
Abstract
FACIAL expression is one of the most efficient, universal and fundamental indicators to identify their emotions and intentions in humans. Various experiments have already been performed on automatic Facial Emotion Recognition (FER) owing to useful significance in medical diagnosis, stress monitoring for drivers, sociable robots, and other human-computer interface devices. Here, this proposed framework consists of two processes namely; “(i) proposed feature extraction and (ii) classification”. Here, a major novelty relies in the initial phase (i.e. feature extraction phase), where the Proposed Local Vector Pattern (Proposed- LVP) based features are extracted. In addition to the proposed-LVP, the other Discrete Wavelet Transform (DWT) and Gray Level Co-occurrence Matrix (GLCM) based features are also extracted. Besides, the Principal Component Analysis (PCA) method is used for reducing the dimension of the features. Further, they are subjected to classification process, where Optimized Neural Network (NN) is used. More particularly, a new Improved Elephant Herding Optimization (EHO) model termed as Self Adaptive-EHO (SA-EHO) is used to train the NN model via selecting the optimal weights. At last, the proposed work performance is computed over the other traditional systems with respect to the positive measures like “accuracy, sensitivity, specificity and precision”; negative measures like “False Positive Rate (FPR), False Negative Rate (FNR) and False Discovery Rate (FDR)”; other measures like “Negative Predictive Value (NPV), F1-score and Matthew’s Correlation Coefficient (MCC)”, respectively.
Nomenclature
Facial Emotion Recognition Local Vector Pattern Elephant Herding Optimization Self Adaptive – EHO Neural Network Human- Computer Interaction Mean Fitness Oriented JA+FF Convolutional Neural Network False Positive Rate Matthews correlation coefficient False Negative Rate Real-world Affective Face Database Negative Predictive Value False Detection Rate Local Binary Pattern Deep Locality-Preserving Spatial-Temporal Recurrent NN Convolutional RNN Feed Forward NN Weighted Mixture Deep NN Whale Optimization Algorithm Grey Wolf Optimization Fire Fly Jaya algorithm Discrete Wavelet Transform Gray Level Co-occurrence Matrix Principal Component Analysis
Introduction
“Facial expressions can be defined as the facial changes in response to a person’s internal emotional state, intentions, or social communication” [15]. FER plays the main role in identifying the emotional conditions of humans like pleasure, sorrow and annoyance, by means of facial outlook and their voices [23,35]. The face detection of human is mostly used in real time applications like security systems, medical field, artificial intelligence, machine learning, research fields etc [3,34,43]. In previous years, the automatic FER systems is concerned in various applications based on the following factors like biometrics, data-driven animation, clinical monitoring, analytics of crowd, interactive games, human-robot communication, and HCI systems [13,15,20,30].
Three main steps involved in an automatic facial analysis system are face detection or alignment, feature extraction and classification [52]. The new approaches have shown impressive performances in highly controlled environments and moreover, the automatic FER is found to be an extremely challenging task in the real-world scenario [41]. Generally, there are two main methods in conventional FER approaches: “(i) Geometric-based methods and (ii) Appearance-based methods” [2,5,27,42]. The Geometric-based methods include the characteristics of deformations, curvatures, distance calculations and various geometric parameters indicating the face geometry [10,39]. The variation in local texture can be measured based on appearance-based methods. The emotional analysis process poses more difficulties owing to its lower tangibility ineffective practical applications [22]. In order to overcome these difficulties, the researchers make use of various electric devices to acquire more emotions from the external signals [16,21,50].
The new achievements on deep learning approach include CNNs that concerned on object recognition and detection, which seems to be a complex task in FER [40,48]. The automatic learning of various levels of data representation regarding the facial emotions at higher levels can be determined by the CNN [1,1,33]. The deep-learning approach can be performed under two possible ways; they are (1) the majority of the applications can hold more data at the present situation (2) current improvement in GPU technology [4,26,32]. The 1st method is exploited in deep architectures for NN training and it avoids the issues regarding over-fitting [31]. Thus, it offers essential information based on the numerical computations that are essential for the training process [11,12]. However, it cannot be deployed in FER field due to the insufficiency of datasets.
The main contribution of the presented model is listed below:
Introduces a novel proposed LVP- based feature extraction model, where the features are extracted in dense spiral form.
Establishes an optimized NN, where the weights are optimally tuned using a new improved EHO algorithm.
For optimization purpose, a Self-Adaptive EHO is introduced, which ensures better recognition outputs.
Finally, the proposed SA-EHO method is analysed based on the performance with respect to specificity, accuracy, precision, sensitivity, FNR, FPR, NPV, F1-score, FDR and MCC.
The sections in the paper are arranged as follows: Section 2 presented the reviews about the FER. Development of a novel FER Model is represented in Section 3. Section 4 portrays the proposed LVP framework for feature extraction. Section 5 depicts the weight optimized NN for classification via SA-EHO model. The result and discussion are analysed experimentally in Section 6. The conclusion to this research work is presented in Section 7.
Literature review
Related works
In 2019, Zhang et al. [51] have proposed a novel FER method based on image edge detection and CNN algorithm. Here the facial emotions were extracted by convolution process; edges were extracted by maximum pooling method, and classification was carried out by softmax classifier. The optimization and network weight update was performed during training process and the CNN was optimized by back propagation model. Finally, the proposed algorithm has offered higher recognition rate when compared over the traditional R-CNN and FRR-CNN algorithms.
In 2019, Kim et al. [19] formulated new techniques depending on a hierarchical deep learning using FER. Here, the proposed algorithms are classified into classical feature extraction method and deep learning-based method. By using autoencoder technique, the facial images with neural emotions were produced and extracted with no required data. Moreover, proposed method involved CNN with LBP features and facial expressions were extracted from the geometrical changes of images. Finally, the combination of static appearance features and dynamic geometric features provided more accurate and efficient output.
In 2019, S. Li et al. [25] introduced to improve the deep features by concerning on inter-class scatter and locality closeness using new DLP-CNN techniques. In the proposed method, a novel facial expression database and RAF-DB included many facial images with different emotions, races and ages and each image were identified from various annotators. In the end, the output results of proposed method were showed improved performance than other existing methods.
In 2019, T. Zhang et al. [53] proposed STRNN in face image-based human emotion recognition. The proposed STRNN included multidirectional RNN layer that were identified by the co-occurring patterns in human emotions and collect long-range contextual cues of spatial portions of each time-frame under various directions by traversing it. Finally, the betterment of the implemented approach was found to be better accuracy over the existing traditional approaches.
In 2018, B. Yang et al. [49] have suggested WMDNN for recognizing the facial emotions. WMDNN included two channels for facial images; they were LBP and facial grayscale images. Hence, the outputs obtained from both channels were combined as a weighted manner. For extracting facial characteristics from the gray scale images, the partial VGG16 networks were established. The proposed network obtained higher performance when compared over the deep networks of multiple channels.
In 2018, P. M. Ferreira et al. [13] have formulated an end-to-end NN architecture for intended loss function. Moreover, the entire learning procedure normalized the loss function and proposed network provided the clear information regarding expression features. The proposed NN included three processes, they were: facial-part components, representation components, and classification component. The experimental outcome offered very high promising results for the proposed method while comparing with other methods.
In 2018, Neha Jain et al. [18] introduced Hybrid C-RNN method consists of CNN and RNN model. CNN models are mainly used for feature extraction and to eliminate the regression layer. In the proposed method, two different signals sources were joined to a spatial-temporal dependency model and the facial emotion in each image was identified. The experimental outputs obtain with high efficiency and better performance when compared to the traditional methods.
In 2018, Shui-Hua Wang et al. [47] proposed the FER model for overcoming the problems occurring in the current FER systems. The stationary wavelet entropy method removed the features and accordingly, this work exploited the single hidden layer FFNN as classifier. Moreover, the JA was deployed in this work that prevented the classifier training at the points of local optimum. The outcomes of proposed method indicate highest accuracy when compared to other traditional algorithms.
Review
Table 1 shows the reviews on FER systems. Initially, CNN was deployed in [51] that offers higher recognition rate and it also increases the training speed. Nevertheless, it needs to overcome the complexity of network structure. DNN was exploited in [19] that offer better performance, but it increases the accuracy rate and hence it needs the consideration of training data. In addition, DLP-CNN was introduced in [25], which offers better performance along with we can learn more discriminative features. However, it has to concern on more quantity and diversity of database. Likewise, STRNN was exploited in [53], which offers high performance and high accuracy. However, it has to overcome the issues of loss function. Moreover, WMDNN method was deployed in [49], which presents better efficiency and improves the recognition ability compared to other traditional methods; nevertheless it needs to speed up the algorithm and to improve the fusion network. DNN was exploited in [13] that are improved efficiency, better performance and provides quite promising results; however, it needs to consider training strategies on small datasets. DNN was suggested in [18] that offer better efficiency, high accuracy and it also reduces the false detection. However, it requires large amount of data. Finally, JA was implemented in [47], which offers increased accuracy. However, it has to focus on performance test.
Reviews on conventional FER methods: features and challenges
Reviews on conventional FER methods: features and challenges
Proposed method
FACIAL expression from the human faces can be taken based on their emotions and objective of communication among them. Various experiments have been performed on artificial FER systems owing to its functional significance in vehicle stress monitoring, medical diagnosis, sociable robots and other HCI systems. The input image is given to the proposed feature extraction process. Here, this proposed framework consists of two processes namely; “(i) feature extraction and (ii) classification”. During feature extraction phase, the Proposed-LVP based features can be removed in dense spiral form. These LVP based features along with the DWT and GLCM features are then subjected to the process of PCA after which they enter the classification phase, for which NN is exploited. Furthermore, to attain more precise classification accuracy, the weights of NN are optimally tuned using an improved EHO model termed as SA-EHO algorithm. EHO is a modern form of swarm-based meta-heuristic search approach that is influenced by the herding activity of the elephant community. Figure 1 illustrates the architectural representation of the proposed method.

Architectural representation of the proposed method.
LVP [17] in the high-order derivative space can create the novel local pattern descriptor for recognizing facial emotions. The vector representation of every pixel is created through calculating both neighboring pixels and reference pixel values for a range of directions using varying distance. For reference pixel, the vector representation can be developed for including one dimensional structure of the micro patterns. Hence, LVP decreases the length of features by transforming the comparative space to represent the different spatial surrounding associations between its neighboring pixels and the reference pixel. In fact, the LVPs concatenation was compressed for creating many individual characteristics. In order to generate the accurate details of specific sub-region, LVP can be optimized through different directions of local derivative in nth order of LVP using
For center pixel
Accordingly, the coordinates of spiral neighbors denoted by
Equation (5) can be performed to limit the number of neighbors within 360° (i.e.) 1 spiral.
Under the condition
Consequently,
From Eq. (6), the values of eight neighbor pixels can be determined in binary form (either 1 or 0). These binary values are then converted to decimal form, which is replaced at the place of center pixel. Consequently, by changing the centre pixel of the image, the above process is repeated and the LVP features are generated.
In addition, the DWT and GLCM [7] features of the image are also extracted. Thus the final features extracted via proposed LVP along with DWT and GLCM is denoted by
Weight optimized neural network for classification: Introduction to SA-EHO model
Optimized neural network
NN [31] contain the features
The model contains input, output, and hidden layers. The output in hidden layer

Neural network model.
In the presented work, it is planned to train the NN model by optimizing the weights
EHO [11,24] helps in finding the near-optimal or optimal function values. Even though, the existing EHO provides better performance, it also involves few drawbacks such that it will not utilize the required information to identify the future and current searches. Therefore, to prevail over the drawbacks of the existing EHO, some improvements are made in the proposed SA-EHO algorithm. Elephants naturally exist in social groups that consist of more number of clans and hence every clan that resides in Matriarch is a female leader. Self-improvement is proven to be promising in traditional optimization algorithms [14,36–38,44]. Elephants naturally exist in social groups and it consists of a variety of clans, each clan resides under the female leader of the Matriarch. Moreover, the male elephant resides apart in these groups, which leave certain clans when growing up [24]. To imitate and implement the characteristics of elephants, the EHO algorithm is summarised into three major rules.
There are number of clans in population with permanent number of female and male elephants are present in every clans.
Some male elephants can live separately apart from clans.
The leader of all clans is a matriarch female elephant.
The elephant population is produced randomly and it is classified into certain number of clans and then arranged based on their fitness. Updating of every clan can be performed separately. Clan updating operators such as a matriarch influence each elephant in clan
Update the elephant j in clan c as follows:
Moreover, the procedure of the proposed SA-EHO is as follows: As per the traditional method, the elephant fittest in every clan could not be indicated in Eq. (11). Therefore in the proposed method, a new evaluation is introduced for evaluating the fitness as given in Eq. (12). Conventionally clan update takes place based on the center clan; however as per the implemented method, the clan update takes place based on best population in current solution.
Separating operator: As mentioned earlier, the male elephants live alone apart from their clans, as they reach maturity. In each generation, the separation process can be determined by the operator modeling with worst fitness of individual elephants that is given in Eq. (13):
The pseudo-code for SA-EHO model is manifested in Algorithm 1 and the flow chart is illustrated in Fig. 3.

Proposed SA-EHO method

Flowchart of proposed SA-EHO algorithm.
Simulation procedure
The proposed SA-EHO algorithm-based FER model is executed using MATLAB with resultant outcomes of each analysis can be observed. In addition, the betterment of the proposed SA-EHO based FER model was evaluated by comparing it over the traditional models like GWO-NN [29], WOA-NN [28], JA-NN [45], FF-NN [46] and MF-JFF-NN [36] with respect to “accuracy, sensitivity, specificity, precision, FPR, FNR, NPV, FDR, F1-score and MCC”. Here, the performances were carried out with respect to variation in hidden neurons that range from 10 to 30.
Performance analysis
The FER method performance using SA-EHO over the conventional model with respect to “accuracy, sensitivity, specificity, precision, FPR, FNR, NPV, FDR, F1-score and MCC” are represented in Fig. 4, Fig. 5 and Fig. 6. Moreover, the analysis of proposed SA-EHO method is compared with the conventional methods like GWO-NN, WOA-NN, JA-NN, FF-NN and MF-JFF-NN is described in this section. Figure 4 revealed the analysis on positive measures. However, in Fig. 4(a) the accuracy of the proposed SA-EHO method with 30 counts of hidden neurons has attained superior to the traditional methods such as GWO-NN, WOA-NN, JA-NN, FF-NN and MF-JFF-NN with 8.76%, 3.13%, 5.63%, 6.88% and 1.87% respectively. In addition, the Fig. 4(b) indicated the sensitivity of proposed SA-EHO algorithm for 30 hidden neuron count is 4.51%, 9.67%, 10.96% and 18.70% better than the traditional models like WOA-NN, JA-NN FF-NN, MF-JFF-NN and EHO, correspondingly. Similarly, the specificity of SA-EHO proposed method with 30 counts of hidden neurons as shown in Fig. 4(c) is 9.73%, 2.63%, 4.66% and 6.18% superior to GWO-NN, WOA-NN, JA-NN FF-NN, respectively. However, in Fig. 4 (d) the number of hidden neurons is 25, the proposed SA-EHO model is 21.87%, 25%, 37.5%, 19.79% and 13.5% superior to GWO-NN, WOA-NN, JA-NN, FF-NN and MF-JFF-NN, respectively with higher precision.
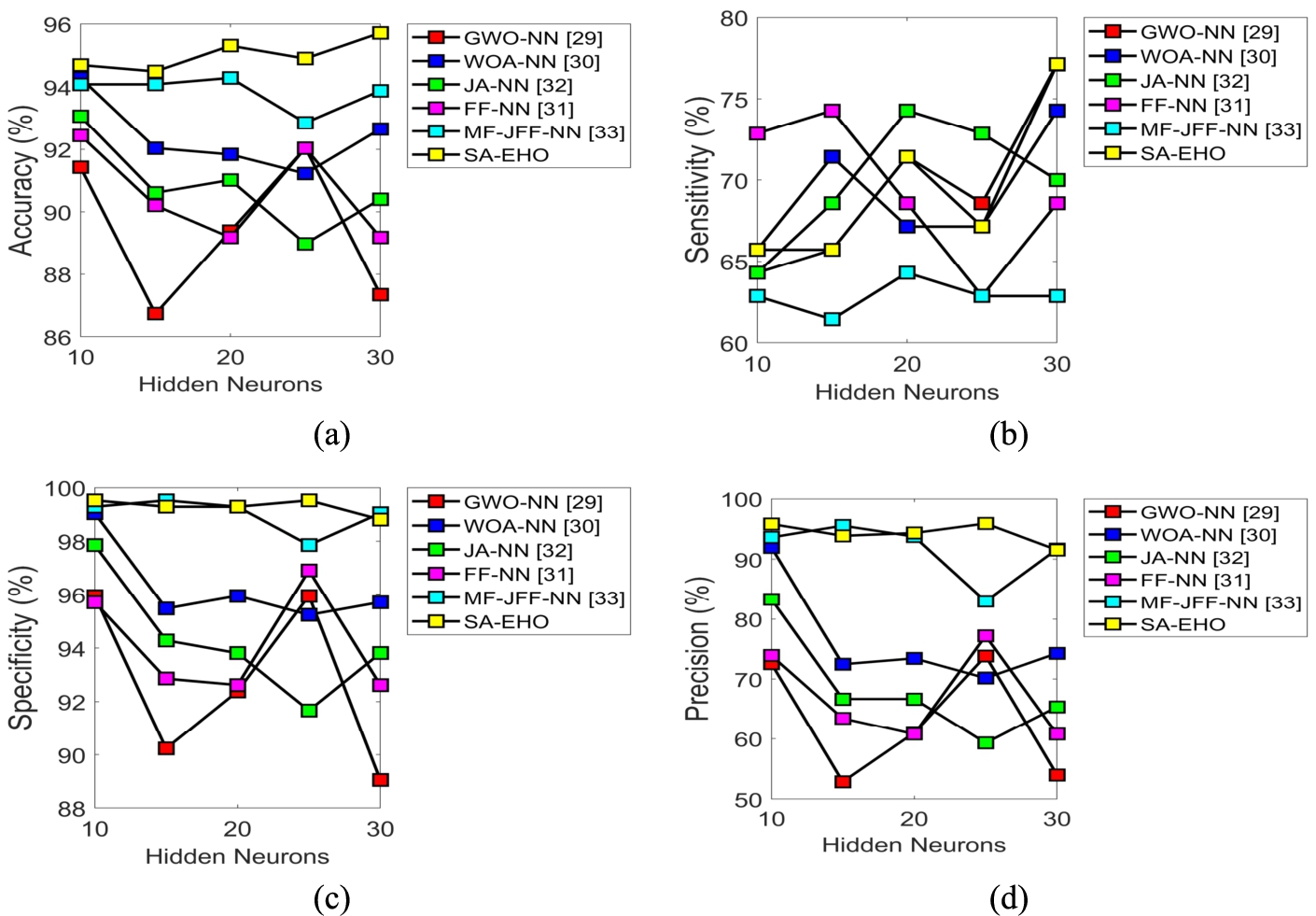
Performance analysis in proposed SA-EHO scheme over existing models for postive measures like (a) accuracy, (b) sensitivity, (c) specificity, (d) precision.
The analysis of negative measures is revealed in Fig. 5. For better performance in Fig. 5(a), FPR measures should be minimized. The presented SA-EHO method holds a value of 1 when the numbers of hidden neuron is 25and it is compared to the traditional method in terms of GWO-NN, WOA-NN, JA-NN, FF-NN and MF-JFF-NN has the values of 4, 4.8, 8, 3 and 2 correspondingly. Moreover, in Fig. 5(b) the FNR of SA-EHO proposed method for 30 counts of hidden neurons attains a minimal value of 23, whereas, the existing WOA-NN, JA-NN, FF-NN and MF-JFF-NN attained the FNR values of 26, 30, 32 and 37. In Fig. 5(c), the FDR in proposed SA-EHO method holds a value 4 for 25 numbers of hidden neuron, whereas the compared to traditional methods like GWO-NN, WOA-NN, JA-NN, FF-NN and MF-JFF-NN has attained values of 25, 28, 40, 23 and 15 correspondingly.
The analysis on other measures is revealed in Fig. 6. An improvement of 3.5%, 4%, 7.53%, 2.51% and 1.5% is obtained by the proposed SA-EHO method over the existing models like GWO-NN, WOA-NN, JA-NN, FF-NN and MF-JFF-NN respectively in terms of NPV with 25 counts of hidden neurons in Fig. 6(a). However, in Fig. 6(b) the F1-score of the proposed SA-EHO method over the existing models like GWO-NN, WOA-NN, JA-NN, FF-NN and MF-JFF-NN shows an enhancement of 23.8%, 11.9%, 19.04%, 22.61% and 10.7%, respectively when the count of hidden neurons is 30. In addition, the Fig. 6(c) MCC of SA-EHO model at 30 counts of hidden neurons is 30.48%, 14.63%, 24.39%, 29.26% and 10.97% better than the existing methods like GWO-NN, WOA-NN, JA-NN, FF-NN and MF-JFF-NN, correspondingly. Moreover, from attained outputs it is clear that SA-EHO proposed method can be better than other traditional methods in terms of performance measures.
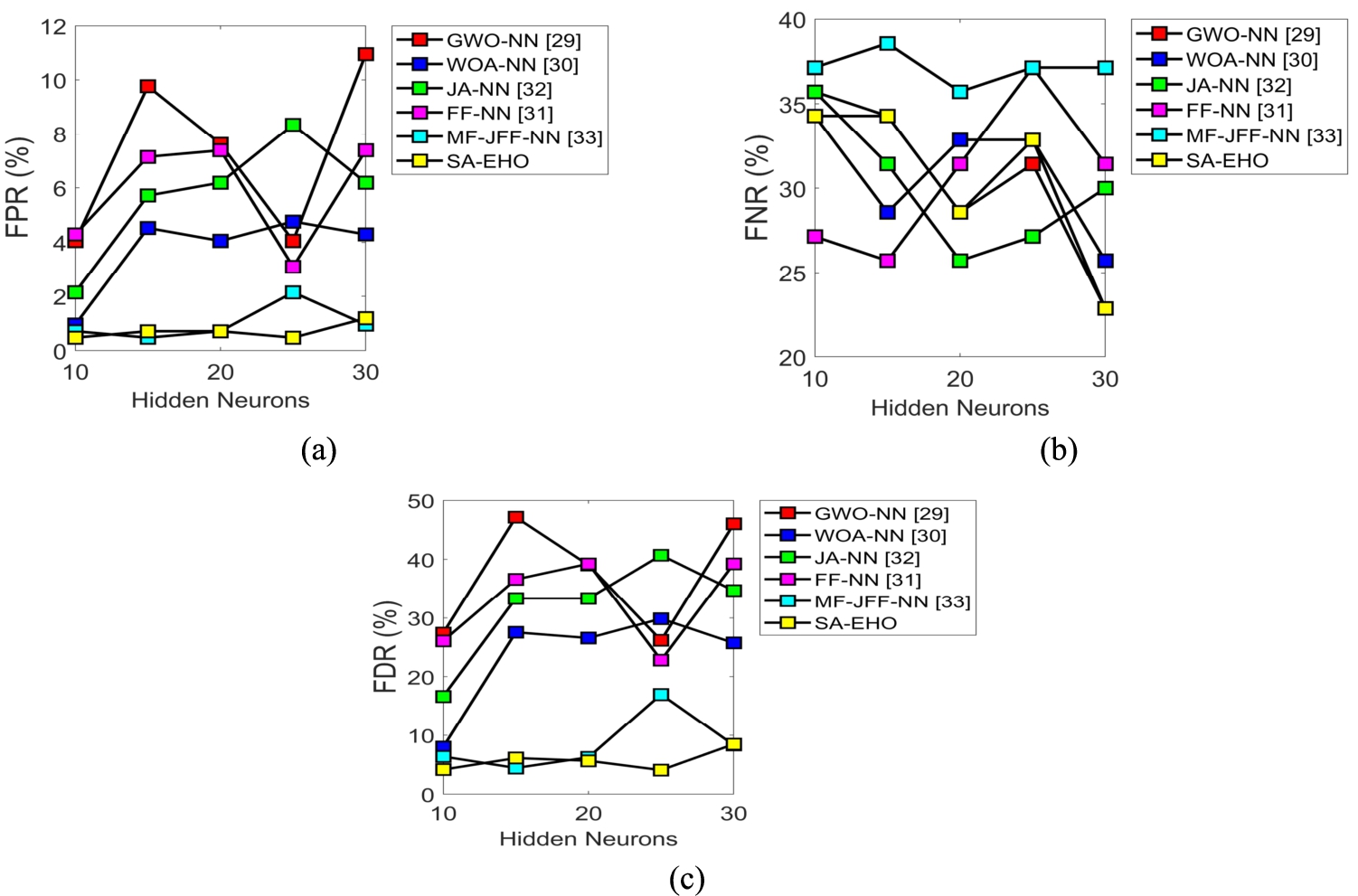
Performance analysis in proposed SA-EHO scheme over existing models for negative measures like (a) FPR, (b) FNR, (c) FDR.
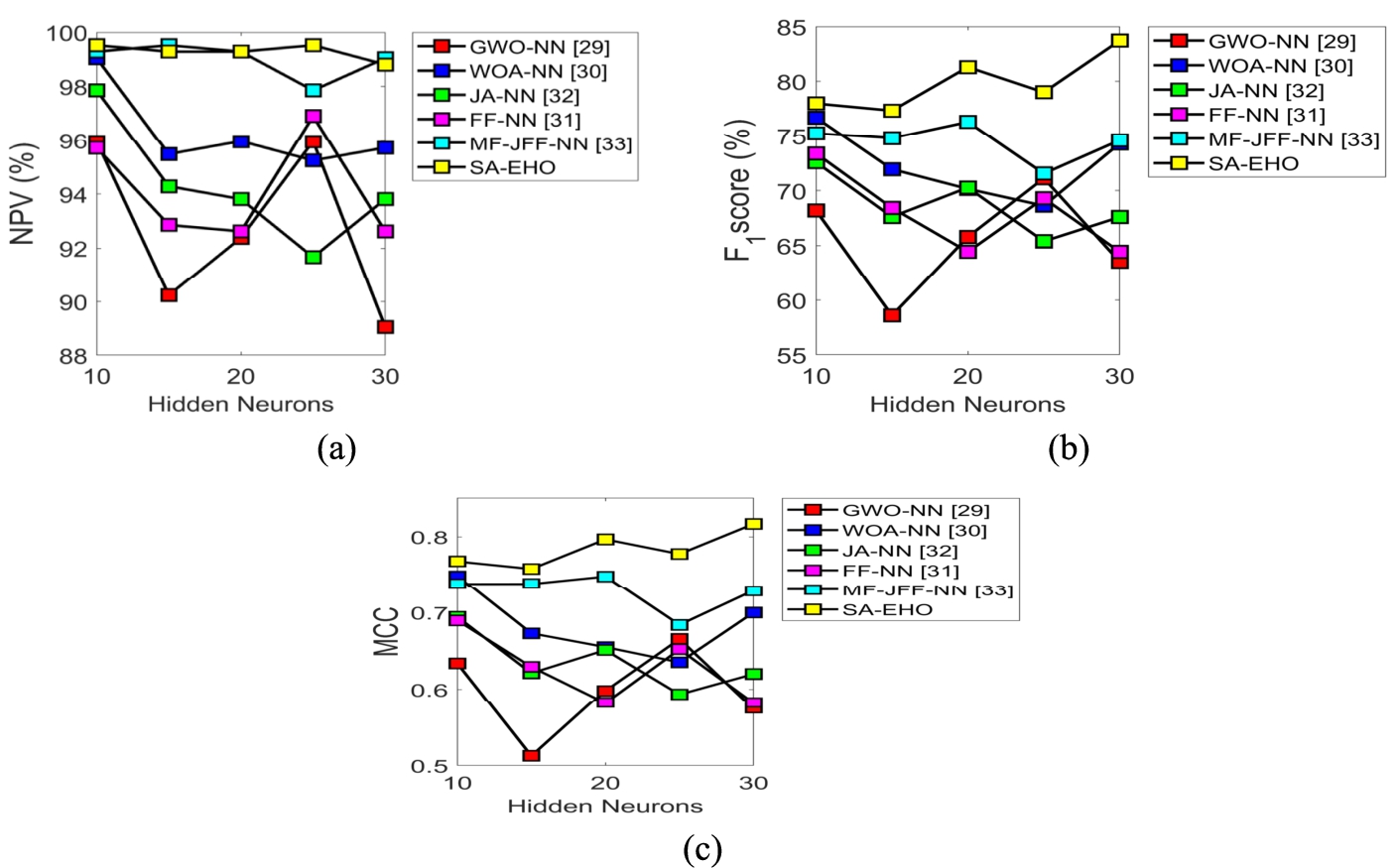
Performance analysis of proposed SA-EHO scheme over existing models for other measures such as (a) NPV, (b) F1-score, (c) MCC.
Table 2 demonstrate the analysis of overall performance in the proposed SA-EHO method over the existing method for different performance measures. When comparing with other traditional methods, the proposed SA-EHO method shows higher outcomes for positive measures and lower outcomes for negative measures, which is necessary for the optimal model. The proposed SA-EHO method in terms of accuracy is 3%, 3.8%, 6.23%, 3% and 2.15% better than the traditional models like GWO-NN, WOA-NN, JA-NN, FF-NN and MF-JFF-NN correspondingly. Moreover, the sensitivity of SA-EHO model is 2.12% and 8.5% superior to the traditional models such as GWO-NN and JA-NN, correspondingly. However, for the specificity measure the proposed SA-EHO is 3.58%, 4.3%, 7.89%, 2.63% and 1.67% is superior to GWO-NN, WOA-NN, JA-NN, FF-NN and MF-JFF-NN model respectively. However, the precision of proposed SA-EHO method will be 23%, 26.86%, 38.17%, 19.52% and13.4% superior to the existing methods with respect to GWO-NN, WOA-NN, JA-NN, FF-NN and MF-JFF-NN, respectively. Moreover, the proposed SA-EHO model of FPR provides the value of 0.0047619, which is better than the traditional method values such as 0.040476, 0.047619, 0.083333, 0.030952 and 0.021429 for GWO-NN, WOA-NN, JA-NN, FF-NN and MF-JFF-NN model respectively. On analysing FNR, the proposed SA-EHO model is 4.34% 17.39% and 13% superior to traditional methods like GWO-NN, JA-NN, FF-NN and MF-JFF-NN model, correspondingly. Further, the proposed SA-EHO methods overcome the conventional methods like GWO-NN, WOA-NN, JA-NN, FF-NN and MF-JFF-NN by 3.58%, 4.3%, 7.89%, 2.63% and 1.67% for NPV. In addition, FDR of existing method holds the value of 0.26154, 0.29851, 0.40698, 0.22807 and 0.16981 for GWO-NN, WOA-NN, JA-NN, FF-NN and MF-JFF-NN, whereas, proposed SA-EHO attains lowest value of 0.040816. In addition, the proposed SA-EHO techniques are 9.97%, 13.13%, 17.22%, 12.28% and 9.42% superior to the traditional methods with respect to GWO-NN, WOA-NN, JA-NN, FF-NN and MF-JFF-NN in F1-score. Finally, MCC of proposed SA-EHO method is 14.4% superior to GWO-NN, 18.29% better to WOA-NN, 23.67% better to JA-NN, 16.12% superior to FF-NN and 12% better than MF-JFF-NN with greater MCC. Thus, the overall performance in SA-EHO proposed method were found to be better when comparing with traditional models.
Overall performance analysis in proposed SA-EHO method with the existing models
Overall performance analysis in proposed SA-EHO method with the existing models
To showcase the effectiveness of the proposed SA-EHO algorithm, analysis is carried out with deep learning methods like DNN [19], CNN [51], and STRNN [53]. The results attained for both the existing and proposed model is illustrated in Table 3. On observing the result, the accuracy of the proposed SA-EHO model is 10.4%, 9.46%, and 4.51% superior to traditional methods DNN, CNN, and STRNN, respectively. In terms of sensitivity, the adopted method is 97.8%, 95.7%, and 42.5% higher than traditional methods DNN, CNN, and STRNN. On analyzing FPR, the proposed SA-EHO model is 86.96%, 30.4%, and 6.16% superior to traditional models like DNN, CNN, and STRNN. Thus, from the result, it can be noticed that the proposed SA-EHO method is much better than the state of art models.
Performance analysis of proposed model with existing classifiers
Performance analysis of proposed model with existing classifiers
The proposed SA-EHO framework consists of two processes, namely, feature extraction and classification. Initially, proposed LVP based features along with DWT and GLCM features were extracted in the feature extraction phase and also PCA was deployed for reducing the dimension of the features. However, they are subjected to a classification process for which an optimized NN were used. Further, a new improved EHO model termed as SA-EHO was exploited for training the NN model via selecting the optimal weights. Finally, the proposed SA-EHO provided better performance when compared to the other traditional models like GWO-NN, WOA-NN, JA-NN, FF-NN and MF-JFF-NN, respectively. On observing the analysis, the proposed SA-EHO method in terms of accuracy is 3%, 3.8%, 6.23%, 3% and 2.15% better than the traditional models like GWO-NN, WOA-NN, JA-NN, FF-NN and MF-JFF-NN correspondingly. Finally, MCC of the proposed SA-EHO method were 14.4% superior to WOA-NN, 18.29% better to WOA-NN, 23.67% better to JA-NN, 16.12% superior to FF-NN and 12% better than MF-JFF-NN with greater MCC, respectively. Thus, the enhancement of the proposed SA-EHO method was validated effectively.