
Abstract
BACKGROUND:
Precise teeth segmentation from dental panoramic X-ray images is an important task in dental practice. However, several issues including poor image contrast, blurring borders of teeth, presence of jaw bones and other mouth elements, makes reading and examining such images a challenging and time-consuming task for dentists. Thus, developing a precise and automated segmentation technique is required.
OBJECTIVE:
This study aims to develop and test a novel multi-fusion deep neural net consisting of encoder-decoder architecture for automatic and accurate teeth region segmentation from panoramic X-ray images.
METHODS:
The encoder has two different streams based on CNN which include the conventional CNN stream and the Atrous net stream. Next, the fusion of features from these streams is done at each stage to encode the contextual rich information of teeth. A dual-type skip connection is then added between the encoder and decoder to minimise semantic information gaps. Last, the decoder comprises deconvolutional layers for reconstructing the segmented teeth map.
RESULTS:
The assessment of the proposed model is performed on two different dental datasets consisting of 1,500 and 1,000 panoramic X-ray images, respectively. The new model yields accuracy of 97.0% and 97.7%, intersection over union (IoU) score of 91.1% and 90.2%, and dice coefficient score (DCS) of 92.4% and 90.7% for datasets 1 and 2, respectively.
CONCLUSION:
Applying the proposed model to two datasets outperforms the recent state-of-the-art deep models with a relatively smaller number of parameters and higher accuracy, which demonstrates the potential of the new model to help dentists more accurately and efficiently diagnose dental diseases in future clinical practice.
Introduction
In the oral field, analysing dental images is crucial as it provides information about the patient’s oral conditions and helps in drawing better treatment plans. Teeth segmentation is one of the prominent tasks for analysing tooth status in dental imaging [1]. The segmented dental images convey essential information for monitoring teeth development, detecting dental structures and location of teeth for teeth numbering and implant planning [2, 3]. Another application of teeth segmentation is in the field of forensics to identify personal details like age and gender based on dental features [4, 5].
Among many dental imaging modalities, panoramic x-ray images are mostly utilized for diagnosing dental diseases. Dentists examine these X-ray images by visualizing them to determine the presence of various dental problems like cavities, fractured teeth, gum diseases, bone abnormalities and oral cancer [6–8]. Analysing panoramic X-ray images manually is difficult and time-consuming, requiring expertise and experience. Even for experts examining X-ray images is more challenging because such images suffer from low contrast at boundaries, the noise produced by machines, overlapped images of teeth etc. thus may lead to incorrect judgements. Also, the presence of jaw and nasal bones makes this task difficult for dentists. Thus, to help young interns and dentists to reduce their fatigue workload and to enhance their analysing skills, accurate and automatic segmentation of dental x-rays is required, which would be very beneficial in the dentistry community.
Many conventional-learning methods have been used for teeth segmentation, these methods are based on thresholds [9], boundaries [10], regions [11, 12], and clusters [13]. Additionally, techniques based on morphological operators [14], template matching [15], active contours [16] and level-set [17] methodologies are also employed for automatically segmenting teeth regions. Binary support vector machines [18] with handcrafted features were also used for the segmentation of teeth. However, most of the classical methods depends on the careful identification and extraction of relevant features which directly affects the performance of these methods. Apart from it, when evaluated on small datasets, these techniques produce good results but perform poorly on large datasets.
With the introduction of deep learning in medical image analysis field, the limitations of traditional approaches for dental image segmentation can be greatly enhanced. The deep learning approaches have an advantage over traditional methods as these approaches has ability to learn features straight from unprocessed data instead of using hand-designed features. Several image segmentation models have been proposed are based on convolutional neural networks of which U-Net [19] and SegNet [20] have demonstrated impressive performance in the field of medical image segmentation, including dentistry.
Yang et al. [21] utilized conventional CNN as the backbone and proposed a pipeline for automatic analysis to diagnose tooth diseases using a small dataset having 196 periapical images. A couple-shaped model with the deep neural net was presented by Wirtz et al. [22] for automatic and robust segmentation of each tooth on low-quality dental panoramic radiographs. Due to insufficient data and shape inconsistencies, their approach results in low segmentation accuracy. To show the efficacy of transfer learning in segmenting dental radiographs Caylak et al. [23] employed the pre-trained Inception-ResNet-v2 and pre-trained U-Net models on small datasets. Only 131 dental panoramic radiographs were used. Nishitani et al. [24] presented a teeth segmentation model using U-Net on 162 panoramic images. This method focuses on the hybrid loss function to train U-Net architecture for tooth edges. However, the drawback of this method is suboptimal hyperparameters tuning and the need for optimization of edge width.
Silva et al. [25] proposed the standard dental dataset of panoramic x-ray images which consists of 1500 images. The authors implemented some traditional methods to segment dental images. Additionally, the Mask-RCNN deep neural network was deployed on this dataset in different categories of this dataset. The results obtained were not up to the mark thus leaving scope for other neural networks to be evaluated on this dataset. Jader et al. [26] used mask regional convolutional networks with Resnet-101 as a backbone for instance segmentation on 1500 panoramic radiographs. The main objective is to detect individual teeth or missing teeth. The limitation of this approach is that it lacks in capability for segmenting mouth and teeth components due to the presence of tooth appliances. Oktay et al. [27] and Pinheiro et al. [28] also used the Mask RCNN for segmenting individual teeth for tooth numbering in panoramic x-ray images. These approaches suffer because of the presence of dental implants and the overlapping of teeth. These models are utilized for instance segmentation in which the focus is on segmenting individual teeth which is a complex and laborious task when compared to semantic segmentation as it requires intensive and careful labelling. In this study, the focus is on semantic segmentation.
Modified U-Net was presented by Koch et al. [29] for accurate tooth segmentation. The authors made patches of original images and combines several techniques to improve segmentation performance. The annotated and patches of images were used which hampers model’s performance. Zhao et al. [30] presented a two-stage attention model based on CNN for accurate tooth segmentation. To locate the tooth area both global and local features were extracted using attention modules in first stage. A fully convolutional network was employed to segment dental region in second stage. The model has approximately 78 million trainable parameters and was evaluated on 1500 panoramic radiographs. The limitation of this method is in handling high number of trainable parameters.
Cui et al. [31] investigated the generative adversarial network with certain conditions on dental dataset comprises 1500 panoramic images for tooth segmentation. This method is highly dependent on annotation which compromises genuine feature extraction. Lin et al. [32] presented a lightweight neural network strategy using knowledge distillation for segmenting dental radiographs to deploy on edge devices. 1321 resized dental X-ray images were utilized to measure the performance. Model designed was lightweight but needs significant improvement in terms of dice and intersection over union (IoU) score.
Panetta et al. [33] developed a new benchmarking multimodal dental database consisting of 1000 panoramic x-ray images. Authors implemented recent state-of-the-art segmentation techniques with image enhancement methodologies to evaluate the dataset. The deep models consisting of Atrous net are yet to be explored on this dataset.
Vision-based automatic dental segmentation techniques employing both traditional and deep learning models have been presented in the literature. Deep learning techniques performed better as compared to traditional methods. These techniques are mainly based on conventional CNN, Mask RCNN and modified U-Net architecture for dental image segmentation. Thus, leaving scope to explore different types of CNN specially Diconvolutional (Atrous Net) layers for accurate and automatic dental panoramic X-ray image segmentation. Models based on Mask RCNN are generally used for instance segmentation while in this study, the focus is on the semantic segmentation of dental panoramic X-ray images which helps provide more clarity of tooth structure for better analysis. The deep models especially based on the attention mechanism possess a huge number of trainable parameters and takes longer training and testing time for model since there is a trade-off between accuracy and trainable model parameters. A lightweight deep model was proposed but it suffers with performance on dice score and IoU score which are important evaluation criteria for segmentation.
Thus, to address above mentioned issues, in this study a multi-fusion deep neural network with less trainable parameters is presented for precise and automatic segmentation of teeth region from dental panoramic X-rays. Following is the summary of contributions: A novel multistage deep fusion model is presented for accurate and automated segmentation of teeth region. The encoder module encapsulates the information gathered from conventional CNN stream features and Dicnovolutional CNN (Atrous CNN) stream features and fuses them at each stage to contain teeth-rich feature information for accurate and sharp teeth region segmentation. Dual types of skip connections, short-type skip connection and long-type skip connection are presented to store detailed information on teeth region between the encoder and decoder. The hybrid loss function comprised of binary cross entropy loss and dice loss is proposed to improve the proposed model’s performance. The proposed deep model is assessed on two different datasets containing 1500 and 1000 panoramic X-ray images and surpasses the state-of-the-art method in terms of IoU, dice score and accuracy while requiring very less trainable parameters for both datasets.
Model and methodology
Overview
The proposed multistage fusion deep model primarily concentrates on the automatically segmenting the entire teeth region from dental panoramic radiographs. The proposed model is based on encoder-decoder architecture. The encoder module is responsible for encoding texture semantic information of dental region by fusing information gathered from two different CNN-based streams i.e., conventional CNN and Atrous (Diconvolutional) Net at each step. Two types of skip connections Long Skip and Short skips are designed to preserve the low-level features of teeth which help in the reconstruction of the segmented teeth region map at the decoder module. The training of the proposed multistage fusion deep net is done in an end-to-end manner.
Detailed architecture
The major components of the proposed network are convolutional-dilated convolutional based encoder, deconvolutional decoder and dual type of skip connections. The proposed model is trained in an end-to-end way using hybrid loss function. The detailed architecture of the proposed multi-fusion deep model is shown Fig. 1.
Encoder: The encoder part of the presented model is composed of two different CNN-based streams. Each stream of the encoder receives the same input in the form of original panoramic x-ray image. The first stream uses simple convolutional layers to capture essential dental information from panoramic radiographs. This stream comprises of six convolution layers having different kernel sizes followed by batch normalization and uses an activation function ReLu. In this stream three Max pooling layers of dimensions [2×2] are used to minimise the spatial dimensionality of image. Second stream of the encoder part contains six dilated-convolutional (Diconvolution) layers having different dilation rates. These layers also use activation function ReLu with batch normalization. Here also, three Max pooling layers of dimensions [2×2] are used to downsample feature maps. Dilated convolution has the advantage of capturing contextual semantic information of teeth region in bigger receptive field. Additionally, it suppresses non-relevant background region without increase in the number of network parameters. The skip connections are also designed in the encoder module. Short-type skip connections are utilized in both streams of encoder that is in simple CNN stream as well as dilated convolution (Atrous) net stream to enhance the training of proposed deep network. Long-type skip connection are present from an encoder part to the decoder part of the network. To exploit the features of multi-CNN, feature maps obtained from each convolution layer of the CNN stream and dilated convolutional layer of the Atrous Net stream are fused by using concatenation operation. These fused feature maps are provided as input to another stream called fused stream which includes three simple convolutional layers having filter size [3×3] with ReLu as an activation function followed by batch normalization layer. The feature maps obtained from all streams are fused at each stage while maintaining symmetry in the encoder. This enables a network to learn more context from feature maps of dental panoramic images. Finally, all the features of each stream are fused and are passed as input to the decoder.

The detailed architecture of the proposed model.
Decoder: The features extracted by the encoder are in compressed form and are the representation of original dental panoramic x-ray images. These compressed features are then fed to the decoder to reconstruct the final segmented teeth image. The decoder accumulates the feature information from various layers and concatenates encoder-extracted features with upsampled feature maps. The symmetry is maintained throughout the encoder and the decoder module. The decoder includes eight deconvolution layers with different kernel sizes. The first seven layers utilizes activation function ReLu and batch normalization. The upsampling layers of dimensions [2×2] are added to increase the spatial dimensions which help in reconstructing the original size of the image. The final layer in the decoder is a deconvolution layer of channel 1 and has a [1×1] kernel size and uses the sigmoid activation function for pixel-wise classification. The training of proposed model is completed in an end-to-end way.
Skip Connections: There are two types of skip connections presented in the proposed deep network. The first are the Short-type skip connections and the second are Long-type skip connections. The objective of these skip connections is to enhance information flow between feature maps. The short-type skip connections are proposed in the encoder module while the Long-type skip connections are between the encoder module and decoder module. The short-type skip connections are utilized in conventional CNN and Atrous net streams to reuse the dental semantic features obtained from earlier layers in the other layers. Additionally, they help in faster convergence of the learning process by stabilizing gradient updates and well distribution of parameter updates. Down-sampling in the encoder part results in a loss of spatial structural information due to different types and shapes of teeth. Thus, to preserve low-level spatial features Long-type skip connections are introduced which originate from an encoder and meet the decoder to enhance the restructuring of the segmented teeth map.
Hybrid Loss Function: Two different loss functions are employed, to optimize the proposed model. Binary cross-entropy (BCE) loss is the first loss function, which is based on distribution loss and is commonly utilized in binary classification and segmentation. BCE is expressed as:
The second loss function is a dice loss inspired by the dice coefficient score is based on region loss and is utilized to refine the overlapping between the two images. This loss is mostly utilized in optimizing medical images. It is described as follows:
To obtain clear teeth segmented maps a hybrid loss function is presented and is defined as:
The BCE loss is considered as a pixel-by-pixel loss that is utilized to minimise the gap between each pixel. The dice loss is considered as a loss of foreground and becomes zero as the prediction of foreground increases assisting the proposed network to emphasize on the foreground. Both loss functions have different benefits the combination of BCE and Dice Loss offers a balanced approach for segmentation tasks, as BCE loss helps in class imbalance and captures global context which ensures overall correct pixel predictions whereas Dice loss is effective in measuring similarity which leads to better localization accuracy also it focusses on capturing finer details. Thus, utilizing them jointly optimizes the efficacy of the proposed network.
Datasets
The two-benchmark dataset are used to assess the proposed deep model. The first dataset was developed at Ivision Lab by Silva et al. [25] and composed of 1500 dental panoramic x-ray images which are categorized into 10 distinct categories based on missing teeth, dental appliances, dental implants and restoration. For training, validation and testing, dataset is segregated in 3 parts with a split ratio of 8:1:1 that is there are 1200 randomly selected images in the training set and remaining 300 images are equally divided between validation set and test set. The original size of the image in this dataset was 1991×1127 which is resized to 512×512 for better memory utilization. The second benchmark dataset used to assess the suggested model is called Tufts dental database prepared by Panetta et al. [33] is openly available for research purposes and has 1000 new dental panoramic x-ray images. This dataset is also segregated in 3 parts with similar split ratio having 800 randomly selected images in training set while 100 image each in test and validation set. The size of the original x-ray image in this dataset is 1615×840 pixels which is downsized to again 512×512 pixels. Both datasets were developed in different conditions with different machines. The two datasets were used to see the generalizability of the model. The sample dental panoramic radiography images of both datasets are shown in Fig. 2.

Samples of dental panoramic x-ray images of both datasets (a) Sample of dental panoramic radiograph and its ground truth from dataset 1. (b) Sample of dental panoramic radiograph and its ground truth from dataset 2.
The proposed deep model is assessed on a variety of quantitative metrics including accuracy, recall, precision, dice coefficient and IoU. The dice coefficient score is broadly utilized to assess the performance of image segmentation models specially in medical imaging, it measures the similarity of predicted segmented map and the ground truth map. The dice coefficient is defined as:
Another evaluation metric commonly used for the segmentation of medical images is Jaccard index or IoU and is defined as:
The image segmentation is regarded as pixel-level classification task therefore common classification metrics accuracy, recall and precision are also employed to assess the performance of the suggested deep model. These are defined as follows:
Experimental setup
The presented deep model is implemented in an end-to-end way on four NVIDIA GeForce GTX 1080i GPUs using Pytorch framework in python. The learning rate, batch size and the number of epochs is set to 0.0001, 16 and 200 respectively. To avoid overfitting, the early stopping method is adopted with the patience parameter set to 4 that is training will be halted if there will be no change in training loss for 4 consecutive epochs. It can be inferred that the proposed network converges at approximately 60 epochs. The training and validation loss for every epoch is plotted and is shown in Fig. 3. Further, the hybrid loss function is optimized by using RMSprop optimizer.
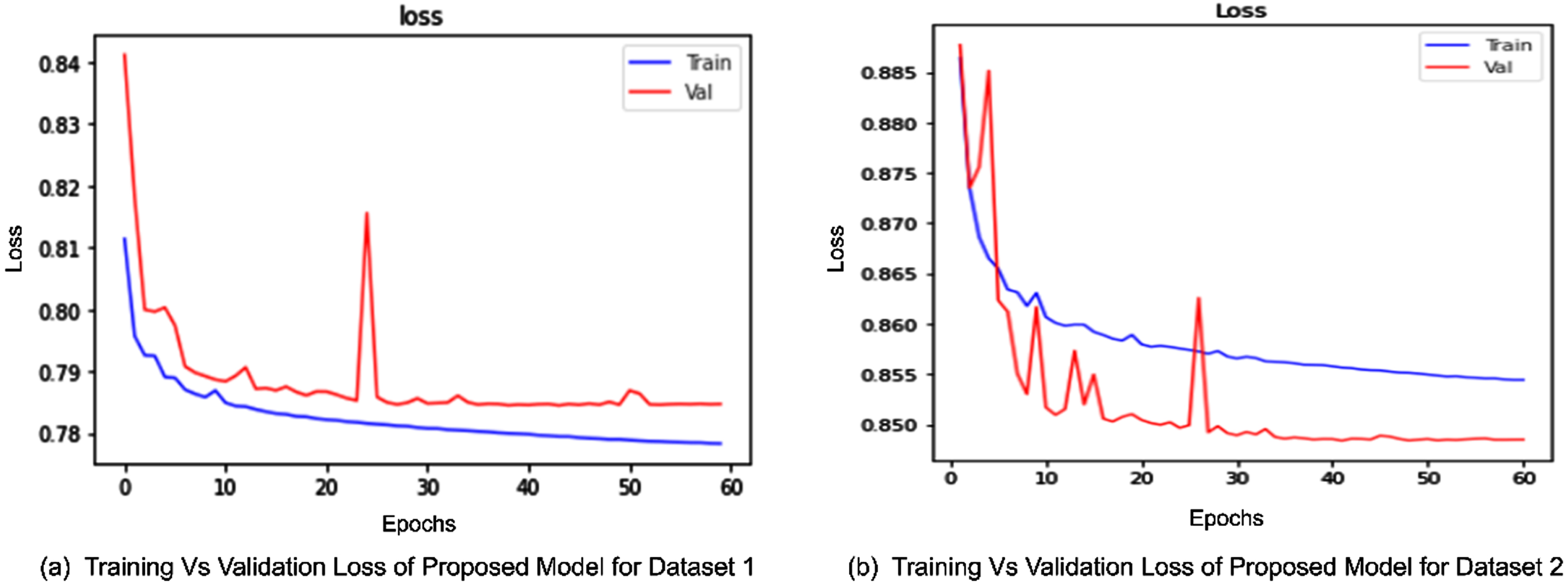
Losses of proposed model for both datasets. (a) The plot demonstrates the training loss and validation loss for dataset 1 it seems the model converges approximately at 55th epoch. (b) This plot demonstrates training loss and validation loss for dataset 2 which seems to be converged at epoch 60.
The proposed model’s performance is compared with recent existing deep learning models all of which can be utilized in segmenting dental panoramic x-ray images. These deep models are SegNet [20], UNet [19], BiseNet [34], CENet [35], Unet++ [36] and Nanonet [37] which were applied to the same benchmark dental image datasets. To have a fair comparison, the same parameter setting has been used and datasets are split in the same ratio for training, testing and validation set. The assessment of the models is done on five different metrics, number of parameters and two different panoramic radiographs datasets. For dataset 1, accuracy, precision, recall, IoU and dice score of the proposed model are 97%, 96.4%, 90.6, 91.1% and 92.4% respectively with only 0.380 million (M) parameters. On dataset 2 the proposed model attains 97.7% accuracy, 95.4 % precision, 92.8% recall, 90.2% IoU and 90.7% dice coefficient while the number of parameters is same.
The quantitative comparison results with other deep models for dataset 1 is represented in Table 1 and for dataset 2 is represented in Table 2. It is observed that the presented deep model completely outperforms the state-of-the-art methods on all evaluation metrics except the number of parameters for both datasets. The presented model is better than all the deep segment state-of-the-art methods in terms of parameters except Nanonet which has only 0.235 trainable parameters. Though Nanonet has shown good performance while having a smaller number of parameters its dice coefficient and IoU score are quite less compared to the proposed model which are considered important segmentation metrics.
Performance summary of the proposed model compared with deep segment state-of-the-art methods for Dataset 1
Performance summary of the proposed model compared with deep segment state-of-the-art methods for Dataset 1
Performance summary of the proposed model compared with deep segment state-of-the-art methods for Dataset 2
The visual results of the proposed model are demonstrated in Fig. 4 for dataset 1 and Fig. 5 for dataset 2. It can be observed that UNet, SegNet, BiseNet, Unet++ and CEnet are prone to misclassify the correct teeth pixels with jaws bone and other facial bone pixels whereas the proposed method correctly identifies segmented teeth region. It can be seen that BiseNet is comparatively weak in dealing with low-contrast images. SegNet, CEnet, and Unet++ suffer in predicting the tooth boundaries while NanoNet seems to perform better in detecting tooth boundaries but shows the teeth structure slightly thicker while the proposed method has predicted the clear and smooth teeth region segmented map by suppressing the other background details of mouth.

Comparison of visual results of proposed model with different segmentation based deep models on Dataset 1. The first two rows represent original image and its corresponding ground truth while the remaining rows represents the predicted segmented teeth map by different methods including the proposed model.

Comparison of visual results of proposed model with different segmentation based deep models on Dataset 2. The first two rows represent original image and its corresponding ground truth respectively while rest shows segmented teeth region mask predicted by various deep models.
The ablation study is carried out to verify the efficacy of the components of the suggested deep model. The experiments are conducted with similar parameter settings but with different components on the same datasets. The taring and validation loss of each module is shown in Figs. 6 and 7 for dataset1 and dataset 2 respectively from which one can infer that all the modules are converged at epoch 60. The assessment metrics used are precision, accuracy, recall, IoU and dice coefficient. Three different modules are developed from the proposed model based on skip connections and are as follows:
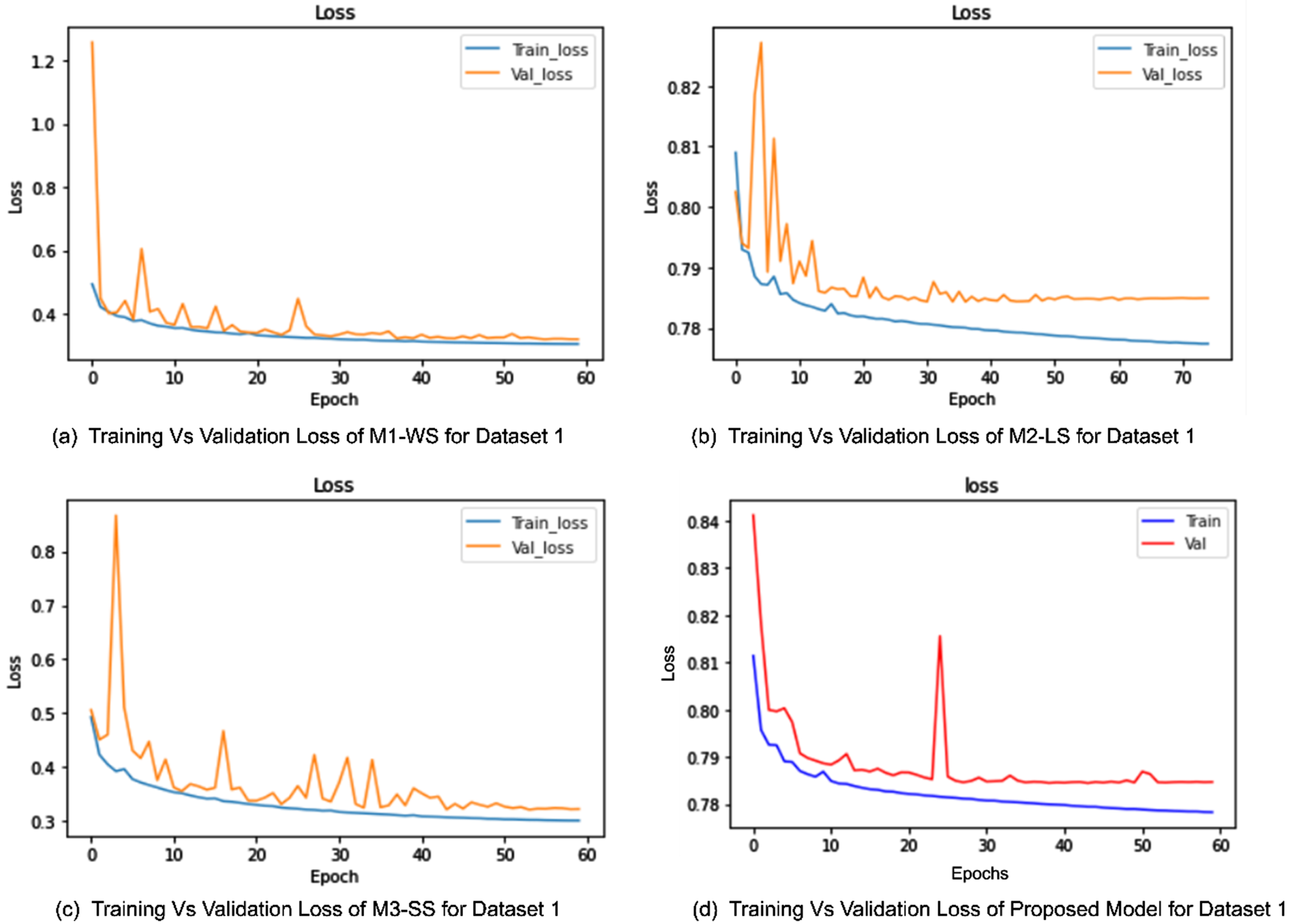
Training vs Validation loss for Dataset 1. (a) This plot represents the training and validation loss for module without skip connections. (b) The loss for module 2 having long skip connections. (c) This plot shows loss for the third module having only short skip connections. (d) This represents the training and validation loss for proposed model. All modules including proposed model is converged at epoch 60.
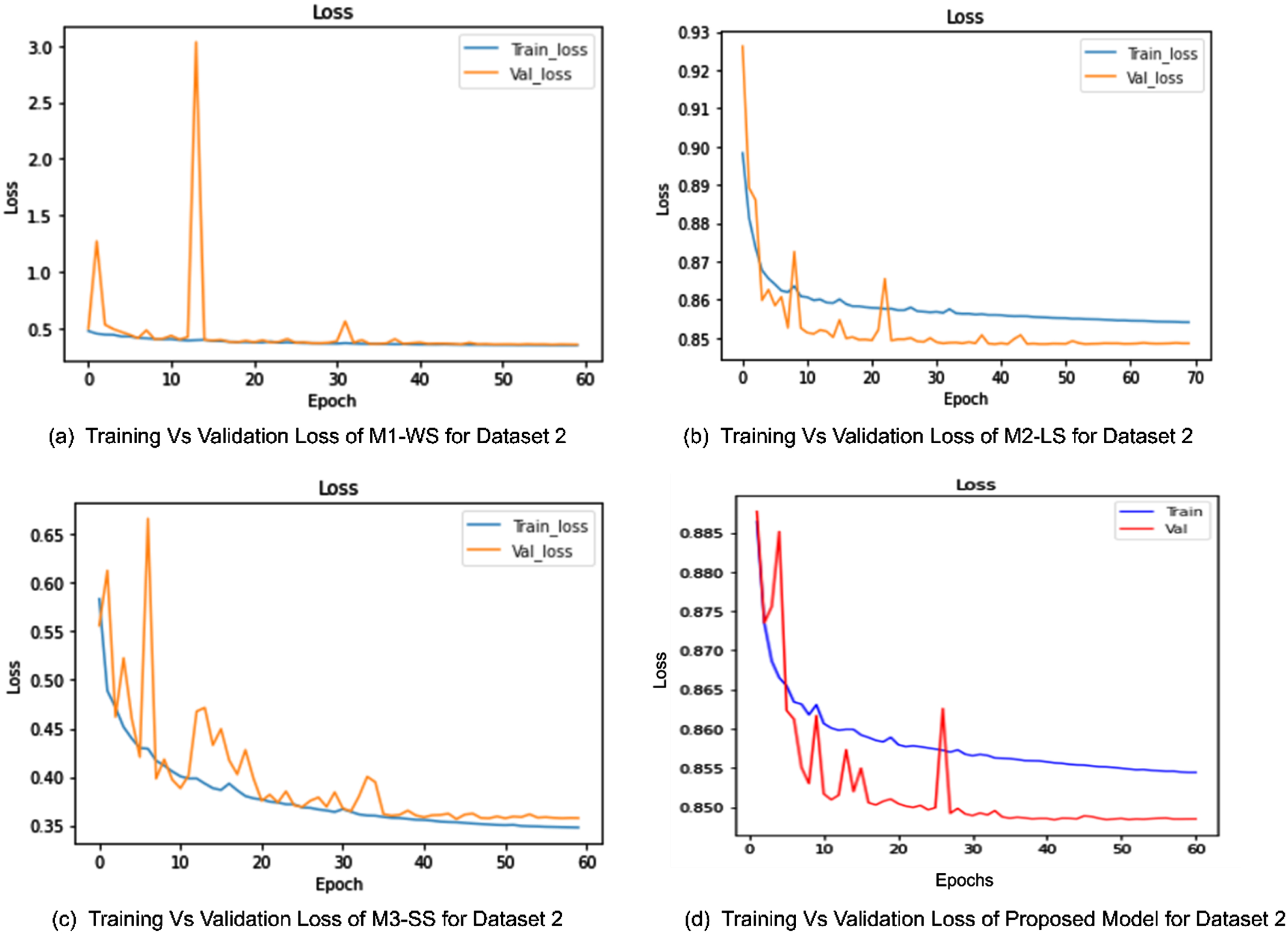
Training vs Validation loss for Dataset 2. (a) This plot represents the loss for first module with no skip connections. (b) The training and validation loss for second module having long skip connections is shown. (c) This plot shows loss for the third module having only short skip connections. (d) This represents the training and validation loss for proposed model. All modules including proposed model is converged at epoch 60.
M1-WS: Module1-Without Skip connections. The first module is composed of the encoder and decoder part of the presented deep network but there are no skip connections present, neither in an encoder nor from an encoder to decoder. M2-LS: Module2-Long Skip. This is the second module which consists of only long skip connections from an encoder to the decoder. M3-SS: Module3-Short Skip. The third module contains only short skip connections which are present in both conventional CNN stream and Atrous net stream of the encoder module.
The effectiveness of each model is represented by the quantitative results are shown in Tables 3 and 4 for dataset 1 and dataset 2 as well as by the qualitative results shown in Fig. 8 1 and for dataset Fig. 9 for dataset 2. It can be inferred that without any type of skip connections, the dice score and IoU are less as compared to a network having only long skip connections. Modules without skip and with short skip connections have similar results except for precision which is high for networks with only short-type skip connection. The long-type skip connection module has the highest recall. The proposed model which includes both short-type skip connection and long-type skip connection has performed superior to each individual module in all evaluation metrics. The visual results demonstrate the proposed model’s segmented teeth map has better visibility than other modules.
Ablation experiment comparison of different modules on Dataset 1
Ablation experiment comparison of different modules on Dataset 2
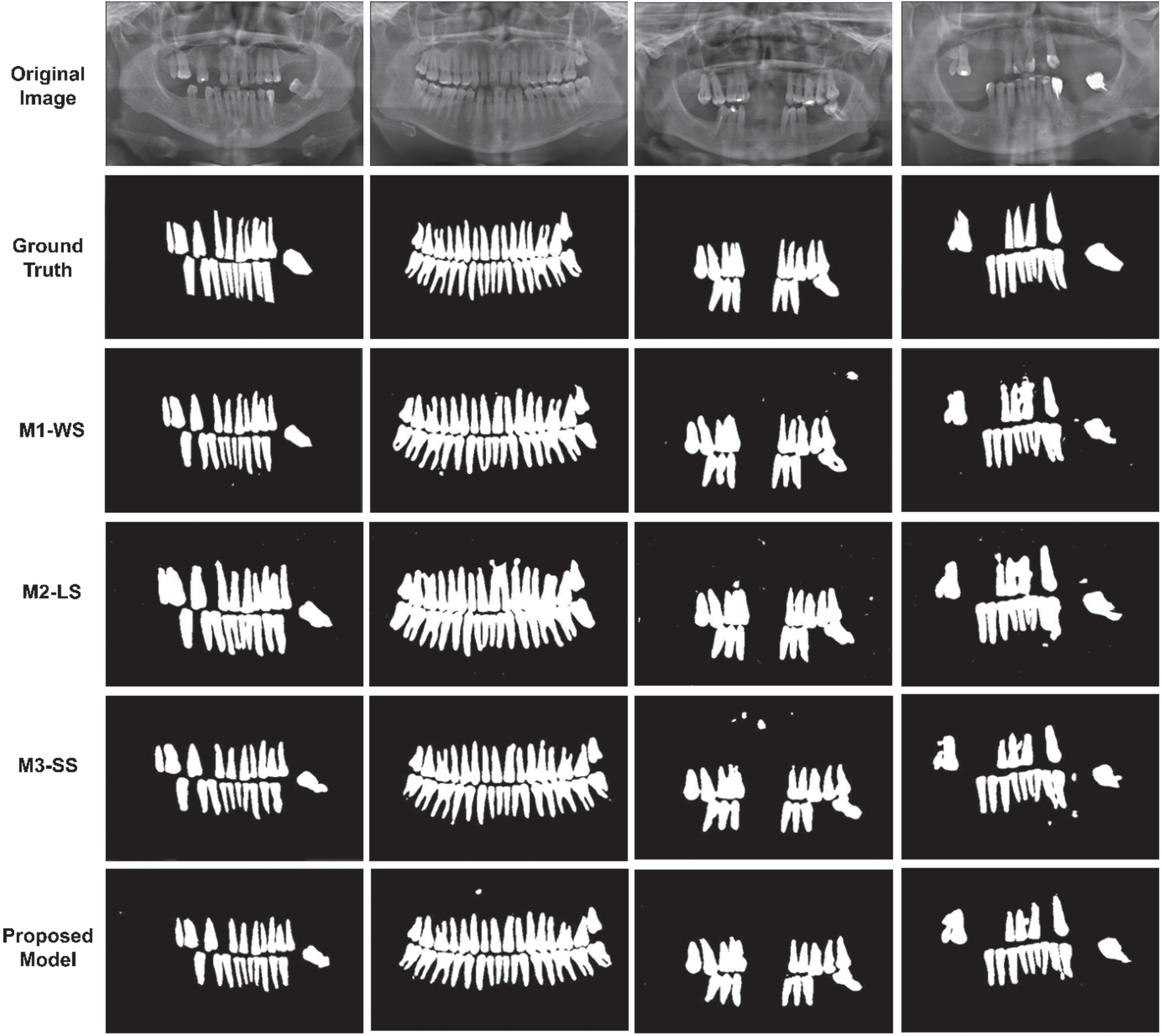
Comparison of visual results from ablation experiment on Dataset 1. The first two rows represent original image and its ground truth respectively. The next three rows demonstrate the predicted segmented map by different modules while the last row represents the predicted segmented map by proposed model.
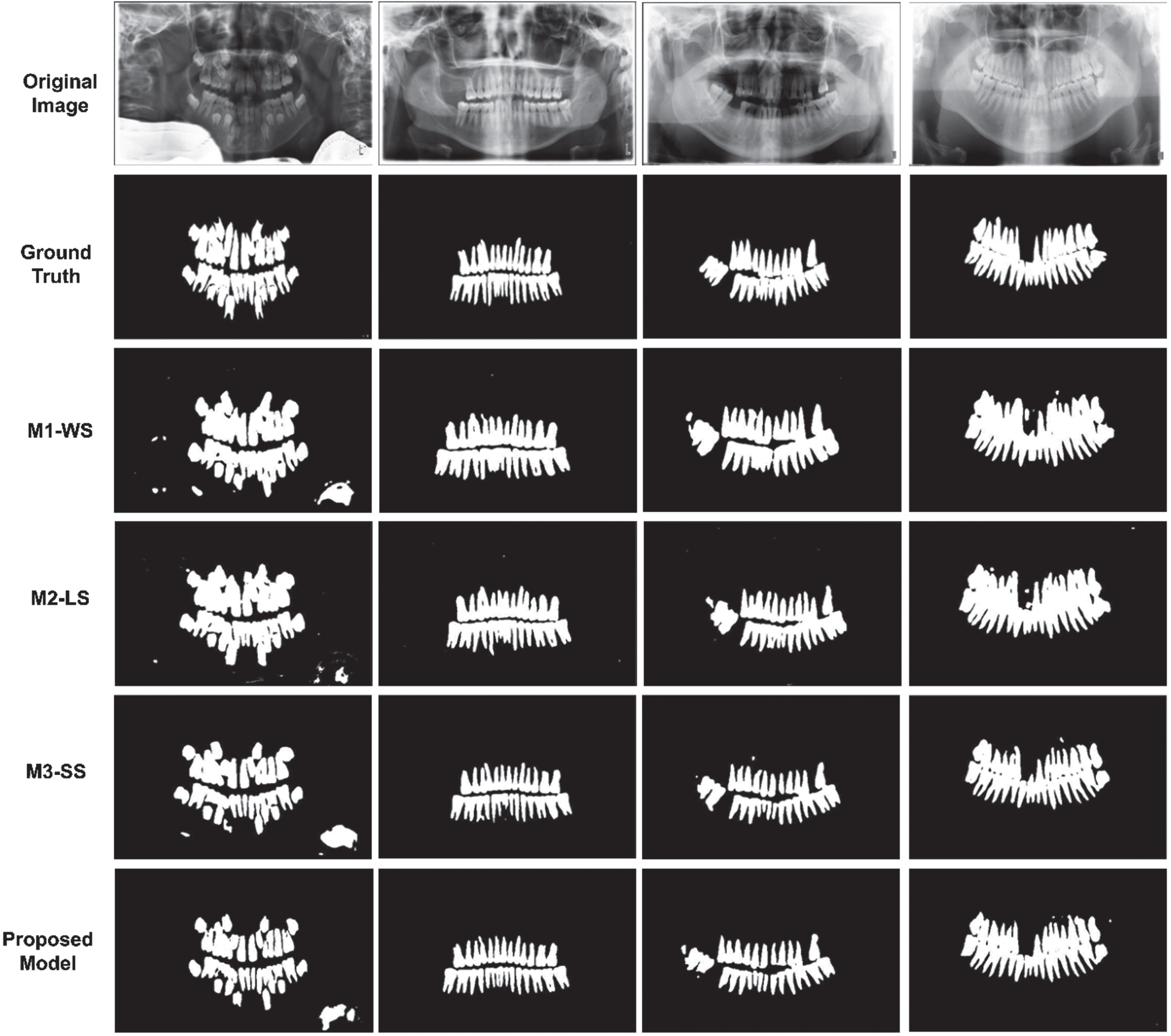
Comparison of visual results from ablation experiment on Dataset 2. The first two rows represent original image and its ground truth respectively. The next three rows show the predicted segmented map by different modules while the last row represents the predicted segmented map by proposed model.
The experiments with various loss settings are executed on the suggested model to assess the efficacy of the presented hybrid loss function. The comparison results for dataset 1 are shown Table 5 and for dataset 2 are shown in Table 6. It can be inferred that BCE loss has a higher performance in segmentation dice score, IoU and recall, and performs similarly to Dice loss in terms of segmented pixel accuracy while dice loss has a higher performance in terms of precision. When both the loss functions are joint to form the hybrid loss function there is a dramatic improvement in IoU and dice score.
Comparison of ablation study with different loss functions on Dataset 1
Comparison of ablation study with different loss functions on Dataset 2
This article proposed a novel multi-fusion deep model based on encoder-decoder structure to obtain clear and accurate teeth region segmented from dental panoramic radiographs. The encoder of proposed model comprised of two different CNN based architectures with fusion of features at each step for extracting diverse features and contextual rich information. The two types of skip connections were proposed in encoder and from encoder to decoder to regain dental features using different connections. The decoder is made-up of deconvolutional layers to restructure the image. The experiments were executed to demonstrate efficacy of the presented model on two different datasets. The results obtained shows that the presented model outperforms the state-of-the-art deep segmentation methods with requiring relatively a smaller number of trainable parameters. In future work, weaker boundaries of the tooth root would be determined and enhanced using attention networks.
Conflict of interest
The authors declare that they have no conflict of interest.