
Abstract
Aspect Sentiment Triplet Extraction (ASTE) aims to extract aspect terms, sentiment polarity and opinion terms explaining the reason for the sentiment from a sentence in the form of triplets. Many existing studies model the context by graph neural networks to learn relevant information from the generated graphs. However, some sentences may have syntactic errors or lack significant grammar, which may lead to poor results on the dataset of the model. In this paper, we propose the Fusing Semantic and Syntactic Information for Aspect Sentiment Triplet Extraction (FSSI) model, which incorporates both syntactic structure and semantic relevance in the context. Specifically, we construct a syntactic graph convolutional network to obtain comprehensive syntactic structure information and a semantic graph convolutional network to obtain global semantic relevance of sentences using the self-attention mechanism. Furthermore, we concatenate the graph representations generated by the two graph convolution networks to obtain the final enhanced representation. Finally, we apply an effective inference strategy to extract triplets. Extensive experimental results on benchmark datasets show that our model outperforms state-of-the-art approaches.
Introduction
Aspect-based Sentiment Analysis (ABSA) [1, 2] is a fine-grained sentiment analysis task that aims to extract the aspect terms and their corresponding sentiment polarities in a sentence. In recent years, peng et al. [3] proposed a more relatively fine-grained task, Aspect Sentiment Triplet Extraction (ASTE) based on ABSA. ASTE focuses on extracting all triplets from the input sentence and every triplet contains an aspect term, the sentiment polarity and an opinion term. As shown in Fig. 1, the sentiment polarities of the two aspect terms “image” and “sound” are “positive” and “negative”, respectively, and the corresponding opinion terms are “great” and “poor”.

An example of an ASTE task with a dependency tree.
Existing sentiment triplet extraction models mainly include two methods. Pipeline approach [3] decomposes the task into independent subtasks, involving the extraction of aspect terms, opinion terms, and the determination of sentiment polarity in two distinct steps. Such technique lacks comprehensive understanding of the task and suffers from the error propagation problem, where the errors generated in the first stage would propagate to the second stage, affecting the final overall performance. Recent end-to-end frameworks [4–9] extract triplets at once by designing a unified tagging scheme. However, these methods do not effectively establish connections between words and linguistic features. There are various information interactions among triplets, more efforts have been devoted to graph convolutional networks (GCNs) and graph neural networks (GNNs) over dependency trees. These networks explicitly exploit the syntactic structure of a sentence to establish syntactic dependencies between words within it. Take Fig. 1 as an example, there is a nominal subject dependency between “image” and “great”, which indicates the presence of an aspect term. The two opinion terms “great” and “poor” are also related to each other and there is a connecting relationship between them, which implies that they have similar attributes. Nevertheless, previous works [8, 9] ignored the importance of modeling semantic information separately and did not effectively address the issues of incomplete extraction of multi-word aspects or opinions.
In this paper, we propose the Fusing Semantic and Syntactic Information for Aspect Sentiment Triplet Extraction (FSSI) model to solve the ASTE task and the overall framework of FSSI is shown in Fig. 2. FSSI takes into account the complementary nature of semantic and syntactic information, which is able to make full use of the relationships between words. First, we construct a syntactic graph convolutional network to obtain rich syntactic knowledge by parsing the probability matrix of dependency arcs using a dependency parser. This network has significant advantages in dealing with complex syntactic structures. By using the probability matrix to represent the dependencies between words, rich syntactic information can be captured for better understanding and parsing of sentence structures. Then, the semantic information is obtained by the semantic graph convolutional network, overcoming the shortcomings of not being able to obtain complete syntactic information due to unclear syntactic structure. Moreover, the primitive dependency tree can be regarded as a hard attention mechanism [10], when the aspect term is distant from its opinion term, the model may suffer performance degradation by failing to accurately capture syntactic information. In order to fully utilize the information in the semantic space, a semantic enhancement module is constructed by using the self-attention mechanism in the graph convolutional network. This attention matrix formed by self-attention can represent the semantic correlation between words. Finally, we concatenate the two modules of syntactic graph convolutional network and semantic graph convolutional network. Our extensive experiments on four benchmark datasets confirm that FSSI achieves predominant performance compared with existing state-of-the-art approaches.
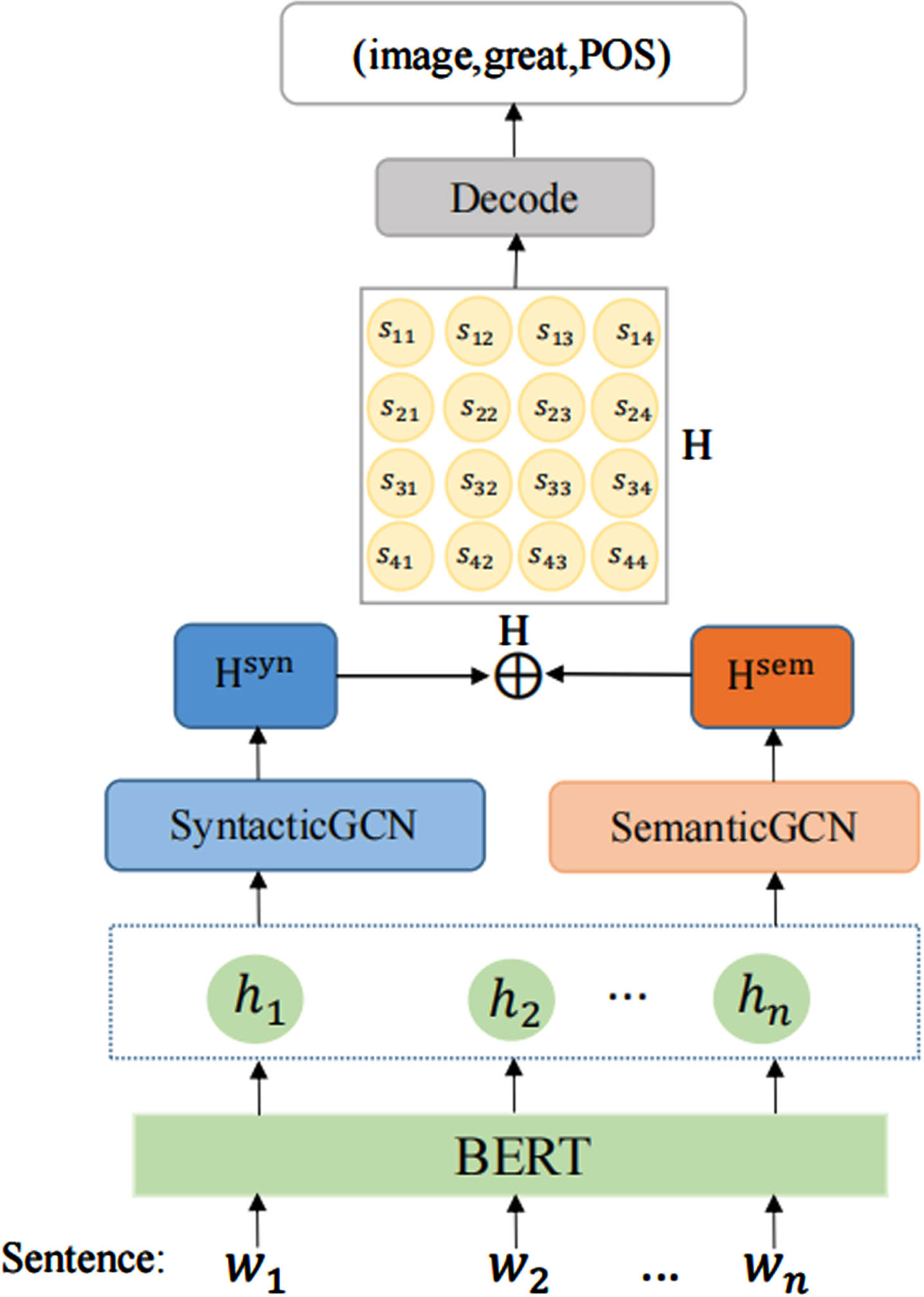
The overall architecture of our end-to-end model FSSI.
Our contributions can be summarized as follows:
1) We propose a FSSI model for the ASTE task. The model utilizes two graph convolutional networks to obtain semantic and syntactic information respectively.
2) We construct a semantic graph convolution module and a syntactic graph convolution module. An attention matrix is obtained as the adjacency matrix by self-attention mechanism to extract the most relevant information in the semantic space. At the same time, the dependency probability matrix is used to capture syntactic structure information.
3) We conduct extensive experiments and the results show FSSI significantly outperforms all state-of-the-art methods for triplet extraction.
Traditional sentiment analysis tasks are typically sentence-level [11, 12] or document-level [13, 14]. In contrast, Aspect-based Sentiment Analysis (ABSA) as a fine-grained sentiment analysis task aims to analyze aspect or entity oriented sentiment tendencies from unstructured text. The research process of ABSA can be divided into three phases: separate extraction, pair extraction, and triplet extraction.
The early task of ABSA is to explore three subtasks. Aspect Term Extraction (ATE) [15–21] and Opinion Term Extraction (OTE) [22–26] are to extract aspect terms and opinion terms in a given sentence, respectively. Aspect Sentiment Classification (ASC) [27–33] aims to predict the sentiment polarity of a given aspect term in a sentence.
Although the performance of a single task can achieve what one would expect, the dependency among these subtasks is ignored. Therefore, with the addition of the new task and the new benchmark datasets, work began on coupling these two subtasks, namely aspect-based pair extraction. There are two main tasks in this category: Aspect Opinion Pair Extraction (AOPE) [34–39] and Aspect Sentiment Pair Extraction (ASPE) [40–43].
Recently, to better understand the relationships between the various subtasks, Peng et al. [3] first introduced the ASTE task and presented a two-stage pipeline model. In the first stage, they treated aspect terms and opinion terms extraction as a sequence labeling problem, where aspect terms and sentiments were co-extracted as unified labels. Then, matching aspects and opinions in the second stage to obtain the final triplets. To further explore this task, [4–9] employ an end-to-end approach to address ASTE task. For instance, Xu et al. [5] proposed the end-to-end model with a new location-aware labeling scheme that jointly extracts the triplets. Wu et al. [4] exploited the Grid Tagging Scheme (GTS) to process ASTE tasks. Yan et al. [7] converted the ASTE task into a generative formulation. Chen et al. [8] addressed the problem via Graph Convolutional Network (GCN). However, these methods usually ignore the effective integration of syntactic structure and semantic relevance, and fail to improve model accuracy when aspect terms or opinion terms consist of multiple words.
Model framework
We design an effective framework to accomplish triplets extraction using an end-to-end fashion. The architecture of the whole model is shown in Fig. 2. In this section, we first define the ASTE task, describe the tagging schema and then decode the triplets.
Task definition
Let X = {w1, w2, … w
n
} denote a sentence of n tokens, the model aims to output a set of triplets T =
Relation definition and table filling
We use 10 labels G = {B-A, I-A, B-O, I-O, A, O, NEG, NEU, POS, N} proposed by Chen et al. [8] to denote the relationship between any two words in the sentence. B-A and I-A denote the beginning and inside of the extracted aspect terms, respectively. B-O and I-O represent the beginning and inside of the extracted opinion terms, respectively. A and O are used to determine whether the word pair consisting of two words belongs to the same aspect or opinion term. In addition, the tags POS, NEU, and NEG are used to determine the sentiment polarity of the aspect-opinion pair. Thus, a table of relation can be constructed for each labeled sentence using table filling [44, 45]. In Fig. 3, we show word pairs and their relations of an example sentence. Here, each cell corresponds to a word pair with one relation.
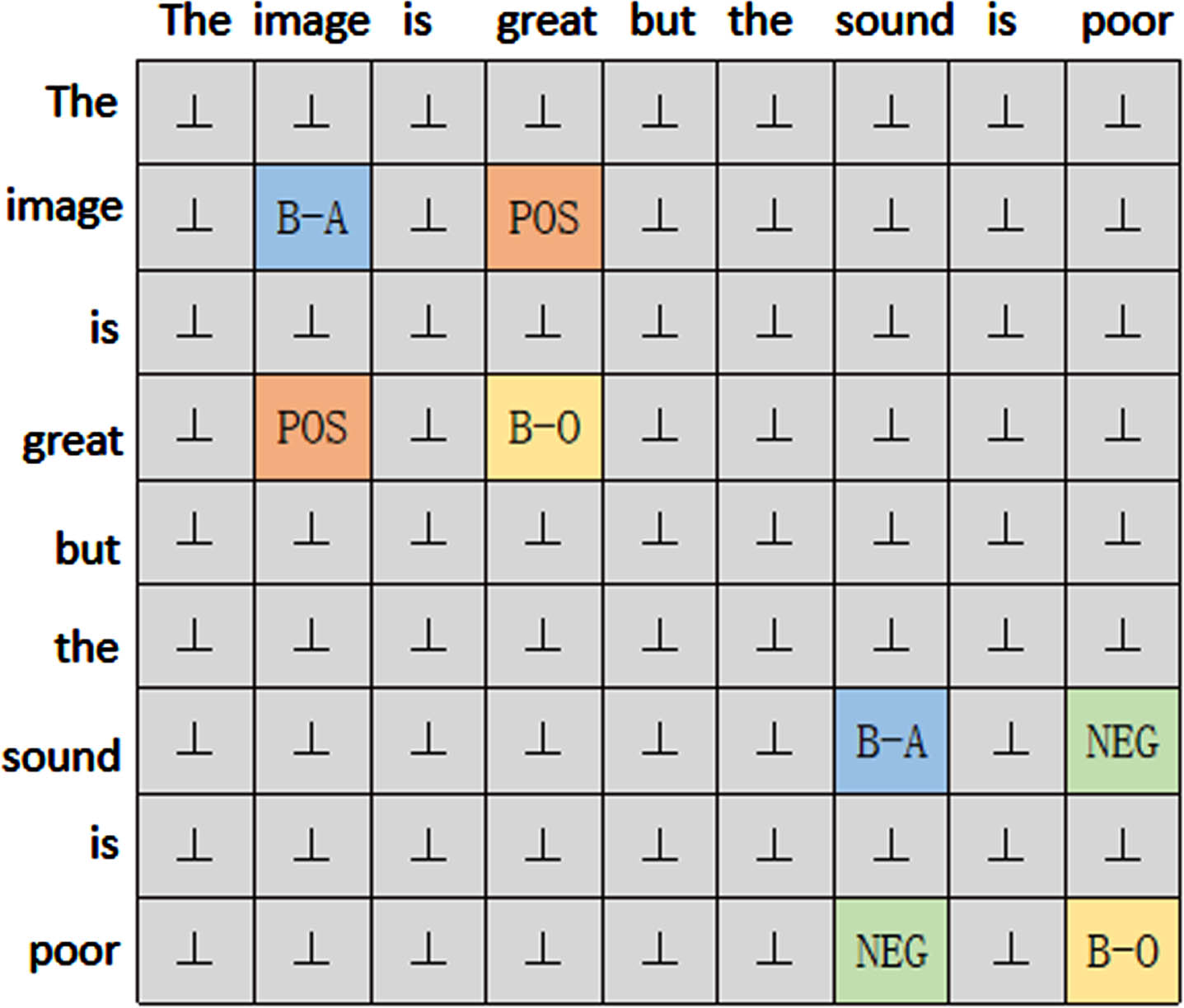
An example of EMC-GCN labeling.
We adopt the decoding algorithm designed by Chen et al. [8]. First, aspect terms and opinion terms are extracted using the predicted relationships of all word pairs (w i , w i ) on the main diagonal. Second, judging whether the extracted aspect terms and opinion terms match. In particular, for the aspect term a and the opinion term o that have been extracted, we compute the predictive relations for all word pairs (w i , w j ), where w i ∈ a and w j ∈ o. The aspect and opinion term are considered to be paired if there is any sentiment relation in the predicted relationship, otherwise they are not paired. Finally, to determine the sentiment polarity of aspect-opinion pair, the most frequent sentiment label s ∈ S is considered to be the sentiment polarity of the triplet (a, o, s).
Semantic and syntactic enhanced module
The aim of the ASTE task is to extract multiple elements from a sentence, so it is necessary to efficiently distinguish the attributes of words and to capture the relationships between them. In order to obtain multifaceted features, we use two GCNs to obtain syntactic dependencies and semantic correlations between words.
Input and encoding layers
For a given sentence X = {w1, w2, … w n } of length n, we utilize BERT [46] to obtain the contextualized word representations. Then, the sentence is represented as H = {h1, h2, … h n }.
Syntactic graph convolution module
We construct a graph convolutional network to obtain comprehensive syntactic information in the sentences, using syntactic information as input, as shown in Fig. 4. First, we utilize the LAL-Parser [47] to obtain the dependency tree of the input sentence. Then, the dependency probability matrix is obtained from the dependency tree, which can alleviate the dependency parsing errors.

Architecture of Syntactic Graph Convolution Module.
Given a graph with n nodes, we use the adjacency matrix A
syn
∈ Rn×n to represent the graph. The element
Utilizing the syntactic encoding of the adjacency matrix A
syn
, and the syntactic graph convolutional module adopts the hidden state vector H in BERT as the initial node representation in the syntactic graph. Then formula (1) is used to obtain the syntactic graph representation H
syn
=
Unlike syntactic graph convolutional representations, semantic graph convolutional representations obtain an attention matrix A sem as the adjacency matrix by self-attention mechanism. The self-attention mechanism can capture the semantic relevance of each word in a sentence, which helps the model to correctly understand the individual words in the sentence, as well as learn the relationship between words. Capturing contextual information by the self-attention mechanism is more flexible than syntactic structure. Moreover, the module can effectively handle sentences that are insensitive to syntactic information.
The attention score for each pair of elements was calculated in parallel via self-attention. In FSSI, we compute the attention score matrix A sem ∈ Rn×n by the self-attention layer. Then, using A sem as the adjacency matrix of our semantic graph convolution module, which can be formulated as:
In order to efficiently capture the relevant features between the two modules, we connect the semantic graph representation with the syntactic graph representation, i.e.,
In order to fully learn the information between the two modules, we impose a constraint, i.e.,
The total objective function is as follows:
Datasets
We evaluate our method on four datasets compiled by Wu et al. [4]. Table 1 lists the statistics of these datasets. 14res, 15res and 16res belong to the restaurant domain, while 14lap belongs to the laptop domain. Each sentence has been labeled with a series of aspect tags and opinion tags, as well as the sentiment polarity of the corresponding aspects. These datasets were originally derived from the SemEval Challenges (Pontiki et al., 2014 [2], 2015 [48], 2016 [49]).
Statistics of the Datasets
Statistics of the Datasets
We compare the performance of FSSI to state-of-the-art baselines. These models are simply categorized into two groups.
1) Pipeline methods
2) End-to-end methods
Implementation details
We use the BERT-base-uncased version as our sentence encoder. The learning rate is 2 × 10-5 for BERT fine-tuning. The learning rate for the other trainable parameters is 10-5, and the dropout rate is 0.5. We use AdamW optimizer [50] as FSSI optimizer. The hidden state dimensions for BERT and GCN are set to 768 and 300. The dropout rate of the GCN is set to 0.1, and the number of GCN layers is 2. The FSSI model is trained in 100 epochs with a batch size of 8. Additionally, we set the hyperparameters λ1 and λ2 to 0.2 and 10-4 respectively. All sentences are parsed by Stanza [51].
Following previous work, we report experimental results based on precision (P), recall (R), and F1 scores. Note that the F1 score measures the performance of the triplets, which means that a triplet is correct only if its aspect span, corresponding sentiment and opinion span are all correct.
Main results
Table 2 gives the main results of the final triplet extraction. The end-to-end approaches achieve more significant improvements than the pipeline approaches because they are able to better integrate the information between these subtasks. Compared to Grid-BERT, FSSI model increases the absolute F1 score by 0.76% and 2.98% on 14res and 14lap, respectively, and significantly outperforms it by 2.41% and 3.14% on 15res and 16res, respectively. And FSSI increases the absolute F1 score by 0.70% and 2.54% on 15res and 16res, respectively, compared to EMC-GCN. These results show that our model effectively utilizes syntactic knowledge and semantic information and is able to accurately match datasets containing formal, informal, or complex comments.
Experimental results of triplet extraction. The best results are shown in bold. The mark “-” indicates that the original code of the IMN method does not contain the resources needed to run on the dataset 16res
Experimental results of triplet extraction. The best results are shown in bold. The mark “-” indicates that the original code of the IMN method does not contain the resources needed to run on the dataset 16res
Ablation experiments
To further investigate the role of different modules in the model, we conduct extensive ablation studies on the ASTE task. The results are shown in Table 3. FSSI represents our full model, and we evaluate the role of each module by using two model variants. Syn means removing the syntactic graph convolution module and Sem means that we remove the semantic graph convolution module. The experimental results show that our two graph convolutional networks are able to accurately capture the syntactic and semantic information in a sentence. In summary, each module in the FSSI contributes to the overall performance of the ASTE task.
Results of ablation experiments for the ASTE task
Results of ablation experiments for the ASTE task
We evaluate the effects of different numbers of graph network layers on model performance on four datasets, as shown in Fig. 5. The experiments show that graph convolutional networks usually get the best performance with two layers, and deeper layers do not give better results for the model. If the number of layers in the graph network is too small, the node representation cannot propagate far. And when there are too many layers, the model becomes unstable.
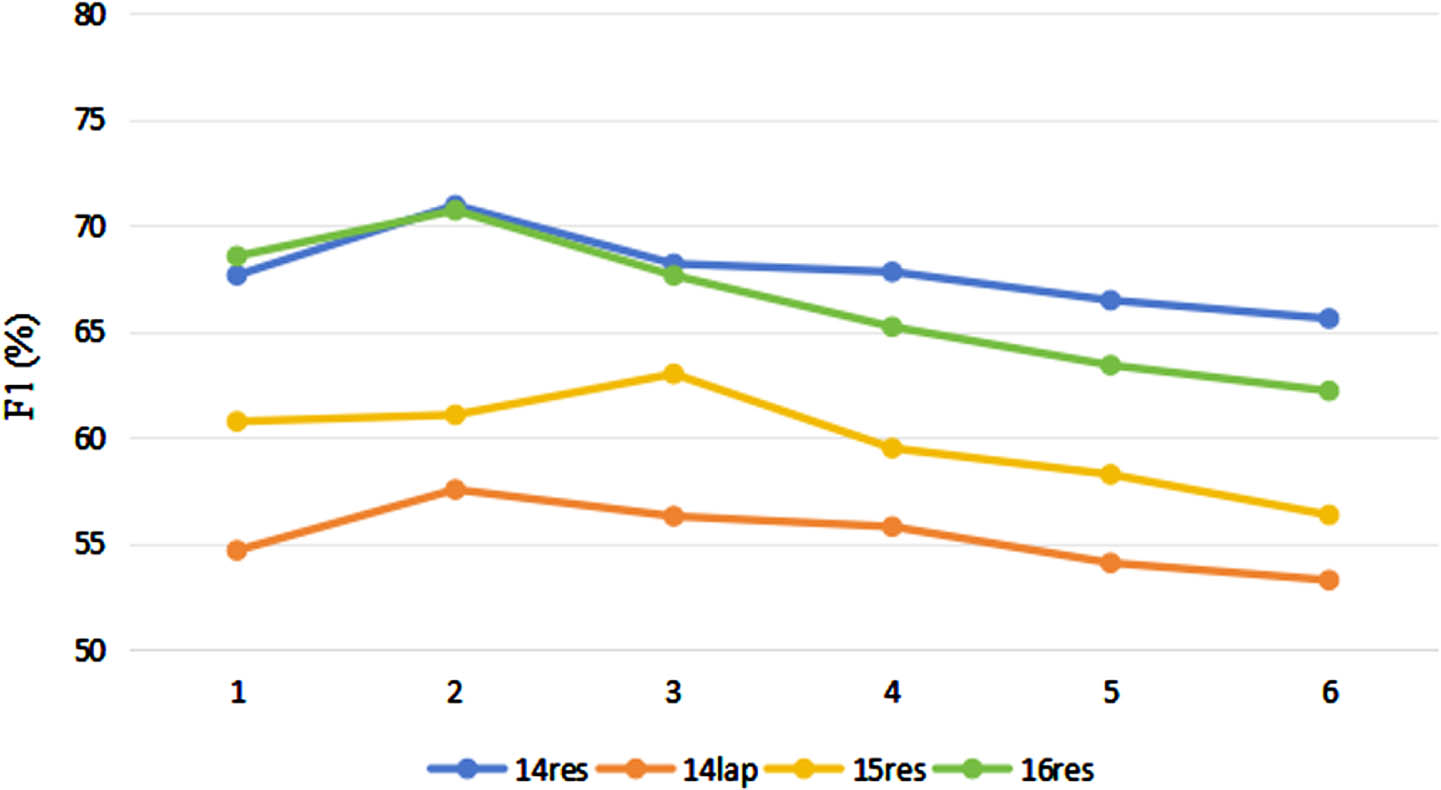
Effect of the number of GCN layers.
Tables 4 and 5 show some typical comment sentences analyzed using the three models. The first column shows four representative sentences, the second column shows the labeled true triplets, and the third column shows the outputs of the different models.
In the first example, all models extract the triplets accurately because the sentences are relatively simple and do not have complex sequences. In contrast, in the second and third examples, aspect terms or opinion terms consist of multiple words with one-to-many or many-to-one relationships. At this point, only model FSSI succeeds in extracting accurate triplets. Although model S3E2 can extract “battery life” and “no issues”, it fails to accurately predict sentiment polarity. Model GTS has incomplete triplets when processing aspect terms or opinion terms composed of multiple words, indicating that it lacks sufficient contextual semantic and syntactic interactions. In the third example, the aspect term “touchscreen functions” is far away from the opinion term “not enjoy”, which prevents both model GTS and S3E2 from extracting the triplet accurately. Our model FSSI can handle this complex and informal sentence by fully considering the complementarity of syntactic knowledge and semantic information. The fourth example involves a complex opinion term “left much to be desired”, which consists of multiple words and is an implicit opinion. All three models fail to accurately extract triplets. Overall, FSSI has the highest accuracy. However, our model still needs to be improved in terms of implicit extraction. Therefore, future work will focus on refining the extraction of multi-word implicit triplets.
Case study of S3E2
Case study of S3E2
Case studies of GTS and FSSI
In this paper, we propose an FSSI model for the ASTE task. In order to effectively overcome the lack of syntactic structure ambiguity that leads to parsing errors, we use two GCN modules to integrate syntactic knowledge and semantic information. Furthermore, we utilize semantic graph convolution module to obtain semantic information and effectively capture the internal connections among the triplets in a sentence. The experimental results show that FSSI achieves strong performance and is able to capture the relationship between word pairs significantly. Additionally, the ablation studies validate the role of each element in the model. In our future work, we will further utilize the semantic relations between contexts to improve the accuracy of one-to-many or many-to-one relations between the aspect terms and opinion terms as well as multi-word implicit extraction in sentences.