
Abstract
Schools and universities shuttered as a result of the worldwide COVID-19 pandemic lockdown, and student screen time skyrocketed. Since the programs are delivered online, a spike in social media use during lockdown resulted in many pupils becoming victims of cyberbullying, which includes criticizing one another, posting sexual comments on images of young ladies, and using fake accounts to bully others. Machine Learning (ML) and Natural Language Processing (NLP) techniques are being used in a growing body of work on automated cyberbullying detection. Different machine learning methods, however, are unable to converge to the requisite accuracy. Thus, numerous classifier systems known as “ensemble learning” are proposed in order to improve predictive performance by aggregating the predictions from various models. In our proposed system, we use a novel method of detecting online harassment (cyberbullying) on the Instagram dataset. The attributes of abusive words are initially analyzed from feature selection and pre-trained word embedding language models like Bidirectional Encoder Representations from Transformers (BERT) and Embeddings from Language Models (ELMO). A knowledge-based frequent pattern method is used to find the intention of the harasser and is created by the Knowledge-BERT (K-BERT). The unsupervised approaches such as Latent Semantic Analysis (LSA), Frequent pattern growth (FP-Growth), and a clustering technique K-Means. The results from the detection models are ensembled using Extreme Gradient Boosting (XGBoost) for classifying the categories of online harassment. The performance of the ensemble model is then cross-validated using machine learning metrics and compared with various existing techniques. An ensemble model performs better with a higher F1 score of 92.04% with less error rate in the classification of harassment categories.
Introduction
In recent years, children gradually get their own Internet devices and utilize the internet regularly. They can quickly become acquainted with technology equipment. As a result, social media and the internet are becoming increasingly popular with this age group. Every day, they invest a sizable amount of time online for enjoyment or instructional determinations. The cyberspace environment presents a variety of opportunities and threats [1]. Cyberbullying, trolling, flaming, doxing, outing, and frapping are just a few of the terms used to characterize the various varieties of online harassment. The offenders utilize your personal information, offensive messages, or bullying behavior to make you feel uncomfortable. Criminals frequently use social media as their platform of choice, and they frequently use hacked or phony identities to find victims [2]. Online harassment is described as someone who repeatedly engages in bidding performance toward others by posting offensive remarks, posts, or further types of public attacks using numerous digital skills [3]. In [4] A Pew Research Centre study found that 22% of respondents have encountered fewer unadorned kinds of cyber harassment, like include foul language and being self-conscious in front of others. More serious forms of harassment, including stalking, physical threats, sexual harassment, and persistent harassment over an extended period of time, were also reported by 18% of the population. According to the study, 34% of men and 21% of women have received obscene or derogatory remarks, 27% of men and 23% of women have intentionally been made to feel humiliated online, 12% of men and 8% of women have received serious threats, and 7% of men and 8% of women have endured harassment for a protracted period of time. The most recent incident, according to individuals harassed, took place on the following categories of websites: 66% on social media 22 percent of websites have a comments section. Online gaming accounts for 16% 16% of emails are personal. Discussion forum (like Reddit) 10% Dating websites or apps 6%
In Fig. 1, The prevalence of internet harassment among teens varies with age. In comparison to those aged 13 to 14, 42% of 15 to 17-year-olds had engaged in at least one of the six online habits. While similar percentages of older and younger teens claim to have been the target of teasing or rumors, older teens are more likely than their younger counterparts to claim to have received explicit images they didn’t request (22% vs. 11%), had explicit images of them shared without their permission (also known as revenge porn), or been the subject of persistent questions about their whereabouts (8% vs. 4%). Statistics show no differences between White, Black, or Hispanic teenagers who have ever experienced online harassment, but some groups are more likely than others to experience particular kinds of online assaults. For instance, White teens are more likely than Black teens to report being the focus of untrue rumors. Teenagers who identify as Hispanic are more likely than White or Black to report that they are frequently questioned by people other than their parents about their whereabouts, activities, and friends. In [35] Research has shown that cyberbullying on social media platforms is a significant and growing problem, particularly among younger generations. For example, a study conducted by Pew Research Center found that 59% of teens have experienced at least one form of cyberbullying on social media platforms. Additionally, the study found that cyberbullying was more prevalent on platforms such as Instagram and Snapchat, where images and videos are more commonly shared.
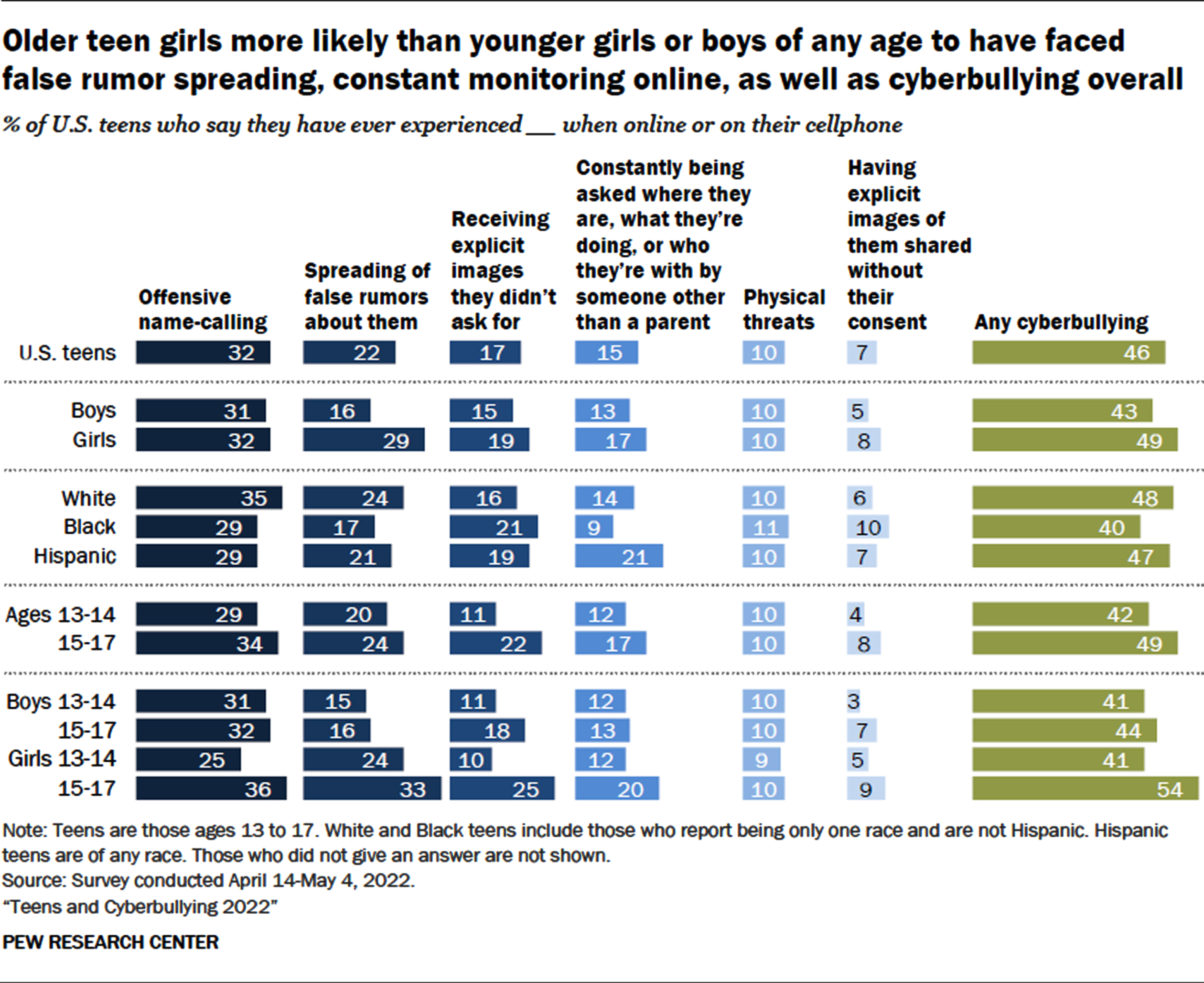
The Pew Research Center’s research report.
In [5] Even if there are advantages to using the Internet, there has been much discussion about whether it might also be detrimental to one’s social and psychological health. In today’s world, harassment affects people of all ages and takes many various forms. People can harass others online constantly through emails, text messages, and social media platforms. Cyberbullying allows harassers to remain anonymous, which gives them an intellect of authority and control that they might not otherwise take if they were confronting their victims in person. According to research, victims of online harassment exhibit rage, academic repercussions that may cause them to continue being victims or harassers, embarrassment, miss school, depression, insomnia, and suicidal thoughts. Even when the situation became serious, victims might not have reported the harassment even if their anxiety and rage increased when they did not know who was attacking them. [6] express that Families who encounter fierceness at home and online could be forced to grieve in stillness if child protective services were restricted or disrupted. The analysis includes a significant section on the factors that have changed as a result of the coronavirus epidemic. In the largest cities, a nationwide lockdown was put into effect, and it lasted for another few months. [7]. The majority of people’s internet activity increased dramatically as a result of this move. More than 80% of respondents in research performed in China during the epidemic reported that their exposure to social media had increased (SME). In [3] describe approximately the key features of harassment are: A desire to cause emotional, psychological, or social harm to the victim. Recurrence of aggressive behaviors across time. An imbalance of physical, emotional, or social dominance between the harasser and the victim.
Remaining silent about cyberbullying can have serious consequences for the victim, such as a decline in mental health, social isolation, and even suicide. Therefore, it is important to report cyberbullying to someone who can help, such as a parent, teacher or counselor. However, some people may feel hesitant to report cyberbullying because they fear retaliation or further harassment. They may also worry about not being believed or being blamed for the bullying. It’s important to understand that reporting cyberbullying can be done anonymously, and there are laws in place to protect those who come forward. It is also important to remember that cyberbullying is a serious issue that can have long-lasting effects, and reporting it can help to prevent it from continuing.
Confiding someone about cyberbullying can be an important step for victims in seeking support and help to deal with the situation. Talking to a trusted friend, family member, teacher, counselor, or professional can help victims to process their emotions, receive advice, and explore their options for responding to cyberbullying. Confiding in someone can also help to reduce feelings of isolation and shame that may accompany the experience of cyberbullying. However, some victims may be hesitant to confide in someone due to fear of being judged, blamed, or not taken seriously. They may also worry about the confidentiality of the information they share or the potential consequences of reporting the incident. It is important for victims to choose someone whom they trust and feel comfortable with, and to communicate their needs and concerns clearly.
Reasons for cyberbullying from respondents’ viewpoints: Anonymity: Cyberbullying allows people to hide behind anonymous usernames, which can make them feel powerful and less accountable for their actions. Revenge: Cyberbullying can be a way for people to get back at someone who they feel has wronged them in some way. Jealousy: Cyberbullying can stem from feelings of envy or jealousy towards the victim, such as if the victim is perceived as more popular or successful. Boredom: Some people engage in cyberbullying simply because they have nothing better to do. Group dynamics: Cyberbullying can sometimes be a group activity, with several people joining in on the harassment of one individual.
Respondents’ viewpoints regarding cyberbullying may vary based on their personal experiences and beliefs. Some respondents may view cyberbullying as a serious issue that requires immediate action and support for the victim, while others may see it as a minor issue that can be ignored or brushed off. Some respondents may also hold victim-blaming attitudes, believing that the victim brought the bullying upon themselves or should be able to handle it on their own. It is important to address cyberbullying in a proactive and compassionate manner, focusing on supporting the victim and holding the perpetrator accountable. Education and awareness-raising campaigns can also help to promote empathy, respect, and responsible use of technology among individuals and communities.
The NCCR site is a government of India program that allows victims of criticism, particularly women and children, to register online complaints. With the assistance of the neighbourhood police, they respond quickly to complaints that have been lodged. Since technology has surpassed all traditional approaches, it has also surpassed the offline procedure for reporting cybercrime. The National Cyber Crime Reporting Portal allows for the registration of cybercrime complaints, which enables the filing of complaints about cybercrimes across the country and allows victims and complainants to easily access cybercrime cells and all relevant information [36]. Table 1, describes the reporting guidelines for cyber harassment on social media platforms.
List of Service Providers and Reporting Link/Email-ID
A theoretical context with the ultimate objective of improving users’ discretion awareness in online social systems to degree the confidentiality hazard of the handlers and awareness whenever their privacy is conceded, and assist the bare users in semi-automatically customizing their privacy side by side by reducing the figure of blue-collar operations through a dynamic learning approach [8]. Since cyber harassment is a real-time issue, detecting harassment comments and classifying them into various categories and finding their severity may lead to preventing online harassment at an early stage. Cyberbullying in social networks can be stopped and the negative effects on the victims are lessened with the help of early detection and tracking down of the harasser. The intention of the harasser may be due to various reasons such as sexual orientation, teasing, low self-esteem, threats, etc. Finding the intentions behind each harassment comment over a long period of time may help in predicting the pattern of a person’s behavior on social media platforms. Therefore, in this study, we present an ensemble method for identifying and categorizing cyberbullying in the dataset of Instagram text comments. An ensemble is often used to combine the predictions of multiple models to improve the overall performance of the system. In some cases, the individual models may not be able to address the problem satisfactorily on their own, but by combining their predictions, the ensemble can achieve better results. Using an ensemble can help to address the limitations of individual models and leverage the strengths of multiple models to address the problem more effectively. The following is the main contribution of the suggested work: Creating a word embedding technique that is contextualized and knowledge-based to extract the relationship and intention of the text comments. To develop an ensemble learning model for identifying and categorizing various types of online harassment on social media sites. To identify the intended audience and purpose of a given textual statement. To reduce the loss function of the time complexity of the ensemble model created utilizing extreme gradient boosting and unsupervised machine learning algorithms.
The remainder of the essay is organized as follows: The study’s contextual and related literature reviews are presented in Section 2. Section 3 details our research methodology. The findings are discussed in Section 4, and the ramifications of the findings and recommendations for further research are presented in Section 5, which brings the work to a close.
Teenagers’ safety and discretion have long remained top priorities, say scholars in the field of Child Computer Interaction (CCI). When children are involved, one of the biggest challenges in cyberspace is security. All online hazards that could harm kids are connected to cybersecurity, as are all protective actions that can be taken to help caregivers, together with children’s responsiveness to the numerous cybersecurity hazards [1]. In [9] explains the body of research on automated cyber harassment detection has grown, particularly in relation to the problem of recognizing cyberbullying on public media networks like Twitter, Instagram, Snapchat and YouTube. Using rule-based models, conventional machine learning approaches, or deep learning representations, the study has been moving toward automated harassment detection. The fields of machine learning (ML) and natural language processing (NLP), which have remained magnificently utilized in areas linked to harassment identification, such as rumor uncovering, gush analysis, and phony news recognition, have made significant strides in the previous ten years. The machine learning workflow is created by a set of systematic stages called the machine learning pipeline, which includes data sourcing, data annotation, data pre-processing, feature assortment, classical training, and model assessment. A feature extraction method [10] includes A-CNN, which is constructed on the Skip-gram typical of word2vec, is projected to signify high-dimension term vectors based on the skip-gram. The study [7] tries to determine which aspects of a person’s personality, use of social media, online gaming, disregard for other people’s sentiments, and antiquity of normal bullying variety more vulnerable to cyberbullying. Recommendation structures primarily utilize sentiment study and give handlers stimulating evidence in harmony with necessities and behaviors [3]. As a special form of sentiment analysis, cyber harassment primarily focuses on the harasser factor of verbal rather than simply splitting attitudes into good and negative ones. To examine the additional text features and find the behaviors, many researchers used feature engineering. The Support Vector Machine can be more accurate by using N-gram and Skip-gram algorithms (SVM). It implies that machine learning techniques have also been introduced in this context, including J48, Fuzzy Fingerprints, logistic regression, Deep Learning architectures, and Random Forest [34].
Text representation and word embedding models
The technique of turning a word into a number is called word embedding. In comparison to traditional approaches, the vector illustration formed by term embedding has dual benefits: a dense, effective depiction of the word in the trajectory space; and contextually linked, identical words have nearer vector values [11]. The contextual integrity of the phrase is preserved by this Word2Vec embedding model, and words’ semantics inside a sentence or document is retained. They remained employed in several supervised linguistic processing applications, including document analysis, sentiment cataloguing, NER, and POS labeling. It is divided into two categories: Continuous Bag of Words (CBOW) and Skip Gram (SG). It is employed in NLP to address language-related issues. In [12] combining the Sentiment Analysis Knowledge Graph (SAKG) and BERT pretraining models, the online-review sentiment scrutiny model. BERT is a transformer-based profound collaborative verbal representation model. The sentence tree incorporates sentiment knowledge to increase the precision of sentiment classification. The couched feature words are occupied by emotion triples. SAKG is better suited for the sentiment classification problem than the linguistic knowledge graph. The entities in a knowledge graph can be thought of as nodes, and the relationships between those nodes can be thought of as connections between those nodes. To enable semantic comprehension and knowledge reasoning, a familiarity graph leverages the semantic network to define perceptions, articles, and their associations. Entity attribute-value pairs and “entity-relation-entity” triples are the primary building blocks. In [13] by signifying BERT: Bidirectional Encoder Representations from Transformers, one can enhance the fine-tuning-based methods. By engaging a “Masked Language Model” (MLM) pre-training goal, BERT alleviates the aforementioned unidirectionality restriction. The representation is able to syndicate the left and right situation thanks to the masked language model, which also randomly conceals some tokens from the input. This enables us to pretrain a deep bidirectional Transformer. Being character-based, the BERT probably struggles to derive meaning from specific terms and words in Chinese news. In [14] provide an ensemble model created on BERT called the BERT ensemble LSTM-BERT(BERT-LB), which accomplishes remarkably fine on mutually extensive and brief Chinese news manuscript and enhances the performance of topic prediction for Chinese news. The BERT has achieved tremendous success thanks to its industry-leading performance in a variety of NER and text classification applications. To handle some specific issues, like answering questions, some recent studies combine BERT with other techniques.
Finding the sentiment or estimation polarity toward a group of characteristics in the method of expressly predefined feature relationships or implied part groups from user-generated normal verbal texts is the work of aspect-based sentiment examination. In [15] explains how the Sentiment Knowledge Graph (KG) is cast off as an exterior cause of sentiment knowledge statistics by the BERT component, pre-trained philological models equipped by means of Transformer, to estimate the equivalent contextualized illustration. This improves the performance of sentiment detection by introducing sentiment domain knowledge into BERT. In [16] a novel standard is designed for unsupervised key phrase mining using a language model that takes already remained trained. On short document datasets, the sentence embedding approach and the autoregressive pre-trained verbal model ELMo produce state-of-the-art results. A pre-trained linguistic model is often a model that has been trained using a neural network structure on a sizable unlabeled corpus and then used for subsequent tasks by sharing or extracting network features. The ELMO model is a technique for deeply contextualized representation of learned functions in the interior positions of a deep bidirectional language model (biLM), which has been pre-trained on a sizable corpus. According to the context, a contextualized embedding technique has been developed that can produce various word vectors [17]. Effective contextualize embedding representations, pre-trained with lots of training data, include ELMO and BERT. It builds a 1024-dimensional ELMO embedding trajectory for a design description with a word count cap of 252.
Classical machine learning methodologies in cyber harassment detection
The proposed approach [18] uses Stochastic Gradient Descent (SGD), Naive Bayes (NB), Logistic Regression (LR), Light Gradient Boosting Machine (LGBM), Random Forest (RF), AdaBoost (ADB), and Support Vector Machine (SVM) were employed as the seven machine learning classifiers. Precision, accuracy, recall, and F1 score were used as performance indicators to assess each algorithm. By mining tweets, categorizing them by means of text analysis algorithms created on predetermined keywords, and formerly categorizing the tweets as invasive or non-invasive, it can identify cyberbullying. It combines many machine learning algorithms with two distinct feature extraction strategies, and the most accurate classifier is Sequential Minimal Optimization (SMO). From numerous cybersecurity studies, some key information about bothersome social spam and spammer accounts [19]. In [20] its goal is to identify a group of helpful features for teaching a machine learning system to recognize content that promotes cyberbullying. The second involves incorporating a machine learning approach obsessed by a mobile app to assist parentages in identifying cyberbullying targeted at their offspring. Support vector machine (SVM), Naive Bayes, logistic regression (LR), K-means neural network (KNN), decision tree (DT), random forest (RF), and AdaBoost (AB) are just a few examples of classifier methods. A kind of machine learning called deep learning, commonly referred to as hierarchical learning, differs from further type-specific procedures like supervised and semi-supervised algorithms in that it may learn from data representation. In [21] One of the vast success sections of unsupervised learning for text categorization is the use of probabilistic approaches, such as Latent Dirichlet Allocation (LDA) and Latent Semantic Analysis (LSA). A method in [22] based on LDA and a TF-IDF weighted hybrid model, the calculation of text similarity takes into account both the possible semantic relationships between texts and the impact of individual words. By using statistical calculations to be applied to a huge corpus of text, the Latent Semantic Analysis (LSA) approach extracts and represents the meaning of words as they are used in context [23]. They said that LSA may serve as a blueprint for how people learn. It is a totally automatic mathematical and statistical technique for identifying relationships between words predicted contextual usage in discourse sequences. It only accepts unprocessed text as input, which is then divided into meaningful passages or samples like sentences or paragraphs and words specified as distinct character strings. In [24] first suggested a methodology for comprehensive reviews of intelligent transportation systems employing word embedding analysis of content-based recommendation systems (ITS).
The detection of hate speech from Twitter sources [25] is based on methods from a variety of disciplines, including text mining, natural language processing (NLP), data mining and machine learning (ML). The unsupervised classification of text comments contains two groups, which are hypothesized to be good and negative remarks [26]. Consider words as features; there are too many elements in the comment vector. Utilize LSA, which employs Singular Value Decomposition, to minimize the dimension. K-means is castoff for clustering. The statistical data is divided into k sets, and k random points are chosen at the centers of each cluster. Subsequently, assign each point a cluster based on its closest cluster center. The clustering findings, which further identify the group association of distinct data, are reached by the algorithm’s convergence. The typical system acquaints with a new architecture [27] that uses the pre-trained GloVe embedding and word embedding under the GRU and BiLSTM algorithms. Both branches’ features have been merged and sent to the sigmoid layer for classification. The model’s classification outcome is contrasted with the XGBoost.
Ensemble model for cyber harassment detection
A disseminated, mountable booster library called XGBoost was created with efficiency, adaptability, and portability in attention [27]. Additionally, it makes use of the hardware architecture to speed up memory utilization and decrease processing times. Regular learning in XGBoost enables smoothing final weight gains and guards against over-fitting. Using clever techniques, police investigations can concentrate on safeguarding children while taking less time to locate digital evidence. XGBoost syndicates the recompenses of text mining, AI, and social scientific ideas including linguistic schemes, criminology, and psychology to identify fraudulent behavior. Machine learning can be used to identify verbal illustrations of tyrannical judders [28] additionally, it can be used to construct a model to distinguish digital tormenting actions.
Harassment messages and remarks on social media are constantly impacting people, especially teens, and frequently result in a string of negative effects, including suicidal thoughts among the victims. Cyberbullying, flaming, denigration, impersonation, racism, sexism, and other forms of harassment are only a few examples. In [29] compare a model architecture to four different classification techniques: Multinomial Naive Bayes (MNB), Linear Support Vector Classifier (LSVC), Logistic Regression (LR), Decision Tree (DT) model and three Ensemble approaches: Gradient Boosting (GBoost) classifier, AdaBoost (AdB), and Bagging; it outperforms the others in terms of performance. When comparing classification algorithms using the assessment metrics Precision, Recall, and F-measure, SVM classifier, Logistic Regression, NB method, and XGBoost classifier are the furthermost effective ones. In [30] it came to the conclusion that the Lexical Syntactical Feature (LSF) framework outperforms traditional methods in identifying offensive content. Building a Cyber Harassment Model can be done in a variety of ways, including the Supervised Learning technique, the Lexicon-Based Approach, the Rules-Based Approach, and the Mixed-Initiative Approach.
More difficult issues like credit scoring, debt behavior scoring, and default prediction have all been addressed by machine learning [31]. As opposed to keyword-based, rule-based association rule mining, metadata/social network analysis based, or natural language processing (NLP) based approaches like Text Mining (TM), Information Retrieval (IR), or NLP for hatred speech identification is thought to be ample more effective. In [32] Gradient Boosting Classifier, Support Vector Machine, Multi-Layer Perceptron (MLP), Random Forest, Decision Tree, CAT Boost, and Logistic Regression are just a few of the hate speech classification methods that are used. Table 2 presents a summary of the existing models for identifying and categorizing cyber harassment.
An overview of the existing research being done to detect online harassment
An overview of the existing research being done to detect online harassment
The limitations of existing practices can help drive innovation and the development of new and improved methods. Some of the limitations of existing practices are listed below: Using just one classifier can have drawbacks of its own, leading to poor performance. The text’s grammar and word choice are given very little thought.Rise in datasets imbalance issue. Buzzwords are increasing. Hence dynamic training dataset should be increased. Data labelling process is often time-consuming and labour-intensive. Determining the severity scoring mechanism is rarely used in cyberspace.
Proposed system
In our proposed framework, the raw text comments are collected. For building a machine learning model, divided the dataset for the training and testing part. The training comments are pre-processed by the python natural language toolkit. Data labeling, which involves manually assigning labels or annotations to a set of data samples, is often a time-consuming and labor-intensive task. This is especially true for large datasets or when the data is complex and requires specialized knowledge for proper labeling. The cost and effort required for data labeling can be a major challenge in the development of machine learning models, as having a large labeled dataset is often necessary for effective training. Hence the cleaned data is passed to the detection model where the cyber-harassment comments are clustered using unsupervised machine learning models. In order to overcome the limitations, it may be necessary to use multiple classifiers or to employ ensemble methods that combine the predictions of multiple classifiers to produce a final prediction. This can help improve performance by capturing the strengths of different classifiers and mitigating their limitations. The clustered results from all the basic learners are ensembled using boosting algorithm to build a stronger learner model. Finally, the ensembled model results are analyzed by various performance measures and compared with the existing algorithms.
Systematic Process Ensemble Model for Detecting and classification of Cyber harassment (EMDCH)
About the dataset
Software requirements
This work requires good knowledge of machine learning algorithms and word embedding techniques, Python, working on Google colaboratory, Spacy library, Numpy, Natural language processing, NLTK. Make sure you have installed all the following necessary libraries: Numpy, Re, Matplotlib, Pandas, NLTK, Word2vec, SimpleTransformers, TextBlob, Tensorflow, ScikitLearn, Mlxtend. The ensemble method needs word embedding layers, unsupervised techniques and a gradient-boosting library for building the EMDCH model.
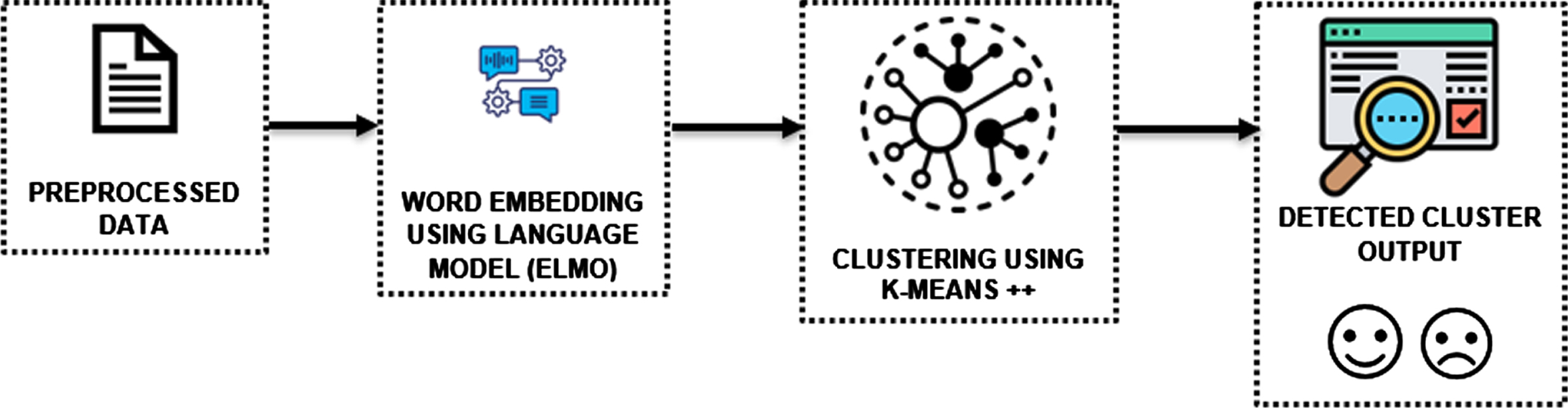
In Fig. 2, the raw Instagram text comments are collected as a CSV file which consists of features such as Indexid and comments with 10k records. 80% of the dataset is used for training, while 20 % is used for testing. The training comments are preprocessed by a python natural language toolkit called NLTK. The features are extracted by word2vec and count vectorizer. The cleaned data is given to the detection model. It detects the harassment data using unsupervised algorithms such as FP-Growth, LSA, and K-Means++methods. The clustered harassment pattern is used by the K-Bert model for identifying the intentions of the harasser and its category. From the detection model, the annotated clusters are classified into different categories using the XGBoost ensemble learning model. The performance of a stronger learning model is evaluated by classification performance metrics. The EMDCH proposed results are related to the various traditional method of detecting cyber-harassment using word embedding techniques and supervised machine learning models.

The architecture of an Ensemble Model for Detecting and classification of Cyber Harassment (EMDCH).
In the Ensemble Model for Detecting and classification of Cyber Harassment (EMDCH), the raw text comments are cleaned by data preprocessing methods such as lowercase conversion, special character, space removal, Lemmatization, Tokenization and stop word removal. EMDCH is divided into four modules where three weak learners are ensembled using a boosting technique to build a strong learner model with better performance. The modules are described below. The overall procedure for the working of the EMDCH model is described in Fig. 3.
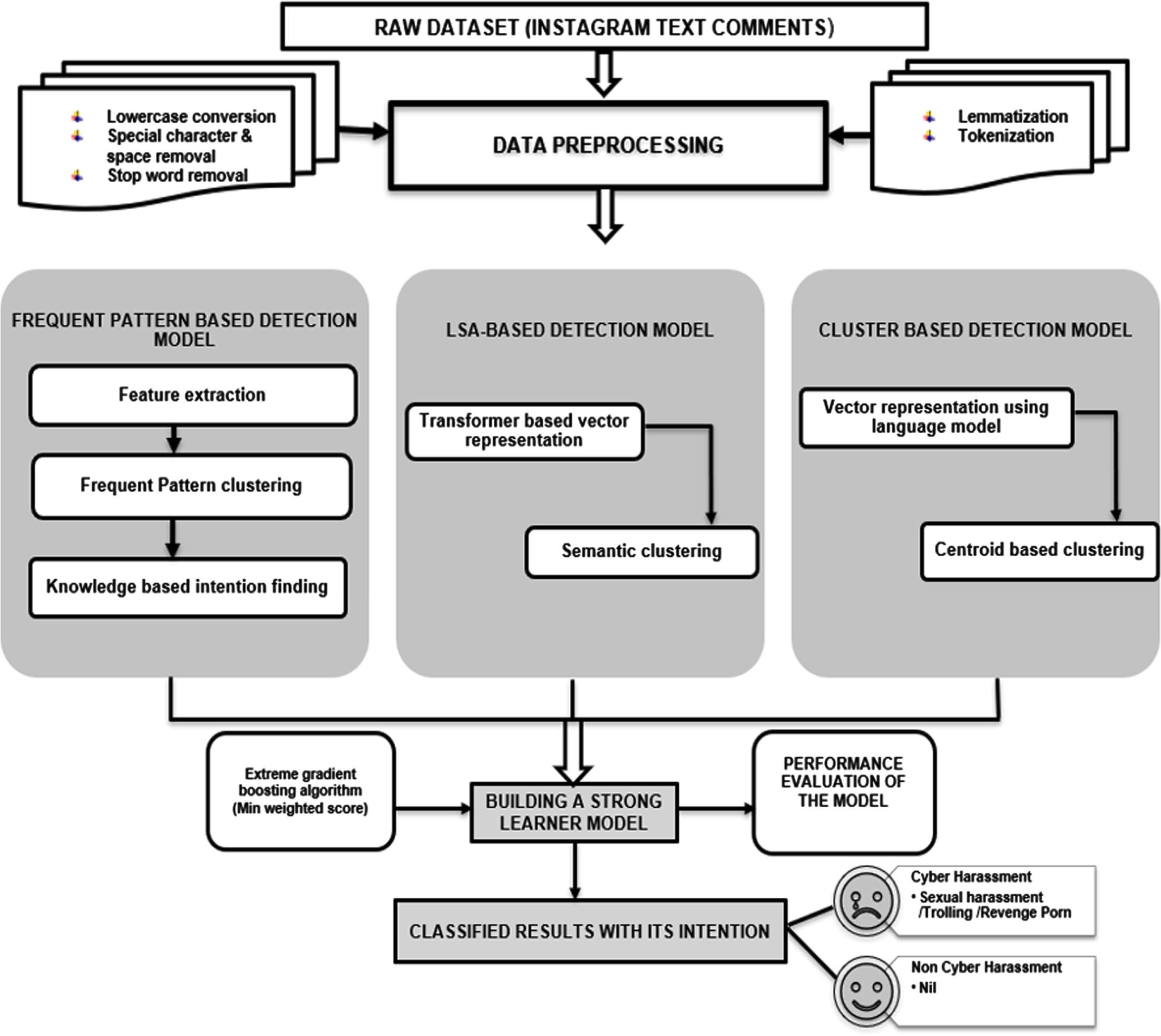
The complete working procedure for the EMDCH model for detecting cyber harassment and non-cyber harassment.
Table 3, shows the algorithmic work for detecting and classification of cyber harassment from Instagram text comments (C1, C2, C3 \dots Cn). Initially, the raw data has to be preprocessed using lowercase conversion (L i ), special character and symbol removal (S i ), lemmatization (LZ i ), and tokenization (T ij ) for all 1 to nth comments. The cleaned data is given to three individual detection modules including frequent pattern association rule, latent semantic analysis clustering, and Kmeans++clustering techniques. In loop1 defines that pattern-based detection involves a count vectorizer. These vectors are given to form pattern-based clusters such as cyber harassment (CH) or non-cyber harassment (NCH). Using knowledge-Bert, the tuples are created to find the intentions of the CH comments. In loop2 defines semantic-based clustering using base case BERT embedding and LSA clustering. In loop3 includes ELMO and Kmeans++for CH and NCH clusters. All the detected results (r1, r2&r3) are ensembled using boosting algorithm to produce a better predictive model with higher accuracy. Thus, the classified output for each comment with its intentions and targeted label (C i , I i , T i ) is determined.
Pseudocode for Ensemble Model for Detecting and Classification of Cyber Harassment (EMDCH)
In the Frequent pattern-based detection module shown in Fig. 4, the features are extracted from cleaned comments using a sum vectorizer and Term Frequency-Inverse Document frequency (TF-IDF). The word2vec process converts the bag of high-frequency words into a vector path representation. From the vectors, the frequent pattern for each word with default minimum and highest support values is determined. FP-Growth is considered to be highly accurate in finding frequent patterns, even in large and complex datasets with high memory efficiency. It has a linear time complexity with respect to the number of transactions, making it much faster and ease to implement than other association rule mining algorithms. Thus, the cyber harassment (CH) and non-cyber harassment (NCH) clusters are formed with the list of words. To find the intention of the harasser, the knowledge-based detection module is created by the Knowledge-BERT algorithm. In K-BERT, triplets are added by naming the entities such as subject, relation predicate, and feature object. The knowledge-based language model is used to determine the purpose of the comments called the Knowledge-based Intention detection Model (K-IDM). K-BERT is specifically designed to encode information from knowledge graphs and provide better representation and robustness in dealing with rare and unseen entities and relationships. K-BERT has the ability to generalize to unseen entities and relationships, making it suitable for NLP tasks that require the ability to understand and reason about new and unseen concepts. The cyber harassment comments are the subjects, intentions with a category are the feature object, and the link between them is the relation predicate. Fit the knowledge-based pattern detection model and evaluate the performance by default protocols. The association rule is evaluated by silhouette score.
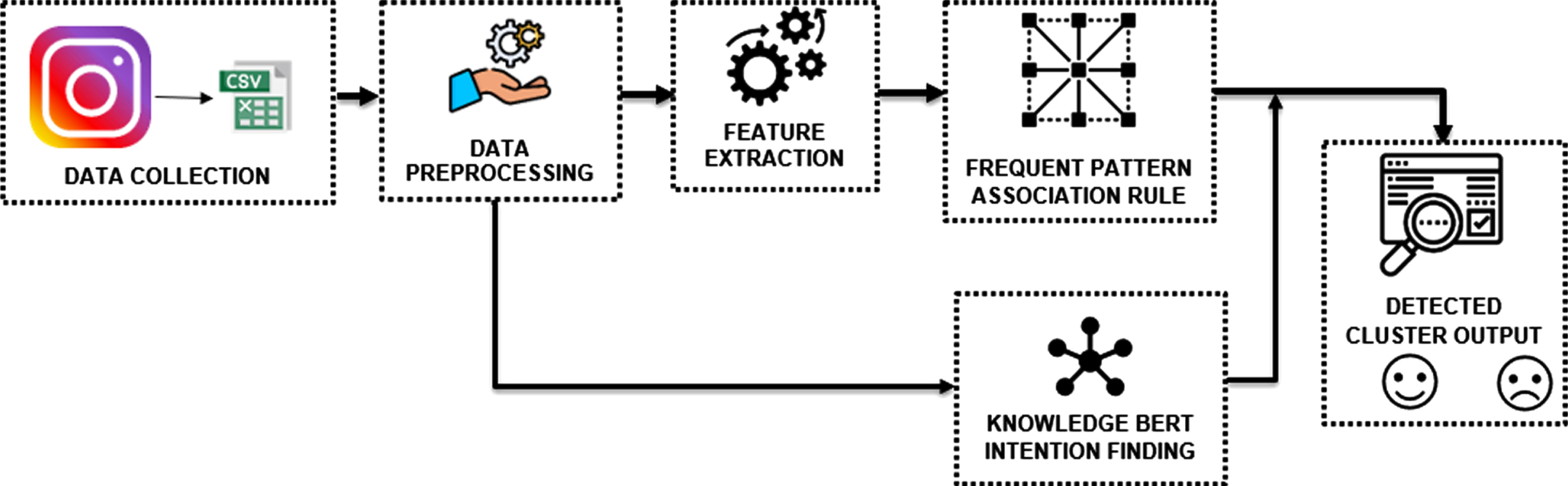
The working of the Frequent pattern-based detection module.
Finding a knowledge-based Intention Detection Model (K-IDM)
A knowledge-empowered linguistic illustration model (K-BERT) with Knowledge Graphs (KGs) in which triples are inserted into sentences as field information. Thus, the overall integration of knowledge graph information in K-BERT enhances its ability to perform knowledge-intensive NLP tasks, making it a useful tool in a range of applications that require an understanding of entities and relationships. Hence it is used to find the intention of the comments called K-IDM. Following is a sample sentence with intention of ‘origin’ which indicates that it is harassment against a particular region of people.\\
[“@user @user...... You weren’t calling me a faggot when you were clapping these cheeks nigga”,
‘_with intention of_’, ‘Origin_as motive’]\\
A Knowledge-graph is a technique of sorting data that has been extracted as a consequence of a data extraction operation. A triple is a set of three things (a subject, a predicate, and an object) used to hold information about something in a knowledge network. K-BERT comprises of four components, i.e., knowledge layer, seeing layer, embedding layer, and mask-transformer. A sentence tree can take several divisions, but its profundity is limited to one, hence object names in triples resolve iteratively derive divisions as seen in Fig. 5.
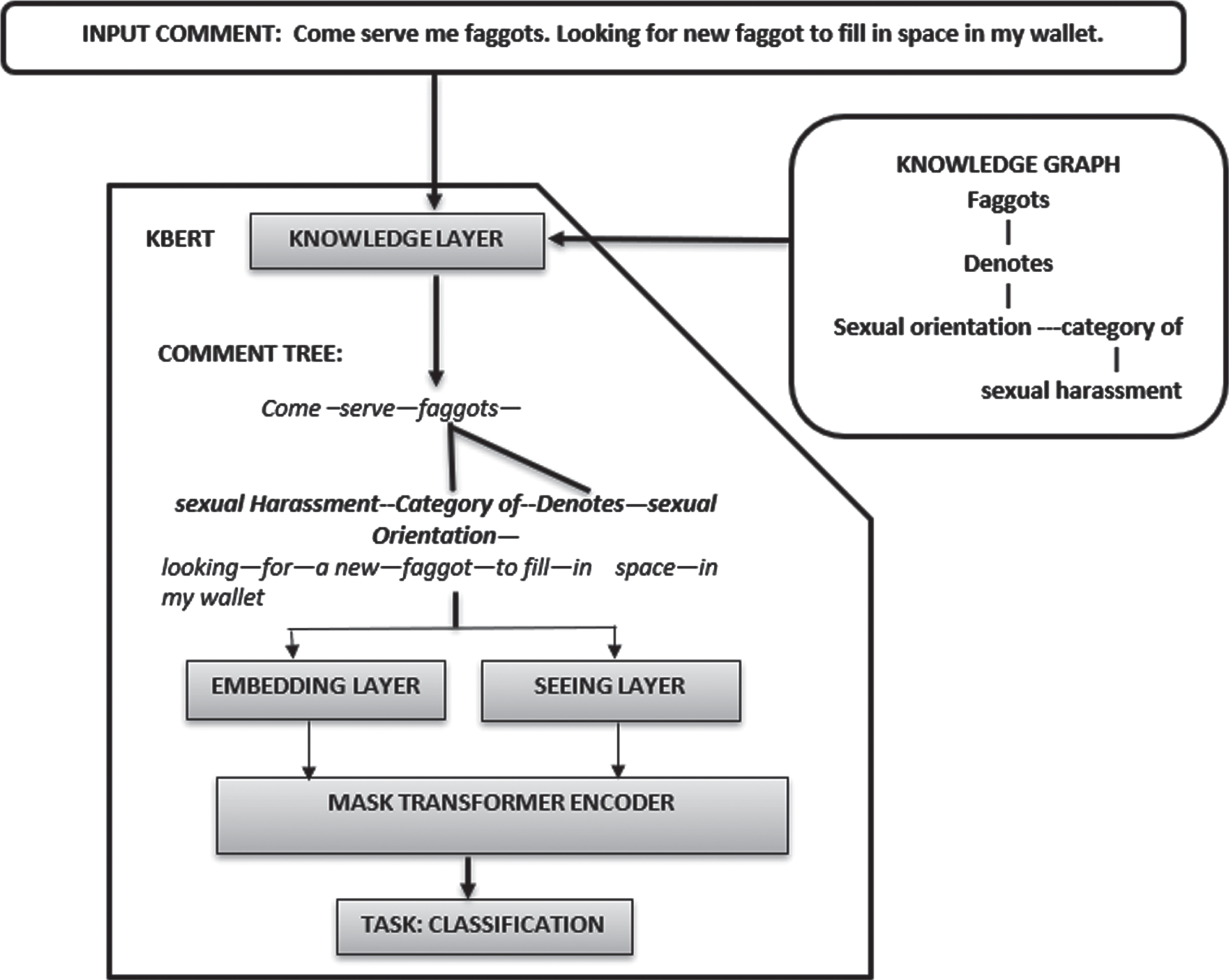
The model structure of K-Bert working for knowledge-based classification of cyber harassment.
Knowledge-based Intention detection module clustered groups results
Steps involved in finding the intention of harassment sentence using the K-Bert language model in Fig. 4:
Sentence Segmentation
Splitting the text comments into sentences is the first step in creating a knowledge graph. Then, only keep those sentences in the list that have precisely one subject and one object.
Entities Extraction
It is not difficult to extract a single-word item from a comment. Nouns and proper nouns are required entities with the use of parts of speech (POS) tags. When an entity spans numerous words, though, POS tags alone are not enough. It is necessary to parse the sentence dependency structure. The nodes and the edges between them are the most critical aspects of constructing a knowledge graph. The entities in the harassing comment will be represented by these nodes. The linkages that connect these items are called edges. Use the language of the comment to extract these pieces in an unsupervised manner. The fundamental concept is to extract the subject and object from a comment.
Relations Extraction
After entity extraction, edges are used to connect nodes (entities) in a knowledge web. These boundaries represent the connections between two nodes. The hypothesis is that the key verb in a comment is the predicate. In the comment, the pattern is defined in the purpose expressions for the source word or the key verb. The design scrutinizes if the source is tracked by a preposition (‘prep’) or an agent term once the root has been recognized. If that’s the case, it will be added to the root expression. Finally, with the recovered objects (subject-object pairs) and predicates, generate a knowledge network (relation between entities).
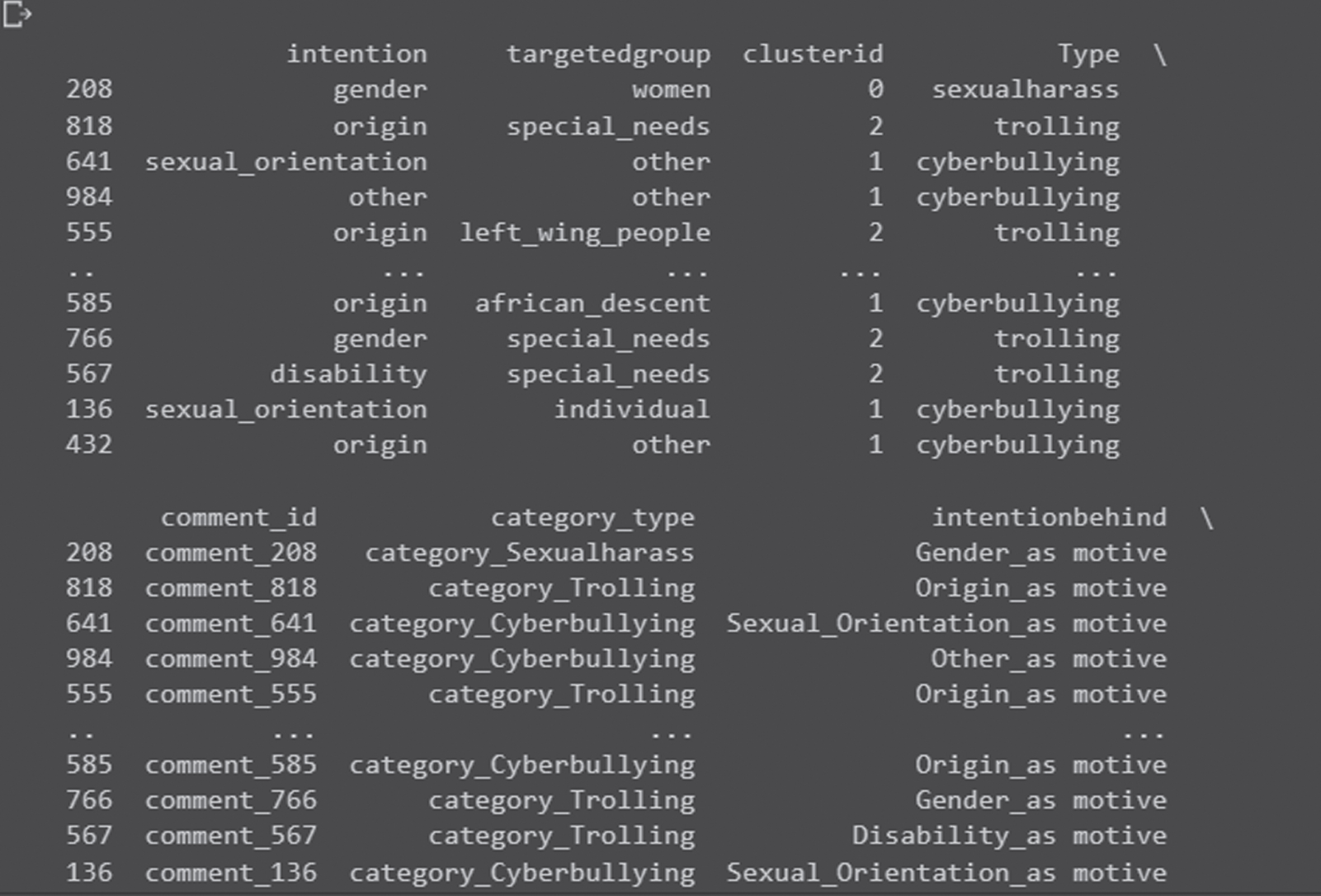
Table 4 shows the results from FP-DM which gives the intention, targeted groups and clustered for the sample text comments. The association rule-based detection grouped three types of clusters Sexual harassment (‘0’), Trolling (‘1’) and Cyberbullying (‘2’). The intentions for various text comments vary for different types. They are origin which denotes the particular region of people, disability indicated the people with specially challenged, gender indicates particular gender, sexual orientation is the intention with sexual motive and remaining as the others category. The K-IDM also finds the targeted groups to whom the text comments are representing. They can be women, special_needs_people, individuals such as racism_people, gay, leftwing people, refugees etc.
Figure 6, Specifying the targeted users and intentions of comments refers to the process of identifying and clearly stating whom the comment is directed towards and the purpose behind it. It helps to ensure that the comment will be received in the intended manner and to establish the tone and purpose of the comment, which can have a significant impact on how it is received.
Specifying targeted users and intentions of the comments.
Figure 7, shows the cyber harassment comments in the Knowledge Bert model. In the KBert model, the text comments are divided into the feature and its predicate. It indicates different categories of CH and the intention behind the bully person. The knowledge of the layer is given explicitly. For each comment, the first row indicates the intentions as gender, origin, sexual orientation etc. and the second row indicates the classified types as trolling, cyberbullying, sexual-harassment etc.
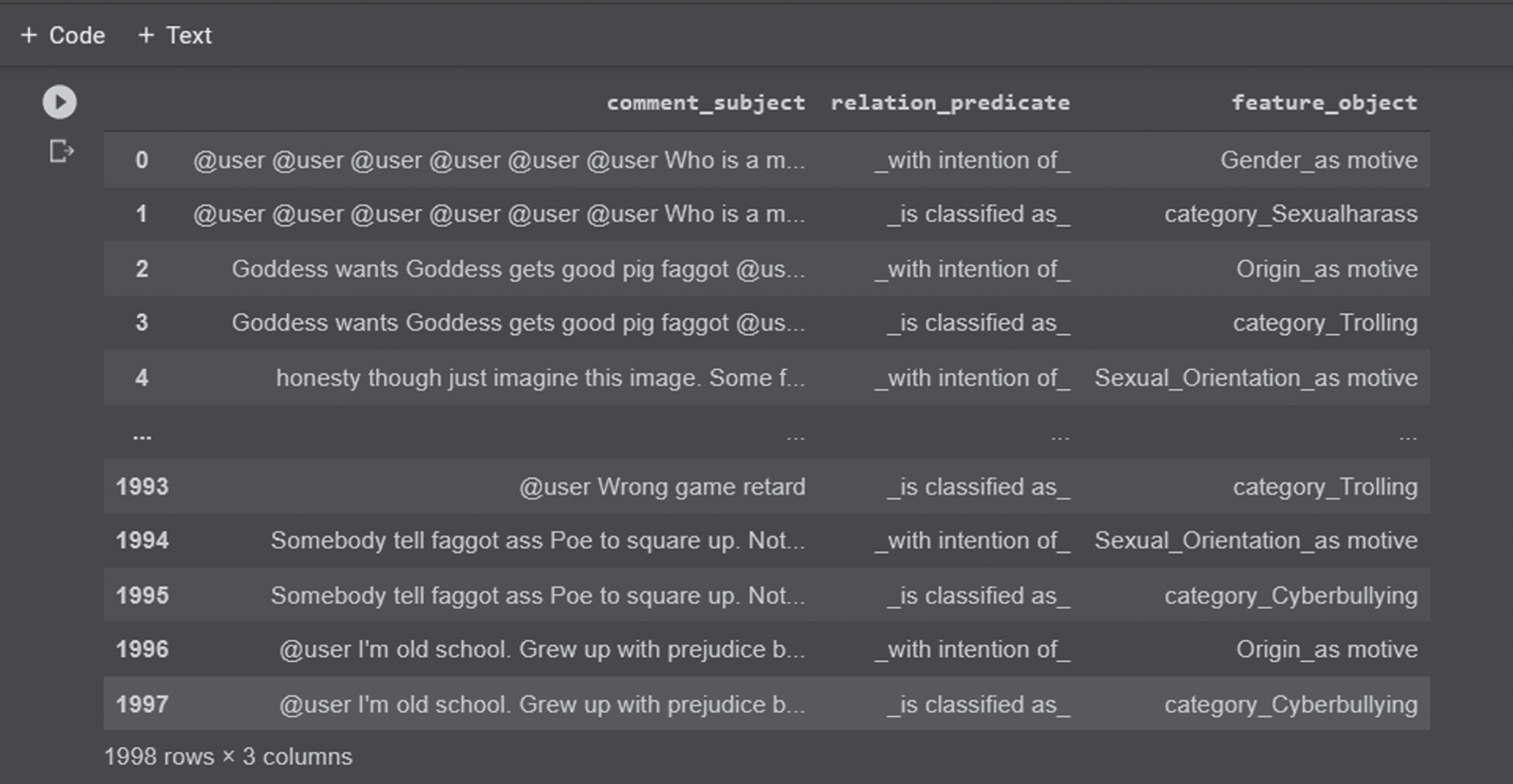
Relationships between triplets in the text comments.
A knowledge graph is a data model that represents entities (such as people, places, and things) and the relationships between them in a graph format, where entities are represented as nodes and relationships are represented as edges. The purpose of a knowledge graph is to provide a clear and comprehensive representation of information, with a focus on the connections and relationships between entities, in order to facilitate reasoning, discovery, and learning. Figure 8, shows the Knowledge Graph for the relationship for 500 comments by mapping intentions.
Knowledge Graph for Instagrams comments by mapping intentions.
In the semantic-based detection module shown in Fig. 9, the cleaned comments are converted into embeddings using Bidirectional Encoder Representations from Transformer (BERT). BERT uses a bidirectional approach to contextual representation, considering both the left and right context of a word, leading to improved performance and robustness in a variety of NLP tasks. BERT allows for task-specific fine-tuning, making it possible to adjust the representations generated by the model to better suit the specific task at hand. The BERT classical method converts the word into embedding. The sentence vectors are formed from these embeddings. The analysis of the semantic meaning of the word is determined using Latent Semantic Analysis (LSA). LSA takes into account the context of words and identifies relationships between words that have the presence of synonyms and polysemous words in the text leading to better results in information retrieval and text classification. LSA represents documents and words as dense, low-dimensional vectors, allowing for a more robust comparison and analysis of the text. LSA is relatively robust to the presence of noise or irrelevant information in a data set, leading to more accurate results in text analysis and information retrieval. Thus, the count vectorizer from feature extraction and Text blob can convert the token into an averaged perceptron tagger. To reduce the dimensions of the embeddings, truncated Singular Value Decomposition (SVD) is used. The tuple of clusters and their magnitudes for the list of keys are clustered by the LSA method.
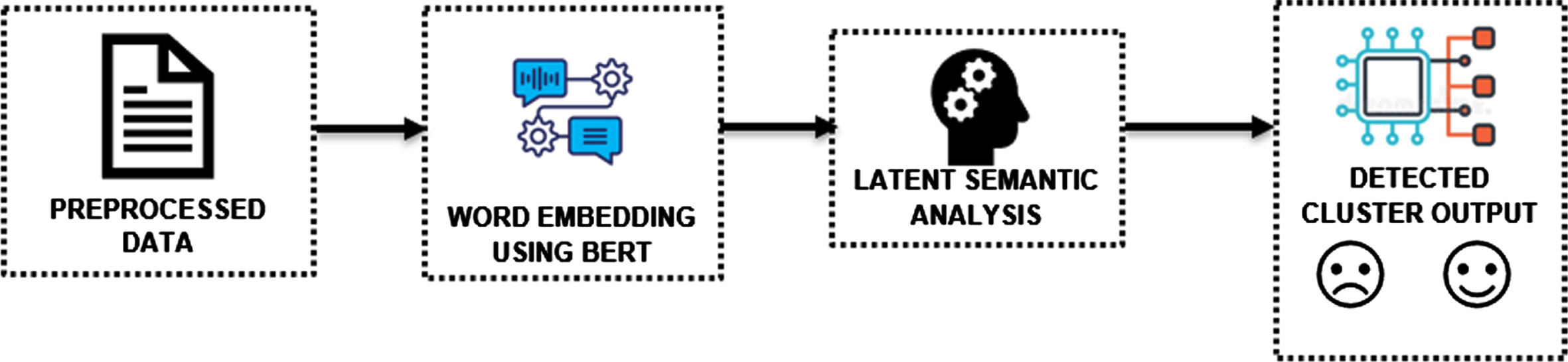
The working of the Semantic-based detection module.
Figure 10, shows the graphical representation of the frequency of harassment words in the dataset. Since the dataset contains natural languages, stop words are not included in calculating the frequency of the words. The top words listed in the Instagram dataset are shown with their count ranging from 50 and more. The most occurring word is “Shit” with a frequency of 678.
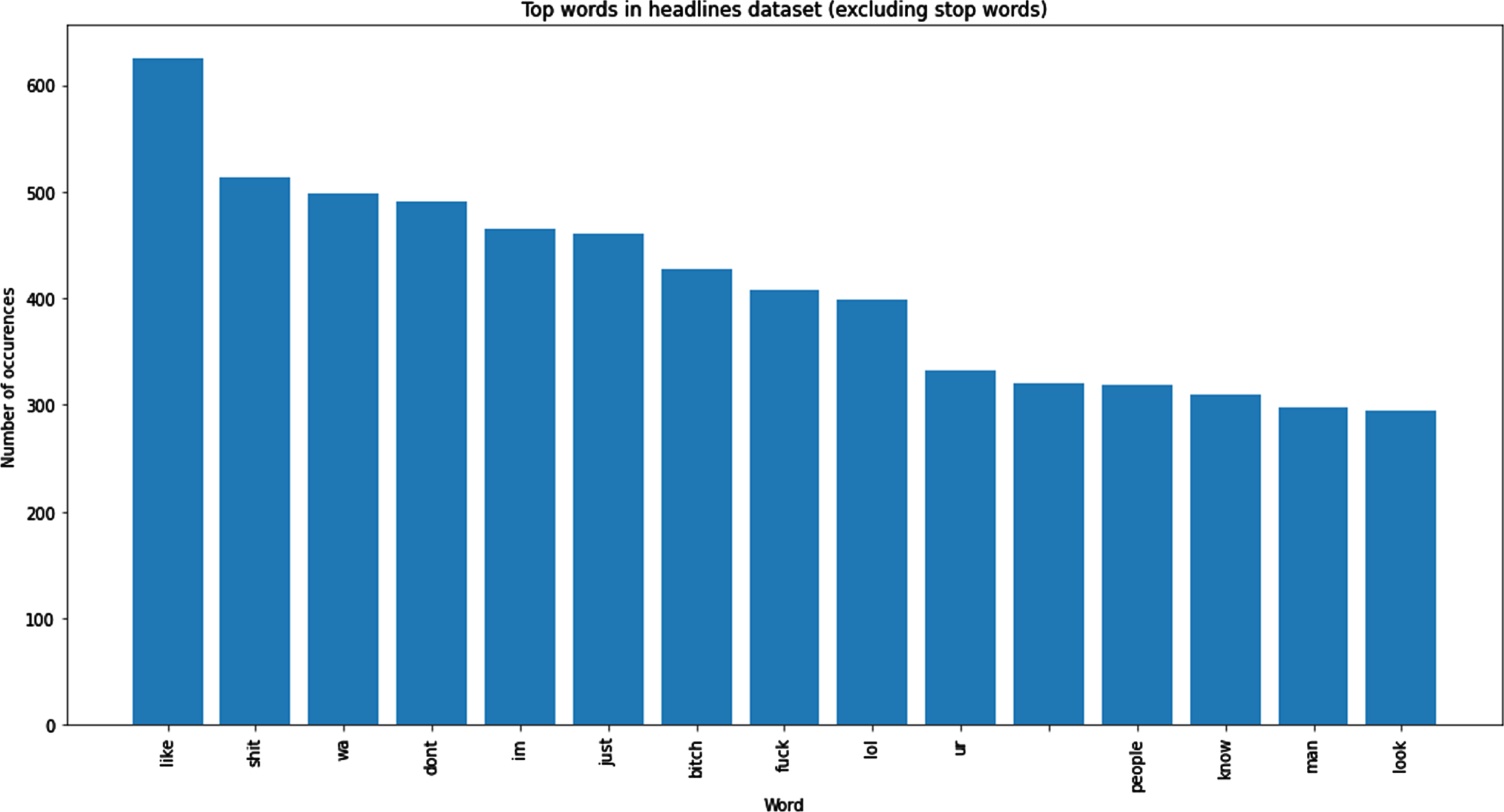
The words with high frequency in the dataset.
List of harassment words in the cluster.
The working of the Cluster-based detection module.
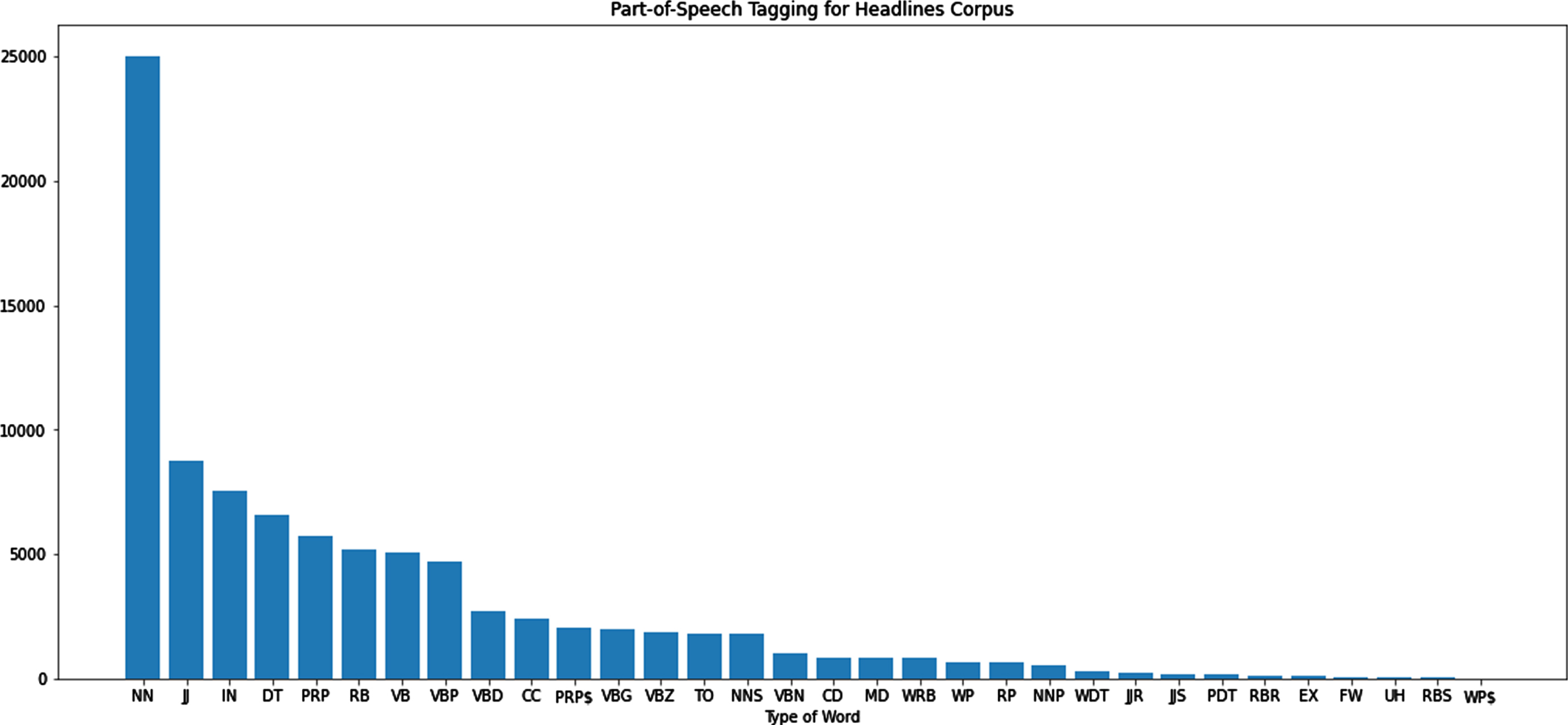
Figure 11, shows the probability values in tagging the comments using the POS method for all the words in the dataset. From this, it shows finding the targeted users using Noun and Pronoun tags. It is further divided into singular and plural tags. The noun form indicates the person, organization, place, things, etc. NounSingular is mapped to individual and NounPlural is mapped to Group of people.
The workflow of a strong ensemble learning model.
In the cluster-based detection module shown in Fig. 12, the embeddings of the tokens are generated by the Embeddings from Language Model (ELMO) method. ELMO s a deep contextualized word representation method that captures the context-dependent meaning of words, providing improved representation for NLP tasks. ELMO models are pre-trained on large amounts of text data, making them widely available and reducing the need for large amounts of annotated data for fine-tuning. It uses character-level information in addition to word-level information to improve its representations, making it suitable for tasks involving rare and out-of-vocabulary words. If the embeddings’ diameters are shrunk by Principal Component Analysis (PCA), the sentence vectors are generated. These vector representations are given as input to the K-means++unsupervised clustering algorithm where ‘K’ denotes the number of optimal cluster sizes. The cluster model is iterated 100 times. The error estimate is calculated for evaluating the cluster model. Hence K-Means is a fast, simple and efficient algorithm for partitioning data into clusters, making it suitable for large datasets. It provides clear and interpretable results, with each cluster representing a distinct group of data points.
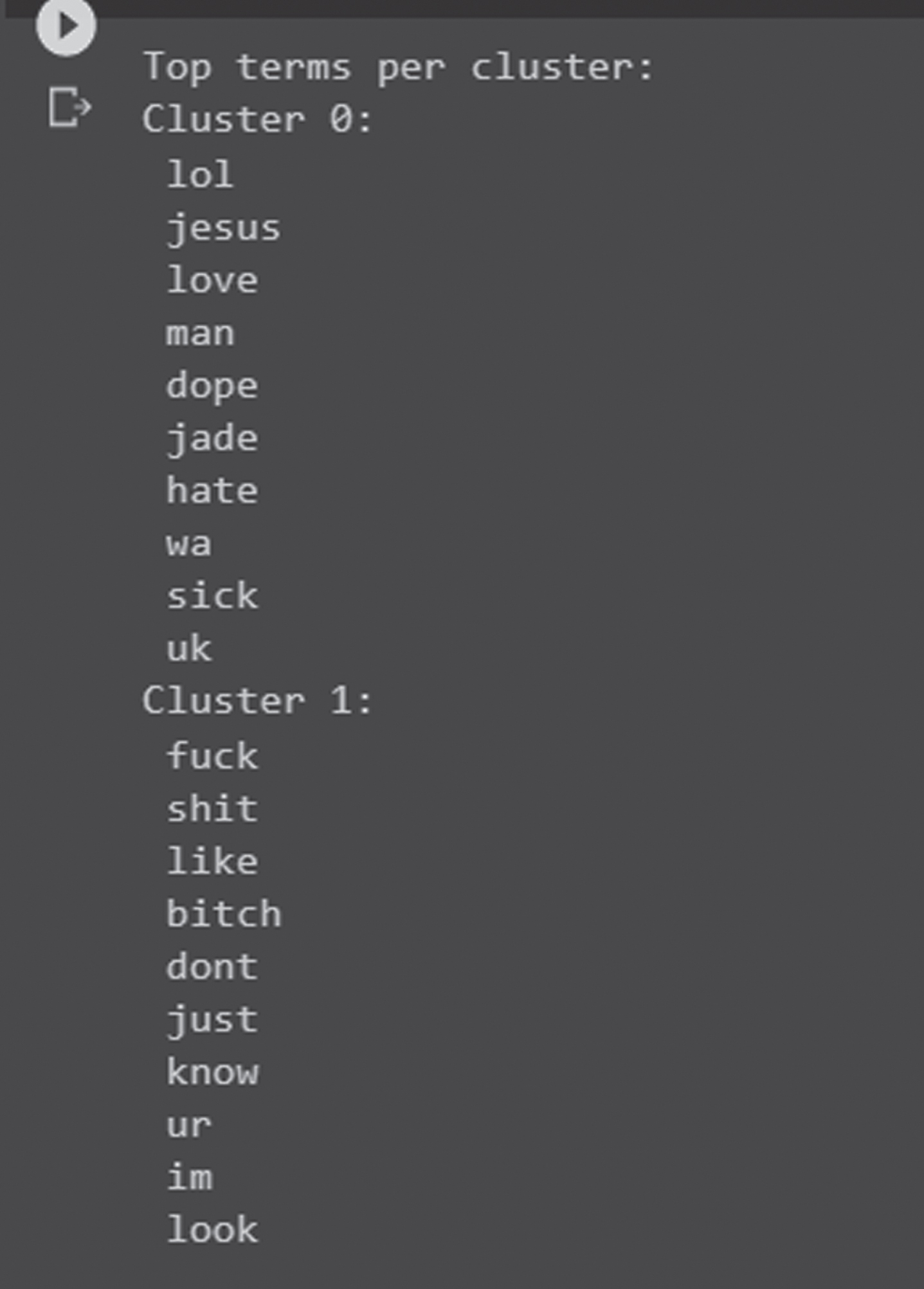
Figure 13, shows the list of words that resulted in the detection process. The K-means clustering model detects the list of CH and NCH words in the training dataset and it forms clusters with centroid values. The new words with probability nearer to the centroid are assigned to that particular cluster group. Each cluster is named with its id starting from 0. Here cluster0 indicates NCH and cluster1 indicates CH words.
List of words formed by K-means clustering.
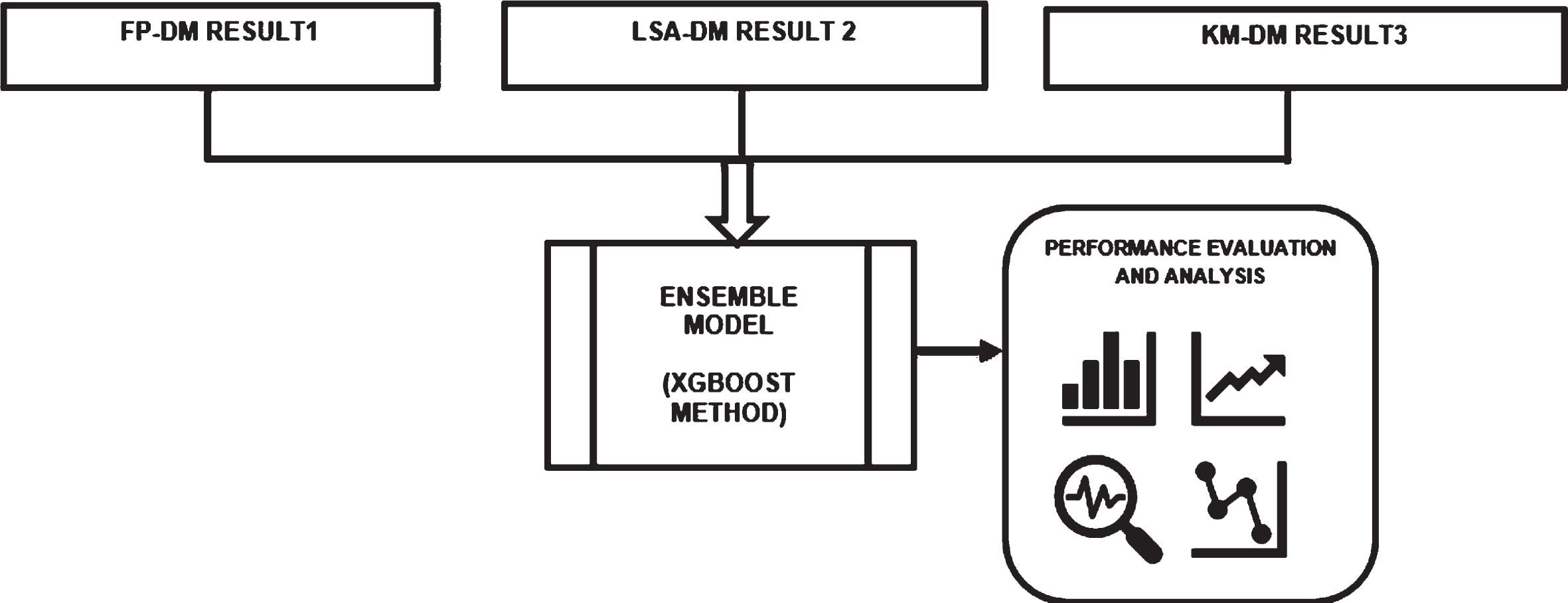
The clustered results from the detection modules are weak learners because the predictions from the single classifier model have high bias and variance. To surge the computational complexity and toughness of the model, an ensemble method called the XGBoost technique is used as shown in Fig. 14, Ensemble methods are machine learning models that combine multiple individual models to produce a more accurate and stable prediction. XGBoost is a popular gradient boosting algorithm that is widely used for various predictive modeling tasks. When XGBoost is used in an ensemble, the resulting model is known as an ensemble XGBoost. The base learners (FPDM, LSADM, and KMDM) are added sequentially that correct the predictions made by previous models’ outputs average weight. Overall, using an ensemble XGBoost can lead to a more accurate, stable, and robust predictive model, making it a useful technique in many applications. Hence the text comments are classified into sexual harassment, trolling, and revenge porn along with the intention of the harasser. Performance measures are used to evaluate the ensembled model.
Figure 15, shows the distribution of classified types of cyber harassment comments. Cluster ‘1’ remains higher when compared to other cluster groups. It indicates Trolling where people tease or low esteem others on social media platforms.
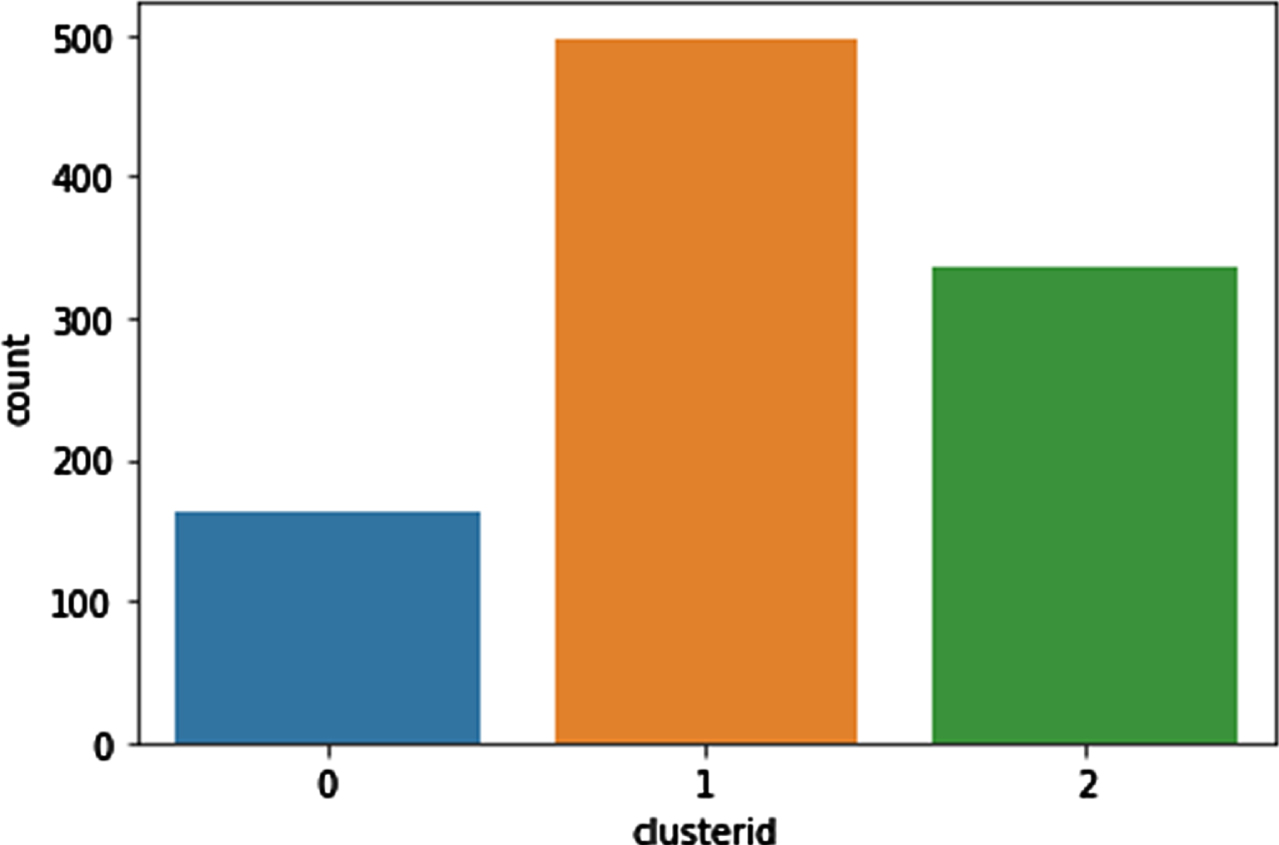
Distribution of three different classified types of cyber harassment.
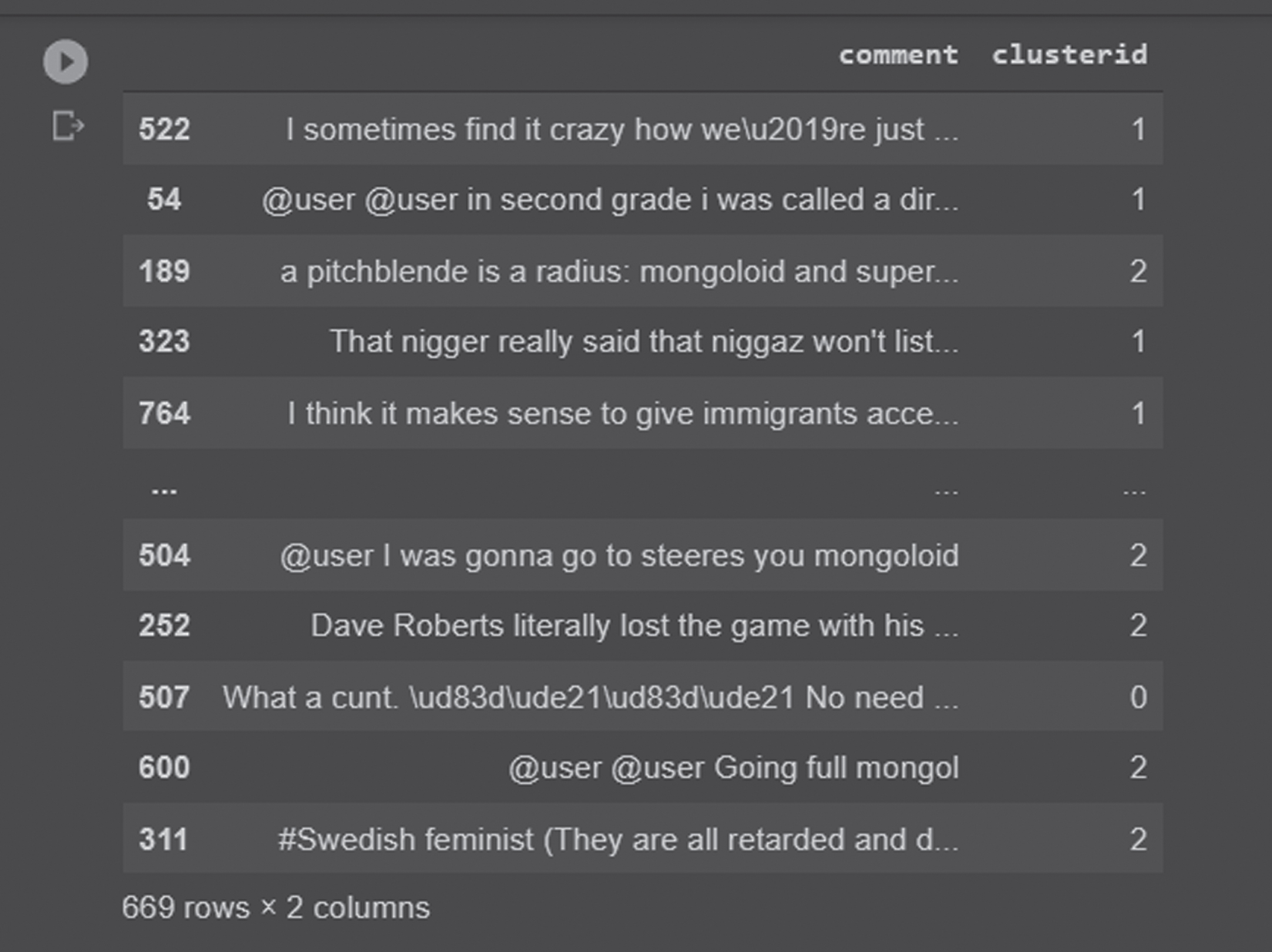
Classification of Instagram text comments into three clusters.
Figure 16, shows the classified clusters for each comment in the testing dataset. The CH comments are identified and grouped into any one of the clusters based on their intention. Its types are Cyberbullying, trolling, sexual harassment, etc. Clusterid 1 indicates Trolling, Clusterid 2 indicates Cyberbullying, and Clusterid 3 indicates sexual-harassment.
Table 5, shows the ensembled classified results for sample Instagram text comments. The text comments are labeled ‘0’ as Non-cyber harassment and ‘1’ as Cyber harassment comments using unsupervised machine learning techniques in the detection module. Further, cyber harassment comments are classified into three types Cyberbullying, Trolling and Sexual harassment. The non-cyber harassment comments are classified as Normal type.
EMDCH ensembled results for sample Instagram text comments
EMDCH ensembled results for sample Instagram text comments
In this sector, a variety of machine learning metrics, including the F1 score, Accuracy, Sensitivity, and Specificity, are used to estimate the model’s performance. The loss function of the model is determined by Mean Squared Error (MSE) and Log Loss. The similarity between the clusters in the detection models is assessed by the Adjusted Rand Index (ARI) and Mutual Information (MI). Micro and Macro average values define the percentage of all the positive predictions in the overall performance.
In Equation (1), where cp signifies correct positive comments, cn is a correct negative comment, ip denotes incorrect positive comments, and in is an incorrect negative comment.
Popular criteria for determining the True positive rate and True negative rate are
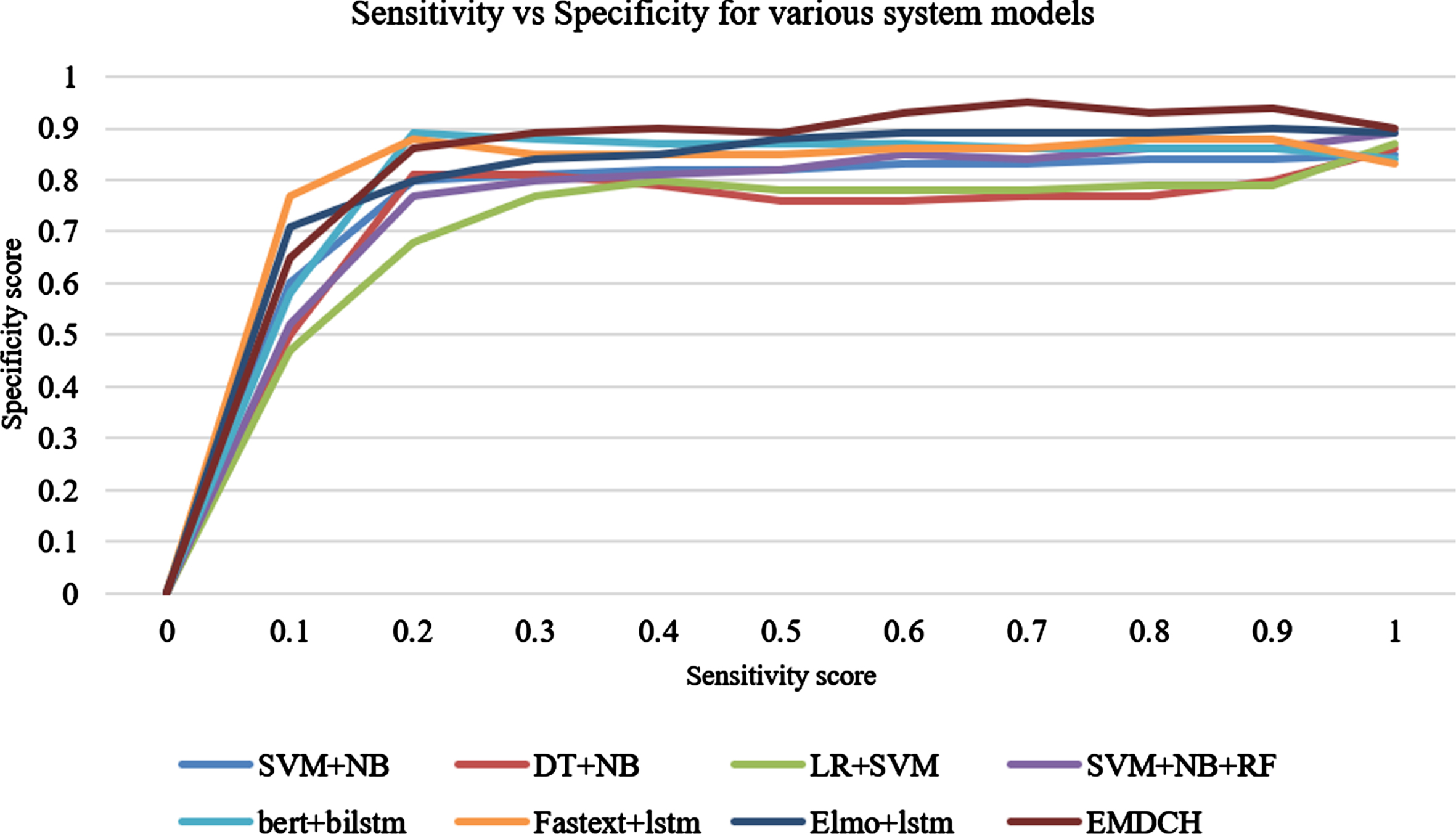
Comparison of Sensitivity and Specificity scores for various experimental models.
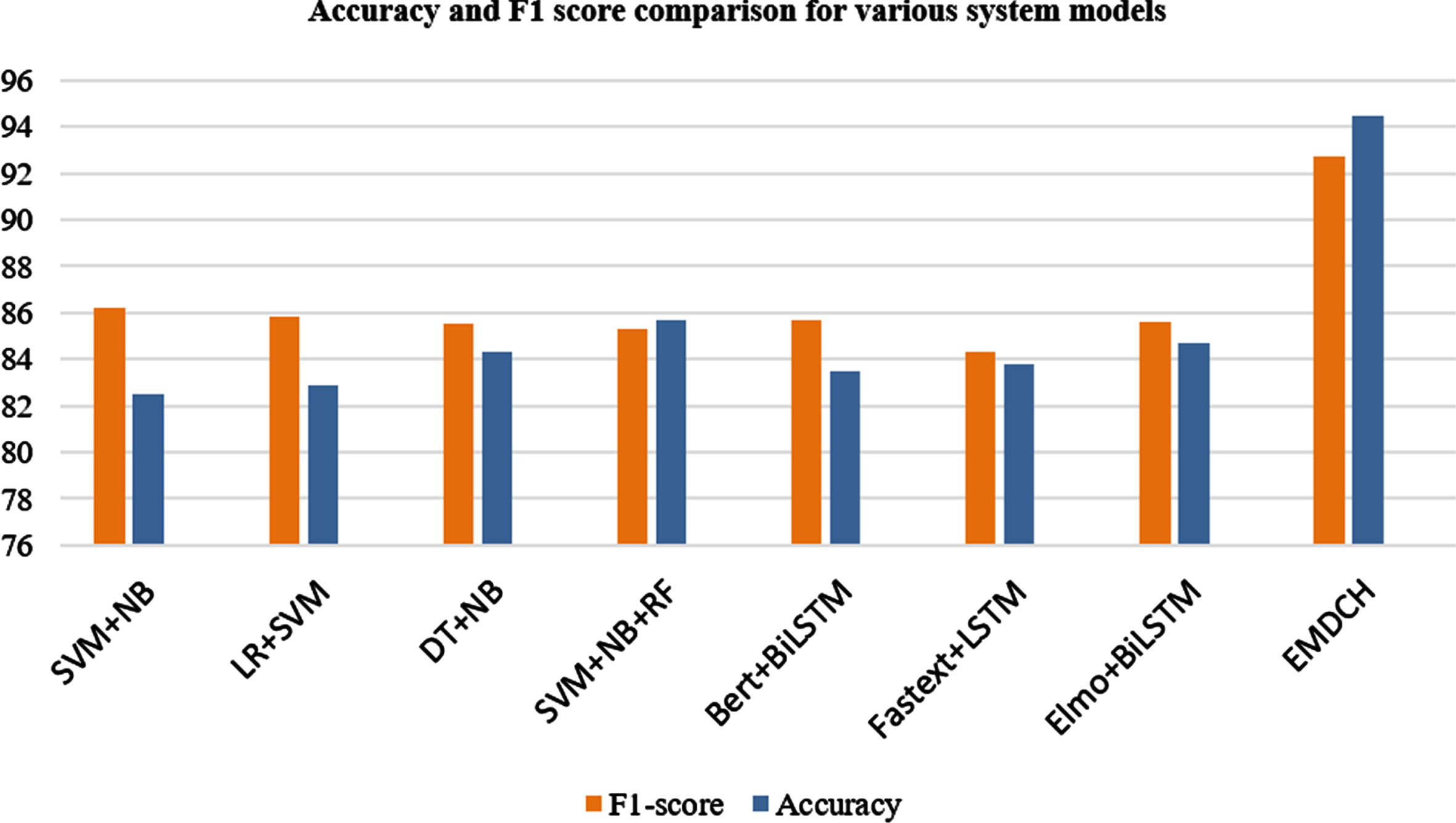
Accuracy and F1-score comparison for various system model.
Where ‘Ps’ denotes precision and ‘Rc’ signifies recall.
For
In Equation (7)
For
In Equation (9),
We have experimented and compared the proposed system with various existing supervised models and neural network models with two different datasets such as Form spring and Instagram text comments. The macro-average values for all the supervised and neural network models are lower than the EMDCH model. For Formpring dataset, the F1 score is higher than any other models. The macro-average precision is higher than other models for Instagram dataset for the proposed model as exposed in Table 6.
Macro average for different system model for two datasets
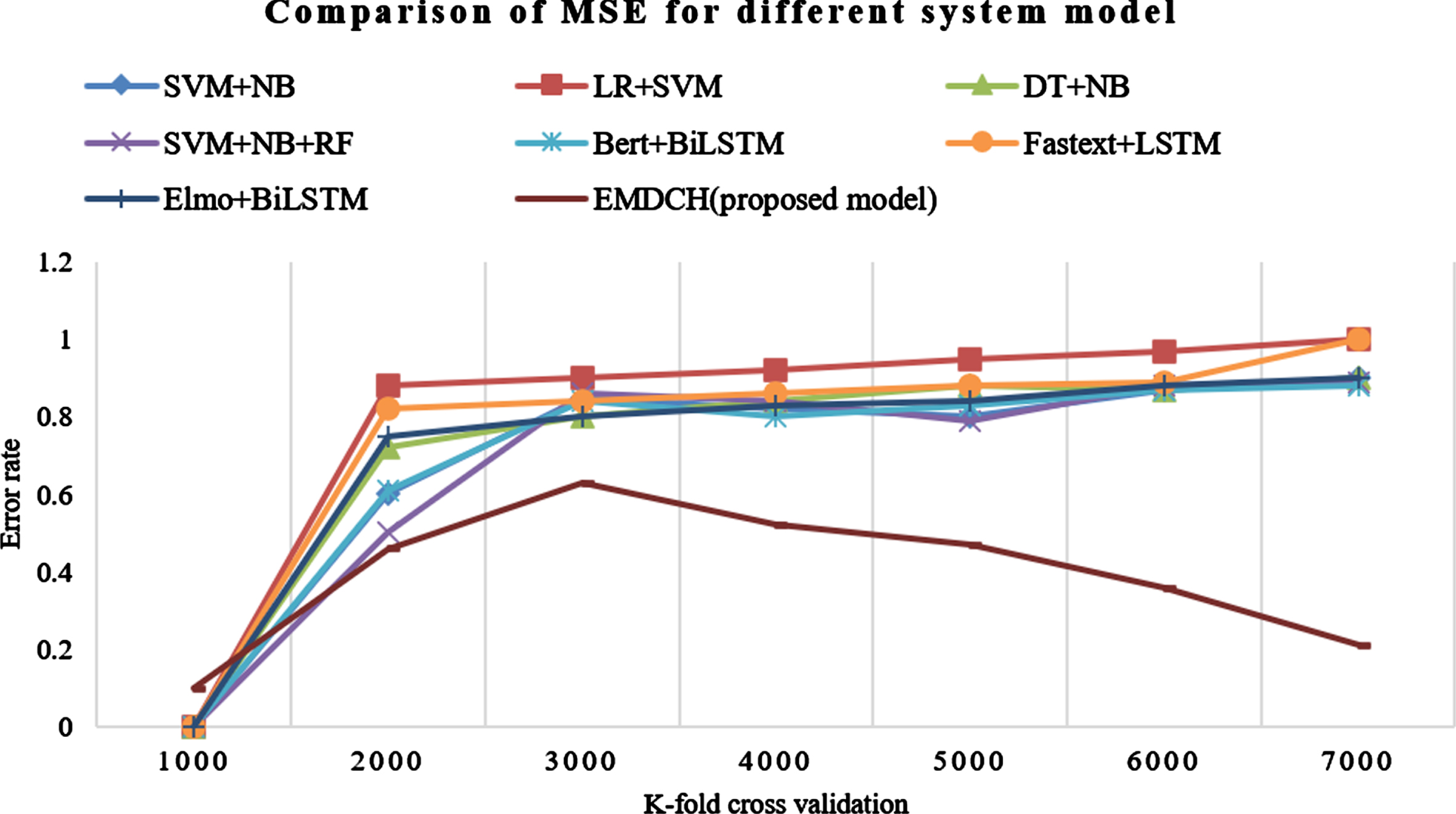
Error rate for various K-fold cross validation of the Instagram dataset.
In Equation (11) where ‘N’ being the number of classes. From Fig. 20, it shows the log loss cost function for EMDCH model with true label = 1 and true label = 0. It takes predicted probability along x-axis and log loss rate values along y-axis. For the proposed model, the error rate for true label = 1 (cyber harassment comments) decreases as the sample size increases with probability values.
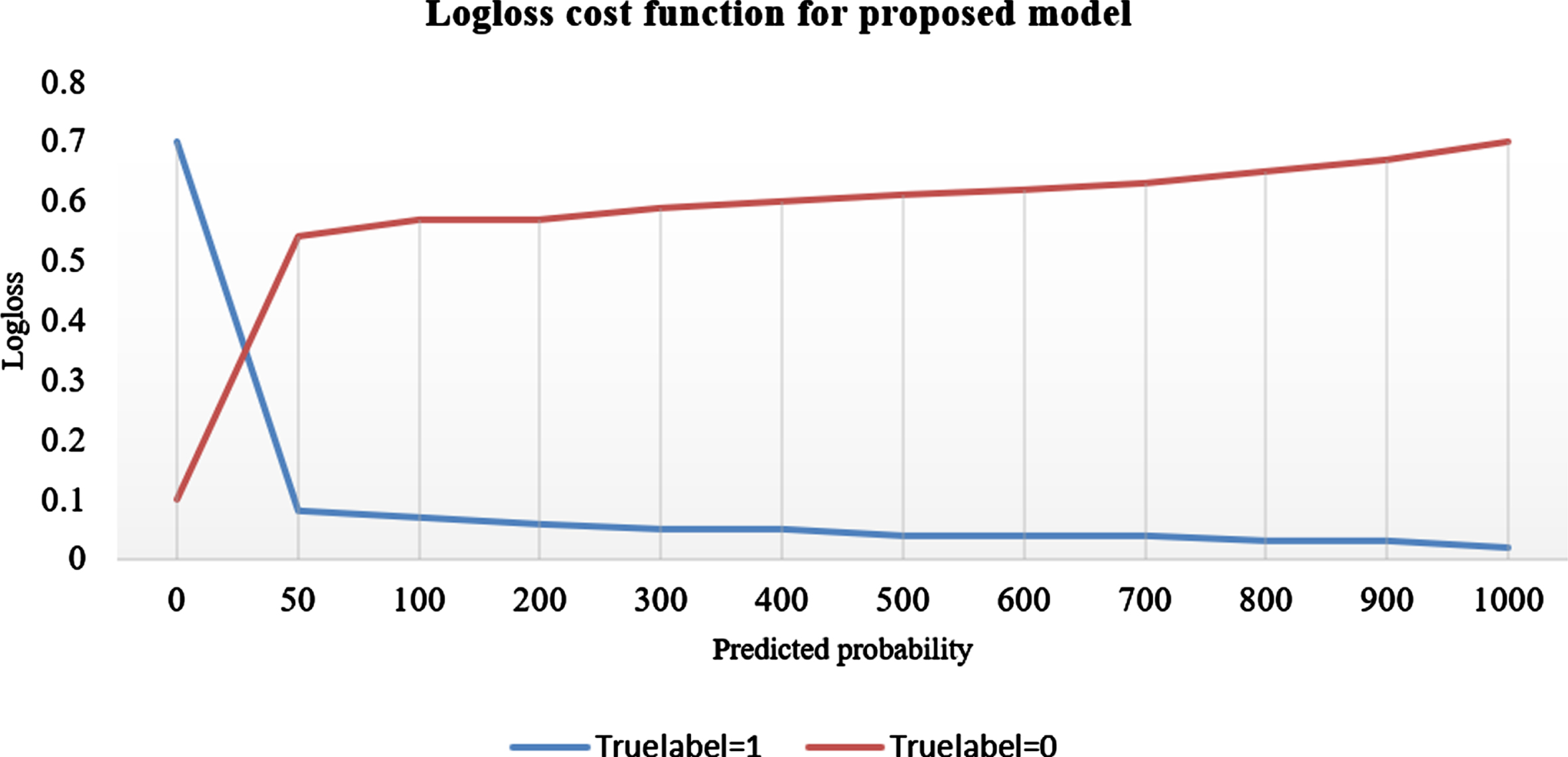
Log loss for predicted probability values for training data.
The
From Equation (12), the
Where |Ui| is the quantity of the illustrations in group Ui and |Vj| is the quantity of the illustrations in cluster Vj. The unsupervised machine learning models used in detecting the cyber harassment comments such as Kmeans++, LSA and F-P growth are executed and compared for ARI and MI based on silhouette score. The Mutual Information is higher for latent semantic analysis and lower for Kmeans++. The time taken for execution is lower for rule based frequent pattern model. The adjusted rand index is higher for LSA when compared to other unsupervised models as shown in Table 7.
The comparison for detection models for k-clusters with information score
Figure 21, shows the silhouette score analysis for various optimal ‘k’ values. It shows that after the value of k = 5, it gets decreased. The values below the optimal level lies between 0.024 to 0.040 which shows better results for association-based clustering such as frequent pattern, latent semantic analysis and Kmeans++.
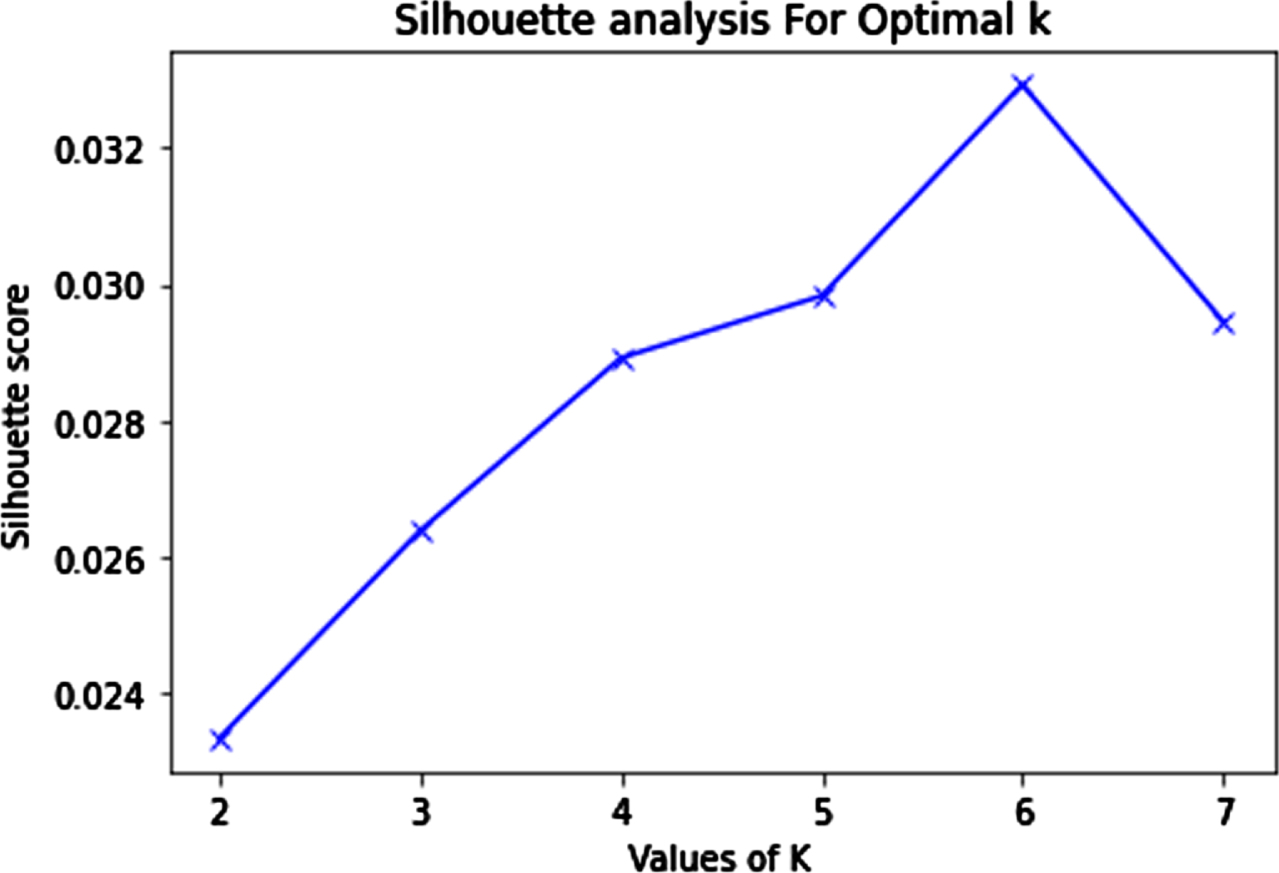
Silhouette score analysis for optimal ‘k’ values.
The temporal complexity of various experimental models used to train and test the cyber harassment categorization model is shown in Table 8 in detail. It suggests that with a forecast time of 1.27 seconds, our suggested model had the best performance. because it employs cluster-based association algorithms and pre-trained text representation approaches. Moreover, it uses the most efficient ensemble technique XG Boost which saves much larger time. The Elmo combined with BiLSTM takes the greater prediction time with 4.32seconds respectively. They’re remained trivial variances among SVM combined with NB and LR as exposed in the analysis. From the analysis, it shows that Bert executes faster when compared to other word embedding techniques because it reads the sentence from both directions. Thus, our proposed model EMDCH has better prediction time when compared with other ensemble models.
Prediction time for Training Instagram dataset
This study analyses and tests a method for systematically identifying online harassment as well as the motivation behind each comment. The knowledge-based Bert embedding model will determine the intention of each comment. All the machine learning models for detecting cyber harassment in the literature survey shows lesser accuracy compared to EMDCH model. It includes ensemble model which combines all the detected results and assign weight values to build stronger better predictive model. XGBoost change the weighted values to predict the most appropriate classification. The intention of the harasser plays crucial role in the analysis of cyber harassment to prevent the activity at earlier stage. Thus, our proposed EMDCH model predicts the intention using knowledge-based system. The semantic information about the comments, patterns in the harassment data and the contextual meaning of the words are involved in the unsupervised based detecting modules. The EMDCH model shows high F1 score of 92.04% compared to existing machine learning models. For each batch of epochs, the precision and recall increases which leads to high F1 score. In future work, the deep learning-based ensemble model can be used for predictive model. This model can be integrated to any other natural language processed application for pretraining the word embedding models with large number of word count. The size of the dataset can be increased to train the model with a greater number of relationships in the knowledge layer.