
Abstract
A fundamental issue concerning the treatment of meaning in context is how to deal with the extremely flexible relationship that appears to hold between descriptions, which are taken as the exchangeable bearers of meaning, and the actual contexts which those descriptions are taken to pick out. Such contexts appear always only to be suggested, or constrained, by descriptions of contexts and so relating levels of description, such as linguistic utterances, to actual contexts of use, such as a situated, fully embodied environment in which language users find themselves, remains an unsolved challenge. The present article sets out a framework and illustrative implementation of an approach to contextualization that combines ontological engineering principles and situated embodied simulations. For concreteness, we illustrate the approach within an already established architecture for situated robotic agents in order to allow implementation and experimentation in a manner that is not generally accessible when considering linguistic analysis alone. The paper then proposes a hybrid, multi-level architecture that contextualizes linguistic utterances by means of embodied simulations, which then serve further as contextualization constraints on semantic interpretation.
Introduction: Background and motivations
A fundamental issue concerning the treatment of meaning in context is how to deal with the complex relationship that appears to hold between descriptions, which are taken as the bearers of meaning, and the actual contexts those descriptions are intended to pick out. A broad range of empirical evidence has shown that this relationship is extremely flexible. To deal with this flexibility, we develop an account in which linguistic expressions are seen as only offering constraints for the construction of abstract contexts, which must then be brought into alignment with actual contexts. Characterizing this process of alignment and the fine-grained properties of the abstract contexts involved is an unsolved challenge at this time.
The extremity of the flexibility in alignment that need to be supported here can be illustrated particularly well by adopting an ‘ontological’ perspective. Traditionally, an ontological description should not ‘vary’ according to context – as a characterization of the necessary entities, relations and structures constituting the world, a truly ‘Ontological’ account (i.e., ‘Ontology’ with a large O) would already be contextualized. One of the earliest explicit discussions of apparent ontological variability due to contextualization can be found in the work by Hobbs (1995). Hobbs considers the challenge of deciding on the ontological category of ‘road’, noting: “When we are planning a trip, we view it as a line. When we are driving on it, we have to worry about our placement to the right or left, so we think of it as a surface. When we hit a pothole, it becomes a volume for us.” (Hobbs, 1995, p. 820)
This situation is problematic since, applying principles of ontological modeling, it should not be possible for single entities to receive classifications simultaneously from such disjoint ontological categories as Hobbs sets out. Nevertheless, such variability is well documented not only for ‘objects’, such as roads, but for all linguistically specified information, spanning spatial relations as expressed in prepositional phrases, events and actions, attributions of properties, etc. Examples of this kind are, therefore, by no means exceptional. This makes it clear that, from an ontological perspective, whatever classifications are adopted by linguistic expressions, their relationships with ontological characterizations need to be considered with considerable care – as Varzi argues: “there is no straight analytic path from language to ontology. …There is, in fact, no way of telling what sorts of things there are given the sorts of things we say” (Varzi, 2007, p. 282). However, as Varzi continues: “neither is there a complete gap between our words and the world out there” – the challenge is then to provide sufficiently powerful characterizations of this relationship that are both constrained but also able to span the range of flexibility observed. This is the goal of the current paper: i.e., to set out a principled framework which renders the kind of flexibility in contextualizations observed empirically both predictable and manageable in formal and computational instantiations.
The framework we present for the contextualization process builds on two pillars. First, it draws on our previous work on two-level semantics and its formalization applying ontological principles (cf. the work by Bateman (2004), Bateman et al. (2007)). Two-level semantics posits a two-stage interpretative process, whereby first a semantic description similar to that used in approaches relying on semantic underspecification is built and, second, that description is used to search out contextualizations that increase overall coherence of the unfolding communication. In many respects, this renders contextualization a discourse mechanism for correlating abstract properties of what was said (or written, etc.) with desired properties of the context. Since, following work on discourse in the dynamic semantics tradition (e.g., the work by Asher and Lascarides (2003)), such discourse interpretation is always abductive and potentially subject to revision, seeing contextualization in these terms offers just the extreme flexibility required while also maintaining a principled approach. The second pillar of our framework goes substantially beyond previous two-level semantics models by directly incorporating components based on embodied simulations. Simulation is currently being granted an increasingly central role in human language comprehension and production quite broadly and our approach similarly commits to this facet of meaning-making as an inherent component of interpretation.
Our discussion is organized as follows. We begin by setting out the origins and requirements of the two-level semantics that we adopt, showing how previous work raises challenges for which considerations of simulation-based semantics appear a promising strategy to pursue. We then introduce a concrete problem scenario drawn from service robotics in which the challenges of flexible contextualization are central. Following this introduction, we describe a computational instantiation of the contextualization process in detail, drawing on both two-level semantics and simulation. We then demonstrate how access to simulation via appropriately managed intermediate levels of qualitative description makes relevant information derived from simulation available for the system as a whole and, by these means, provides both early constraints on appropriate linguistic semantic interpretations and uses those constraints for constructing correspondences with context. Finally, we briefly discuss some relevant related work and conclude with an outlook of targeted future developments.
The framework
Motivations for our approach
Several kinds of account have been proposed to deal with the relationship between language and context, which generally echoes the classic division between semantics and pragmatics introduced by Morris (1938). One common strategy is to treat the relationship between semantics and contextualized interpretations as a process of rendering an ‘underspecified’ semantic description derived from the language that occurs more specific, thereby ‘filling in’ contextual detail (e.g., the work by Alshawi (1992), Ceusters et al. (2003), Copestake et al. (2005)). Another type of approach sees the relationship in terms of grounding (Harnad, 1990), where symbols of a linguistic semantics (e.g., linguistic terms) are matched to objects in the environment (e.g., the work by Nüchter and Hertzberg (2008)), thereby assuming a strongly referential semantics. Both kinds of approach are limited; the relation between language expressions and the interpretations that those expressions actually receive exhibits a flexibility and variability far beyond that predicted by either account.
As an example, consider the task “set the table for lunch”, which is a command a human user might give a service robot. The command is extremely underspecified, even at the level of what items to bring to the table, and that the kinds of problems it raises are not just about grounding – apart from “the table”, no item is being referred to. Clearly, deciding what to bring needs more information and reasoning, such as what dishes are available, and what would be an ‘appropriate’ or ‘usual’ dish for lunch; one can imagine such information being more or less hard-coded or learned from user preferences. However, item selection does not end here: having decided what food to bring, the robot needs to decide what cutlery, crockery, and other support items should be brought, to afford the human users the ability to eat the food in a socially acceptable manner. Attempting to hard-code such a list would be too brittle, since the same items are not always available – e.g., some items might be in the dishwasher, or broken – and the robot needs to ‘think of’ replacements. Some items may end up re-purposed, and will play the role of a missing item; for example, if all soup plates are in the dishwasher, soup might be served from bowls instead. The bowl is not a soup plate, but can be conceptualized as, or rather play the role of, one, because it offers the relevant affordances that the soup plate offers.
Notice here the similarity with Hobbs’ road example above: a road affords several things, and it depends on the context which of those affordances is more salient or relevant, and thus how the road is conceptualized. Likewise, the table setting example reveals the importance of being able to reason about what an object allows to happen, or an agent to do, i.e. the object’s affordances decide what kind of roles it can play in a situation, and therefore how that situation should be understood. As a consequence, although there are many cases where underspecification appears an appropriate and plausible mechanism (see the discussion in the work by Lukassek et al. (2017)), there is strong evidence that this view alone is insufficient. Similarly, with respect to grounding, it is well known in discussions of linguistic reference (Clark, 1996) that speakers may well use terms that are logically or factually inappropriate for their intended referents, but which present few problems for their interlocutors if sufficient contextual knowledge is available (concerning both the intentions of the speaker and the situation). The relationship must, therefore, be considerably more complex.
Nevertheless, it is unlikely that the relationship between contextualized interpretation and linguistic descriptions is unconstrained or arbitrary. If this were the case, the reliability and learnability of contextualization would not only be unexplained but also unexpected. In our framework, therefore, linguistic terms are seen as flexible ‘indicators’ of possible contextual elements which, rather than transparently referring, instead constrain relevant contexts without over-committing to those contexts’ properties. This leads contextualization to take on a new and absolutely central role. Moreover, we capture the additional levels of description that our framework requires by adapting a formal two-level semantics model; this offers new opportunities for leveraging distinct but mutually supportive regularities that support inferences of particular kinds ‘internally’ while, on the other hand, applying only indirectly to, as Varzi describes it, ‘the world out there’.
For concreteness, our discussion below will show this framework in action drawing on examples from the domain of service robotics, where there is growing interest in the use of natural language interactions with robots in order not only to support more flexible interaction between robots and humans (Kruijff et al., 2006), but also to enable robotic systems to gain much needed deeper semantic knowledge of their working environments in general (Bastianelli et al., 2013a). Both areas make reference to the fundamental problem of grounding linguistic entities in actual environments (Roy, 2005) as a basic task of contextualization but rarely address the flexibility of the language-context relationship observed in actual human interactions. Our embedding of our approach within a robotic scenario is, however, solely for illustrative purposes; the paper will not address the particular demands of human-robot interaction (HRI), although we do point out some consequences for the design of such systems when relevant. Many approaches are currently exploring HRI using a variety of methods (e.g., the work by Bastianelli et al. (2015), Scheutz et al. (2017)); further references are given below. Our claim with the current paper, however, is that, regardless of task, an appropriate embedding of simulation within interpretation will be beneficial, and often necessary. The account we propose is therefore intended as a general characterization of the necessary properties and mechanisms of natural language contextualization as such – although, as we shall see, the robotic system we draw on also provides some particular tools and capabilities for managing simulation semantics that will be central to our account. In this sense, we follow Bastianelli et al. (2013b) in seeing a highly beneficial complementarity between natural language understanding and architectures developed for robotics.
Two-level semantics and linguistic ontology
We suggested above that the ‘road’ example discussed by Hobbs raises several ontological issues for the treatment of natural language semantics and the relation of that semantics to context. Most particularly, it is evident that the ontological entities picked out ‘in the world’ by single linguistic classifications can diverge considerably in their identity criteria. The criteria for identifying a three-dimensional space are, for example, quite different to those identifying a line. Upholding the ontology design principle of rigidity (e.g., the work by Welty and Andersen (2005)) then motivates the maintenance of two, ontologically distinct domains: one oriented to the properties committed to by linguistic semantics, the other oriented to the properties required ‘in the world’. A clear separation of ontological tasks of this kind permits the principles of ontological engineering (e.g., the work by Guarino and Welty (2004)) to be beneficially applied to both levels, or ‘strata’, following the notion of stratified ontologies set out by Borgo et al. (1996). The two levels may receive different, if arguably not fully divergent, ontological categorizations and the challenge becomes one of characterizing their relationship appropriately.
Bateman (2004) suggests this ontological stratification corresponds well with the notion of ‘two-level’ semantics developed on linguistic grounds by Bierwisch and Lang (1989), Bierwisch (1999), Lang and Maienborn (2011) and others. In such a two-level approach, semantic specifications describe entities in the world; they do not give properties of those entities in the world. Each of the possibilities for a ‘road’ constrained by the grammatical patterns within which the lexical item occurs (e.g., ‘in the road’, ‘along the road’, etc.), therefore, commits (rigidly) to a certain range of semantic properties for the discourse entity so described. Discourse entities are then only indirectly related to ontological properties of entities in the world in a process of (typically interactive) mediation (cf. the work by Bateman et al. (2007)). Even the selection of apparently simple linguistic categories, such as ‘road’, can never be taken as a neutral labeling.
The linguistic and semantic aspects of this application of ontological principles are articulated in detail by Bateman et al. (2010), where a ‘linguistically-motivated’ ontology is introduced that provides an ontology-like level of semantic description for natural language called the Generalized Upper Model (GUM). In contrast to many traditional semantic representations, such as FrameNet (Baker et al., 1998), the categories and relationships defined within GUM are motivated solely by grammaticalization patterns within any natural language addressed. This has several advantages, amongst them a stronger orientation to ontology design principles, broader coverage of spatial information than is typically found in lexically-oriented accounts, and stronger generalizations across syntactic constructions; for further discussion, see the work by Bateman (2010b).
The grammaticalization principle draws on the history of development for ‘interface’ ontologies within natural language processing systems, which were designed specifically to relate linguistic knowledge to world, or domain, knowledge. The first interface ontology of this kind was developed in the 1980s for the Penman Upper Model (cf. the work by Bateman et al. (1990), Bateman (1990)) of the Penman text generation system (Mann, 1983). This level of knowledge organization was always explicitly conceived, therefore, as a means of supporting contextualization. The architecture was subsequently extended both to apply across diverse languages (cf. the work by Henschel and Bateman (1994), Bateman et al. (1994), del Socorro Bernados Galindo and Aguado de Ceo (2001)) and to support natural language analysis and situated interaction in addition to language generation (Bateman et al., 2010, Ross, 2011). We draw particularly on this latter development below.
For the purposes of the present discussion and the examples that we show, we will focus specifically on the contextualization issues raised with respect to the particular extensions to GUM for the semantics of natural language construals of space, spatial entities, and events and activities unfolding in space (and time) as described at length by Bateman et al. (2010). As suggested above in the citation from Hobbs, spatial language offers a particularly challenging test case for any approach to contextualization because the degrees of variation observed are so wide and are, moreover, already extensively documented in the literature (e.g., the work by Herskovits (1986), Casati and Varzi (1999), Levinson (2003), Coventry and Garrod (2004a), Bennett and Agarwal (2007)). The view of contextualization developed by Bateman et al. (2010) takes this literature, and the flexibility of contextualization shown, as its starting point.
The situated meanings of spatial expressions are consequently divided into, on the one hand, a linguistic specification and, on the other, a contextualization of those specifications broadly following the account originally set out by Eschenbach (1999). In Eschenbach’s approach, formalization of spatial expressions such as ‘left’/‘right’, ‘in front of’/‘behind’, etc. proceeds in terms of an abstract geometric structure, capturing the semantic commitments brought by language, which is then imposed on some concrete spatial situation, depending on the binding of specified contextual anchors. The linguistic semantics is couched in terms of abstract algebraic structures, with their own entities and properties – for example, that required for ‘left’/‘right’ involves half-planes, that for ‘in front of’/‘behind’ involves oriented half-lines, and so on – which may then be ‘anchored’ into particular contexts in a flexible but well-defined fashion.
Following this line of development, Bateman et al. (2010) emphasize that it is important that any semantics provided for linguistic descriptions does not over-commit regarding its contextual assumptions. For example, assigning an ontological characterization of ‘road’ to a ‘2D physical object’ over-commits because it precludes descriptions of that entity both in terms of something that may have ‘bumps’ – an ontological feature requiring additional dimensionality – and in terms of something that may best be considered as a one-dimensional connector in a navigation system. Similarly, ‘support’ does not necessarily have to involve the supporting object and the supported object being vertically positioned with respect to each other, nor that the objects are physically in contact, while ‘near’ will vary in terms of actual distance depending entirely on the intended function of the linguistic description such a term appears in (‘near the phone’ vs. ‘near New York’), and so on. Over-commitments commonly occur when geometric interpretations are given of spatial language terms because language does not, by and large, operate geometrically (cf. the work by Talmy (2000)). Producing geometric readings of spatial terms can only be attempted once relevant contexts have been determined; assigning geometric readings before this has been done limits the set of contexts that will then be possible prematurely so that certain perfectly acceptable meanings of terms and expressions are ruled out. Avoiding misreadings induced by ontological over-commitment of this kind is then one essential design principle of the account we set out here. Examples of such over-commitments and their consequences are given by Bateman (2010a).
A corollary of this design in the subsequent development of the GUM spatial ontology was that the categories defined in the linguistic ontology became progressively less geometric in orientation and increasingly functional in the sense of Coventry and Garrod (2004a). Only by these means did it appear possible to derive an account compatible not only with individual cases of the extreme flexibility observed in language use, but also the sheer range of such phenomena in natural language usage as a whole. Functional uses of spatial terms in language constitute a well-known challenge area of their own, in which it is not the geometric position or shape of some spatial entities that play the leading role but rather the extent to which spatial entities adopt positions, orientations, etc. that are appropriate for the fulfilment of their intended functions. In a host of empirical studies (e.g., the work by Coventry (1998), Coventry and Garrod (2004b), Andonova et al. (2010)), robust results have been found for many spatial linguistic expressions indicating the importance of functional considerations – such as, for example, umbrellas being judged to be ‘above’ their carriers just to the extent that they protect their carriers from rain (which can diverge significantly from the vertical when a strong wind is blowing), etc. Variation of this kind is also naturally a further component of the overall high degree of flexibility in contextualization already observed above.
Many of the categories defined within GUM for spatial configurations, grouped within a submodule of the GUM linguistic ontology called the ‘spatial modality’ module, consequently make reference to functional notions such as ‘support’, ‘control’, ‘access’, ‘denial of access’, ‘nearing’ (i.e., increasing access), and many more. This, however, raises many issues of formalization that are not present in the more geometric characterizations explored in the spirit of Eschenbach. Whereas axiomatizations for abstract geometrical configurations can be provided straightforwardly so as to support geometric reasoning, it is often by no means clear how functional notions could be captured within such a scheme. In the formalization of the GUM linguistic ontology described by Bateman et al. (2010), therefore, many categories were labeled as functional but lacked the formalizations necessary for pursuing reasoning with those categories. Consequently, when given a sentence such as ‘put the plates on the table’, which we will use below as an example when we embed it within our application scenario, our natural language parsing component produces a semantic description asserting a GUM functional spatial modality of ‘support’ holding between the discourse entities ‘plate’ and ‘table’, but precisely how that notion was to be further formalized was unspecified.
The two-level semantics is, nevertheless, central here in that there is abstract information provided by the linguistic description that must be respected in any contextualization attempted and which offers additional constraints on interpretation. That is: whatever contextualization is finally assumed for the sentence, it must still be compatible with the constraint that a functional ‘support’ relationship holds. Doing justice to precisely these two facets of linguistic semantics – not over-committing to geometric details while still being able to use the semantic contribution for early disambiguation and interpretation – is then a major challenge. As a contribution to achieving both requirements, Bateman (2013) suggests that one way in which functional constraints might straightforwardly be brought into the contextualization process without over-commitment during interpretation could be using techniques of simulation. Whereas functional constraints are difficult to formalize ‘in advance’ for all contexts, it appears intuitively likely that testing simulated scenarios would be able to deliver evaluations similar to those involved in judging functional relations as well. Functional descriptions of this kind are then also clearly related to work employing ‘affordances’ (Gibson, 1977).
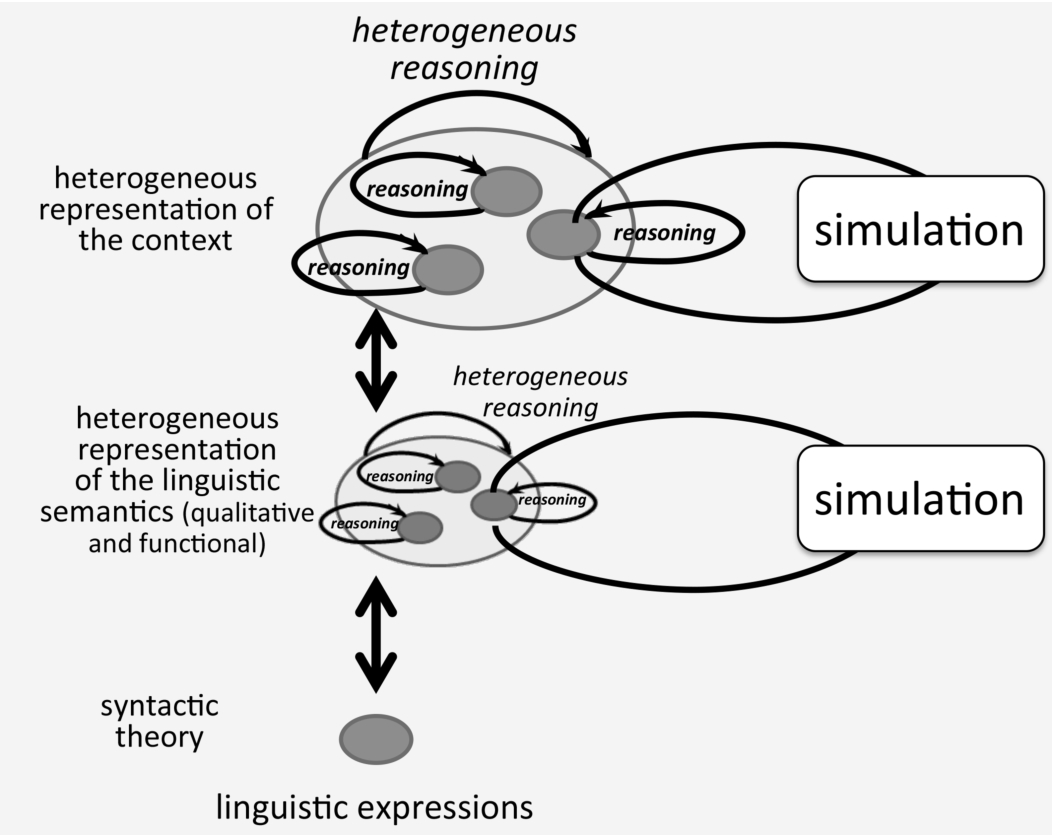
Multistratal contextualization model employing heterogeneous reasoning from Bateman (2013, p. 310), extended here to explicitly show the place of simulation.
The contextualization architecture overall then corresponds to the third type of model suggested by Bateman (2013, p. 310), repeated here graphically in Fig. 1 and extended to explicitly show the place of simulation as a further source of reasoning within a heterogeneous set of reasoning resources. Simulation is thus considered to play a potentially beneficial role at each of the levels of semantic abstraction covered. As we shall see below, the upper level of heterogeneous reasoning including simulation for context representations corresponds well to the robotic architectures already proposed by, for example, Stulp and Beetz (2008) and Tenorth and Beetz (2013); Bateman et al. (2018) offer further discussion from the ontological perspective. The lower level of abstraction is a novel addition proposed here, suggesting that simulation can be applied even before full contextualization in order to further restrict the range of models to be considered for contextualization according to the discriminations that linguistic expressions articulate by means of their linguistic semantics.
In the sections following, we explore this model further in order to show how contextualizations can be seen as embodied simulations in which actions and movements specified within linguistic descriptions are ‘performed’ at several layers of abstraction. Those actions and movements will naturally vary drawing on a range of parameters, thereby providing, on the one hand, a formalized connection between linguistic descriptions and contextualized representation and, on the other hand, considerable flexibility concerning just what actions and movements ensue. In particular, we will explore the extent to which the intermediate level of analysis opened up by an ontologically-based two-level semantic approach allows for a more transparent connection with fully contextualized descriptions of situations of use.
We heard above how contextualization is often restricted to issues of fixing ‘indexical’ language expressions such as pronominal reference and performing grounding. In contrast, the two-level ontological approach argues that contextualization is pervasive and applies to almost all aspects of the semantics of natural language expressions – that is, rather than constituting a final process of ‘fine-tuning’ unfilled parameters for underspecified semantics, recovering fully contextualized meanings of utterances demands a far more extensive consideration of the influences that contexts have on de-contextualized semantics and the mechanisms by which such influences are enacted.
Our selected application scenario of an intelligent robot (or set of robots) performing everyday household activities with guidance or instruction from humans using natural language brings out the full force of contextualization for uncovering the meanings of linguistic expressions. First, the situation that a robot finds itself in with respect to the contextualization of any instructions that it might receive demands an explicit solution to the contextualization problem in order for the robot to operate both effectively and appropriately. The extent to which proposed solutions fail to provide appropriate contextualizations offers a ready-built set of evaluation metrics that can be employed for focused critique and improvement. And second, modern robotic systems can provide a rich, but nevertheless fully interrogatable, embodied environment, in which robotic agents (and their developers) have access to sensor feedback, perception and knowledge, thus addressing all of the components now commonly assumed necessary for simulation-based accounts of commonsense understanding and contextualization.
The contextualization challenge of relating natural language of the kind produced by human participants in such a scenario to the actions and movements actually performed by a robot is considerable. Natural language describing everyday activities is typically multiply ambiguous and underspecified while the movements and actions performed need to be sufficiently precise as to actually drive robot behavior. However, the same holds for natural language comprehension in humans as well. The only difference in this respect is that considering the robotic scenario gives us arbitrarily fine-grained access to all aspects of that scenario, including motor control, perception and sensory feedback, which is a considerable benefit when exploring the mechanisms required in formalization.
In the robotic environment we adopt, robots have the possibility of simulating their own future actions in order to obtain feedback about the potential outcomes of scenarios without having to actually perform those actions. We take this to be a likely property of human language comprehenders as well, since the evidence that language use gives rise to partial simulations is already considerable (e.g., the work by Barsalou (2003), Kaup et al. (2010), Richardson et al. (2003), Gennari (2012), Arbib et al. (2014)). Embodiment is increasingly seen as a crucial component of conceptual processing of all kinds (e.g., the work by Gallese and Lakoff (2005), Aziz-Zadeh and Damasio (2008), Barsalou (2016)). For the human cognitive system, the precise mechanisms are, however, still unclear. As Dudschig et al. describe the situation: “Despite behavioral studies providing strong evidence for the experiential-simulations view of language processing, the underlying mechanisms are still underspecified. Controlled top-down simulations probably occur subsequent to comprehension and capture the meaning of the sentence or larger phrase. In addition, there may be an early bottom-up component by which individual words or combinations of words activate experiential traces in memory.” (Dudschig et al., 2012, p. 1090)
A concrete scenario
For concreteness in the discussion that follows, we address three distinct illustrative aspects of contextualization drawn from a single everyday scenario: setting and clearing a household table for purposes of eating a meal and then clearing up afterwards. Despite the apparent simplicity of the situation, instructions in this domain require extensive contextualization precisely because the situation is so everyday, i.e., well-known. As a consequence, typically occurring natural language is highly schematic. All of the items referred to, their intended and dispreferred spatial relationships, and kinds of activities involved, as well as how precisely those activities are to be performed, are left undetermined in language. This is therefore a typical case for contextualization: human background knowledge and, above all, embodied experience, generally provide the information necessary to provide fully-fledged meanings for any utterances describing or guiding the situation. Addressing this with the goal of enabling a robotic agent to perform flexibly with respect to such language serves to make the gaps and potential sources of such information startlingly clear.
Consider again, for example, the following simple instruction that we passed over briefly above:

We can immediately distinguish several sources of underspecification. First, there is the basic anchoring of discourse elements into the context regularly termed grounding (e.g., the work by Roy (2005)). Many approaches to embodied language processing consider grounding a component of the comprehension-perception loop. An interpreting agent anchors discourse elements, i.e., the semantic referents of the nominal phrases in the utterance, to contextual referents either present in the perception of the agent or in the context model maintained by the agent. Second, there is the resolution of the location to which the plates are to be moved: all that is expressed linguistically is that location stands in a particular relationship (that indicated by the preposition ‘on’) to the reference object (i.e., the ‘table’) and so there would in theory be many solutions – even though most of these would actually be (contextually) inappropriate. And third, there is the manner of action that is to be performed as the instantiation of ‘putting’, both relating to the precise manner of motion performed and concerning the resulting state of the moved objects.
None of these aspects can be filled in from the linguistic semantics alone, although we argue that linguistic semantics does provide important constraints on what are to be considered valid, i.e., conformant, states of the world prior to, during and following the designated action. These will be taken below as parameterizations of the range of simulations that may be employed when performing contextualization. The primary contribution to this process made by the two-level semantics, and particularly here of the GUM treatment of space, movement and action, is then to achieve a level of semantic representation that is, on the one hand, ‘rigid’ with respect to its characterization of discourse entities while, on the other hand, still being supportive of flexible contextualization where quite diverse properties, aspects, and ‘conceptualizations’ of states of affairs can occur. More specifically for current purposes, we focus on context aspects related to the situation an agent finds itself in, and the constraints put on that agent’s interactions with its environment, i.e. its embodiment. We use information obtained from this context to disambiguate and further refine the meaning of the linguistic expressions involved.
Analysis
Following the two-level approach introduced above and defined by Bateman et al. (2010), the shallow linguistic semantics for example (1) structures the utterance into several semantic components which are derived compositionally by automatic analysis. For this we employ a combinatory categorial grammar (CCG: Steedman, 2000) that produces semantics in terms of the semantic types of the linguistic ontology directly. For the utterance as a whole, the GUM linguistic ontology then provides a generalized semantic configuration of ‘putting’, ‘placing’, etc. that involves an agent moving some designated object to a designated place. Again, it is crucial here to remember that these categories are derived by their distinctive grammaticalization patterns and do not, directly, characterize actions in the world. Then, since the backbone of GUM is expressed within the description logic

The object(s) being moved play the role of the
The kind of entity that GUM allows to fill the

As noted above, spatial relations are captured within GUM by a rich subontology of
The semantics of the utterance is then the following instance created compositionally with respect to the categories defined within GUM by our natural language processing analysis component:1
Our CCG analysis component actually produces HLDS (hybrid-logic dependency semantics) representations in the manner introduced by Baldridge and Kruijff (2002); this is equivalent to the SPL notation used here.

The semantics here is expressed using the ‘Sentence Plan Language’ (SPL) notation originally defined for this form of natural language semantics by Kasper (1989). SPL subsequently formed the basis for representations such as the Abstract Meaning Representation (AMR: Banarescu et al., 2013) used in several current natural language processing projects. As in AMR, in this notation the symbols before slashes (e, p, l and t) are instance variables, the symbols after slashes are semantic types, and the symbols marked by colons (‘:actee’, etc.) are semantic roles or 2-place relations. The ranges of semantic roles immediately follow the role labels; the domains of roles are implicitly given by the immediately dominating instance variable. In SPL expressions, moreover, all semantic categories are taken either directly from the GUM ontology or from a semantic lexicon (i.e., ‘plate’, ‘table’) subordinated to the GUM ontology. The use of semantic types drawn from GUM therefore relates the semantics directly to the ontology constraints given in definitions (2) and (3). Although in principle any natural language processing scheme could be employed at this stage, what is crucial here is precisely the link to the generalized functional categories supplied by our ontology since it is these that enable flexibility of interpretation to be maintained.
A semantic characterization of our example utterance in terms of functional support covers the vast majority of situations where a spatial location is expressed via ‘on’, but it also says rather little about any actual geometric location that might be required. Communicating to a robotic agent, or having a human actually perform the action intended, therefore requires that appropriate and inappropriate actual positions or ranges of positions be determined: this is what we are considering here in terms of contextualization. The same issue holds for all linguistic specifications of linguistic spatial relationship between objects (for example, “in”, “over”, or “near”) when these are to be instantiated in the real world or actual domain of application.
As introduced above, the treatment of spatial relationships characterized linguistically within GUM requires each linguistic ontological category to be associated with an abstract qualitative model of spatial relationships augmented by statements of functional import. A fundamental assumption of this approach is then that contextualization of such models should in principle be able to draw on rich structural mappings from the qualitative descriptions maintained as part of GUM to ‘embodied’ instantiations of those qualitative descriptions. In other words, in order to assess whether a functional relationship holds or not, it is also necessary to consider the behavior that is intended for the situation involved. Thus, for functional support, an embodied interpretation of the kind that an object attached to some location would ‘move’ if that location were moved and would no longer be supported should that location no longer be present.
Although proposed in previous work (e.g., the work by Bateman (2013)), it was not known how such functional constraints might be implemented, leaving a gap in the two-level semantics account. As we will argue below and demonstrate in our trial implementation, this is now precisely the kind of behavioral characterizations that lend themselves well to simulation. We can therefore envision a hybrid architecture along the lines summarized in Fig. 1 in which the linguistic semantics provides a functional qualitative description of what has to obtain and a simulation component specifies situations that conform, rejecting those that fail to give rise to the intended behavior. The GUM-perspective then takes its responsibility to be capturing those dimensions of qualitative description committed to by language, while the embodied-perspective places those commitments in physical (but still abstract) situations of use. By these means, it is hypothesized that an appropriate and beneficial factorization of tasks can be achieved, resulting in an increased overall functionality for systems dealing with situated actions and their description.
A host of further kinds of contextualization issues can be considered in this way within our illustrative application scenario. For example, the actual movement that is performed in order to result in the ‘plates’ being functionally supported by the ‘table’ can also be anchored into the world in various ways. The linguistic semantics specifies only that an agentively-caused spatial locating will come about; it does not indicate how and in what way that action may be performed: in this sense, therefore, the meaning of the utterance is still radically underspecified – especially when the instruction is actually to be performed, by a human or by a robot, as concrete ‘decisions’, or commitments, have then to be made in order for appropriate movement to follow. Nevertheless, the form of the linguistic utterance given still commits to a range of possibilities (i.e., functional support must obtain) and these may serve further to provide evaluation metrics for the appropriateness of any actual simulations (or, indeed, actions) performed.
For the situational contextualization, for example, one way to interpret the utterance is to place each plate such that its bottom surface contacts the table surface directly. If the table and the plates are aligned with each other and gravity appropriately, then situations of this kind would conform to the shallow linguistic semantics of functional support. However, another plausible interpretation is to put a stack of plates on the same table. This is again conformant with the utterance (relying on the fact that a functional support interpretation does not necessarily involve direct contact or touching) but is arguably not the final interpretation that would be considered the most appropriate contextualization. In order to complete the contextualization appropriately, therefore, it is unavoidable that the intended purpose of the action be explicitly addressed as well. In other words, which interpretation is correct or appropriate also depends on the reason for bringing the plates to the table. If people expect to eat from the plates, then leaving them stacked is not an appropriate interpretation precisely because functional access to the food-supporting surface is denied. An agent can consider a broad range of possible physical instantiations of this situation, but it is the functional characterization which provides the evaluation metrics necessary for judging how well any such instantiation satisfies intentions. This is brought out further by the following related set of examples:

The fact that commonsense reasoning of this kind appears so ‘obvious’, and yet has proved so difficult to capture formally, is a perennial problem for service robotics. Unless the robotic agent is given explicitly formulated procedures to disambiguate what ‘is meant’ by the utterance, such agents will never perform well.
Ad hoc, hard-coded ‘if-then’ procedures (e.g., ‘if setting the table, do not stack’, etc.) also cannot be expected to scale to handle the variability of even a semi-structured environment like the home. And, apart from this practical concern, such procedures do not supply the robot with any kind of understanding of what the tasks it performs are for and so would not support the currently growing goal of achieving explainable AI. If the robot makes a contextualization decision that a human user considers inappropriate, it should be in a position to answer the question as to why it decided as it did. Thus, although it certainly needs to be acknowledged that understanding is costly, for fully acceptable assistance robotics this will not be avoidable. Moreover, not even humans understand everything about eating and so, arguably, neither should a robot be expected to understand everything: but the human agent will also mostly be able to answer ‘why’ questions concerning their (imperfect) decisions. In order to be effective, therefore, a robotic agent will need to know that there are only so many ways to put food on a plate, and then eat it from a plate. That is, it will need to have a basic grasp of the geometrical and physical constraints imposed by the particular behaviors that are expected to follow the performance of table setting. Here again, we propose simulation as a powerful means of acquiring such knowledge; below we show our exploratory efforts in this direction as well.
Principles for organizing relevant information about context, including embodiment-related constraints, and of describing hybrid reasoning procedures that combine linguistic analysis with subsymbolic methods such as simulation, can be derived by considering what it would require to allow robots to answer such questions as “would it be appropriate to use stacking now? if not, why not?” Crucially, this is not just a question of the robot being able to explain its behavior to a human – although this is a desirable secondary outcome. The first agent who should ask questions such as whether to use stacking or not is the robot itself. If the robot cannot answer such questions, then it will not be able to achieve flexible, human-level contextualizations of even the simplest instructions.
A similar range of contextualization needs can be seen to occur in the following examples:

This ‘place near’-example set is another illustration of spatial relations exhibiting radical underspecification. The basic problem is the perennial one of answering the question: ‘what is near?’. The distance itself may be vague and vary with the objects involved in the relation (example 6a) – or, more precisely, with respect to the functional activities that may be relevant for those objects. Or the ‘near’ may also require some ‘not too near’ meaning, as placing something near the sink usually requires not placing the things inside the sink itself – even though this may be considered logically (and even perceptually) consistent with being ‘near’ depending on the formalization and domain (cf. the work by Logan and Sadler (1999)).
Limits to how near something may be to something else may also have reasons grounded in physical, embodied constraints (plates too close to the edge may be unstable). And ‘near’ may also require additional spatial orderings between more objects than just those in the ‘near’ relation itself: the cutlery placed near the plates should follow an iterating fork-plate-knife arrangement. In this case, a naive distance threshold approach could also produce a fork-plate-fork knife-plate-knife arrangement. Why this is incorrect again require more ‘embodied’ knowledge of what the arrangement is for; it would be inconvenient for the diners to reach over each other for their eating utensils for example (although given an appropriate context, such as the social goal of getting people to know one another, this could well be a solution!). In short, and as long known in principle, without knowing why a spatial relationship is being expressed, it is difficult, and often impossible, to know how it should be contextualized.
Another contextualization task where simulation is often necessary is to check whether an item in the robot’s environment has the necessary affordances to allow it to fill some role in the robot’s task. Consider another instruction: “cover the pot”. One might know that the pot has a lid which is an appropriate cover, but in the absence of the lid, is a plate appropriate? Is a spoon appropriate? The answer to these questions can be obtained by simulating scenarios informed by a functional characterization of the lexical semantics of ‘cover’: an obstruction renders the inside of a container inaccessible (denies access) to some intruder. Similarly, one can test in simulation whether some item is capable of acting as a support for another by simulating a scenario constructed precisely to test a functional description of ‘support’: i.e., a supporter prevents the supported from falling.
A final range of equally challenging but inescapable contextualization concerns relates to the performance of the action itself. The previous example (6e) with the plates and cups is another apparently simple case of task context being used to disambiguate an action, only in this case both tasks were of the same type. On the simulation side, one may find out, for example, that plates can stack but (some particular) cups are not very stable in such a configuration, nor are plates particularly stable on cups. It may consequently be preferable to stack the plates, but not the cups, so that both tasks can be performed well. Another suggestion the simulation may reveal is to put plates at the back of the shelf first, rather than block the shelf front with a wall of cups that makes the rest of the area hard to access. These are the kind of embodied experience constraints built up early in life and then extended to an increasingly diverse range of situations as ‘commonsense’ knowledge.
On the linguistic side, however, such information is regularly avoided, precisely because it is ‘commonsense’ and so to make it explicit would in most communicative situations violate Gricean maxims of cooperative communication. The linguistic utterances provided commit to precisely the functional relationships that are required to delimit the desired situation from others, but not more. Moreover, although in this case there is a relatively common range of simulations to be applied (corresponding to their grouping as a single kind of action linguistically), there are also individual kinds of actions where different simulations may need to be invoked. Consider the examples:

In such cases, it would be difficult to motivate the particular instantiations of these actions as performed behaviors without drawing on physical properties of the objects involved and this, in turn, will typically draw on embodied experience on the part of interpreters when trying to perform particular tasks effectively. Thus, even though picking up an object may appear to be a simple request, it in fact contains many sources of complexity. There are many ways to grasp an object; Fig. 2 shows some examples drawing from the robotics domain we use below. On being asked to pick something up, how should a robot’s end effector actually be placed around an object? And, how should the object be approached? To some extent, the geometry of the object constrains what end effector poses are possible, but even then many choices remain feasible. Deciding which is appropriate often depends not only on the pure semantics of a picking up instruction (which, at most, might be construed to indicate the target object’s geometry), but also on the context in which it is given, in particular with respect to the task for which the picked up object will be used.

Some different ways to grasp a spoon. Deciding which one is appropriate will depend on context, such as what the spoon is to be used for.
Even apparently ‘simple’ actions that receive a single linguistic categorization may, therefore, need to be contextualized into very different actions, movements and positions. The underspecified linguistic contribution (‘pick up’) gives constraints on what is to be considered a successful performance of the action – again in functional terms as the spoon needs to be in the ‘functional control’ of the agent performing the action – but does not (unless the situation requires it) offer more explicit information on performance. It is, then, precisely this degree of flexibility that is targeted by our approach to combining linguistic specification with embodied simulation, as we shall now see.
As motivated in the previous two sections, our approach to contextualization is to employ simulations of situations whose broad constitution is given by a generalized, context-independent natural language semantics, in order, on the one hand, to derive plausible parameters for any motions and situated actions to be performed and, on the other, to provide early disambiguating feedback to the linguistic semantic interpretation. This offers a mechanism for relating language expressions to possible contextualizations that makes full use of environmental and physical constraints that are rarely expressed linguistically, while also incorporating the more abstract constraints on intended situations that are contributed by language.
The overall framework achieves this by constructing a simulated environment and a sequence of tasks for some agents to execute in that environment, and subsequently querying the simulation world state and a record of events after the tasks have been attempted. The simulated environment is constructed based on a combination of the constraints that come from the linguistic semantics and the knowledge the robot has of its real environment. The simulation attempts to check whether a task is feasible or appropriate, or whether a simpler environment containing only a few objects is sufficient, when, for example, affordances of a group of objects need to be checked.
The tasks to be run are also inferred in part from the linguistic expression – i.e., the ‘main’ task the robot is commanded to do – and in part from the discourse context and other contextual information the robot may have about what should happen in the near future, e.g., time of day and routines (Porzel et al., 2006). Moreover, one difference between our approach and other situated robotics research is that we consider tasks other agents will perform to also be part of the context. On the one hand, this is because service robots do not act in a vacuum: they set the table so that people can eat later, or they bring plates to the sink so that the plates can be washed; while, on the other hand, sensible definitions of communication must also always assume that communication takes place in a social context with other speakers and hearers. Considering social groups of interactants is therefore always the ecologically preferable choice.
We now show this form of contextualization in action, first introducing in more detail the particular techniques that we import directly from the robotic assistance scenario and implementations supporting it. We then show these mechanisms being applied to the forms of contextualization proposed above.
The cognitive robot abstract machine (CRAM)
There already exists an abstract language for reactive robotic agents within the robotic framework we use and we employ this directly for simulation-based contextualization. This language is specified as the Cognitive Robot Abstract Machine (CRAM: Beetz et al., 2012), a software framework for the development of concurrent reactive programs for robotic agents. CRAM includes a high level programming language based on Lisp (Beetz et al., 2010), a library of basic robot actions, logging of task executions into an episodic memory (Winkler et al., 2014), and ‘projection’ (Mösenlechner and Beetz, 2013), a light-weight simulation environment that can test for collision, visibility, and stability of an arrangement. Projection, which is intended to simulate scenarios quickly, abstracts away from intermediate waypoints in a robot trajectory and considers only end-points. Simulating the intermediate points in a trajectory is expensive whereas most of the queries relevant to the robot are about a trajectory goal, e.g. whether it is reachable, visible, or in collision. In certain respects, therefore, this already moves the level of description to become more abstract, potentially supporting the connection with underspecified linguistic descriptions as well.
Program arguments in CRAM are usually designators: i.e., lists of key-value pairs that describe an entity symbolically, such as “an object of type cup and color blue”, or “a location near an object of type cup”. For our current purposes of supporting more flexible contextualization, however, we will talk of objects that are ‘recognisable’ as certain entities rather than being of fixed types. Apart from objects and locations, designators may also describe actions. Note that the entity referred to by a designator is not necessarily specifically identified. This allows a more high-level and generalizable description of what a program should do, rather than committing it to a particular environment. Examples of designators for three different types of entities are then as follows:

During actual execution, designators need to be ‘grounded’ as mentioned above for discourse entities in general. In the current case, this means an entity in the robot’s current environment needs to be found, or an action chosen, such that the designator describes it. The different types of designators – object, location, action – come with different reasoning mechanisms to perform this process. Action designators are ground using Prolog rules that match action types to robot programs.
Object designators are ground using Prolog rules as well, making use of recognizers, which are procedures that assign labels to objects in the robot’s environment. The prototypical recognizer is the visual perception system, which uses 3D mesh models of objects as reference. These 3D models may also be used to populate simulation scenarios. Essentially the visual system of our robotic agents already attempts to classify objects using an everyday ontology similar to that underlying the shallow semantics and lexical information on the linguistic side; clearly it will be an interesting question for further development as to whether this similarity can be made even stronger by unifying some of the ontological resources concerned. Other recognizers are also possible. In particular, we will showcase a recognizer that operates by testing an object’s affordances. Which recognizer is appropriate to use depends on context, and to make this decision, we simulate programs using the various object recognizers that are known to the robot.
In contrast to object designators, location designators are grounded using a generate and validate pattern, and employ location costmaps of a kind familiar from spatial reasoning and representation in general (e.g., the work by Zimmer et al. (1998), Regier and Carlson (2001)). A location costmap is consequently a probability density constructed as needed based on features of a designator. For example, a location costmap for nearness to some coordinate will have a peak at that coordinate and fall off with distance; Gaussian or sums of Gaussians are often used to create the costmaps, although other distributions, such as uniform, are also supported by the framework. The location costmap influences the ‘generate’ half of the generate-validate process: based on the probability density, location candidates are randomly chosen and validation then checks these candidates to test whether they satisfy constraints specified in the designator – such as, for example, that some other point be visible from the candidate. Both generation and validation functions can be added or disabled at runtime. Just as resolving an object designator involves a decision on which object recognizer is appropriate to use, resolving a location designator involves a decision concerning which costmap, or which candidate generation function, will be considered appropriate. We saw such a situation for the alternative interpretations for the “on” relation above: stacking items vs. placing them individually on a support surface. Similarly to the case of object recognizers, which location grounding procedure should be used depends on context; we give an example of how simulation offers a reasoning mechanism to enable this decision below.
The CRAM framework also includes a program library providing a set of programs for basic robot actions: such as opening/closing the robot’s grippers, placing its arms in a particular configuration, picking up an object, placing an already gripped object at a given location, moving the robot base to a location, or searching for an object using perception. A few more complex combinations of these actions are also available: for example, transport is a program that searches for an object, picks it up, and delivers it at a particular location. There are also programs that grip the handle of a door from a piece of furniture (cupboard or fridge) in order to open or close it. While these programs are very low on an action hierarchy – usually, household tasks would involve long sequences of manipulation actions – they are nonetheless fairly flexible in that the arguments they expect are designators. That is, the programs can be called to perform basic actions described symbolically, with the understanding that there is enough knowledge in the system to convert the symbolic descriptions into actionable, exact ones, in the manner described for designator grounding above.
CRAM programs of this kind are, moreover, robot agnostic: that is to say, they abstract over a hardware interfacing layer that manages a particular robot’s sensors and actuators and provides meaningful groupings for them. There is a driver for the robot’s arms, a driver for its mobile base, a driver for its (visual) perception. This is therefore a source of further modularization and again reflects potential benefits of adopting differing levels of abstraction within a complete working system.
An ontological characterization of the actions available in the CRAM program library on the robotic side is currently underway as a development of the KnowRob ontology (see Section 6 below). However, these actions are typically those that robotics engineers have found useful as action primitives, plus the very common tasks of transport and furniture manipulation. They do not, therefore, necessarily align with the linguistically-motivated action categories of the GUM ontology since the motivations for the two levels of abstraction are very different. As we have seen, GUM categories are usually too general to pinpoint an exact action for the robot and so require contextualization. This is, in fact, an important property of linguistic expressions: their power largely comes from their ability to generalize across contexts. To relate these two levels for the purpose of contextualization, therefore, we define a new rule-based system capable of selecting and composing CRAM programs based on the linguistically-motivated information present in an SPL for an action. This is shown in detail in Section 4.2 following.
Finally, CRAM’s mechanism of projection – fast and lightweight simulation – allows the robot to try out a program several times before attempting it in the real world. This can be done immediately before a task needs to be performed, or during some longer idle time such as at night, in order to gather simulated experience. Logs of the task performances are recorded and can be analyzed later for contact events, or manipulation failures such as required poses being unreachable. Since the method by which CRAM grounds location designators always involves a random element in its behavior, it makes sense to simulate the same program several times. One might then, for example, learn which relative placements of a robot base are more likely to be bad for performing certain reaching actions (Stulp et al., 2012, Winkler et al., 2017).
Mapping from linguistic semantics to CRAM simulation specifications
The first stage of contextualization in our framework is the construction of a simulation specification, realized now as a CRAM program, on the basis of linguistic semantics. This is what permits an underspecified linguistic semantics to play out in simulations of various degrees of abstraction and detail. We achieve this by defining a translation mechanism between our underspecified linguistic semantic representations and CRAM programs for driving simulations; our characterization of this process draws on the overall mechanism as first introduced by Pomarlan and Bateman (2018).
As set out above, linguistic utterances are first parsed into corresponding shallow linguistic semantic forms, such as that given in the SPL of example (4) above. This provides semantic configurations in terms of the categories defined by the GUM linguistic ontology. This linguistic semantics is then converted into a corresponding CRAM program that can drive simulation for the performance of the instruction or the creation of a state of affairs from some description by applying transformation rules. These rules construct CRAM function objects and their arguments compositionally on the basis of the information contained in the SPL semantic specification.
Translation rules are defined in terms of an antecedent, a consequent, and a scope restriction. The antecedent is a pattern to look for in an SPL or previously transformed semantic specification. The consequent is an expression to replace the found pattern with. The scope restriction controls where in the SPL or semantic specification to look for the antecedent, analogously to a path description within a typed feature representation. Pattern matching is done by unification, and resulting variable bindings are used to parameterize the consequent. Taking then the SPL given in example (4) as a starting point, the procedure is as follows. First, the actee value is converted into a CRAM designator by a rule of the form:

In this listing, the antecedent is “Let us note, once more, that to say a truck can play the role of a MeansOfTransport in a given TransportationTask is quite different from saying that it is a MeansOfTransport in the ground ontology.” (Porzel and Warden, 2010, p. 5)
Placement terms present in the SPL specifications are similarly converted into designators by rules of the form:

Rule (10) converts an SPL
Although the action designator grounding mechanisms of CRAM already support mapping between some action types and programs from the CRAM program library, as mentioned above these action types do not necessarily align with linguistic semantic action types from the GUM. For example, there is no CRAM program for an ‘affecting action’; this is a linguistically-motivated action type and so is too general to be used by a robot directly. Our SPL conversion rules consequently identify that this is an affecting action with an

In this rule, the rule’s scope restriction is empty (“nil”), because the antecedent may be matched at the top level of the semantic specification. However, the consequent is a more complex object: a pair consisting of the keyword “Fn” and an executable function object. This function object is further parameterized according to the variables given and their unification with other components of the rule, and consequently with other components of the SPL. In the present case, the result of performing this matching and unification is the following CRAM program:

which is a description of the robot placing a plate on a table at a level of abstraction that may then be directly executed (or simulated) by the robot following the CRAM implementation. The objects used in those simulations also combine several sources of heterogeneous information: for example, knowledge that the robot has concerning what would be recognizable as a plate or table suggests generalized manifestations that can be drawn on for constructing scenarios; in addition, the shallow linguistic semantics provides further functional constraints, such as an object being construed as a 2D-object (thus capable of support), and so on.
Querying the simulation
The next step in contextualization is to ‘run’ the simulation derived from the linguistic semantics in order to provide appropriateness conditions for any contextualization that is finally to be accepted. For this, we rely on mechanisms provided by CRAM that are specifically defined to query the state of a simulated world and to check whether that world conforms to some description. As we show below, this allows plausible readings of the underspecified linguistic expressions to be determined which are derived from the fully specified actions and movements ‘actually’ carried out within simulation. By these means, the existing CRAM framework can be seen to offer an extensive implementation supporting abstractly specified simulations that we can apply directly as an evaluation testbed for two-level semantics involving simulation.
CRAM provides several ways to extract information from a simulation run. The simplest is to look at the execution status of the simulated behaviors: have they completed successfully, and if not, with what error did they end. However, simulation also produces a timeline of events that can be queried using the predicates in Table 1. These predicates can be used to describe the commitments that a functional spatial relation or an affordance make, and therefore how to test it.
Predicates for physics-based inference
Predicates for physics-based inference
We define an execution context to be a CRAM programming object containing information about how to parametrize, run, and interpret a simulation. Parameterization here means to specify what objects are present and how they are placed relative to each other, which can be done either by specifying exact positions when known (such as when a map of the environment is available) or by using designators as qualitative descriptions. To describe how a simulation is to run means to provide a list of actions that agents in the simulation need to perform; the designator resolution functions – such as recognizers and costmaps – that are enabled for any task are also configurable. Finally, simulation interpretation is done via checking that certain predicates hold on the timeline produced by the simulation. It is this that then provides the interface between the qualitative symbolic categories of the linguistic ontology and any states of affairs produced by subsymbolic simulation methods.
The information necessary to fill in each of the components of the execution context is obtained from the linguistic descriptions as described above, augmented by the simulation-checking now provided by CRAM. This can be seen in the following example of checking whether some two-dimensional object can stably support some three-dimensional object (see Table 2). Such a simulation is relevant whenever a grammatical construction involving functional support is at issue. The conditions associated with functional support are expressed in terms of the Prolog-like predicates made available by CRAM which check the simulated world. This then fills in the embodied understanding of what functional support must entail in any world within which functional support is being asserted to hold, either as a state of affairs or as a goal-state to be achieved.
Execution context for testing affordance: support

A similar mechanism can be shown for the more complex functional relationship of ‘covering’. As in the previous case, a linguistic description including the grammatical construction ‘something covers something else’ is converted into a description of a scene in terms of the linguistic commitments it makes. Further constraints are then added concerning whatever linguistic information is provided about the objects being related in the grammatical construction. The constraints as a whole are then all subject to (joint) contextualization.
For example, if the linguistic specification actually states, or requires, that some lid be used to cover a pot, then what is actually asserted linguistically is that there is some object in the world for which the lexicalization ‘lid’ is considered appropriate and this object stands in a functional relationship of denying access (the linguistic functional semantics of ‘cover’) to a further space for which the lexicalization ‘pot’ is considered an appropriate descriptor. The additional constraints that can be added include, for example, the linguistic knowledge that objects lexicalized as ‘lids’ tend to be flat and afford coverage, while linguistic knowledge of ‘pots’ includes facts of the kind that objects so lexicalized are three-dimensional objects whose ‘insides’ are accessible for serving as containers. In addition, both objects may have information derived from their common usage and intended design, such as being resistant to heat, etc. For the present discussion, however, we remain focused on the spatial information and its functional characterization.
Denial of access is then characterized by the failure of an agent to infiltrate the container. This linguistic semantics is used to articulate what to test after the simulation runs. In this case, the need to test accessibility is converted into a pair of programs to run together with a condition to test at the end. The program to run is a motion planning query to discover whether an intruder (some object) finds a path to the inside of the pot. This is shown in Table 3.
Execution context for testing affordance: cover

The previous subsection has shown how the simulation language provided by CRAM can be used to directly specify abstract ‘simulations’ corresponding to categories defined within our linguistic ontology. This is particularly useful for the functional categories, although other constraints can also be transferred as required. The final remaining stage of contextualization is then to embed such abstractions within simulations of context including non-linguistic information, such as assumed properties of the objects being manipulated and of the environment within which the manipulation is to occur. For this, we close the loop and relate our former simulation specifications to fully executable robot plans.
As an illustration of this, we can consider the case when it is sufficient to find what way of performing a task will result in its success, or the success of tasks it is supposed to enable/prepare for. This corresponds to the ‘top-down’ source of simulation constraints mentioned in our quotation from Dudschig et al. (2012) above. As before, starting with the linguistic description “put the plates on the table” produces a designator for a task for the robot to perform; the linguistic semantics indicates what functional situation will need to hold subsequent to the performance of the action as described above. However, this does not yet indicate any basis for deciding whether to leave plates stacked, or to place them individually on the table. In the present case, however, the scene description is taken from the robot’s model of the world and we must also know from context that people will eat from the plates that will be brought to the table. This gives us the conditions with respect to which the execution of any derived plans needs to be evaluated in order to assess their adequacy.
A corresponding execution context for this situation is shown in Table 4. This states that a real-world model is to be run within which some plates are to be brought to a table and then two humans are to use those plates in parallel for eating. The success of this parallel activity is then to be assessed from the result of running the simulation. For present purposes, we assume that this background knowledge is present and so could be used to answer ‘why’ questions concerning the activities concerned. One might also consider how such knowledge could be acquired, for example, from more explicit linguistic descriptions of what is to occur during meals; we leave such questions for future consideration.
Execution context for testing task performance: stacked placement

Execution context for testing task performance: stacked placement
Note, however, that there is not yet a human model – i.e., a collection of meshes, kinematic trees, and controllers shaped to represent a human – available within CRAM in its projection environment, and so we reuse the robot model for the human agents in the execution context of Table 4. While using the robot model for the eating program may not be entirely appropriate from the robot’s perspective – the robot does not need to eat, nor is its kinematics exactly the same as any human’s – we believe a service robot should nonetheless have some executable representation of the activities its users are expected to perform in the environment it attends to, precisely because having such a representation, as we will now show, allows the robot to reason about its own activities in cooperation with those to be performed by humans. Thus, using the robot model in this example to represent a human is only a workaround for a temporary limitation of the implemented CRAM resources.
In this section, we test the mechanisms described in Section 4.1 as they are used to check affordances and interpretations of spatial relations, given contextual clues such as an environment model, properties of objects in it, or knowledge about other agents and their tasks. For purposes of illustration, we use situations similar to those introduced in Section 4.3: testing a support affordance, testing a covering affordance, and deciding between a ‘stacked’ and ‘not-stacked’ interpretation of a support relation.
Testing support affordances
The problem given to our simulation-based inference here is to decide if an object A can act as supporter for an object B. An example of such a situation was described in the execution context in Table 2 above. We now use the simulation based inference to test several object pairs, such as forks, cups, plates and so on (see Fig. 3). Each simulation is described by an execution context like the one in Table 2, where only the objects placed in the test environment differ. Since location grounding in CRAM has a random component, the same execution context is generally run several times. In this case we tested each object pair 20 times to see how well one of the objects may support the other. The counts of how many simulations revealed stable support situations are summarized in Table 5.
Simulation based inference reveals that placing a cup on a plate or a tray, for example, usually results in the cup being supported. Conversely, the cup usually does not offer stable support to items such as the plate or the fork, but it can support another cup. Such information might then serve in structural disambiguation for instructions such as “pick up the plate and the spoon on the cup”. Since functional support between plates and cups is clearly unlikely, one could (abductively) rule out looking for a plate on a cup to pick up. Alternatively, one might use the difficulty indicated in achieving functional support to motivate word selections such as: “carefully place the plate on the cup”.

Pairs of items in the support affordance test. Image pairs show an initial and final states of the world, where a final state is computed by letting the simulated world run through several physics steps.
Scenarios reporting successful support relations

Selecting an item to cover a pot (left); pairs of items in the cover test (right).
In this case the robot is given the instruction “cover the pot with the lid”, which is transformed into the program description in (13):

We assume for purposes of discussion that the environment of the robot is known and is as shown in Fig. 4 (left). This is an everyday kitchen environment with a pot and some other movable items: a cup, a spatula, and a plate. The execution context to test then constructs a simulation environment containing these items, within which the program in (13) is to be run.
At this point there is a difficulty concerning what object recognizer to use. In the usual robotic application scenario, the default would be to use visual perception – that is, in order to ground the object descriptor ‘recognizable-as lid’, the robot would look for a lid. In the present case, however, this results in a failed simulation because there is no object that is visually recognizable as a lid. Since this recognizer results in the program failing, we can instead attempt an affordance-based recognizer for “lid”. This recognizer decides whether to apply the label “lid” to an object by creating a new simulation world containing the tested object and some known object in the environment that is recognizable as a container, and running the execution context for testing the cover affordance that we saw in Table 3 above. If the query in the execution context is answered in the affirmative, the recognizer is licensed to apply the label “lid” to the test object.
As before, we run the simulations several times; in this case there is a random component in the behavior of the motion planner used to test accessibility. In all simulations, a visual recognizer for lids fails, as there is no lid in the environment. Further simulations are then run with the affordance-based recognizer. In this case, the affordance-based recognizer does not label the cup as a lid in any of 20 simulation runs; nor, in 20 simulations, is the spatula ever accepted as a lid. However, in all 20 simulation runs, the affordance-based recognizer labels the plate as a lid, giving the desired behavior as specified in Table 3 (i.e., functional denial of access to the insides of the pot).
These results should not be surprising to our human common-sense, since this physical embodied understanding of the world is precisely what we are trying to incorporate – some items are definitely unable to block access to the inside of the pot, whereas the plate, although it is not designed for this purpose, can block access very reliably. We appear able simply to ‘see’ whether a path exists around the would-be blocker or not. However, if asked to explain why an item would, or would not, be a good coverer, we could well point to a path between the covered item interior and the outside. What our approach does, therefore, is to provide an agent with a formalized, plausible implementation of this type of reasoning. The contribution of the linguistic semantics is, as before, to define the success conditions for the simulation scenarios that are run: if one is instructed to ‘cover’ something, then this demands that denial of access be enforced. By these means, we achieve a chain of inference that leads directly from a linguistic specification to a simulated world together with the conditions necessary for evaluating action performances within that simulated world in a manner consistent with the instructions given linguistically.
Deciding on stacking support
For our final example, we illustrate the use of simulation to decide between different ways of performing an abstractly specified action: in particular, the action of getting plates onto a table. For this, we first fill in task context objects for ‘table setting’ with whatever resolvers for CRAM’s ‘on’-predicate are available. For our example, we have both contact and stacking varieties of ‘on’ defined: these are seen as embodied ways of achieving an ‘on’-relationship within the robot’s world. In addition, the purpose role of the task context is filled in with either the eating or washing up programs to test the extent to which knowledge of the goal will further constrain the simulations that are deemed appropriate. This results in the following four task contexts: set the table for eating with plates stacked (‘EatStk’ in Table 6), set the table for eating with plates individually placed (‘EatInd’), set the table for washing up with the plates stacked (‘WashStk’), and set the table for washing up with the plates individually placed (‘WashInd’).
Total simulation count, number of simulations ending in failure, and a breakdown of failure types for the various task contexts
Total simulation count, number of simulations ending in failure, and a breakdown of failure types for the various task contexts
Each execution context was then simulated 20 times in projection to make use of the randomized initial object placement. The generate/validate method of grounding for location designators also adds a component of randomness to the robot behavior: when individual placement of plates is used, the locations generated for the plates are sampled randomly from a distribution with several peaks; when stacking plates, the location of the first plate in the stack is chosen randomly on the destination table. This therefore gave 40 simulations for table setting for eating, and 40 simulations for table setting for washing up, resulting in 80 simulations in total. For each simulation, a log of failures was kept to see which situations posed more problems for the robot (cf. Table 6).
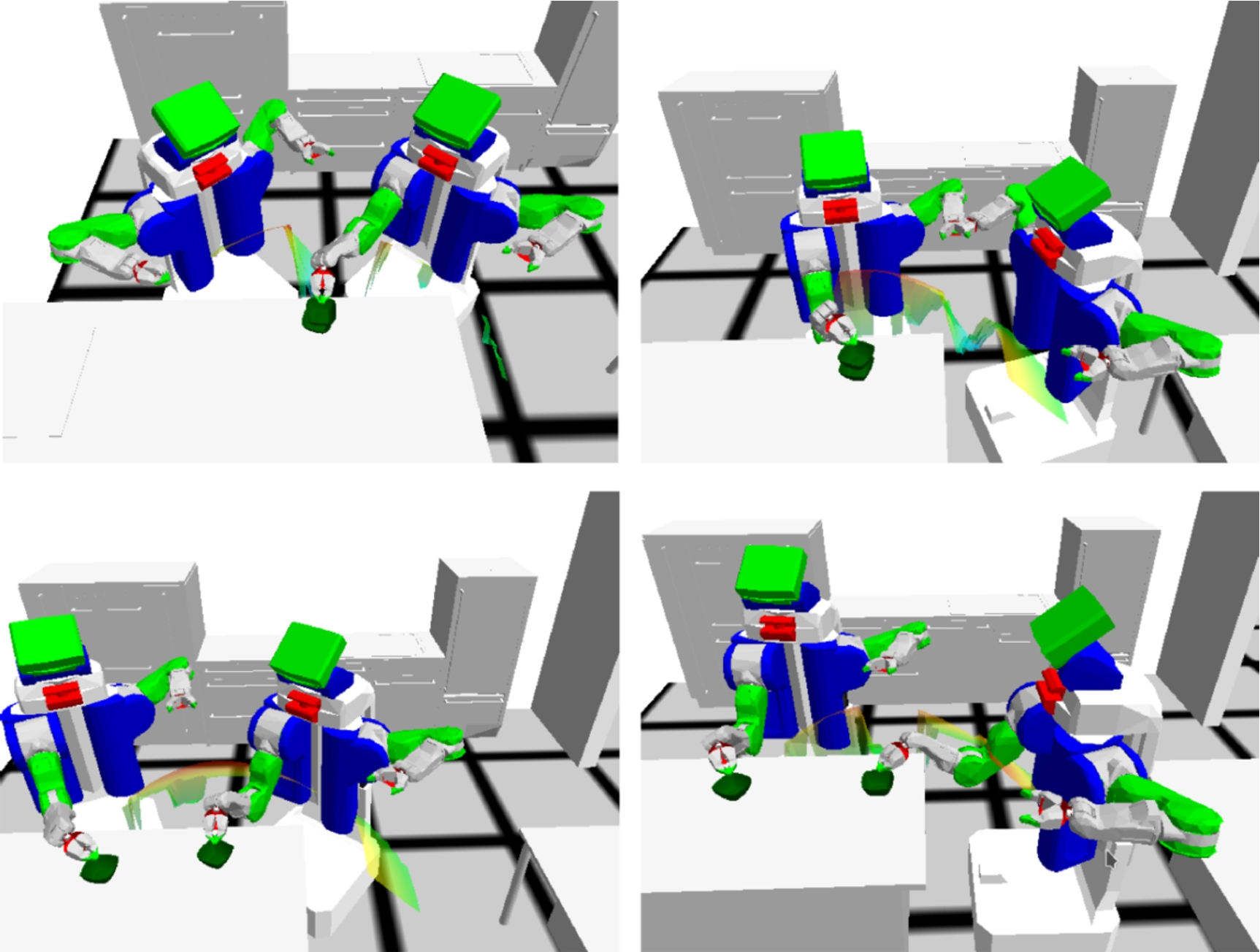
Robot configurations at projection end. Above: example end configurations for the eating from stacked plates scenarios; below: eating from individual plates.
For the two conditions, leaving plates stacked or putting them separately on the table, there were no ill effects on the performance of the ‘washing up’ program: all the 40 simulations of execution contexts with ‘washing up’ as the purpose complete without failure. In contrast, when the ‘eating’ program follows the plate placement, the two conditions produce different results. With the plates stacked, and two simulated robot both trying to access them, 18 out of 20 simulations end in failure. Failures involve visual occlusions (one of the robots covers enough of the plate so that the other does not see it), collisions between end effectors, or one robot being unable to reach the plate from its position around the table. If the plates are placed individually on the table however, only 6 out of 20 simulations result in failure, and all of these are the result of the ‘eating’ robot randomly choosing a location too distant from the plate that it will attempt to ‘eat’ from.
Figure 5 shows screenshots from the projection environment during simulations of execution contexts including the ‘eating’ task. The screenshots are taken after the plates have been put on the table (either stacked, as in the top row of the figure, or individually as in the bottom); the robots then attempt to access the top surfaces of the plate with their end effectors. It is when the second robot attempts to do this that failures happen in the eating from stacked plates scenario, usually because the arm of the first robot prevents the second one from getting a good view of the plate. When the plates are placed individually on the table, each robot usually has access, both visually and in terms of manipulation, to its plate.
The simulation therefore reveals plausible physical and geometric reasons for why it is a lot more awkward for two robots to attempt to access the same plate, because of perception, location selection, and manipulation problems. Simulation in projection then suggests that if ‘eating’ is to follow the placing of the plates on the table, the plates should not be left stacked, thereby leading to very different contextualizations for the basic linguistic utterance (and its semantics) of ‘placing plates’.
Our approach to contextualization as now described posits a relatively high degree of heterogeneity in both the processes and kinds of ontological information maintained. Indeed, hybrid reasoning systems have already been recognized as useful in robotics for several years. This is because while logical knowledge representation is a mature technique in AI, it proved unsatisfactory for many of the challenges faced by robots, such as grounding symbols into perceptions and actions, dealing with uncertain knowledge, or learning from experience. Heterogeneity is then one of the basic organizational principles of the KnowRob system that we have drawn upon above (Tenorth et al., 2010, Tenorth and Beetz, 2013). The KnowRob ontology itself is open source and available at
Several lines of research have looked specifically into the interpretation of natural language instructions in the broad context of situated interaction and robotics and Liu and Zhang (2017) offer several pointers in their detailed review of the state of the art. More specifically in relation to generating robot programs, the translation to such a program is sometimes expected to be fairly straightforward, as seen in the work by Matuszek et al. (2013), where a system takes a natural language instruction that may include control structures such as loops or conditionals, and creates a corresponding robot program from them. The TellMeDave system presented by Misra et al. (2014) learns associations between instruction texts and logs of activities performed by human users reading the instructions. And the PRAC system (Nyga et al., 2017) uses Markov logic networks to find the most likely ‘action core’ (a list of role-value pairs) when given an instruction text as ‘evidence’; the PRAC system has been trained on a large corpora of instructional texts from wikiHow and has learned to do such tasks as reference resolution and filling in missing roles. For example, it can infer an appropriate tool (e.g., a spatula) given the action to perform (e.g., ‘turn’) and the object to perform it on (e.g., a pancake). A limitation of these systems, however, is that they do not take the larger task context into account, and focus purely on the ‘de-contextualized’ instructions themselves. For example, it is only from the immediate linguistic form of an instruction that PRAC infers the role values, while the actions learned in the TellMeDave system are similarly associated directly with the natural language instructions given. Some filtering of interpretations has been investigated by Pomarlan et al. (2017), where a program is considered an unlikely interpretation if it fails to respect preconditions for its actions according to some STRIPS domain, but more general solutions to the contextualization problem have not been forthcoming.
Rather different but more closely overlapping work on interpreting natural language in the context of robotic systems is also undertaken by Bastianelli et al. (2016), who in addition give a useful further review of the literature. Bastianelli et al. focus on the task of making natural language analysis more sensitive to the environment of a robot, extending beyond traditional grounding to include the ability to restrict syntactic parses on the basis of perception of the environment. This is, in certain respects, similar to the effects targeted in our proposed communication between simulation and linguistic processes, but does not yet consider the rather different kinds of information that independently ‘running’ simulations can provide. Bastianelli et al. (2013b), furthermore, seek more explicitly to utilise information that can be derived from linguistic processing by drawing on established linguistic semantics such as frames combined with work from the cognitive linguistic tradition examining spatial linguistic semantics (e.g., the work by Zlatev (2007)). This leads to semantic representations that can show considerable similarities with those defined by Bateman et al. (2010), although two differences are that the semantic categories provided by the GUM ontology generalize over a broader range of grammatical constructions at a semantic level of abstraction and that the semantic specifications are already anchored into natural language analysis and generation pipelines (e.g., the work by Ross (2011)). It would be of considerable interest, however, to compare and contrast the semantics used in the two approaches in more detail in order to find complementarities. Again in this case, however, there has not yet been a consideration of how the abstract level of semantics employed can be formally related to embodiment, which will impose further design guidelines on the semantics – particularly, we predict, in the direction of making explicit the functional nature of linguistic semantic categories.
A more semantics-intensive approach is found in the dialog system presented by Bos and Oka (2007), which operates by first translating an instruction or question into a first-order logic statement, and then verifying its consistency with a similarly first-order logic description of an environment by attempting to prove its negation. A model finder runs in parallel with the theorem prover and tries to find a consistent execution history (for an instruction) or select the parts of the environment that constitute an answer (for a question). This incorporates the specific environment into reasoning. Serious issues remain here, however, concerning the scalabilty of such logic-heavy approaches. Strong formalizations of even the simplest of everyday actions are well known to require extensive and highly expressive logics that involve substantial formal complexity. Davis describes this challenge with reference to some proposed interpretations of short narratives as follows: “the fact that this inference involves second-order logic, …does not mean that we would be justified in simply ignoring it. On the contrary: the text here is easily understood, and an understanding of the text clearly involves a collection of regions of unspecified cardinality. So there must be some way of dealing with this. …The inferences that are actually needed for commonsense reasoning …must surely lie in some fairly narrow, reasonably tractable, corner of that space. What we have to do is to find out what that corner is.” (Davis, 2013a, p. 268)
Bateman (2013), critiquing Davis’ attempt to maintain a more homogeneous, logic-based architecture, proposes the more radically heterogeneous approach that we have adopted above (cf. Fig. 1). Such a technique offers many opportunities for ‘offloading’ complexity, including both qualitative spatial reasoning of various kinds and simulation, as developed further here. Davis (2013b), in turn, responds that he would also favor such a model and further (Davis and Marcus, 2016, p. 70) suggests that several forms of reasoning may be employed, including symbolic reasoning about physical domains, qualitative reasoning, analogical reasoning, and meta-level reasoning – albeit without providing an indication of how heterogeneous specifications using such forms would be supported (for one general solution, see: Mossakowski et al., 2015, OMG, 2015). The general conclusion reached, however, is that simulation has several inherent weaknesses and so could offer only limited support in any application to commonsense reasoning.
Given the growing role that simulation is currently accorded in models of intelligent behavior, such a position appears in many respects counterintuitive and points to as yet unaddressed architectural problems – problems that lie primarily, we have argued above, in overly homogeneous conceptions of the problem space. Here it is important to allow heterogeneous solutions also within the distinct kinds of simulations that might be employed. In contrast to very fine-grained real world simulations, for example, the projection environment employed above adopts simulation at a much higher level of abstraction, thereby simplifying in many respects the interface between simulation specifications and linguistically derived semantic information. Further distinct kinds of simulation can be envisaged and remain for future work exploring multiply heterogeneous architectures.
Reconnecting the application of simulation, and all other components involved during contextualization, with the constraints imposed by narrative teleologies, such as the particular tasks involved at any time, allows us to address many of the difficult questions commonly raised concerning how to make selections of simulations, how to determine appropriate granularities and how to evaluate the results of any simulations achieved. As suggested above, such issues cannot be treated in isolation, just as contextualization in general cannot be treated in isolation: contextualization is always purposeful. Purposes are included in the model we have set out above in two ways and at two levels of abstraction: first, in terms of establishing everyday tasks within which actions are performed and only with respect to which the relevance and appropriateness of actions can be evaluated and, second, in terms of the abstract functional constraints imposed by the linguistic semantics: e.g., covering the pot is compatible with any physical actions with objects that bring about simulations where accessing the insides of the pot fail.
Finally, within linguistic theories and approaches to semantics, there are also now several accounts embracing the position that aspects of the semantics of natural language expressions will necessarily involve simulation. This can be seen particularly in embodied construction grammar approaches (Bergen and Chang, 2005) as well as proposals made (but still rarely implemented) in cognitive linguistics (cf. the work by Johnson and Lakoff (2002)). The nature of the linguistic information that needs to be maintained often lacks detail in these accounts, however, and simulations are rarely sufficiently detailed to drive the performance of actual tasks as illustrated here. Nevertheless, bringing these research directions together as mutually compatible orientations offers a promising range of research tasks for the future.
Conclusions
In this paper, we have proposed a framework and trial implementation of a multiple-level ontology-based approach to contextualization that combines ontological engineering principles and situated embodied simulations involving robotic agents. The use of simulation was intended to allow implementation and experimentation at a level of abstraction that is not usually accessible when considering linguistic analysis; in particular, simulation captures the ways in which objects interact physically, and reveals affordances offered by object combinations. We have demonstrated how it is possible to use the various levels to advantage, leveraging off the different strengths and purposes of the levels involved. The linguistically-motivated ontology provides a decontextualized, but still functionally-oriented and abstract characterization of states of affairs, motions and spatial relationships; the simulation-level invokes situations compatible with the abstract descriptions but filled out in sufficient detail to support simulation using interacting robotic agents within simulated physical environments. The results of performing simulations were then used in connection with the linguistic semantics in order to offer contextualizations of that semantics in terms of appropriate ‘parameterizations’ for the actions, locations, spatial and functional relations, and movements specified.
Our multistratal ontological model captures the linguistic semantics of space and functional relations between objects using the Generalized Upper Model (GUM) and its GUM-Space extension. General domain knowledge is captured by ontology modules developed within the KnowRob framework. And functional relations between objects, such as support and coverage, are characterized via ‘execution contexts’, which are prototypical simulation scenarios consisting of a description of an initial placement of objects and agents, a program for the agents to run, and a query to be performed on the resulting timeline of simulation events. By these means, we establish and formally specify connections between domain and formal ontologies, on the one hand, and subsymbolic reasoning procedures such as simulation, on the other. We have argued that such a modeling is essential for ‘deep’ understanding of natural language, particularly – but not only – in situations involving embodied agents. Although for specific cases it will always be possible to provide more ‘direct’ connections between language and action, for example by employing end-to-end learning techniques, such shortcuts remain just that: shortcuts. Understanding, and important concomitant functionalities such as explainability (to oneself and others), demands more.
Our linking between abstract linguistic semantic configurations and potential robot actions and resolvers is still, however, relatively rigid within the current implementation. As one of our main directions for development, therefore, we are currently investigating how to progressively make ontological characterizations of the different levels of abstraction involved perform more work. That is, we are seeking abstractions over the kinds of simulation descriptions that would allow the translation rules themselves to become more general. A particular focus here is a consideration of the extent to which more ‘action-oriented’ but nevertheless ‘functional’ characterizations of entire classes of simulations may offer a useful internal interface level. For this, cognitive notions such as image schemas (e.g., the work by Johnson (1987), Talmy (2006)) and their ontological formalizations (cf. the work by Hedblom et al. (2015)) are under investigation. Contact may also be productive with accounts of ‘affordances’ and their ontological specification as a further source of contraints to be applied on the range of simulations considered (cf. the work by Varadarajan and Vincze (2012), Min et al. (2016)).
Moreover, the consequences of retaining the results of simulations as ‘default’ or task-related forms of contextualizations for utterances to construct a growing body of experiential knowledge can also not be underestimated. Enabling a robot to build a large enough repository of rules that its decisions become as reflexive as human decisions would clearly be a significant advance. In short, it is likely that all of these directions together will make increasingly important contributions in understanding flexible intelligent behavior and the central role that ‘flexible contextualization’ plays within that.
Footnotes
Acknowledgements
The research reported in this paper was supported by the German Research Foundation (DFG), as part of the Collaborative Research Center (Sonderforschungsbereich) 1320 “EASE – Everyday Activity Science and Engineering”, University of Bremen (