
Abstract
While deep learning based object detection methods have achieved high accuracy in fruit detection, they rely on large labeled datasets to train the model and assume that the training and test samples come from the same domain. This paper proposes a cross-domain fruit detection method with image and feature alignments. It first converts the source domain image into the target domain through an attention-guided generative adversarial network to achieve the image-level alignment. Then, the knowledge distillation with mean teacher model is fused in the yolov5 network to achieve the feature alignment between the source and target domains. A contextual aggregation module similar to a self-attention mechanism is added to the detection network to improve the cross-domain feature learning by learning global features. A source domain (orange) and two target domain (tomato and apple) datasets are used for the evaluation of the proposed method. The recognition accuracy on the tomato and apple datasets are 87.2% and 89.9%, respectively, with an improvement of 10.3% and 2.4%, respectively, compared to existing methods on the same datasets.
Introduction
The global fresh fruit trade is a representation of modern globalization. Increasing fruit consumption is a vital component of the change to a healthier and more sustainable diet [1]. Fruit yield estimate is important for fruit production, beneficial to orchard management and decision making, regarding labor requirements, storage, transport, and marketing [2]. Object detection is an important step towards fruit yield estimation, whose result can be counted to provide the fruit number in images [3].
As a core problem in computer vision, object detection has been intensively studied with traditional image processing techniques and machine learning methods. Currently, two-stage [4] and one-stage [5–8] deep learning methods have been developed and applied in plant phenotyping including fruit detection, achieving state-of-the-art performance. However, these supervised learning methods for detection, regardless of two-stage or one-stage, rely on vast quantities of training samples and assume that the training and test samples are drawn from an identical distribution. Generalizing a pre-trained model on a source domain to an unseen target domain that has a different distribution, may not necessarily perform well due to the existing domain shift.
To address the above problem, fine-tuning methods resort to annotation in the target dataset, whereas domain adaptation (DA) methods facilitate the transfer of learned knowledge from a pre-trained network in the source domain to the target domain, thereby eliminating the need for extensive annotation in the target domain dataset.
Under the generative adversarial networks (GAN) framework, feature-level and image-level alignment approaches are normally employed to reduce the distribution difference between the source domain and test domain. With regard to plant phenotyping applications, relatively limited research of DA methods have been proposed for object detection. Existing DA methods use CycleGAN [9] for image-to-image transformation [10] and contrastive unpaired translation (CUT) [11] for image patch-level transformation [12]. While these approaches successfully preserve the inherent details of the target itself, it may inadvertently result in the loss of background information in the images, consequently leading to domain discrepancies. It is desirable that the alignment is performed on the local object region to detect.
In this paper, we propose a DA method that fuses image-level and feature-level alignment for cross-domain fruit detection. First, an attention-guided GAN [13] is used to achieve image-level alignment from the source image to the target domain, which suppresses unimportant background features in the source domain and migrates the target features from the source domain to the target domain. The adopted attention-guided GAN helps the network to generate images with a more realistic background and a more detailed target during the transformation that migrates the labels of the source domain to the target domain.
A multiple alignments domain adaptive yolov5 (MADA-yolov5) detection method was then implemented, which integrates the yolov5s (6.0) [7] network and the knowledge distillation framework [14] with the mean teacher model approach [15] for feature-level alignment. The method allows feature changes from the learning source domain to the target domain, so that the student model acquires features from the target domain for higher accuracy. A spatial context perception module [16] is employed to enable the network to filter out unimportant background information, thereby learning the characteristics of the target itself. Experimental results on several public datasets demonstrate the improvement in detection accuracy with the proposed method compared to existing methods.
Related work
Supervised Object detection
Typical two-stage detection algorithms include Faster-RCNN [4], while one-stage methods include yolo-series [5–8], FCOS [17], etc. The region-based convolutional network [4] first generates many object proposal candidates by a region proposal module, and then further classifies the proposals and refines their locations by regression. Faster-RCNN was used to detect fruit in [18], achieving high detection accuracy and demonstrating robustness to field imaging conditions. Combined with the feature pyramid networks, Faster-RCNN was used for fruit detection in [19] with an improved loss function, in which a focal loss term was included. With a modified definition of intersection of union, Faster R-CNN was used to detect apple, orange, tomato, pomegranate and mango in [20]. Although accurate results can be achieved with these methods, the processing is complex and slow for their adopted two stages strategy.
Different to previous two-stage method, the one-stage detector unifies the category confidence prediction and the bounding box regression in a single-shot manner. An improved yolov3 object detection structure was used in [21] for apple detection, in which densely connected convolutional networks was integrated to process feature layers with low resolution. Furthermore, in addition to the densely connected convolutional networks integrated into yolov3 [5], circular bounding box replacing the traditional rectangular bounding box was adopted in [22] for tomato localization; Swish activation function, and prior box optimization were used for the detection of oil palm fruits in [23]. Compared to the two-stage method, the one-stage method has a clear superiority in terms of inference speed.
Domain adaptation object detection
Domain adaptive detection methods can be broadly classified into feature-level and image-level alignment ones. In the feature-level method, invariant feature learning using adversarial network is typically embedded in a basic detection model, such as the Faster R-CNN [4]. Faster R-CNN based gradient inversion module in [24] inverts the features of the source domain to the those of the target domain. The region mining and alignment based approach in [25] demonstrates that the key implicit for domain adaptation is local region attention that bridges domain gaps. The detector in these methods is trained to produce domain-invariant features that can deceive the domain discriminator of the GAN, which distinguishes between the source and target domains. The detector that generates domain invariant features may be very slow. In recent work, many domain adaptive detection methods have been proposed based on single-stage methods [14, 27]. In addition to the feature alignment approach, image-level alignment has been adopted to mitigate the domain gap for DA detection [28, 29]. The alignment is normally implemented with GAN based image-to-image translation [9]. For plant phenotyping applications, image-to-image translation was used for DA fruit detection and wheat detection in [10, 12], respectively. Zhang et al. [10] converted the source fruit images into target fruit ones by CycleGAN networks [9], and then performed a pseudo-labelling process to automatically label the target fruit images. The self-learning method improved the labeling accuracy of the pseudo-labelling. CycleGAN [9] networks and clustering methods were used in [30] to generate domain-adaptive images to expand the diversity of datasets on wheat heads. CUT [11] was used in [12] to transfer sorghum labels to the wheat dataset. The source domain was transferred from a computer-synthesised 3D grape model to a real-world grape model in [31]. This method can preserve the position and geometric information of the fruit well, but other objects such as leaves, sky and tree trunks are not restricted.
Image-to-image translation can reduce the domain gap between the source and target domains significantly. Such a image level translation, however, is prone to mix object distribution with that of the background and leads to noise in the background region, resulting in degradation of the detection accuracy of the subsequent detection process. As a remedy, the detection result on the target domain, called pseudo-label in [10], was refined through a self-learning approach. The self-learning used a cyclic update operation to fine-tune the detection model using the detection result with varied confidence threshold, which is time-consuming. CUT [11] adopted in [12] went further to use patch-wise contrastive learning for image-to-image translation. The alignment is local, whereas it is not context-aware. A post-processing pipeline was employed to reassign and validate the labels after image translation [12]. As a preparation process for the subsequent object detection, it is desirable that the transform between images is context-aware and can differentiate the object and background region. Context-aware instance-level alignment was realized in the adversarial learning embedded DA method [31], in which additional network structure was employed for the local alignment. Our proposed MADA-yolov5 method combines feature and image alignments, which can well suppress the influence of background and enhance the weight of the target itself.
Attention mechanisms
The attention mechanism is integrated with yolov5 [7] for apple and dragon fruit detection in [32, 33], respectively. The attention mechanism is also combined with FCOS [17] for blurry green fruit detection in [34], where a residual feature pyramid network is used instead of the feature pyramid network in FCOS. In addition to fruit detection, yolov5 with integrated attention mechanism is also used for weed detection in [35, 36] for seedling detection and ear detection, respectively. In [26], a DA method based on an attention mechanism is proposed, and a self-attention method is introduced to make the target focus on the main region and reduce the effect of domain bias. Adding an attention mechanism to the network can bias the assignment of the most informative feature representations, while suppressing the less useful ones. In our method, a context-aware module is added to the detection network with a self-attention-like operation that assigns attention weights to the network using global features.
Materials and methods
Datasets
Two groups of datasets were adopted to validate the proposed domain adaptive detection method: image transformation and object detection datasets. The image transformation dataset [9] consists of apple2orange and orange2tomato, which share same orange subset. The details of the three subsets are listed in Table 1, in which the training sets were used to train our image transformation model between orange and tomato/apple and the (underscored) test sets were not used in this study. The object detection dataset consists of a source domain orange dataset
Image transformation dataset
Image transformation dataset
Object detection dataset
The proposed method consists of the following steps: (1) training of the attention-guided generative adversarial networks using the training sets of the image transformation dataset (Table 1) to obtain a generator G that transforms orange image into apple or tomato style image; (2) feeding the source domain dataset images

Framework of the proposed method. From left to right, there are training of the generative model G using the image transformation dataset; The source domain dataset D
S
and the target domain one D
T
are input into G to obtain the fake target domain dataset
To reduce the domain shift between the source and target datasets, the generative model G is trained to transform source images into target domain ones in an unsupervised learning framework. Instead of the images in the object detection dataset (Table 2) with big size, the training set of the image transform dataset (Table 1) with small size is used to train the model G. We adopt the attention-guided GAN [13] to achieve the transformation, which incorporates two attention mechanisms on the basis of CycleGAN [9].
The network implements a transformation between two sets X and Y, denoting the training set of the image transform dataset listed in Table 1. As shown in Fig. 2, it consists of two attention-guided generator networks, G : X → Y and F : Y → X, and two discriminators, D
X
and D
Y
. With the same structure, the generators G and F both contain three subcomponents: a parameter-sharing encoder G
E
/F
E
, a content mask generator G
C
/F
C
, and an attention mask generator G
A
/F
A
. The feature information of image x ∈ X is extracted by G
E
, shared between G
A
and G
C
. Following the feature extraction, G
A
generates q attention masks with 4 output channels, including a background attention mask A
b
and q - 1 foreground attention masks

Attention-guided GAN model for image transformation, consisting of two generators G and F, and two discriminators D Y and D X .
The generated image G (x) is composed of the attention masks, the content masks and the input image x as:
To balance the transformation between the two domains, the mapping needs to be regularized using a cyclic consistency loss, as follows,
To match the distribution of generated images from the source domain to that of the target domain, an adversarial loss is defined as:
The use of an identity preserving loss helps to preserve the color of the image and prevent color confusion, and the loss is represented as follows,
Based on the above-mentioned losses, the overall optimization objective of the image transformation
After training the attention-guided generative adversarial network through the image transformation dataset and obtaining the generator G, the source domain images
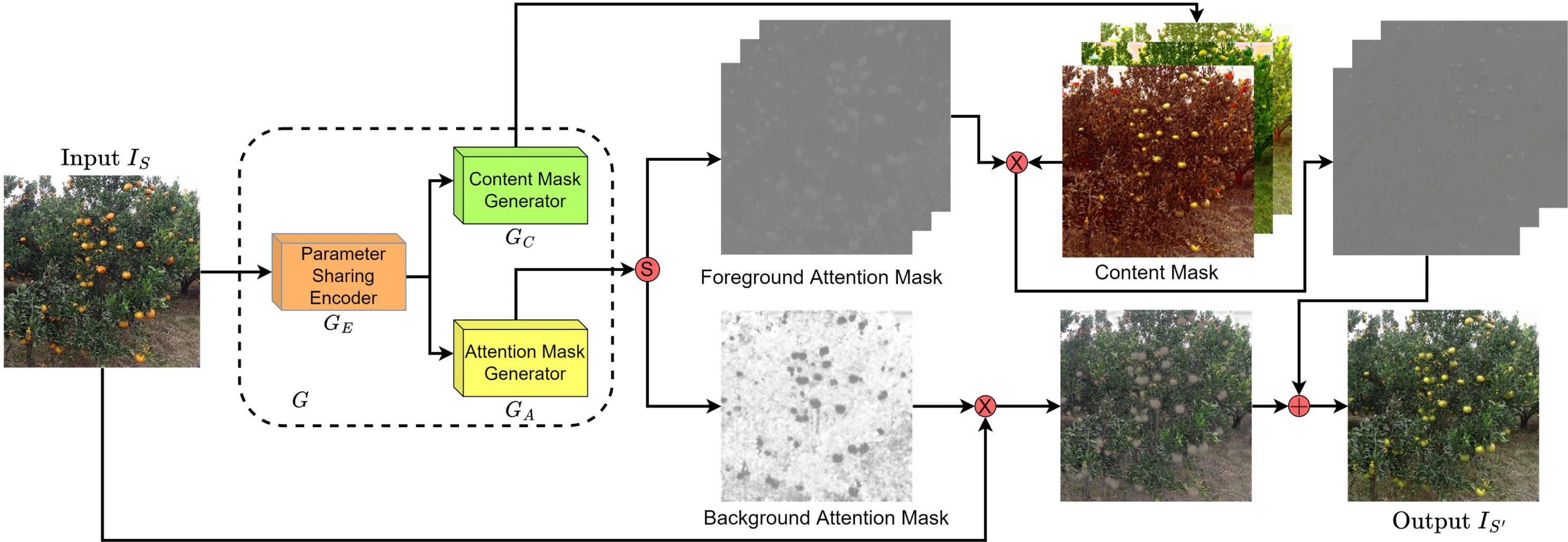
Illustration for the inference of G using the source domain image I S to get the fake source-like target domain image IS′. The symbols ⊗, ⊕ and circledS denote element-wise addition, multiplication, and channel-wise Softmax, respectively.
After the previous transformation, the images in the fake target domain DS′ retains the background of the source domain D S while the key features are converted to the style of the essential features in the target domain D T . This property is beneficial for generalization of the detection model trained with the fake target domain image to the real target domain. However, false detection may be possible due to the size, shape and colour difference between the fake target domain image and the real target domain image. Thus, besides the previous image transformation to align the distributions between the source and target domain, feature alignment is implemented along with the detection model training to reduce the missed detection of the detector.
Knowledge distillation with mean teacher model [14] is employed for the feature alignment in the proposed method. The teacher and student models are connected by exponential moving average (EMA). The teacher model learns the characteristics of the target domain, as shown in Fig. 1, and then teaches the student model how to identify the correct target features. The teacher and student models use the same network structure, as shown in the top of Fig. 4, which integrates yolov5 [7] and a context aggregation block (CA) [16].

Backone, Neck and Head are the original yolov5 constructions with the addition of the context aggregation block between the Neck and Head.
The base model yolov5(v6.0) includes three modules: Backbone, Neck and Head. The Backbone module consisting of C3 and Conv module is used for feature extraction. The specific composition of C3 module is shown in the bottom of Fig. 4, where the Conv module consists of Conv2d, Batch Normalisation (BN) and Sigmoid Weighted Linear Units (SiLU). The Backbone network generates three-layer feature maps with sizes of H/8 × W/8, H/16 × W/16, and H/32 × W/32, with the input size of image being H × W × 3. These feature maps are fused in the Neck module through the feature pyramid and path aggregation network structures. Finally, the Head module outputs three detection layers, with the output feature map sizes being H/8 × W/8, H/16 × W/16, and H/32 × W/32. The last target is realised through non-maximum value suppression and IOU filtering. To improve the feature fusion ability of the network, the CA [16] is added between the Neck and Head modules, which is similar to the self-attention mechanism, and a jump link is added to enrich the network features.
The overall loss function of the network is as follows,
The distillation loss function
The added spatial context awareness module is shown in Fig. 5. The mapping is performed by 1 × 1 convolution, replacing the matrix multiplication between the query and the key with a linear transformation, while reducing the computational complexity and improving the implementation of self-attention.
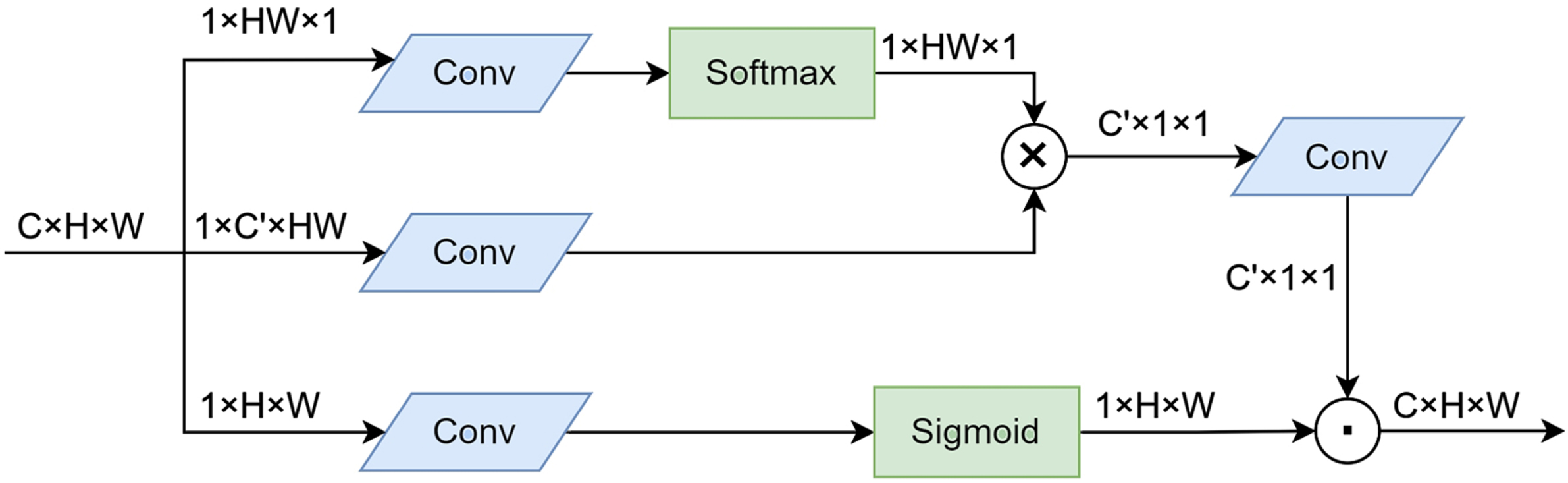
The context aggregation block. C, H and W denote number of channels, height, and width, respectively. ⊗ and ⨀ denotes batched matrix multiplication and broadcast hadamard product, respectively.
The proposed DA fruit detection method was tested with the datasets described in Sec. 3.1. The training sets of the image transformation dataset were used to train the the generative model G that transforms orange domain to apple and tomato ones. Inference of G on the source and target images of the object detection dataset produced fake source-like target, and fake source images, respectively, which were used to train the object detection model R along with the real source and target images. Inference of R on the real target domain (test sets) of the object detection datasets produces the last detection result. Precision, Recall, F1 score, and mAP were used to evaluate the detection results.
The experiments were conducted with PyTorch (1.11.0) on Ubuntu 20.04.4 LTS with an NVIDIA GeForce RTX3060 (12G) graph-ics card. For training of the generator G, linear recession was adopted for the learning rate. The learning rate was set as 2 × 10-5 for the first 100 training cycles and gradually declined to 0 for the subsequent 100 training cycles. The momentum factor and batch size were set as 0.5, and 1, respectively.
The inference of G on the source domain images D
S
produced the fake source-like target domain

Comparison of the generated images using different image transformations. (a) Result using CycleGAN; (b) Result using attention-guided GAN; (c) Target domain image.
Further comparison of the transformed results by CycleGAN and attention-guided GAN is presented in Fig. 7, where T-SNE [42] dimensionality reduction algorithm is employed to analyze and display the feature distribution of images.

Feature distribution of the target domain overlapping with that of the transformed source domain (i.e. fake source-like target domain) using CycleGAN and attention-guided GAN separately. As indicated by the arrows, the distribution of the transformed source using attention-guided GAN is closer to target domain than that using CycleGAN.
Training a yolov5 model using the training set images of D
S
,
Evaluation results for test datasets of D
S
,
and
Evaluation results for test datasets of D
S
,
The last row of Table 4 shows the detection accuracy of our method, i.e. the inference accuracy on the target domain tomato dataset. The proposed method achieves high accuracy. For the image transformation stage shown in Fig. 8, the proposed method is higher than the CycleGAN method in terms of generated image quality, background realism, and similarity between the target and source domains.
Comparison of different models for tomato detection
Comparison of different models for tomato detection

Comparison of the generated images using different image transformations. (a) Result using CycleGAN; (b) Result using attention-guided GAN; (c) original image.
Table 5 presents a comparison of the detection accuracy of the MADA-yolov5 method with other methods on the target domain tomato dataset. In the table, KD stands for knowledge distillation and CA stands for context aggregation block. Through the knowledge distillation method, feature alignment is achieved across domains, which allows the target domain information to be passed to the student model. This improves the model’s ability to identify targets (Fig. 9b). Compared to the original yolov5 network, improved yolov5 identified the top right corner of the different colour of tomato.
Comparison of different models for tomato detection

(a) Original yolov5 detection result; (b) Detection result after adding knowledge distillation structure; (c) Detection result after adding context aggregation block.
To illustrate the role of the CA block, a heat map is used to show the attentional weights of the network. As shown in Fig. 10, after adding the CA block, the network learns the global features and the attention weight of the network shifts from the lower left corner to the target itself.

CA block contrast heat map. (a),(c) heat map without CA Block. (b),(d) that with CA block added. The heavier the colour in the heat map, the higher its weighting.
The last row of Table 6 shows the detection accuracy of our method, i.e. the inference accuracy on the target domain apple dataset. The proposed method achieves high accuracy. For the image conversion stage shown in Fig. 11, the image conversion using the CycleGAN method loses some image information in the target domain (Fig. 7a), and the background of the image becomes cluttered with many noisy spots, all of which greatly affect the detection accuracy of the subsequent model. This results in many leaves being identified as targets, whereas the use of attention-guided GAN ensures that the background is realistic and converts the vast majority of targets to the style of the corresponding domain, ensuring the accuracy of the detector and a much lower probability of recognition errors.
Comparison of different models for apple detection
Comparison of different models for apple detection

Comparison of the generated images using different image transformations. (a) Result using CycleGAN; (b) Result using attention-guided GAN; (c) Original image.
Table 7 presents a comparison of the detection accuracy of the MADA-yolov5 method with other methods on the target domain apple dataset. As shown in Fig. 12, yolov5 misses many targets when tested on the apple dataset (Fig. 12a), and its recall rate increases dramatically after alignment by target features through knowledge distillation. This is because after alignment by target features, its darker targets are transformed into brighter source domain targets (Fig. 12b). This part of the target features will be learned by the student model and will therefore improve the performance of the detector. However, with feature matching the network, as the occlusion in the apple dataset will be very high, the feature reversal learning will also partially learn the leaf information into the network, resulting in an increase in the false positive rate. With the CA block, however, the network will learn context-rich features, and its accuracy will therefore increase and false detections will decrease (Fig. 12c).
Comparison of different models for apple detection

(a) Original yolov5 detection result; (b) Detection result after adding knowledge distillation structure; (c) Detection result after adding CA Block.
As can be seen from the heat map (Fig. 13), with the addition of the CA block, the network has a richer feature extraction capability, with its attentional weight shifted to the apple target itself, reducing the network error detection and increasing the accuracy of the network. This improves the overall efficiency of the model.

CA Block contrast heat map. (a) Heat map without CA Block, (b) That with CA Block added. The heavier the colour in the heat map, the higher its weighting.
This paper proposes an attention-guided domain adaptive fruit detection method. The generated images using the adopted attention-guided GAN are more similar to the target domain image with a more realistic background. Integrating knowledge distillation with the mean teacher model method achieves feature alignment. Introducing the context-aware module obtains rich feature learning and improves network detection capabilities. Image-to-image transformation is an admissible method for DA fruit detection. Local transformation that is context-aware is more desirable and contributes to the subsequent detection. Existing problem of this study is that the performance is not stable enough in the label transfer process, which depends on the setting of the hyperparameters. Efforts will be made to address these issues in the future work.