
Abstract
In the present day, online users are incentivized to engage in short text-based communication. These short texts harbor a significant amount of implicit information, including opinions, topics, and emotions, which are of notable value for both exploration and analysis. By alleviating the sparsity in short texts, topic models can be used to discover topics from large collections of short texts. While there is a large body of surveys focused on topic modeling, but only a few of them have focused on the short texts. This paper presents a comprehensive overview of topic modeling methods for short texts from a novel perspective. Firstly, it discusses short text probabilistic topic models and outlines the directions in which they can be improved. Secondly, it explores short text neural topic models, which can be categorized into three groups based on their underlying structures. In addition, this paper provides a detailed investigation of embedding methods in topic modeling. Moreover, various applications and corresponding works are surveyed, with a focus on short texts. The commonly used public corpora and evaluation indicators for topic modeling are also summarized. Finally, the advantages and disadvantages of short text topic modeling are discussed in detail, and future research directions are proposed.
Introduction
In the age of the Internet, users are motivated to engage in online interactions using short texts. A large number of short texts has emerged in e-commerce, social media, social software, community Q&A and other platforms, including microblogs, comments, SMS messages, search snippets, etc. These short texts hide rich information on opinions, motivations, emotions, and topics, making short texts extremely valuable for research. Unlike long-text data, short-text data is characterized by sparse semantics, lack of contextual information, non-standardization, and immediacy, which creates a huge gap between the underlying text features and the high-level semantics.
The boom in topic modeling first started with the Latent Dirichlet Allocation (LDA) [1], which proposed by David Blei in 2003. LDA uses Dirichlet distribution as a prior condition to model the process of modeling from topics to documents by approximating the joint probability between words, topics, and documents. However, LDA uses word co-occurrence information in documents as the basis, and the sparse problem of short texts causes LDA failed to capture sufficient word co-occurrence information from documents. Furthermore, LDA does not limit the number of topics in one document, but short-text document usually contains only a few topics. LDA is less effective in short texts. Dirichlet Multinomial Mixture (DMM) [2] model works slightly better than LDA because DMM follows the assumption that each document is sampled from only one topic. However, this is a strong assumption and worthy of further refinement, which will be discussed in Section 2.
Traditional probabilistic models usually characterize the semantic links of words in terms of document-level word co-occurrence information. However, semantically related words in short texts often do not occur in the same document, which makes it impossible for traditional methods to construct high-quality semantic links. Short-text-oriented topic modeling methods have effectively alleviated these problems. These studies aim to complement the missing feature information in short texts. Improvements include improving generative models, introducing external knowledge, incorporating neural networks, and combining pre-trained word vectors. These measures have achieved good performance in short text topic mining. Therefore, topic modeling has become one of the mainstream algorithms for processing short texts.
In the existing review of short text-based topic models, Likhitha et al. [3] summarized several representations of short texts and classified topic models into three categories: based on the window, based on self-aggregation, and based on word embeddings. Albalawi et al. [4] reviewed the metrics and advantages required to evaluate topic models, selected Latent Semantic Analysis (LSA), LDA, Non-negative Matrix Factorization (NMF), Random Projection (RP), and Principal Component Analysis (PCA) were examined to summarize the advantages and disadvantages of these five types of models and compared the model performance on two different datasets to provide a reference for model selection; Qiang et al. [5] classified probabilistic short text topic models into three categories based on the improved DMM, the improved global word co-occurrence-based model and the improved self-aggregation-based model. The performance of models was texted in six different short text datasets, providing a reliable reference. Murshed et al. [6] conducted qualitative and quantitative analysis of representative short-text topic models.
Most of the existing reviews have paid little attention to neural topic models, and few reviews have exhaustively investigated embedding methods in topic modeling. In addition, the applications of short texts and related works has not been described in detail.
We provide a detailed review of short-text topic modeling from a novel perspective by investigating a large body of literature. The main contributions of this paper are as follows: We provide a novel perspective to classify probabilistic topic models for short texts, which can guide directions of future improvements. In particular, we analyzed the shortcomings in the assumptions from the problems that traditional models encountered on short text, then provide the investigation of models for short texts based on the corresponding improvements both in terms of improving the internal structure and expanding the external data features. We investigated the studies of neural topic modeling and classify them based on structures. Neural topic modeling is an emerging hot field but has rarely been mentioned in previous reviews. We investigated the combination of embedding methods and topic modeling, which not only improves the efficiency of topic discovery in short texts but also provides some completely new ideas for topic modeling. We focus on applications in real-life short-text scenarios and provide a detailed summary of the tasks and the corresponding topic models. We discuss in detail the advantages and disadvantages of the short text modeling methods and suggest several directions for future research.
Topic modeling methods for short texts
In the era of online communication, short text messages such as SMS, comments, and conversations have become prevalent. However, traditional probabilistic topic models are inadequate in capturing the word co-occurrence information on the document level, leading to poor topic coherence. Therefore, enhancing the semantic information of words becomes a significant task. In this study, we explored and proposed novel perspectives for addressing the challenge of short texts. The improvements for probabilistic topic models are classified into three directions. First, using external data and enhancing the model structure. Second, using neural networks to reconstruct topic modeling. Third, combining embedding methods and topic modeling.
Probabilistic topic models for short texts
The traditional probabilistic topic model extracts topics by capturing word co-occurrence information. However, unlike the rich features of long texts, the features of short texts are sparse. Traditional models do not perform well in modeling short texts. Existing improvement strategies for the data sparsity problem in short texts can be broadly grouped into two categories: Provide additional semantic information to the model by expanding the data features. Adaptation to the data characteristics of short text document collections by changing the prior conditions in the probabilistic topic model.
Extending external features
The key to processing short text data is to alleviate the semantic ambiguity caused by the sparsity of the underlying features, so expanding the data features has become a major task in short text topic modeling. Early research has focused on the semantic expansion of short texts by learning features from external data. The external knowledge can be sourced from a general knowledge dataset such as Wikipedia or a domain-specific knowledge dataset. However, external knowledge is inherently difficult to construct. On the one hand, it gets extremely costly to update and maintain knowledge sources, and on the other hand it is not possible to ensure that an authoritative source of knowledge is available for each domain. However, constructing external datasets is often difficult. Specifically, domain knowledge datasets are less general and cannot guarantee data pathways, while large general knowledge datasets are often difficult to achieve a comprehensive and uniform distribution of data across domains. It also aims to develop self-aggregation models that do not require auxiliary information, enabling short texts to self-aggregate into long pseudo-documents.
External knowledge source
Early approaches focused on using discrete topic features from external knowledge datasets to enhance classification. Phan et al. [7] introduced a large external general-purpose dataset to the short text classification task, integrated the topic features mined from the general-purpose dataset into the original short text dataset to form a new dataset containing background knowledge, and then used the new dataset to train a text classifier. By restoring the semantic context of the words, the model can have a better “knowledge” of the set of words, increasing the reliability of the classification results and reducing the confusion caused by ambiguous information. However, topic features in different feature spaces in the external knowledge datasets do not have the same impact on different classification tasks, and direct use of all features is not suitable for training classifiers with different task goals. Long et al. [8] used migration learning to mine external data and constructed a classifier for the source domain using both labelled and unlabeled data in the source domain, which not only trained the classifier with the most effective features but also reduced the annotation work on the external knowledge datasets. Zhu et al. [9] analyzed the effect of different external knowledge datasets and different feature weights on classification accuracy and found that the highest accuracy was achieved when topic features were jointly extracted from multiple external knowledge datasets, and that adjusting the feature weights when extracting topics would improve the classification results. Qiang et al. [10] expanded each short text using word-word correlation information, making short texts richer in word co-occurrence information.
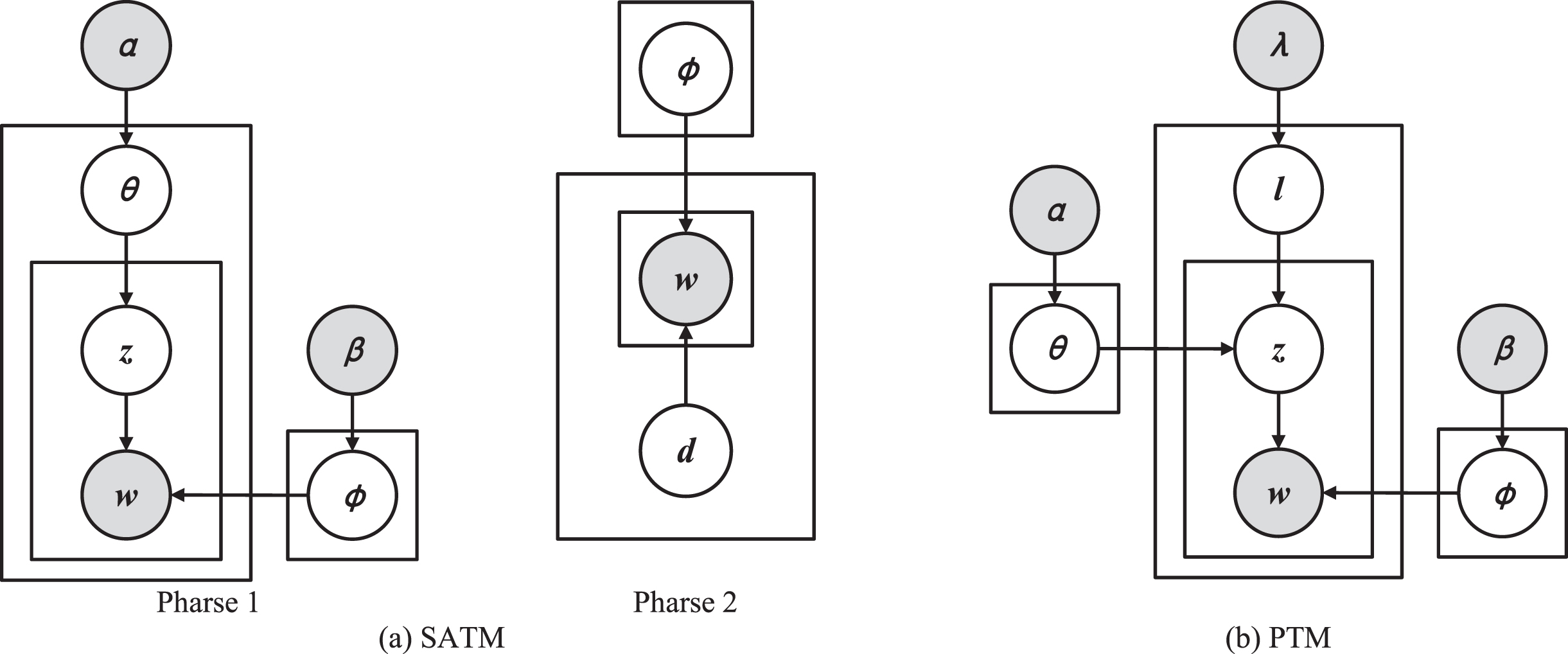
Self-aggregation Topic models.
Another direction is to aggregate short-text subsets into longer pseudo-documents with richer word co-occurrence information to enhance semantics without heuristic information. Quan et al. [11] proposed the Self-Aggregation Topic Model (SATM), which aggregates short texts with similar topics prior to topic modeling to construct more valid word co-occurrence information. SATM first simulates the process of short text generation by assuming that each short text comes from a random fragment of a long pseudo-document (i.e. all short texts are sampled from a corresponding long pseudo-document). Specifically, SATM hypothesis generation process consists of two stages: In the first stage, D documents are generated following the standard LDA generation process; in the second stage, S short text fragments are generated from the D documents by the mixture of unigram process. However, since in the second stage SATM needs to estimate the topic distribution of all pseudo-documents independently, the number of parameters grows linearly with the amount of data, which will lead to severe overfitting. To tackle these problems, Zuo et al. [12] proposed the Pseudo-document Topic Model (PTM) based on SATM. Unlike SATM, which distinguishes a two-stage generation process, PTM generates pseudo-documents by direct reference to the standard process of LDA. Latent Topic Model (LTM) [13] also assumes that one short text document is a fragment of an original long document, but LTM only uses the topic assignment of each short text in the original long document as a latent variable, which also alleviates the overfitting problem that can occur during the two-step generation process.
The challenge for the self-aggregating topic model is to cope with the non-semantic word co-occurrence information that emerges when short texts are aggregated into pseudo-documents, which can lead the model to mine inconsistent topics. In PTM, by introducing Spike and Slab priors into the topic distribution of pseudo-documents, Zuo reduced the co-occurrence of non-semantic words when the number of pseudo-documents is relatively small. Niu et al. [14] considered that short texts in social media (e.g. Twitter) obey a power-law distribution among themselves, and used the Pitman-yor process to aggregate short texts into pseudo-documents. This process enables a power-law distribution between short texts and corresponding pseudo-documents, so that more semantically related short texts are aggregated into the same pseudo-document.
Graph is a non-linear data structure in the form of a graph consisting of nodes, directed edges and weights indicating the importance of the edge. In natural language processing, chapter structure, syntactic structure and the sentence itself exist as graph data. The graph structure, with its nodes reflecting text features, directed edges reflecting order relations and co-occurrence information between features, and weights reflecting the degree of association between semantics, is clearly more consistent with the natural structure of text than the bag-of-words, which does not reflect word sequence. In graph structures, word (node) information is propagated in edges that capture not only explicit connections between neighboring nodes but also implicit connections between distant nodes. Zuo et al. [15] store a collection of short text documents in Word Network Topic Model (WNTM) using a word co-occurrence network in the form of a weighted undirected graph. Nodes store features (words) in the graph and the weights on the edges connecting two nodes represent the number of times the words stored in the two nodes co-occur in a context window of specified length. Using the graph structure to store a global corpus of short texts is equivalent to reorganizing the contextual information of the words, and the pseudo-document generated from the word co-occurrence network will contain the global semantic information of the words. Unlike LDA, WNTM approximates the parameters by Gibbs sampling in the pseudo-document, resulting in a distribution of potential word groups for each word rather than a topic distribution for the corpus.
The advantage of the pseudo-document-based topic model is that it can enrich word co-occurrence information by self-aggregation without introducing auxiliary information, compensating for the sparse data features in the original short texts.
Improving the priors
External datasets can alleviate the sparsity of short texts to some extent, but in practical scenarios the process of constructing external datasets presents significant challenges. There is not always a corresponding domain knowledge data for particular domains, and it is even more difficult to construct a comprehensive and evenly distributed general knowledge datasets.
Comparing the principal assumptions of short text probabilistic topic models
Comparing the principal assumptions of short text probabilistic topic models
A more robust and more general approach is to improve the assumptions of the topic model. The most classical LDA and DMM are used here as a starting point to analyze how the model structure can be improved to make the topic model applicable to short texts.
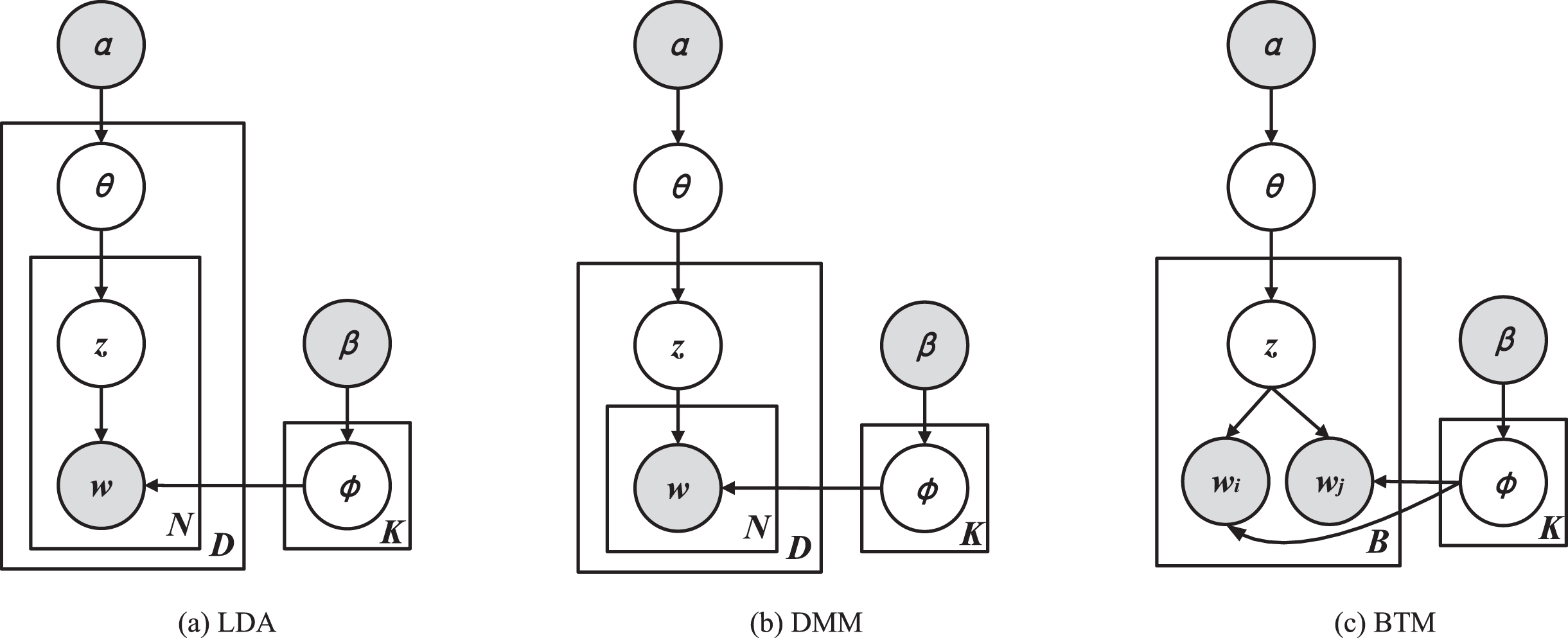
Assumption A, LDA assumes that a document is sampled from several topics and does not limit the number of topics, however, short texts are limited in the amount of information they can provide and a short text is often sampled from only a few topics, so setting too many topics will reduce the accuracy of the sampling. Assumption B, LDA models the document generation process by capturing word co-occurrence information at the document level. For each document, LDA first selects a document-level document-topic distribution θ d , and in assigning a topic z to each word w in the document, the iterative sampling process of zdepends on θ d , in other words, the topic to which each word belongs depends on the rest of the words in the document. However, short text documents do not provide sufficient word co-occurrence information at the document level, resulting in LDA model failing to accurately capture semantically coherent topics. Assumption C, the prior distribution of documents. Currently, most models make the same assumptions as LDA and DMM, using Dirichlet-multinomial as a prior for the topic distribution; however, Dirichlet-multinomial requires the user to set the number of topics in advance, which is a major drawback because in practice the number of topics in the corpus is an unobservable variable.
DMM assumes that one document is sampled from only one topic, limiting the number of topics in each document. In addition, DMM assumes that one document obeys the same topic distribution, capturing word co-occurrence information at the corpus level. Compared with LDA, the assumptions of DMM are more in line with the characteristics of short texts, and short text-based topic models based on DMM have been proposed successively. Yin & Wang [29] proposed the collapsed Gibbs Sampling algorithm for DMM and explained the inference process of GSDMM using the Movie Group Process (MGP). After assigning a maximum number of topics to GSDMM, GSDMM automatically generates the right number of clusters and is able to strike a balance between completeness and consistency, i.e. assigning a cluster to all texts while ensuring that the texts in the same cluster are as similar as possible. Further, based on GSDMM, Yin & Wang [32] proposed accelerated GSDMM (fast GSDMM), which achieved lower time and space complexity.
Structures and brief descriptions of neural topic models for short texts
The assumption in DMM that one document has only one topic, while better than LDA assumption, is still too strict for practical purposes and affects topic consistency. Li et al. [23] introduced the Poisson process into the topic sampling process of DMM (Poisson-based DMM, PDMM), allowing one document to be sampled from a few topics. As opposed to DMM which assumed that the topics of document obey a multinomial distribution, PDMM first selects the number of topics based on the Poisson distribution and then samples topics based on the number. Biterm Topic Model (BTM) [28] combines the advantages of DMM and LDA in that it models global word co-occurrence patterns in the corpus directly and allows a document to be generated from a small number of topics. BTM first generates a corpus-level topic distribution parameter θ and K topic-word pair distribution parameter φ, and then assigns a topic z to each double word in the corpus. BTM has achieved good results in short text-based topic modeling tasks and has become one of the classical short text-based topic models. Further, by introducing contextual features into BTM, it is able to model realistic scenarios of short texts more accurately. For example, Chen et al. [33] proposed the Twitter-BTM model, which introduces user features into the BTM modeling process and replaces the corpus-based word co-occurrence model of topic modeling with a user-based aggregation approach.
While the above topic models work well for short text modeling, the number of topics needs to be entered in advance before sampling, and in practice we do not know what the number of topics in the corpus is. This is why the use of Dirichlet-multinomial as a prior encounter a difficulty. To compensate for this problem, Qiang et al. [30] used Pitman-yor multinomial as a prior and Mazarura et al. [31] assumed that the topics obeyed a Gamma-Possion distribution, both of which could automatically reason about the number of topics in the corpus, addressing the drawback of needing to pre-determine the number of topics for the model.
Probabilistic Topic Model is kind of probabilistic language model, based on Naive Bayes. It approximates natural language sequences by learning the joint probability distribution of discrete word sequences, and predicts the words in the sequences based on the posterior probabilities. In practice, the probabilistic language model faces the problem of “curse of dimensionality”. When computing the joint probability distribution of a discrete sequence, the number of parameters grows exponentially with the number of words, which leads to poor generalization of the model.
To address this problem, Bengio [38] proposed a neural probabilistic language model using continuous variables. The model transforms words into continuously distributed feature vectors and uses the distance of the feature vectors in the vector space to represent the similarity between words. Neural probabilistic language models alleviate the generalization problem of probabilistic language models. Similarly, probabilistic topic models face the same challenge. As an extension, neural topic models are proposed, which use neural networks to reconstruct the topic modeling process.
Based on feedforward neural network
Cao et al. [34] explained the document generation process in a traditional topic model from a neural network perspective by converting the conditional distribution of document-word in the topic model to a vector representation in a neural network, illustrated in Equation (1).
Based on these ideas, Cao et al. propose a feed-forward neural network-based unsupervised topic model (NTM), which takes as input a collection of D documents and an n-gram. The first part handles the word input, first converting the n-gram into a word vector in the word embedding layer, and then generating the topic-word distribution vector φ (w) in the word-topic hiding layer (generated from the weight matrix by sigmoid); The other part processes the document input, generating a vector of document-topic distributions θ (d) in the topic-document hidden layer (generated by softmax from the weight matrix). the final output of the NTM is the dot product of the two hidden layers, the document-word conditional distribution p (w|d).
Variational Auto-Encoders (VAE) is a generative network structure based on variational Bayesian proposed by Kinma and Welling [30]. VAE consists of a combination of an inferential network and a generative network connection. Inferential network is used to generate the variational probability distribution of the hidden variables from the original input, and the generative network is used to reduce the variational inference to an approximate probability distribution of the original input. By using the backward propagation algorithm as an optimizer, the VAE outperforms topic models based on Gibbis sampling or variational inference. the VAE has become one of the most classic neural network topic model structures, but some VAE-based topic models still suffer from sparsity when dealing with short texts.
To make the model applicable to short texts, the researchers used pre-trained vectors as a prior knowledge input to the inferred network to enhance the semantic information, while improving the quality of the topic modeling by augmenting the components in the VAE structure. Zhao et al. [35] used pre-trained word and entity vectors from a large external dataset and a manually labeled large knowledge graph as prior knowledge for the VAE structure in a Variational Auto-Encoder Topic Model (VAETM) for short texts, and used the Dirichlet distribution as the hidden variable distribution for the VAE. The improvements made by Zhao increased the interpretability of the neural network and the addition of pre-trained prior knowledge enabled the model to generate more consistent topic words from short texts. Feng et al. [36] proposed the Context Reinforced Neural Topic Model (CRNTM), which combines pre-trained word vectors with Gaussian distributions (or Gaussian hybrid distributions) in a generative network (a Gaussian decoder) and uses the pre-trained word vectors to introduce contextual information of words in the decoding process, effectively alleviating the lack of word co-occurrence information in short texts.
Based on graph neural network
The use of graph structures to represent text effectively preserves the semantic information between feature items while reflecting the structural information of the text, and has an inherent advantage over other representation methods such as bag-of-words and vector space models in representing complex text. Graph Neural Network (GNN) extends traditional neural networks to model structures that can handle graph data by emulating the ideas of neural networks such as convolutional networks, attention networks and self-encoders. Zhu et al. [37] sed the graph structure G = (V, E) in the GraphBTM model to store a collection of biterm features, where V is the set of nodes storing biterm features and E is the set of edges with biterm co-occurrence counts (weights). The adjacency matrix of the bipartite graph G = (V, E) is fed into the graph neural network to generate graph embeddings, and the graph embedding features are fed into the neural network inference model to calculate the variational parameters.
Topic modeling with embedding methods
The concept of word embeddings [16] was originally proposed by Hinton and Williams. Word embedding is a distributed representation of text. It projects syntactic and semantic information about words into a potential word vector space, with highly related words being closer together in the vector space. Word co-occurrence information available from short texts is sparse, and highly semantically related words often do not co-occur in the same document. Whereas pre-trained word embeddings can effectively mitigate the semantic deficit by capturing global semantic information in advance from external datasets. The most popular word embedding methods are Google’s Word2Vec (including both Skip-gram and CBOW) [17, 18] and its extension Doc2Vec [19], and Stanford’s GloVe [20].
The combination of topic modeling and embedding methods can be divided into three categories: a) leverage topic models to training word embeddings; b) incorporate word embeddings in the topic modeling procedure; and c) direct topic modeling in the embedding space.
Training word embeddings with topic models
This research direction uses global semantic information learned from the topic models to train word vectors.
Topic models learn global semantic features of words based on global word co-occurrence patterns, while word embeddings learn local semantic features based on contextual windows. Liu et al. [40] were the first to propose combining them to train word vectors, training word vectors and LDA models in corpus. They assumed that the topic embedding is the mean of the word vectors under the topic, linking the word vector of a word with the topic embedding to which the vector belongs to form the word embedding for the word. TWE achieves better results in both classification tasks and contextual similarity detection tasks than TWE achieves better results than Skip-gram in both classification and contextual similarity detection tasks.
Enhancing topic modeling with word embeddings
These studies incorporate word vectors into the traditional generative process to increase the probability of semantically similar words under the same topic.
Nguyen et al. [22] first integrated word vectors trained from a large corpus into a topic model using a hybrid component consisting of a Dirichlet-multinomial component and a word embedding component to replace the topic-word Dirichlet-multinomial component in LDA/DMM to form the topic model LF-LDA/LF-DMM with latent features. Latent features improve the clustering performance to some extent; however, the optimization process is computationally expensive and results in a slow running model.
Similarly, Li et al. [23] proposed GPU-DMM that first trained word vectors from a large collection of external documents using the Skip-gram in Word2Vec, and combined the word vectors with the generalized Pólya Urn (GPU) model during the sampling process to filter out words with high semantic GPU-DMM is a simpler process than LF-DMM for topic modeling and runs faster on a large corpus of short texts. In addition to Skip-gram, CBOW in Word2Vec, and Doc2Vec, which extends from Word2Vec, are also used as word embeddings in the document modeling process [24, 25].
Li et al. [41] constructed a new generative model by integrating word embeddings and topic embeddings into LDA. Particularly, topic embeddings are sampled from the hypersphere distribution, intending to approximate the centroid of the semantic clusters in the embedding space. Because word embeddings are integrated in the generation process, TopicVec does not need to be trained on a large number of documents, and experiments show that the model can still generate coherent topics even within a single document, showing that the pre-trained word vectors provide the model with rich semantic information.
Word vectors trained from external datasets contains a lot of noisy data, and too much unfiltered semantic information will produce interference, making the model less consistent in terms of topic. Considering this, Yu & Qiu [26] proposed ULW-DMM, a DMM-based model that combines internal features trained by user-LDA with word vectors trained from large external datasets, using internal features to filter external features and suppress the influence of external noise.
Topic modeling in embedding space
These studies use pre-trained word embeddings to form embedding space and define topic as a point in continuous embedding space.
Das et al. [21] proposed GaussianLDA and sampled topics from the embedding space for the first time. In GaussianLDA, topics are treated as multivariate Gaussian distribution in the embedding space, while the discrete word representation of the document is replaced by the continuous word vector representation. When dealing with words that are out of vocabulary, GaussianLDA is able to assign topics to them based on the semantic similarity in the word embedding space. It demonstrates greater robustness than LDA which uses a fixed vocabulary.
Dieng et al. [42] combined LDA and word embeddings to develop a generative model named Embedded Topic Model (ETM). In the generative process, word embeddings and topic embeddings are parameters. An amortized variational inference algorithm is proposed to inference them. Instead of carefully filtering the stop words when using LDA, ETM is robust to stop words because they are mapped to specific location of embedding space and are assigned their own topic. The incorporation of word vectors allows ETM to perform better in large vocabulary, learning interpretable topics.
Tasks and brief descriptions of topic models for on-line topic detection
Tasks and brief descriptions of topic models for on-line topic detection
In the same year, inspired by Word2Vec and Doc2Vec, Angelov et al. [42] proposed Top2Vec, which jointly modeling words, topics and documents in the same continuous semantic space. After clustering the document vectors, the centroid of the cluster is the topic vector, and the word vector closest to the topic vector may represent the topic information. Top2Vec compensates for many of the shortcomings of traditional topic modeling. For example, traditional topic models use word co-occurrence patterns to capture semantic links between words, which results in models that require careful filtering of stop words to obtain interpretable topics. In contrast, in top2vec, stop words that appear in most documents are clustered in a range equidistant from all documents, and words near the topic vector rarely have stop words, so Top2Vec does not require pre-filtering of stop words Therefore, top2vec does not require pre-filtering of stop words to generate interpretable topics. In addition, top2vec automatically performs a hierarchical topic reduction during the iteration, eliminating the need for a pre-set number of topics.
However, Top2Vec uses density-based clustering of document vectors, but selects topic words based on the distance from the word vector to the topic vector. In the sphere space around the centriod, word vectors of other clusters may be wrongly selected. To overcome this problem, Grootendorst et al. [44] used the class-based TF-IDF procedure to measure the importance of words in clusters and sample topic words. In the TRUMP Tweets dataset, BERTopic perform better than Top2Vec.
In the real world, there are many situations where short texts are the main form of data, such as social media, e-commerce reviews, conversations, etc. Topic modeling methods are wildly applied in these situations for topic detection, semantic analysis, and recommendation system. In this section, we summarized the applications and corresponding models in detail.
On-line topic detection
On-line Topic Detection (OTD) task aims to process new documents in real time. OTD can be divided into two sub-tasks, real-time topic detection and burst topic detection, depending on the applications.
Cheng et al. [46] proposed two online algorithms, online BTM (online BTM, oBTM) and incremental BTM (iBTM). Where oBTM partitions the set of biterms according to time slices, calculates the total number of biterms
Sentiment analysis and opinion mining
Sentiment Ananysis, also known as Opinion Mining, is an important task in natural language processing that aims to use natural language processing techniques to discover from text the opinions, emotions, attitudes, etc. that users express about someone, something, or an event.
Topic-Sentiment Mixture (TSM) model [50] can model the mixed product of sentiment and topic in a document by first sampling words from the background topic model and later classifying sentiment through the sentiment model words. However, TSM constructs a topic model and a sentiment model independently of each other, and does not really model topic and sentiment jointly in the process. Whereas Joint Sentiment/Topic (JST) model [51], which extends LDA, first constructs a joint topic-sentiment distribution, and then selects words from the joint distribution, highlighting the connection between topic and sentiment. JST first assumes there are number of sentiment labels, and then assumes that each document is generated from joint sentiment/topic-document distributions, where each of them corresponds to a sentiment label. JST introduces a sentiment layer into the document generation process so that the topic is closely related to the sentiment label, and each word in the document is determined by both the topic and the sentiment label. Similar to JST, Aspect and Sentiment Unification Model (ASUM) [52] also assumes that words are generated by topic/aspect-sentiment pairs and that sentiments are generated before topics. The difference is that JST models the word generation process at the document level, whereas ASUM models the word generation process at the sentence level.
Tasks and brief descriptions of topic models for sentiment analysis
Tasks and brief descriptions of topic models for sentiment analysis
However, the small number of sentences in short text documents and the sparse number of words in each sentence make it difficult for JST to mine valid sentiment topics at the document level. While ASUM, although able to discovery sentiment and topics at the sentence level, is unable to estimate parameters from the sparse sentences.
One kind of strategy is to improve the process of generating topic models. Word-pair Sentiment-Topic model (WSTM) [53] treats the whole corpus of short comments as a bag of words composed of biterms, and models the generation process of the biterm set at the corpus level, so that the sentiment-topic information in the global word co-occurrence model can be effectively captured. In addition, WSTM relaxes the assumption of ASUM to allow for multiple topics/aspects in a single sentence.
The second strategy is to add semantic information to words to obtain a richer word representation. Topics and topic words inferred from the raw data can be used as external sentiment features to input into the model or corpus, such as enriching word representations in short texts with sentiment-topic features [54], or training sentiment classifiers with sentiment-topic features to improve their classification performance [55]; introducing word embeddings trained from external datasets to add semantic information [54, 56]; using the contextual information in the environment in which the short texts are located can also be used as features to improve the accuracy of the model, e.g. emotions, the microbloggers’ personality [57] and product descriptions corresponding to product reviews [58]; in addition, the use of biterm instead of unigram can also enhance semantic links in short texts [59].
The third strategy is to perform fine-grained topic extraction. For example, Tang et al. [60] divided general opinion words, general aspect words, specific aspect words and aspect-specific opinion words, which together influence the word generation process; Ozyurt and Akcayol [61] treat comments as consisting of sentence fragments, assuming that each sentence belongs to one topic. Aspect extraction at the sentence level can mitigate the effects of sparsity.
Tasks and brief descriptions of topic models for recommendation system
One type of study models stance characteristics directly using topic models. Jin et al. [67] used a joint topic-viewpoint probability model [62, 63] to mine topic-opinion pairs from tweets related to a news item and clustered them into two categories of conflicting views (support or against); Thonet et al. [64] separated topic words and opinion words based on lexicality to improve the accuracy of identifying opinions; Du et al. [68] compared the differences between the distribution of topics in the headline/profile texts of news videos and the comments of news videos to find differences between the author’s viewpoints and the popular viewpoints.
Another type of research uses topic features extracted from the dataset to enhance the stance detection model. Wei et al. [65] used BTM to extract topics from a dataset and incorporated topic features as implicit expressions in the text representation; Choi and Ko [69] adjusted the weights in a stance detection model by comparing the difference features between the topic (stance) distributions of user comments and video descriptions; Lin et al. [66] used topic features to adjust the weights of different words in a text representation.
Corpora and indicators
In this section, commonly used corpora (especially short texts) and indicators for topic model analysis are summarized for a practical reference.
Corpora
Commonly used corpora for short-text topic modeling are presented on Table 6. It can be seen on Table 6 that one of the most commonly used corpora is 20NewsGroup, a newsgroup dataset containing about 20,000 news documents divided into 20 topics (categories). 20NewsGroup has a mix of short and long text in its documents, with nearly 30% of the documents being under 30 words long. 20NewsGroup is often used to compare the performance of short-text topic models with that of baseline models (usually classical traditional probabilistic models), and has also been used in some articles [37] to evaluate the effectiveness of short-text modeling in comparison with long-text datasets due to the proportion of short-text documents it contains. Secondly, the Web-Snippet dataset, which is derived from Google search snippet text and contains a total of 12,340 short text data, assigned under eight category tags, is also more frequently used.
Types, descriptions and related works of frequently used public corpora
Types, descriptions and related works of frequently used public corpora
The indicators of a topic model can usually be assessed from two perspectives. First, evaluated the own performance by topic coherence, perplexity, and semantic performance. Second, evaluated the performance of specific tasks such and clustering and classification by their relevant indicators.
Quality of topics
The quality of topic generation is mainly assessed in terms of two categories of indicators: Perplexity and Coherence.
Perplexity is commonly used to determine the optimal number of topics, which expressed as an exponential form of the cross-entropy of the model distribution and the real distribution. A smaller value representing a more reasonable number of topics. Perplexity is calculated as Equation (2).
However, models with better Perplexity usually have a more uninterpretable potential semantic space [85], i.e. models with lower Perplexity generate topic words that often do not conform to human understanding. Coherence is a better way to evaluate quality, which is often measured by Point Mutual Information (PMI). PMI assesses the relevance between topics and topic words, which is calculated as follows:
The semantic of topics is mainly assessed by examining whether the topics are interpretable and consistent with human comprehension. A common method is to represent the topic-word lists. There are also articles [37] that use ranked relevance for evaluation.
Classification
Accuracy, Precision, Recall and F-score are common indicators for classification. Firstly, the results are classified into true positive (TP), false positive (FP), false negative (FN) and true negative (TN). The indicators are calculated as Equations (4)–(7).
Purity and Standard Mutual Information (NMI) are commonly used to assess clustering performance. Purity reflects the number of correct samples in a cluster as a percentage of the total number of samples after clustering. The higher the purity, the better the clustering performance. Purity is calculated as Equation (8).
where N is a content that imposes the total number of samples, k is the number of clusters, ω
i
is a cluster in Ω, c
j
is a classification in
NMI is the normalization of mutual information and maps it to the [0,1]. NMI is calculated as Equations (9) and (10).
In this section, we discuss, analyze, and summarize the advantages and disadvantages of the models mentioned in the article. We hope that these contents can bring enlightenment to the research of short text topic modeling.
In general, the short text probabilistic topic models are improved based on the traditional topic models. Including increasing external knowledge, improving the priors, etc. The ultimate goal is to make up for the lack of semantics in short texts.
Aggregating short texts into long pseudo-documents is a natural idea. Classical works are SATM, PTM, LTM, etc. As SATM divides the generated model into two stages, it leads to slow computational efficiency and parameter over-fitting. PTM constructs pseudo-documents according to the generation process of LDA. With one-stage process, PTM solves the parameter overfitting problem. WNTM does not construct a generative model, but generates pseudo-documents directly from the word co-occurrence network. The word network is more consistent with natural language than the bag-of-words model. However, the computational complexity of this structure is high. WNTM is limited in its application in large-scale datasets.
The pseudo-document topic model does not need to rely on external knowledge, but is highly dependent on the raw data. If there are too few documents, topic ambiguity will occur when building pseudo-documents. When there is too much dirty data in the document, the topic probability in the pseudo-document is severely affected.
Another type of research is to improve the structure of the generative model. Traditional LDA does not work well in short texts for the following reasons: a) LDA captures word co-occurrence patterns at the document level, which short texts can hardly provide; b) LDA does not limit the number of topics in a document, yet most short texts tend to contain only a few topics; c) LDA uses the bag-of-words assumption, this text representation that does not capture the sequential relationships between words.
Compared with LDA, the structure of DMM is more suitable for short texts. As shown in Fig. 2, DMM assumes that topics are distributed over the whole corpus to capture global word co-occurrence information. DMM assumes that one document has only one topic, which is more compatible with the characteristics of short texts.
Comparing different assumptions in LDA, DMM and BTM.
Although DMM has achieved good results in short text clustering tasks, it still has drawbacks. The single topic assumption of DMM is too strong. BTM combines the advantages of LDA and DMM, uses global word co-occurrence information, and allows a small number of topics in one document. In addition, BTM takes biterm as the smallest unit which introduces sequential information. However, BTM, like LDA, is unable to reason adaptively the number of topics.
To solve this problem, one approach is to replace the Dirichlet multinomial prior with Pitman-yo multinomial prior, Gamma-Possion prior, etc. These methods can automatically reason the number of topics. However, changing or adding prior constraints sometimes increases the computational complexity, which may limit the performance of the model in large-scale data.
Neural topic models reconstruct the topic modeling process with neural networks. They use distributed representations of words and documents to be able to obtain stronger semantic input than bag-of-words representations. The neural topic model allows for parallelized training and GPU acceleration, which enhances the efficiency of model training.
However, the neural topic model needs to be trained on a large-scale dataset to effectively capture meaningful topics and may be prone to overfitting when trained on small datasets. Since the training process is a black box, the interpretability of the neural topic model is relatively poor. We cannot gain insights into the inner workings of the model.
Embedding methods in topic modeling have achieved remarkable results. We discuss the developments in this area separately in the paper.
A group of studies use topic models to train word embeddings, such as TWE. This approach combines global topic semantic and local contextual semantics, providing better support for short text analysis.
Another group of studies use word embeddings to enhance the topic modeling process, which can improve the probability of semantically similar words being assigned to the same topic, even if they are not captured by co-occurrence patterns. LF-DMM adds a word embedding component to the generative process of DMM, which achieves better clustering results on short text datasets. However, it has the disadvantage of a high time cost for the optimization process. GPU-DMM introduces auxiliary word embeddings through the Pólya Urn process. The topic modeling process is simpler than LF-DMM, and it has a faster running speed on large-scale corpora. Since word embeddings themselves contain rich semantic information, the model may not even need to be fed with a large number of documents. This advantage has been confirmed in TopicVec.
However, word vectors are not entirely beneficial. An unfiltered set of word vectors can instead provide noisy semantics for the model. Therefore, it is necessary to carefully compare different word vector libraries when using them in practice.
Embedded topic modeling presents novel topic modeling ideas. We can directly perform topic modeling by dimensionality reduction, clustering, and sampling in the embedding space.
These models alleviate some of the weaknesses in traditional models. First, the bag-of-words representation uses a fixed vocabulary, which makes LDA unable to handle the word out of vocabulary. Topic models using word vectors are able to assign high probability topics to word out of vocabulary by computing semantic similarity. GaussianLDA, ETM, Toc2Vec have such advantage. In practice, this capability is more suitable for dealing with short text scenarios. Second, traditional topic models require high data quality because they cannot identify the difference between content words and stop words. It needs to filter the stop words carefully when processing the corpus, which is very time-consuming. If not processed properly, the stop words will greatly disturb the results. The embedded topic models alleviate this problem well. In the embedding space, stop words are clustered in specific regions and belong to their own topics. Embedded topic models are extremely robust to stop words. Lastly, some embedded topic models can automatically infer the number of topics. For example, Top2Vec performs hierarchical topic reduction during iteration, and BERTopic merges class-based TF-IDF representations of similar topics during iteration, both of which require no prior knowledge of the number of topics.
These topic modeling approaches combined with deep learning techniques face the same problems of poor model interpretability and high training costs. These issues need to be focused on in future work.
Topic models are an enduring area of research in text mining. Traditional topic models have achieved good results in long-text documents. However, when dealing with short-text documents the lack of word co-occurrence information prevents traditional topic models from exploring meaningful topics. Therefore, the research of topic models for short texts has always revolved around how to bridge the gap between the underlying features and the high-level semantics. Although many methods have been proposed, there is still room for improvement in short text-oriented topic models. The future progress can be sought in the following directions. Combining generative models to enhance the semantics of the topic output. The standard output of topic model is a collection of discrete topic words, which leads to poor semantics of the results. Combining topic output with generative models enables the use of contextual information learned by the model to reconstruct topic semantics and integrate discrete topic words into logically related complete sentence [86]. Similarly, in the future it will be possible to fuse topic models with image generation models to generate images from topic words. Improving the interpretability of neural topic models. While the combination of topic modeling and neural networks improves the interpretability of the output by listing the topic words, the inner processes of the neural network remain a “black box”. To address this issue, explainers for neural network can be used to make the topic modeling process better transparency by, for example, constructing dialog trees. Further integration of topic modeling and deep learning techniques. Deep learning techniques are constantly making progress. In the future, topic modeling could combine with newer word embedding techniques [87] and optimization methods [88, 89]. Multimodal-aware topic modeling. Short texts are often surrounded by heterogeneous contextual information, such as images, audio, video, geographic location, etc. Vectorization provides the basis for the federation of heterogeneous data, and some attempts at multimodal topic modeling have achieved good results. In recent years, neural network-based techniques have made great progress in multimodal modeling. Future developments of neural topic modeling in multimodal data is promising.
Conclusion
Short texts have become an important form of data on the Internet, including SMS messages, news headlines, e-commerce reviews, etc. The sparse vocabulary of short texts has resulted in the lack of semantic information within the documents.
One group of studies worked on improving probabilistic topic models. Such studies enhance the semantic information of words in short texts by expanding the data features or capturing the global semantics from the corpus by improving the model structure, thus reducing the gap between the underlying features and the high-level semantics. The other group of studies migrated the multilayer Bayes structure of the probabilistic topic model into the corresponding neural network layers, mapping discrete words in short texts into a continuous numerical form and using a neural network approach to topic modeling. In addition, topic modeling combined with embedding methods have also yielded good results in bridging semantic gap and developed a new way to extract topics.
Short text topic models are widely applied in various real-life scenarios. Topic models can modify their structure according to the target data to improve the effectiveness in specific applications.
Further improvements in topic modeling for short texts can be made in the direction of combining with generative models, improving the interpretability of neural networks, incorporating deep learning methods and enhancing multimodal-aware topic modeling.
Footnotes
Acknowledgment
This work is supported by the Fundamental Research Funds for the Central Univer sities (No. CUC23GY006), the National Key Research and Development Program of China (No. 2022YFC3302103), and Guangxi Natural Science Foundation (2021GXNSFBA196054).