
Abstract
A software defect is a common cyberspace security problem, leading to information theft, system crashes, and other network hazards. Software security is a fundamental challenge for cyberspace security defense. However, when researching software defects, the defective code in the software is small compared with the overall code, leading to data imbalance problems in predicting software vulnerabilities. This study proposes a heterogeneous integration algorithm based on imbalance rate threshold drift for the data imbalance problem and for predicting software defects. First, the Decision Tree-based integration algorithm was designed following sample perturbation. Moreover, the Support Vector Machine (SVM)-based integration algorithm was designed based on attribute perturbation. Following the heterogeneous integration algorithm, the primary classifier was trained by sample diversity and model structure diversity. Second, we combined the integration algorithms of two base classifiers to form a heterogeneous integration model. The imbalance rate was designed to achieve threshold transfer and obtain software defect prediction results. Finally, the NASA-MDP and Juliet datasets were used to verify the heterogeneous integration algorithm’s validity, correctness, and generalization based on the Decision Tree and SVM.
Introduction
In recent years, many people have relied on convenient, practical, and robust applications of software functions. Software security is intertwined with daily living and is related to cyberspace security. The factors that cause software insecurity come from the security loopholes caused by the software’s errors, defects, and external attacks. The software’s robustness can be improved, and cyberspace security can resist external attacks if the software is designed to reduce security vulnerabilities and detect defects.
In this case, improving software developers’ capabilities enhances the quality of software products. Investigation into software defects shows an imbalance and fewer defective modules in the software code than defect-free modules. This situation can interfere with the validity of prediction for software defects and make the accuracy of prediction results very challenging. The integrated approach to software defects is currently the most common method to solve the class imbalance problem. This approach effectively improves the final classification results by integrating the strengths of individual learners [1, 2]. All base classifiers are of the same importance, and the higher the difference between the results, the better the integrated model effect.
The integration comprises homogeneous integration and heterogeneous integration, according to the same individual classifiers. Homogeneous integration shows that the integrated individual classifier groups are all the same. In machine learning [3], homogeneous integration algorithms comprise the current popular algorithm of Random Forest, ExtraTrees, and Gradient-Boosted Decision Trees (GBDT). The Classification and Regression Trees (CART) are the base classifiers of these three integrated algorithms. Enhancing the diversity of basic classifiers is the key to improving the generalization ability of ensemble learning. The enhancement methods include data, parameters, and model structure. However, homogeneous integration does not consider the model structure diversity [4]. Heterogeneous integration is a method that combines different types of machine learning algorithms to improve the accuracy and robustness of the model. However, performance bottlenecks may occur because of the vast structural differences between heterogeneous classifiers, resulting in the difficulty of integration and the performance degradation of the entire algorithm. Therefore, this study explores the heterogeneous integration algorithm.
Three main problems with software defects are as follows: (1) the imbalance of defect data in software needs must be considered; (2) the classifier structural diversity is not considered in the research using an isomorphic integration algorithm; and (3) heterogeneous integration algorithms cannot guarantee integration algorithms’ performance and generalization ability. This study proposes a Software Defect prediction method based on Heterogeneous Integration algorithms (SDHetInt) to improve the effectiveness and generalization ability of the integration algorithm on imbalanced datasets. In response to the three above-mentioned problems, this article proposes a SDHetInt integration algorithm. Compared with the currently popular isomorphic ensemble algorithms such as Random Forest, ExtraTrees, and GBDT, SDHetInt uses different machine learning models to construct the basic classifier, considers the diversity of data samples and input attributes, and moves the threshold based on the imbalance rate of defect data. Compared with single machine learning models and isomorphic ensemble algorithms, the SDHetInt heterogeneous ensemble algorithm can effectively solve the problem of low defect prediction performance caused by data imbalance by predicting software defects.
This study provides the following contributions: We analyze the correlation between software features and defects based on unbalanced software defect data. Sample perturbation and attribute perturbation construct two software defect classifiers with different structures. A SDHetInt heterogeneous integration classifier is constructed using software defect classifiers with different structures. The results of predicting software defects in NASA datasets show that the SDHetInt heterogeneous integration classifier offers a good prediction effect on unbalanced data processing. Moreover, SDHetInt offers better heterogeneous integration algorithm performance than the current popular Forest, ExtraTrees, GBDT integration algorithm, and isomorphic integration algorithm. We achieved good prediction results by applying the SDHetInt heterogeneous integration classifier to NASA and Juliet’s unbalanced software defect data. The proposed SDHetInt has excellent generalization ability.
The rest of this paper is organized as follows. Section 2 describes the related work. Section 3 discusses the heterogeneous integration method and algorithm, including constructing the Decision Tree and Support Vector Machine (SVM) based classifier, the fusion of the base classifier, and the threshold shift based on the imbalance rate. Section 4 describes our experimental evaluation and the results of SDHetInt. Section 5 discusses the limitations of SDHetInt and problems to be addressed in future research. Section 6 presents the conclusions.
Related work
Data security has garnered increasing attention due to the frequent occurrence of network security events. Software defect prediction is a meaningful way to analyze software quality and reduce development costs. Software defect prediction is a research problem in the field of software engineering. Many research achievements have been made, which have occupied a leading position in software security [5–9]. Software defect analysis includes static, dynamic, and dynamic static combination analysis methods. The static analysis method consists of the static analysis of source and binary codes. Dynamic analysis and dynamic static combination analysis are used to analyze binary files.
Due to the binary software limitation, most current research applies the static analysis of software source code to predict software defects. At the initial stage of software development, Czibula et al. [10] proposed a model of relationship association discovery based on software defect prediction. They applied and compared all the NASA datasets with other evaluation models. They have better accuracy, specificity, and detection probability and cover evaluation prediction results. In a previous study on software defect prediction, supervised learning consumes considerable effort when labeling training data.
Patil et al. [11] used explicit semantic analysis to classify software defect reports based on concepts, analyze the source code’s semantic information, and predict software defects. This method determines the semantic similarity between the defect type label defect report in the conceptual space of Wikipedia. Then, this method assigns the defect type with the highest similarity to the defect report. However, in the practical field of software development, the software projects that must be predicted are usually brand-new software projects that need more labeled data to build defect prediction models. Zhao et al. [12] proposed a cross-project defect prediction method based on stream feature transformation in cross-project software. Currently, several studies have proposed on-the-fly techniques to predict defective changes. Ardimento et al. [13] proposed an on-the-fly software defect prediction technique based on temporal convolutional networks using features from source code metrics detected in the commit history of software projects. Ardimento et al. [14] proposed a comprehensive feature set approach that can promptly predict the defect propensity of code components and improve the performance of the on-the-fly defect prediction model. Table 1 summarizes the related work on software defect prediction.
The related work on software defect prediction
The related work on software defect prediction
In the current software development environment, the size of software code data increases as the software becomes more complex. Since the software code with fewer defects is higher than the code without defects, an imbalance is noted when predicting defects. This issue makes data classification difficult. Most algorithms focus on classifying primary samples while ignoring or mistakenly classifying a few samples. The class imbalance has become the biggest problem in data mining. Machine learning uses five technologies for processing unbalanced data: oversampling, undersampling, cost-sensitive learning, ensemble learning, and combined class methods [15–19]. Oversampling is balanced by increasing the size of rare samples. SMOTE is the primary technique of oversampling. This method is limited based on the assumption that the local space between two positive instances belongs to a few classes and that the training data are not linearly separable. This assumption may sometimes be correct. Undersampling processes of an unbalanced dataset are critical by reducing the number of classes. Cost-sensitive learning adds misclassification costs by minimizing the total cost. This technology aims to achieve high accuracy when classifying instances into a group of known classes. Integrated learning technology combines multiple classifiers to improve the performance of a single classifier. This method modifies the inductive ability of a single classifier by assembling different classifiers. It also incorporates the output of multiple primary learners. The composite class method is to combine various techniques.
In predicting software defects, some studies use oversampling or undersampling to balance datasets and solve the problem of category imbalance. Goyal proposed a neighborhood-based undersampling algorithm to solve the class imbalance problem [20]. The algorithm under-samples the dataset to maximize the visibility of a few data points while limiting the excessive elimination of most data points to avoid information loss. Other scholars solve the problem of category imbalance in predicting software defects. Aankush et al. used a combination of simple noise removal, unbalanced class distribution, and software metric selection techniques to optimize defect prediction in software [21]. Pandey et al. manually added various noise levels and determined their impact on the performance of software defect prediction models [22]. They devised techniques to guide the baseline model’s possible range of allowable noise. Liu et al. proposed a weighted Gini coefficient embedding feature selection method to solve the category overlapping problem [23].
Some scholars predict software defects based on distance metrics to solve the category imbalance problems. Jin proposed a distance-measure learning method based on cost-sensitive learning to reduce the impact of sample category imbalance. They applied this technique to the sizeable marginal distribution machine to replace the traditional kernel function [24]. The CS-ILDM model is proposed to predict the defects in software. The improvement and optimization of Large margin Distribution Machine based on Cost-Sensitive Learning are used to predict software defects. Chakraborty et al. proposed a hybrid method of the Hellinger network model [25]. Hellinger network is a tree-to-network mapping model and a deep feed-forward neural network with a built-in hierarchical structure. This method improves software defect prediction based on an insensitive skew distance metric when dealing with class imbalance problems.
To be more robust than using absolute distance information to predict software defects, Zheng et al. introduced the relative density to reflect the importance of each instance in their class. They used the probability density estimation based on the K-nearest neighbor to calculate the relative density of each training instance. They also designed the fuzzy membership degree of the sample based on the relative density to predict the defects of the software [26]. Table 2 summarizes the methods to solve the category imbalance.
The methods to solve the category imbalance
The methods to solve the category imbalance
Due to their advantages in solving unbalanced data, integration algorithms have been used to predict software defects. The integration methods based on machine learning comprise isomorphic integration and heterogeneous integration. Most studies focus on isomorphic integration algorithms based on feature selection and bagging strategy.
In integration methods based on machine learning, some scholars have proposed methods based on feature selection. Jiang et al. proposed a feature selection method based on sorting integration to avoid the instability of standard sorting feature selection [27]. They used a logical regression algorithm to build prediction models for frequent redundant or irrelevant features in defect datasets.
Bagging integration algorithms are used based on machine learning. Iqbal et al. proposed an integrated classification framework based on MLP for predicting software defects by using three dimensions: tuned MLP, tuned MLP with bagging technology, and tuned MLP with pressurization [28]. Mousavi et al. predicted software defects by integrating bagging and static and dynamic integration selection strategies [29]. This method uses a new packaging method for category imbalance learning.
In researching heterogeneous integration algorithms, some scholars have adopted the method of constructing new datasets. For example, Yu et al. analyzed the impact of class balance on model performance [30]. They showed that the performance of many personal classifiers will decrease with an increase of unbalance rate. However, the performance of logistic regression and stochastic forest model is superior to that of other algorithms, proving the integration algo-rithm’s accuracy based on the decision tree. Table 3 summarizes the integration methods in machine learning.
The integration methods in machine learning
The integration methods in machine learning
Although deep learning models can achieve excellent results in classification algorithms, they require massive datasets and high-performance intensive computing hardware. Small sample data are required to demonstrate software defects because of data imbalance when predicting software defects. Thus, traditional machine learning has better performance and offers hardware resource efficiency advantages.
Different from isomorphic integration algorithms such as Random Forest, ExtraTrees, and GBDT, as well as using the method of constructing new datasets to construct heterogeneous integration algorithms. Based on the current research on integration algorithms, this study proposes a heterogeneous integration method based on imbalanced rate threshold shifts to predict software defects and handle imbalanced software defect data. Machine learning algorithms are an appropriate choice when selecting a primary classifier for predicting software defects because they are fast, efficient, robust to noisy data, and suitable for binary classification and high-dimensional data.
In addition to meeting the above advantages, the calculation amount of the Decision Tree is relatively small, and it is easy to convert into classification rules. Decision Tree can also handle continuous and category fields insensitive to missing values and irrelevant features. It only needs one construction and can be used repeatedly. The maximum number of calculations for each prediction is the depth of the Decision Tree. SVM can use kernel function to map to high-dimensional space. When dealing with prediction defects, SVM can solve the nonlinear classification of binary classification and avoid features such as over-fitting and generalization errors in Decision Trees. Therefore, this study selects Decision Tree and SVM model with significant differences to build two sets of basic classifiers. Then, a heterogeneously integrated classifier is constructed based on the fusion of two basic classifiers.
The algorithm comprises three parts: (1) data on software defects were preprocessed to select features more effectively to predict software defects. (2) Based on software defect data training, a group of decision tree classifiers with diversity was trained using sample disturbance. A group of SVM classifiers with diversity was trained using attribute disturbance. (3) Two sets of base classifiers were combined, and the prediction of two sets of base classifiers was considered as the probability value of defect samples. The final prediction probability value of the heterogeneous ensemble algorithm was obtained through a simple average method. Based on the imbalance rate, a threshold was set, and the samples with a probability more significant than the threshold were classified as defect samples. In comparison, the samples with a probability less than the threshold were classified as non-defect samples. Figure 1 shows the specific process.

Software defect prediction framework based on heterogeneous integration.
Software measurement is a quantitative measurement technique for software projects, development processes, and software products [31, 32], which provides a quantitative standard for evaluating code quality. The structured software metrics method is an example of the quantitative software method. Among the classical structured metric methods of program software, the metrics methods based on line of Code, Halstead, McCabe, Cyclomatic Complexity, Essential Complexity, Design Complexity, Integration Complexity, C&K, and MOOD have been proven to predict software defects accurately and efficiently [33–35]. This study establishes a defect prediction model based on the structured software metrics method. The study predicts defects in software based on Halstead, Cyclic Complexity, Essential Complexity, Design Complexity, and other metrics methods. See Section 4.1 for details.
Analyzing the internal correlation between each feature and defect category is vital because software defects contain many duplicate data. This approach effectively reduces the feature dimension and improves the algorithm’s operation efficiency.
The historical data preprocessing of software defects is as follows: (1) the first step is to delete the duplicate data samples in the historical data. Deleting will include features with zero values, missing values, and the same feature values. (2) Second, the relationship between features and software defect categories is analyzed. According to the filtering method, feature selection is performed on the dataset. Selecting the feature corresponding to the software defect category as the feature subset is essential.
Common external features of the software include lines of code, lines of declaration class code, lines of execution class code, number of function nesting levels, program execution path, and cyclomatic calculation complexity. Common internal features of the software include function names and function calls in the source code. The univariate feature selection of the filter selection method consists of the Chi-square test, Pearson’s correlation coefficient, and mutual information. Pearson’s correlation coefficient feature selection is a method that can analyze the relationship between features and response variables. This method measures the linear correlation between variables. Thus, we chose the Pearson’s correlation coefficient for feature selection. When Pearson’s correlation coefficient is used to measure the relationship between features and categories in the data on software defects, the larger the value, the stronger the correlation between features and categories. The feature is strongly correlated, as shown in Equation (1):
where X represents software features; Y represents whether the software contains defects, and n is the total number of samples. Xi represents the feature of the ith sample. Yi represents the category label of the ith sample; μ
x
is the mean value of X; and μ
y
is the mean of Y.
After deduplication and feature selection, this paper divided the feature subset of software defect history data into DDT and DSVM. The DDT and DSVM datasets were divided into several sub-datasets according to the corresponding number of base classifiers. Thus, randomness was introduced into the homogeneous individual classifier to enhance the diversity of individual learners and build an ensemble classifier with strong generalization ability. Additionally, two data samples and attribute disturbance methods were selected to improve diversity.
Data sample disturbance is usually based on the sampling method. When classifiers such as the decision tree and neural network change slightly in the training samples, the learners will change significantly. Therefore, the data sample disturbance is very effective for this unstable base learner. The dataset DDT={DDT1, DDT2, \dots , DDTn} and these sub-datasets were used to train different decision tree classifiers’ IDT.
Since SVM belongs to a stable classifier and is insensitive to the disturbance of data samples, input attribute disturbance is adopted for SVM. Different attribute sub-datasets were generated in the DSVM dataset DSVM={DSVM1, DSVM2, \dots , DSVMn} according to the input attribute disturbance method. These sub-datasets were used to train different SVM classifiers for ISVM.
Construction of the decision tree base classifier
We obtained a subset of a specific defect training data sample size through resampling. Then, we randomly extracted a fixed number of defect attributes from the obtained training subset to allow the base classifier to be as diverse as possible in the training stage of the base classifier of the decision tree. Multiple defect training subsets for DDT were obtained by sample disturbance in the training set {DDT1, DDT2, \dots , DDTn} and input to the decision tree base classifier for training. Finally, a set of base classifiers with improved generalization performance IDT={IDT1, IDT2, \dots , IDTn} was obtained.
A decision tree algorithm is a tree structure that classifies instances based on features. The decision tree has two types of nodes: internal nodes and leaf nodes. Internal nodes represent attributes in software defect data, such as code lines, the number of operators, and cyclomatic complexity. Leaves indicate whether the software code module has defects. During classification, the decision tree starts from the root node to test the attributes of the test sample, and each internal node corresponds to the value of a feature. According to the test results, the sample is analyzed to the branch node of the lower level, which is a recursive process until the sample reaches the leaf node, and the corresponding category is obtained.
The construction process of a decision tree-based classifier includes decision tree generation and pruning. The detailed process is as follows: Generation of Decision Trees: For software defect classification, the generation of the decision tree is a top-down, divide-and-conquer process, which is essentially a greedy algorithm. Measuring the training dataset for testing is vital, starting from the root node for each leaf node. According to the different test results, the dataset is divided into training sets. Each child training set constitutes a new non-leaf node. The above process is repeated and divided until the termination conditions are met to form a leaf node. Thus, we use the Gini index to measure the impurity of the data partition D. Pruning of Decision Trees: The cost complexity pruning algorithm is used to prune the tree. In this process, the tree complexity is a function of the number of leaf nodes in the tree and the error rate of the tree. Starting from the bottom of the tree, for each internal node N corresponding to a software defect feature, the subtree of N and the cost complexity of the subtree of N after pruning are calculated to decide whether to prune.
The decision in the algorithm takes the Gini coefficient as the splitting point of the metric index. The training dataset D is divided into D1 and D2, depending on whether the metric index F takes a certain possible value. Under metric index F, the Gini index definition of set D is shown in Equation (2).
The Gini index Gini(D, F) shows the uncertainty of set D after F = fi segmentation. The sample’s uncertainty is higher with a larger Gini index. Finally, the single decision tree model is trained to predict defects in the software code module through the test set indicators.
The above is the generation process of a single decision tree. Several trees with different structures must be trained to obtain a set of IDT base classifiers, as shown in Fig. 2. Since each tree is trained from random sampling and random attribute extraction, the independence of each tree is guaranteed.
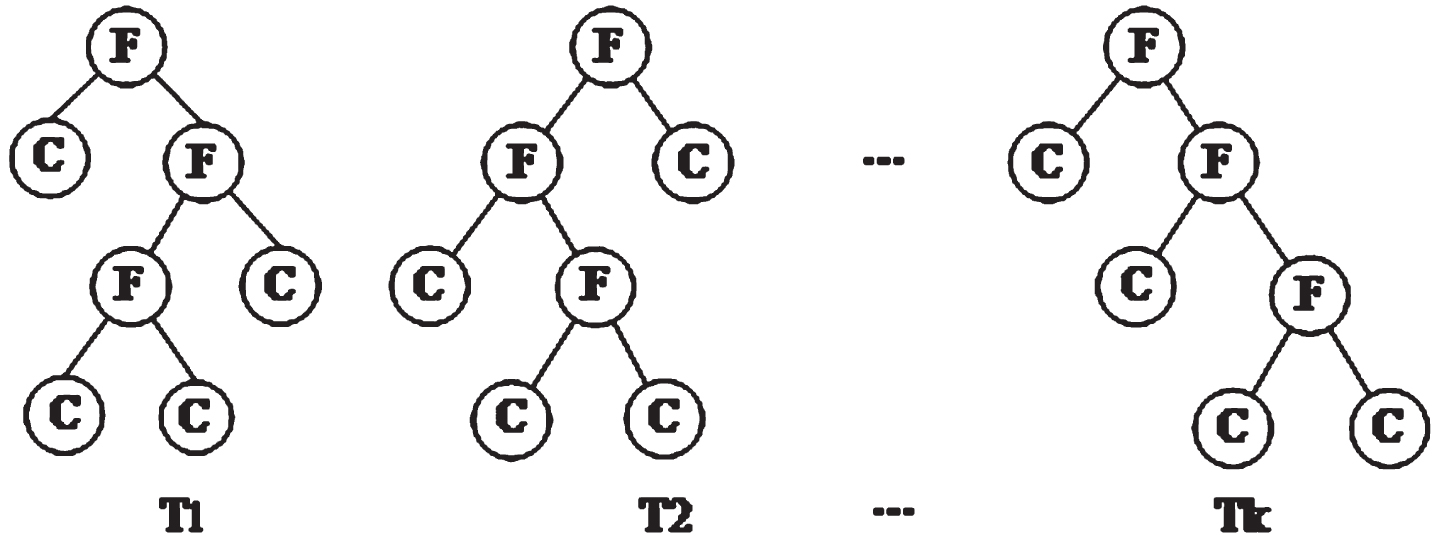
Composition of the decision tree integration model.
Pseudocode 1 introduces the construction process of the IDT basic classifier. Pseudocode 2 introduces the construction process of the decision tree. When the number of decision trees is N, the training sample set of software defects is set as D={(x1, y1), (x2, y2), \dots , (xn, yn)}. After random sampling and random extraction of attributes, the newly generated sub-training set becomes Di, Di ⊆ D, Software Metrics Set F={f1, f2, \dots , fn} and Fi is the metric set in the newly generated sub-training set Di. Fi ⊆ F.
Lines 1–4 of Pseudocode 2 create a decision tree; lines 5–7 create the leaf node that carries the defect category; lines 8–9 look for the best features to divide the defect dataset; and lines 10–18 recursively create a decision subtree for each partitioned defect dataset. Pseudocode 1 calls Pseudocode 2 several times to generate multiple decision trees. Line 5 conducts a simple average based on the prediction results of the created multiple Decision Trees to obtain the probability value predicted as the defective category. A set of decision tree base classifiers, constructed by traversal Pseudocode 2, outputs the probability values of positive classes after voting all Decision Trees.
Independence should enhance the diversity of the base classifier. In the training stage of the SVM integrated model, multiple defect training subsets DSVM were obtained through attribute disturbance in the training set DSVM={DSVM1, DSVM2,..., DSVMn}. By inputting the sub-dataset into the SVM base classifier for training, a set of base classifiers with improved generalization performance, ISVM={ISVM1, ISVM2,..., ISVMn}, is obtained. In the classifier, software defects are predicted by the decision boundary of the SVM to learn the maximum margin hyperplane of software defect samples. Figure 3 shows the detailed principle of SVM.
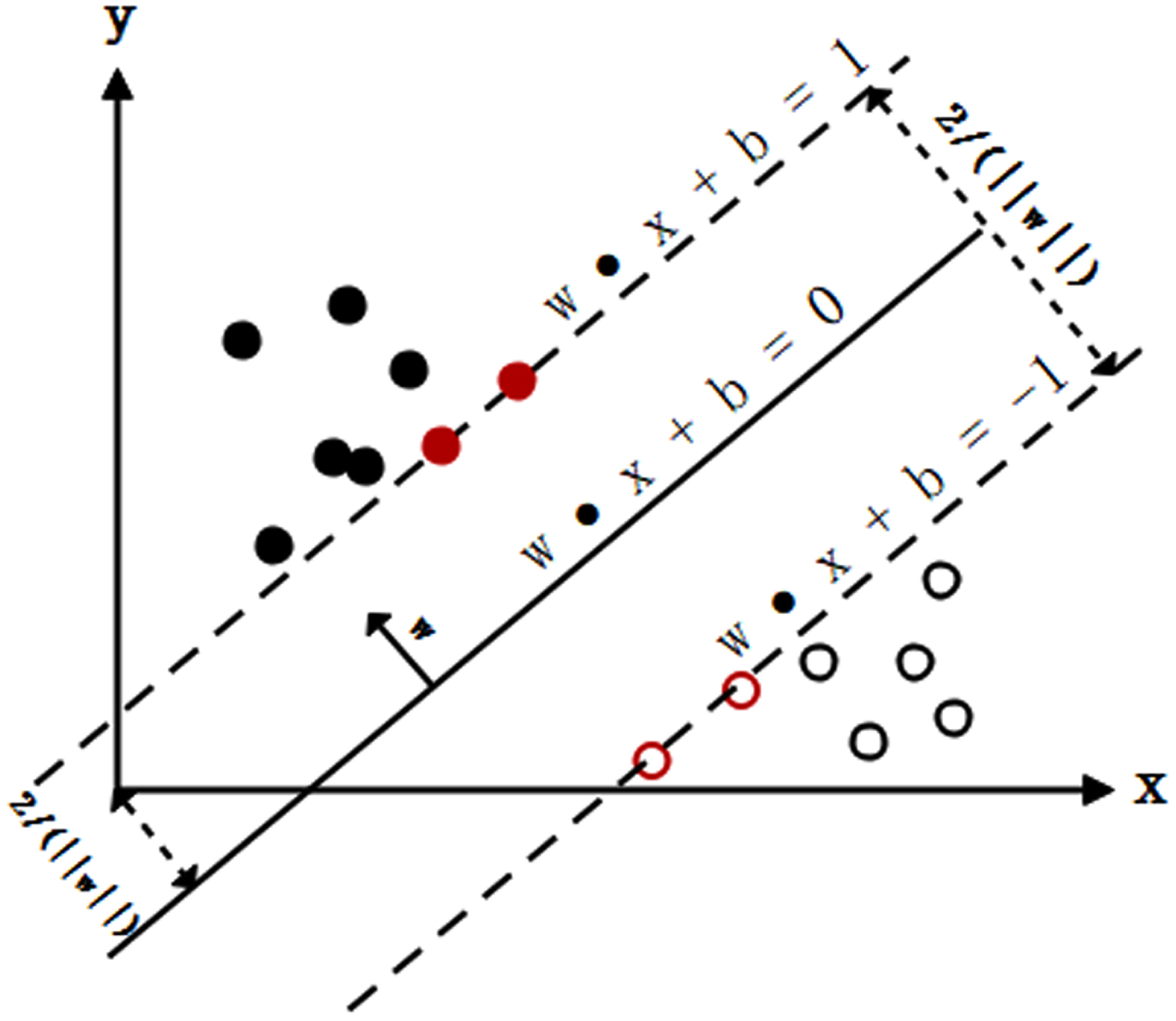
Principle of the support vector machine.
When predicting software defects, the dataset is D={(x1, y1), (x2, y2),..., (xN, yN)}. Each input data sample contains multiple software defect features, and the feature is Xi =[X1, X2,..., XN] ∈ X = Rn, thereby forming the feature space. The classification target is the binary variable y ∈ Y={– 1, 1}, where y indicates no software defect or software defect.
Xi in Equations (3) and (4) is the defect feature of the ith sample; yi indicates whether the ith sample contains defects; w is the normal vector of the hyperplane; and b is the intercept of the hyperplane. The decision boundary satisfying this condition constructs two parallel hyperplanes used as interval boundaries to determine whether the software contains defects. Solving the separation hyperplane and classification decision function is as follows: first, the penalty parameter C > 0 is selected to construct and solve the convex quadratic programming problem.
The above is the training process of a single SVM model, in which the feature space Xi =[x1, x2,..., xn] is the set of feature attributes based on software metrics. Each SVM is trained from a new data subset with random sampling and attribute disturbance. A set of highly independent SVM base classifiers is obtained.
When the number of SVM algorithms is M, the training sample set of software defects is set as D={(x1, y1), (x2, y2),..., (xn, yn)}. After random sampling and random attribute extraction, the newly generated sub-training set becomes Di, Di ⊆ D; the probability of test sample x is W(x), and a logical regression model is wj. Pseudocode 3 introduces the construction process of the ISVM basic classifier, and Pseudocode 4 introduces the construction process of the SVM classifier.
Combining multi-base classifiers
After the above training process, the trained IDT and ISVM base classifiers were obtained, and the two base classifiers were combined to form a heterogeneous integration algorithm. Combining multiple disturbance mechanisms makes the differences between base classifiers more significant. The effect of the classifier is improved with an increase in the degree of difference between individual learners.
The combination methods of classifiers are in two categories: the first is based on the construction of classifiers, and the second is based on the output of classifiers. We use the second method to calculate the classification to obtain a better prediction effect.
The single base classifier generated by the training samples outputs a probability of the category predicted to have defects for each sample in the defect test set. The output result of the final strong classifier is calculated using the probability value of all the internal single-base classifiers. The calculation is as follows:
With great differences, two groups of base classifiers IDT and ISVM were built into heterogeneous integration models by setting the imbalance rate for threshold movement. This section introduces the predicted probability values obtained from each model with the imbalance rate for prediction.
In the dichotomy problem of software defects, the classifier’s probability of predicting defects is P, and the probability value of no defects is 1– P. M is the ratio of two categories of probabilities, called the odds ratio or probability, as shown in Equation (11).
The imbalance rate K is defined according to the proportion of categories in software defect data. In the data, the number of samples with defects is m, and the number of samples without defects is n. The imbalance rate is shown in Equation (12).
This value is also known as the observed probability of defect data, M’=K. In algorithm classification, the samples will be classified into defective categories when the prediction probability M is greater than the actual observation probability M’. Meanwhile, (13), (14) are further calculated.
When the classifier makes a prediction, two types of samples will reach equilibrium based on default. Thus, the observation probability is 0.5; the threshold value of the classifier defaults to 0.5. When it is more significant than 0.5, it is a defect class; when it is less than 0.5, it is a non-defect class. However, the defect data could be more balanced. It will also disturb the effectiveness of the prediction algorithm and bring significant challenges to the accuracy of the prediction results. Therefore, adjusting the decision rules is critical through the threshold movement. Adopting the original unbalanced historical defect samples is also essential for learning. In the prediction of the trained classifier, the observation probability of the historical defect samples was used as a new threshold to alleviate the influence of unbalanced data on the classifier.
First, the output results of the base classifier are counted. Then, the integration strategy of soft voting for probability is adopted. The IDT and ISVM base classifiers are combined into a final robust classifier using a simple average fusion strategy. According to the data of software defects, the unbalance rate K and the observation probability M’ are obtained. M’ is taken as the classification threshold to adapt to different datasets. Samples with a probability greater than M’ are classified into the defect class. Those with a probability less than the threshold are classified into the non-defect class. Finally, the prediction of software defects is achieved. Compared with the single classifier and the homogeneous ensemble algorithm, the proposed method enhances the model’s prediction accuracy and generalization ability.
Pseudocode 5 describes the specific process of the SDHetInt heterogeneous integration algorithm based on unbalanced rate threshold movement. The number of decision trees is N. The number of SVM algorithms is M, and the training sample set of software defects is D={(x1, y1), (x2, y2),..., (xn, yn)}.
Pseudocode 5 is based on the fusion of IDT and the ISVM base classifier of a simple average method. The output results are calculated to obtain the probability value P. The observation probability of the unbalanced data is obtained according to the imbalance rate K to judge whether the software contains defects by the moving threshold value.
Experimental data
This study collected NASA MDP data, which include 13 actual NASA projects [36]. Each dataset represents the NASA software system or subsystem and records defects in each module identified through error tracking system counting. A software module is a function, method, or procedure, and each software in the dataset contains several code modules. MDP datasets can accurately reflect the defects in the formation of large software systems, and many researchers use these datasets to predict software defects. Each item in the MDP dataset contains category labels and software metrics features. The feature type is the value type of the category label, indicating whether or not the software code module is defective. Moreover, the float type data are the value type of metric software feature. Table 4 shows the software-metric feature.
Description of features
Description of features
Shepperd et al. [37] provided a cleaned-up version of NASA’s dataset that addresses conflicts and inconsistencies in the data. However, we used a cleaned version of the dataset. We used representative software subsystems written in C language since C language is a widely used programming language. Thus, we selected the PC1, PC3, and PC4 datasets.
Table 5 shows the software defect data, revealing that the dataset’s defect rate is lower than 15%, confirming that the software defect data have the feature of class imbalance and indicating that most data do not contain defects.
Software defect data
The PC1, PC3, and PC4 datasets include defect feature values and the probability of containing defect labels. The software defect feature data type is the floating point type in which the feature value comprises numbers. It also consists of the feature type of letters N and Y, where Y shows that the sample has software defects, and N indicates that the sample does not have software defects.
The model is evaluated from multiple perspectives due to the unbalanced distribution of software defect datasets and the diversity of software systems. The classification algorithm takes accuracy as the evaluation performance when predicting the data with balanced sample categories. However, the classifier’s performance cannot effectively describe the unbalanced data classification. Moreover, the AUC and G-mean values are used as the evaluation indices. The AUC value is the area enclosed by the Receiver Operating Characteristic (ROC) curve and the coordinate axis, and the value range is within [0, 1]. The AUC was used to evaluate the model’s accuracy. The closer the AUC value is to 1, the better the model performance. The curve is a two-dimensional graph with the probability of detection (PD) as the vertical axis and the probability of false alarm (PF) as the horizontal axis. PD represents the percentage of defect modules correctly classified in the defect class, and PF represents the percentage of non-defect modules misclassified in the non-defect class. The G-mean represents the geometric mean of the defect recall rates and non-defect types. The prediction model with better performance should accurately predict both defect and non-defect classes, i.e., a high G-mean value. In the software defect dataset, the G-mean can reflect the change in PD. The definition is as follows:
Classification algorithms adjust threshold parameters to find suitable models. When predicting software defects, an increase in PD comes at the expense of an increase in PF. The ROC curve is formed by adjusting the PF and PD values generated by the algorithm threshold. In evaluating the classifier’s performance, the ROC curve correctly observes the classifier’s proportion. Moreover, it incorrectly identifies the non-defect class as the defect class. It also identifies the defect class and the proportion of the classifier incorrectly.
Since the point (PF = 0, PD = 1) is the ideal point in the ROC curve, and all prediction errors are correctly identified at (0,1), the measure Balance calculates the true (PF, PD) point to (0, 1) Euclidean distance. The definition is as follows:
Compared with PD and PF, the AUC, G-mean, and Balance have the advantage of insensitivity to data class distribution. Therefore, the experiment uses these three comprehensive indicators to evaluate the performance of the heterogeneous ensemble prediction model.
Feature selection results
This experiment adopts Pearson’s coefficient to measure the relationship between features and categories. Its value range was between – 1 and 1. The higher the value, the stronger the correlation between the feature and category. The feature is strongly correlated and tends to be retained. We select the features with the strongest correlation according to the Pearson’s coefficient between the feature and category. Moreover, we calculate the Pearson’s correlation coefficient values of 37 features in PC1, PC3, and PC4 datasets, as shown in Table 6.
Pearson’s correlation coefficient values
Pearson’s correlation coefficient values
Then, we selected features with positive Pearson’s correlation coefficients for all datasets according to the Pearson feature selection method. This experiment selected 27 features and provided better features for the subsequent training of decision trees and SVM models. This approach helps to build basic classifiers, as shown in Fig. 4.

Selected features.
This experiment randomly selected 80% of the data from the original dataset and labeled them as the training dataset. The training set calculated the unbalance rate K value. The disturbance of the input sample number and input attribute number was introduced in the training stage of the decision tree and SVM base classifier to construct the different base classifiers. When constructing a decision tree and SVM base classifier, 80% of the samples and 70% of the attributes were randomly selected to train each classifier.
The experiment was divided into three steps to determine the number of two base classifiers during integration: First, a group of decision tree algorithms or SVM served as the integration algorithm. The optimal number of base classifiers was found through the grid search strategy. The corresponding decision tree classifier IDT was trained according to the DDT dataset. Moreover, the corresponding SVM classifier ISVM was trained according to the DSVM dataset. Second, the IDT and DSVM base classifiers were combined by the simple averaging method to obtain an optimal heterogeneous ensemble classifier. According to all classifiers’ probabilities, the defects’ probability value was finally predicted. The threshold value of the final classifier was calculated according to the K value, and the final classification result was obtained. Table 7 shows the experimental results of datasets PC1, PC3, and PC4.
SDHetInt heterogeneous integration algorithm results
SDHetInt heterogeneous integration algorithm results
As shown in Table 7, the heterogeneous integration algorithm SDHetInt based on the unbalanced rate threshold movement achieved good results based on the values of the three indices. The algorithm could analyze each dataset according to the unbalance rate of the software’s defect data. This algorithm can achieve a high prediction performance.
The most popular integrated learning algorithms are Random Forest, ExtraTrees, and GBDT. However, their implementation technologies and applicable data are different.
Both Random Forest and ExtraTrees are based on decision trees. When constructing each decision tree, Random Forest will randomly select some of the features for partitioning. However, ExtraTrees will randomly select features and partitioning points on each node. This technique gives ExtraTrees better generalization and anti-noise ability than Random Forest. GBDT is an algorithm based on gradient lifting, which continuously fits the residuals through iteration and finally obtains a powerful model. GBDT is more suitable for dealing with high-dimensional sparse data and nonlinear problems than Random Forest and ExtraTrees. However, Random Forest and ExtraTrees are suitable for dealing with high-dimensional data and noisy situations, whereas GBDT is more suitable for dealing with nonlinear problems and regression problems.
Compared with Random Forest, ExtraTrees, and GBDT, SDHetInt implements a technology that integrates a decision tree based on sample perturbation and an SVM based on attribute perturbation. This method achieves threshold transfer by setting an unbalanced rate to obtain software defect prediction results. We compare the SDHetInt algorithm with Random Forest, ExtraTrees, and GBDT algorithms to verify the validity and correctness of the experiment. We used the AUC, G-mean, and Balance as the evaluation criteria. Tables 8–10 present the comparison results.
AUC value of SDHetInt and other integration algorithms
G-mean value of SDHetInt and other integration algorithms
Balance value of SDHetInt and other integration algorithms
Tables 8–10 show that the AUC, G-means, and equilibrium values of the SDHetInt algorithm are higher than those of the Random Forest, ExtraTrees, and GBDT algorithms, respectively. From this result, it can be seen that the prediction model has higher accuracy than other homogeneous integration algorithms, effectively improving the algorithm’s prediction of the unbalanced defect dataset. Tables 8–10 show that SDHetInt is more suitable for datasets with unbalanced data than Random Forest, ExtraTrees, and GBDT.
We compare the SDHetInt algorithm with a decision tree (DT), logistic regression (LR), KNN, naive Bayes (NB), and SVM single classifier to verify the validity and correctness of SDHetInt. The single classification algorithm must build a single classifier according to its algorithm structure. This approach helps predict the defects in the software. SDHetInt integrates two heterogeneous classifiers and sets the unbalance rate to achieve threshold transfer and obtain the software defect prediction results. The AUC, G-mean, and Balance were the evaluation criteria selected for the experiment. Tables 11–13 show the experimental results.
AUC value of SDHetInt and other single classifiers
G-mean value of SDHetInt and other single classifiers
Balance value of SDHetInt and other single classifiers
Tables 11–13 respectively show that the SDHetInt heterogeneous integration algorithm significantly improves the AUC, G-mean, and Balance indices compared with DT, LR, KNN, Naive Bayes, and SVM. The high efficiency of the SDHetInt heterogeneous integration algorithm for processing unbalanced data is illustrated.
This study selects the PC5 dataset in NASA and the CWE121_Stack_Based_Buffer_Overflow_S01 (S01) dataset in Juliet as the test datasets to further verify the generalization ability of SDHetInt. The PC5 dataset contains 17001 data samples, including 503 software defect samples and 16498 samples without software defects. The S01 dataset contains 1088 data samples, including 234 software defect samples and 854 samples without software defects.
We used the Understand tool to extract 81 software defect features from the executable program written in C language in S01 because the S01 program code is written in C language. Then, we selected the Pearson’s correlation coefficient values, which were positive features to predict software defects. After feature selection, a heterogeneous DT and SVM integration algorithm was built based on the unbalance rate threshold drift. Table 14 shows the AUC, G-mean, and Balance values of PC5 and S01 datasets predicted by the SDHetInt heterogeneous integration algorithm.
SDHetInt heterogeneous integration algorithm results
When the proposed SDHetInt heterogeneous integration algorithm was used in PC5, as shown in Table 14, the AUC for predicting software defects was 97.54%; the G-mean was 95.70%, and the Balance was 94.73%. When using the SDHetInt heterogeneous integration algorithm in S01, the AUC value for predicting software defects was 92.49%; the G-mean was 89.19%, and the Balance was 87.87%.
This study proposes a heterogeneous integration algorithm called SDHetInt based on an imbalanced rate threshold shift to address the data imbalance in software defect prediction. Experiments have shown that the SDHetInt heterogeneous integration algorithm is more advantageous in AUC, G-means, and Balance than the existing Random Forest, ExtraTrees, and GBDT integration algorithms, as well as DT, LR, KNN, naive Bayes, and SVM single classification algorithms. The generalization ability of SDHetInt to predict software defects was verified by using the PC5 dataset and the CWE121_Stack_Based_Buffer_Overflow_S01 dataset. The structure of the DT is nonlinear, and the structure of the SVM is generalized linear. The SDHetInt algorithm can integrate heterogeneous algorithms, DTs, and SVM. It is also more effective for the classifier’s diversity than the existing simple methods, such as noise removal, integrated feature selection, and the use of existing ensemble algorithms.
Therefore, the SDHetInt heterogeneous ensemble algorithm is more effective than single machine learning models and isomorphic ensemble algorithms in solving low defect prediction performance caused by data imbalance. The algorithm also enhances the generalization ability when predicting software defects.
However, some limitations are identified in the design and implementation of the algorithm. The design and implementation of the algorithm limit its vulnerability detection ability through software source code or software code features. Moreover, the algorithm cannot detect executable file programs when the source code is unavailable. Designing and detecting vulnerabilities in executable files are more challenging problems. This method can predict software defects, but it cannot predict the type of defects. We will study the types of software defects in future work.
Conclusion
This paper proposed a heterogeneous integration algorithm, SDHetInt, based on a threshold shift of the unbalance rate to solve the common problem of class imbalance in software defect prediction. The SDHetInt heterogeneous integration algorithm combined the base classifiers with different model fusion structures and moved the threshold based on the historical defect data imbalance rate. Compared with the homogeneous integration algorithm, SDHetInt introduces the heterogeneous integration algorithm, which solves the problem of imbalanced software defect prediction categories and ensures the accuracy of software defect prediction. The SDHetInt heterogeneous ensemble algorithm provides a new and efficient ensemble method for software defect prediction.
Footnotes
Acknowledgment
This work was supported by the National Natural Science Foundation of China (no. 61972334), Central government guided local science and Technology Development Fund Project (no. 226Z0701 G), the Natural Science Foundation of Hebei Province (no. F2022203026), Science and Technology Project of Hebei Education Department (no. BJK2022029, QN2021145) and Innovation Capability Improvement Plan Project of Hebei Province (no. 22567637 H).