
Abstract
Human pose estimate can be used in action recognition, video surveillance and other fields, which has received a lot of attentions. Since the flexibility of human joints and environmental factors greatly influence pose estimation accuracy, related research is confronted with many challenges. In this paper, we incorporate the pyramid convolution and attention mechanism into the residual block, and introduce a hybrid structure model which synthetically applies the local and global information of the image for the analysis of keypoints detection. In addition, our improved structure model adopts grouped convolution, and the attention module used is lightweight, which will reduce the computational cost of the network. Simulation experiments based on the MS COCO human body keypoints detection data set show that, compared with the Simple Baseline model, our model is similar in parameters and GFLOPs (giga floating-point operations per second), but the performance is better on the detection of accuracy under the multi-person scenes.
Introduction
Human pose estimation is also called human bone keypoints detection. It refers to detecting human joint points (also called keypoints, such as wrists, ankles, knees, etc.) from a single image or a video, and then connecting keypoints to represent the human skeleton according to body structure. Because human skeleton contains most of the pose information and ignores other unimportant information in the image, pose estimation is widely used in many downstream fields, such as action recognition, video surveillance, and human trajectory tracking [3, 4, 5].
Traditional pose estimation methods are based on graphical structural frameworks deformable component models, and artificial features. Although these methods have a fast speed, they need to construct specified models for various human poses. Due to the diversity of human posture, the applications of above algorithms are constrained from extending to the general cases [6, 7]. DeepPose [2] is the first model that uses deep learning to solve the task of two-dimensional human pose estimation. It can recognize different human poses through autonomous learning, and has strong applicability Thereby, deep learning has gradually become the mainstream method to solve the problems of two-dimensional human pose estimation [10, 20, 23].
Two-dimensional human pose estimation can be divided into single-person pose estimation and multi-person pose estimation. The single-person pose estimation is only applicable to a small number of scenarios where only one person exists, which will meet some difficulties in the complex environments [2, 20, 21]. In contrast multi-person pose estimation algorithms can describe multi-person behaviors simultaneously, and thus people pay more attention to the exploration of this field. There are two mainstream methods for the multi-person pose estimation: top-down [8, 9, 10, 11, 12] and bottom-up [13, 14, 15, 23]. The bottom-up model first detects all keypoints of human bodies in the image, and then adopts grouping algorithm to categorize detected keypoints. Since all keypoints are simultaneously found, the speed is relatively fast, but the hardware requirements are higher. In addition, as the number of human instances in the image increases, the bottom-up approach is difficult to group keypoints. Contrary to bottom-up pose estimation, the top-down approach uses the object detection algorithm to detect all the human instances in the image, and next detects keypoints of human instances one by one. The typical top-down pose estimation methods utilize a series multi-resolution networks to extract effective features, which enhance the resolution of the feature map to facilitate the location of keypoints [8, 11, 12]. The type of algorithms is of high accuracy and hardware requirements are lower. For example, Simple Baseline extracts features by ResNet [22], and employs deconvolution to obtain heatmaps with higher resolution.
The human body structure tends to be flexible, and change of location between each human joint can form different postures, especially for the situation where the human body is occluded. How to locate the invisible keypoints becomes a significant direction for correctly estimating the human body posture. In recent years, people have used the attention model to achieve good results in some computer vision tasks (such as classification, object detection and segmentation) [26, 28, 29]. The advantage of this model is that it can comprehensively employ local and global information. In view of this characteristic, Chu et al. proposed multi-context attention partially solving the problem of pose estimation in the complicated environments. However, the multi-context attention algorithm uses stacked hourglass networks (SHN) [20] as the basic network, hence the whole structure is more complex and difficult to operate [30].
This article studies the top-down two-dimensional multi-person pose estimation. Inspired by Pyramidal Convolution [24], we propose a new module base on Simple Baseline [10]. It adopts a small-size convolution kernel to extract the features of small targets and local details, whilst applying a large-size convolution kernel to obtain the features of large targets as well as context information containing human body structure information. We also introduce the attention model GC-Net [28] to further strengthen the connection between global and local information. Therefore, the model we present can better locate some keypoints that are difficult to detect by inferring human body poses, as shown in Fig. 1.
Detection results of pose estimation through our model. Those pictures are randomly selected from COCO. It should be noted that our model successfully detects some overlapped or invisible keypoints.
The remainder of this article is arranged as follows. Section 2 introduces the current work about top-down two-dimensional multi-person pose estimation, and Section 3 illustrates the principle and the structure of this model. Main steps and comparison experiments on the MS COCO database as well as corresponding analysis are shown in Section 4. The conclusion is given in Section 5.
One of the typical bottom-up approaches was given by Cao et al. [13], which encodes the position and direction of the limb and then is combined with the heatmap of keypoints for joint learning and prediction. But under some circumstances, detecting keypoints and grouping in the bottom-up method are dependent, thus the two steps should be merged and implemented simultaneously [15]. Short-Range Offset method is used to predict keypoints of the human body while predicting heatmaps, and at the same time Mid-Range Offset is utilized for grouping [14]. Cheng et al. [23] applied the parallel structure in HR-Net [12] as the backbone network, and proposes a bottom-up pose estimation. The authors found that the model’s capabilities are reduced due to the change of resolution of the model. Therefore, an additional module containing deconvolution and residual blocks is added to obtain a higher resolution heatmap.
Different from bottom-up method, top-down method is popular for its high accuracy. Fang et al. [8] proposed a multi-person pose estimation network RMPE on the basis of the single-person pose estimation network Stacked Hourglass Networks [20]. The network provides a symmetrical space transformation module for processing keypoints location errors caused by object detection frame positioning deviation. To cope with the difficulty of various keypoints, Chen et al. proposed CPN algorithm to detect keypoints separately [11]. Easy-to-detect joint points such as eyes and elbows are detected by GlobalNet, while keypoints difficult to detect (knees, hips, etc.) are acquired by RefineNet with higher-level semantic information. The article also employs online hard keypoints mining to calculate the loss of the most difficult (the largest loss) 8 keypoints. Motivated by networks such as CPN and Stacked Hourglass Networks, Xiao et al. proposed a simple and effective single-stage Simple Baseline [10], which has achieved good results through connecting several deconvolutions based on ResNet framework [22]. However, the prediction ability of this type of multi-stage human pose estimation methods cannot be enhanced with the increasement of stages. In response to this problem, MSPN [9] provides an improved Hourglass module, which uses different Gaussian kernels to generate heatmaps between different modules. Those heatmaps achieve the intermediate supervision from coarse to fine. HR-Net [12] design a parallel structure of high-resolution and low-resolution branches. In each downsampling process, a new parallel low-resolution branch can be obtained from the original high-resolution branch. Meanwhile the high-resolution branch will exchange information with the low-resolution branch, which is beneficial to the fusion of global and local information.
The work of Chu et al. [30] shows that attention models used in computer vision tasks such as object detection are also suitable for pose estimation. The squeeze-andexcitation (SE) block in SE-Net proposed by Hu et al. employs global average pooling to obtain global information, and utilizes some hidden layers with a sigmoid function to learn the inter-channel relationship. Wang et al. [29] proposed a Non-local Network that can query the paired relationship between each location and all other locations to form an attention map. It has a good effect but with huge computational cost. Base on the work of Non-local Network, Cao et al. Presented a more lightweight attention model GC-Net [28] combined with SE-Net. Because GC-Net algorithm is lightweight and can also obtain global context information, it is used widely in pose estimation models.
Mixture model for pose estimate
In this article, we adopt the top-down pose estimation method. In order to correctly and quickly detect the keypoints of human body that are partially occluded or invisible, we construct a combined local and global structure model (CLGS) by introducing the pyramid convolution and attention module. First, we use the object detection algorithm to detect the object boxes of all human bodies in the input image, and then apply the pose estimation algorithm to find the keypoints in each object box. Obtaining contextual information can help the model learn some information about the human body structure, thereby facilitating the location of keypoints. Moreover, CLGS algorithm may extract contextual information containing human body structure information through different convolution kernels.
Principle of the fundamental module
The Simple Baseline method uses ResNet as the backbone network to extract effective features, and bottleneck module is the basic component of ResNet. The structure of bottleneck module is shown in Fig. 2a. The input feature vector is convoluted by 1
where input and output are the same as the Bottleneck; conv1, conv2, and conv3 of Bottleneck are three convolutions of size 1
Illustration of two typical modules of current classification networks. (a) is the basic module Bottleneck in ResNet, (b) is the basic module Pyconv Bottleneck in PyConvHGResNet.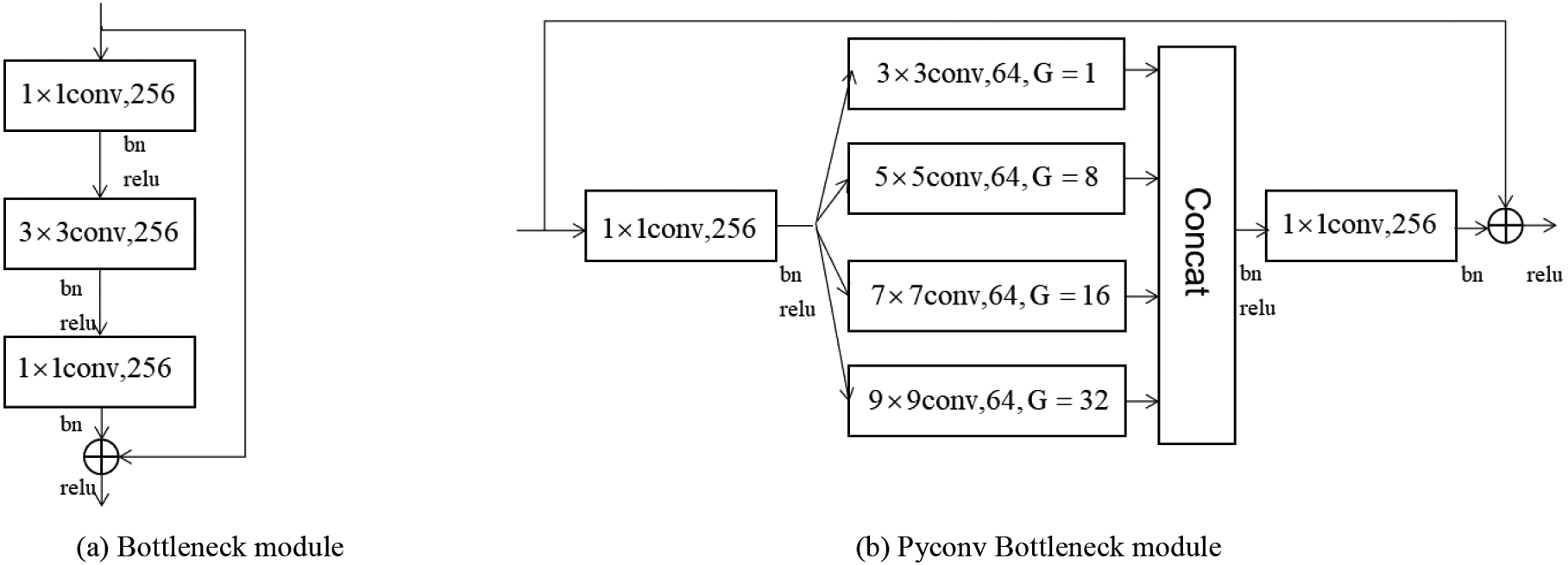
Pyramidal convolution (Pyconv) [24] is based on Bottleneck in ResNet, and its structure is shown in Fig. 2b. In Pyconv Bottleneck, the input features first are convoluted with the kernel of size 1
where
Since the model based on the attention mechanism can fuse the local and global information of the visual scene and thus facilitate the location of keypoints, in this paper, we try to combine a model of self-attention mechanism with Pyconv bottleneck. It mainly contains two parts: context modeling and transform. The former uses 1
Comparison of GC block and our improved mixture module. (a) is the attention module global context block (GC Block); (b) is the improved mixture module, which is formed by combining GC Block and Pyconv Bottleneck.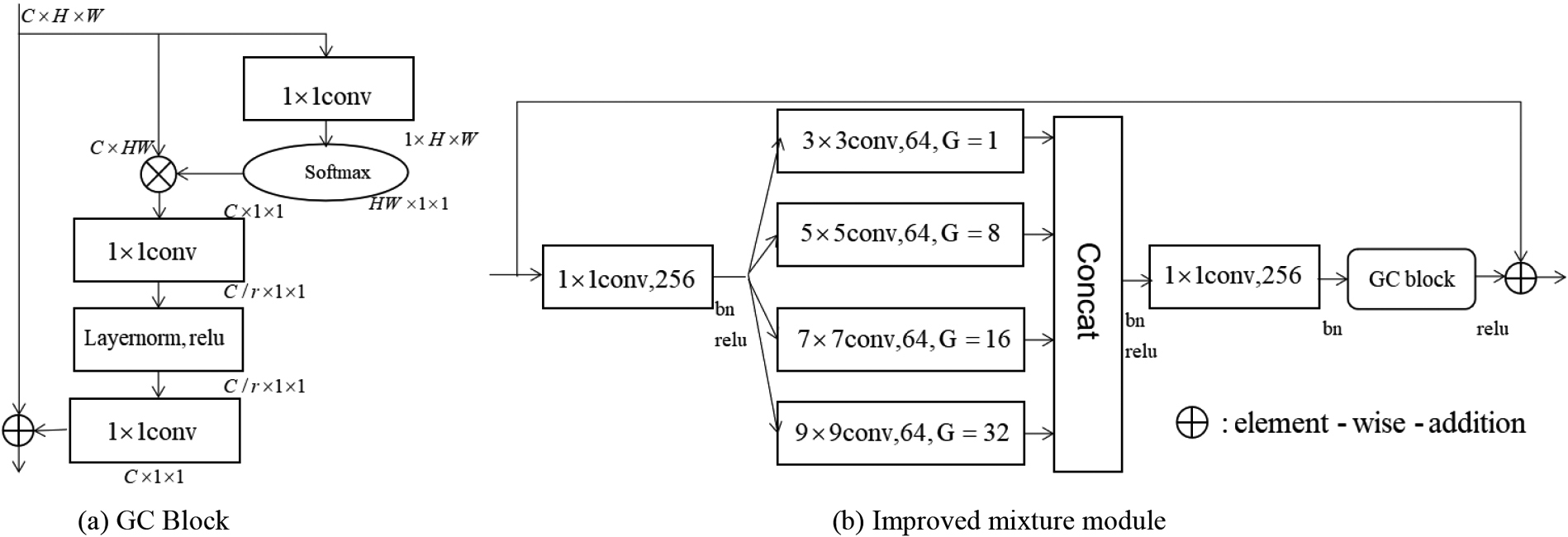
In recent years, many pose estimation algorithms use a series of high-resolution to low-resolution networks to extract effective features, which will increase the resolution of feature maps and thus facilitate location of keypoints as well as reduction of errors. Among them, Simple Baseline [10] is regarded as the one of fundamental methods in pose estimation. Although the structure of Simple Baseline is simple, it has achieved relatively good results. Our network is inspired by this concise and effective baseline idea, but we make improvements from the following two aspects:
In view of pyramidal convolution [24], we adopt the Pyconv Bottleneck module proposed in PyConvHGResNet as the basic block and then use deconvolution to enhance the resolution of the feature map. In order to further improve the performance of the model, we add an attention module GC Block to Pyconv Bottleneck.
Local and global structure in the model. C2-C5 are units that contain 3, 4, 6, and 3 structures consisting of Pyconv bottleneck and GC block, respectively.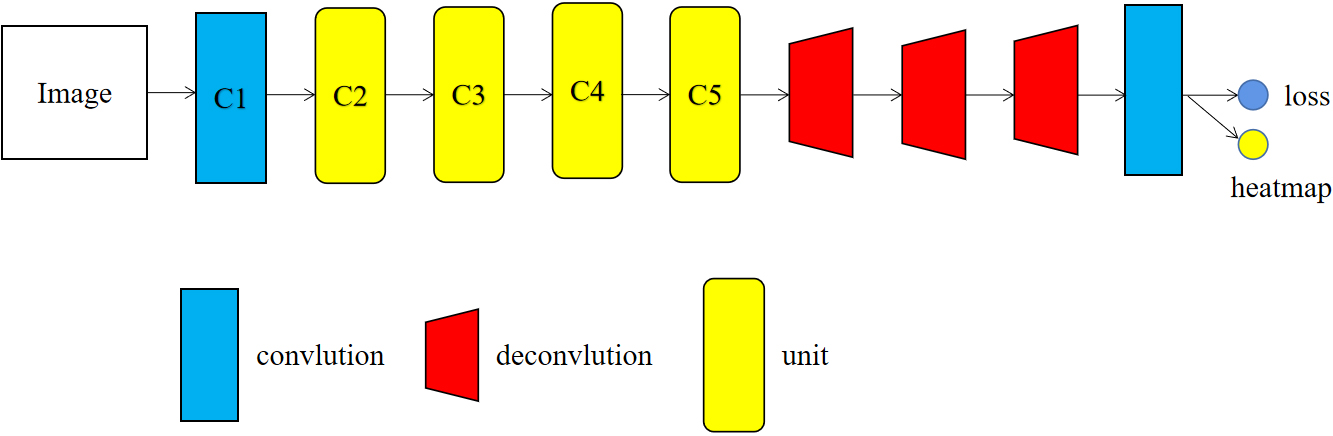
The specific structure of our model is shown in Fig. 4. C1-C5 is the backbone network for extracting effective features (PyConvHGResNet50), where C1 is the 7
In this paper, we adopt mean square error as the loss function to calculate the error of the model, and the mathematical expression is as follows:
where
Keypoints are obtained from local information and are also intrinsically connected, for the two-dimensional multi-person pose estimation, global information such as body structure information of limbs are helpful to the connections between adjacent joints.
Pyramid convolution used in our model can effectively extract the features and local details of small targets by small-size convolution kernels. At the same time, large-size convolution kernels are applied to extract contextual information of human body structure. In addition, the added lightweight attention module (global context module) further correlates global and local information, so that our improved model can not only obtain accurate positions of keypoints, but also connection relation among keypoints. The improved model has a coherent understanding of the human body structure and can find those keypoints that are not easy to detect for the estimation of human body posture. The use of grouped convolution in the model also reduces the number of model parameters and calculation cost.
Experiment
Dataset
The MS COCO dataset [27] is widely used in a variety of deep vision tasks. It is divided into three versions: COCO2014, COCO2015, and COCO2017. We utilize COCO2017 as our dataset, which contains 80 categories, 200,000 images, and 5 types of annotation information such as object detection and human keypoint detection. Among them, there are 250,000 human body instances marked with keypoints of the human body, and each human body instance has 17 marked keypoints. COCO2017 is divided into train2017, val2017 and test-dev2017. Among them, train2017 contains 57,000 images, where 150,000 human body instances marks keypoints. Val2017 involves 5000 images and test-dev2017 includes 20,000 images. We use train2017 for the training task and val2017 for the validation and evaluation of our model, respectively.
Evaluation metric
We apply object keypoint similarity (OKS) to measure the similarity between predicted keypoints and ground truth label keypoints. The calculation formula is given by:
where
Our experiment is carried out on a 2
Comparison of the test results on Simple Baseline and test results in our model on Val2017. “CPN+OHKM” refers to the improved algorithm containing OHKM [11], “pretrain” indicates whether the algorithm uses a pre-trained model or not, and “
GC” implies that GC Block is added to Pyconv Bottleneck
Comparison of the test results on Simple Baseline and test results in our model on Val2017. “CPN+OHKM” refers to the improved algorithm containing OHKM [11], “pretrain” indicates whether the algorithm uses a pre-trained model or not, and “
This paper proposes a two-stage, two-dimensional multi-person, and top-down pose estimation method. The human instances are detected by the object detection algorithm and then the keypoints are predicted through our model. In the verification set val2017 and stest-dev2017 of the MS COCO data set, we adopt faster R-CNN [25] as the object detector to detect the corresponding human instance detection frame. As for the predicted heatmaps, we compute the average of the original image heatmaps and the flipped heatmaps as the final output. The position offset by
Results on the validation set
In Table 1, we show the test results of our network on COCO val2017. The number of parameters in our model without GC Block is 33.7M, and GFLOPs is 8.9. Compared with Simple Baseline (ResNet50), our model without GC Block has lower parameters and GFLOPs, and the test results on val2017 show that our model without GC Block has a certain improvement in main indicators. Among them, AP, AP
Results on the test-dev set
In Table 2 we show the test results of our network model on COCO test-dev2017. The test results shows that our model without GC Block on test-dev2017 is better than Simple Baseline (ResNet50), since two main indicators AP and AR are 70.7 and 76.4, which increase by 0.7 and 0.8, respectively. Similarly, the test results implies that our model combined with GC Block on test-dev2017 is also improved in the accuracy and recall aspects. Compared with Simple Baseline (ResNet50), AP and AR are 71.1 and 76.6, which increase by 1.1 and 1.0, respectively. Therefore, our improved model is better than Simple Baseline (ResNet50) in main indicators.
Comparison the test results on Simple Baseline and the test results of our model on test-dev2017. “pretrain” indicates whether the algorithm uses a pre-trained model or not, and “
GC” indicates that GC Block is added to Pyconv Bottleneck
Comparison the test results on Simple Baseline and the test results of our model on test-dev2017. “pretrain” indicates whether the algorithm uses a pre-trained model or not, and “
The visualization results of our final model and Simple Baseline (ResNet50).
Our model can accurately detect some keypoints of human bodies that Simple Baseline (ResNet50) is difficult to detect. The visualization results of our final model and Simple Baseline (ResNet50) on Val2017’s prediction results are shown in Fig. 5. The results are given in pairs. The left side of each group of pictures is the prediction results of our model, and the right side denotes the Simple Baseline (ResNet50). Red circles are marked to show the difference of two models.
Conclusion
In this article, we propose a top-down two-dimensional multi-person pose estimation model based on the pyconv bottleneck and the lightweight attention model GC Block. The new algorithm can effectively utilize the local information of the image as well as the global structure information to obtain the human body structure information. Based on those improvements, we may infer some invisible or overlapped keypoints which are difficult to locate in the pose estimation task. At the same time, since the grouped convolution is applied, and GC Block is lightweight, the number of our model parameters does not increase and is analogous to the algorithm Simple Baseline. Experiments show that our model has outperformed Simple Baseline on the two datasets of Val2017 and test-dev2017 after we train our network on the standard MS COCO human body keypoints detection dataset. Due to the limitation of backbone network presented in our model, computational cost is still relatively large.
Footnotes
Acknowledgments
This work is supported by the Science and Technology Program of Beijing (No Z181100009218012).