
Abstract
In this study, an innovative approach that combines least square support vector regression (LSSVR) with uncertainty theory to enhance its performance in dealing with low-quality or imprecise data from real-world be proposed. The resulting model, called uncertain least square support vector regression (ULSSVR), incorporates chance constraints and simplified parameter selection, which are critical to handle imprecise observations. A numerical algorithm called the conjugate residual method (CR) is introduced to reduce the computational complexity of the model solution. The experimental results using both small and medium-sized datasets demonstrate the superior performance of ULSSVR in terms of prediction accuracy and generalization ability compared to other models such as uncertain support vector regression (USVR), uncertain linear lodel, uncertain polynomial model, and uncertain growth models. ULSSVR not only improves prediction accuracy by at least 28.49% but also demonstrates faster computational speed. Overall, ULSSVR presents a promising solution for data science and internet applications where dealing with imprecise and low-quality data is a common challenge.
Keywords
Introduction
Least square support vector machine (LSSVM) has been extensively applied in academia and industry due to its impressive generalization performance. Devised by Suykens and his collaborators in 1999 [1], LSSVM is based on support vector machine (SVM) proposed by Vapnik et al. [2, 3]. Similar to SVM, LSSVM maps the input vector into a high-dimensional feature space through a nonlinear mapping. Furthermore, LSSVM can be divided into least square support vector classification (LSSVC) and LSSVR [4] with respect to purpose, the latter being the main focus of this work. In contrast with SVM, LSSVM uses equality constraints instead of inequality constraints in traditional SVM. This has contributed to that LSSVM will solve a least square (LS) problem instead of a quadratic programming (QP) from SVM, LSSVM runs significantly faster [4]. LSSVM has now attracted many researchers devote into. Suykens et al. [5] utilized conjugate gradient method (CG) [6] to solve LS problem in LSSVM and presented a large-scale algorithm, the CG method can reduce space complexity of LSSVM effectively. Suykens and Vandewalle [7] structured a recurrent network based on LSSVM, which utilized early stopping as a form of regularization, reducing its computational complexity. In terms of practical applications, LSSVR has been applied successfully in various fields such as stock market [8], river flow forecasting [9] and wind power generation [10].
The input data of the aforementioned researches is precise. In many cases, however, data or observations are imprecise or low-quality, especially those from humans. The traditional statistics was inefficient when dealing with such imprecise data, which has prompted researchers to search for solutions. Zadeh [11, 12] had proposed the fuzzy set theory, and based on this theory, fuzzy SVM be structured by Lin and Wang [13]. Xie [14] introduced fuzzy parameters to LSSVM and thus proposed fuzzy LSSVM. Sun and Pan [15] established a data domain description fuzzy LSSVR to solve isolated points problem. Over time, researchers need more effective and better-performing tools for processing imprecise observations. Liu [16] put forward the uncertainty theory and perfected it [17]. This theory, which is based on the normality, duality, subadditivity, and product axioms, provides a useful method for handling imprecise observations. In uncertainty theory, the imprecise observations can be regarded as uncertain variables, using statistics tools from uncertainty theory can cope uncertain variables efficient and excellent. The uncertainty theory has now evolved into an attractive field of research. In moments of uncertain variable, Sheng and Kar [18] proposed several methods via inverse uncertainty distribution. In uncertain regression, Yao and Liu [19] proposed the uncertain least squares (LS), which became a widespread used estimation method at present. Lio and Liu [20] applied the residual analysis to uncertain regression analysis and proposed the interval estimation of predictive value. Li et al. [21] proposed uncertain SVR with chance constraints and hard margin. In this work, the uncertain vectors are treated as input vectors, while the output variables are uncertain variables, and ULSSVR will handle this imprecise data and calculate the expectation of prediction. ULSSVR is a novel option with marvelous performance for the research of regression analysis.
The paper rest part is organized as follows. The elementary knowledge be introduced in Section 2. Introduction to LSSVR with precise observations in Section 3. In Section 4, some definitions and theorems be given, then ULSSVR be proposed and properties be discussed. An algorithm for ULSSVR with low space complexity be presented in Section 5. Methods and theories in Sections 4 and 5 will be applied to two numerical examples in Section 6, and ULSSVR shows the better generalization performance via comparing with other uncertain regression models. Finally, some conclusions of this work are drawn in Section 7.
Preliminaries
In this section, axioms and a theorem in the uncertainty theory will be introduced as foundation knowledge.
For uncertainty space
Least square support vector regression with precise observations
LSSVR was devised by Suykens with his collaborators [4] in 2002. Based on SVR, which proposed by Vapnik et al. [2], the inequality constraints in SVR were replaced by equality constraint in LSSVR, then a QP can be converted to a LS problem via Karush-Kuhn-Tucker (KKT) conditions.
Similar to SVR, the goals of LSSVR are to find a linear equation
Solution of the following optimization problem is the key to access the regression Equation (1)
To solve the optimization problem (2), the Lagrange multipliers β i , i = 1, 2, ⋯ , n, which is a real number, be introduced to structure Lagrangian
Solving
Now, LSSVR will be introduced into the uncertainty theory. But before that, some settings and methods be presented as follows.
Suppose
Following Definition 4.1, a theorem about inverse uncertainty distribution of residual variable can be proofed.
this can be denoted as
For the sake of simplicity, the parameter vector
In more general situation, if ω
j
≥ 0 and
The parameters of Equation (6) can be obtained by the following constrained optimization problem
In many cases, however, researchers already know the inverse distribution of each variable, the equivalent form in the following theorem can keep thing simple in this situation.
The optimization problem (13) can be rewritten as
Taking the partial derivative of
This ULSSVR has some properties: Parameters Model (13) has two parameters, which chosen a priori, the regularization constant C and belief degree α. It is less than USVR [23]. In USVR [23], seeking optimal width of the margin may take a lot time and computing power because the value range of the width is [0, + ∞). However, ULSSVR does not have this parameter, thus parameter selection may be simpler. Lack of sparseness According to Equation (20), no β
i
value will normally be exactly equal to zero, every input vector is support vector. From this a drawback of ULSSVR is the lack of sparseness can be clearly concluded.
The lack of sparseness may cause solving of the linear system (21) with increased difficulties. For example, the space complexity of solve system (21) is O (n2), it may run out of memory if scale of n is large. Therefore, an algorithm with low space complexity will be presented in next section to solve linear system (21).
The conjugate residual method (CR) [24] is a low memory requirements method for solving linear system
In the case of one dimension, the minimum of function (23) be sought by
An important definition of forecast value should be given here before ULSSVR be employed in examples. A dataset be divided into test set D and train set D c , where D need to be predicted, and regression function be estimated from D c . A definition of forecast value as follows.
In this section, a toy dataset will be employed to verify feasibility of ULSSVR and reveal properties at first. Then the generalization performance of ULSSVR be shown via a medium-sized dataset. The pipeline of using ULSSVR to process imprecise observations is shown in Fig. 1.
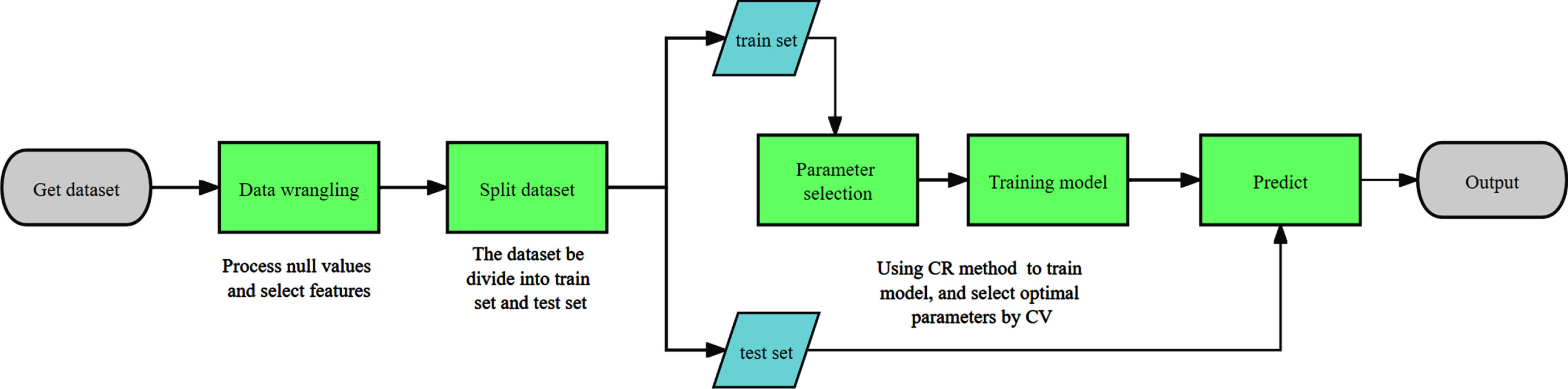
Pipeline.
The dataset which shown in Table 1 will be trained by ULSSVR to show some properties. Let first 8 data as train set D
c
and last 2 data as test set D. Using Algorithm 1 to train D
c
and set C = 10, α = 0.95, kernel function is linear, the ULSSVR-based equation as follows
Toy dataset
where b* = -1.76 and
According to model (29), every element in

Comparison of sorted |
Forecast value
The uncertain abalone dataset has 4177 instances, each instance has a 5-dimensional uncertain vector as input vector and an uncertain variable as output. The output is weight of abalone, and each dimension in input vector is represent sex of abalone (Sex), longest shell measurement (Length), diameter perpendicular to length (Diameter), height with meat in shell (Height), rings which +1.5 gives the age in years (Rings).
In this subsection, every model will be trained 10 times and the test set D which accounts for 10 percent of dataset is randomly selected for each time. In each training, after D and D c are selected, the optimal parameters will be selected. Several methods for search parameters had been proposed, Runarsson and Sigurdsson [26] introduced asynchronous parallel evolution strategy to do this work. Li et al. [27] proposed quantum butterfly optimization algorithm (QBOA) to find hyper-parameters of a hybrid forecasting model, this algorithm used quantum computing to expand the ergodicity of the search and improve the original butterfly optimization algorithm. However, no universal methods and criterions are available to select these parameters of LSSVR at present. Smets et al. [28] found v-fold cross-validation is an accurate and autonomous way also with low test error for parameter selection of LSSVR. Therefore, the cross-validation method (CV) [23] be applied to find the optimal parameter, the average test error (ATE) [23] be metrics for CV. Then the model trained by D c and compute the forecast value, the root mean squared error (RMSE) [23] be used to measure the generalization performance of models.
In parameter selection for ULSSVR, the average of 10 ATE(4) be shown in Fig. 3. Therefore, the optimal parameters in this dataset are kernel function is polynomial with degree 3 and C = 1. 1
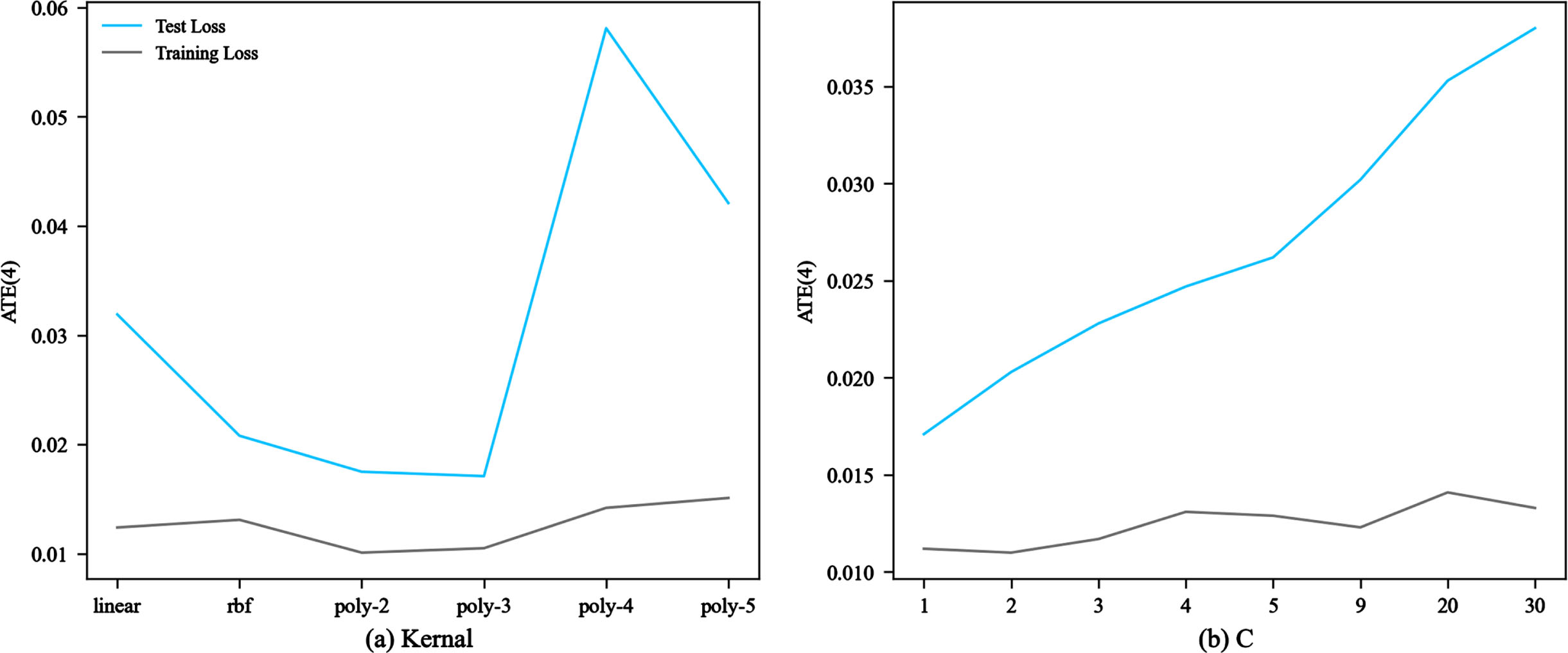
Parameter selection for ULSSVR1.
Some uncertain regression models also be employed to process this dataset. These models use same D, D
c
and procedure as ULSSVR, then compute RMSE of each model. The results and optimal parameters are shown in Table 3. From Table 3, two results can be drawing: Generalization Performance RMSE has the same dimension as data, and sensitive to large errors, thus it is commonly used as a standard to measure the generalization performance of machine learning models. Comparing RMSE of each model, in the uncertain abalone dataset, the ULSSVR has shown a superior performance in prediction accuracy compared to the USVR, uncertain linear model, uncertain polynomial model and two uncertain growth models. The lower RMSE value of 0.1097 (shown in Table 3) indicates that ULSSVR is state of the art, RMSE was 28.49% lower than USVR, which is crucial in many real-world applications. This advantage becomes even more significant when dealing with complex and noisy datasets. Parameters ULSSVR and USVR have same kernel function but different optimal C, the two model have analogous structure and ideology, while different in penalty function and sparseness. ULSSVR has less parameters than USVR, less time be wasted in parameter selection, but more time for features engineering.
RMSE of each model
In computational performance, the memory footprint and the elapsed time of two models shown in Table 4. Based on the data in Table 4, the following conclusions can be drawn: Elapsed Comparison ULSSVR is faster than USVR in terms of elapsed. This means that when performing model training and prediction, ULSSVR takes less time and can complete tasks more quickly. This advantage is especially important in applications that deal with large datasets or require real-time responses. By reducing runtime, ULSSVR is able to increase the efficiency of data processing, leading to faster feedback and more efficient decision support for real-world applications. Memory Footprint Comparison ULSSVR has a significantly higher memory footprint than USVR, which generally means higher resource consumption and a potentially negative impact on computer performance. Therefore, when choosing to use ULSSVR, it is important to consider the computer hardware configuration and available memory capacity to ensure that the system can withstand the memory demands of model operation. Applicable Scenario Analysis Considering the advantages of ULSSVR in terms of running speed and the shortcomings of memory consumption, the following analysis of applicable scenarios can be derived: 1. ULSSVR may be more suitable for applications that require fast response and high real-time requirements, such as financial market forecasting or real-time control systems. Its fast runtime reduces latency and improves decision making. 2. USVR may be more advantageous for applications that have limited memory resources or need to operate in resource-constrained environments, such as embedded systems or mobile devices. Its lower memory footprint can help reduce the burden on the system and improve overall performance. 3. For applications with large-scale data processing and analysis, ULSSVR may be more suitable. Despite its higher memory footprint, it typically outperforms USVR when processing large data sets. Tradeoffs and Choices The choice to use ULSSVR or USVR needs to be weighed against the needs and limitations of the specific application. ULSSVR can be chosen if there is a high demand for model speed or if it needs to run with sufficient memory resources; USVR can be chosen if there are limited memory resources or if it needs to run in a resource-constrained environment. choosing according to different application scenarios and actual needs can better leverage the advantages of each and meet specific needs.
Memory footprint and elapsed time
ULSSVR with imprecise observations was proposed in this paper, which had the same data loss ‖
In the future work, ULSSVR may be applied to multi-layer network. Kernel function in uncertainty theory may be researched in the future.
Footnotes
Acknowledgments
This research was supported by the Natural Science Foundation of China (Nos. 12061072 and 62162059) and the autonomous region’s key R&D plan project (No. 2022B01006).
In figure (a), poly-n means polynomial with degree n.