
Abstract
BACKGROUND:
Low dose computed tomography (LDCT) uses lower radiation dose, but the reconstructed images contain higher noise that can have negative impact in disease diagnosis. Although deep learning with the edge extraction operators reserves edge information well, only applying the edge extraction operators to input LDCT images does not yield overall satisfactory results.
OBJECTIVE:
To improve LDCT images quality, this study proposes and tests a dual edge extraction multi-scale attention mechanism convolution neural network (DEMACNN) based on a compound loss.
METHODS:
The network uses edge extraction operators to extract edge information from both the input images and the feature maps in the network, improving the utilization of the edge operators and retaining the images edge information. The feature enhancement block is constructed by fusing the attention mechanism and multi-scale module, enhancing effective information, while suppressing useless information. The residual learning method is used to learn the network, improving the performance of the network, and solving the problem of gradient disappearance. Except for the network structure, a compound loss function, which consists of the MSE loss, the proposed joint total variation loss, and the edge loss, is proposed to enhance the denoising ability of the network and reserve the edge of images.
RESULTS:
Compared with other advanced methods (REDCNN, CT-former and EDCNN), the proposed new network achieves the best PSNR and SSIM values in LDCT images of the abdomen, which are 33.3486 and 0.9104, respectively. In addition, the new network also performs well on head and chest image data.
CONCLUSION:
The experimental results demonstrate that the proposed new network structure and denoising algorithm not only effectively removes the noise in LDCT images, but also protects the edges and details of the images well.
Keywords
Introduction
Computed Tomography (CT) plays a very important role in modern medical diagnosis. However, the radiation hazards from the X-ray have attracted more and more people’s attention [1, 2]. The high dose radiation generated during CT scanning cause harm to the human body. Seriously, it even causes various cancers. Low dose CT (LDCT) technology is an effective method to reduce the radiation hazard to human body. As the radiation dose decreases, the quality of the reconstructed images decreases, with many artifacts and noise. Degraded images are not sufficient for clinical diagnosis [3–6].
In recent years, Convolutional neural network (CNN) has been verified to have good potential to solve the images denoising task and obtains better performance than most of the current traditional methods [7, 8]. Chen, et al. have proposed a fully connected CNN which maps LDCT images to corresponding normal dose CT (NDCT) images [9]. The denoising method has exceeded the traditional methods substantially, but the network has a problem of gradient disappearance. They have proposed an encoder-decoder convolutional network with residual connection (RED-CNN) [10]. By using the deconvolution network and fast connection, RED-CNN has solved the problem of gradient disappearance. Although RED-CNN has achieved good objective values, the denoised images are over-smoothed. Yang, et al. have proposed a generation adversarial network with Wasserstein distance and perception loss, which improves the phenomenon of images over-smooth [11]. Li, et al. have proposed an unpaired convolutional neural network for denoising low-dose CT images [12]. Park, et al. have used the improved U-net network to achieve end-to-end mapping between low- and high-resolution images [13]. Zhang, et al. have proposed a network based on dense connection and deconvolution (DD-Net), which uses fast connection to speed up the training speed of the network and improves the expressive ability of the network [14]. You, et al. have proposed a generation adversarial network based on cycle-consistency (GAN-Cycle), which strengthens the consistency between the output images and input images and finally recovers the high-resolution images from the LDCT images efficiently [15]. Wang, et al. have proposed a non-convolution visual transformer (CT-former) for LDCT images denoising which preserves the local context information well [16]. Liu, et al. have proposed a diffusion probabilistic prior for Low-Dose CT images Denoising, which is based on denoising diffusion probabilistic model - a powerful generative model [17], but the model does not perform well in preserving the edge information of the images.
In many previous research studies, edge information and attention mechanism have been verified to be useful to improve the performance of images processing tasks. Wang, et al. have proposed a ship images classification method by using edge extraction operators and multi-scale modules [18], improving classification accuracy. Woo, et al. have proposed a Convolutional Block Attention Module (CBAM) to improve the classification accuracy by using channel attention and spatial attention mechanisms [19]. Liang, et al. have proposed a dense connection network based on edge enhancement and a compound loss for low-dose CT denoising [20], which better preserves the edge information in the process of noise reduction. Luthra, et al. have proposed a visual transformer denoising network based on edge enhancement (E-former) [21], to enhance the edge information of the restored images to obtain higher quality images. However, these algorithms only perform edge extraction on the input images, ignoring the role of the feature map in the network training.
Inspired by the good performance of the edge operators in edge preservation and the success of multi-scale attention mechanisms in classification tasks, this paper proposes a dual edge extraction densely connected CNN network based on multi-scale attention mechanism for LDCT images denoising.
Materials and methods
Dataset and LDCT image noise description
In the experimental study, a dataset from the 2016 NIH AAPM-Mayo Clinic LDCT Challenge is used. It contains paired normal-dose CT (NDCT) images from 10 patients and synthesized one-quarter dose abdominal CT images, one-quarter dose head CT images, and one-tenth dose of chest images.
LDCT images denoising is seen as a mapping problem from LDCT images to NDCT images. Assuming z ∈ Rm×n represents a LDCT image and x ∈ Rm×n represents the corresponding NDCT image, z is expressed as:
The contributions of this paper are summarized as follows: The learnable edge convolutional operators with multiple directions are used to extract the edge from both the input images and the feature map obtained in the training process, which enable feature reuse and strengthen the edge information of the restored images.
The multi-scale module and attention module form a new module, named MA module. The MA module makes full use of the multi-scale information in images and focuses on important features. It reduces noise interference and improves the generalization ability of the model.
The residual noise learning method is used for training network, which improves the performance of the network and avoids the disappearance of gradient. The corresponding experiments have been implemented in this paper to prove that the residual learning method is superior to the traditional learning method for medical images denoising.
A new compound loss function which is composed of MSE loss, a total variation based joint loss and edge loss is introduced in the training stage. By using the proposed loss function, the denoising ability and edge preservation ability of the network are further improved.
Edge information is helpful to preserve details and edges in images denoising task [22]. Due to its good performance in edge detection, the learnable Sobel operators are used as edge extraction block in the proposed network. As shown in Fig. 1(a), the Sobel operators have four sub-templates with four directions including 0°, 90°, 45° and 135°. A learnable factor α is designed to control edge extraction intensity, which is more flexible and applicable compared with the traditional Sobel operators with fixed parameters.
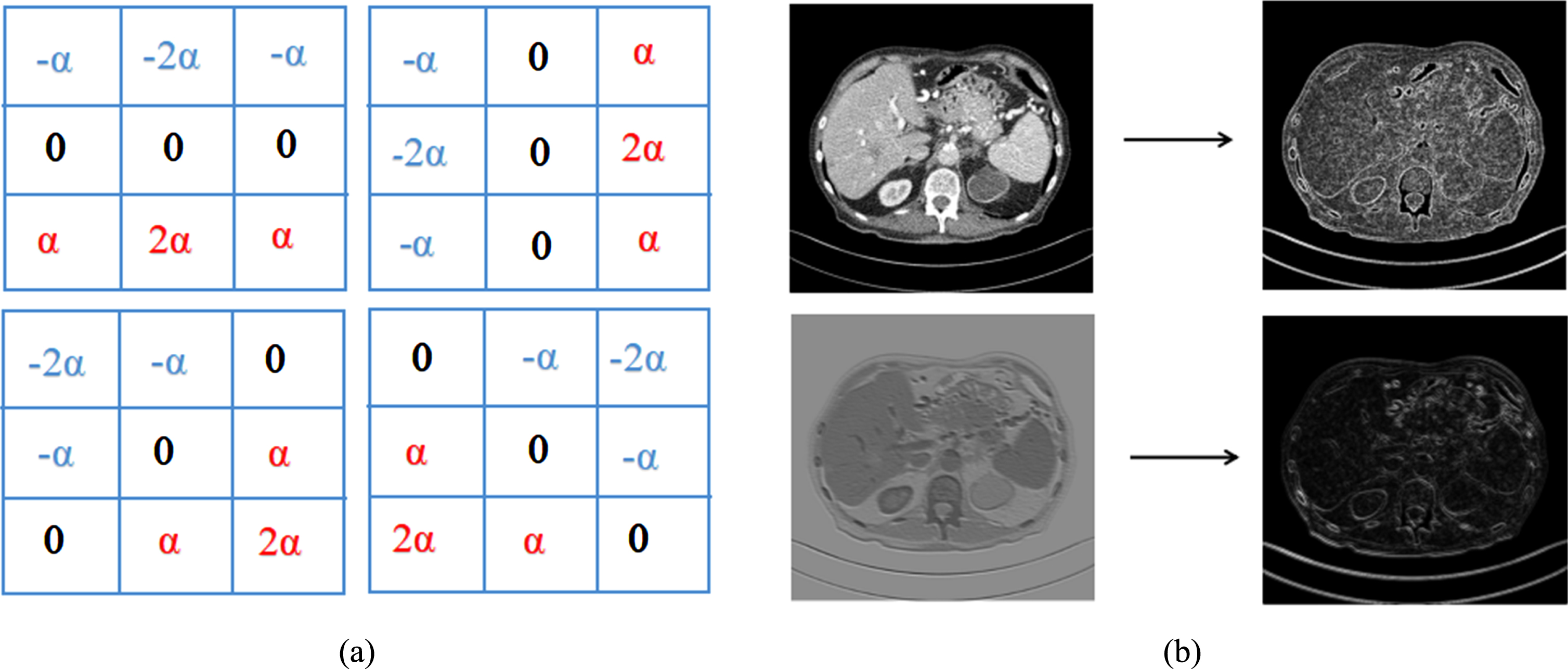
(a) Four different sets of Sobel operators (b) An example of edge extraction from the input image and the feature map, respectively.
Different from other methods, in this paper the edge information is extracted by using the learnable Sobel operators not only from the input images, but also from the feature maps obtained in the network. To better illustrate our point of view, the visualization results of edge extraction on the input images and the feature maps are shown in Fig. 1(b). The top one is the result after edge extraction of LDCT image and the bottom one is from the feature map obtained after four 3 × 3 convolutions. In Fig. 1(b) we see that after the edge extraction of the feature map, the edge information of the image is still available and contains less noise. In other words, the edge features obtained from the feature maps not only contain the edge information of the original images, but also can resist noise compared to the edge features of the original images. Therefore, the edge information is better utilized by fusing with the edges of the original images and the edges of feature maps. The edges of the denoised images are better preserved.
To verify our idea, the actual thoracic phantom is used for experiments. The results are shown in Fig. 2 as shown below. In the left column, from top to bottom, the images are NDCT images, LDCT images and the feature maps extracted from the low-dose images (the output of the fourth convolutional layer), respectively. The images in the right column are the corresponding edge images extracted from the left column. From Fig. 2, in the LDCT images, there are lots of artifacts and noise compared to the NDCT images. In addition, we see that the edge images extracted from the LDCT images are severely disturbed by noise, whereas the edge images extracted from the feature maps not only contain the edge information like the one of NDCT images, but also contain less noise than the edge information of LDCT images.

Results of edge extraction on the modal image.
The MA module is composed of multi-scale module and attention module. By combing the advantages of spatial attention, channel attention and multi-scale features, the MA module increases the ability of the network to extract features and enables the network to focus on the important information of the images.
Multi-scale module
In general, the performance of CNN is improved by increasing the convolution layers. However, the network parameters increase greatly, and the gradient disappearance phenomenon is prone to occur [23, 24]. In addition, when the training data set is small, the trained network is likely to over-fit. Muti-scale network architecture alleviates the above-mentioned problems to a large extent [25]. Inspired by [26], the multi-scale module designed in this paper is shown in Fig. 3.
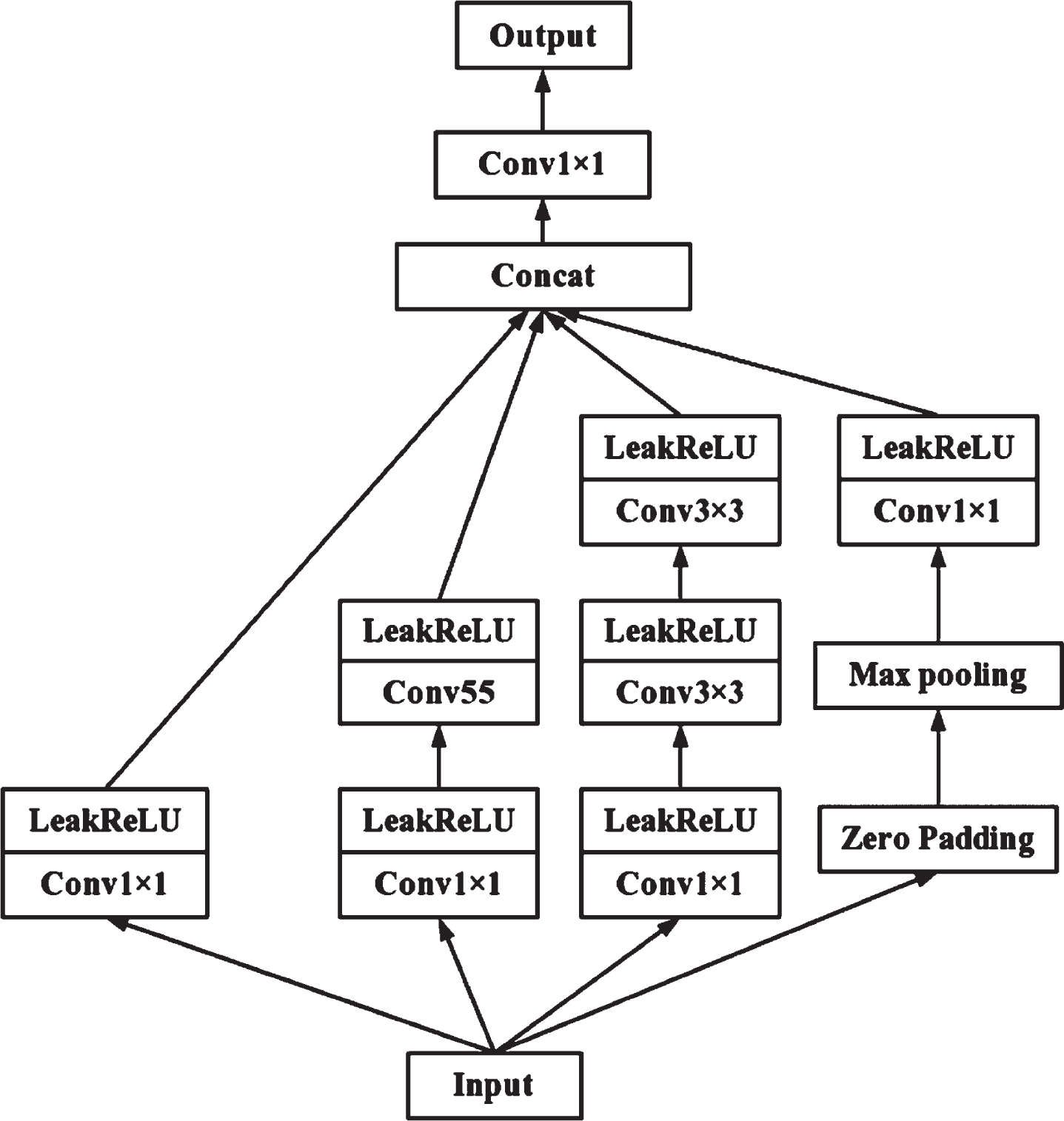
Multi-scale module designed in this paper.
Each convolution layer is activated by the LeakReLU layer to maintain non-linearity. For the rightmost branch, a zero-padding operation is performed on the input images before pooling to ensure that the pooled result matches the output size of the other three convolutional layers. The convolution kernel of different sizes is combined to improve the feature extraction ability of the network. In addition, each path uses a 1 × 1 convolution kernel for reducing the number of parameters and avoiding the problem of excessive computation.
In general, the attention mechanism of deep learning selects a small amount of important information from many available data and focuses on important details. It suppresses unimportant information to improve network performance. CBAM is a simple and effective attention module. Given an intermediate feature map, the CBAM module infers the attention map sequentially along two independent dimensions (channel and space) and multiplies the attention map with the input feature map for feature optimization. Referring to [19], the attention model shown in Figs. 4 5 is adopted.
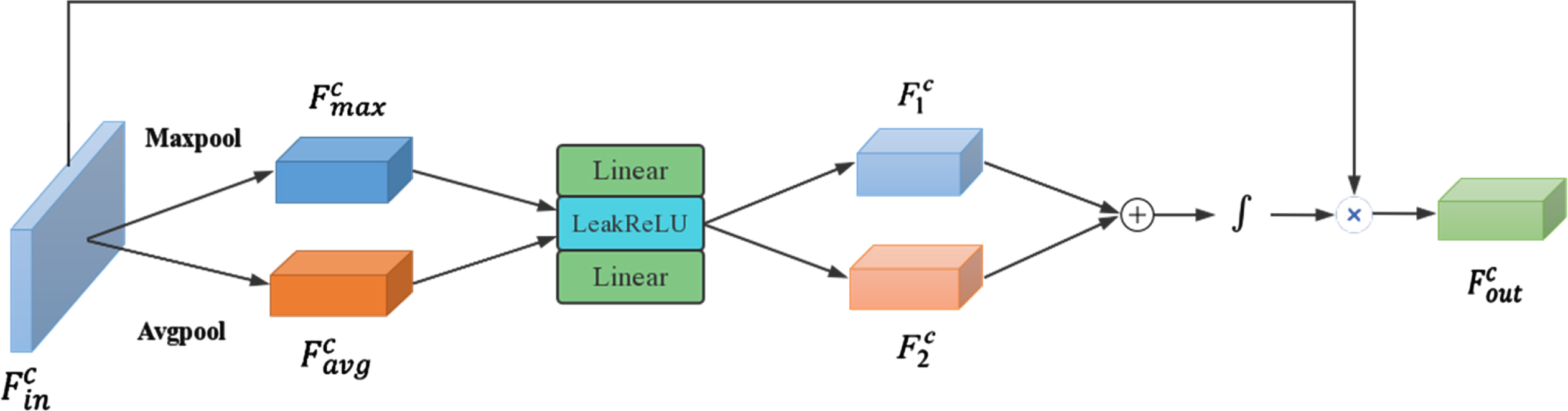
Channel attention network structure.
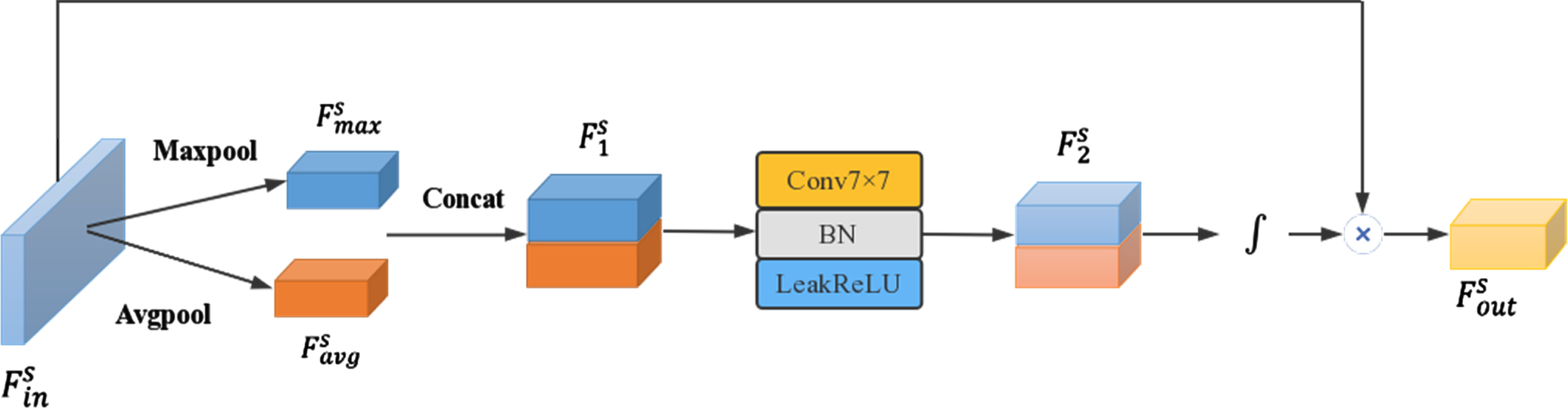
Spatial attention network structure.
The main purpose of the channel attention module is to pay more attention to the effective feature channel of the network. Through the average pooling layer and the maximum pooling layer, the input features
The spatial attention module uses the spatial relationship between features to focus on the information of features. Therefore, the spatial attention module is a supplement to the channel attention module. The input feature
According to formula 6, the spatial attention feature
Deep neural networks lead to gradient problems, training difficulties, degradation of network performance, and waste of resources [27–29]. Residual learning solves the problem of deep network degradation and improves the convergence speed of the network [30, 31]. The goal of residual learning is to implicitly remove latent clean images in the hidden layer. Input a noise image x = y + v into our network, here x is the noise image. In our paper, it is an LDCT image. y is true value and is residual noise. Our network does not directly output the denoised image
In contrast, residual noise learning typically uses residual connections in a single network to learn residual noise representations. Residual noise learning focuses on learning residual noise representations to improve denoising performance effectively. To verify the effectiveness of residual learning in medical images denoising, the paper also compares it with deterministic learning, which is described in the experiments part.
The proposed network architecture
Overall, a dual edge extraction densely connected CNN network based multi-scale attention model (DEMACNN) is proposed for LDCT images denoising. The architecture of the proposed network is shown in Fig. 6.
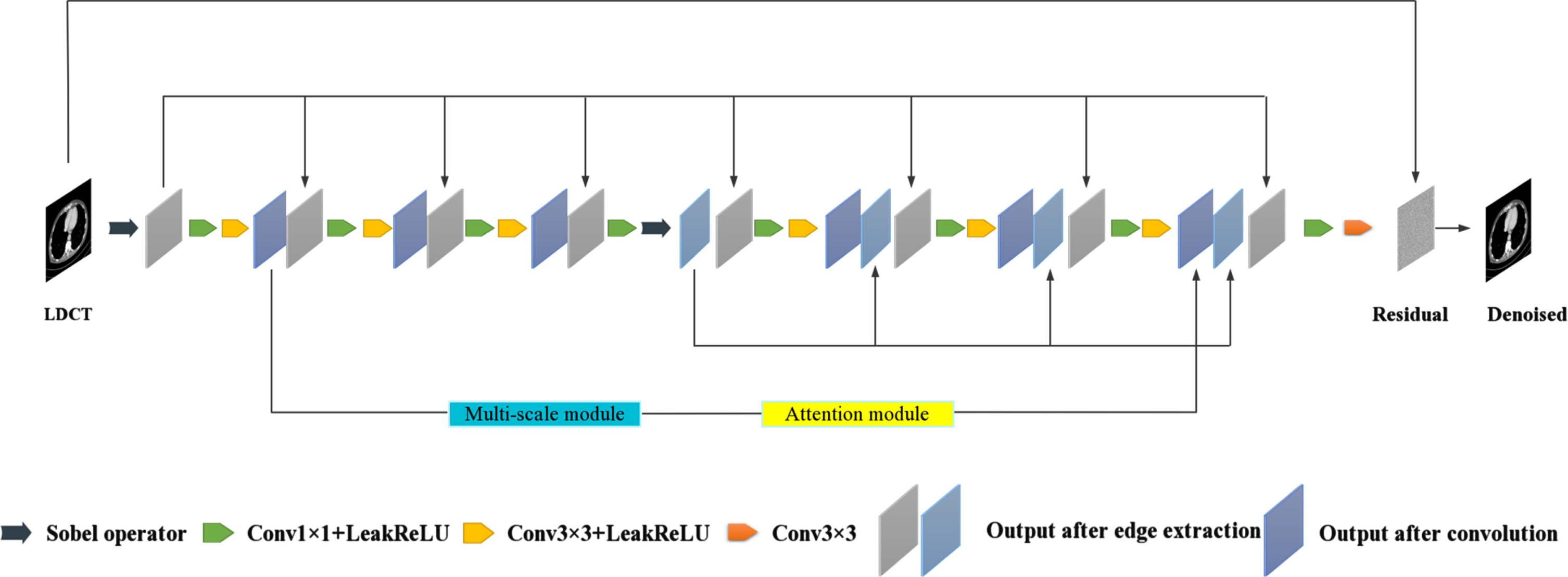
Proposed overall network architecture.
The trainable Sobel operators are used for both the input images and the feature maps. The number of trainable Sobel operators is 32. In the network, dense connections are used to make full use of the extracted edge information and original input [34]. Specifically, as shown in Fig. 6, we convey the output of the Sobel operators to each convolution block through skip connection and concatenate them in the channel dimension. Except for the last layer, the convolutional layer consists of convolutional kernels of size 1 × 1 and 3 × 3, and the number of convolutional filters is all set to 32.
In the last layer, the number of 3 × 3 convolutional filter is 1 for obtaining the output of a single channel. The activation function is LeakReLU. In each block, the output of the previous layer and the output of Sobel operators are fused using convolution with a 1 × 1 kernel, and features in the images are typically learned using convolution with a 3 × 3 kernel. The MA module, which integrates a multi-scale module and an attention module, is to increase the depth of the network and obtain more effective information. We import the result of the first 3 × 3 convolutional layer into the MA module and fuse the output of MA module with the result of the sixth 3 × 3 convolutional layer. In addition, to keep the output size the same as the input size, we pad the feature mapping in the model to ensure that the space size does not change during forward propagation. The predictable result of the network is the residual noise and the final denoising image is obtained by connecting the residuals.
Mean-square error (MSE) is a loss function, and it is widely used in various deep learning methods, which calculates the average of the squared differences between the predicted and true values. It is expressed as:
Although wildly used in images restoration tasks, MSE loss has some disadvantages. For example, the evaluation index of MSE has no good correlation with the subjective perception of the images. Because it considers the average values and does not consider the influence of some significant features.
This paper introduced a joint total variation loss function which is better representation the sparsity of images and an edge loss function which well considers high-frequency texture structure information and improves images detail performance.
The joint total variation loss is constructed based on the total variation loss (TV Loss), which shows the advanced performance in improving images sparsity and reducing noise in the image’s restoration task [35, 36]. The proposed joint constraint loss L
JTV
is defined as:
To determine the weighting parameter factor τ in the joint total variation loss function, we select the parameter τ from {0, 0.1, 0.3, 0.5, 1.0}. The results of the experiment are shown in Fig. 7. The results show that the weighting parameter τ= 0.5 achieves the lowest loss, which is used in following experiments, and the two components of the joint total variation loss the two components of the joint total variation loss need to be jointly minimized under a bidirectional constraint.
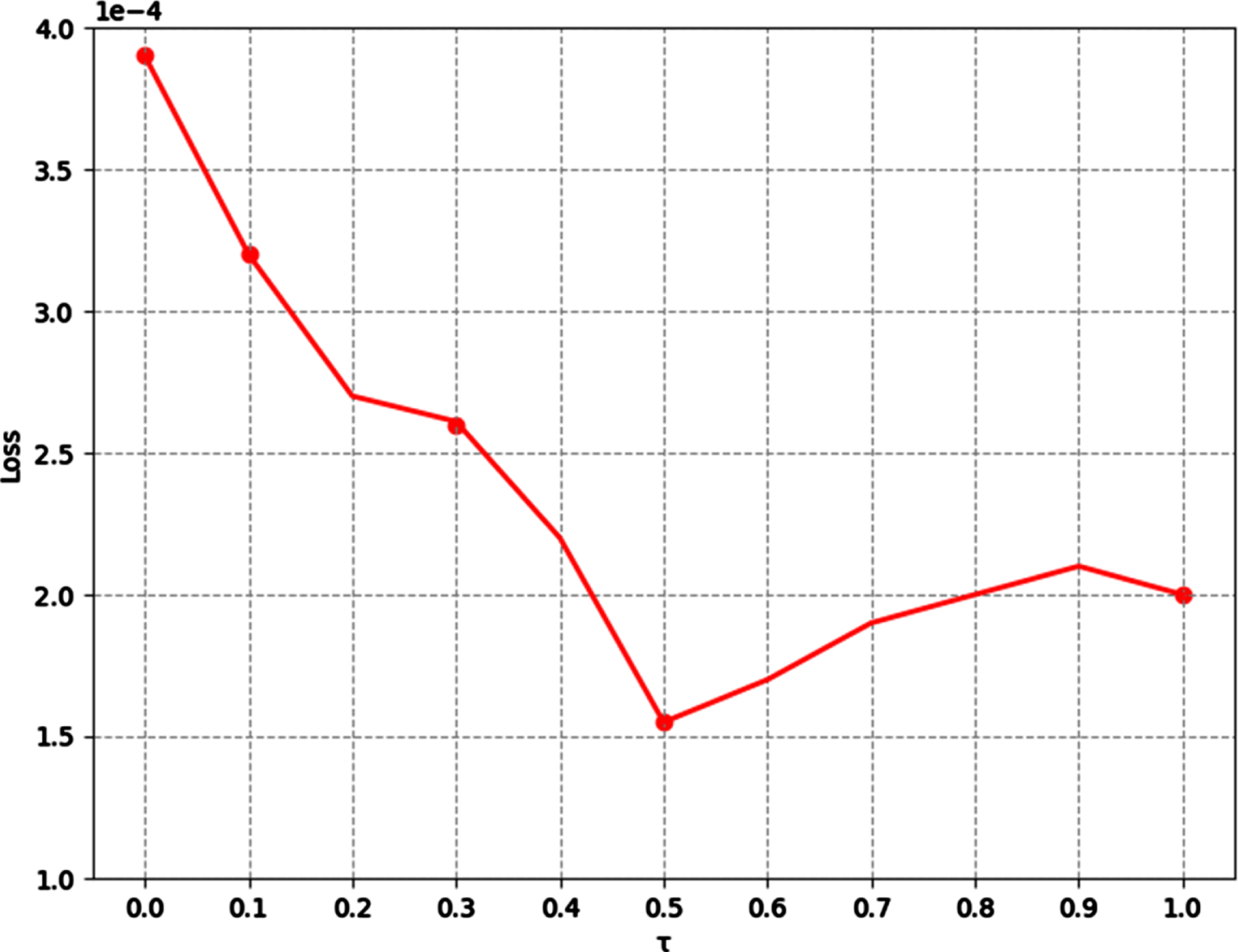
The effect of parameter τ on training loss.
The edge loss function is expressed as follows:
Finally, our network is fine-tuned end-to-end to minimize the following objective functions:
Similarly, we select the parameter β1, β2 from {0, 0.05, 0.1 0.2, 0.3, 0.4, 0.5}. The results of the experiment are shown in Fig. 8, which shows that for the joint total variation loss, the lowest loss is obtained when β1= 0.1, while for the edge loss, the lowest loss is obtained when β2= 0.05, which is used in following experiments.
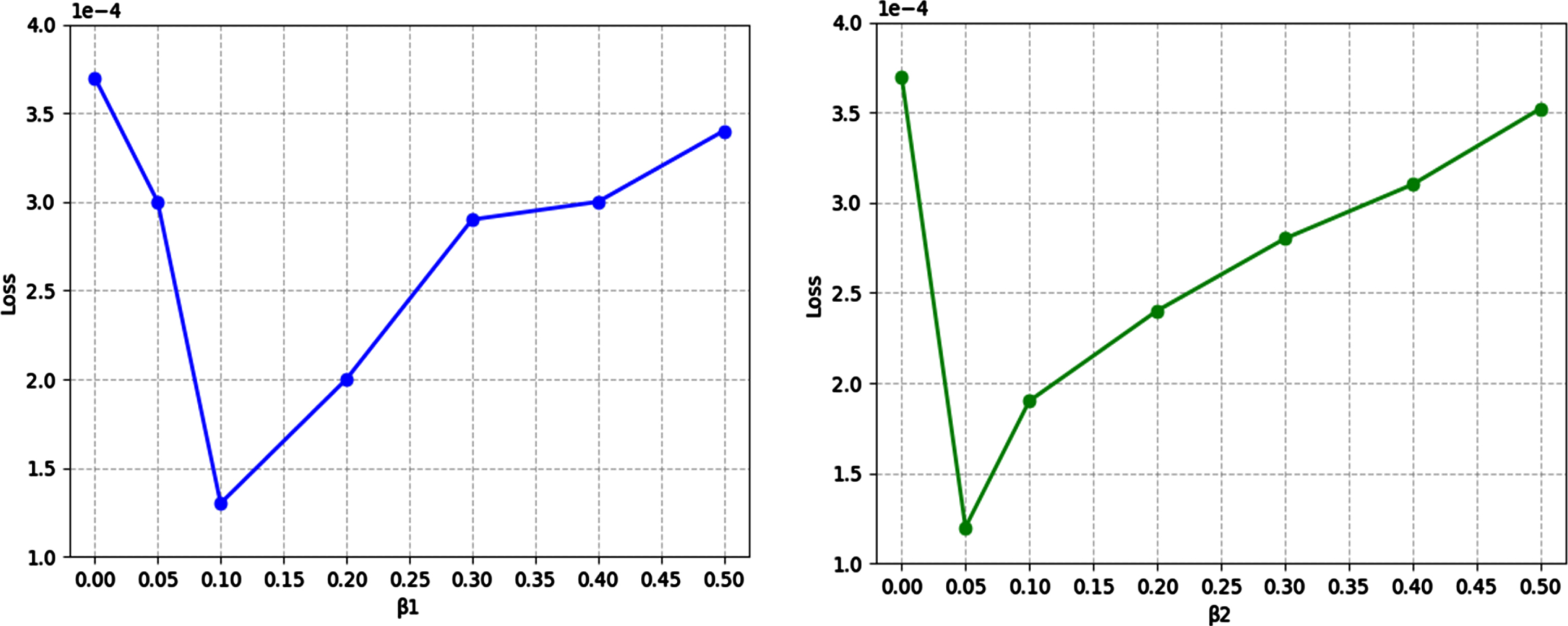
The effect of parameter β1, β2 on training loss.
Experimental data
The number of slices in the data set is 2080. The size of image is 512 × 512. The network uses the supervised training process. In terms of data preparation, this paper uses a k-fold cross-validation approach to train and test the network. First, the data from 10 patients are randomly disrupted to avoid the effect of data order on cross-validation. Then, the data set is divided into k = 5 copies. For each k, select the k-th copy as the test set and the remaining k-1 copies as the training set. Therefore, the number of training sets in this paper is 1664 and the number of test sets is 416. This paper uses the training set to train the model and uses the test set to evaluate the performance of the model. Repeat until each k has been used as a test set. The mean value of k cross-validation results is calculated as the result of all model performance evaluation.
Experimental setup
This paper is based on the implementation of the Pytorch framework. The convolution layer in this model uses the default random initialization and the Sobel operators of all edge extraction modules are initialized to 1 before training. Conclusion based on section 3.5, the τ in the loss function L JTV is set to 0.5. The joint variation coefficient β1 in the overall loss function defined in formula (10) is 0.1 and the edge loss coefficient β2 is 0.05. In the optimization process, the default configuration of the Adam optimizer is used. Batch size is 16 and the Epoch is 200. In this paper, the initial learning rate is set to 0.0001, and a learning rate decay factor γ= 0.5 is defined, which means that during the training process, the learning rate decreases to half of the original one after every 3000 iterations. When testing the model, use the 64 × 64 LDCT images as the input and directly output the denoising results. The running environment is Pytorch 1.11, Windows 10, CUDA11.3, NVIDA GeForce RTX 3080GPU.
Experimental results
This section shows the experimental results. Three related algorithms including REDCNN, CT-former and EDCNN are used for comparison. In this paper, the objective indicators of the four models are calculated by using Peak Signal to Noise Ratio (PSNR), Structural Similarity (SSIM) and Root Mean Square Error (RMSE). The unit of PSNR is dB. A higher PSNR value means better image denoising effect. Higher SSIM value means higher similarity between the denoised image and the NDCT image. RMSE value represents the error between the denoised image and the NDCT image. The smaller the RMSE value, the better the quality of the recovered image.
Objective comparison results of these methods are shown in Table 1 3(including the abdomen, head, and chest datasets). In this paper, objective indicators are calculated as the average of five cross-validation results. Figure 9 shows the results of our five cross-validation, from which it is seen that the results of the five tests are similar. The difference between the highest PSNR value and the lowest PSNR value is about 0.26, the difference between the highest SSIM value and the lowest SSIM value is about 0.0033, and the difference between the highest RMSE value and the lowest RMSE value is about 0.3. The LDCT represents the original input image, which contains lots of artifacts and noise. In Tables 2 6, LDCT represents the same meaning. It is seen that the proposed DEMACNN model obtains the two highest values compared with other related models in Table 1. The proposed DEMACNN models obtain the highest average SSIM value and the second highest average PSNR value compared to other related models in Tables 2 3. In addition, when adding the residual learning to the DEMACNN, the performance of the proposed network is further improved, and the objective values are improved. It indicates that the proposed DEMACNN algorithm shows more proficiency in LDCT image denoising.
Comparison of the mean value of objective indicators of different models in after five cross-validations(abdomen)
Comparison of the mean value of objective indicators of different models in after five cross-validations(abdomen)
Comparison of the mean value of objective indicators of different models after five cross-validations(head)
Comparison of the mean value of objective indicators of different models after five cross-validations(chest)

Results of the cross-validation test for DEMACNN+residual.
Performance comparison on model structure
Model Structure Performance Comparison in RENDCNN
Research on the number of MA blocks
The denoising abdominal, head and chest results of various algorithms are shown in Figs. 10 12. In order to observe the details of the image more clearly, the region of interest which is marked in the red box in Figs. 10(a1)-(f1) 12(a1)-(f1) is enlarged. We also label the objective indicators for the denoising results of each method in Figs. 10 12.
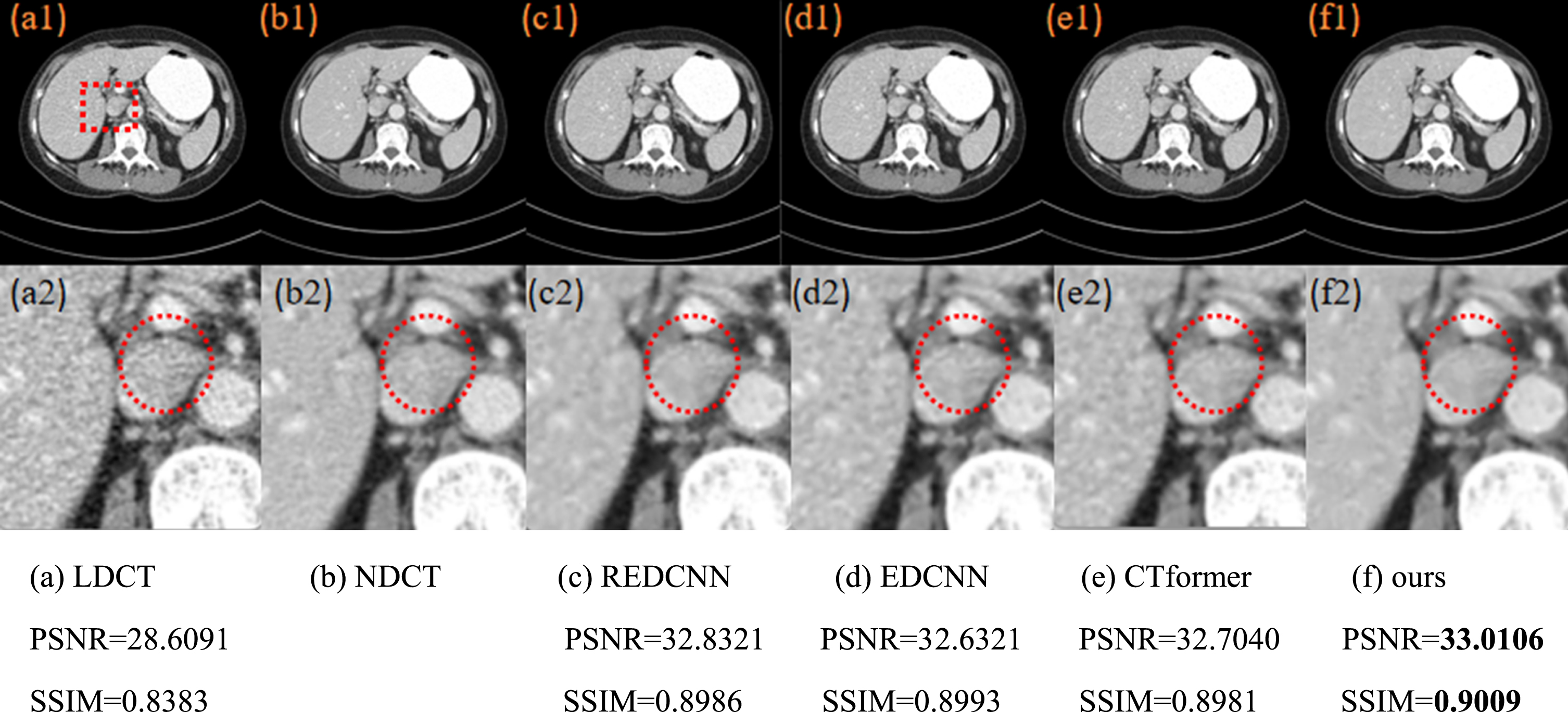
The denoising results of different models in abdomen images and the region of interest (ROI) in the red box is enlarged.
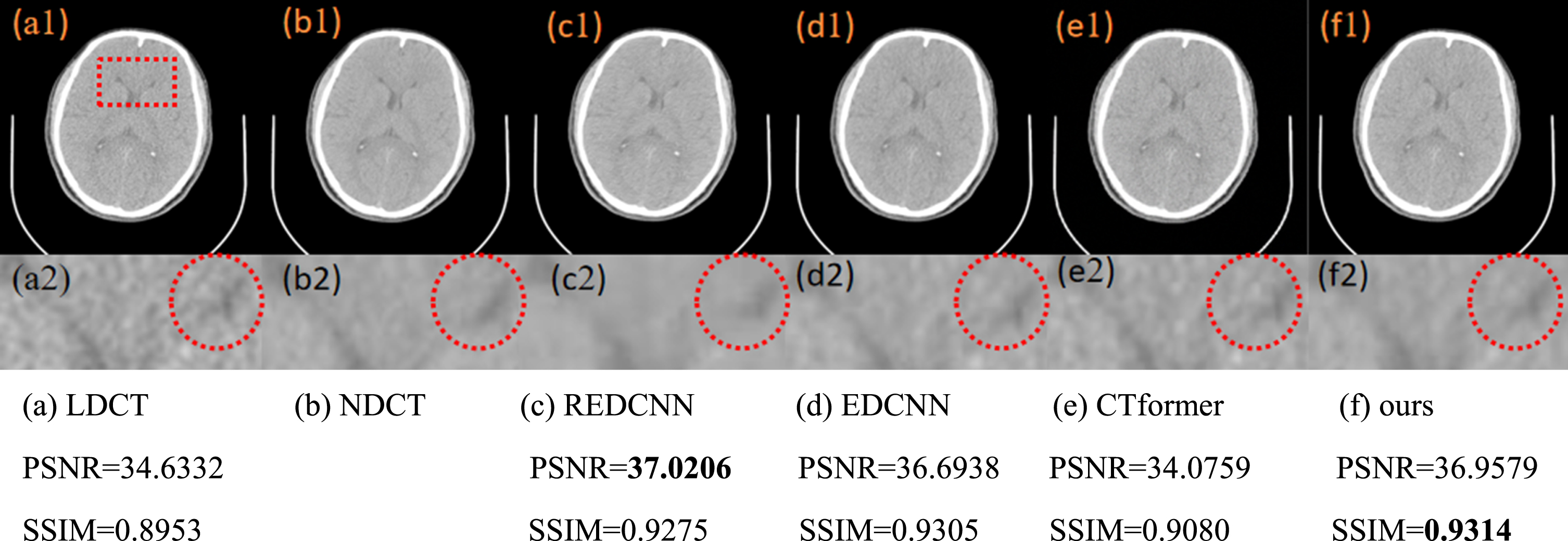
The denoising results of different models in head images and the region of interest (ROI) in the red box is enlarged.
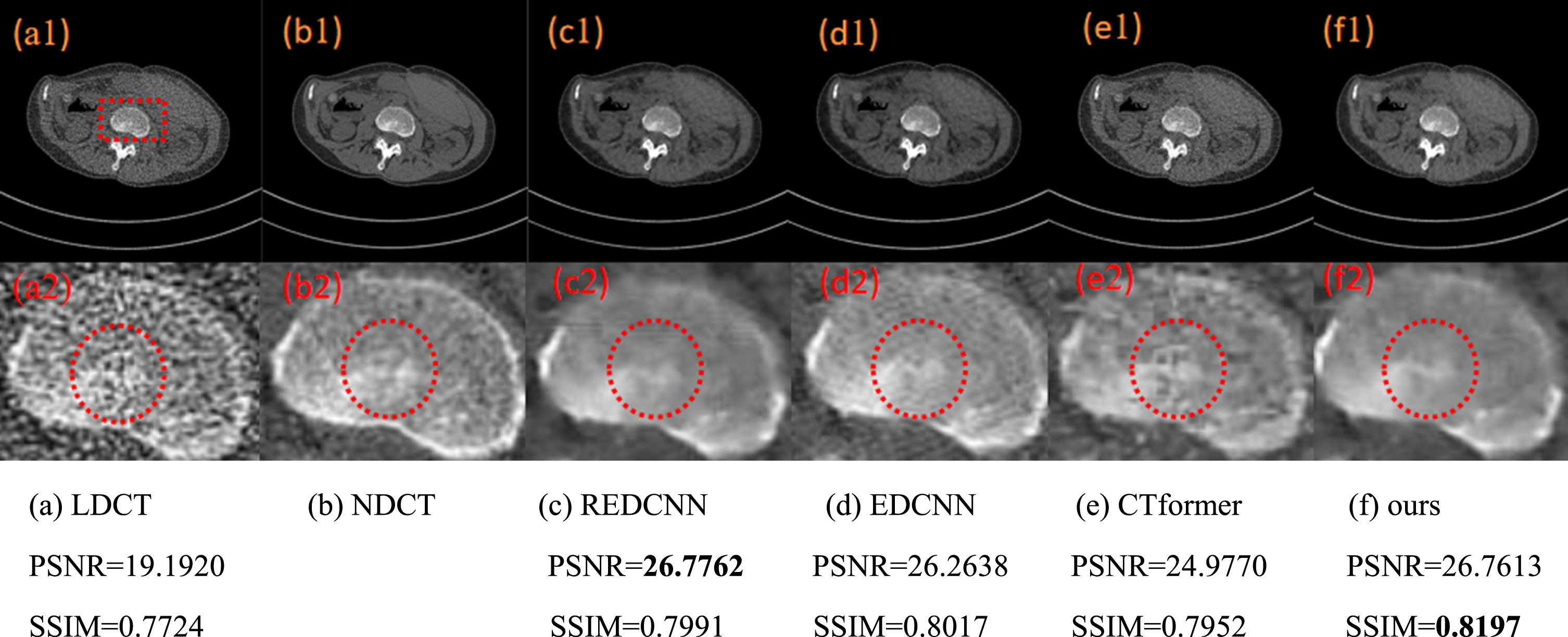
The denoising results of different models in chest images and the region of interest (ROI) in the red box is enlarged.
Figure 10(a) is the abdomen LDCT image and Fig. 10(b) is the corresponding NDCT image. Figure 10(c1)-(f1) are the denoising results of REDCNN, EDCNN, CT-former and the proposed method respectively. It is seen that there are more noises in Fig. 10(a2) than Fig. 10(b2). It is seen from Fig. 10(c1) and 10(c2) that REDCNN removes the noise well, but the edges and details of the image are blurred. The edge information of Fig. 10(d2) and 10(e2) are well preserved but there are still residual noises. In Fig. 10(f2), we see that the proposed algorithm strikes a better balance between noise removal and edge preservation. In the region marked by the red circle the edge of our method is much closer to the NDCT image. The edge of other methods is much closer to the one of LDCT image, in which the image edge is disturbed by noise. It is also seen from the objective indicators that the proposed method achieves a PSNR value of 33.0106 and a SSIM value of 0.9009, both of which are better than the compared methods.
Figure 11(a) shows the head LDCT image and Fig. 11(b) shows the corresponding NDCT image. Figure 11(c1)-(f1) show the denoising results of REDCNN, EDCNN, CT-former and the proposed method in this paper, respectively. It is seen that there are more noises in Fig. 11(a2) than in Fig. 11(b2). From Fig. 11(c1) and 11(c2), it is seen that REDCNN removes the noise well, but the edges and details of the image are over-smoothing. Figure 11(d2) has better preservation of edge information, but there is still residual noise. In Fig. 11(e2), there are more noises into the image in CTformer, making it difficult to distinguish the density distribution of this tissue. In Fig. 11(f2), we see that the proposed algorithm strikes a better balance between noise removal and edge preservation. In the region marked by the red circle the edge and detail of our method is much closer to the NDCT image. It is also seen from the objective indicators that the proposed method achieves the second best PSNR value of 36.9579 and the best SSIM value of 0.9314.
Figure 12(a) shows the chest LDCT image and Fig. 12(b) shows the corresponding NDCT image. Figure 12(c1)-(f1) show the denoising results of REDCNN, EDCNN, CT-former and the proposed method in this paper, respectively. It is seen that there are more noises in Fig. 12(a2) than 12(b2). From Fig. 12(c1) and 12(c2), it is seen that REDCNN is better, however, there is obvious over-smoothing phenomenon at the edges. CTformer has obvious residual noise. EDCNN and the proposed DEMACNN are effective in recovering the details and overall structure, and DEMACNN performs better than EDCNN in suppressing artifacts. It is also seen from the objective indicators that the proposed method achieves the second best PSNR value of 26.7613 and the best SSIM value of 0.8197.
In this section, we compare and analyze the performance of our model under different structures and loss function configurations.
Network structure
To explore the influence of each part in the DEMACNN model, a decomposition experiment on its structure is carried out in this section. For the convenience of description, we define six networks’ abbreviations bellow. BCNN: A basic network which removes the MA module and the two edge extraction modules from the structure shown in Fig. 6 and uses MSE loss to guide network training. TEI: TEI module refers to the edge extraction of the input images using the traditional Sobel operators with fixed parameters. TEF: TEF module refers to the edge extraction of the feature maps by using the traditional Sobel operators with fixed parameters. EI: The EI module refers to using the learnable Sobel edge operators to extract the edge of the images. EF: The EF module refers to using the learnable Sobel edge operators to extract the edge of the feature maps. BCNN+TEI: A network by adding the TEI module to BCNN. BCNN+TEI+TEF: A network by adding the TEI and TEF module to BCNN. BCNN+EI: A network by adding the EI module to BCNN. BCNN+EI+EF: A network by adding the EI module and EF module to BCNN. BCNN+EI+EF+MA: The proposed network DEMACNN, which is constructed by adding EI module, EF module and MA module to BCNN.
Table 4 shows the PSNR, SSIM and RMSE values of the six networks mentioned above. From Table 4, it is seen that as TEI, TEF, EI, EF and MA modules are added sequentially to the base network BCNN, the objective indicators values increase sequentially and BCNN+EI+EF+MA (DEMACNN) obtains the highest PSNR, SSIM values and it has the lowest RMSE values. Table 4 also shows that the learnable Sobel edge operators achieve better results than traditional Sobel operators. This demonstrates that the learnable edge operators used in this paper perform better than the traditional edge operators.
Figure 13 shows the curves of PSNR values changing with the number of iteration epoch under BCNN, BCNN+EI, BCNN+EI+EF, BCNN+EI+EF+MA(DEMACNN) structures. It is worth noting that the PSNR values increase continuously by adding the EI module, EF module and MA module. In addition, the EI module, EF module and MA module accelerate the convergence process of the model.
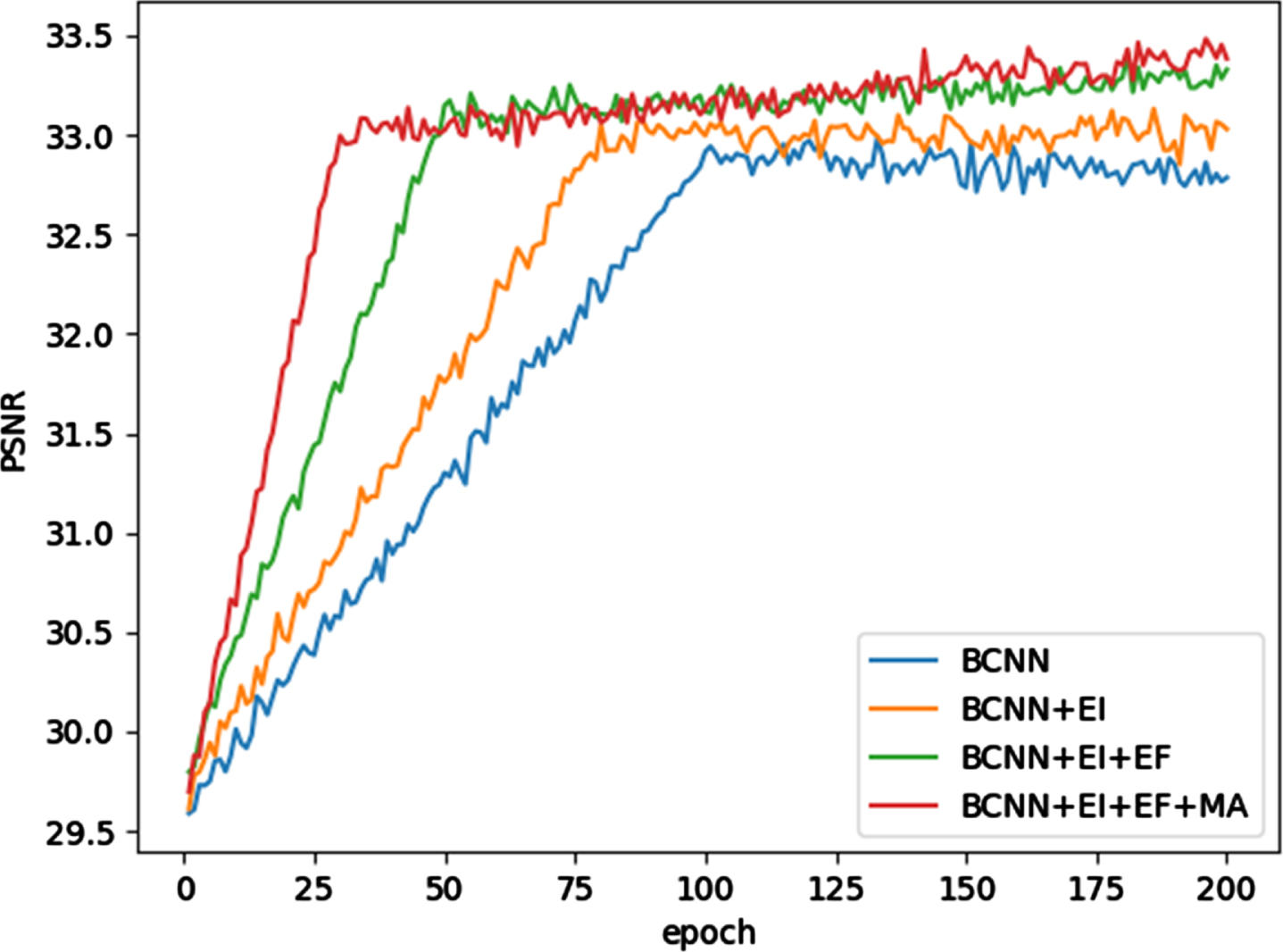
The PSNR curves in the training process.
The classic REDCNN network is used to further verify the effectiveness and generalization of the various modules in our network. We perform the EI, EF, and MA module on the REDCNN network, and the results are shown in Table 5 below, which shows that after adding the EI module, EF module and MA module sequentially to the REDCNN network, the values of the objective indicators obtained also increase sequentially, which proves the effectiveness and generalization of the three modules.
In addition, this paper explores the impact of the number of MA modules on the network. Based on the BCNN model, this paper adds MA modules between the output of the first 3 × 3 convolution kernel and the output of the sixth 3 × 3 convolution kernel (BCNN+MA). Based on BCNN+MA, adds a MA module between the output of the second 3 × 3 convolution kernel and the output of the fifth 3 × 3 convolution kernel (BCNN+2MA). Then, based on (BCNN+2MA), adds a MA module between the output of the third 3 × 3 convolution kernel and the output of the fourth 3 × 3 convolution kernel (BCNN+3MA). The results are shown in Table 6.
The objective denoising results of different networks including BCNN, BCNN+MA, BCNN+2MA and BCNN+3MA are shown in Table 6. It is seen that with the increase of MA modules, the performance of the network is declining. It is best to add only one MA block between the outputs of the first and the sixth convolution kernel. Moreover, adding one MA module to the BCNN network has fewer parameters than adding multiple MA modules, making the proposed network easier to train. Therefore, this paper adds one MA module.
To prove the effectiveness of our loss function, in this section the MSE loss, the edge loss (eloss) and the ResNet50 perception loss (Res50) are used for comparison. For the convenience of description, we define the following symbolic representations. MSE: Use the MSE loss function to guide the proposed DEMACNN network. MSE+Res50: Use the MSE loss function and the ResNet50 perception loss to guide the proposed DEMACNN network. MSE+eloss: Use the MSE loss function and edge loss function to guide the proposed DEMACNN network. MSE+TV+eloss: Use the MSE loss function, traditional total variation loss function and edge loss function to guide the proposed DEMACNN network. MSE+JTV+eloss: Use the proposed loss function which is defined in formula (10) to guide the proposed DEMACNN network.
The denoising results of the proposed DEMACNN network by using the above five different loss functions are shown in Fig. 14. We see that the edge information of Fig. 14(b) is blurred. Figure 14(c) and 14(d) are better preservation of the edge information but there are residual noises. Figure 14(e) and 14(f) strike a better balance between the edge information preservation and denoising effect. In addition, the joint total variation loss used in this paper achieves better results than the traditional total variation loss in the denoising effect and suppressing artifacts.
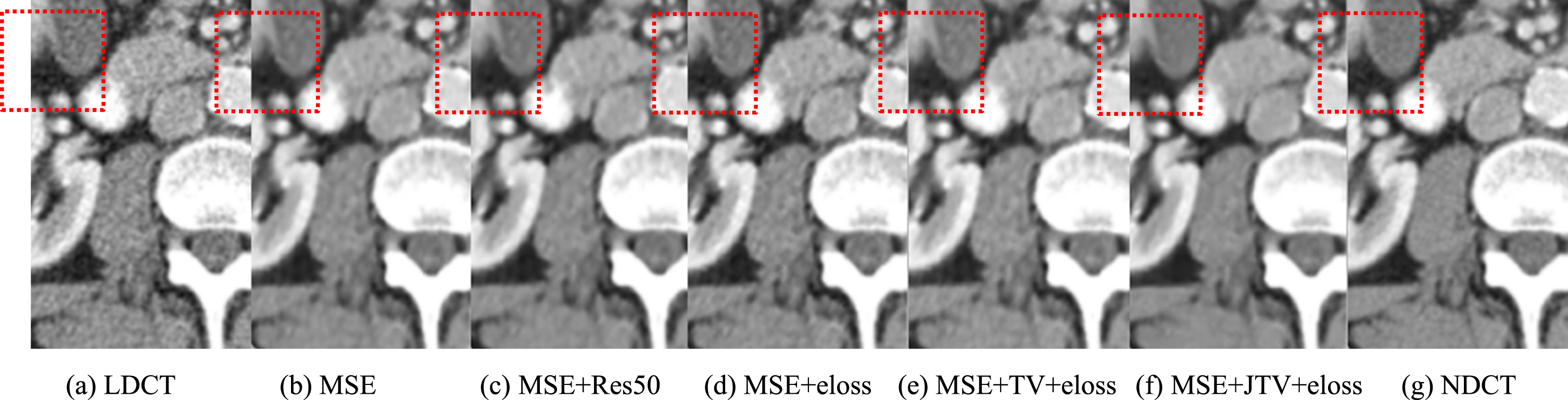
The visual effect of denoising with different loss functions (local area) and the area of interest (ROI) in the red box is selected to calculate objective indicators.
The objective indicators in the red box of Fig. 14 are shown in Table 7. It is seen that when adding the traditional total variation loss to the MSE+eloss function, MSE+TV+eloss obtains higher PSNR and SSIM values and lower RMSE value than MSE+eloss and MSE+Res50. In addition, when adding the joint total variation loss to the MSE+eloss function, MSE+JTV+eloss performs better objective indicators than MSE+TV+eloss. It proves the proposed joint total variation loss is effective.
Comparison of different loss functions
To sum up, this paper proposes an LDCT images denoising model based on multi-scale attention mechanism and the compound loss. In this paper, we use edge extraction module and multi-scale attention module to produce high quality images. Construct a joint total variation loss to enhance the denoising ability of the network and introduce an edge loss to preserve the edge information of the images. Use the residual learning method for training the network to avoid the disappearance of the gradient. The comparison with the previous models proves the effectiveness of our method.
Footnotes
Acknowledgments
This work was supported in part by (1) the State Council and the central government guide local funds of China under Grant YDZX20201400001547, (2) the Natural Science Foundation of Shanxi Province under Grant 202203021222015, and (3) Scientific and Technological Innovation Programs of Higher Education Institutions in Shanxi under Grant 2020L0051 and 2020L0048, and (4) Practice and Innovation Programs of Postgraduates in Shanxi Province under Grant 2023SJ011.
Ethics approval
Not applicable.
Conflicts of interest/Competing interests
We declare that we have no conflict of interest.
Availability of data and material
The data that support the findings of this study are available from TCIA (The Cancer Imaging Archive) but restrictions apply to the availability of these data, which were used under license for the current study, and so are not publicly available. Data are however available from the authors upon reasonable request and with permission of TCIA.
Code availability
The code can be made available on request.
Authors’ contributions
All authors developed the idea and accomplished the manuscript writing and performed the experiments. All authors read and approved the final manuscript.