
Abstract
Gradient descent is prevalent for large scale optimization problems in machine learning, especially its major role is computing and correcting the connection strength of neural network in deep learning. However, choosing a proper learning rate for SGD can be difficult. A too small rate may lead to painfully slow convergence, while too large one would hinder convergence. In this paper, we present a novel variance reduction technique which applies the moving average of gradient termed SMVRG. SMVRG can take a large learning rate by using variance reduction technique. And, we only need to preserve current gradient and the previous average gradient. Our method is employed to Long Short-Term Memory (LSTM). The experiment on two data sets, the IMDB (movie reviews) and SemEval-2016 (sentiment analysis in twitter) shows our method can improve the results significantly.
Introduction
In machine learning and statistics, we always encounter the optimization auxiliary objective function Eq. (1) with respect to a set of parameters. And nowadays, for a given network architecture in deep learning, one usually starts with an auxiliary objective function w.r.t. the weights which are the connection strengths between units. Thus, most learning algorithms are based on iterative methods, which aim to find a set of parameters by taking small steps iteratively towards a direction until it reaches a desired solution. In Eq. (1),
The general idea of the algorithms (such as SGD and SPGD) are that gradient computed on subset is to approximate true gradient on the whole datasets, and the algorithms use mini-batches of data instead of all data which causes gradient noise and variance. But if using all data to compute gradient, it will be compute-intensive and require much storage of gradients. Due to the variance introduced by random sampling, SGD obtain a slower convergence rate than GD. This means that we have a trade-off of fast computation per iteration and slow convergence for SGD versus slow computation per iteration and fast convergence for GD. To improve the stochastic gradient descent, one need a variance reduction technique, which allows us to use a large rate
We can take a large learning rate by using variance reduction technique replacing average gradient with moving average gradient. And by using variance reduction technique can reduce the variance and noise of SGD.
Our method does not require the storage of full gradients and is not compute-intensive, and we only need store the current gradient and the previous average gradient.
The rest of paper is organized as follows. Section 2 proposes our method Stochastic Moving Average Gradient (SMVRG). Section 3 describes the experimental design and discusses the results. The final section concludes the work.
Stochastic moving-average variance reduction gradient (SMVRG)
Choosing a proper learning rate can be difficult. A learning rate that is too small leads to painfully slow convergence, while a learning rate that is too large can hinder convergence and cause the loss function to fluctuate around the minimum or even to diverge [9]. So we always need a small learning rate due to the variance of SGD. The general idea of SGD is that gradient computed on subset is to approximate true gradient on the whole datasets, and the algorithms use mini-batches of data instead of all data which causes gradient noise and variance. And the gradient noise is caused by variance of magnitude introduced by random sampling. In this paper, we propose a variance reduction technique regarding moving average of gradient as average gradient, thus we only need to preserve current gradient and the previous average gradient. At each time, we keep a version of
Thus, we can have that the weights are close to the weights on all data set.
The algorithm of SMVRG
The algorithm of SMVRG
We test the proposed algorithm on well-known benchmark problems for video classification and emotional classification. Using large models and data sets, we demonstrate the proposed algorithm can efficiently solve practical deep learning problem. And SGD is one of the most common training algorithms in use for neural network training, and some algorithms, such as SPGD, and so on. The experiments in this section compare the proposed algorithm above with SGD and SPGD. In this paper, we set
Datasets
The experiments is conducted on two data sets, the label distributions of two datasets is in Table 2.
Label distributions of two datasets
In this work, we conducted the experiment on LSTM (Long Short-Time Memory) which is a kind of time recurrent neural network. LSTM enforces constant error flow through ‘constant error carrousels’ within special unit, and multiplicative gate units of LSTM learn to open and close access to the constant error flow [12,13]. We trained with 128 hidden units with final softmax output layer on top. Our methods was trained on mini-batches of 32 movie review or tweets per batch for 50 epochs through the training set. And We use standard deterministic cross-entropy objective function relative to parameters as the cost function to evaluate the fitness of trained model.
Result
Dropout
The critical point of dropout is to randomly drop units along with their connections from the neural network during training which avoids over-fitting from co-adapting too much. According to [15], during training, dropout samples from an exponential number of different “thinned” networks; at test epoches, dropout approximates easily the effect of averaging the predictions of all these thinned networks dropped some units along with their connection by simply using a single unthinned network that has smaller weights.
We pre-process the IMDB movie reviews data set and SemEval-2016 (Sentiment Analysis in Twitter) data set into bag-of-words (Bow) feature vector for each review and Twitter which are highly sparse. As suggested in [16], we apply stochastic regularization methods (in this paper we use 50% dropout noise), which are an effective way to prevent over-fitting and often used in practice due to their simplicity, to the Bow features during the training. Figure 1 is the histograms of our method for 50 epoches with dropout and on both date sets. Figure 2 compares the performance (including train accuracies and train error) of dropout with SGD and our methods without dropout. Comparing the curves of without dropout and using dropout, with dropout, the train accuracies are larger and test errors is lower. Thus, dropout is a useful technique for improving the performance of neural networks. Dropout [16,17] is applied during training to prevent over-fitting. And, we compare the effectiveness of our methods to other methods on LSTM trained with dropout noise. The x-axis of figures of our method is gradient computations divided by n.
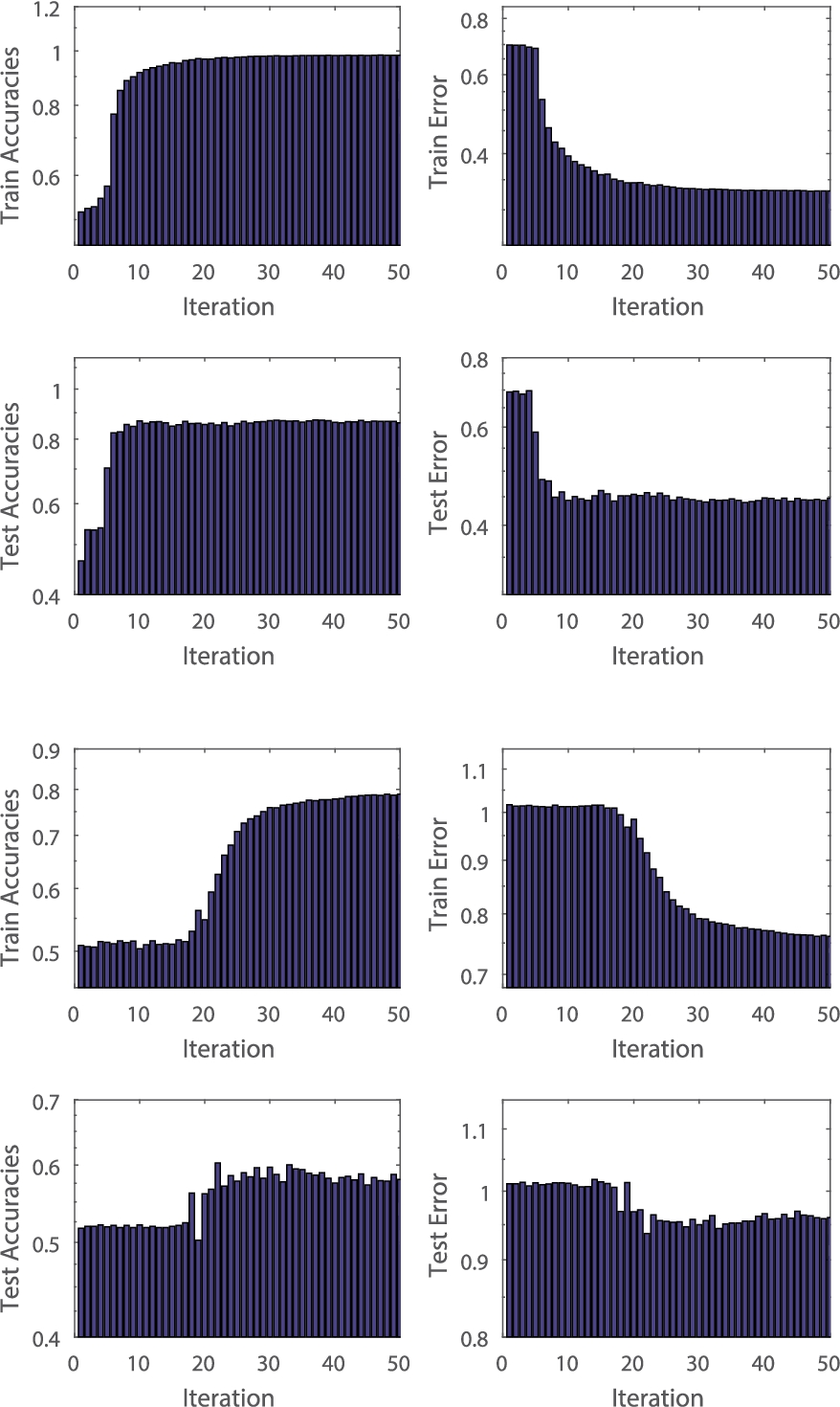
Left: the accuracies and errors of our method on IMDB for 50 epochs; Right: the accuracies and errors of our method on SemEval-2016 for 50 epochs. Top: our method on train set; Bottom: our method on test set.
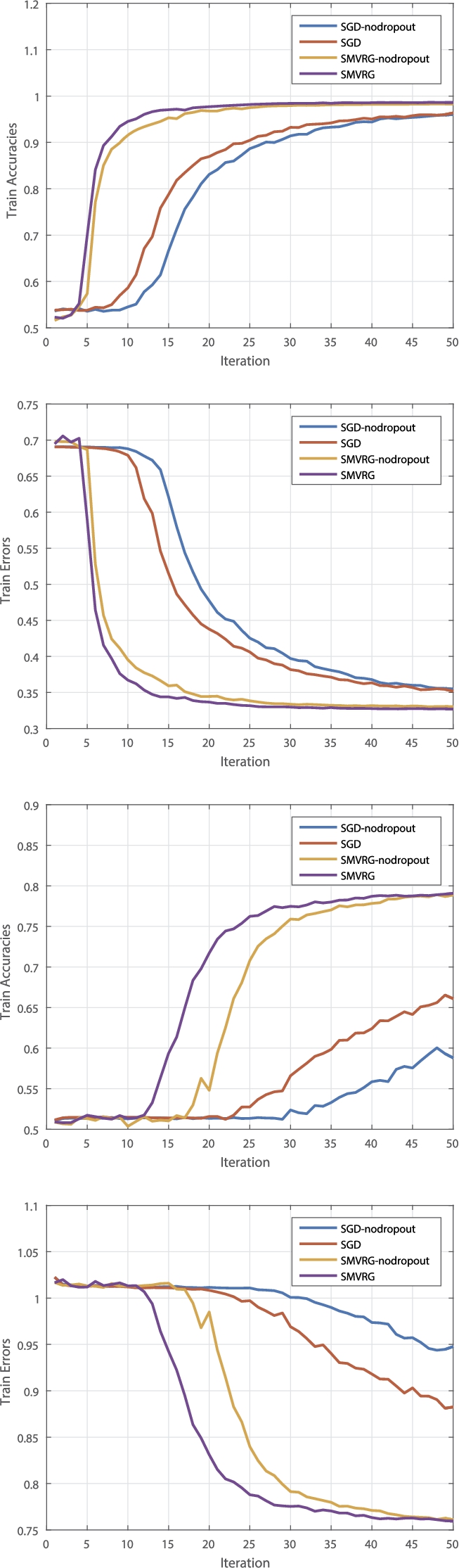
Top: the train accuracies and train errors of SGD, SMVRG on IMDB for 50 epochs; Bottom: the train accuracies and train errors of SGD, SMVRG on SemEval-2016 for 50 epochs.
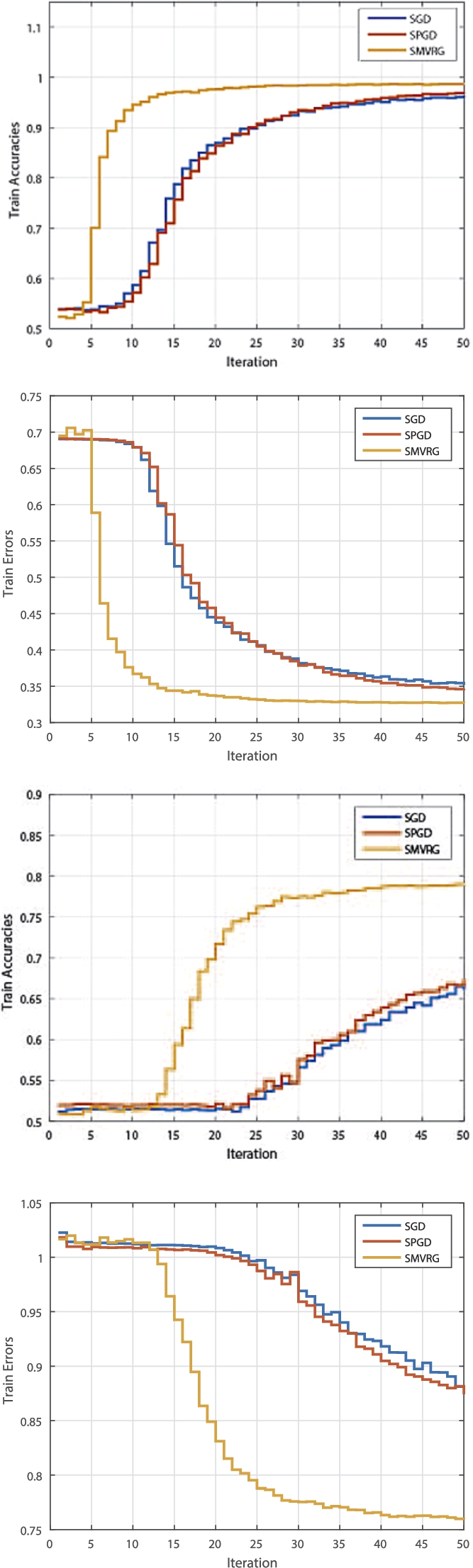
Top: the train accuracies and train errors of SGD, SPGD and SMVRG on IMDB for 50 epochs; Bottom: the train accuracies and train errors of SGD, SPGD and SMVRG on SemEval-2016 for 50 epochs.
In Fig. 3, we compare SGD, SPGD and our methods in the train set from train accuracies and train loss, the best common SGD method does worse in this case, SMVRG performances well for the 50 epochs of training. And the empirical performance of our algorithm with variance reduction technique is consist with our theory and our algorithm obtains the best performance. Figure 4 indicates the strength of SMVRG and the weakness of SGD. That is, training loss of SGD with a relatively large learning rate drops fast at first, but it oscillates above the minimum. With a small learning rate, the minimum may be approached eventually, but it will convergence slowly. However, using a relatively large value of learning rate, SMVRG smoothly goes down faster than SGD and convergences fast. Figure 5 shows parameter updates
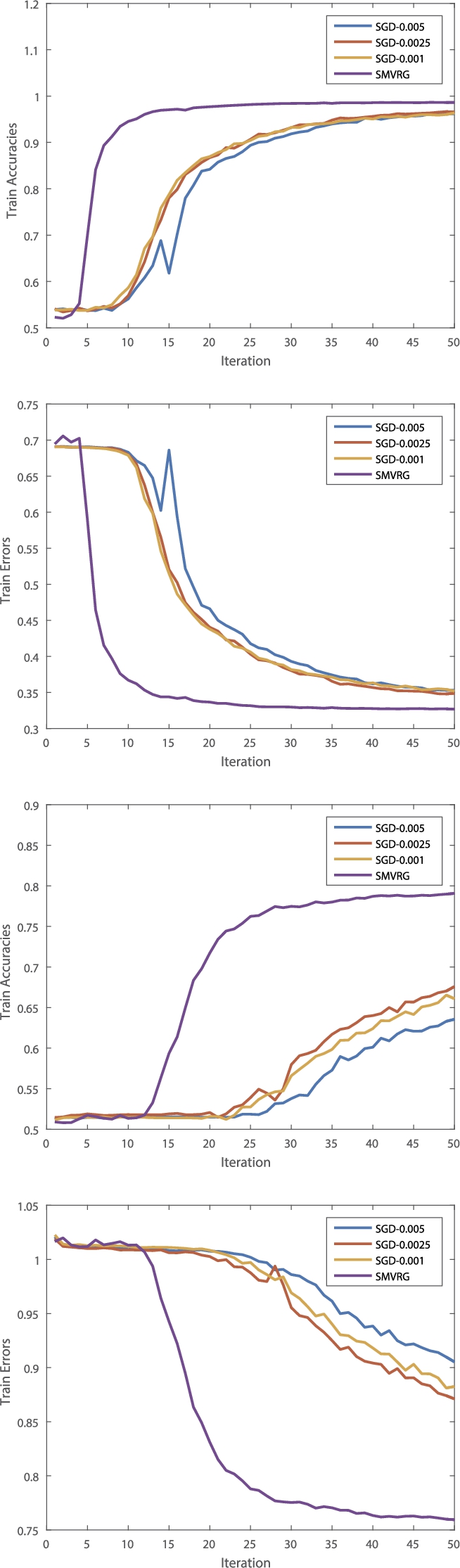
Top: the train accuracies and train errors of SGD with different learning rate and SMVRG on IMDB for 50 epochs; Bottom: the train accuracies and train errors of SGD with different learning rate and SMVRG on SemEval-2016 for 50 epochs.
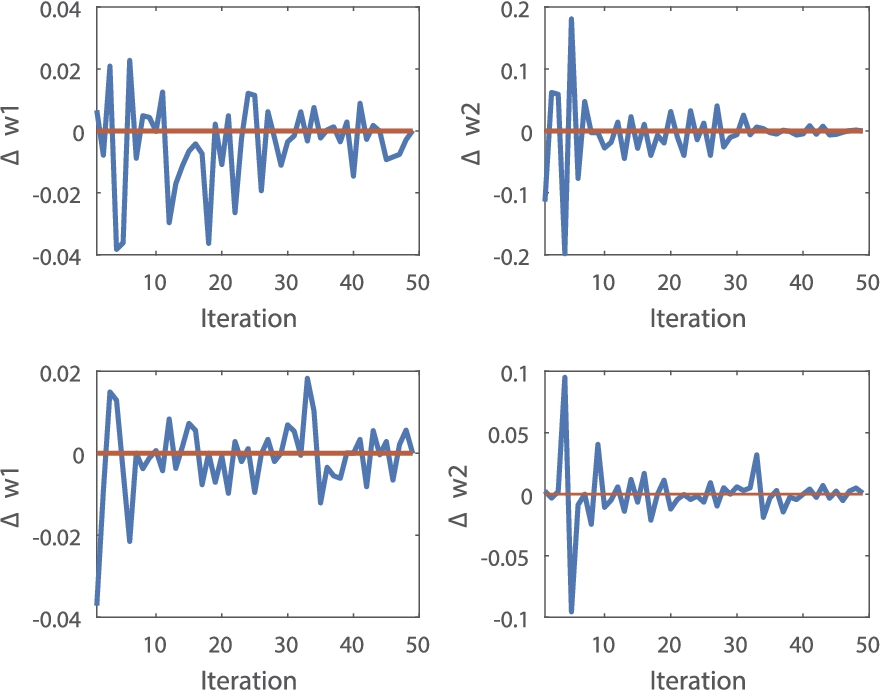
Top: Parameters update
In this paper, we have introduced a variance reduction technique for SGD regarding moving average gradient as average gradient (SMVRG). SMVRG is a simple and computationally efficient method for the trade-off of fast computation per iteration and slow convergence for SGD versus solw computation per iteration and fast convergence for GD, and it can take a large learning rate by using variance reduction technique replacing average gradient with moving average of gradient. Using LSTM (Long Short-Term Memory) which is a kind of time recurrent neural network, we show promising results compared to other methods on two real data sets movie review data set (IMDB) and SemEval-2016 (Sentiment Analysis in Twitter). And, our methods can improve the training accuracies and train error to some extend, and have fast rate of convergence.
Footnotes
Acknowledgements
The work was supported by the Fundamental Research Funds For the Central Universities (No. XDJK2 017D059), Scientific and Technological Research Program of Chongqing University of Education (No. KY2016TZ02 and No. 2017XJPT07), Key Research Program of Chongqing Education Science 13th Five-Year Plan 2017 (No. 2017-GX-139). Li Li is the corresponding author for the paper.