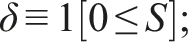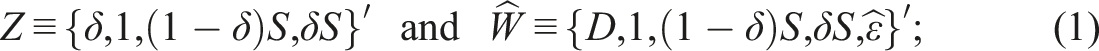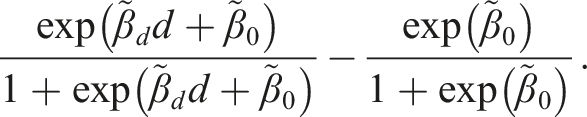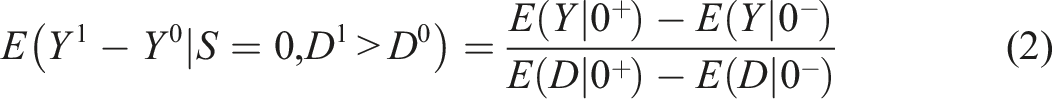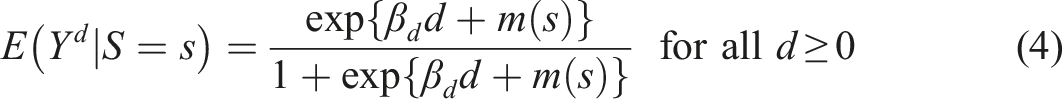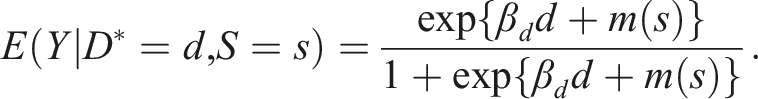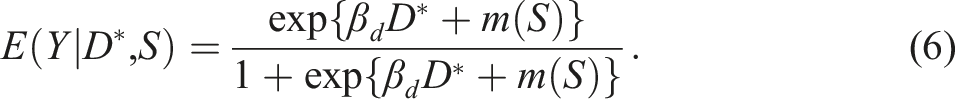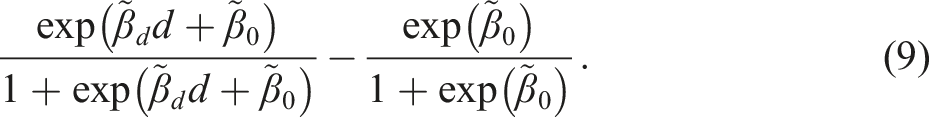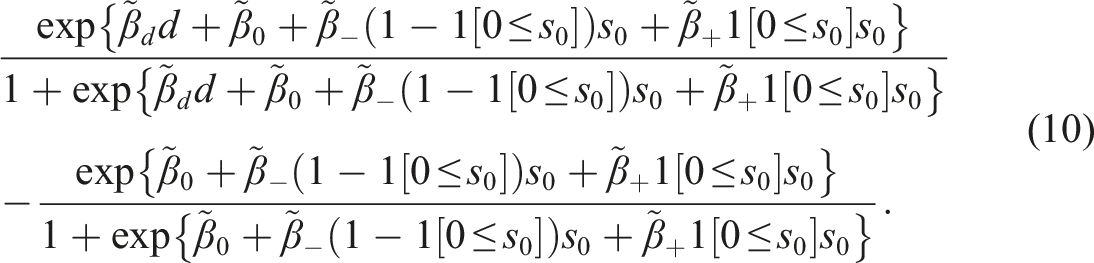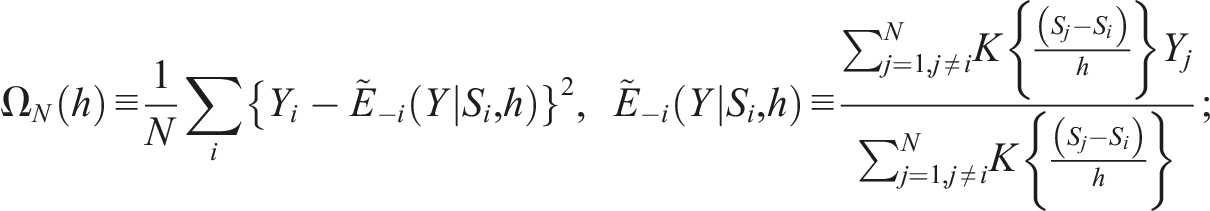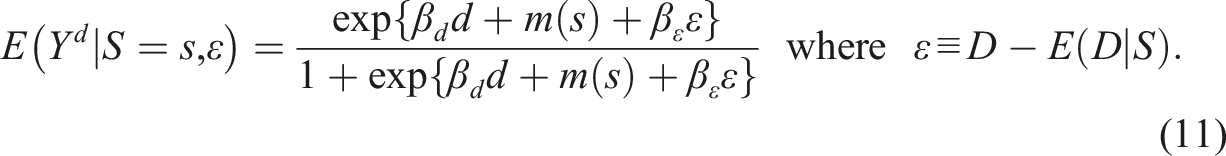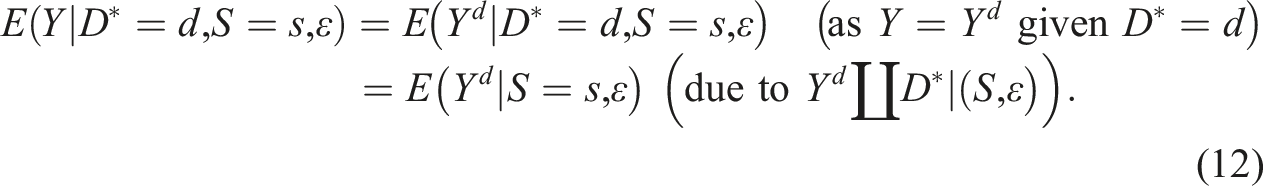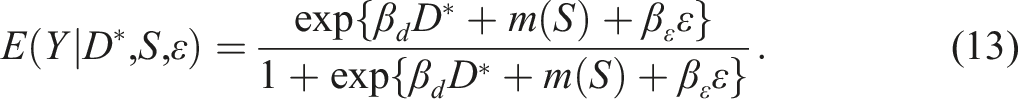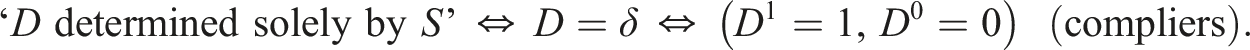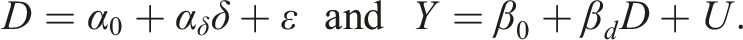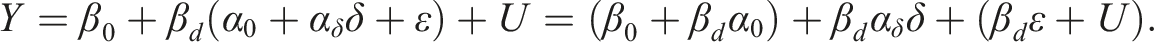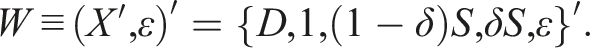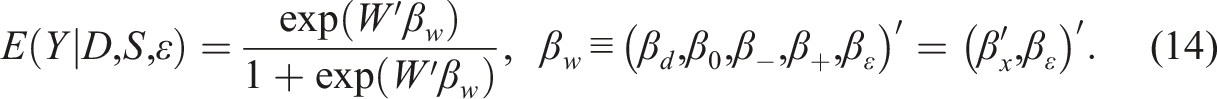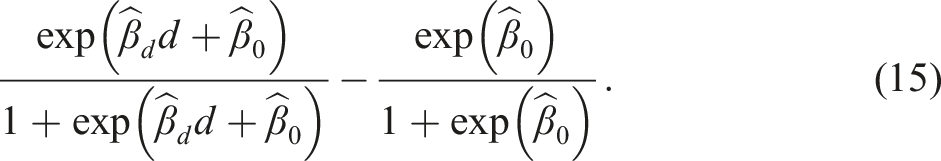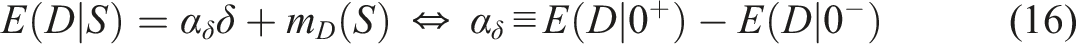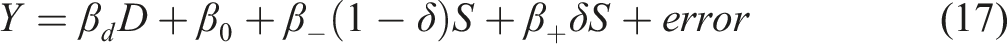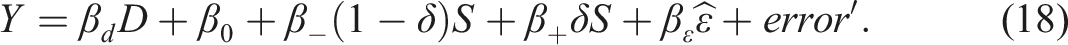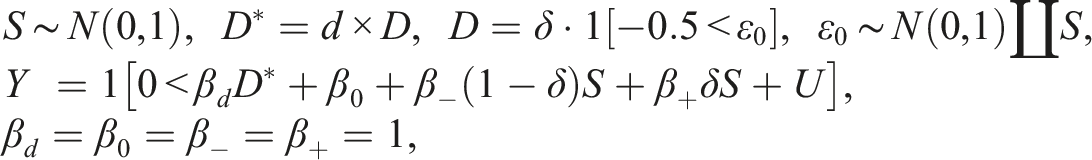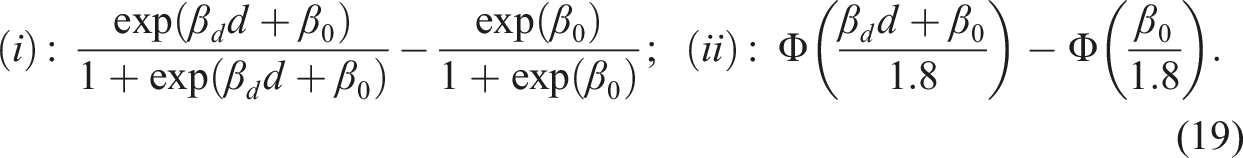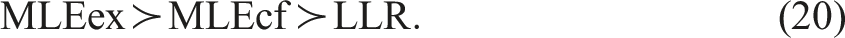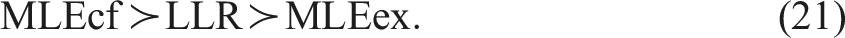Regression discontinuity is popular in finding treatment/policy effects when the treatment is determined by a continuous variable crossing a cutoff. Typically, a local linear regression (LLR) estimator is used to find the effects. For binary response, however, LLR is not suitable in extrapolating the treatment, as in doubling/tripling the treatment dose/intensity. The reason is that doubling/tripling the LLR estimate can give a number out of the bound , despite that the effect should be a change in probability. We propose local maximum likelihood estimators which overcome these shortcomings, while giving almost the same estimates as the LLR estimator does for the original treatment. A simulation study and an empirical analysis for effects of an income subsidy program on religion demonstrate these points.
Regression discontinuity (RD) is popular in social sciences to find treatment/policy effects when a binary treatment is determined by a continuous variable (or “score”) crossing a known cutoff or not; see Imbens & Lemieux, 2008; Lee & Lemieux, 2010; Lee, 2016; Choi & Lee, 2017, 2021; Cattaneo & Escanciano, 2017; Cattaneo et al., 2019, and references therein. In practice, not just the treatment , but also the outcome/response variable is often binary. Then, the treatment effect on becomes a change in probability.
To fix ideas for this paper, consider Collins et al. (2018), who estimate the impact of a food subsidy on food security (a binary ). In practice, one would often test such a policy at a specific value of the subsidy, say $30 per month. Then one might want to extrapolate to other values, such as $60 (doubled) or (tripled). Ideally, the policy would be implemented with or as well, which is, however, a costly proposition. Not just or , but also there are many other doses/levels of interest for the treatment, and certainly not all of them can be tried to make extrapolation unavoidable.
Suppose that assignment to the food subsidy program takes a RD form of a score (say, income) relative to : the subsidy is provided if . Write this as , where if holds and otherwise—the food subsidy in Collins et al. (2018) is not a RD though. In this case, RD is the natural estimator, but how to extrapolate is less clear. Extrapolation in RD with binary is the question addressed in this paper. Since extrapolation is the flip side of interpolation, our discussion on extrapolation applies mostly also to interpolation, which will not be thus further mentioned.
In RD, if is determined only by , then the RD is called a “sharp RD (SRD)”; if is determined by where is an error term, then the RD is called a “fuzzy RD (FRD).” In FRD, becomes endogenous/confounded if affects ; in SRD is always exogenous because no appears. We have in the above example, but we set in this paper either as for SRD or its “fuzzy version” for FRD. Also, we set , which can be always arranged by redefining as (and multiplying by to reverse the inequality, if necessary). With the normalized , define
in SRD, and is used as an instrument for endogenous in FRD.
For practitioners not interested in the theoretical details, we present our main recommendation to do extrapolation in SRD and FRD for binary with regressors
is introduced shortly. For SRD with , using a local sample with for a chosen “bandwidth” , apply the logistic maximum likelihood estimator (MLE) of on to obtain the estimators for , for , and so on. Then the SRD effect of on ( for extrapolation) relative to around is
For FRD with , still using the local sample, first, obtain the ordinary least squares estimator (OLS) of on to get the residual . Second, apply the local logistic MLE of on to obtain the estimators for , for , and so on. Third, find the effect of on relative to around with
In the following, we introduce notation and some results in the RD literature to facilitate our discussion in Logistic Causal Model and Local MLE. Practitioners not keen on theoretical details may want skip the following to move on to Simulation Study and Income Effect on Being Evangelical for simulation and empirical studies.
Let be the potential binary treatments corresponding to , and be the potential versions corresponding to of the observed ; for SRD, and due to . Under , Hahn et al. (2001) showed
where and , which are the right- and left-limits at . The left-hand side of (2) is a “local average treatment effect” in Imbens and Angrist (1994), and those with are called “compliers” (Angrist et al., 1996). The right-hand side can be estimated with sample means around , or more generally, with a “local linear regression (LLR) estimator” or a local polynomial regression estimator.
Suppose we want to know the effect of an extrapolated treatment changing from to ; since is a counterfactual treatment, we use the notation to distinguish it from the actual binary treatment . An immediate answer based on (2) is a linear extrapolation:
However, despite that the effect should be a number in because is binary, (3) may not respect the bound, which is the problem with (3).
Linear extrapolation in (3) is simple, but it may not hold if the very fact of receiving the treatment per se shifts the intercept in much while the treatment dose/intensity effect is relatively small, in which case increasing the dose has less than proportional effects. For instance, in the aforementioned food security study (for children), Collins et al. (2018) implemented the policy with , , and monthly subsidies, where doubling to increased the policy effect far less than twice.
The issue of dose extrapolation is nowhere more critical than in toxicology, where a drug that has been tried only for some species or a group of humans (e.g., adults) has to be administered to other species or a different group of humans (e.g., infants); see Sharma and McNeil (2009) and references therein. An “allometric” scaling equation is often employed for dose extrapolation, where is a metabolic rate, is a parameter, and is the body weight in kilogram with , because the metabolic rate slows down as the individual gets heavier due to the surface area (to lose the metabolic heat) increasing less than proportionally to the body weight. The point is that many things in life increase less than proportionately (e.g., in ), which is inevitable if there is an upper bound.
In a probability distribution, typically the majority of the probability mass is around the center of the distribution. This implies that increasing becomes harder at the tail areas of the latent continuous response, say . This “probability-metric scaling” analogous to the allometric scaling is not taken into account in the linear extrapolation, as if increasing at a tail area of is only as hard as it is at a central area. Essentially, this is why the bound for is violated in finding the effect of an extrapolated treatment with (3).
A simple solution to the problem of violating the bound is using a proper distribution for , for which we establish a “logistic causal model,” and propose a “local logistic MLE.” We then make the following points. First, the local logistic MLE always respects the bound. Second, for the usual treatment level , the MLE gives almost the same effect estimate as the popular LLR does in RD, and when , the MLE still gives estimates in , which is not the case for LLR. Third, although we use logistic distribution, normal distribution may be adopted instead. These points are demonstrated through simulation and empirical studies.
We are not the first to consider local MLE’s for RD. Local logistic MLE for RD appeared in Berk & de Leeuw, 1999; Berk & Rauma, 1983. Koch and Racine (2016) applied local multinomial logit to SRD, which includes local logistic MLE as a special case. Xu (2017) examined ordered/categorical responses including binary as a special case for SRD; the proposed estimator takes a form of probability difference. Xu (2017) noted that his method can be extended to FRD by dividing the probability difference for by the corresponding difference for , but such a division may not fall in in extrapolating the treatment. Extrapolating treatment bears resemblance to the “external validity” issue in RD (Angrist & Rokkanen, 2015; Dong & Lewbel, 2015), yet these studies differ from this paper because they are about extending the RD identification range on from the cutoff, not for extrapolating the treatment.
In addition to this introductory section, there are four more sections in the remainder of this paper. The next section introduces a causal model and the local logistic MLE for SRD and FRD, which is then followed by two sections on simulation and empirical studies. The last section concludes this paper.
Logistic Causal Model and Local MLE
To prevent confusion, we make it clear how the counterfactual extrapolated treatment is related to the original binary treatment D:
This includes an implicit assumption for FRD that the complier group does not change when does. That is, those who take the treatment when still take it when the treatment is , and those who do not take the treatment when still do not take it when the treatment is .
Since is just a constant times , (in-)dependence between and other random variables still hold for . For instance, letting “” stand for the independence between and given , we have . With these and , we address SRD first in this section, and then FRD.
Logistic Causal Model for SRD
Suppose that a “marginal structural logistic model” holds for the potential outcome for
where is the treatment effect, and is an unknown function that is continuous at . The term “marginal” in causal analysis refers to the fact that many ’s indexed by are jointly considered, and is just one of them. The potential treatment level in does not have to be compatible with ; for example, (4) with is entertained for SRD with the treatment .
Consider an exogenous in the sense which is called “selection on observables”; is the observable. For a compatible
Because in (4) is just a constant, (4) does not specify how is related to and ; it is (5) that specifies the relationship as the exogeneity of for given . We can then use (6) and observations on to estimate , to which we turn next.
Local Logistic MLE for SRD
Slightly differently from the regressors in (1), define
Then we can do logistic MLE of on with the local sample satisfying , where for a chosen small bandwidth .
In (8), that is supposed to be continuous at is approximated by a piecewise linear function with , which allows different slopes around : on the negative side, and on the positive side. Since as the sample size , this approximation of is innocuous.
Denoting the local logistic MLE for as , the mean treatment effect for relative to on the subpopulation can be estimated with
This was already presented in Introduction.
More generally, to extrapolate to on some value of other than , say , we may use
For this to work, we need three main conditions to hold:
If differs much from , then we may have to use a more extensive specification for , so that the unknown functional form of can be captured better.
A few remarks are in order. First, the asymptotic inference can be done with the usual logistic MLE variance estimator using only the local sample. Second, instead of (8), we may set to do local probit MLE, where is the distribution function. Third, in choosing , Imbens and Kalyanaraman (2012) and Calonico et al. (2014) proposed optimal bandwidths for RD, but they do not necessarily work well in practice, which was pointed out by Card et al. (2017) for “regression kink” design. In practice, one may use the simple “rule-of-thumb” bandwidth as a benchmark, and report estimates for different bandwidths around the benchmark, such as or .
Alternatively to , one may use the minimizing
is a “kernel function” such as the density, and this -choosing scheme is called “cross-validation (CV).” In , is a “leave-one-out” kernel nonparametric estimator for ; tends to behave well, being nearly convex in . Appendix A provides more discussion on choosing with CV.
Logistic Causal Model for FRD
Suppose a “marginal structural logistic model augmented by ” holds for : for a parameter
Consider an endogenous in the sense , which is “selection on unobservables”; is the unobservable. Although the mean independence (5) of from given only no more holds, it holds given .
In , the “-part” cannot be the source for the endogeneity of . Hence the only way for to be endogenous is through the part of other than , which is .
As will be seen shortly, we find the treatment effect at . Conditioning on is no surprise because the identified treatment effect in RD is at the cutoff. What is notable is conditioning on , which is equivalent to
That is, ensures that the treatment effect on the compliers is identified as in of (2), despite that the ratio form in the right-hand side of (2) is not used. We explain the difference between our -controlling approach in (11) to (13) and the ratio-based approach in (2) in the remainder of this subsection, using simple linear models.
Consider two models for and endogenous : with some and parameters,
Substitute the model into the model to obtain
An “indirect” way to find the treatment effect is a two-stage ratio estimator: do the OLS of on to get the slope and the OLS of on to get the slope for the last display, and then use the ratio as an estimator for . This ratio is in essence the same as the ratio in (2), revealing that the ratio in (2) is an indirect approach.
In contrast to the indirect approach, a “direct” way to find is applying instrumental variable estimator (IVE) for on with as an instrument for . This IVE is the same as the OLS of on with being the OLS residual of ; see, for example, Lee (2012). The extra regressor is called a “control function,” whose role is to remove the endogeneity.
In short, the -controlling approach in (11) to (13) is a direct approach to find the left-hand side of (2), whereas the right-hand side ratio of (2) is an indirect approach. Appendix B explains the indirect ratio-based approach for in detail, as it is the dominant conventional approach to find the FRD effect of at the cutoff, although it is not well suited for when is binary.
Our proposal for FRD is a two-stage procedure using the local observations: the first stage is the local OLS of on (which depends only on ) to obtain the OLS and the residual , and the second stage is the local logistic MLE of on . Although was defined as in (11), we set , whose justification is shown shortly below.
Denoting the local logistic MLE for as , the asymptotic inference can be done with the usual logistic MLE asymptotic variance, and “ (i.e., exogeneity)” can be tested with . Although there is the first-stage error affecting the second stage, its influence can be ignored under the . Just in case, Appendix D provides an asymptotic variance estimator fully accounting for the first-stage error. Alternatively, we may use bootstrap, which is simpler.
Analogously to (9), the mean effect of changing from to at can be estimated with
This was already presented in Introduction.
The basis for using as a control function has two parts. The first part is an equivalence: for an unknown function continuous at
which is proven in Appendix C. Then, replacing with a linear spline gives , where . The second part is the fact that the IVE for the linear model
with instrumented by is equal to the part of the OLS for
The local logistic MLE with to account for the endogeneity differs from the IVE for LLR of (17) only in that the -bounded logistic function is used instead of the linear model, which makes a good sense for binary .
To extrapolate to on some value of other than , say , we may use (10) with replaced by . For this to work, we need five main conditions to hold:
Compared with the three main conditions for SRD extrapolation with right after (10), (iv) and (v) are extra, which may be viewed as conditions for the denominator of (2): (iv) ensures that the denominator is not zero, and (v) ensures that is estimable by the OLS of on . If differs much from , then we may have to use more extensive specifications for and , so that the unknown functional forms of and can be better captured.
Simulation Study
This section presents a simulation study to demonstrate three points. First, for , local logistic MLE (“MLE” in the remainder of this section) performs almost the same as LLR estimator does. Second, for , MLE does much better than LLR. Third, MLE performs well even if probit is used instead of logit. If we want to distinguish MLE’s for exogenous and endogenous , we write “MLEex” and “MLEcf,” respectively.
Effect and Bias Under Logistic Error and Exogenous .
and
True effect
LLR (bias)
MLEex (bias)
MLEcf (bias)
0.15
0.15 (0.003)
0.15 (0.012)
0.14 (0.037)
0.22
0.30 (0.36)
0.22 (0.028)
0.20 (0.11)
0.26
0.60 (1.3)
0.26 (0.022)
0.22 (0.15)
, (sd-asy, sd)
—
1.0 (0.35, 0.35)
1.0 (0.70, 0.70)
Reject exogeneity
—
—
0.051 (0.045)
and
0.15
0.15 (0.001)
0.15 (0.005)
0.15 (0.024)
0.22
0.30 (0.35)
0.22 (0.014)
0.21 (0.068)
0.26
0.60 (1.3)
0.26 (0.011)
0.24 (0.079)
, (sd-asy, sd)
—
1.0 (0.26, 0.26)
1.0 (0.52, 0.53)
Reject exogeneity
—
—
0.051 (0.048)
and
0.15
0.15 (0.000)
0.15 (0.001)
0.15 (0.017)
0.22
0.30 (0.35)
0.22 (0.010)
0.21 (0.047)
0.26
0.60 (1.3)
0.26 (0.007)
0.25 (0.049)
, (sd-asy, sd)
—
1.0 (0.23, 0.23)
1.0 (0.44, 0.44)
Reject exogeneity
—
—
0.049 (0.048)
Bias: ; sd-asy: avg. SD with asy. var.; sd: SD in simulation; reject exogeneity: rejection proportion with sd-asy (proportion with sd-asy ignoring ).
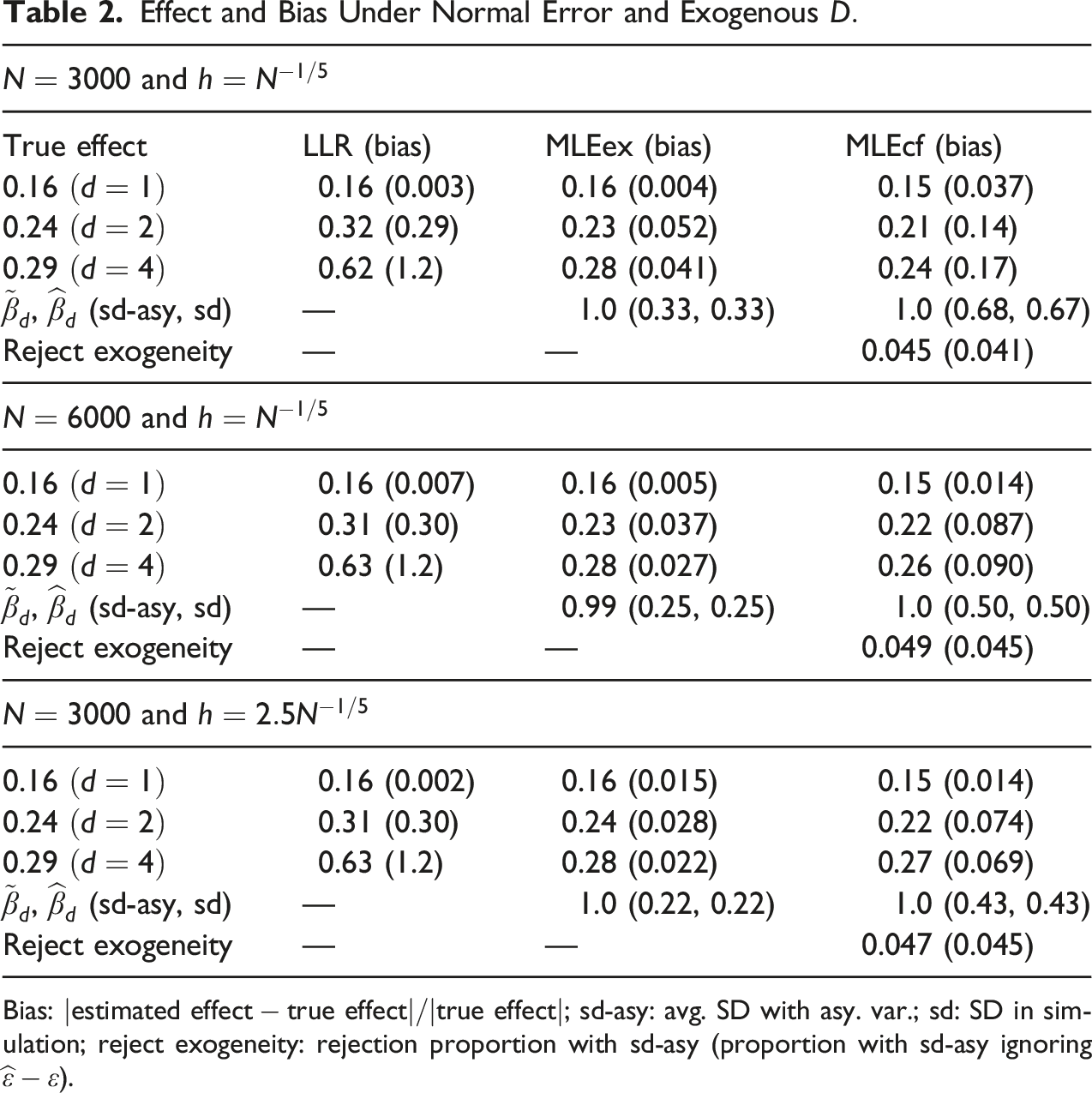
Effect and Bias Under Normal Error and Exogenous
and
True effect
LLR (bias)
MLEex (bias)
MLEcf (bias)
0.16
0.16 (0.003)
0.16 (0.004)
0.15 (0.037)
0.24
0.32 (0.29)
0.23 (0.052)
0.21 (0.14)
0.29
0.62 (1.2)
0.28 (0.041)
0.24 (0.17)
, (sd-asy, sd)
—
1.0 (0.33, 0.33)
1.0 (0.68, 0.67)
Reject exogeneity
—
—
0.045 (0.041)
and
0.16
0.16 (0.007)
0.16 (0.005)
0.15 (0.014)
0.24
0.31 (0.30)
0.23 (0.037)
0.22 (0.087)
0.29
0.63 (1.2)
0.28 (0.027)
0.26 (0.090)
, (sd-asy, sd)
—
0.99 (0.25, 0.25)
1.0 (0.50, 0.50)
Reject exogeneity
—
—
0.049 (0.045)
and
0.16
0.16 (0.002)
0.16 (0.015)
0.15 (0.014)
0.24
0.31 (0.30)
0.24 (0.028)
0.22 (0.074)
0.29
0.63 (1.2)
0.28 (0.022)
0.27 (0.069)
, (sd-asy, sd)
—
1.0 (0.22, 0.22)
1.0 (0.43, 0.43)
Reject exogeneity
—
—
0.047 (0.045)
Bias: ; sd-asy: avg. SD with asy. var.; sd: SD in simulation; reject exogeneity: rejection proportion with sd-asy (proportion with sd-asy ignoring ).
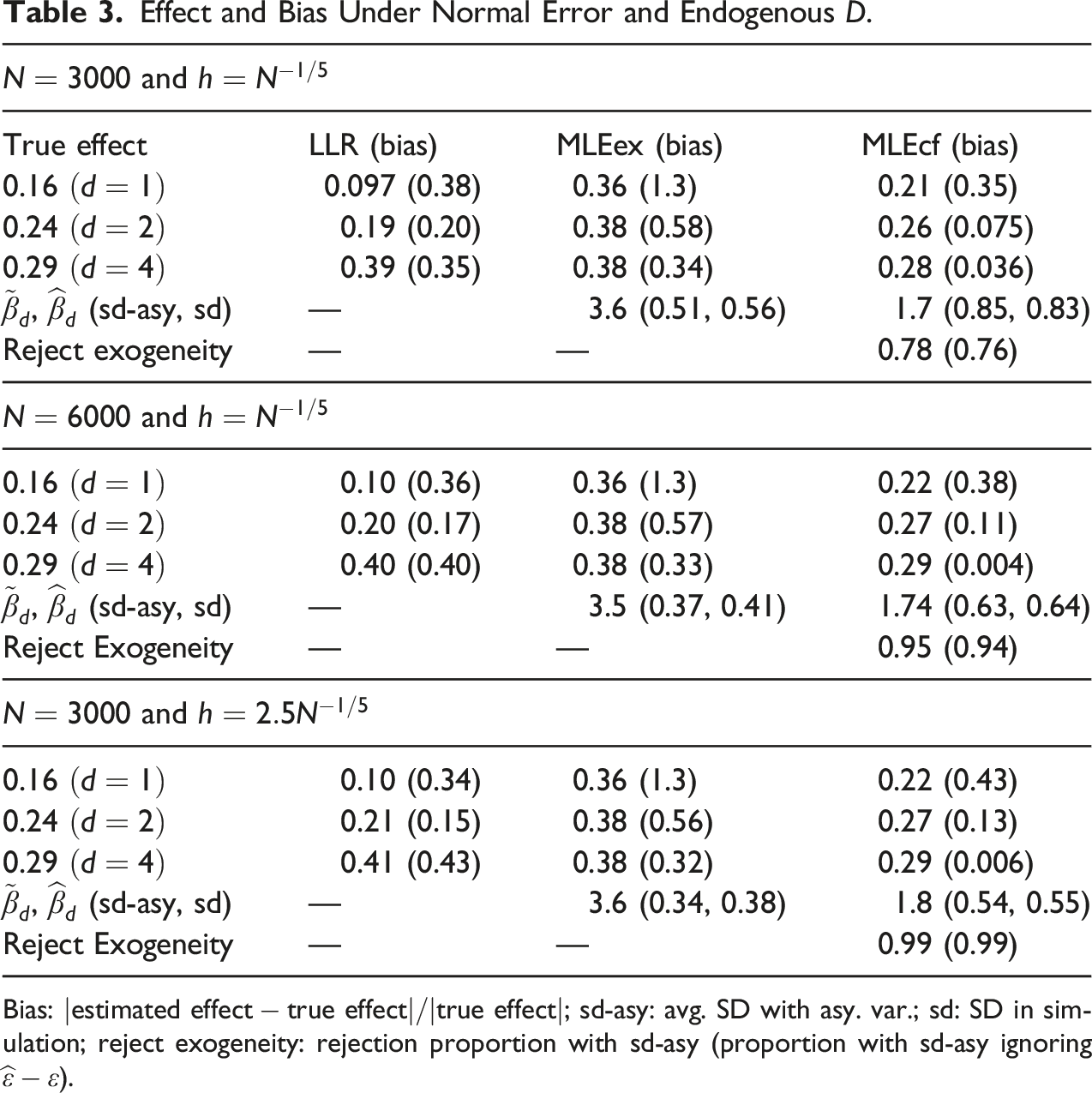
Effect and Bias Under Normal Error and Endogenous .
and
True effect
LLR (bias)
MLEex (bias)
MLEcf (bias)
0.16
0.097 (0.38)
0.36 (1.3)
0.21 (0.35)
0.24
0.19 (0.20)
0.38 (0.58)
0.26 (0.075)
0.29
0.39 (0.35)
0.38 (0.34)
0.28 (0.036)
, (sd-asy, sd)
—
3.6 (0.51, 0.56)
1.7 (0.85, 0.83)
Reject exogeneity
—
—
0.78 (0.76)
and
0.16
0.10 (0.36)
0.36 (1.3)
0.22 (0.38)
0.24
0.20 (0.17)
0.38 (0.57)
0.27 (0.11)
0.29
0.40 (0.40)
0.38 (0.33)
0.29 (0.004)
, (sd-asy, sd)
—
3.5 (0.37, 0.41)
1.74 (0.63, 0.64)
Reject Exogeneity
—
—
0.95 (0.94)
and
0.16
0.10 (0.34)
0.36 (1.3)
0.22 (0.43)
0.24
0.21 (0.15)
0.38 (0.56)
0.27 (0.13)
0.29
0.41 (0.43)
0.38 (0.32)
0.29 (0.006)
, (sd-asy, sd)
—
3.6 (0.34, 0.38)
1.8 (0.54, 0.55)
Reject Exogeneity
—
—
0.99 (0.99)
Bias: ; sd-asy: avg. SD with asy. var.; sd: SD in simulation; reject exogeneity: rejection proportion with sd-asy (proportion with sd-asy ignoring ).
With , the normal distribution has as the logistic distribution does. Although the “structural form error” in causes the endogeneity of unless , differs from the “reduced form error” .
We use two bandwidths: with , the rule-of-thumb bandwidth and ; CV takes too much time to implement in simulation. The sample size is with the simulation repetition . The sample size may look large, but the actual size used for estimation is much smaller due to . For instance, equals when , and consequently equals : only observations are used for estimation. The true effect of changing from to given is, depending on logistic or
In Table 1, the upper panel is for and , the middle panel is for and , and the lower panel is for and . In each panel, the first column shows the true effect (19) for ; the second column shows the LLR effect using the linear extrapolation as in (3), and the (relative) bias (e.g., the LLR effect for has the bias ; the third column shows (9) using MLEex, and its bias; and the fourth column shows (15) using MLEcf, and its bias. The row “, (sd-asy, sd)” presents the averaged or , the averaged SD using the asymptotic variance estimator (sd-asy), and the actual SD in the simulation repetitions (sd). The row “reject exogeneity” is the rejection rate for “ : is exogenous” using the t-value of the slope of and the critical values . The test is done with the asymptotic variance formula in Appendix D that takes the first-stage error into account first, and then with the asymptotic variance ignoring whose rejection rate is in ().
In Table 1 with logistic and exogenous , the overall performance ranking in terms of the sum of the three biases for is, with “” for “better than”,
LLR does best for , and the MLE’s do almost as well for . For , however, LLR is highly biased. Comparing the sd-asy’s to the actual simulation SD’s, the asymptotic SD formulas work well for the MLE’s. The false rejection rates are all close to to validate the exogeneity test with or without taking into account . Increasing by times in the bottom panel makes little difference.
In Table 2, is normal with still exogenous. Although the distribution of changes, still all points made for Table 1 hold for Table 2, including the ranking in (20).
In Table 3, is still normal, but is endogenous. Although no estimator works particularly well because binary endogenous regressor with binary response is particularly difficult to deal with (see, e.g., Lee, 2012, and Clarke & Windmeijer, 2012), still MLEcf works much better than LLR and MLEex, and the performance ranking in terms of the sum of the three biases is
The -exogeneity is easily rejected, with the rejection rate or higher.
In summary, comparing Table 1, Table 2 and Table 3, MLEcf renders the most robust performance all around, although MLEex does better when is exogenous. The asymptotic SD formula of MLEcf works well, almost equaling the actual SD, and its -exogeneity test also works reliably even when the first-stage error is ignored. Hence, a sensible scenario to follow in practice for FRD is applying MLEcf first to test forexogeneity. If rejected, stick to MLEcf; otherwise, use MLEex.
Income Effect on Being Evangelical
This section provides an empirical illustration using the same data as used in Buser (2015), although Buser (2015) did not examine the issue of treatment dose extrapolation. This section will confirm that both LLR and local logistic MLE effects are almost the same for the original treatment , but they differ much for extrapolated treatment doses. This section will also demonstrate that the bound can be violated for a high treatment dose.
According to Buser (2015), Ecuador is a highly Catholic country: are Catholic, and belong to the Evangelical Christian denomination which is non-Catholic. But being Evangelical is more demanding than being Catholic in terms of money and time, because Evangelical churches are highly integrated and more participative, and they also require a tithe. This financial commitment deters the poor from becoming Evangelical even if they like Evangelism. Hence, more income may induce more religious and poor people to become Evangelical .
A RD setup occurred due to a government cash subsidy program giving per month to the poorest households based on a wealth index . Although sounds small, that is not the case because is about of the monthly total expenditure. Location-normalizing and then multiplying by , we have . Since the sampling was done already only from the individuals within distance from the cutoff, Buser (2015) used all data without selecting any subsample, and we will do the same; that is, no issue of choosing arises in this empirical analysis.
Buser (2015) found significantly positive effects of on , and noted that the effects come mostly from the above-average religious individuals. In the survey data with , there is a religiosity variable with being the most religious; the average is . We thus use the above-average-religiosity subsample with and . We also use the most religious group with with . See Buser (2015) for the details on the data, as well as the usual RD plots visually demonstrating breaks in and . As in the simulation section, we examine treatment dose extrapolation from the original . Buser (2015) used polynomial functions for , but we stick to the linear spline. Also, Buser (2015) controlled covariates sometimes, which we do not do though, because controlling covariates is not essential in RD.
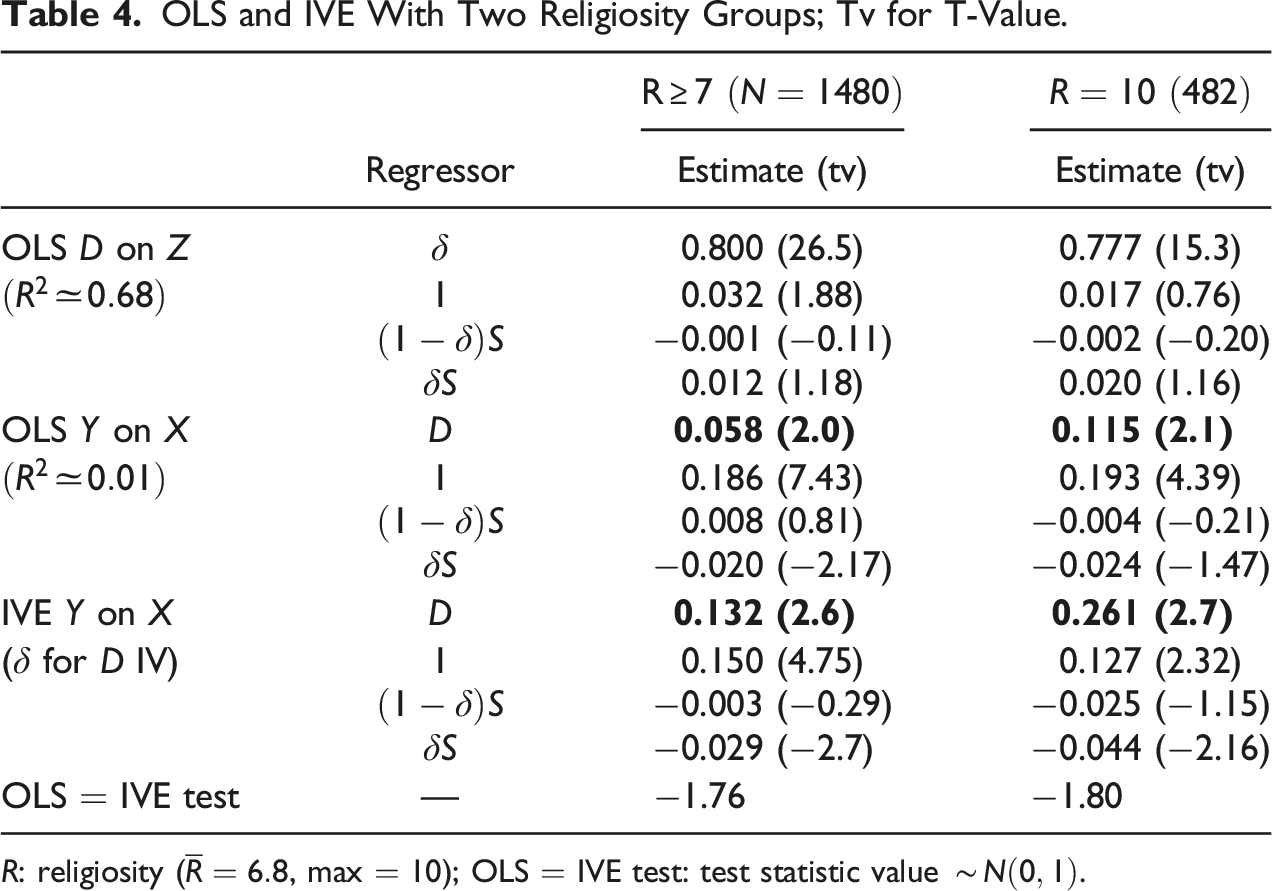
Table 4 presents the OLS of on , the OLS of on , and the IVE of on . The rows for are in a different font to make it easy to compare them. The OLS of on shows that is highly influential for because most eligible people for the program received the subsidy.
OLS and IVE With Two Religiosity Groups; Tv for T-Value.
Regressor
Estimate (tv)
Estimate (tv)
OLS on
0.800 (26.5)
0.777 (15.3)
0.032 (1.88)
0.017 (0.76)
−0.001 (−0.11)
−0.002 (−0.20)
0.012 (1.18)
0.020 (1.16)
OLS on
0.058 (2.0)
0.115 (2.1)
0.186 (7.43)
0.193 (4.39)
0.008 (0.81)
−0.004 (−0.21)
−0.020 (−2.17)
−0.024 (−1.47)
IVE on
0.132 (2.6)
0.261 (2.7)
( for IV)
0.150 (4.75)
0.127 (2.32)
−0.003 (−0.29)
−0.025 (−1.15)
−0.029 (−2.7)
−0.044 (−2.16)
OLS IVE test
—
−1.76
−1.80
: religiosity (, max ); OLS IVE test: test statistic value .
In Table 4, the treatment effect of on is increasing as the religiosity goes up, and the OLS under-estimates the treatment effect severely because the OLS effect is only , whereas the IVE effect is . We test for the difference in the last row, where an asymptotically standard normal test statistic value is presented for the null hypothesis that the effect parameters are the same in the OLS and IVE: the test statistic values are on the “borderline” of rejecting the null hypothesis. There are reasons to make the receipt of the subsidy endogenous; for example, for an eligible (i.e., ) individual to take up the subsidy, he/she might have to overcome the “stigma” of receiving the subsidy, and this psychological burden may be related to .
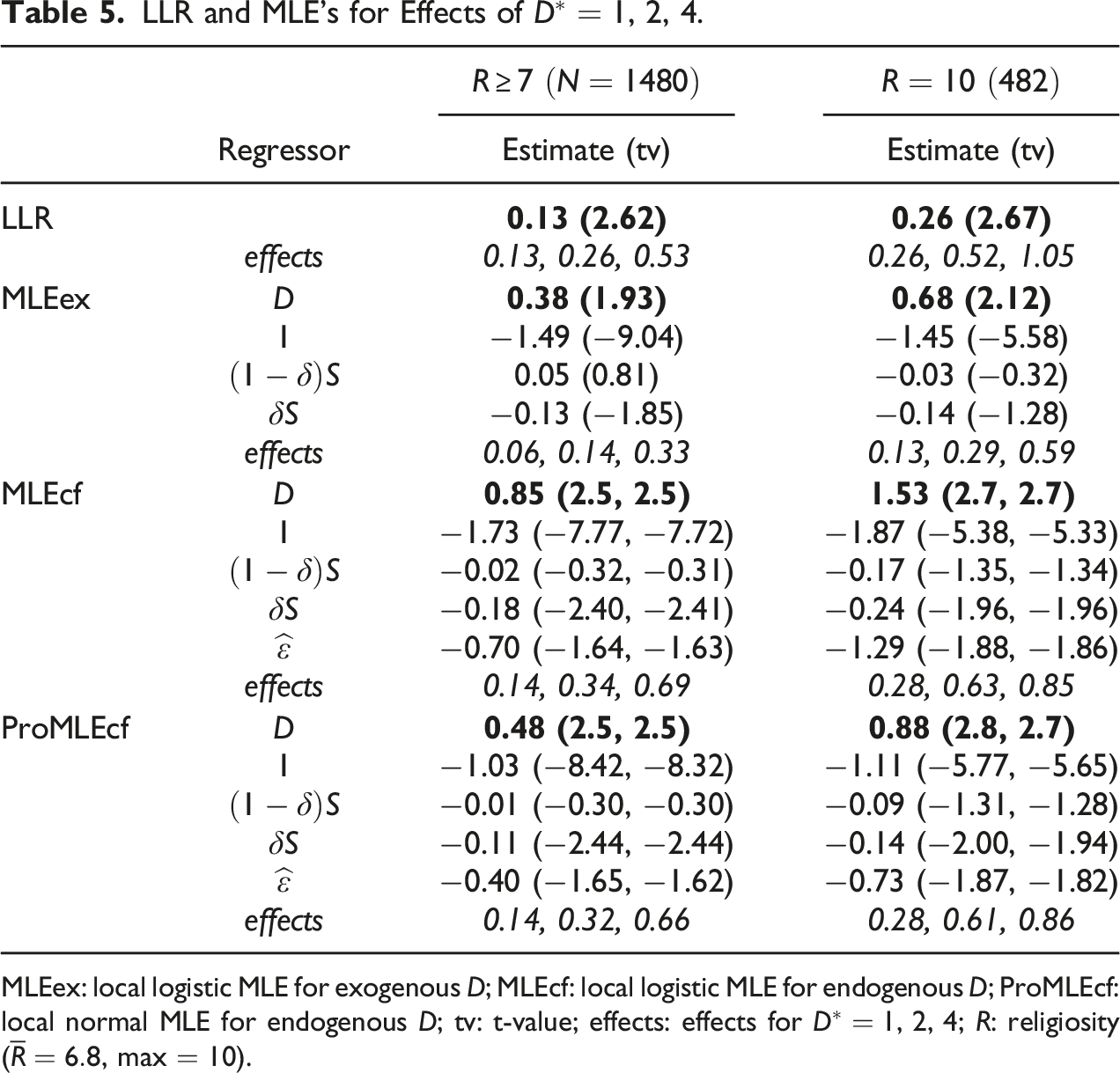
In Table 5, “ProMLEcf” is the same as MLEcf except that is used instead of (14). To ease reading Table 5, the mean effects for are in italics, and the estimates for and their t-values are in bold font. When two t-values appear in many entries for MLEcf and ProMLEcf, the first one ignores the error , while the second takes it into account. The difference between the two t-values is always very small, and thus, it seems safe to use the simpler t-value ignoring . As well known, logit estimates and probit estimates are almost the same, once the probit estimates are multiplied by because . This is also the case in Table 5, and the effect estimates based on (19)(i) and are nearly identical. Hence, we will no longer mention ProMLEcf.
LLR and MLE’s for Effects of .
Regressor
Estimate (tv)
Estimate (tv)
LLR
0.13 (2.62)
0.26 (2.67)
effects
0.13, 0.26, 0.53
0.26, 0.52, 1.05
MLEex
0.38 (1.93)
0.68 (2.12)
−1.49 (−9.04)
−1.45 (−5.58)
0.05 (0.81)
−0.03 (−0.32)
−0.13 (−1.85)
−0.14 (−1.28)
effects
0.06, 0.14, 0.33
0.13, 0.29, 0.59
MLEcf
0.85 (2.5, 2.5)
1.53 (2.7, 2.7)
−1.73 (−7.77, −7.72)
−1.87 (−5.38, −5.33)
−0.02 (−0.32, −0.31)
−0.17 (−1.35, −1.34)
−0.18 (−2.40, −2.41)
−0.24 (−1.96, −1.96)
−0.70 (−1.64, −1.63)
−1.29 (−1.88, −1.86)
effects
0.14, 0.34, 0.69
0.28, 0.63, 0.85
ProMLEcf
0.48 (2.5, 2.5)
0.88 (2.8, 2.7)
−1.03 (−8.42, −8.32)
−1.11 (−5.77, −5.65)
−0.01 (−0.30, −0.30)
−0.09 (−1.31, −1.28)
−0.11 (−2.44, −2.44)
−0.14 (−2.00, −1.94)
−0.40 (−1.65, −1.62)
−0.73 (−1.87, −1.82)
effects
0.14, 0.32, 0.66
0.28, 0.61, 0.86
MLEex: local logistic MLE for exogenous ; MLEcf: local logistic MLE for endogenous ; ProMLEcf: local normal MLE for endogenous ; tv: t-value; effects: effects for ; : religiosity (, max ).
The slope of estimated by MLEex and MLEcf is the structural form parameter residing in the logistic distribution function, and its estimates are much greater than the LLR estimate. But looking at the mean effect versus , the mean effects are almost the same except for MLEex: for , and for . This degree of similarity is remarkable. The mean effects, however, diverge as we look at versus . The mean effects based on the logit structural form parameter respect the bound .
According to Table 4, the effect of by IVE is depending on , and the same effects can be seen in the LLR row of Table 5. The “effects” row just below the LLR row shows the effects of for subsidy, for , and for using the linear extrapolation as in (3). Although the linear extrapolation works fine when the effect magnitude is small, it goes over the bound when becomes large in the most religious group with , which demonstrates our main point.
Is endogenous? The t-values of in Table 5 give borderline test statistic values as the last row of Table 4 does. Despite much difference in the linear models for Table 4 and non-linear ones for Table 5, seeing this level of coherence is reassuring. Despite the border line test statistic values, we would take the effect estimates allowing the endogeneity for two reasons. First, the conventional test level is too conservative, intended to make it difficult to reject the null hypothesis lest the rejection results in a much greater harm than otherwise, which is, however, unwarranted in our test; that is, raising the test level slightly results in rejecting the exogeneity. Second, for , the three estimators (LLR, MLEcf, and ProMLEcf) give the almost identical estimates in unison: after all, the goal is estimating treatment effects at the possible presence of endogeneity, which is allowed by the three estimators without necessarily concluding the endogeneity or exogeneity.
Conclusions
Regression discontinuity (RD) estimators are often applied to binary response with binary treatment without any modification. As when linear models are applied to binary responses, this practice typically does not pose problems. However, a problem occurs when we want to extrapolate the treatment from to a number higher than , because the estimated effect for the new treatment may go out of the bound which should hold for changes in . A solution to this problem is estimating the structural form effect parameter for that appears inside a proper regression function for , that is, a probability distribution function. We explored this line of approach in this paper, using the logistic distribution.
Specifically, for sharp RD, we proposed “local logistic MLE,” which is nothing but the usual logistic MLE using a local sample around the RD cutoff point . For fuzzy RD, we proposed a two-stage procedure, where the first stage is the ordinary least squares estimator (OLS) of on some regressors including the dummy for the RD running variable crossing , and the second stage is the local logistic MLE using the first-stage OLS residual as an extra regressor to control for the source of the possible endogeneity of .
The popular local linear regression (LLR) for RD amounts to applying instrumental variable estimator to a local linear model, which is the same as applying OLS to the equation while using the -equation OLS residual as an extra regressor. In essence, our approach allowing endogenous treatment does the same, but with the logistic distribution function to respect the bound for . Through a simulation study, we showed that our local logistic MLE dominates LLR in the sense that both give almost the same estimates for the effect of relative to , but only our approach gives valid estimates for larger values of such as .
We applied our proposed methods to a data set where is an income subsidy program and is being Evangelical. The empirical analysis illustrated the aforementioned pitfall of LLR: when the income subsidy amount quadrupled, the effect on turned out to be higher than one. In contrast, our approach of estimating structural form parameters gave effects respecting the bound . Other than this, the effect estimates for the original treatment in LLR and our approach were remarkably close. We were thus able to maintain the popular LLR for , while overcoming the LLR bound problem in extrapolating the treatment dose, which was the very motivation for this paper.
Footnotes
Acknowledgments
The authors are grateful to the Editor and two anonymous reviewers for their helpful comments. This paper was originally circulated as a single-authored paper of Myoung-jae Lee, and Goeun Lee came on board contributing extra seven pages in the final version to tighten the theoretical part of the paper.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The research of Myoung-jae Lee has been supported by a Korea University research grant.
ORCID iD
Goeun Lee
Appendix A: More Discussion on Choosing Bandwidth with Cross-Validation (CV)
and for with at least some observations on its right when , and on its left when .
The idea for is simple: if , then only the left observations with are used; if , only the right observations with are used. However, tends to give too large a bandwidth that makes most ’s zero and predicts the few remaining ’s well to make small, which happened in Ludwig and Miller (2007), and Choi and Lee (2018a) as well for a two-dimensional . Although is inconsistent for when is near zero and has a break at , since the goal is finding a reasonable value of , not necessarily predicting well, we recommend the conventional CV in the main text as Choi and Lee (2018a) did. In the empirical analysis of Choi and Lee (2018a), the conventional CV gave values similar to .
Appendix B: Indirect Ratio-Based Approach for FRD Extrapolation
Here we provide the details on the indirect approach for FRD similar to (2), drawing partly on Choi and Lee (2018b). The discussion here reveals what kind of conditions are needed for the indirect approach, and why it fails in binary treatment extrapolation for binary outcome.
As in the main text, our non-binary treatment is
SRD: (, , depending on );
FRD: (, , depending on ).
With the potential response for , the “realized” response is
Note that we use the term “realized” instead of “observed” because is never observed for the counterfactual extrapolated treatment .
It is important to bear in mind that, even when , still take only on ; it is just that the treatment dose is , not , when extrapolatedly treated. This setup is necessary for compliers to be defined still as regardless of . Maintaining this complier definition that does not change when allowed is unavoidable, because only are realized. If the complier group changes as does, then we cannot identify the treatment effect on compliers for . To simplify notation, define
Recall , which implies that is equivalent to (i.e., complier). Putting all of requisite assumptions for the indirect approach in advance, they are:
Among these assumptions, (i)-(iii) are the continuity of , and at , respectively; (i) was assumed in Hahn et al. (2001), and (ii) and (iii) are weaker than the assumption on in Hahn et al. (2001) when . The “monotonicity condition” (iv) is weaker than “ on ” in Hahn et al. (2001), and the condition rules out so that takes only on . (22)(v) is hardly a restriction, because it requires only the existence of the right limits at , not the continuities at . Finally, (22)(vi) is the usual break assumption of in FRD at , so that the treatment break is not zero at , even if the break magnitude is not one as in SRD.
Take and on the realized response to get
Replace the two ’s in (23) with and , respectively, because given , and given
Take the difference of the two equations in (24) to remove and due to (22)(i). This gives
Invoke (22)(ii) to replace with , so that (25) can be written succinctly as
(due to the monotonicity (22)(iv)).Substituting this into in (26), the first and last terms of (26) render
Under the -break assumption in (22)(vi), this can be rewritten as
The ratio in (2) can be defined as because it is the effect of changing from to . Analogously, we can define the ratio in (27) as because it is the effect of changing potentially from to (with changing from to ):
The point is that the assumptions in (22) do not imply . That is, in the indirect approach, there is no guarantee for
although this is what is needed for the linear extrapolation (3).
(29) reveals that the indirect approach based on localization around is not well suited for extrapolation. Instead, our direct approach using the control function with a proper distribution function (such as the logistic distribution function) can be used to rein in the misleading linear growth as goes up in the linear extrapolation. Of course, the price to pay is specifying the parametric distribution function, but the price is almost zero, as long as the direct approach gives almost the same results as the indirect approach gives for . This was amply demonstrated in our simulation and empirical studies.
Appendix C: Proof for Equivalence E ( D | S ) = α δ δ + m D ( S ) ⇔ α δ ≡ E ( D | 0 + ) − E ( D | 0 − )
First, take and on to get, as
Hence, “” implies “”.
Second, for the reverse, define using the local mean difference , and take and on
“” implies , which is the continuity of at . Hence, with continuous at follows from the definition .
Appendix D: Asymptotic Distribution for Local Logistic MLE with Control Function
Let and be the logistic distribution and density functions, respectively:
The score function for the logistic MLE is then
Let denote with and replaced by and .
It holds that
Although tedious, it can be shown that the presence of in matters only for , which gives ( terms omitted)
using the linear approximation .
Observe
Because
we have, omitting terms again,
Since , this can be written as
Define
also define and as and with replaced by . Now, rewrite as
This shows that the asymptotic variance of can be estimated with
The second term of is the “correction term” accounting for , which drops out under the null hypothesis ; that is, under the null hypothesis of exogeneity, can be ignored. This way of accounting for the first-stage error can be found in Lee (2010), among others.
References
1.
AngristJ.RokkanenM. (2015). Wanna get away? Regression discontinuity estimation of exam school effects away from the cutoff. Journal of the American Statistical Association, 110(512), 1331–1344. https://doi.org/10.1080/01621459.2015.1012259
2.
AngristJ. D.ImbensG. W.RubinD. B. (1996). Identification of causal effects using instrumental variables. Journal of the American Statistical Association, 91(434), 444–455. https://doi.org/10.1080/01621459.1996.10476902
3.
BerkR.de LeeuwJ. (1999). An evaluation of California’s inmate classification system using a generalized regression discontinuity design. Journal of the American Statistical Association, 94(448), 1045–1052. https://doi.org/10.1080/01621459.1999.10473857
4.
BerkR.RaumaD. (1983). Capitalizing on nonrandom assignment to treatments: A regression-discontinuity evaluation of a crime control program. Journal of the American Statistical Association, 78(381), 21–27. https://doi.org/10.1080/01621459.1983.10477917
5.
BuserT. (2015). The effect of income on religiousness. American Economic Journal: Applied Economics, 7(3), 178–195. https://doi.org/10.1257/app.20140162
CardD.LeeD.PeiZ.WeberA. (2017). Regression kink design: Theory and practice, advances in econometrics 38. In CattaneoM. D.EscancianoJ. C. (Eds.). Emerald Publishing Limited.
8.
CattaneoM. D.EscancianoJ. C. (2017). Introduction, advances in econometrics 38 (entitled ‘Regression discontinuity designs: Theory and applications’). In CattaneoM. D.EscancianoJ. C. (Eds.). Emerald Publishing.
9.
CattaneoM. D.IdroboN.TitiunikR. (2019). A practical introduction to regression discontinuity designs. Cambridge University Press. https://doi.org/10.1017/9781108684606
ChoiJ. Y.LeeM. J. (2018a). Regression discontinuity with multiple running variables allowing partial effects. Political Analysis, 26(3), 258–274. https://doi.org/10.1017/pan.2018.13
12.
ChoiJ. Y.LeeM. J. (2018b). Relaxing conditions for local average treatment effect in fuzzy regression discontinuity. Economics Letters, 173, 47–50. https://doi.org/10.1016/j.econlet.2018.09.010
13.
ChoiJ. Y.LeeM. J. (2021). Basics and recent advances in regression discontinuity: Difference versus regression forms. Journal of Economic Theory and Econometrics, 32(3), 1–68. http://es.re.kr/eng/upload/jetem%2032-3-1.pdf
14.
ClarkeP.WindmeijerF. (2012). Instrumental variable estimators for binary outcomes. Journal of the American Statistical Association, 107(500), 1638–1652. https://doi.org/10.1080/01621459.2012.734171
15.
CollinsA. M.KlermanJ. A.BriefelR.RoweG.GordonA. R.LoganC. W.WolfA.BellS. H. (2018). A summer nutrition benefit pilot program and low-income children’s food security. Pediatrics, 141(4), Article e20171657. https://doi.org/10.1542/peds.2017-1657
16.
DongY.LewbelA. (2015). Identifying the effect of changing the policy threshold in regression discontinuity models. Review of Economics and Statistics, 97(5), 1081–1092. https://doi.org/10.1162/rest_a_00510
ImbensG. W.AngristJ. (1994). Identification and estimation of local average treatment effects. Econometrica, 62(2), 467–475. https://doi.org/10.2307/2951620
19.
ImbensG. W.KalyanaramanK. (2012). Optimal bandwidth choice for the regression discontinuity estimator. Review of Economic Studies, 79(3), 933–959. https://doi.org/10.1093/restud/rdr043
KochS.RacineJ. (2016). Health care facility choice and user fee abolition: Regression discontinuity in a multinomial choice setting. Journal of the Royal Statistical Society (Series A), 179(4), 927–950. https://doi.org/10.1111/rssa.12161
22.
LeeD.LemieuxT. (2010). Regression discontinuity designs in economics. Journal of Economic Literature, 48(2), 281–355. https://doi.org/10.1257/jel.48.2.281
23.
LeeM. J. (2010). Micro-econometrics: Methods of moments and limited dependent variables. Springer.
24.
LeeM. J. (2012). Semiparametric estimators for limited dependent variable (LDV) models with endogenous regressors. Econometric Reviews, 31(2), 171–214. https://doi.org/10.1080/07474938.2011.607101
LudwigJ.MillerD. (2007). Does head start improve children’s life chances? Evidence from a regression discontinuity design. Quarterly Journal of Economics, 122(1), 159–208. https://doi.org/10.1162/qjec.122.1.159