
Abstract
It is essential to use search engines to get the needed information. A search engine uses result matching to match the user’s query with appropriate web pages. Users see the search results in a certain order based on how they are ranked. A website or web page may be made better using search engine optimization (SEO), which will increase the amount of organic traffic it receives from search engines. If we can’t manage efficient SEO techniques to rank at the top of organic search results, a lot of money will be spent on sponsored adverts for certain keywords. The process of building rank estimate algorithms for search engine results pages (SERP) or applying data analysis to find the best SEO tactics has been employed in several research projects. The datasets of existing studies were undiversified since they only included web pages from one or a small number of categories. This research will improve rank estimation algorithms by using multi-category web pages in the training datasets and will provide demonstrations of improvement on SERP rank estimation algorithms for English web pages. Since Google receives more than 90% of all internet search submissions, scraping will be used there. For the chosen web pages, a collection of on-page SEO variables will be retrieved. The methodology starts with choosing a set of search terms and scraping search engines, then crawling SERP web pages to extract certain SEO criteria from the contents of web pages, and lastly getting to data preprocessing. Various machine learning techniques were used to compare performance and choose the optimal approach. The main finding of research is the enhancement of SERP rank estimation by more than 25% on performance with the proposed dataset improvements for building models.
Keywords
Introduction
Search engine optimization (SEO) is a method for improving a website or web page so that it receives as much organic traffic from search engines as possible. A website with strong SEO will probably rank higher on a search engine results page (SERP), enabling you to reach more people, grow your online presence, and establish yourself as a market leader. Compared to other traditional marketing channels, search engine optimization has been determined to be more useful and advantageous (Almukhtar et al. [3]).
Potentially, 92,26% of internet users utilize the Google search engine, with many of them making it their default choice when using Google Chrome (Ziakis & Vlachopoulou [27]) As of May 2022, Google has a 92.48% global market share across all platforms, while the market shares of the other search engines were 3.08% for Bing, 1.3% for Yahoo, 1.05% for Yandex, 0.79% for Baidu, and 0.62% for DuckDuckGo (StatCounter Global Stats [23]).
People frequently choose websites from the top five search results when using search engines to find information. Businesses should successfully implement SEO techniques to boost their online presence, user engagement, sales revenue, and product promotion (Ziakis & Vlachopoulou [27])
Search engines like Google utilize the Page Ranking Algorithm to assign websites a ranking depending on the type of information they contain and how popular they are online (Almukhtar et al. [3]). Search engines use algorithms to rank online sites according to several key criteria. The golden rule that will position a website at the top of the search results page is not disclosed by search engines, even though they may offer broad tips on SEO attributes (Matošević et al. [13]).
To increase visibility, website providers must build their web pages in accordance with search algorithms. To assist content creators and digital marketers in maintaining the high rankings of their websites, they need to understand the new search engine criteria that are currently being implemented. SERP can be scraped to look at the web pages that might show up in the first SERP results to learn how search engines rank web pages. The web scraping method, which involves gathering URLs from search engine results pages, was employed in numerous research projects.
One of the challenges in web mining is the use of inappropriate data while that data should be accurate and in the right format (P. S. Sharma et al. [21]). One of three major sources of algorithmic bias is data bias (Akter et al. [1]). The main objective of this study is to suggest an improved ranking algorithm that can calculate the Google SERP ranking of a web page for English websites via desktop devices, using newly generated datasets from SERPs, concerning various categories and types of search terms. The conclusions of this study can help webmasters make important modifications to their sites to gain higher rankings on search engine results pages. Also, this research will identify new SEO strategies for better improvement of website ranking in SERP results.
This study uses machine learning models to develop SERP rank estimation algorithms for web pages. It uses three datasets, each with a specific set of keywords, to retrieve web pages and extract on-page SEO factors. The methodology involves scraping search engines with English keywords from various domain fields, extracting more information using various SEO tools, and employing data preparation procedures. The main objective is to investigate the impact of using datasets from single-category or multi-category web pages. The study found that using multi-category web pages improved classification performance by over 25% compared to single-category ones. Gradient Boosted Trees was the best classifier, with 77.58% accuracy for multi-class classification and 86.56% accuracy for binary classification. Internal linking was found to be the most effective on-page SEO factor affecting web page ranking in Google search engines.
Background
Second only to e-mail in terms of frequency is web browsing. A search engine on the internet detects the information that is accessible on the enormous internet (Pant et al. [16]). Crawling, indexing, sorting, and retrieval are a few of the most crucial tasks performed by search engines (Almukhtar et al. [3]). Crawling is the process of visiting websites in order to scan the pages and copy them in order to build a search engine index (Attia et al. [6]). The URLs are gathered by the web crawler from many sources and then downloaded to its database. To give visitors the most recent information, web search engines use recursive web crawling. In order to match the user’s query with related web pages in the online database, a search engine performs result matching. The ranking of the search results determines the order in which they are shown to the user. The user may see thousands of results, but the order in which they are presented is crucial. The ideal situation is when the user can find results that are related to them on the first two pages. Search engines rate the results using a sorting algorithm. Following a site crawl, search engines analyze the content to create an index that points to the relevant result (Pant et al. [16]). Typically, results are ranked by relevance scores in descending order by web search engines (Zhang et al. [26]). Considering that different factors can have different effects on online search visibility depending on the industry, numerous research have looked at the main factors that influence online search visibility (Mladenović et al. [14]).
SEO is a free strategy to enhance website performance on search engine results pages, utilizing both on-page and off-page methods (Alfiana et al. [2]). The webmaster has complete control over all on-page SEO factors, including the text on a web page, text in meta tags, links, images, clear navigation, page title, using H tags, URL, and HTML (HyperText Markup Language) code (Matošević et al. [13]). The use of an SSL certificate, specific keywords, mobile-friendly design, and website loading speed are all examples of on-page criteria (Ziakis & Vlachopoulou [27]) (Tsuei et al. [25]). The most important role in the SEO process is played by keywords, which are search queries made up of one or more words used when looking for information on search engines (Matošević et al. [13]). To raise a website’s ranking, some experts advise including its focus keywords in both on-page and off-page elements. Several researchers have shown that increasing the frequency of keywords in the title, full text, or both the title and full text can boost web page exposure. Many studies have shown that Meta tags can significantly improve search effectiveness. Online pages with a lot of hyperlinks are seen to be more important or influential than sites with few connections (Tsuei et al. [25]).
On the other hand, off-page is a separate website construction style that contains elements impacted by readers, visitors, and other publications (Dramilio et al. [8]). Off-page SEO focuses on building domain authority by acquiring links from other websites (Patil [17]). Off-page variables include things like recommendations from social media sites, incoming links, and their quality or relevance to the website’s specialty. As a result, it was claimed that web pages with more referral links were more significant and ought to show up higher in search results (Matošević et al. [13]) (Tsuei et al. [25]). But linking from spam websites is a negative factor (Matošević [12]).
Search engines rarely disclose the significance of ranking factors in the ranking process, despite revealing some of the ranking variables that they use. To ascertain the level of correlation between these factors and web page ranking values, several studies have been carried out such as Matošević et al. [13] and Portier et al. [18]. Data mining can be used to discover knowledge behind relationships between SERP ranking and SEO attributes and can discover regular expressions that describe best practices of SEO-friendly websites. Machine learning algorithms can be used for building classifiers to estimate the position of a web page for SERP ranking.
Related work
While providing some of the ranking variables they utilize, search engines seldom discuss the importance of ranking criteria in the ranking process. Many studies have been conducted to determine the degree of relationship between these criteria and web page ranking values (Matošević et al. [13]). Several papers tried to explain the significance of various SEO ranking criteria like Giomelakis & Veglis [9], Ziakis et al. [28], and Ziakis & Vlachopoulou [27], and examined the relationships between particular SEO tactics and search engine results rankings. Several studies, including Sharma & Verma [22] and Dramilio et al. [8], examined and evaluated data gathered from website analytics to determine the relationship between page visits and SEO parameters. Some studies utilized statistical analysis of the chosen features to identify the most effective feature combinations, or they employed machine learning methods to create classifiers for rank estimation of a web page such as Portier et al. [18], Salminen et al. [20], Su et al. [24], Arora & Bhalla [5], Manohar & Punithavathani [11]; Jayaraman et al. [10], and Matošević et al. [13]. Others made suggestions, presented strategies, and conducted tests using certain SEO techniques to demonstrate the value of their work such as An & Jung [4] and Roslina & Nur Shahirah [19].
Sources of dataset creation
Several machine learning techniques were used by Portier et al. [18] to describe the ideal SEO variables for landing a web page on the first page of search engine results. They gathered their data by using a set of search queries to scrape the Google search engine, and they retrieved factors after scanning the websites of the SERP-resulting URLs. For each search query, Portier et al. [18] selected the top 100 results from the Google search results page. They did not explain the process they used to choose their keywords, and it is unclear which categories their keywords come from.
In order to forecast the Google search engine rank for a new web page, Banaei & Honarvar [7] employed ANN. To extract the three factors: number, density, and proximity for the chosen search keywords, they used a crawler to scrape the Google search engine. They collected the first 5 pages of the Google results page, and they used an HTML parser to extract and calculate these three values for 15 tags from each HTML web page to create a dataset of 45 features. They chose keywords in the categories of medical, students, and sports. They employed 148 keywords in all.
A learn-to-rank machine learning system was used by Salminen et al. [20] to forecast the position of websites in Google search results. Their data was produced by scraping SE using 30 blogs in the gift industry-related search queries and by extracting several SEO characteristics from SERP web pages. The significance values of the retrieved SEO variables were also computed. To get the best parameters for the basic model, they used hyperparameter random optimization.
Matošević et al. [13] evaluated five classifiers’ accuracy to see which one would best predict the SEO ranking of a web page. Instead of obtaining their data and class labels by scraping search engines, they obtained data from a directory library and had SEO professionals manually label the dependent attribute. They relied on three SEO professionals to categorize their data into three pre-defined classes “Low SEO,” “Medium SEO,” and “High SEO”. Their generated data included websites from 16 different categories.
By measuring correlation, Ziakis et al. [28] determined the importance of each SEO element in their dataset. They had a dataset generated from just 3 keywords and 15 search results for each keyword, yielding a total of 45 URLs. While their dataset was relatively small, they determined the average value for each SEO component for web pages resulting from SERP by each search query.
180 English search queries were used in Ziakis & Vlachopoulou [27] scraping of the Google search engine, and the top 40 results were recorded using Australia country code. They utilized their dataset to use analysis and statistics to see whether there is a connection between the adoption of online content management systems and the top SERP results.
SEO factors’ extraction
As for the methods of SEO factors’ extraction, Matošević et al. [13] extracted keyword frequencies using Porter stemmer. Salminen et al. [20] created a special Python script and used Netpeak Checker to download web page HTML and extract a set of factors. Portier et al. [18] combined elements from two SEO software packages and utilized a customized scraper. Özkan et al. [15] used the Majestic tool for backlink analysis and off-page factor extraction, along with GTmetrix and PageSpeed Insights to extract a set of SEO performance factors, W3C markup, and CSS validation services to extract SEO design factors, and other SEO analysis websites to extract SEO content factors like Moz, SEOTestOnline, SEOSiteCheckup, Woorank, SEOptimer, and SiteAnalyzer. Ziakis & Vlachopoulou [27] used the whatcms.org API to determine which WCMS their collected URLs via SERP scraping belong to.
Building classifiers
As for using machine learning algorithms, Portier et al. [18] employed a binary classification strategy to categorize web pages as either being on the first page of SERP (top 10) or not. They employed the four classification models: Catboost, Regularized Greedy Forest, Gradient Boosting Machines, and Random Forest. They measured performance using metrics based on the confusion matrix. To optimize the performance of classification models, they employed hyperparameter tuning. Nevertheless, their issue was utilizing Alexa rank, which Amazon has recently quit using and it is seen as a dependent variable. Salminen et al. [20] employed the Learning to Rank method, which uses supervised machine learning to address ranking issues because it is a ranking problem. For this, they used the LambdaRank method with the two Python modules LightGBM and XGBoost. However, their learn-to-rank algorithms can not be suitable for classifying a single web page, instead, they should sort an array of web pages. The five classification methods used by Matošević et al. [13] were Decision Trees, Naive Bayes, KNN, SVM, and Logistic Regression. For testing each classifier’s accuracy, they used the hold-out technique and 10-fold cross-validation. They also used hyperparameter adjustment to specify the best values for each classifier. But their dilemma was in using a dataset of web pages from a repository and using manual labeling instead of getting data directly from search engines.
Results and findings
As for attained results, according to Portier et al. [18], Catboost is the best classifier, and the best factors are Alexa rank, the number of backlinks, keyword repetition, the total number of words in the content, the number of internal links, keyword density, and the number of pages indexed by Bing SE. They disregarded the importance of using SSL or a keyword in the domain name or having a web page serve as the homepage. For XGBoost and LightGBM, Salminen et al. [20]’s average cross-validation NDCG scores were 0.852 and 0.848, respectively. Internal links, SSL, H3 length, incoming links, meta keyword count, and external links were the top identified significant aspects from F score evaluation in their results. Matošević et al. [13] investigated the top SEO websites and found that these websites included using the keyword in the page title, H1, and text body of the web page. Moreover, utilize 1-3 repetitions of the keyword in the title, meta description, and H1, as well as 2-4 repetitions in the body content. They discovered that the high SEO websites have an average page title of 8 words long, the meta description is 10 words long, and the H1 tag is 6 words long.
Research gap
Upon reviewing the literature, it was discovered that studies only included search queries from a small number of categories. This can lead to problems in the method used to create rank estimation because classifiers won’t be trained on all website categories. Additionally, there wasn’t enough variation in the terms used, which might be accomplished by utilizing both highly and lowly competitive keywords with high and low traffic.
Methodology and results
In this study, machine learning models were applied to three datasets, each of which contributed new knowledge for rank estimation algorithms through discovering the effect of single and multi-category datasets on training models and finding the correlations between SEO features and SE ranking. A specified set of keywords was used to retrieve a collection of web pages by submitting keywords to the search engine. After this, on-page SEO factors will be extracted for web pages to create the dataset. It is feasible to create SERP rank estimation methods using machine learning. Many parameters of web pages need to be extracted for this procedure to be correct and successful. The act of gathering URLs, descriptions, or other data from search engines is known as search engine scraping. The methodology of this study involves scraping search engines with a large collection of English keywords from various domain fields. After that, more information will be gathered from the retrieved web pages using various SEO tools. A series of data preparation procedures will be used. Datasets will be employed in processes of the development of rank estimation algorithms and data analysis.
This research methodology’s main objective is to investigate the impact of using datasets extracted from either single-category or various multi-category web pages for developing SERP rank estimation algorithms. By using English keywords from various categories, the methodology will create SERP rank estimation algorithms for web pages. The methodology will gather information from on-page SEO factors for the search engine-scraped web pages. Figure 1 summarizes the process of research.

Overview of the whole process of research experiment.
The choice of keywords is a crucial step in the creation of effective classifiers using machine learning. To test the hypothesis of being important to have diversity in keywords, it is needed to have multi-category keywords from numerous fields of web pages. An illustration of a keyword dataset utilized in this study is shown in Table 1. The search query that will be submitted to a search engine is listed in the “Keyword” column, along with the number of monthly queries sent for that term in the Google search engine, and the general subject of the web pages that utilize that keyword in the “Category” column. Although the “keyword ideas” feature in the “Google AdWords” web system can provide information on search volume, this research employed the “Keywords Everywhere” Chrome extension tool since it allows for the bulk submission of keywords.
Example subset of keywords
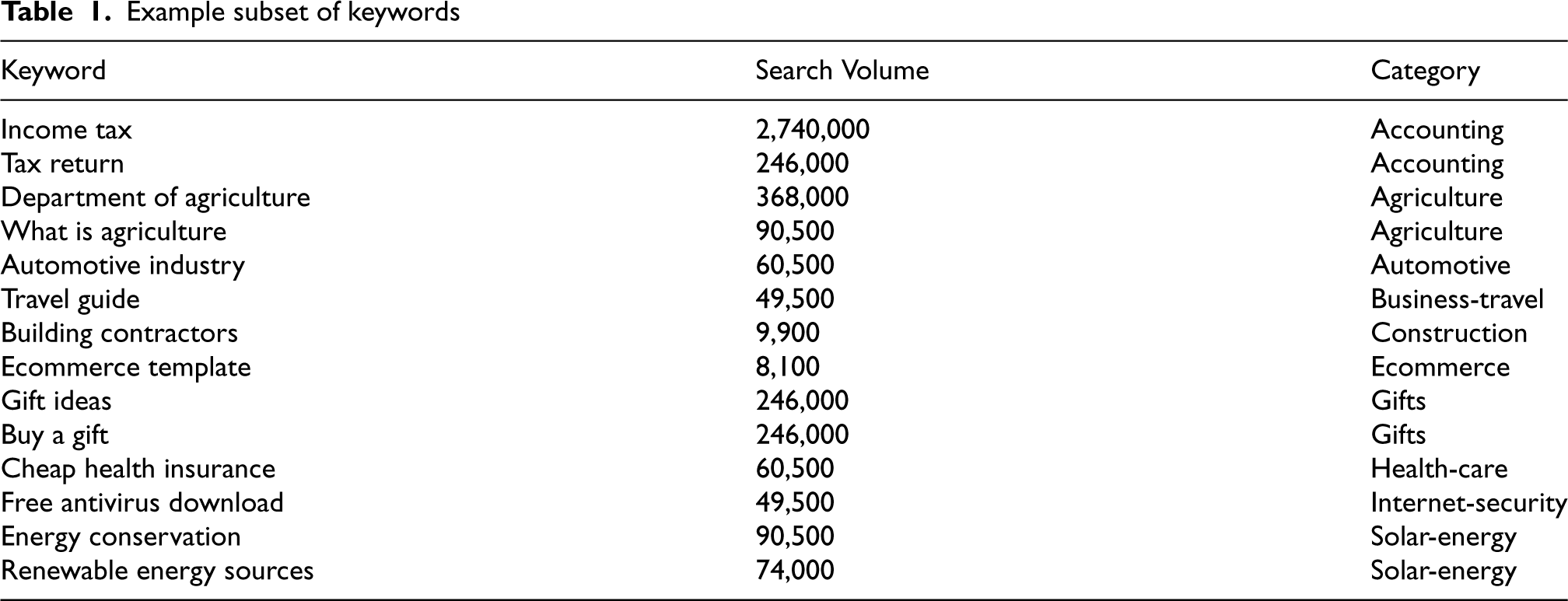
Example subset of keywords
Three keyword datasets, each containing 100 keywords, were chosen. The first dataset contained keywords from one category which is “gifts” which was used by Salminen et al. [20], the second contained keywords from one category which is “accounting”, and the third contained various keywords from 16 diverse categories. Selected keywords had search volumes ranging from hundreds to thousands and millions of submissions per month, this indicates that, in terms of their popularity and significance, keywords were varied.
To submit each keyword to the search engine and obtain results, the keyword datasets were added to the automated Google Search Results Scraper tool in the apify.com console which was used by Ziakis & Vlachopoulou [27]. The input setup was set to allow for a maximum of three result pages per search phrase, ten results per Google page, desktop results, and US country, with setting the language as default. Figure 2 demonstrates the monitor graph used to execute the SE scraping task on Apify. To facilitate subsequent data preparation procedures, the output of the apify scraping task was exported as a CSV file containing a table with 25 columns, the most crucial of which were:
Position: each URL in the SERP is sorted according to its position, which ranges from 1 to 30. Search result page: the page number associated with each URL in the SERP, with values ranging from 1 to 3. The type of result: has the values “organic” and “paid.” Search term: contains the entered search term that caused a URL to appear in SERP. URL: the web address of the page that appeared in the SERP.

Google search results scraper.
Because Google does not return the same URL twice on the same result page for a single query, duplicate results are incorrect and should not be displayed. A set of duplicated URLs for the same search query were discovered and removed from the output data of apify scraper. The output data also included paid and organic search results, but it shouldn’t include the paid ones because their positions in SERP don’t follow the search engine ranking algorithm. Also, records with missing values of search terms or URLs were eliminated. A process on the RapidMiner software was developed to eliminate duplicates, paid results, and missing values (Fig. 3).

RapidMiner process for removing duplicates, missing values, and paid results.
After the execution of the procedure in Fig. 3 on each of the three datasets, the resulting numbers of instances were as follows: 2596 instances in the multi-category diverse dataset, 2622 instances in the accounting dataset, and the gifts dataset had 2151 instances. The varied numbers of duplicates, missing values, and paid URLs amongst the three datasets were the reason for the variation in the number of instances.
To perform SERP rank estimation based on machine learning, classifiers need to be trained on a dataset of SEO attributes that define the collection of the chosen web pages. There are many ways to extract on-page factors. To collect on-page factors, websites may be crawled, and their HTML information parsed. This may be done with a variety of SEO tools that are available online, such as majestic.com, sitechecker.pro, similarweb.com, and seobility.net, or desktop application such as ScreamingFrog or Netpeak Spider.
ScreamingFrog was chosen for extracting the on-page factors from web pages in the three datasets because it can process up to 500 URLs for free with repeated runs indefinitely. It was also chosen because it is a speedy and accurate tool that extracts many on-page features and has the option to export the output as a CSV file. A screenshot of the ScreamingFrog crawl operation is shown in Fig. 4.
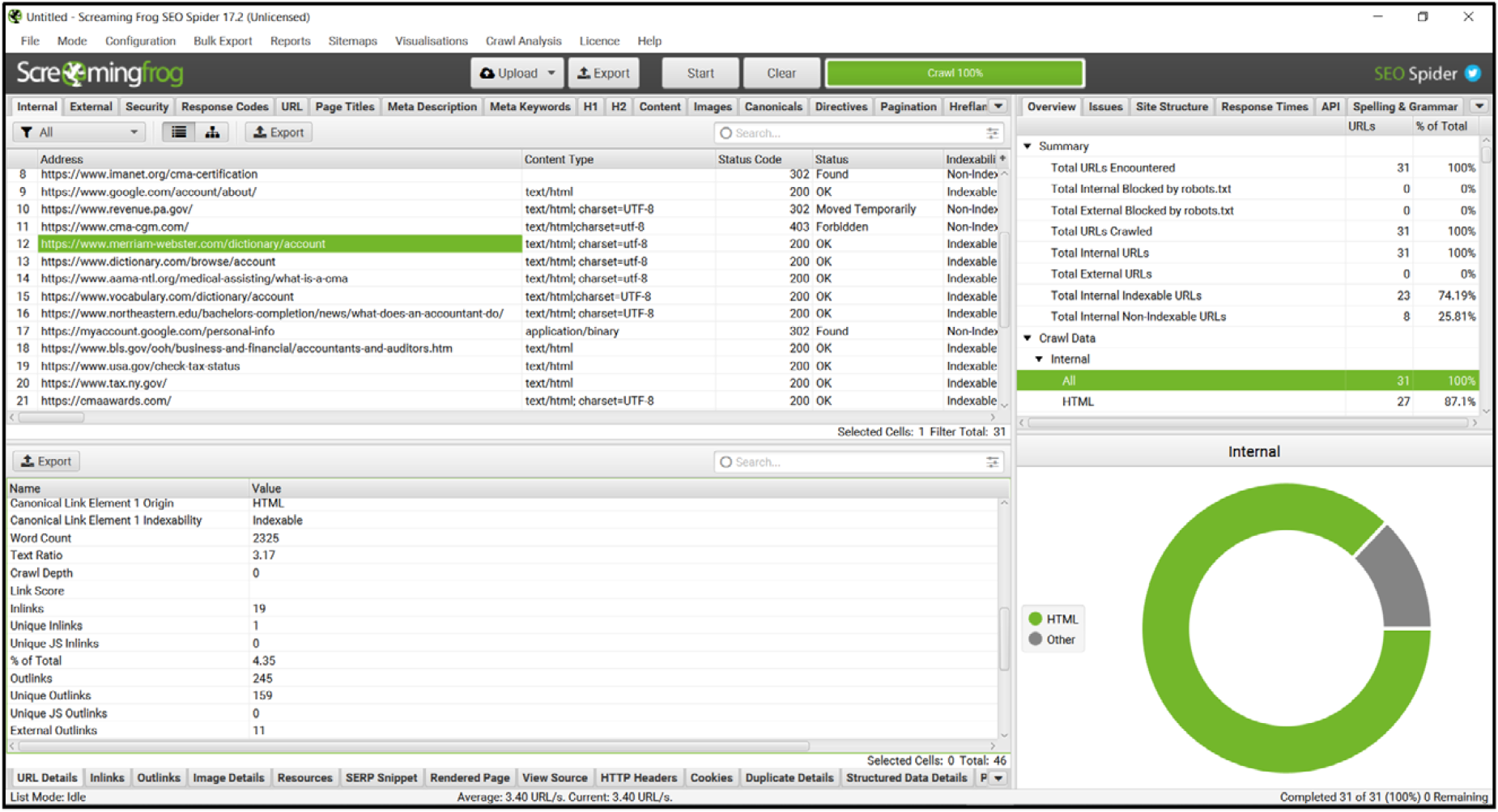
An example of ScreamingFrog’s crawl operation.
RapidMiner process to join output data from apify and ScreamingFrog.

RapidMiner sub-process: data pre-processing.
ScreamingFrog’s output dataset had 71 attributes, however not all of them will be used because some of them have text values (like title or description), are unique (like crawling time), have only one value (like HTTP version 1.1), or are identities (such as Hash).
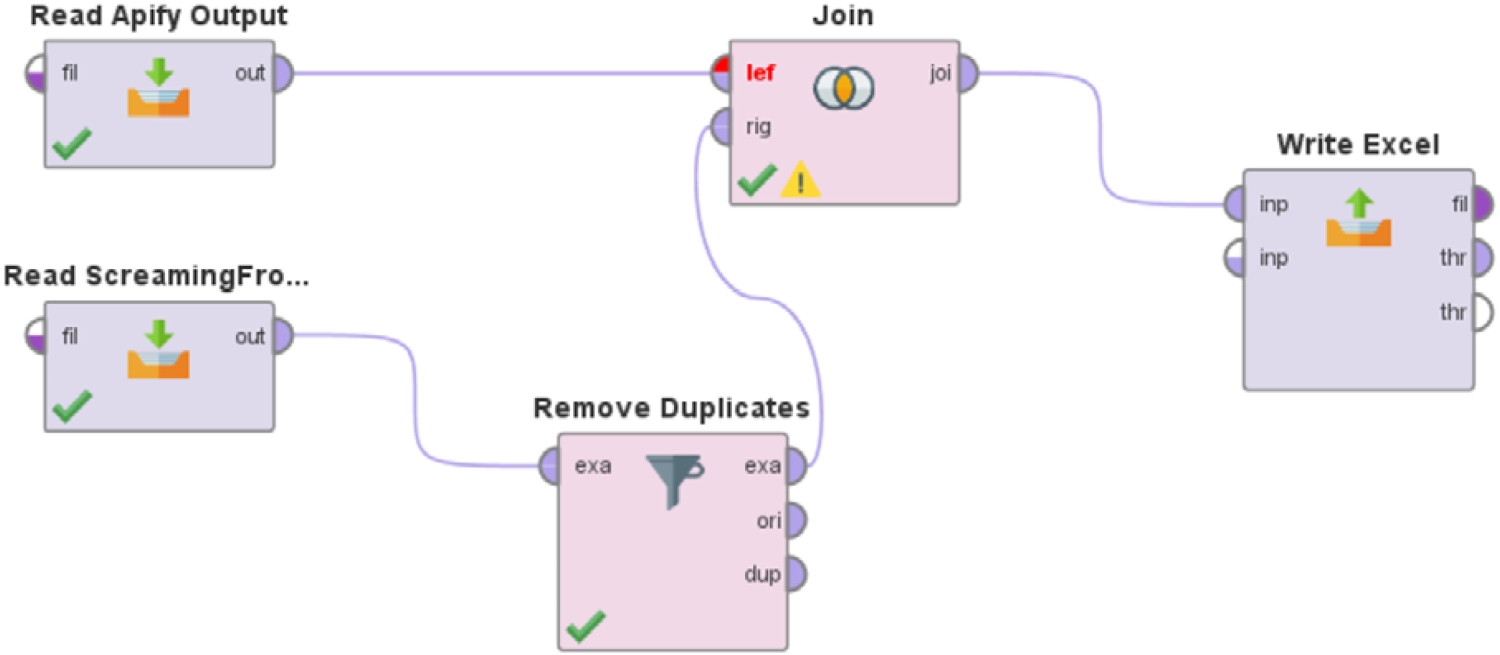
One dataset containing all of the attributes taken from both ScreamingFrog and apify’s output datasets should be produced. To combine the results from apify and ScreamingFrog for each of the three datasets (multi-category, gifts, and accounting), a RapidMiner algorithm was developed. Figure 5 depicts the RapidMiner process structure, which contains an operator to remove any duplicated URLs in the output of ScreamingFrog (SEO factors) because they will have the same features. On the other hand, duplicate URLs in apify data (SERP results) can’t be removed because the same URL may appear in search results for many search keywords. The URL was used as a key attribute because it is a common key value in both the apify and ScreamingFrog datasets when the join operator in Fig. 5 runs a join of the type left making the apify dataset the left. After this process, datasets are regarded as being ready for the further processes of data preparation, analysis, and classification.
Each of the three input datasets was subjected to a RapidMiner sub-process to prepare the data for classification. The pre-processing sequence operators have depicted in Fig. 6. Procedure phases include:
Removing redundant attributes that won’t be used in the classification or analysis processes. The list of attributes that were eliminated is shown in Fig. 7 on the left list. Create new features for data analysis relevant to the use of the search query in the title, meta description, and meta keywords. The equations used to get these values from other attributes are displayed in Fig. 8. Delete the entries of the paid SE results on the SERP because they are not organic results. Choose the potential classification attributes. The list of chosen attributes is displayed in the right list of Fig. 9. Because the values of the attribute “Status Code” relate to numerical codes that have meanings and aren’t used in computations, it was changed from a numerical to a polynomial (e.g values are: 200, 302, 403). Because the classification model uses it, the attribute “Search Result Page” was changed from numeric to poly-nominal (its values are: 1, 2, and 3). The “Search Result Page” property will be selected by the operator “Set Role” as the class label for learning and testing the classification model.
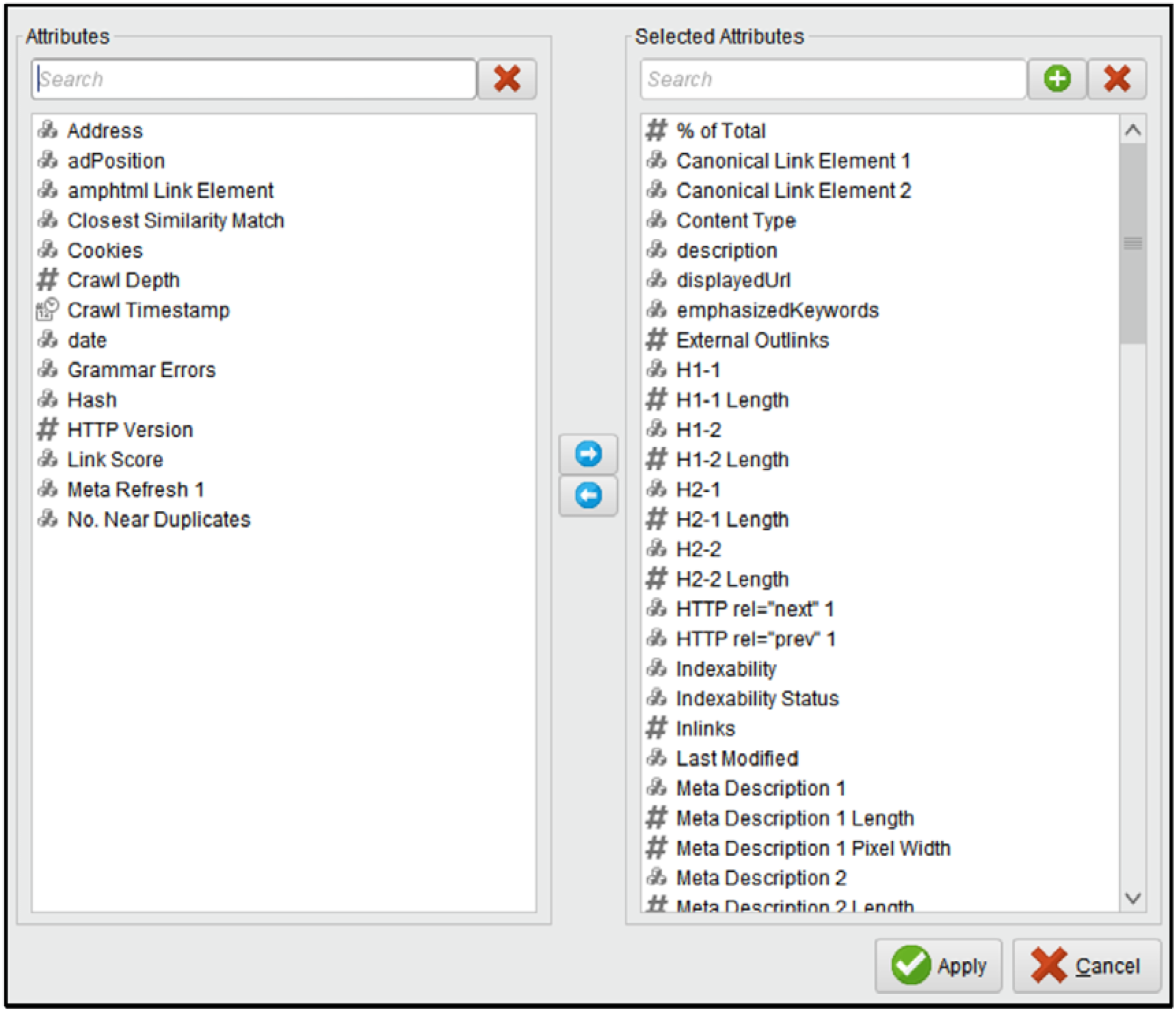
The removed redundant attributes.
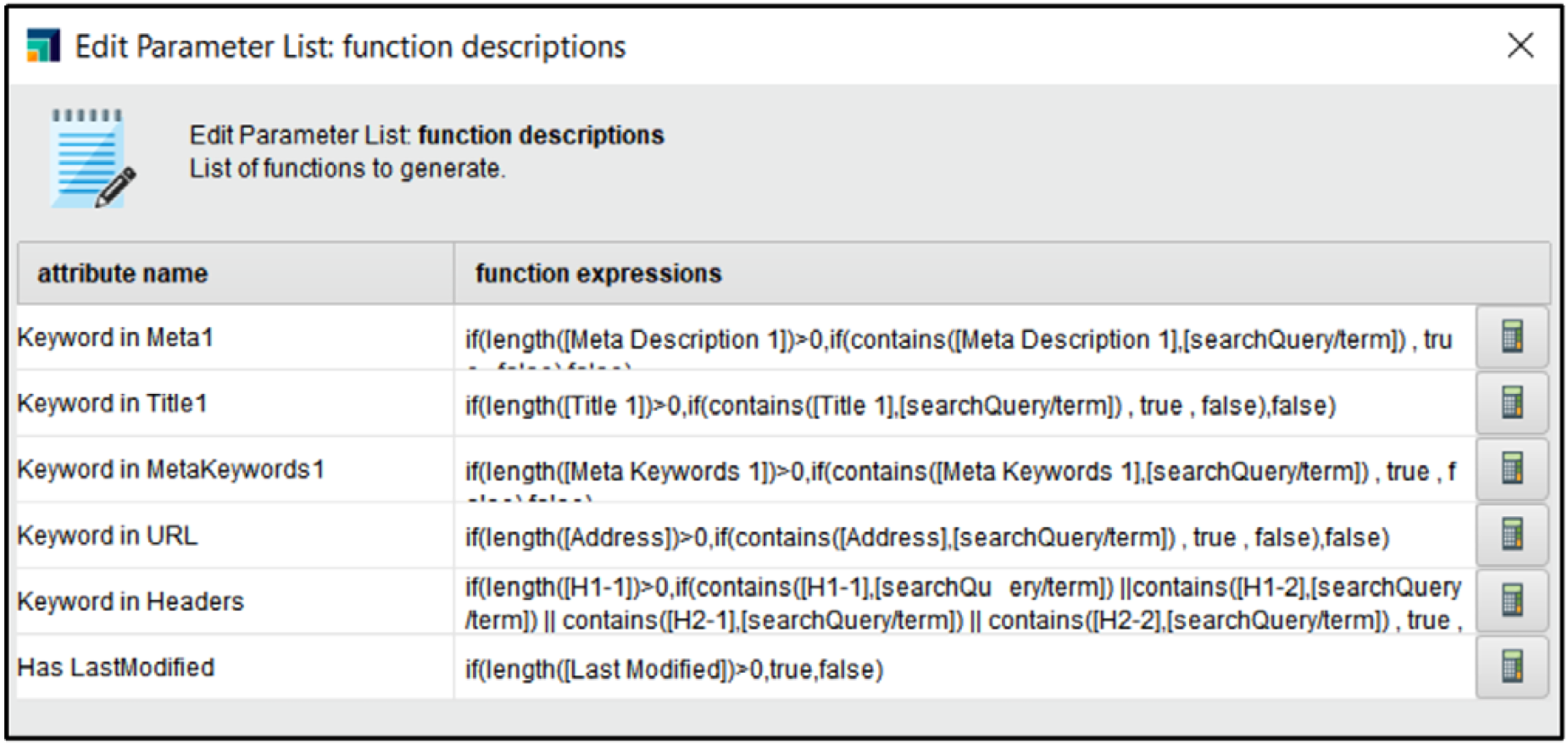
Function expressions of generated attributes.

The selected attributes for classification.
For the three datasets, a comparison was conducted. Each dataset was pre-processed before moving on to classification and validation. A RapidMiner process was created for this, which was then repeated for each dataset, the process was applied using 8 classifiers for each of the 3 datasets (24 permutations). The outcomes of these procedures are listed in Table 2, which uses cross-validation to emphasize the best accuracy value for each dataset. This comparison was applied similarly for the 3 datasets where all of the input datasets were created from 100 search terms and went through the same pre-processing with the same attributes and the “Search Result Page” as the class label, using the same classifications with the same parameter values.
A second set of comparison experiments was conducted between the datasets using Gradient Boosted Tree classification, split validation with stratified sampling and local random seed, and search page number as a class label with its three possible values: 1, 2, and 3. This classification was tested using samples from the multi-category dataset. The outcomes are shown in Table 3.
The final comparison used binary classification. The two values “Top10” and “Not Top10” were present on the newly utilized class label. The function expression used by RapidMiner to create this new attribute is displayed in Fig. 10. 10-fold cross-validation was used in this series of tests for each of the classifiers listed in Table 4.
Discussion and analysis
Since the majority of SERP rank estimation studies used datasets for web pages from a single category, this study will simulate those studies’ experiments by comparing datasets for web pages from a single category to datasets from multiple categories to demonstrate that it is preferable to create datasets from web pages from multiple categories. This section will describe the set of comparisons by presenting findings and discussing the outcomes. The main objectives of these comparisons were:
Gather proof that it is preferable to include pages from several categories when constructing the dataset of SEO parameters for training the SERP rank estimator. Test out multi-class classification and binary classification, identify differences, and check results with both.
The first set of comparison experiments mentioned in the preceding section was aimed at finding the top classifiers for ranking English websites and determining whether the multi-category search terms were the best to generate the dataset for training the classifier of SERP rank estimation or not. According to the accuracy rate numbers obtained from the first comparisons group and presented in Table 2, the following conclusions can be drawn:
The dataset created from a variety of keyword categories was able to attain the greatest classification accuracy rate among the other datasets. This can support the idea that it is preferable to use a variety of web pages from different categories to train a classifier for SERP rank prediction. This can be done by choosing keywords from various categories to scrape the search engine.
With six classifiers out of the eight that were examined in this series of comparative tests, the multi-category dataset had the greatest accuracy rates (Fig. 11). This is considered another example of how choosing a variety of multi-category keywords might produce better results than a single category.
Because the Gradient Boosted Trees classifier had the highest performance rates across all datasets (Fig. 11), it was the best classifier for websites and will thus be used in tests with split validation.
Accuracy results of classifiers for all datasets

Accuracy results of classifiers for all datasets
Accuracy of split validation for GBT classification using testing data from multi-category web pages


Function expression for generating the attribute “Top10”.
Results of classifiers using binary classification in terms of accuracy

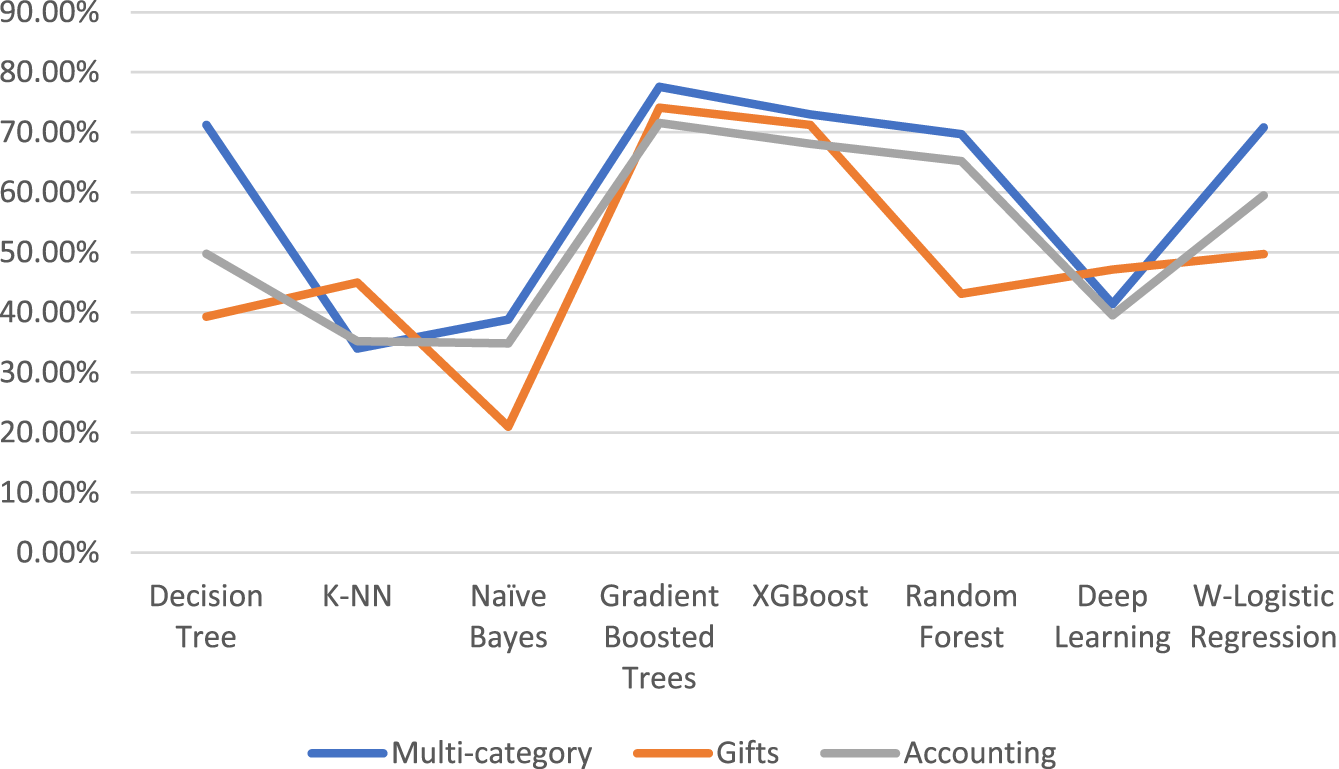
Classifiers’ performance on several datasets.
By training the classifier using each of the three datasets of English web pages and testing it with input from web pages obtained from SERP using various multi-category keywords, the second set of comparison experiments aimed to imitate the real operation of the rank estimation technique. This is a simulation of a real-world scenario in which any website from any category—news, sports, education, the arts, retail, or any other category—should be able to have its rank estimated. To determine which of the three datasets will be ideal for creating the most reliable classifier, testing data for web pages from various categories will be used. As a result of the performance values shown in Table 3, it can be deduced that the dataset of web pages from multiple categories was the best for training the classifier since it allowed the classifier to perform 45% better than training with the Gifts dataset and 15% better than training with the Accounting dataset (Fig. 12). So, by this finding, it was supported that it’s better to use multi-category web pages to generate the dataset for training the classifier used in SERP rank estimation.

Results of classification performance using test data from multi-category web pages.
The final set of comparison tests was used to reproduce Portier et al. [18]’s method of applying binary classification for rank estimation. The Bing Index and Alexa rank, however, were not included in these tests because they were regarded as dependent variables and Alexa isn’t available anymore. The following conclusions can be obtained from the outcomes of these tests, which are reported from Table 4:
The multi-category dataset also had the greatest accuracy rates with binary classification (Fig. 13). This, therefore, supports the findings of the first set of comparison tests and the claim that using multi-category keywords is preferable when scraping SERPs. Binary classification often has higher accuracy rates. This might be due to the use of fewer classes in binary classification or the high degree of similarity between the web pages on the second and third pages of search engine results, which made it difficult for the classifier to distinguish between them in the case of using three classes.

Performance of binary classification with each dataset.
For doing correlation analysis to discover the relationship between SEO factors and Google’ SERP ranking, a RapidMiner process was created (Fig. 14). The process included a pre-processing step for selecting the candidate attributes, removing paid URLs and missing values, and setting the class label. It also appended the three datasets to apply correlation analysis on a big set of web pages. Results of attributes’ weights by correlation (Fig. 15) concluded that the “Unique Inlinks” attribute (number of internal pages in a website that include referral links to some web page) is the most correlated to page ranking in Google SERP, followed by “% of Total” which is the percent of unique inlinks to the total pages of a website, followed by “Unique External Outlinks” which is the number of external links in a web page without repetition, followed by “Response time” which is time in seconds to download the web page, and “Word Count” which is the number of content words in a web page. These are the top five SEO factors that were weighted as top correlated with Google SERP ranking. It was also noted from between the keyword-related attributes, that placing the search keyword in the meta description is the most important part to include the focus keyword in. However, correlation analysis shows that unlike the publicly known, placing the search keyword in URL, title, or headers is not the most important SEO factors.

RapidMiner process for correlation analysis.
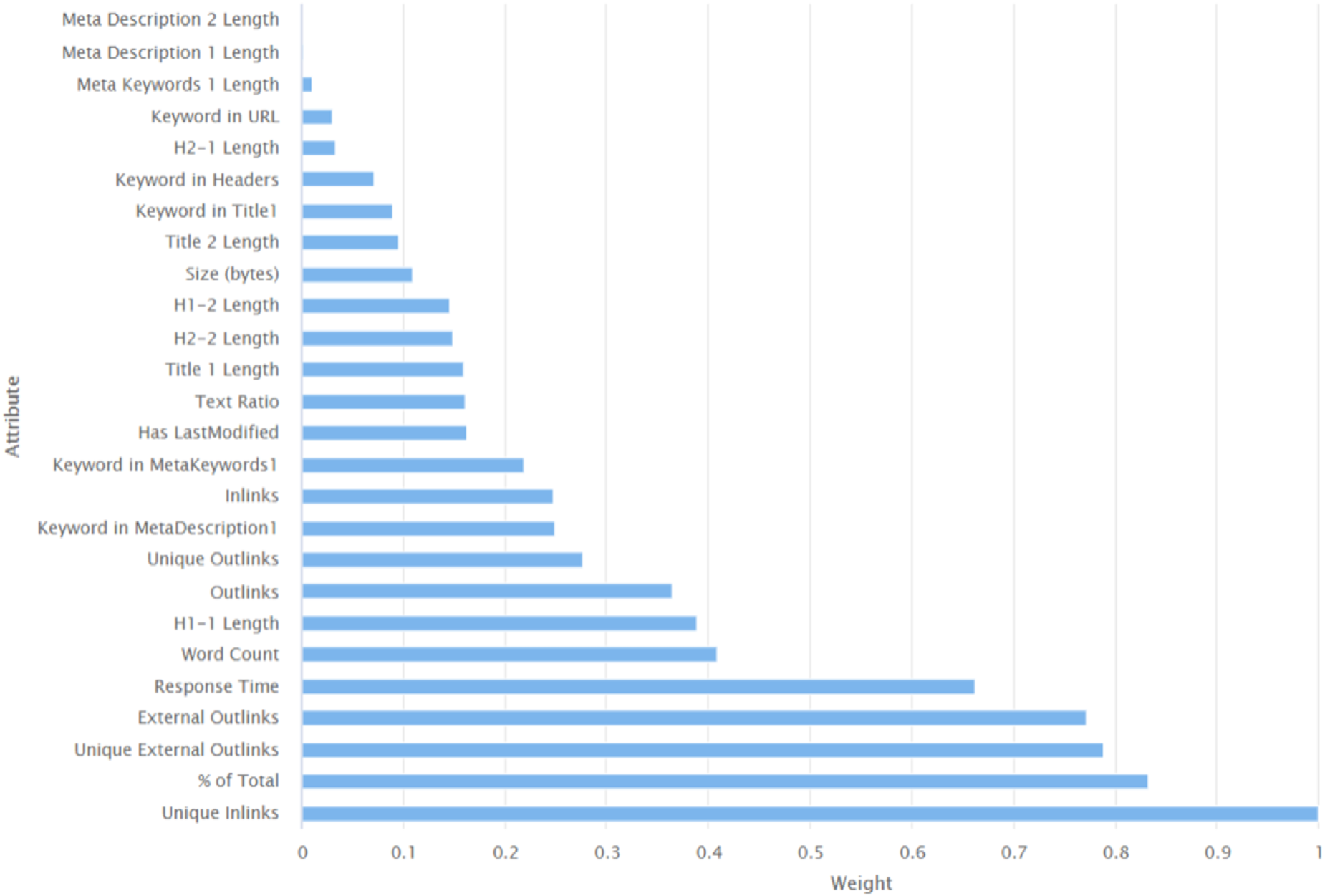
Attribute weights by correlation.
To make web pages of a website highly ranked by the Google search engine, the behavior of the search engine’s algorithm in ranking web pages should be tracked. The best method for understanding SE ranking methodology is by scraping SERP with a set of search keywords and building classification models using datasets of characteristics extracted from the resulting web pages on SERP. So, the performance of the SERP rank estimation algorithm will be related to the nature of training datasets. Based on that, this research came to add a contribution by enhancing SERP rank estimation and improving the dataset that will be used for training classifiers.
The literature included datasets of SEO factors for web pages from one category or a limited number of categories. By this research it was hypothesized that using multi-category web pages for building the training dataset will give better classification performance. So, this research followed a methodology of submitting multi-category keywords to the search engine to scrape SERP and crawl the resulting web pages for extracting SEO factors and building training datasets. data pre-processing tasks were applied, and a set of machine learning models were built for discovering the best model. A comparative approach was used to compare the performance of classifiers when using single or multi-category datasets. a binary and multi-class classification was used to simulate the experiment of previous research.
Results show that a good enhancement occurred in classification performance when using multi-category web pages rather than single-category web pages. An improvement of more than 25% in the performance of classification has been achieved by using a multi-category dataset over using the single-category one. Also, by comparing many machine learning algorithms, it was discovered that Gradient Boosted Trees was the best classifier by having 77.58% of accuracy for the multi-class classification and 86.56% of accuracy for the binary classification. This can support the hypothesis better to use a multi-category dataset for training machine learning algorithms to estimate the SERP ranking for a web page. In addition, correlation analysis confirmed that the ever-best on-page SEO factor that affects web page ranking in the Google search engine was internal linking.
In future work, it will be good to use hyper-parameter configuration to improve classification accuracies and extract off-page SEO factors for increasing the robustness of classifiers and improving performance. Also, it will be better to use more search keywords to have a larger training dataset to find more comprehensive classifiers that can work with high performance in ranking web pages from all expected categories or contents.
Supplementary data
Supplementary material.
Footnotes
Funding
This research did not receive any specific grant from funding agencies in the public, commercial, or not-for-profit sectors.
Declaration of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.