
Abstract
This paper proposes an intelligent warehouse-picking approach using radio frequency identification (RFID) indoor positioning and natural language processing (NLP) speech recognition. A forward maximum matching algorithm segments speech into domain terminology. Location was estimated by RFID signal strengths between reference tags and pickers. Simulation results demonstrated a 50% reduction in segmentation runtime versus conventional methods. Speech recognition accuracy reached 90–95%, improving by 23% over baseline. Positioning accuracy also increased substantially. The techniques can reduce picking errors and costs. Further work should evaluate performance in real-world environments.
Keywords
Introduction
Natural Language Processing (NLP) is an interdisciplinary field of computer science, artificial intelligence, and linguistics aimed at enabling computers to understand, analyze, generate, and operate human language (Tabakh et al., 2019). The increasing maturity and popularity of Radio Frequency Identification (RFID) technology provide new application scenarios and opportunities for NLP algorithms (Surantha et al., 2019). The main challenges currently faced by warehouse sorting include the inefficiency and error-prone nature of manual operations, common sorting errors leading to customer dissatisfaction and additional costs, difficulties in inventory management, growing demand for rapid response, and the need for large amounts of data processing and analysis. In this context, the introduction of RFID and NLP technology can significantly improve the efficiency and accuracy of warehouse sorting. RFID can achieve fast and automated item tracking and identification, while NLP can be used to improve interaction with warehouse management systems, such as fast queries and data processing through natural language commands. The combination of these technologies has the potential to address the aforementioned challenges and improve overall warehouse operational efficiency. In logistics warehousing, NLP technology is mainly applied to improve customer service through intelligent chatbots, optimize picking operations through voice command systems, automatically process and analyze documents and data, and enhance supply chain communication efficiency. These applications help improve the efficiency and accuracy of warehouse operations, accelerate processing processes, and improve customer experience (Hartiwi et al., 2020). In summary, the combination of RFID technology and NLP algorithm has shown great potential and application prospects in the field of logistics warehousing and picking. This study focuses on leveraging RFID technology and NLP algorithms in software engineering to develop an innovative method for logistics warehouse picking. By integrating indoor positioning and speech recognition, the aim is to enhance the efficiency of logistics warehouse operations. The challenge of this research is how to achieve efficient warehouse sorting by combining the RFID technology and NLP algorithm. The solution idea is to use the RFID technology to automatically mark and track goods and apply the NLP algorithm to process and analyze a large number of order information, so as to improve the speed and accuracy of sorting. The framework includes an RFID system indoor positioning technology, terminology voice recognition, and warehouse selection based on RFID technology and voice recognition. Through this research, the intelligence and automation of warehouse sorting can be realized, and production efficiency and accuracy can be improved. The innovation of this study lies in the in-depth research and exploration of the application of term speech recognition based on RFID technology and NLP algorithm in logistics warehouse picking. Compared with existing technologies, the research method fills a key gap. This study is mainly divided into four parts. The first part is related works, summarizing the current research achievements in RFID technology and other aspects. The second part is the research method, that is, the content of the framework. The second part is the research methodology, including RFID system indoor positioning technology, terminology speech recognition, and warehouse picking based on RFID technology and speech recognition. The third part is the result analysis, mainly conducting simulation analysis on the research methods. The fourth part is the conclusion, summarizing the research results and future research directions.
With the widespread application of RFID tags, RFID indoor positioning becomes an effective solution to solve indoor positioning problems. Numerous scholars conducted extensive research and achieved good research results. Wei C et al. constructed a model using indoor semantic networks and grid navigation to improve indoor positioning and navigation and achieve internal semantic positioning. Research results indicated that this method improved the accuracy of stay area matching, indoor positioning, and navigation (Wei & Ge, 2022). To improve the efficiency of tag search in RFID systems, scholars such as Yan N proposed a tag search protocol using the Bloom filter, which utilized composite filtering vectors to remove local tags. Results showed that it improved time efficiency by 50%, and the performance of this protocol was superior to other common protocols (Yan et al., 2023). Duan R and other scholars proposed an improved Location Identification based on Dynamic RSSI Calibration (LANDMARC) to address the accuracy issue of RFID-based LANDMARC indoor positioning algorithms being easily affected by labels. The algorithm utilized Newton interpolation to obtain the distance between the tested label and the reader. The research findings demonstrated that this method successfully enhanced indoor positioning accuracy, substantially reduced errors, and minimized the impact of labels on the algorithm (Duan, Li & Yin, 2020). Zhang Y and other researchers designed an indoor positioning and navigation system using QR codes and databases to achieve a low-cost and strong anti-interference signal ability indoor positioning and navigation method. The research results indicated that the system achieved precise and efficient indoor positioning and navigation, effectively reduced costs, and significantly improved positioning and navigation effectiveness (Zhang et al., 2019). To improve indoor positioning, Ma H et al. proposed an RFID-based deep learning algorithm for indoor positioning, and used a Kalman filter to eliminate fluctuations caused by signal reception. They optimized the fingerprint method using a deep neural network to achieve nonlinear mapping. Research results indicated that the research method effectively improved positioning accuracy, with an average estimation error of 0.347 m (Ma et al., 2021).
Logistics warehouse picking is an important link in the entire logistics process, directly related to order accuracy and delivery efficiency. Through efficient logistics warehousing and picking, enterprises can achieve faster, more accurate, and reliable logistics operations, improve customer satisfaction, and reduce operating costs. Jiang H proposed a picking optimization method based on a dynamic clustering algorithm to solve the sum of average similarity and picking times of each picking station. The research results indicated that this method balanced the number of picking times and distances, significantly improving the picking efficiency (Jiang, 2020). Sebo J. et al. proposed a path optimization method using the genetic algorithm to shorten the distance of the warehouse pickup journey. They investigated and compared the routes and obtained the best path. The experimental results indicated that this method had a shorter distance compared to other methods and improved the efficiency of warehouse operations (Sebo & Busa, 2020). To improve warehouse order picking, scholars such as Ozden SG designed an open-source computer software system to solve the warehouse’s optimal layout. Results indicated that the system improved the efficiency and accuracy of order picking (Ozden, Smith & Gue, 2021).
The above research shows that RFID indoor positioning technology has good navigation and positioning effects. In the modern logistics industry, the use of automated equipment and NLP algorithms, as well as the latest developments in RFID technology, has led to an increasing trend towards intelligence and automation in logistics warehouse picking. Given that traditional picking methods face increasing pressure from the development of the logistics industry and also have some shortcomings, this study proposes a voice picking method using RFID technology and NLP algorithm to address the shortcomings of traditional picking methods in some special environments, which is expected to promote technological innovation in the field of logistics warehousing.
Research method
RFID technology and NLP algorithms in software engineering have broad application value in different fields and gradually become key technologies for improving the logistics warehousing and picking process. The study first introduces RFID indoor positioning technology and elaborated on terminology speech recognition based on NLP algorithms. Next, it introduces the LANDMARC algorithm based on RFID indoor positioning technology and combines it with speech recognition to promote more intelligent and efficient warehouse picking under logistics speech recognition.
RFID Indoor positioning technology of the system
RFID technology refers to the use of wireless radio frequency signals as a carrier for information transmission, and the exchange of information between readers and tags to achieve applications. RFID is a type of information exchange that utilizes wireless communication technology. Its characteristics are non-contact, fast, and reliable. RFID systems have the advantages of faster reading and writing speed, longer working time, and easier reading and writing. They can also recognize multiple objects and have broad development space (Li et al., 2020). The RFID basic structure is shown below.
From Fig. 1, the RFID system includes a reader, a label, and a computer control network. Among them, the reader is a device in the RFID system used to read and write information about RFID tags that communicate with it. A tag is a device on an identified object in an RFID system. When a tag communicates with a reader within a certain range, the tag processes the received signal and replies with data about the tag itself and the object it represents. The computer control network is a core component of the RFID system, used to control and manage the operation of the RFID system. These three parts work together to form a complete RFID system (Zhang, Kane & Wang, 2019). The reader reads the data of the label, the computer control network processes and manages it, and takes corresponding measures according to the needs. This system architecture provides enterprises and organizations with more efficient, accurate, and intelligent logistics management and control capabilities.
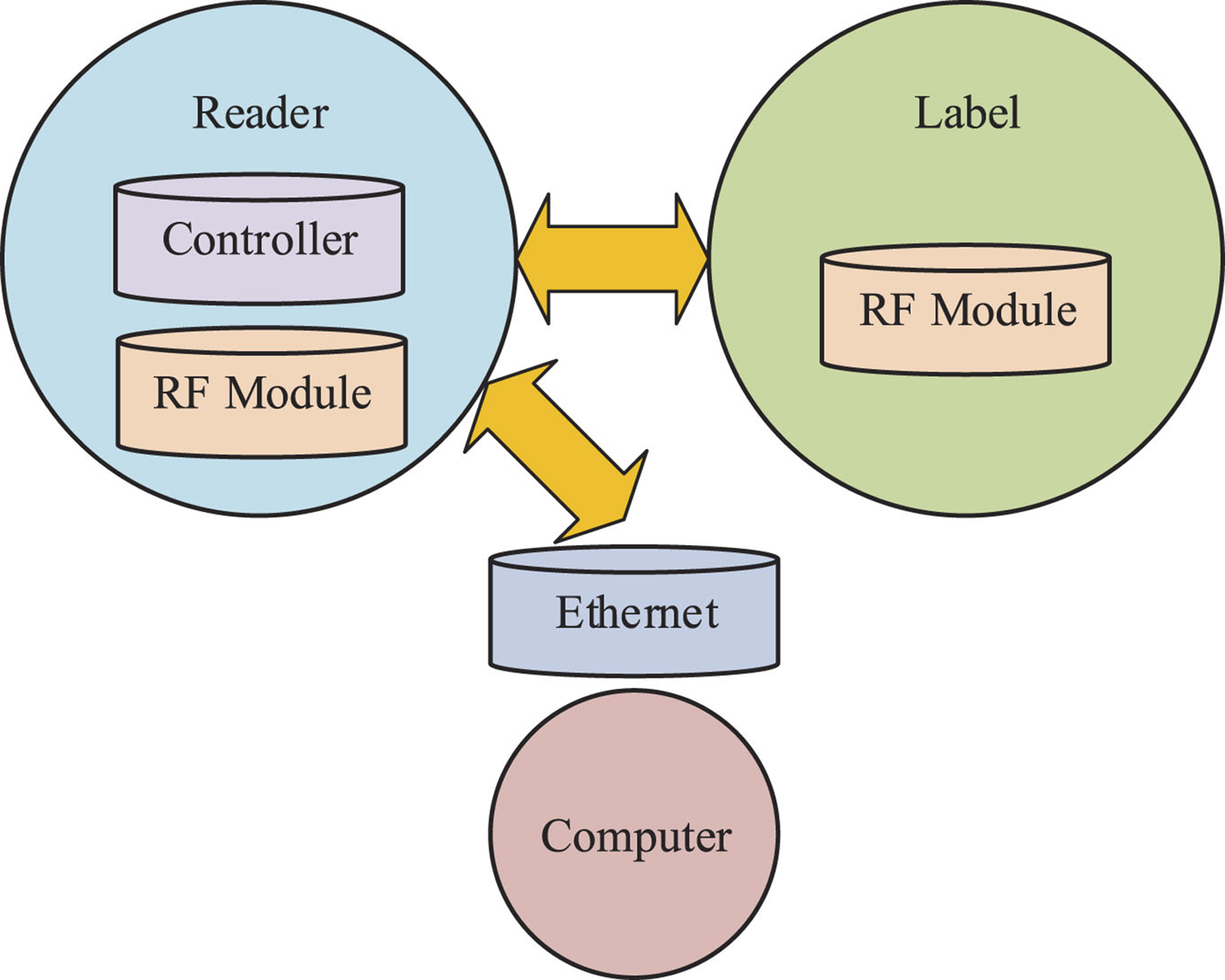
The Basic Structure of RFID System
The RFID indoor positioning is a technique that utilizes the RFID technology to determine the indoor location by leveraging the interaction between tags and readers within RFID systems. RFID indoor positioning requires the deployment of RFID tags, which can be attached to objects or fixed in specific locations. The position of the tags can be selected and set according to positioning needs and scene characteristics. Then, the reader-tag interaction is carried out, followed by information processing and calculation. After receiving the information returned by the tag, the reader will transmit this information to the computer control network for subsequent processing. Computer control networks can process and calculate the received signals through algorithms and technologies to achieve indoor positioning. Then, positioning calculations can be carried out to calculate the distance and orientation of the tag relative to the reader by calculating the signal transmission time and strength between the tag and multiple readers. Finally, the indoor location calculation can be used to calculate the tag’s indoor location based on the relative distance and orientation information between the tag and the reader (Zan, 2022) (Yike, Pengyuan & Yonghong, 2019).
NLP-based term speech recognition
NLP-based term speech recognition is an innovative technology that combines the capabilities of speech recognition and NLP, providing a new way to understand and process speech information. Speech recognition technology has achieved tremendous success, and the NLP-based term speech recognition has been widely applied in different fields. It can improve user experience, improve operational efficiency and accuracy, and has broad development prospects.
This study mainly focuses on speech recognition of terms, so it mainly focuses on word segmentation and semantic analysis. The core of dictionary-based word segmentation is the dictionary and rules. A dictionary is like a dictionary, which contains indexes and body text. The difference lies in its query process. It saves words or combinations of words that appear in the segmented corpus in the dictionary and then matches them through query mechanisms to complete word segmentation, such as the maximum matching algorithm and minimum word segmentation algorithm. Among them, in the general field, the maximum matching segmentation algorithm has a 99% accuracy and the widest application range (Malek & Bohac, 2020).
The maximum matching segmentation algorithm is a basic segmentation method used in Chinese NLP, mainly divided into three types: forward, backward, and bidirectional. Forward maximum matching and backward maximum matching are two commonly used word segmentation algorithms in Chinese NLP. Their main difference lies in scanning and matching from the beginning and end of the text to be processed. The error rate of forward and reverse maximum matching segmentation algorithms is as low as 0.6%, but the latter is greatly limited by the size of the vocabulary. Therefore, the research will utilize the forward maximum matching segmentation algorithm to form a segmentation algorithm that is more suitable for term speech recognition. Before that, it is necessary to first build a domain dictionary, which will use two methods: extraction tools and manual direct addition. The specific process is depicted below.
From Fig. 2, the collected terminology corpus is first preprocessed, then extracted by a vocabulary extraction tool, and finally filtered manually to construct a domain dictionary. Term extraction software can be used to automatically extract terminology corpus. The vocabulary is initialized to facilitate queries on words and word attributes. Arrays dictionary [ ] and hash [ ] are defined. The former mainly stores all words, while the latter mainly stores words with consistent key values. Firstly, the first word w and length L of the word in the vocabulary are obtained, the hash function is used to calculate the w corresponding hash value, and the value is obtained. The expression is shown in Equation (1).

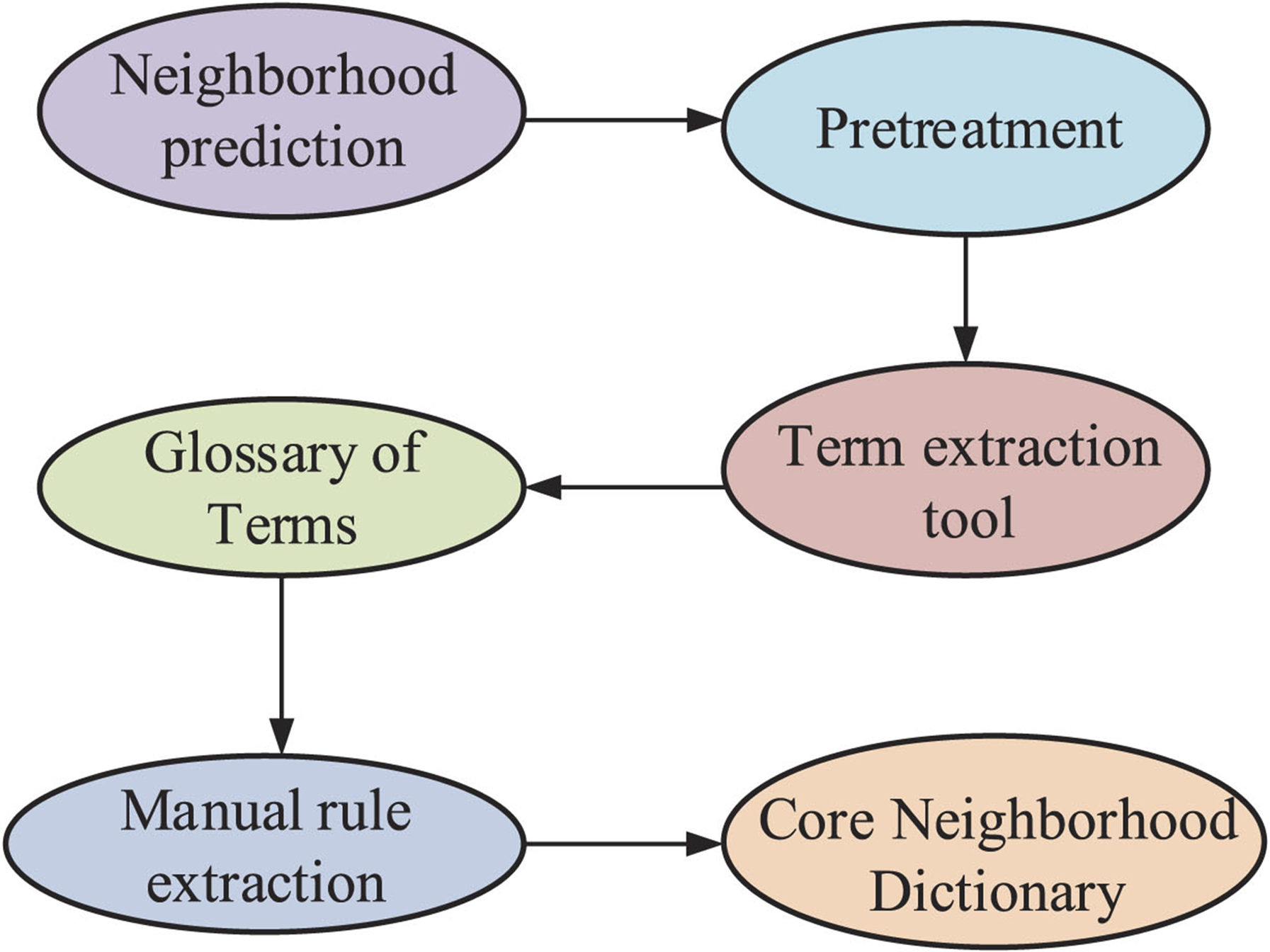
The construction process of domain dictionaries
In Equation (1), v represents the value. Assuming that key = v %n in the hash function, due to the small size of the vocabulary, n = 300 is assigned to make the data distribution more uniform (Chen, 2021). Then the key values of the words are combined and stored in the corresponding hash[key], following this process until all the words are stored in the hash[]. Then, the forward maximum matching algorithm is used for word segmentation, part of speech tagging, and stopping word filtering, as shown below.
From Fig. 3, after initialization, all words with the same initial word and word count are stored in the same linked list. During the segmentation process, when encountering scenarios with no logged-in words or single-character words, the algorithm efficiently filters out stop words or identifies keywords by traversing the dictionary only once. This approach reduces the number of searches and significantly decreases the algorithm’s running time (Dujmešić, Bajor & Rožić, 2018).
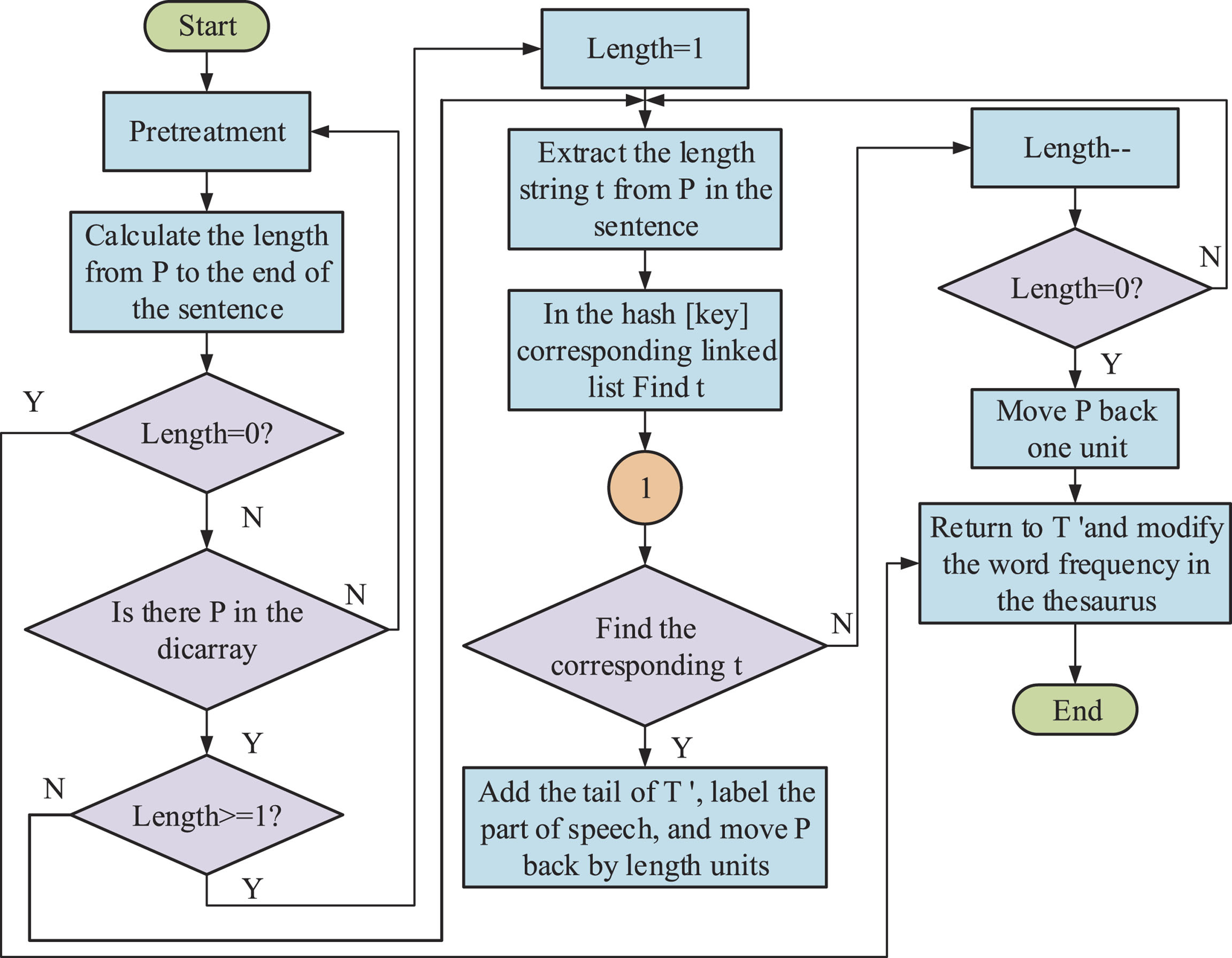
Forward maximum matching word segmentation algorithm process
After completing the segmentation, semantic analysis can be performed. Semantic templates can abstract database terminology into a model and divide it into two types: conceptual and relational, with sentences represented by conceptual relational models (Zhong et al., 2022). The study will utilize concepts, their attributes, and interrelationships to form a semantic template and calculate the probability parameters of language statistical models based on statistical semantic templates to determine the likelihood of language components appearing in sentences.
The semantic template is composed of 2 tuples 〈M, N〉, with M and N representing keywords and keyword weight sets respectively (Hou et al., 2020). In the implementation process of semantic analysis based on the semantic template, it is necessary to first input segmentation text, then extract vocabulary, complete the matching of the semantic template, and finally obtain the results and output them. Semantic analysis based on semantic templates utilizes keyword matching to understand the semantics of sentences. The algorithm first stores some basic semantic templates with N values, each corresponding to a semantic. Then, it extracts vocabulary from the segmented text and matches them one by one with the template. If the matching is successful, the corresponding semantics will be output. Except for the keyword part, other parts have no impact on semantics, so they will not be considered.
Intelligent warehouse picking based on LANDMARC algorithm and speech recognition
RFID-based indoor positioning algorithms are mainly divided into range-based and non-range-based positioning algorithms. The latter is currently the most popular indoor positioning method on the market due to its small impact on multipath effects (Peng, Zhao, & Jiang, 2019). The LANDMARC algorithm is a relatively mature algorithm among non-ranging positioning algorithms. It is based on the Received Signal Strength Indicator (RSSI) of wireless signals and achieves the localization of moving objects in indoor environments by establishing an association model between RSSI and location. The LANDMARC structure is shown below.
In Fig. 4, the tag to be located can be connected to an RFID reader through a reference tag. In the LANDMARC algorithm, it is assumed that there is n RFID readers, m reference tags, and u tags to be tested (Legowo & Wijaya, 2022). When positioning, the reader first sends out an RF signal, and within the RF range, the tag returns the RF information identifying itself, and the reader obtains the strength value. Assuming the obtained signal strength vector of the tag to be tested is
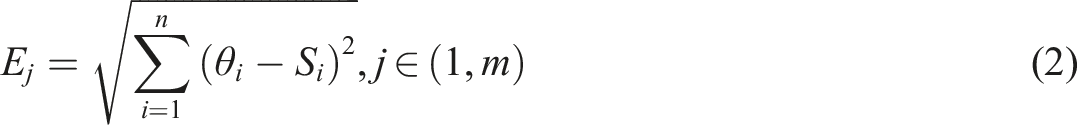
Schematic diagram of LANDMARC structure
In Equation (2), E
j
is used to describe the Euclidean distance between the reference label and the label to be tested. The smaller the value, the closer the signal strength of the two labels is, that is, the closer the actual distance is. Among the m reference labels,

In Equation (3), w
i
is used to describe the coordinate weight value of the i nearest neighbor label, and the weight value of the k nearest neighbor label is 1. Each reference label must be assigned values according to a certain pattern. From the relationship between signal strength and transmission distance, the closer the distance is, the greater its reference weight. The calculation is shown in Equation (4).

In Equation (4), when E
j
is the smallest, its weight is the highest. Next, the positioning error distance e is located, which means the algorithm estimates the geometric distance between the coordinates (x, y) and the time coordinates (x0, y0) of the tag to be tested, as shown in Equation (5).

The LANDMARC algorithm is influenced by various factors when using k nearest neighbors, but k size plays a crucial role in the LANDMARC positioning accuracy. Scholars have found that the cumulative error of the tested label is the most ideal (Pier & Weidinger, 2022). In the LANDMARC algorithm, a reference label is added, which does not require distance measurement in the environment, thus achieving higher positioning accuracy. Typically, when the location of the items to be picked is known, the k-nearest neighbor labels of the items are utilized as a reference to identify the operator nearest to the items. This approach helps minimize positioning errors resulting from selecting the wrong neighbor label in LANDMARC.
In LANDMARC, assuming there are n readers, m reference tags, and u tags to be located, the signal strength matrix of u tags to be located concerning n readers is obtained as shown in Equation (6).

Then four reference labels are obtained on rectangular fixed points surrounding the goods to be picked, and their signal strength matrix expressions for n readers are shown in Equation (7).

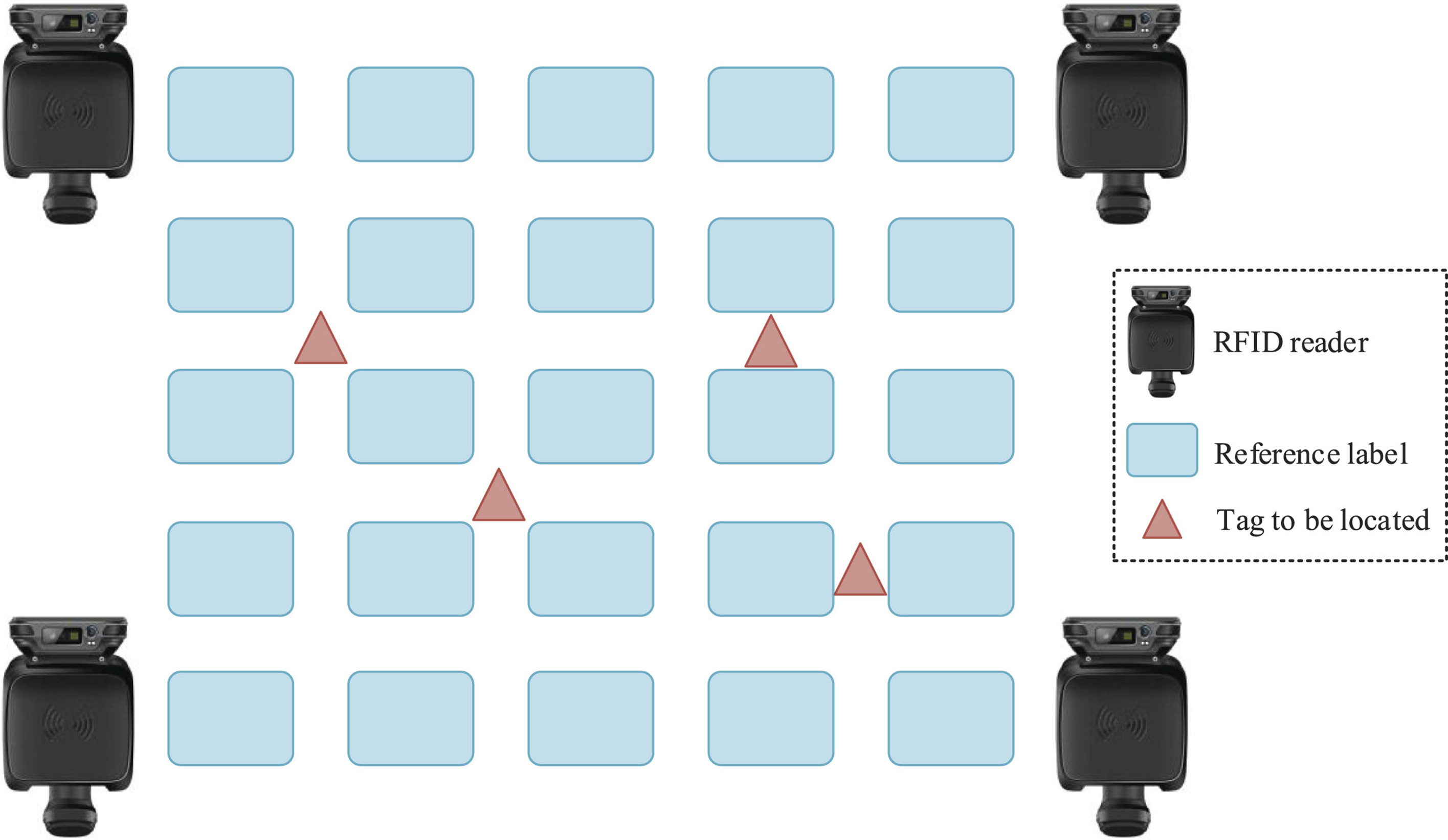
When the goods to be picked are within the box area enclosed by the four reference labels ③, ④, ⑦, and ⑧, as shown in Fig. 5.
In Fig. 5, if the goods to be picked are located near reference labels 3, 4, 7, and 8, then reference labels 3, 4, 7, and 8 can be used as neighbor labels. Equation (8) can be used to calculate the E
j
values of these four neighbor labels and the test label, which is the Euclidean distance.
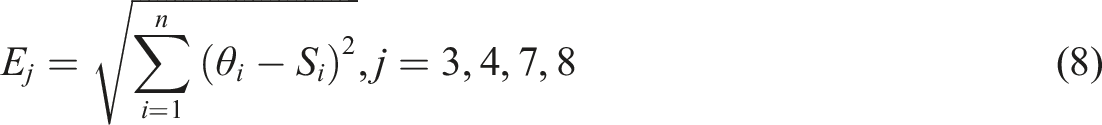
Schematic diagram of indoor positioning layout for voice warehouse sorting
Then, based on the distance relationship between the reference label and the goods to be picked, the E
j
values of each label to be picked are calculated, as shown in Equation (9).

The calculation of k
j
in Equation (9) can be obtained by Equation (10).
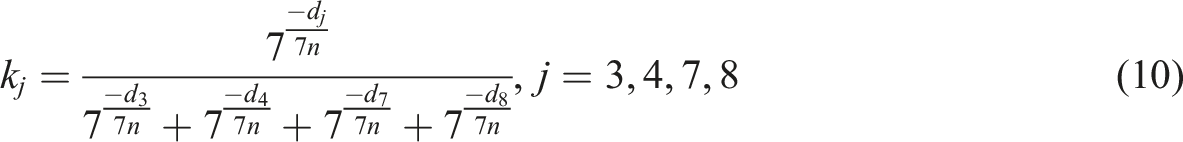
In Equation (10), is the corresponding distance. The smallest label is selected, which is the operator closest to the goods to be picked. Then, using speech recognition, staff can use voice commands to interact with the system, such as indicating the location, quantity, or special requirements for picking goods. The system will convert voice commands into text and perform corresponding processing and execution. This speech recognition technology can reduce manual input and search time in warehouse operations and improve operation speed and accuracy. It can also improve the work experience of staff and reduce fatigue and errors. By integrating voice technology with warehouse picking systems, more intelligent and efficient warehouse management and operation can be achieved. In addition, it can also adapt to the needs of diversity and flexibility, providing solutions for different warehousing environments and work scenarios.
Experimental and results
To investigate the practical application of LANDMARC and speech recognition based on the NLP algorithm in warehouse picking using RFID indoor positioning technology, this study initially analyzed the performance of the LANDMARC algorithm and speech recognition with NLP. Subsequently, the warehouse picking performance was evaluated for both the LANDMARC algorithm and speech recognition, considering the integration with RFID indoor positioning technology. Finally, a logistics voice recognition warehouse picking simulation environment was set up to verify the method application effect in logistics warehouse picking.
Warehouse picking performance analysis
Firstly, the forward maximum matching segmentation algorithm performance was verified. This algorithm, combined with the hash function, was beneficial for reducing search times and running time, and improving the efficiency of the algorithm. Due to the overall small size of the corpus, this study did not separate the training and testing sets. To maximize the training corpus, cross-validation was used for testing. That was to randomly divide the 500-sentence sample into 50 copies, each with 10 sentence samples, and the total number of Chinese characters included was close (Ali, Elrouby & Haddad, 2022). During the testing process, 20 copies were selected for testing, and the remaining 30 copies for training. Two different methods were used to segment sentences, namely the forward maximum matching segmentation algorithm and the traditional segmentation algorithm. The two algorithms’ running time and processing speed were compared in Fig. 6.
From Fig. 6, after combining the hash function, the overall running time of the forward maximum matching segmentation algorithm was reduced by 50% compared to traditional segmentation algorithms. When there were fewer stop words, the algorithm ran relatively less time. The emergence of stop words had a greater impact on the running time of traditional algorithms, as it required traversal of the word library, which consumed more time. After combining with the hash function, the forward maximum matching word segmentation algorithm only needed to use one operation to remove the stop word when it appeared, greatly reducing the impact of the stop word on the algorithm’s operation time (Gajšek et al., 2022). Meanwhile, the overall processing speed of the forward maximum matching segmentation algorithm was significantly faster than traditional segmentation algorithms.
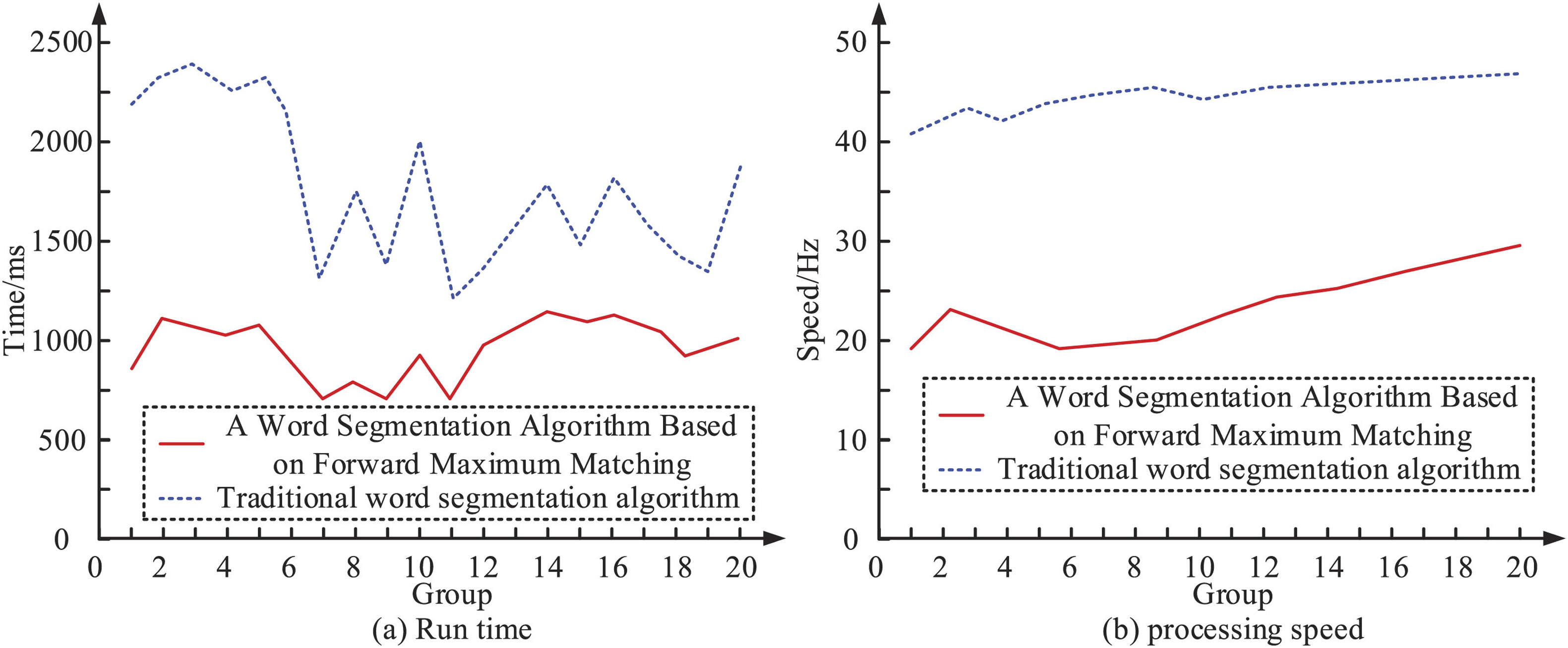
Running time of word segmentation algorithm using forward maximum matching
Then, the speech recognition performance based on NLP algorithms was verified and compared with traditional speech recognition methods. The accuracy, recall, and F1 values of the two methods were compared, as shown in Fig. 7.
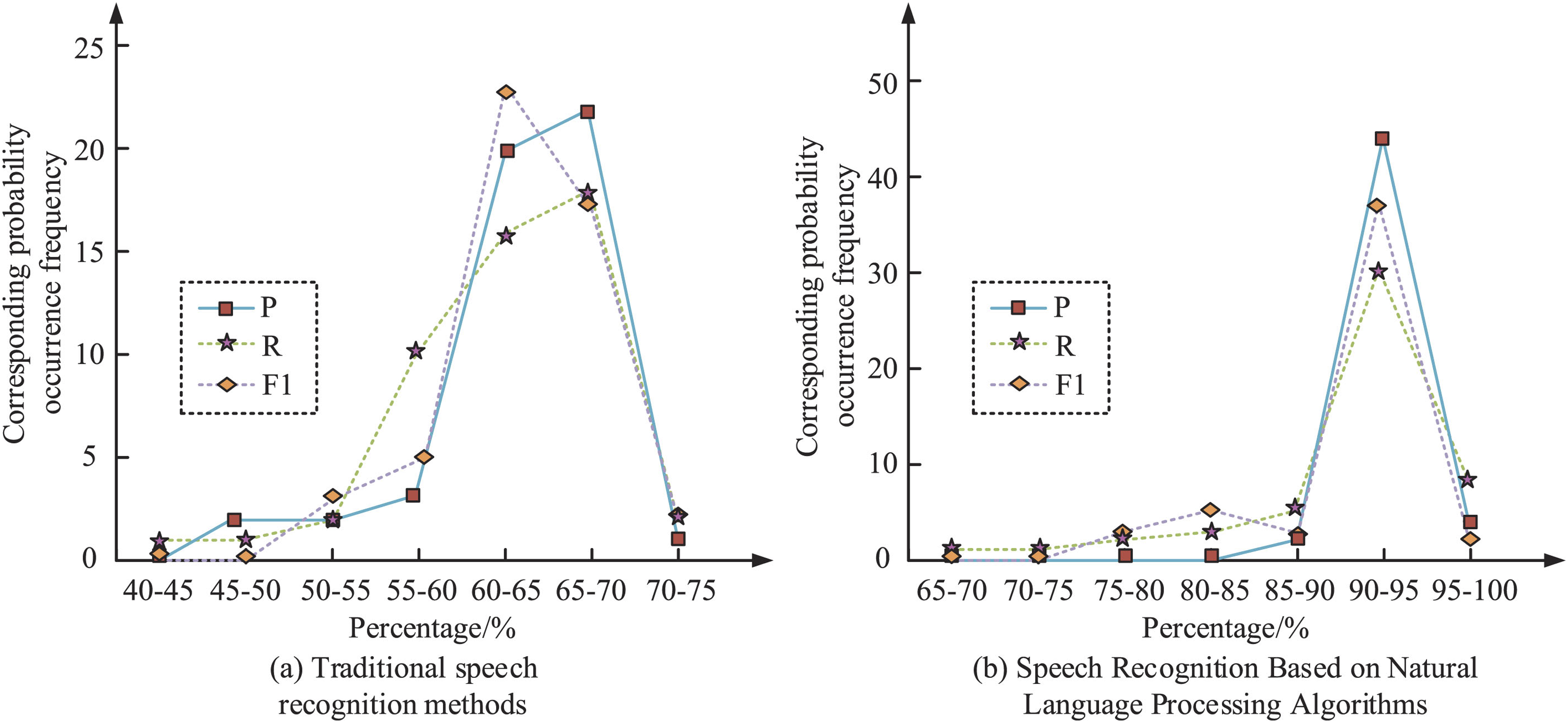
Speech recognition performance based on NLP algorithms
In Fig. 7, the accuracy of traditional combined speech recognition methods was between 60% –70% . However, due to its loose distribution and a higher concentration within smaller ranges, a large amount of the corpus goes unrecognized. Speech recognition based on NLP algorithms had a more centralized distribution and the addition of domain word banks, greatly reducing the number of unrecognized corpus and improving accuracy, and the accuracy was concentrated between 90% –95% . The accuracy, recall, and F1 values of traditional combined speech recognition methods were 66.72% and 61, respectively. 23%, 63%. 45%, the accuracy, recall, and F1 values of speech recognition using NLP were 90.15%, 92.32%, and 91.67%, respectively. Compared with traditional methods, the accuracy of speech recognition using NLP improved by 23.43% . Speech recognition based on NLP algorithms was more suitable for application in speech recognition, which ensured the accuracy of the application effect. This indicated the efficiency of NLP technology in processing and understanding speech data. The NLP method effectively reduced the number of unrecognized corpora, and improved accuracy, recall, and F1 value through the use of domain lexicons and a more refined algorithm design. This improvement meant that speech recognition became more reliable and better captured and understood user voice commands, especially in specific fields. This progress was of great significance for improving user experience and developing more efficient voice interaction systems in specific fields.
Finally, an analysis was conducted on the CPU usage during the warehouse picking process using the LANDMARC algorithm and speech recognition based on RFID indoor positioning technology, and it was compared with conventional warehouse picking. The results are shown in Fig. 8.
From Fig. 8, there was little difference in CPU usage between the LANDMARC algorithm and speech recognition warehouse picking process based on RFID indoor positioning technology and conventional warehouse picking. The research method can ensure improved accuracy and efficiency while not occupying too much CPU memory, indicating good overall performance.
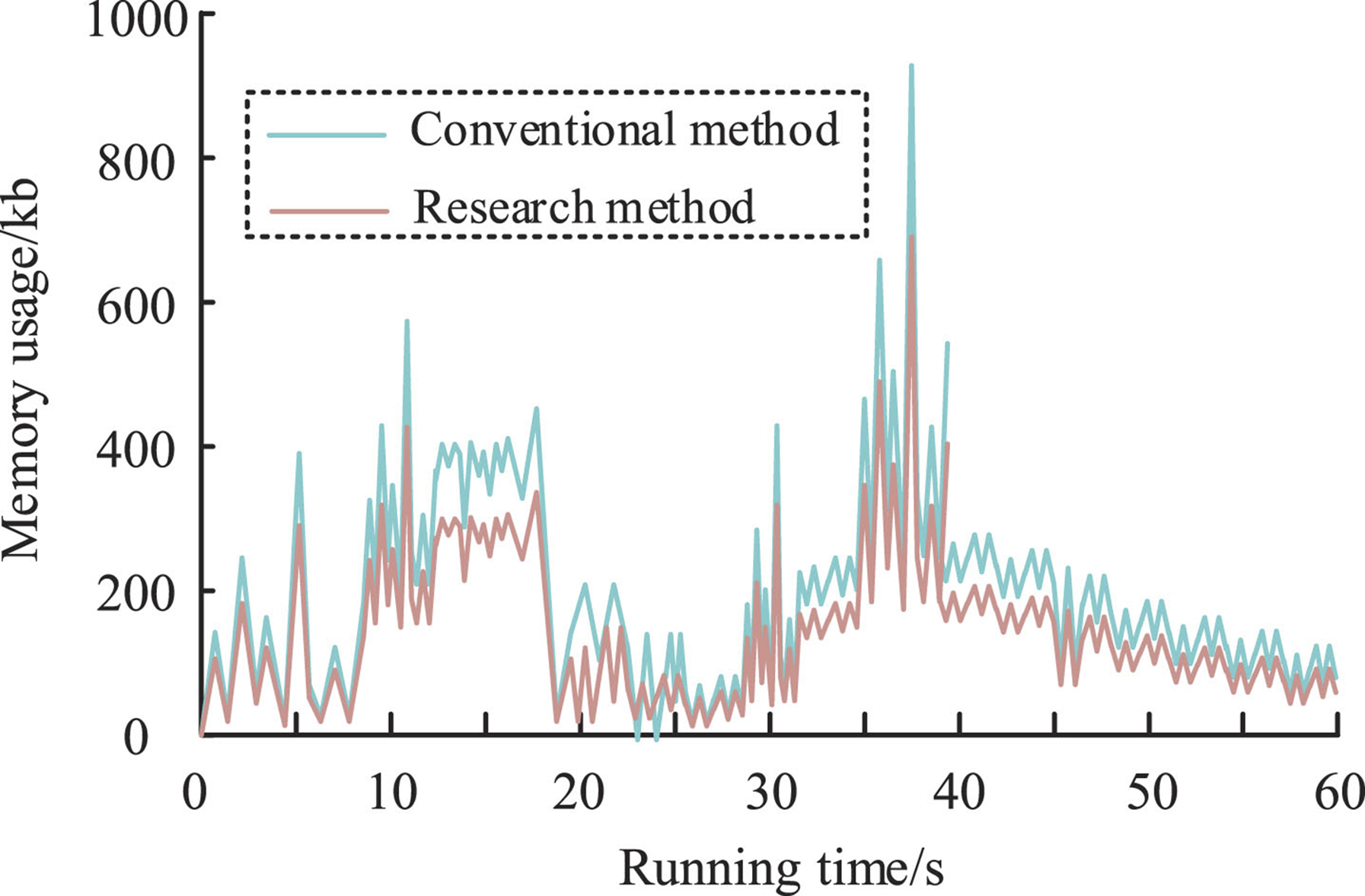
CPU usage of warehouse picking operation based on RFID indoor positioning technology and speech recognition
Warehouse picking simulation analysis
This study conducted a simulation analysis on the LANDMARC algorithm and speech recognition warehouse picking based on RFID indoor positioning technology. Firstly, the simulation environment was set up below.
Environment for simulation experiments
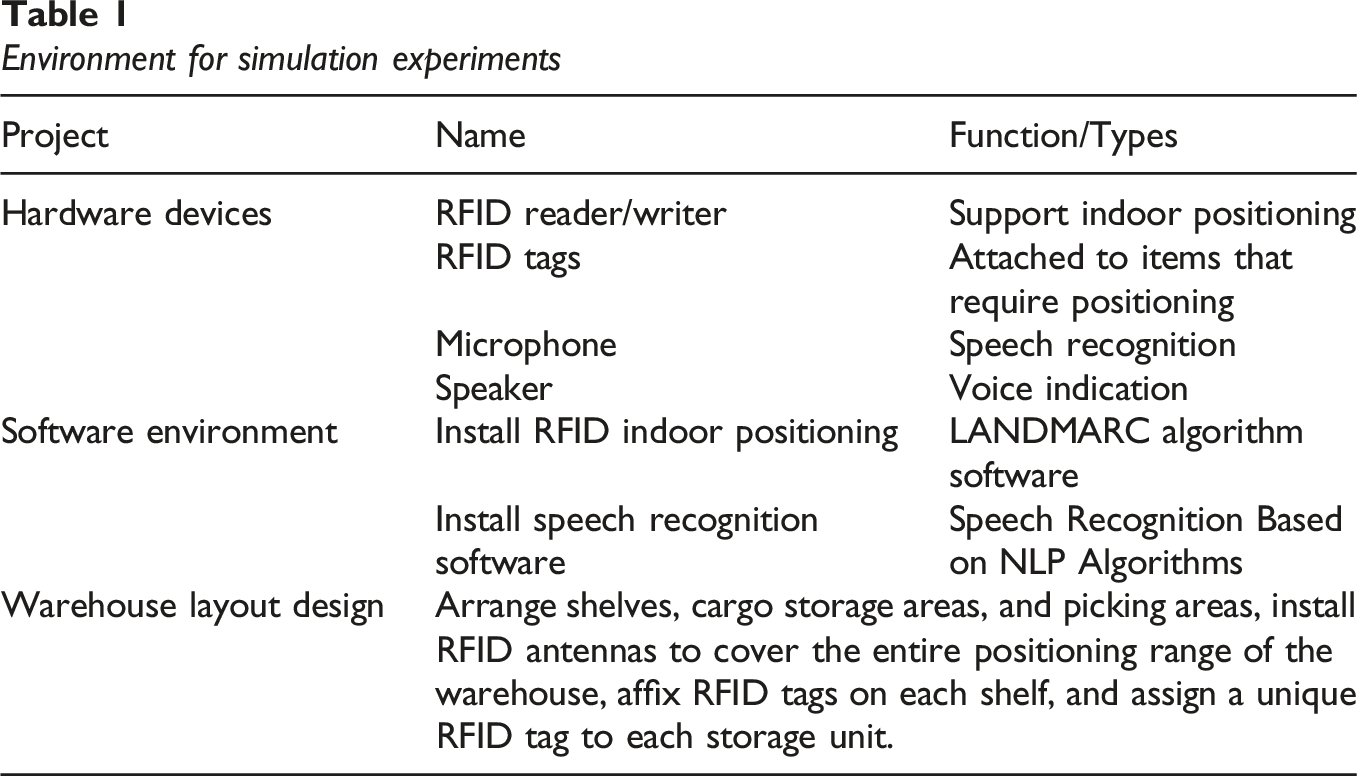
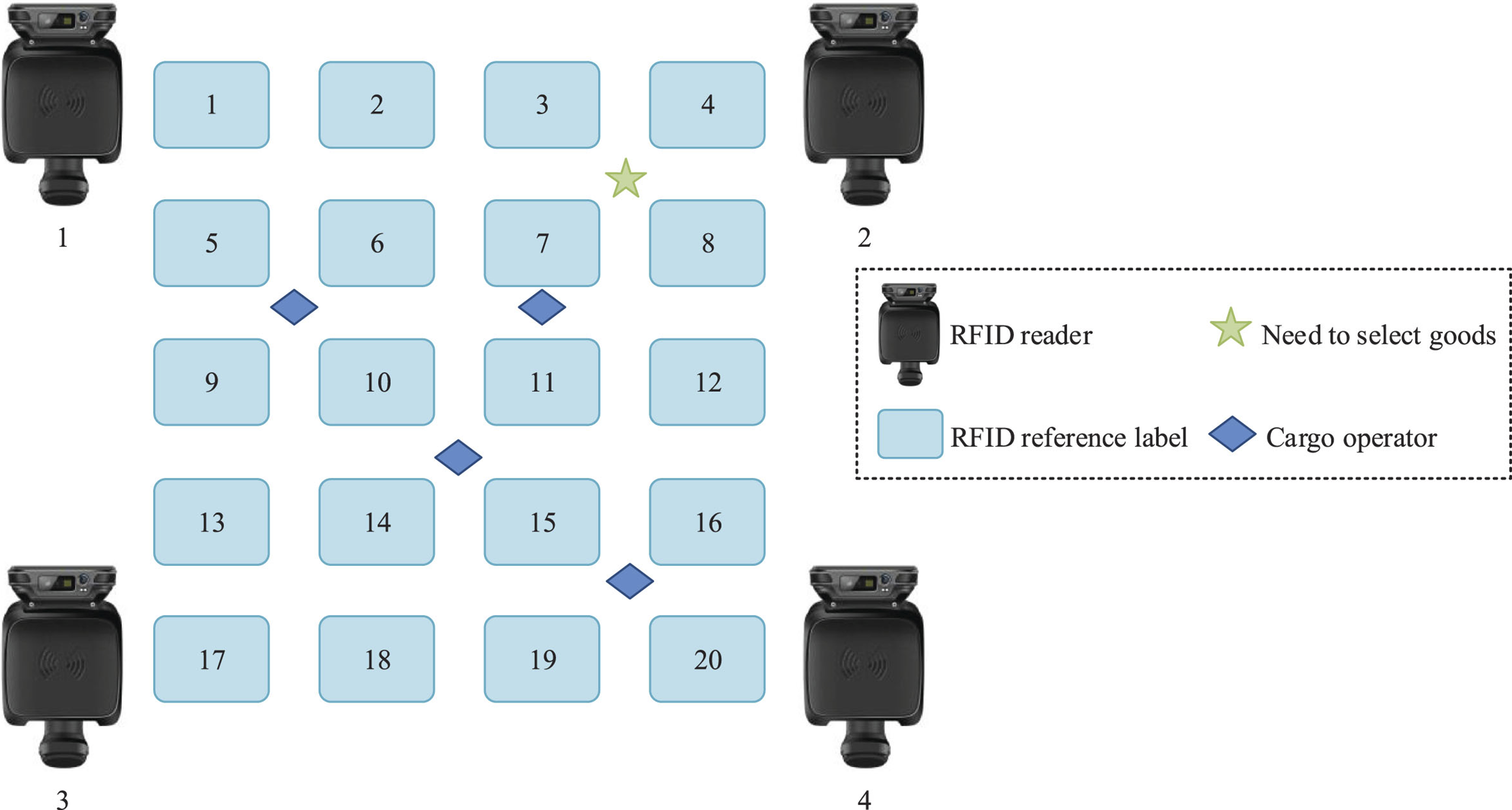
In the warehouse layout, it was necessary to arrange shelves, cargo storage areas, and picking areas, install RFID antennas to cover the entire positioning range of the warehouse, affix RFID tags on each shelf, and assign a unique RFID tag to each storage unit. The specific simulation design of the logistics warehouse picking layout is shown in Fig. 9.
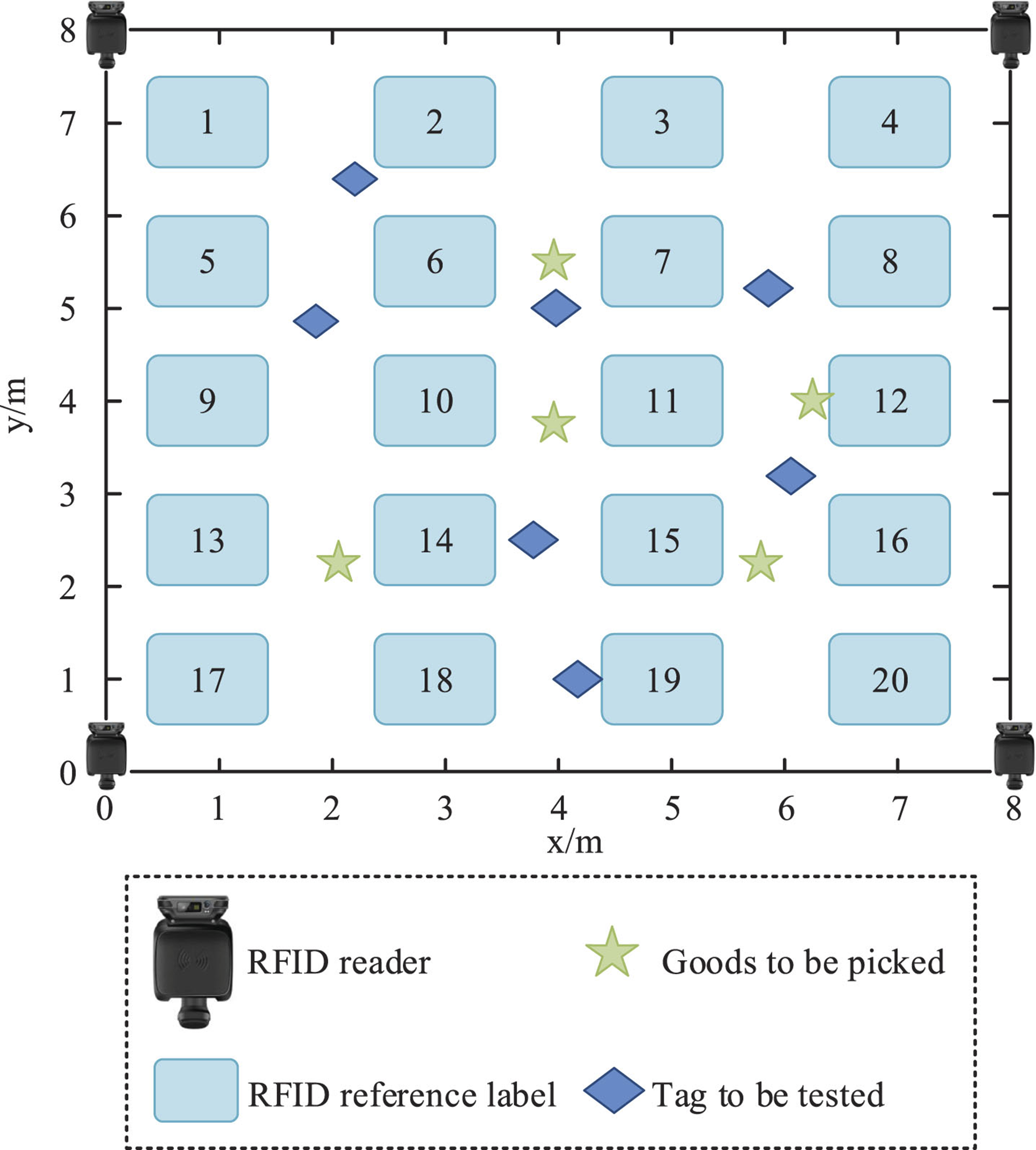
Simulation Design of Logistics Warehouse Picking Layout
From Fig. 9, within an 8 m×8 m area, there were 4 readers, 20 reference tags, 7 test tags (operators), and 10 items to be picked. The distance between adjacent reference tags in each row was 2 m, and there was 1.5 m between the two rows. Subsequently, simulations were conducted on the research method and traditional method for warehouse picking, and the results are shown in Fig. 10.
Simulation Design of Logistics Warehouse Picking Layout
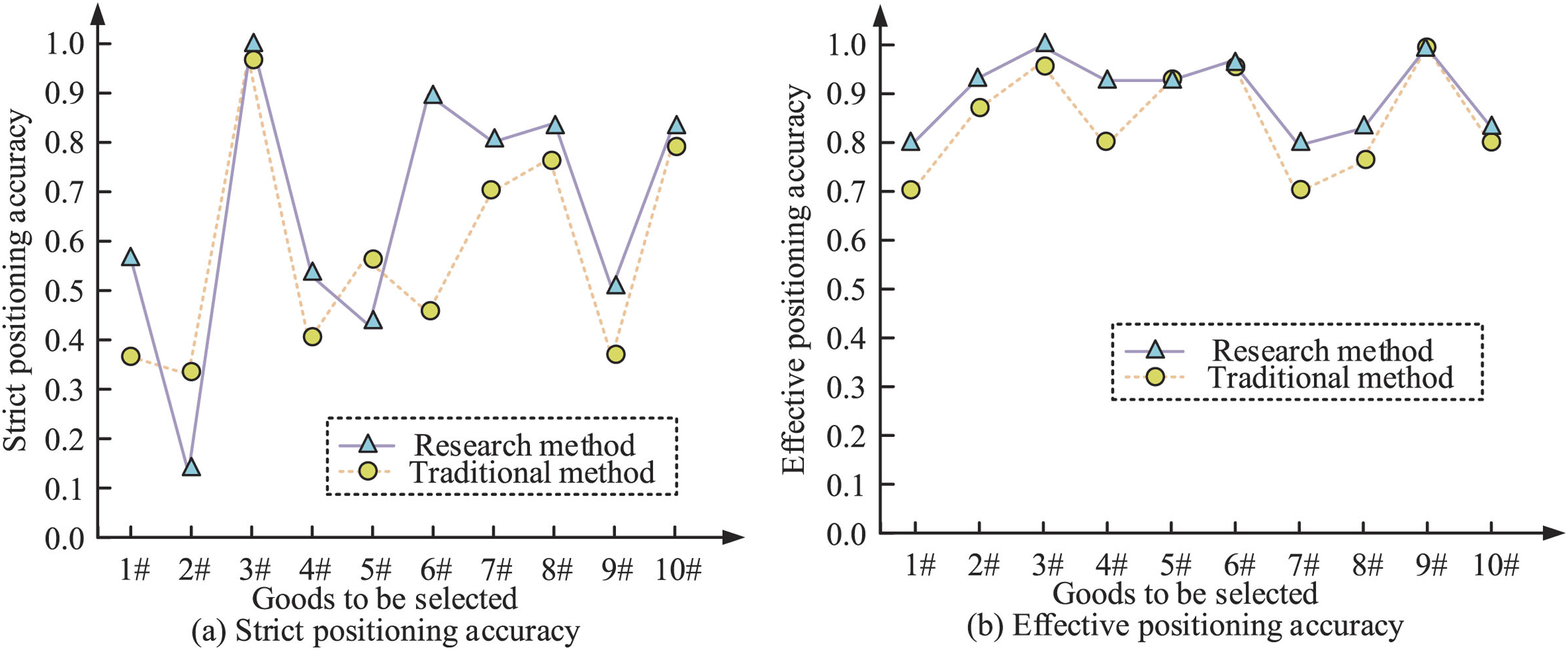
Figures 10 (a) and 10 (b) show the strict positioning accuracy and effective positioning accuracy. Compared with traditional methods, the research method’s accuracy was greatly improved. For example, the strict positioning accuracy of research methods and traditional methods for picking goods 1 were 0.57 and 0.38, respectively, and the effective positioning accuracy was 0.80 and 0.70, respectively. In addition, in experiments, when operators made mistakes, they were often located closest to the position of the goods to be picked. Therefore, the positioning accuracy of the system can satisfy picking and positioning. In the case of strict positioning, the goods to be picked with relatively low positioning accuracy had a significant improvement in effective positioning, and the final effective positioning accuracy of the research was relatively high or the same. The research method ensured high precision and effective positioning accuracy, thereby ensuring the efficiency of warehouse sorting. In terms of effective positioning, both methods had high accuracy, proving the applicability and reliability of these technologies under general conditions. This is very useful in ordinary warehouse operations and daily item picking and selection.
Conclusion
Logistics warehouse picking is an important link in the logistics field, which is of great significance for improving logistics efficiency, reducing costs, and meeting user needs. However, the traditional logistics warehousing and picking process often faces problems such as long manual processing time and error prone. Therefore, studying how to apply RFID technology and NLP algorithms in software engineering in logistics warehouse picking is of great significance. This study applies RFID indoor positioning technology and speech recognition based on the NLP algorithm to intelligent picking and selection in logistics warehousing. The results showed that the overall running time of the forward maximum matching segmentation algorithm was significantly shorter than that of traditional segmentation algorithms. Compared with traditional methods, the accuracy of speech recognition based on NLP algorithms improved by 23.43% . Research methods can ensure improved accuracy and efficiency while not occupying too much CPU memory. The simulation results showed that the research method ensured high strict positioning accuracy and effective positioning accuracy. Studying the application of NLP algorithms in RFID technology and software engineering in logistics warehouse picking can provide technical support and innovative ideas for logistics enterprises, helping to achieve intelligence and optimization of the logistics process.
The method proposed by the research institute provides a practical intelligent picking solution for the logistics and warehousing field with lower resource consumption by improving accuracy and efficiency. This represents important progress in industrial automation and intelligence, which can help warehouses achieve automation more efficiently and cost-effectively while enhancing system flexibility and availability. Considering the complexity of the current global supply chain and the urgent need for efficiency, this technology can create advantages for logistics enterprises in competition, and most importantly, significantly improve customer experience. There are still some shortcomings in this study, and the current system may mainly be suitable for standardized warehousing environments. In complex or non-standard environments, such as ever-changing warehouse layouts or special item handling, the efficiency of the system may be limited. Future research can prioritize enhancing system adaptability to diverse environments and complex tasks, leveraging advanced machine learning models and flexible algorithm designs. Additionally, the integration of RFID and NLP technologies with other advanced technologies can be explored to further enhance the efficiency and accuracy of picking systems.