
Abstract
Recently, with the emergence of many image editing tools (photoshop, Topaz studio, etc.), the authenticity of images has been severely challenged. However, the performance of some existing traditional feature extraction methods and detection methods based on convolutional neural network (CNN) is poor, and the information provided by the features extracted from the network is limited and single. In this paper, an end-to-end ringed residual U-Net is proposed to detect image splicing forgery by blending features of non-natural regions. Some regions with significant differences from the image background are defined as non-natural regions(such as the irregular border at the splicing of images). In this paper, a feature enhancement module for non-natural regions is constructed, which the image through the pooling of four different scales, and these features are then combined with the original image and input to the backbone network for processing, aiming to highlight regions of the image that differ significantly from the background. Therefore, after adding the feature enhancement module for non-natural regions to the end-to-end ring residual U-Net, more attention will be paid to the tampering regions in the feature extraction stage, image manipulation detection and localization will also become more accurate. Compared with some mainstream methods, this method achieves better performance on the three standard datasets(CASIA2.0, NIST2016, COLUMBIA). In addition, it has excellent robustness under JPEG compression attack and noise corruption attack.
Introduction
Nowadays, the storing and transmission of digital images are becoming more and more typical and easy due to the rapid growth of computers and the Internet. It is unexaggerated that with the development of Internet globalization, digital images exist almost everywhere in people’s daily lives. However, with the popularity of digital images, people can use the image editing tools such as photoshop to tamper with the images they want with almost no cost and no threshold in recent years. Moreover, most of these tampered images are difficult to distinguish the tampering traces through human eyes, and it’s hard to tell if an image is real. This situation makes the digital image security risk increasingly serious, such as piracy and information security issues. In the field of image forgery, splicing forgery is very common, and the social problems caused by splicing forgery are particularly serious. Copying a part of the donor image to a region in the source image to create a new, tamperedimage is known as splicing forgery. In the process of splicing forgery, because every image has different image attributes, there are usually many differences in the essential attributes of images between the splicing regions and the real regions, such as noise, texture, lighting, and so on. These differences can be used as the key point to the image splicing forgery detection and location.
The main task in the field of image forgery is the detection and location of image forgery, and the detection and finding and locating image tampering regions is really difficult. They can be split into two categories based on the methods currently used for image splicing forgery detecting and locating: 1) Traditional tamper detection and location based on feature extraction;2) Tamper detection and location based on convolutional neural network (CNN).
Traditional tamper detection and location
To detect whether the image has been tampered with and locate the tampered regions, the researchers have tried in many ways. Currently, popular traditional image tampering detection methods can be divided into three parts: 1) pixel-based methods;2) imaging equipment based methods;3) hybrid methods.
In the pixel-based methods. Mahdian et al. [1] proposed an image passive tamper detection method that can find resampler and interpolation traces based on the characteristics that interpolated signals and their derivatives contain specific detectable periods, and this method has high application value in the fields of detecting image security and the authenticity of people’s identities. Stamm et al. [2] adopted the detection method based on the intrinsic fingerprint to realize image tampering detection through contrast enhancement of global image and local image. The tampered image with contrast enhancement can obtain better detection results by using this method. Anand. [3] combined speeded up robust features transform with a variety of wavelet transforms to detect tampered images. Different from other algorithms, this algorithm did not partition images into blocks to extract features, but extracted features on the whole image range.
In the imaging equipment based methods. Hsu et al. [4] used camera response function to achieve image tampering detection and locally planar irradiance. The geometric invariant of points is used to estimate the CRF of each automatic segmentation region, calculate the CRF-based cross-fitting and local image features and transmit them to the statistical classifier, and finally determine whether the image is tampered with. Since single-sensor digital cameras obtain color images through internal color filter array (CFA) interpolation, each camera has its own unique CFA structure and algorithm, and also has its unique linear relationship between adjacent pixels of the output image. Ferrara et al. [5] used the color filter matrix mode to re-interpolate the detected image after sampling, and then compared it with the original image to obtain the estimation error, to tamper detection on the image according to the different estimation errors of the two types of pixels.
Most traditional methods can only detect images tampered with a certain tampering method, but the types of tampered images are often diverse. Therefore, image tampering detection methods based on combinators have been proposed by some researchers. Gaborini et al. [6] proposed an integrated photo response non non-uniformity (PRNU), Image tamper detection method based on block matching detector and image source-detector, this integrated image tampering detection method enhances uniformity to some extent. Li et al. [7] proposed a set framework, which included a statistical feature-based detector and a copy-move tamper detector, and finally detected the tamper regions of the image through threshold processing. Although the image tamper detection method based on combinator improves the detection accuracy, it also increases the complexity of the model because it integrates multiple detectors into one framework.
Traditional image tamper detection has limitations, such as its performance is not particularly excellent when detecting carefully designed tampered images. Further research is needed to achieve excellent performance.
Tamper detection and location based on convolutional neural network
Convolutional neural network (CNN) has made brilliant achievements in computer vision tasks, and Wang et al. [8] and Zhang et al. [9] have made contributions. CNN has the advantage of adaptive feature extraction, and many researchers have applied CNN to the field of image tampering detection and made some achievements. For example, Rao and Ni [10] applied convolutional neural networks to the field of image tampering detection for the first time, but the limitation was that this detection could only be limited to detecting whether the image had been tampered with at the image level and could not locate the tampering regions. Zhang et al. [11] proposed a block-based method for image tampering detection, but it can only roughly locate the tampered regions of the image.
At the same time, some researchers also apply deep learning methods to the correlation of imaging equipment. Baroffio et al. [12] proposed for the first time to use convolutional neural network to realize image tampering detection based on camera source. The model can directly obtain camera features from the images to be detected, to judge whether the images to be detected have been tampered with. Bondi et al. [13] used convolutional neural networks to locate tampered regions in images according to different noises in photos taken by different cameras.
In recent years, researchers have used steganographic analysis to improve the detection framework. By analyzing the local noise characteristics between adjacent pixels in the image, the difference between tampered regions and non-tampered regions can be more accurately detected. Cozzolino et al. [14] combined the convolutional neural network with SRM(spatial rich model) features to locate the image tamper regions. Zhou et al. [15] proposed a two-stream convolutional neural network based on Faster R-CNN, in which one branch of the network is RGB stream and the other branch is noise stream. The network fused the two branches into a network framework, further improving the accuracy of detection.
To sum up, the majority of currently used image tamper detection methods concentrate on how to use the network to extract tamper features better, but the features are limited and single, so the further improvement of detection performance is affected. Aiming at the shortcomings of traditional feature extraction and further solving some problems existing in current detection and localization methods based on convolutional neural networks, this paper proposes a network framework for image splicing detection, which is a ringed residual U-Net that integrates features of non-natural regions. The network is an end-to-end image segmentation network independent of human visual system. It can make perfect use of the regions and context information that are significantly different from the background in the image, so that the tampered regions can be highlighted more significantly. In addition, it does not require any preprocessing or post-processing to locate the tamper regions.
Even though CNN based image tamper detection has developed to a relatively excellent level, there are still some problems, such as insufficient performance in detecting tampered images outside the training set. In this paper, a feature enhancement module for non-natural regions is proposed to improve the extraction ability of areal features that have been tampered with in the image. The tampered areal features are extracted more efficiently and more targeted, making this method more universal, improving the accuracy of tamper detection, and having good performance in detecting images that are not part of the training set.
Related work
In recent years, numerous researchers have focused on enhancing the network’s ability to extract more useful features, but doing so will result in the loss of many particular and vital features. The following work does not preprocess the images to get more important features. Xiao et al. [16] proposed a two-stage VGG network, and in order to locate tamper regions on coarse and refined scales. but this method is relatively complex in calculation. Salloum et al. [17] proposed a multi-task FCN(MFCN) with two output branches for multi-task learning, in which two branches are used to learn the tampered regions and learn the boundary of the tampered regions respectively. A ringed residual U-Net (RRU-Net) was proposed by Bi et al. [18], in which the ringed residual structural module is mostly made up of two functional modules: residual propagation and residual feedback. RRU-Net structure is an end-to-end image tamper detection network structure that requires neither any preprocessing and post-processing. Both MFCN and RRU-Net have some difficulties in training, and the results of tampering detection need to be improved, and its features are limited. In order to learn the spatial correlation between non-overlapping image blocks, Bappy et al. [19] inserted a long and short term memory (LSTM) network between the second and third layers of five-layer CNN. Shi et al. [20] used VGG network to learn the difference of image noise fingerprint extracted by SRM layer between tampered and non-tampered regions, and then detected tampered regions. Huh et al. [21] extracted EXIF metadata from images automatically recorded by cameras as key indicators and then used the Siamese network to detect whether some regions in the image were generated by a single imaging pipeline, but many images have serious loss of EXIF metadata resulting in poor prediction results. Liu et al. [22] extracted noise and JPEG compression features through DenseNet to locate the tampered regions, but this method only learns specific image fingerprints, and it is easy to get wrong decisions. Wu et al. [23] proposed an image processing tracking feature extractor and local anomaly detection network. Zhang et al. [24] used spatial rich model (SRM) to obtain the noise residuals of images, then used DenseNet for binary classification, and finally obtained the prediction results through upsampling. The methods of Bappy et al. [19], Wu et al. [23] and Zhang et al. [24] attempt to enhance the autonomous learning of image fingerprint through specific image fingerprints, but pre-training requires a large number of forged samples to improve detection results. This method focuses on the most original features after image input before entering the feature extraction network, and this method will pay attention to the features of those non-natural areas and enhance them, so that the network can learn more useful information in the subsequent feature extraction process. Utilizing this new approach to improve the performance of image tamper detection is unique and effective.Experiments have shown that this method can improve model performance and is superior to some other methods. In addition, the computational complexity of this model is not high and does not require complex post-processing.
Proposed Method
The difference of the image’s essential attributes is one of the most crucial foundation for image splicing forgery detection. However, in some networks, there is no attention paid to regions of the image that have essential attribute differences before the image is input to the network, which leads to an unsatisfactory result. Therefore, this paper proposes a ringed residual U-Net that integrates the feature enhancement module of non-natural regions for the detection of image splicing forgery. This article focuses on a new perspective. First, this method constructs a feature enhancement module of non-natural regions. This paper defines the regions with large differences from the image background as non-natural regions(such as the irregular border at the splicing of images), and the module carries out feature enhancement for these regions. One extremely important aspect of image tampering detection is to find traces of forgery. After the above process, some non natural tampered regions are found, and when passing through the backbone network, more attention will be paid to the non natural tampered areas, and the detection results will also become better. After feature enhancement, the features and the input original image are merged, and the ringed residual U-Net is then used for down-sampling and up-sampling, and finally output the predicted result image. To solve the problem of limited and single input features, this method enhances the features of non-natural regions to enrich the input features, so that more features that play a positive effect in the prediction results can be input into the network, and improve the detection and localization ability of the network for tampering regions.
Enhanced features of non-natural regions
In most of the tampered images people see, there are often some differences in the tampered regions and background. Therefore, this paper proposes a module to enhance the features of non-natural regions to solve the problem. The module first carries out average the pooling of four different scales of the input image, and then the pooled features are subtracted from the original image respectively to obtain the feature difference. Finally, the four feature differences obtained in the above process are combined and then spliced with the original image as input to the ringed residual U-Net. In this module, the local feature of a pixel is represented by its value, and the average value in the areas surrounding a pixel serves as a representation of the significant feature of that pixel.The non-natural regions feature enhancement module is shown in Fig. 1.

Non-natural regions feature enhancement module.
The average value of the pixels in the regions represents the significant features of pixels as follows:
Where μ represents the average value of pixels, F[i,j] represents the pixel value at the position [i,j], H r and W r represent the height and width of the regions respectively.
Equation (2) is used to measure the difference between features and salient features in the regions around pixel points. The difference D[i,j] is expressed as follows:
The standard deviation σ is expressed as:
This method uses multi-scale pooling to enrich features and calculate significant features in different regional ranges so as to find the tampered regions more accurately. This method takes the whole input image as a regions, and use 1×1 average pooling to take the average value of all pixels as the significant features of the image, and then subtract the significant features from the original image. And in convolutional neural networks, the pooling layer plays an important role in reducing the amount of data and highlighting the key features, to more accurately identify non-natural regions. Therefore, this method uses the average pooling of different pooled cores (11×11, 7×7, 3×3) and corresponding padding (5,3,1) was used to find the significant features, it also keeps H and W consistent, and the subtraction was also carried out with the source image. This method calculates significant features in different regions, and uses multi-scale pooling to more accurately identify non-natural regions.
In the non-natural regions feature enhancement module, the input image is detected in the local non-natural regions and combined with the input image. This module can enhance the feature of the non-natural regions in the image, while preserving the relatively complete spatial information of the input image. In the subsequent feature extraction network, these non-natural regions can get more attention, enhance the network’s learning of these regions, and thus improve the accuracy of image splicing detection.
After the image input, the image first passes through the feature enhancement module of the non-natural regions, more features are being extracted, and the difference of the image’s essential attributes between the non-tampered regions and the tampered regions also expands. Moreover, these features are critical to the down-sampling and up-sampling of the backbone network connected after the module, and the final detection effect is also improved accordingly. The backbone network of this model draws on the RRU-Net network structure proposed by XiuLi Bi et al. [18] in 2019. RRU-net is an end-to-end image critical attribute segmentation network that performs exceptionally well in extracting features from images and locating tampered regions. The residual feedback integrates the input feature information, which highlights the differences in the image attributes between the tampered regions and the non-tampered regions. Residual propagation in RRU-net solves the gradient degradation problem in deep networks by recalling the input feature information. The specific network framework is shown in Fig. 2.
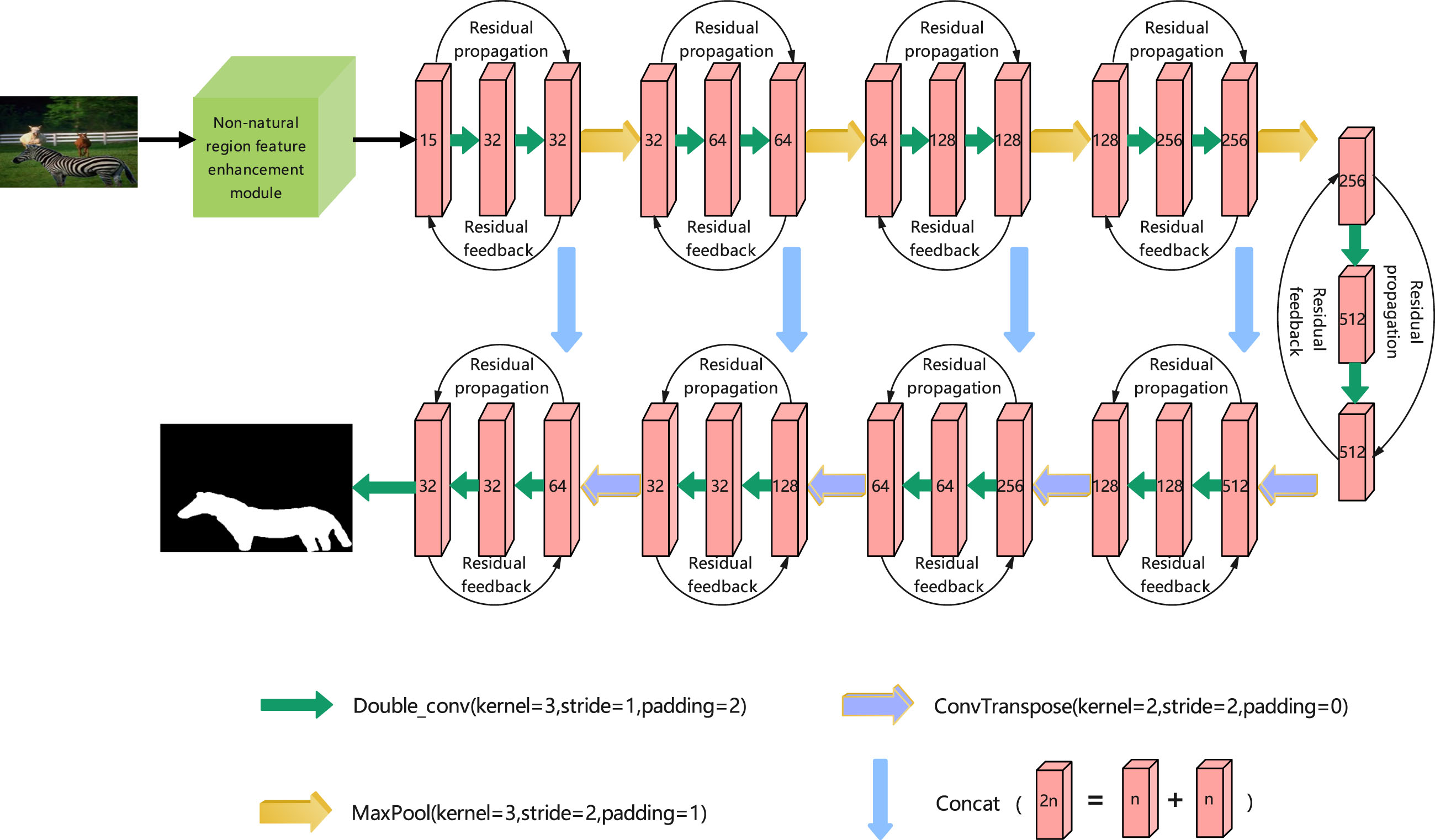
The architecture of the proposed method, the number in the cuboid represent the number of features.
After the image is entered into the network, it will get the features of 15 channels after it passes through the non-natural regions feature enhancement module, and then the features will be up-sampling and down-sampling. After the process of up-dimension and down-dimension reduction, the network outputs a predicted binary mask graph to display the location of the tampered regions. Meanwhile, it will be compared with ground-truth to get the predicted mask and evaluation scores.
Datasets
Introduction to datasets
To make a fair comparison, this method is evaluated on three public forgery datasets: CASIA v2.0 [25], Columbia [26], and NIST16 [27]. CASIA v2.0 contains 5123 forged images in TIFF and JPEG formats, including splicing and copy-move, in which the tampering regions of the tampered images is small and delicate, and there are a large number of real-life scenes in the images, which are closer to reality and more challenging. CASIA v2.0 is one of the most commonly used datasets in the field of image manipulation detection. Columbia also provides 180 forged images in TIFF format, including splicing and copy-move, in which the tampering regions of the tampered images is large and easy to be detected, and the number of images is relatively small. Colombia is one of the commonly used datasets in the field of image manipulation detection. There are 564 JPEG image forgeries in NIST16, including splicing, copy-move and remove, in which tampering regions of the tampered images is small and difficult to detect, and the number of images is relatively small. NIST16 is also one of the commonly used datasets for image manipulation detection.The details of the above three datasets are shown in Table 2.
The table lists the year, image format and number of splicing images of CASIA v2.0, Columbia and NIST16
The table lists the year, image format and number of splicing images of CASIA v2.0, Columbia and NIST16
Test results of splicing forgery detection
To better train the network, the training set and the test set’s image sizes was changed to 384×256, and then enhanced all the data with JPEG random compression horizontal flip, and vertical flip, thus increasing the capacity of the above three datasets by 4 times. This paper randomly selects 5% of the images in the datasets after data enhancement as the test set of the experiment for testing, and the other 95% of the images as the training set to train the network. JPEG random compression: The splicing forged image for JPEG compression, which has different compression quality factors(50-100) and saved in JPEG format. Gaussian noise: Add Gaussian white noise with a mean of 0 and different variances(0-0.01) to the splicing forged image. Horizontal and vertical flip: 1) Horizontal flip: flip 180 degrees from left to right or right to left; 2) Vertical flip: flip 180 degrees from the top down or from the bottom up.
Because JPEG images can only be detected using the detection method based on compression characteristics, to be fair, all TIFF images in the datasets are uniformly converted to JPEG format with a quality factor of 100%.
Evaluation Metrics
For image splicing forgery detection, one of the important evaluation at pixel level is the accuracy of location tamper regions. Therefore, Precision, Recall and F-measure were used to evaluate the performance of the image splicing forgery detection method, where TP represents the number of pixels that can be correctly detected, FP represents the number of pixels that are incorrectly detected, and FN represents the number of non-tampered pixels detected by errors. Precision is defined by equation (4), and is expressed as the ratio of correctly detected pixels to all detected pixels. Recall is defined by equation (5) and expressed as the ratio of correctly detected pixels to ground-truth. F-measure is a comprehensive evaluation metrics combined with Precision and Recall, defined by equation (6).
Comparison with other methods
During the experimental comparison, this paper only takes into account methods that can pinpoint pixel-level tamper regions. They are: error level analysis (ELA) [28], aligned double quantization (ADQ) [29], noise inconsistency (NOI) [30], color filter array (CFA) [5], ringed residual u-net (RRU-Net) [18], coarse-to-refined network (C2RNet) [16], reality transform adversarial generators (RTAG) [31] and ObjectFormer [32]. All of above methods can detect tamper regions at the pixel level. Some detection methods can only determine the type of forgery and are therefore not included in this comparison, such as in [33]. The first four methods are based on traditional feature extraction methods, the source code for these methods was put into practice and publicized by Zampoglou et al. [34]. The RRU-Net is based on CNN, whose source code is provided by the author, and the code of RRU-Net runs on our own server. The positioning performance of this paper and other detection methods was evaluated using Precision, Recall, and F-measure, and its performance values were shown in Table 1.
Analyzing the data in Table 2, it can be seen that the F-measure on the three datasets are almost all higher than those of other methods, indicating that the performance of our method is superior to other methods.Among them, the F-measure tested by this method on the NIST16 dataset is 5.3% higher than RRU-Net. This is because the tampered regions in the images in the NIST16 dataset are relatively small and difficult to detect, resulting in a severe imbalance in sample proportions. Other methods overlook this point, resulting in poor detection performance on NIST16, while also demonstrating the superiority of this method.
In the three datasets, except for F-measure slightly lower than RTAG in CASIA v2.0, the Precision and F-measure were higher than other comparative methods. The accuracy and F-measure of traditional detection methods are lower than those based on CNN, but the recall rate is very high. In CASIA v2.0 and Columbia, the recall rate of this method is worse than the four traditional methods (ELA, ADQ, NOI, CFA) because these four methods almost detect the entire image area as a tampered area. In this method, the detection performance of network structure on CASIA v2.0, Columbia, and NIST16 is superior to other detection methods based on CNN.
Compared with the most advanced image splicinging forgery detection methods, the advantage of this method is that it extracts more useful features for training, resulting in better training results. Before inputting features into the network, four different scales of pooling are used to extract features that are likely to be tampered with regions. Adding these features to network training will make it more effective, the training process will be more targeted, and the training results will be better.The disadvantage of this method is that it involves four different scale pooling operations after image input, as well as residual propagation and residual feedback in the network, making the network training time longer. In addition, this method only focuses on image splicing detection, and the detection type is relatively limited.
Prediction result display
Precision, Recall and F-measure are important in image splicing forgery detection, and the positioning performance of image splicing forgery detection is also important. In order to more prominently see the performance of the network in the detection of image splicing forgery, the prediction image is concentrated in Fig. 3. It is worth mentioning that to better highlight the superiority of this method, we predicted images that do not belong to the three datasets in this paper, and the predicted results are shown in the last column of Fig. 3. It can be seen that this method can obtain wonderful prediction results no matter there is one or more tampered regions in the tampered image.

Splicing forgery detection results of this method and RRU-Net. From top to bottom, this figure shows forged images, ground truth, predictions.The tampered image in the last column of the figure does not belong to the dataset used in this article.
After the image was tampered, JPEG compression and noise blurring are usually used to make the image more blurred. Therefore, to further confirm the reliability and robustness of the proposed detection method, this paper also evaluate the detection method’s performance under JPEG compression and noise blurring. Under JPEG compression attacks, the compression quality factors are set to 100-50. under noise corruption attacks, add Gaussian noise with mean value of 0 and variance of 0-0.01. This paper randomly selects 20% of the images from CASIA v2.0, Columbia and NIST16 respectively for JPEG compression and adding Gaussian noise. The three evaluation metrics(Precision, Recall and F-measure)were used to compare with various methods.The visualization results of the robustness experiment are shown in Fig. 6, which respectively show the prediction images under JPEG compression attack and noise corruption attack.
Experimental Results under JPEG Compression Attack
The comparison experiment results under JPEG compression attack are shown in Fig. 4. In Fig. 4, (a)-(c) represent Precision, Recall and F-measure under the image of different JPEG compression quality factors on CASIA v2.0, Columbia and NIST16, respectively. It is easy to see from Fig. 4 that in CASIA v2.0, the Precision and F-measure of this model are better than those of other methods. However, since ELA, NOI and CFA almost regard all regions as tampering regions, the Recall of this model is not higher than those of the above methods. In Columbia, the proposed model outperforms alternative methods in terms of Precision and F-measure, and only NOI and CFA methods are not exceeded in Recall. On NIST16, it is also superior to other methods in Precision and F-measure, and close to the best method in the figure in Recall. Through the above experiments, it is evident that the proposed model’s detection results are superior to those of existing detection methods and have great robustness under JPEG compression attack.

Experimental results under JPEG compression attacks. (a)-(c) are the experimental results on CASIA v2.0, Columbia and NIST16 respectively.
The comparative experimental results under noise corruption attack are shown in Fig. 5. In Fig. 5, (d)-(f) represent Precision, Recall and f-measure under the image of mean 0 and different variances on CASIA v2.0, Columbia and NIST16, respectively. On the CASIA v2.0, Columbia and NIST16 datasets, this method is superior to other methods in Precision and F-measure, and close to the best method in Recall. It can be observed from the above analysis, the proposed model exhibits higher robustness against the noise corruption attack on the above three datasets.

Experimental results under noise corruption attacks. (d)-(f) are the experimental results on CASIA v2. 0, Columbia and NIST16 respectively.

Robustness experimental prediction results. The (g) and (h) columns are under JPEG compression attacks, the (i) and (j) columns are noise corruption attacks. Each column represents the original image, the attacked image, the groundtruth, and the binary mask predicted by RRU-Net and this method from top to bottom.
In the experiment, Adam training optimizer is used for training. The batch size is 12, the initial Learning rate is 3e-4, the attenuation rate is 0, and the epoch is 400. Note that in our observation, when the batch size is greater than 1, the performance of the network decreases sharply, while when the batch size is less than 12, the effect is not as good as that of a batch size of 12. For data augmentation, all images are adjusted to 384×256. All training processes are implemented on NVIDIA Corporation GP104 [GeForce GTX 1070] GPU.
Conclusion
This paper proposes an end-to-end ringed residual U-Net that combines the features of non-natural regions to detect the image splicing forgery. This network can detect the image splicing forgery without any preprocessing and post-processing. The non-natural region features are obtained by the output of the non-natural region feature enhancement module proposed by us. In this module, features of four different scales pooling are extracted. After pooling at four scales, more regions with large differences from the background are highlighted, and then the differences between the non-tampered region and the tampered region are amplified. In this way, the features of these non-natural regions can be more prominent in the subsequent up-sampling and down-sampling networks, to improve the performance of the network to image manipulation detection and localization. Extensive experiments on different datasets demonstrate the effectiveness of the proposed method, and it has more stable robustness under JPEG compression and noise attack. This method can be used to identify the authenticity of images in national security departments, government departments, commercial departments, etc, so as to avoid the adverse impact of forged images on social stability and unity. However, the tampering detection effect of this method for relatively small regions is not good enough. Nowadays, there are still many images where only a small region has been tampered with and cannot be detected and located. Based on this challenge, someone has proposed using region loss to solve the problem of tampering with small areas in the image and has achieved initial results. In the future, we will continue to explore how to accurately detect multiple or small tampering regions, the this network can be optimized based on current experimental results, making it more practical.
Footnotes
Acknowledgment
The authors would like to thank all the people who have contributed to this paper for their selfless work. This work is supported by the 14th Graduate Education Innovation Fund of Wuhan Institute of Technology(CX2022351).