
Abstract
In networks, dynamic phenomena such as opinions, behaviors, and information are propagated through connections between entities. Indeed, one of the main issues about a dynamic process is to find a set of individuals with a high influence on other’s decisions which is defined as the “influence maximization” problem, and aims to find a subset of nodes to maximize the total number of adopters at the end of the process.
In this paper, by combining the community structure and influence maximization problem, we proposed a two-layered method for identifying influential nodes so that in the first layer an optimization-based method is applied to detect the potential communities. Then, in the second layer, a criterion is used which is a tradeoff between the low-relevant centralities and methods with high complexity. Our method is implemented on real social networks with different scales, and the performance is evaluated by using the total number of infected nodes at the end of the process. The experimental results indicate the superiority of our method in comparison to other considered approaches by considering the efficiency and scalability.
Keywords
Introduction
Social networks are an abstract representation of social systems where information and ideas are propagated through the interaction between entities [58]. Moreover, everybody can use a social network based on its interests indicating the flexibility and high potentiality of these networks [23].
One of the most important tasks in analyzing social networks is the detection of community structure [38], which have been used in a wide range of applications [3, 4, 21, 22, 29]. In fact, a community is defined as a group of entities that the number of interactions within the group is much higher than the number of interactions outside the group [35]. Figure 1 represents an example of a social network with 23 nodes divided in 2 communities.
A social network including 2 communities.
On the other hand, with the rapid development of online social networks such as Facebook, Twitter, YouTube, etc., the influence maximization problem has become one of the main issues in diffusion process. And, it is defined as a way to find influential nodes in order to propagate innovations and information so that at the end of the process a large part of individuals adopt the information (or product) [7]. Meanwhile, influential nodes refer to nodes who have more influence on their neighbor’s behaviors and decisions [5, 35] – in other words, they have proper spreading features in networks [34]. Indeed, studying influential nodes can help us better understand the features of a complex network necessary for controlling actions occurring through these networks [55]. Figure 2 represents a directed social network consisting of 7 nodes where node 2 is considered as an influential node based on degree centrality metric. Although the degree centrality can be defined based on both in-degree and out-degree of a node, but in the given example, just the out-degree of nodes are considered.
An example of influential node based on degree centrality.
On the one hand, by considering the importance of the community structure, and on the other hand because of the considerable influence of nodes within a community on their neighbor’s decision, it can be a good estimation to choose influential nodes from candidate communities instead of the whole network. So limiting a social network to its proper extracted communities leads to a cost reduction for identifying influential nodes [35, 51].
Thus, in this paper, a two-layered method called CNLPSO-SL is proposed so that in the first layer the communities of a given social network are identified. Then, in the second layer, by applying a semi-local centrality, the influential nodes within candidate communities are detected.
The rest of the paper is organized as follows: Section 2 overviews related works of the influence maximizationproblem. In Section 3, the main concepts of influence maximization are stated. In Section 4, our method is proposed in two subsections: the method description and implementation. In Section 5, datasets, methods, final results of experiments, and the comparison between mentioned methods are presented. Finally, Section 6 concludes the paper.
In recent years, many methods have been proposed for identifying influential nodes in order to solve the influence maximization problem. Richardson and Domingos were the first who studied influence maximization as an algorithmic problem in which customers represent the nodes of the social network, and their influence was modeled as Markov Random field [8]. Then, in [42], they extended and applied their idea, inspired from their previous work, for knowledge-sharing sites. Indeed, they expressed how to find the optimal viral marketing plans, and also to reduce the computational costs. Also, authors in [20] were among the first who formulated influence maximization as a discrete optimization problem. They presented a greedy algorithm which obtains a solution with 63% of optimality for several classes of models. In [20], by applying a hill-climbing strategy, a simple greedy algorithm was proposed for influence maximization problem. In [10], a set greedy algorithm was proposed which deals with overlapping neighbors. In this method, nodes with the highest uncovered neighbors were selected as influential ones, and the process continues until all the K seed nodes were selected. In [25], a Cost Effective Lazy (CELF) algorithm was proposed which used a sub-modularity feature to reduce the number of evaluations in influence diffusion, and two improved versions of this method was proposed by [17, 31]. In [48], a genetic greedy algorithm was proposed which combines the strength of genetic and greedy algorithm. Many other greedy-based approaches were also proposed for influence maximization problem [49, 56, 59].
Furthermore, for detecting influential nodes, many other methods considered the importance of nodes which is a fundamental criterion to specify the structure and also dynamics of complex networks. Degree, betweenness, and closeness centrality are among the widely used criteria in the influence maximization problem [9, 14, 28, 33, 55]. Degree centrality [36] considers the degree of a node to select the influential users. In other words, more the number of the neighboring are, more the important the nodes are [55]. Another widely used criterion is betweenness centrality [11] defined as the number of shortest paths passing through a given node. The closeness centrality [12] is based on the distance between nodes which studies how long it will take information to spread from a given node to others. Authors in [28] proposed a neighborhood centrality which considers the centrality of a node and its neighbor’s. DIL method was proposed by [27] which is based on the degree and the importance of lines, and only the local features of nodes are required to evaluate the importance of them. Moreover, many extended versions of aforementioned centralities have been proposed by researchers [1, 18, 45, 47].
In addition to mentioned methods, some approaches were proposed by considering the community structure. For example, in [2], authors identified existing communities of a given social network by applying Pareto’s Law, and then considered degree, link, and closeness centrality for identifying influential nodes. In [51], CGA algorithm was proposed in which social network communities were selected based on label propagation method. Then, Mix-greedy algorithm was used to select the influential nodes in each candidate community, where was selected by dynamic programming method.
Because optimization-based methods have become one of the most effective ways for solving community detection problem, in our proposed method, CNLPSO-DE was applied to identify the communities of a given network. And also, because large communities include more nodes in comparison to smaller ones, we then considered the size criterion to select the candidate communities, and finally identified the influential nodes based on a semi-local centrality which is a trade-off between the low-relevant centralities and methods with high complexity.
Preliminaries
In this section, by assuming
Influence maximization problem
The issue is defined as a discrete optimization problem in which at first an initial “seed set” with cardinality
Structure of the influence graph [50].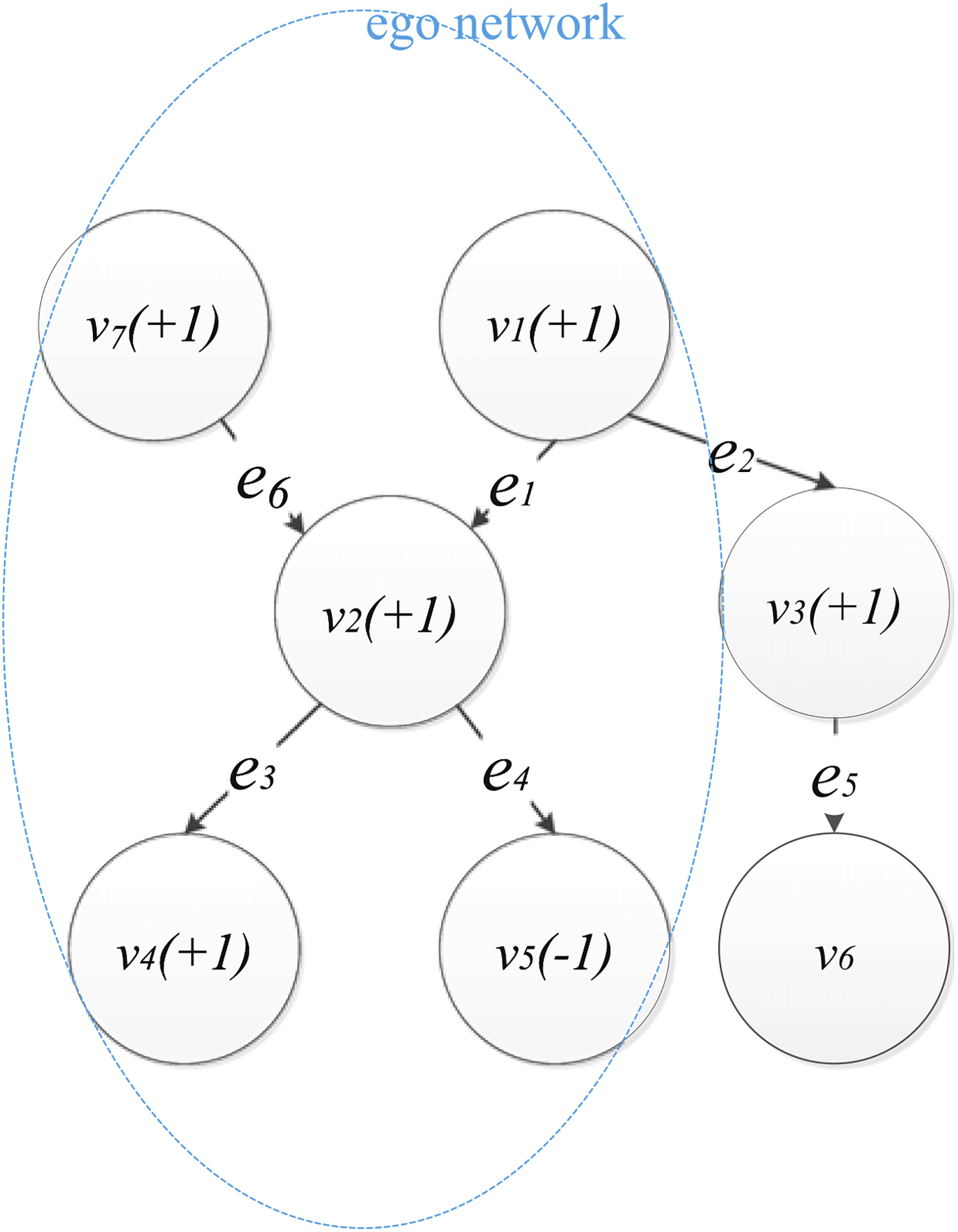
The influence graph is a directed graph representing the relation of who influences whom. Figure 3 shows a social influence graph in which the edge
Diffusion models
Diffusion models are essential elements for simulating the propagation process of ideas, products, information, disease, etc. For this purpose, in this section, we describe two of the most widely used diffusion models named independent cascade and linear threshold model. In both cases, a node can be in one of two states either “active” or “inactive”. Indeed, in these models, all the nodes are inactive at the beginning so that after adopting the information the node will become active. Also only the conversion from “inactive” state to “active” state is allowed in these models [58].
Independent cascade (IC) model
In this model, a random value
When a typical node
Independent cascade model [57].
Influence propagation in linear threshold model [24].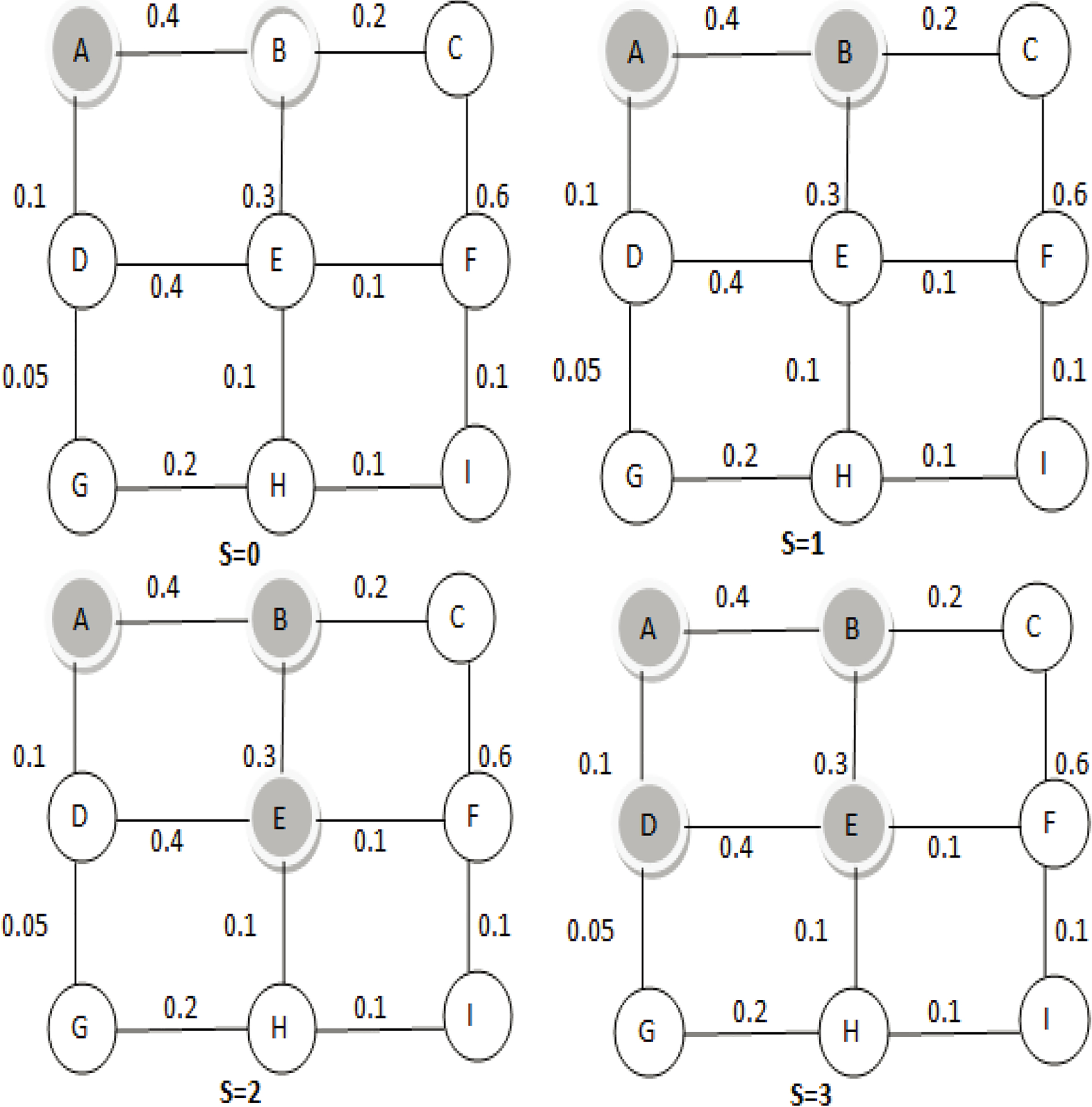
In this model, a uniformly distributed threshold
Figure 5 shows an influence propagation process for LT model. Authors considered a same threshold value for each node
By considering the importance of community structure feature, and its considerable effect on influence maximization issue, in this paper, we proposed a two-layered method, CNLPSO-SL, for detecting influential nodes by combining community detection and influence maximization problem so that in the first layer the existing communities of a given social network are identified, and then in the second layer by applying the size criterion candidate communities were selected. Finally, we used a heuristic based measure for identifying influential nodes within candidate communities. In fact, this section is presented in two sub-sections. First, in Section 4.1, each part of CNLPSO-SL method is described, and then the implementation is given in Section 4.2.
Method description
In our proposed method, an optimization-based algorithm named CNLPSO-DE was applied for network partitioning. Then, by considering a size criterion, the candidate communities were selected, and the influential nodes were identified by applying a semi-local centrality (within candidate communities). An overall architecture of CNLPSO-SL is represented in Fig. 8 which each of its part is explained in detail as follows.
Network partitioning
Recently, using optimization-based methods have become one of the most effective ways for solving the challenges of community detection [16]. So, in the network partitioning phase, a multi-objective optimization method CNLPSO-DE was applied [39]. In fact, it utilizes some of the benefits of evolutionary algorithms such as strength and flexibility on the one hand, and convergence speed along with high performance of particle swarm optimization method on the other hand. And also, in comparison to single-objective approaches has the following benefits [46]:
Detected solutions are always as well as or better than the single objective ones. Evaluates community structure from different aspects. The number of communities can be automatically determined during the process.
The algorithm starts with a population of particles which each particle is a partition
Where
First of all, particles are initialized by applying an initialization method based on opposition-learning strategy [41]. Then, the particles move toward the search space to find the optimal solution, and update their current states by updating the position and the velocity of particles. Also, in order to maintain the diversity of the population, and escape from the local optima, a mutation operator was applied. The accuracy of the partition was evaluated by the most common multi-objective function (for further details, readers can refer to [39]).
After detecting communities in the given social network, the main challenge is to select the suitable communities for identifying the influential nodes. One of the criterion for solving the issue is to select large communities because they include a large number of nodes in comparison to smaller communities, and selecting initial nodes within this communities will result in more activation in diffusion process [54].
Decoding process of a particle [39].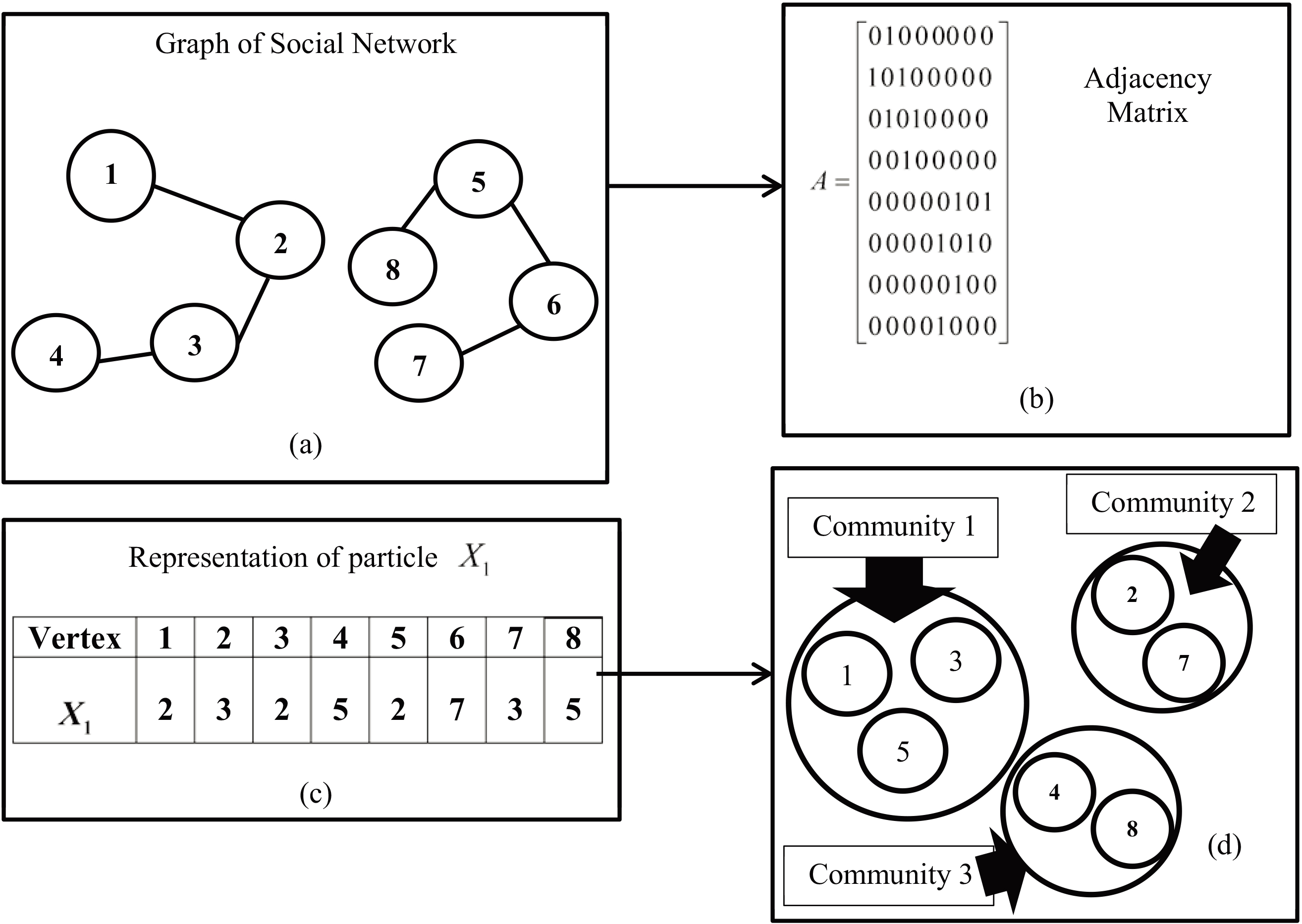
An example of a network consisting of 23 nodes and 40 edges. Although node 23 has lower degree than node 1, it may have even higher influence [6].
The architecture of CNLPSO-SL.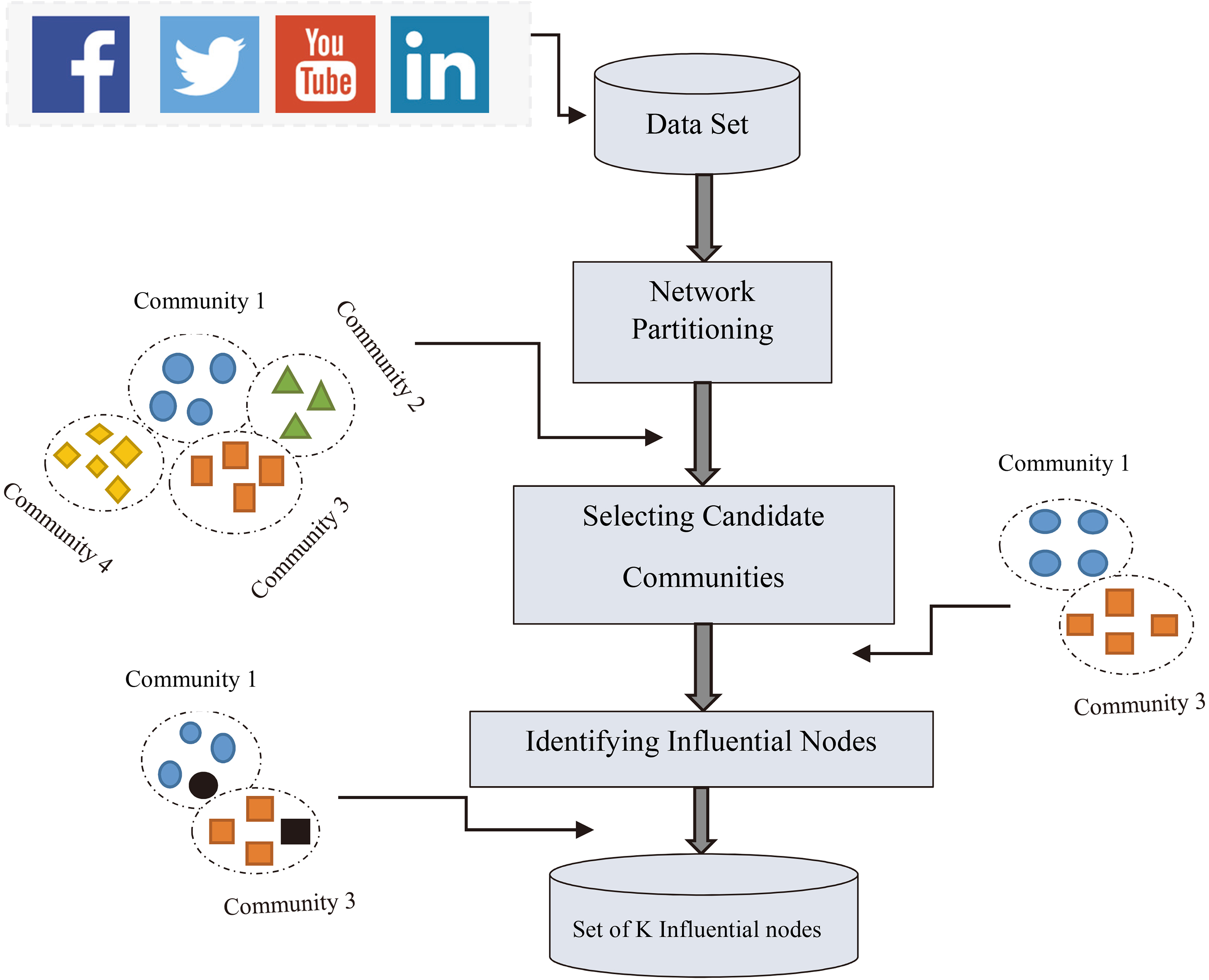
Detecting influential nodes is a main challenge in complex networks where a large number of centrality criteria were proposed by researchers. In addition to their application in solving influence maximization problem, they face some challenges [9]. For example, the high-degree centrality is one of the most widely used criterion which considers the number of directly connected links to a node as its degree [27], and also it has a reasonable runtime performance [45]. But, it is still a less relevant measure. In return, global measures such as betweenness and closeness centrality may have a better ability for detecting influential nodes, but because of their high computation complexity they are not suitable for large scale networks [6].
On the other hand, experimental results indicate that measures considering the neighbor of nodes are more accurate for identifying influential nodes [28]. So, we applied a semi-local centrality [6] which is a trade-off between the low-relevant degree centrality and the time-consuming criteria such as betweenness and closeness centrality. Indeed, it outperforms high-degree centrality [32] because of considering more structure information, and also in comparison to closeness centrality has a lower computation complexity [6]. The criterion considers both the nearest and the next nearest neighbor of a given node, and is computed as follows:
Where
After detecting candidate communities, semi-local centrality is computed for each of the nodes within candidate communities, and then the computed values are sorted in a decreasing order where the node with the maximum centrality value is selected as the initial active node. After determining the initial active nodes set, by applying IC diffusion model [10, 44, 57], propagation unfolds through the given network.
In this section, the implementation of the proposed method is presented, consisting of two parts where the overall implementation of the method is presented in the first part, and in the second part the implementation of applied heuristic is proposed.
Implementation of CLPSO-SL approach
Figure 9 represents the pseudocode of CNLPSO-SL where a social network
Pseudocode of CNLPSO-SL algorithm.
Pseudocode of the heuristic [7].
Because selecting seeds from large communities in comparison to smaller ones can trigger more adoptions of a product or information, some configurations were adjusted [7] where their basic idea is to use heuristics “
Indeed, the adjustment is for investigating whether selecting nodes from large communities will result in more influence spread where the influence spread
Dolphin social network [15].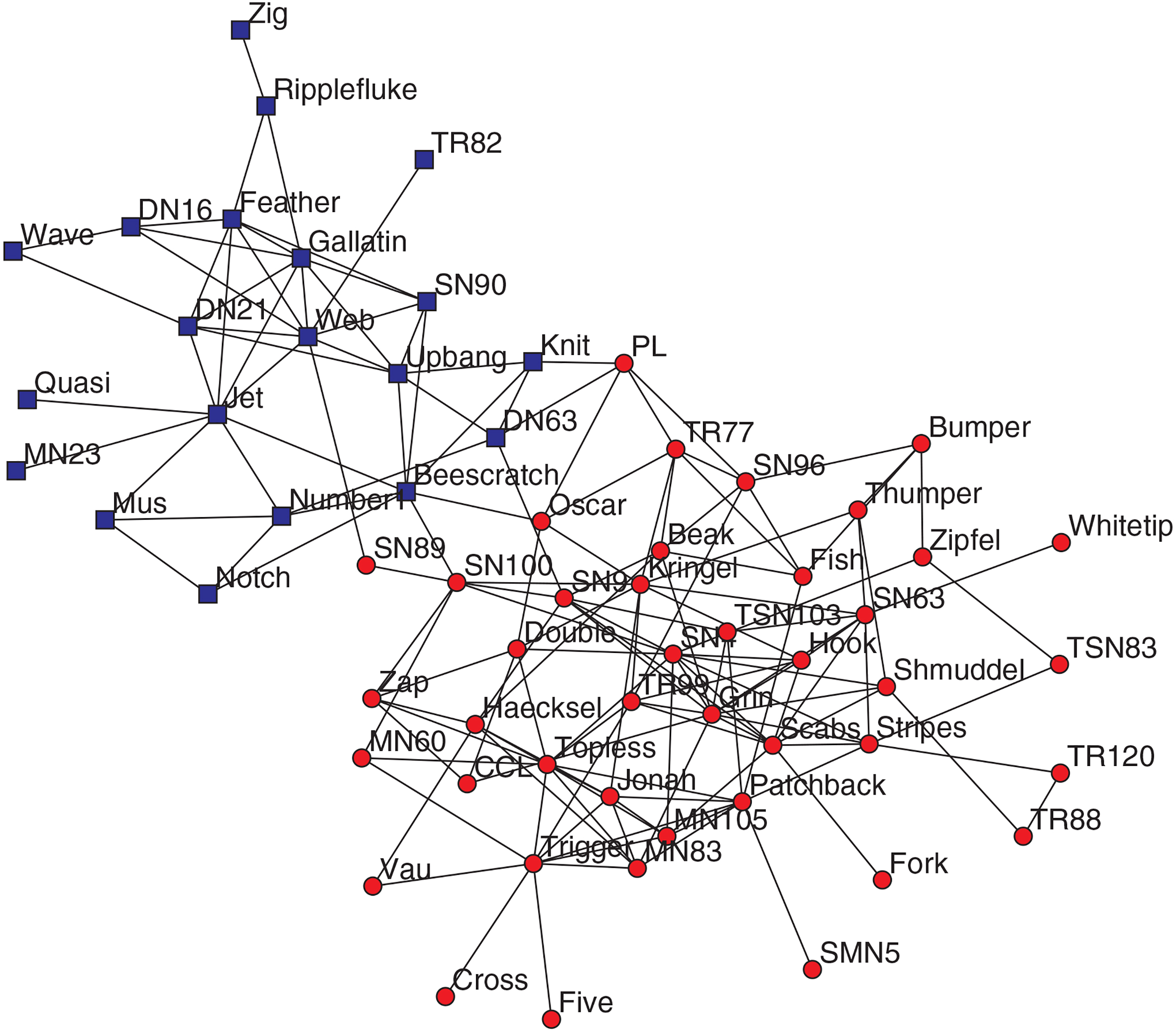
This section is organized in 5 parts. First, the datasets are described in Section 5.1. Then, the main idea of the comparing methods is explained in Section 5.2. In Section 5.3, the evaluation metric is stated. The results of experiments are presented in Section 5.4. And finally, the discussion is proposed in Section 5.5.
Dataset
In our experiments, datasets with three different scales (small, medium, large) were used which some of them are ground truth so that the exact number of their communities is specified, such as dolphin social network, but in contrast there exists other datasets with unknown number of communities like Netscience and Hep-physics (Datasets were extracted from
The first dataset is a network with 62 dolphins (Fig. 11) obtained by Lusseau during 7 years studying the behaviors of dolphins. The network is naturally divided into two communities, and each edge was established based on frequent associations [15, 37].
Netscience, the second dataset, is a network with 1589 nodes where nodes represent scientists, and each edge connects two authors having collaboration on the same article. Indeed, is a network of co-authorship of scientists working on network theory and experiment [16, 46].
The third dataset including 10748 nodes is a weighted network of co-authorship between scientists posting preprints about high-energy theory [18, 35, 46], where an unweighted version of the network was handled in this paper. These datasets have been widely used by researchers in both community detection and influence maximization problem [16, 27, 28, 32, 46, 52], and their details are denoted in Table 1.
Dataset description
Dataset description
Degree centrality is one of the widely used heuristics proposed for estimating the influence of a node in complex network in which a node with maximum degree is selected as an influential node. Indeed, it represents a large number of connections between the node and its neighbors, and is defined as follows [13]:
Dolphin network with 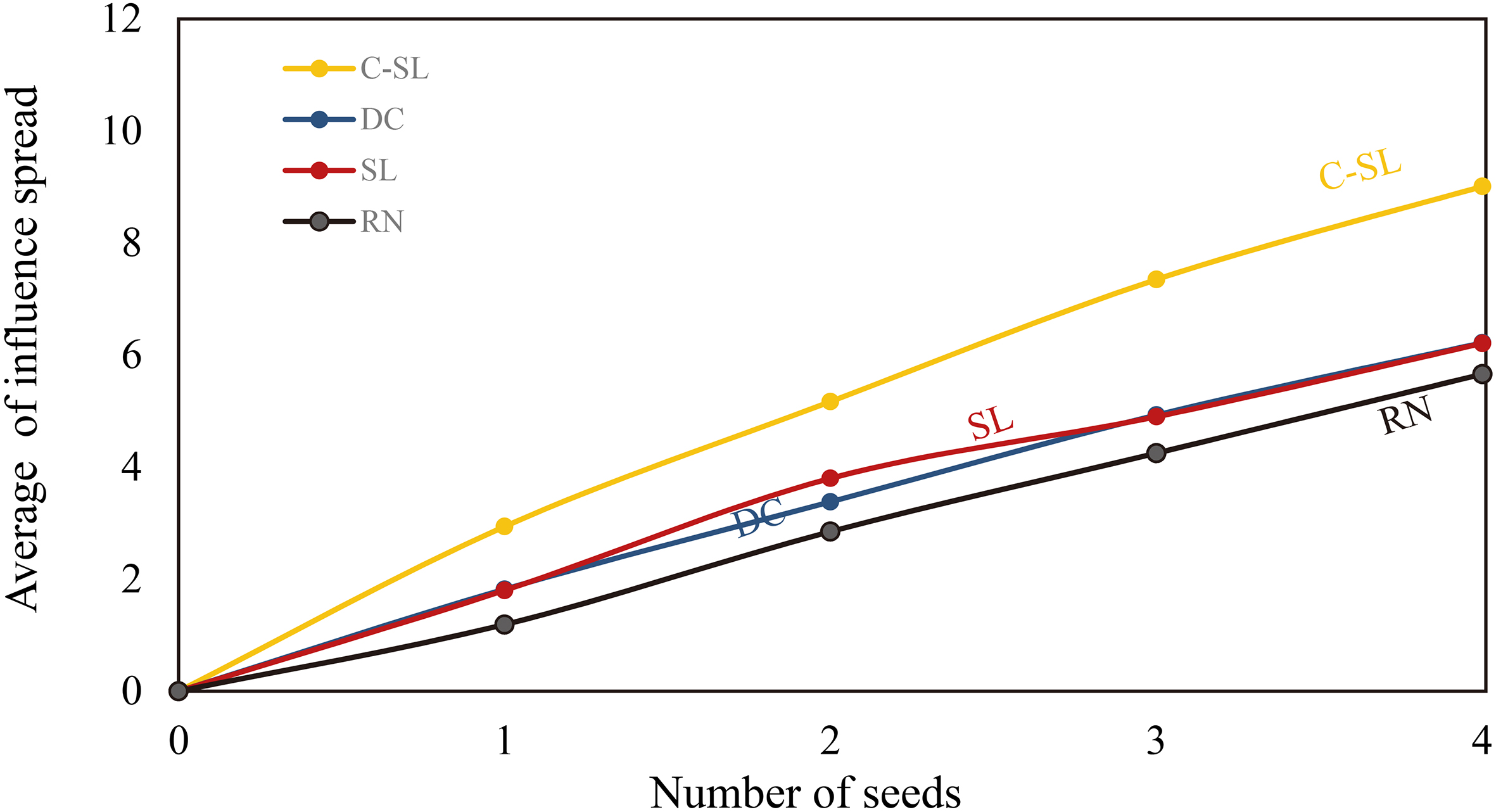
Dolphin network with 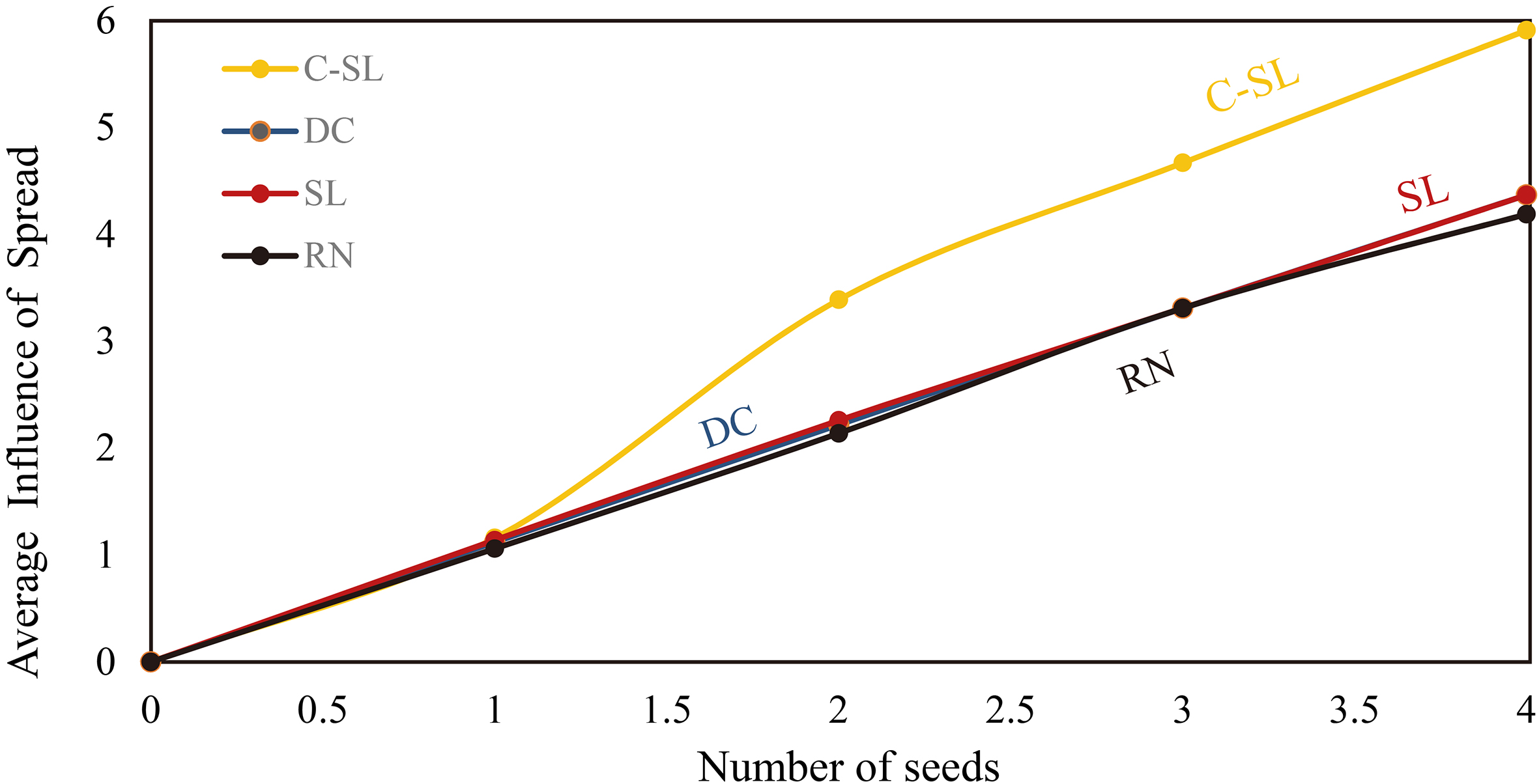
Where
Net-science network with 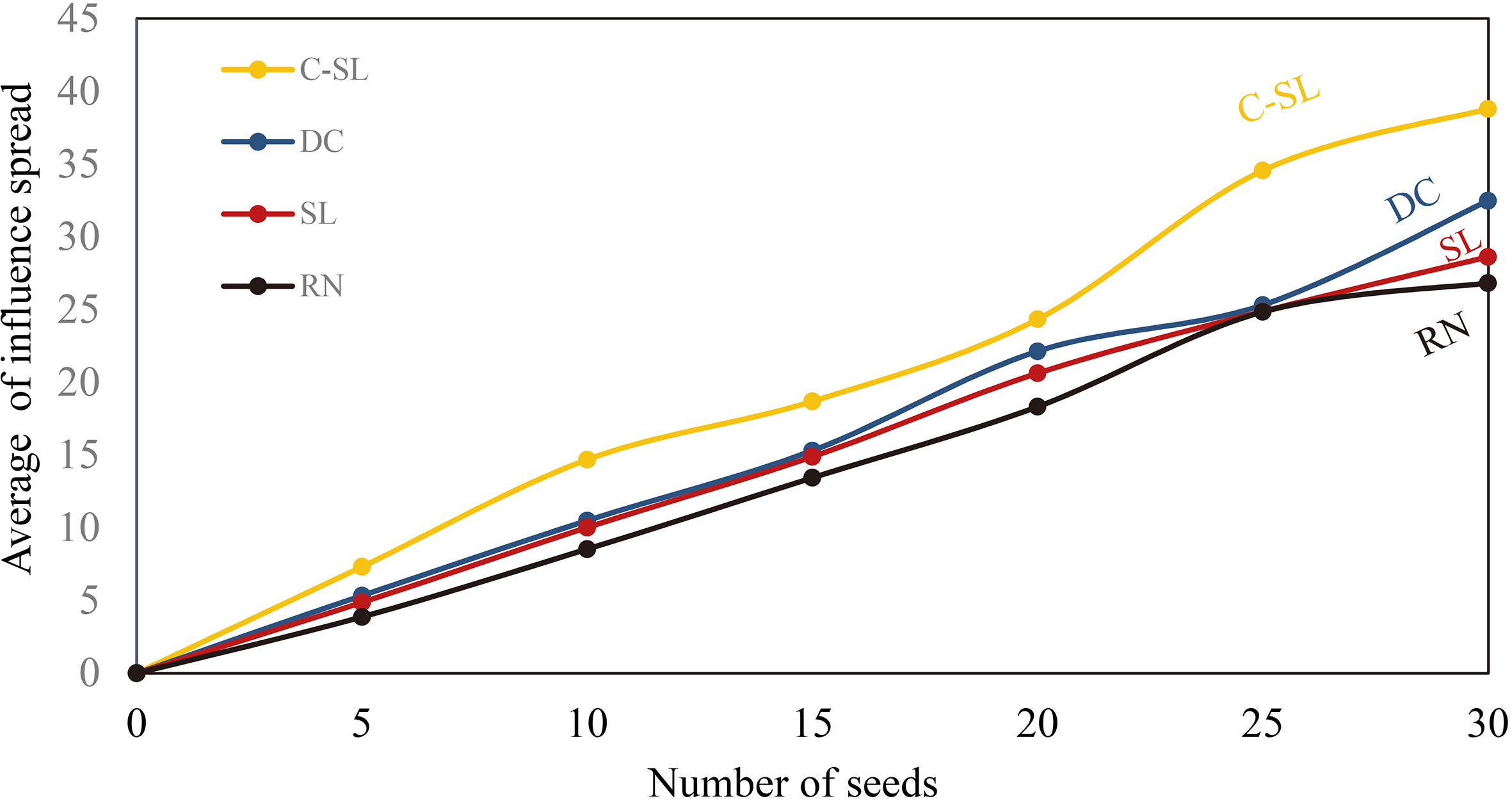
Netscience network with 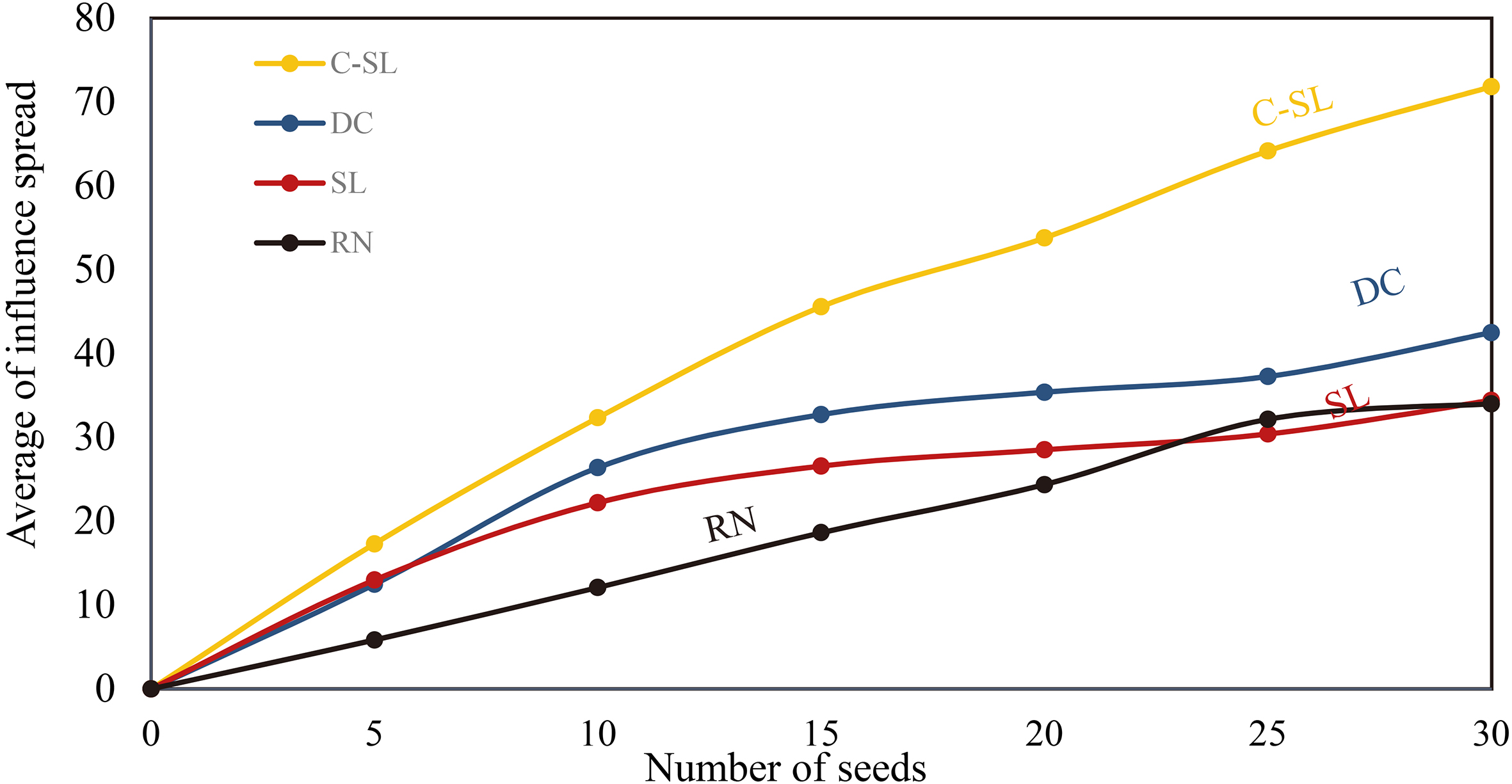
Hep-physics network with 
Hep-physics network with 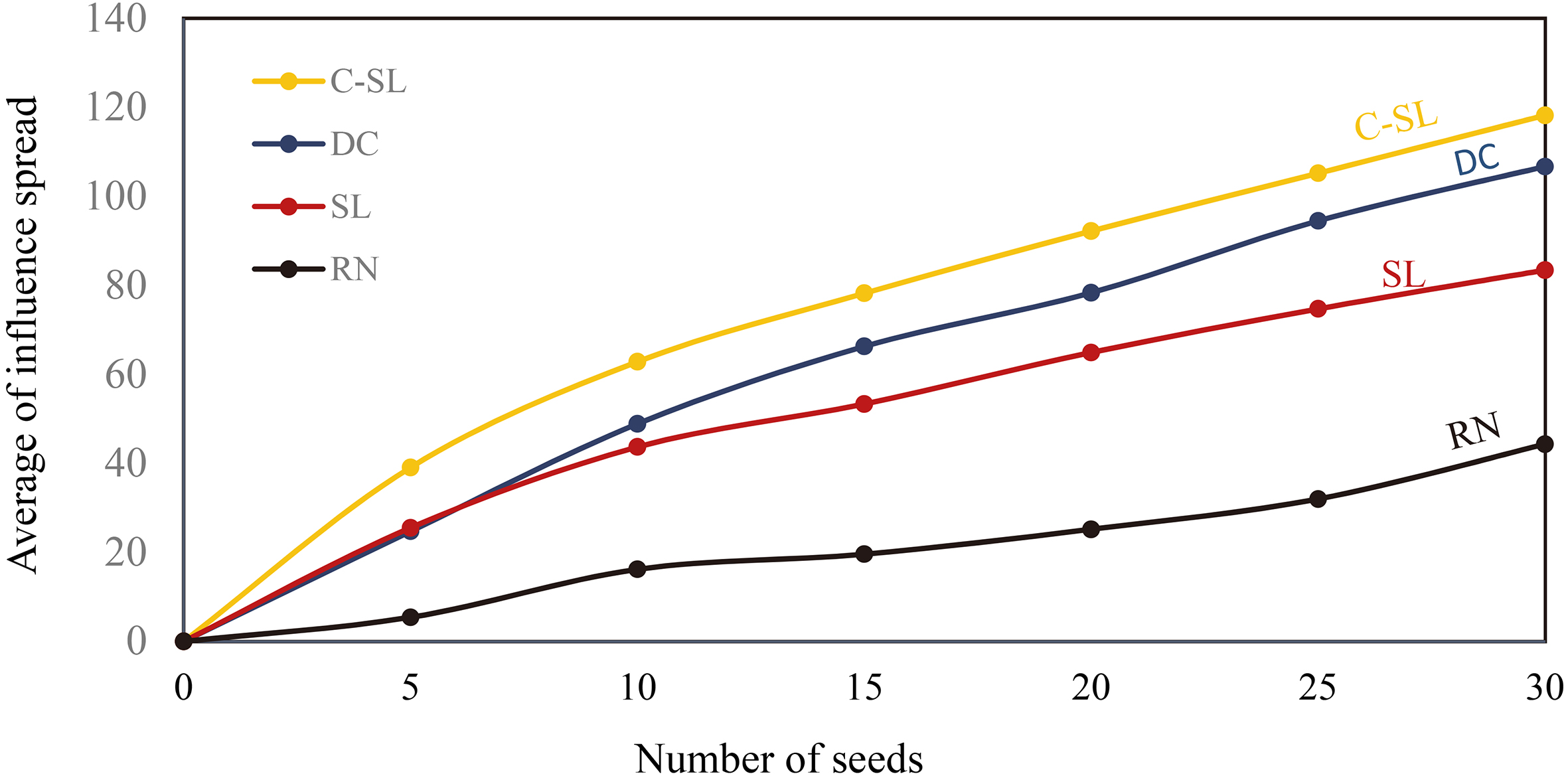
Hep-physics network with 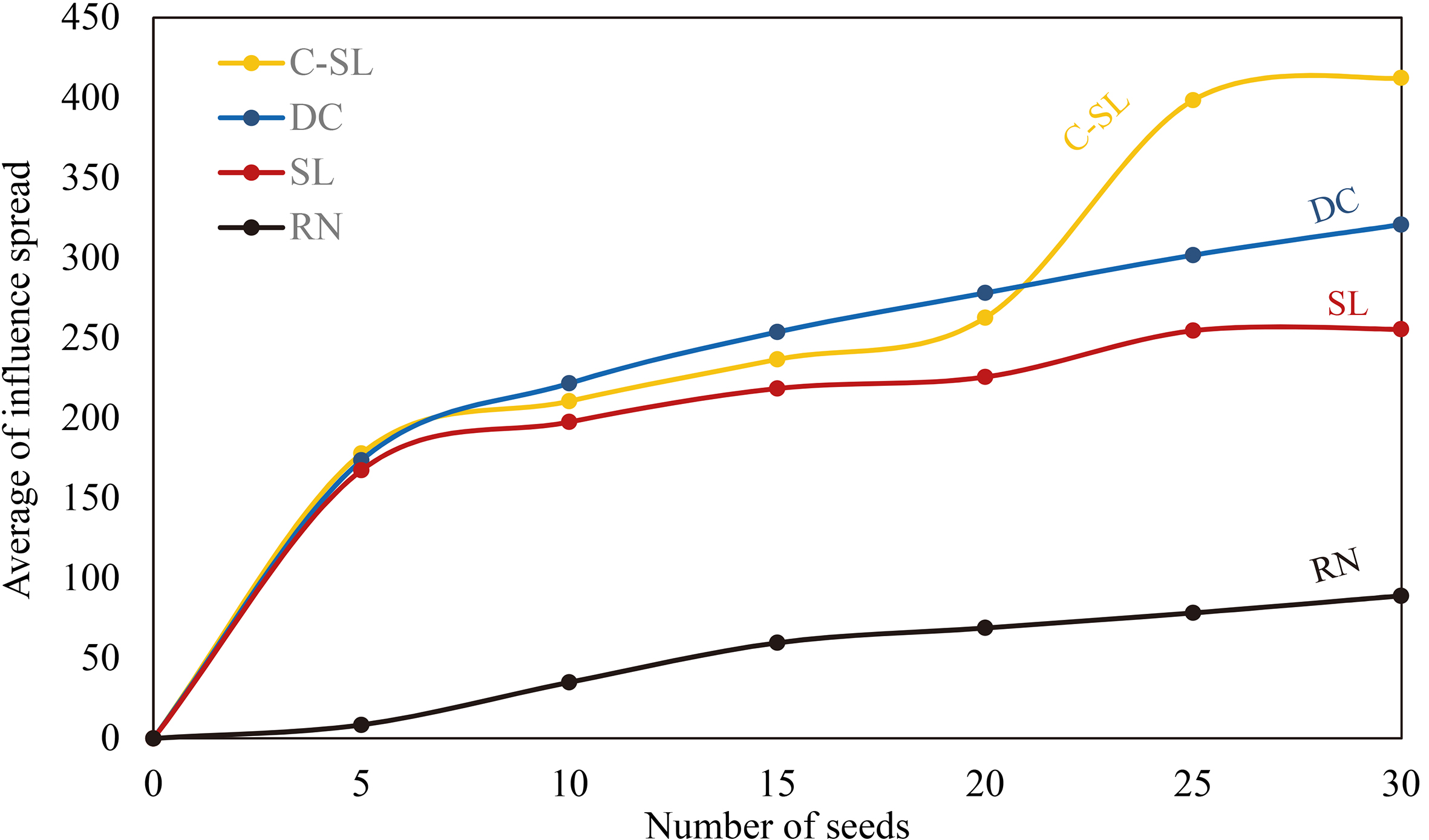
Hep-physics network with 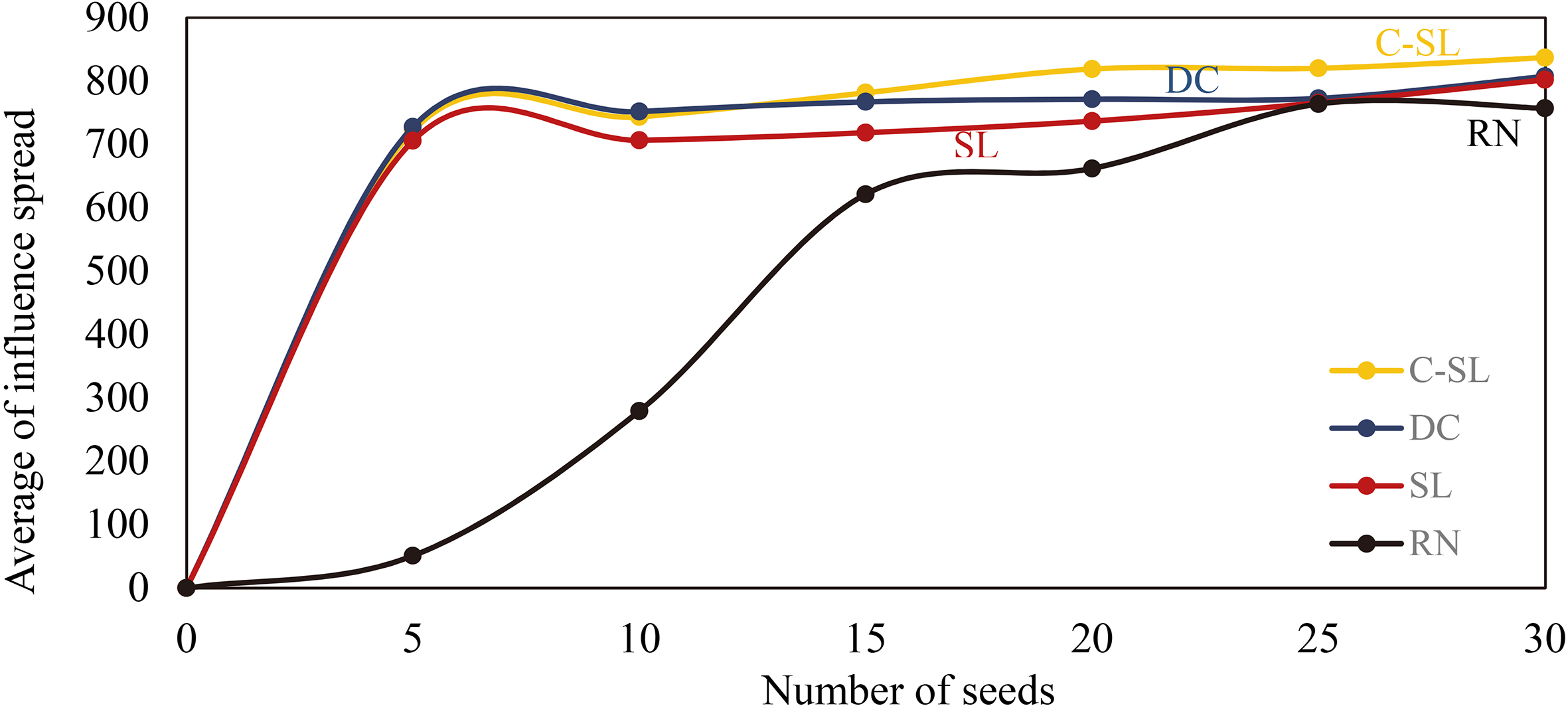
This method is widely used as a benchmark by many researchers for identifying influential nodes [9, 26, 27, 28, 32, 40, 53, 55]. The ranking random method was the next method for comparison [2, 6, 43, 45, 52] in which
Influence spread is a function for evaluating the performance of methods so that by assuming an initial set of active nodes
Where
After network partitioning, selecting candidate communities, and identifying the influential nodes, the diffusion model (IC) is applied in order to propagate the information or product over the network. Eventually, based on the total number of influenced nodes, the influence spread is calculated.
Furthermore, there should be a relation between the number of communities and the given value of
The results of the experiments are represented from Figs 12 to 19 where x-axis and y-axis denote the number of seeds and the average number of influence spread, respectively.
Our first dataset is the dolphin network divided naturally in two communities while our method had identified 4 potential communities. Thus, we considered the maximum value of
The next data set is related to a network with medium scale, Netscience, consisting of 1589 nodes. The results are represented in Figs 14 and 15 by considering two different diffusion probabilities:
The last dataset is Hep-physics network with a large scale including 10748 nodes and 52992 edges shown in Figs 16 to 19 while four diffusion probabilities
Discussion
In this research, because of combining the community detection and influence maximization problems, our method has gained benefits in comparison to other mentioned approaches. First of all, instead of searching the whole network for identifying influential nodes, only candidate communities were studied which leads to the cost reduction while in degree centrality, ranking random method, and semi-local centrality the whole network was searched. Also, our method detects the communities which may trigger more adoption of information or products, and in turn can maximize the influence spread. Besides, as experiment results shown, by increasing the scale of the networks (from a medium-scale network to a large-scale network), our method still maintains its good efficiency, and outperforms the comparing methods so that the scalability can be the next advantage of our proposed method. Furthermore, in order to study whether selecting nodes from large communities will result in more influence spread, some heuristics were considered.
Our method was implemented under IC diffusion model with different diffusion probability, and was run on three real social networks which results shown the good efficiency of CNLPSO-SL in comparison to other mentioned approaches. According to the experiments, the random ranking method has the worst performance in almost all datasets. The results of degree centrality is close to semi-local centrality in most datasets. Nevertheless, the degree centrality performs better than semi-local centrality because of the nature of considered datasets. Indeed, the semi-local centrality is sensitive to the structure of the network, and is more suitable for heterogeneous networks. However, it gained acceptable results in experiments. And, finally, our method by considering the community structure had the best performance on all networks.
Conclusion
In this research, by combining community detection and influence maximization, a two-layered method CNLPSO-SL was proposed to identify the influential nodes so that in the first layer an optimization-based algorithm named CNLPSO-DE was applied for network partitioning. Then, the main challenge was to select the candidate ones for identifying influential nodes which the size criterion was considered and communities were sorted in a decreasing order, and then the