
Abstract
This article combined BERT (Bidirectional Encoder Representation from Transformers), Bi-LSTM (Bidirectional Long Short-Term Memory), and CRF (Conditional Random Field) models to transform unstructured legal text into structured data through information extraction, improving the effectiveness of legal information extraction. The BERT model can be used for deep semantic embedding of legal texts, generating context-sensitive representations for each word. The Bi-LSTM network can capture long-distance dependencies in the text, extract sequence features, and apply CRF layers to globally optimize sequence labels to ensure accurate annotation of entity boundaries and relationships. In the dataset for extracting legal entity relationships related to prostitution constructed in this article, the accuracy, precision, recall rate, and F1 score of entity classification reached 93.6%, 92.7%, 92.1%, and 92.4%, respectively. All 153 samples in the Engage_in_ prostitution relationship were correctly classified. In order to analyze the stability of legal information extraction and classification, the model proposed by this article was tested on five datasets: CAIL2019, CJRC (Chinese Judicial Reading Comprehension), LexGLUE (Legal General Language Understanding Evaluation), COLIEE (Competition on Legal Information Extraction/Appointment), and ECHR (European Court of Human Rights). The accuracy of the article’s model fluctuated only 1.2% on different datasets, while the precision remained stable and the recall fluctuated by 0.7%. This article provided reliable technical support for legal intelligence research by combining BERT, Bi-LSTM, and CRF to accurately extract and classify legal information.
Keywords
Introduction
The digitalization process of legal documents is constantly accelerating, providing broad prospects for efficient management and analysis in the legal industry. Despite the significant increase in digitalization of legal texts, there are significant differences in writing standards and formats among different types of legal documents,1,2 which poses a huge challenge to automated processing. Legal text information extraction aims to automatically identify and extract key information from a large number of complex legal documents, such as legal entities, cases, and judgments. Due to the professionalism, complex syntactic structure, and semantic dependence of legal language, information extraction technology is very important for improving legal document processing. Legal texts3,4 have complex language structures and specific terminology, and rule-based methods are difficult to handle all types of legal documents. These issues make it an important research topic in legal information processing to extract valuable information from unstructured legal texts and achieve the transformation of structured data. This article improves the accuracy and efficiency of legal text information extraction and classification by combining BERT, Bi-LSTM, and CRF models, provides a more advanced method for intelligent legal document processing, and helps promote the informatization and intelligent development of the legal industry.
The named entity recognition example of the pipeline relationship extraction method is shown in Figure 1. Named entity recognition.
The traditional pipeline relationship extraction method usually includes two main steps: (1) named entity recognition can be performed to identify relevant entities from input statements; (2) the recognized entities can be combined in pairs without repetition, and these combinations can be concatenated with the original statement for relationship classification, thereby determining the relationship triplets between entities. One major drawback of this method is the tendency to accumulate errors. Because the two steps of relationship extraction are closely related, the results of named entity recognition are directly used as inputs for relationship classification. If there is an error in the naming entity recognition in the previous step, the erroneous result can be passed to the relationship classification stage, leading to further amplification of the errors in the entire process. In addition, the pipeline method also has the issue of computational redundancy. All recognized entity combinations are paired and passed on to the relationship classification step, and many of these entity combinations are actually unnecessary because they do not have meaningful relationships. Excessive redundant calculations not only increase computational complexity and time costs but may also lead to a decrease in the efficiency of the model when dealing with large amounts of invalid data. The existing pipeline relationship extraction method has the problems of strong model independence and insufficient information transmission. The errors of the previous tasks can gradually accumulate, affecting the accuracy of subsequent tasks. In addition, the inability to effectively capture contextual information limits the overall performance of relationship extraction.
Relationship extraction process.

In the task of processing legal texts, existing methods face the problems of low processing efficiency and poor adaptability. In recent years, the application of deep learning technology in legal information extraction has gradually received attention. Bidirectional long short-term memory networks are widely used for feature extraction of text sequences due to their superior performance in capturing long-range dependencies of sequence data. The conditional random field model,5,6 due to its optimization ability in sequence annotation tasks, can effectively integrate contextual information and improve the coherence of annotation results. By combining these two models and introducing the BERT model to generate vector representations of text, the semantic understanding of legal texts can be further improved, and the model’s extraction and classification capabilities can be enhanced. BERT’s pre-trained language model provides Bi-LSTM with richer semantic features, while CRF optimizes the output of Bi-LSTM to improve the automation level of legal information processing through model combination, thereby promoting the further development of intelligent legal service systems.
This study innovatively combines BERT, Bi-LSTM, and CRF models and simultaneously performs entity recognition and relationship extraction through an end-to-end method, which improves the accuracy and efficiency of information extraction. The innovation of this article lies in the mixed application of BERT, Bi-LSTM, and CRF models, each utilizing its advantages to improve overall performance. BERT captures deep semantics in legal texts, Bi-LSTM models bidirectional dependencies, and CRF ensures accurate tagging of entities and relationships. This integrated model enhances classification accuracy and addresses context and sequence prediction challenges. Tested on datasets like CAIL2019 and ECHR, it proves adaptable and effective for legal information extraction.
Related work
Recent research in legal information extraction and classification focuses on leveraging natural language processing and machine learning to automate the processing of large unstructured legal texts. Legal information extraction7,8 involves identifying entities, relationships, events, or facts from documents like judgments and contracts. Traditional rule-based methods, though effective for specific formats, struggle with complex legal language and diverse text styles. As a result, data-driven approaches using deep learning models,9,10 such as convolutional neural networks, long short-term memory networks,11,12 and attention mechanisms, have become popular. These models, trained on extensive legal corpora, capture complex patterns and contextual relationships. Pre-trained language models like BERT 13 significantly enhance legal entity recognition and text classification. Combinations like BERT-LSTM (Long Short-Term Memory), 14 BERT-GRU (Gated Recurrent Unit), and BERT-CNN (Convolutional Neural Network) further improve accuracy and generalization. Hierarchical attention networks and multi-task learning methods provide strong results in multi-level classification tasks, handling long texts and complex contexts. In legal extraction and classification,15,16 challenges such as uncertainty, data imbalance, and noise demand more robust model architectures and data augmentation techniques for better real-world performance. This shift from rule-based processing to deep semantic understanding, powered by deep learning, marks a new era in legal information processing. Previous research mainly relies on rule-based methods, which are difficult to handle complex legal language and diverse text styles.
The Bi-LSTM-CRF model excels in sequence annotation tasks and is highly applicable to legal information extraction and classification. Bi-LSTM17,18 captures contextual features by considering input sequence information, improving semantic understanding in complex texts. CRF,19,20 a probabilistic graph model, optimizes sequence labeling by handling dependencies between adjacent labels. The combination of Bi-LSTM for feature extraction and CRF21,22 for global label optimization enhances entity recognition and relationship extraction in legal texts. Research shows this model23,24 outperforms traditional methods, especially in tasks like named entity recognition across fields such as legal, medical, and bioinformatics. When paired with BERT for embedding, the Bi-LSTM-CRF architecture significantly improves accuracy and F1 scores, offering superior performance in extracting key information from complex legal documents. Previous studies often lack an in-depth understanding of complex legal texts and fail to effectively capture the dependencies between contextual features and labels. In addition, the limitations of a single model make the accuracy and robustness of legal information extraction insufficient, and it is difficult to adapt to the diversity of different legal datasets.
Methods for extracting and classifying legal information
Building a legal corpus
In this article, the original corpus of training data is sourced from publicly available legal documents related to prostitution on the China Judgments Online platform. The original corpus of training data comes from the China Judgment Documents Network, mainly including legal documents on prostitution. These documents cover a variety of case types, including criminal judgments and rulings, and provide a wealth of legal clauses and judgment basis. The openness and diversity of the corpus ensure the representativeness of the data and help improve the performance of the model in legal information extraction and classification tasks. In order to ensure the effectiveness and accuracy of the constructed dataset, the fact description part of the case in the document is extracted through regular expressions. It includes specific case circumstances and the facts on which the legal judgment is based. Based on the preliminary extracted text fragments, a “rule coarse labeling manual recall” annotation mode is adopted to gradually construct the training dataset. Text can be roughly annotated using preset rules and manually checked and corrected by professional annotators to ensure annotation quality and accuracy. By using a dual annotation mechanism to reduce annotation errors and inconsistencies, the overall quality and robustness of the dataset can be improved.
When constructing a dataset for extracting legal entity relationships related to prostitution, the annotation process is similar to the annotation mode of traditional relationship extraction, while annotating the location of entities and the corresponding types of relationships between entities. This joint annotation approach can handle both entity recognition and relationship classification tasks within a single annotation framework, reducing the problem of error accumulation caused by task decomposition, and more effectively capturing complex semantic relationships between entities in text. The joint labeling method can effectively share information and context by processing entity recognition and relationship classification in a single framework, thereby reducing the error accumulation that may occur when decomposing tasks. This method allows the model to consider the relationship between entities while identifying them, improving overall performance and accuracy. In addition, joint learning reduces the time and resources required for model training and improves efficiency.
Display of relationships related to prostitution.

Provide_sthelter_for refers to the act of providing a venue for prostitution activities. Arrange_induction_for refers to the act of organizing or arranging others to engage in prostitution activities. Engage_in_ institution refers to individuals who directly engage in prostitution activities. Patronize_prostitution refers to the act of a client paying money or other forms of compensation in exchange for sexual services. Facilitate_prostitution refers to the act of assisting or promoting prostitution activities through various means, including providing transportation and communication tools. Manage_brothel refers to the operation of venues specifically designed for prostitution activities, including brothels or massage parlors.
Dataset distribution.
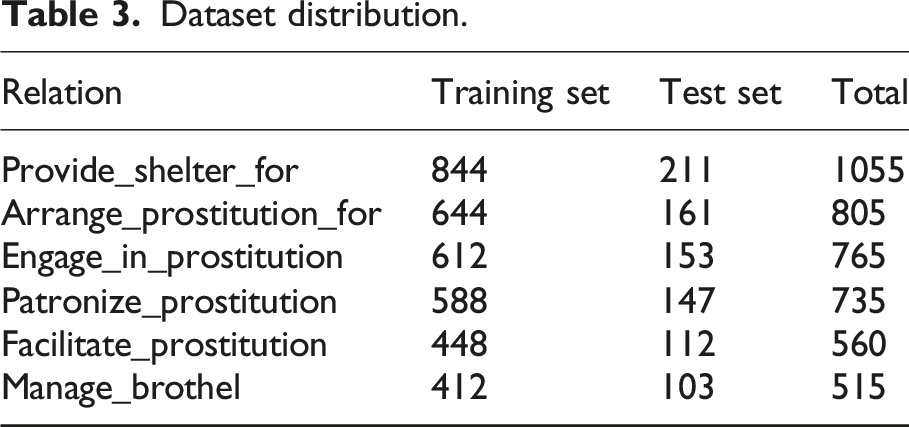
In the dataset of legal entity relationships related to prostitution, the distribution of training and testing sets for each type of relationship is as follows: for the “Provide_shelter_for” relationship, the training set contains 844 samples and the testing set contains 211 samples, for a total of 1055 samples. The training set sample size for the “Arrange_prostitution_for” relationship is 644, the testing set is 161, and the total number of samples is 805. The relationship of “Engage_in_prostitution” contains 612 samples in the training set and 153 samples in the testing set, for a total of 765 samples; the training set for the “Patronize_prostitution” relationship has 588 samples, the testing set has 147 samples, and the total number of samples is 735; the training and testing set samples for the “Facilitate_prostitution” relationship are 448 and 112, respectively, for a total of 560 samples. The training set samples for the “Manage_brothel” relationship are 412 and the test set is 103, totaling 515 samples. Each relationship category has sufficient data for learning the characteristics of entities and relationships, which helps the model to identify in legal document information extraction tasks. Among all the training data, Provide_shelter_for has the most training data, 844, and Manage_brothel has the least.
The sentence length distribution of entity relation triplets in the dataset is shown in Figure 2. Distribution of sentence length.
The distribution of sentence length for entity relationship triplets shows significant differences in the number of sentence lengths in each interval. There are 250 sentences with a length less than 40, which accounts for a relatively small proportion. There are 543 sentences between 41 and 80 in length, and the number of sentences between 81 and 120 has increased to 689. As the sentence length increases, the number of sentences ranging from 121 to 160 reaches 789, and the number of sentences ranging from 161 to 200 further increases to 921, becoming the interval with the highest number of sentences. The number of sentences with a length between 201 and 240 is 826, while the number of sentences with a length exceeding 240 is reduced to 417. This distribution indicates that most sentence lengths are concentrated between 161 and 200 words, indicating that the expression of entity relationship triplets in legal documents is complex and lengthy. The entity relationship triples in legal documents are usually relatively complex and lengthy, mainly due to the professionalism and rigor of legal texts. Legal clauses, case descriptions, and reasons for judgments often need to be elaborated in detail to ensure accurate communication of information and clarity of legal application. Although this lengthy expression is necessary in law, it also brings greater challenges to information extraction and classification.
Label strategy.
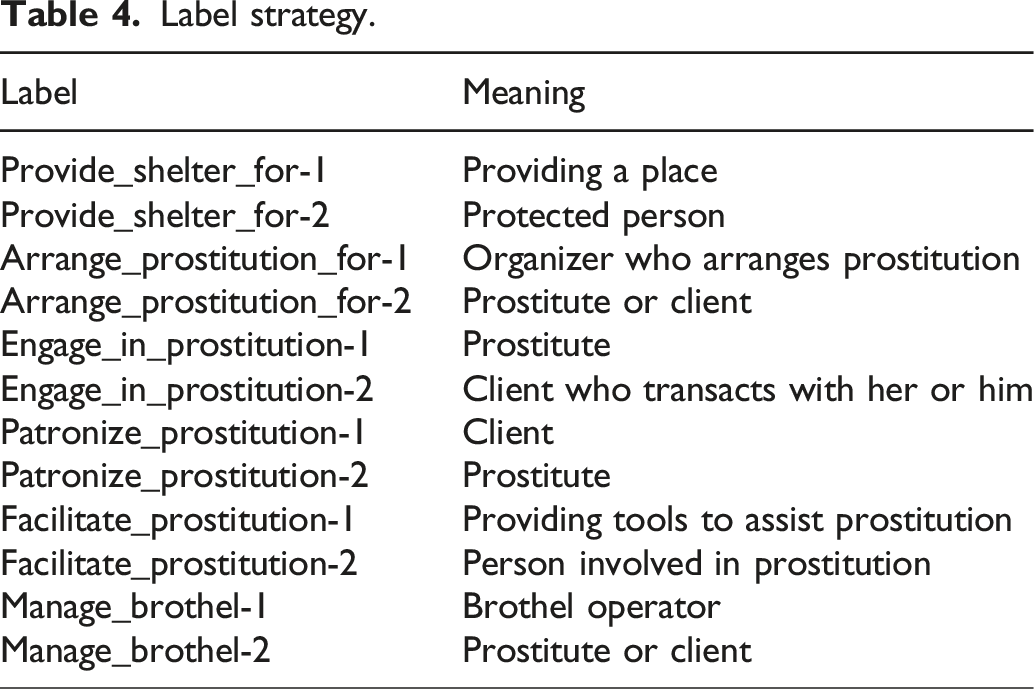
The entity (head entity) containing “1” in the tag can only match the nearest entity (tail entity) containing “2” backwards; on the contrary, entities containing “2” in the label can only match the nearest “1” entity forward. This matching rule effectively avoids confusion in relation extraction.
Construction of BERT-Bi-LSTM-CRF model
This article combines BERT,25,26 Bi-LSTM, and CRF to extract and classify legal information. The BERT-Bi-LSTM-CRF model structure is shown in Figure 3. BERT-Bi-LSTM-CRF model structure.
The word vectors generated by BERT can be input into a bidirectional long short-term memory network. Bi-LSTM captures contextual features of sequence data through two LSTM layers, forward and backward, and can remember remote dependencies in the sequence. This process enhances the model’s understanding of legal terms and entity relationships by learning the before and after correlations of each word in the text, thereby extracting semantically rich feature representations. The contextual feature vectors output by Bi-LSTM can be input into the conditional random field layer for sequence annotation. CRF can model the global dependencies and constraints of label sequences, further optimizing the accuracy of sequence prediction. By combining Bi-LSTM output with CRF decoding algorithm, the model can output the optimal label sequence, avoiding the problem of inconsistent labeling in independent classification models, thus achieving the effect of legal information extraction and classification.
The foundation of BERT is the Transformer architecture, which is composed of multiple encoders stacked together. Each encoder consists of a self-attention mechanism and a feedforward neural network. Each encoder layer of BERT maps the input sequence to a new vector space, generating higher-level semantic features layer by layer. BERT is based on the Transformer architecture and has a strong ability to understand context. Its bidirectional encoding characteristics enable the model to consider both left and right text information, improving the ability to capture complex semantics.
The calculation process of self attention mechanism is as follows: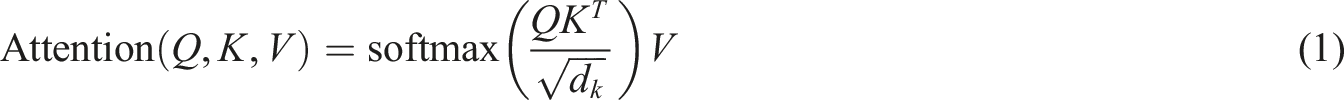
Q, K, and V are matrices obtained by linear transformation of the input sequence, and
BERT uses two main pre-training tasks, including masking language models and next sentence prediction. BERT’s pre-training improves the model’s language understanding ability through masked language model and next sentence prediction tasks. The masked language model allows the model to learn vocabulary relationships in context, while the next sentence prediction helps capture the logical relationship between sentences. This pre-training method enables BERT to effectively handle a variety of natural language processing tasks, significantly improving performance and generalization capabilities. The goal of masking language models is to randomly mask some words in the input sequence and then train the model to predict these masked words. 15% of words can be randomly selected for masking. For the selected words, there is an 80% probability of being replaced with special MASK tags, a 10% probability of being replaced with random other words, and the remaining 10% remains unchanged. The input of the model includes complete sentences and masked words, and the model needs to predict the original words of each masked word.
The masking language model uses cross-entropy loss to calculate the accuracy of the model in predicting masked words, and the formula is as follows:
The goal of the next sentence prediction task is to predict whether two pieces of text are adjacent in the original corpus. The input is two pieces of text: A and B. The model input is CLS mark + A + SEP mark + B + SEP mark. There is a 50% probability that B is the real next sentence after A. A 50% probability that B is a sentence randomly selected from the corpus. The loss function of the next sentence prediction is used to calculate the accuracy of the model when predicting the next sentence relationship. The formula is as follows: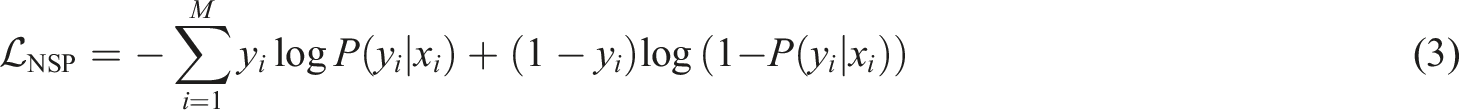
In formula (3), M is the number of training samples and
The input of the BERT model consists of three parts: input embedding, positional embedding, and segmented embedding. Each word in the input embedding is transformed into a vector representation through a word embedding matrix. Position embedding indicates a word’s position in a sentence, while segmented embedding distinguishes between sentences. BERT’s output is a sequence, with each word’s representation computed through a multi-layer Transformer. Each layer’s output captures both contextual and deep semantic information. Input embedding is responsible for converting vocabulary into vector representation, and position embedding provides the position information of words in sentences to capture the relative position of words in the sequence. Segment embedding is used to distinguish different sentences in the input and help the model understand the relationship between sentences. The combination of these three embeddings enables BERT to effectively capture the semantic and structural information of the text.
Bi-LSTM27,28 is a bidirectional long short-term memory network that excels in sequence annotation by capturing contextual features from both forward and backward directions. By combining two LSTM layers, Bi-LSTM effectively handles long dependencies in natural language, enabling better understanding of the global context within sequences. The advantage of bidirectional LSTM is that it considers both the forward and backward information of the input sequence, so that it can capture the contextual relationship more comprehensively. This structure enables the model to perform better when processing long dependencies, improves the ability to understand complex language phenomena, and makes it more accurate and effective in natural language processing tasks.
The formula for the forget gate is as follows:
Input gate:

The unit status has been updated as follows:
The output gate formula is as follows:

If the input sequence is set to 
CRF29,30 is a conditional probability model that measures the transition probability of each pair of adjacent labels in a sequence and the strength of the association between each label and the features of the input sequence by defining a set of feature functions, thereby learning the complex relationship between input and output. In this article, conditional random fields are used to optimize sequence labeling tasks, combined with the feature extraction capabilities of the Bi-LSTM model. By learning the transition probabilities of adjacent labels and the associations between input features, CRF can enhance the accuracy of entity recognition and relationship extraction in legal texts, and improve the model’s ability to understand and process complex legal relationships. Given the input sequence X, the conditional probability of the output label sequence Y can be expressed as follows: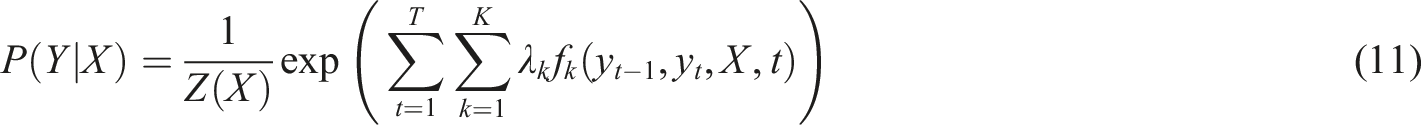
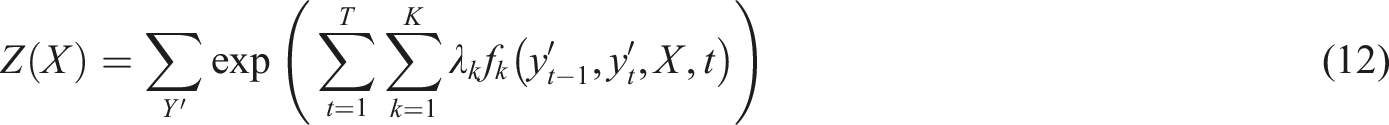
CRF is used in the sequence decoding part of legal information extraction models. In legal entity extraction tasks, adjacent labels often have strong dependency relationships. By using CRF, the model can learn the dependency relationships between these labels and output the most likely label sequence for a given input sequence based on these relationships.
Model training and evaluation
This article combines the legal information extraction and classification of BERT, Bi-LSTM, and CRF models for model training in Python environment. The BERT model uses bert-base-uncased, Bi-LSTM sets the hidden layer dimension to 128, uses bidirectional LSTM, the learning rate is set to 0.001, the batch size is 32, CRF uses a linear chain structure, and the number of iterations is set to 20. Pre-trained BERT models can be used to encode legal texts and generate contextual representations for each word. These representations are processed through the Bi-LSTM layer to extract sequence features and capture bidirectional dependencies of the text. The output of Bi-LSTM can be passed to the CRF layer for sequence annotation, and the global characteristics of the CRF layer can be utilized to optimize the label sequence. The loss function can be used for model training, and the Adam optimizer can be used for parameter updates. The model is iteratively optimized multiple times on the training set, and its performance is evaluated through the test set. The hyperparameters are tuned to improve precision, recall, and F1 score.
Experimental environment and parameter setting information.

In the task of combining BERT, Bi-LSTM, and CRF models for legal information extraction and classification, the evaluation of the model considers multiple evaluation metrics, including accuracy, precision, recall, and F1 score. These evaluation indicators are analyzed separately at the levels of entity classification and relationship classification, and detailed evaluations are conducted for different datasets to comprehensively measure the performance of the model.
Public datasets.

Information on different model structures.

Results
Results of legal information extraction
The combined application of BERT, Bi-LSTM, and CRF models constructs a structured data format by automatically identifying and extracting key information from a large number of unstructured legal documents. The advantage of legal information extraction is that it can quickly and accurately extract key information from massive unstructured legal documents, reduce manual review time, and improve work efficiency. At the same time, by constructing a structured data format, it is convenient for subsequent data analysis and legal research. By extracting legal information, the article provides basic data support for legal analysis and intelligent trials, assisting legal practitioners in quickly obtaining the necessary information, reducing the workload of manual screening, and promoting the development of automation and intelligent technology in the field of legal technology. The legal information extraction results of this method are shown in Figure 4. Results of legal information extraction.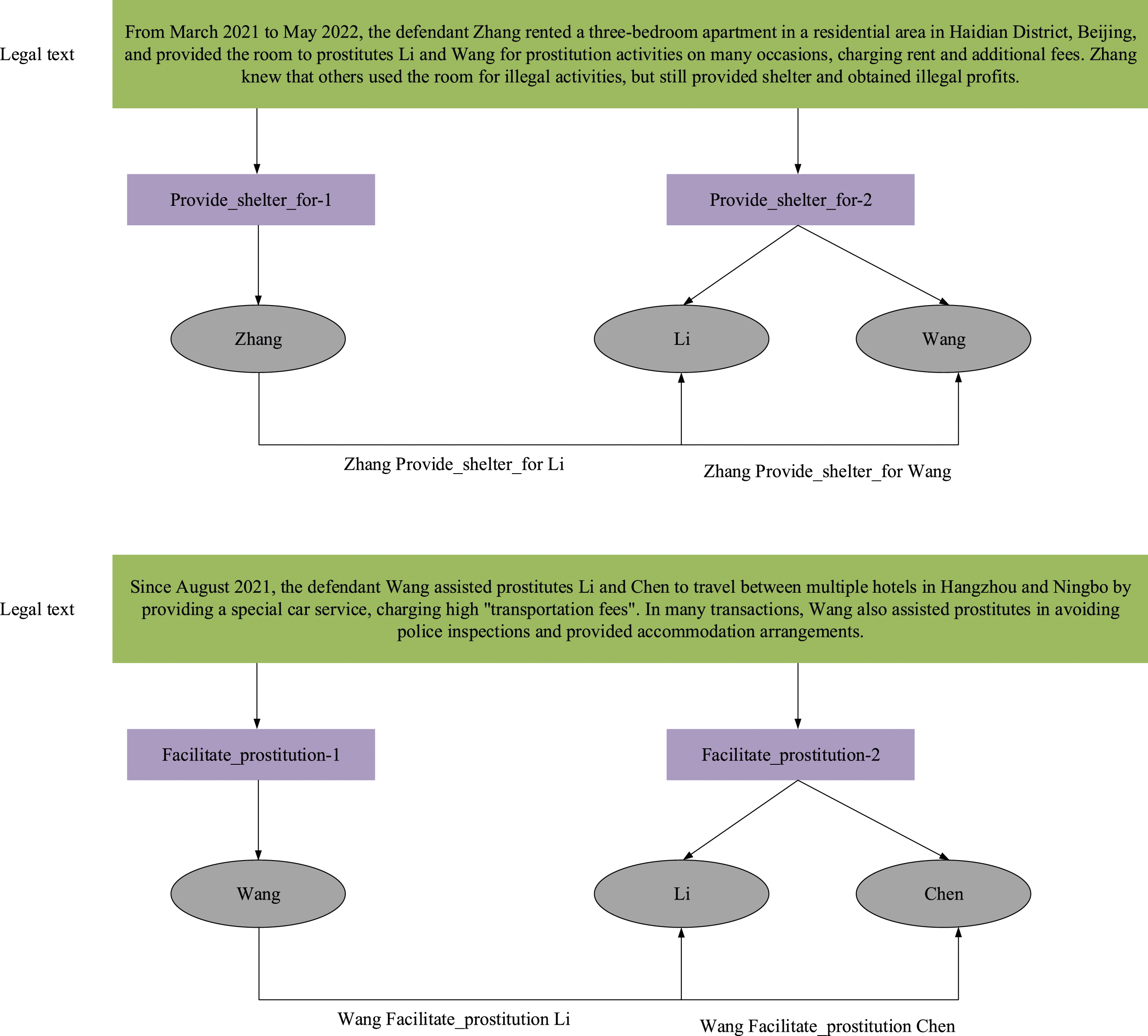
In the task of legal information extraction, this article uses the BERT-Bi-LSTM-CRF model to extract information and classify relationships from complex legal texts. Using BERT to generate context-rich word vector representations, Bi-LSTM captures the bidirectional features of the input text and finally decodes and optimizes the label sequence through the CRF layer to ensure the accuracy of entity relationships. The effect of the model can be seen through two examples. In the example of “Provide_shelter_for,” “Zhang” is accurately extracted as the head entity providing shelter, and “Li” and “Wang” are used as the tail entities, and the relationship between “Zhang Provide_shelter_for Li” and “Zhang Provide_shelter_for Wang” is established. This type of extraction can accurately reveal the subject object relationship of criminal activities in the text, that is, Zhang provided a place for Li and Wang to engage in illegal activities.
Entity classification results
Results of entity classification.
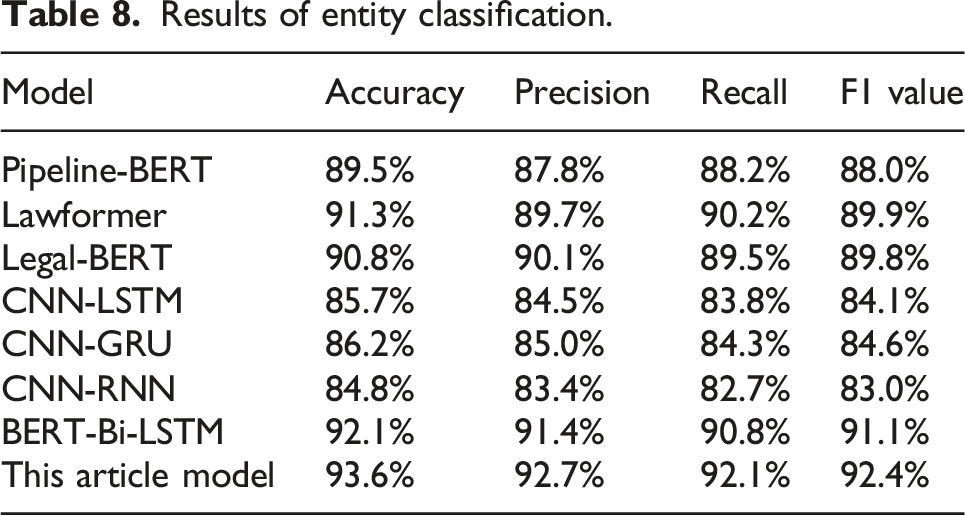
The model achieved the highest accuracy of 93.6% in legal text entity classification, outperforming BERT-Bi-LSTM (92.1%), Lawformer (91.3%), and Legal-BERT (90.8%). Traditional models like CNN-LSTM and CNN-GRU scored lower (85.7%–86.2%), indicating limitations in capturing complex legal features. The article’s model leads in precision (92.7%) and recall (92.1%), surpassing BERT-Bi-LSTM and Lawformer, demonstrating superior sensitivity, while CNN models missed important information with lower recall rates.
The F1 score, reflecting precision and recall, shows this model at 92.4%, outperforming others and indicating strong precision and coverage. BERT-Bi-LSTM follows at 91.1%, while Lawformer and Legal-BERT score 89.9% and 89.8%, respectively. Traditional CNN models fall below 85%, struggling with complex legal semantics. BERT-based models excel in legal tasks due to their contextual understanding. This model’s performance across all metrics confirms its effectiveness in legal information extraction.
Relationship classification results
Relationship classification identifies semantic links between entities, enhancing the accuracy of legal information extraction. The confusion matrix for relationship classification is shown in Figure 5. Confusion matrix for relationship classification.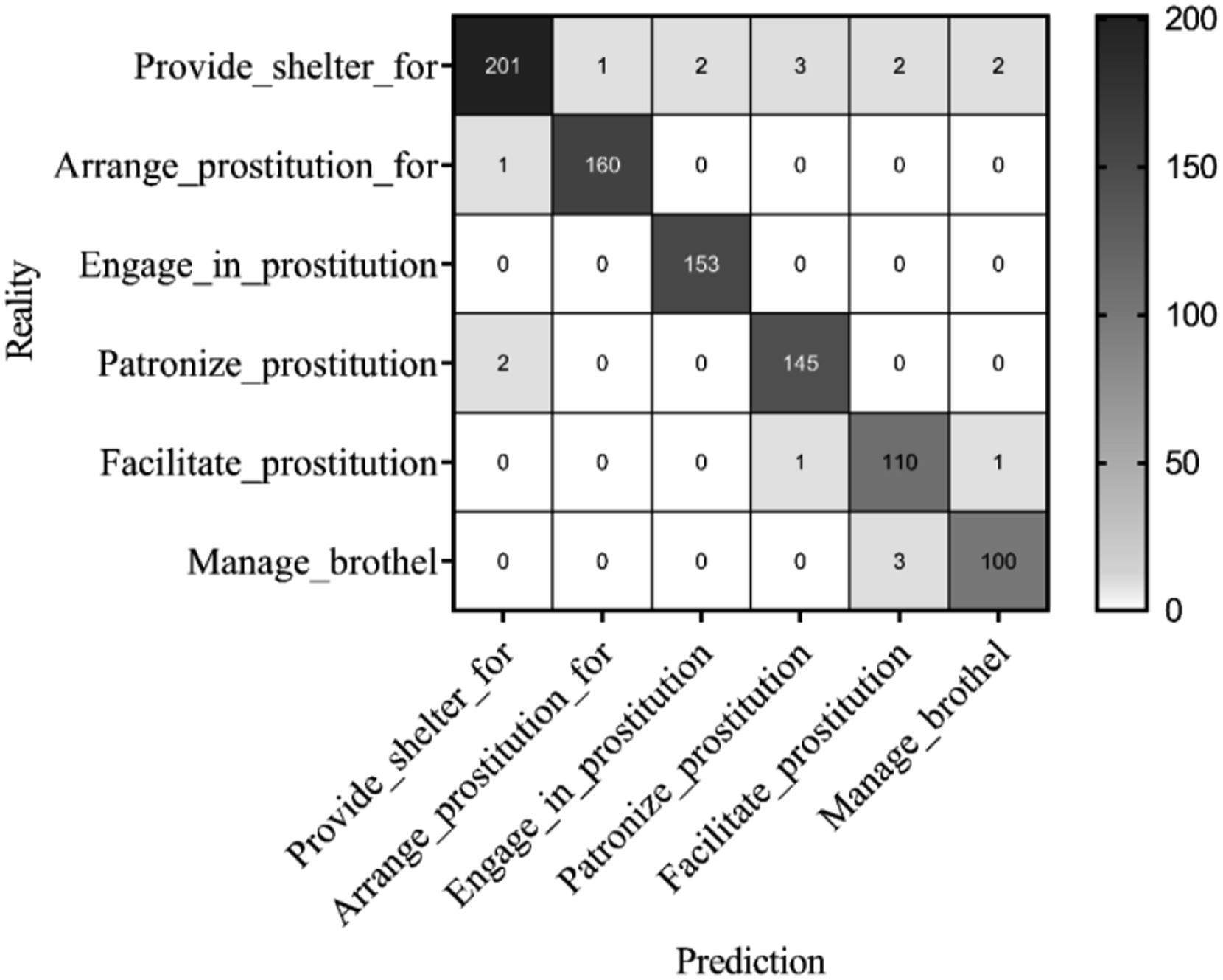
This confusion matrix shows the performance of models for different relationship classifications in legal information extraction tasks. The model in this article has a relatively accurate classification performance for most relationships, with 153 samples correctly classified in the “Engage_in_ prostitution” class and no classification errors. “Arrange_prostitution_for” also showed high classification accuracy, and only 1 sample was misclassified as “Provide_shelter_for.” The performance of the “Patronize_prostitution” category was also better. A total of 145 samples were correctly classified, and the number of misclassifications was small. Only 2 samples were misclassified as “Provide_shelter_for.” For the “Facilitate_prostitution” class, 110 samples were correctly classified, but 1 was misclassified as “Patronize_prostitution” and 1 was misclassified as “Manage_brothel.” The misclassification of the “Manage_rotate” category is slightly higher, with 3 samples misclassified as “Facilitate_destion.” The performance of the article’s model in relation classification tasks is relatively stable, especially in distinguishing between relationships such as “Engage_in_prostitution” and “Arrange_prostitution_for,” with high classification accuracy. However, there is a certain degree of confusion regarding “Provide_shelter_for.”
The relationship classification performance of different models is shown in Figure 6. Relationship classification performance of different models.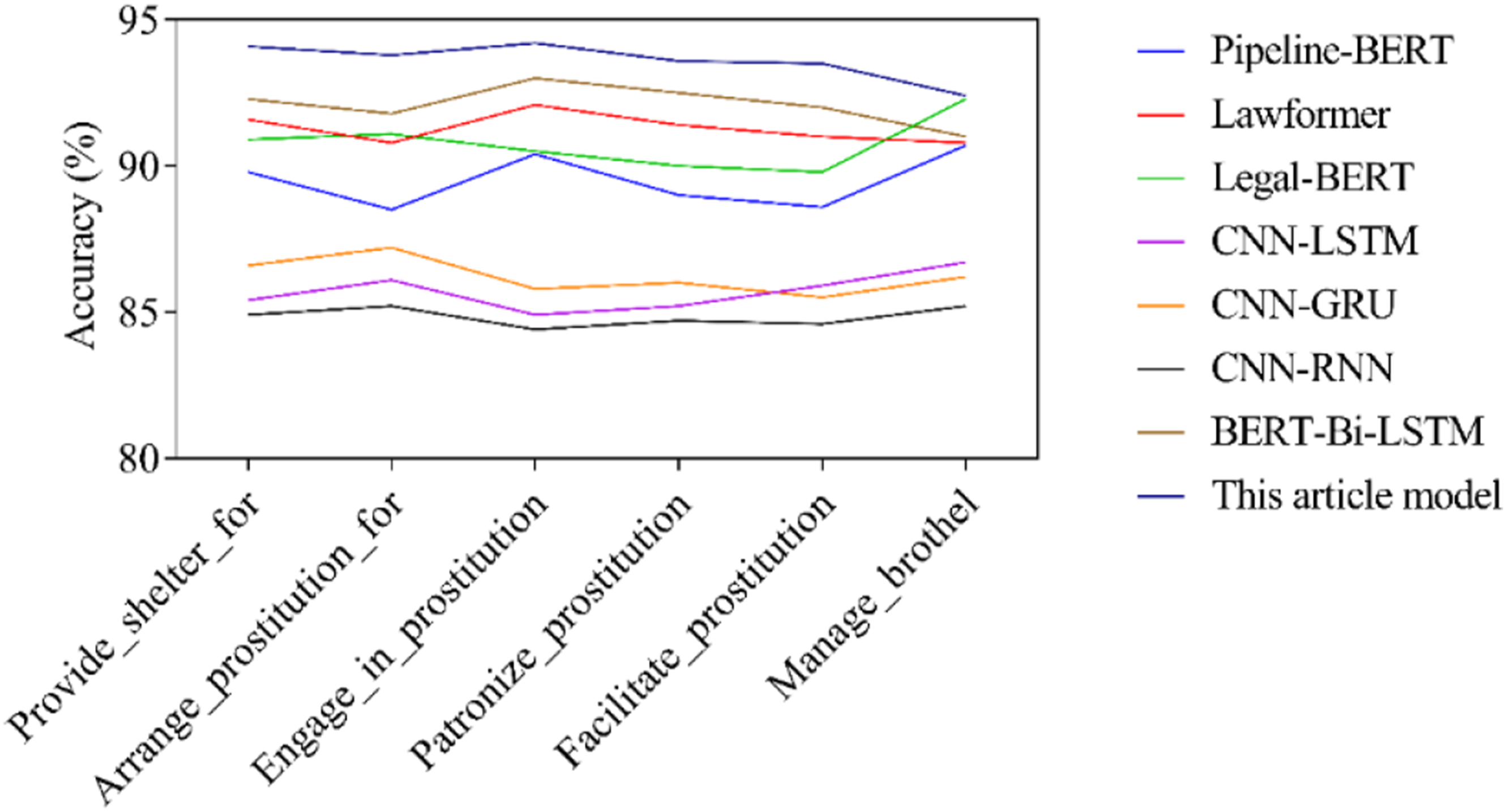
The model presented in this article outperforms other models with an average accuracy of 93.6%, particularly in relation classification tasks such as “Engage_in_prostitution” and “Provide_shelter_for,” achieving 94.2% and 94.1%, respectively. In contrast, BERT-Bi-LSTM also performs excellently, with an average accuracy of 92.1%, especially in the “Engage_in_prostitution” category, where its accuracy reaches 93.0%. These results indicate that the improved model based on BERT can better capture complex semantic and contextual information in legal texts, thereby improving the accuracy of relationship classification. The average accuracy of traditional deep learning models CNN-LSTM, CNN-GRU, and CNN-RNN is 85.7%, 86.2%, and 84.8%, respectively, which are relatively low. Especially when dealing with complex semantic structure relationship classification tasks, these models show significant shortcomings. In the “Manage_brothel” classification task, the accuracy of CNN-RNN is only 85.2%, which reflects its limitations in handling high complexity and high dependency contextual relationships. The Pipeline BERT and Lawformer models also performed well, with average accuracies of 89.5% and 91.3%, respectively. The performance advantages of these models stem from the rich semantic representation ability of their pre-trained language models on large-scale text data, as well as their good ability to capture fine-grained features during task fine-tuning. In the task of extracting and classifying legal information, this model can significantly improve the accuracy of relationship classification, providing effective technical support and practical basis for future legal text automation processing and intelligent legal analysis systems.
Stability analysis
To analyze the stability of the model in this article, different legal information disclosure datasets were selected for validation. The results of the stability analysis are shown in Figure 7. Results of stability analysis.
The model’s stability analysis across various legal datasets shows consistent performance, with accuracy fluctuating only 1.2% (94.6% for CAIL2019 to 93.4% for ECHR). Precision remains stable at 92.7%, and recall varies minimally by 0.7%. Overall, the model exhibits strong adaptability across different legal texts. Its high accuracy on CAIL2019 is due to richer training samples, while the lower accuracy on ECHR reflects the complexity of international legal provisions, underscoring the model’s robustness in legal information extraction and classification. The model in this article shows consistent performance on multiple legal datasets, highlighting its adaptability in different legal texts.
Conclusions
This article introduced a deep learning method for legal information extraction and classification, combining BERT, Bi-LSTM, and CRF models. It evaluated on public legal datasets, the model excels in entity and relationship classification, particularly in complex scenarios. By leveraging BERT’s semantic representation, Bi-LSTM’s feature extraction, and CRF’s optimization, it provides an efficient and versatile solution for legal intelligence research. This article provided technical support for applications such as automatic analysis of legal documents, case retrieval, and legal risk assessment in the judicial field, helping legal practitioners improve their work efficiency. The limitation of the research is that the model has poor adaptability to data outside the field. When processing complex sentences or non-standardized legal texts, the extraction effect is reduced, which may affect the generalization ability. The future prospect is to optimize the domain adaptation ability of the model, further improve the processing effect of complex legal texts, and explore more efficient deep learning methods to expand to more legal application scenarios.