
Abstract
This article aimed to explore the development of an artificial intelligence model for English grammar correction based on computational linguistics methods. Traditional grammar correction systems suffer from problems such as complex rules, sparse data, and insufficient utilization of contextual information. To address these issues, this article adopted Transformer’s pre-trained language model, utilizing its powerful context understanding and automatic feature extraction capabilities to improve the processing performance of complex syntax structures and long-distance dependencies. Meanwhile, by constructing large-scale and diverse datasets and combining them with data augmentation techniques, the model’s generalization ability and robustness were enhanced. This article also investigated hyperparameter tuning, model integration, and continuous optimization strategies in the process of model training optimization, and provided a detailed description of model evaluation and experimental validation. In the evaluation, the average precision, average recall, and average F1 score for most common grammar errors were 0.8, 0.805, and 0.801, respectively. The model in this article has excellent grammar correction ability. Through comprehensive experiments and evaluations, the potential and advantages of a new grammar correction artificial intelligence model developed based on computational linguistics methods in improving grammar correction effectiveness and practicality have been demonstrated.
Introduction
In today’s information and digital age, the accuracy of language is crucial for effective communication and information transmission, especially in the context of English as the global lingua franca. The correct use of English grammar1,2 is not only related to an individual’s written expression ability, but also directly affects the clarity and efficiency of information communication. Traditional rule-based grammar checking tools have many problems when dealing with complex grammar structures and diverse contextual usage. With the rapid development of artificial intelligence and NLP technology, computational linguistics has attracted attention as an important approach to solving grammar correction challenges. Computational linguistics combines the theories and methods of computer science and linguistics, dedicated to developing intelligent systems capable of understanding, generating, and processing natural language. In the field of grammar correction, computational linguistics methods can more accurately analyze and understand grammar errors in text by constructing automated language processing models, and provide effective grammar correction suggestions. Traditional grammar checking tools 3 are typically based on predefined rules and dictionaries. Grammar checking tools perform well in dealing with simple grammar errors, but they are inadequate in handling complex grammar structures and diverse language usage. The writing and maintenance of rules are both time-consuming and cumbersome, making it difficult to cover all grammatical phenomena and language variants. Traditional methods often rely on surface form analysis and lack the ability to understand deep semantic and contextual information, resulting in high false positive and false negative rates. The latest developments in the field of NLP, particularly the introduction of deep learning (DL) and pre-trained language models, provide new possibilities for addressing these issues. DL models can automatically extract features and capture complex language patterns through learning from large amounts of data, while pre-trained language models have strong contextual understanding and generation capabilities, and can perform well in multiple language tasks. Therefore, applying these advanced computational linguistics methods to grammar correction has certain advantages.
To develop an efficient grammar correction model, this article collects and uses a large-scale and diverse corpus. After collection, the data is cleaned, annotated, and enhanced to improve the model’s generalization ability. This article chooses the Transformer architecture for model construction. The Transformer architecture is chosen to develop the English grammar correction model mainly because its self-attention mechanism can effectively capture long-distance dependencies, which is particularly suitable for processing complex language structures. This article chooses the Transformer architecture for model construction. This article uses indicators such as precision, recall, F1 score, BLEU (Bilingual Evaluation Understudy) and ROUGE (Recall-Oriented Understudy for Gisting Evaluation) to comprehensively evaluate the performance of the model. This paper chooses BLEU and ROUGE as the main evaluation indicators because they can comprehensively measure the generation quality of the grammar correction model. BLEU measures the accuracy of vocabulary selection and sentence structure by evaluating the matching degree between the model output and the n-gram fragments of the reference sentence; ROUGE focuses on evaluating the model’s performance in retaining the important content and order of the original sentence. Combining these two indicators can more accurately reflect the overall effect and content retention ability of the model in correcting grammatical errors. The performance of the model in different contexts and language variants can be validated through cross validation and test set evaluation. After verification, the developed grammar correction model can be applied to practical language usage scenarios, such as writing aids, online education platforms, etc. Through user feedback and usage data, the model can be continuously optimized and improved.
In order to verify the performance of the model, multiple sets of comparative experiments were conducted. During the training process, the cross entropy loss function was used to optimize the model parameters, and the model performance was improved through hyperparameter tuning and model ensemble strategies. Through extensive experiments and evaluations, this article demonstrates the superior performance of the proposed model on different indicators. The experimental results show that the grammar correction model developed based on computational linguistics methods performs well in various language tasks, especially in dealing with complex grammar structures and long-distance dependencies, significantly better than traditional rule-based methods. The innovation of this article in the field of computational linguistics is mainly reflected in the application of the Transformer architecture and its self-attention mechanism to the grammar correction task, which breaks through the limitations of the traditional sequence model and significantly improves the ability to handle complex syntactic structures. At the same time, the research introduced a multi-level grammatical feature representation method and optimized the multi-head attention mechanism, allowing the model to more accurately understand and correct grammatical errors.
Related work
In recent years, with the rapid development of DL technologies, significant progress has been made in the field of English grammar correction. Traditional grammar correction methods mainly rely on rules and statistical models, while modern methods make more use of DL and pre-trained language models. Combining artificial intelligence of large language models4,5 with grammar correction is a new trend. Various grammar correction methods have been proposed in academia and industry. 6 In recent years, DL and artificial intelligence 7 have gradually become research hotspots in grammar correction. O'Neill R proposed the view of academic learning advisors on the use of online grammar checkers 8 for checking grammar errors online. The researchers also used convolutional neural networks of DL 9 for syntax error detection, demonstrating the potential of DL in handling complex language tasks. Another study proposed a syntax correction method for DL-based generative adversarial networks, 10 which further improves the robustness and accuracy of the model by introducing adversarial training mechanisms. However, grammar correction methods still need improvement in the face of data sparsity and long-distance dependencies, making it difficult to provide feedback on errors in grammar construction. 11 The online grammar checker 12 also has significant issues, with inaccurate grammar correction results and poor ability to recognize errors. Fitria T N, Bin Y, and others have combined artificial intelligence13,14 models with English teaching practices, greatly improving the accuracy of grammar correction. Although statistical models can handle some grammar errors, they often perform poorly in long-distance dependencies and complex syntactic structures. Although DL methods have alleviated these issues to some extent, their reliance on large-scale, high-quality annotated data remains a significant challenge. Current models generally have high requirements for computing resources, and the training and inference processes are time-consuming, making them difficult to apply in practice.
To further improve the performance of the grammar correction system, an intelligent algorithm is applied to construct a grammar correction model. Zhang 15 established an English grammar error correction model based on seq2seq, and improved the training efficiency and error correction ability of the model by using advanced edge computing technology. Tarish 16 utilized an automatic speech recognition system to identify and correct grammar errors. Zhong 17 proposed an algorithm model with high error correction performance using DL methods, introduced the framework of adversarial learning networks, continuously improved and optimized model parameters, and introduced convolutional neural networks to enhance algorithm training effectiveness. Solyman 18 proposed a system based on convolutional seq2seq learning. Yuan 19 optimized the effectiveness of English grammar teaching and improved the level of grammar correction by integrating machine learning algorithms into teaching methods. Alkhatib 20 studied the method of using deep neural network technology for error detection in Arabic text, which can effectively solve the problem of detecting and correcting words with formatting errors that do not conform to the Arabic morphological system.
Data processing and feature extraction
Data collection
Data is the cornerstone of building high-performance grammar correction models, and the quality of data directly affects the performance and generalization ability of the model.
Utilizing publicly available corpora is one of the main ways to obtain large amounts of language data. This article uses large corpora such as BNC (British National Corpus) and COCA (Corpus of Contemporary American English) as datasets. The dataset selection in this paper is based on the following criteria: the dataset needs to cover a wide range of grammatical error types to ensure that the model learns and corrects a variety of errors; the dataset should be large and diverse enough to enhance the generalization ability of the model; the dataset should include examples of different contexts and language structures to improve the accuracy of the model in processing complex syntactic structures. These criteria ensure that the model is exposed to diverse and representative corpora during training, so that it can show stronger robustness and higher error correction capabilities in practical applications.
Data preprocessing
Data preprocessing can be performed on the collected data.
The text cleaning and standardization operations in this article include removing redundant characters, processing punctuation, expanding abbreviations, unifying capitalization, standardizing numbers, restoring lemmas, and removing stop words. These operations are designed to ensure the consistency and high quality of input data, thereby improving the training effect and performance of the grammar correction model, reducing the impact of noise data on model learning, and ultimately enhancing the generalization ability of the model.
The median can be used to fill in missing values in the data, as shown in the formula (1):

Among them,
After filling in missing values, perform Min-Max normalization on the data and scale it to [0,1]. The specific formula is shown in formula (2).

Among them,
In data preprocessing, after abnormal data is identified through statistical methods or machine learning algorithms, this paper removes, corrects or marks them to ensure that they do not affect model training.
After normalization, perform text preprocessing by removing all punctuation marks and special characters, retaining only letters and numbers. Convert all characters to lowercase to ensure text consistency. Restore the word to its stem form and restore the word to its form.
Each grammatical error can be classified and annotated, such as subject verb inconsistency, tense errors, article usage errors, etc. Each error can be marked with its specific location in the sentence, so that the model can accurately locate and correct the error.
Sentences can be segmented into word sequences for subsequent feature extraction and model training. Each word’s part of speech can be annotated to provide additional grammatical information, helping the model better understand sentence structure.
In all available data, the data order is first randomly shuffled to ensure that the distribution of samples is uniform and not affected by the original order. 80% of all data is used as training set and 20% as validation set.

Data enhancement
Error types.

Data enhancement.

The insertion method generates new sentences by adding words or phrases at specific positions in the sentence, which helps the model learn how to deal with redundant components in the sentence and the correct way to add words in the context, thereby enhancing the model’s ability to handle similar errors in practical applications. The deletion method generates new sentences by removing a certain word or phrase from the sentence, which is used to train the model how to identify grammatical errors caused by the lack of key components. The replacement method generates new sentences by replacing a certain word or phrase in the sentence with other words or phrases, which can help the model understand the applicability of different words in the context and the impact of replacing words on sentence structure and grammatical correctness. The out-of-order method generates new sentences by changing the order of words or phrases in the sentence, which is used to train the model to identify grammatical errors caused by improper order of words or phrases.
Data feature extraction
Feature extraction is the process of transforming raw data into feature representations suitable for machine learning model processing. For English grammar correction models, feature extraction typically involves extracting meaningful vocabulary, grammar, and contextual information from textual data. This article uses bag of words model and dependency parsing for feature extraction, and captures semantic relationships between sentences using word embedding, N-gram model, and sentence embedding. The reason why these methods are suitable for grammatical correction tasks is that they can capture language information from different levels: the bag-of-words model and the N-gram model effectively identify errors at the vocabulary and phrase levels, dependency parsing reveals the grammatical structure of sentences and helps deal with complex syntactic errors; word embedding and sentence embedding provide semantic information, allowing the model to understand the context and overall sentence meaning. The combination of these methods enables the model to comprehensively analyze the text and accurately identify and correct various types of grammatical errors.
The bag of words model is the simplest and most widely used feature extraction method, which ignores word order and grammar during the extraction process, only considering the frequency of word occurrence. The bag of words model extracts all unique words from the training data, constructs a vocabulary, and represents each text as a vector. If a word appears in the text, its corresponding vector position value is word frequency, otherwise it is 0.
Word embedding maps words to a continuous vector space, capturing semantic relationships between words.
Dependency parsing uses a dependency parser to analyze sentences, extract dependency relationships, and encode them into feature vectors.
The N-gram model captures richer contextual information by considering the sequential information of N consecutive words. The N-gram model extracts a combination of N consecutive words from text and represents each text as a vector of N-gram features.
Sentence embedding uses a pre-trained sentence embedding model to convert each sentence into a sentence embedding vector.
After completing feature extraction, part of speech tags can be assigned to each word to provide grammatical information about the word. It can analyze the dependency relationship graph of sentences, capture the grammatical dependency relationships between words, and input the dependency relationships as additional features into the model. The specific location of each grammar error in the sentence can be annotated as an additional input feature for the model, and positional encoding in Transformer can be used to capture the relative position of words in the sentence. Sentiment analysis can be performed on sentences to indicate their emotional tendencies (including positive, negative, neutral, etc.), which may be helpful in correcting certain grammar errors. It can analyze the tone of sentences (such as declarative sentences, interrogative sentences, imperative sentences) and provide additional contextual information.
Model construction and training optimization
Model architecture design
Choosing the appropriate model architecture is a key step in building a grammar correction model in this article. Modern grammar correction models typically use DL methods such as RNN, LSTM, GRU, and Transformer. Modern grammar correction models can capture contextual information in sequence data and effectively handle grammar errors.
RNN is a neural network used to process sequential data, which can predict the current output based on the previous information in the sequence.
LSTM (Long Short-Term Memory) 22 effectively solves the long-distance dependency problem of RNN by introducing memory units and gating mechanisms, making LSTM perform better in processing long sequences. LSTM can retain sequence information over a longer time span and is suitable for handling complex syntax structures.
GRU (Gated Recurrent Unit) is a simplified version of LSTM with higher computational efficiency, suitable for similar sequential tasks. GRU also performs well in handling long-distance dependencies while reducing computational complexity.
Transformer captures the dependency relationships at different positions in a sequence through self-attention mechanism, making it suitable for handling long sequence tasks. The Transformer architecture is currently widely used in natural language processing (NLP) tasks.
This article chooses Transformer as the syntax correction model architecture. Using BERT pre-trained language models, pre-training is performed on large-scale general corpora, and then fine-tuned on grammar correction tasks to improve the model’s generalization ability and task specific performance.23,24 The same dataset was used for training and testing in the experiment to ensure that all models were compared under the same input data conditions to eliminate the impact of data differences on the results. The hyperparameters of all models were kept consistent in the experiment to ensure that the performance differences between different models only came from the structure and algorithm of the model itself, rather than parameter adjustment. The same random seed was set in the experiment to control the randomness of model initialization and data partitioning to ensure the repeatability and comparability of the experimental results. The training set and validation set partitioning method was kept fixed in the experiment to ensure that different models were evaluated on the same training and validation data to eliminate the impact of data partitioning on model performance. The specific architecture is shown in Figure 1. Transformer architecture diagram.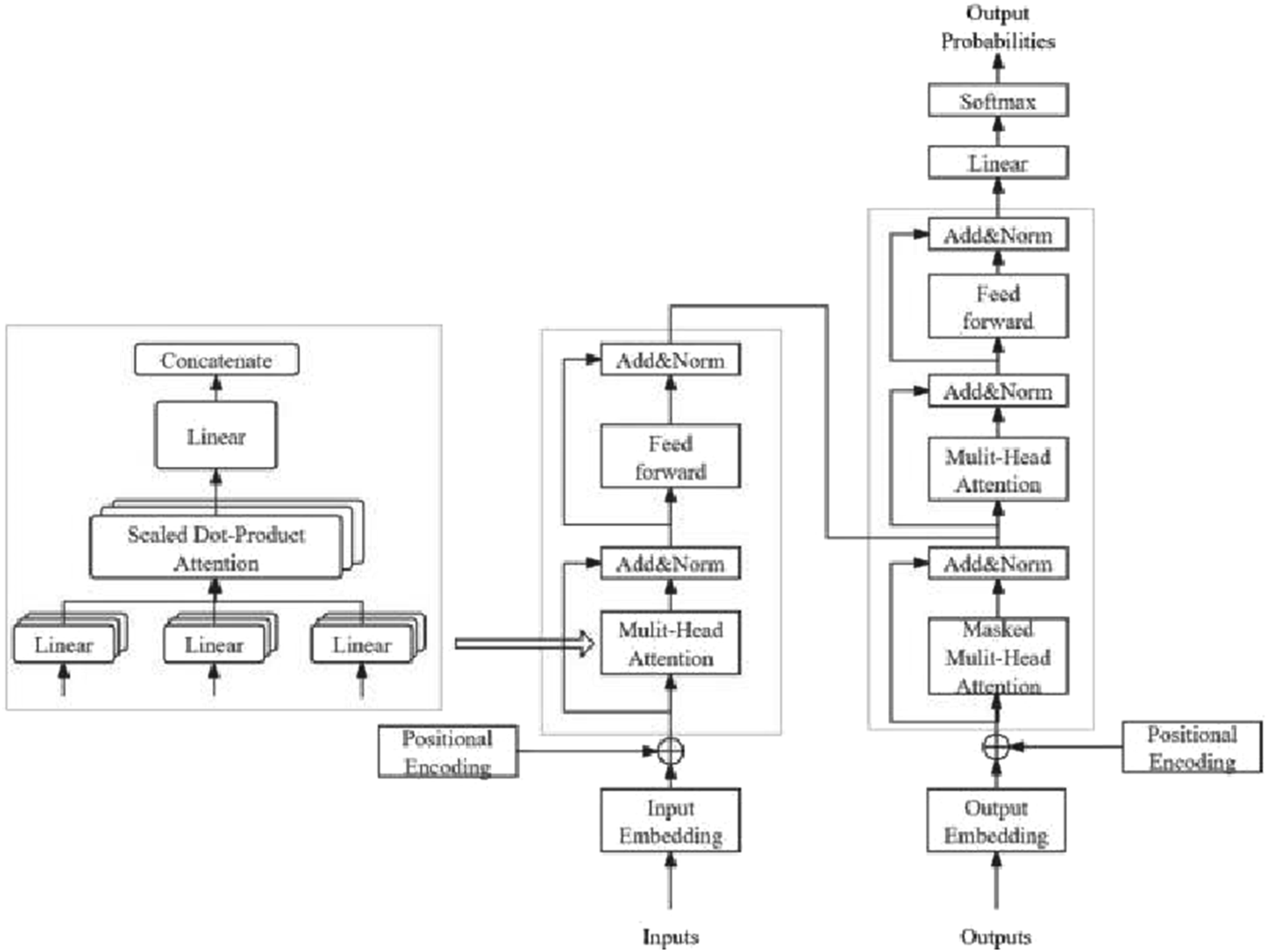
Loss function design
When constructing an artificial intelligence model for English grammar correction,25,26 the design of the loss function is the core aspect of model training. The change in loss value can reflect the performance of the model in correcting different types of grammatical errors. By using multi-task loss or weighted loss, the loss values of the model when dealing with different types of errors can be calculated and observed separately. If the loss value of a certain type of error decreases slowly or remains at a high level, it means that the model is less effective in correcting this type of error. Analyzing the changing trend and distribution of loss values can help identify the weaknesses of the model, so as to optimize it in a targeted manner and improve the overall error correction capability.
Cross entropy loss is the most commonly used loss function in classification tasks, particularly suitable for eq2seq (sequence to sequence) models,
27
such as syntax correction tasks. Specifically, it is formula (3):
Among them,
In the sequence-to-sequence model, the cross entropy loss can be applied to each time step, accumulating the loss of all time steps. For a sequence of length T, the loss function can be expressed as formula (4).
Label smoothing reduces the risk of model overfitting by assigning a small smoothing value to the target label. The loss function is modified and expressed as formula (5).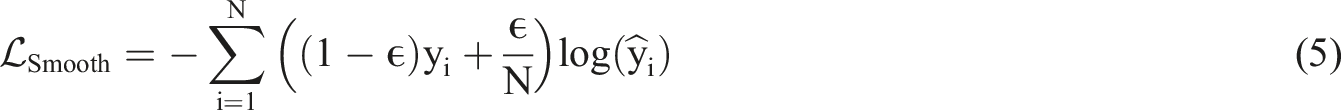
Among them,
The weighted cross entropy loss addresses the problem of class imbalance by assigning different weights to different categories, expressed as formula (6).
Among them,
Index loss focuses on uncertain predictions of the model by introducing weight decay. This loss function has a greater penalty for prediction errors and helps the model converge faster during the optimization process, expressed as formula (7).
The cross entropy loss function can be used to measure the difference between predicted sentences and real sentences, guiding model optimization. This article combines the characteristics of seq2seq tasks to design a sequence loss function suitable for syntax correction, and evaluates its performance using BLEU score and ROUGE score.
Training strategy design
To ensure that the model can effectively learn and avoid overfitting during the training process, a scientifically reasonable training strategy can be adopted. The training strategy adopted in this paper includes cleaning and enhancing the data, training through mini-batch gradient descent and learning rate scheduling, and combining Dropout and L2 regularization to prevent overfitting. Early stopping and hyperparameter tuning are used to ensure the best performance of the model on the validation set, while monitoring multiple evaluation indicators, and finally saving the best performing model for testing, thereby improving the learning ability and generalization performance of the model.
The initial learning rate can be set to
Adam optimizer
28
can be used for model optimization. The Adam optimizer combines the advantages of momentum and adaptive learning rate, making it suitable for most DL tasks and accelerating model convergence. The Adam optimizer was selected due to its ability to combine the advantages of momentum and adaptive learning rates. This combination not only accelerates model convergence but also smooths parameter updates, making it particularly robust when dealing with sparse data and noisy environments. Additionally, Adam’s capacity to automatically adjust the learning rate enhances training efficiency, improves the model’s generalization capabilities, and reduces the risk of overfitting. To further optimize performance, a cosine annealing strategy was employed. This approach dynamically adjusts the learning rate throughout the training process, thereby enhancing the overall effectiveness and stability of the model’s training. The specific formulas are represented as formulas (8)–(12).




Among them,
The learning rate determines the step size of each parameter update and is one of the most important hyperparameters. The batch size affects the frequency and computational efficiency of model parameter updates. The L2 regularization parameter and the Dropout rate are important hyperparameters to prevent model overfitting. When using a momentum optimizer (such as Adam), the momentum coefficient controls the inertia of the gradient update. Apply Dropout in the hidden layer of the model, randomly discarding a portion of neurons to prevent overfitting of the model. Add L2 regularization term to the loss function to penalize the weights of the model and limit its complexity. In model training, this paper selects L2 regularization and Dropout as the main regularization methods. L2 regularization limits the size of model parameters and prevents overfitting by adding a weight penalty term to the loss function. Dropout reduces the model’s dependence on specific nodes and improves generalization ability by randomly discarding some neurons. The combination of these two methods effectively improves the stability and performance of the model on different data sets, expressed as formula (13).
Among them,
This article’s early stopping strategy sets a patience parameter based on the performance on the validation set, allowing the model to continue training for 5 to 10 epochs without significant improvement in validation loss or accuracy. If the validation set performance does not improve above the set improvement threshold during this period, training will automatically stop and the model with the best performance on the validation set will be saved, thereby preventing overfitting and ensuring that the output model has optimal performance. During the training process, the loss and performance indicators on the validation set can be monitored. When the performance of the validation set no longer improves, the training can be stopped in advance to avoid overfitting. It can periodically save the checkpoints of the model and select the model with the best performance in the validation set for evaluation and application after training.
The hyperparameters of the model (including learning rate, batch size, number of layers, etc.) can be optimized through grid search, random search, and other methods to improve model performance. Multiple models’ prediction results can be combined, and methods such as voting and weighted averaging can be used to further improve the effectiveness of grammar correction.
Model evaluation and comparative analysis
Grammar correction model evaluation
Evaluation results of different types.

According to Table 4, it can be analyzed that the precision, recall, and F1 score values of the article’s model for common grammar errors are relatively high. The average precision, recall, and F1 score of common grammar errors are 0.8, 0.805, and 0.801, respectively. The English grammar correction model designed in this article has a good recognition effect on common grammar errors, and can identify most grammar errors with high precision.
The model has the highest precision for Vform and the lowest precision for VO. The highest precision is 0.863 and the lowest is 0.708. The average precision is 0.8, with a difference of 0.155 between the highest and lowest values. The precision of Vform is 21.89% higher than that of VO. The model has the highest recall rate for Pform and the lowest recall rate for Pref. The highest recall rate is 0.895 and the lowest is 0.718. The average recall rate is 0.805, with a difference of 0.177 between the highest and lowest values. The Pform recall rate is 24.65% higher than the Pref recall rate. The model designed in this article has a high recall rate for most syntax errors.
Model comparative analysis
Comparison between Transformer and the Grammarly
Grammarly 29 is an online grammar checking tool based on a large number of rules and statistical data. Grammarly has high precision in correcting simple sentences and common grammar errors. Grammarly analyzes the text entered by users by combining language rules and machine learning models, extracting grammatical structure and contextual semantic features, and using context-aware technology to detect grammar, spelling and style issues. It provides correction suggestions in real time to help users optimize grammar, vocabulary usage and writing style, thereby improving writing quality.
According to Figure 2, the Transformer model is better than the Grammarly model in terms of precision, BLEU score, and ROUGE score, but worse than the Grammarly model in terms of F1 score. The BLEU score and ROUGE score of this model are both 0.93. The BLEU score and ROUGE score of the Grammarly model are 0.89 and 0.87, respectively. The reason for generating the graph may be due to Grammarly’s insufficient understanding of the context in different emotional situations, complex recognition and correction rules, and incorrect judgments. Comparison between Transformer and the Grammarly model.
Comparison between Transformer and HMM
HMM (Hidden Markov Model) 30 can perform structural analysis and grammar correction on sentences, and estimate the most likely word sequence through probabilistic models. HMM is representative in the field of grammar correction because it can effectively model word order and simple grammatical structure, and capture the correlation between words through state transition and emission probability. The generative characteristics and strong interpretability of HMM make it widely used in early grammar checking tools.
According to Figure 3, the Transformer model is better than HMM in precision, F1 score, BLEU score, and ROUGE score, but worse than HMM in recall. The BLEU score and ROUGE score of this model are 0.91 and 0.94, respectively. The BLEU score and ROUGE score of HMM are 0.87 and 0.83, respectively. The BLEU score of HMM is lower than that of the model in this article. This may be due to the HMM model’s inability to understand longer contextual meanings, coupled with the high complexity of the model, making it difficult to identify grammatical errors in paragraphs. Comparison between Transformer and HMM.
Comparison between Transformer and SVM
SVM (Support Vector Machine) 31 can classify and correct grammar errors, and use feature vectors to represent sentence structure and grammar features.
According to Figure 4, the Transformer model outperforms the SVM model in terms of precision, recall, F1 score, BLEU score, and ROUGE score. The BLEU score and ROUGE score of this model are 0.84 and 0.88, respectively. The BLEU score and ROUGE score of the SVM model are 0.8 and 0.75, respectively. The reason for the poor performance of SVM models may be due to insufficient human intervention during the feature extraction stage, resulting in inadequate processing of contextual information. Comparison between Transformer and SVM.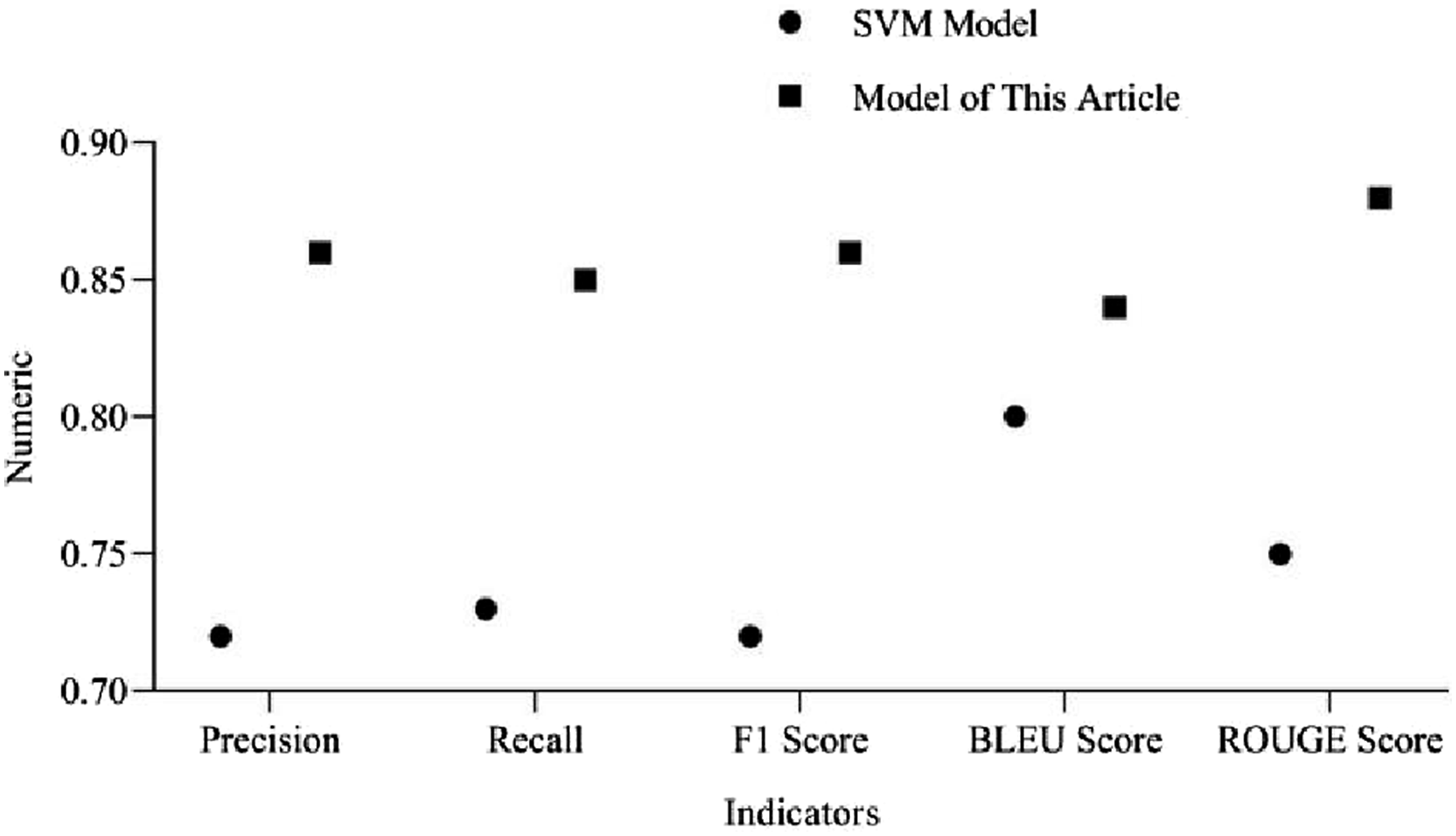
Comparison between Transformer and the Microsoft Word Grammar Checker
Microsoft Word Grammar Checker 32 is a built-in grammar checking tool in Microsoft Word that combines rules and statistical methods. The Grammar Checker model of Microsoft Word combines rule base and machine learning to detect grammatical errors by analyzing sentence structure and part-of-speech tagging. It uses grammatical rules and statistical models to identify common and complex grammatical problems, and provides real-time correction suggestions for spelling, grammar and style to help users improve the accuracy and fluency of their writing.
According to Figure 5, the Transformer model outperforms the Microsoft Word Grammar Checker model in terms of precision, recall, F1 score, BLEU score, and ROUGE score. The BLEU score and ROUGE score of this model are both 0.92. The BLEU score and ROUGE score of the Microsoft Word Grammar Checker model are 0.75 and 0.81, respectively. The BLEU scores of the two models differ significantly. This may be due to the use of a large number of complex syntax errors during training, and the Microsoft Word Grammar Checker model performs poorly in correcting complex syntax errors. Comparison between Transformer and the Microsoft Word Grammar Checker.
Comparison between Transformer and the RNN model
RNN 33 can accurately detect and correct grammatical errors in sentences.
According to Figure 6, the Transformer model is better than the RNN model in precision, F1 score, BLEU score, and ROUGE score, but worse than the RNN model in recall. The BLEU score and ROUGE score of this model are 0.92 and 0.95, respectively. The BLEU score and ROUGE score of the RNN model are 0.9 and 0.92, respectively. The difference in grammar correction between the two models is relatively small, but their performance is similar. The reason why the RNN model is inferior to the model in this article may be that the model training time is shorter, the performance of the RNN model is not fully utilized, and there is a lack of sufficient model training. Comparison between Transformer and the RNN model.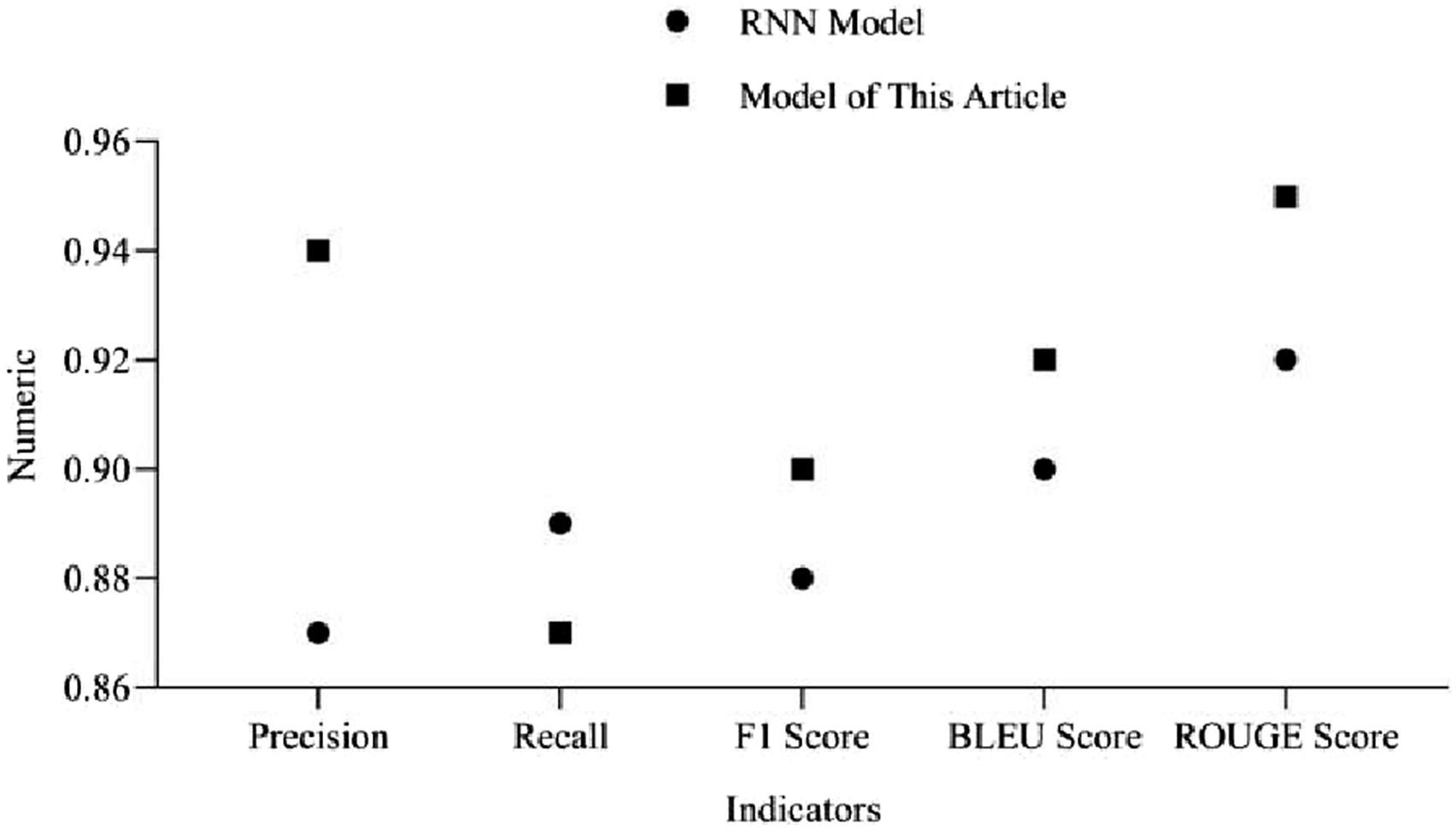
Comparison between Transformer and LanguageTool
LanguageTool 34 is an open-source multilingual grammar, style, and spelling checking tool. LanguageTool supports over 20 languages, including English, German, Spanish, French, and Chinese. LanguageTool can run on various platforms, including desktop applications, browser plugins, and integrated development environments. The core of LanguageTool is based on rules and statistical models.
According to Figure 7, the Transformer model outperforms the LanguageTool model in terms of precision, recall, F1 score, BLEU score, and ROUGE score. The BLEU score and ROUGE score of this model are both 0.9. The BLEU score and ROUGE score of LanguageTool model are 0.8 and 0.79, respectively. The performance indicators of the two models are significantly different, and the LanguageTool model has much lower performance than the model in this article. The reason why the performance of the LanguageTool model is lower than that of the model used in this article may be that the LanguageTool model used in this article has not been customized and has weaker processing capabilities for complex syntax structures. Comparison between Transformer and LanguageTool.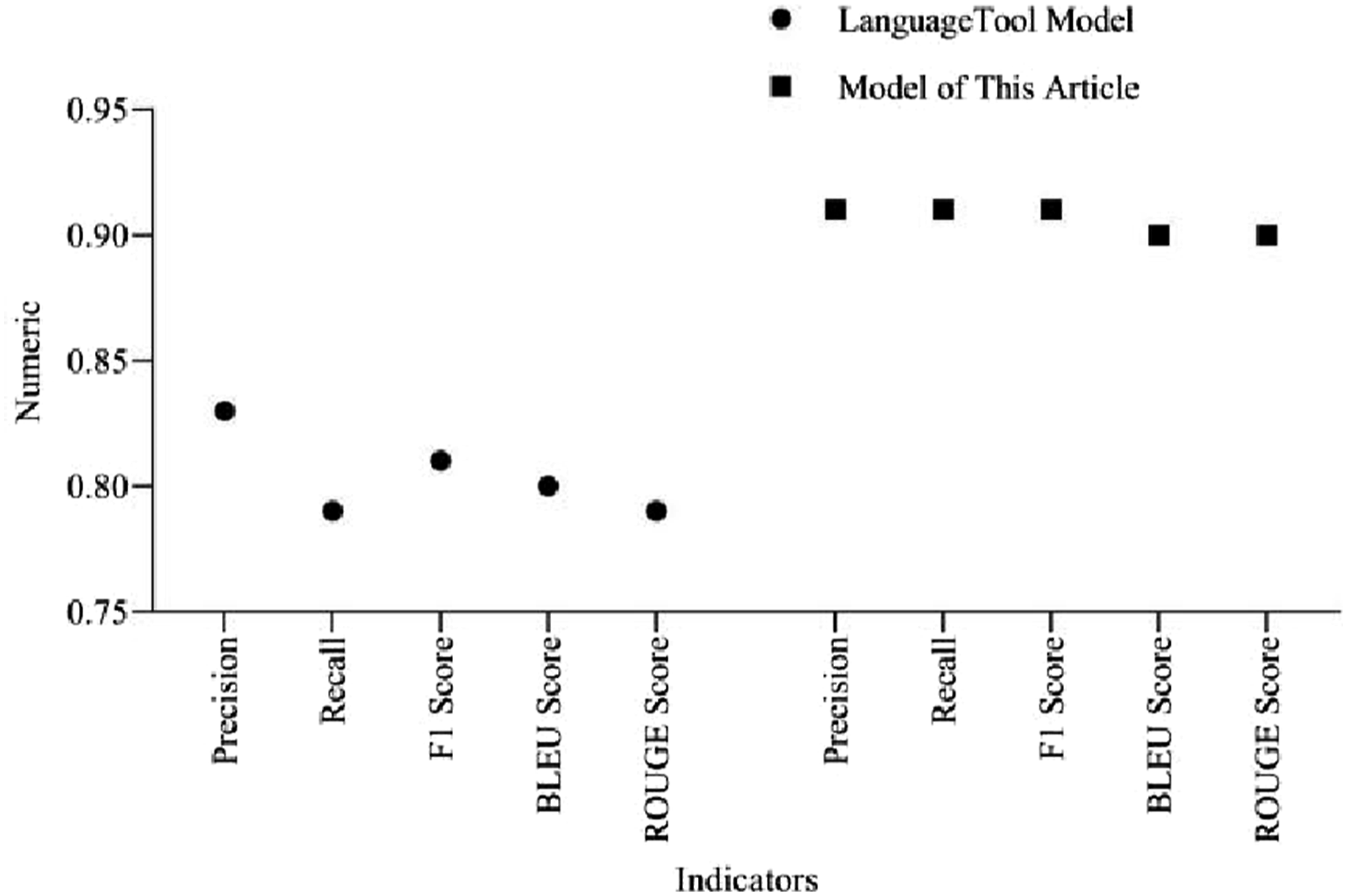
Comparison between Transformer and the decision trees model
Decision trees 35 is a fundamental but powerful supervised learning algorithm widely used in classification and regression tasks.
According to Figure 8, the Transformer model outperforms the decision trees model in terms of precision, recall, F1 score, BLEU score, and ROUGE score. The BLEU score and ROUGE score of this model are 0.96 and 0.95, respectively. The BLEU score and ROUGE score of the decision trees model are 0.77 and 0.79, respectively. The reason why the decision trees model is inferior to the model in this article may be due to overfitting, which affects the model’s generalization ability and results in poor performance in grammar correction. The reason why decision trees perform poorly is that they are sensitive to high variance in data, have poor ability to handle linear relationships, have poor generalization ability under sparse or complex features, and may ignore the relationships between variables. Comparison between Transformer and the decision trees model.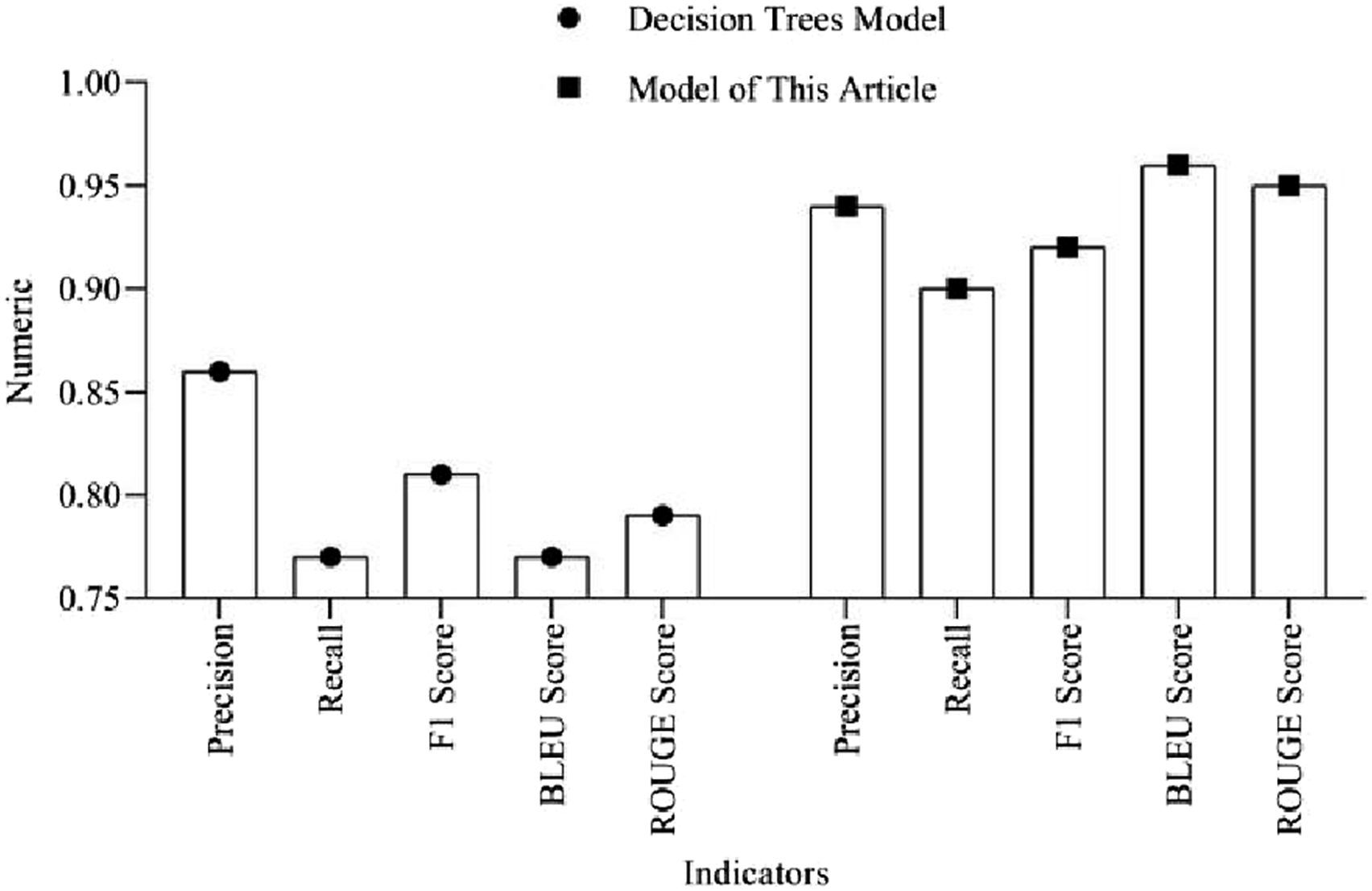
Model exploration
This article explores the development of an efficient English grammar correction artificial intelligence model using computational linguistics methods. Traditional grammar correction systems often rely on manually written rules and dictionaries, which results in limited effectiveness in handling complex syntactic structures and long-distance dependencies. Traditional methods also face problems such as data sparsity and insufficient utilization of contextual information. This article designs a language model based on the Transformer architecture. In terms of model construction, this article adopts advanced DL models and improves the model’s generalization ability and robustness through data augmentation techniques. Although the model performs well in English grammar correction, its limitations include dependence on a specific corpus, lack of generalization ability, efficiency issues when processing long texts, and challenges in identifying low-frequency grammatical errors. In addition, the model has limitations in multilingual support, semantic understanding, and real-time applications, and there is room for improvement in bias, fairness, and interpretability. These limitations need to be addressed in future research to improve the practical application effect of the model.
Conclusions
Through experimental verification, the model used in this article performs excellently in handling different types of grammar errors and can effectively identify and correct complex grammar structure problems. This indicates that combining computational linguistics and DL techniques can significantly improve the effectiveness and practicality of grammar correction systems. The model in this study shows significant potential in multi-language support, thanks to its design based on the Transformer architecture, which has a high degree of language versatility. By adapting appropriate training data and preprocessing steps, the model can be extended to grammar correction tasks in other languages, especially languages that are structurally similar to English, such as French and German. In addition, the development of multi-language pre-training models will further enhance the model’s multi-language processing capabilities, giving it broad application prospects in fields such as translation proofreading, language learning, and cross-cultural communication. This article uses a pre-trained language model based on the Transformer architecture and adopts an advanced deep learning model. This artificial intelligence model can grasp the overall semantics of the entire text without the need for setting too many correction rules and manual intervention. It can identify complex grammar errors and has excellent grammar correction performance. The model in this paper can be integrated into text editing and document processing systems to automatically identify and correct grammatical errors, improve text accuracy and writing efficiency, and is particularly suitable for publishing, law, and academic fields. The model in this paper can also be applied to intelligent customer service systems to ensure that the automatically generated text content remains highly grammatically accurate, thereby improving the quality and satisfaction of customer interactions. This study provides new ideas for future grammar correction techniques and serves as a reference for further development in the field of NLP. The English grammar correction model developed in this paper has a wide range of practical applications, especially in education, content creation, business communication, academic research, and language translation. However, in the future, improvements can be made by expanding multilingual support, enhancing semantic understanding, optimizing long text processing performance, improving low-frequency error recognition capabilities, and improving the model’s interpretability and user feedback mechanism to further improve the model’s practicality and user experience. Future research can further explore how to combine more language resources and technological means to improve the performance of models and achieve more efficient grammar correction in multilingual and cross domain applications. Future research will incorporate user feedback into English grammar correction. By analyzing user feedback, the model can identify and correct its own deficiencies and dynamically adjust to meet user needs. In addition, the feedback mechanism helps the model learn new grammatical patterns or handle complex errors, thereby improving its accuracy, robustness, and overall user experience.
Statements and declarations
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.