
Abstract
OBJECTIVE:
Content-based medical image retrieval (CBMIR) has become an important part of computer-aided diagnostics (CAD) systems. The complex medical semantic information inherent in medical images is the most difficult part to improve the accuracy of image retrieval. Highly expressive feature vectors play a crucial role in the search process. In this paper, we propose an effective deep convolutional neural network (CNN) model to extract concise feature vectors for multiple semantic X-ray medical image retrieval.
METHODS:
We build a feature pyramid based CNN model with ResNet50V2 backbone to extract multi-level semantic information. And we use the well-known public multiple semantic annotated X-ray medical image data set IRMA to train and test the proposed model.
RESULTS:
Our method achieves an IRMA error of 32.2, which is the best score compared to the existing literature on this dataset.
CONCLUSIONS:
The proposed CNN model can effectively extract multi-level semantic information from X-ray medical images. The concise feature vectors can improve the retrieval accuracy of multi-semantic and unevenly distributed X-ray medical images.
Introduction
With the rapid development of medical imaging technology, many modalities and protocols have been used to generate digital medical images [1, 2]. Over the past decade, more than tenfold of diagnostic images together with genomic information has been collected, with an estimated volume of 2314 Exabytes in 2020 [3]. Of this amount, diagnostic imaging accounts for a large portion. Digital imaging techniques include X-ray, ultrasound, computed tomography (CT), hybrid positron emission tomography and computed tomography (PET-CT), magnetic resonance imaging (MRI) and others. These images are typically managed using Picture Archiving and Communication System (PACS) in the Digital Imaging and Communications in Medicine (DICOM) format [4]. Radiologists can search PACS using patient ID, study ID, time range, or some textual keywords. However, this traditional search method is time-consuming, labor-intensive and inefficient for clinical decision support, which gets worse when faced with an ever-increasing number of images per body region.
Content-Based Medical Image Retrieval (CBMIR) [1, 6] can search medical images of the same anatomical region or similar disease conditions from existing databases via visual content. The main purpose of CBMIR is to reduce the “medical semantic gap” which is formed by the difference between physician’s image reading and image features get from different computer algorithms [1]. Nowadays, CBMIR has become an important part of computer-aided diagnostics (CAD) [7]. The literature on medical image retrieval can be divided into two major directions. One class of methods retrieves medical images of the same imaging modality, body region, body orientation, etc. from a PACS-like database. [8–10]. Another class of methods aims to retrieve medical images representing similar diseases for clinical diagnostic comparison [11, 12]. In this paper, we focus on retrieving medical images in the way of the previous methods. Considering the huge volume of diagnostic images in modern medical institutions, there is an urgent need for efficient image retrieval methods.
With the very rapid development of deep learning technology, deep convolutional neural networks (CNNs) have been successfully applied for various tasks in the medical field and promising results are emerging [7, 13–15]. Deep CNNs with many hidden layers can effectively describe low-, mid-, and high-level semantic features of images. Recently, deep CNNs have also been introduced into the field of CBMIR, and experiments show that deep CNNs have made significant progress compared to traditional search methods [8, 16–20]. Typically, training a deep CNN requires a large number of labeled images to learn the millions of parameters. In the general image domain, there are several large-scare image datasets available for deep CNNs’ training, such as ImageNet [21], COCO [22], PASCAL VOC [23], etc. While in the medical field, such large annotated medical image datasets are quite rare, due to the unsustainably high cost of domain experts’ manual image labeling and annotation [1, 15]. Medical image datasets are often unbalanced, this is because of the different imaging protocols and devices for different body parts and the uneven incidence rates of different malignancies [1]. The most common scenario in medical image retrieval is to use feature vectors to represent images. Typically, feature vectors range in length from a few hundred to several thousand dimensions [1, 17]. In a real-world clinical environment, image search using too long feature vector is time-consuming and not suitable for practical clinical requirements [1]. Therefore, reducing the size of the feature vectors or creating a very sparse search space is one important aspect that many scholars in this field are trying to make improvement [8, 25]. The main difficulty in this regard is that retrieval accuracy plays a crucial role in medical image analysis, and it is a very challenging work to construct concise feature vectors with good discriminability [1].
In this paper we focus on learning concise feature vectors through deep CNNs to efficiently retrieve medical images while maintaining high retrieval accuracy for imbalanced X-ray medical images. The IRMA dataset [5] with rich medical semantics from ImageCLEF is employed to validate the proposed method. The contributions of this paper are given below: A modified residual structure [26] is used as medical image feature extraction block. With identity mapping, the deep CNN model built on this block can be trained more effectively on small and extremely unevenly distributed image datasets. A new network model for medical image retrieval is proposed in this work, which adopts feature pyramid structure [27] to extract feature vectors from different scales. The final feature vector for retrieval is learned from different feature pyramids. In this way, we obtain a succinct yet powerful discriminative feature vector to perform nearest-neighbor similar medical image search, which is crucial for medical image retrieval, especially when faced with retrieval tasks with a large volume of image data.
Related work
Retrieval precision is a very important factor in medical image analysis. Clinical decision-making can be better supported with retrieving more relevant images. There are two key factors that determine the performance of retrieval systems: (1) Feature representation: generally medical images are represented using feature vectors that represent the image content and can be linked to visual perceptions of the images by the physicians. Good feature vector is the fundamental for achieving good performance in medical image retrieval (2) Retrieval strategy: among CBMIR literature, classification based retrieval strategy, nearest-neighbor search strategy or their combination are commonly used for similar feature search. Retrieval strategy should be carefully chosen for different medical retrieval tasks.
Hand-engineered features
In the field of medical image retrieval, traditional features also called hand-crafted features are widely used. Common hand-crafted features include: texture features, keypoint-based features, local features and global features [1, 29]. Camlica et al. [30] extracted LBP features from salient regions of an x-ray image, and used SVM to make classification for retrieval. LBP features were successfully applied on 2D-Hela and brain MRI retrieval tasks of ImageCLEFmed [31]. Jiang et al. [32] used region of interest (ROI) of mammography as query input, then retrieve breast tumor with SIFT features. Xu et al. [33] proposed a high speed corner-guided partial shape matching strategy for spine x-ray images retrieval. Wang et al. [34] retrieved basal-cell carcinoma with SIFT features. Venkatachalam et al. [35] combined Gabor filters and Walsh-Hadamard transform to extract brain tumor features from MRI, and then used fuzzy-c means to cluster Minkowski distance to implement retrieval.
Deep CNN features
Deep CNN is a powerful tool for image feature expression, and has achieved leading results in many challenges such as image classification, object recognition, object detection and so on. In the medical field, deep CNNs have also been introduced into CBMIR applications, and there have been some very enlightening pioneer works showing promising results. In [8, 16], Khatami et al. proposed two deep CNN based search space shrinking strategies for medical image retrieval: one method used multiple CNNs together to produce the shrunk search space. The other method employed two-stage data augmentation to train and fine tune deep CNN to shrink search space. Qayyum et al. [9] trained a CNN framework to retrieval a multimodal medical image dataset collected by the authors. They tried retrieving medical images with and without predicted class lable. And they also tested their method on a public x-ray dataset IRMA [5]. Pelka et al. [17] tried different image enhancement strategies on IRMA dataset using Random Forest classifier, Inception-v3 and Inception-ResNet-v2 to annotate each axial and the complete IRMA code. Ahn et al. [18] proposed an unsupervised feature learning framework for medical image retrieval and classification. They combined kernel learning method into CNN framework to learn sparse initial features from unlabeled medical images. They optimized their kernel learning layer-by-layer, and then stack all layers in a feedforward way to construct the final feature representation. Hofmanninger and Langs [36] used clinical routine images and radiology reports to train CNN, then they fine-tuned CNN for the current medical image retrieval task. Zhang et al. [37] tried a new deep CNN based method that took advantage of multiple information components generated by the empirical mode decomposition method. They trained deep CNN by feeding original medical image with its multiscale empirical mode decomposition components, and derived a concise feature vector to retrieve. Their method got very good performance for medical image retrieval. Alenezi et al. [38] proposed a W-shaped contrastive loss function to train CNN for imbalanced skin lesion image retrieval. Alizadeh et al. [39] got effective hash code for histopathology image retrieval by using Siamese deep network structure. Chen et al. [40] developed a multi-scale triplet hashing algorithm for X-ray, Skin Cancer and COVID-19 radiography datasets retrieval.
Retrieval strategies
Due to the close relationship between classification and retrieval in medical image processing, there are two common medical image retrieval strategies:
Materials and methods
Dataset
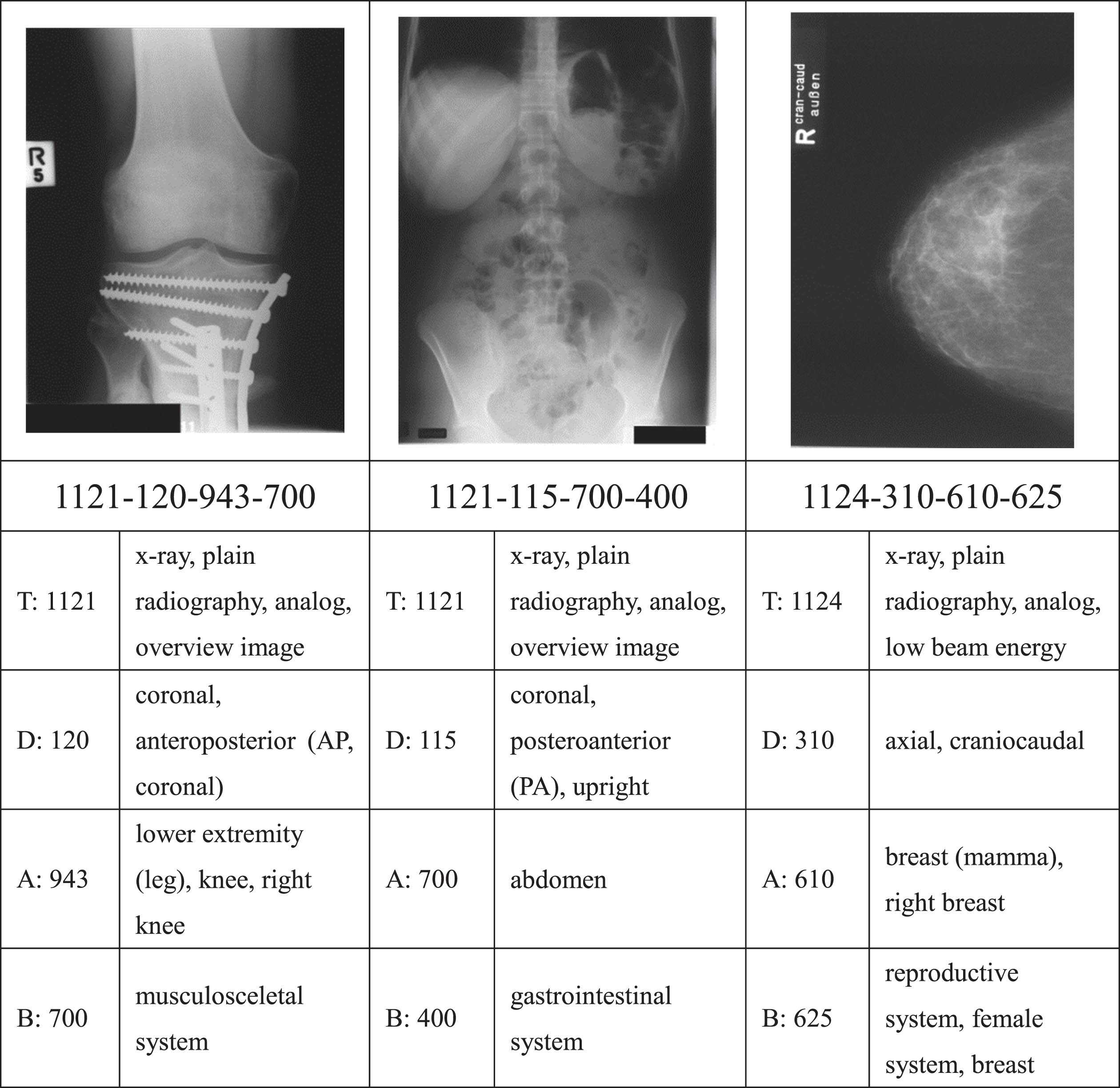
Image Retrieval in Medical Application (IRMA) X-ray dataset published on ImageCLEF. IRMA is a widely used benchmark for medical image annotation and retrieval [31], and its 2007 version [41] consists of 11,000 training images and 1000 test radiographs divided into 116 classes. Each X-ray image is annotated with a 13-character string TTTT-DDD-AAA-BBB along four hierarchical axes including: imaging modality T, body orientations D, the body region examined A, and the biological system examined B. The difficulty for retrieval on the IRMA dataset is that the similarities assessed using the IRMA codes exist in different semantic directions. And meanwhile, the limited amount of images and heavily imbalanced distribution make the CNN prone to overfitting. Figure 1 shows three examples of images from the IRMA dataset along with their IRMA codes and descriptions. Figure 2 is the data distribution of IRMA2007.
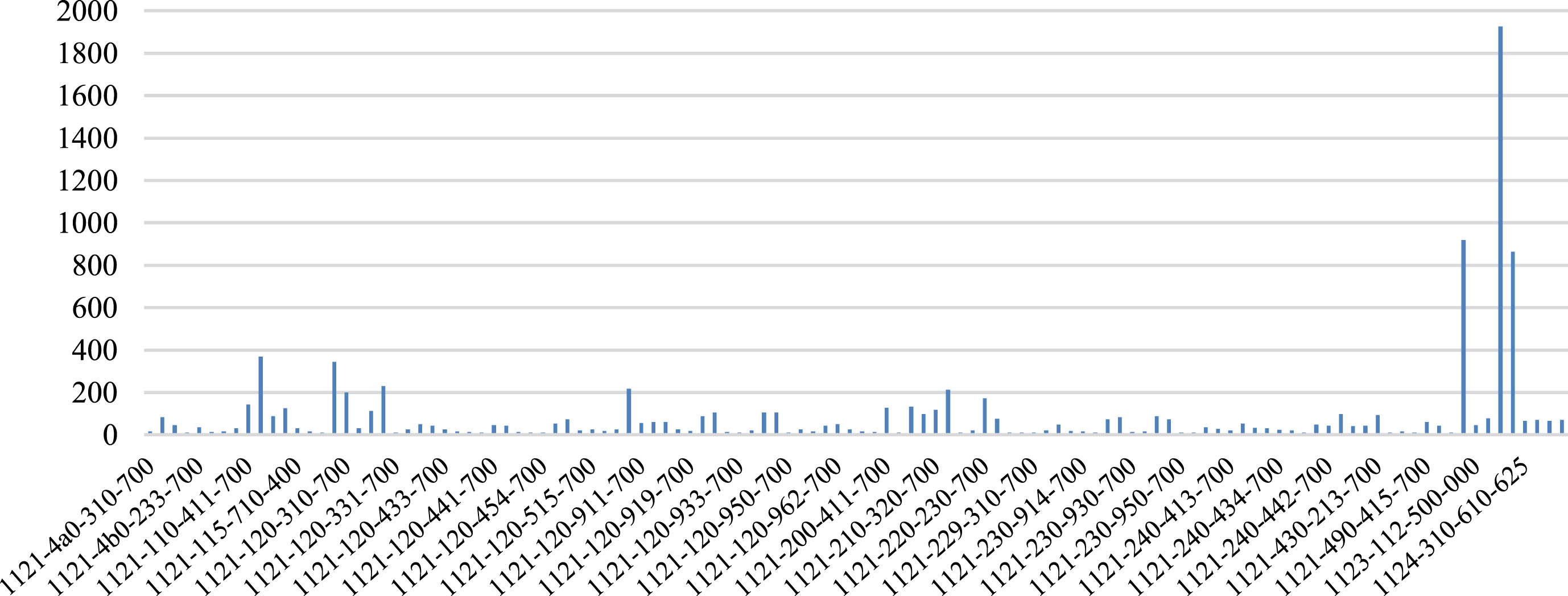
The data distribution of IRMA2007 dataset.
Similar to many medical analysis tasks, the problems of insufficient labeled images and highly unbalanced data distribution are two major difficulties in applying deep CNNs in medical image retrieval tasks [1]. Pilot studies have shown promising results by using deep CNNs [8, 16]. These efforts demonstrate that feature vectors learned by deep CNNs outperform traditional methods in medical image retrieval. Our recent work [37] further advances this research in terms of both accuracy and efficiency. In [37], the authors incorporated the empirical mode decomposition components into the CNN model to increase the input of multi-scale information, and learned concise feature vectors to perform more effective similarity retrieval. To further improve the expressive power of feature vectors, in this work, we propose a new method equipped with two characteristics to deal with these two difficulties separately. First, we choose the identity mapping version ResNet50 (ResNet5V2) as the backbone to extract medical image features to alleviate the performance degradation due to the severe data imbalance. Second, we adopt the Feature Pyramid Network (FPN) framework to make decisions at different scales to improve the performance of the model on complex medical semantics with a very limited amount of training. A brief description of proposed framework is presented as follows.
Residual blocks, also called “Residual Units” [42] are the basic unit for building deep residual networks (ResNets) [26]. ResNets have achieved one of the best results on ImageNet [21] dataset, and ResNets with different network depths are currently one of the most widely used deep CNN network structures. ResNet50V2 is an improved version of the original ResNet50 [26] that reduces overfitting and improves the optimization process. By rearranging batch normalization (BN) and ReLU, ResNet50V2 propagates information through the entire residual network more directly. The full pre-activation design [26] places BN and ReLU before weight layers that makes identity mapping available in both residual block and shortcut. With this design, information can be propagated forwards and backwards, making the optimization process much easier. Considering the limited amount labeled medical images and very uneven data distribution, we choose ResNet50V2 as the backbone of our network for feature extraction for better generalization. The structure of ResNet50 and ResNet50V2 convolutional blocks are shown in Fig. 3 [26].
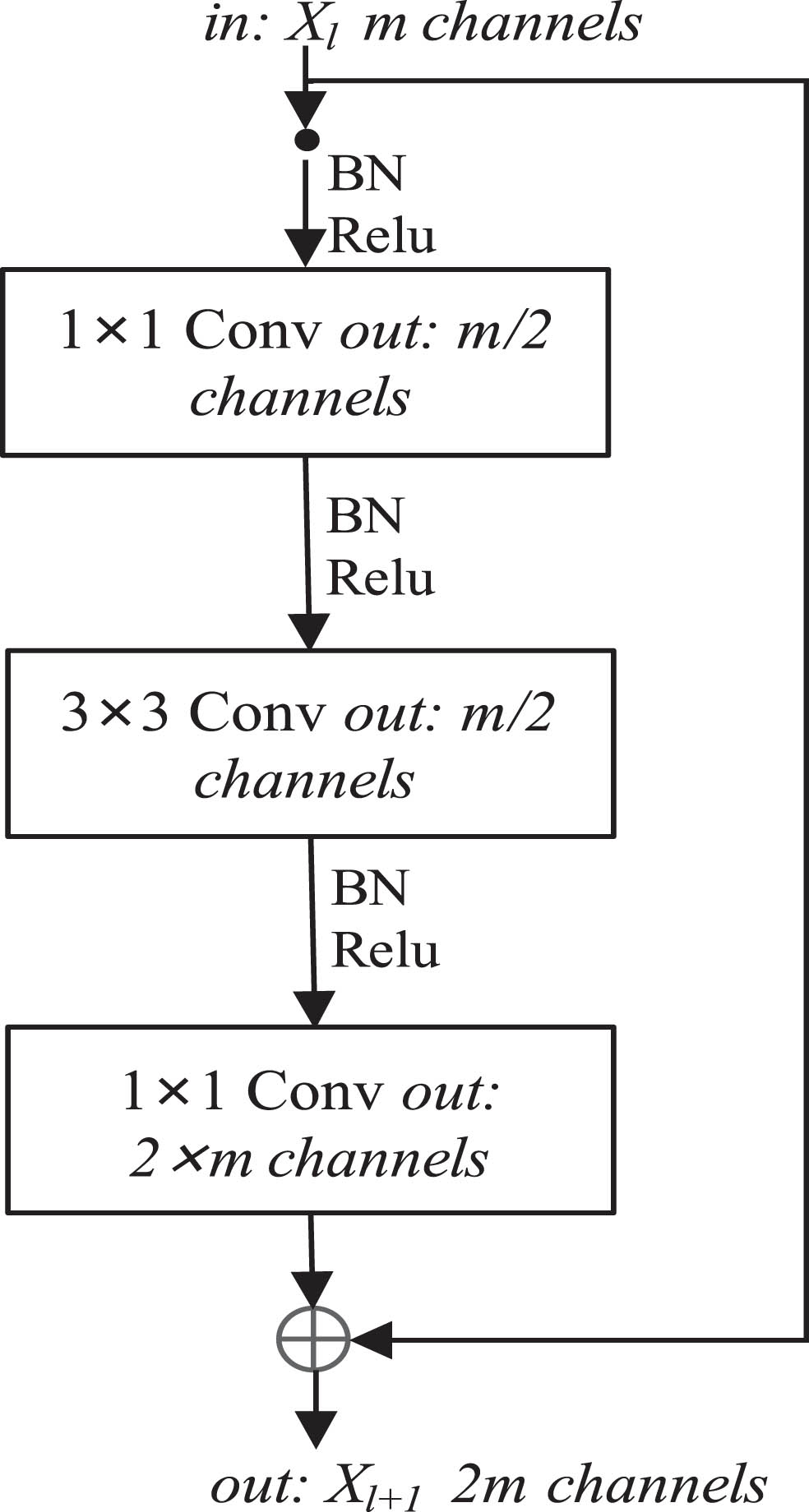
The structure of ResNet50 and ResNet50V2 convolution blocks.
As shown in Fig. 3, the difference between ResNet50 and ResNet50V2 is the position of BN and ReLU. Let F denote the residual function, f denote ReLU and W denote the weights of convolve layers. The output of the ResNet50 and ResNet50V2 units in Fig. 3 can be described by Equations (1) and (2), respectively.
Feature pyramid network (FPN) was introduced by Lin et al. [27], and utilized in the one-stage object detector RetinaNet [43] and the two-stage object detector Faster RCNN [27]. FPN constructs multi-scale feature pyramids by attaching a top-down pathway and lateral connections to standard convolutional networks. In object detection scenarios, FPN attaches a head to each level of the feature pyramid for detecting objects at multiple scales.
In this work, we take advantage of the rich, multi-scale and semantically powerful features extracted from FPN across all level scales to build our classification-based medical image retrieval framework. Helps physicians make comparative diagnoses by searching for similar anatomy and/or case through content-based image retrieval. The similarity of medical images is defined in terms of multiple aspects of clinical medical knowledge, that is, from multiple aspects of semantics. These semantics include image modalities, body orientations, anatomical regions, biological systems, etc., and can be recognized at different scales. The similarity between medical images may exist at different scales, so using FPN helps to exploit various semantic features extracted from input images. Our proposed model identifies medical images from different scales using rich semantic information and, more importantly, provides concise feature vectors to perform similarity retrieval, which is a very significant advantage when retrieving large amounts of medical images. The general process of medical image retrieval is showed in Fig. 4.

The deep CNN-based content-based medical image retrieval flowchart.
The architect of the proposed network is shown in Fig. 5. ResNet50V2 is used as the backbone for image feature extraction in multiscale, pyramidal way. We use FPN to combine high- and low-resolution features, with which we can fuse recognition results from different scales to make more accurate predictions. In medical image retrieval, nearest neighbor search is the most widely used retrieval method, which requires comparing feature vectors of different images by computing some distance measures. Therefore, concise feature vectors with strong expressive ability are an important factor in handling large-scale medical image retrieval. In our framework, we construct short feature vectors at each level of FPN and concatenate them to form the final feature vector. Figure 5 details our proposed framework.
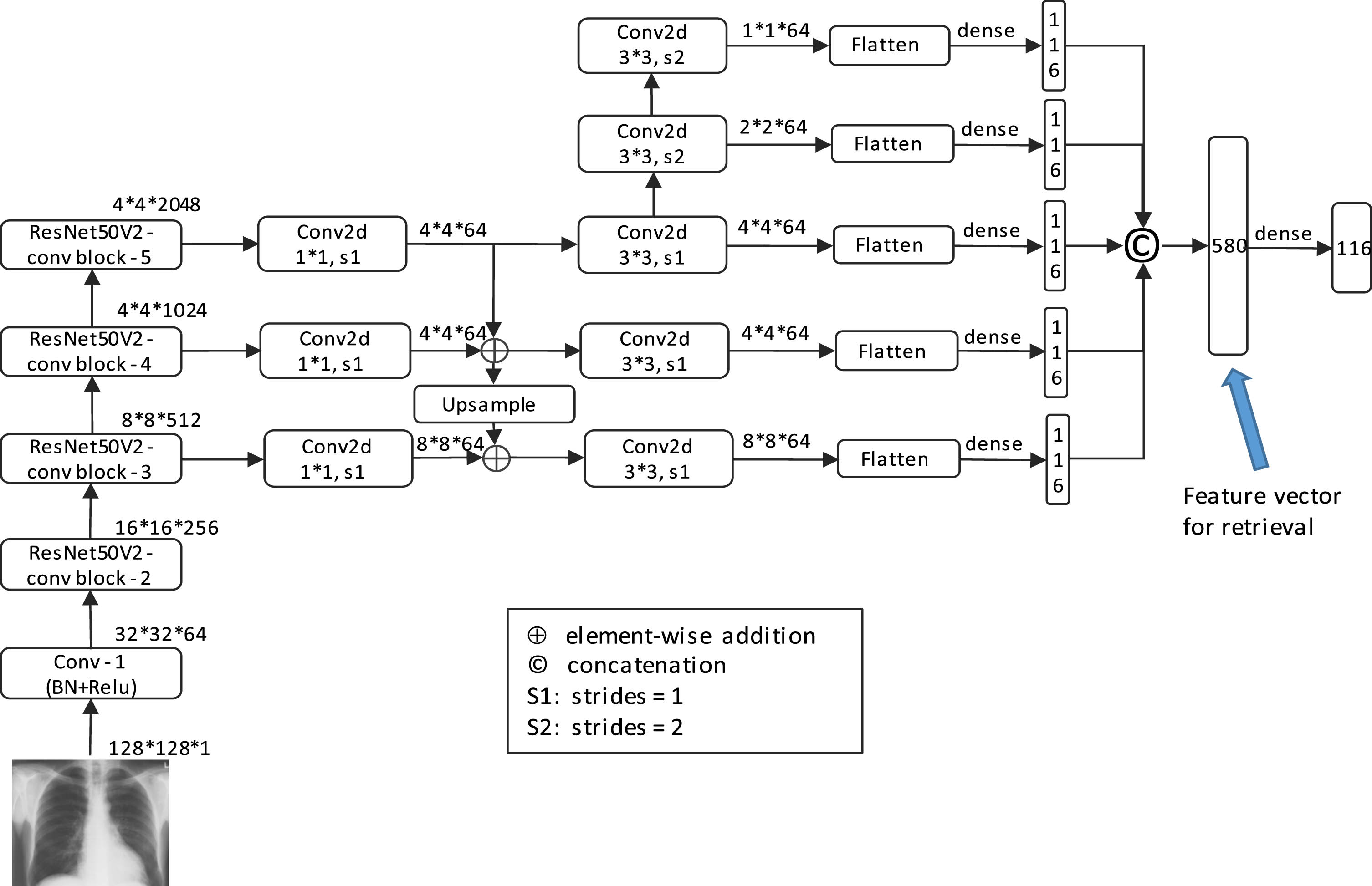
The proposed medical image retrieval framework.
All images are grayscale images. For the case of different image sizes, each image is scaled to 128*128 size and input to the network after normalization. In order to balance the number of each class, data enhancement is performed on the entire dataset using transformations such as rotation, oblique cutting, scaling, etc., to about 200 images per class. For classes with more than 200 classes, random sampling is used to select 200 images as training images. We set the batch size as 16, and turn on the early stopping, the maximum epochs is 500. We train all the networks on Ubuntu 18.04, with Intel(R) Xeon(R) Gold 6154 CPU and 256 G RAM, and a NVIDIA TITAN V graphic card with 12 G RAM.
Experimental results and discussion
Performance measures
For classification performance, IRMA error [44], average precision(AP), average recall(AR), accuracy(Acc) and F1 measure are adopted to evaluate classification accuracy. For retrieval, in addition to IRMA error obtained by nearest-neighbor search, common measurement mean average precision (MAP) is also used to evaluate retrieval accuracy.
Classification performance measures
IRMA error
The total IRMA error [44] can be computed by the following formula
Here,
AP (average precision)
In above, TP means true positive, representing the number of images which are correctly classified as class k; FP means false positive, representing the number of images which are misclassified as class k; TN means true negative, representing the number of images which are correctly classified as not class k; FN means false negative, representing the number of images which are misclassified as not class k; and K is the total number of classes of the IRMA dataset that is 116 in this paper.
MAP (mean average precision) [45] is a common metric for evaluating image retrieval performance. MAP calculates the mean of average precision (AP) upon the whole query image set Q.
In this work, we compare the classification and retrieval performance of our model with other CNN-based methods in literature.
Classification
Classification IRMA error using CNN
The classification IRMA error of different CNNs is recorded in Table 1. The results show that with the fast development of deep CNN the classification accuracy of deep CNN is getting better and better. Our proposed method gets lower IRMA error than other methods in literature. Though the classification IRMA error score between our previous work [37] and this work is at the same level, the dimension of input image to CNN in [37] is four times than this work (256×256 in [37] vs. 128×128 in this work, in Table 1 we set the same input image size as 128×128 to network of [37]).
Classification IRMA error of proposed method and other CNN based methods in literature. § indicates that the input image size of CNN in [37] is 256×256, while the input image size of the proposed method is 128×128 that is four times smaller
Classification IRMA error of proposed method and other CNN based methods in literature. § indicates that the input image size of CNN in [37] is 256×256, while the input image size of the proposed method is 128×128 that is four times smaller
The score of commonly used classification measures AP, AR, and F1 measure computed by using prevalent deep CNNs including VGG [46], ResNet50 [26], and ResNet50V2 [42] are shown in Table 2, and we also attached IRMA error in Table 2. These methods are set as the same training parameters. From Table 2, ResNet50V2 is much better than ResNet50, the main reason is that identity mapping makes ResNet50V2 easier to be optimized for small and heavily unbalanced dataset. The proposed framework gets the best F1-measure.
Comparison of classification performance of the proposed framework with other commonly used deep convolution models on IRMA images
Comparison of classification performance of the proposed framework with other commonly used deep convolution models on IRMA images
Retrieval IRMA error
Nearest neighbor search is the most common implementation in medical image retrieval. During the nearest neighbor search, we need to calculate the distance between the feature vector of the query image and that of each image in the dataset to find the one with the smallest feature vector distance under a certain distance measure. The IRMA code of the query image is determined by the image closest to it. Thus effective feature vector is the key factor affecting accuracy. In Table 3 we compare the retrieval IRMA error of our method with other methods in literature. Our proposed framework gets the best score.
Retrieval IRMA error comparison between proposed method and other methods reported in literature
Retrieval IRMA error comparison between proposed method and other methods reported in literature
MAP is a common evaluation indicator in normal image retrieval. In Table 4, we compare MAP of proposed method with other methods reported in the literature, we also compare different MAP values using different distance measures, and IRMA error is attached as reference and calibration. Table 4 lists feature vector dimension in to illustrate potential for large-scale medical image data retrieval. The data in Table 4 shows that MAP may not be a good indicator for medical image dataset. MAP indicators on different distance measures are insensitive to IRMA dataset retrieval accuracy. For example, MAP values obtained by using method in [37] and our proposed method are at the same level, while for the more important indicator IRMA error annotated by clinical experts, our method has an advantage with a big gap.
Retrieval performance comparison between proposed method and other state-of-the-art CNN models on IRMA dataset. * is the case that input image size is 128×128 same as the proposed method, and # indicates 256×256 input size as original set in [37]
Retrieval performance comparison between proposed method and other state-of-the-art CNN models on IRMA dataset. * is the case that input image size is 128×128 same as the proposed method, and # indicates 256×256 input size as original set in [37]
The observations in Tables 2 and 4 show that ResNet50V2 is much better than ResNet50 in both classification and retrieval on IRMA dataset. This observation is consistent with the design idea of identity mapping proposed in [42], which is mean to make optimization process of the residual convolution network easier especially on small and unevenly distributed datasets.
From Table 2, we can observe that the proposed method is not significantly superior to the original ResNetV2 for classification performance. The proposed method is slightly better than the original ResNetV2 on F1-measure and slightly worse than the original ResNetV2 on IRMA error. This may be due to the fact that the classification output is a direct prediction of the label of the image. For the experiments in this paper, it is the predicted output of 116 categories. The feature vector of the penultimate layer in Fig. 5 is compressed to 116 dimensions by weight, which does not reflect the advantages of the feature vector that reflects multi-scale information constructed by FPN.
The retrieval process is performed by calculating the similarity between the feature vectors of different images through a similarity measure. The label of the query image is determined by the closest image obtained by calculating the similarity. The feature vector of an image is the penultimate layer of the proposed network (marked in Fig. 5). In the retrieval scenario, the multi-scale information extracted using FPN shows advantages in the calculation of similarity. From Table 4, we can see that the proposed method has a significant improvement in retrieval performance compared to ResNet50V2. This is in line with our analysis that multiscale information is more appropriate for IRMA multi-semantic labeling. And our proposed network obtains the best IRMA error through similarity retrieval. The main reason is that it is an effective way to extract multiple perspective semantic information from the inherent feature pyramid of deep CNNs.
Table 5 shows the ablation experiments for classification and retrieval, using IRMA error as an indicator.
Ablation experiments for classification and retrieval
Ablation experiments for classification and retrieval
We compare the computation time of different networks in Table 6.
Ablation experiments for classification and retrieval
Figure 6 shows the mAP-Recall curves of the proposed method and other CNNs. In Fig. 7, we show an example of a good query result and an example of a poor query result.
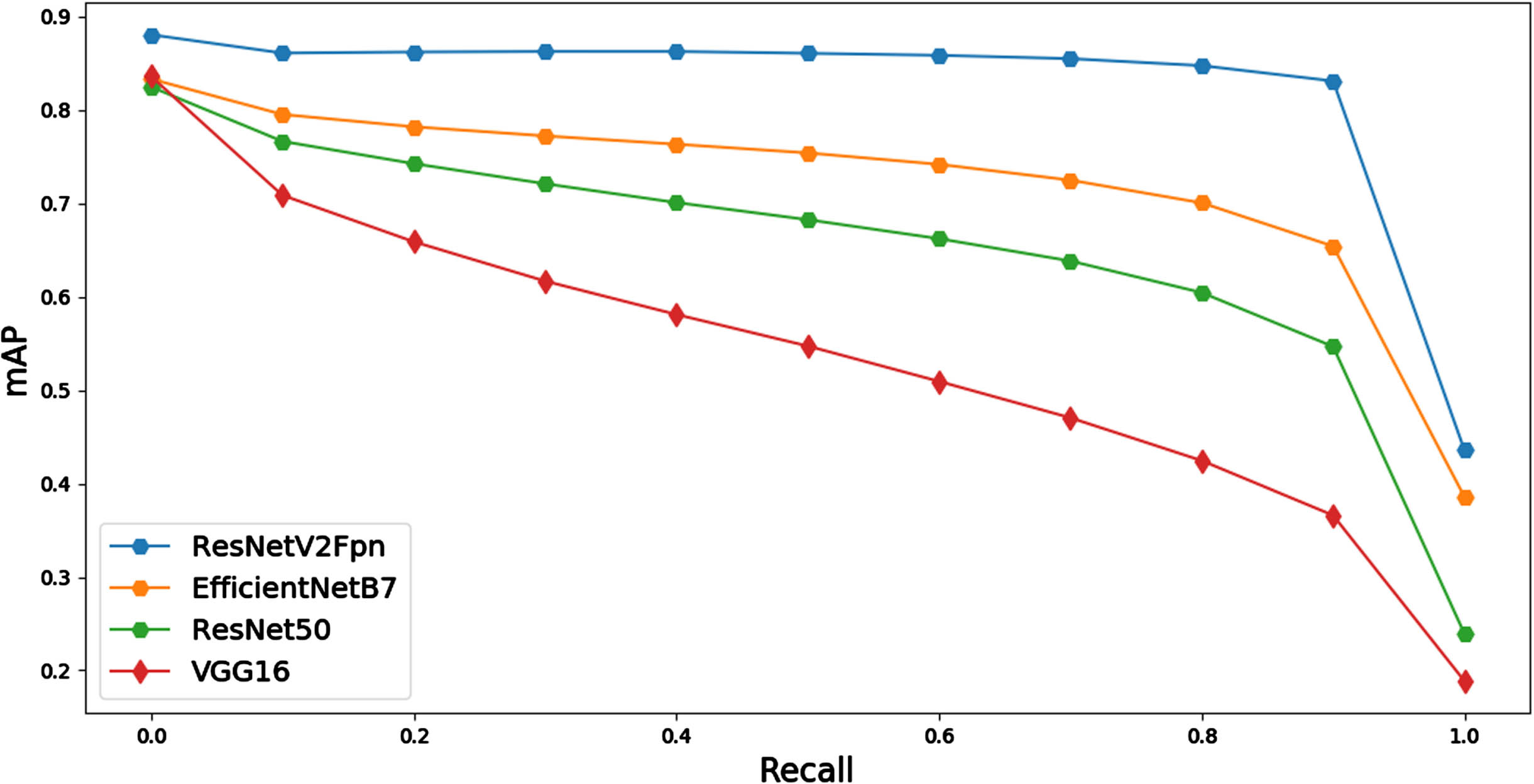
The mAP-Recall curves of the proposed method and other CNNs.
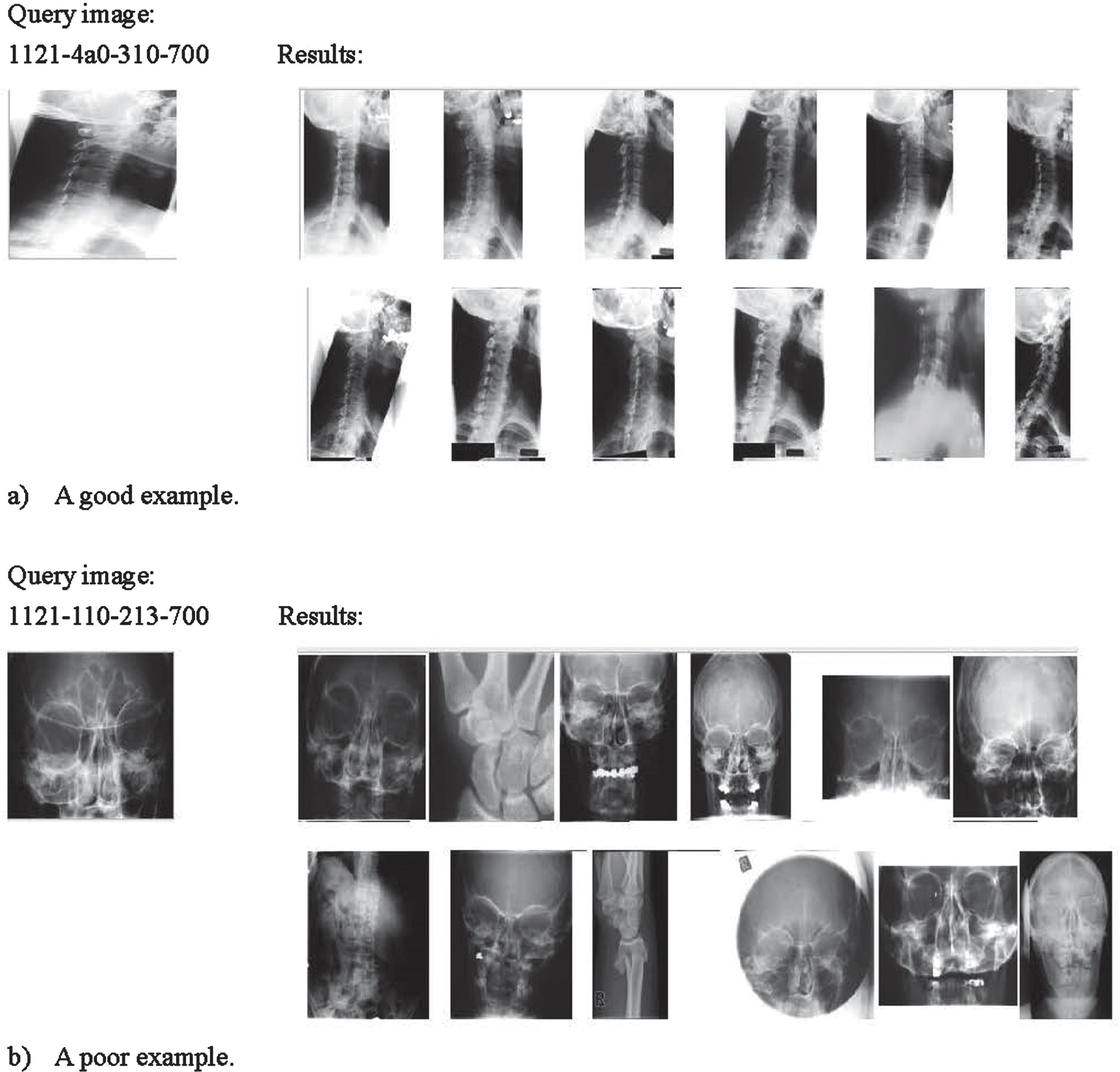
An example of a good query result and an example of a poor query result.
CBMIR can efficiently support medical image analytics by retrieving images with similar medical diagnostic semantic content in multiple perspectives (e.g., anatomy regions, modality, imaging direction, organic systems). This can significantly facilitate domain experts performing comparative medical image diagnosis. Concise yet highly distinguishable feature vectors are essential for medical image retrieval systems. A new convolutional neural network has been proposed in this paper, which improves the accuracy of medical image retrieval with complex semantics by a large margin. The new method takes advantage of the multi-scale information brought by the feature pyramid network to construct feature vector for effective nearest-neighbor search. On the very imbalanced IRMA dataset with complex medical semantics, the proposed method is significantly lower than other methods on IRMA error by a large margin. Through our experiments, we show that retrieval methods are much more effective than classification methods for medical image data with complex semantics. Concise feature vector has also shown the ability of the new method to handle retrieving relative images from big medical image archive. However, the correspondence between multi-scale information and multi-semantics is still complex and needs to be further clarified. And the ability for computational pathology image retrieval is not clear. We intend to further examine CBMIR on other medical datasets, different modalities, and 3D volumetric applications. We intend to further investigate the application of CBMIR on multi-modality medical datasets.
Footnotes
Acknowledgments
We thank Prof. Dr. T. M. Deserno of the Dept. of Medical Informatics, RWTH Aachen, Germany, for providing us with the IRMA medical image dataset. This work was supported in part by Ningxia Natural Science Foundation under Grants 2023AAC03263 and 2022AAC05040.