
Abstract
Speaker Identification denotes the speech samples of known speaker and it identifies the best matches of the input model. The SGMFC method is the combination of Sub Gaussian Mixture Model (SGMM) with the Mel-frequency Cepstral Coefficients (MFCC) for feature extraction. The SGMFC method minimizes the error rate, memory footprint and also computational throughput measure needs of a medium-vocabulary speaker identification system, supposed for preparation on a transportable or otherwise. Fuzzy
Introduction
The speaker identification method depends on options influenced by each the organic structure of associate individual’s vocal tract and therefore the activity characteristics of the individual [1, 9, 13]. The objective of acoustic modeling is to take information from isolated data as an input system which are built using large quantities of training data. However, the performance of
On comparison with the
The system takes input from isolated data as an input and performs the speech processing. Feature Extraction, Clustering and Classification are done with the best approaches and the results obtained in speaker identification system. The Fuzzy based system has efficient speech process on comparing with the The overall speaker recognized processing accuracy rate has been increased in the SGMFC system. By implementing confusion matrix, the accuracy rate has been calculated and the results are produced.
Reynolds et al. [1, 3, 4] proposes speaker identification and verification through Gaussian Mixture model for high recognition accuracy. The maximum likelihood classifier approach is described for the speaker identification and the likelihood ratio hypothesis is discussed for the speaker verification using background speaker normalization.
Leon et al. [26] proposes GMM based speaker identification using simple
Verma and Khanna [28] proposes speaker identification using
Povey et al. [27] propose Sub gaussian mixture model for symmetric approach. It avoids the likelihood evaluation and parameter estimation. It provides explicit factorization of speech and speaker information.
Baid and Talbar [31] propose the study of
Sahu and Dharmale [30] observed voice communication using FCM and
Ghosh and Kumar Dubey [29] proposed where behavior pattern of
SGMFC methodology
In Gaussian distribution model, accuracy of the result is low since it depends upon the short segments of the single speaker [31]. To overcome this problem UBM model is introduced in speaker identification. Here improvement is shown better whereas the problem of speaker sub segment is not concentrated. Hence the proposed SGMFC method concentrates on the sub segment with efficient accuracy. The feature extraction of the SGMFC is based on Sub Guassian Mixture Model (SGMM) and Mel frequency cepstral coefficient (MFCC). The clustering algorithms
SGMFC process
The SGMFC method consists of various processing steps as a system flow design which are discussed as follows. The speaker identification analysis for SGMM with Fuzzy
Input audio files
The SGMFC method with Fuzzy
Database
Data from THE CHAINS CORPUS – Speech database designed to help to characterize speakers individually. There are 16 individual sentences selected from CSLU Corpus and TIMIT corpus, for further processing of the input audio is converted as.wav format.
Feature extraction module
The variation in the mean and mixture weight of an acoustic model in a subspace is said to be as SGMM. After acquiring the input data, SGMM is applied with feature extraction which is efficiently by using MFCC method. Preprocessing, framing, windowing, Mel Filter Bank as well as Frequency Wrapping are done for the input audio files and logarithm values taken. After taking the values of logarithm to calculate Discrete Cosine Transform (DCT) and they are step into clustering process.
Clustering module
The clustering technique involves in grouping the distinct type of data from the extracted values center point is calculated and based on distance between data points clustering is performed. In existing system
SGMM for
-means clustering
SGMM for
In this SGMFC work classification is done using Support Vector Machine (SVM). The classification involves two processes i.e., Training and Testing. In training phase, all the training datasets will be trained and placed in the template database. In testing phase, the test dataset available in the test database will be trained and is compared with template database for the decision to be made.
Decision module
The decision is made based upon the match scores generated by the classifier in this module. After the classification, the predicted results by using the two clustering techniques are compared with actual results. The performance analysis is done by using confusion matrix. Accuracy rate is calculated and analyzed.
Performance evaluation
The performance results obtained through the SGMFC method helps in measuring performance of speaker identification method with precision, recall and accuracy.
Accuracy
Accuracy rate could be calculated from formula given as follows,
Precision value with their true positive and false positive can be defined as,
The sensitivity is also called as recall, where there are two different incorrect conclusions which could be drawn in a statistical hypothesis test and it can be inappropriate. An analyzed data for a positive test which accurately reflects the tested for activity. Let us consider p be the prediction, TPR be recall or True Positive Rate, TP be a true positive and FN be false negative which could defined as,
The negative value results are obtained for TN. Let the TNR be the True Negative Rate, TN be true negative, FN be False negative and it can be defined as,
Let FP be the false positive, TN be the true negative and
SGMM for fuzzy
The FN is obtained when the predicted output is
The implementation results for the SGMFC method of SGMM with the
The classes comparison for
Classes comparison.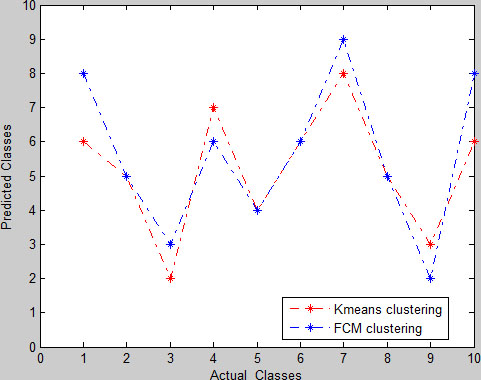
The accuracy of SGMFC with
Accuracy comparison.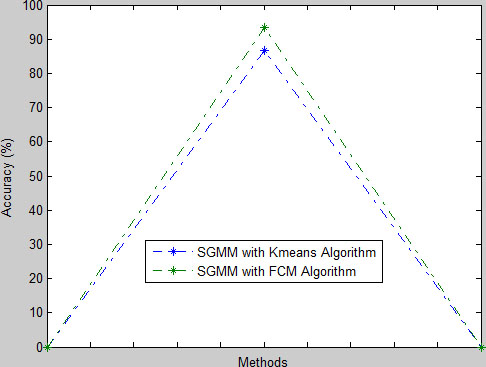
The error rate comparison between the
Error rate comparison.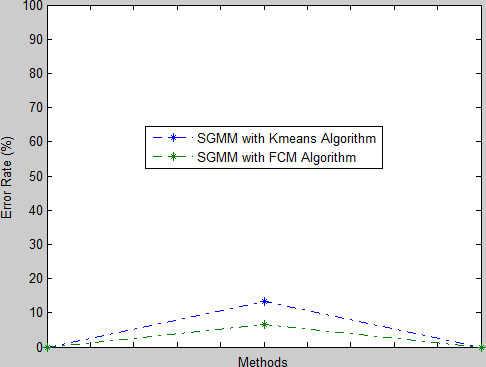
The precision can be calculated from the Eq. (2) for the SGMFC system and the obtained result is shown in Fig. 4.
Precision chart for 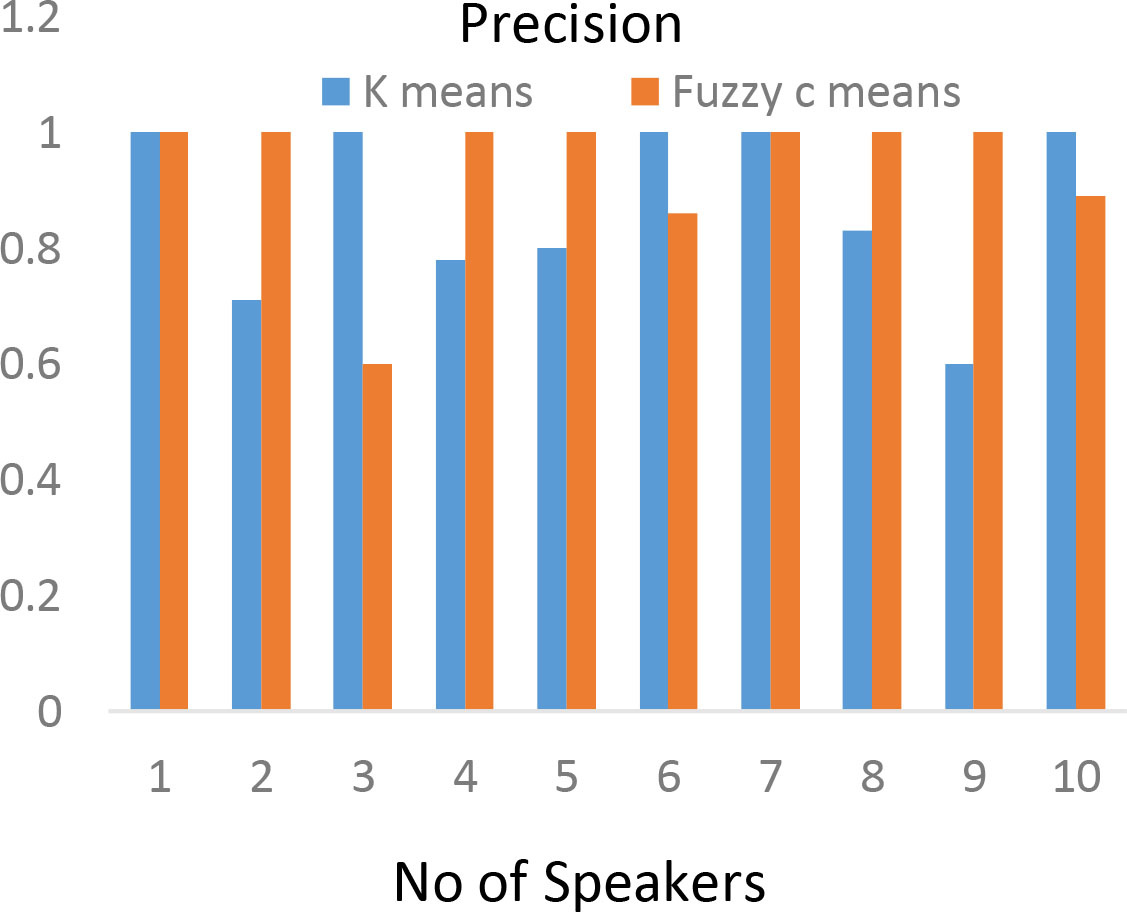
The sensitivity can be calculated from the Eq. (3) for the SGMFC system between
Sensitivity chart for 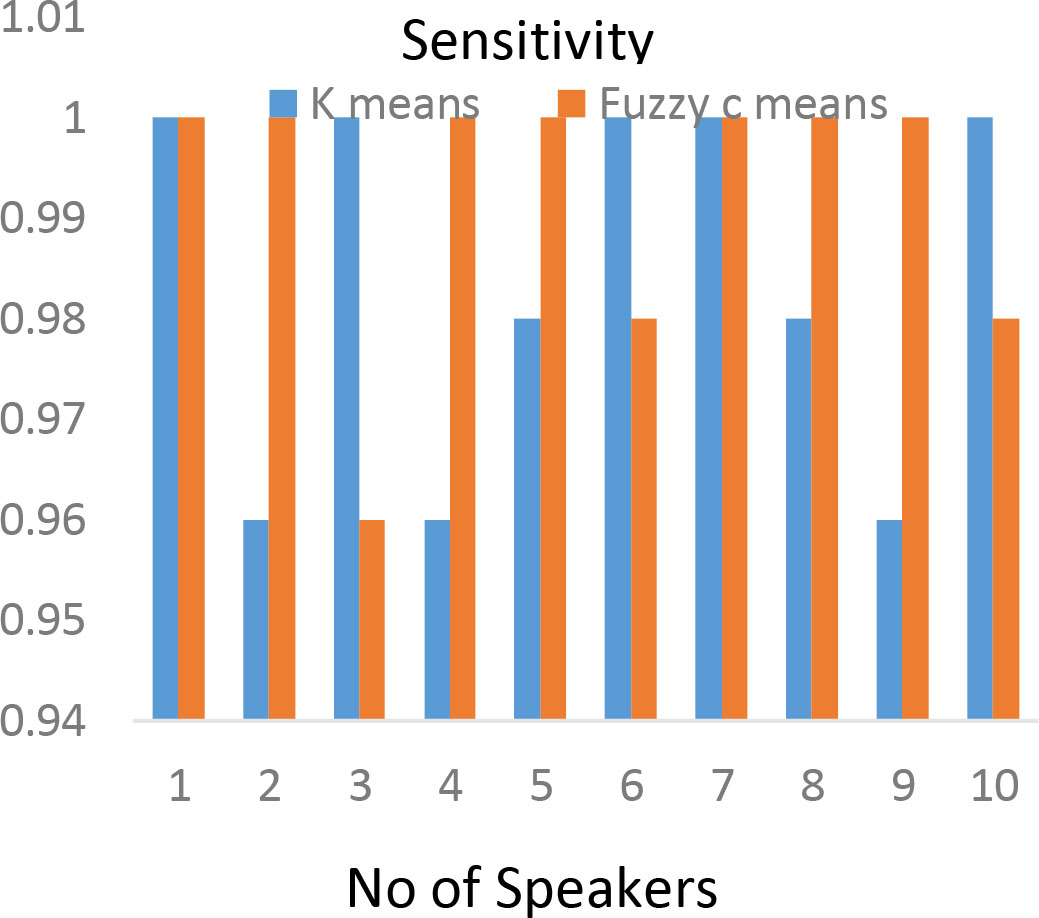
Specificity chart for 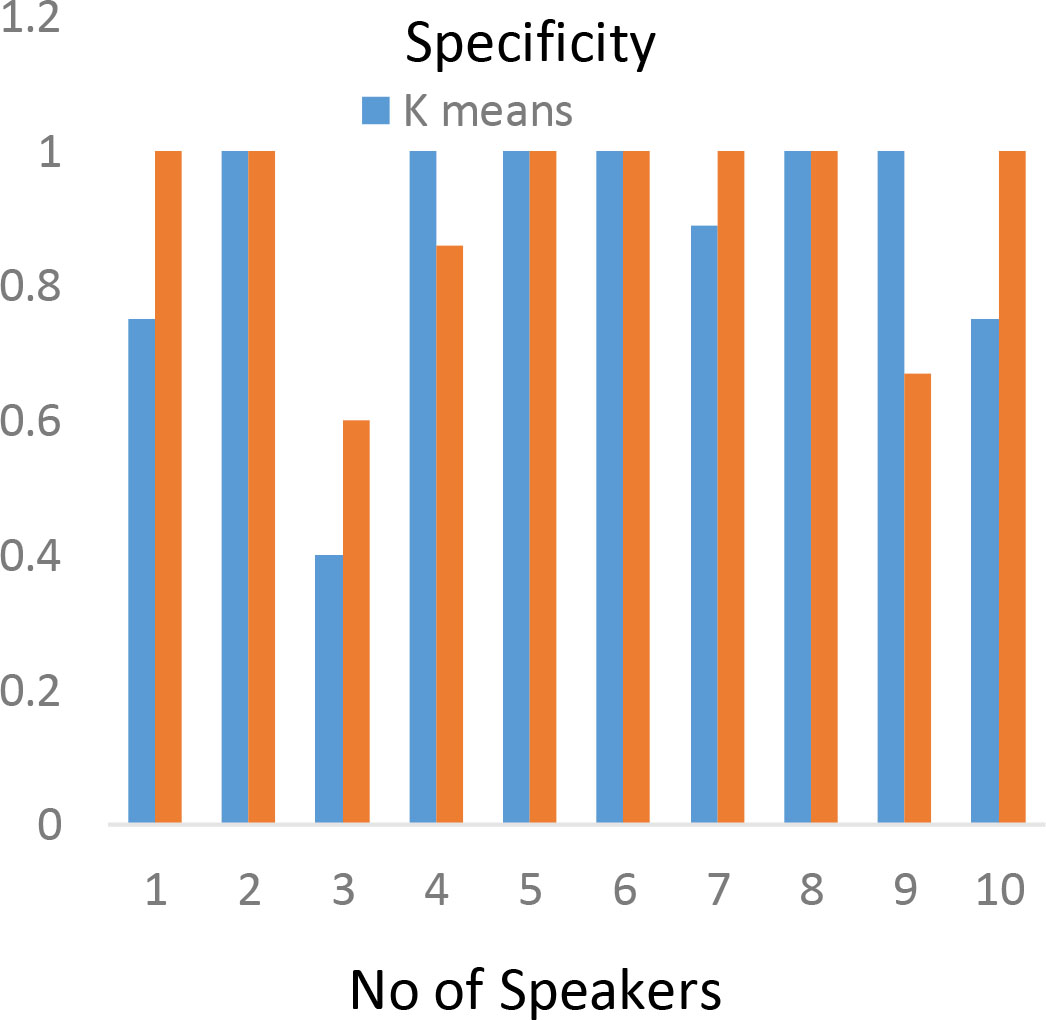
The specificity can be calculated from the Eq. (5) for the SGMFC system between
Comparison for SGMFC using fuzzy
-means clustering
Comparison for SGMFC using fuzzy
This approach is normally used to extract the unknown pattern from large set of data for business as well as real time application. It is a computational intelligence discipline which emerged as valuable tool for data analysis. The outcome of clustering process and efficiency of identification of speaker is generally determined through algorithms. This algorithm is widely applied in agriculture, engineering, astronomy, chemistry, geology, image analysis, medical diagnosis, and shape analysis and target recognition. Finally, the error rate is reduced by augmenting the standard feature vector with the cluster classification component.
Limitations and future direction
The study was limited to the text dependent speaker verification task. In future text independent speaker environment can be choose in an intended investigating proposed on various fusion methods. Modern hybrid.
Conclusion
The SGMFC method isolate SGMM data features and implemented in Fuzzy