
Abstract
Active learning for semi-supervised clustering allows algorithms to solicit a domain expert to provide side information as instances constraints, for example a set of labeled instances called seeds. The problem consists in selecting the queries to the expert that are likely to improve either the relevance or the quality of the proposed clustering. However, these active methods suffer from several limitations: (i) they are generally tailored for only one specific clustering paradigm or cluster shape and size, (ii) they may be counter-productive if the seeds are not selected in an appropriate manner and, (iii) they have to work efficiently with minimal expert supervision. In this paper, we propose a new active seed selection algorithm that relies on a k-nearest neighbors structure to locate dense potential clusters and efficiently query and propagate expert information. Our approach makes no hypothesis about the underlying data distribution and can be paired with any clustering algorithm. Comparative experiments conducted on real data sets show the efficiency of this new approach compared to existing ones.
Introduction
Semi-supervised clustering algorithms have gained a lot of attention from the clustering community, as they promise to improve the relevance and the efficiency of traditional methods [21] thanks to the introduction of an expert domain knowledge. This side information can be either provided as class labels for a small set of instances, also called seeds [6, 5], or as pairwise constraints between instances [36, 48]. When paired with semi-supervised clustering algorithms, active learning provides an efficient way to solicit an expert to provide the value of a class label or a relation between instances based on what should be the most appropriate for the clustering. However, some studies [46, 47] have shown that constraints or seeds that are not properly chosen can be counterproductive and lead to poor clustering performance, even in the case when the answer of the expert is good.
In this paper, we are interested more specifically in active seed based semi-supervised clustering algorithms that solicit the expert to retrieve class labels. For the time being, research conducted in the field have mainly focused on adapting well-known clustering methods to this new semi-supervised context, with the objective to either guide the exploration of the search space to relevant solutions, or to overcome some inherent limitations of clustering algorithms.
However, these methods do not address the problem of how selecting the most appropriate seeds while minimizing the expert solicitations. While numerous researches have been conducted in the context of active semi-supervised classification [38], only few methods have been proposed in the clustering context. Moreover, the existing methods are limited by hypothesis on the underlying data distribution and on the shape and sizes of expected clusters [42] or tailored for specific algorithms [51].
To this aim, this paper describes a new active seed selection algorithm, that can be paired with any seed-based clustering algorithm. The idea is to handle the diversity of shapes of clusters with a k-nearest neighbors graph structure to identify the regions of data space in which requesting the expert for labeled instances. Moreover, this graph allows us to query the expert in dense regions of the data sets where the labels provided by the expert can be easily propagated to the neighbors. Experiments on real data sets show the efficiency of our approach with either prototype or density based seed clustering algorithms, its ability to reduce the number of expert queries and finally its robustness to the parameter k in the k-nearest neighbors graph.
This paper is organized as follows: Section 2 presents an overview of the semi-supervised literature and presents the main active seed-selection methods. Then, Section 3 describes our new active seed selection method based on a k-nearest neighbors graph. Section 4 describes the experiments that were carried out and discusses the results. Finally, Section 5 presents the conclusions and perspectives of this research work.
Related works
This section first recalls some of main algorithms in the literature of semi-supervised clustering and stresses the sensitivity of these approaches to the quantity and the quality of the side information that is provided. Second, this section describes some of the main active seed selection approaches that can help an expert to efficiently – e.g. with minimum expert solicitation – feed semi-supervised clustering algorithm with domain knowledge.
Semi-supervised clustering algorithms aims at extracting patterns from data sets, based on a partial supervision provided by a domain expert [5]. This kind of methods have been shown to be of great interest in the clustering community as recalled in [21]. Indeed, these methods bridge the gap – to a certain extent – between clustering that is a purely unsupervised process, and classification that is a completely supervised learning process. Semi-supervised clustering [49] in this respect allows to add external expert knowledge that may be available to a clustering algorithm, generally as instance level constraints. There are two main types of instance level constraints: either class labels provided for some instances (also called seeds) [5, 6] or pairwise constraints between instances [36, 48]. There are two types of pairwise constraints: Must-Link (ML) constraints indicate that 2 points should belong to the same cluster while Cannot Link (CL) constraints indicate that 2 points should not be in the same cluster. Other constraints can be found in the literature, such as group-level constraints that are used to overcome constraints consistency problem and allow to express multiple pairwise constraints from a single group constraint [30, 15, 31, 29], or as constraints on the compacity and separability of clusters [13] or such as order preferences on distance [28]. Some works also propose to express preferences on the order of the attributes to guide the search for an efficient metric toward a preferred subset of possible Mahalanobis distances [40, 50].
Most of the research effort until now in the semi-supervised field has been conducted to adapt well-known clustering methods to this new semi-supervised context, with the objective to either guide the exploration of the search space to solutions that are more relevant to the user, or to overcome some inherent limitations of clustering algorithms. For example, seed k-means (SKM) [6, 12] or seed fuzzy c-means [7, 32, 33] allow to reduce the sensitivity of these methods to their initial partition. Similarly, seeds have been used to estimate distinct local density parameters in density-based algorithms like SSDBSCAN, HISSCLU [26, 10].
Additionally, these semi-supervised approaches can be divided in three main categories depending on how they use constraints. Strict enforcement methods explicitly ensure that ML and CL constraints are not violated during the clustering process [6, 49], but as a consequence they sometimes fail to produce a clustering. Soft enforcement methods add a penalization term in the objective function to favor the solutions that best fit constraints [33, 11, 3]. Finally, some other method performs a soft enforcement that relies on the learning of an adapted metric space that minimizes the number of violated constraints [54, 8, 24, 4, 28].
However, all these methods do not address the problem of how selecting the most appropriate constraints for their needs. While numerous researches have been conducted in the context of active query selection for classification [38], very few methods have been proposed in the clustering context. First attempts have been conducted to evaluate the quality of constraints or their utility [14, 45]. Then, most of the existing methods are limited by hypothesis on the underlying data distribution and on the shape and sizes of expected clusters [42].
As stated in [41], and contrary to traditional classification, active learning is “a selective sampling technique where the learning protocol is in control of the data to be used for training”. Although active learning for classification has been widely studied [37, 38], it is still under investigation in the clustering community since the advent of semi-supervised clustering [42] and a need for expert interactivity in real-world applications. Two main families of methods can be identified [41]: either Query-by-Committee approaches that rely on several classifiers to decide which query to ask the expert for or Uncertainty Sampling approaches that rely on a single classifier and select the example for a potential user query based on those of the examples that exhibit the smallest confidence from the classifier. In the case of clustering, most of the active learning approaches rely on the uncertainty sampling as they decide on the query to ask the expert based on the assignment of points on which an error is more likely to penalize the objective function. As an example, spectral clustering methods have been particularly studied in recent years [9, 51, 52, 53]. In this case, the general principle consists in querying the constraints which maximally reduce the expected error of the clustering algorithm. However, these active learning methods are generally tailored to work specifically with only one single clustering method in mind. Our objective is to propose general methods that can fit any clustering context.
The problem of selecting the best seeds in the context of clustering algorithms has already been partially covered by papers related to the problem of initialization of centers in k-means like algorithms [1, 7, 17, 20]. As recalled by [34], this problem has been deeply studied but one can identify four major approaches to initialize the centers in k-means like approaches: the random creation of the initial partition, the classical Forgy method as reported by [2] in which initial seeds are randomly selected (and then all points are assigned to the nearest seed), the MacQueen method in which, similarly to Forgy, seeds are chosen randomly, but then each time a point is assigned to a seed, the corresponding cluster center is updated, and finally the Kaufman approach [23] in which the first seed is the center of the data set and all the other seeds are selected according to a criterion that depends on the number of data in the neighborhood of the seed candidate and the distance to the seeds that are already selected.
Other approaches like [19, 39] also select the seeds based on their distance to the set of seeds already selected. More precisely, in [39], authors propose two heuristics that either maximize the sum of the distance or the minimal distance to the existing seeds. Finally, [18] initializes the first seed as the center of the data set and then selects randomly other point that are averaged with the center coordinate with an appropriate weight to cover the entire data set while being more resistant to outliers.
All the previous methods (random selection or maximization of the distance to already selected seeds) allow an efficient coverage of the data space and some of the approaches like [23] also take into account a density measure (number of data points in the neighborhood) to choose from all the possible distant seeds. More recently, [27] propose an active learning method based on Minimum Spanning Tree (MST) to deal with multi-densities and imbalanced data sets while minimizing the number of experts solicitations. The main idea is to build a MST from a sample of the data set and then cut this graph into
We now describe with more detail the two main methods named S-Min-Max and S-Min-Max-D that have been proposed to allow the active selection of seeds by an expert in the context of semi-supervised clustering [42].
Min-Max approach
the objective of the Min-Max approach is to build a set of seeds
where
The active seed selection algorithm based on the Min-Max approach, called S-Min-Max, is an iterative process where, at each step, a new seed candidate
Limit of the Min-Max approach. The seeds selection process heavily depends on the first seed that is randomly selected and the size and the shape of clusters. Left: data set with 3 clusters and selection of 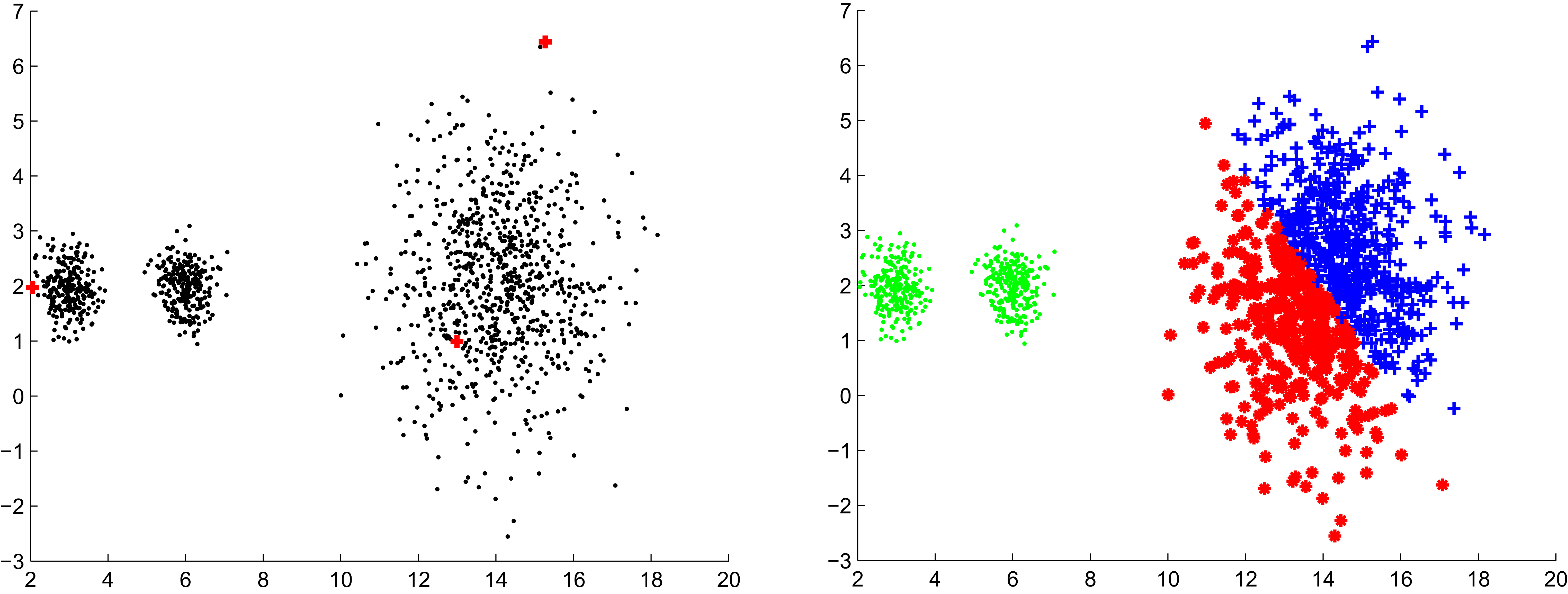
Min-Max approach based on local density
the previous S-Min-Max approach relies on the hypothesis that clusters are mainly hyperspherical, so that maximizing the distance between each proposed seed, maximizes the chances that the seeds belong to distinct clusters. However, the method becomes sensitive to the relative position of the first selected seed compared to the expected clusters. The improved Min-Max Local Density Score (S-Min-Max-D for short) improves the S-Min-Max approach by initializing the seeds near the clusters centers, that is to say, in dense regions of the data set. In order to determine the potentially interesting regions of the data space with high density, the S-Min-Max-D relies on a k-nearest neighbors graph structure, similarly to what have been proposed for active constraint selection algorithms [43, 44, 45].
The k-nearest neighbors graph
(
where NN(.) denotes the set of
The LDS value of a point
As the proposed S-Min-Max-D aims at focusing on candidate seeds near the centers of potential clusters, the previous S-Min-Max approach is modified by integrating a preliminary filtering of the candidate seeds Candidate_Set on the basis of their LDS scores and a minimum density threshold
where
Figure 2 illustrates a Candidate_Set obtained on the previous data set with 2 clusters. As expected, seed candidates, marked as red plus symbols, are selected in dense regions of the data space, near the cluster centers and can thus favor
Illustration of seed candidates obtained with the S-Min-Max-D algorithm with parameters 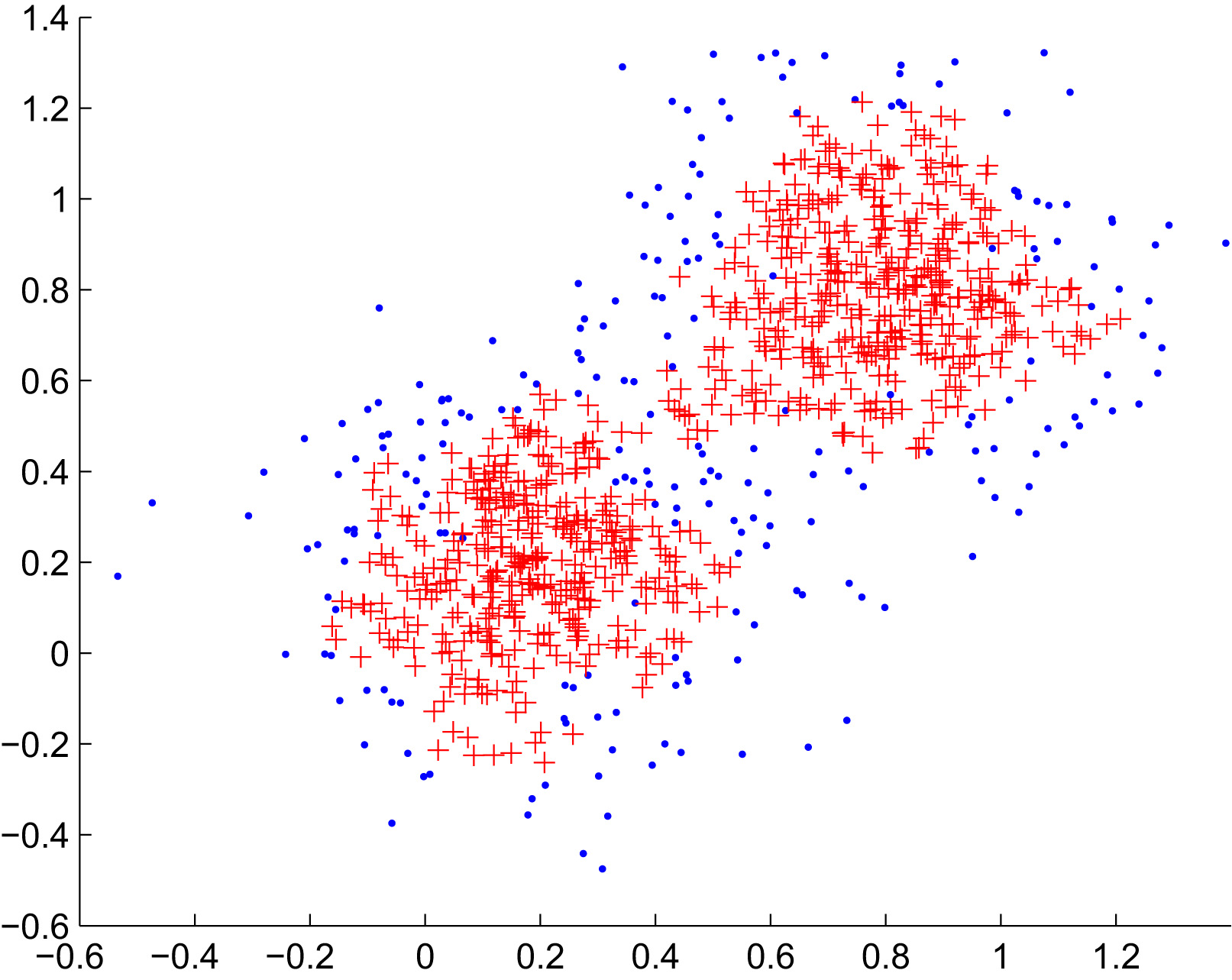
In this paper, we are interested more specifically in active seed based semi-supervised clustering algorithms that query the expert to retrieve interesting class labels. To this aim, Section 3 describes our new density-based approach that can deal with any cluster shape and can adapt equally to different data densities.
Our active learning seed selection method falls into the category of uncertainty sampling approaches, but contrary to these methods that try to find regions of the data space where clustering algorithms are supposed to make assignment mistakes, we focus on determining regions where we are almost certain that the points belong to a single cluster.
Moreover, our approach avoids the Min-Max scheme that allows for a good coverage of the data space for two main reasons. First, Min-Max methods make the assumption that clusters are hyper-spherical. Even if this works well in the case of k-means-like semi-supervised algorithms, this may as well lead to ask several queries to the expert in case of elongated clusters that are to be detected with density-based semi-supervised clustering algorithms. Second, Min-Max approach is very sensitive to outliers as it chooses as seed candidates, the points that maximize their minimal distance to already found clusters. Again, this may be counter-productive to ask the expert to label outliers.
The solution that we propose relies on the efficient detection of clusters as dense regions of the data space. It is then possible to discover either hyper-spherical or elongated clusters as well. But then, the difficulty, as illustrated with previous semi-supervised density-based clustering algorithms [26], is that the algorithm has to seamlessly adapt to distinct densities to be usable in our context. To this aim, our method relies on a k-nearest neighbors graph structure (k-NNG) as in the previous S-Min-Max-D method [42] to detect the potentially interesting dense regions of the data space. Contrary to this previous method that only uses the k-NNG to filter seed candidates, our new approach takes full advantage of the structure to reduce expert solicitations. Indeed, the interesting regions are represented as connected components of the k-NNG, that is to say, set of points that are highly related with their direct neighbors. In a k-NNG, the weight
In our proposal, an initial set of seeds candidates is determined by considering only the edges of the k-NNG whose weight
where
Then, the set of seeds candidates is used to support the active generation of queries to the expert. In order to minimize the annotation effort, each query to the expert should ideally maximize the number of class labels that can be inferred. To that aim, our algorithm builds the connected components of the previous candidate set on the basis of the k-NNG and order the resulting components in the descending order of their cardinality: the larger connected component is ranked first.
As in other active seeds selection methods, the seed selection is an iterative process that stops when the experts decide to, or when the candidate set is empty. It is also assumed that the expert can answer every query (s)he is asked for. At each iteration, the algorithm chooses randomly a seed candidate from the first ranked connected component that has not been queried, generates the query and retrieves the corresponding class label provided by the expert. The novelty here is that it is possible to naturally propagate the class label to all the candidate seeds that belongs to the same connected component, similarly to what is done in classical supervised learning. Then, in order to avoid soliciting the expert several times for the same potential cluster, each time a candidate seed is labeled, its corresponding connected component is removed from the list of potentially interesting connected component so that no other seed candidate from the same region can be submitted for a query to the expert. As a summary, the main steps of our active seeds selection algorithm are presented in the Algorithm 1 hereafter.
Active seeds collection method based on a k-NN graph
Build the set of connected components from
Randomly select
Propagate the class label of
The complexity of this approach depends heavily on the complexity to build the k nearest-neighbors graph which in turn depends on the dimensionality of the data space. As noted in [43], the complexity can range from
Several experiments have been conducted to assess the quality of our new approach. As our main objective is to propose an active method that makes no hypothesis on the shape or the size of the expected clusters, comparative experiments are performed with either seed k-means (SKM) [6] or SSDBSCAN [26] semi-supervised clustering algorithms. The section is organized in three main parts: (i) first, it details the experimental protocol for each of our tests, (ii) second, it shows the results related to the quality of our approach based on a clustering evaluation and the number of expert solicitations and, (iii) it discusses the robustness to the parameters
Experimental protocol
Data sets description
As shown in Table 1, we use 6 well-known real data sets from the Machine Learning Repository [16] named: Iris, Soybean, Protein, Zoo, Thyroid, and LetterIJL and 6 data sets extracted from CALTECH-101 image data set [16], to evaluate our algorithm. These data sets have been chosen because they facilitate the reproducibility of the experiments and because some of them have already been used in constraint-based clustering articles. As can be seen in Table 1, these data sets cover several difficulties for a clustering algorithm. Data set sizes range from very small (47 instances in Soybean) to small (672 instances in Test6). Here, we have preferred to favor small data set because of the complexity of the k-NNG structure that grows with the number of attributes that ranges from 4 (Iris) to 128 (Caltech image data sets). Finally, various cluster numbers and sizes are also investigated.
Main characteristics of the real data sets
Main characteristics of the real data sets
Rand Index for 4 methods of seeds selection with Seed K-Means and SSDBSCAN for 6 UCI data sets.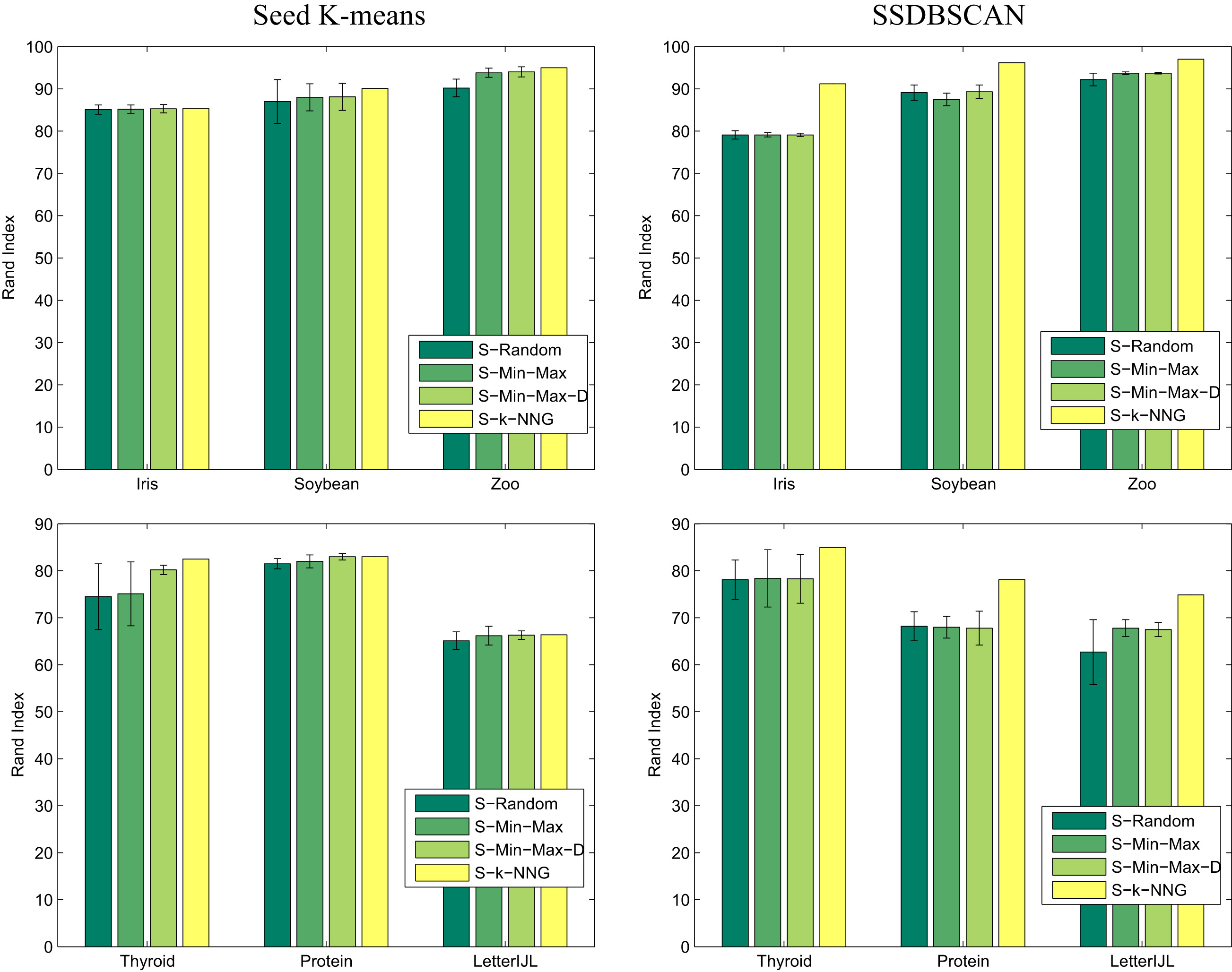
Compared methods
In the experiments, we denote the methods as follows:
S-Random refers to a complete random seeds selection from the whole data set. It is a naive approach that we use as a baseline for reference purpose;
S-Min-Max refers to the simple Min-Max approach as formalized by Eq. (1);
S-Min-Max-D refers the extended Min-Max approach with a preliminary filtering of candidate seeds with a k-NNG;
S-k-NNG refers to our new approach that identify seed candidates and propagate class labels with a k-NNG.
Evaluation of the results
As all our benchmark data sets contain a class label, we use the Rand Index (RI hereafter) [35] in our experiments to evaluate the agreement between the theoretical partition of each data set and the output partition of the evaluated algorithms. RI takes values between 0 and 1; RI
We also evaluate, for each data set, the number of expert queries needed to collect the set of seeds. For each method, the process of collecting seeds stops when at least one seed was chosen in each of the clusters.
Rand Index for 4 methods of seeds selection with Seed K-Means and SSDBSCAN for 6 images data sets.
Figures 3 and 4 present the Rand Index (RI) scores for the four previous active seeds selection methods.
First, it can be noticed that the S-Random method, even if simple, allows for comparable RI scores with the other heuristics on some of our data sets. The S-Random performances decrease mostly on the LetterIJL data set (with SSDBSCAN) or the Caltech image data sets Test1 (with SKM or SSDBSCAN) or Test4 (with SSDBSCAN). This can be explained by the fact that as the expert always provides a good answer, it is sufficient on some of our data sets to improve the clustering quality. However, this relatively good results come at the price of a higher number of expert queries (see Fig. 5).
Conversely, when paired with Seed k-means, our approach is always either similar or slightly better in terms of RI than than the other methods. It is interesting to notice that in this case, our approach still performs better than S-Min-Max-D, even if it does not rely on a Min-Max approach that favors k-means like methods. It can be explained by the fact that the k-NNG allows our approach to identify correctly the neighborhood of the cluster centers without a need for a Min-Max heuristic to explore data space.
When paired with SSDBSCAN, our S-k-NNG approach is significantly better than the other methods. Indeed, contrary to the S-Random and S-Min-Max that do not necessarily search for seeds in the dense region of the data set, our S-k-NNG method and S-Min-Max-D benefits from more appropriate seeds in the center of potential clusters to start a density-based clustering algorithm. In this case however, S-Min-Max-D does not allow to label as much instances of each cluster as our new approach that benefits from an efficient propagation mechanism. This mechanism allows for a more accurate labelling of points in each cluster near the decision frontier, which in turn advantages SSDBSCAN that stops the growth of a cluster as soon as an instance with an other cluster label is to be merged in the current cluster. The ability of our method to cover more instances with its propagation mechanism is indirectly illustrated by the number of queries that is lower for the S-k-NNG than the S-Min-Max-D method as shown in Fig. 5.
Number of question for 4 methods with 12 data sets.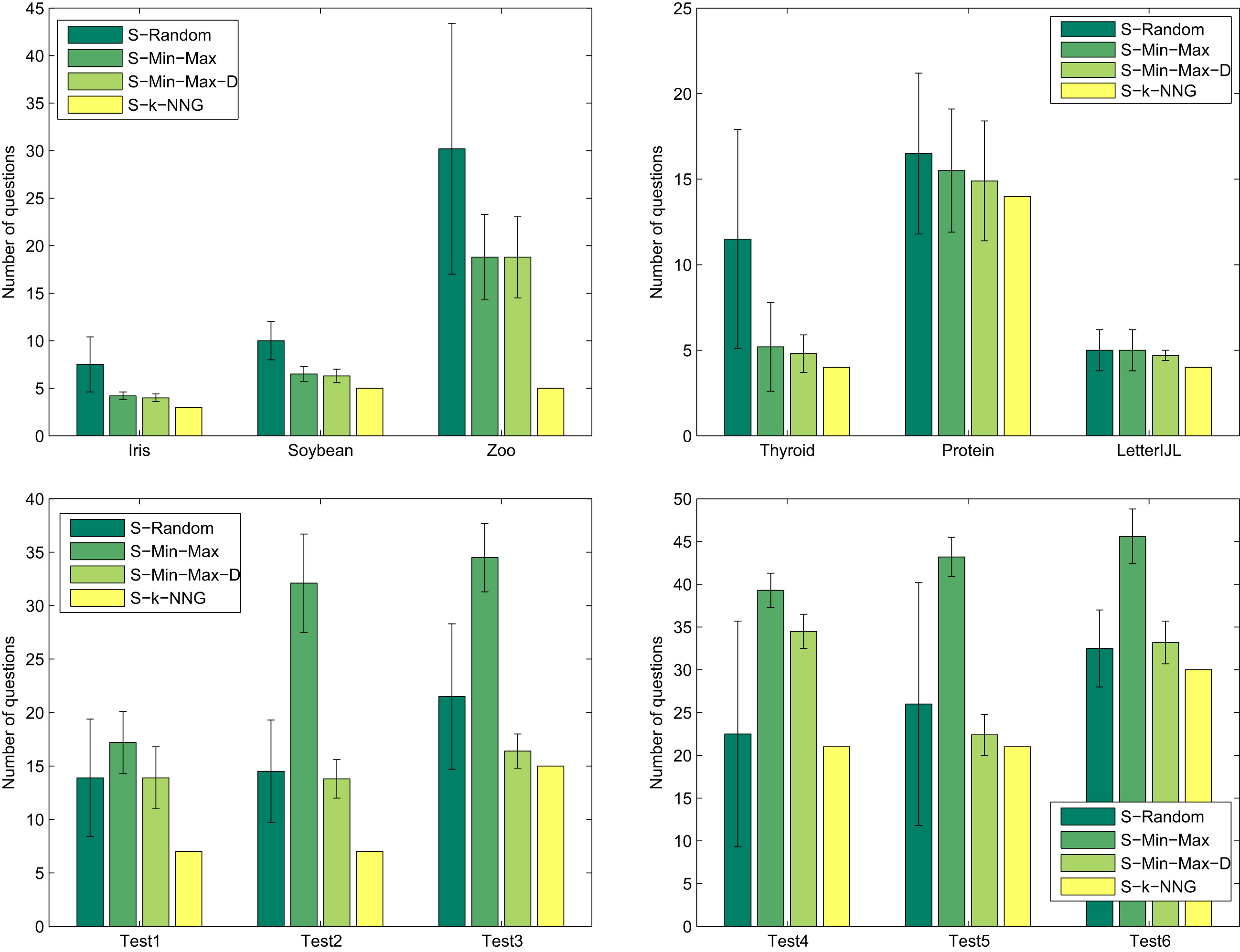
As shown in Fig. 5, it is interesting to notice that S-Random is generally the less efficient method regarding this particular criterion. Indeed, selecting seeds at random does not allow to find the most appropriate labels for SKM and SSDBSCAN and thus require a lot more “test and try” before converging to a good clustering solution.
As expected, the S-k-NNG obtains the best results with up to 4 times less questions than the worst approach for the Zoo data set (7 queries versus more than 30 queries for the S-Random approach in this case). This experiment shows the advantage to use a k-NNG graph representation and the effectiveness of our propagation mechanism of class labels according to connected components. It is also interesting to notice that this propagation allows our method to be resistant to unbalanced clustering while other approaches like S-Random and S-Min-Max will ask several queries for the largest clusters. As a conclusion, even if the clustering quality is sometime similar with previous approaches, our new S-k-NNG solicits less the expert on all our benchmark data sets.
Robustness and parameter settings
Influence of the number of nearest neighbors
A study has been conducted to evaluate the influence of the number of nearest neighbor
Rand Index for 6 UCI data sets with the SSDBSCAN algorithm paired with our S-k-NNG seeds selection method for 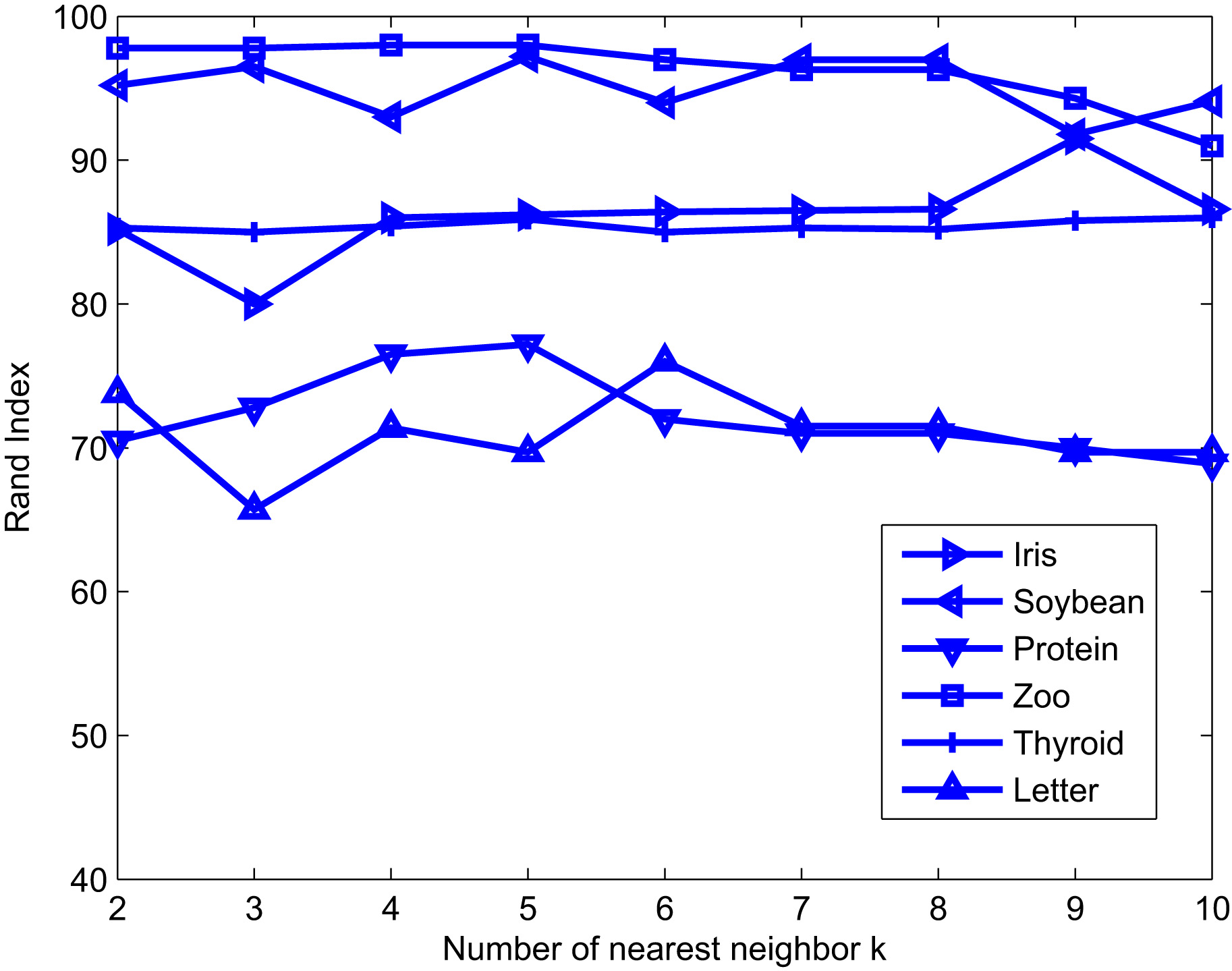
Rand Index for several 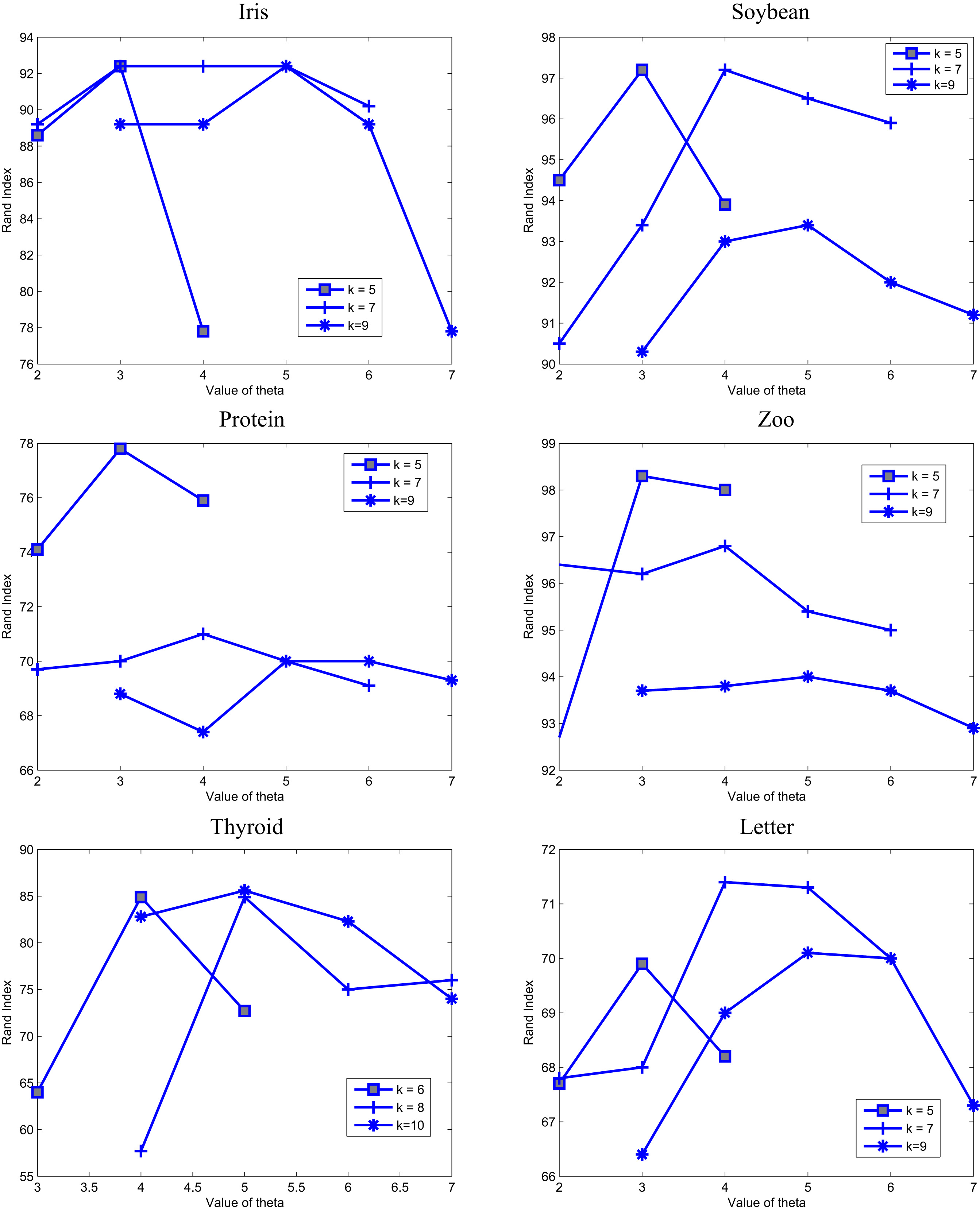
Influence of the parameter
The value of
This paper introduces a new active seed selection method named S-k-NNG that is efficient with any kind of semi-supervised clustering algorithms. Similarly to some previous approaches like Min-Max-D, S-k-NNG relies on an underlying k-nearest neighbors graph structure to build the set of initial seed candidates. However, and contrary to previous methods, S-k-NNG also uses the k-nearest neighbors graph to produce a first clustering of the data set based on the density, that allows for an efficient propagation of instance labels provided by an expert. Experiments on real data sets suggest that our new active method is comparable or more efficient than the others when paired with a representative-based clustering like Seed K-Means and that it is much more efficient when paired with a density-based clustering algorithm like SSDBSCAN. Then, our experiments show that our approach allows for less expert solicitations than other methods which is crucial in most real use cases. Finally, our tests show that our approach is robust to its two main parameters, the number of nearest neighbors
The bottleneck of the S-k-NNG approach, as for the previous Min-Max-D, is the building of the k-nearest neighbors graph which can be costly when the dimensionality of the data space increases. Thus, future work aims at evaluating approximate heuristics to determine efficiently the nearest-neighbors. Other possible extensions of this work concerns an in depth analysis of the behavior of S-k-NNG in an interactive context when all the seeds are not provided before clustering but during the clustering process. This interactivity raises new questions such as how to evolve the parameters
Footnotes
Acknowledgments
This research is funded by Vietnam National University, Hanoi (VNU) under project number QG.17.43.