
Abstract
With the immense growth in the multimedia contents for education and other purposes, the availability of video contents has also increased. Nevertheless, the retrieval of content is always a challenge. The identification of two video contents based on internal content similarity highly depends on extraction of key frames and that makes the process highly time complex. Recently, many research attempts have tried to approach this problem with the intention to reduce the time complexity using various methods such as video to text conversion and further analysing both extracted text similarity analysis. Regardless to mention, this strategy is again language dependent and criticised for various reasons like local language dependencies and language paraphrase dependencies. Henceforth, this work approaches the problem with a different dimension with reduction possibilities of the video key frames using adaptive similarity. The proposed method analyses the key frames extracted from the library content and from the search video data based on various parameters and reduces the key frames using adaptive similarity. Also, this work uses machine learning and parallel programming algorithms to reduce the time complexity to a greater extend. The final outcome of this work is a reduced time complex algorithm for video data-based search to video content retrieval. The work demonstrates a nearly 50% reduction in the key frame without losing information with nearly 70% reduction in time complexity and 100% accuracy on search results.
Keywords
Introduction
The ease of effective computing is a research direction, which works towards empowering computing devices for human intelligence. One highly popular human mode of communication is expression with verbal communication. These expressions usually include hand gestures, body posture and facial expression. For making the computing devices at per with the human intelligence, the inclusion of capabilities to interpret video contents. The work of Cowie et al. [13] has demonstrated that during a human machine interaction, the video components as an input feed is an essential part. Based on this phenomenon, the work by Scheutz et al. [11] demonstrates the proof of concept and reports the improvements over other communication methods. During the training of these computing devices, the video content libraries are used. The fundamental purpose of the training process is to make the computing devices enabled for classification, clustering and detection of the expressions or context. These actions can be achieved by empowering the devices or the software agents or the applications to match with the similar video contents (Fig. 1).
Traditional video mining process.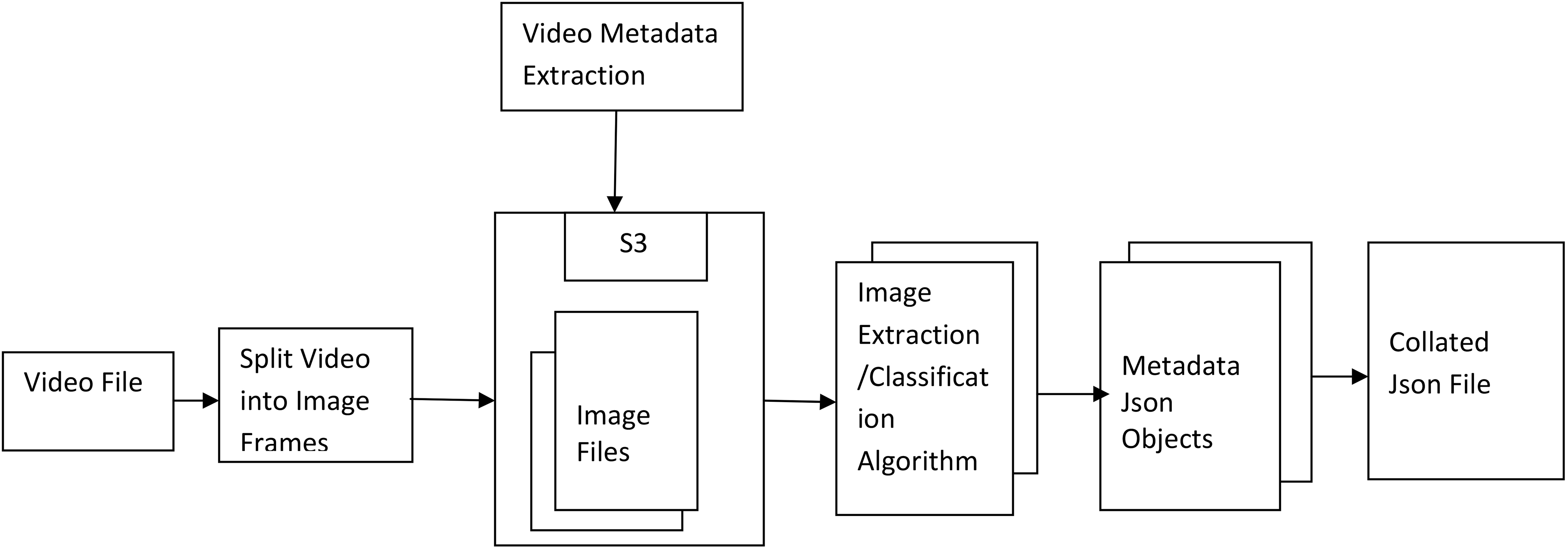
The similarity measuring algorithms for the video content retrieval are highly popular and widely accepted. The YouTube’s video relevancy algorithm by Covington et al. [12] or the NetFlix’s movie recommendation algorithm by Gomez-Uribe et al. [2] are highly admired in the field of this research. Also, the content mining for audio is not very different from these two states of the art algorithms. The report by Schedl et al. [10] have also expressed that the challenges in music recommendation system are not very different from video content retrieval or content search.
The different research findings have reported the complexities of the research is multiple directions. The work by Duque et al. [9] suggests that the video contents can be highly difficult to be classified or matched as in case of human presence in the content, the change in expression can lead to high change in the video content. Thus, in spite of similar content and context, the video frames can show different characteristics. In addition to that, many of non-computing researches have also demonstrated that, the use of emotion as a factor during video retrieval can be highly disastrous. The work by Worthy et al. [3] has confirmed this theory by her case studies. Henceforth many of the parallel research attempts have suggested to ignore the human intelligent properties and rather focus on the image specific properties for the content retrieval. Later this theory was made stronger with the case study by Etkin et al. [6].
Henceforth, this work attempts to reduce the time complexity of the retrieval process only using the physical properties of the key frames extracted from the video library contents.
The rest of the work is elaborated such that in Section 2, the standard video mining or video retrieval framework functionalities are elaborated, in Section 3, the outcomes from the parallel research works are analysed, in Section 4, the problem is formulated using the mathematical models, in Section 5, the proposed algorithms are discussed with the purposes and the advantages, in Section 6, the used datasets are discussed to demonstrate the purpose of use, in Section 7, the obtained results are discussed and in the Section 8, the work presents the final research conclusion.
In this section of the work, the fundamentals of video content retrieval process are mathematically presented. This analysis will help in realizing the bottlenecks of the existing systems.
The initial component of the vide data mining or retrieval is the search content. The searching content can be a limited frame or limited duration video data or an image file.
Here assuming that the input searching content is a video data (
Where,
The second important component is the video library (
Again, the individual video contents (
The video file frame contents must be processed for extraction of object information, in order to find out the eligibility of this frame for key frame. If the frame is identified as key frame, then this frame will take a key part in identification of the matching content.
The key frame extraction process defines the object extraction [Obj] process and for any two key frames (
And,
Now, if the extracted contents from each frame are different, then the first frame will be considered as key frame due to the change in the objects in the frame.
Hence, here, the initial frame must be considered as key frame (
With this principle, a number of key frames from each video content data will be extracted. As,
The similar action is also to be taken on the searching video content and that content will as well generate a set of objects in return, which can be formulated as,
Finally, based on the match between
The fundamental bottleneck in this process is the higher time complexity. During the key frame extraction process, a little change in the object shape of object location can also create a significant difference in identification of the key frames. As identified, a greater number of key frames can increase the time complexity of the process to a greater extend.
The solution to this problem is further analysed and presented in the forthcoming sections of this work.
In this section of the work, the recent and parallel research outcomes are analysed for better formulation of the problem in the next section of the work.
During the video mining process, the behavioural analysis of the objects in the video frame can be considered in order to identify the key frames and the content similarity as projected by Ardissono et al. [8]. The further enhancement of this work was proposed by Hawalah et al. [1]. This work proposes to model the behavioural pattern of the objects and further utilize the same for pattern mining during video retrieval. The work uses a case study for user modelling. The video content retrieval for social media-based content can be easy as demonstrated by Yin et al. [5] as the profiling of the users and the relevant objects can be tracked and identified from thebeginning of the existence.
Yet another dimension of the research is to incorporate the neural networks for classification and retrieval. The work by Li et al. [7] has considered the online business situation and proposed a cross breed encoder utilizing the structure of a neural system for session-based suggestion framework. Be that as it may, the quantity of thing qualities considered were extremely less with the nonattendance of a portion of the significant ones including value relations and thing classes.
Other research outcomes have demonstrated the use of sequential model for the content retrieval. This model for allosteric guideline of catalysts proposes that the subunits of multimeric proteins have two conformational states. The official of the ligand causes conformational change in different subunits of the multimeric protein. Even though the subunits experience conformational changes freely, the switch of one subunit makes different subunits bound to change, by decreasing the vitality required for resulting subunits to experience the equivalent conformational change. The work by Smirnova et al. [4] establishes the similar process and showcased higher performances.
Henceforth, with the detailed understanding of the parallel research outcomes, this work, elaborates the problem in the next section of the work.
Problem formulation
With the detailed understanding of the fundamentals of video content extraction and the recent research outcomes, in this section of the work, the problem is formulated with the help of mathematical lemma.
Lemma
Reduction of the key frames without reducing the key content of the video data can reduce the time complexity of the video content matching and retrieval process.
Proof
In programming that help activity, particularly 3D designs, there are numerous parameters that can be changed for any one item. One case of such an article is light. Lights have numerous parameters including light power, shaft measure, light shading, and the surface cast by the light. Assuming that an artist needs the bar size to change easily starting with one esteem then onto the next inside a predefined timeframe, that could be accomplished by utilizing keyframes. Toward the beginning of the liveliness, a shaft estimate esteem is set. Another esteem is set for the finish of the liveliness. Consequently, the product program naturally inserts the two qualities, making smooth progress.
Firstly, assuming that any video data
The total number of key frames are assumed to be
In the due course, the reduction this time factor,
Further, each frame in the key frame set must go through a reduction process, where the similarity of any two frames must be considered based on the contour, C, of the object present, displacement, D, and finally the variation of image pixel density, P. Regardless to mention, the frames are considered in this situation with single object.
Henceforth, firstly for any two key frames,
And,
Also,
And,
Further,
And,
Furthermore, if the frame object contours are nearly 50% similar to the consecutive frames, then the key frames can be considered as nearly similar frames and one of these two frames can be dropped.
Similarly, for the displacement, the formulation can be presented with the respect to the complete frame size.
Correspondingly, for the image pixel intensity, the formulation can be presented with respect to the rate of pixel intensity change of the key frames,
Henceforth, due to these processes, the number of key frames,
Assuming that the contour detection time,
It is natural to realize that the number of key frames after the reduction process will reduce to 50% to be at the least. Thus,
Further, assuming that,
Hence, from Eq. (20),
Realizing the fact that
Further, this work applies the machine learning methods to obtain the similarity scales, hence these three tasks can be performed in parallel. Hence, the final time complexity can be viewed as,
Hence, it is natural to realize that,
Thus, the reduction of the key frames without reducing the information from the key framesets, can significantly reduce the time complexity of the process.
Further, realization of the algorithms proposed in this lemma is presented in the further section of this work.
In this section of the work, two novel algorithms are presented.
Firstly, the algorithm for image key frame similarity is presented. The distinction as for different methods referenced already, for example, MSE or PSNR is that these methodologies gauge supreme blunders; then again, SSIM is an observation-based model that considers image debasement as saw the change in auxiliary data, while likewise joining significant perceptual marvels, including both luminance concealing and differentiation covering terms. Basic data is the possibility that the pixels have solid between conditions particularly when they are spatially close. These conditions convey significant data about the structure of the articles in the visual scene. Luminance veiling is a marvel whereby image twists (in this unique situation) will, in general, be less unmistakable in brilliant areas, while differentiate covering is a wonder whereby bends turned out to be less obvious where there is the noteworthy action or surface in the image.
The second algorithm is responsible for video content matching and extraction from the video library. Video content analysis (VCA) is another innovation. New applications are as often as possible found, anyway the reputation of various kinds of VCA contrasts generally. Functionalities, for example, movement location and individuals checking are accepted to be accessible as business off-the-rack items with a respectable reputation, even freeware, for example, probiotics Flowstone can deal with development and shading investigation. In numerous spaces VCA is actualized on CCTV frameworks, either circulated on the cameras (at-the-edge) or incorporated on committed preparing frameworks. Video Analytics and Smart CCTV are business terms for VCA in the security area. In the UK the BSIA has built up a presentation control for VCA in the security space. Notwithstanding video examination and to supplement it, the sound investigation can likewise be utilized.
Further, in the further section of the work, the obtained outcomes from these algorithms are analysed.
Dataset description
Dataset description
Key frame reduction results
Key frame reduction.
In this section of the work, the used standard datasets are discussed. For validating the proposed algorithms this work tests the algorithms on five different datasets. The enthusiasm for CBIR has developed due to the constraints intrinsic in metadata-based frameworks, just as the expansive scope of potential uses for proficient picture recovery. Printed data about pictures can be effectively looked utilizing existing innovation, however this expects people to physically depict each picture in the database. This can be unfeasible for huge databases or for pictures that are produced consequently, for example those from reconnaissance cameras. It is likewise conceivable to miss pictures that utilization various equivalent words in their depictions. Frameworks dependent on classifying pictures in semantic classes like “feline” as a subclass of “creature” can maintain a strategic distance from the mis-categorization issue, however will require more exertion by a client to discover pictures that may be “felines” yet are just delegated a “creature”. Numerous measures have been created to order pictures, however all still face scaling and mis-categorization issues.
The details of the datasets are listed here (Table 1).
In this section of the work, the highly satisfactory results obtained from the proposed algorithms are analysed. The results are discussed in four different sections as the result of key frame reduction method, key frame-based error threshold, the retrieval process accuracy and finally the time complexity.
Error threshold analysis.
Error threshold analysis
Video content retrieval analysis based on percentage of matching
Time complexity analysis
Content retrieval accuracy.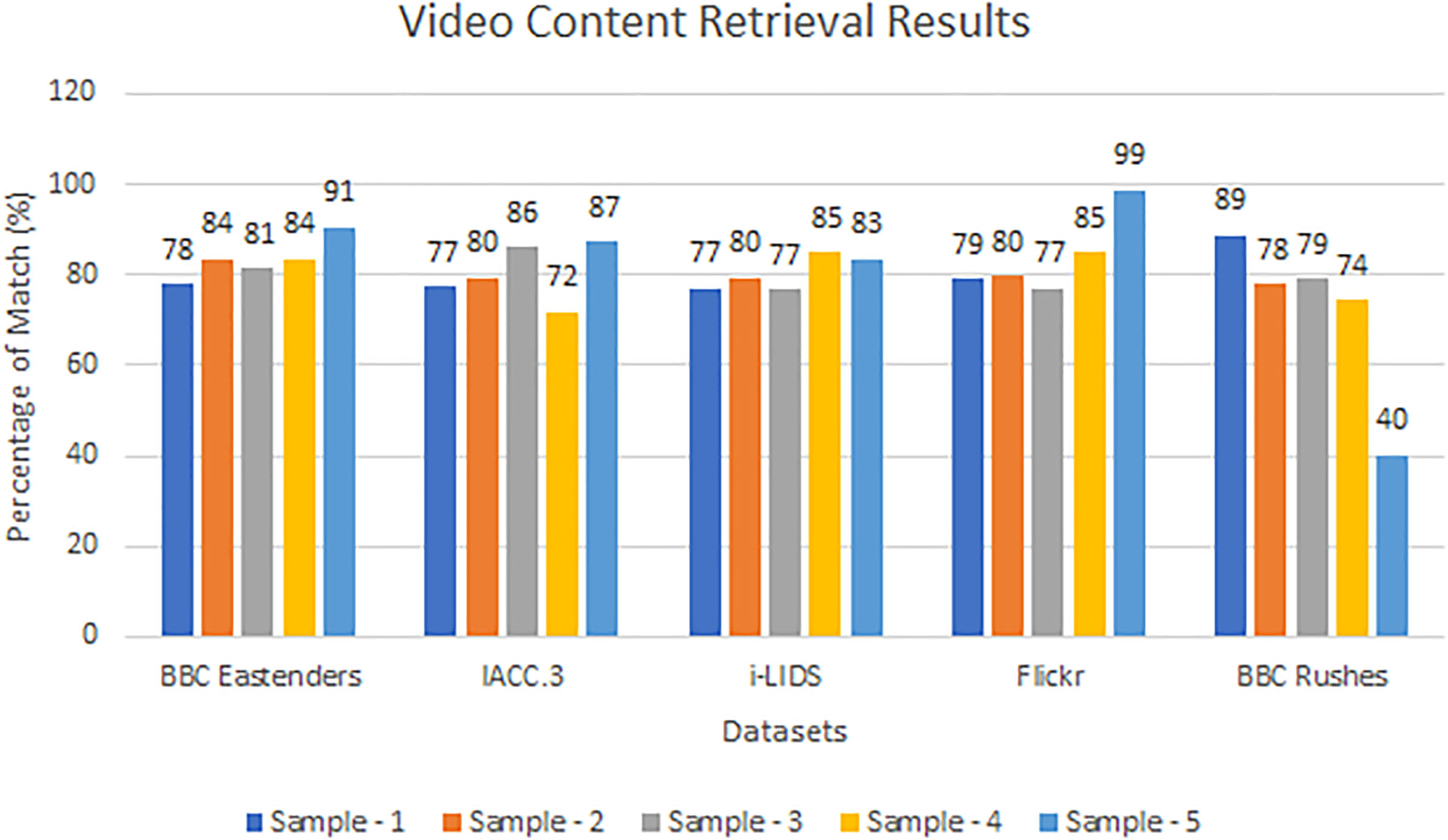
Percentage of time complexity reduction.
Firstly, the key frame reduction process results are elaborated here (Table 2).
The result is also visualized graphically (Fig. 2).
It is natural to visualize that the reduction is nearly 50% for majority of the datasets.
The detailed advantages of this process are elaborated in the prior section of this work.
Video library based error threshold
Secondly, the video library-basederror threshold results are elaborated here (Table 3).
The result is also visualized graphically (Fig. 3).
The detailed advantages of this process are elaborated in the prior section of this work.
Video content retrieval accuracy
Third, the video content retrieval accuracy results are elaborated here (Table 4).
The result is also visualized graphically (Fig. 4).
Time complexity analysis
Finally, time complexity analysis results are elaborated here (Table 5).
The result is also visualized graphically (Fig. 5).
Conclusion
Motivated by the popularity and growth of the video contents for various purposes, a good number of research attempts have tried to make the video retrieval process a less time complex process. Nonetheless, the advanced video content libraries demand video content-based searching, where based on the similarity of the input search video, the related video contents will be returns as search results. During this process, the searching video and the contents from the video library must be divided into key frames and these extracted key frames must be analysed and compared for similarity. For a video content bigger in length, this process can be highly time complex. Thus, reduction in time complexity without compromising on the accuracy of the search results is objective of recent research trends. This work mathematically proves that, reduction on the key frames without losing the information from the content can significantly reduce the time complexity of the retrieval process. Hence, this work deploys a novel approach to reduce the key frames using similarity analysis based on object contour, object displacement and finally using the pixel intensity rate of changes. The work also deploys CUDA based parallel processing methods to analyse the key frame similarities to reduce the time complexity to a greater extend. Further the similarity of the key frames extracted from the searching video and the library video contents are also analysed for generating the search results. The reduction of the key frames, the reduction of the searching time complexity and finally the accuracy of the video data retrieval process is highly satisfactory, and the improvement is nearly 70% over the parallel research outcomes. This work is a newer dimension on this research direction and makes the video content mining process ready for the mission critical data with reduced time complexity and higher accuracy.