
Abstract
With the rapid advancement of deep learning technologies, self-supervised learning utilizing large-scale unlabeled datasets has emerged as a dominant learning paradigm across multiple fields. This paradigm aligns well with the nature of medical imaging data, which has led to significant research efforts in applying self-supervised learning methods to this domain. However, many of these approaches fail to fully consider the unique characteristics of medical imaging, particularly the critical role that texture information plays in the diagnosis of thorax diseases. To address this gap, we propose a novel texture-aware self-supervised learning framework that leverages the Gray-Level Co-occurrence Matrix (GLCM) as an auxiliary signal to strengthen the model’s capacity to extract disease-relevant texture features. Additionally, we integrate curriculum learning into our approach, which gradually emphasizes texture information throughout the training process. This method enables the model to more effectively capture the inherent characteristics of medical imaging data. Our qualitative and quantitative experimental results show that our approach surpasses the current state-of-the-art methods on both the NIH CXR and Stanford CheXpert datasets.
Introduction
With the rapid progression of deep learning techniques, state-of-the-art methods have achieved notable success across various domains, including natural language processing (NLP) and computer vision (CV). Most deep learning approaches are heavily data-dependent, requiring large amounts of accurately labeled data to train models that are both precise and reliable. In this context, self-supervised learning (SSL) methods have emerged as a leading paradigm in deep learning, as they leverage intrinsic signals within the data itself to guide the learning process [21,25].
Recently, SSL approaches can be broadly classified into two main categories: contrastive methods and reconstruction-based methods. Contrastive learning focuses on bringing similar data points closer in the feature space while pushing dissimilar points apart, resulting in a discriminative semantic feature representation. Notable examples of contrastive methods include Contrastive Predictive Coding (CPC) [22], SimCLR [4], and MoCo (Momentum Contrast) [13] and so on. On the other hand, reconstruction-based methods train models by recovering the original input from its corrupted or transformed versions, thereby learning semantic features that are closely aligned with the original data. Recently, BEiT [2] and Masked Autoencoder(MAE) [12] have become popular self-supervised learning methods in the field of CV. Regardless of the specific approach to self-supervised learning, their effectiveness has been demonstrated on a large number of validation results for various downstream tasks.
The SSL method has been widely employed in the medical image domain, leading to several well-performed models. [29,37] apply contrastive approach to enable encoder learns discriminative representations. [35] employ the MAE strategy to pre-train the CNN-based and ViT-based encoder. [10] combine these two strategies to further enhance its representation ability. However, many of these methods are adaptations of original approaches intended for natural images, often overlooking the unique characteristics of medical imaging. This oversight can lead to several challenges: (1) The training data may be randomly sampled, lacking a structured or progressive learning process; (2) Medical images often exhibit high inter-class similarity, making it difficult for methods designed for natural images to significantly improve model performance. Therefore, there remains substantial potential for developing models that better integrate the specific characteristics of medical images, thereby enhancing their interpretative capacity in the field of medical imaging.
After a lot of observation, we found that in the training of radiologists, the learning process follows a progressive sequence from simple to difficult cases. Moreover, although medical images exhibit high inter-class similarity, radiologists are skilled at accurately capturing low-level features such as texture and shape that distinguish between images of different patients. [38] attempted to utilize the GAN to decouple texture information from the overall representation of samples, resulting in an encoder that focuses on texture information. ssl method, at the same time, this method requires the use of another encoder and a discriminator to assist the texture encoder in the decoupling process. This leads to the presence of a large number of redundant parameters in the training process. [23] try to mimic the progessive training scheme to enhance model’s detecting abnomarty ability. ssl method, their method is only limited to abnormality detection in radiographs and does not explore its extensive applications.
Motivated by these observations, we propose a curriculum texture-aware self supervised learning framework for thorax disease classification. [9] Our approach allows the model to better capture the intrinsic characteristics of medical imaging data, as shown in the Figure 1. First of all, we organize the entire dataset into several curriculum based on the complexity of texture information, with increasing difficulty levels. Then, similar to [35], our method also utilizes the reconstruction of masked radiographs for pre-training. We utilize the grayscale co-occurrence matrix (GLCM) [11] of the original input as an auxiliary supervisory signal to constrain the texture information in the reconstructed images. In other words, our approach aims to not only reconstruct the original input but also capture similar texture features as the original radiograph. In order to extract texture information from radiographs to the maximum extent, we replaced the linear projection of patch embedding in the original MAE [12] with a set of lightweight CNN networks. In short, texture information plays a crucial role in our method as it serves as a significant motivation, process, and objective.

Comparison of our proposed curriculum-based pretraining strategy with conventional random arrangement methods.
Afterward, we fine-tuned and validated our pre-trained model on several thorax disease classification datasets. The experimental results demonstrated that our method outperforms previous state-of-the-art (SOTA) approaches. In addition, we performed visualization and analysis of the reconstructed images and extracted feature representations of our method. From the visualization results, it is evident that our method indeed enhances the attention of ViT towards texture details.
In summary, our research makes four-fold contributions:
Our proposed training framework mimic the radiologist training currirulum, from easy samples to complicated ones. We measure the texture complexity of radiographic samples in the pre-training dataset and use this information to divide the entire dataset into several pretraining curricula of increasing difficulty. This progressive process gradually enhances the model’s perception of texture information. We have deeply considered the differences between ViT and CNN and introduced a CNN-based patch embedding module into ViT. This allows us to extract texture information from the input radiograph to a greater extent and alleviate ViT’s tendency to overly focus on the shape characteristics of the input samples. The constraint of the gray-level co-occurrence matrix (GLCM) during the reconstruction process serves to supervise the entire framework and preserve the texture information. Quantitative and qualitative experimental results on public datasets illustrate that our method achieve performance improvement on pretrained representation quality than SOTA methods.
Curriculum learning
Curriculum learning is a learning paradigm inspired by the human-recognition construct process, where easy patterns are recognized before hard pattern. This paradigm was first raised and applie by Yoshua Bengio [3]. Its main idea is to utilize a progressive approach on model learning, where progression can occur either at the data level, from easy to hard samples, or at the task level, from simple to complex tasks. A few studies show that this paradigm results in better generalization and taking less training epochs to convergence.
In pratical applications, [32] combine speech-text translation task and sample’s internal understanding task, creating a simple to hard curriculum at task aspect. [20] utilizes both original data and strongly augmented data to construct a curriculum, gradually enhancing the 3D point cloud representation capability of the model. [15] apply this strategy in multimodal retrival task. [19] All these previous works use shown that curriculum learning can boost the convergence and level-up model effectiveness. Our method differs from these previous work in two ways: (1) Our method measures the texture information of the input samples, create the texture-based curriculum. (2) We apply curriculum learning in the pretraining stage on the pretext task learning, which gradually enhance the model’s texture capture ability.
Self-supervised learning in medical image analysis
Self-supervised learning aims to leverage internal supervision signals inherent within the data samples themselves to guide deep learning methods in learning rich and meaningful semantic features. Recent self-supervised learning protocols can be divided into two categories: Contrastive method [4,5,8,13] and restoration method, [2,12,18,36]. Contrastive method [4,5,13] maximize the mutual information of different augmentation views of same images, and minimize the mutual information of representation from different images to encourage deep encoder extract the discriminative representation. Restoration method aims to encode the input sample into a latent represent and decode the acquired latent representation to the original image. MAE [12] and SimMIM [36] mask a large ratio of a input image, using pixel reconstruction loss to guide encoder learns rich semantic representations. BEiT [2] encode the image patches into discrete semantic token to make BERT [6] pretrain protocol applied on continuos visual information. These self-supervised show competitive result on several natural image tasks.
Recently, few researches [10,10,29,30,35,37], has employed visual self-supervised learning on medical image anaylsis. Swin-UNETR [30] utilize self-supervised learning to enhance Swin-transformer’s low-level and high-level extraction ability in order to get accurate organ segmentation result. [35] explored the impact of utilizing different hyperparameters on the classification task performance after pretraining on chest X-ray in-domain data. [10] tries to employ multiple self-supervised learning strategy to enhance the DenseNet’s performance on several medical image benchmarks including 2D medical images and 3D medical images.
However most of these methods directly apply the natural image self-supervised learning framework on the medical image analysis, lacking the prior knowledge of the medical image area. Our proposed work are different from these work at two aspects: (1) The overall pretraining process mimics the radiologist training procedure, from easy pattern to hard pattern. (2) We emphasize the human-observed statistical texture feature to guide ViT learns special texture pattern.
Methodology
In this section, we will provide a detailed explanation of our proposed method and the preliminary concept involved. In Section 3.1, we introduce the preliminary concept of the Gray-Level Co-occurrence Matrix (GLCM). Moving forward, Section 3.2 describes the overall structure of our proposed model. Subsequently, in Section 3.3, we present our novel curriculum learning approach, which leverages the complexity of image textures. Then, in 3.4 we introduce the texture-aware patch embedding modules. In Section 3.5, we detail the Masked Radiograph Modeling method, which involves reconstructing the original input radiograph using an asymmetric decoder and calculating the L2 (MSE) loss. Finally, the loss function employed by our whole architecture will be explained in Section 3.6.
Preliminary: Gray-level co-occurrence matrix
Before proposing our method, we briefly introduce the Gray Level Co-occurrence Matrix(GLCM), a statistical tool to extract visual signal’s texture features.
The Gray Level Co-occurrence Matrix (GLCM) [11], also known as the Gray-Level Spatial Dependency Matrix(GLSDM), is a widely used texture analysis method in image processing and computer vision. It provides a statistical representation of the spatial relationships between pairs of pixels in an image, revealing the statistical texture pattern of an input image.
Considering a grayscale image

In practical applications, various statistical features, including energy and entropy, can be extracted from the GLCM to effectively describe the texture characteristics of an entire image. This process is usually conducted within local patches of the image, allowing us to capture the relationships between different local textures and structures. A common approach involves partitioning the image into patches and utilizing the GLCM features of these patches to represent the central pixel. This procedure enables the construction of a GLCM graph, as illustrated in our pipeline figure. Moreover, in our study, we adopt global statistical GLCM features from chest radiographs to quantify the texture complexity of input samples, thereby facilitating the creation of a pretraining curriculum. Further details about the curriculum strategy are provided in the subsequent section.
Our overall method can be divided into two parts: the curriculum selection module and the texture-aware MAE pre-training. The curriculum selection module initially reorders the entire scattered and unordered pre-training dataset by the texture complexity presented by each sample, arranging them in ascending order of texture complexity. Subsequently, the selection module select the corresponding subset of course data from the entire dataset based on the current pre-training curriculum stage. As the currilum stage progresses, the size of the curriculum subset increases, and curriculum subset includes a larger number of samples with complex textures. In the final curriculum stage, the curriculum selection module considers the entire dataset as the current curriculum dataset. The curriculum selection progress is illustrated in the Figure 2. Once the selection module chooses the current pre-training dataset, the sampler will take batch from the current dataset to serve as input for subsequent model.

Overall structure of our proposed method, where the curriculum selection module selects an appropriate subset from the pre-training dataset, tailored to the current stage of the training process.
The input radiograph firstly go through the CNN-based texture-aware patch-embedding module, obtaining a
Our curriculum strategy is based the texture complexity of the input radiograph samples. As shown in the Figure 1, the curriculum selection module determines the training data subset of each training stage, such that the size and overall difficulty of the subsets are gradually increasing throughout the training process. In the last pre-training curriculuim stage, the curriculum will give the entire dataset to the model, which is the final curriculum.
We merge the two commonly used chest radiograph datasets [14,34] into one large-scale pretraining dataset, obtaining 336,436 chest radiographes. however, these 336,436 chest radiographes are randomly ordered and not arranged based on the inherent information within each photo.The entropy of global GLCM is usually used to describe the texture of a visual signal. Based on these hypothesis, we rearranged the entire dataset in an ascending order according to the entropy and energy values of each photo’s GLCM. The entropy value of GLCM is formulated as:

We can take the whole training process as T stages,
Inspired by [7], we propose a light-weight CNN-based texture-aware patch embedding module to mitigate the preference of ViT towards structural and geometric information. In vanilla MAE structure, the patch embedding step is achieved through a delicating designed Conv2D layer so the shape of embedded patch sequence equals
As demonstrated by previous research, a CNN-based encoder tends to focus on texture information, while a ViT-based encoder emphasizes structural and shape information. Therefore, we begin by utilizing a texture-sensitive light-weight CNN to encode the input radiograph into a feature map of the same size as the original image, capturing rich texture information. After that, we patchify the feature map into
Masked radiograph modeling
Similar to the original MAE framework, we also employ an asymmetric decoder in our approach to reconstruct the original input radiograph from a sequence composed of mask tokens and visible tokens. Here, we use the L2(MSE) loss to measure the distance between the reconstructed patch and the original patch:

After the decoder reconstruct the original input sample, we use formula (1) to calculate its mean GLCM

We also compute the local patches’ GLCM L2 loss between the original masked patch and the reconstructed patch, which can be formulated as:

The whole GLCM constraint loss is:

For summary, the overall pretraining loss function is:

In this section, we first introduce the setups of our pretraining process. Then we evaluate the pretrained model with various downstream tasks, including multilabel thorax disease classification, disease location detection. After that we conduct the ablation study on our proposed modules of GXMAE. The final visualization result shows that our method can capture the texture information within the radiograph images.
Pretrain setups
Pretraining dataset
We merge the NIH Chest X ray [34] and Standford CheXpert [14] datasets into one large-scale unlabeled images set as the pretrain dataset. The NIH Chest X-Ray 14 dataset includes 112,120 radiographs from 30,805 unique patients, labeled with 14 thorax disease classifications. The Stanford CheXpert dataset comprises 191,028 frontal-view chest radiographs from 65,240 patients. In total, our pretraining dataset consists of 336,436 frontal-view chest radiographs. For data preprocessing, we applied random resized cropping and horizontal flipping as part of our data augmentation strategy to ensure variability in the training data, which helps the model generalize better to unseen cases.
Implementation details And ViT blocks’ parameters are initialzed with xavier uniform
Evaluations on downstream tasks
We validated our method on two commonly used datasets for lung disease classification. The experimental results demonstrate that our approach outperforms previous methods, indicating its ability to extract low-level and high-level features highly relevant to the diseases. This validates the effectiveness of our improvements and underscores the significance of our approach in extracting disease-related information. Moreover, we use our pretrained encoder finetuned on the NIH subset of thorax disease location, the result shows our method achieve acceptable result compared with other single-task thorax disease detection method.
Thorax disease classification
NIH chest X ray We take the official training spilt of NIH CXR dataset as the fine-tuning dataset. The final validation result was evaluated on the official validation split of NIH dataset. Due to NIH dataset’s multilabel feature, we use the Area Under ROC curve (AUROC, AUC) value to evaluate our framework on the disease classification task. As shown in the Table 1, our approach improves the mean AUC by 0.15 compared to the original MAE method, underscoring the critical role that texture-aware design plays in enhancing the overall performance of the model. This validates the inclusion of GLCM and curriculum learning as essential components in our framework. Due to the lack of inductive biases and the hunger for data in ViT, we observed that the classification results of randomly initialized ViT were even worse than those of a CNN network under the same conditions.however it can be observed that the self-supervised pretrained ViT outperforms the self-supervised pretrained CNN networks. This indicates the crucial importance of in-domain self-supervised pretraining for ViT. The fact that our method outperforms other self-supervised strategies also highlights the importance of texture information for thorax disease classification.
Fine-tuned classification result on NIH CXR dataset. The official train split was used for finetuning the pre-trained ViT encoder, and validation was conducted using the corresponding official validation split.
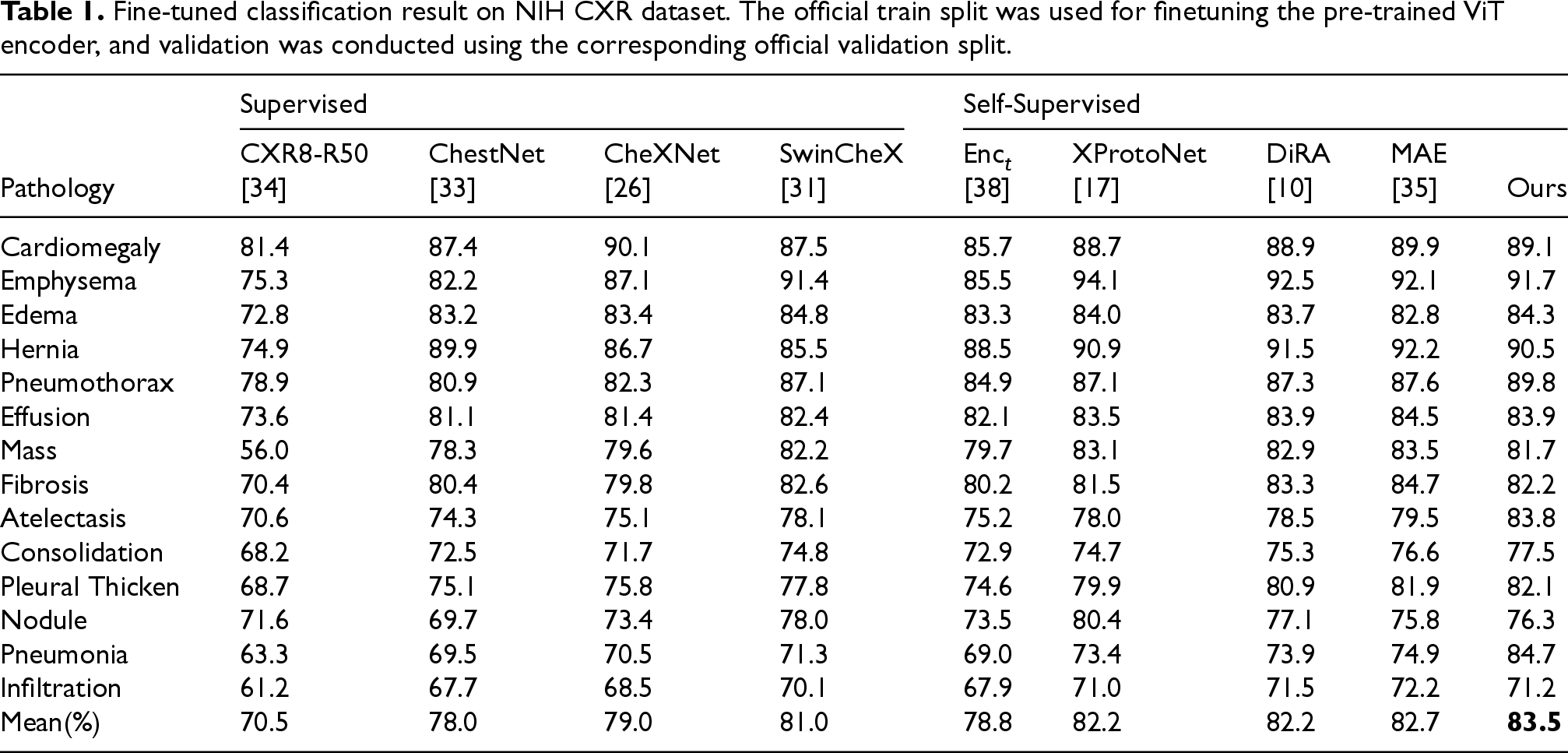
Fine-tuned classification result on NIH CXR dataset. The official train split was used for finetuning the pre-trained ViT encoder, and validation was conducted using the corresponding official validation split.
Stanford CheXpert Standford cheXpert [14] is large-scale chest x ray image dataset contains 191,028 frontal-view and 33,288 lateral-view radiographs of 65,240 patients. Training set images was annotated with 14 thorax disease labels. In this study, we evaluated our fine-tuned method using the official validation set of CHEXPERT, which includes five common thorax diseases, as the benchmark metrics. This allows for a direct comparison with existing methods on the same set of diseases. As shown in Table 2. Here we use the mean AUC values to evaluate our method compared with other popular methods.
Comparison of fine-tuned classification performance on the CheXpert dataset. Various methods and backbones are evaluated, with mAUC serving as the performance metric.

Using the official validation split of NIH chest X ray 14 thorax disease classification dataset, we conducted the ablation study of the GLCM information and curriculum learning strategy. As shown in Table 3, the vanilla ViT-B model trained from scratch achieves 0.741 mean AUC. With the vanilla MAE pretrain setting, the mean AUC of the ViT-B model fine-tuned on NIH achieves 0.823. Under our proposed pretrain setting, ViT-B achieves 0.835 mAUC. Only applying the curriculum sampler, ViT-B achieves 83.1% mAUC. Combining the GLCM constraint, curriculum learning, and MAE pretraining, the ViT-B model achieves the highest mAUC of 83.5%.
Ablation study results for the key components of the proposed architecture. The table compares the impact of including or excluding GLCM constraint, curriculum learning, and MAE on mAUC, demonstrating the benefits of the full model over baselines.

Ablation study results for the key components of the proposed architecture. The table compares the impact of including or excluding GLCM constraint, curriculum learning, and MAE on mAUC, demonstrating the benefits of the full model over baselines.
In addition, we conducted ablation experiments based on different pre-training strategies to compare our pre-training strategy with others. As shown in Table 4, our pre-training strategy achieved the highest mAUC value in all experiments, demonstrating its effectiveness.
Ablation study results comparing various pre-training strategies and their impact on model performance (measured by mAUC) across different network architectures.

In this section, we conducted a comprehensive analysis of our model using a series of visualization methods. Firstly, we visualize the features extracted by our method using t-SNE for dimensionality reduction. Then we employed a GLCM method to visualize the texture in our reconstructed images. Finally we utilize the Grad-CAM [27] method to extract the attention of the last layer of our ViT encoder and generate attention heatmaps on the input radiograph to visualize model’s attention region for predicting disease.
Reconstruction GLCM visualization And we use the visualization of the GLCM feature graph to analyze the reconstruct image texture information. As shown in the Figure 3, the visualization of GLCM is achieved by dividing the image into 2 × 2 patches, calculating the GLCM and its features for each patch, and then mapping the feature values onto the central pixel of the patch. the reconstructed radiograph by our method contains more sharp edges, which illustrates that our method preserves more texture details.

GLCM visualization comparison. Our method reconstruct more texture detail compared with the vannila MAE method.
We present a curriculum self-supervised CXR representation learning method based on texture information. Leveraging a data sampler that reorders the entire pretraining data according to the complexity of texture in each learning sample, we construct different subsets (referred to as “curricula”) arranged from easy to difficult. Our improved MAE CXR representation learning framework is pretrained in a progressively increasing difficulty manner. The results from various downstream experiments demonstrate that our approach achieves superior performance compared to the baseline method while addressing the issue of ViT’s limited sensitivity to texture in the original MAE. Furthermore, the proposed module indeed enhances the effectiveness of the baseline method according to the results of downstream experiments. In the future, we will explore methods to enhance the causal interpretability of our approach and improve its credibility in clinical applications.
Footnotes
Acknowledgements
This work is supported by National Natural Science Foundation of China under Grant 22033002 and Grant 92370127.
Conflict of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Data availability
The datasets used in this study are publicly available and can be accessed from the following sources:
NIH Chest X-ray Dataset: This dataset contains 112,120 frontal-view X-ray images of 30,805 unique patients, annotated with 14 disease labels. It is available at https://nihcc.app.box.com/v/ChestXray-NIHCC. Stanford CheXpert Dataset: This dataset includes 224,316 chest radiographs of 65,240 patients, annotated with 14 disease labels. It is available at https://stanfordmlgroup.github.io/competitions/chexpert/.