
Abstract
Audio Event Detection (AED) and classification of acoustic events has become a notable task for machines to interpret the auditory information around us. Nevertheless, it has been a difficult and cumbersome task to extract the most basic characteristics of acoustic events that encapsulate the fundamental elements of the audio events. Previous works on audio event classification utilized supervised pre-training as well as meta-learning approaches that happened to depend on labeled data therefore facing instability. Deep Learning is progressing in an increasingly mature direction, and the application of deep learning methods to detect acoustic event has become more and more sought after. The proposed hybrid method called Greedy Regression-based Convolutional Neural Network and Differential Convex Bidirectional Gated Recurrent Unit (GRCNN-DCBGRU) is introduced to learn a vector representation of an audio sequence for Audio Event Classification (AEC). Differential Convex Bidirectional Gated Recurrent Unit is analogous to long short-term memory and involves time-cyclic long-term dependencies with a lesser processing complexity. The model first extracts acoustic features from the sound event dataset through a Differential Convex Bidirectional Gated Recurrent Unit employing Gabor Filter bank features and then extracts the local static acoustic features through the Greedy Regression-based Convolutional Neural Network by utilizing Mel Frequency Cepstral Coefficients (MFCC). Finally, the Differential Convex Meta-Learning classifier is used for the final acoustic event classification. Extensive evaluation on large-size publicly available acoustic event database like Findsounds2016 will be performed in Python programming language to demonstrate the efficiency of the proposed method for the AEC task. To demonstrate the visualizations of individual modules and their influence on overall representation learning for AEC tasks, several parameters like audio detection time, audio detection accuracy, precision, and recall are measured.
Keywords
Introduction
Acoustic Event Classification (AEC) or audio event detection plays a major role in validating the environmental consciousness for intelligent machines and has in the past few years fascinated a sizeable amount of awareness. One predominant objective of audio event detection is to extract prejudiced characterizations that are vigorous enough to apprehend the acoustic event content. Over the past few years, numerous endeavors have been detailed in this direction.
An unsupervised learning method to learn the vector representation of an audio sequence was proposed by integrating a Gated Recurrent Unit-Recurrent Neural Network (GRU-RNN). This method included a Recurrent Neural Network (RNN) encoder and an RNN decoder that in turn transformed variable-length audio sequences into fixed-length vectors. With the transformed generated vector, the input sequence was reconstructed [1].
Upon successful training of the encoder-decoder, the resultant audio sequences were fed to the encoder wherein the learned vectors were obtained as audio sequence representations via GRU. With this, a significant improvement was observed in terms of the F1 score. Though significant improvement was observed in terms of F1 score, the time and accuracy involved in audio sequence representations for large-size databases involving distinct classes were not focused. To address this issue, Differential Convex Bidirectional Gated Recurrent Unit-based predominant feature extraction is designed with differential convex function not only reduces the audio detection time. The Gabor filter function is also used to enhance the audio detection accuracy.
A method called, Deep Belief Network (DBN) for audio signals classification to enhance the work activity identification and remote surveillance concerning construction projects was proposed. The objective of the work remained to obtain accurate and flexible tools for constantly executing and managing unmanned construction site monitoring by utilizing a distributed acoustic type of sensors. Here, the input was first obtained by concatenating numerous statistics measured via spectral feature sets [2].
Finally, the efficiency of the method was evaluated in terms of accuracy, precision, recall, and training time. Though improvement was found in precision and recall, the error function involved in audio signal classification for large-size databases involving distinct classes was not addressed.
Deep Convolutional Neural Networks (DCNN) were introduced to extract the audio features with regularization and data enhancement. However, the audio detection time was not minimized [3]. On the other hand, an advanced integrated model was proposed combining Convolutional Recurrent Neural Networks (CRNN) and Deep Neural Networks (DNN) to enhance Sound Event Detection (SED) classifiers. This integrated model is further enhanced by the incorporation of an Optimally Modified Log-Spectral Amplitude Estimator (OMLSA), aimed at significantly improving the robustness of the SED system in noisy environments. But, the computational cost was very high [4]. To focus on this aspect, a Greedy Regression-based Convolutional Neural Network-based static acoustic Classifier is designed that, with the aid of the Greedy Regression function, improves the precision and recall rate by also taking the loss into consideration.
The contributions of the proposed GRCNN-DCBGRU method are listed below: We have chosen the hybrid model known as GRCNN-DCBGRU, specifically designed to enhance the classification of audio signals from seven distinct classes. This model aims to achieve both higher accuracy in terms of classifications and faster audio detection times. A novel DCBGRU incorporates the Gabor Filterbank and the Differential Convex technique. Through the utilization of the Gabor Filterbank, the preservation of frequency information during the initial processing phase is ensured. This safeguards the critical frequency components of the audio signals. Subsequently, the primary audio signals are efficiently captured from the entire raw audio input, leveraging both the forward and backward representations facilitated by the Differential Convex approach. The outcome is a streamlined process that minimizes the time complexity. The Greedy Regression-based Convolutional Neural Network employs Mel Frequency Cepstral Coefficients (MFCC) to intricately fine-tune its weight, enabling a comprehensive grasp of complex audio signal associations. The greedy loss function is also used to ensure precise audio detection.
This paper is outlined as follows. Section 2 reviews the related work on different learning techniques applied for acoustic event detection. Section 3 introduces details of our proposed Greedy Regression-based Convolutional Neural Network and Differential Convex Bidirectional Gated Recurrent Unit (GRCNN-DCBGRU) method. In the fourth and fifth Sections, the experiment results and discussion are presented. Finally, Section 6 gives concluding remarks.
Related works
Sound information analysis is useful for surveillance of audio, information retrieval for multimedia purpose, forensic applications and so on. Amongst them, the recognition of audio scene from the environment and sound event recognition for the purpose of audio surveillance are said to be the most complicated issues. This is owing to the multiple source presence, background noises and so on.
A mechanism for learning robust and compact representations for environmental and sound events with the aid of mel-frequency cepstral coefficients was proposed. Also, a hybrid method for learning generative model representation was also designed, therefore improving the accuracy rate. However, with the involvement of time-variant signals, the representation proved to be inefficient [5]. To address this issue, a score–audio music retrieval mechanism with the objective of identifying relevant audio recordings even in the presence of time-variant signals was designed.
Owing to the reason that machine learning techniques have evolved over the past few years, improvement has been observed in terms of scalability and robustness in classifying sound events. However, a significant amount of noise would further deteriorate the detection process [6]. Three distinct two-dimensional time-frequency features were explored with the purpose of classifying the audio event classification using deep neural network-based classifiers. Here, spectrogram, and cochleogram were employed for the classification of 50 distinct classes in differing acoustic background noise levels. With this type of classifier, the noise was also reduced during the detection of corresponding events [7]. Yet another method with the ensembling of Convolutional neural networks to improve audio events in the presence of distinct animal sounds was proposed [8].
An auditory scene consists of numerous distinct sound events that protrude both in time and frequency, therefore causing a complicated array of acoustic information to arrive in the human’s visual system. In spite of the intricacy, a human can make sense of the information fluently and therefore make sense of the information obtained. Nevertheless, making an attempt to recreate this potentiality utilizing computational means is far from insignificant.
A novel method employing Nonnegative Matrix Factorization (NMF) in a supervised fashion was proposed. Here, an integrated mechanism utilizing transfer learning and semi-supervised learning framework was proposed that in turn approximated strongly labeled the data. As a result, sound event detection was accurately made. However, precise results were not ensured [9]. Weakly supervised representation learning was proposed for different object types therefore resulting in the improvement of the F1-score [10]. A review of bioacoustics method using deep learning was investigated [11].
Over the past few years, advancements in audio signal recognition employing deep neural networks have found that features being learned can be easily classified from raw signals. Despite accurate classification, Acoustic Scene Classification (ASC) yet is not found to be at part with the traditional spectral feature model.
A raw waveform-based end-to-end ASC employing CNN utilizing a non-hierarchical model with the objective of enhancing classification performance was proposed. However, the noise factor was not analyzed [12]. To focus on this aspect, deep learning classifiers in the presence of noise using a Convolutional recurrent neural network were designed. Despite improvement observed in the noise cases, the overlap involved during classification was not focused [13]. A hybrid clustering and classification method using Mel Frequency Cepstral Coefficient was presented [14] that in turn improved accuracy even in the presence of overlap [15].
A feedback model for sound event classification employing CNN was proposed that, with the aid of weighted recurrent function was found to be improved in terms of accuracy for both indoor and outdoor environments. Despite improvement in accuracy, the time factor was not focused [16].
The past decades have found a steep minimization as far as the sound acquisition hardware cost is concerned, processing, transmission, and storage of the audio signals. Owing to this, digital audio detection techniques have received a great amount of attention beyond the range of human communication.
A pilot study on a deep learning-based method possessing audio clips for conducting surgery was presented. Autonomous Recording Units (ARUs) record wildlife sounds over constant time periods therefore ensuring scalability in a minimally invasive manner [17]. Several machine learning algorithms were integrated with the purpose of increasing the generalizability across heterogeneous acoustic environments. [18]. As a result not only accuracy was improved but also minimized the execution time to a great extent.
Sound event detection involving polyphonic signals detect sound event types that persist in the audio clips provided as input. Moreover, the onset and offset times where multiple sound events were said to occur concurrently. However, overlapping between events and overfitting issue was found to be common. To solve these two issues, a capsule network-based model for sound event detection involving polyphonic signals was proposed [19]. Three deep architectures, logistic regression, support vector machine, and Convolutional neural network were proposed for accurate sound analysis [20].
Yet another hybrid CNN model to categorize audio signals according to emotion in a timely manner was proposed [21]. Sound event classification from noisy audio signals employing a standard evaluation model was presented [22]. Also, Bayesian analysis was used for significant classification.
AEC is a demanding concern since the audio includes high diversity due to the difficult acoustic surroundings. The feature selection approach was automatically choosing vital features for a precise class, but, it is a demanding issue. In audio event classification, the classification task is an important task to discover the acoustic event. Due to the huge size database, the accuracy of audio event classification is a challenging task. Since the machine learning techniques use the entire feature for classification it is infeasible and inaccurate. Hence, the dimensionality of the dataset needs to be minimized for precise audio event classification with minimum time. To tackle the challenges mentioned above a novel Greedy Regression-based Convolutional Neural Network and Differential Convex Bidirectional Gated Recurrent Unit (GRCNN-DCBGRU) method for an audio detection time, audio detection accuracy, precision, and recall with significant feature selection is designed in an accurate manner. An elaborate description of the GRCNN- DCBGRU method is provided in the following sections.
Methodology
Audio is considered an information carrier; it has been formulated as an important means to perceive the outside environment. Also with the evolution of signal processing and computer science, the audio-processing task of information extraction assisted by machines has received a great amount of attraction over the past few years. Applying an unsupervised learning paradigm for extracting semantic representations of acoustic features forms the major study as far as large-size datasets are concerned. A novel method called Greedy Regression-based Convolutional Neural Network and Differential Convex Bidirectional Gated Recurrent Unit (GRCNN- DCBGRU) is introduced for precise and accurate robust acoustic classification. At first, Differential Convex Bidirectional Gated Recurrent Unit used Gabor Filterbank features to generate predominant acoustic features from the signals of the overall sample based on the Gabor filter and Differential Convex function.
Then, a Greedy Regression-based Convolutional Neural Network-based static acoustic Classifier was modulated by updating weight based on the Greedy Regression function, Mel Frequency Cepstral Coefficients (MFCC). In this way, robust acoustic classification is achieved. The overall structure of GRCNN-DCBGRU is given in Fig. 1.
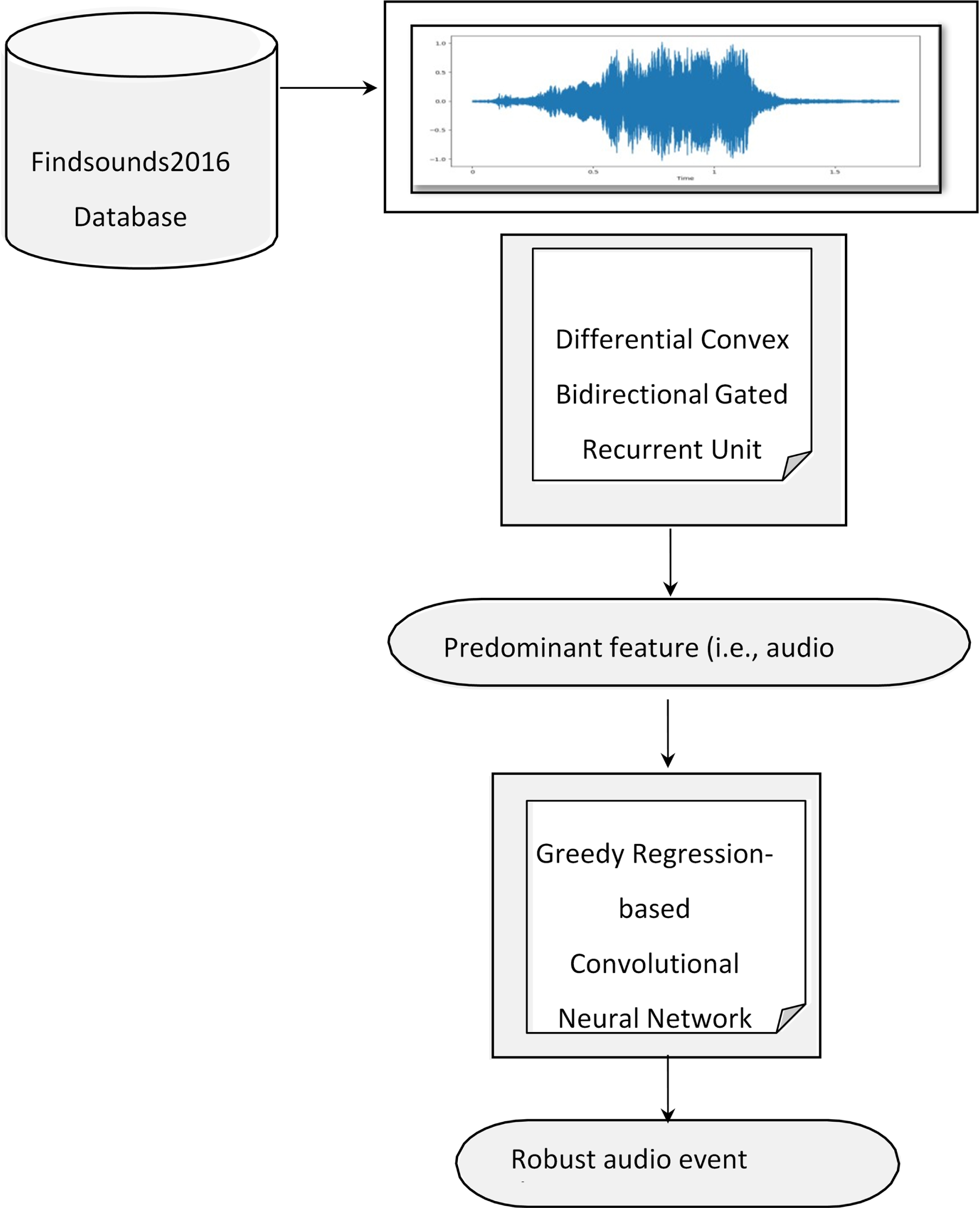
Structure of GRCNN-DCBGRU.
As shown in the above figure, a hybrid method called Greedy Regression-based Convolutional Neural Network and Differential Convex Bidirectional Gated Recurrent Unit (GRCNN- DCBGRU) for audio event classification is proposed. With the raw input signals obtained as input from the Findsounds 2016 Database, initially, predominant features are extracted by employing the Differential Convex Bidirectional Gated Recurrent Unit. Here, filters based on the Gabor function are applied to the raw signals, and the resultant output forms the input to the Bidirectional Gated Recurrent Unit. Next, the resultant features are subjected to the Differential Convex function, therefore extracting acoustic features for significant classification of acoustic signals in a computationally efficient manner.
Audio streams like broadcast news, meeting recordings, and personal videos comprises of sounds from numerous sources. Some of them include, audio events pertaining to human, animals, birds and so on. The detection of these audio events helps in turn interpreting the auditory information around us. As distinct level annotations characterize different acoustic events the predominant acoustic features have to be first extracted from the sound events. Several works have contributed in this line, however audio detection time and accuracy were less focused with the increasing dataset size. With the objective of improving the detection time and accuracy, first, the Differential Convex Bidirectional Gated Recurrent Unit employing Gabor Filterbank features is designed for extracting predominant acoustic features. Figure 2 shows the structure of the Differential Convex Bidirectional Gated Recurrent Unit.
As given in the below figure, raw signals obtained from databaseFindsounds2016 are provided as input. First, the Gabor filter is applied to the raw input signals so that the frequency presence can be observed. Next, based on the frequency of present input signals (i.e., Gabor filtered signals in the input layer), forward representation, and backward representation, the output generated is finally applied with Differential Convex to extract the predominant features in a computationally efficient manner.
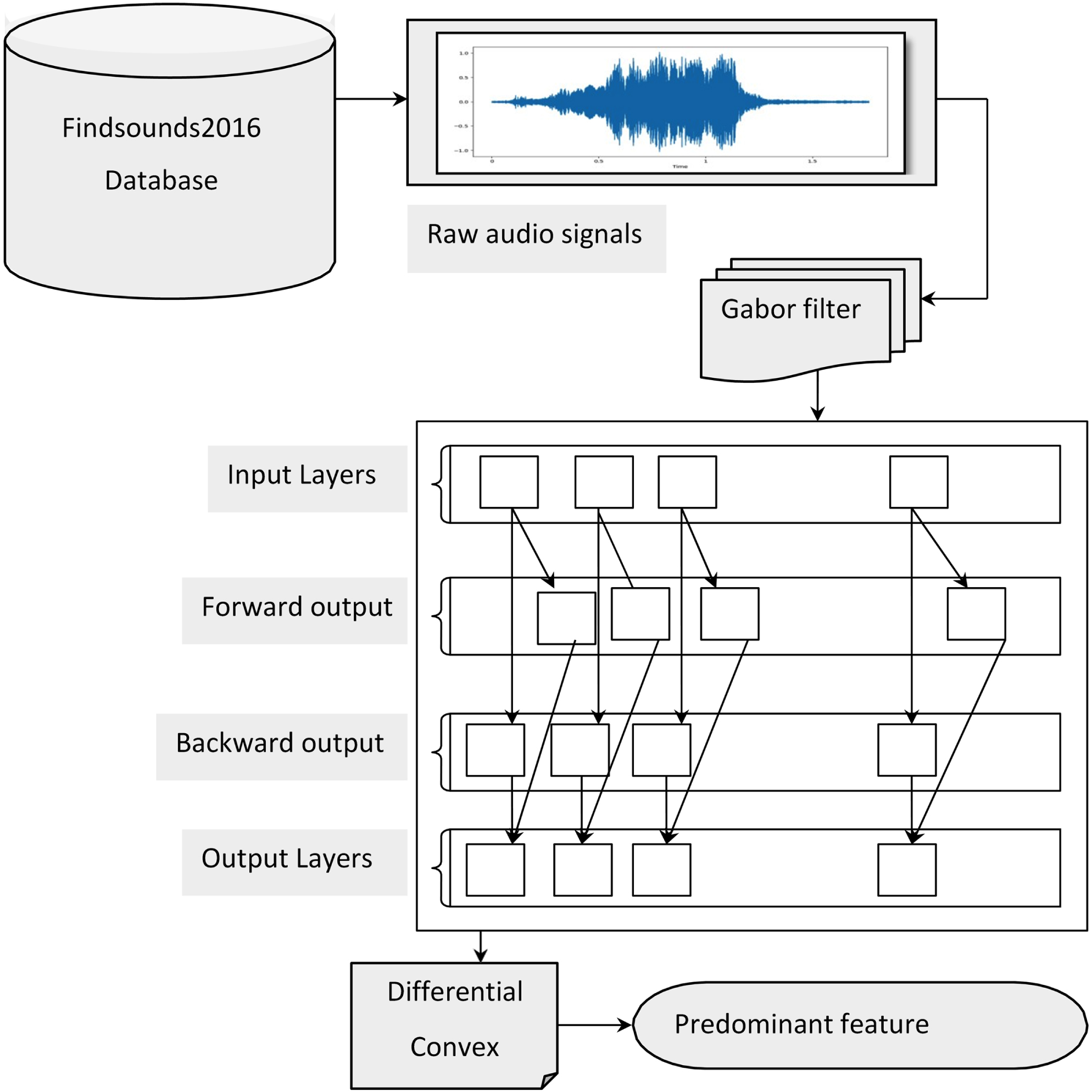
Structure of Differential Convex Bidirectional Gated Recurrent Unit-based predominant feature extraction.
Let us consider the raw audio signal to be ‘S’ of an acoustic event recording, segmented by the sliding window, then ‘Wsize’ represents the index of window with ‘size’ denoting the window size. Moreover in the raw audio signal ‘S = {S
i
, i = 1, 2, …, n}’, here ‘n’ represent the length in frames. Also in the raw audio signal an analysis of frequency content in a localized region has to be made so that higher flexibility in the shape can be maintained. Gabor Filter is initially applied to the raw audio signal with the purpose of analyzing the presence of frequency in it around the region of analysis. Each Gabor filter with two-dimensional sinusoid carriers involving temporal modulation ‘ω
Temp
’ and spectral modulation ‘ω
Spec
’ is formulated as given below.
From the above Equation (1), ‘GFS’ Gabor filter audio signals are measured on the basis of the raw audio signals ‘S’ involving temporal modulation ‘ω Temp ’ and spectral modulation ‘ω Spec ’, event detector ‘θ j ’ comprises of two events either the presence of target event ‘θ j = 1’ or presence of background noise ‘θ j = 0’ respectively. Also as with the distinct time intervals, the target events modulation also gets changed. Hence, in our work, followed by the presence of target event ‘θ j = 1’ is placed as input in the Bidirectional Gated Recurrent Unit. With the Bidirectional Gated Recurrent Unit (BiGRU) the signal modulations are said to be processed with time series data and as a result, better performance is attained for signal data with time series features. Moreover, the BiGRU processes signal data in both directions with forward and backward hidden layers.
The results obtained in both directions (i.e., forward and reverse audio signals) are then concatenated to produce the output. Let  represent the forward output of BiGRU by processing Gabor filtered audio signals ‘
represent the forward output of BiGRU by processing Gabor filtered audio signals ‘ denote the backward output of BiGRU by processing Gabor filtered audio signals ‘
denote the backward output of BiGRU by processing Gabor filtered audio signals ‘ ’.
’.
From the above Equations (2)–(5), ‘UGi’, ‘RGi’, ‘CGi’ and ‘Oi’ represents the updated gate, reset gate, candidate gate and output gate results for Gabor filtered audio signals provided as input signals respectively. Next, the intermediate results of the updated gate, reset gate, candidate gate are stored in the form of matrices ‘MUG’, ‘MRG’ and ‘MCG’ and bias ‘BUG’, ‘BRG’ and ‘BCG’ forming weights ‘WUG’, ‘WRG’ and ‘WCG’ respectively. However, with the increase in the feature size (audio sample size), there results in a modest increase in computational overhead. To solve this issue, finally, the obtained output ‘Oi’ is subjected to Differential Convex to obtain necessary gradients (i.e., extracts acoustic features). This is mathematically stated as given below.
From the above Equation (6), the differential convex is measured
As given in the above algorithm with the objective of obtaining computationally efficient feature signals, raw signals are provided as input obtained from FindSounds dataset, BiGRU is subjected to Gabor filter. By applying this Gabor filter the presence of frequency around the region of analysis is obtained. Second, with the Gabor filtered signals provided as input to the BiGRU, signals are generated both forward and backward (i.e., reverse) directions. Finally with the obtained output, Differential Convex is applied to generate computationally efficient features for further processing.
Next, with the computationally efficient predominant acoustic features extracted, depending on the environmental conditions and bird sounds may reveal explicit local static acoustic features. Therefore, an acoustic event detection system should possess the potentiality to not only acquire melodic cues in a timely manner but should also be robust to local static acoustic frequency shifts. To address this issue, a Greedy Regression-based Convolutional Neural Network by utilizing Mel Frequency Cepstral Coefficients (MFCC) is proposed for extracting features that are invariant to local spectral and temporal shifts.
A Greedy Regression-based Convolutional Neural Network learns spatial and/or temporal information due to the reason that it possesses the property of local static acoustic features. The local static acoustic feature means that each hidden neuron in a Greedy Regression-based CNN is not associated with all the neurons in the previous layer, but only a local static acoustic feature of the input neurons to the Convolutional layer. Moreover, multiple local static acoustic features with similar sounds are said to be defined to extract different features by working parallel to each other. Owing to this reason, the weights and biases of each of these local static acoustic features define a feature map. The local static acoustic feature is transformed via all the input neurons and the same local static acoustic features weights and biases are applied to the entire input space. Figure 3 shows the structure of a Greedy Regression-based Convolutional Neural Network-based static acoustic Classifier.
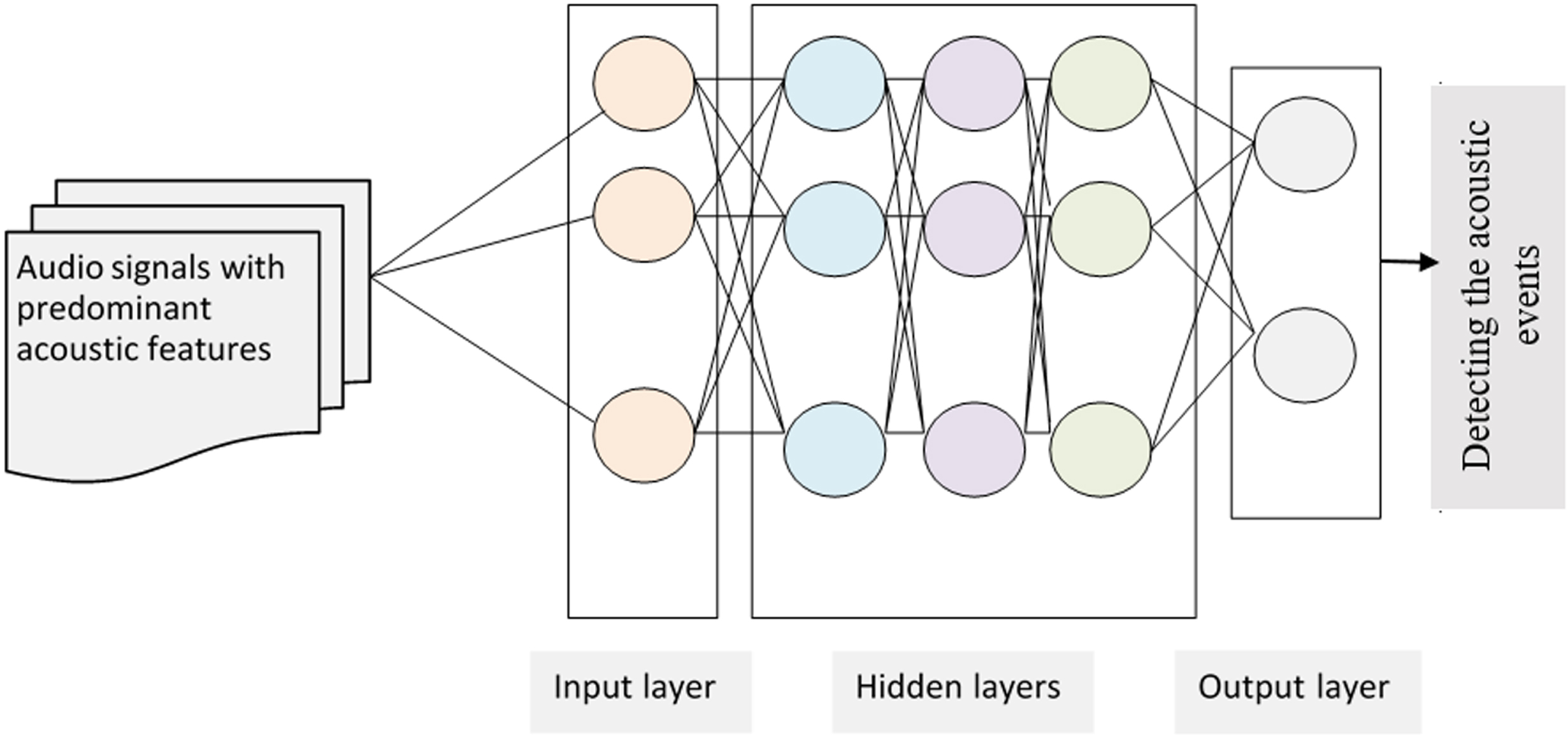
Structure of greedy regression-based convolutional neural network-based static acoustic classifier.
As shown in the above figure, the overall structure is split into three layers, namely, an input layer, three hidden layers and one output layer. The audio signals with predominant acoustic features are provided as input to the input layer. Next, in the three hidden layers, three distinct operations are performed (i.e., weight initialization, Mel scale Magnitudes evaluation, and greedy loss-based classification). Finally, the detected output from seven distinct classes is provided in a robust manner to the output layer. The objective in the classification stage along with the extraction of local static acoustic features is to model the nonlinear relationship between the predominant feature extracted spectrum ‘PF’ and the target outputs ‘Y ∈ Rm*n’ as given below.
Where the input layer is denoted as ‘IL’. Next, in the first hidden layer weights are initialized with Mel scale filter bank magnitude response with the purpose of combining human perception in feature learning. This is mathematically stated as given below.
With the above Mel scale filter bank magnitude response ‘Fmn’ as in the Equation (9), frequency ‘f’ is set to ‘1kHz’, in the second hidden layer, Mel scale Magnitudes are measured as given below.
From the above Equation (10), the Mel scale Magnitudes ‘MM’, is measured based on the Mel scale filter bank magnitude response of the corresponding predominant feature extracted spectrum ‘S’ respectively. Finally, in the third hidden layer, a Greedy Regression function is employed for extracting local static acoustic useful representations from sequential inputs by increasing mutual information between extracted at each distinct time instance. With the Greedy Regressive-Mel scale Magnitudes, the classified outputs are drawn from all available audio signals predominant acoustic features.
Each pair of Mel scale Magnitudes ‘F
mn
S [PF
mn
]’ is scored using a function ‘f (.)’ to detect and it is given ‘S [PF
mn
]’ is the positive sample (i.e., ‘Ym,n’ is set to ‘1’) employing a log-bilinear function ‘
From the above Equation (11), the final results i.e., either acoustic event detection ‘Ym,=1’ or not detected with acoustic ‘Ym,=0’ is obtained. Also to minimize the loss function in a greedy manner by extracting local static acoustic features that diverge between random pairs of samples. At the same time, the scoring log-bilinear function ‘fk’ learns to utilize those features to correctly detect the matching pair as given below.
From (12), the greedy loss function is estimated. Finally, the resultant output from ‘Ym,’ is provided to the output layer. With the above steps, the pseudo code representation of Greedy Regression-based Convolutional Neural Network-based static acoustic Classifier is formulated as given below.
As given in the above algorithm with the objective of improving the number of times the corresponding acoustic events are predicted to a specific class with minimum error, a Greedy Regression-based Convolutional Neural Network-based static acoustic Classifier is designed. With this objective, first, the audio signals of predominant acoustic features were provided as input to the input layer. Next, with the design of three hidden layers, the first hidden layer (i.e., initializing weight based on Mel scale filter bank magnitude response), the second hidden layer (i.e., evaluating Mel scale filter bank magnitude), and the third hidden layer (i.e., applying greedy loss function to obtain the detected acoustics) precise and robust acoustic event detection are made. Finally, the obtained output is forwarded to the output layer.
The proposed Greedy Regression-based Convolutional Neural Network and Differential Convex Bidirectional Gated Recurrent Unit (GRCNN-DCBGRU) method is explored and tested with other significant methods, namely Gated Recurrent Unit-Recurrent Neural Network (GRU- RNN) by [1], Deep Belief Network by [2], and Deep convolutional neural networks (DCNN) by [3]. A persuading characteristic for the assessment metric is their potentiality to differentiate between results of different acoustic event detection methods developed and evaluated in Python programming language using the FindSounds Dataset accessed from https://www.findsounds.com/types.html. The dataset was separated into two sets, namely the training set and the testing set. Most sample signals (70%) were used for training, and the minimum sample signals (30%) were taken for testing. The whole experiment is conducted in an Intel Core i5- 6200U CPU @ 2.30 GHz 4 cores with 4 Gigabytes of DDR4 RAM. Experimental evaluation of the GRCNN-DCBGRU method is carried out on factors such as audio detection time, audio detection accuracy, precision, and recall with respect to distinct numbers of audio signals. The efficiency of the audio event detection method is determined by monitoring the performance by several performance metrics.
Dataset details
The FindSounds Dataset accessed from https://www.findsounds.com/types.html which provides a huge number of distinct sounds already classified. For ease of use and avoid unbalanced class distributions, combined “birds” and “animals” classes into a single class “Animals”. As a whole the dataset consists of seven classes of sounds. (i.e., people sounds from 45 different human behaviors, like, coughing, laughing, moaning, kissing, baby’s cry, animals sounds from 69 distinct non-bird animals, nature sounds collected from 19 kinds of nature sounds, vehicle sounds produced by 34 distinct types of vehicles, noisemakers consisting of 13 distinct types of sound events, office space sound events, and musical instrument sounds from 62 distinct musical acoustic and electronic instruments. The details of the FindSounds Dataset and classes utilized are provided in Table 1. In Table 1, the dataset includes 16,930 sound instances with durations ranging between 1 and 10 seconds that correspond to 15 hours approximately of environmental sounds. All sound files were converted into raw 16-bit encoding, and 16 kHz sampling rate.
Find sounds dataset details
Find sounds dataset details
Tables 2–5 displays the corresponding results of audio detection time, audio detection accuracy, precision, and recall using audio event detection methods, GRCNN-DCBGRU, GRU- RNN by [1], DBN by [2], and DCNN by [3].
Performance comparison of audio detection time
Performance comparison of audio detection accuracy
Performance comparison of precision rate
Performance comparison of recall rate
Performance analysis of audio detection time
Audio event detection refers to the task of recognizing the sound events and their corresponding temporal start and end times in a recording. The objective of audio event detection methods is to identify what and when a situation is happening in an audio signal. To be more specific, the objective remains in identifying at what temporal instances distinct sounds are active within an audio signal. Target sound sets for task detection task are said to be specific to certain applications and hence are said to occupy a significant time during detection. The audio detection time is mathematically stated as given below.
From the above Equation (13), the audio detection time ‘AD time ’ is measured on the basis of the sample signals involved in simulation ‘Si’ and the time consumed in actual detection of events ‘Time [AD]’. It is measured in terms of milliseconds (ms).
Figure 4 given above shows the graphical representation of audio detection time results based on sample signals soil samples acquired from seven different classes or categories (i.e., people, animals, nature, vehicle, noise makers office and musical instruments respectively). With the seven different classes or audio sample signals utilized, the audio detection involved was analyzed and plotted in the above figure. An increase in the graph is inferred using all the four methods, GRCNN-DCBGRU, by [1], DBN by [2], and DCNN by [3]. However, simulations performed with 1500 sample signals showed audio detection time of 225 ms using GRCNN-DCBGRU method, 345 ms using [1], and 480 ms using [2], and 580 ms using [3] respectively. However, the audio detection time was found to be decreasing using GRCNN- DCBGRU upon comparison with [1], DBN by [2], and DCNN by [3]. The decrease in time employing the GRCNN-DCBGRU method was due to the application of the Gabor filter bank to the raw input signals with the objective of preserving the frequency involved during the initial processing stage. By applying this function, but precise audio signal features were obtained based on the forward representation and backward representation. This in turn assisted the GRCNN-DCBGRU method in minimizing the audio detection time by 24% compared to [1], 39% compared to [2], and 44% compared to [3].
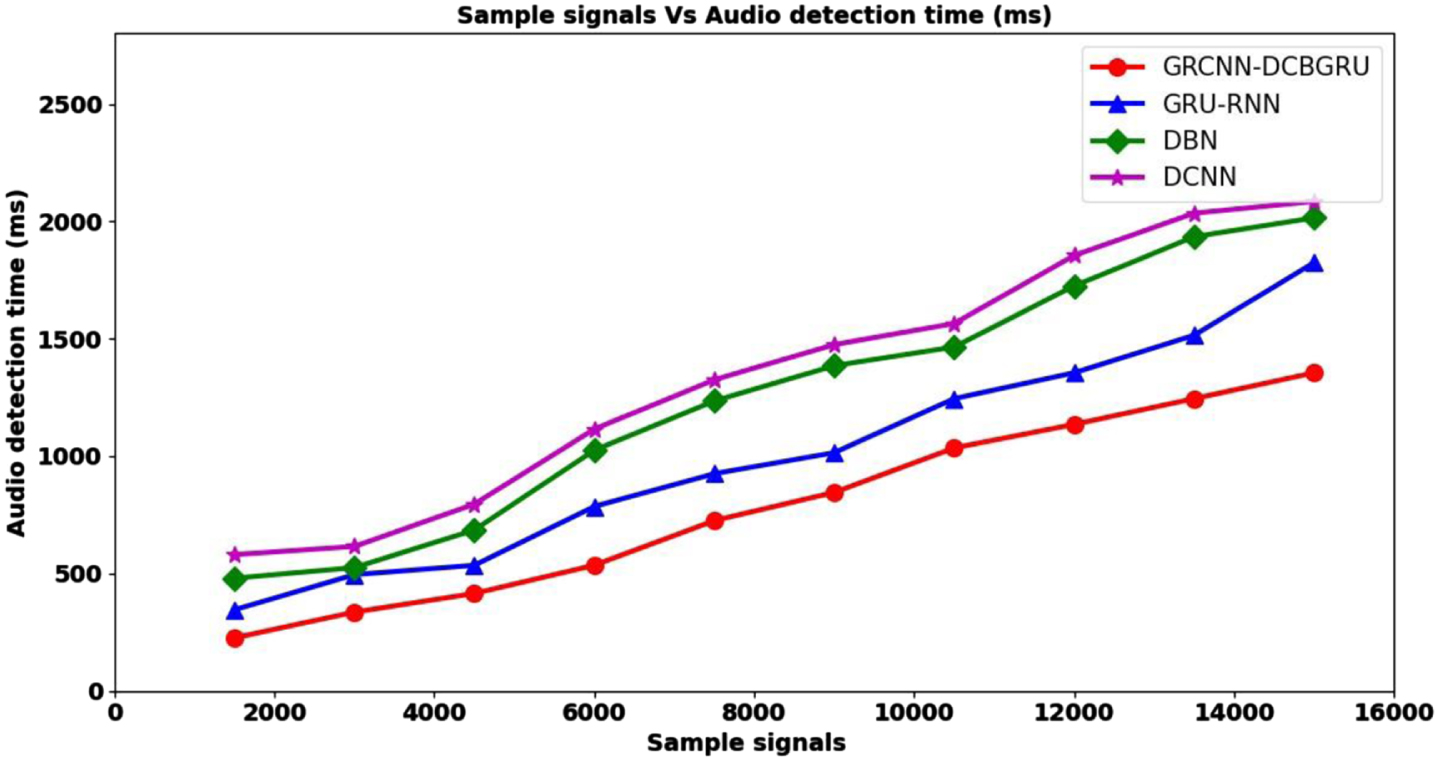
Graphical representation of audio detection time.
The number of probable sound event classes or categories is boundless owing to the reason that any object may generate a sound as a clearly happening circumstance. This is entirely distinct from other types of classification domains as they have a definite set of classes. As a result, the accuracy with which the audio detection made is said to be further complicated. The audio detection accuracy is mathematically formulated as given below.
From the above Equation (14), the audio detection accuracy ‘ADacc’ is measured based on the audio samples ‘Si’ involved in simulation purpose and the audio samples accurately detected ‘S ADA ’. It is measured in terms of percentage (%).
Figure 5 given above illustrates the graphical representation of audio detection accuracy based on seven different types of classes or categories, i.e., people, animals, nature, vehicle, noisemaker, office, musical instrument respectively. From the above figure, a small deviation was observed in obtaining the audio detection accuracy rate though found to be in the decreasing trend when increasing the audio sample signals. This is owing to the reason that as audio sample signals sizes increases the detection has to be made that differed for different categories. However, simulations performed with 1500 sample signals found an improvement of 97.66% audio detection accuracy using GRCNN-DCBGRU, 93.66% audio detection accuracy using [1], 90.33% of audio detection accuracy using [2], and 86.55% of audio detection accuracy using [3] respectively. However, the accuracy was found to be comparatively better using GRCNN-DCBGRU upon comparison with by [1], DBN by [2], and DCNN by [3]. The reason behind the improvement was due to the application of Differential Convex Bidirectional Gated Recurrent Unit to identify feature combinations that were not associated with each other audio sample signals. Also with the aid of this Differential Convex function mathematically formulation is made for seven distinct types of audio samples separately. This in turn assists in improving the audio detection accuracy using GRCNN-DCBGRU method by 5% compared to [1], 15% compared to [2], and 23% compared to [3] respectively.
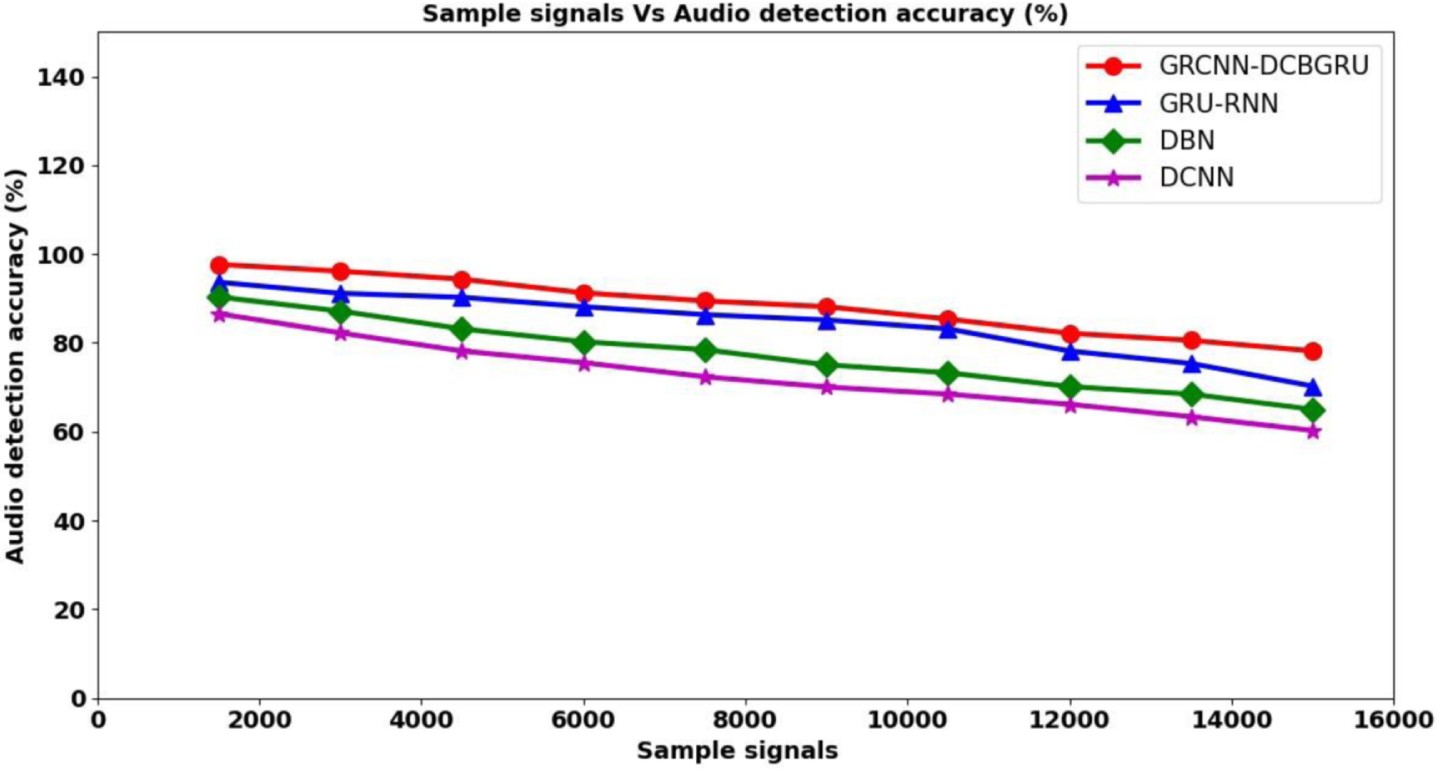
Graphical representation of audio detection accuracy.
Precision rate refers to the ratio of relevant instances (i.e., relevant audio event detected) among retrieved instances (i.e., retrieved audio event). This is mathematically expressed as given below.
From the above Equation (15), the precision rate ‘P’ is measured based on the true positive instances ‘TP’ (i.e., animal audio event detected as animal audio event) and the false positive instances ‘FP’ (i.e., people audio event detected as animal audio event) respectively.
Figure 6 given above shows the graphical representation of precision for 15000 distinct audio sample signals obtained obtain at different time instances from seven distinct classes or categories. From the above figure it is inferred that the precision rate was found to be comparatively higher using GRCNN-DCBGRU upon comparison by [1], DBN [2], and DCNN by [3]. The increase in the precision rate using GRCNN-DCBGRU method was false prediction results was lesser than by [1], DBN by [2], and DCNN by [3]. However, simulations conducted with 1500 sample signals observed the precision rate of 0.96 when applied with GRCNN-DCBGRU, 0.95 using [1], 0.94 using [2], and 0.93 using [3] respectively. The reason behind the minimization of false prediction results was due to the application of Greedy Regression-based Convolutional Neural Network-based static acoustic Classifier. By applying this model, Mel Frequency Cepstral Coefficients (MFCC) was utilized in updating the weight. By applying this MFCC weight parameters were fine-tuned that in turn made the interval between sample audio signals and positive samples to be smaller than interval between sample audio signals and negative samples. As a result, the precision rate was found to be comparatively better using GRCNN- DCBGRU method by 5% in comparison with [1], 9% in comparison with [2], 13% in comparison with [3] respectively.
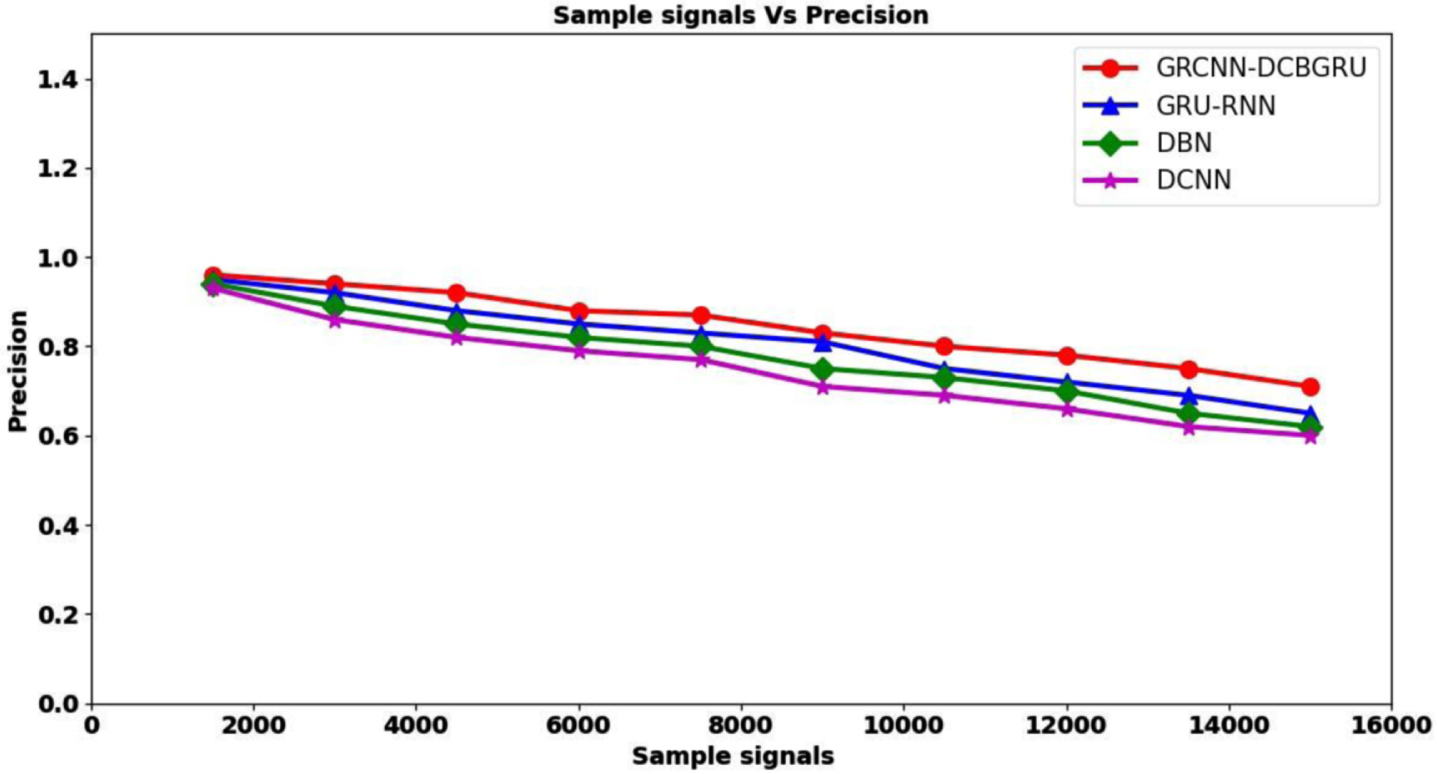
Graphical representation of precision.
Finally, recall is measured that refers to the ratio of relevant instances (i.e., relevant audio detection) that were retrieved.
From the above equation (16), recall rate ‘R’ is measured using the true positive instances ‘TP’ and the false negative instances ‘FN’ respectively.
Figure 7 given above shows the recall rate for different audio samples employing the seven different types of categories acquired from Table 1 separately. Also a linear trend is observed i.e., increasing the audio sample signals causes an increase in the false negative rate. This is due to the reason that by increasing the audio sample signals size, false negative rate increases and on the other hand, true positive rate increases. However, simulations conducted with 1500 sample signals observed the recall of 0.96 when applied with GRCNN-DCBGRU, 0.95 using [1], 0.93 using [2], and 0.91 using [3] respectively. However, the false negative rate using GRCNN-DCBGRU is found to be comparatively lesser than the three existing methods, by [1], DBN by [2], and DCNN by [3]. The reason behind the minimization of false negative rate was owing to the Greedy Regression-based Convolutional Neural Network-based static acoustic Classifier algorithm for audio event detection. With this algorithm, fine tuning weight parameters makes interval audio sample signals and positive samples to be larger and the interval between audio sample signals and negative samples to be smaller. Also, by utilizing three hidden layers, first hidden layer for initialization of weight on the basis of Mel scale filter bank magnitude response, second hidden layer for estimating Mel scale filter bank magnitude and finally, the third hidden layer for application of greedy loss function to acquired detected acoustics, relevant features and information is combined in a weighted manner that in turn passes on to the next layer. This in turn improves the recall rate using GRCNN-DCBGRU by 3% compared to [1], 16% compared to [2], and 23% compared to [3].
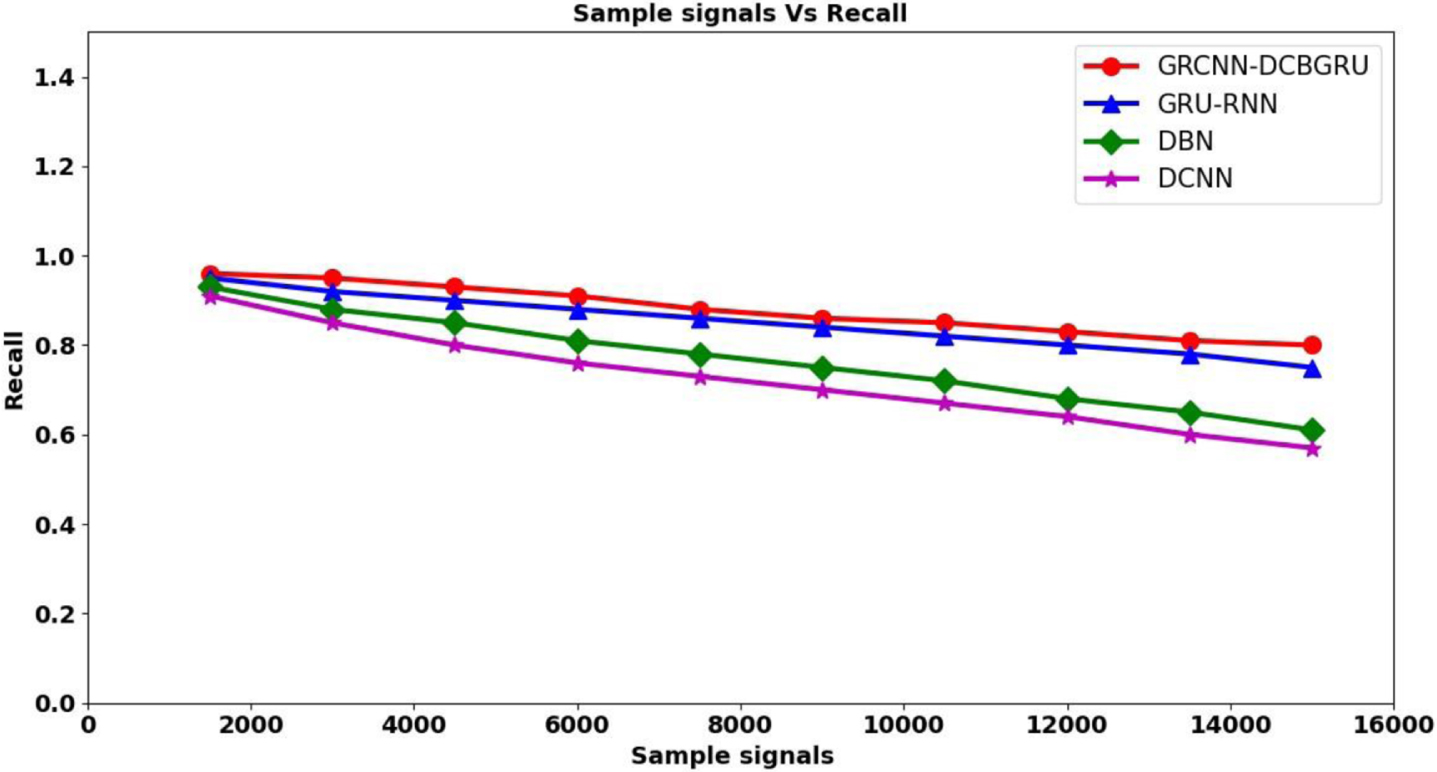
Graphical representation of recall.
In this paper, a novel method called Greedy Regression-based Convolutional Neural Network and Differential Convex Bidirectional Gated Recurrent Unit (GRCNN-DCBGRU) for audio event detection to interpret the auditory information around us. Here, with several classes audio sample signals in consideration and only computationally efficient predominant acoustic features selected employing Differential Convex Bidirectional Gated Recurrent Unit in turn improve audio detection in an accurate, precise and timely manner. Also, the proposed method is designed in such a manner to fine tune the weight using Greedy Regression-based Convolutional Neural Network via Mel Frequency Cepstral Coefficients (MFCC) that improves the precision and recall rate. Simulation results demonstrate the efficient performance of the proposed GRCNN- DCBGRU method. Also, comparison simulation results disclosed that the proposed method outperforms current state-of-the-art audio detection methods for interpreting auditory information in terms of audio detection accuracy and precision. Also, it is shown that the audio detection time of GRCNN-DCBGRU method is minimal with respect to the optimal solution showing greater recall, ensuring audio quality analysis.
Data availability statements
The data that support the findings of this study are openly available.
Declaration of interests
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.