
Abstract
Social recommendations enhance the quality of recommendations by integrating social network information. Existing methods predominantly rely on pairwise relationships to uncover potential user preferences. However, they usually overlook the exploration of higher-order user relations. Moreover, because social relation graphs often exhibit scale-free graph structures, directly embedding them in Euclidean space will lead to significant distortion. To this end, we propose a novel graph neural network framework with hypergraph and hyperbolic embedding learning, namely HMGCN. Specifically, we first construct hypergraphs over user-item interactions and social networks, and then perform graph convolution on the hypergraphs. At the same time, a multi-channel setting is employed in the convolutional network, with each channel encoding its corresponding hypergraph to capture different high-order user relation patterns. In addition, we feed the item embeddings and the obtained high-order user embeddings into a hyperbolic graph convolutional network to extract user and item representations, enabling the model to better capture the hierarchical structure of their complex relationships. Experimental results on three public datasets, namely FilmTrust, LastFM, and Yelp, demonstrate that the model achieves more comprehensive user and item representations, more accurate fitting and processing of graph data, and effectively addresses the issues of insufficient user relationship extraction and data embedding distortion in social recommendation models.
Keywords
Introduction
Recommender systems assist the purpose of assisting users in discovering their latent interests in items, thereby mitigating the issue of information overload. With the rise of social media platforms, individuals have a tendency to share their personal lives, interests, and experiences, leading to the formation of vast social networks and an abundance of user-generated content. Concurrently, some research has indicated that individuals are often influenced by the opinions and behaviors of others within their social networks. These social influences play a crucial role in individual decision-making, resulting in changes in their behavior patterns, purchase decisions, and attitudes. Based on these findings, social information has been incorporated into recommender systems to alleviate the cold-start problem. Social recommendation is a type of recommender system that uses user social relationships and behavioral data. It aims to provide personalized recommendations by considering both user-item interactions and user-user relationships within a social network. Based on this paradigm, numerous social recommendation models have been proposed [1–4], and they outperform general recommendation models in terms of performance.
Recently, Graph Neural Networks (GNNs) [5] have emerged as a popular trend in the industry. Among the various variants of GNNs, Graph Convolutional Networks (GCNs) [6] have been extensively studied and are considered one of the most important. GCNs exhibit powerful capabilities in handling graph-structured data by propagating and aggregating information on the graph to update node representation vectors, thereby capturing both structural and semantic information and generating rich node feature representations [7]. On the other hand, social networks and historical user interactions in social recommendations can be represented as graph structures, where entities such as users and items are nodes, and the user’s historical interaction records and social connections are edges in the graph. Therefore, GCNs are well-suited for modeling user social relationships and user behavior data, enabling the learning of node representations for users and items. Many social recommendation algorithms based on GCNs have been proposed accordingly [8–9], which help to comprehensively understand user interests and behavior patterns and provide more accurate recommendation results.
Although existing social recommendation models based on graph convolutional networks have achieved remarkable success in improving effectiveness, they still have certain limitations. First, most models only consider simple pair-wise relationships in social networks, ignoring the higher-order relationships that prevail among users. For example, users who are socially connected and have purchased the same item are more closely related to each other than users who are only socially connected. However, previous social recommendation models typically ignore the common purchase information of former users. Second, user-item graphs, especially large-scale social networks, typically exhibit characteristics similar to scale-free graphs, where the degrees of nodes follow a power-law distribution, i.e., most nodes have only a small number of edges, whereas a few nodes have many edges. Current social recommendation algorithms usually embed the nodes in a user’s social network in a Euclidean space. However, in Euclidean space, the number of nodes increases to the center in a polynomial manner relative to the radius. The general representation ability of its space can be summarized as the square level, and modeling user item or user user data with exponential growth and tree structure may lead to high distortion [10]. In contrast, in hypergraphs, nodes can belong to multiple hyperedges simultaneously, which means that relationships between users and interactions between users and items can be simultaneously modeled by hyperedges. In addition, user-item interaction graphs and social networks typically exhibit complex features similar to scale-free graphs, which are related to the underlying hierarchical structure. Hyperbolic space has stronger representational power (exponential) than Euclidean space, because given the same radius, hyperbolic space has a larger space and can contain more nodes, allowing for more accurate fitting of data. We hypothesize that the occurrence of these geometric properties in hypergraph and hyperbolic space may be better suited for modeling the relationships between highly connected nodes in a network and capture the underlying hierarchical properties of nodes, thereby reducing distortion. These motivations drive us to propose a new social recommendation model that aims to overcome the above problems and improve the performance of recommendation systems.
The HMGCN is proposed to address the above mentioned problems in current social recommendation models. Specifically, we adopt an advanced approach, namely hypergraph convolution, and combine it with a multi-channel setup to more comprehensively mine the higher-order connectivity information between users and items. This innovation helps to capture the complex relationships between users and items more accurately, especially in terms of co-socialization and purchase behavior. We introduce the concept of hyperbolic space by projecting items embeddings and full user embeddings into this non-Euclidean space. The advantage of this step is that it exploits the property of exponential neighborhood growth in hyperbolic space, which allows user and item embeddings to better maintain hierarchical structure and semantic relationships. Compared to the traditional Euclidean space, this embedding is more in line with the scale-free nature of social network graphs, thus reducing information distortion. In addition, our model uniquely considers hierarchical social influence in the process of aggregating neighborhood information, which allows for a more detailed differentiation of the influence of different social relationships on users and items. This point is crucial for improving the accuracy and adaptability of personalized recommendations.
The major contributions of this study can be summarized as follows:
(1) Utilize hypergraphs to model users in social networks and employ a multi-channel setting to obtain various types of high-order user relationships. In comparison to traditional graph network methods, it is more capable of comprehensively representing complex relationships between users and items, offering a greater variety of recommendation outcomes.
(2) Learning hierarchical embeddings of users and items with encoded social influence information in hyperbolic space for social recommendation, thus alleviating the distortion problem in previous Euclidean methods.
(3) Empirical studies were conducted using three public datasets: FilmTrust, LastFM, and Yelp. The experimental results validate the effectiveness of HMGCN in improving social recommendation performance.
Related work
Social recommendation
Social recommendation is a recommendation system that uses information about users’ behaviors, relationships, and interests in social networks to recommend content, products, or services to users through algorithms and models. By analyzing user interactions and information dissemination in social networks, recommendation system tries to more accurately understand the interests and needs of users, so as to provide a personalized and social recommendation experience [11]. Due to the understanding that matrix factorization (MF) [12] is effective in capturing social connections, the initial architectures of social recommender systems primarily rely on MF techniques. These MF-based social recommender systems either simultaneously factorize the matrices of ratings and social relationships or impose constraints from social connections to regulate user-item embeddings [13–16]. For example, TrustMF [15] and ContextMF [16] consider the utility of social context and mutual trust to measure the influences between users with each other, respectively. These models leverage first-order social connections to recommend, thus partially addressing the data sparsity issue.
Recent advancements in social recommendation systems have capitalized neural elements to significantly enhance recommendation accuracy [17–19]. For instance, DeepSoR integrates a multi-layer perceptron to discern users’ latent preferences from social network data, complemented by probabilistic matrix factorization [18]. Meanwhile, SAMN takes into account variations at both aspect and friend levels, employing memory networks and attention mechanisms for more effective social recommendations [16]. Latest research on social recommendation mostly employ graph convolutional networks for implementation, and Section 2.2 lists relevant studies. These social recommendation methods model user-item interactions and user-user social relationships separately, ignoring higher-order relationships between users and items.
Graph convolutional neural network for recommendation
With the rise of deep learning, many graph neural network-based recommendation models have been proposed to capture structural information related to user behavior [20–22]. Among them, GCN has been widely applied in recommender systems in recent years, resulting in significant performance improvements. For example, He et al. [23] simplified the application of GCN in recommendation fields by removing the nonlinear activation function and feature transformation module. Liao et al. [3] applied convolutional operations on both interaction and social graphs to enhance the framework’s effectiveness in handling social recommendation problems. Wu et al. [24] employed disentangled contrastive learning for knowledge transfer by learning disentangled user representations from items and social domains. Wu et al. [8] proposed the DiffNet model for the impact of users on user iteration, which solves the problem of only considering static social network relationships in previous social recommendation systems through GCN. Building upon [8], DiffNet++ [25] additionally uses higher-order information from the interaction graph to optimize user and item representations. It employs an attention mechanism to distinguish the importance of different neighbors, thus mitigating performance degradation issues. Liang et al. [26] enhances content-aware recommendation accuracy by incorporating both content-based information and user-item interactions in a dynamic graph framework. Liu et al [27] proposed a novel privacy-preserving POI recommendation model based on a simplified graph convolutional neural network and integrated the user’s privacy preferences for recommendation. [28] proposed an approach called ITGCN, which aims to synthesize the interactions between users and POIs and temporal dynamics in continuous POI recommendation.
Despite the promising performance achieved by these methods, most of them rely on conventional graph convolution approaches, wherein representation vectors are learned in Euclidean space. However, due to the polynomial capacity of Euclidean space, their capability to represent data with prevalent scale-free characteristics and tree-like structures commonly found in recommendation systems is limited.
Hyperbolic learning
User-item graphs and social networks often present characteristics similar to those of scale-free graph. These properties are related to the underlying hierarchical structure, which can be well modeled in hyperbolic space [29]. Nickel proposed the Poincaré sphere model [30] to learn the hierarchical representation of embeddings, and experimental results demonstrated that the Poincaré sphere embedding outperforms the Euclidean embedding. However, because of the numerical instability of the Poincaré sphere model, Nickel later proposed the Lorenz model [31], which is more efficient than the Poincaré sphere model for embedding.
Recent research offers insights into the application of hyperbolic geometry in social recommendation systems. Sun et al. [29] proposed a collaborative filtering method using hyperbolic geometry for recommendations, which combines user and item similarities and calculates their similarity in hyperbolic space. Vinh et al. [32] used hyperbolic geometry to model relationships between users and items, enabling personalized recommendations. Mirvakhabova et al. [33] presented a similarity measure based on hyperbolic distance and demonstrated its effectiveness in recommendation systems.
Proposed methodology
In this section, we present our designed HMGCN model, as shown in Fig. 1. Next, we present the problem formulation and detail each model component. Finally, we describe the model training process for recommendation.

The overall structure of the proposed HMGCN.
First, we present the problem definition and briefly introduce some foundational concepts of the hypergraph and Lorentz model, which are necessary for our work. We begin by plotting the mathematical symbols in the paper in a table for reading as Table 1.
Description of mathematical symbols throughout the text
Description of mathematical symbols throughout the text
The metric tensor g is defined as follows:
Each point
Where
In this section, we employ multichannel hypergraph convolution to model users, aiming to extract their higher order information. The specific implementation is described as follows:

Triangular structure in social networks. Points of the same color represent the user’s social relationship (for example: follow), while points of different colors represent the interaction between the user and the item (for example: Purchase).
In social networks, motifs refer to subgraph patterns with specific topological structures. The identification and analysis of motifs allow for a more comprehensive understanding of the intricate interconnections between nodes in social networks. Fig. 2 showcases the prevalent triangular relationship structures commonly found in social networks based on motif representations. It consists of a total of ten patterns, labeled as M1 - M10. We categorize these patterns into three groups based on their underlying semantic characteristics. The first group, comprising M1 to M7, summarizes all possible explicit triangular relationships within the social network. These relationships can be interpreted as "having common friends" and are named as "social motifs". The second group, consisting of M8 and M9, represents compound relationships in which individuals and friends make joint purchases of the same item. These relationships possess a stronger influence compared to the previous group and are named as "Joint Motifs". The third group, denoted by M10, represents users who lack explicit social connections. It is characterized by non-closed triangular structures. This group encapsulates implicit high-order social relationships, where users lack direct social links but engage in common item purchases, which is named as "Purchase Motif". Under the regulation of these three types of motifs, different hyperedges are obtained, which guide the construction of the three hypergraphs. The adjacency matrix of the hypergraph is defined as
After L layers of convolution, we combine embeddings at each layer with weighted sum to obtain user representations for each specific channel, which is expressed as
First of all, given the aligned graph of
Formally, given a user u, an item i and a social influence s, with their corresponding embeddings
Then, the user and item embeddings can be transformed into hyperbolic space through exponential mapping exp
These hyperbolic embeddings are used to initialize the GCN module for all users
The key insight of GCNs is that node representations can be updated by aggregating information from neighboring nodes. Based on the findings reported in [23], we simplify our model by excluding the feature transformation and non-linear activation function in the GCN (In section 3.2, the same two components in hypergraph convolution are also removed). This is because the benefits obtained from these two components are relatively minor in collaborative filtering (CF) tasks and may even harm recommendation performance. However, we still encounter a technical challenge because the conventional Lorentz model does not encompass certain operations, such as vector addition and multiplication, which are commonly defined in Euclidean space. Consequently, it is not feasible to directly employ the Lorentz model for the essential information propagation and aggregation operations required by the GCN in hyperbolic space. Therefore, inspired by [35], similar vectorial operations are implemented in tangent space
These transformed vectors in
We combine all intermediate layers to obtain:
The loss function used during model training is the margin ranking loss function, and its specific formula is as follows:
For each user u, we select a positive item sample i(r
ui
=1) and a negative item sample j(r
uj
=0). Where
Datasets and baselines
To evaluate the effectiveness of HMGCN, we conducted experiments on four benchmark datasets: FilmTrust, Yelp, LastFM, and Ciao. We summarize the statistics of the three datasets in Table 2.
Statistics of datasets
Statistics of datasets
To demonstrate its the effectiveness, we compared our proposed HMGCN with the following methods, including two CF models, two recommendation models based on social relationships, and four social recommendation models based on deep learning:
BPR [38]: BPR uses implicit feedback data from users and ranks items by maximum a posteriori estimation obtained from Bayesian analysis of problems to generate recommendation results.
FM [39]: FM is a machine learning algorithm based on matrix factorization, which is designed to solve the problem of feature combination in large-scale sparse matrices.
TrustMF [40]: TrustMF is a matrix factorization-based approach that maps users into two spaces and optimizes user embeddings in order to retrieve the trust matrix.
TrustSVD [16]: TrustSVD incorporates embedding vectors of friends in predicted ratings for target users based on matrix factorization.
LightGCN [17]: LightGCN retains the most important component (neighborhood aggregates) of GCNs for collaborative filtering. The embeddings of users and items are learned by linearly propagating collaborative information over the user-item bipartite graph.
SAMN [16]: It is a powerful baseline for social recommendation based on a new social attention memory network. It designs an attention-based memory module to learn user vectors and adaptively select informative friends for user modeling.
HGCF [30]: It is a collaborative filtering model that encodes higher-order neighborhood information via graph convolution.
Diffnet [8]: It is a hierarchical influence propagation structure that models how user embeddings evolve with the social diffusion process.
In order to evaluate the performance of the baseline models and the proposed HMGCN model, our experiments use Top-K recommendations with K set to {5, 10, 20, 50}. We consider two different evaluation metrics: Recall and Normalized Discounted Cumulative Gain (NDCG):
Recall@K: This metric indicates the number of items a user actually like and is correctly recalled. A higher Recall value indicates better coverage of positive examples by the model, and the formula is given as follows:
NDCG@K: This metric is a location-aware ranking metric. It considers the relevance of items to the user and ranks them accordingly in the recommendation list. A higher NDCG value indicates a more accurate recommendation, and the formula is given as follows:
For the experimental details, we randomly separate them into three parts: a training set (80%), a validation set (10%), and a test set (10%). These sets are independent of each other without any crossover. For all baseline methods, we followed the best settings in the original paper. For our model, the hyperparameters used in the training stage are obtained through the validation set, which are set as: the node embedding dimension d = 64, the batchsize is 2048, the learning rate is 0.001, and the number of layers in two GCN modules are set to L1 = 2 and L2 = 3, respectively. As for the research part of hyperparameters, this paper investigates the cases of L1 = {1, 2, 3, 4, 5}, L2 = {1, 2, 3, 4, 5} and d = {16, 32, 64, 128} respectively. We follow the settings of these models in their original paper. The implementation codes of the baselines are available at: https://github.com/OldKingIs-dead/HMGCN.
Experimental Results and Analysis
Table 3, 4, 5, and 6 report the performance comparison results. On the basis of these results, we make the following observations:
Comparision results of recall and NDCG on FilmTrust dataset
Comparision results of recall and NDCG on FilmTrust dataset
Comparision results of recall and NDCG on LastFM dataset
Comparision results of recall and NDCG on Yelp dataset
Comparision results of recall and NDCG on Ciao dataset
TrustSVD and TrustMF outperform BPR and FM at various baselines, indicating that social information helps improve recommendation performance. LightGCN, HGCF, and Diffnet outperform TrustSVD and TrustMF, demonstrating that the deep learning-based social recommendation models perform better than the other models.
Our HMGCN model achieves the best performance on all three datasets. Compared to the HMGCN model, BPR and FM models often require a substantial amount of data for training to achieve accurate recommendation outcomes. They typically treat items as independent entities, disregarding potential associations or similarities among them. Their heavy reliance on user-item interaction behaviors might constrain these models’ ability to handle sparse and long-tail data effectively. Models like TrustMF and TrustSVD, representing a category of trust-based matrix factorization models, consider auxiliary information such as user social relationships. However, their reliance on matrix factorization techniques might limit their capability to capture complex social network structures. Moreover, these models, being essentially black-box models, struggle to provide explanations for user interests or item characteristics, potentially restricting the interpretation and understanding of recommendation outcomes in certain scenarios. While SAMN introduces attention mechanisms, it necessitates more complex models and additional parameters, potentially resulting in higher training and deployment costs. Diffnet incorporates social relationships but models user-item historical interactions separately from user social networks. This approach might require larger models and more training data and might struggle to comprehensively capture users’ higher-order information. LightGCN is a lightweight graph convolutional network which focuses on user-item interaction relationships. However, it doesn’t incorporate additional auxiliary information and learns user and item representations in the traditional Euclidean space. This space, due to its polynomial expressiveness, struggles to accurately fit data inherent in recommendation systems that exhibit tree-like structures and scale-free graph properties, limiting the learned feature representation capabilities. Compared to these conventional GNN-based models, HMGCN achieves better results in terms of NDCG and recall evaluation metrics. This demonstrates that the hyperbolic space better captures hierarchical structures similar to scale-free graphs, providing more accurate embeddings. HGCF models within a hyperbolic space effectively learn hierarchical user and item features. However, they do not consider additional auxiliary information, also facing limitations in modeling complex social relationships. In comparison to HGCF, our HMGCN model attains superior results, indicating that performing multi-channel hypergraph convolution on social networks effectively models complex and higher-order social relationships among users, thereby enhancing recommendation performance.
In this section, ablation studies are conducted to further demonstrate the rationality behind the sub-components in HMGCN. To achieve this goal, we implemented three variants of HMGCN and compared them under the evaluation metric Recall@K to demonstrate the impact of each component on the overall model performance. The three variants are as follows:
HMGCN-h (Higher-order relationship modeling culled version): This variant removes the higher-order user relationship modeling component from Section 3.2, which embeds the user-item bipartite graph and the social network graph directly into a hyperbolic space and then learns the representation vectors of users and items in that space via the graph convolution module. The removal of this component deprives the model of the exploration of higher-order connectivity information, thus missing the innovative advantages of hypergraph convolution and hyperbolic space embedding. In the Ablation study, a degradation of the model’s performance was observed, highlighting the importance of higher-order relationship modeling.
HMGCN-g (hyperbolic space embedding culling version): This variant removes the hyperbolic space embedding learning component from Section 3.3 and therefore performs multi-channel hypergraph convolution operations directly in user-item bipartite graphs and social networks, but in Euclidean space. This deprives the model of the advantage of capturing exponential neighborhood growth properties in hyperbolic space and weakens the hierarchical modeling of social influence. In the Ablation study, a degradation in model performance was observed, emphasizing the importance of embedding in hyperbolic space.
HMGCN-m (multichannel setup culling version): This variant randomly removes one of the channels in the multichannel hypergraph convolution process in order to study the impact of the multichannel setup, while retaining the other two channels in order to observe changes in performance. This variant is designed to help analyze the relative contribution of the multichannel setup to model performance. If a significant performance degradation is observed in the ablation study, this will further emphasize the importance of the multi-channel setup for the overall performance of the model.
The experimental results on three datasets are shown in Fig. 3, Fig. 4 and Fig. 5.

Comparison results of recall on FilmTrust dataset.
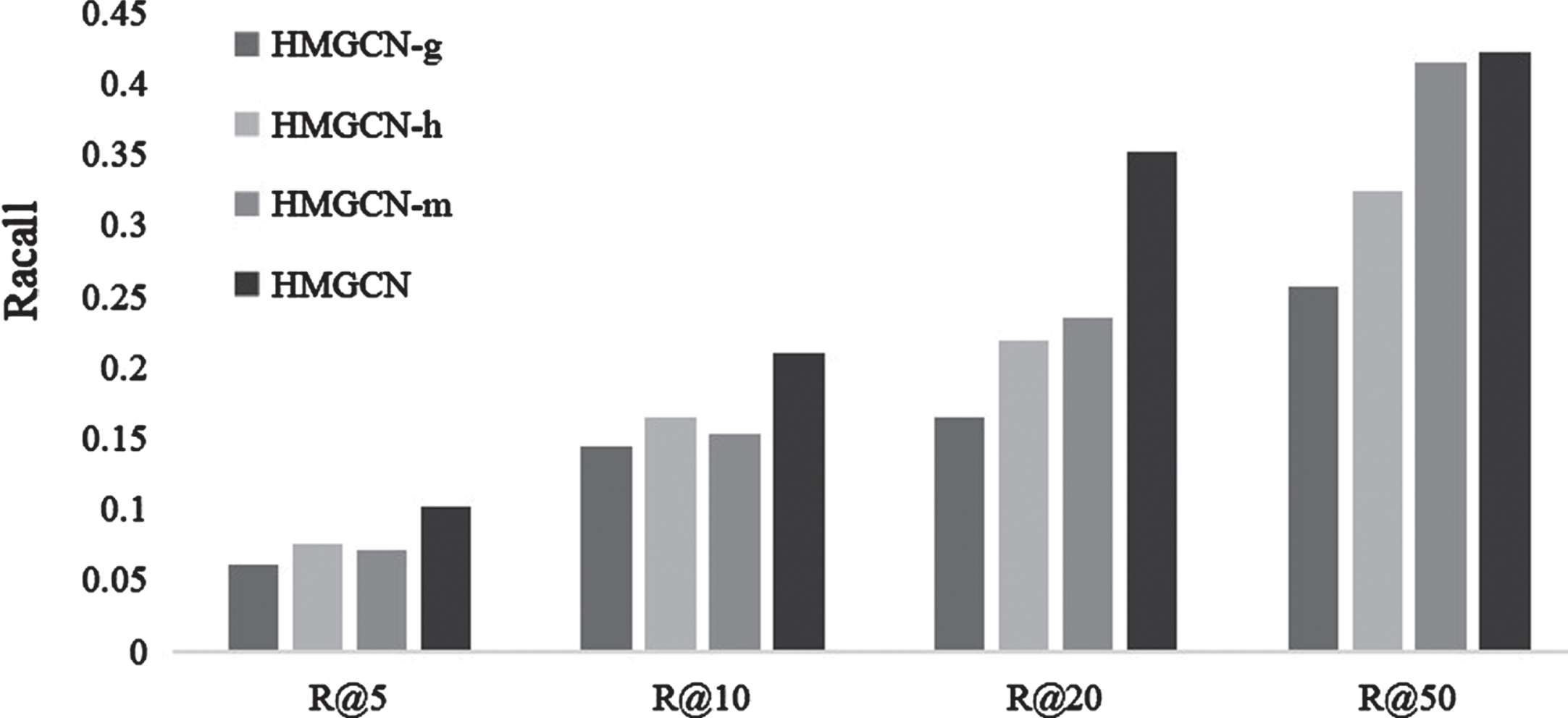
Comparison results of recall on LastFM dataset.
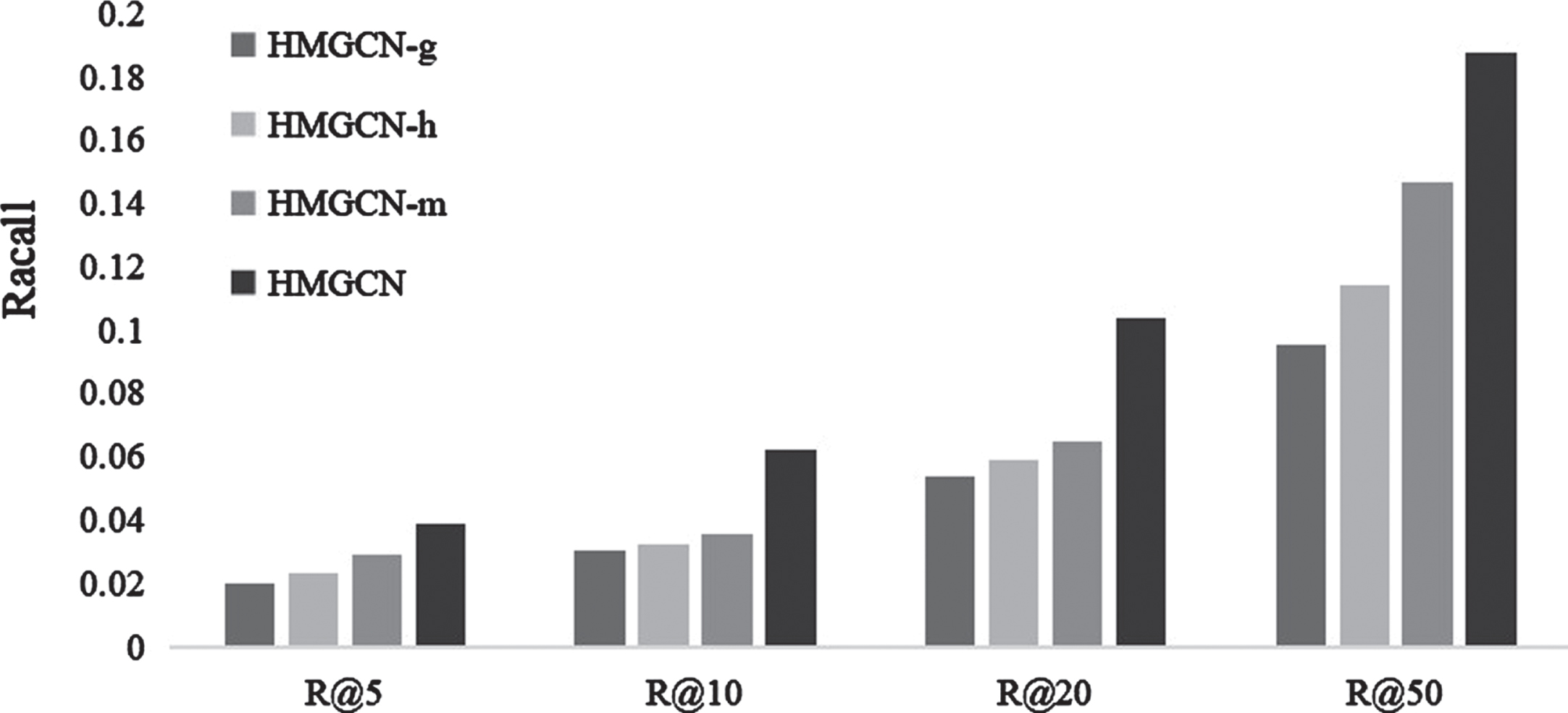
Comparison results of recall on Yelp dataset.
The results in the three figures verify the following: (1) If the high-order user relationship modeling component in HMGCN is removed, the higher-order user relationships cannot be captured. This indicates that the hyperbolic graph convolution model fails to adequately process the complex connections formed by the combination of user-item interactions and social networks, thereby impacting the final recommendation results. (2) Without hyperbolic embedding learning, scale-free graphs such as social network graphs exhibit severe distortion when embedded in Euclidean space, resulting in a significant performance drop. This highlights the necessity of the hyperbolic embedding learning component in our model. (3) For multi-channel hypergraph convolution, the configuration of multiple channels is necessary. Removing any channel affects recommendation performance.
In this section, we explore the impact of two hyper-parameters: number of layers L1 and L2 in two GCN modules, and embedding size d. The experiments were conducted using the FilmTrust and Yelp datasets.
We investigate the number of layers separately for the multichannel hypergraph convolution and hyperbolic graph convolution modules since we use GCN to learn distinct node representations in both networks. As shown in Figs. 6 and 7, the two networks achieved the best performance with two and three-layers, respectively. This is because the information propagation capability of a single layer GCN is limited, and nodes can only update their representations based on their immediate neighbors. For a complex graph structures, it may fail to fully capture the global context and intricate relationships among nodes. As the number of layers increases, the performance of the HMGCN deteriorates across all datasets, primarily due to issues such as overfitting and excessive smoothing.
An optimal embedding size d is essential. If it is too large, the recommendation framework may incur increased computational complexity and overfitting. Smaller dimensions might be more computationally efficient but could be limited in capturing complex patterns in large and intricate datasets. According to Figure 8, HMGCN achieves the best performance on both datasets when d is set to 64, and thus, we adopt this setting.
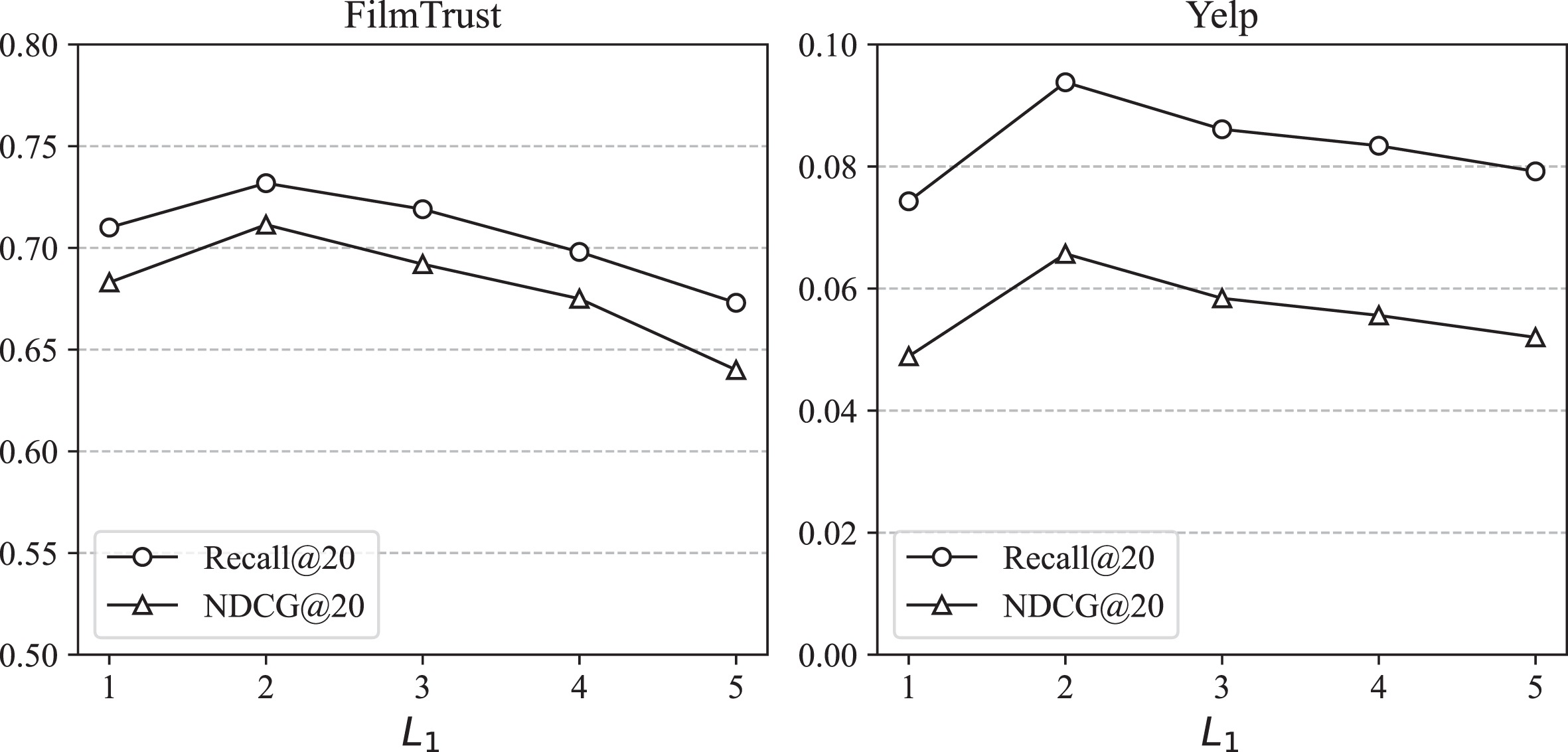
Experimental results for exploring the layer numbers of hypergraph convolutional networks.
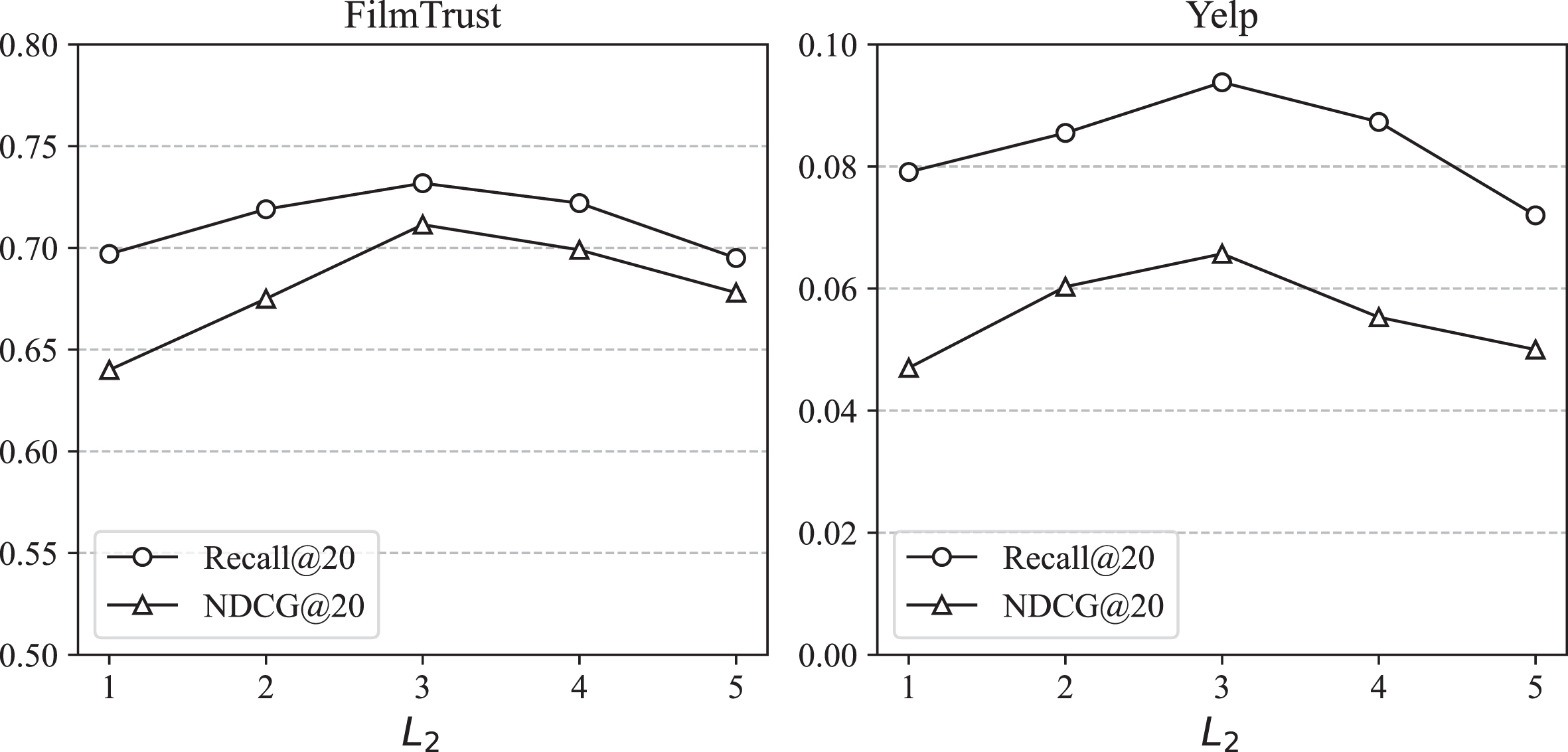
Experimental results for exploring the layer numbers of hyperbolic graph convolutional networks.
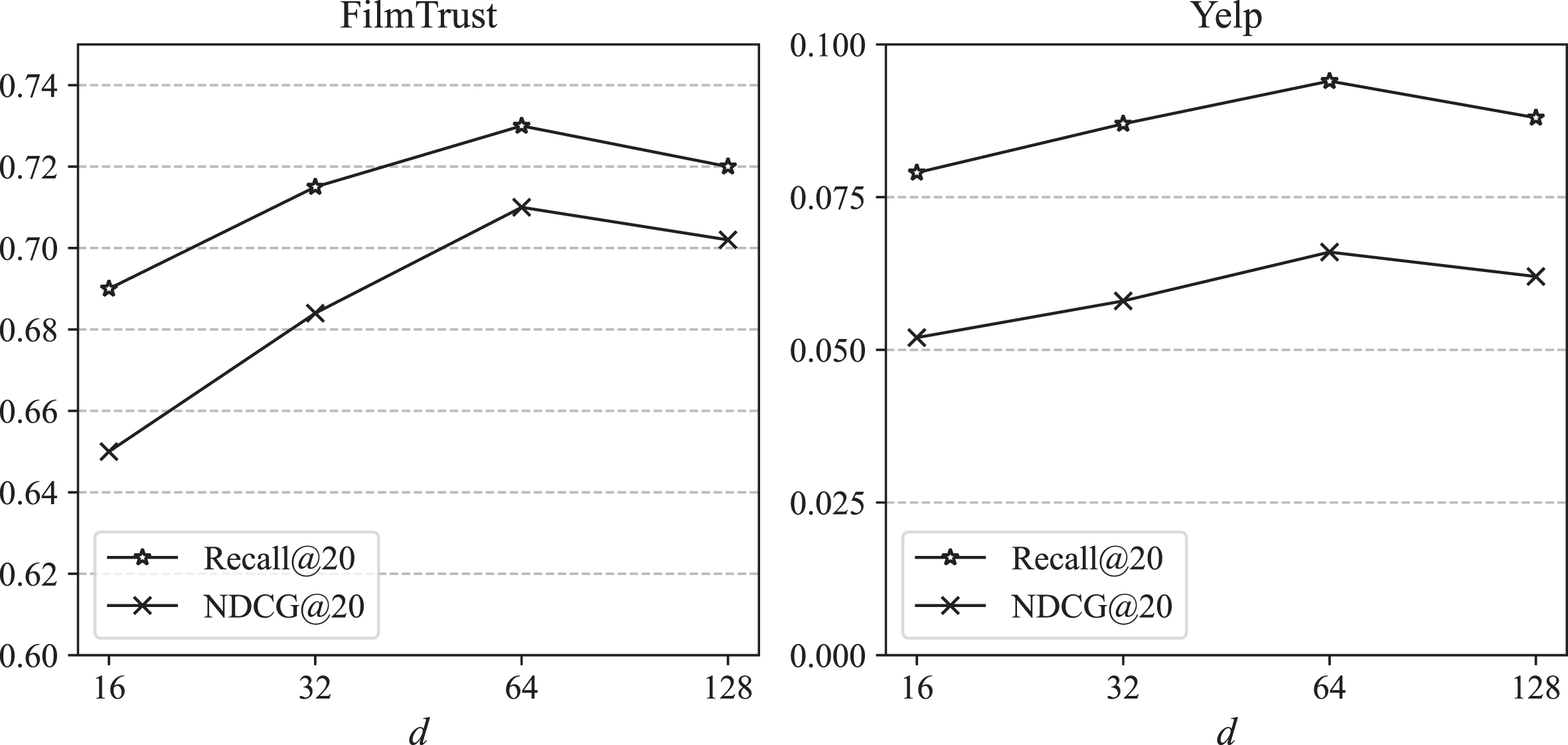
Experimental results for exploring embedding size.
In this study, we propose a novel framework called HMGCN, which combines GCN with a social network and a user-item bipartite graph. HMGCN leverages multi-channel hypergraph convolution to capture higher order user relationships from the aligned graph. Then, it transfers both the acquired user embedding with high-order information and the item embeddings, along with the encoded social influence, into hyperbolic space to capture hierarchical structures in the complex structured graph data. The experimental results demonstrate that HMGCN produces competitive performances compared with many state-of-the-art models. Currently, most social models are based on static interaction diagrams, but in real-world applications, social relationships among users are not fixed. In our future work, we aim to address the dynamic nature of social information to enhance user relationships and further improve the performance of recommendation algorithms.
Acknowledgment
This study received support from the following funding projects: Natural Science Foundation of Xinjiang Uygur Autonomous Region of China (Grant No.2023D01C17, 2022D01C692); National Natural Science Foundation of China (62262064,61862060); Education Department Project of Xinjiang Uygur Autonomous Region (XJEDU2016S035); Doctoral Research Start-up Foundation of Xinjiang University (BS150257); horizontal project named Information System for Labor Dispatch Management (202212140030).