlations between the features of modalities having imperfections together with representation, translation, alignment, and co-learning. This task was first undertaken by authors in [4] where they performed encoded text classification using multimodal data. We have attempted this task in order to prove the importance and efficiency of neutrosophic concepts over fuzzy ones. This is the reason, we are forced to come up with a solution to this classification problem using neutrosophic concepts and theories that also allows a combined representation of an image and a text description while taking into account the indeterminacy present in them. In this study, we offer a novel approach using neutrosophy that creates an information-enriched image by fusing text attributes with image data. In order to feed a NCNN, we combine text encoding and images into a single dataset. We show that the best uni-modality (image/text) result can be surpassed by multi-modal classification results when encoded text information is added to an image. Below is a list of the paper’s most significant contributions: We describe a unique data fusion mechanism for multi-modal categorization using neutrosophy based on the image and its corresponding text description in encoded form. We demonstrate the classification of fused data using a neutrosophic CNN-based architecture for addressing uncertainty. We demonstrate the efficacy of our methodology by conducting an evaluation of the multi-modal approach using two datasets and by comparing them with previous approaches.
The abundance of information in various modalities having indeterminacy requires sophisticated models for their representation, indexing, and retrieval. There have been many state-of-the-art approaches for dealing with imperfections, but researchers in the field of multimodal information retrieval have relied mostly on soft computing techniques, specifically fuzzy and machine learning techniques. Machine learning techniques need a lot of labelled data for better performance. Sometimes the available data is not labelled or partially labelled and contains uncertain, indeterminate, and ambiguous information. On the other hand, fuzzy techniques are based on the expert’s opinion and knowledge and, most of the time, create a problem when no prior knowledge is available, or it is uncertain, indeterminate, and not known. Hence, most fuzzy techniques face the problem of uncertain, indeterminate, and unknown information when dealing with unsupervised data in information systems. Moreover, the presence of the giant semantic gap between human understandable semantics and machine understanding becomes the bottleneck issue for both the researchers of industry and academia. Most researchers rely on the multimodal fusion technique, i.e., a combination of information from multiple modalities, to cope with the semantic gap and indeterminacy issue. However, this fusion architecture lacks in handling indeterminacy since there is scarcely a way to handle it at this level [3]. Keeping in mind the practical significance of multimodal information retrieval in this work, we describe a novel method using neutrosophy for fusing text features and images into a single, information-rich image. This work proposes a novel multi-modal technique that combines images and textual descriptions. The goal of this work is to improve multi-modal classification performance in real-world scenarios using NCNN. The approach is developed as part of this research and with the introduction of neutrosophy in previous approaches. When trained with a large number of examples of input values, neural networks have historically been put to use for classification and prediction purposes. Nevertheless, a degree of uncertainty is likely to be involved in any forecast or classification that is made. Within the neural network community, the outputs of neural networks are accompanied by two types of uncertainty: uncertainty in the training dataset and uncertainty in the model structure. As a subset of deep neural networks, convolutional neural networks (CNNs) are among the most often used for visual data interpretation [4]. CNNs are also referred to by their other name, convolutional neural networks. CNNs have also seen extensive application in the image recognition industry, both in the capacity as feature extractors and as classification models. Earlier works in image classification area have been performed by conventional Convolutional Neural Networks (CNNs) to learn feature representations for a classification task. Convolutional neural networks suffer from poor performance when it comes to classifying noisy data because of the possibility of unknown noisy and indeterminate situations during the testing phase. This is because accurate forecasting is challenging in conditions whose nature is unclear, loud, and uncertain. Consequently, a novel convolutional neural network (CNN) model called NCNN (Neutrosophic Convolutional Neural Network) is used for multimodal classification tasks in this research. Because of its flexibility, this model can deal with ambiguous data. This Neutrosophic Convolutional Neural Network has its roots in the philosophy of Neutrosophy. The study of neutralities and the relationships between them is called neutrosophy, and it is the foundation of NS logic [13]. The term “neutrosophy” can also refer to a “philosophy of neutrality.” The term “NS” wasn’t coined until Smarandache [14] introduced the idea. A wide range of image processing tasks, including segmentation, thresholding, edge detection, retinal image analysis, content-based image retrieval, liver image analysis, breast ultrasound image analysis, data classification, uncertainty handling, and image and data clustering [15, 69], have all been successfully applied to this theory since its introduction to image processing by Guo et al. Segmentation of images describes the method used to isolate individual features inside an image.
Related work
The fusing of different types of data is an essential step in the multimodal information retrieval process. The correctness of the multimodal framework is frequently determined by the fusion mechanisms that are put into place. This is important because data that can be used for analysis and retrieval of information do not always occur in isolation and are usually associated with metadata. This makes it more difficult to locate the data that is needed for these purposes. To be more explicit, whenever the image and the textual metadata that is connected with it are addressed, the issue of data heterogeneity always comes into the picture, just as it does whenever other modalities are discussed. Processing each modality on its own and then combining the results using fusion methods is a popular approach to solving the problem of heterogeneity. As a result, multimodal fusion is receiving an exponentially growing amount of attention in information access and retrieval tasks; researchers [16, 17], and [18] have extensively studied this phenomenon. The information concerning this can also be discovered in the relevant published works [19]. Despite the fact that the issue of heterogeneous data can frequently be resolved by fusion, this is not the case the vast majority of the time because of defects in a variety of modalities. Because textual imperfections are only partially considered in the context of multimodal fusion, a problem involving imperfections in the textual modality has arisen as a result. Due to these imperfections in the language, the intended semantic meaning of the images cannot be conveyed. The concept of textual imperfections is tackled by virtually all cutting-edge methods these days, the vast majority of which rely on tag relevancy to do so. The issue of incompleteness is extensively acknowledged in the literature; nevertheless, work on imprecision and uncertainty is far behind, as seen by examples such as noisy tags [20, 21], and [22]. Even though there are many different kinds of research that are done in the field of multimodal fusion, very few of them have focused on handling imperfections in the data; in other words, handling imperfections does not appear to be their primary goal while they are performing multimodal fusion tasks. This leads to the problem of indeterminacy in multimodal fusion. There are various approaches to multimodal fusion. These approaches are early fusion, late fusion, and transmedia fusion. In early fusion, the modalities are represented separately and later fused together using a joint feature model. In the late fusion strategy, modalities are represented separately as in early fusion, but the similarity among the modalities is calculated before the fusion process. In the late fusion strategy, the fusion is carried out using an aggregation function. Transmedia fusion works in the same manner as late fusion but the process of fusion is called the diffusion process. There exists many approaches for achieving the mentioned tasks.
Chen et al. carried out multimodal fusion at the level of individual words [23]. They placed a lot of importance on the Temporal Attention Layer (TAL) when it came to forecasting sentiments using sentiment analysis. In addition to this, they discussed the noise that was found in the data collected from the various modalities. Morency et al. showed that conducting sentiment analysis using a variety of modalities is both successful and efficient [24]. Despite the fact that they demonstrated how the Internet might be a source of information while utilizing other modalities such as audio, video, and text, it appeared that they did not address the imperfections that were present in the data while they were performing the multimodal fusion. It was also highlighted in the literature [25] how errors in sentiment classification might be decreased by taking into account the combination of several types of modalities. When the authors of the study compared utilizing a single modality versus using several modalities together, they found that combining multiple modalities together reduced inaccuracy by 10%. Convolutional MKL and support vector machine (SVM) techniques were used in a recent study that investigated sentimental analysis and emotion recognition [26]. This effort brought to light a number of imperfections that are present in multimodal systems. The method described in [27] achieved the desired results in a different way. They devised a multimodal fusion technique that relied on late fusion as its foundation. Their strategy relied entirely on the predictions that the classifiers derived from the visible characteristics of the objects. After obtaining these predictions using the visual modality, they were averaged. In addition to this, the results of this were then averaged with the predictions that were acquired from the linguistic modality. Wang et al. carried out their research in accordance with SVM, in which the results of several distinct classifiers were incorporated into SVM [28]. They suggested developing two different classifiers, one for the textual modality and the other for the visual modality. A third classifier was implemented to combine the confidence of the prior two, and it was responsible for making conclusive predictions.
Guillaumin et al. did their work with the MKL framework, which is widely regarded as a successful implementation of the feature fusion method [29]. The authors’ proposed semi-supervised method for learning a classifier made use of both textual and visual features in the initial step of the process. Later on, the MKL framework was utilized in order to make text modality predictions based on the visual material that was supplied. Although Kawanabe et al. (2011) utilized a method that was quite close to MKL [30], their method was slightly different. It used trained SVMs and uniform kernel weights, and it produced results that were comparable to those obtained using the MKL approach. Zhang et al. [31] combined kernels that were learnt from textual data with kernels that were learned from visual features using the same way. Authors in [32] decided to use a method that was predicated on the selection of features and utilized Grouping Based Precision & Recall-Aided (GBPRA) in the assembly of classifiers. The approach that they selected to take improved the accuracy of the classification. Dempster’s rule was utilized by Liu et al. in order to combine the predictions of the several classifiers and produce the best classification results [33]. Selective Weighted Late Fusion is the name given to the fusion strategy that was developed by Liu and colleagues (SWLF). It worked toward improving the mean average precision by choosing the weights in a selected manner, which in turn improved the optimization [34]. Kim et al. worked on categorising human emotions using multimodal signals and neural networks [35]. Even though the data that they used included imperfect landmarks, sounds, and images at the fusion level, these imperfections did not appear to be addressed in any way. Vielzeuf et al. investigated a number of different multimodal fusion procedures with the intention of achieving the same aim of emotion recognition. They made use of a supervised classifier in order to determine emotion labels, and they then proposed 2D and 3D Convolution Neural Network (CNN) techniques in order to produce more accurate face descriptors [36]. Neverova et al. worked on identifying gestures, putting more of an emphasis on the modality initialization step, and then subsequently on fusing the modalities utilizing the late fusion technique [37]. It was also reported in [38] that researchers were working on combining late fusion with dual attention mechanisms. Their technique was used in presenting an architecture that could be used in the creation of efficient question-and-answering (Q&A) systems, and it was successful in doing both of those things. In [39], a Deep Multimodal Attentive Fusion (DMAF) was proposed for the purpose of doing sentiment analysis using data obtained from social media platforms. They utilized a late fusion strategy in order to achieve an efficient combination of modalities such as image and text; nevertheless, when it came time to manage imperfections, their approach appeared to be wanting on this front. The study done by Escalante et al. [40] was entirely predicated on the predictions derived from classifiers. The predictions were initially acquired using textual and visual modalities, and then afterwards integrated in a sequential manner. Pandeya et al. developed a dataset that could be efficiently exploited for sentiment analysis, drawing inspiration from the music-video combination as a source of creative motivation [41]. In their method, they retrieved elements of music and video independently. Subsequently, they were characterised by utilizing long short-term memory (LSTM), and several machine learning techniques were employed to evaluate sentiments. Several publications make use of averaging, voting methods, variance, and other fusion procedures [42, 43]. A comparison of early and late fusion multimodal approaches was presented in the research that was published in [44]. Late fusion yielded superior performance when compared to the early fusion method; nevertheless, it comes at the cost of an increased amount of effort put into learning it. In addition to this, a method must be devised in order to assign a weight to each of the classifiers that are used. The implementation of a late fusion technique faces yet another obstacle as a result of this. In the domain of information retrieval, the approaches of early fusion and late fusion that have been discussed are effective; yet, they do not model the uncertainty and indeterminacy that arises when extracting information. Therefore, it is possible to draw the conclusion that all of the methods, despite their significance in integrating multimodal information, are lacking on the grounds of the fact that they cannot handle imperfections in the data. ComFinTab, a new benchmark that supports both table recognition and understanding tasks, was released [61]. Authors introduced the CTUNet framework, which combined the compromised visual, semantic, and location features with a graph attention network to address both the difficult table comprehension challenge and the challenging table identification task. They created a dataset and transformed image-based tables into digital structural representations. For the purpose of video-text retrieval, an innovative method known as the Hierarchical Transformer (HiT) was devised [62]. HiT achieved multi-view and complete retrieval results by doing Hierarchical Cross-modal Contrastive Matching on both the feature level and the semantic level. In addition, the authors inspired by MoCo, created Momentum Cross-modal Contrast for cross-modal learning. The purpose of their cross-modal approach was to enable large-scale negative sample interactions on the fly, which contributed to the construction of representations that were more precise and discriminative. While identifying fake news over social media platforms my multimodal approaches are proposed in literature which are having certain set of limitations like first, they fail to employ multi-modal context information and extract high-order complementary information for each news to improve the identification of false news. Second, they mostly disregard the complete hierarchical semantics of textual content to aid in learning a better news representations. By utilising BERT and ResNet to acquire more accurate representations for text and images, authors presented a unique hierarchical multi-modal contextual attention network (HMCAN) for fake news detection to get over these constraints. Their strategy appears to be effective at fusing modalities together [63].
The notion of indeterminacy and modelling of unsupervised, uncertain and indeterminate data while retrieving the information using various modalities is now dominating future applications in the field of information access and retrieval. This research work is an attempt to study and address these issues by exploiting the potential of neutrosophic techniques, for the effective retrieval of information using various modalities in multimodal information systems. There are certain areas where neutrosophy has been applied successfully like a unique detection system was developed to identify MRI pictures as either benign or cancerous using neutrosophy. In the first place, picture segmentation was accomplished through the application of neutrosophic set–expert maximum fuzzy sure entropy (NS-EMFSE). After that, the CNN deep learning technique was applied in order to extract the features from the MRI images that had been segmented. Later on, different classifiers such as SVM and KNN were utilized in order to apply these features to the process of categorising MRI pictures into benign and malignant tumours. The effectiveness of these two classifiers was evaluated and compared in this study. The SVM classifier combined with CNN-extracted features produced the best results, achieving an accuracy of 95.62% [64]. Due to the complexity of Carnatic music, authors employed neutrosophic principles to determine Raga in music. According to them, this is done because the concept of neutrosophic logic is built on the neutralities that exist between truth and falsehood. This provides an element of uncertainty, which will make raga identification more precise and fluid. Utilizing neutrosophic reasoning, a reduced collection of musical characteristics that can be considered of as raga-defining characteristics is determined for each raga. Each raga is classified using a set of musical characteristics that are NCM solutions. This is one of the earliest attempts to classify all 72 melakartha ragas using neutrosophic reasoning [65]. In the most current use of neutrosophy in the realm of healthcare, researchers employed the Neutrosophic (NS) domain-based ResNet-50 module to diagnose COVID patients across a balanced database acquired from a COVID-19 radiography database. The experimental results demonstrated that the proposed method attained an accuracy rate of 98.05 percent, surpassing the accuracy value obtained from prior studies utilising the same database [66]. The Slantlet transform (SLT) and neutrosophy, a generalisation of fuzzy logic, which is a relatively new logic, were discussed, and a novel composite NS-SLT model was proposed as a source to derive statistical texture features that were used to determine the malignancy of brain tumours. The MR images in the neutrosophic domain were defined using three membership sets, true, false, and indeterminate; subsequently, SLT was applied to each membership set. Using three statistical measurement-based techniques, texture features were extracted from MRI brain images. Later on, in order to determine the nature of the brain tumour, four different neural network classification methods, namely Support Vector Machine Neural Network (SVM-NN), Decision Tree Neural Network (DT-NN), Nearest Neighbor Neural Network (KNN-NN), and Naive Bayes Neural Networks (NB-NN), were utilized [67]. Recent research provides an overview of various methods and models for medical modalities processing that are based on neutrosophic sets. These methods and models range from low-level to higher-level analysis. The many medical imaging modalities and their advantages and disadvantages were summarised, along with a comprehensive look at each type. In conclusion, contemporary state-of-the-art neutrosophic approaches for medical modalities processing were presented, together with a full explanation of open research problems and directions [68].
The method presented in this paper is inspired by the early fusion strategy where encoded text features are concatenated into the corresponding image to obtain information-enriched images. In this work, we use an encoding scheme similar to that presented in [45] to encode text features onto an image. In this work, we extract text features from a NCNN network that was trained using every word in a description and used for text classification. In the following sections, a summary of the encoding methodology will be shown. This is the method that is used to graphically display the text that is located above the image. The work is also motivated by the probable applications of neutrosophy and therefore some its applications are mentioned above.
Proposed approach
This proposed work is motivated by the assumption that when, explicitly, the indeterminacy, uncertainty, and imperfection aspects of data both at the representational level and decision level are taken into account, it improves the performance of information retrieval in multimodal systems. In fact, machine learning techniques are inseparable from indeterminacy and uncertainty as data that is used during the training phase is most of the time imprecise, incomplete, indeterminate, and noisy. The problem is also faced in classifier learning because the primary objective of classifier learning is prediction accuracy. Handling indeterminate and uncertain data should be a major concern of classifier learning since indeterminate data may impact not only interpretations of data and designed models but also impacts the sole purpose of the classifier, that is, prediction accuracy. Moreover, the generalization beyond that data, the process of induction, is still affected by uncertainty. Due to the fact that convolutional neural networks are susceptible to unknown noisy conditions during the testing phase, their performance suffers when it comes to the classification of noisy data, particularly multimodal data classification. The primary motivation of this work is to characterise the uncertainty of multimodal data in the neutrosophic domain. This is done in order to ensure that CNN classification algorithms are able to effectively deal with noisy data. Therefore, we have proposed to use neutrosophic CNN for performing classification task image and endoded text using multimodal data. This task was taken by authors in [4] using traditional CNN models.
Neutrosophy is a subfield of philosophy that investigates the nature, extent, and interconnections of neutralities, which forms the foundation of NS logic [46]. Smarandache made the initial suggestion for NS theory in the year 1995 [47]. A generalisation of fuzzy sets and intuitionistic fuzzy sets is denoted by the notation “neutrosophic sets” (NSs). The truth membership function (T), the indeterminacy membership function (I), and the falsity membership function (F) are what distinguish neutrosophic sets from other types of sets (F) [70]. In addition to providing an explicit definition of indeterminacy, the independence of the truth membership function, the indeterminacy membership function, and the falsity membership function makes this theory applicable to a wide range of problems. First, the image must be converted to the neutrosophic domain before neutrosophic sets (NS) may be applied to the image processing domain. Only then can NS be applied to the image processing domain. Although the authors of [48] presented the preliminary method for achieving this transformation, the particulars of how it is now put into practise are extremely variable and depend heavily on the image processing application that is being utilized. There are a few different ways that scholars have implemented the idea of uncertainty and indeterminacy into their work by making use of the concept of neutrosophic theory [49, 50]. The utility of neutrosophy in the field of research as it relates to the handling of multimodal data such as text and image is the primary inspiration for the work that has been proposed. There are plenty of other works [71–75] in field of neutrosophy and these could be referenced for better understanding of the field. In this work, the text document is transformed onto an image by taking a cue from the work performed in [45] which is later classified using neutrosophic-CNN. Instead of employing the Word2Vec model’s numerical representation of a text document, our novel method employs a neutrosophic-CNN specifically trained for text classification. In the first step, we take the text document and turn it into a visual representation so that we may build an information-enriched image that includes text features as well as an image. Finally, we tackle the multi-modal challenge by training a NCNN for image classification with this image. For the classification of text documents, we also employ NCNN model that was proposed in [51] for multimodal classification. This approach is different from other approaches of handling text using CNN and can be understood by the following figures:
As depicted in Fig. 3, Kim [56] trains a network for phrase classification consisting of one convolutional layer followed by a max–over time pooling and a fully connected layer with dropout and softmax output layer. This “one convolutional layer” is composed of three parallel convolutional layers with varying filter sizes. The model is trained with two channels, however only one channel’s parameters are updated throughout training. word2vec is a feature of input. This model is evaluated on the following datasets: movie reviews with positive/negative labels [57] (MR), Stanford Sentiment Treebank, (SST–1, which is a dataset containing movie reviews with very positive, positive, neutral, negative, and very negative label [58]), same dataset as SST–1 but with only positive/negative labels).
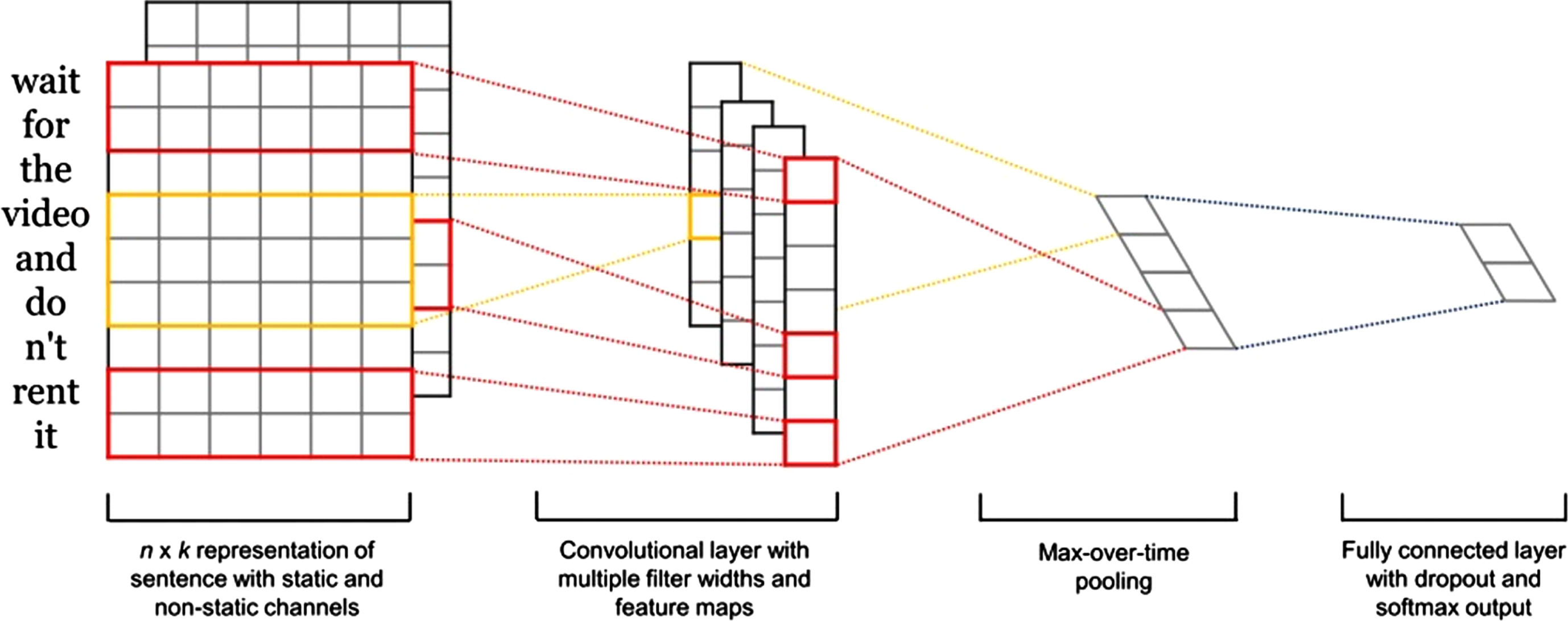
Convolutional Neural Networks for Sentence Classification [56].
Zhang, X. et al. [59] looked into applying temporal (one-dimensional) ConvNets to text, considering it as a sort of raw signal at the character level. One large and one small ConvNet were created by them (Fig. 4). They both have 9 layers total, 6 of which are convolutional and 3 of which are fully linked. According to their character quantization method, the input has 70 features, and the input feature length is 1014. It appears that 1014 characters can already encompass the majority of interesting texts. In order to regularise, they also included 2 dropout [60] modules in between the 3 completely linked layers. They have a 0.5 dropout probability.

Character-level Convolutional Networks for Text Classification [59].
Figure 5 is a representation of the parallel two-path CNN that is included in the model that has been presented to account for indeterminacy in CNN. Following a series of tests that were carried out on a wide variety of models, it was found that the structure that included five convolutional layers, three pooling layers, and three fully-connected layers provided the best performance. This conclusion was reached as a result of the testing that was carried out. Table 5 provides a more in-depth demonstration of the suggested structure for the CNN. The text document serves as input for a convolutional neural network (CNN) that is composed of a total of five convolution layers, three pooling layers, and three fully connected layers. The unpredictability of the text document is also supplied into a second CNN with the same structure. In the current work, text is taken as the input data, and the noise that that is associated and produced while text handling is characterised as uncertainty. The level of uncertainty associated with each time-frequency point on a text spectrogram is calculated in a manner analogous to that of a pixel. This results in the creation of an uncertainty matrix in the NS domain that has the same size as the spectrogram. In the initial stage of this process, we think of the text spectrogram as an image. After transferring this image to the NS domain, a new definition of data uncertainty is provided for the spectrogram’s individual pixel locations. The completion of this exercise will result in an uncertainty matrix that is the same size as the spectrogram. After that, a CNN with two parallel pathways is suggested. The spectrogram is generated from one of the two paths, while the uncertainty matrix is generated from the other path. The categorization results from two different paths are blended using a variety of different approaches.

CNN structure with considering indeterminacy.
Structure of Neutrosophic CNN
Text features are retrieved from the layer that is fully connected, and then translated into an RGB encoding. This allows the text features to be overlay onto an image that is related with the text content. How these text features are converted into equivalent RGB encoding could be understood as all the words tk in a document Di were first encoded into a square area of size P pixels with uniform colour using a trained word2vec model. Next, the horizontal or vertical space in pixels between close visual words was modified using the super-pixel approach. An example of an encoded visual word with modified parameters is shown in the following figure.
Figure 6 shows a simple encoding image of size W×H = 9×9, with three visual words

A schematic example of text encoding scheme.
CNN & NCNN trained over clean datasets
CNN & NCNN trained over noisy datasets
The advantage NCNN over Kim’s [52] recommended CNN model was applied in order to grasp the encoding scheme. This model translates text to visual features in a single pass and was chosen because of its benefit over the CNN model. The method of encoding that was applied to this work was able to convert an array into an image representing the encoded text. This image was then superimposed on top of the image that had been used in the beginning. This was achieved by running a reshape operation on the layer that contained all of the completely linked objects. The process of obtaining features from the trained NCNN model and manipulating those features ultimately results in the creation of a visual representation of the document. In order to successfully transform a grayscale image into a colour one, the feature vectors that we utilized in practise had to have a size that was a multiple of three and read as L = 3×w×h. It is possible to depict a sequence of three values that belong to L as an area with a uniform colour that has a dimension of P×P by employing the idea of superpixel, which is described in [6]. Textual characteristics are rendered in this manner as a succession of superpixels, which are drawn from left to right and from top to bottom, commencing at a specific location on the scaled image (Fig. 3). Finally, but certainly not least, we encode an entire text document within the image plane. Following this step, the ensuing multi-modal NCNN model is able to work simultaneously on both modalities. Encoding lengthy text documents is something that we are able to achieve in the context of our work. This is made possible by the fact that we encode the entirety of the document in the same image region, which has a fixed size equal to w×h×3; this enables us to do so.
Experiment & results
Datasets
The modalities that make up a multi-modal dataset come from a variety of distinct input sources. The datasets that are utilized for this work consist of images and text descriptions that accompany them. For performing the experiments we have taken a very specific dataset i.e. Ferramenta dataset [6] (Fig. 7).

Ferramenta dataset with 52 classes.
The Ferramenta dataset has a total of 88,010 images; 66,141 are put to use in the training process, while 21,869 are put to use in the testing process. These images represent each of the 52 different categories (paint brush, hinge, tape, safe, cart, etc.). The textual descriptions that are part of the Ferramenta dataset include a total of 22045 unique words for the train set and 20083 for the test set respectively. These words were picked out of a hat in a random order. This is a well-known multimodal dataset that was derived from an online shopping website. This dataset is use only to show the effectiveness of the proposed approach of multimodal retrieval using neutrosophy. We have also used UMPC Food-101 [21] as used in [4]. The UPMC Food-101 multi-modal dataset [21] is the second dataset that we employ in our studies. This dataset contains around 100,000 items of food dishes that have been categorised into 101 different categories. The information for this dataset was gathered on the internet, and each item includes an image as well as the HTML page on which it was discovered. We have taken the step of extracting the title from the HTML document in order to make use of it rather than the text description. The dataset contains classes that correspond to the 101 categories that received the most views on the culinary photo sharing website1. This is also a multimodal dataset which is utilized in this work to show that the proposed approach can also be used in other domains of research. The information on these datasets can be found in Table 3. The amount of class labels that can be applied to datasets is displayed in the first column. While the second and third columns represent the difference between train and test sets. The language of any text descriptions that are available for these datasets is indicated in the very last column.
Multi-modal datasets used in this work
The images and accompanying text descriptions displayed in Table 4 were randomly picked from each multi-modal dataset.
Example from a multi-modal dataset containing a random image and an associated written description that have been conveniently translated from Italian to English
The multi-modal method that is being employed in this process alters the text descriptions and embeds them onto the relevant images in order to produce information-enriched images. One example of an image that has been “improved” by the addition of new information is shown in Fig. 2. The adjusted text description is embedded in an RGB image that is 227 by 227 pixels in size and is used for the UMPC Food-101 and Ferramenta multi-modal datasets.
Parameter setting
Table 5 shows the fundamental network layer structure employed in the CNN model. Two different kinds of inputs— a spectrogram and an uncertainty vector— are fed into CNN simultaneously. NCNN is the name of the suggested model. Our training environment networks with no changes made as done in [51]. The size of the window in the NS domain is one of the parameters in the network that is considered to be among the most crucial. The size of the window determines the manner in which data are transported into the NS domain. The transfer of more generic spectrogram data to the NS domain occurs when the window size is increased. On the other hand, a lower window size ensures that local data remains within the NS domain. Therefore, local indeterminacy can be modelled with a small window size, while global indeterminacy can be modelled with a big window size. In order to make an objective comparison between image-only studies and fusion-only experiments, we utilize the identical NCNN settings for both. Python’s Tensorflow packages have been used to implement the used NCNN architecture. While tangent hyperbolic is utilized in convolution layers, all activation functions in output layers are assumed to be LERU. The NCNN model is trained using stochastic gradient decent with a batch size of 33. Three thousand fifty iterations have been set as the ceiling. Table 5 details the NCNN layer structure, including the number of layers, layer sizes, filter sizes, stride, and output sizes.
For comparing NCNN with other methodologies, we use the default configuration for AlexNet and GoogleNet [6, 51], which are both typical neural networks. Experiments with only images and those with fused images are compared using mentioned NCNN settings for consistency. Normalized convolutional neural network hyperparameters are employed. Stochastic Gradient Descent (SGD) is used as the optimizer, with a learning rate of 0.01. To avoid over fitting, the network is trained for a total of 60 epochs or until no more improvement is seen. Our investigations employ accuracy as a metric for evaluating categorization results. The study’s goal is to demonstrate that neutrosophic classification techniques can improve classification results using encoded text information in images as compared to the best results achieved using a uni-modal (Text/Image) approach using traditional CNN. In order to achieve this goal, we carried out the following experiments for classification utilizing neutrosophic CNN (NCNN) with only images. Also classification utilizing NCNN with only text descriptions is also carried out. Further, classification utilizing NCNN with fused images is done and results are compared with both early and late fusion procedures. The first experiment involves taking multi-modal datasets and extracting solely text descriptions from them as performed. After that, a text classification model similar to the one depicted in Fig. 2 is trained. The findings are presented in the very first column of Table 6. It is also crucial to make a careful observation of the ways in which the text information, the images, and the text encoding all differ from one another.
Classifcation results obtained by earlier researches [51] versus results obtained using current neutrosophic method
Classifcation results obtained by earlier researches [51] versus results obtained using current neutrosophic method
The findings are compared using DIGITS in [6] and [51], and they were obtained by training CNNs named AlexNet and GoogleNet from scratch. After this step is complete, only the images contained within the multi-modal datasets are extracted. These findings are presented in Table 6, in the second and third columns, respectively. The fact that the images in the Ferramenta multi-modal dataset contain items placed against a white background provides an explanation for why the classification results attained by using simply the images are so good. On the other hand, the images included in the UPMC Food-101 multi-modal dataset feature a noisy background and were captured in a wide variety of settings. As a consequence, the performance of the classification on images alone is subpar. The subsequent experiment will involve the utilisation of fused images derived from multi-modal datasets. When we train neutrosophic CNN, we begin at the very beginning. The results presented in Table 6 indicate that the performance of the proposed fusion technique is superior to that of the performance of unimodal methods. However, the text descriptions of Ferramenta are written in Italian despite the fact that the method does not depend on a particular language. The data from UPMC Food-101 indisputably show to the benefits of our suggested approach, which results in an improvement in classification performance that is twice as high as the previous level. The utilisation of multimodal representation learning is responsible for this performance gain, which may be attributed to it.
Our approach was compared with early and late fusion in the final experiment, and the findings are summarised in Table 7. The experimental apparatus and procedures were created with the assistance of the work [6]. This technique makes use of a Random Forest model, which is then utilized to analyse the results of a 1000-word bag-of-words dataset. On the other hand, for early fusion, we employ a Support Vector Machine, which is applied to the concatenation of Doc2Vec features and 4096 visual features that are derived from a trained NCNN. These features come from the network convolutional neural network. The fact that our suggested method performs exceptionally well in early and late fusion procedures, both of which are considered to be industry standards, provides additional support for the validity of our method.
Comparison of Early F., Late F. approach with proposed approach
As can be seen, the performance of the fused architecture is significantly higher when compared to that of the text only architecture, even when the text embedding dimension is reduced. As the embedding dimension continues to grow, eventually both architectures reach a peak. The fused image architecture, on the other hand, always makes sure to prioritise the upper bound above the other.
Through this body of work, we presented an innovative approach to classification and fusion. Neutrosophic concepts are utilized to combine images with the written descriptions of those images, hence making it possible for neutrosophic-CNN or any other CNN architecture to be utilized as a multimodal categorization system. In this work, in order to carry out the classification task, a CNN classification model with data uncertainty handling was utilized, and two parallel classification pathways were used to create the model. The datasets’ images and texts are used as input data, and the noise that comes from using those data sources is modelled as uncertainty in the NS domain. The method that is being presented makes use of text data and visual data simultaneously, and then casts them both to a single source utilizing neutrosophic notions. Because of this, it is possible to use just one classifier instead of multiple ones. Taking the strategy that has been proposed is beneficial for dealing with noisy data. According to the findings of the experiments, the classification model is durable against noisy data in the test phase when it is trained with clean data. Additionally, when the classification model is trained using noisy data, it has a greater resistance to noisy data during the testing phase. This makes the model more robust. We are able to obtain some positive findings, and whether compared to fusion techniques or single modalities, the classification accuracy that we are able to accomplish by utilizing our method is always more than what can be achieved using either of those options alone. The simultaneous portrayal of two separate modalities within the same source is yet another highly essential addition that has been made by this piece of work. This is a pretty major advance in the right direction. This component paves the way for a still-open collection of difficulties that are related to the translation from one modality to another in circumstances in which the relationships between modalities are subject to interpretation.