
Abstract
In a data grid, nodes have a limited storage space and cannot accommodate all the replicas they need. Therefore, data replication is used to copy only important replicas that may be requested in the near future. In this paper, a dynamic data replication strategy is implemented in order to increase the number of requests served locally and reduce both the total elapsed time and total bandwidth consumption. This strategy is based on Bandwidth Hierarchy based Replication (BHR) and modified BHR strategies, but superior to them. This is because of the features this strategy has. This strategy selects a region header in each region based on a modified version of closeness centrality and stores all the replicas in the data grid in the region header. Regarding the other nodes in the region, only important replicas will be copied to them based on their number of requests per mega bit (NoRpmb) that shows how much important the replica is in relation to its size.
Introduction
A data grid is a set of storage and computational resources that are distributed in a large geographical area. The goal of the data grid is to share data and other resources [1, 2, 3].
In the data grid, the user needs to access data that might be located far from it. As a result, a large amount of bandwidth is consumed and the elapsed time to send it to this user is expected to be long. Data replication is the process of making more than one copy of the same file at different nodes. This helps the user to fetch the replica from its own storage or in the worst case from the storage of the closest node to it. This results in reducing both the consumed bandwidth and delay [4]. Many replication strategies [5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19] were implemented to decide the best nodes to copy the files in. Among these strategies is a well-known strategy named bandwidth hierarchy based replication (BHR). In BHR [9], the access time is decreased by averting network congestions. This is done by having many regions connected to each other and in each region there is more bandwidth than the bandwidth between the regions. Additionally, the distance and number of intermediate nodes (e.g. routers) between two nodes in the same region are usually small. Thus, copying a file from a node in the same region consumes less time and bandwidth than bringing it from a node in another region. In each region, there is a region optimizer that records the number of requests for each replica. If the requested replica does not exist on a node in the same region, then it is brought from a node in another region. If the requesting node has enough space to store the requested replica, it is saved on its storage. On the other hand, if the requesting node has no space to store it, the requesting node sees if the requested replica is stored on any node in the same region. If it is stored, the copying process is canceled. Otherwise, all the replicas that are stored in both the storage of the requesting node and in the storage of any node in the same region (duplicated replicas within same region) are sorted based on Least Frequently Used (LFU) order. Then, the LFU replacement strategy [20] will start deleting the sorted replicas until there is enough space to store the requested replica. LFU replacement strategy discards the least frequently used replicas first.
In [21], a modified version of BHR is proposed. This modified version of BHR differs from original BHR in two things. First, it selects one of the nodes in each region to be the region header which has all the replicas in the data grid. If a node requested a replica that does not reside on its storage then it will search the nodes in the same region starting from the closest one until it finds it. When the replica is found, it will be brought to the requesting node. By having a region header in every region, they ensure that the requested replica will always be brought from a node in the same region because at least this replica will be stored in the storage of the region header. Second, the requested replica will be copied to the node in the region that requested it the most. The idea behind this is that this node is also expected to request it the most in the future. However, the modified BHR does not mention the used criteria to select the region header in every region. Moreover, it only considers the number of requests to determine the importance of each replicas and does not consider the size of it. Finally, if the requested replica needs to be copied, then it copies this replica to the node that requested it the most. As a result, this replica will be brought to two nodes which are the node that requested it and the node that requested it the most except in the case when the requesting node is also the node that requested it the most. By bringing this replica to two nodes, more time and bandwidth will be consumed.
In this paper, a new replication strategy, named enhanced BHR, is proposed. (1) In enhanced BHR, the region header is selected based on a modified version of closeness centrality [22] which defines the farness of a node as the sum of its DistMultiINs to all other nodes in the same region, and its closeness is defined as the inverse of the farness. DistMultiINs is defined as the distance between this node and the other checked node multiplied by the number of intermediate nodes between them. (2) In the search process for a replica that does not exist on the storage of the requesting node, both original BHR and modified BHR only consider the distance between the two nodes to decide the next node to be visited in order to find the requested replica, while enhanced BHR considers both the distance and the number of the intermediate nodes between the two nodes to make this decision. (3) Enhanced BHR considers both the number of requests and the size to determine the importance of the replica, while original BHR and modified BHR consider only the number of requests. Enhanced BHR achieves this by dividing the number of requests of each replica on its size in mega bit. (4) There is a difference in the comparison process when deletion is required in order to store the requested replica. In both original BHR and modified BHR, the number of requests of the requested replica is compared to the number of requests of each stored replica separately, while in enhanced BHR, the number of requests per mega bit (NoRpmb) of the requested replica is compared to the NoRpmb of a group (one or more replicas depending on the space still needed to store the requested replica) of replicas at once. (5) Enhanced BHR just brings the requested replica to the requesting node. This strategy does not copy the requested replica to the node that requested it the most. The first reason is that the node with the highest number of requests if not already have it will request it in the near future and then this node will copy it. Sending the replica also to this node consumes unnecessary time and bandwidth, because this node is going to copy this replica when it requests it in the near future. The second and last reason is that the nodes do not need to keep information about how many times the other nodes in the same region have requested the replica. Finally, having the requested replica stored in other nodes in the same region does not affect the decision to copy it to the requesting node. The reason is bringing this replica from one of the nodes in the same region might consume large amount of time and bandwidth. This is because the consumed time and bandwidth depends on the size of the transmitted replica and the number of intermediate nodes between the sender and receiver as seen in Eqs (4) and (5).
The rest of this paper is organized as follows. Section 2 presents the employed network structure and the new proposed strategy. Section 3 describes the simulation and performance comparison including the metrics for measuring the performance, how the simulation is setup, and the comparison results. Related works are presented in Section 4. Section 5 concludes the key points and mentions future work.
Network structure and enhanced bandwidth hierarchy based replication strategy
The network structure is divided into regions. Each region consists of a region header and a number of nodes that are located closely. There is also a master site that contains all the replicas and which are distributed to the region headers. The normal nodes have a small storage and cannot accommodate all replicas. Thus, some of the requested replicas will be brought from other nodes.
When a replica is requested by a node, it is first searched for in the requesting node’s storage. If it is stored there, it is used. Otherwise, the node looks for the replica in a number of nodes until a copy of the replica is found. Then, this copy is sent through a number of intermediate nodes to that node. Figure 1 shows the used network structure, where RH is the region header. The intermediate nodes are not shown in the figure.
Network structure.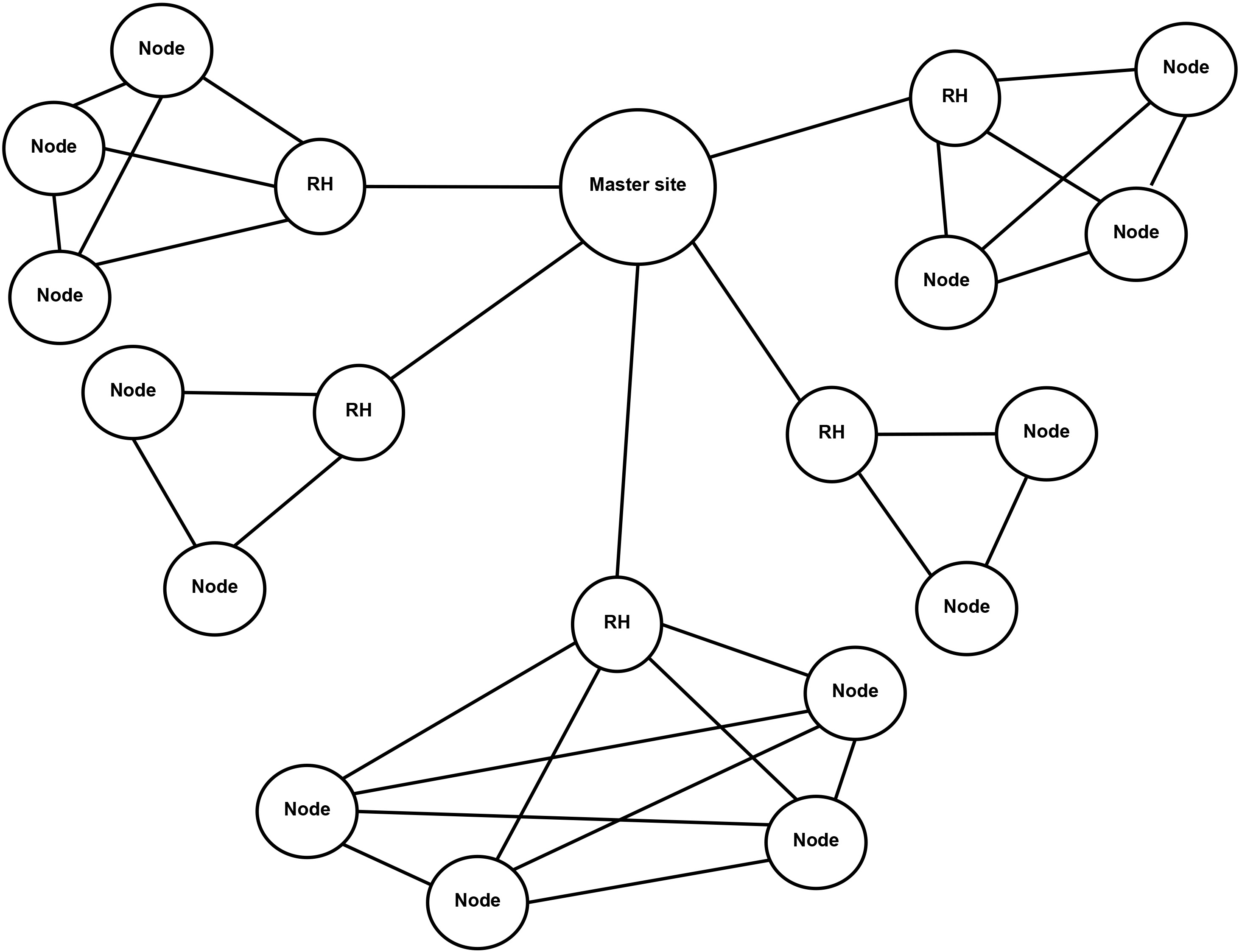
Enhanced BHR strategy is based on original BHR and modified BHR strategies, but has features that those do not have. The first feature is that the region header is selected based on a modified version of closeness centrality, where the farness of a node s is equal to the sum of its DistMultiINs to all other nodes in the same region as in Eq. (1), and its closeness is defined as the inverse of the farness. DistMultiINs is equal to the distance between this node and the other checked node multiplied by the number of intermediate nodes between them. This helps in reducing the total time and total bandwidth when sending replicas from the region header to the requesting nodes.
where
The second feature is that the order of nodes that will be visited in order to find the requested replica in the case the requesting node does not have it depends on both the distance and the number of intermediate nodes between the requesting node and the checked node as follows:
where NVN is the next visited node, Dist is the distance between the requesting node and the checked node, and NoINs is the number of intermediate nodes between the requesting node and the checked node.
So the next visited node will be the node that has the smallest value of distance multiplied by number of intermediate nodes, then comes the node with the second smallest value and so on.
The third feature is taking into account both the number of requests and size of replica and not just the number of requests to determine its importance to the node. This is achieved by dividing the number of requests of the replica over its size in mega bit (NoRpmb). Considering the size is important because if the replica has a small size then it will occupy less space of node’s storage.
where
The fourth feature is comparing the importance of the requested replica to a group of replicas at once. The number of replicas in the group depends on the space still needed to store the requested replica. However, in both original BHR and modified BHR, the requested replica is compared to each stored replica separately and not to a group.
The fifth feature is sending the requested replica only to the requesting node, while sending this replica to the node that request it the most only occurs when this node requests it. This helps in reducing the consumed time and bandwidth by preventing unnecessary transmissions. Additionally, the nodes do not need to have information about how many times every node in the same region requested each replica in order to know the node with the highest number of requests for each replica.
The last feature is having no relation between the same replicas that reside on different nodes in the same region. In the previous strategies, the requested replica is not copied to the requesting node in the case the free storage space is not enough to store this replica and the replica exists on one of the nodes in the same region. The only exception is having it stored in the region header in the case of employing the modified BHR strategy. This is based on the assumption that if this replica resides on a close node in the same region, then bringing it from this node will be fast. However, the size of transmitted replica and the number of intermediate nodes between the sender and the receiver are also important factors in determining the transmission time. Therefore, we assume that even if this replica resides on other nodes in the same region, the deletion of some replicas in order to provide space to store it if it is more important than them is worthy.
The elapsed time (ET) is calculated as follows:
where TT is the transmission time, PT is the propagation time, NoINout is the number of intermediate nodes between the sending and receiving nodes and which are outside their regions, RS is the replica size, DRout is the data rate outside the regions, NoINin is the number of intermediate nodes between the sending and receiving nodes and which are inside their regions, DRin is the data rate inside the regions,
On the other hand, the bandwidth consumption (BC) is calculated as follows:
where NoIN is the number of intermediate nodes between the sending and receiving nodes, and RS is the replica size.
In enhanced BHR strategy, every node stores the number of requests of each replica stored in it. The number of requests of a replica is increased by one each time it is requested by the node that resides on it. As in modified BHR strategy, all the replicas in the data grid are stored in the storage of the master site and distributed to the region headers in the regions. Since the region header will accommodate all the replicas in the data grid, its storage should be larger than the storage of other nodes in the region.
Algorithm 1 shows the algorithm of enhanced BHR strategy. For definitions of variables used in the algorithm, refer to Table 1.
If a node makes a request for a replica that resides on it, then it just uses it. On the other hand, if the replica does not reside on that node, it starts searching for it starting from the node that has the smallest value of distance to the requesting node multiplied by number of intermediate nodes between them.
When the requested replica is found on one of the visited nodes, it is brought to the requesting node. The requested replica is copied to the requesting node under two conditions. The first condition occurs when the requesting node has enough free storage space to accommodate it. The second condition occurs when the requesting node’s free storage space is less than the size of the requested replica, and the replica is found more important than a group of stored replicas. The size of that group needs to be greater than or equal to the storage space still needed to store the requested replica. In this case, that group of replicas is replaced with the requested replica. The requested replica is considered more important than that group of existing replicas if its NoRpmb is greater than the NoRpmb of that group. The NoRpmb of a group is equal to the sum of number of requests of all the replicas in that group divided by the sum of their sizes in mega bit.
Enhanced BHR strategy
Initialize
Use
Copy RR
Break
Delete
Variables in the algorithm of enhanced BHR strategy
In the current work, there are
In this paper, three metrics are used to measure the performance of the three strategies: total elapsed time, total bandwidth consumption, and number of requests served locally. The first two metrics need to be minimized, while the third metric needs to be maximized. Elapsed time is the time the replica takes to be transmitted from the sending node to the receiving node. Minimizing it means that the nodes will obtain the replicas in less time. If the node has the requested replica, the elapsed time is considered zero. During the simulation, the sum of all elapsed times is calculated. Bandwidth consumption is the consumed bandwidth for replica transfers between nodes. The consumed bandwidth for replica transfers should be reduced, because it is limited. During the simulation, the sum of all bandwidth consumptions is calculated. Number of requests served locally shows the number of requested replicas that were found on the requester’s storage (locally). The node does not consume time or bandwidth for the requests that were served locally and that is why this metric needs to be maximized.
Table 2 shows the metrics used to measure the performance of strategies. Because the calculated values of total elapsed times and total bandwidth consumptions through the duration of the simulation are so large, the constants
Metrics of strategies
Metrics of strategies
We used Java to write an event-driven simulator for evaluating three strategies which are original BHR, modified BHR, and our new proposed strategy named enhanced BHR. The simulator was verified by ensuring that the obtained output (for a small environment with small number of nodes, regions, and replicas) matches with the results obtained by hand calculations. A performance comparison between the three strategies is made to determine the best performing strategy. In the first comparison, the probability of requesting any of the replicas is the same. For the other comparisons, we selected one of the replica groups to be the group with the highest number of requests (GHNR). Since there are 10 replica groups and each group contains the same number of replicas, this group contains 10% of the total number of replicas, and each node has its own GHNR. The probability of making a request for replicas in GHNR is higher than the probability of making a request for the rest of replicas. In comparisons two to five, the probability of requesting a replica in GHNR is set to 20%, 40%, 60%, 80%, respectively.
In modified BHR, the region header of each region is selected randomly since the authors of this strategy did not mention anything about the selection process, while the region header is selected based on a modified version of closeness centrality (refer to section 3) in our proposed strategy.
In each simulation, all the nodes are set to employ one of the strategies under a set of parameters. For each strategy, the simulation is run five times; one for each of the comparisons. Since three strategies are compared; the total number of simulation runs is 15 (5
In all simulations, the same region nodes are distributed in a 10000
The uniform distribution is used to represent the inter-arrival times of nodes’ requests.
Table 3 shows the simulation parameters and their values.
Simulation parameters
The performance of the our new proposed strategy (enhanced BHR) is compared to original BHR and modified BHR strategies. From Figs 2 to 4, it can be seen that enhanced BHR strategy is superior to original BHR and modified BHR strategies. This is because of the six features it has and that were described in Section 3.
Additionally, it appears that the performances of all strategies improve when increasing the probability of GHNR. This is because many of the replicas kept in the storage of each node belong to GHNR, and those replicas are requested more frequently than the other replicas in other groups. As a result, the probability of finding the requested replicas locally is relatively high.
Total elapsed time achieved by original BHR, modified BHR, and enhanced BHR under five different comparisons.
Finally, it is shown in Figs 2 and 3 that original BHR consumes large amount of time and bandwidth. This is because of not having region headers in the various regions and therefore sending the replicas that do not exist in the same region from the nodes in other regions or master site.
Total bandwidth consumption achieved by original BHR, modified BHR, and enhanced BHR under five different comparisons.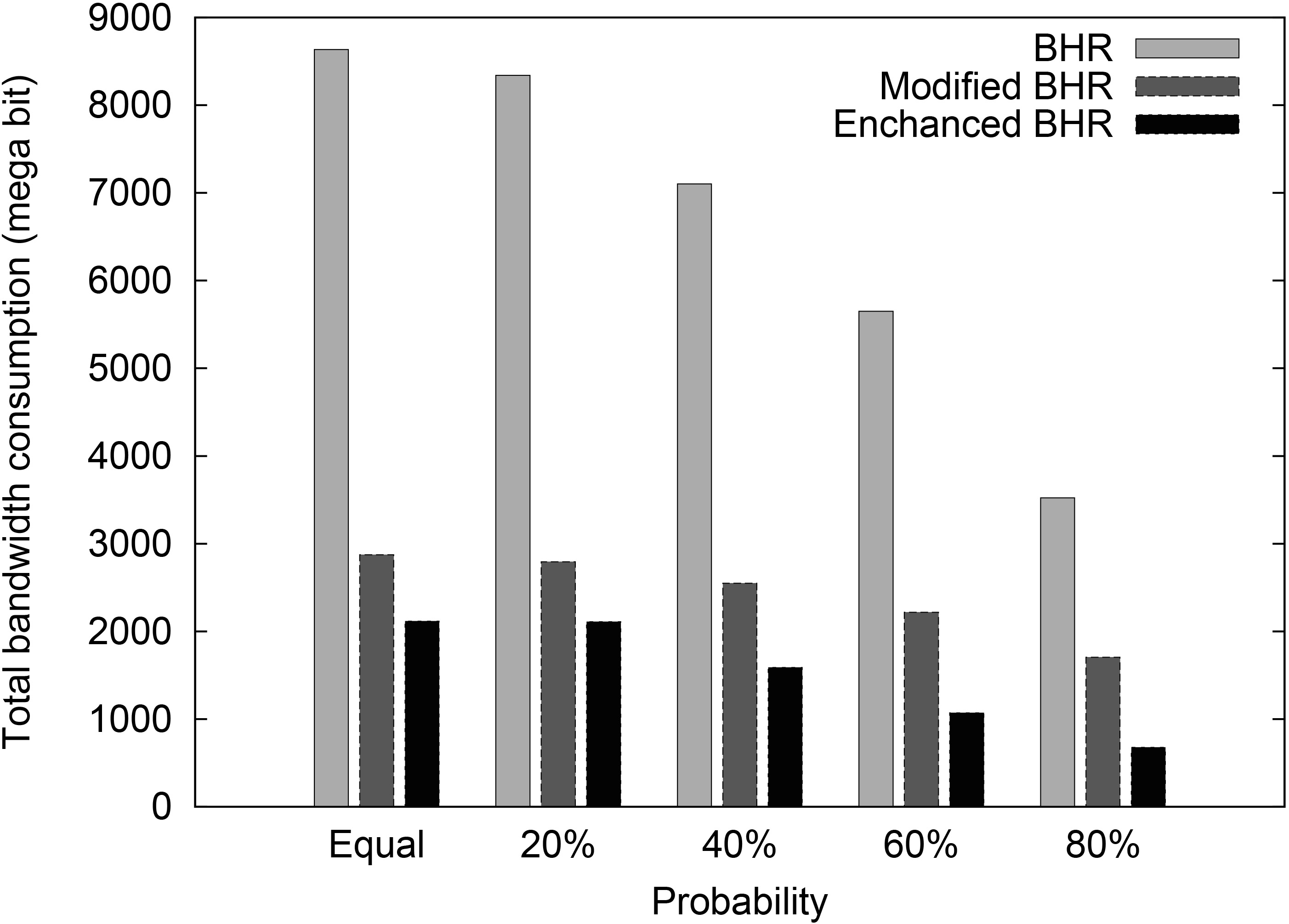
Number of requests served locally achieved by original BHR, modified BHR, and enhanced BHR under five different comparisons.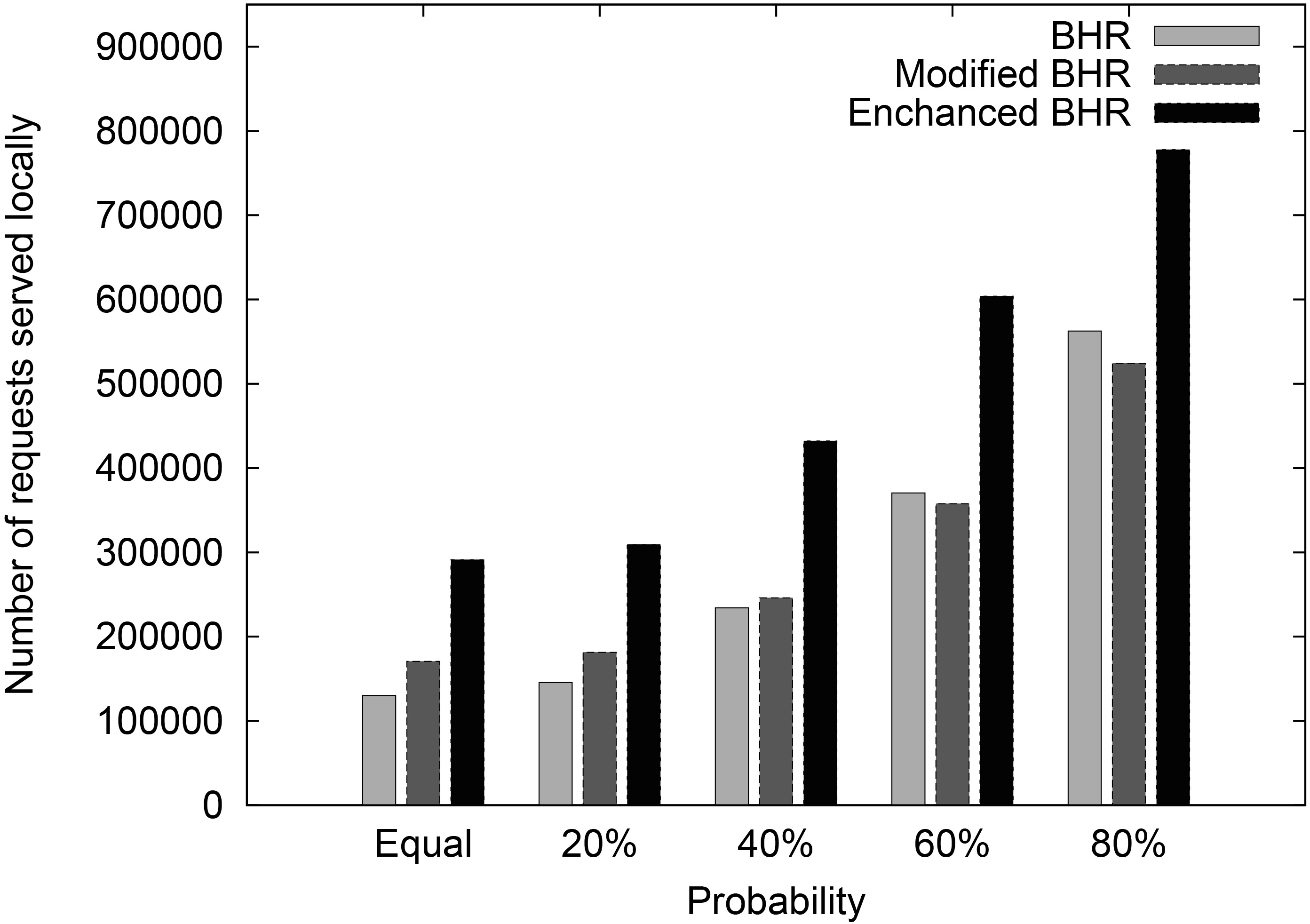
Much work has studied the problem of dynamic replication in data grid. In [8], a dynamic data replication algorithm called Latest Access Largest Weight (LALW) that assigns different weights to different access records was implemented. The assignment is based on the difference between the current time and the time of access record. This algorithm does not specify to which cluster node each file has to be copied. Additionally, this algorithm takes only one factor into account to determine the importance of files which is the number of requests .
In [12], the authors presented two new algorithms. The first one attempts to balance the load on different nodes, and the second one calculates the number of replicas that need to be copied to each node based on its storage size. These two algorithms assume that the user behavior is fixed which is not always true.
The authors of [5], proposed two dynamic replication algorithms called Simple Bottom-Up (SBU) and Aggregate Bottom-Up (ABU). The aim of these algorithms is reducing the data access average response time by placing the replicas close to the nodes with high number of requests. Both algorithms only considers the number of requests to determine to where the files are copied.
In [7], an approach called Fair-Share Replication (FSR) was implemented. Its goal is to balance the load and storage use of different nodes. This is achieved by taking into account the number of requests and the available space on the nodes when deciding to copy the replicas or not. This approach does not take into account the node centrality when deciding to copy the replica or not to the node. Taking node centrality into consideration reduces the consumed time and bandwidth to get the requested non-existing files. This approach also assumes that the user behavior is always fixed.
The authors of [14] presented an algorithm that is based on Fast Spread. However, this algorithm uses a threshold to determine if to copy the requested replica or not to the node that requested it. The number of requests is the only factor used to determine the replica importance in this algorithm.
In [13], an algorithm that is also based on Fast Spread was presented. The difference between the previous algorithm in [14] and this algorithm is that this algorithm takes into account more factors to specify the replica importance to each node. These factors include the number and frequency of requests, the replica size, and the last request time for the replica. This algorithm does not consider the variation in the user behavior.
In [16], an algorithm named Dynamic Hierarchical Replication (DHR) was proposed. In this algorithm, the replicas are copied to the nodes with the highest number of requests for these replicas. This algorithm only takes into consideration the number of requests to specify if to copy the file or not. Moreover, it is assumed that there is no variation in user behavior.
The authors of [23] presented a new algorithm called Popularity Based Replica Placement (PBRP). The aim of this algorithm is reducing the access time by making replicas for files that have high number of requests and placing these replicas in locations close to the nodes that requested them so many times. This algorithm only considers the number of requests to determine the importance of the file and assumes that the user behavior is always fixed.
The authors of [24] proposed a category-based dynamic replication strategy (CDRS) for replicating files on the data grid. This strategy takes into account that the files on a node belong to different categories. Each category is given a value that determines its importance for the node. When the node’s storage is full; the node will only save the files that belong to the category with the highest value. This strategy only considers one factor to determine the importance of a category which is the number of requests.
In [9], an algorithm named Bandwidth Hierarchy Replication (BHR) was implemented. This algorithm averts congestions in order to reduce the access time. The data grid is divided into regions. It is assumed in this paper that the bandwidth of the links between the nodes that belong the same region is higher than the bandwidth of the links between the nodes that belong to different regions. Therefore, if the requested replica is in the same region, less time will be needed to bring it to the node that requested it. The replica is stored in a node that has a large bandwidth between it and the node where the job will be executed.
In [21], a modified BHR algorithm was proposed. It is assumed in this work that each region has its own region header. The algorithm copies the replicates to the nodes that have a large number of requests for them. Furthermore, this algorithm improves the data availability by coping the replicas to the region headers. Thus, when a node needs a replica, it can bring it from the region header located in the same region.
In the proposed algorithms in [9, 21], number of requests is the only factor used to determine the importance of a file. Additionally, both algorithms compare the number of requests of the new file to the number of requests of each existing file separately and not to the number of requests of a number of existing files when deletion is needed to provide free space to copy the new file.
In this paper, we propose a new replication algorithm that is based on the two well-known BHR and modified BHR algorithms but overcomes their limitations.
Conclusion
In this paper, a new data replication strategy named enhanced BHR has been proposed. Enhanced BHR is based on two existing strategies which are original BHR and modified BHR. However, enhanced BHR strategy has a number of features that makes it superior to them in terms of total elapsed time, total bandwidth consumption, and number of requests served locally. Those features determine how to select the region header of each region, where the requested replica must be sent to, the factors to be considered in determining the importance of the replica, the order of nodes that will be visited in order to find the requested replica, and the replicas that need to be deleted in order to have enough space to store the requested replica.
In future work, there are two main areas of consideration: considering having more features for enhanced BHR, and undertaking further experimental investigations.
Footnotes
Authors’ Bios