
Abstract
Automated reading of license plate and its detection is a crucial component of the competent transportation system. Toll payment and parking management e-payment systems may benefit from this software’s features. License plate detection and identification algorithms abound, and each has its own set of strengths and weaknesses. Computer vision has advanced rapidly in terms of new breakthroughs and techniques thanks to the emergence and proliferation of deep learning principles across several branches of AI. The practice of automating the monitoring process in traffic management, parking management, and police surveillance has become much more effective thanks to the development of Automatic License Plate Recognition (ALPR). Even though license plate recognition (LPR) is a technology that is extensively utilized and has been developed, there is still a significant amount of work to be done before it can achieve its full potential. In the last several years, there have been substantial advancements in both the scientific community’s methodology and its level of efficiency. In this era of deep learning, there have been numerous developments and techniques established for LPR, and the purpose of this research is to review and examine those developments and approaches. In light of this, the authors of this study suggest a four-stage technique to automated license plate detection and identification (ALPDR), which includes, image pre-processing, license plate extraction, character segmentation, and character recognition. And the first three phases are known as “extraction,” “pre-processing,” and “segmentation,” and each of these processes has been shown to benefit from its own unique technique. In light of the fact that character recognition is an essential component of license plate identification and detection, the Convolution Neural Network (CNN), MobileNet, Inception V3, and ResNet 50 have all been put through their paces in this regard.
Keywords
Introduction
The accumulative effects of vehicle traffic in metropolitan settings have become more problematic in recent years. Congestion, rule breaking, and vehicle theft are all problems plaguing today’s transport infrastructure. Many technologies have been developed to address these issues, such as those for intelligent traffic surveillance [1-14, 15], autonomous cars [13], automated vehicle monitoring, and speed detection [16]. An integral part of today’s advanced transportation infrastructure is ALPDR, i.e., Automatic License Plate Detection and Recognition. The license plates of passing automobiles were seen by the ALPDR system, which used computer vision and AI. The first of ALPDR’s three main processes, pre-processing involves converting the captured picture from colour space to grayscale, shrinking it, and eliminating any noises that may have been introduced during the recording process. Identifying where the license plate is located in the picture of the vehicle is the second phase of license plate localization. Character recognition, the third phase, is critical for identifying vehicles by reading license plates.
License plate recognition systems use optical character recognition (OCR) technology to convert images of vehicle license plates into alphanumeric characters. These systems play a crucial role in various applications, including law enforcement, toll collection, parking management, and traffic monitoring. License Plate Recognition (LPR) in the dynamic context of Indian roads represents a formidable yet crucial challenge in the realm of computer vision. As vehicles navigate the diverse landscapes of Indian cities and highways, each bearing license plates reflecting a rich tapestry of regional languages, scripts, and designs, the task of automated recognition becomes inherently complex. The Indian Road scenario is characterized by a myriad of factors that intensify the challenges associated with LPR. Firstly, the vast linguistic diversity of the country is mirrored on its license plates, where various scripts coexist. This demands a recognition system that is not only adept at deciphering the conventional Latin alphabet but also capable of handling scripts such as Devanagari, Tamil, Bengali, and more. Moreover, the variable environmental conditions on Indian roads add an extra layer of intricacy. From glaring sunlight to heavy monsoon rains, the lighting conditions are highly dynamic. Computer vision systems must contend with these variations to ensure robust and reliable performance. Additionally, the bustling and often chaotic traffic scenarios on Indian roads introduce complexities such as occlusions, varying distances, and diverse vehicle orientations, further challenging the accuracy of license plate recognition. In the realm of computer vision tasked with LPR, the issues are compounded by the need for real-time processing. The rapid flow of traffic demands swift and accurate recognition to contribute to tasks such as traffic management, law enforcement, and overall road safety. Addressing these challenges requires an innovative and adaptive approach. Image processing techniques must be tailored to handle the diverse visual conditions on Indian roads, encompassing pre-processing steps that enhance contrast, handle reflections, and adapt to varying lighting. The incorporation of advanced technologies such as Convolutional Neural Networks (CNNs) and their applications such as object detection, optimization, quality of the images, autonomous driving and traffic monitoring systems [25-33], specifically, transfer learning becomes pivotal. Transfer learning allows models to leverage knowledge gained from broader contexts, making them more resilient and versatile in adapting to the unique nuances of Indian license plates.
Indian license plates come in various formats, with differences in fonts, colors, and designs across states. Some vehicles may not even have standard plates, posing a challenge for recognition algorithms. Likewise, the Indian roads are often congested with vehicles of different shapes and sizes. The presence of bikes, autorickshaws, and pedestrians adds complexity to the task of isolating and recognizing license plates. Similarly, the lighting conditions can vary significantly, from well-lit urban areas to poorly lit rural roads. Adapting to these variations is essential for accurate license plate recognition. Apart from these issues the vehicles in India are frequently parked haphazardly, making it difficult for license plate recognition systems to capture clear and consistent images. Considering the weather conditions, including heavy rains and fog. Robust license plate recognition systems must perform well under these challenging circumstances. Many systems for automated license plate identification and detection have limits and only provide partial satisfaction in some cases, despite the fact that significant study has been done on the topic. General limitations include lighting, noise, blur, distortion, tilted images, and more. Different cars, states, and nations use a wide range of typeface styles, and these styles, in turn, are reflected in a wide range of sizes and colors for each sign [33-49].
Automated License Plate Detection and Identification (ALPDR) is a sophisticated process tailored to the intricacies of India’s dynamic road environment. The journey begins with Image Pre-processing, a crucial step to refine raw images captured in diverse conditions. Noise reduction techniques, like blurring or filtering, are employed to enhance image clarity, while contrast adjustments address challenges posed by varying lighting scenarios. This prepares the image for the next stage. License Plate Extraction is the system’s ability to pinpoint potential license plate regions amid the complexity of Indian roads identifying regions that might contain license plates. In crowded scenes, this step is particularly challenging as it involves distinguishing between multiple vehicles. The subsequent selection of a Region of Interest (ROI) further refines the focus, setting the stage for detailed analysis. Moreover, the character segmentation addresses the intricacies of isolating individual characters on a license plate. Refining the bounding box around the license plate, especially in tightly packed scenarios, enhances accuracy. Segmentation techniques, like contour or connected component analysis, then dissect the characters for further scrutiny. The final phase will consider the character recognition, a task accomplished through Optical Character Recognition (OCR) algorithms. These algorithms analyze the segmented characters, converting them into machine-readable text. To accommodate the diverse designs of license plates across Indian states, the system must be adaptable to different fonts, styles, and languages [50-62].
Throughout this ALPDR process, challenges abound. Variability in license plate designs necessitates training on a comprehensive dataset reflecting the diversity of Indian plates. Real-time processing demands optimization and potentially parallel processing techniques for efficiency. Environmental adaptability is essential to handle the gamut of conditions, from varying lighting to inclement weather. Moreover, seamless integration with existing surveillance and traffic management systems requires the development of robust APIs and communication protocols. In navigating these challenges, ALPDR emerges as a crucial technology, enhancing efficiency and accuracy in license plate recognition on India’s dynamic roads.
The acquisition of a picture of the vehicle, the extraction of the license plate (LP), the preprocessing of the image of vehicle, next license plate characters were broken down into their component parts, and finally the identification of the characters are all components of the architecture that has been put forward for ALPDR. License plate data extraction is a time-consuming and sometimes inaccurate process that has a direct bearing on the success of subsequent phases. That’s why it’s crucial to find answers in settings where there’s enough of light and where there aren’t any distracting visual distractions. This work proposes and implements the unique ALPDR system, and it compares those efforts to others that have been made to recognize characters from license plates.
The distinctive contribution of for the proposed work lies in its innovative fusion of image processing techniques and a transfer learning scheme. Image processing serves as the initial layer of innovation, where the researchers likely implemented specialized algorithms to preprocess and enhance the raw input images. This step is crucial for mitigating challenges posed by diverse environmental conditions on Indian roads, such as variations in lighting, weather, and plate orientations. The integration of transfer learning further amplifies the novelty of the approach. By leveraging a pre-trained CNN model on a general image recognition task, the researchers capitalize on a wealth of knowledge acquired from diverse visual data. This pre-training phase imparts the model with a foundational understanding of generic features and patterns.
The subsequent fine-tuning using a dataset specifically tailored for Indian vehicle registration plates represents a key innovation. This dual-step process not only accelerates the adaptation of the model to the intricacies of Indian plates but also enhances its ability to discern the unique characteristics of regional languages, scripts, and designs. Using the impressive operational schemes of deep neural networks, the authors have demonstrated that the desired outcome can be accomplished in variety of applications [46-48]. The synergy between image processing and transfer learning brings a holistic solution to the challenges inherent in recognizing Indian number plates. The image processing stage refines the input data, while transfer learning equips the model with a versatile and context-aware understanding. This combination enhances the overall accuracy, robustness, and efficiency of the system, making it adept at handling the complexities of Indian roads and vehicle registration plate variations. In essence, the novelty of this work lies in its thoughtful integration of image processing techniques tailored for the Indian context and a transfer learning scheme that harnesses the power of pre-existing knowledge to address the unique challenges in vehicle registration plate detection and recognition. This approach positions the research at the forefront of advancements in computer vision, particularly in the domain of specialized applications for diverse and dynamic real-world scenarios.
We have compiled two datasets, one for character recognition and one for license plate extraction. The following are the primary contributions of this paper: To build an end-to-end learning framework within the CNN model that jointly optimizes license plate extraction and character recognition. This holistic approach contributes to improved overall system performance by considering the interdependencies between these tasks. To improve and develop a robust character recognition model capable of effectively handling different styles of the English languages. It also ensures the model’s adaptability to diverse linguistic characteristics, demonstrating its versatility across various writing styles. To conduct a comprehensive benchmarking study using diverse datasets that represent challenging scenarios commonly encountered in real-world applications. It provides a thorough analysis of the model’s performance, highlighting its strengths and areas for improvement under various conditions.
The rest of the article are organized as below: Section 2 discusses the literature review, Section 3 details the proposed technique with equations and diagrams, Section 4 analyses the implementation results and discusses the suggested algorithm, and Section 5 provides a conclusion and lists the sources used.
Literature survey
For the purpose of identifying and recognizing number plates, a number of different frameworks, including diverse techniques to image processing and AI, have been offered. X. Ascar et al. [1] has put forth a technique for identifying license plates that made use of both the kernel density function and binary methods. We were able to determine the precise location of the license plate by binary multiplication by the value in that it had when it was first added to the photo being multiplied. The binary value that was obtained by filtering the picture has been employed in the programs that came after. Ravi Kiran et al. [2] provided a strategy based on image processing for identifying and distinguishing license plates based in Indian in tough environments such as those containing noise and unique viewing angles. During the pre-processing stage, a number of techniques were used. During the text recognition stage of their segmentation approach, they made use of contours and the K-nearest neighbor technique. Hanit Karwal et al. [3] have presented an alternative approach for reading Indian license plates. Both the character position identification and the scaling issues are dealt with. Moreover, various significant assessment measures are available that use deep learning mechanisms in different application areas [47].
Fei Xie et al. [4] has proposed a technique for the identification of license plates and character recognition that makes use of a hybrid model that consists of a potent feature extraction approach and a Back-Propagation Neural Network (BPNN) classifier. This method employs a hybrid model to perform the tasks. The author asserts that their technique can function in low-light conditions and difficult environments. After the vehicle’s picture has been preprocessed to improve its clarity, a feature extraction model has been developed, and a backpropagation neural network model has been used to recognize the license plate. Simmani et al. [5] propose a framework in which the transfor technique is used with two-dimensional wavelet for the purpose of extracting vertical edges from the input picture. This is done in light of the fact that it is known that the number plate is easier to read because it has many vertical edges. The CNN classifier is used to accomplish the task of recognizing the characters that are printed on the vehicle’s license plate. The author claims that the approach they have proposed may correct a number of issues related to the detection of number plates. Sathya et al. [6] developed the capsule network architecture for reading license plates in blood vessels. The author asserts that his framework is reliable and accurate regardless of the license plate’s initial position, scale, rotation, or flip. The segmentation capabilities of the capsule network architecture were highlighted as important to the success of this framework. Finding the license plate requires the system to be trained and recognized. Swati Jagtap [7] has developed a system that uses license plate checks against a database of permitted cars. The histogram of directed gradient method has been used here for feature extraction. How well this structure works may be seen in the total number of automobiles found. Tejas K et al. [8] suggested a framework for automated license plate identification that employs morphological operations for segmentation and the Sobel edge detection technique for identifying license plate regions. The vehicle’s database is regularly updated via the IoT. Priyanka et al. [9] demonstrated the method for identifying characters and locating license plates in spite of difficulties such as illumination and tilt. It can take a colour video or photo and convert it to a black and white one. Finally, we have the technology to accurately identify every letter, number, and number plate. Young Jung et al. [10] a technique for the identification of license plates was developed in which a colour picture (RGB) is first transformed to a grayscale image, and then the grayscale image is binarized into a black-and-white image. This not only makes it possible to localize the license plate, but it also makes character segmentation much easier. According to the author, several preprocessing processes are skipped, including noise filtering, histogram equalization, contrast enhancement, and a few others. To deal with the dynamic environmental conditions for license plate and vehicle detection, the authors have proposed a significant feature extraction capability enabled deep learning-based model [39, 40] whose performance was found promising. Anci Manon et al. [11] developed a method for automatically identifying vehicle license plates that can read the plates of passing cars. This method may be used to identify vehicles that have broken traffic laws, such as those pertaining to speeding or disregarding traffic signals, and can also aid in the search for stolen vehicles. Shobayo et al. [12] presented an Internet of Things (IoT) based car number plate identification system with a high-resolution camera for capturing images of number plates and sophisticated image processing algorithms for pinpointing, segmenting, and detecting vehicle numbers. OpenCV, along with other Internet of Things–related hardware is used for implementation. Similarly, the techniques of morphological operations, optical character recognition, implementation of CNN, and object detection techniques have been also applied and obtained a good performance [35-38].
For the proposed automated license plate identification and detection system, the stages of license plate photo preprocessing, character segmentation, and character recognition are all suggested to be included. Each stage requires a different innovative approach and methodology that has been used to recognize characters to this point. Results from implementing the suggested CNN approach and comparing it to other character recognition strategies have been compared.
Proposed algorithm
License plate (Region-of-Interest) Extraction is the first step in number plate identification. Next comes Pre-processing of the recovered Character Segmentation, ROIs, then and lastly identification of the characters on the number plate. Figure 1 provides a full explanation of each stage. The methods used at each step are also detailed below.
A step wise summary for the proposed algorithm along with the additional micro-operations is hereby given below:
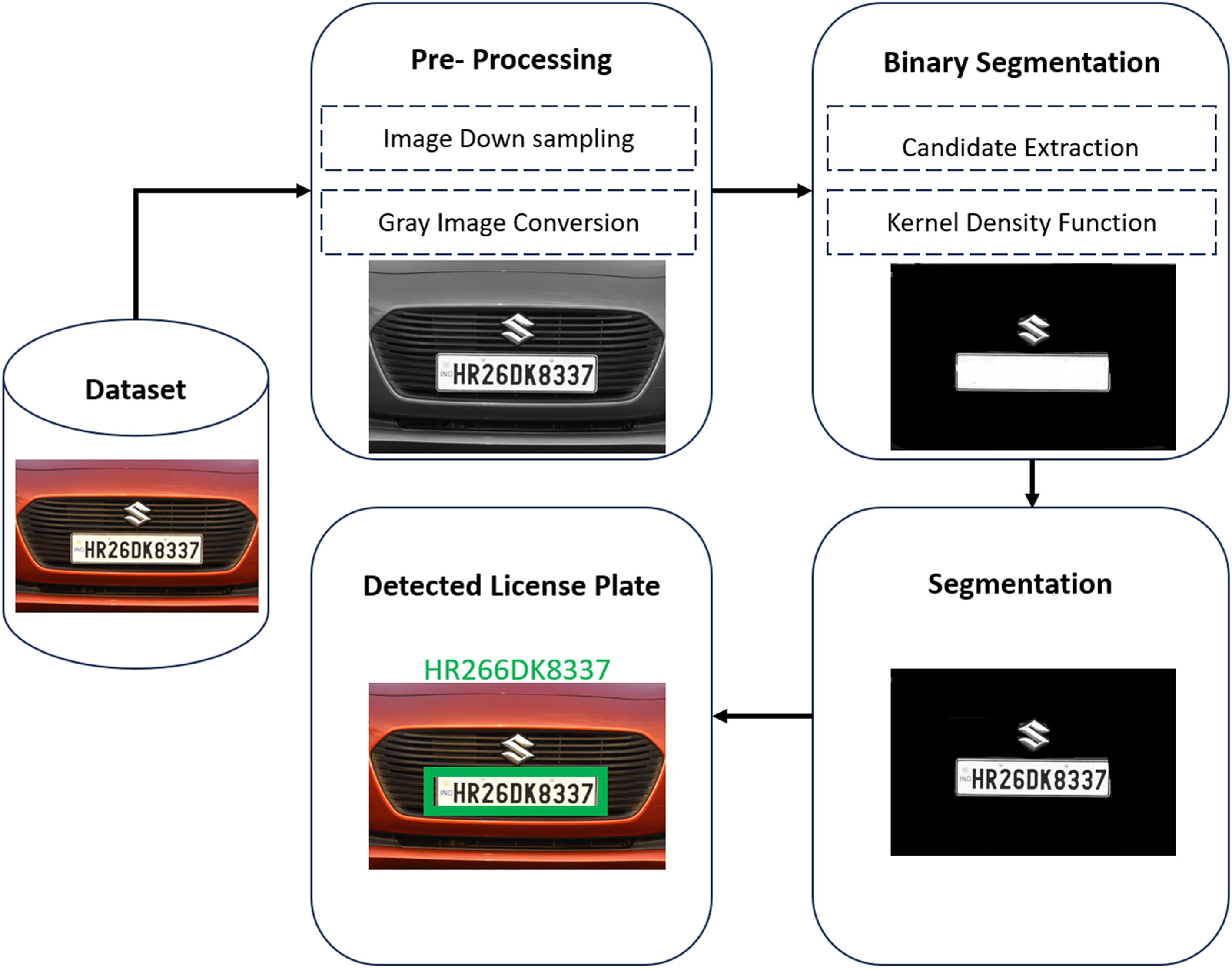
Proposed workflow for license plate recognition system.
In order to extract license plates, a pre-trained Haar Cascade Classifier has been included into our system. Images and videos may have objects and faces detected with the help of the Haar Cascade Classifier, which is based on the Haar Cascade object recognition technique. The concept of features is central to this work. It is the cornerstone of the Haar-like features technique for object identification. The cascade classifier in Haar cascade is trained with a large collection of examples of both good and bad pictures. Cascade-Classifier was trained using our Indian license plate dataset and the Cascade-Trainer-GUI. To further refine the classifier’s prediction, we additionally used a dataset of 3000 negative photos. We put the training through 10 rounds of testing. At last, an XML file with weights was produced. The picture characteristics are stored in an XML file and used as the foundation for the algorithm [17]. Our cascade classifier does an excellent job of separating license plates throughout the extraction phase. Positive images –For our classifier to succeed, a picture must first be labelled as a “positive image.” Our data collection included 1100 upbeat pictures. Negative Images –For our purposes, any random photos that are useless because they do not include the item we want our classifier to recognize are considered negative images. Our data collection includes 3000 photographs taken in negative.
Pre-processing of image
Following the recovery of license plate in image processing, next steps will need to be completed in order to filter out any undesirable noise [18].
Image transformation
In this case, the picture gets changed to a black-and-white one. This is a very typical approach among the several that exist [19]. As indicated in Equation 1, it averages across all possible combinations of the three colour components.
In thresholding, a grayscale or colour picture is transformed into a binary one. We have used two distinct thresholding strategies. When applied to a grayscale picture, the threshold function converts it to a binary one, where each pixel’s value is either 0 or 1. Black is represented by a number of 0 and white by a value of 1. The threshold, whose value is in the range of 0 to 255, accomplishes this. Here, a threshold value of 200 is used, which implies that all pixels with a value more than 200 will be converted to binary value 1, while all pixels with a value less than 200 will be converted to binary value 0 [20].
Simple Thresholding
In the most fundamental kind of thresholding, each and every pixel receives the same threshold value. According to Equation 2, the value of the pixel is reset to 0 if its intensity value is lower than the threshold that has been specified.
It does this by iteratively determining the amount of increase for the pixels positioned on either side of the estimate, i.e., the background and foreground pixels, respectively, using the total threshold estimate as a starting point. The goal is to get a threshold estimate under conditions when the total of foreground and background growth is minimal. As shown in Equation 3, the method iteratively determines a threshold value ‘t’ that minimizes intra-class (within-class) variance.
It starts with the calculation of the histogram of the image, i.e., the frequency of occurrence of each intensity level. Once the optimal threshold is found, all pixels with intensity values below this threshold are assigned to the background, and those above are assigned to the foreground. It is worth noting that the parameter P(i) indicates Probability of occurrence of intensity level i in the image. Similarly, μ1t indicates the mean intensity of pixels in the background and μ2t indicates the mean intensity of pixels in the foreground under the class variance of the parameters
By determining an optimal threshold that maximizes the variance between object and background intensities, we can effectively isolate structures of interest, aiding in the diagnosis and analysis process. This not only enhances the efficiency of our image processing pipeline but also ensures a more accurate and reproducible segmentation result. Otsu’s thresholding has proven to be a robust and adaptive solution, particularly in scenarios where the image’s intensity distribution may vary, and manual thresholding might be impractical. Its ability to dynamically determine the optimal threshold based on the image’s characteristics aligns well with the demands of our application, contributing significantly to the success of our image analysis workflows.
Morphological processes are utilized for the aim of filling images. A subset of image processing, known as “Morphological Operations,” modifies digital photos in accordance with the shapes included within them. Each pixel’s value is related to the values of the surrounding pixels in these processes. The success of a morphological function for a given input picture form depends on the selection of the shape and size of the neighborhood pixels. Applying any of the two fundamental morphological operations on a binary picture yields different outcomes [21].
Erosion
Erosion involves wiping off the border pixels. Since it reduces the picture’s borders, it also reduces the amount of white in the image.
Dilation
It’s like erosion, but in reverse. The white space around a picture is expanded during this procedure. It’s purpose is to fix things by putting them back together again.
Character segmentation
To prepare the extracted number plate for the next step, preprocessing operations are conducted, followed by segmenting the characters from the image of the license plate, as shown in Fig. 2.
Segmentation process.
As was previously shown, number plate dimensions and character bounding boxes are compared to produce a segmentation. The license plate is acceptable if and only if the bounding box of characters fits inside the license plate’s specified size. An array contains the range of valid dimensions. The license plate’s characters are obtained by iteratively scanning each of its pixels and saving the results in an array. The output then displays the reversed characters.
After going through the process of character segmentation, we will now concentrate on character recognition. Character recognition, also known as the process of extracting characters and numbers from the region of the license plate that has been identified, is an essential stage in the process of developing an Automatic License plate Recognition and Detection system. As a result, during the character recognition phase, we proposed using a total of four models, which included CNN, MobileNet, Inception V3, and ResNet50. Below, an in-depth discussion is provided for each of the three ways of character recognition.
CNN model
Deep learning architectures known as convolutional neural networks employ input photographs to discriminate between images that are otherwise quite similar. This is accomplished by assigning biases and weights to objects in the image. When compared to other classification techniques, CNN models need less preprocessing. A general deep learning model requires three distinct sorts of layers [22].
Convolutional neural networks typically consist of the following layers:
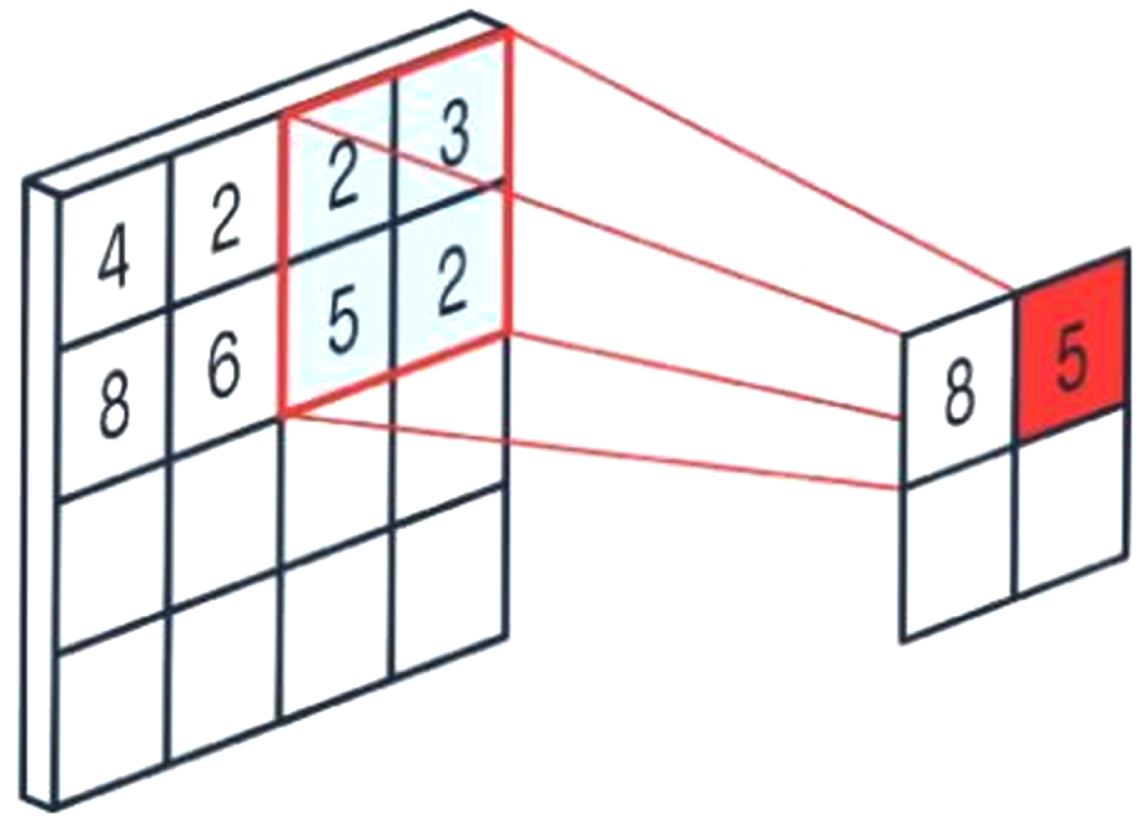
Max pooling layer.
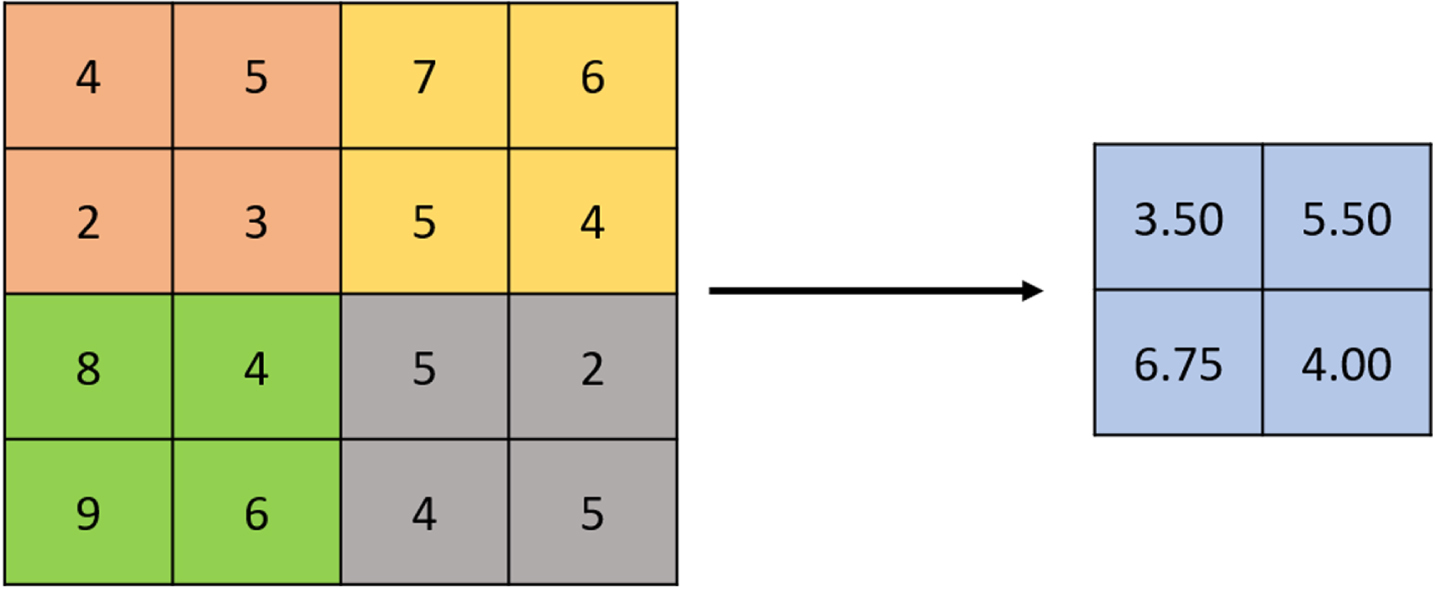
Average pooling layer.
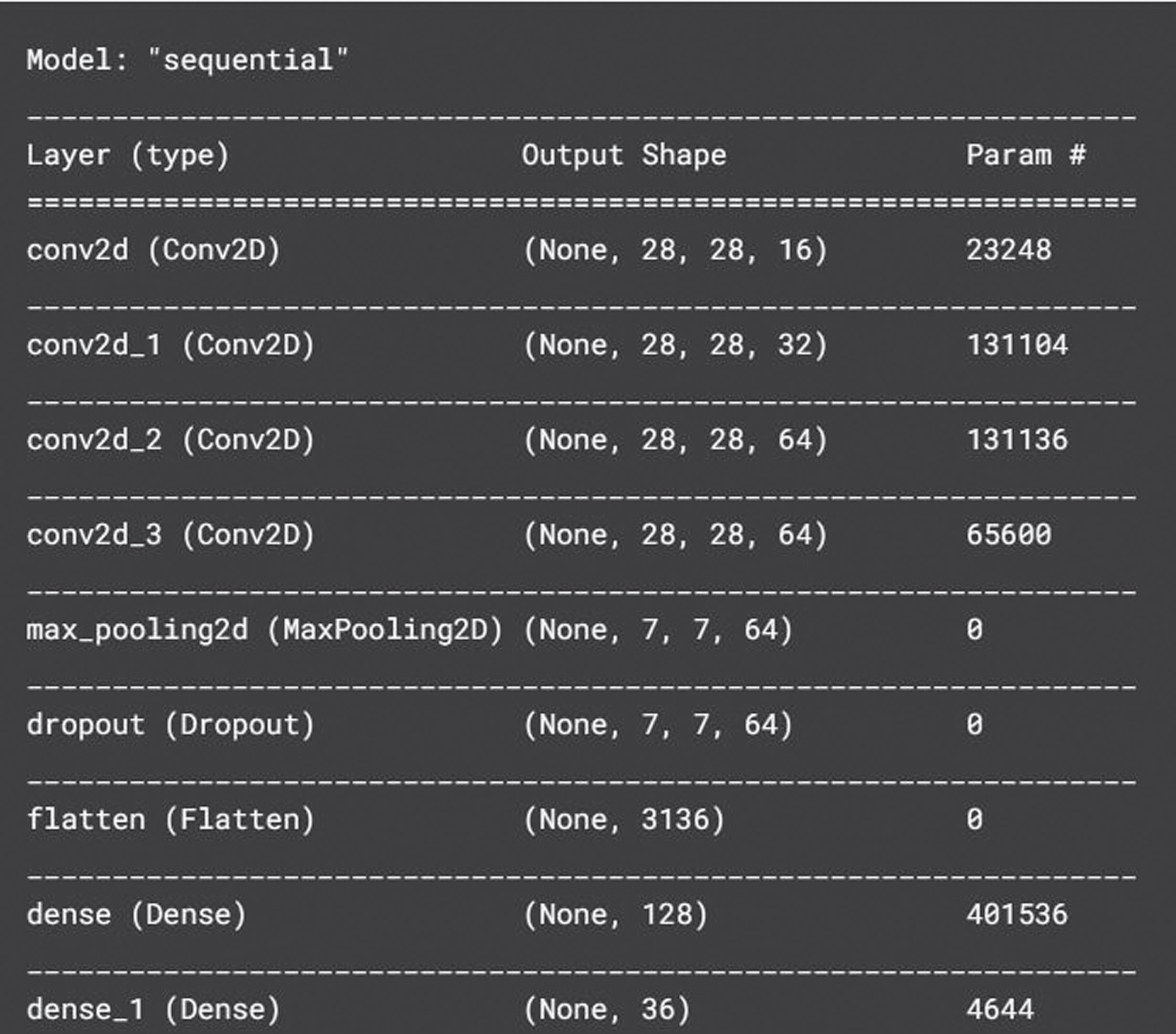
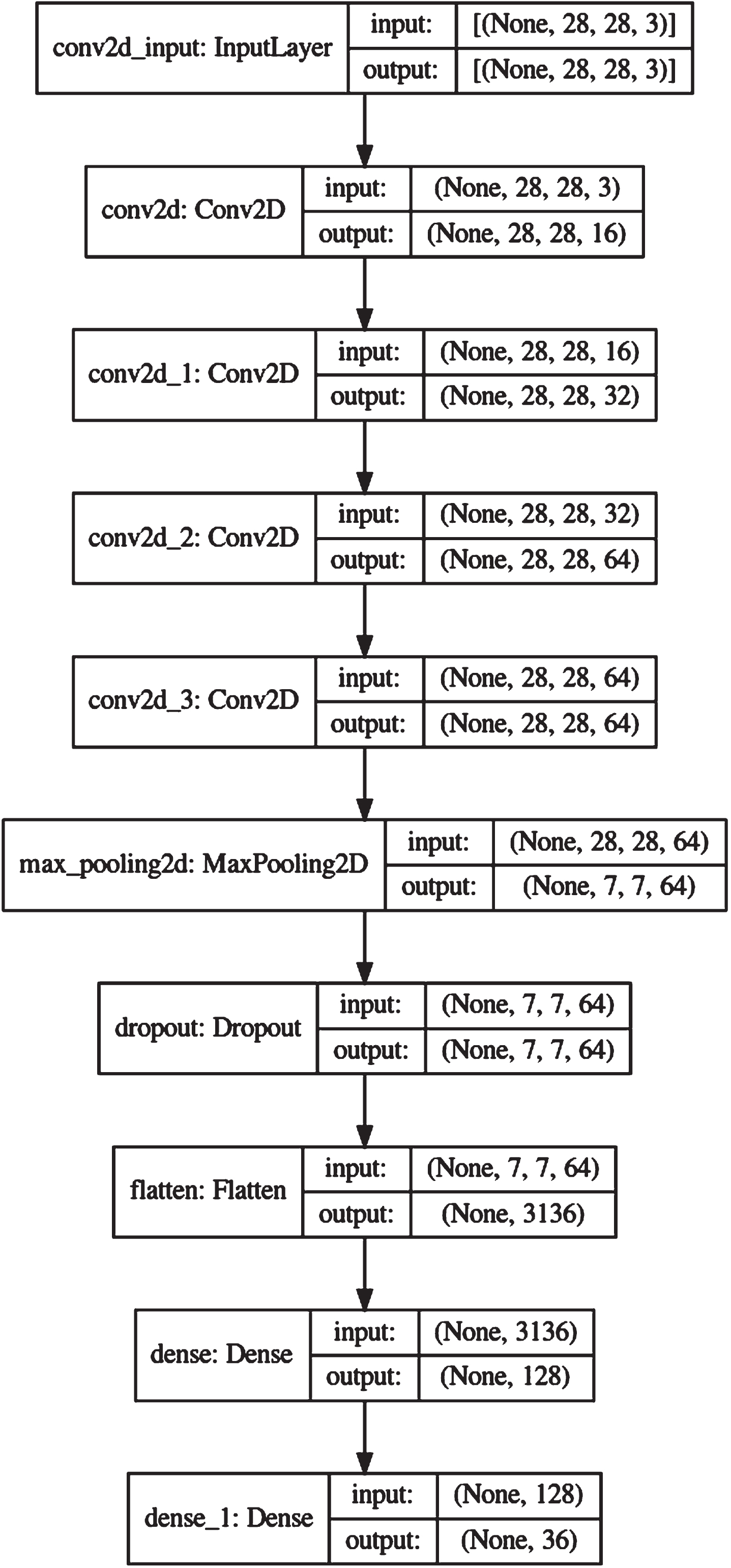
Model summary.
To begin, a sequential object must be made. Input tensor size (28,28) and 16 output filters should be added to the first convolutional layer. The ReLU Activation Function is widely utilised in deep learning models. Equation 5 is a mathematical version of this, while Fig. 6 is a graphical representation.
As stated before, add three more conv2d levels after the first one. After the last conv2d layer, a max pooling layer is added with a window size of (4,4). After that, we give the model a dropout layer with a dropout rate of 0.4. To simplify the layers into a 2D image, we may add a “Flatten Layer” to the model. The model has had two more thick layers added recently. The last dense layer uses SoftMax as its activation function and contains 36 outputs (26 alphabets+10 digits).
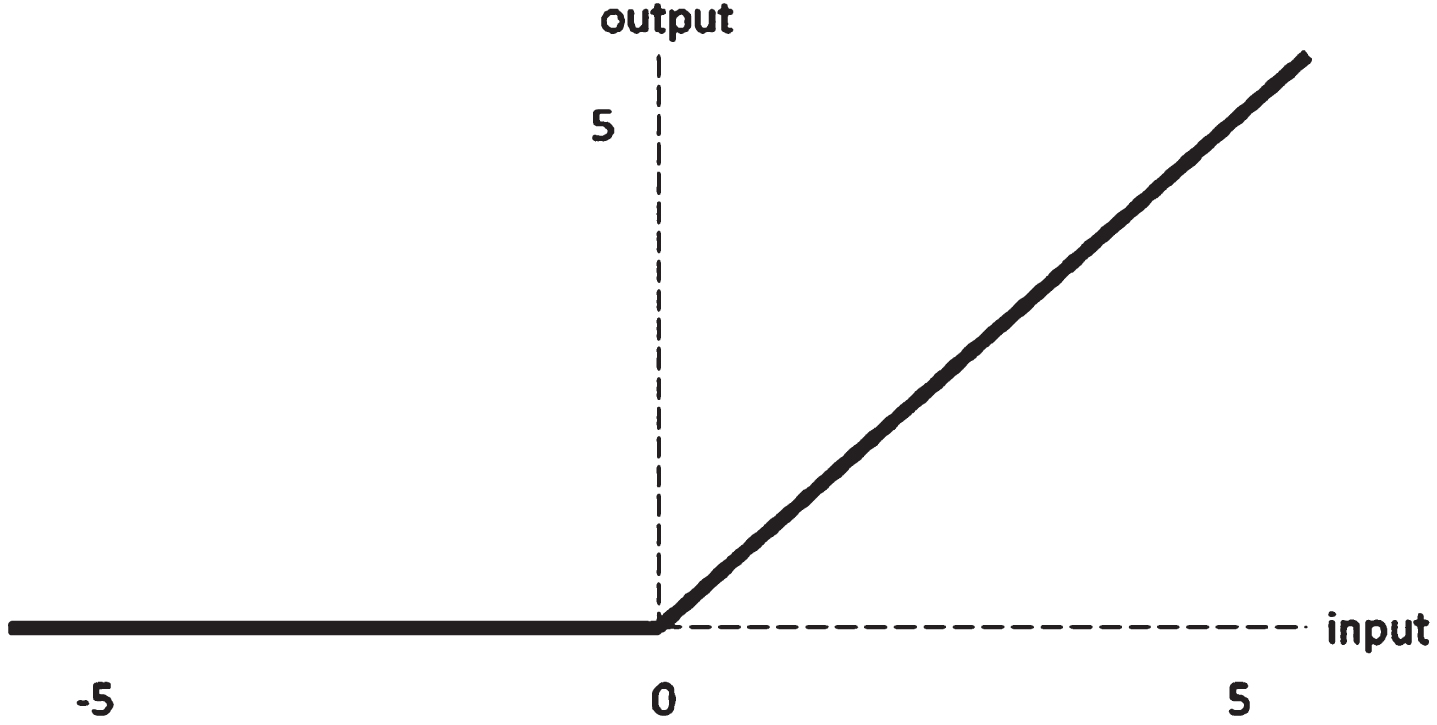
ReLU function.
Flowchart of CNN model.
In terms of CNN models, MobileNet V2 has 53 layers. The ImageNet dataset was used to pre-train the model. Its primary focus is on mobile vision and image categorization. Transfer learning takes far less mental processing than more conventional teaching approaches. This model makes use of a technique known as Depth-wise Separable Convolution [23], which can be seen in Fig. 8; this model’s goal is to decrease the size of existing models in use of deep learning so that it may be used more effectively in mobile versions.
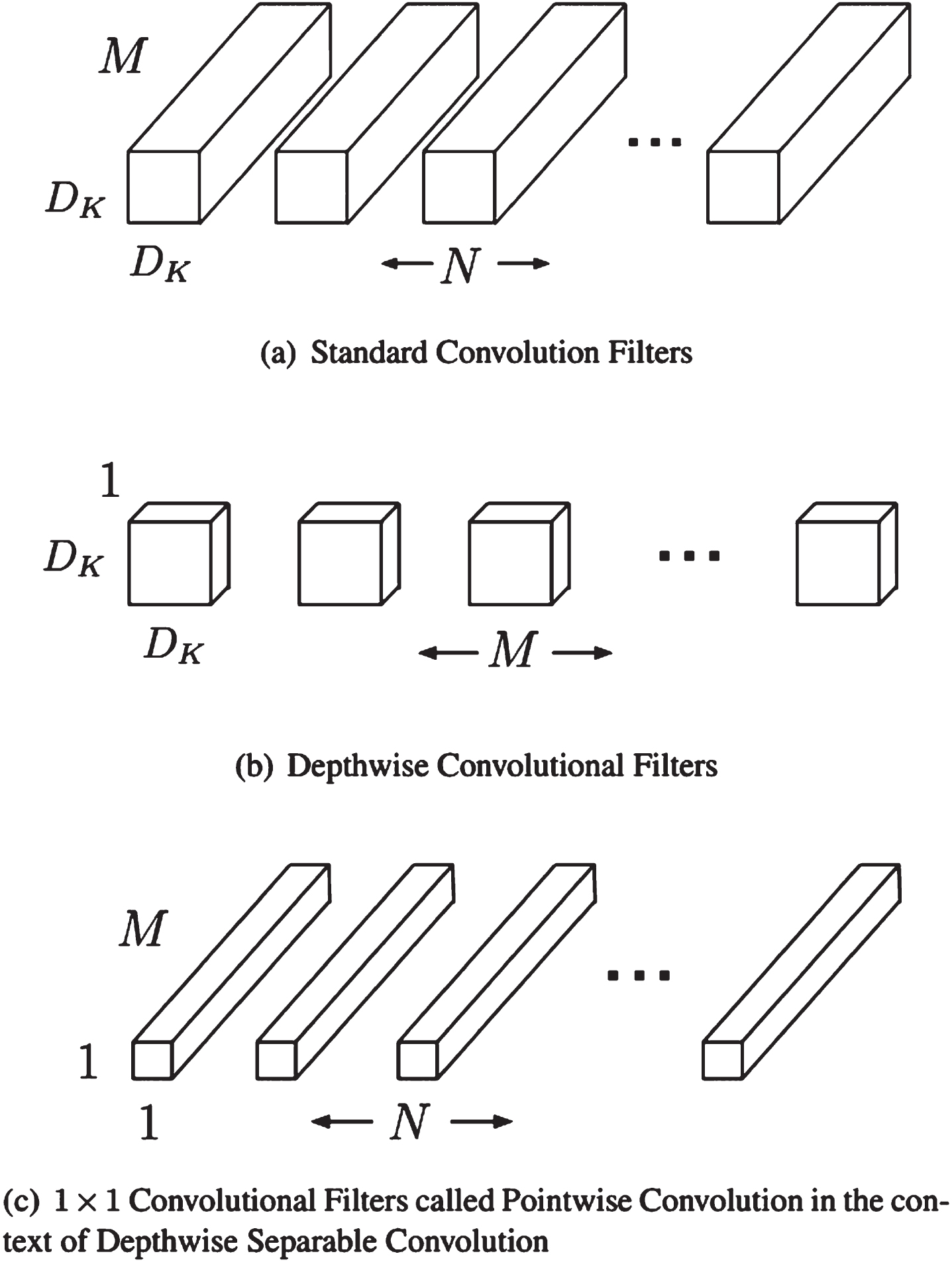
Convolution in MobileNet based on depth wise, point wise and depth wise separable filter [41].
The architecture of MobileNetV2 can be seen below in Figure 9, and it is made up entirely of convolution layer, which contains 32 filters, and the subsequent 19 bottleneck layers that come after it.
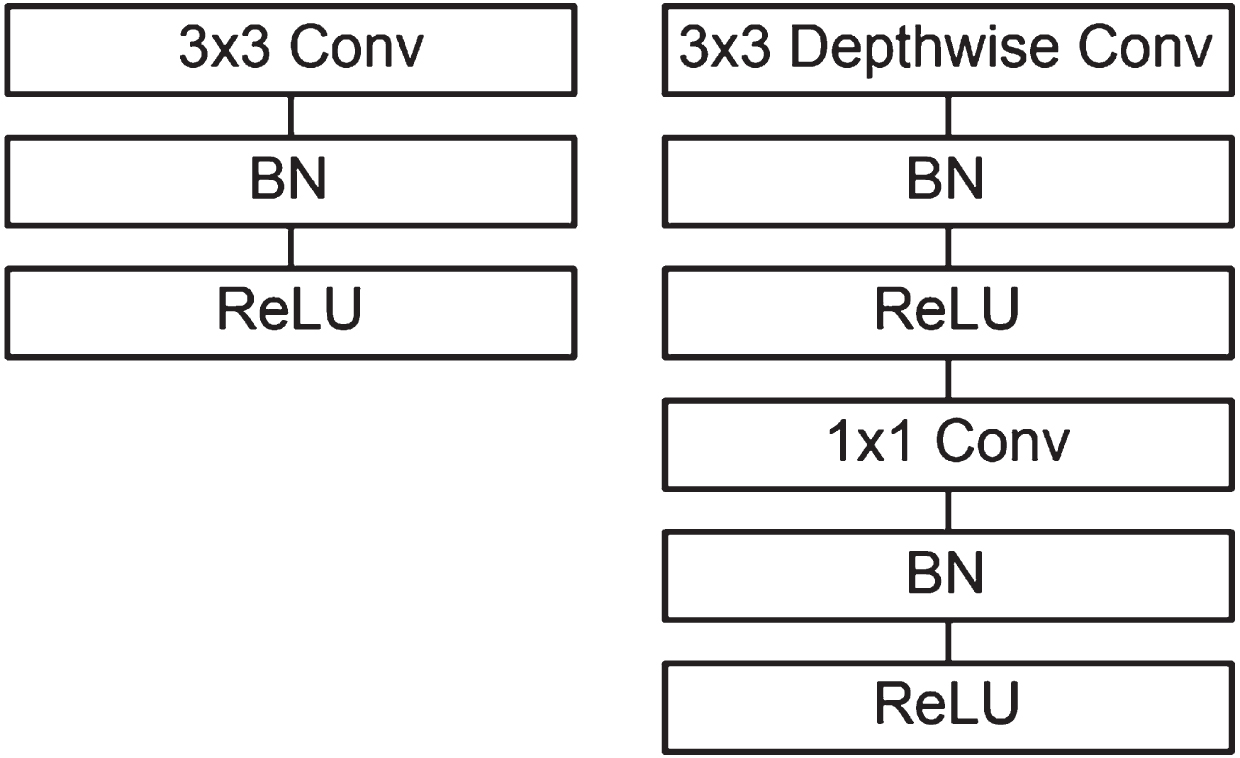
MobileNet architecture in regular convolutional with batch normalization and ReLU. Likewise the second block represents the depth wise separable convolutions with batch normalization and ReLU.
On the ImageNet dataset, we have used the MobileNets architecture with pre-trained weights. You can find it shown in Fig. 9. From the Keras Application package, the model is brought in immediately. Several essential details call for your attention, including: Remove the final output layers from MobileNets’s standard design and replace them with our own. There would be 36 nodes in the output layer, one for each of the 36 characters. Since our input photos have a shape of (80,80,3), we must set up our input layer with the same parameters. Initialization of learning rate and also the decay value is done, then model is combined with losses and metrics such categorical cross entropy and accuracy, and a check is made to see if training = True, which designates all of the basic model’s layers as trainable layers (weight may be changed during training).
Image recognition is its primary use. There are millions of photos in the ImageNet collection. Bounding boxes describing the precise position of the named items are included in these pictures [8].
On the ImageNet dataset, we used the inception v3 architecture with pre-trained weights. This design is shown in Fig. 10. The model is loaded in place from the Keras Application package itself. In the final layers, adjustments are done based on the classes. First, we need to get rid of the default inception v3 architecture’s final output layer and replace it with the one we want. We must set up our input layer with the same dimensions (80,80,3) as the input photos. All layers in the basic model should be trainable (weights may be changed during training) if training = true. After the learning rate and decay value have been initialised, the model is assembled with categorical cross entropy and accuracy serving as the losses and metrics, respectively. This step follows the further initialization.

Operational scheme of Inception V3 model [42].
ResNet50 is a pre-trained Residual Neural Network with a depth of 50 layers that was fed data from the enormous ImageNet dataset. This data was used to train the network. The model is instantly pulled in from the Keras Application package where it was originally found. In the same way that it was done with MobileNet and conception v3 [24], various alterations are made to the final layers depending on the classes.
The ResNet50 model has five separate stages all together. Each step has its own unique set of convolutions and identity blocks. Three layers make up each iteration of the convolution block and the identity block. Figure 11 presents the whole make-up of the ResNet50 framework for deep learning.

Descriptive diagram of ResNet50 model [43].
The four primary phases that make up the proposed ALPDR architecture are known as License plate Extraction (the acquisition of a region), Character Segmentation (where the characters are extracted from the surrounding area), Character Recognition, and Image Pre-Processing (wherein the details of an image are improved). There was a single method used for the first three phases, but four models (CNN, MobileNet, Inception V3, and ResNet50) were used for recognition. The image processing application OpenCV is used on a personal computer that has a processing speed of 1.2 GHz, 8 GB of RAM, and uses the proposed ALPDR system for its implementation.
Datasets
For our picture categorization, we used two distinct data sets. The 1100 photos that make up the Indian License plate collection all include plates from automobiles registered in India. Our Haar Cascade classifier was trained on this dataset to extract license plates from their source images. The following collection of data will be used for license plate character recognition. There are 32,000 photos in this collection, split across 36 categories. The alphabetic characters (a-z and 0-9) make up the vast majority of the classes.
Results based on pre-processing of license plate extraction & image
Figure 12 is a visual representation of the output of the extraction of License plate and Pre-processing procedures that were covered in Sections 3.1 and 3.2.

Different images based on extraction & pre-processing results.
In Section 3.3, we see how to do Character Segmentation after License Pre-processing and Plate Extraction. The end result of the character segmentation is seen in Fig. 13.

Vehicle license plates based on segmentation results.
CNN, MobileNet, Inception V3, and ResNet50 are the four separate models that we proposed for character recognition applications. In the sections that follow, I will describe in further depth the results obtained by putting each of these character recognition algorithms into exercise. Accuracy, recall, F1Score, and loss are the five measures that are used in the process of recording how well these techniques’ function.
The learning curves have been shown from Figs. 14 to 17. They simply portray the learning behavior of the different employed models during training. The considered evaluation measures describe the resemblance between the qualitative and quantitative measures. Moreover, it is inferred that the chance of overfitting is minimized when the gap between the validation and training curves are closer to each other that is not found with the Inception model. It is worth noting that the less fluctuation in the learning curve is also found that indicates the network is stable throughout the training. Maintaining a tradeoff between all these considerable measures should be optimal and in the proposed work the performance is said to be optimal in both qualitative and quantitative measures.

Character recognition results using CNN.
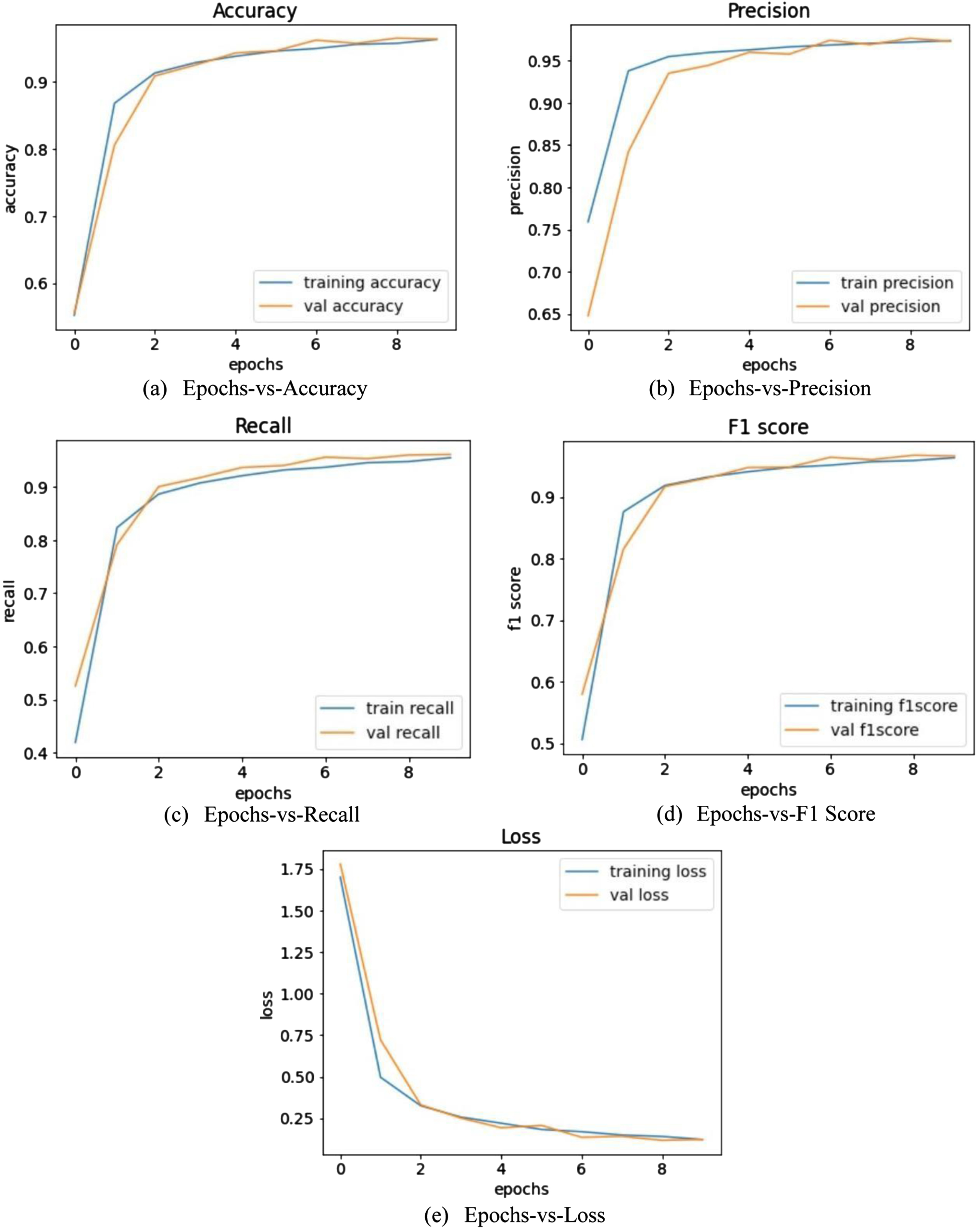
Character recognition results using MobileNet.

Character recognition results using inception V3.

Character recognition results using ResNet50.

Model character prediction result.
The results of a comparison with three more character-recognition models, namely MobileNet, Inception V3, and ResNet 50, are shown in Figs. 19 and 20, respectively. The system seems to have potential given that it has a projected accuracy of about 98.5 percent and suffers a loss of just 4.25% while performing character recognition using a convolutional neural network. In addition to the existing approaches, Ganta et al. applied unique and distinct series of morphological transformation in the data sample of the license plates then the Gaussian smoothing was taken into consideration [34]. After that contours were applied under the character dimensions and spatial localization and in the final stage the character recognition phase was operated through the K-nearest neighbor algorithm that gives the 98.02% accuracy.

Performance results under various metrics: Precision, Recall, Accuracy, Loss F1 & Score.
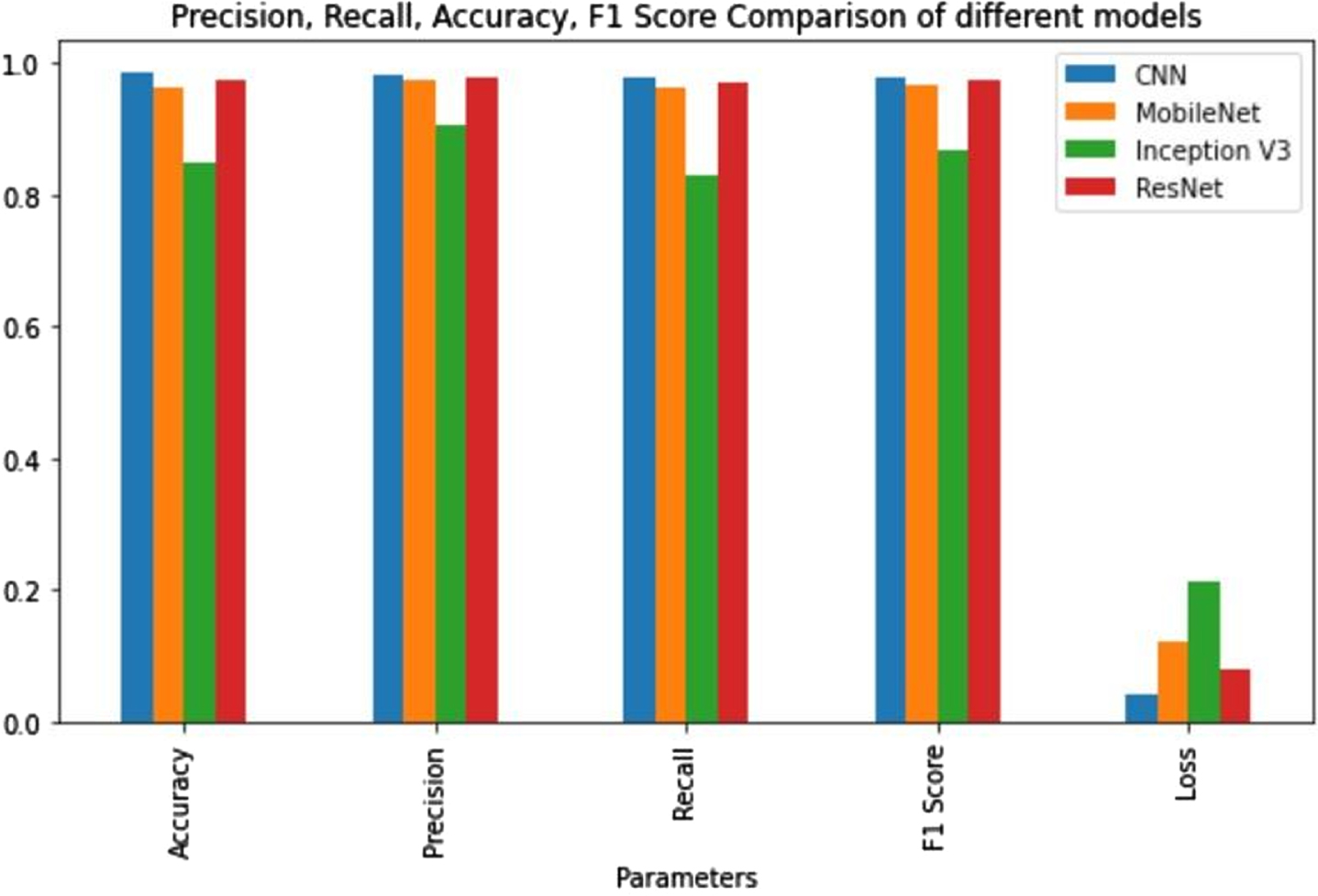
Comparison of evaluation scores: Accuracy, Precision, Recall, F1 Score & Loss.
Our license plate detection model, employing depth convolution within a CNN architecture, stands as a beacon of optimal performance in the realm of computer vision. With a commitment to precision and speed, our model outshines state-of-the-art methods, offering unparalleled accuracy in localizing license plates. The depth convolutional approach in our CNN model showcases a revolutionary leap in license plate detection, surpassing the capabilities of contemporary methods. In comparative evaluations, our model consistently emerges as a front-runner, setting new benchmarks for reliability, efficiency, and robustness in license plate localization. The fusion of depth convolution and CNN techniques empowers our model to excel in challenging scenarios, including varying lighting conditions, angles, and diverse license plate designs. Unprecedented precision characterizes our license plate detection, minimizing false positives and negatives and establishing a new standard for reliability in the field. The adaptability of our model is a testament to its prowess, performing exceptionally well across a spectrum of real-world scenarios and outperforming existing methods. Our model’s ability to generalize across diverse environments positions it as a versatile solution, offering optimal performance in a wide range of practical applications. The comprehensive validation of our license plate detection model against state-of-the-art benchmarks underscores its superiority, making it a compelling choice for deployment in autonomous vehicles and smart city initiatives. Character recognition using depth convolution within our CNN model further amplifies its performance, ensuring swift and accurate extraction of alphanumeric information from license plates. The synergy of depth convolutional techniques enhances character recognition accuracy, providing a robust solution for extracting license plate information with a high degree of reliability. Our approach to character recognition leverages the full potential of depth convolution, resulting in a model that outperforms existing methods in terms of speed, adaptability, and language diversity. Comparative studies highlight the superior performance of our character recognition model, showcasing its effectiveness in deciphering characters across various fonts, languages, and styles. The depth convolutional architecture contributes to the efficiency of our character recognition model, enabling real-time processing without compromising on accuracy. The depth convolutional CNN not only elevates character recognition accuracy but also ensures resilience to noise and distortion in input images, contributing to a more robust overall system. The seamless integration of license plate detection and character recognition within our CNN architecture establishes a holistic solution, streamlining the workflow for comprehensive vehicle identification. Through meticulous optimization, our model achieves optimal results in character recognition, ensuring high precision in extracting alphanumeric information crucial for various applications. The depth convolutional approach significantly enhances the model’s ability to handle multilingual scenarios, making it adaptable to diverse linguistic characteristics in license plates. Our model’s superior performance is not limited to controlled settings; it excels in real-world environments, demonstrating its practicality and reliability for deployment in a variety of applications. The depth convolutional CNN approach represents a paradigm shift in license plate detection and character recognition, offering a compelling solution that outpaces state-of-the-art methods and sets new standards for excellence in computer vision.
Moreover, the depth convolutional architecture in our method facilitates multiscale feature extraction, allowing the model to discern relevant patterns and information even in images with varying levels of noise and contrast. This adaptability enhances the model’s ability to generalize across diverse scenarios. The method utilizes dynamic thresholding techniques during the detection and recognition phases. This adaptability allows the model to adjust its sensitivity based on the characteristics of the input, ensuring reliable results even when confronted with images containing noise or low contrast.
Our novel method for Indian Vehicle Registration Number Plate Detection and Recognition using Convolutional Neural Networks presents a promising advancement in automating the crucial task of license plate recognition. The CNN model exhibits robust performance in capturing the diverse designs across Indian states. As we move forward, continued refinement and adaptation of the model for multilingual plates, optimization for real-time applications, and addressing privacy concerns will be pivotal. This research lays the foundation for enhanced traffic management, law enforcement, and smart city initiatives, contributing to the evolution of intelligent systems in the realm of vehicular identification. In this investigation, we propose a four-step technique for automatically detecting and recognizing license plates (also known as ALPDR): license plate extraction, image enhancement, character recognition, and segmentation followed by the Convolution Neural Network (CNN), MobileNet, Inception V3, and ResNet 50. The outcome shows that Character Recognition using a CNN achieves higher results, with an accuracy of 98.5% and a loss of 4.25%. The suggested technique works effectively even when the lighting is dim, the picture is blurry, or the license plate is tilted. However, still some of the data samples under extreme noise and improper illumination are not will processed by the proposed approach; therefore, the more robust features considering the heterogenous conditions considering the other techniques like transformer will be considered in the future scope of the work. The next steps involve expanding the model’s capabilities to recognize multilingual license plates, optimizing for real-time processing, integrating privacy features, exploring scalability, and establishing collaborations with government agencies for practical deployment.