
Abstract
This study proposes a model for creating facial wound-covering masks to support patients recovering from injuries, especially those with scars or deformities resulting from accidents and wars. The model aims to increase patient confidence, improve wound hygiene, and protect the environment. A novel dataset was developed, consisting of diverse facial images with various scar conditions simulated from real human scars. The study employs self-supervised learning (SSL) with a pretrained base model to convert 2D images into 3D representations without compromising critical facial features. SSL is implemented during the encoding phase, allowing the model to familiarize itself with new data. Through the integration of 3D printing technology, the entire process, from wound reconstruction to product manufacturing, has been tested in the laboratory. The results indicate that the model not only effectively covers wounds but also restores the original facial structure nearly perfectly. The improvement is clearly demonstrated through error reduction and increased accuracy across experiments with diverse datasets. This research opens new possibilities for practical applications, particularly for war victims, by offering a novel, safe, and convenient treatment solution.
Introduction
Traffic accidents,1,2 occupational accidents, and the aftermath of war not only result in loss of life 3 but also leave many patients with severe injuries and permanent disabilities. 4 Among these, the head and face are particularly vulnerable due to their complex soft tissue structure,5,6 which is difficult to clean and highly susceptible to environmental influences.5,7 Reconstructing and restoring the functionality of this area is a significant challenge, 8 especially in covering and aesthetically restoring wounds to protect patients from the risk of reinjury9,10 and improve their confidence.7,11
Thanks to advances in 3D printing and 3D scanning technologies,12–14 recent research has made notable progress in restructuring body parts15–17 such as hands, feet, spines,18,19 and skulls,20,21 as illustrated in Figure 1. However, the head and face remain underexplored due to the complexity and high risk associated with interventions in this region.22,23 Pioneering studies have experimented with virtual surgeries, microsurgery, and reconstruction techniques using extended forehead flaps to restore severely damaged areas such as the nose and mouth, 24 as shown in Figure 2. Although some promising results have been achieved, 25 these methods have not yet been widely applied due to their complexity and high costs.
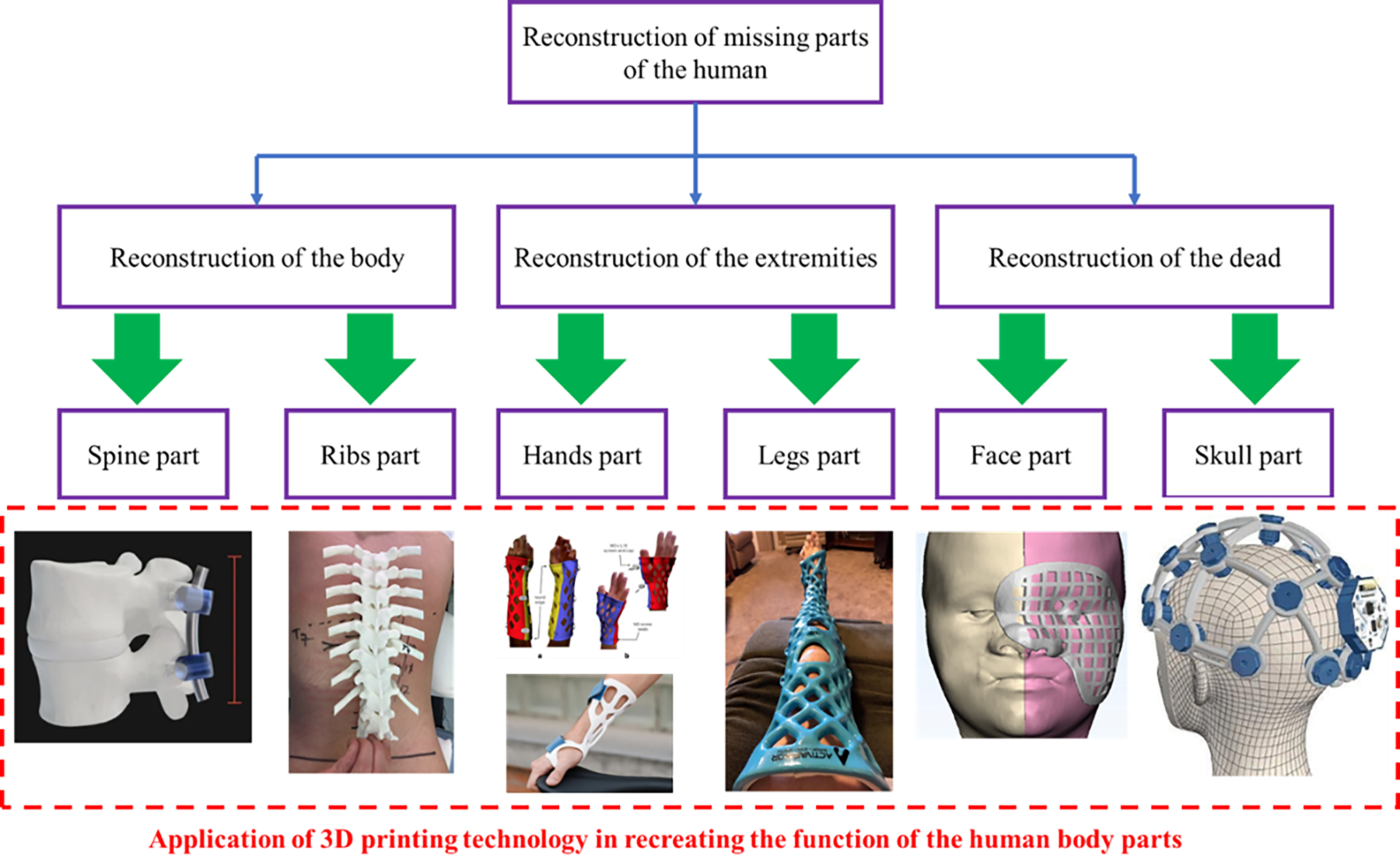
Replacement of certain body parts using 3D printing technology.
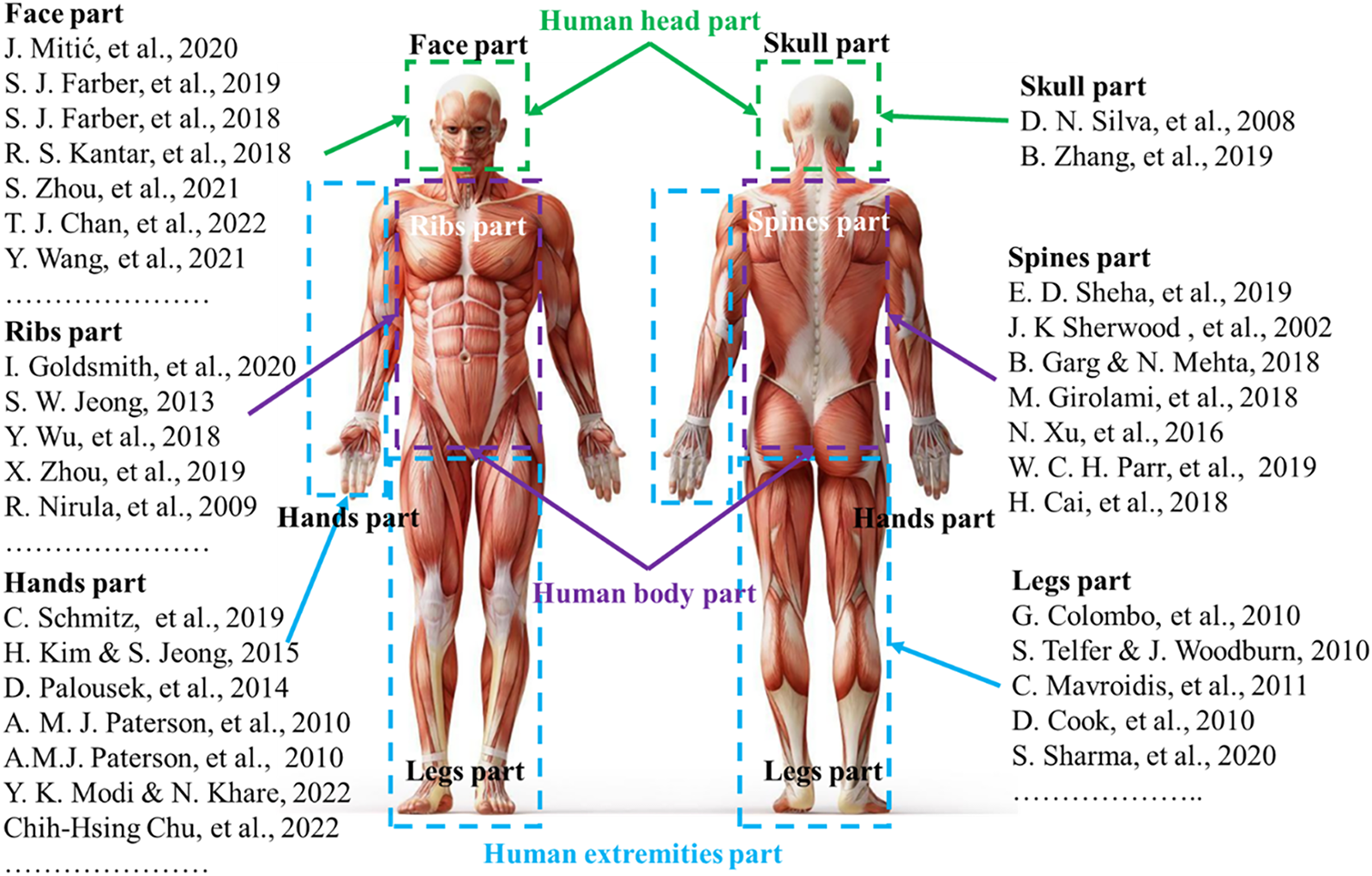
Studies on reconstructing body parts.
In contrast to traditional approaches that aim to completely reconstruct a damaged part,18,19 this study proposes a novel method that uses 3D printing and artificial intelligence to develop products for wound coverage.26,27 Instead of completely replacing the injured part, 25 this approach focuses on creating masks or cover products that protect wounds, support healing, and improve aesthetics. The proposed model not only reduces the risk of reinjury but also improves patients’ quality of life, particularly for those in difficult circumstances or affected by war.
Although this research has made significant advances in reconstructing and covering facial wounds using 3D printing and artificial intelligence,28,29 certain limitations
30
and gaps need to be addressed to enhance the feasibility and effectiveness of practical applications.
Limited testing: The product has been tested in laboratory settings and has not yet been deployed in actual patients or clinical environments, making it difficult to comprehensively assess its effectiveness and feasibility in real-world applications. To ensure long-term usability and sustainable effectiveness,8,12,20 more clinical trials are needed to evaluate durability, biocompatibility, and performance in various scenarios.21,30 These trials will be crucial to validate the potential and meet practical requirements in patient recovery and treatment. Data limitations: The dataset used in this investigation is limited in diversity, focusing only on specific types of scars and injuries, reducing the comprehensiveness and its ability to apply broadly to various real-world injuries.
31
The lack of cases involving severe burns, congenital defects, and complex surgical trauma poses challenges in fully evaluating the effectiveness of the model.32,33 This limitation may affect the precision and practical applicability of dealing with more complex conditions,
34
highlighting the need to expand the dataset to ensure that the model can perform well in various scenarios and meet clinical requirements. Computational challenges: While the application of self-supervised learning (SSL) with the entire dataset has yielded high performance,35,36 it also incurs significant computational costs and long training times, posing challenges for deployment in real-world conditions with limited resources and time constraints.
37
Additionally, the scalability and integration of the model with smart health care systems, such as the Internet of Things (IoT) for remote monitoring, have not been fully explored, limiting its practical applicability. To improve feasibility and effectiveness, further model optimization is required to reduce computational time and resources, along with expanding integration capabilities with new technology platforms, enhancing flexibility and practical deployment. Lack of personalization: A key limitation of this research is the lack of personalization. The current model is primarily based on generic wound templates, lacking the flexibility to adapt to the unique facial structures and injury conditions of individual patients. This could impact treatment effectiveness, especially for complex injuries that require precise customization. Furthermore, the absence of a real-time feedback system to monitor recovery and make timely adjustments is a gap that needs to be addressed. Such a feedback system would not only optimize the treatment process but would also ensure that the product adapts effectively to wound changes throughout the recovery period, improving both effectiveness and practical applicability in clinical settings.
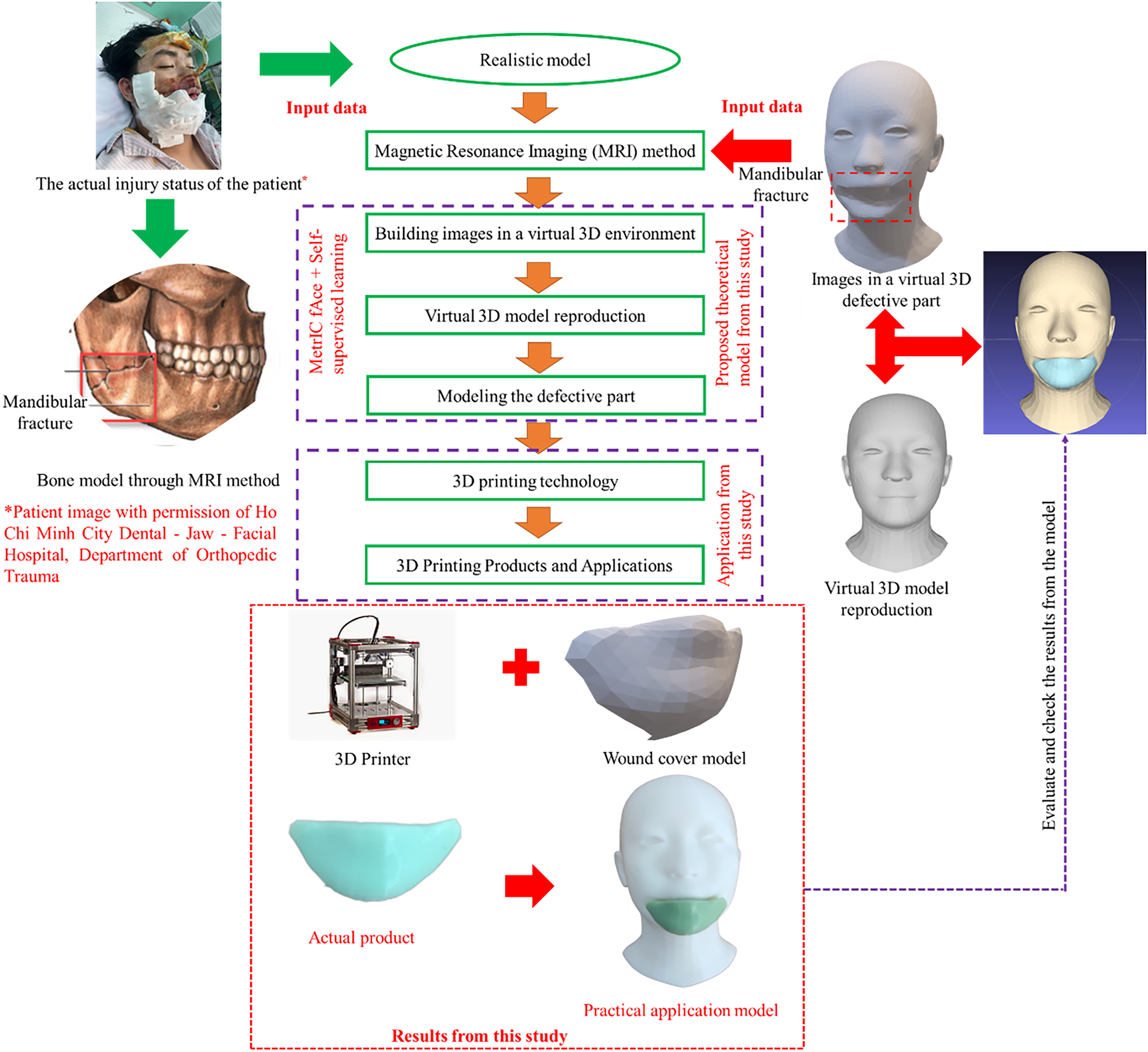
To achieve the research objectives, we developed a new facial dataset that focuses on scars and injuries in various locations and conditions. This dataset is designed to be highly diverse, reflecting the real-life scenarios that patients may encounter, ranging from minor to severe and complex injuries. The uniqueness of the dataset lies not only in the detailed simulation of different types of injury but also in its ability to switch between 2D images with wounds and 3D models without injuries while preserving key biometric features of the face, as illustrated in Figure 3. This transformation process is implemented using advanced machine learning models to ensure accurate replication of all essential facial morphology elements, such as nose structure, skin thickness, and basic contours. At the same time, 3D printing technology plays a crucial role in the transformation of these models into practical covering products. The production process, from virtual modeling to completed products in the lab, ensures that the product can be easily used in treatment, meeting recovery needs and improving quality of life, as illustrated in Figure 4. This approach not only facilitates wound care and protection against environmental influences but also provides aesthetic recovery opportunities for individuals without access to complex and expensive treatments. The study hopes that with this innovative approach, patients around the world, especially impoverished and war victims, will have access to a safe, effective, and affordable recovery solution. This represents not only a step forward in the application of modern technology to regenerative medicine but also a humanitarian solution that offers new hope to those who have experienced significant hardship.
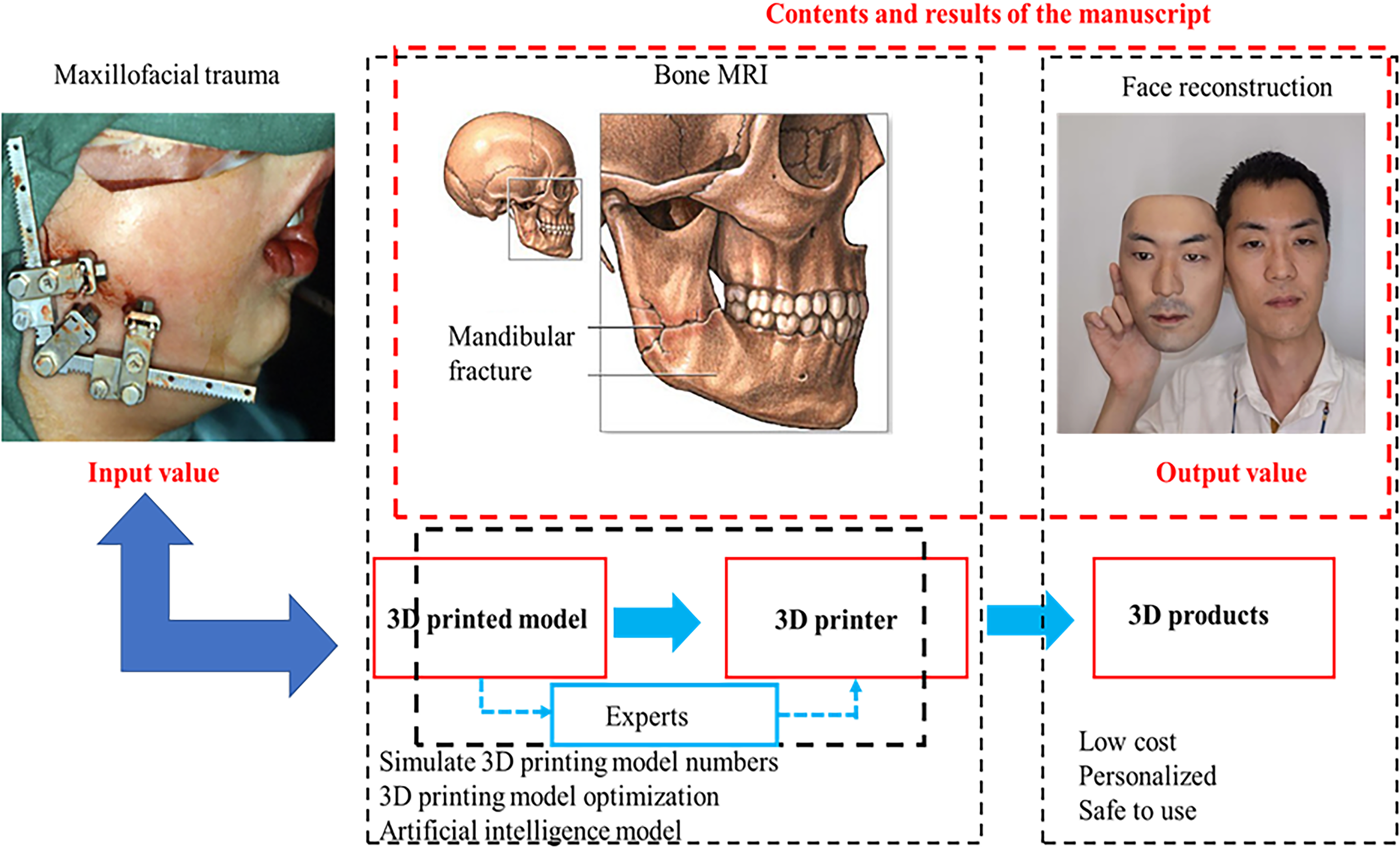
The proposed model and the results of this study.
The production process from virtual model to finished product.
Proposed Method
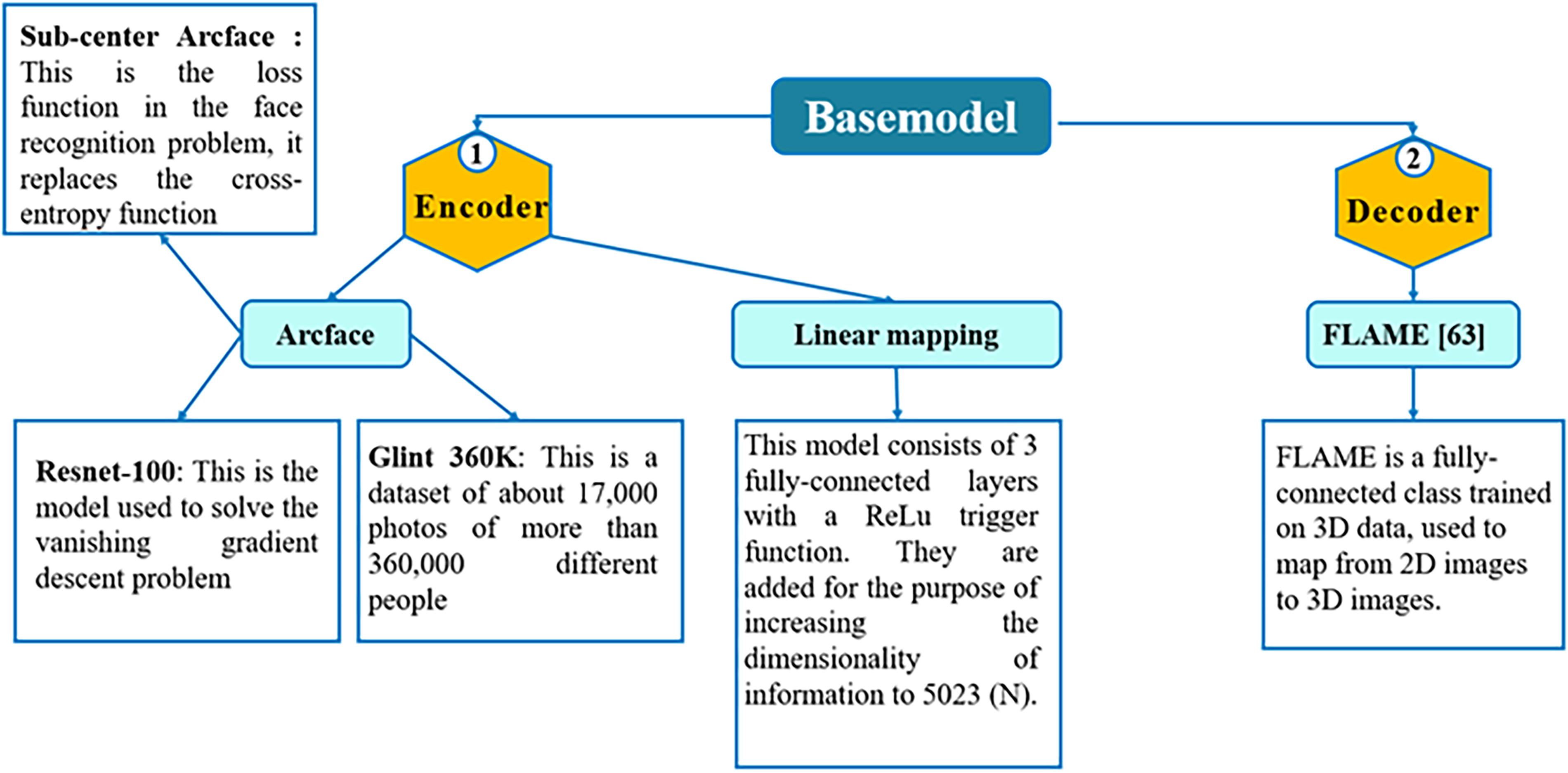
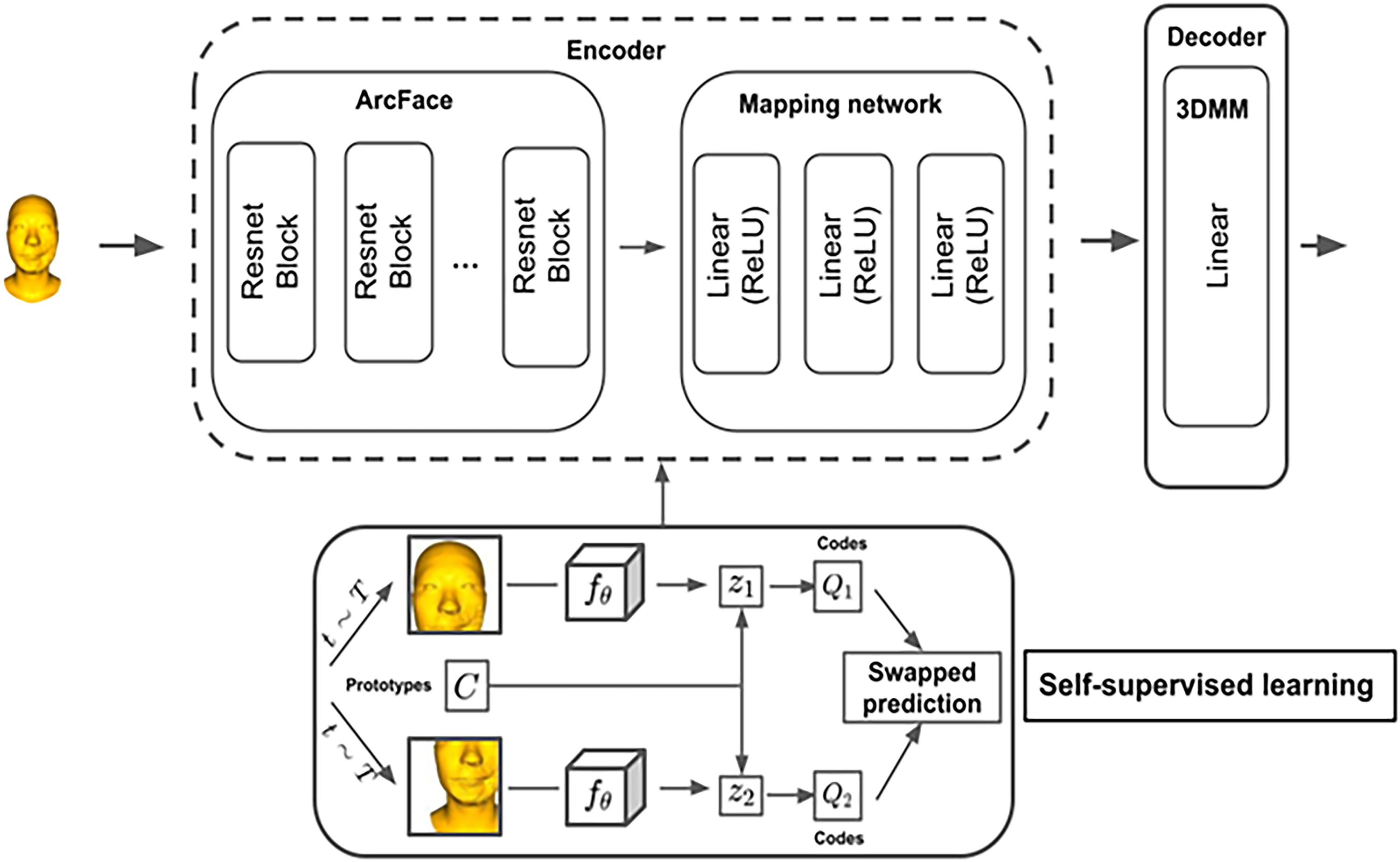
The theoretical model in this study is based on the pretrained Multimodal Image-conditioned Character Animation (MICA) model, 29 which serves as the base model for the self-supervised training process, as described in Figure 5. However, the study introduces several modifications to the input and output to meet the specific requirements for reconstructing injured facial areas, as illustrated in Figure 6. The model input consists of 2D images of the patient’s face with visible wounds, represented using three Red, Green, Blue (RGB) channels. The goal of the output is to generate an accurate 3D model of the original face along with the wound features. Therefore, the base model in this study is structured with two main components: an identity encoder (to encode facial features) and a geometry decoder (to decode geometric information for 3D reconstruction).
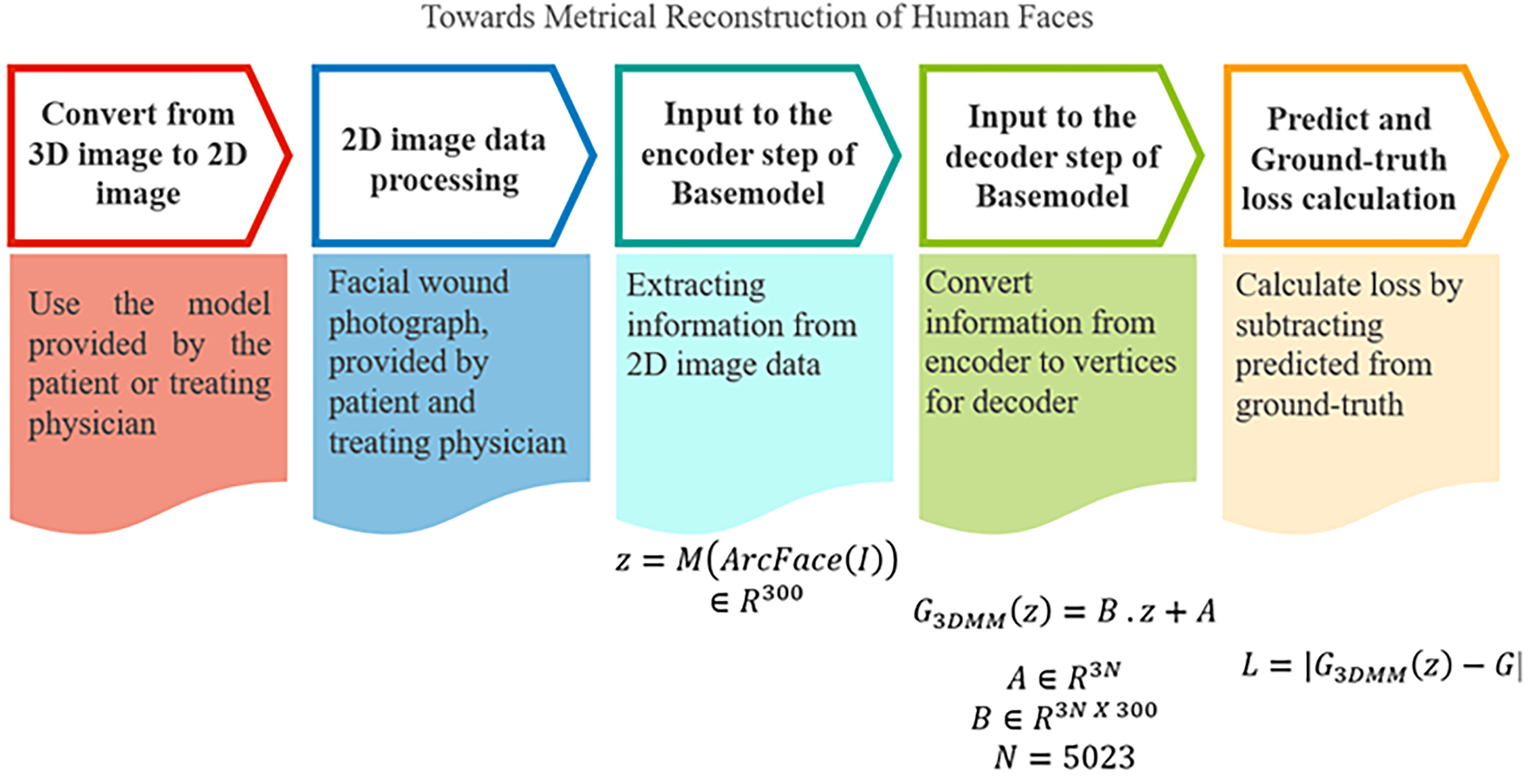
The process of using algorithms in the article.
The proposed research model.
The article has incorporated a comprehensive review of the literature focusing on 3D printing techniques applied in biomedical engineering, particularly for facial reconstruction. Various 3D printing technologies, such as fused deposition modeling (FDM), stereolithography (SLA), and selective laser sintering (SLS), have been widely utilized due to their unique capabilities. FDM offers cost-effectiveness and compatibility with biocompatible materials, SLA provides high precision for intricate anatomical structures, and SLS is recognized for its ability to fabricate durable and complex geometries. In the context of facial reconstruction, significant advancements have been made. For example, Cao et al. 15 reviewed SLA applications for nasal cartilage regeneration, demonstrating its potential in craniofacial prosthetics, whereas Shahrubudin et al. 26 addressed challenges and material innovations for 3D-printed facial implants. Furthermore, Zhu et al. 19 highlighted the integration of artificial intelligence and 3D printing to improve the customization and accuracy of facial models. Building on this foundation, our study employs a novel SSL approach to generate wound-covering models that are subsequently transformed into physical prototypes using FDM technology. This integration ensures accurate reconstruction, aesthetic restoration, and practical applicability, as demonstrated by the workflow in Figure 5. These additions contextualize our research within existing advances and underscore its contribution to advancing 3D printing applications in reconstructive medicine. The ultimate goal is that the parts reproduced from our proposed model will build on our previous in-depth research on 3D printing, 38 ultimately producing complete 3D-printed models. As illustrated in Figure 5, the process transforms the wound cover model through the 3D printer into an “actual product,” which can then be fitted to the “imperfect face,” resulting in a “practical application model.”
Identity encoder
The identity encoder comprises two main components:39,40 ArcFace41,42 and linear mapping,43,44 with the task of extracting identity characteristics from the input 2D images. The objective is to analyze and encode facial recognition information to facilitate accurate 3D reconstruction in the geometry detector phase.
ArcFace (
ArcFace is an advanced model based on the ResNet-100 architecture, which uses skip connections to directly transmit information between layers, minimizing the problem of vanishing gradients.39,40 Preventing vanishing gradients plays a crucial role in weight updates, ensuring uninterrupted training and effective learning of essential features. ArcFace also uses additive angular margin loss instead of traditional cross-entropy loss, enhancing its ability to classify and extract fine-grained facial features. This is especially important given that input images often have a limited color range, making it challenging to distinguish identities. This technique allows the model to detect even the smallest differences in the face, ensuring high recognition accuracy. Trained on the Glint360k dataset, which contains 170 million images from 360,000 individuals on four continents, ArcFace offers a wealth of diverse information. This study uses ArcFace pretrained weights to enhance recognition capabilities, enriching encoding and reconstruction results.
Linear mapping (
In the final stage of the model, the study integrates a block of three fully connected layers with ReLU activation functions to process and adjust the ArcFace information to fit the input size of the geometry decoder.43,44 This block plays a critical role in the transformation and normalization of information to ensure smooth and precise data transmission through subsequent steps.39,45 Using ReLU not only strengthens the nonlinear learning ability of the model but also helps avoid vanishing gradients, optimizing the training process. Furthermore, the study utilizes pretrained weights from other models and fine-tunes them with new data specific to this research. This approach reduces training time while ensuring faster and more efficient learning, improving the quality and accuracy of the 3D reconstruction process. The combination of ArcFace and linear mapping enables accurate encoding of identity information while preparing the output data for subsequent decoding steps in the geometry decoder.
Geometry decoder (G′)
This section employs Faces Learned with an Articulated Model and Expressions (FLAME), a renowned model for transforming 2D feature vectors into 3D anthropometric facial structures.46–48 FLAME is trained on 33,000 3D faces with precise alignment, allowing it to recreate facial features with subtlety and realism. The chosen base model utilizes an extended version of FLAME, further trained on various datasets such as Liverpool-York Head Model (LYHM), FaceWarehouse, and Stirling to enhance its ability to reconstruct key features such as nose size, facial thickness, and overall structure.40,49 Due to its training across diverse datasets, the geometry decoder not only reconstructs complex facial forms but also ensures precision and consistency during the transformation of 2D images.39,50 In this study, FLAME will be fine-tuned and retrained with new data specific to this research, helping it adapt and optimize for the reconstruction of injured faces, as detailed in Figure 7. This ensures that the model accurately restores the original facial characteristics and is also capable of reconstructing complex wound deformations, effectively supporting the recovery and wound-covering process. 45
Building the base model with FLAME.
Research Proposals
Self-supervised learning
To improve the learning capacity of the encoder, this study applies an SSL algorithm, which allows the model to familiarize itself with new datasets before entering the supervised learning phase.35,36 It is well known that when a pretrained model is further trained with new data, it may struggle to learn effectively if only a small amount of new data are provided.51,52 This situation can lead to undesirable weight changes, which prevents the model from sufficiently capturing new features.29,41,42 Therefore, the SSL algorithm is implemented to allow the model to autonomously recognize and adapt to differences in the new dataset before proceeding to supervised learning.
In this study, the supervised learning algorithm used is Swapped Assignments between Views (SwAV),53,54 which is based on contrastive instance learning and clustering techniques. Traditional clustering methods are typically performed offline, assigning samples to clusters and predicting their characteristics from various views of the data.55,56 However, these approaches are unsuitable for online learning as they require extensive computations throughout the dataset to identify the necessary characteristics for clustering.
SwAV offers a different approach by comparing multiple augmented versions of the same image and clustering them based on the characteristics of each version.
57
Specifically, this study computes a representative code from one augmented version of an image and predicts this code through other augmented versions of the same image. Given an original image with two augmented versions, represented by feature vectors
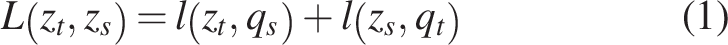
Online clustering
In the online clustering method, each image
Once the augmented view

This normalization ensures that the feature vectors remain within a consistent range, improving the effectiveness of the model comparison and clustering processes.
Prototype mapping and code calculation
Each feature vector

The mapping of a feature vector
Significance and effectiveness of online clustering
Using online clustering, the model can continuously learn from new data without stopping to recompute clusters for the entire dataset, as in offline clustering methods. This is particularly useful for online learning, where new data are continuously added and the model must quickly adapt. The online clustering method not only optimizes learning efficiency but also reduces computational costs, ensuring scalability and applicability in real-time systems.
Swapped prediction problem
In SwAV, the swapped prediction problem is formulated through a loss function with two terms. Each term predicts the code
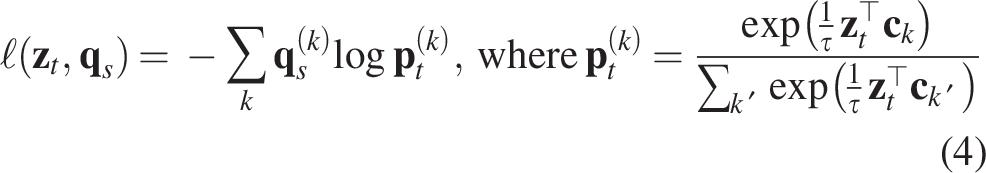
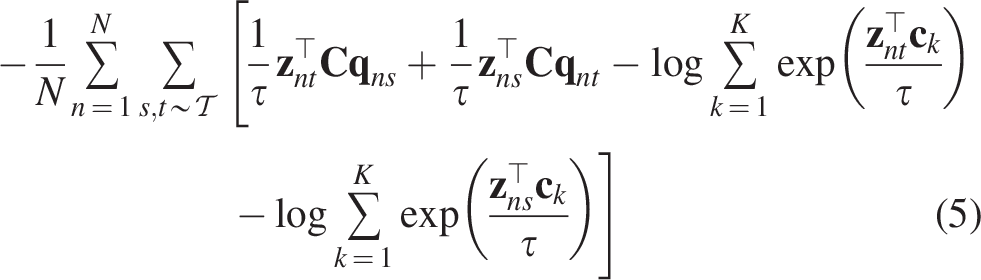
This loss function is minimized with respect to two parameters:
Prototype matrix C: The prototype vectors are trained to represent different clusters of features in the dataset. Image encoder parameters
Optimizing this generalized loss function ensures that the model learns invariant features from various views of the images. Additionally, it guarantees that the predicted codes and image features align with the trained prototypes, resulting in effective data clustering and precise recognition of new features.
Calculate codes online
To enable the article method to be used online rather than only offline, the study computes the codes using image attributes within a single batch. Since prototypes
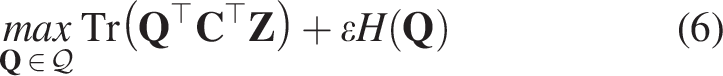
Given a characteristic vector
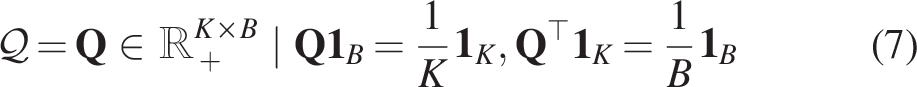
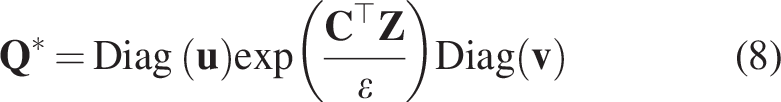
Supervised learning
The proposed model will be trained and optimized using key components in the encoder and decoder to ensure accurate encoding and reconstruction of 2D to 3D images, as shown in Figure 8. The training process aims to optimize the weights in the linear mapping layer of the encoder and the parameters of the FLAME model in the decoder while keeping the pretrained ArcFace weights unchanged to leverage the features learned from a large dataset:
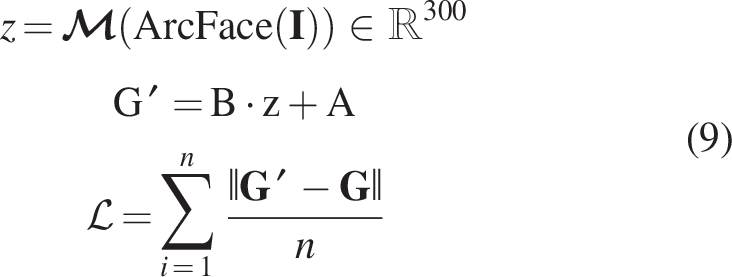
The proposed self-supervised learning model.
Encoder components
ArcFace: The ArcFace component in the encoder has been pretrained in the Glint360k dataset, which contains approximately 170 million facial images. Its weights remain fixed during training to efficiently utilize the recognition features already learned, reducing computational time and resources.
Linear mapping: The linear mapping block, consisting of three fully connected layers with ReLU activation functions, will be trained to optimize its weights. This block adjusts the output of ArcFace to fit the input requirements of the decoder. Training the linear mapping ensures that the model can encode features specific to the dataset used in this study.
Decoder component (FLAME)
The FLAME component in the decoder will continue to be trained and fine-tuned to optimize the reconstruction of 3D faces from 2D images, as illustrated in Figure 9. FLAME has been trained on various datasets, such as LYHM, FaceWarehouse, and Stirling, ensuring it can reproduce complex facial features, including nose size and facial thickness. However, to meet the objectives of this study, FLAME will undergo further fine-tuning with new data to improve the accuracy of reconstructing injured faces.
The FLAME component in the decoder, optimized for 3D facial reconstruction.
Model training algorithm
The model training process consists of the following steps:
Data input and augmentations: 2D facial images with visible wounds are transformed into augmented views using transformations from the set T. These augmented versions are passed through ArcFace to extract features as vectors Feature transformation via linear mapping: The feature vector Mapping and prediction with FLAME: The transformed feature vectors are inputted into the FLAME model within the decoder to reconstruct a 3D morphology from the 2D image. Code and prototype calculation: Prototypes are mapped, and codes are calculated from the augmented features, ensuring consistent recognition across multiple augmented versions of the same image. Loss function optimization: The swapped prediction loss function is used to optimize the weights of the linear mapping and FLAME components by minimizing the error between the predicted codes and the actual features. Weight update: The weights of the linear mapping and FLAME models are updated after each epoch, while the ArcFace weights remain fixed to preserve the features it has learned.
Conclusions on the training process
The training process demonstrates the model’s capability to effectively learn from new data while utilizing preexisting features extracted by the ArcFace component. Fine-tuning the linear mapping and FLAME components enables precise adaptation to the specific characteristics of facial injury datasets, significantly improving encoding and reconstruction accuracy. This optimized approach not only enhances precision but also reduces computational time, making the model highly applicable for practical use in regenerative medicine and aesthetic treatments. By ensuring efficiency and adaptability, this training methodology supports the development of reliable and scalable solutions for complex facial reconstruction tasks.
Experiments
Dataset construction
The construction of the dataset for this study was carried out through two main steps to ensure diversity and data quality for the task of reconstructing faces from 2D to 3D images. The dataset not only includes real injuries but also includes simulated wounds to increase the challenge and effectiveness.
Step 1: Collecting and generating 3D data with simulated scars
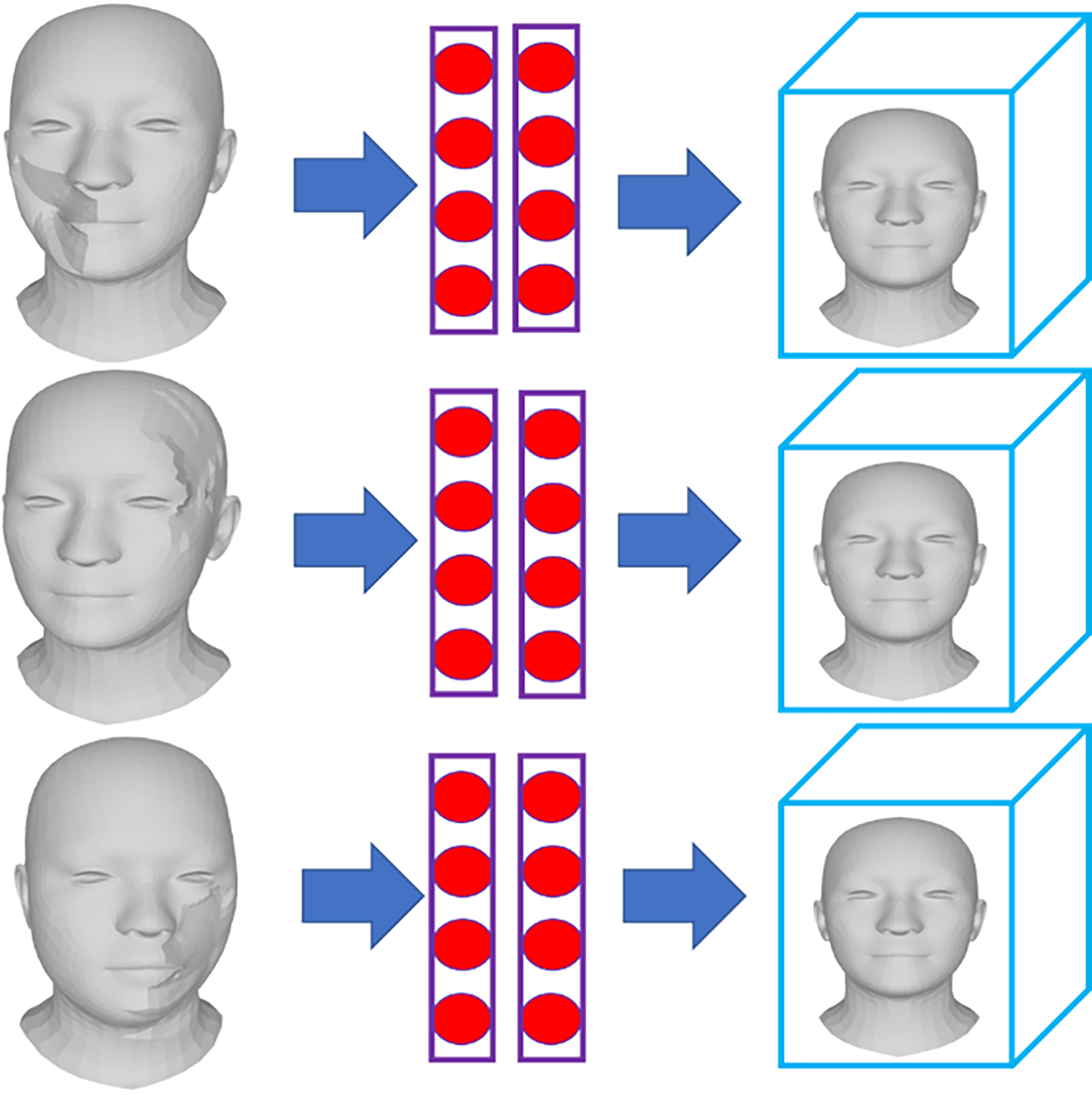
The study used 3D scanners to scan the faces of volunteers, collecting data in .obj files. These files serve as the ground truth for the 3D facial reconstruction task. From the original files, simulated injuries were created by selecting random areas of the face and altering the vertex values in those regions. These changes could generate protrusions or depressions on the 3D model, replicating real-world injuries such as scars and deformities that patients might experience. Furthermore, to increase the challenge and ensure the generalizability of the model, the study created unrealistic wounds that do not exist in real life. These wounds test the model’s ability to handle and accurately reconstruct even the most complex injuries. The face was augmented with multiple scars at different locations, such as the forehead, nose, mouth, cheeks, and eyes, enriching the dataset and ensuring the generalization capabilities.
Step 2: Generating 2D data and splitting the dataset
After 3D data with scars and injuries, the faces were rotated to a frontal position and photographed to create 2D images. Each photo was taken at 1024 × 1024 pixels, ensuring high resolution suitable for the task of reconstructing 3D models from 2D images. The dataset consists of more than 3000 2D images collected from more than 30 individuals, each individual having multiple images showing various wounds in different facial regions. During training preparation, data were split into three sets with a 6:2:2 ratio, corresponding to the training, validation, and test sets. To maintain objectivity and prevent overlap in physical characteristics between sets, the images of each individual were assigned to different sets. This ensures that the data in the train, validation, and test sets do not overlap, allowing for an accurate evaluation of the model’s ability to recognize and reconstruct unseen faces. The dataset was built with diversity and richness in the positions and types of injuries, improving the model’s ability to handle complex cases and generalize effectively. The combination of 3D data and 2D images, along with the careful data-splitting process, ensures that the model is trained efficiently and can accurately and consistently reconstruct new data during testing.
Configuration of parameters in the research model
Runtime and experimental setup
The experiments in this study were conducted on the Google Colab Pro platform, utilizing the power of Graphics Processing Units (GPUs) to accelerate the training process. The study only updates the weights for the linear mapping ( First epoch: Approximately 30 min to complete both the training and validation steps. Subsequent epochs: With cached data, each epoch takes only 90 s to run.
This optimization significantly reduces experimental time, allowing the model to converge quickly and achieve stable performance.
Hyperparameters and optimization algorithm
A consistent set of hyperparameters was used in all experiments to ensure consistency during training and evaluation.
Optimization algorithm: The study uses AdamW, a powerful optimizer suitable for models with many parameters, with an initial learning rate of 1 × 10−31. This learning rate remains unchanged throughout the training process to ensure stable convergence. Batch size: Each epoch uses a batch size of 50 images, balancing training speed with the hardware’s computational capacity. Number of epochs: The study runs 50 epochs for each experiment, ensuring that the model has sufficient time to deep learn the features from the data and achieve optimal convergence.
Figure 10 illustrates the changes in the loss values in two scenarios:
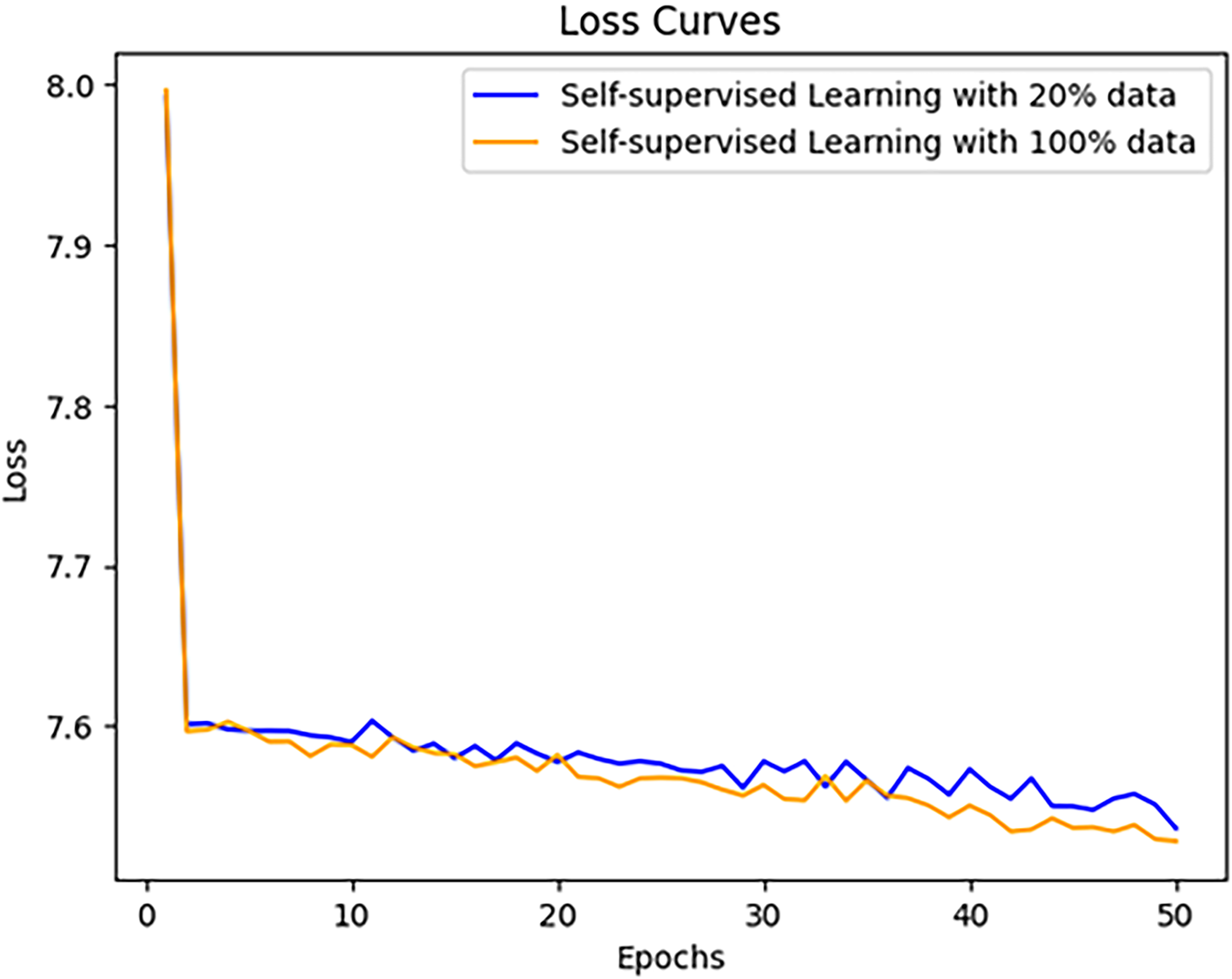
Loss values for each epoch.
20% of the data
100% of the data.
The results of Figure 10 show that in both cases, the loss values decrease similarly during the first 30 epochs. However, with 100% of the data, convergence occurs faster over the next 20 epochs, indicating that using the full dataset enables the model to learn more effectively and achieve greater stability during the training process.
Conclusions on stability and effectiveness
Thanks to the use of appropriate optimization strategies and efficient management of computational time, the model demonstrated exceptional stability during training. Faster convergence with 100% of the data indicates that the model effectively leverages the data to improve performance and accuracy. The training process was executed efficiently with well-tuned weights, ensuring that the model achieves optimal results in a short time while minimizing the required computational resources.
Dataset creation process
The dataset creation process in this study was carefully designed to provide a high-quality dataset that meets the research objectives of facial wound reconstruction and coverage. The dataset contains not only 3D and 2D facial images but also variations of wounds with different levels of complexity, from common injuries to rare deformities.
Stage 1: Collecting original data and creating 3D facial models
Participant selection: Volunteers of various sex and ages were selected to scan their faces, enriching the input data. This diversity helps the model learn a wide range of real human facial features. 3D face scanning: Volunteers of various sex and ages were selected to scan their faces, enriching the input data. This diversity helps the model learn a wide range of real human facial features. Capturing from multiple angles: After scanning, the faces were recorded from various angles to generate 2D images from the 3D models. This increases data diversity and enhances the training process.
Stage 2: Simulating scars and data augmentation
Simulating injuries and deformities: On each scanned 3D facial model, simulated injuries were created by selecting specific areas (e.g., forehead, nose, cheeks, or mouth) and adjusting the vertices in those regions. These injuries were designed as protrusions or depressions, mimicking real-world wounds and deformities. In addition to common injuries, the study introduced rare and unusual wounds to challenge reconstruction abilities, ensuring that it is applicable to complex cases. Generating 2D images: From each 3D model, 2D images with a resolution of 1024 × 1024 pixels were generated from multiple angles. This allows the model to train not only with 3D data but also with 2D data, improving its performance across various scenarios. Data augmentation: In this study, explicit data augmentation techniques were not applied separately. Since SSL inherently incorporates data enhancement during the training process, the model automatically generates enriched data representations. Through transformations such as random cropping, rotation, brightness variations, and noise injection within the SSL framework, the model learns more effectively. This integrated approach eliminates the need for separate data augmentation steps, ensuring that enriched data variations are seamlessly covered throughout the SSL training process.
Stage 3: Dataset splitting and training preparation
Dataset splitting: The dataset was divided into three sets with a 6:2:2 ratio for different purposes. Training: 60% of the data for model training. In this study, 60% of the data was allocated not only for training but also for model optimization. Instead of separating validation for optimization purposes, the optimization process was integrated directly into the training phase. This approach ensures that the model continuously fine-tunes its parameters during training, enhancing its performance, and reducing the need for a dedicated validation step for optimization. Validation: 20% of the data to adjust and optimize the model parameters. In this study, 20% of the data was allocated for validation, helping to assess the training progress and decide when to stop the training process in the model’s optimal state. The validation set monitors the model performance throughout training, ensuring that learning does not lead to overfitting and stopping the process when the model achieves its best performance. Testing: 20% of the data for evaluating the model performance on unseen data. In this study, 20% of the data was reserved for testing, which is used to evaluate the model’s performance on unseen data. This step ensures an objective assessment of the model’s ability to generalize and perform accurately on new, untrained inputs, reflecting its real-world applicability. Preventing data leakage: To ensure objectivity, each set contains images from different participants, preventing the model from memorizing the training data and ensuring that it truly learns how to reconstruct and cover wounds.
Significance of the dataset in research
The dataset enables the transformation of 2D images of scarred faces into complete 3D models. The diversity and richness of the dataset ensure that the model can effectively handle a wide variety of wounds, from minor injuries to complex deformities. The careful preparation and strict control of the dataset ensure accuracy and reliability in the results, which improves the potential application of this research in regenerative medicine and aesthetic surgery.
Experiment settings
This study conducted a total of five experimental cases to evaluate the effectiveness of the model under different training conditions. In the first case, the pretrained base model was used and further trained with new data to enrich and diversify the dataset. This was a fundamental step to evaluate the model’s ability to integrate old and new data during deep learning. In the remaining four cases, the study applied the SSL algorithm described in the “Supervised learning” section to enhance the encoder’s learning capacity before entering the supervised learning phase. SSL was carried out over 50 epochs to optimize the model’s ability to learn from unlabeled features. The experiments were carried out under two primary conditions:
Using 20% of the training dataset. Using 100% of the training dataset.
Figure 11 illustrates the changes in training loss during the SSL phase using 20% and 100% of the dataset. In general, the results do not show significant differences in loss between the models during the early stages of training. Both cases maintained a steady decline in loss during the first 30 epochs. However, in the later epochs (between epochs 30 and 50), the loss using 20% of the data decreased more effectively than with 100% of the data. This indicates that while using a larger dataset provides the model with more information, the self-learning process struggled to adapt to the increased volume of data. This difficulty may arise from the complexity of processing and learning from the entire dataset, affecting the model’s ability to converge effectively in the final stages of training. The experimental results suggest that SSL helps the model learn better from unlabeled data before transitioning to supervised learning. Although both cases, 20% and 100% of the dataset, performed similarly in the early epochs, the 20% dataset case showed better performance near epoch 50. These findings highlight that the model can achieve more stable learning with smaller datasets during SSL, whereas larger datasets can pose challenges in processing and adaptation. These results emphasize the importance of choosing the appropriate data volume for SSL, particularly for models that need to learn from diverse and complex data, such as reconstructing faces from 2D to 3D images.
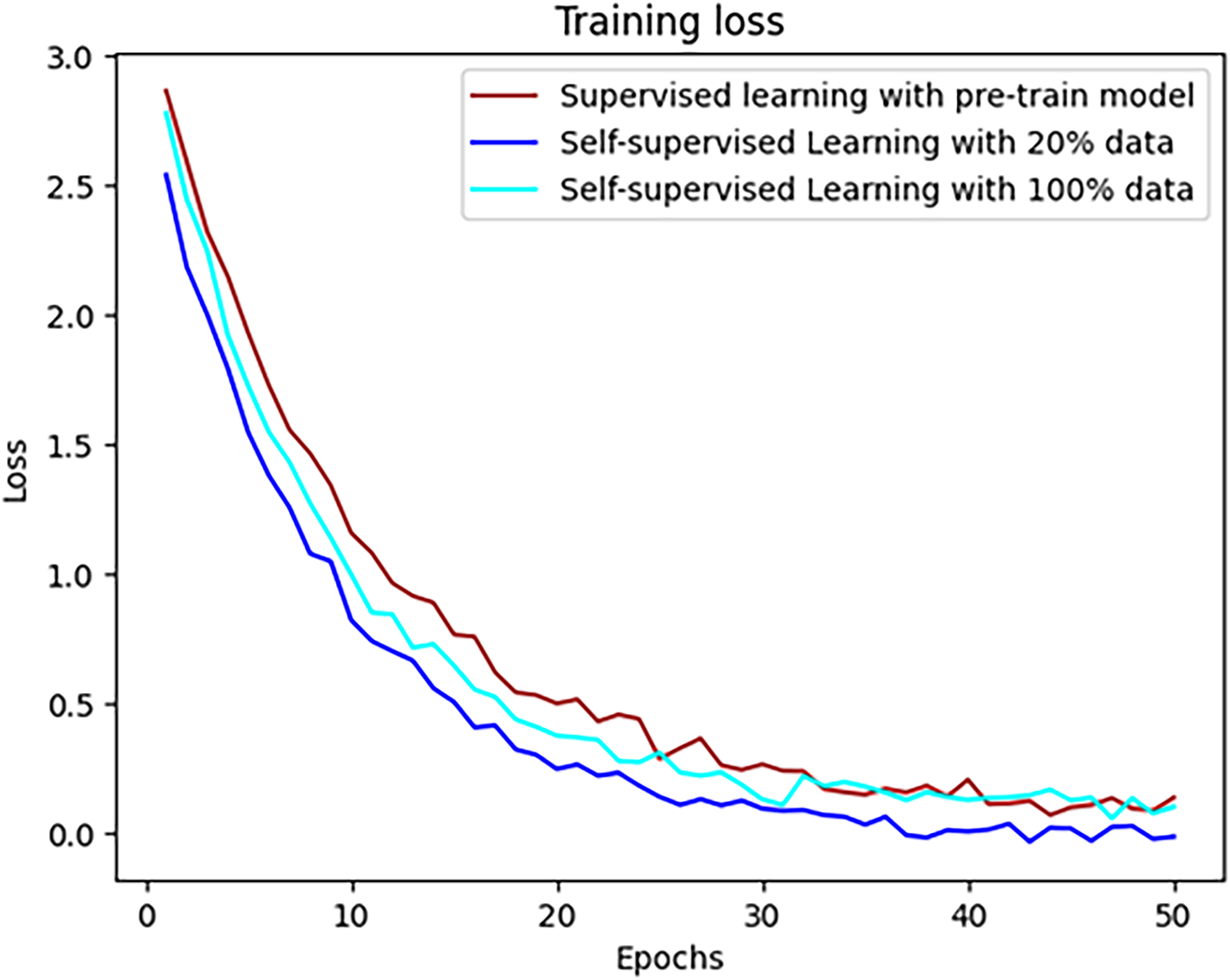
Training set loss.
The results in Figure 12 demonstrate the stability of the loss function during training in three scenarios:
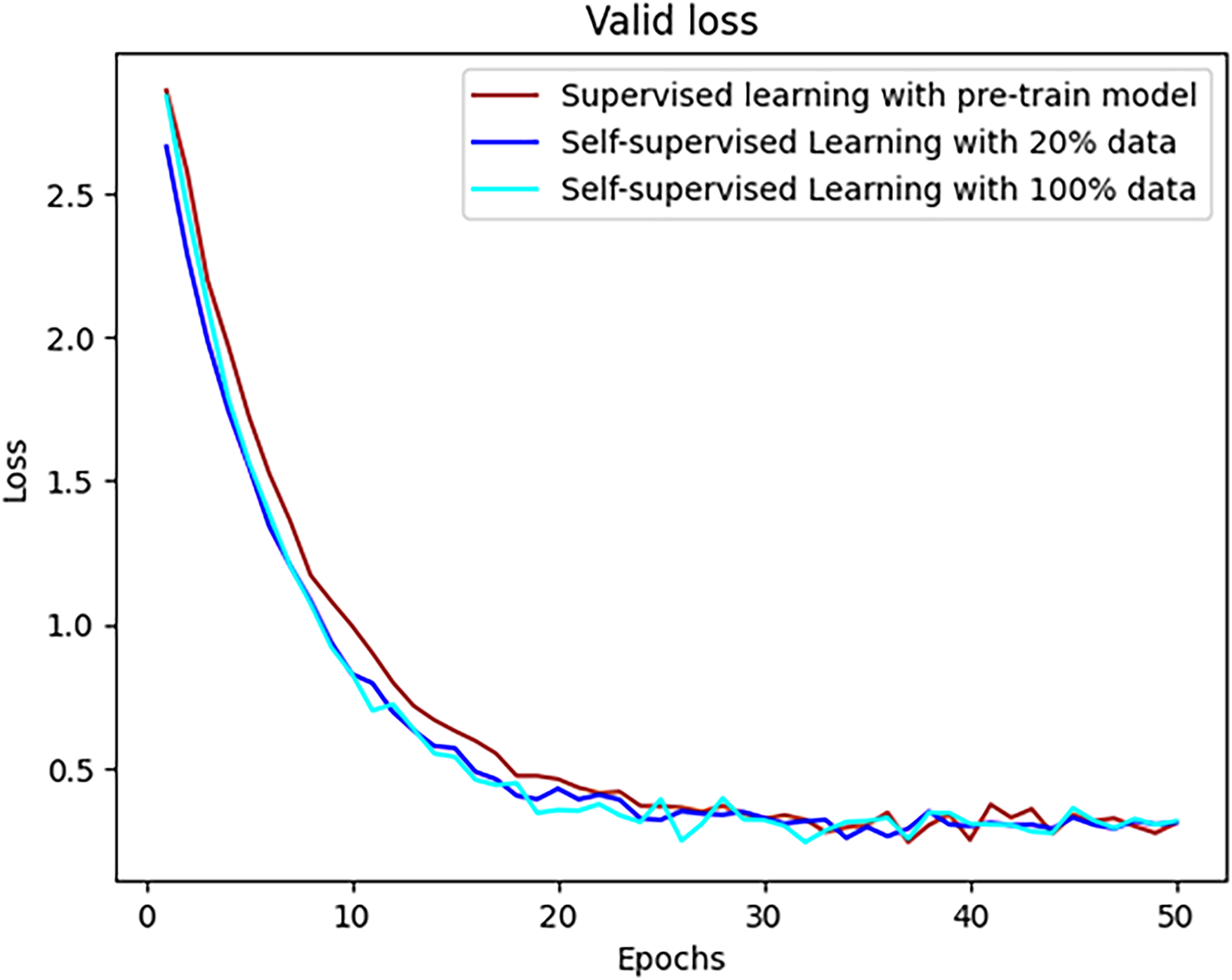
Loss of validation set.
Using only the pretrained base model.
Apply SSL to the base model with 20% of the data.
Apply SSL to the base model with 100% of the data.
Training set loss: In all scenarios, the training loss stabilized early, around epoch 10, with values approaching below 0.5. After epoch 10, the loss reduction slowed, but it maintained a steady downward trend, nearing zero by epoch 50. Overall, the three loss curves remained stable throughout the training process, with no significant differences, indicating that the different training methods achieved similar effectiveness in reducing training loss. Validation set loss: On the validation set, the loss curves showed more fluctuation around epoch 10, but they gradually stabilized and continued to decline toward epoch 50. These fluctuations may result from differences between new and training data samples or from the model’s weight adjustments during the early epochs. However, after these initial fluctuations, all cases converged to a stable loss level.
Comparison of training methods
The results of Figure 12 reveal the following information:
SSL with 100% of the data achieved the lowest validation loss after epoch 50, demonstrating that using the entire dataset helps the model learn more features and improves generalization. SSL with 20% of the data also performed well, achieving a lower loss than the pretrained supervised learning model, although not as optimal as the case with 100% data.
Conclusion of training methods
The training results highlight the superior effectiveness of SSL when using the full dataset, achieving minimal loss, and improved generalization. In particular, SSL with 20% of the data also demonstrated strong performance, indicating its potential for effective training with limited data. In contrast, the pretrained supervised learning model exhibited lower overall performance but maintained stability throughout the training process. These findings emphasize the critical role of SSL in enhancing model learning capacity and optimization, particularly in scenarios involving diverse and complex datasets. This approach provides a robust foundation for advancing applications in data-intensive fields.
The results of Table 1 demonstrate that the methods proposed in this study have brought significant and stable improvements in the facial reconstruction process.
Loss Values Across Different Methods

Presupervised learning achieved a loss of 0.36, which is an acceptable outcome to reconstruct facial wounds. However, there is still room for improvement in reconstruction performance.
SSL with 20% of the training data reduced the loss to 0.3, indicating a noticeable improvement. This result confirms that allowing the model to learn from unlabeled data improves performance before entering the supervised learning phase.
Increasing the data to 100% further reduced the loss to 0.2, a 0.1 improvement compared with the 20% case. This result highlights that providing more data during the SSL phase allows the model to learn deeper features, improving its ability to reconstruct the face.
These findings show that enabling the model to self-learn with a smaller data volume before entering the main training process provides significant improvements without increasing model complexity. This opens up the potential for model optimization at a lower cost, especially useful in tasks requiring the handling of complex and diverse data, such as facial reconstruction.
Figure 13 provides a visual example of the discrepancy between the reconstructed results and the actual data when the model reconstructs the structure of the facial wounds. In the image, brightness is used to indicate the degree of error: brighter areas correspond to larger deviations, whereas darker areas indicate minor or negligible errors.

Derivation between results and reality.
The results show that the model accurately reconstructed most of the undamaged areas of the face, with near-perfect accuracy. This confirms the ability to preserve morphological features in unaffected areas, despite using only 2D images as input. However, in areas with wounds, some errors are inevitable due to the complexity and variability of the scar morphology.
However, these errors remain within acceptable limits and fully meet the requirements for reconstructing damaged facial areas. These findings emphasize that the model can effectively recover facial structures, even when the input data consist only of 2D images—a significant challenge in the field of reconstruction and aesthetics.
Model comparison and evaluation
In evaluating the effectiveness of the model, loss serves as a key indicator of the overall discrepancy between the predicted output and the original data. However, to ensure comprehensive accuracy and assess the model’s ability to reconstruct detailed 3D facial structures, additional statistical metrics such as mean absolute error (MAE), root mean square error (RMSE), and intersection over union (IoU) are used. Table 2 provides a detailed comparison of these metrics together with the experimental results.
Comparison of MAE and RMSE Among Methods

MAE, mean absolute error; RMSE, root mean square error.
The experimental results show that applying SSL significantly reduces MAE and RMSE compared with the supervised learning pretrain model:
Presupervised learning achieved MAE of 0.052 and RMSE of 0.065, indicating a relatively high discrepancy between the reconstructed faces and the actual data, highlighting the need for improvements. SSL with 20% of the data reduced the MAE to 0.041 and the RMSE to 0.055, indicating a substantial improvement, although it remained suboptimal due to the limited amount of self-learned data. SSL with 100% of the data achieved MAE of 0.035 and RMSE of 0.048, reflecting the lowest error and the highest accuracy among the methods.
These results demonstrate that providing the model with full access to the data during SSL enables it to learn complex features more effectively, improving the precision of facial reconstruction. The gradual reduction in MAE and RMSE highlights the progression and effectiveness of the self-supervised approach, showing that the model operates more stably and efficiently when exposed to comprehensive data. This underscores the value of self-learning in improving model performance, especially in applications such as reconstructive medicine and aesthetic surgery, where high precision and reliability are crucial.
The IoU results in Table 3 reveal significant improvements with the application of SSL, especially when the full dataset is used. IoU measures the overlap between the reconstructed wound areas and the ground truth, reflecting the model’s ability to accurately segment and reconstruct.
IoU Results for Different Reconstructed Regions
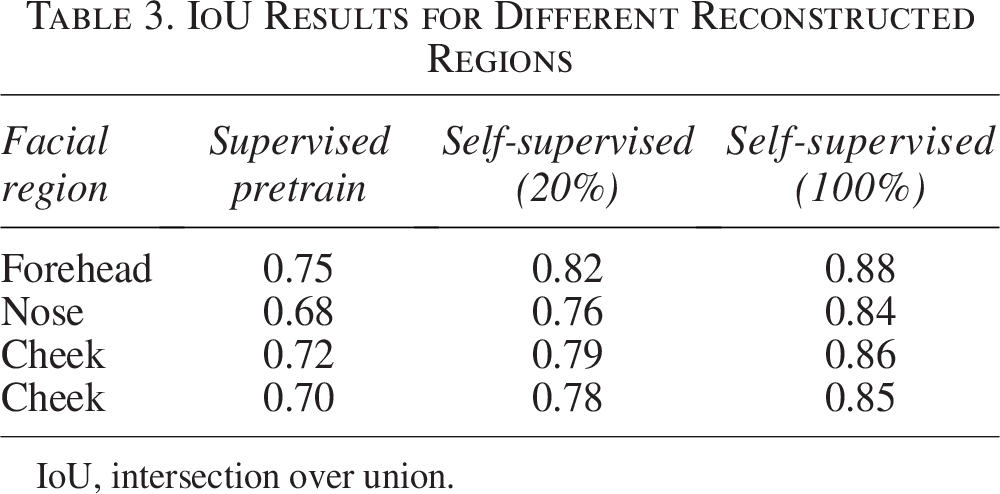
IoU, intersection over union.
In the supervised pretraining model, the IoU values in regions such as the forehead, nose, cheeks, and mouth ranged from 0.68 to 0.75, indicating limited precision and highlighting the need for better reconstruction.
When 20% of the data were used for SSL, the IoU values improved to a range of 0.76–0.82, demonstrating enhanced recognition and reconstruction ability.
The most significant improvement was observed with 100% of the data for SSL, with IoU values reaching 0.84–0.88 in different regions. This shows that the model can accurately and precisely reconstruct facial structures, even in challenging areas such as the nose and mouth.
These results highlight several key findings:
Superiority of SSL: The model trained with 100% of the data using SSL achieved the lowest MAE and RMSE, along with the highest IoU across various reconstructed regions. This demonstrates that exposing the model to data before formal training improves its ability to recognize features and minimizes reconstruction errors. Significance of MAE and RMSE: MAE reflects overall accuracy, whereas RMSE emphasizes large errors. With a lower RMSE, the model shows the ability to accurately reconstruct even complex injuries. IoU and accurate segmentation: IoU measures the alignment between the reconstructed results and the truth of the ground. High IoU values, particularly in regions such as the nose and mouth, demonstrate the ability to accurately reconstruct fine and critical details of the face.
The findings underscore the value of SSL in improving model performance, particularly when working with complex and diverse data. The ability to learn effectively from unlabeled data before supervised training enables the model to achieve greater accuracy and precision. This approach has significant potential for applications in reconstructive surgery and aesthetic medicine, where high-quality and reliable results are essential.
Comparison and evaluation of data models
The comparison between methods demonstrates that SSL improves model performance in terms of loss and error reduction, albeit at the cost of increased computation time. Improvements in accuracy and facial reconstruction capabilities highlight the significant potential of this approach for future applications in reconstructive medicine.
Comparison methodology
This study evaluates the effectiveness of the model based on the following criteria:
Loss function: Measures the progress during training and convergence over time. Computation time: Assesses the time required per epoch and the total training duration.
Model performance comparison
The results in Table 4 show that the application of SSL played a crucial role in improving performance and accuracy. This method allowed the model to learn from unlabeled data before the formal training phase, helping it to grasp the complex characteristics of the input data.
Loss Results
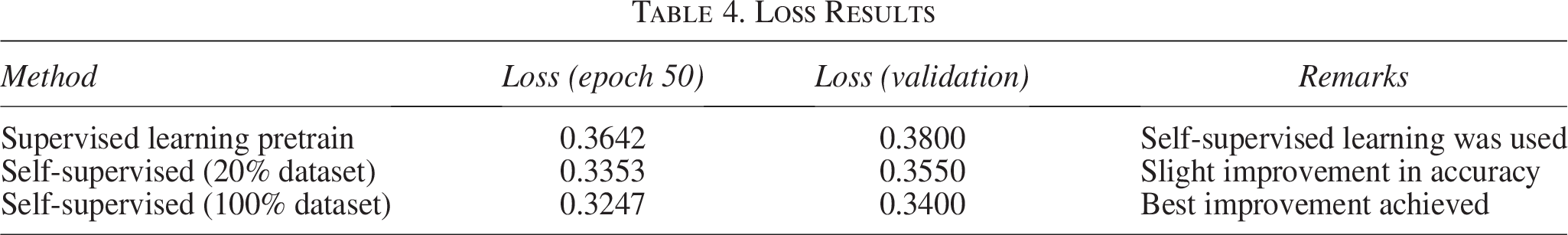
Using SSL with 100% of the data enabled the model to capture the full range of data variations (e.g., facial shapes and scar locations), significantly enhancing its recognition and reconstruction abilities. Experiments show that SSL helps reduce loss and accelerate model convergence. By familiarizing itself with the data beforehand, the model avoided starting from scratch and quickly fine-tuned its parameters during the supervised learning phase.
This process also mitigates the risk of gradient vanishing and prevents overfitting, especially when working with complex and diverse training data. Although using 100% of the data required more computation time, the tradeoff is justified in applications requiring high accuracy, such as reconstructive and aesthetic surgery. Access to the full range of data features ensured more stable performance, helping the model avoid common training issues.
The results in Table 5 show that the application of SSL slightly increased the training time, particularly when using 100% of the data. Specifically:
Training and Computation Time

The pretraining base model learning took 30 min per epoch, completing 50 epochs in 25 h.
SSL with 20% of the data increased the time to 32 min per epoch, totaling 26 h and 40 min for the entire process.
SSL with 100% of the data further increased the time to 35 min per epoch, resulting in 29 h and 10 min for 50 epochs.
Although the increase in computation time was unavoidable, the benefits in terms of improved accuracy and convergence make the tradeoff worthwhile. By familiarizing itself with the data before formal training, the model achieved faster loss reduction and greater stability. Although the computation time increased, the resulting improvements in accuracy and facial reconstruction performance validate the value of this method in reconstructive medicine, where high quality and reliability are top priorities.
The comparison between methods confirms the superiority of SSL in improving model performance. Using 100% of the data during SSL led to the lowest loss and the highest IoU in different facial regions. This demonstrates that allowing the model to familiarize itself with the data prior to supervised training improves its ability to recognize features and reduces reconstruction errors.
Key insights include:
Effectiveness of SSL: The model with SSL and 100% data achieved the best MAE, RMSE, and IoU scores, confirming that this approach improves feature recognition and minimizes errors. Significance of MAE and RMSE: MAE reflects the general accuracy, whereas RMSE emphasizes larger errors. A lower RMSE shows the model’s ability to accurately reconstruct even complex wounds. IoU and accurate segmentation: The IoU measures the overlap between the reconstructed results and the ground truth. High IoU values in regions such as the nose and mouth highlight the model’s ability to precisely reconstruct fine details, which is critical in applications requiring high accuracy.
Although SSL with 100% of the data requires more computation time, the improvement in accuracy and reconstruction quality makes this tradeoff reasonable. This method ensures that the model performs reliably and stably, making it suitable for use in reconstructive surgery and aesthetic applications, where high standards of precision and reliability are essential.
Analysis and evaluation
The research results demonstrate that SSL plays a crucial role in improving the model’s accuracy and reducing loss compared with the supervised learning pretrain method. When the model is familiarized with the data beforehand, it learns essential features more effectively, making the formal training process faster and more accurate. However, this approach comes with a slight increase in computation time, particularly when using the entire dataset, due to the additional SSL step.
Although training time increases, the results show a significant reduction in error, indicating that the tradeoff between time and performance is reasonable. The ability to accurately reconstruct faces and reduce errors in complex cases, such as diverse facial injuries, underscores the value of SSL. This superior performance demonstrates that SSL not only improves technical outcomes but also improves the stability and reliability of the model.
Due to its high reconstruction accuracy and low error rate, the proposed model has significant potential for applications in reconstructive medicine and aesthetic surgery, as shown in Figure 14. Given the strict accuracy requirements in these fields, the use of SSL presents opportunities to improve treatment outcomes and optimize recovery processes for patients.
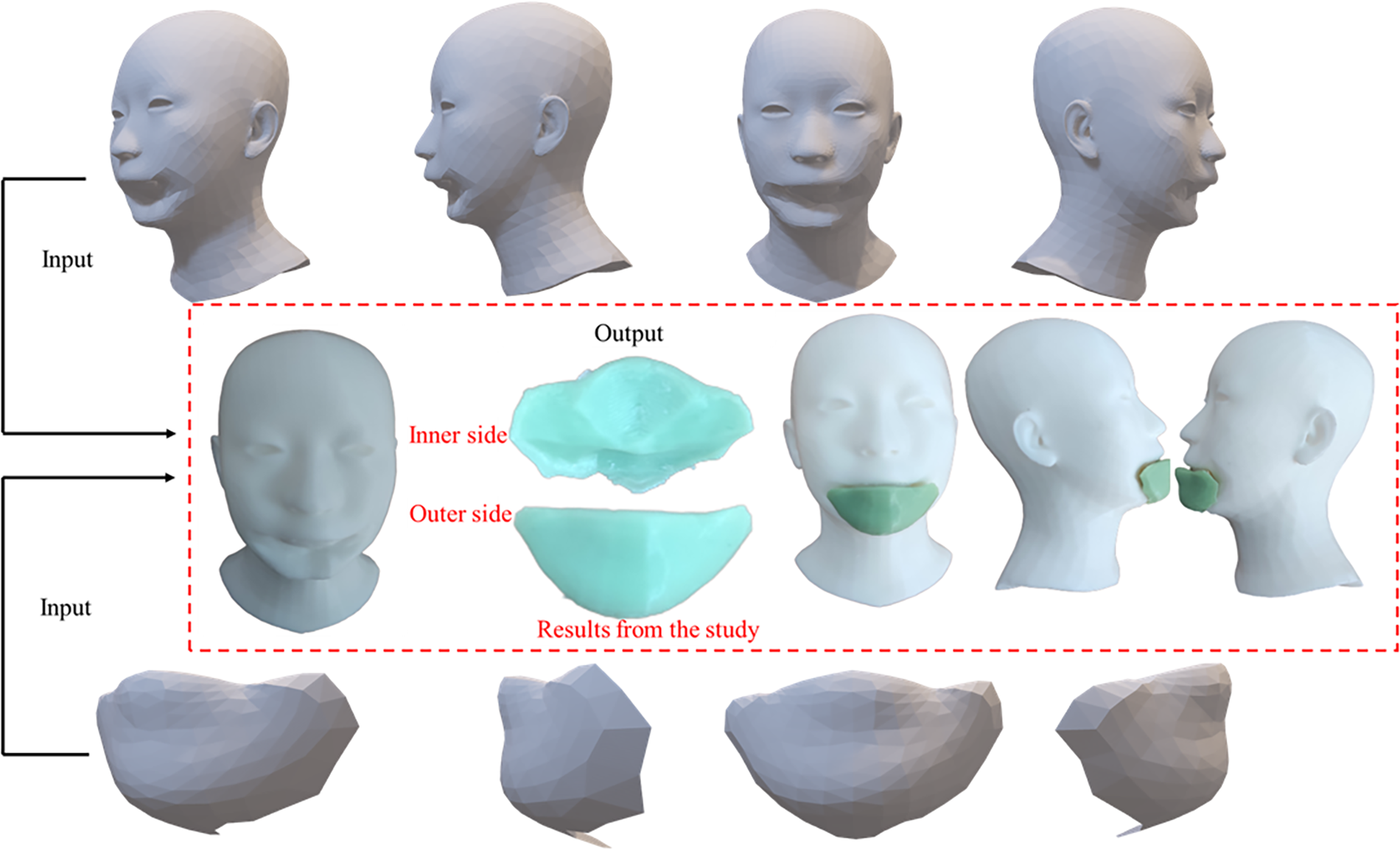
Research results from the proposed model.
To perform the final stage of 3D printing the defective parts, as illustrated in Figure 14, we used a popular FDM plastic printer, the Elegoo Neptune 4 Pro. The printing process was divided into two independent steps: first, printing the defective face part, and second, printing the cover part calculated by our model. The resulting cover part was found to completely conceal the defective facial region.
The printing parameters were derived from the optimal printing parameter prediction technique of our previous study. 38 Specifically, the printing speed was set at 120 mm/s, utilizing Polylactic Acid (PLA) plastic with a printing temperature of 210°C. The remaining settings were automatically configured based on the recommendations from the aforementioned study.
Conclusions and Future Directions
Conclusions
This study successfully integrates a pretrained model with SSL to achieve effective 3D facial reconstruction for cases involving injuries and deformities. By leveraging pretrained models, the research optimizes computational efficiency while allowing flexibility in fine-tuning and expanding datasets. The SSL approach significantly enhances the model’s ability to adapt to new data, resulting in improved reconstruction accuracy and reduced errors compared with traditional methods.
Experimental evaluations demonstrate substantial improvements in key metrics, including MAE, RMSE, and IoU, showcasing the model’s robustness in handling complex cases with severe injuries. This methodology not only addresses the technical challenges of facial reconstruction but also provides practical solutions for the surgical and recovery processes. The findings underscore the potential of this approach to advance applications in reconstructive medicine and aesthetic surgery, paving the way for innovative and patient-centric solutions in these critical fields.
Future directions
Integrating more diverse data sources: Develop an expanded dataset that includes a wider variety of injuries and facial structures, increasing the model’s applicability for diverse populations.
Application of IoT and real-time machine learning technologies: Aim to integrate the model with IoT technologies and smart devices, enabling real-time monitoring and updates to the model to better support treatment processes.
Strengthening collaboration with hospitals and research centers: Test the model in real-world medical environments to further optimize and customize it to meet clinical treatment needs.
Enhancing automation and improving computational speed: Develop additional optimization algorithms to improve training and computational speed, meeting time-sensitive requirements in emergency situations.
Expanding applications to other body parts: While this study focuses on facial reconstruction, the model can be extended to other parts of the body such as the hands, legs, or torso to provide comprehensive reconstruction solutions for patients.
With these future directions, the study aims to continue to improve the practical applications of the model in reconstructive medicine and contribute advanced solutions for patients requiring functional recovery and reconstruction.
Authors’ Contributions
N.T.T.: Conceptualization, software, and writing—review and editing. N.D.C.: Formal analysis and investigation. N.N.N.: Conceptualization, methodology, and writing—review and editing. T.Q.N.: Supervision, writing—review and editing, and visualization.
Footnotes
Author Disclosure Statement
No conflicts of interest declared by the authors. This is to certify that to the best of authors’ knowledge, the content of this article is original. The article has not been submitted elsewhere nor has been published anywhere.
Funding Information
This research was conducted without any financial support from funding agencies. No grants were received from governmental, private, or non-profit organizations for the execution of this study. The authors carried out the research independently, and any resources used were funded by the authors themselves.
Originality Statement
Thanh Q. Nguyen hereby declare that this submission is my own work and, to the best of my knowledge, it contains no materials previously published or written by another person, or substantial proportions of material. Any contribution made to the research by others, with whom I have worked in draft or elsewhere, is explicitly acknowledged in the draft.
Informed Consent Statement
Informed consent was obtained from all participants involved in this study. Prior to participation, the objectives, procedures, potential risks, and benefits of the study were thoroughly explained to each participant, ensuring they understood and voluntarily agreed to participate.