
Abstract
Slime mould algorithm (SMA) is a novel meta-heuristic algorithm with fast convergence speed and high convergence accuracy. However, it still has some drawbacks to be improved. The exploration and exploitation of SMA is difficult to balance, and it easy to fall into local optimum in the late iteration. Aiming at the problems existing in SMA, a multistrategy slime mould algorithm named GCSMA is proposed for global optimization in this paper. First, the Logistic-Tent double chaotic map approach is introduced to improve the quality of the initial population. Second, a dynamic probability threshold based on Gompertz curve is designed to balance exploration and exploitation. Finally, the Cauchy mutation operator based on elite individuals is employed to enhance the global search ability, and avoid it falling into the local optimum. 12 benchmark function experiments show that GCSMA has superior performance in continuous optimization. Compared with the original SMA and other novel algorithms, the proposed GCSMA has better convergence accuracy and faster convergence speed. Then, a special encoding and decoding method is used to apply GCSMA to discrete flexible job-shop scheduling problem (FJSP). The simulation experiment is verified that GCSMA can be effectively applied to FJSP, and the optimization results are satisfactory.
Keywords
Introduction
Many practical problems can be transformed into optimization problems, e.g., wireless sensor network [1], feature selection [2], scheduling problem [3]. Notably, scheduling problem is one of the important combinatorial optimization problems, which exists in various fields such as industrial production, transportation and energy industries [4]. Job-shop scheduling problem(JSP) is one of the important scheduling problems, so the research on it has essential theoretical significance and application value. Flexible job-shop scheduling problem (FJSP) is a typical optimization problem, which is an important extension of traditional job-shop scheduling problem (JSP) [5]. It has been proven to be a NP-hard problem [6]. Compared with JSP, FJSP is more complex as it includes not only operation sequencing problem but also machine assignment problem [7]. However, the scheduling processing route of FJSP is optional, making the processing more flexible and controllable. Moreover, FJSP is more suitable for actual production practice activities [8]. Therefore, it is of great significance for manufacturing systems to develop efficient algorithm.
Due to the superiority and efficiency in solving difficult optimization problems, meta-heuristic algorithm has attracted the interest of scholars in the past decade [9]. Many scholars use various meta-heuristic algorithms and their improved versions to solve FJSP, such as grey wolf optimization [10], artificial fish algorithm [11], and Jaya [12]. However, these algorithms designed specifically for FJSP are complex and not suitable for other optimization problems. More importantly, these new algorithms usually have the disadvantages of long optimization time and low optimization accuracy [13]. Based on No Free Lunch theorem [14], there is no single algorithm can achieve satisfactory results for all optimization problems. Therefore, There is a growing need for novel effective algorithms.
Meta-heuristic algorithms can be divided into nine groups: physics-based, swarm-based, evolution-based, human-based, biology-based, math-based, music-based, probabilistic-based and system-based [15, 16]. The physics-based algorithms simulate objective physical rules in nature. Common physics-based meta-heuristic algorithms include Optics Inspired Optimization (OIO) [17], gravitational search algorithm (GSA) [18], henry gas solubility optimization [19]. The evolution-based algorithms are mainly inspired by biological evolution, such as genetic algorithm (GA) [20] and dierential evolution (DE) [21].
The swarm-based algorithms are generated by imitating the collective behavior of biological populations, which is favored by most scholars because of its simple principle and good optimization performance. Some of the most well-known swarm-based algorithms are particle swarm optimization (PSO) [22], Artificial Bee Colony Algorithm (ABC) [23], and Ant Colony optimization(ACO) [24]. Various novel swarm-based algorithms have been developed successively in recent years, e.g., Grey Wolf Optimization (GWO) [25], Whale Optimization Algorithm (WOA) [26], Harris Hawks Optimization [27], and Sparrow Search Algorithm [28]. Despite the emergence of a large number of meta-heuristic algorithms, there is still room for further improvement in efficiency.
Slime mould algorithm [29] or SMA is one of the recent swarm-based meta-heuristic algorithms that has attracted a lot of attention and been used in many applications. It is inspired by the behavioral morphological changes of slime mould during foraging process. SMA is a stochastic optimizer with strong global search ability and fast algorithm convergence. As a global optimization algorithm, SMA has been applied in different fields, e.g., parameter determination [30], neural network optimization [31], and path planning [32].
Nonetheless, The original SMA still has some shortcomings. The local search ability of SMA is poor when faced with high dimensional issues, and it is easy to converge prematurely and fall into local optimum [33]. The quality of slime mould population generated by random initialization is generally poor. In view of the drawbacks of the SMA, many new variants of SMA are proposed to improve their performance on specific types of problems. Aiming at the problem of unbalanced exploration and exploitation of SMA, Tang et al. [34] proposed a MSMA which combines learning strategy based on chaotic opposition, adaptive parameter control strategy and spiral search strategy. Jui et al. [35] used Levy distribution instead of uniform distribution, and proposed a Levy SMA algorithm to improve the problem that that SMA is prone to fall into local optimum. Houssein et al. [36] proposed a multi-objective SMA (MOSMA), which used external archives to store Pareto optimal solutions of multi-objective optimization. Yin et al. proposed an equilibrium optimizer (EO)-guided SMA (EOSMA) for engineering design problems, inverse kinematics (IK) of complex manipulators and job shop scheduling problem [37]. Hu et al. [38] proposed a DFSMA with a dispersed foraging strategy to avoid a decrease in population diversity. Although many scholars have proposed different variants of SMA, they are not suitable for all optimization problems.
Because SMA performs well in many applications, we use it to solve FJSP in this paper. SMA has been widely used to solve continuous optimization problems. However, FJSP is a discrete problem. Therefore, premature convergence should be avoided as much as possible. At the same time, the efficiency of SMA needs to be further improved. Aiming at improving the drawbacks of SMA and apply it to FJSP accurately and efficiently, a dual chaotic slime mould algorithm based on Gompertz dynamic probability and Cauchy mutation is proposed.
The main contributions of this paper can be summaried as followed. First, by combining Logistic map with Tent map to generate uniformly distributed chaotic sequence, which is used to generate a higher quality initial population. Second, by introducing Gompertz dynamic probability to adjust the exploration and development of SMA. Third, by introducing Cauchy mutation operator based on elite individuals to enhance the global search ability, and avoid it falling into the local optimum. We combine these three contributions in a novel version of SMA named GCSMA. In addition, a special encoding and decoding method is used to apply GCSMA to discrete flexible job-shop scheduling problem.
Specifically, the remaining sections are organized as follows: FJSP is introduced in section 2. Introduction of SMA and its detailed principle are presented and analyzed in section 3. The proposed GCSMA with three improvement strategies is presented in section 4. The experiment for benchmark functions and results are provided in section 5. GCSMA is used to solve FJSP in section 6. Finally, the conclusion and expectation are in section 7.
FJSP description
The FJSP can be described as n jobs are processed on m machines [39]. Each job contains one or more operations in a given sequence that need to be processed, and each operation can be assigned to one or more machines with different processing time [40]. The processing satisfies the following constraints: A job can only be processed on one machine at a certain time; A machine can only process one job at a certain time; The processing sequence must meet the operation sequence requirements of each job; Once the operation starts, it cannot be interrupted.
Table 1 is a 3 × 3 FJSP, which contains 3 jobs (J1, J2, J3) and 6 operations to be processed. Taking job 2 for example, this job has 2 operations to be processed, O (2, 1) is the first operation, and the three columns on the right are the set of available machines for this operation. "–" means that this operation cannot be processed on that machine, so the set of available machines is M2, M3, and the processing time of this operation on M2 is 7, and the processing time on M3 is 3.
3 × 3 FJSP job processing time
3 × 3 FJSP job processing time
There are various optimization objectives for job shop scheduling problem, such as the maximum completion time (makepan) [41], the total delay [42] and the energy consumption [43], etc. The most common one is the maximum completion time. Aiming at minimizing makespan, the objective function of FJSP in this paper is as follows:
The iterative process of SMA is presented in detail in this section. The algorithm simulates the behavior and morphological changes of slime moulds during foraging. Each slime mould has two attributes: weight and position. During the foraging process, the weights are updated according to it’s own positions, and then the positions are updated according to the weights. Each slime mould goes through the following three steps in each iteration [29]
1.Fitness calculation and sorting:
Traverse each slime mould, calculate and sort the fitness according to the fitness function.
2.Update individual weight:
The weight W is defined by Equation (2):
According to Equation (2), it can be found that the weight of the first half of superior individuals is larger, within [1, 1.3]. The weights of the worse individuals take on values within [0.7, 1].
3.Update individual location:
The position X is updated by Equation (3):
vb is a random number between [- a, a], and a is defined by Equation (4):
We can know that as the number of iteration t increases, a gradually decreases to 0.
vc is a random number between [- b, b], and b is defined by Equation (5):
p is defined by Equation (6):
In Equation (4).(5), it can be found that as t increases, the value of a and b gradually approach 0. Therefore, v b and v c also gradually oscillate and tend to 0.
According to Equation (3), when r1 < z, individual performs a global search in the entire solution space, so that it can explore as far as possible, and try not to fall into local optimum. When r1 > z and r2 < p, it suggests the individual search around the current optimal solution Xb (t) in the late iteration, and gradually converges to the current optimal position. When r2 > p, the individual do local search by Equation (7). It means the individual gradually converge to 0 in the late iteration.
Although the original SMA has the advantages of strong global search ability and fast convergence speed, it still has some aspects to be improved according to Equation (3). In particular, it is easy to fall into local optimum, resulting in low convergence accuracy [44]. The setting of the parameter z is difficult to balance the exploitation and exploration. Moreover, the local search near the optimal position is insufficient, resulting in a decrease in population diversity [45]. Aiming at improving the above deficiencies of SMA, a dual chaotic slime mould algorithm based on Gompertz dynamic probability and Cauchy mutation is proposed. To be specific, the improvements in this paper are as follows:
Logistic-Tent double chaotic map initialization strategy
The quality of the initial population usually affects the convergence accuracy and stability of the algorithm [46]. The random initialization method of population has the problems of uneven population distribution and insufficient search space exploration. Chaotic sequences with ergodicity, randomness and regularity can solve the above problems [47]. The basic idea is to use chaotic sequences to replace pseudo-random sequences. The population based on chaotic map initialization is more uniform distributed in the search space [48], which can usually achieve better results. Therefore, chaos map are often used in meta-heuristic algorithms by some scholars in recent years [49, 50]. Generally speaking, Chaotic map is often used to initialize the population of meta-heuristic algorithm in some papers [51]. Common chaotic models mainly include: Sine map, Logistic map [52] and Tent map [53] and so on. The distribution of the sequence generated by Logistic map and Tent map is shown in Fig. 1(a)(b).
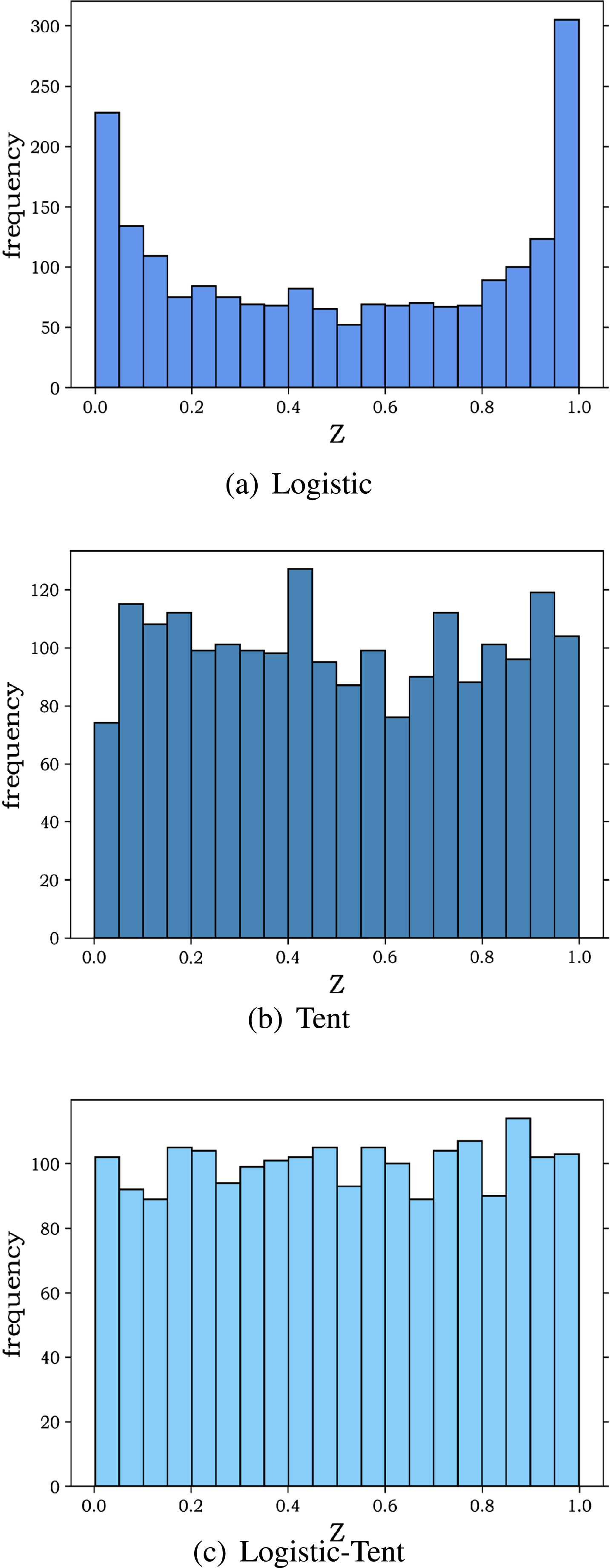
Chaotic map frequency distribution.
The Logistic map is defned as followed:
The Tent map is defned by Equation (9).
It can be found that the sequences generated by Logistic map are mainly concentrated at the two ends, with less distribution in the middle region. The sequences distribution of Tent map is less uniform in Fig. 1(b). The Logistic sequences has strong global ergodicity but is not uniformly distributed in the phase space, while Tent chaotic sequences has strong chaotic perturbation ability. Therefore, in this paper, a Logistic-Tent double chaotic map [54] is used to initialize the slime mould population, as shown in Equation (10):
Among them, Z n is the chaotic sequences, n is the current iteration, and Z0 ∈ (0, 1), r is the system parameter. The frequency diagram of the sequences generated by Logistic-Tent map is shown in Fig. 1(c).
It can be seen from Fig. 1(c) that the sequences generated by the Logistic-Tent dual chaotic map is relatively uniform in the phase space. Therefore, applying it to the population initialization can generate a more diverse population in solution space.
The individual position initialization combined with the Logistic-Tent dual chaotic map is as follows:
It is often not easy to balance the exploration and exploitation of meta-heuristic algorithms. The optimizer searches globally as much as possible during the exploration step. In contrast, the optimizer does local mining around the solution obtained during the exploration step to further improve the accuracy. Therefore, how to balance the exploration and exploitation is the key to improve the performance of SMA. The probability threshold z in equation (3) is vital to balance exploration and exploitation. Regarding the setting of parameter z, a dynamic adjustment probability threshold strategy based on the Gompertz curve [55] is proposed to coordinate the global search and local mining. The probability threshold z is updated by:
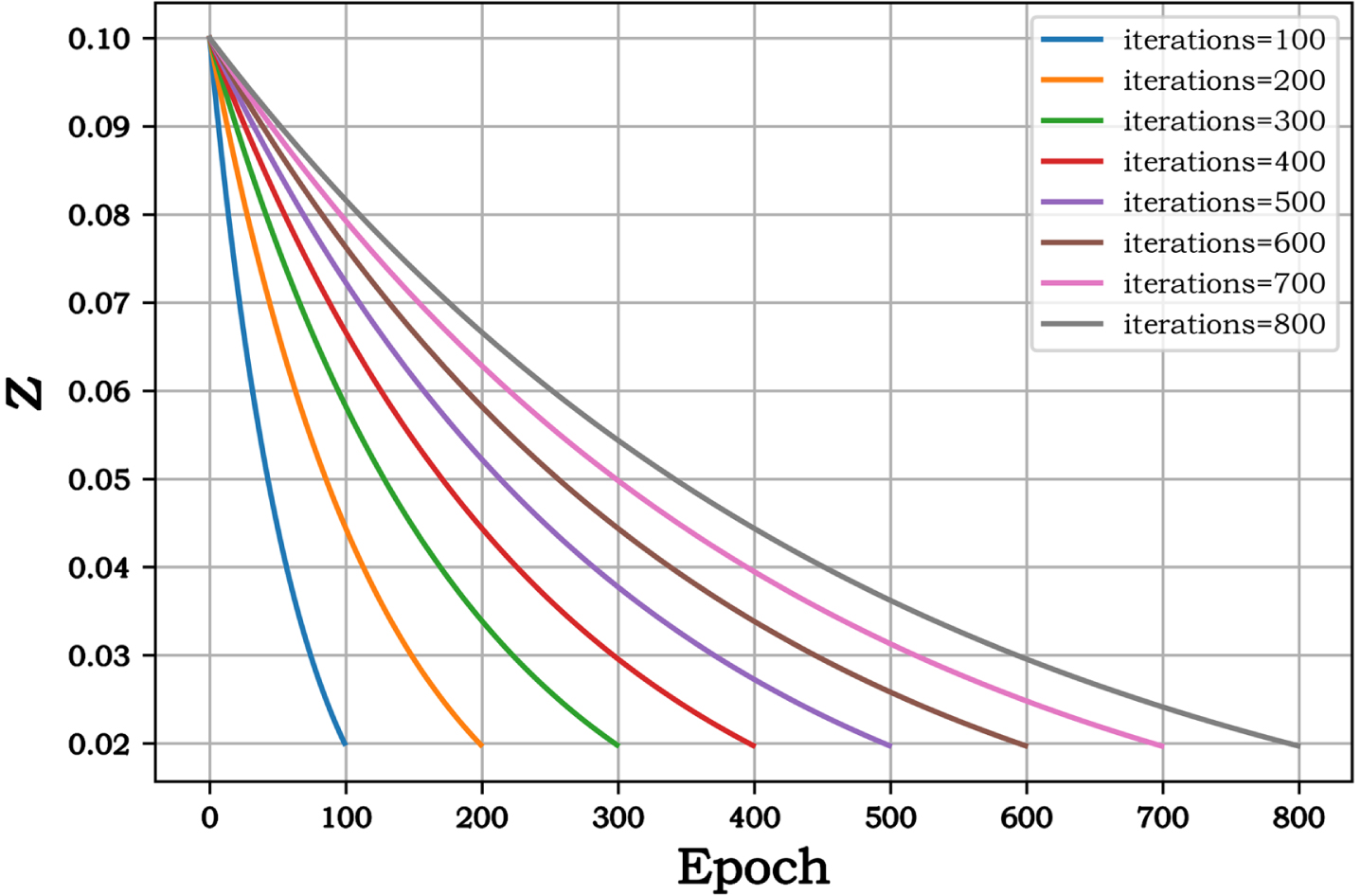
Variation of probability threshold z.
Similar to most other algorithms, SMA is prone to fall into local optimum in the late iteration, resulting in low convergence accuracy. A common practice is to enhance the population diversity by introducing mutation operators [56]. In this paper, the global search ability of SMA is enhanced by introducing Cauchy mutation operator. The Cauchy operator is used to optimize the global optimal individual by making full use of the variation at both ends of the Cauchy distribution function. The Cauchy operator has superior disturbance ability. The tail of the Cauchy distribution function is thicker and longer than other normal distribution, which makes it easy to generate random numbers far from the origin [57]. In terms of probability, the distribution range of Cauchy distribution is wider [58]. That is to say, a relatively wide search space can be obtained by using the random number generated by Cauchy distribution as the disturbance factor. Therefore, the individuals disturbed by the Cauchy operator are more likely to jump out of local optimum and find the global optimum [59]. The Cauchy mutation is widely used in many meta-heuristic algorithms [60, 61]. In this paper, the Cauchy mutation is used to avoid premature convergence and improve the global search ability of SMA. The Cauchy mutation is derived from the Cauchy distribution, and the expression of the standard Cauchy distribution is as follows:
Pseudo–code of GCSMA
Pseudo–code of GCSMA
1: Initialize: pop_size: N; maximum iterations: tmax; Gompertz parameter: k
2: Initialize: individual positions X i (i = 1, 2, . . . , N) by Equation (11)
3:
4: Calculate the fitness F (i) of each slime mould individual and sort the fitness
5: Update the optimal individual Xb (t) and its fitness FD
6: Calculate individual weights W using Equation (2)
7: Update Gompertz threshold z by Equation (12)
8:
9: Update p by Equation (6)
10: Update v b , v c by sampling
11:
12: Update individual i position X i by Equation (13)
13:
14:
15: Implement a Cauchy disturbance Cauchy (0, 1) on the optimal slime mould individual Xb (t)
16: Randomly select two slime moulds: XA (t) , XB (t)
17: Update individual i position X i by Equation (16)
18:
19: Update individual i position X i by Equation (7)
20:
21:
22:
23: t = t + 1
24:
The global optimal individual after introducing Cauchy operator is given in Equation (15):
In the late iteration, slime mould search near the optimal individual disturbed by Cauchy mutation, which makes it easier to jump out of the local optimum and converge to the global optimum, so as to improve the convergence accuracy.
The procedures of the improved SMA with the above three strategies are shown in Algorithm 1, and the flow chart is shown in Fig. 8 (see Fig. 8 in appendix).
Experiment for benchmark functions
In order to test the effectiveness of the improvement strategies, the optimization performance of different meta-heuristic algorithms on different benchmark functions is compared in this section.
Prepared works
12 benchmark functions [62] are selected for experiments, as shown in Table 2. f1 ∼ f5 are unimodal benchmark functions, which is used to test the convergence speed and convergence accuracy of the algorithm. f6 is a discontinuous step function with one global minimum. f7 is a quartic function with noise. f6 and f7 are used to test the ability to jump out of the local optimum. f8 ∼ f12 are multimodal benchmark functions with many local optimum, which is used to evaluate the global search and local mining ability. All benchmark functions are minimization optimization problems. The 3D view of partial benchmark functions are shown in Fig. 3. Dimension D is set to 30, 50 and 100 respectively to test the optimization performance of different algorithm in different dimensions.
Benchmark functions(optimum = 0)
Benchmark functions(optimum = 0)
Four novel heuristic algorithms and two proposed earlier heuristic algorithms are selected for comparative experiments, including Grey Wolf Optimizer (GWO) [25], Whale Optimization Algorithm (WOA) [26], Harris Hawk Optimization (HHO) [27], Moth-Flame Optimization(MFO) [63], Genetic Algorithm (GA) [20], and Artificial Bee Colony Algorithm (ABC) [23].
All algorithms run using python 3.8 running on a computer with intel i5 processor, 11300CPU, 3.10GHz with a 16.00GB RAM and a 64-bit Windows. The parameter settings of each algorithm are consistent with the original literature, as shown in Table 5. The population size is set to 30, and the maximum iteration is set to 500. Each algorithm is run independently for 50 times and recorded. The initial search points of different algorithms are generated by random initialization within the same upper and lower bounds. In order to evaluate the convergence accuracy and stability of each algorithm, the mean value, standard deviation, worst and best value of the optimization results are recorded respectively. The test results of each algorithm under D = 30 are shown in Table 7 (see Table 7 in appendix).
FJSP instances test results
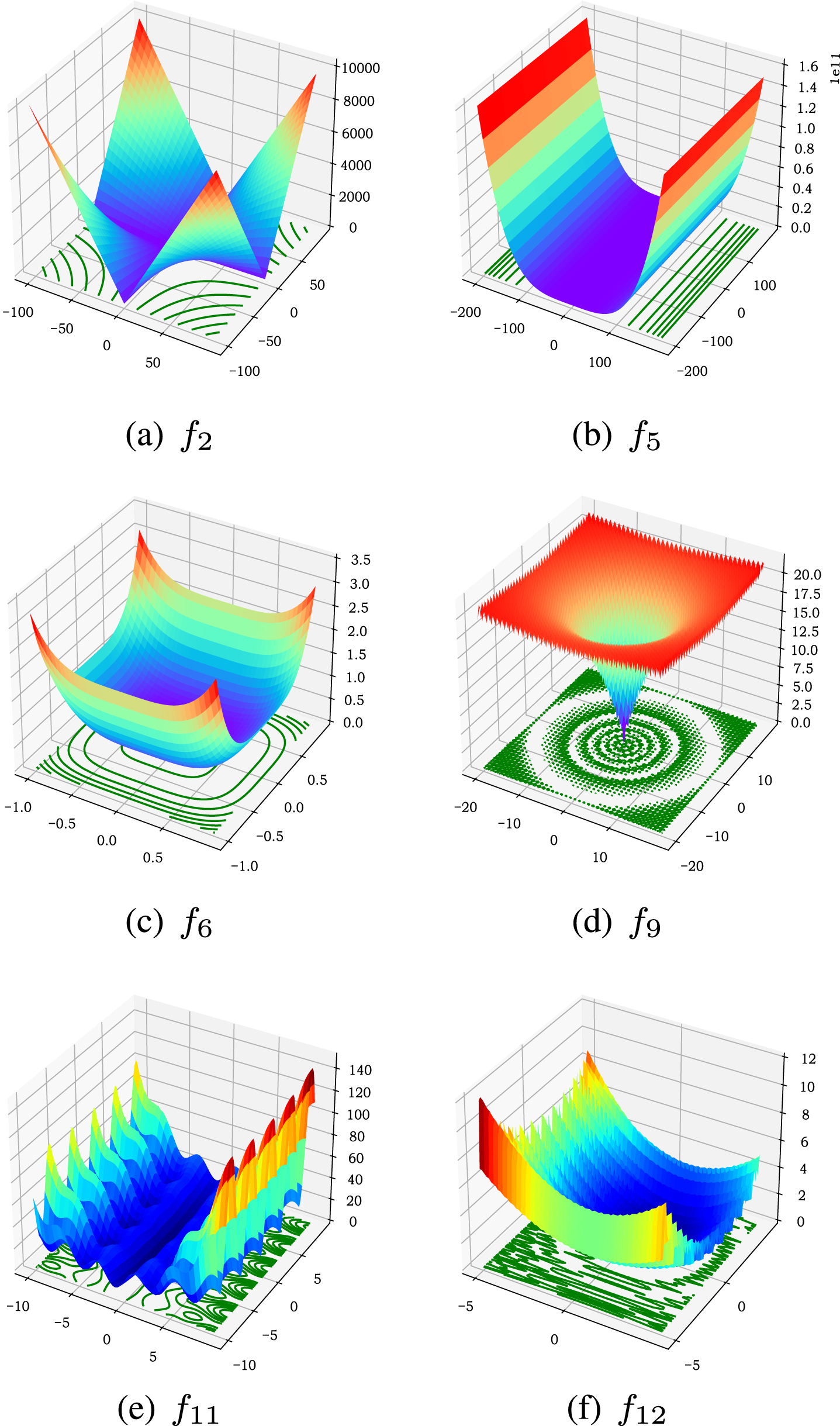
3D view of partial benchmark functions.
From Table 7, for the f1 ∼ f5 function, GCSMA can converge to the global optimum 0 on f1 ∼ f4, the results of GCSMA are much higher than the other seven algorithms, Although GCSMA can not reach the global optimum on f5, the optimization results obtained by GCSMA are 1 ∼ 5 orders of magnitude better than other algorithms. The stability of GCSMA is also far better than other algorithms. For f6 ∼ f12, GCSMA can reach the global optimum of the function f6, f8 and f10. The convergence accuracy of SMA is worse than that of HHO on f5 and f11, which may be due to the poor global search ability of the original SMA. It tends to converge prematurely and fall into local optimum. However, the performance of GCSMA and HHO is consistent on f5 and f11. In general, the optimization performance of GCSMA is better than 3 novel algorithms: MFO, GWO,WOA and 2 classical algorithms:GA, ABC on f1 ∼ f12. Most importantly, its convergence accuracy is about three orders of magnitude better than SMA. It is verified that GCSMA has better global and local search ability, so it also has higher convergence accuracy, which proves that GCSMA has superior performance.
Strategy performance experiments
In order to better analyze the impact of proposed strategies on algorithm performance improvement, the performance of the three strategies and different combinations was tested. In the following experiments, we denoted double chaotic mapping as I, Gompertz dynamic probabilistic strategy as II, and Cauchy mutation as III. The unimodal benchmark functions f2, f4, discontinuous functions f7, and multimodal benchmark functions f11, f12 were selected for the experiment. Each algorithm is run for 30 times and take the average of the optimization results as the final result. The results are shown in Table 6 (see Table 6 in appendix).
It can be seen from Table 6, for unimodal benchmark functions f2, f4, strategy I, II have greatly improved the optimization accuracy. For f7, f11 and f12 with many local optimum, strategy III plays a major role. The reason is that strategy III can help the algorithm jump out of local optimum. In contrast, strategy I, II can improve the global search ability of SMA, thus improving the accuracy of optimization.
High-dimensional optimisation experiments
Generally speaking, the robustness and stability of algorithm are poor in high-dimensional cases. In order to test the high-dimensional performance of GCSMA, 8 benchmark functions f1 ∼ f8 are selected for comparative experiments when D = 50 and D = 100. The results are shown in Table 8 (see Table 8 in appendix).
It can be seen from Table 8 that when D = 50 and D = 100, GCSMA can still converge to the theoretical optimum on f1 ∼ f4, f6 and f8. In contrast, The original SMA failed to find the global optiuml on f2 and f4, which proves the improvement of accuracy. The performance on f5 and f7 decreases slightly. However, the convergence accuracy of other algorithms, especially MFO, in high dimensions has decreased to varying degrees. It is worth mentioning that the convergence accuracy of GCSMA is still 3 orders of magnitude higher than that of SMA in high-dimensional situations. In other words, as the dimension increases, GCSMA still shows good optimization performance, which verifies the high-dimensional stability of GCSMA.
Analysis of convergence curves
In order to intuitively compare the convergence speed and convergence accuracy of different algorithms, the experiment data of four benchmark functions (f2, f5, f6 and f12) (D = 30) is selected to draw the convergence curve. The convergence curve is shown in Fig. 4.
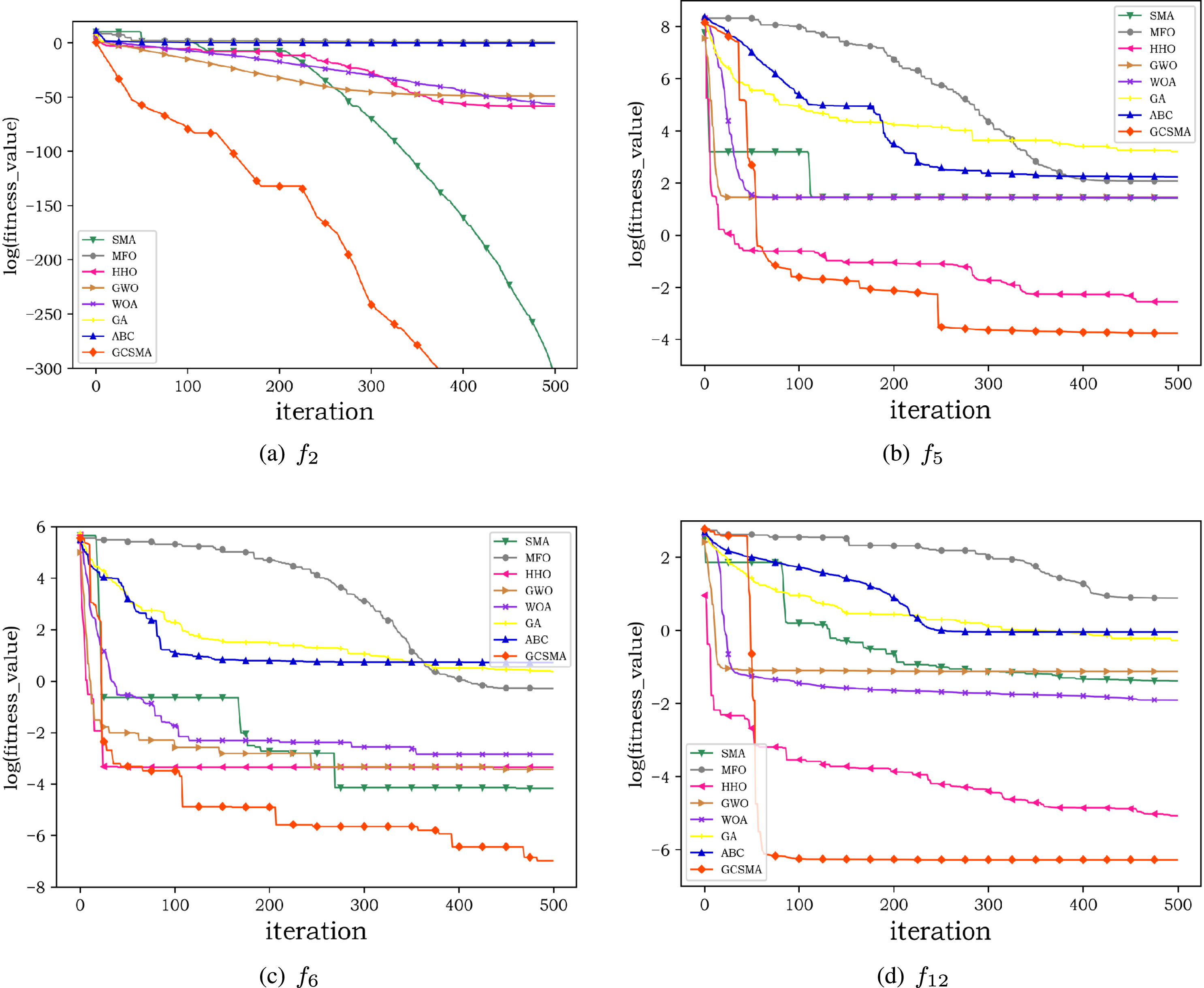
Convergence curves of functions f2,f5,f6 and f12 (D = 30).
Where the horizontal axis is the number of iterations, and the vertical axis is the fitness value. In order to better show the optimization process of each algorithm, the fitness value is taken as the bottom 10 of the logarithm. Figure 4(a) shows the convergence curves of each algorithm on the unimodal benchmark function f2. From the convergence curves of f2, it can be found that GCSMA converges the fastest and has the highest accuracy. Similarly, it can be seen from f5 and f6 that GCSMA still has the potential to jump out of the local optimum in the late iteration it jumped out of the local optimum through the Cauchy mutation strategy, and finally found a better solution, which proves that it has a strong global search ability. For multimodal benchmark function f12, it shows that GCSMA converges very fast, which shows that it has good optimization performance. In addition, the convergence accuracy is further improved compared with SMA, which proves the effectiveness of the improvement strategies.
In order to further evaluate the effectiveness of the proposed improved strategy and test whether GCSMA is significantly different from other seven meta-heuristic algorithms, Wilcoxon rank-sum test [64] with significance level of 5% was performed on the selected 7 benchmark functions (D = 30). Table 4 shows the p values calculated of GCSMA and other algorithms. Where bold is the difference is not significant or the performance is comparable. When p value is less than 0.05, it indicates that there is significant difference between the two algorithms. N/A indicates that the optimization results of two algorithms are 0, so the performance is comparable.
P value of Wilcoxon rank-sum test(D = 30)
P value of Wilcoxon rank-sum test(D = 30)
Except SMA is N/A in f1, the performance of GCSMA is significantly different from that of other meta-heuristic algorithms in f1, f2 and f6. It can be seen from Table 3 that GCSMA is significantly better than other meta-heuristic algorithms on the above benchmark functions. In f6, f8, the performance of GCSMA is comparable to that of SMA, HHO and GWO, and significantly superior to that of MFO, GA and ABC. In f5, f11, the difference between GCSMA and HHO is not significant, but GCSMA is significantly better than other meta heuristic algorithms. In general, On the above functions, GSSMA is significantly better than most comparison algorithms, which further proves the effectiveness of the proposed strategy.
Algorithm parameter settings
Double-stranded chromosome encoding and decoding strategy
In this section, the proposed GCSMA is used to solve FJSP. In order to establish the mapping between discrete space of FJSP and continuous space of meta-heuristic algorithm, a encoding and decoding method based on double-stranded chromosomes is designed. Taking the 3×3 FJSP of section 2 for example, as shown in Fig. 5.
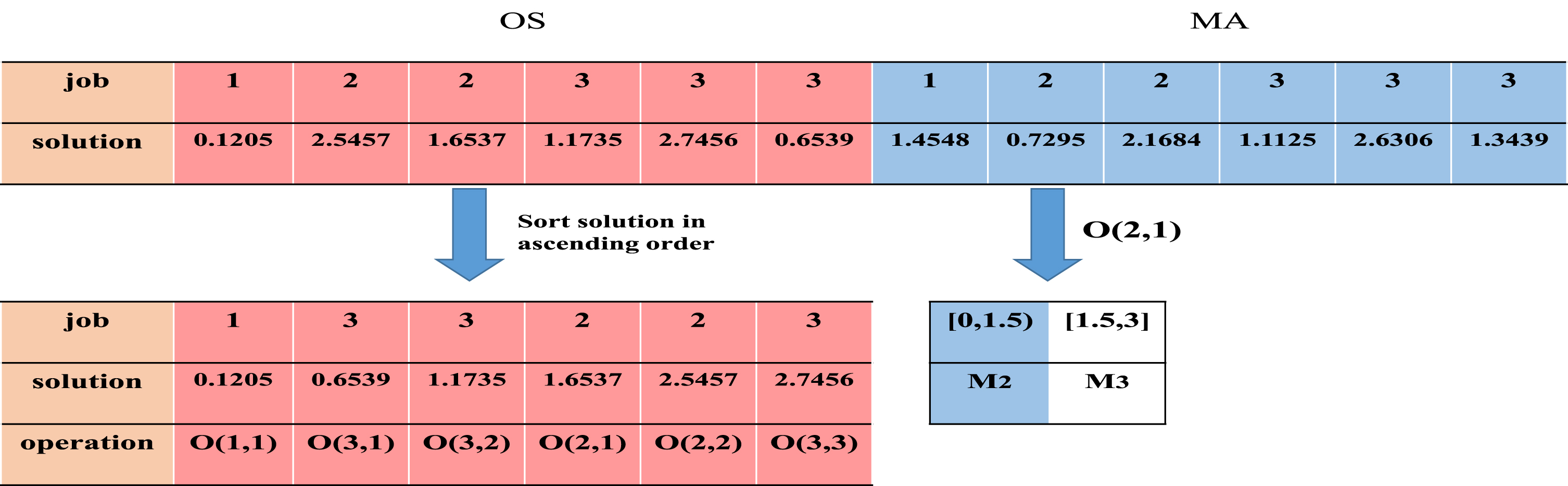
Chromosome encoding and decoding of OS and MA.
SMA is an algorithm for continuous variables, while FJSP is a discrete combinatorial optimization problem. We adopt a double-stranded chromosome encoding method. The details are as follows: the first chromosome is encoded based on operation sequence (OS) and machine assignment (MA). The operations in OS are all represented by the corresponding job serial numbers, and the kth job serial number that repeats from left to right represents the kth operation of the job, which determines the processing sequence of the jobs. MA allocates a machine for each operation, corresponding to the OS of the first half chromosome, and determines the machine of the OS. Combining OS and MA, a scheduling solution of FJSP can be obtained. The second chromosome is the independent variable directly optimized by the algorithm, which is generated by random initialization within the upper and lower bounds.
Decoding
Sorting the solutions of OS from large to small, the sequence of job serial numbers can be obtained, that is, processing order of jobs. For MA, machines are selected according to the order of the job and the set of available machines, and a solution space bisection method is used to allocate the processing machines. First, the upper and lower bounds of the solutions are bisection according to the number of available machines, and the corresponding solution of MA is matched with it to allocate processing machines. Taking the operation O (2, 1) for example, the solution corresponding to the operation O (2, 1) is 0.729579, and the available machine set of the operation O (2, 1) is M2, M3. Therefore, the solution space [0, 3] is divided into two equal parts [0, 1.5) and [1.5, 3]. Thus, the solution of the operation O (2, 1) matches the first solution space [0, 1.5), so the machine of operation O (2, 1) is M2. Combining OS and MA, a feasible scheduling scheme and makespan C max can be obtained.
Algorithm flow
The proposed GCSMA is used to solve single-objective FJSP, and flow chart is shown in Fig. 6.
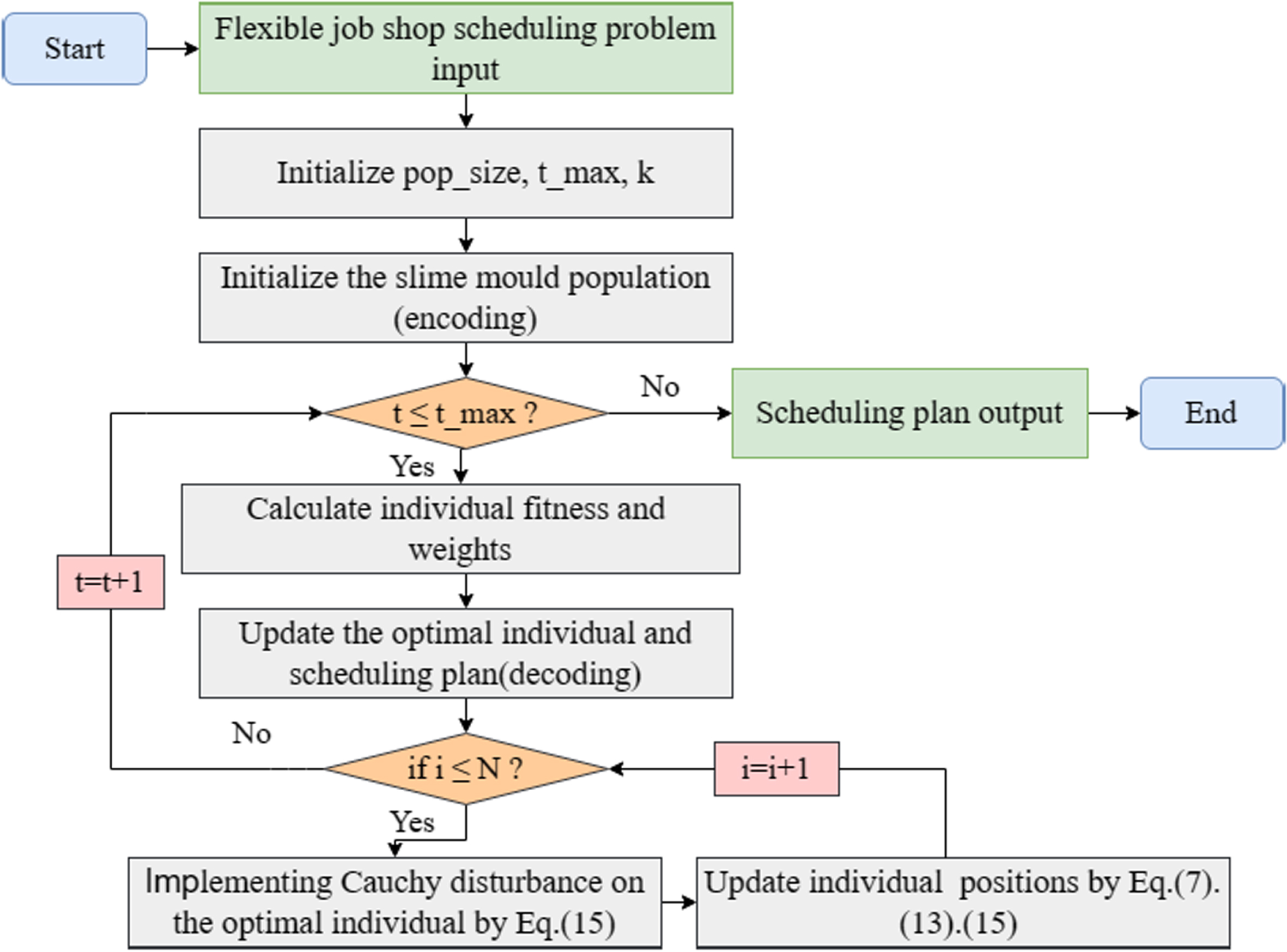
Flowchart for solving FJSP by proposed GCSMA.
In order to test the performance of GCSMA for solving FJSP, and compare the performance of different meta-heuristic algorithms. Benchmark case comparison tests is conducted on Grey Wolf Optimizer (GWO) [25], Harris Hawk Optimization (HHO) [27], Slime Mould Algorithm (SMA) [29], Moth-Flame Optimization (MFO)[63], Genetic Algorithm (GA) [20] and GCSMA. 10 classical FJSP instances called Brdata designed by Brandimarte [65] are selected for test.
In detail, the parameter settings of each algorithm refer to the suggested values of the original paper. The population size and the maximum iteration for each algorithm on the same instance are the same. To be precise, the population size of each algorithm is set in the range of 50 ∼ 500. In order to make the results consistent and avoid accidental effects, each algorithm is run independently for 20 times and the results are recorded. The test results are shown in Table 5.
Analysis of experiment results
n and m represents the number of jobs and machines in Table 5, and LB denotes the optimal lower bound currently known. The best and average value of each algorithm is recorded.
It can be seen from Table 5 that the performance of SMA on the 10 instances is obviously better than that of HHO and GWO, and it is almost the same as that of MFO. Compared with GA, the solution of SMA is slightly worse. The GCSMA using three strategies has a significant improvement in solution accuracy, slightly better than GA on MK01, MK03, MK04, MK07. MK08 ∼ MK10 are very complex, but the solution of GCSMA is not too bad, which proves that GCSMA has the potential to solve large-scale FJSP. In summary, GCSMA has better performance in terms of the best and average scheduling results compared with other algorithms, which proves the feasibility of GCSMA to solve the FJSP, and the accuracy of the solution is satisfactory.
FJSP is a discrete optimization problem with a large number of local optium. How to avoid the algorithm falling into local optima is the key to improve accuracy [66]. Because we used Gompertz dynamic probability threshold to balance the early exploration and later exploitation of SMA. In the early stage, the algorithm can search as much as possible in the discrete space of FJSP. In the late stage, due to the introduction of Logistic-Tent chaotic initialization strategy, the agents of SMA can still be evenly distributed in the solution space of FJSP, so that most of them will not converge to the local optimum. At the same time, Cauchy mutation can avoid the algorithm from falling into the local optimum.
The proposed GCSMA has the advantages of fast convergence and high convergence accuracy. Moreover, the algorithm has good global search performance, and it can be applied to other optimization problems at the same time. In general, the introduction of the three strategies can greatly improve the global convergence ability of SMA and improve the accuracy in solving FJSP.
The Gantt chart of the best result on Mk01, MK02 is shown in Fig. 7.
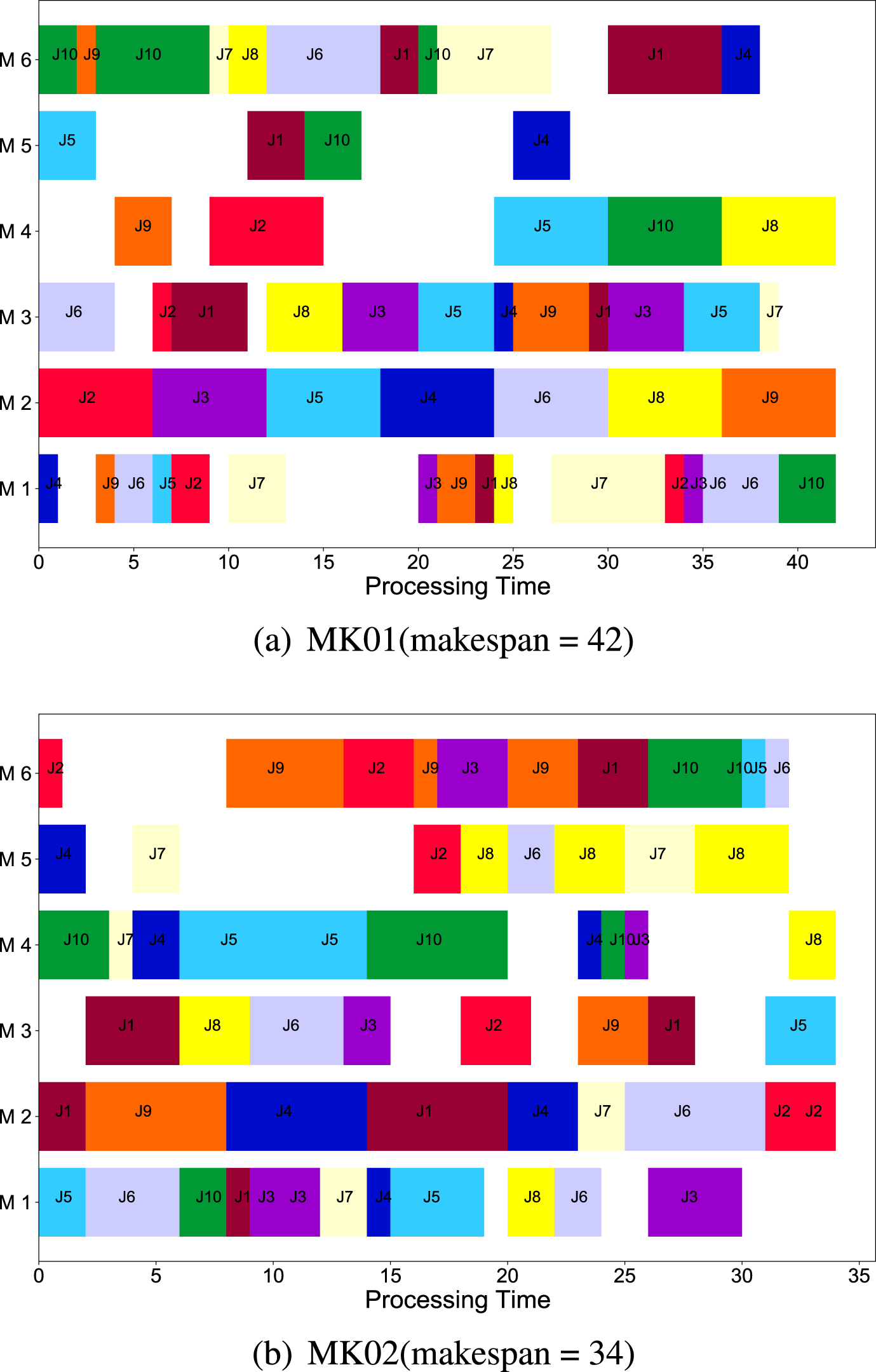
Gantt chart for MK01, MK02.
It can be seen from the above results that SMA can be well applied to solve the single-objective FJSP, and the results are satisfactory, which provides a new idea for the solution of FJSP. It also provides a new idea for using the continuous meta-heuristic algorithm to solve the discrete combinatorial optimization problem.
There is a growing demand for simple and efficient meta-heuristic algorithms. In this paper, a multistrategy slime mould algorithm named GCSMA is proposed for global optimization. Specifically, firstly, a Logistic-Tent chaotic map is used to initialize the population to obtain a uniformly distributed initial population and increase the diversity of the population. Secondly, by using a Gompertz curve to dynamically adjust the probability threshold strategy, the global exploration ability of SMA is appropriately improved. Finally, a disturbance strategy of Cauchy mutation is introduced to enhance the local search ability, improve the lack of local search, and fully balance the global search and local search ability of original SMA. Because SMA is a continuous global algorithm, a double-stranded chromosome encoding and decoding method is designed, which make it possible to apply SMA to discrete single-objective FJSP. The simulation results show that GCSMA can be used to solve FJSP, and the performance is satisfactory.
FJSP is usually complicated by scenarios such as dynamic tasks and multi-objective solutions, but we only solve the single-objective FJSP in this paper. Therefore,our future research will focus on the complex FJSP, such as considering machine load, insertion of urgent tasks and carbon emission constraints, etc. Most importantly, We only verify the feasibility of GCSMA to solve FJSP, and a certain degree of excellence. Therefore, in order to further improve the solution accuracy, GCSMA will be combined with the variable neighborhood search algorithm as a two-stage algorithm. Furthermore, GCSMA will be applied to more practical engineering problems, such as parameter optimization and dynamic resource reallocation.
Footnotes
Appendix
See Appendix Fig. 8.
See Table 6.
Comparative experiment of GCSMA
Function
SMA
I-SMA
II-SMA
III-SMA
I-II-SMA
I-III-SMA
II-IIISMA
GCSMA
f
2
1.53E - 315
3.94E - 313
f
4
5.76E - 308
5.32E - 314
7.87E - 305
1.14E - 307
f
7
2.60E - 04
6.48E - 05
9.02E - 04
7.44E - 08
1.07E - 03
1.13E - 07
2.34E - 06
f
11
7.84E - 02
3.32E - 01
6.09E - 03
5.82E - 05
8.64E - 03
3.71E - 06
4.33E - 03
f
12
1.54E - 04
7.42E - 05
2.12E - 07
6.60E - 06
6.05E - 07
5.22E - 07
6.83E - 08
See Appendix Table 7.
See Appendix Table 8.