
Abstract
The ability to control one’s thoughts and actions is broadly associated with health and success, so it is unsurprising that measuring self-control abilities is a common goal across many areas of psychology. Puzzlingly, however, different measures of control––questionnaire ratings and cognitive tasks––show only weak relationships to each other. We review evidence that this discrepancy is not just a result of poor reliability or validity of ratings or tasks. Rather, ratings and tasks seem to assess different aspects of control, distinguishable along six main dimensions. To improve the psychological science surrounding self-control, it will be important for future work to investigate the relative importance of these dimensions to the dissociations between self-control measures, and for researchers to explain which aspects of control they are studying and why they have focused on those aspects of control when one or both types of measures are deployed.
A typical day includes numerous obstacles to achieving one’s goals. For example, one might have to start a difficult project, juggle multiple tasks, ignore distractions, resist temptations, and/or tamp down strong emotions. Overcoming these challenges requires controlling one’s thoughts and actions. Individual differences in such control abilities are associated with numerous health and success outcomes (Diamond, 2013; Sharma et al., 2014), so it is unsurprising that control abilities have been extensively studied. Within the psychological literature, there are two major approaches to measuring control abilities. The first involves “self-control” or “self-regulation” questionnaires that ask participants (or their families and friends) to rate their typical behavior when confronted with certain challenges (henceforth referred to as “ratings”; Table 1). The second involves laboratory “cognitive control” or “executive function” tasks (henceforth referred to as “tasks”; Fig. 1).
Examples of Rating Scales That Assess Control
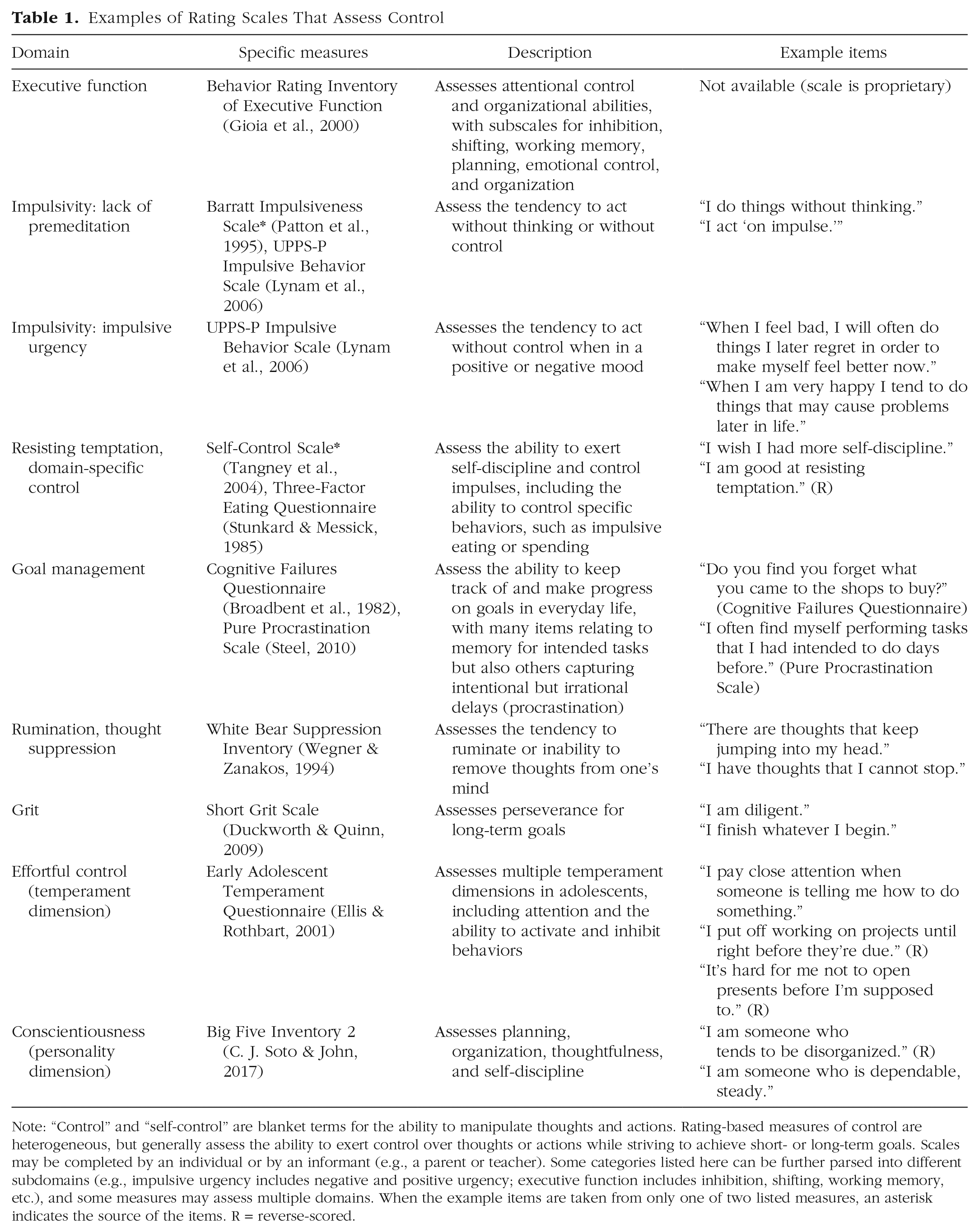
Note: “Control” and “self-control” are blanket terms for the ability to manipulate thoughts and actions. Rating-based measures of control are heterogeneous, but generally assess the ability to exert control over thoughts or actions while striving to achieve short- or long-term goals. Scales may be completed by an individual or by an informant (e.g., a parent or teacher). Some categories listed here can be further parsed into different subdomains (e.g., impulsive urgency includes negative and positive urgency; executive function includes inhibition, shifting, working memory, etc.), and some measures may assess multiple domains. When the example items are taken from only one of two listed measures, an asterisk indicates the source of the items. R = reverse-scored.
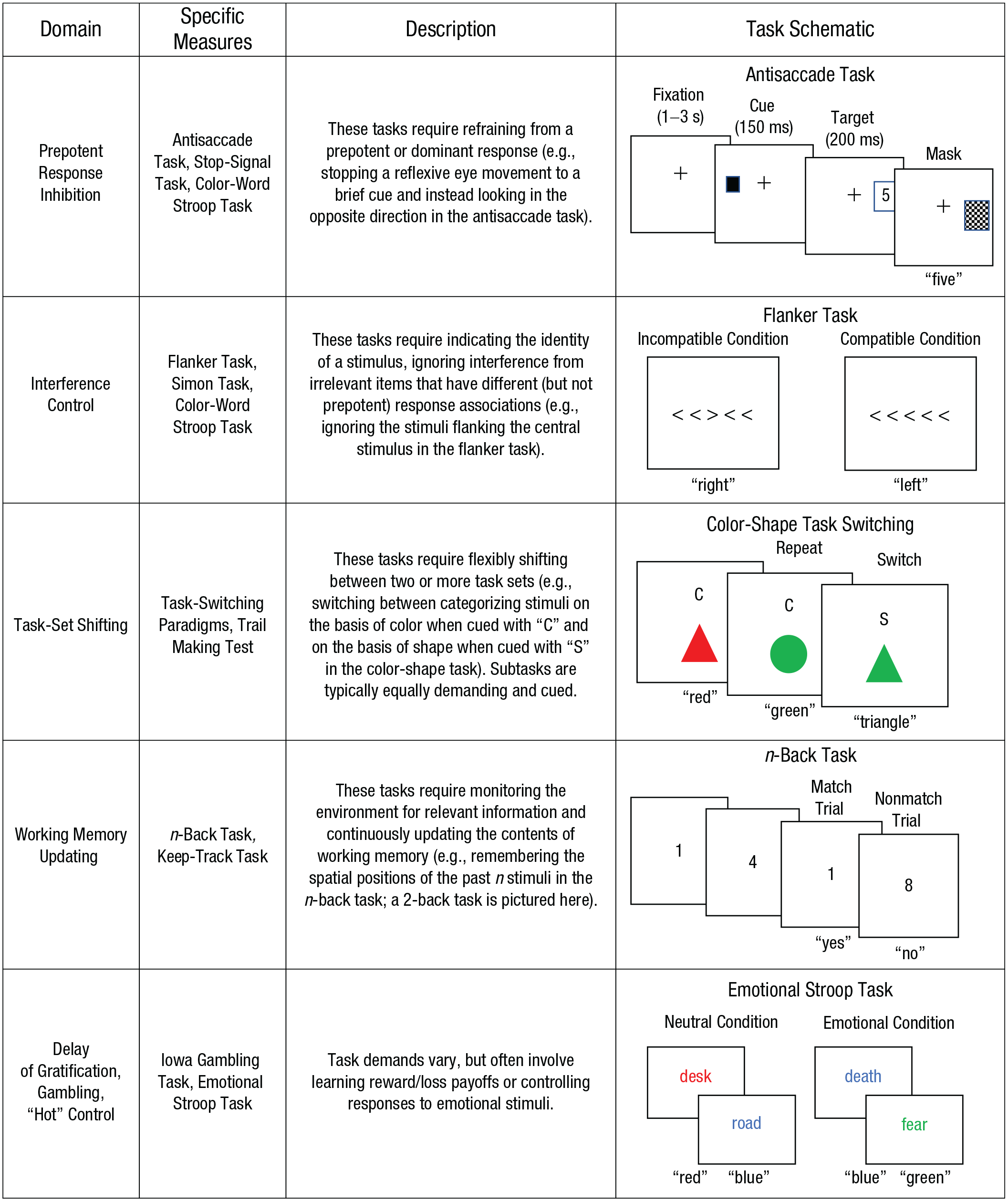
Examples of task-based measures of control (e.g., executive-function tasks). Task-based measures are heterogeneous, but generally assess the ability to exert control over thoughts or actions while striving to achieve one or more concrete short-term goals. In the task schematics, correct answers are shown in quotation marks. Interference control can be further parsed into different subdomains, and some tasks may assess multiple processes. For example, in the color-word Stroop task, participants are slower to name the ink color in which color words are printed when the word and ink color are incongruent (e.g., “red” printed in blue ink) compared with when the word and ink color are congruent (e.g., “red” printed in red ink). This task can be considered a measure of interference control; however, it is also used to tap prepotent-response inhibition because there is an asymmetry in the potency of interfering stimuli (i.e., word reading is a prepotent response, whereas color naming is not).
Ratings and tasks are often discussed as alternative measures of conceptually similar control processes, such as stopping inappropriate responses. Rating scales get at individual differences in these processes through subjective reports of typical behaviors across multiple contexts, whereas tasks provide a more objective window into the cognitive mechanisms that may underlie these behaviors. Surprisingly, however, ample evidence now suggests that tasks and ratings do not correlate well with each other (Cyders & Coskunpinar, 2011; Sharma et al., 2014). For example, a meta-analysis (Duckworth & Kern, 2011) found that the average correlation between executive-function tasks and self-report ratings was only .10. Although significantly larger than zero, this correlation indicates only a small overlap. In contrast, tasks or ratings within a given domain (e.g., working memory tasks or lack-of-premeditation scales) typically correlate well with one another (rs = .3–.5), though there are exceptions (inhibition tasks typically correlate poorly with each other; Friedman & Miyake, 2004).
In this article, we consider two primary explanations for this surprisingly low overlap between tasks and ratings and discuss their implications for the psychological science of self-control: The first explanation is that tasks and/or ratings do not reliably measure control, and the second is that tasks and ratings measure different aspects of control. We argue that both ratings and tasks can be valid and reliable measures of control, but that they assess different—both meaningful—aspects of control. Clarifying these differences will be important for the design and interpretation of studies of control.
Can Poor Measurement Explain the Low Correlation Between Ratings and Tasks?
Reliability is the extent to which a measure correlates with itself (e.g., when repeatedly administered). When interpreting correlations, knowing the reliability of the measures involved is crucial because a measure that does not correlate well with itself will not correlate with something else. Ratings tend to be reasonably reliable, whereas task reliabilities are more variable (Enkavi et al., 2019). In particular, many control tasks use difference scores to isolate control processes. For example, in the color-word Stroop task (see Fig. 1 caption), average response time in a control condition that does not involve interference from a prepotent response is usually subtracted from average response time in the incongruent condition to remove variation attributable to simple color-naming speed. Although such differences improve the theoretical interpretability of the resulting measures, the reliability of difference scores can vary (Hedge et al., 2018): Even if participants complete a large number of trials and show strong experimental effects, reliability will be poor if there are not strong individual differences in the magnitude of those effects (e.g., if everyone shows a similarly sized effect).
Another issue with control tasks is the “task impurity” problem. Because control must be measured in the context of the lower-level processes that are being controlled, task performance can reflect these noncontrol processes (e.g., in the color-word Stroop task, these processes include color perception, word reading, and vocal speed). Task impurity is thought to be a major reason that control tasks generally show low correlations with each other (Friedman & Miyake, 2017), even when they are reasonably reliable. One solution to the task-impurity problem is to administer multiple tasks that tap the same control process but differ in their lower-level requirements (e.g., to administer the color-word Stroop, antisaccade, and stop-signal tasks to tap response inhibition) and extract their common variance with latent variable (factor) analysis. Because latent variables capture only variance that correlates across tasks, they are purer measures and remove random measurement error (unreliability). Indeed, latent variables for task-based measures of control show high test-retest reliability (rs = .86–.97), even over intervals of 5 to 6 years (Friedman et al., 2016; Gustavson et al., 2018).
If tasks and ratings show low correlations because of tasks’ unreliability and impurity, then these correlations should be much higher at the level of latent variables. Surprisingly, however, they are not (Eisenberg et al., 2019; Friedman et al., 2020; Snyder et al., 2021). For example, a latent variable capturing performance on nine control tasks had only small correlations with latent variables for the Behavioral Rating Inventory of Executive Function (r = .11) and the Early Adolescent Temperament Questionnaire (r = .21; Snyder et al., 2021). This pattern suggests that unreliability and task impurity cannot explain the low correlations between ratings and tasks.
Ratings may also be impure or invalid measures of control. Individuals’ perceptions of their own behavior may be inaccurate, or participants may respond to some questions in a socially desirable manner. These factors may not simply introduce noise, which could be removed with latent variables; instead, they may introduce systematic variation into the data (i.e., variation that might be reliable and correlate with other measures). Such biases are a major concern considering that ratings often predict outcomes better than tasks do (Eisenberg et al., 2019; Friedman et al., 2020), because these outcomes are also typically self-reported and thus could have similar biases. For example, individuals who are reluctant to admit that they have poor self-control may similarly filter their responses about their substance use problems. Conversely, people who have difficulty managing substance use may answer questions about self-control on the basis of these experiences. Indeed, one meta-analysis found that ratings were more associated with self-reported undesired behaviors than with objectively observed undesired behaviors (de Ridder et al., 2012), although this difference was statistically significant only for one of the rating scales examined. Thus, using objective measures of behaviors (when possible) may lead to a more balanced comparison of their associations with ratings and tasks. Ratings from other informants (e.g., parents or teachers) may also help balance the comparison, but they have their own limitations, as informants cannot know what is going on in another individual’s mind.
In addition to unreliability and task impurity, another important consideration when interpreting the low correlation between ratings and tasks is the extent to which they are associated with outcomes of interest, which speaks to their criterion validity. If these measures validly assess individual differences in control, they should predict behaviors that reflect lack of control.
Ratings generally show large associations (R2 = .03–.29) with outcomes of interest, such as substance use and psychopathology (Eisenberg et al., 2019; Friedman et al., 2020). However, as noted earlier, some of these associations could be due to using self-report measurements for both control ratings and behavior problems. In contrast, tasks show more variable prediction of real-world control problems. Some studies have found no associations (e.g., with measures of substance use; Eisenberg et al., 2019), even at the latent variable level. Others have found significant relationships of task latent factors with substance use and psychopathology (Friedman et al., 2020; Gustavson et al., 2017), although those associations are generally smaller (R2 = .00–.10) than associations with ratings. Such patterns have been interpreted as evidence that rating scales are better assessments of control deficits than are tasks (Barkley & Fischer, 2011; Eisenberg et al., 2019). However, meta-analytic reviews suggest that tasks are associated with a range of mental-health conditions (Snyder et al., 2015). Moreover, some outcomes, namely, academic behavior (Malanchini et al., 2019; E. F. Soto et al., 2020) and income and life milestones (Eisenberg et al., 2019), seem to show relationships with tasks that are stronger than the associations of mental-health outcomes with tasks.
Regardless of the relative magnitudes of ratings’ and tasks’ associations with behavioral outcomes, an important question is whether ratings and tasks are associated with the same variance in these outcomes. If ratings and tasks tap a common control ability, then they should explain overlapping variance in behavior. However, several studies that have used both ratings and tasks to predict behavior have demonstrated that they account for independent variance in outcomes (Ellingson et al., 2019; Friedman et al., 2020; Kamradt et al., 2014; Malanchini et al., 2019; Sharma et al., 2014). For example, in two independent samples, we found that latent variables for self-reported impulsivity and task-based executive function were both significantly associated with a latent variable for externalizing psychopathology in an analysis controlling for their overlap (Friedman et al., 2020). Such patterns suggest that ratings and tasks may predict these outcomes for different reasons.
Do Tasks and Ratings Have Low Correlations With Each Other Because They Measure Different Constructs?
The persistently low correlations between tasks and ratings, even when measured reliably, as well as their independent associations with behavioral outcomes, suggest that they measure separable constructs. What, then, are these constructs? It may be that ratings and/or tasks measure something other than control; it is also possible that both ratings and tasks are valid measures of control but measure different aspects of control. Here we briefly discuss six main dimensions that distinguish them (see Fig. 2; for more discussion, see Dang et al., 2020, and Wennerhold & Friese, 2020):
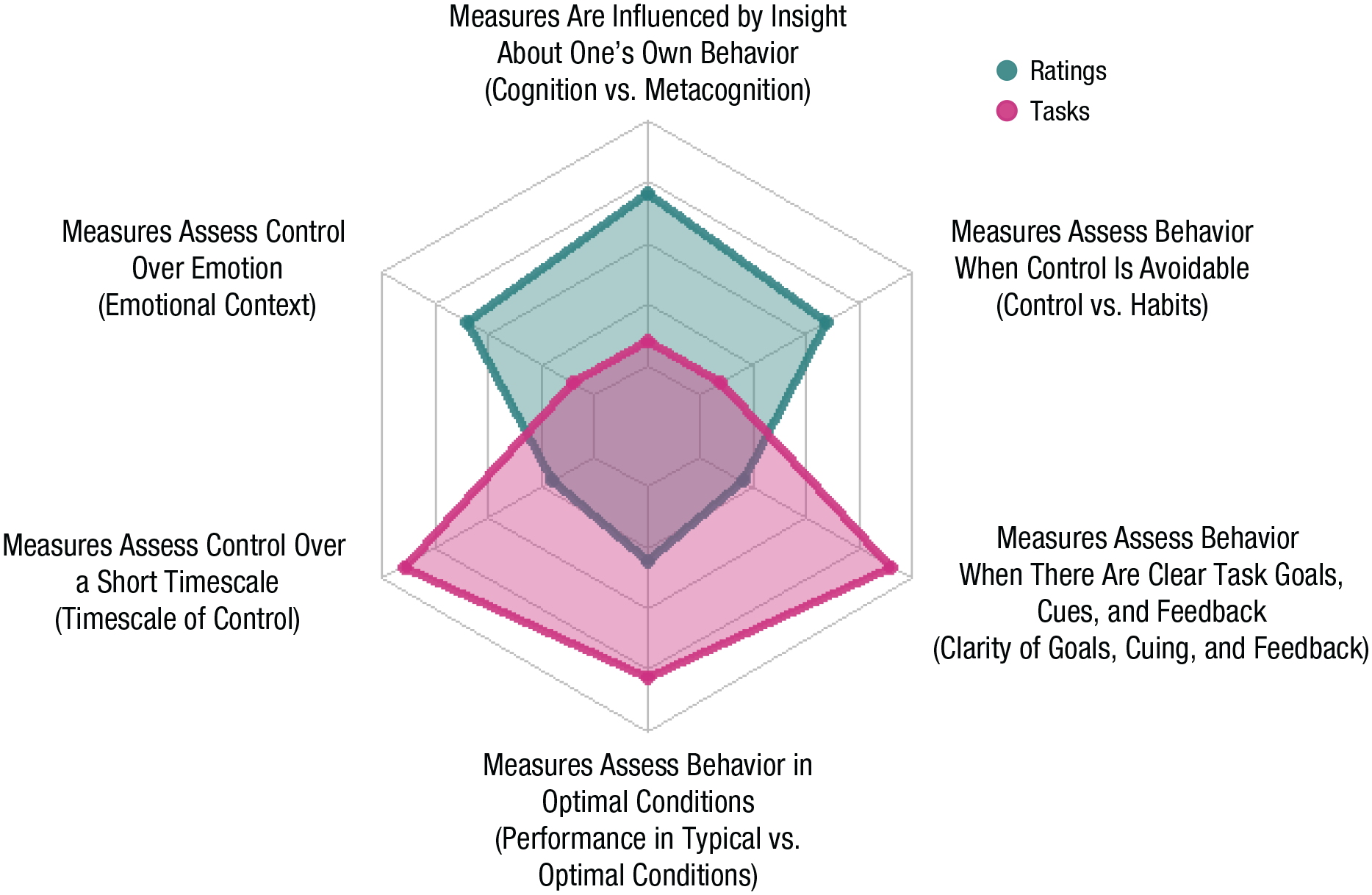
Six dimensions that distinguish task-based and ratings-based control measures. Each vertex in the diagram is labeled with a specific characteristic and (in parentheses) the dimension it represents (as described in the text). Each type of measure is represented by a colored shape whose outer points indicate values on the dimensions. Points further away from the center reflect more consistency with the indicated characteristic (e.g., for cognition vs. metacognition, the higher value for rating scales mean that ratings are more influenced by one’s insight, or metacognitive awareness, than tasks are). Task-based measures typically provide clear task goals, focus on short-term measures of control, and assess participants’ performance in optimal situations. In addition, the need to exert control is typically unavoidable, and responses are not influenced by one’s metacognitive awareness. Tasks typically focus on attentional control in emotionally neutral situations, though there are exceptions (i.e., hot executive-function tasks). In contrast, rating-based measures focus on long-term control and ask about how a person typically performs. The everyday control reported on in such scales typically involves situations without clear goals, cues, or feedback and sometimes involves situations in which control is avoidable (e.g., by adjusting habits or the environment); it often involves control over emotions or in emotional contexts. Ratings may also be influenced by metacognitive beliefs (i.e., insight into one’s own abilities).
Cognition versus metacognition: As mentioned earlier, ratings are subjective measures that require the rater to have some insight into the behavior and abilities of the person being rated; moreover, the rater and person being rated are usually one and the same. In contrast, tasks are more objective measures that do not require participants to be aware of how they are doing. Thus, ratings may in part reflect differences in metacognitive awareness, whereas tasks assess only cognitive control.
Emotional context: Rating scales often ask whether individuals can exert control in emotional situations (e.g., scales of impulsive urgency). Such emotional control may differ from attentional control, which is typically assessed in emotionally neutral situations. Moreover, because ratings are based on real-world experiences, they more likely reflect behavior in situations in which failures of control have negative consequences. Therefore, they may involve additional emotional investment compared with tasks (for which compensation rarely depends on performance). Research with “hot” executive-function tasks (those that use emotional stimuli or include rewards; Zelazo & Carlson, 2012) provides a way to examine this possibility. A recent study implementing inhibition tasks in a gaming framework (Verdejo-Garcia et al., 2021) found somewhat larger associations between impulsivity ratings and cognitive measures (rs = .2–.3), compared with prior work, possibly because the researchers adjusted for reliability and added motivational (emotional) aspects to the cognitive tasks. However, studies have not yet examined associations between latent variables for hot executive-function tasks, standard (“cool”) executive-function tasks, and rating measures.
Timescale of control: Control assessed by computerized tasks reflects operations that take place in just a few hundred milliseconds. In contrast, rating measures ask individuals about how well they can attend to tasks in everyday life, often across very long periods of time. The attentional-control demands for tasks may differ from the control necessary to make progress on long-term goals such as homework assignments or projects that take hours, days, or weeks to complete. Even when individuals must exert rapid control (e.g., when they are angry), the situation does not resolve immediately, and they may have to continue exerting control for an extended period of time.
Performance in typical versus optimal conditions: A related distinction is that rating scales tend to ask about typical performance (i.e., across a range of contexts and occasions), whereas tasks often assess performance in optimal, experimentally constrained, conditions (Toplak et al., 2013; Wennerhold & Friese, 2020). Although individuals may be capable of high levels of control during experiments in the lab (particularly when tasks include incentives for good performance), they may not necessarily use it regularly in everyday life. Thus, being “good at” control may not mean that individuals typically “act self-controlled” (Grund & Carstens, 2019). Computerized tasks that are administered online are becoming more popular and may assess performance in conditions that are somewhere between typical and optimal. Specifically, online computerized assessments require individuals to exert control in experimentally constrained situations, but even with careful study design (e.g., including items to check attention, ensuring that the task will function across Internet browsers and computers, instructing participants to do the experiment in a quiet setting), there may be unexpected environmental disruptions that experimenters cannot control that influence performance.
Clarity of goals, cuing, and feedback: Task goals are clear in the laboratory but are not always spelled out in the real world. Even if the final goal is clear (e.g., “buy bread”), individuals typically need to develop and execute a plan themselves. Tasks are also typically cued, which allows individuals to know exactly when they need to exert control. Everyday situations are much more variable, requiring personal reminders or self-cuing (e.g., remembering to stop at the store on the way home). Laboratory tasks also organize distracting or irrelevant information in a systematic manner that may not represent real-world contexts. Finally, error signals may also be clearer or more consistent in laboratory tasks compared with the real world.
Control versus habits: Because individuals have some control over their environments, they can sometimes reduce the need to exert control in their everyday life. One intriguing proposal is that ratings may not reflect active control abilities at all, but rather may reflect the use of habits that are associated with lessening the need for control (de Ridder et al., 2012; Galla & Duckworth, 2015). Individuals who score higher on self-control rating scales also practice more habits such as eating healthy snacks, exercising regularly, and sleeping at regular times. To the extent that individuals structure their own environments so that these behaviors become habitual (Vohs & Piquero, 2021), control is no longer required; one may have less temptation to eat unhealthy snacks if one does not keep them in the house. This possibility is consistent with findings that people who report higher self-control report having to exert self-control less often (Grund & Carstens, 2019) and experience fewer occasions of temptation (Hofmann et al., 2012). If ratings reflect habits rather than abilities, then their lack of correlation with tasks is unsurprising.
These potential explanations for the incongruity between tasks and ratings are not mutually exclusive, and future research is needed to evaluate their relative importance. We hope that this brief discussion inspires studies in which these dimensions are systematically manipulated in both task and rating paradigms. For example, to manipulate the dimension of clarity of goals in ratings measures, researchers could ask participants to set clear goals and establish implementation intentions for when control is needed (or assign particular implementation intentions), and then ask participants questions about their success. These manipulations might improve the clarity of goals, monitoring, and cuing in ratings measures and/or reduce variance in goal representations across individuals in the sample. Another approach that may reduce ratings being influenced by insight (the cognition-vs.-metacognition dimension) would be to use experience sampling and passive data collection (e.g., with mobile phones or wearable devices), which can assess everyday control more directly, reducing reliance on retrospective judgments. For example, accelerometry and location data can be used to obtain measures related to exercise, sleep habits, and substance use (e.g., hand movements during smoking, proximity to substance use outlets).
In addition to sampling behaviors under different conditions, researchers could gain more information about the conditions participants set up for themselves in their everyday lives. If configuring the environment (reducing the need for control) is a significant component of individual differences in everyday self-control, it may be important to assess individuals’ abilities and spontaneous inclinations to take such steps (the control-vs.-habits dimension). For example, self-regulation or emotion regulation is enhanced by adopting strategies such as psychological distancing (e.g., in the classic marshmallow delay-of-gratification task, thinking of marshmallows as clouds instead of tasty treats; Mischel & Baker, 1975). There is some evidence that instructed self-distancing (e.g., instructing participants to make decisions as Batman instead of themselves) can also improve children’s performance on cool executive-function tasks (White & Carlson, 2016). Such results raise a number of questions: To what extent do individuals spontaneously adopt such strategies to regulate their behavior, and what factors affect the tendency to do so? Do individual differences in use of these strategies influence variance in self-control ratings and tasks? Do ratings correlate better with tasks that enable such reconfiguration compared with tasks that do not enable reconfiguration? Experiments targeting such questions may yield insights into the divergence between tasks and ratings.
Finally, it may be useful to consider that the constructs tapped by some control measures may be broader than researchers often posit. Task-based research frequently focuses on “inhibition” tasks, with the assumption that self-control requires active suppression of impulses or distractions. However, everyday self-control and success may be more about creating good goals and monitoring the environment for cues about when to implement these goals and when to increase control. Indeed, self-control rating scales often include reverse-scored items assessing whether individuals are organized, reliable, neat, and scheduled, which do not obviously reflect inhibitory control. Thus, other control tasks may be more useful than inhibition tasks, which may be particularly susceptible to poor reliability and low cross-task correlations (Friedman & Miyake, 2004; Hedge et al., 2018; Rey-Mermet et al., 2018). Similarly, it may be useful to reevaluate whether items pertaining to organization should be included in rating scales as indicators of control or if their inclusion conflates control with general goal-management abilities.
Concluding Remarks
In summary, rating-based and task-based control measures assess only slightly overlapping variance, even when both are measured reliably. A pessimistic view of this low convergence of tasks and ratings is that it is bad news for psychological science: If ratings and tasks indeed measure different constructs, then the specific cognitive mechanisms targeted by tasks cannot be used to understand individual differences in control as measured by ratings and vice versa. A more optimistic view is that their distinction presents an opportunity to better understand what each really measures by systematically investigating the dimensions that may distinguish them. We have characterized these constructs as different “aspects” of control because we see similarities to other multidimensional constructs: Just as two different kinds of artistic ability (e.g., painting and singing) may show small correlations but may nevertheless both be described as artistic, task and ratings measures may show small correlations but nevertheless both be described as control related. However, future research is needed to evaluate whether it is indeed accurate to characterize both these constructs as aspects of a more general control ability. If ratings and tasks do capture different aspects of control, then they may be used to supplement one another, increasing prediction and insight. Evidence for such incremental validity for predicting some outcomes (Ellingson et al., 2019; Friedman et al., 2020; Kamradt et al., 2014; Malanchini et al., 2019; Sharma et al., 2014) suggests that there is reason to study both aspects of control. It may be useful to administer both sets of measures more routinely, as each may provide a different window into important individual differences.
Recommended Reading
Eisenberg, I. W., Bissett, P. G., Enkavi, A. Z., Li, J., MacKinnon, D. P., Marsch, L. A., & Poldrack, R. A. (2019). (See References). Reports a study in which measures from online behavioral tasks were less reliable than survey ratings and only ratings strongly predicted most substance use and mental-health outcomes, even when factor scores for tasks were used to increase test-retest reliability.
Friedman, N. P., Hatoum, A. S., Gustavson, D. E., Corley, R. P., Hewitt, J. K., & Young, S. E. (2020). (See References). Reports a study in which impulsivity ratings and latent variables based on executive-function task performance showed low correlations with each other and independently predicted psychopathology in two large samples of adult twins.
Galla, B. M., & Duckworth, A. L. (2015). (See References). Reports six studies demonstrating that the links between rating measures of control and positive outcomes (e.g., related to health and academic achievement) are explained by the use of beneficial habits.
Malanchini, M., Engelhardt, L. E., Grotzinger, A. D., Harden, K. P., & Tucker-Drob, E. M. (2019). (See References). Reports a study of twins (3rd through 8th grade) in which a latent variable based on executive-function task performance and ratings related to self-regulation and achievement (impulse control, openness, and conscientiousness) showed modest overlap and predicted independent variance in academic performance.
Wennerhold, L., & Friese, M. (2020). (See References). Provides further discussion of the ways in which self-control ratings and inhibition tasks may assess different constructs.