
Abstract
Neuroimaging technology is considered a non-invasive method research the structure and function of the brain which have been widely used in neuroscience, psychiatry, psychology, and other fields. The development of Deep Learning Neural Network (DLNN), based on the deep learning algorithms of neural imaging techniques in brain disease diagnosis plays a more and more important role. In this paper, a deep neural network imaging technology based on Stack Auto-Encoder (SAE) feature extraction is constructed, and then Support Vector Machine (SVM) was used to solve binary classification problems (Alzheimer’s disease [AD] and Mild Cognitive Impairment [MCI]). Four sets of experimental data were employed to perform the training and testing stages of DLNN. The number of neurons in each of the DLNNs was determined using the grid search technique. Overall, the results of DLNNs performance indicated that the SAE feature extraction was superior over (Accuracy Rate [AR] = 74.9% with structure of 93-171-49-22-93) shallow layer features extraction (AR = 70.8% with structure of 93-22-93) and primary features extraction (AR = 69.2%).
Keywords
Introduction
Since entering the new century, with the sustainable development of social economy, people’s living environment and way of life and great changes have taken place, brain disease became an important cause of human death, and timely diagnosis and treatment, help to reduce the mortality of patients. Under the traditional way for brain tumors, Alzheimer’s disease, the diagnosis of brain diseases such as Parkinson’s disease, surgery planning and surgery treatment effect evaluation is usually used in Magnetic Resonance Imaging (MRI), Computed Tomography (CT), and other medical Imaging techniques, These technologies because there are a lot of image data, the process requires a lot of time and energy are interested area is extracted and the manual time-consuming, so urgently need a kind of advanced imaging technology to improve the efficiency of brain disease diagnosis, and based on the deep learning algorithms of neural imaging is a representative of the technology.
Domestic and foreign experts and scholars have also carried out in-depth research on the application of neuroimaging technology based on deep learning algorithm in disease diagnosis, and achieved fruitful research results. In reference [1], Babin (2012) et al proposed Differential Structuring Element (DSE) to achieve the description of each pixel, and used a new descriptor function to judge whether each pixel belongs to blood vessels. In order to improve the image processing speed, Babin also proposed (line-shaped profile) to replace DSE to achieve the segmentation of blood vessels. In reference [2], Abiwinanda (2018) used the CNN structure with multiple hidden layers to classify brain tumor MRI images. In reference [3], Muhammed (2019) used ResNet34, a pre-trained CNN model, as a deep transfer learning model to classify small-data brain tumor images.
Neuroimaging techniques have also been widespread use in Alzheimer’s disease and the diagnosis of mild cognitive dysfunction. Combining with the results of pathology, the Alzheimer’s disease caused by the contraction of the brain usually start from the medial temporal and edge part of the brain, the parietal lobe of the brain develop gradually and eventually spread to the frontal lobe cortex. In reference [4], Yao et al. (2021) used DMN (default network) to reveal the lesion characteristics unique to AD spectrum patients, providing important ideas for early screening, progression monitoring, efficacy evaluation and differential diagnosis of related cognitive disorders of AD spectrum diseases.
In summary, although many surprising achievements have been made in the diagnosis of brain diseases using neuroimaging techniques, on the whole, the application of neural influence techniques based on deep learning algorithms in the diagnosis of early brain diseases is still a great challenge for researchers, and the use of neuroimaging techniques to extract image features of brain diseases is still the focus of current research [5].
Diagnosing brain diseases using deep learning algorithms and neural imaging techniques is an emerging and promising area in medical research and healthcare. Neural imaging techniques, such as MRI (Magnetic Resonance Imaging), CT (Computed Tomography), PET (Positron Emission Tomography), and more, provide detailed structural and functional information about the brain [6, 7]. Deep learning algorithms can be applied to analyze and interpret these images for the purpose of disease diagnosis. In this regards, choosing an appropriate deep learning architecture for the specific diagnostic task is the key element in diseases analysis. Convolutional Neural Networks (CNNs) are commonly used for image analysis tasks. Depending on the problem, you may use 2D CNNs for image classification or 3D CNNs for 3D medical image analysis (e.g., 3D MRI scans) [8–11]. The deep learning model learns to identify patterns and features in the images that are indicative of various brain diseases. Moreover, an appropriate loss function (e.g., cross-entropy for classification tasks) and evaluation metrics (e.g., accuracy, sensitivity, specificity, ROC curves) is determined based on the nature of the diagnosis task. Leveraging pre-trained models on large image datasets, such as ImageNet, can be beneficial. Transfer learning allows scholars to use the knowledge gained from one task to improve performance on the medical image diagnosis task. In medical diagnostics, model interpretability is crucial [12–15]. Techniques like Grad-CAM (Gradient-weighted Class Activation Mapping) can help visualize which regions of the image contribute to the model’s decision, making it easier for doctors to trust and understand the model’s predictions. Overall, this provides an estimate of the model’s generalization to new cases after performing training and testing stages. On the other hand, collaborating with medical professionals to integrate the deep learning model into the clinical workflow would be considered as a forthcoming research direction. This may involve developing user-friendly interfaces and ensuring compliance with regulatory and ethical standards. Regularly update and fine-tune the deep learning model as new data becomes available, and as the model gains more clinical experience. Common brain diseases that can be diagnosed using these techniques include Alzheimer’s disease, Parkinson’s disease, brain tumors, multiple sclerosis, and various forms of encephalopathies. Deep learning-based diagnosis can significantly improve the accuracy and efficiency of diagnosis, potentially leading to early intervention and better patient outcomes [16–20].
From relevant literature, Deep learning algorithms play critical roles in the detection and diagnosis of brain diseases, contributing to improved accuracy, efficiency, and early intervention. Some of key merit aspects of deep learning algorithms in this context would be listed as follows: (i) Image Segmentation: Deep learning algorithms can segment neural images, such as MRI and CT scans, to identify and delineate brain structures and abnormalities. This is crucial for pinpointing regions of interest in the diagnosis process. (ii) Feature Extraction: Deep learning models can automatically extract relevant features and patterns from images, which may not be apparent to the human eye. This enables the identification of subtle structural or functional changes associated with brain diseases [21–25]. (iii) Classification and Diagnosis: Automated Diagnosis: Deep learning algorithms can classify neural images into different categories based on the presence of specific brain diseases, such as Alzheimer’s disease, brain tumors, multiple sclerosis, or stroke [25–29]. (iv) Multimodal Data Fusion: Deep learning can handle multimodal data, including the integration of different imaging techniques (e.g., MRI, PET, CT) and clinical data (e.g., patient history and genetic information). This comprehensive approach enhances the accuracy of diagnosis. (v) Research and Drug Development: Deep learning algorithms can assist researchers in identifying potential biomarkers and targets for drug development and in conducting large-scale population studies. (vi) Telemedicine and Remote Diagnosis: Deep learning-based diagnostic tools can be integrated into telemedicine platforms, enabling remote diagnosis and consultation with specialists, particularly in underserved or remote areas [30–32]. (vii) Decision Support Systems: Deep learning algorithms can serve as decision support systems for healthcare professionals, providing additional information and insights to aid in clinical decision-making [33].
In this paper, the application of neural imaging technology based on deep learning algorithm in the diagnosis of brain diseases is studied. The key contributions of this paper are presented as follows: A feature extraction method based on stacked auto-encoder network is established, and the specific flow of the algorithm is given. According to the nature of unsupervised learning of stacked auto-encoder model, a supervised learning step is introduced, and the whole training and learning process is divided into pre-training and fine-tuning steps to eliminate the problem that deep neural networks are easy to fall into local optimal solutions. The classification accuracy of AD and MCI is verified based on the stacked auto-encoder network constructed in this paper. Experimental results would be quantified in terms of accuracy and specificity when are compared to the original feature extraction.
Neuroimaging technology based on deep learning algorithm
Deep learning is a kind of study on machine learning paradigm of further data model, it is mainly used by the many hidden layers of deep structure, using nonlinear processing unit for feature extraction and transform, automatic under the way of supervision or unsupervised learning multi-level representation of the original data. Deep learning can understand and learn the complex representation of the signal directly from the original signal, and has the advantage of automatic extraction of advanced features required for classification, which is increasingly applied to the diagnosis of brain diseases [6]. The current in the depth of the learning algorithm is commonly used in disease diagnosis with recurrent neural networks (RNN), auto - encoder (AE), the depth of the RNN learning algorithm framework are shown in Fig. 1 below.
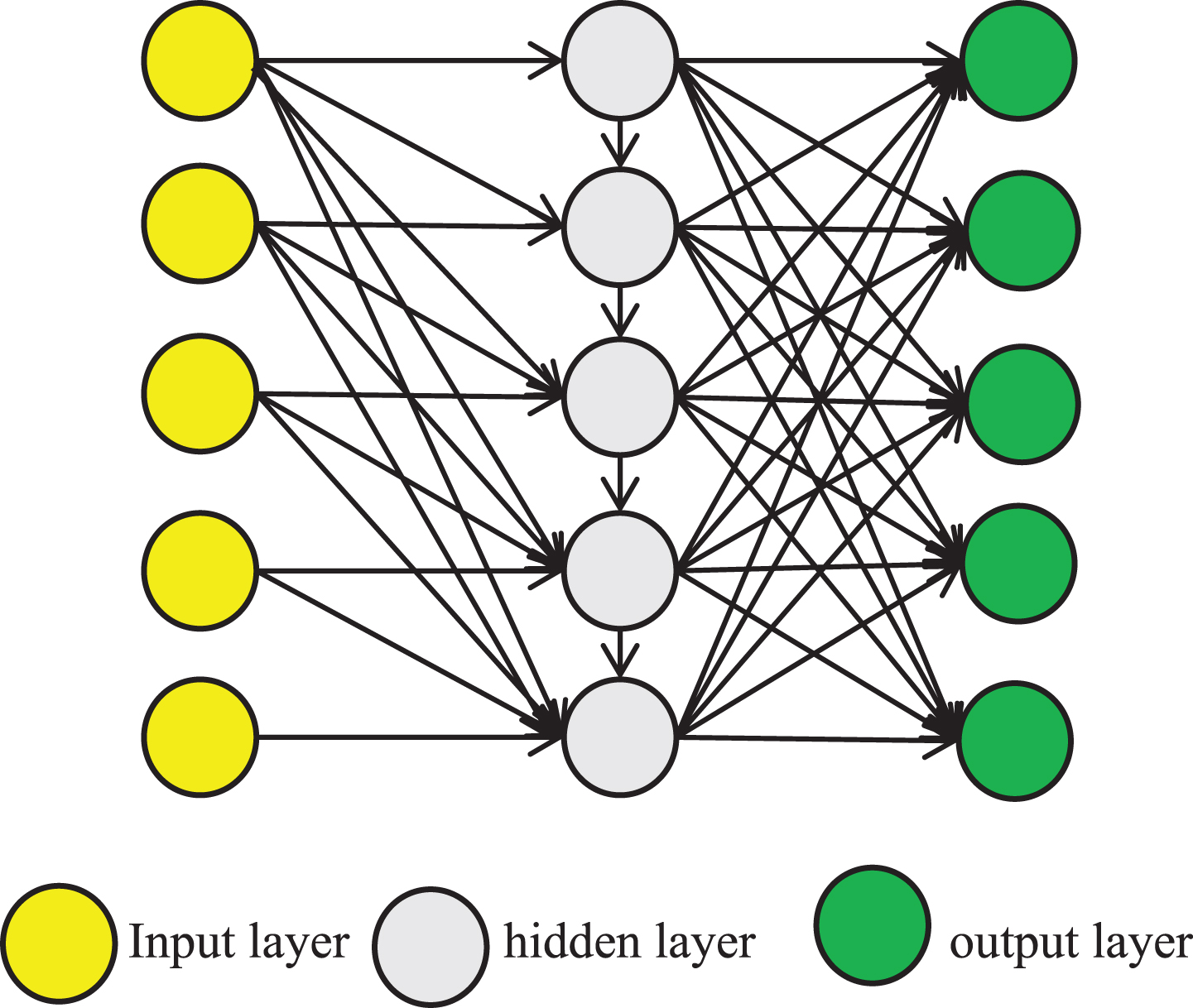
RNN deep learning algorithm framework.
Neuroimaging is a non-invasive technique used to acquire images of the brain, eliminating the need for surgical procedures, incisions, or direct internal contact. Due to its ability to visualize both the structure and function of the brain without causing harm, neuroimaging has emerged as a potent diagnostic tool in both research and clinical medicine [7]. As the central organ of the human central nervous system, the brain resides within and is safeguarded by the cranial vault. While sharing structural similarities with other mammals’ brains, it distinguishes itself through an extensively developed cortex. Enveloping most of this intricate organ, the human cerebral cortex comprises a substantial layer of neural tissue. The brain is further divided into interconnected right and left hemispheres via trabeculae and septa. The surface of the cerebral hemispheres is covered with sulci, and the slender part between the sulci is called the gyri. The depth and curvature of the sulci vary from individual to individual [8]. A schematic diagram of the longitudinal section of the brain is shown in Fig. 2, in which some major structures of the brain are marked in detail, including the cerebrum, cerebellum, brainstem, cerebral cortex, etc.
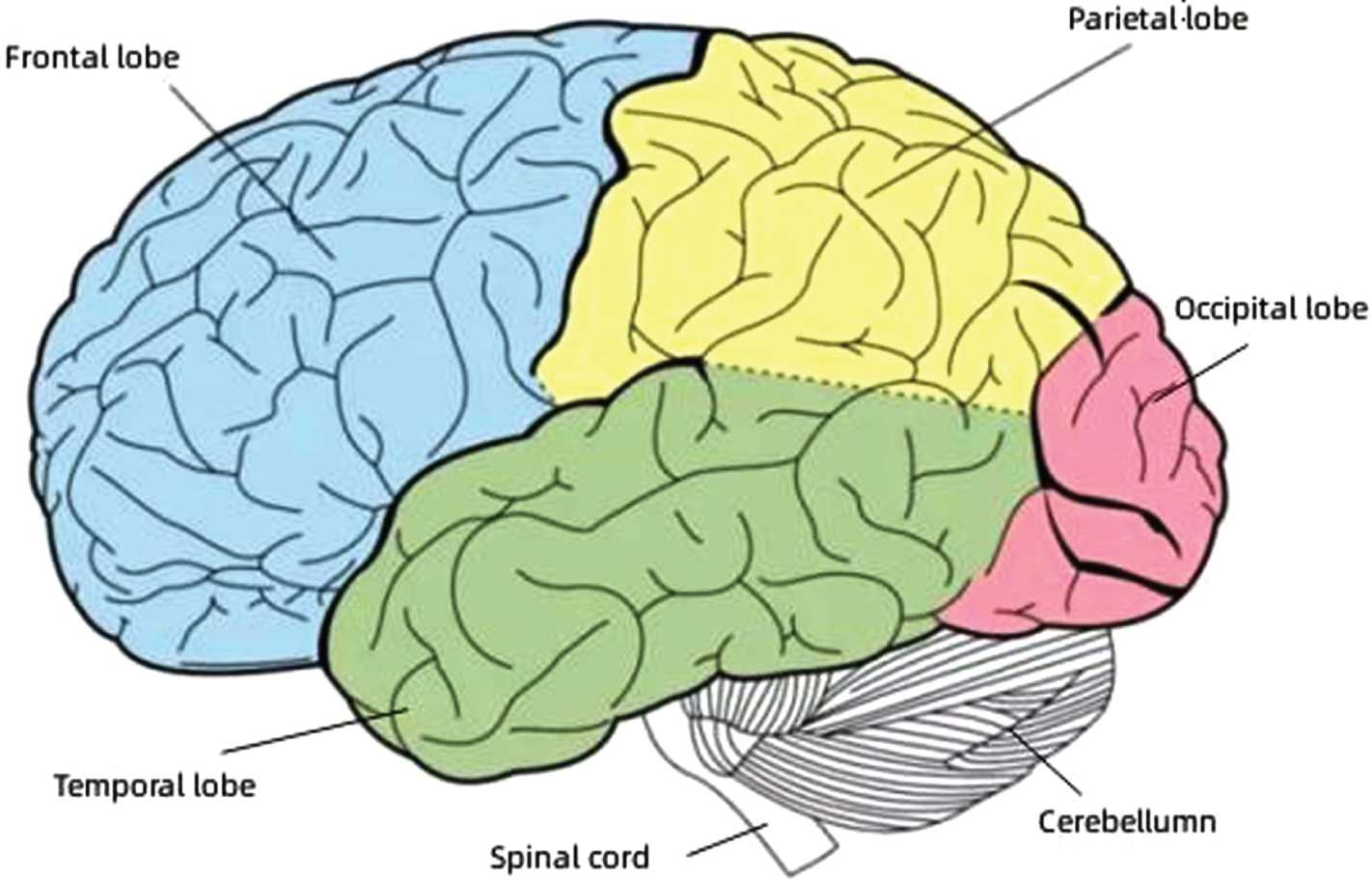
Diagram of major brain structures.
Studies have shown that Alzheimer’s disease (AD) and Mild Cognitive Impairment (MCI) are increasingly harmful to human health, but there is no effective treatment for AD/MCI at present. So in the clinic, the early diagnosis of AD/MCIMCI and prediction is particularly important, especially in the aging of the population today, even cause a small delay to the onset of AD and intervention, can also be a great help to health for all [9]. Therefore, with the help of the latest neuroimaging technology and network learning methods to assist diagnosis has become a new research field.
In the field of AD/MCI classification, many researchers have studied it from various aspects such as classifier training and multimodal image fusion, trying to improve the accuracy of AD/MCI classification. However, a significant limitation of the previous research lies in our exclusive consideration of simple low-level features for classification purposes. Therefore, with regards to feature extraction, this chapter assumes the existence of hidden or potential high-level feature information within these low-level features [10]. The incorporation of such latent feature information at higher development of more robust AD/MCI diagnostic and predictive models. To extract these high-level latent features effectively, we introduce a stacked autoencoder network in this section.
Sparse auto-encoder model
Combination with the characteristics of automatic encoder mining potential structure information, this paper adopts steam automatic encoder model, by minimizing the input signal and the reconstruction of the hidden layer stimulation output error to study said potential, compression of the input signal. Let DH and DI denote the number of units in the hidden layer and input layer in the neural network, respectively. Given a training sample of a set of N objects
Where W1 is the coding weight coefficient matrix and b1 is the bias vector. For the activation function, in this paper
In this paper, we consider the unified use of the logical sigmoid function
Logic sigmoid function is most widely used pattern recognition and machine learning field activation function [11]. From the viewpoint of learning and training, our purpose is to adjust the training parameters to minimize the error between input signal x
i
and output signal z
i
reconstruction. In this paper, we assume
ρ is the labeled average excitation intensity and
Inspired by the great help of deep learning hierarchical architecture for improving high-level nonlinear and complex pattern features, this paper uses Stacked Auto-Encoder (SAE) to represent and extract features from neuroimaging and biological data. In this model, the auto-encoder is regarded as one component, and then they are stacked and connected sequentially [12]. The output of the lower hidden layer is used as the input of the higher input layer. The specific structure is shown in Fig. 3 below.
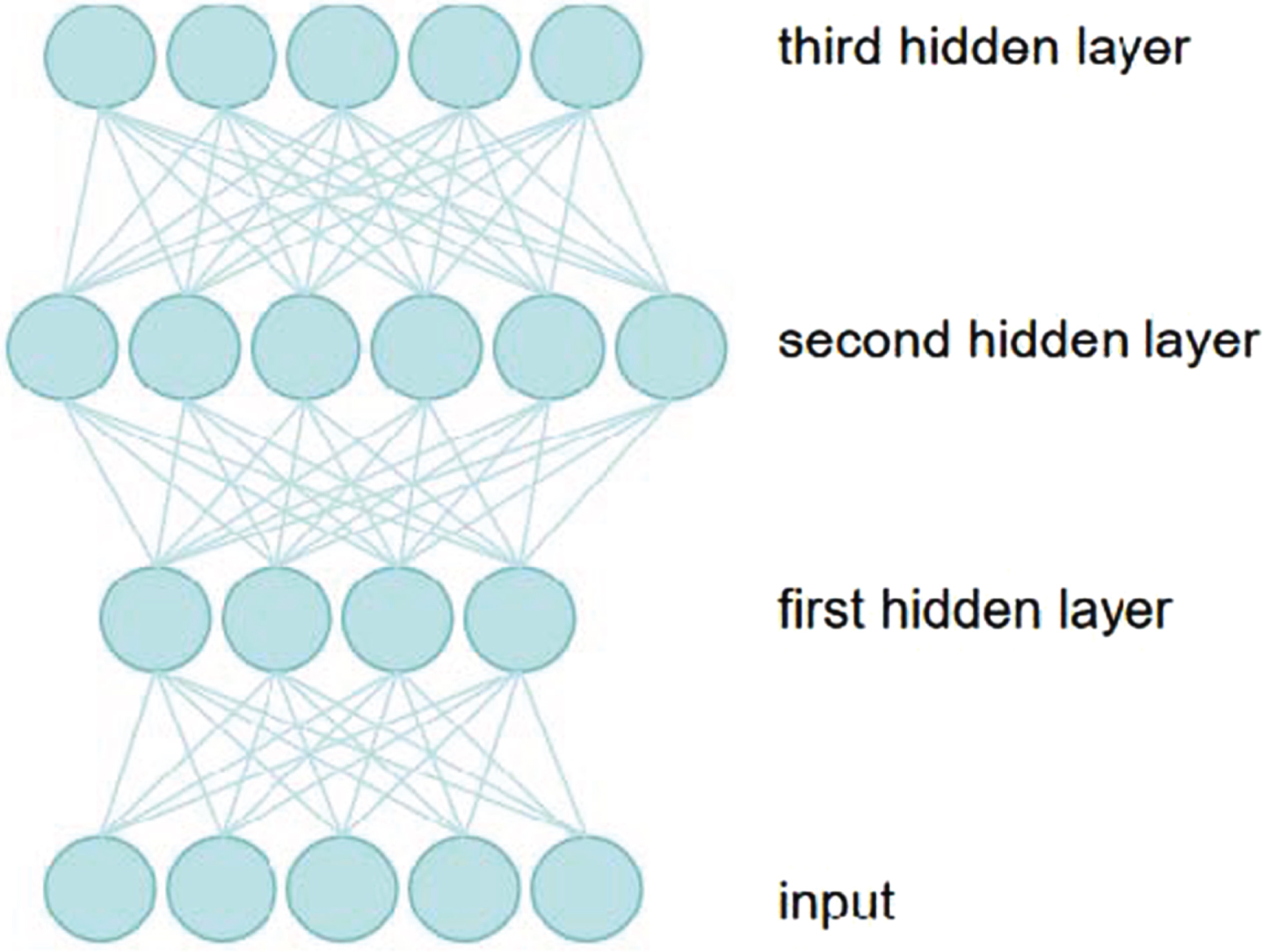
Three-layer structure stacked auto-encoder.
As can be seen from the Fig. 3, the number of input layer neurons and the dimensions of the input feature vectors are equal, an important characteristics of deep learning is characteristic of potential said can be obtained directly from the original data in the training [13]. Using its representable, self-learning nature, we can extract low-level features directly from neuro-images. For the training of the weight coefficient matrix and bias coefficient matrix parameters of our stacked auto-encoder model, the most direct method is to use the backpropagation algorithm and then update the parameters based on gradient optimization. It is equivalent to treating the stacked auto-encoder model as a traditional multi-layer artificial neural network, and the specific algorithm flow is as follows:
Input: Input feature vector set
Output: weight coefficient matrix W
i
, bias coefficient matrix b
i
Assign random initial values to weight coefficient matrix W
i
and bias coefficient matrix b
i
; Some of them were randomly selected from the training samples as input data. The output of the model was calculated according to the initial weight coefficient matrix and bias coefficient matrix. The error between output and input and its partial derivatives for each neuron were calculated. The weight coefficient and bias coefficient of the model were adjusted one by one according to the partial derivative value of error to each neuron. After the reverse adjustment, whether the error met the requirements was judged, if so, the calculation was stopped. If not, step 5 will be re-executed.
Considering that the BP algorithm of the deep learning network is very sensitive to the initial value, the random initial weight coefficient matrix and bias coefficient matrix will lead to the inconsistent results of each training of the deep learning network, and the results will not reach the global optimal solution [14]. In this paper, according to the nature of the stacked auto-encoder model belongs to unsupervised learning, a supervised learning step is introduced, and the whole training and learning process is divided into pre-training and fine-tuning. It overcomes the
The core of the pretraining-fine-tuning two-step algorithm is to train the weight coefficient and bias coefficient matrix of only one layer at a time, so that the operation can maximize the lower bound of the whole deep network [15]. The specific operation steps of the pretraining-fine-tuning algorithm are as follows: suppose that it is required to solve the bias coefficient matrix of the weight coefficient matrix of a two-layer stacked autoencoder. Input layer, the first and second hidden layer neurons number of hidden layers respectively for n1, n2, and n3.Coefficient of the connection between the input layer and the hidden layer parameters with W1, b1, said the connection between the first and second hidden layers of hidden layers on the coefficient parameters with W2, b2 said. Since the integrity of the encoder network stack type architecture as shown in Fig. 4.
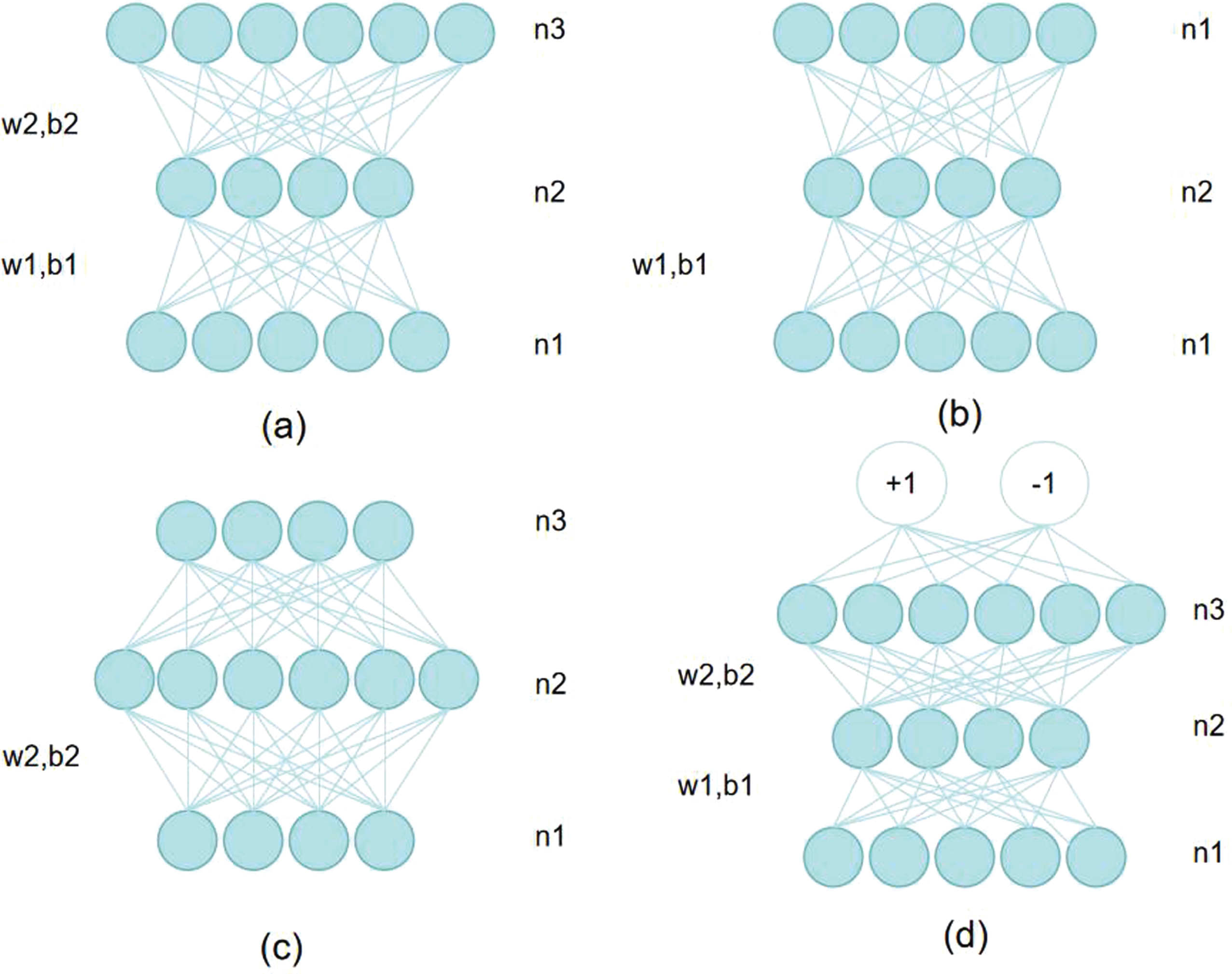
Pretraining-fine-tuning two-step algorithm flow.
From this figure, it can be seen that the pretraining-fine-tuning algorithm of the stacked auto-encoder is as follows:
Input: Training feature sample: X ∈ RD1×N, training sample label: L ∈ R N , sparsity parameter: γ, target average activation intensity: ρ.
Output: weight coefficient matrix
Step 1: Pre-train the hidden layers
Initialize: Y0 = X, for each hidden layer h∈ { 1, . . . , H }, the coefficient parameter
Step 2: Fine-tune the entire neural network
Initialize
To evaluate the efficacy of features extracted by the stacked sparse auto-encoder network, a classifier is employed to categorize data samples and classification accuracy is utilized to assess feature quality [16]. Support vector machine (SVM) was implemented for sample classification. Considering that what needs to be solved is the AD/MCI binary classification problem, only the binary support vector machine is considered below. C-SVC model is a more common binary support vector machine model, and the basic steps of its classification are as follows: Let the training set be known
Select the appropriate kernel function K (x, x′) and the appropriate parameter C, construct and solve the optimization problem: A positive component of is selected a = (a1, . . . , a1)
T
, and the threshold is calculated based on this:
Construct the decision function:
The SVM classifier designed in this paper can realize a series of models such as binary classification support vector machine, multi-classification support vector machine, and linear separable vector machine by setting different parameters to solve regression and classification problems.
Experimental design
In order to verify the effectiveness of the feature extraction based on the stacked auto-encoder network constructed in this paper, this chapter takes typical brain disease features as an example to conduct experimental analysis to verify whether the features extracted by the stacked auto-encoder network constructed in this paper are more conducive to brain disease classification tasks. In order to ensure the coverage of the experimental data, 129 normal subjects, 98 AD patients, 136 MCI non-conversion patients and 67 MCI conversion patients were selected in this paper. The experiment was divided into four control groups. In the first experiments, the two cohorts consisted of patients with mild cognitive impairment (MCI) who converted to Alzheimer’s disease (AD) and patients with MCI who did not convert. The second set of control experiments, the two cohorts included AD patients and healthy individuals [17]. In the third group of control experiments, the two types of subjects were MCI patients (including MCI patients and non-MCI patients) and normal subjects. In the fourth control experiment, two types of subjects were AD patients and MCI patients (including conversion and non-conversion patients). On this basis, a set of comprehensive experiments were carried out, taking MCI patients and MCI non-converted patients as experimental subjects, combining the two steps of feature extraction based on stacked autoencoder to classify, calculating the classification accuracy and evaluating the performance of the proposed stacked auto-encoder in the feature extraction of the new classifier. The whole experimental process is as follows: According to the idea of k-fold cross test, the whole dataset was divided into 10 parts, of which 9 parts were used as the training set and 1 part as the test set. Ten groups of training sets and 10 groups of corresponding test sets were obtained by cyclic operation 10 times. The training set was used to learn a stacked auto-encoder model, and the parameters of the stacked auto-encoder model were adjusted by the pre-training-fine-tuning two-step algorithm. The label information of the training samples in the supervised learning was used to make the model reach the optimal solution. The trained stacked auto-encoder model was used to extract features from the training set and the test set, respectively. The primary and SAE features of the same training set were used to train the corresponding SVM classifier, and the primary and SAE features of the same test set were used for classification, respectively [18]. The classification accuracy, sensitivity and specificity were obtained and compared. The experimental flow chart is shown in Fig. 5 below.
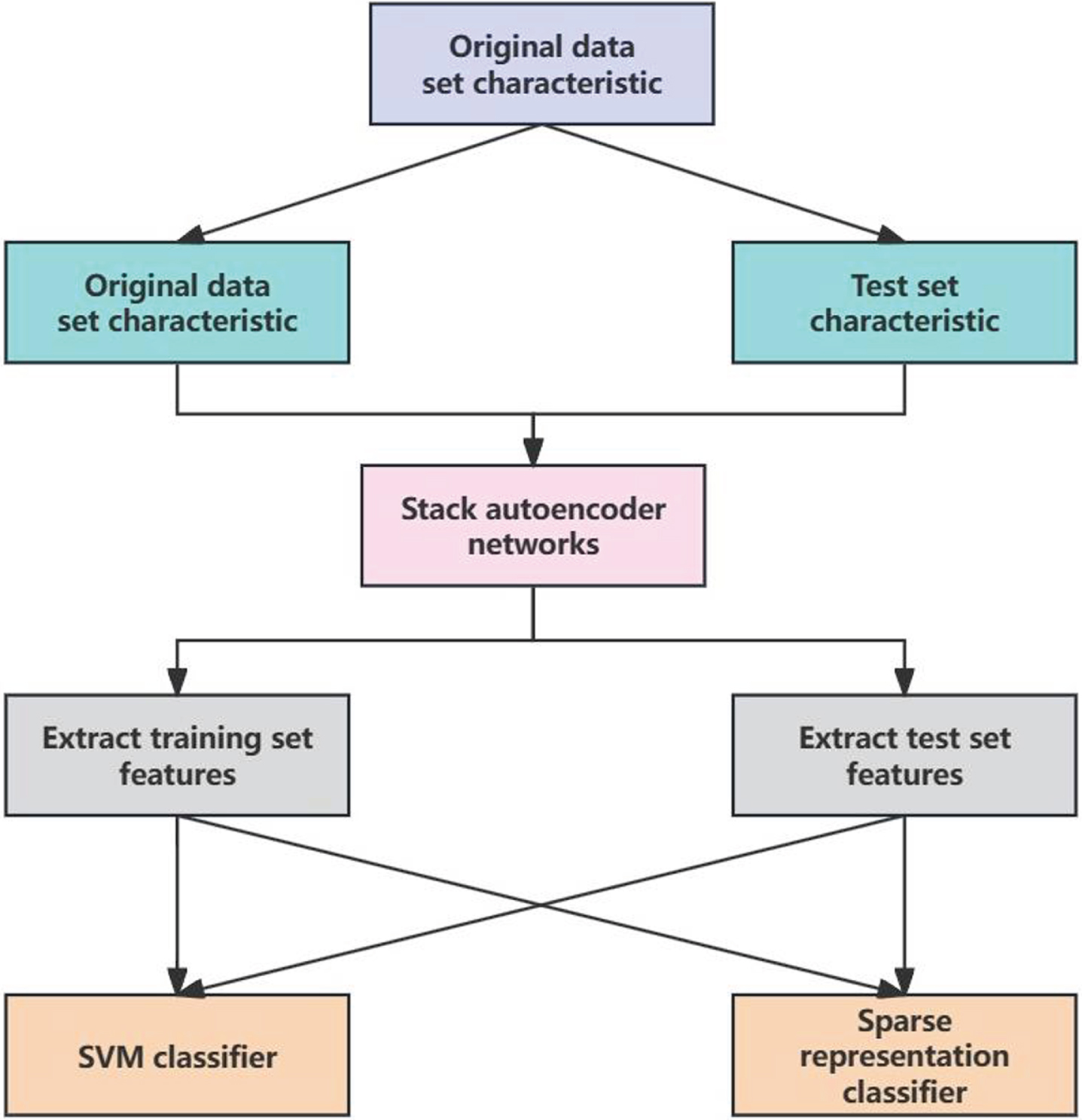
Experimental flow chart.
The first set of experiments
The experimental object is MCI-C and MC-NC. First, with the optimal parameters of the neural network training samples to determine stack, with the method of positive grid search, in turn, determine the three layers of hidden layer neurons number is 182105 and 10, respectively. Thus, for this set of experiments, the configuration of neurons in the stacked auto-encoder model was 93-182-105-10-93. The relationship between changes in neuron count within these hidden layers and classification accuracy is depicted in Figs. 6, 7, and 8.

The relationship between the classification accuracy of the first hidden layer and the number of neurons.
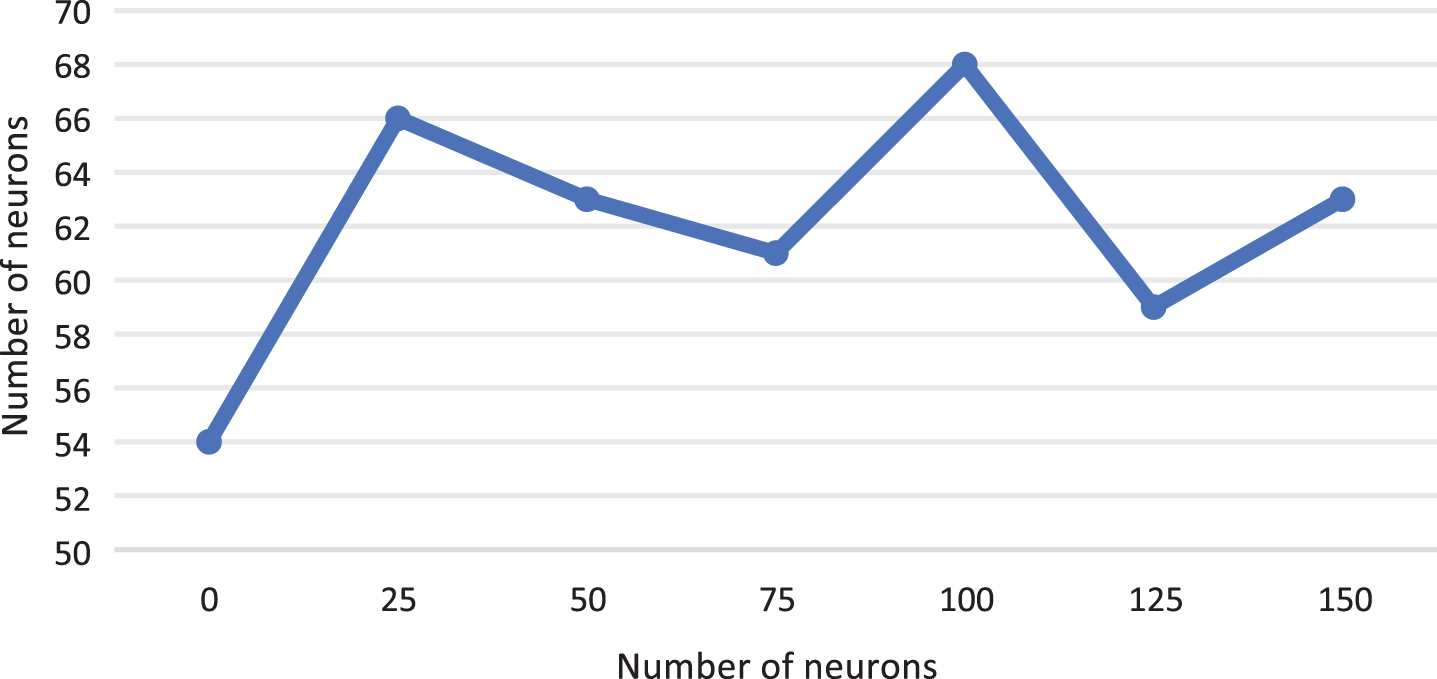
The relationship between the classification accuracy of the second hidden layer and the number of neurons.
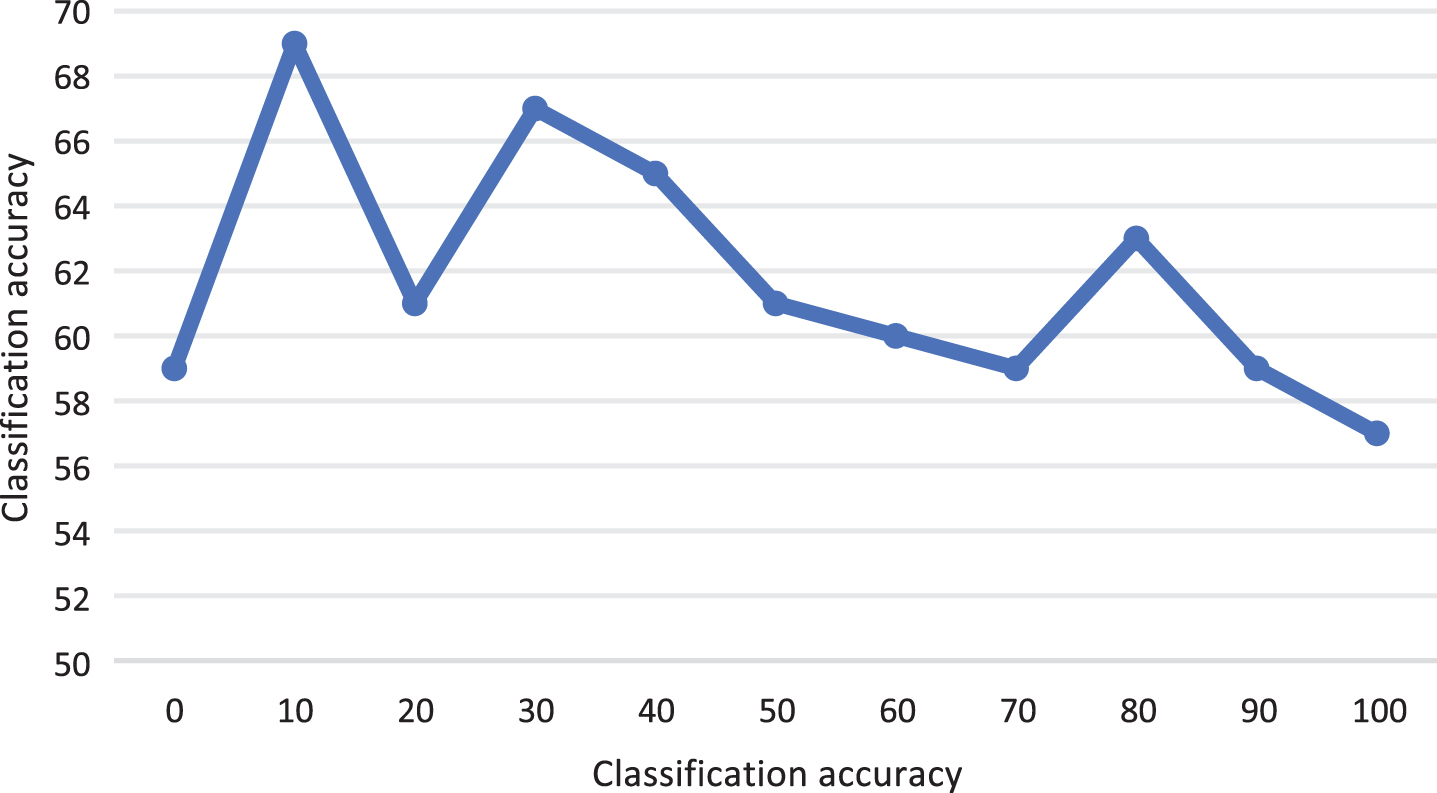
The relationship between the classification accuracy of the third hidden layer and the number of neurons.
After stacked auto-encoder network is obtained, the features of the original data samples can be extracted using the coefficient matrix. According to the number of neurons in the third hidden layer is 10, we know that the newly extracted feature is a 10-dimensional feature vector. This study includes the 93-dimensional primary extracted features (introduced as input) and the 10-dimensional SAE extracted features into the same SVM classifier. The classification accuracy, sensitivity and specificity results are shown in Table 1.
Classification accuracy corresponding to different feature vectors of MCI-C vs MCI-NC
As can be seen from the data in the table, the classification accuracy of the features extracted by the simple shallow auto-encoder is not only lower than that of the features extracted by the stacked auto-encoder, but also lower than that of the original features. This is because the features extracted by the shallow auto-encoder only compress their dimension on the basis of retaining the original information to the greatest extent, which will inevitably lose part of the information that is conducive to classification, resulting in the decline of the classification accuracy.
The study involved patients with Alzheimer’s disease (AD) and individuals without the condition, serving as normal subjects. Initially, the training samples were utilized to determine the optimal parameters for the stacked neural network [19]. Through a forward grid search approach, the number of neurons in each of the three hidden layers was determined. Consequently, the structure of the stacked auto-encoder model was established as 93-48-148-33-93. By considering the neuron count in the third hidden layer, it was possible to ascertain that new features extracted by this stacked auto-encoder network would possess a dimensionality of 33. The specific experimental results are presented in Table 2 below.
Classification accuracy corresponding to different feature vectors of AD vs NORMAL
Classification accuracy corresponding to different feature vectors of AD vs NORMAL
As can be seen from the data in the table, the classification accuracy of the feature vector extracted by SAE was slightly higher than that of the primary extraction, which increased from 86.2% to 87.6%, and the sensitivity and specificity changed from 85.9% and 86.5% to 84.9% and 90.0%, respectively. Similarly, we constructed a shallow auto-encoder with the structure of 93-33-93 to verify the effectiveness of the deep learning network. It can be seen that the classification accuracy of the features extracted by the shallow auto-encoder is only 83.2%.
The participants in this study consisted of individuals with mild impairment (including both those who converted to dementia and not) as well as healthy controls. Initially, the optimal parameters for the neural network were determined using the training samples. The forward grid search method was employed to calculate the number of neurons in each of the three hidden layers, resulting in 215, 207, and 61 neurons respectively. Thus, the network structure was defined as 93-215-207-61-93. Similarly, it was determined that the dimensionality of the newly extracted features would be 61. The specific experimental results are presented in Table 3 below.
Classification accuracy corresponding to different feature vectors of MCI vs NORMAL
Classification accuracy corresponding to different feature vectors of MCI vs NORMAL
As can be seen from the data in the table, the classification accuracy, sensitivity and specificity of the SAE extracted features are higher than those of the primary extracted features [20]. This shows that the stacked auto-encoder model we trained can well extract the potential high-level feature information from the original features, and these features are conducive to our classification task, that is to say, these features have a certain degree of discrimination.
The experimental object is patients with MCI and AD patients. In the first step, the optimal parameters of the neural network are determined using the positive grid search method in order to define the number of hidden neurons in each layer. Then, the number of hidden layer neurons obtained 171, 49, and 22. The experimental results are shown in Table 4 below.
Classification accuracy corresponding to different feature vectors of MCI vs AD
Classification accuracy corresponding to different feature vectors of MCI vs AD
According to the data in the table, the feature extraction work of this group was also done well, and the classification accuracy of the feature vector extracted by SAE increased by 5 percentage points.
To investigate the effect of feature extraction on the data of multiple time points, we trained the corresponding feature extraction network with the data of five time points. The experimental objects were MCI-C and MCI-NC patients, and the solution for the data object without multiple time points was to replace the data of the benchmark time point. The experimental results are shown in Table 5 below.
Comparison of feature extraction accuracy of MCI-C vs MCI-NC at multiple time points
Comparison of feature extraction accuracy of MCI-C vs MCI-NC at multiple time points
In addition, also by ROC curve drawing (ReceiverOperatingCharacteris - ticCurve) to calculate the area under the curve to evaluate the SAE to extract the features, the primary extraction and shallow to extract features of performance. The receiver operation characteristic curve is obtained by tracing the true positive rate as the vertical axis and the false positive rate as the horizontal axis under different threshold conditions. The receiver manipulates the feature curve as a tool to help us select an optimal model and discard the remaining models that do not meet the optimal criteria without relying on the threshold and sample class distribution. The closer the receiver operation characteristic curve is to the vertical axis, that is, the area under the curve is close to 1, indicating the better performance of the classifier. The specific results are shown in Fig. 9 below.
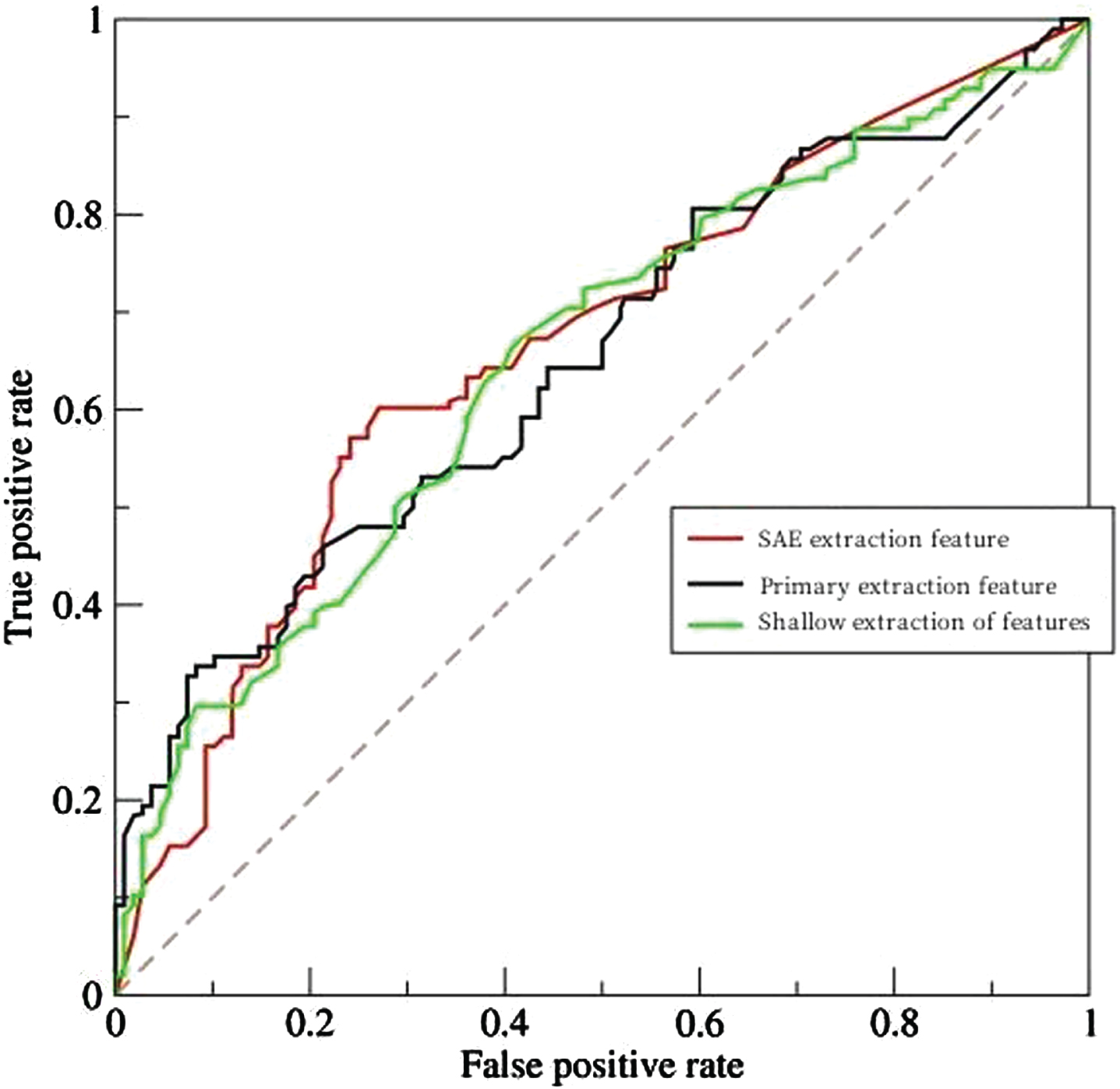
Receiver operation characteristic curves of different methods.
It can be seen from the data in Table 5, the accuracy of features extracted by the stacked autoencoder network is 3.2% higher than that of the primary extraction. Combined with the ROC curve, it is sufficient to prove that the operation of feature extraction by using the stacked autoencoder in the deep learning network for the original data samples is completely feasible and effective. Abstract and extracted features perform better when applied to classification tasks.
To sum up, as the most common brain diseases are cerebrovascular diseases and brain tumors, which are of great harm to human health, an accurate diagnosis system can provide help for the treatment of brain diseases. In this paper, the feature diagnosis of brain diseases such as AD and MCI is studied based on the neuroimage technology of deep learning algorithm, and a feature extraction method based on stacked autoencoder network is designed. The experiment verifies that the method has better accuracy and better classification performance than the traditional primary feature extraction. However, on the other hand, this study mainly focuses on the diagnosis of AD and MCI brain diseases, so whether the feature extraction method based on the stacked autoencoder network can be applied to other types of brain diseases needs to be further verified. In the future research work, the author will continue to improve the feature extraction method of the stacked autoencoder network. Finally, a learning algorithm covering multiple types of brain diseases is established.