
Abstract
Babies who can’t communicate through language use crying as a way to express themselves. By identifying the unique characteristics of their cries, parents can quickly meet their needs and ensure their health. This study aimed to create a lightweight deep learning model called Bbcry to classify the cries of babies and determine their needs, such as hunger, pain, normal, deafness, or asphyxia. The model was trained using the Chillanto dataset and underwent three stages of development. Initially, the Wav2Vec 2.0 model was utilized as a teacher for the Knowledge Distillation (KD) method and applied to the transformer and prediction layers to reduce the number of required parameters. Then, a projection head layer was added and linked to the transformer layers to control their impact on the Wav2Vec 2.0 model. This resulted in the first version of the Bbcry model with an accuracy of 93.39% and an F1-score of 87.60%. Finally, the number of transformer layers was reduced to create the Bbcry-v4 model with only 9.23 million parameters, which used only 10% of the parameters of Wav2Vec 2.0 while only slightly reducing accuracy and F1-score. The study concludes with a software demonstration that shows the proposed model’s ability to accurately recognize and determine the needs of infants based on their cries.
Introduction
The cries of a baby are a means of communication for infants who are unable to communicate verbally. This is how a baby expresses their emotions about things they are unable to resolve or communicate to alert their caretakers or those around them about what they are feeling. Such expressions could be hunger, a desire for comfort and care, or discomfort. For most young couples, being unprepared for the arrival of a newborn makes the first few months a major challenge for both the baby and parents, who often misunderstand and handle situations incorrectly, making the problem worse. During the first few months, newborns need to be regularly checked as it relates to many important physical developments, particularly the development of the immune system. Approximate 20% of newborns cry excessively, with 5% of that being due to physical disorders, mainly digestive disorders. This can provide important information for clinical investigation [1]. In some cases, early detection can prevent and address damages and conditions that cannot be cured, such as deafness or brain damage from breathing issues [2, 3]. For new parents who are not fully prepared or have caregivers with limited experience and untrained ears, they may not understand the needs of the baby and thus use ineffective methods to deal with it. This can affect new couples as the baby’s crying can cause stress, postpartum depression, and potentially disrupt the family’s motivation, work schedule, and income [4]. Although there are childcare services or public seminars for new parents, they are not widely available, especially in rural areas [5].
According to Dunstan [6], infants initially try to communicate their immediate needs through a proto-language consisting of five distinct sounds associated with their necessities such as hunger, thirst, discomfort, the need to burp or release gas, and the need to sleep. This language, known as the Dunstan Baby Language (DBL), is used before crying as a form of communication. The theory has been supported by empirical evidence and physiological assessments of infants in research. However, most parents become worried and lose their composure, leading to mistakes when intervening. Common actions include jostling the baby, checking the surrounding environment, or checking for objects that may be affecting the baby, which can result in hasty or untimely decisions to address the baby’s needs, or even regrettable situations [7]. Therefore, developing an algorithm to interpret the emotional signals in an infant’s cries to support the early stages of parenting in a scientific manner is very valuable.
The improvements in Artificial Intelligence (AI) technology in speech and sound processing have a wide range of applications in caring children. Previous studies could not directly process raw audio data, which resulted in high computational costs and limited the optimization of many models. Recent advances in Wav2Vec [8] models have achieved remarkable results in direct raw audio processing. By using Knowledge Distillation (KD) [9], raw audio data can be processed more efficiently as it eliminates the need for pre-training and reduces computation costs. This technique involves transferring knowledge from a large, pre-trained model to a smaller one, enabling it to achieve similar results in a more efficient manner. In this study, we present a framework named Bbcry, which focuses on the classification of infant cries through the optimization of a Wav2Vec 2.0 [10] based model. The method employs Wav2Vec as a teacher model to transfer its knowledge to the Bbcry model, which is specifically designed for this task. The Bbcry model is designed to be more efficient, with fewer layers and the use of knowledge distillation to reduce computational cost. The experiment is conducted on the Chillanto dataset [11], which includes labels for gender and age in months. We also address the challenges faced in the realistic detection of baby cries and aim to advance research in this area. The Bbcry model can help adults identify potential health problems or emergency situations, improving the care of children, reducing stress for mothers and caregivers, and promoting better child development. The key contribution of our research is summarized as follows: A modified Wav2Vec 2.0 model called Bbcry has been created to effectively classify baby cries. The proposed model can detect and classify five different types of baby emotional cries in real-time, even on computers with limited resources. Fine-tuning the pre-trained Wav2Vec model with Chillanto dataset, and using it as the teacher model for the knowledge distillation process. Applying the KD method to transfer knowledge from Wav2Vec to our proposed model Bbcry model for deploying the smaller model on edge devices.
We believe that this system will help families better understand the needs of their baby, allowing them to respond promptly and even assist caregivers in avoiding confusion regarding the infant’s needs. The research is organized into the following sections: Section 2 presents useful basic concepts related to the work. Section 3 discusses the proposed method of the work. Section 4 presents a discussion of the obtained results and compares them with the recent state-of-the-art. Discussions are introduced in Section 5, and finally, a conclusion and future work are presented in Section 6.
Related works
Traditionally, there are many ways for parents to deal with their crying infants. Some turn to objects like toys or pictures, which can cause attachment issues later in life [12]. Others seek advice from pediatricians and clinical research, such as the study by Roberts et al. [13], which found that 95% of parents used their own methods when accessing websites, and 51% of those participated in training courses to improve their skills in dealing with the crying. Another method, introduced by Giesbrecht et al. [14], is the cry out strategy to minimize problematic behaviors in children. The study conducted with mothers of infants under one year old found that the effectiveness of this approach is related to the characteristics of the parents and the crying is not related to the bond between the mother and the baby.
However, there are inherent weaknesses in these methods that affect the accuracy of identifying the child’s needs. First, determining the needs of children based on crying often depends on the experience and subjectivity of the evaluator. This can lead to discrepancies and inconsistencies in making assessments and decisions. Second, the crying of children can be diverse and individually specific, which can complicate the task of distinguishing and determining the specific cause of the crying.
In order to address the limitations of traditional, manual techniques, various classic methods have been employed for DBL classification such as K-Nearest Neighbor (KNN), Support Vector Machine (SVM) [15, 16], and Mel Frequency Cepstral Coefficient (MFCC) [17, 18]. Most techniques are capable of distinguishing between hunger and discomfort with a good rate of detection but cannot distinguish between discomfort and pain because they lack sensitivity. In addition, Convolution Neural Network (CNN) models are more commonly used for analyzing speech signal converted images to classify the state of the infant [19–21]. In particular, Chunyan [22] utilized transfer learning with a CNN on the Chillanto and Baby2020 datasets to address the issue of limited training data. The accuracy of this approach was found to be higher by 7.36% and 3.59% compared to a conventional CNN that used 80% labeled data. Speech recognition models that use neural networks tend to become more accurate with an increase in training data. However, analyzing spectrogram images can be challenging due to their non-transparency compared to the transparency of sound events.
Furthermore, converting sounds into spectrogram images can be difficult and complicates the process because it requires complicated signal processing techniques and analysis algorithms for conversion, making the model complex and difficult to deploy on low-configuration devices. In addition, methods of analyzing spectrogram images from crying can be limited in their ability to generalize for different cases of children. The charts and image patterns can vary based on each specific child, and applying a model or method to all children may not be effective. Therefore, the use of a model capable of processing raw data from sound and quickly classifying is necessary to improve these weaknesses.
Currently, Wav2Vec is one of the state-of-the-art (SOTA) technologies for audio representation and transfer learning. Its approach involves masking parts of audio signals and allowing the transformer layers to decipher them, making it an ideal solution for infant cry classification tasks that rely heavily on acoustic analysis. It has established itself as a self-supervised framework and has achieved top-notch results on benchmark datasets like TIMIT [23] for phonemes and LibriSpeech [24] for words, even with only minimal fine-tuning using a small labeled dataset. Zhang et al. [25] combined SpecAugment, Conformer, and Wav2vec 2.0 pretraining to identify noisy students in their study and achieved WERs of 1.4% /2.6% on the LibriSpeech dataset. Wang et al. [26] investigated fine-tuning Wav2Vec 2.0 for speech emotion recognition and achieved a weighted accuracy of 73.01% for speaker-independent settings on IEMOCAP. Li et al. [27] applied bag-of-audio-words visualization based on features extracted from Wav2Vec 2.0 to identify infant vocalizations. The results showed that their model achieved 89.8% accuracy in recognizing infant speech. A different study by Millet et al. [28] compared the idea of infant natural language acquisition with self-supervised training for speech recognition and compared the language learning ability of the Wav2Vec 2.0 model to that of a child’s brain. The study on Wav2vec 2.0 was initially introduced by Baevski et al. [10]. The research was performed on both the base and large models, with the large model having 317 million parameters. The model’s high number of hyperparameters resulted in extended inference time. To improve its efficiency and minimize its ecological footprint, the Wav2Vec 2.0 was compressed into Bbcry to decrease the number of parameters and by applying KD process to transfer information from Wav2Vec 2.0 to Bbcry. This creates a smaller and more manageable model that can be utilized on computers with low configurations, making it useful for the detection and classification of universal baby cries.
Methodology
Overview of proposed system
The details of our approach are shown in Fig. 1. To run the software on common configurations, we used KD to transfer knowledge from the Wav2Vec 2.0 model to our proposed Bbcry model using the Chillanto dataset. After processing the data, we split it into 70% for training and 30% for testing. The Wav2Vec 2.0 model is fine-tuned to act as a teacher for the training data. To train the Bbcry model we use both prediction layer and transformer layer distillation.

Schematic diagram system.
The Chillanto dataset consists of recordings of infant cries made by medical doctors. These cry signals were carefully labeled based on the reason for crying such as if the infant was sick or hungry, the infant’s age, and other factors. Each cry signal was divided into one-second segments, which were grouped into five different categories as listed in Table 1.
The specification of sensor nodes and local center
The specification of sensor nodes and local center
The dataset used in the experiment is made up of 1-second audio samples that have different sampling rates and are individual sounds. To make sure the results are consistent, the sampling rate for all of the cry signals was set to 16 kHz using the Librosa library [29] in Python. This program was utilized for two purposes: to train the Wav2Vec 2.0 teacher model and to transfer the knowledge from the teacher model to the student model.
Wav2Vec 2.0 is the latest iteration of the Wav2Vec speech representation learning model cre-ated by OpenAI. It is a deep learning model that is capable of learning the mapping of raw audio signals to high-level representations without explicit tran-scription. The model was pre-trained using self-supervised learning on the LibriSpeech dataset and fine-tuned for better results. It is designed to predict speech units for masked parts of audio and consists of three main components: the features encoder, transformer, and quantization module as shown in Fig. 2.

Wav2Vec 2.0 architecture.
This latest version of Wav2Vec has been trained using self-supervised learning techniques and large amounts of data, leading to outstanding performance in various speech recognition tasks. The model is suitable for long-form audio, making it ideal for use in speech recognition, machine translation, and other natural language processing applications. Wav2Vec 2.0 represents a major advancement in speech representation learning and has the potential to greatly impact numerous industries and applications.
The feature encoder in the model is made up of several blocks that include normalization layers and a ReLU activation function. The raw audio input is first normalized so that it has zero mean and unit variance. The encoder consists of seven CNN layers that convert the raw mono waveform at 16 kHz into a latent representation Z with a dimension of 512. The waveform has a frequency of 49 Hz and the time-steps are separated by a 20 ms stride with a receptive field of 25 ms. The transformer module then takes the latent representation Z as input and generates the output C. Finally, the quantization module quantizes the output of the feature encoder Z into a finite set of audio representations using product quantization [30]. The quantization is achieved by selecting inputs from codebooks and then concatenating them.
Our Bbcry model consists of two main components: a compact Wav2Vec 2.0 model with fewer parameters, containing only 8 transformer layers and a hidden state size of 384, and a projection head layer used to project the output of the feature extraction process. Then, we utilized the Wav2Vec 2.0 model as the teacher model and transferred its knowledge to the Bbcry model. We carried out two steps of distillation including transformer layer and prediction layer distillation as shown in Fig. 3.
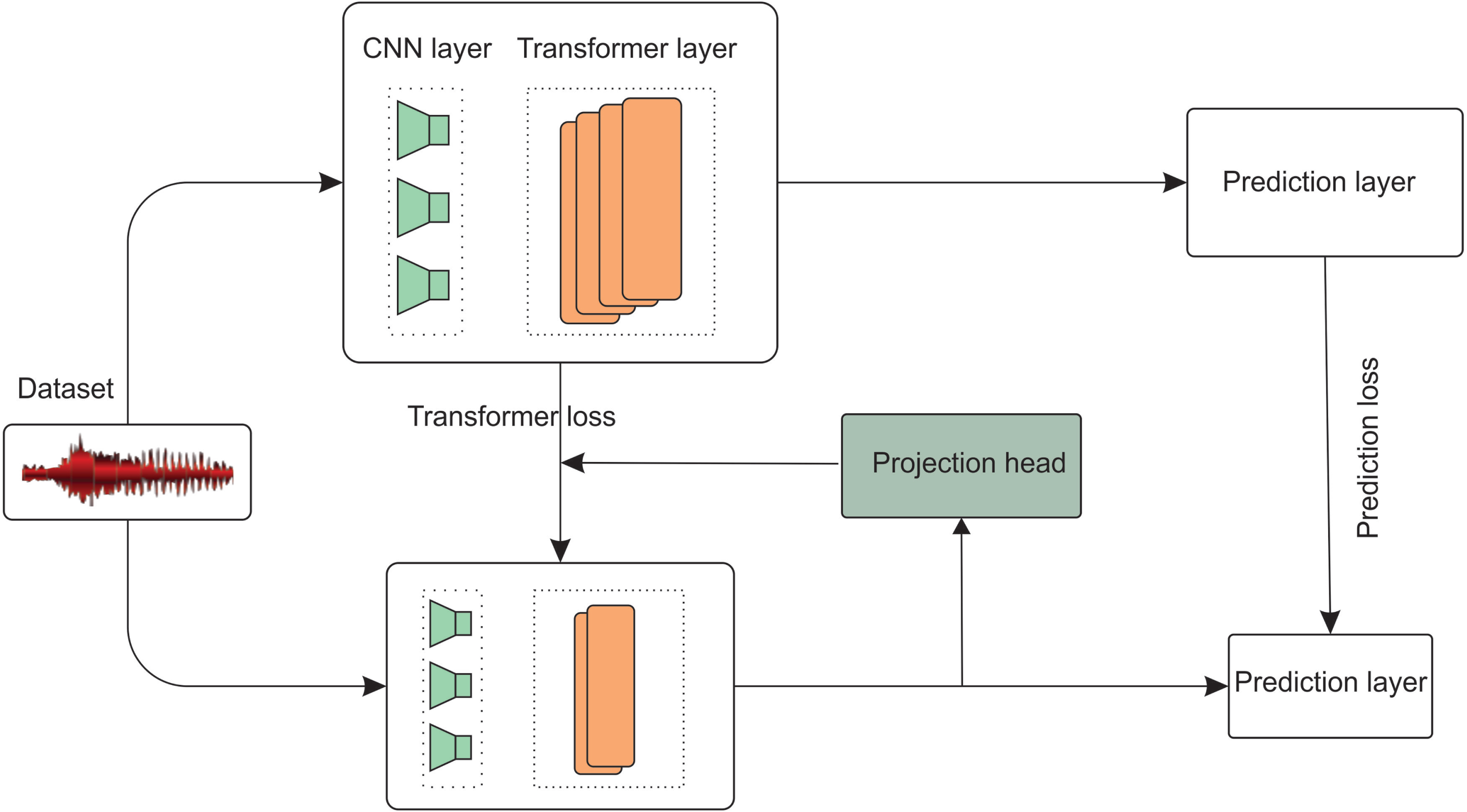
Proposed model architecture.
In KD, a teacher model that has been trained on a large labeled dataset is used to guide the training of a student model. The objective is to transfer the knowledge from the teacher to the student model so that the student performs similarly to the teacher on the target task. The process involves two main steps: training the teacher and training the student. The teacher is trained until it reaches a satisfactory level of accuracy, then the student is trained by minimizing the cross-entropy loss between the teacher’s outputs and the student’s outputs. The idea behind KD is to leverage the teacher’s knowledge to improve the student’s performance. In the Wav2Vec 2.0 model, the transformer layer is the main layer that processes the building of meaningful representations from the features encoded from the encoder layer. This makes the transformer layer the layer with the most parameters. The knowledge from the transformer layer is extracted based on the hidden state output is express by this function:
Where: M, N = g (M), are number of transformer layers; H T , H S are output of Wav2vec 2.0 and Bbcry, respectively. W is trainable linear transformation matrix, MSE is mean squared error loss function, and g (i) is the function that maps the index of Wav2vec 2.0 to the layers of Bbcry.
To avoid the error that occurs when the number of layers in the teacher model is much greater than the student model, some layers will be ignored during the distillation process, resulting in information loss. We use adaptive distillation transformer layers with a loss function represented by the following formula:
The coefficients a
i
are assigned to the transformer layers of Wav2Vec 2.0 and optimized during training. The coefficient represents the contribution of each layer, with higher values for layers that have a greater impact. These coefficients are calculated using a projection head to map the output from the student model’s feature extraction process. At the prediction layer, we use KD by implementing the soft cross-entropy loss [31] between the logit vectors produced by Wav2Vec 2.0 and Bbcry. This step aims to significantly minimize the loss function in order to get outputs from the two models that are as similar as possible. The loss function is expressed as follows:
Where: z
S
and z
T
are the logit vectors predicted by Bbcry and Wav2Vec 2.0, respectively, CE represents the cross-entropy loss. Finally, the proposed loss function is comprised of two parts and is formulated as follows:
We employed the pre-trained Wav2Vec 2.0 model as a teacher model, which was trained on the LibriSpeech dataset. To achieve the best results in the distillation process, we used the Chillanto dataset for both the fine-tuning of the teacher model and the KD process from Wav2Vec 2.0 to Bbcry. To avoid overfitting, the value of epoch was set to 50. The process was performed on Google Colab with the GPU configurations of Tesla T4, 16 GB RAM. The batch-size is set to 32 to meet the configuration of the graphics card. We also employed a default learning rate of 2e-5 for fine-tuning teacher model process and 2e-4 for KD process, and the Adam optimizer [32] for hyper-parameter optimization.
Evaluation models’ performances
In this project, we use the Accuracy and F1-score to assess the efficiency of our model after training. The Accuracy metric is a ratio of the number of points classified correctly to the total number of points. This measurement helps us assess how well the model performs on a dataset. A higher Accuracy means that the model is more precise. However, the drawback of using only Accuracy is that it doesn’t take into account the accuracy for each label, making it challenging to reflect the significance of predicting each label accurately. To overcome this limitation, we use the F1-score, which is a more comprehensive measurement that considers the importance of correctly classifying the labels. F1-score provides a better evaluation of the model’s accuracy in classifying labels. The four basic elements of prediction evaluation are used to calculate these metrics - True positive (TP), True negative (TN), False positive (FP), and False negative (FN). TP represents the number of actual positive reviews that were accurately classified, TN refers to the actual negative reviews that were correctly classified, FP is the amount of fake positive reviews wrongly classified as positive, and FN is the number of fake negative reviews mistakenly classified as negative. Accuracy, and F1-score are computed as follows respectively:
These are the results of the evaluation of four different models on the Chillanto datasets, as shown in Table 2.
Performance of the classification models
The teacher model, Wav2Vec 2.0 achieved an accuracy of 95.15% and an F1-score of 91.35% . The student model, Bbcry, achieved an accuracy of 90.30% and an F1-score of 81.46% . When using normal KD, the accuracy and F1-score of the Bbcry model increased to 92.07% and 86.43% , respectively. During the KD process, adding a projection head layer improved the results significantly compared to normal KD, with an accuracy of 93.39% and an F1-score of 87.60% , respectively. The projection head serves as a mapping of the student’s feature extraction output to adjust the impact levels of the teacher’s transformer layers. This results in filtering more of the teacher’s information and selecting which information is more important. The comparison of the accuracy rate between the proposed method and the normal KD model is closely similar over time as shown in Fig. 4.

Comparison accuracy of different KD methods.
While both models start with a similar rate of accuracy growth, after 10 epochs, the proposed method starts to surpass the normal KD model in terms of accuracy and F1-score. The projection head serves as a filter to better incorporate the teacher’s knowledge, selecting the most important information and adjusting the impact levels of the teacher’s transformer layers. This is due to the role of the projection layer and the combination of the two, which greatly improves the accuracy of emotion classification.
Our goal was to create a more efficient emotion classification model that could be used on devices with limited computational power. To do this, we altered the architecture of Bbcry by reducing the number of transformer layers, which resulted in a reduction in the number of parameters. The results of these changes can be seen in Table 3.
Results in various modified Bbcry models
Results in various modified Bbcry models
Despite the decrease in accuracy that comes with reducing the number of transformer layers, we ultimately chose the Bbcry-v4 model with two layers for its balanced size, number of parameters, and accuracy of 92.95% and F1-score of 86.26% for the task of detecting an infant’s emotional state through their crying sounds.
After conducting the experiments and determining the model with the least number of parameters while still ensuring classification performance, we evaluated this model using different classification methods. In this experiment, we compared the accuracy and F1-score of the Wav2Vec 2.0 and Bbcry-v4 models with three different classification methods including Multi-layer Perceptron (MLP), SVM and Random Forest (RF). The results from the evaluation are shown in Table 4.
Performance evaluation with several classifiers
Performance evaluation with several classifiers
For the MLP classifier, it is a neural network model that allows for learning complex functions for various data types. Its strength lies in its good performance for classification tasks, making it the best classifier in terms of performance for both models. Specifically, Wav2Vec 2.0 achieved 95.15% accuracy and 91.35% F1-score. Our proposed Bbcry-v4 model achieved 92.25% accuracy and 86.26% F1-score. This is a good result as our model was only lower by 2.9% in accuracy and 5.09% in F1-score while requiring 10% fewer parameters than Wav2Vec 2.0.
Using the SVM classifier resulted in similar results compared to the RF classifier in this experiment. Specifically, for SVM, the accuracy scores obtained from the two models were 95.75% and 91.62% for Wav2Vec 2.0 and Bbcry-v4 respectively, while for RF it was 95.44% and 88.54% . The F1-score shows a 4% difference between the two methods for the Bbcry-v4 model, while for Wav2Vec 2.0, the results are all greater than 92% . Therefore, the best results in terms of accuracy and F1-score were obtained using the MLP classification method. The results obtained from the SVM and RF classifiers showed no significant difference between the two methods in evaluating the Wav2Vec 2.0 and Bbcry-v4 models.
In this comparison, four methods are being evaluated, including our proposed method. The first study, by Ji et al. [22], utilized spectrogram generation techniques, transfer learning with CNN feature extraction, and GCN classification to attain an accuracy of 87.03% . While this study utilized image processing, it displayed a marked improvement compared to utilizing a standard CNN. The second study by Onu et al. [33] aimed to classify asphyxia in children and utilized MFCC for feature extraction and a SVM for classification, but only achieved an accuracy of 85%. The third study, by Zabidi [34], addressed the same classification task, but used a combination of MFCC and CNN for sound feature extraction, resulting in the highest accuracy rate of 92.78% . The comparison results are provided in Table 5.
Comparison of the SOTA on Chillanto dataset
Comparison of the SOTA on Chillanto dataset
In our research, we managed to obtain impressive results despite taking steps to decrease the number of parameters. By using a combination of KD and a projection head and limiting the number of Transformer layers to two, we achieved an accuracy of 92.95% with only 9.23 million parameters.
After the training process, the results were extracted in “torchscript” format to optimize inference time. The software, written in Python language, uses the Kivy library [35] to build the interface for detecting and classifying baby cries. There are two options for audio loading: a file path to the audio file or recording directly from the microphone, even for computers with low configurations. The software interface is shown in Fig. 5.
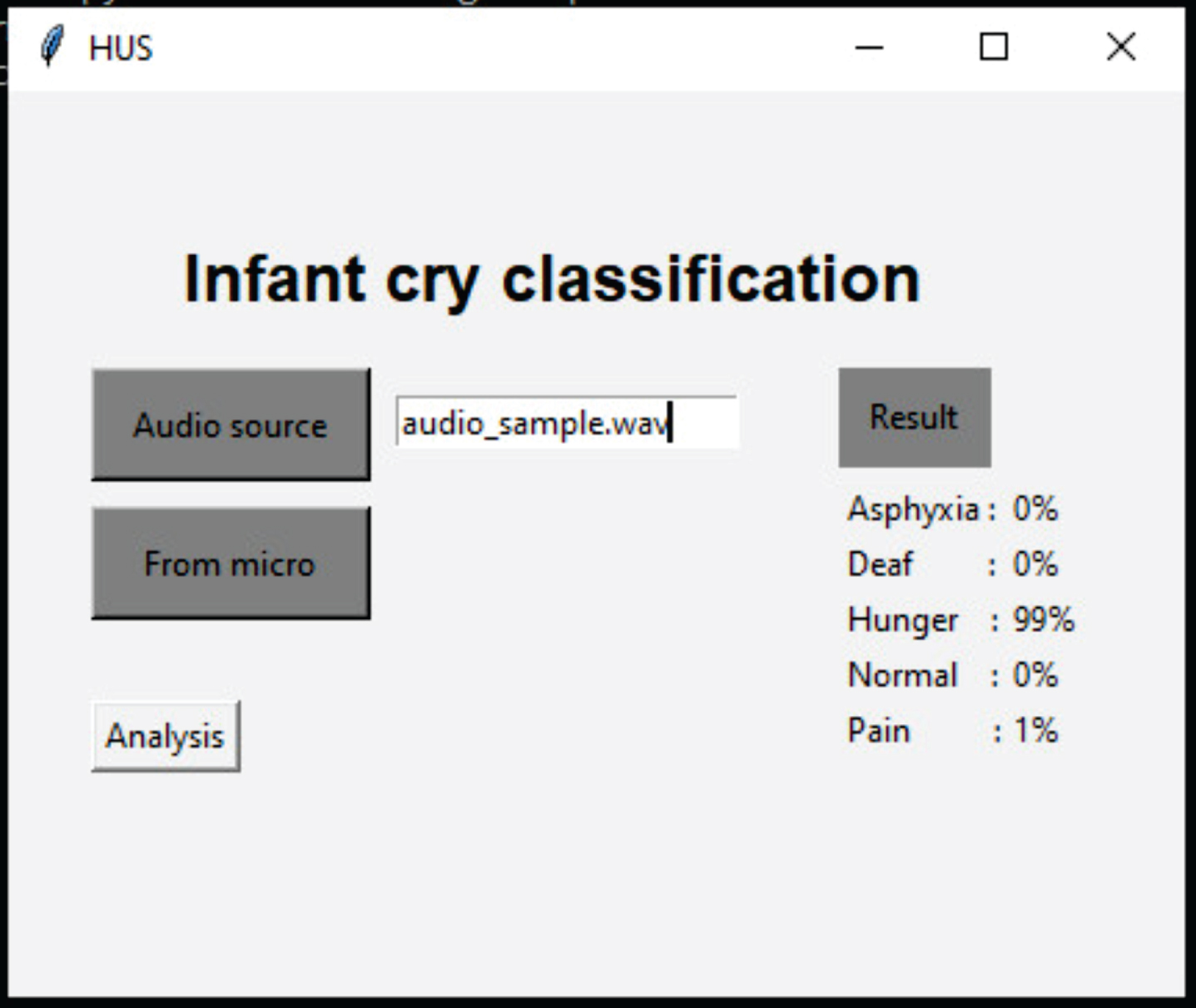
Infant cry classification demonstration interface.
The audio data is pre-processed to a 16 kHz sampling rate and mono format and then fed into the classification process, transforming the baby’s cry into a probability distribution vector indicating the reason for the cry. This helps parents understand their baby’s communication through cries, reducing misunderstandings and preventing negative consequences, making the parenting experience easier
In this study, the application of KD techniques and project head to the Wav2vec 2.0 model was proposed for the purpose of analyzing newborn cries, which could assist parents in child care and health assessment. The development and evaluation of the proposed method involved the conduction of five experiments, yielding extremely promising results. A detailed analysis of each experimental result will be carried out subsequently.
Outstanding performance of Bbcry constructing method
Two significant features were noticed in our first experiment. First, significant performance improvement was observed when the KD technique was applied to both transformer and prediction layers, as opposed to only the prediction layer. It is posited that this occurs as the transformer layer in the model takes responsibility for processing information and learning the data structure, which aids the Bbcry model in learning from the deep and complex knowledge of the Wav2vec 2.0 model. Furthermore, when KD is applied to both the transformer and prediction layers, it provides a diverse and detailed understanding of the relationship between features and labels, thereby enhancing the classification ability.
In the subsequent experiment, the number of transformer layers in the model was adjusted with the goal of reducing parameters and enhancing the model’s generalization ability. The number was systematically reduced from 8 layers to 2 across four different versions, and each was compared to the original 12-layer model. The results indicated a considerable decrease in accuracy, from 93.39% to 92.80%, when comparing the Bbcry-v3 model to Bbcry-v1. However, there was also a significant reduction in the number of parameters, even by as much as 4.7 times compared to the original model. Surprisingly, when the number of transformer layers was further reduced to 2, the parameter count decreased even more, up to 10 times compared to Wav2vec 2.0 and twice compared to Bbcry-v1, which used 8 transformer layers. Moreover, Bbcry-v4, with only 2 Transformer layers, demonstrated an increase in accuracy by 0.15% compared to Bbcry-v3 with 4 Transformer layers, a contradiction to the initial prediction. Two hypotheses have been proposed to explain this anomaly. First, the Bbcry-v3 model might have been overfitting the training data, implying that it may have “learned” excessively from the training data and performed poorly on the test data. Conversely, Bbcry-v4, with 2 transformer layers, might have evaded this overfitting, leading to better generalization on new data. Second, the training data features might be more compatible with Bbcry-v4 when using 2 transformer layers, enhancing the model’s understanding of the data features. It is worth noting that although the difference is marginal (0.15%), determining the actual reason behind this increase necessitates rigorous analysis to assure the results’ objectivity and reliability.
In the final experiment, the Bbcry-v4 model was optimized by utilizing different classifiers: SVM, RF, and MLP. Changes in Accuracy and F1-score were observed upon switching these classifiers. The decrease was minor when transitioning from MLP to SVM, yet more significant with the RF classifier. This change can be attributed to two reasons. Firstly, the complex, non-linear features of audio data might be better handled by MLP. Secondly, while MLP is capable of managing a variety of features, RF performs better with a large number of decision trees and fewer features, which makes it less suitable for the audio data that boasts numerous features in this study.
Compare to recent methods and deployment
In this experiment, a comparison was conducted between our method and those suggested in other studies. It was noted that most of the studies in this subject area have focused on image processing techniques, bypassing the direct processing of collected audio information. This observation is supported by the fact that all studies compared here employed techniques to convert audio into a spectral form before any analysis was conducted. The audio collected by these studies was converted into forms like MFCC and Mel-frequency spectrum.
The term Mel-frequency, used extensively in audio signal processing, represents audio frequency in a manner perceivable by humans. From the Mel Scale, which uses Mel units to measure frequency in the way humans hear it, the Mel-frequency spectrum was developed to represent the range of audio frequencies. This spectrum is widely used in applications such as audio signal processing, voice recognition, sound recognition, and voice processing. The MFCC, on the other hand, combines Mel-frequency and Cepstrum concepts through an eight-step audio input processing procedure to represent the frequency and temporal characteristics of sound. These techniques serve as powerful tools for transforming audio signals into images, allowing image processing methods with CNN to be applied. However, it is our contention that these methods are less than optimal and more costly due to their need to transform audio into images prior to processing, as opposed to our approach that uses input audio data directly.
Regarding accuracy, it was found that two of the three studies used a different dataset from ours, making the accuracy figures not truly representative given the variability in the data sets’ characteristics. One study applied SVM to classify MFCC images to determine a child’s needs, and used the Baby Chillanto dataset, similar to ours. However, the accuracy of this study was found to be 8% lower than our results. Therefore, it can be asserted that our research has made significant strides in comparison to earlier studies on the classification of children’s crying.
Following the evaluation of the model’s performance, a software application was developed with the assistance of the Kivy library for real-world testing. The software operates by inputting an audio file of a child’s crying and classifying it according to the identified needs of the child. In practical tests, two main issues were identified that need addressing in future work. Firstly, the software was found to require manual operation, making it inconvenient for users to identify a child’s needs automatically. This could lead to delays in identifying the child’s needs. It is proposed that a more advanced software tool needs to be developed, considering that the model we propose can fully operate even on devices with limited configurations. Secondly, when audio samples of a child crying in noisy environments were input, such as children crying at a party or outdoors, the classification process faced many difficulties due to the model’s inability to accurately identify the child’s needs. This was observed when the ambient noise was too loud, obscuring the features of the child’s crying. It is suggested that this issue can be tackled by collecting a dataset of children’s crying in complex environments and training the model on this high-complexity dataset, which would help in enhancing the model’s capability to determine a child’s needs in environments with high complexity sounds.
Conclusions
The research aimed to build a Bbcry model using the Wav2vec 2.0 model for classifying children’s cries to identify their needs. The researchers used Knowledge Distillation (KD) and Project Head techniques to develop the Bbcry_v1 model, which showed improved results compared to Wav2vec 2.0 with 1.76% lower Accuracy and 3.75% lower F1-score. They then reduced the number of Transformer layers to lower the number of parameters in the model, resulting in the Bbcry_v4 model with only 9.23 million parameters, which achieved 92.95% Accuracy and 86.26% F1-score on the Baby Chillanto dataset. Comparison with Wav2vec 2.0 using different classifiers showed that both models performed best with Multi-layer Perceptron (MLP). The Bbcry_v4 model also showed significant differences in Accuracy and F1-score when evaluated using Support Vector Machine (SVM) and Random Forest (RF) compared to the state-of-the-art methods.
Declarations
Acknowledgements
Not applicable.
Funding
The research did not receive funding from any sources.
Availability of data and materials
The data used to support the findings of this study are available from the corresponding author upon request.
Contributions
LQT-Conceptualization, experiment, data analysis, writing.
NCB, DDC-Data analysis, coding.
LKL-Writing, data analysis, experiment.
The authors read and approved the final manuscript.