
Abstract
Association Rule Mining (ARM) is a fundamental data mining task that is time-consuming on big datasets. Thus, developing new scalable algorithms for this problem is desirable. Recently, Bee Swarm Optimization (BSO)-based meta-heuristics were shown effective to reduce the time required for ARM. But these approaches were applied only on small or medium scale databases. To perform ARM on big databases, a promising approach is to design parallel algorithms using the massively parallel threads of a GPU processor. While some GPU-based ARM algorithms have been developed, they only benefit from GPU parallelism during the evaluation step of solutions obtained by the BSO-metaheuristics. This paper improves this approach by parallelizing the other steps of the BSO process (diversification and intensification). Based on these novel ideas, three novel algorithms are presented, i) DRGPU (Determination of Regions on GPU), ii) SAGPU (Search Area on GPU, and, iii) ALLGPU (All steps on GPU). These solutions are analyzed and empirically compared on benchmark datasets. Experimental results show that ALLGPU outperforms the three other approaches in terms of speed up. Moreover, results confirm that ALLGPU outperforms the state-of-the-art GPU-based ARM approaches on big ARM databases such as the Webdocs dataset. Furthermore, ALLGPU is extended to mine big frequent graphs and results demonstrate its superiority over the state-of-the-art D-Mine algorithm for frequent graph mining on the large Pokec social network dataset.
Keywords
Introduction and background
General concepts
Association Rule Mining (ARM) is a fundamental data mining task, which consists of discovering hidden patterns in transaction databases. It is applied in many real world problems such as: Constraint Programming [23, 24], Information Retrieval [25] and Business Intelligence [26, 27]. The ARM problem is defined as follows [10]. Let
In real-life, transactional databases can be very large. Database size has a major impact on the runtime of traditional ARM algorithms such as Apriori [10] and FP-Growth [5], which have been originally evaluated on small or medium size datasets. These algorithms may run extremely slow on very large data sets. To address this issue, metaheuristics approaches have been designed, which can find approximate solutions to difficult ARM problems in less time. Swarm Intelligence is a category of such promising metaheuristics, which includes many approaches such as Ant Colony Optimization (ACO), Particle Swarm Optimization (PSO), Bee Swarm Optimization (BSO). These approaches have been adapted for solving the ARM problem in the PSOARM [11],
Although metaheuristics considerably improve performance compared to exact algorithms, they still show long execution times when dealing with big databases. Parallel programming is the most effective available option nowadays for boosting the speed of such algorithms. In this context, many HPC-based approaches have been recently developed for ARM, which can be categorized into two classes. The first class is algorithms using cluster-based architectures. Different version of parallel Apriori have been proposed in [21, 17, 4, 19], Fp-Growth in [3] and algorithms exploiting metaheuristics in [33, 34]. The second class are those using new emerging cost-effective parallel architectures such as GPUs (Graphical Processing Units) and FPGAs (Field Programming Gate Array). This paper considers the GPU architecture, which is presented next.
The GPU architecture
GPUs are graphical cards, which have historically been designed for video games and entertainment. From 2007, GPUs have started to be used as an efficient computing tool for various applications [1, 9]. The GPU framework is mainly composed of two hosts as presented in Fig. 1.
GPU architecture.
The CPU host contains a processor and a main memory. The GPU-based thread host is logically composed of several blocks of threads. Each block may be seen as a collection of threads that can access a shared memory. All the blocks can also access some constant and global memories. Physically, the threads of a block are organized into warps of 32, 64 or 128 threads. To design any GPU-based parallel approach, three constraints must be taken into account [15]: i) CPU/GPU communication and data transfer should be minimized, ii) parallelism control and efficient mapping of threads to data should be done to deal with memory constraints and the thread divergence problem should be considered, iii) memory overhead should be managed.
The BSO-ARM approach.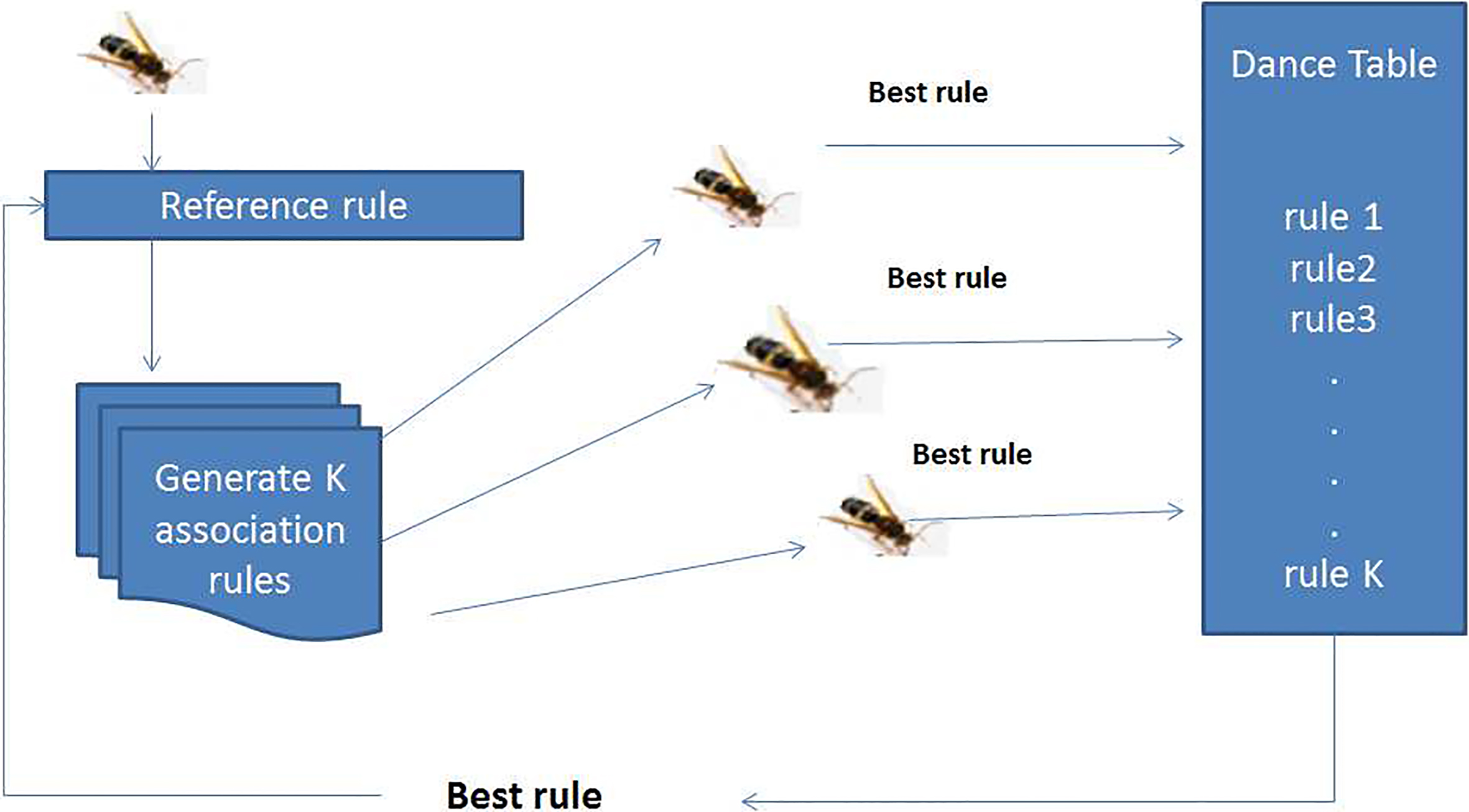
The BSO-ARM process is performed as follows. It starts by generating a random initial solution named Sref, from which the search area of each bee is determined by using one of three possible diversification strategies, i) Modulo, ii) Next, and iii) Syntactic. Each bee explores its region during what is called the intensification step, using a neighborhood search method. All the bees communicate via the queen bee that selects the best solution as the reference solution for the next iteration. This process is repeated until a predefined maximum number of iterations has been completed. Figure 2 illustrates the BSO-ARM approach. In BSO-ARM [28], a solution
In the following, the different steps of BSO-ARM are presented.
Many intensification-based strategies have been proposed in the literature. Without loss of generality, this work focuses on two of the best strategies, namely SLS (Simple Local Search) and TS (Tabu Search). The former strategy consists of randomly and iteratively changing a bit from a given solution
Diversification step
This step consists of applying a strategy to determine the search area. Given a reference solution, Sref, and a colony of
Modulo strategy: The
Next strategy: A predefined number Flip is used where the
Syntactic strategy: This strategy defines a weight for each solution. The weight of a solution,
If an item If the item First,
The goal of this paper is to address scalability issues of ARM for big datasets using swarm intelligence metaheuristics. An approach is developed that exploits the GPU architecture for mining big transactional databases using swarm intelligence based metaheuristics. The main contribution is to exploit the power of GPU parallelism for all steps of the metaheuristic process, contrarily to existing approaches such as CudaApriori [15], SEGPU [30], MEGPU [31] and TDGPU [32], that only use the GPU for the evaluation step, and perform the remaining steps sequentially on the CPU.
It is is to be noted that a previous work [16] has proposed to use swarm intelligence based metaheuristics, running on a GPU. However, that study solves a different problem. It proposes a generic framework to solve optimization problems by using a GPU-based local search strategy.
The contribution of the paper are listed as follows:
This paper investigates various GPU-parallelism strategies to improve the performance of Bee Swarm Optimization (BSO) for the ARM problem in the context of big databases. Three approaches are proposed, namely DRGPU (Determination of Regions on GPU), SAGPU (Search Area on GPU) and ALLGPU (All steps on GPU). To validate the proposed approaches, an experimental evaluation has been carried out using medium, large, very large and big datasets. Results show a considerable speed up on the challenging big Webdocs dataset. Results also reveal the superiority of the fourth approach (ALLGPU) over existing GPU-based ARM approaches. A case study in social network analysis shows that ALLGPU outperforms DMine [38] to discover interesting rules from the big Pokec social graph that contains 1.63 million nodes.
The remainder of the paper is organized as follows. Section 2 discusses related work about recent parallel ARM algorithms. Section 3 describes the proposed solutions, and a theoretical study is presented in Section 4. A performance evaluation is presented in Section 5. Finally, Section 6 draws a conclusion.
Many solutions have been proposed in the ARM literature. In this related work section, only GPU-based ARM approaches are discussed. The first GPU-based ARM algorithms were introduced by Fang et al. in [18]. Two parallel versions of the Apriori algorithm [10] have been proposed, called PBI (Pure Bitmap Implementation) and TBI (Trie Bitmap Implementation). PBI represents transactions and itemsets using a bitmap data structure. The bitmap for itemsets is a
Adil and Sadaf proposed a new Apriori algorithm for the GPU architecture [14]. It is applied in two steps. First, the generation of itemsets is performed on the GPU host. Each thread block computes the support of a set of itemsets. Then, the generated itemsets are sent back to the CPU to generate the rules corresponding to each itemset and to determine the confidence of each rule. The main drawback of this algorithm is the high cost of CPU/GPU communications.
In [13], the authors proposed a parallel version of the DCI algorithm where the intersection and computation operators (which represent the most frequent operations of DCI) are parallelized. In the latter, two strategies have been proposed, i) transaction wise approach
In [20], the Bit_Q_Apriori algorithm that simplifies the process of candidate generation and support counting is proposed. Unlike the Apriori algorithm, which generates k-candidates by combining two (k-1)-frequent itemsets, the Bit_Q_Apriori algorithm generates k-candidates by joining 1-frequent itemsets and (k-1)-frequent itemsets. The bitset structure is used to store transaction identifiers that correspond to each candidate. Therefore, support counting can be implemented by using boolean operators, instead of scanning the database. Some researchers have recently introduce bio-inspired approaches for ARM in [35, 30, 31]. In [35], an evolutionary algorithm is proposed to solve the ARM problem on GPUs. First, the rule is saved on constant memory. Then, the consequent and the antecedent of the rule are evaluated concurrently. Each thread
From this brief review of related work, it is found that all the proposed approaches have attempted to improve ARM algorithms by only parallelizing the evaluation step on GPU. The intuition behind this is that this operation is the most time consuming for the CPU. However, for big transactional databases, diversification and intensification may also be time consuming as well. The main contribution of this work is to investigate several GPU parallelism strategies that take into account all the constraints of GPU architecture and CPU/GPU communications, which is relevant when dealing with big transactional databases.
Proposed solution
This section presents the proposed method, which is inspired by the BSO-ARM algorithm. The section is divided into three sections corresponding to the three steps performed by the proposed method: diversification (also know as determination of regions on GPU), intensification, and evaluation. The main difference between the proposed approach and BSO-ARM is that the three steps are designed to be run on a GPU. For the diversification step, it will be shown that regions explored in parallel and sequentially are the same. Based on these GPU implementations of the three steps, four different versions of BSO for ARM will be presented.
Diversification
In the GPU-based BSO-ARM algorithm, each bee independently explores its region. In this paper, to take advantage of all blocks of the GPU, each block is associated to a bee for exploring its own region. To do this, the task of determining the search area will be divided into several fragments (subtasks), each consisting of creating a region for a bee. That is, the threads of the
GPU implementation of the Modulo Strategy
Correctness of the Definition
(Correctness of the Definition).
The modulo strategy on GPU is correct in terms of producing the same result as a single-processor architecture. Formally speaking, let
.
Let’s consider
The first bee modifies bit 1, which corresponds to The second bee modifies bit 3, which corresponds to The third bee modifies bit 5, which corresponds to The fourth bee modifies bit 7, which corresponds to
Implementation.
In this strategy, each thread in a block modifies a bit of Sref, while the remaining threads of the same block copy the remaining bits of Sref. That is, the thread
GPU Kernel of the Modulo Strategy[1]
(Correctness of the Definition).
The Next strategy on GPU is correct in terms of producing the same result as the sequential version executed on a single-processor architecture. That is, in the two cases, the
.
Consider the previous example with the same parameters. The regions are determined as follows:
The first bee modifies bits 1 and 2, which correspond to The second bee modifies bits 2 and 3, which correspond to The third bee modifies bits 3 and 4, which correspond to The fourth bee modifies bits 4 and 5, which correspond to
GPU Kernel of Next Strategy[1]
A thread performs a modification of a bit in the reference solution.
A thread calculates the weight of the generated solution.
GPU Kernel of Syntactic Strategy[1]
In the pseucode of Algorithm 3.1.3,
The intensification step (SLS or TS) ensures that each region is explored by one bee. To parallelize this operation on a GPU, each block of threads is associated to a region, and each thread of a block modifies one bit of the reference solution. Indeed, for
GPU Kernel of Local Search Strategy[1]
The evaluation step
According to prior studies [30, 31], the most CPU intensive operation for the ARM problem using swarm intelligence techniques is fitness computation, which requires to scan the database multiple times. Thus, parallelizing this step on a GPU could intuitively reduce the overall runtime. To parallelize this step, multiple rules are simultaneously evaluated on the GPU. Every block of threads evaluates a rule. Threads of the same block are launched to collaboratively calculate the fitness of a single rule. Therefore, there are as many rules as blocks. Transactions are subdivided into subsets and each subset is associated to exactly one thread. Hence, each thread calculates only its corresponding subset of rules. After that, a sum reduction is applied to aggregate the fitness value. Such a strategy attempts to benefit from the massively parallel power of GPU by launching a large number of threads per rule and to reduce CPU/GPU communications. The general procedure of slave kernel is given in Algorithm 3.3.
GPU Kernel for evaluation of multiple association rules[1]
Four novel GPU-based approaches for ARM using BSO
The previous subsection has presented GPU implementations of the three main steps of the BSO process. This section explains how these steps are combined to create four versions of the proposed GPU-based BSO method for ARM in big databases.
The DRGPU algorithm
The first algorithm is called DRGPU (Determination of Regions). In this algorithm the reference solution is first created by the CPU, which then sends it to the GPU. Afterwards, region determination is performed on the GPU. Each generated bee is transmitted to the CPU, which explores its own region thanks to the neighborhood computation strategy. Each solution is then evaluated and the best one is considered as the reference solution for the next iteration. This process is repeated until the maximum number of iterations is reached. Figure 3 shows the framework of the proposed approach.
DRGPU framework.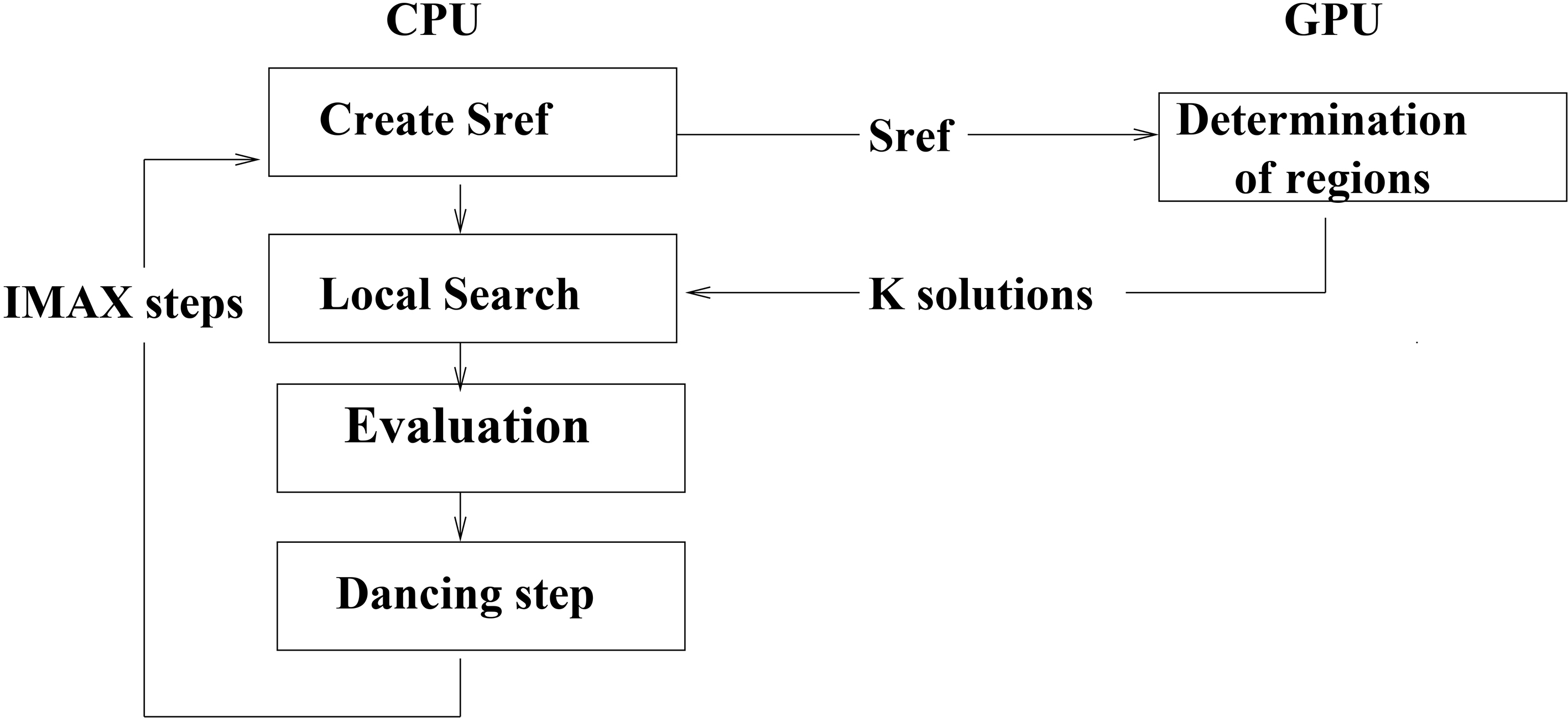
The second algorithm, called SAGPU (Search Area on GPU), creates the reference solution and perform region determination on CPU. After that, each generated bee is sent to the GPU, where the local search of each region is done in parallel. The generated solutions are then sent to the CPU for the evaluation and the selected best solution is then considered as the reference solution for the next iteration. This process is repeated until the maximum number of iterations is reached. Figure 4 shows the framework of the proposed approach.
SAGPU framework.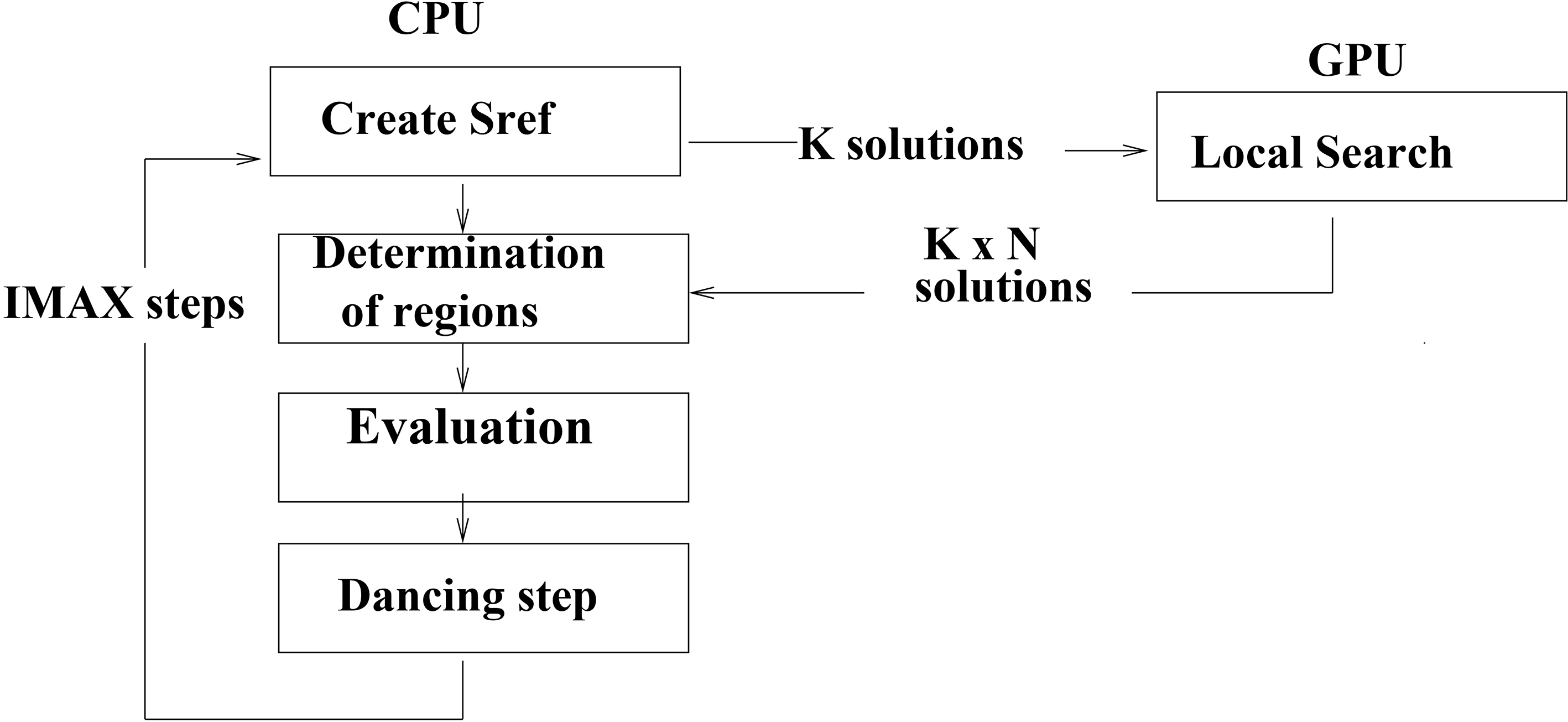
The third algorithm, called MEGPU (Multiple Evaluation on GPU), performs reference solution creation, region determination and local search on the CPU. Then, each generated bee is sent to the GPU for the evaluation where multiple solutions are evaluated in parallel. The fitness of each solution is then sent to the CPU for the dancing step. The best solution becomes the reference solution for the next iteration. This process is repeated until the maximum number of iterations is reached. Figure 5 shows the framework of the proposed approach.
MEGPU framework.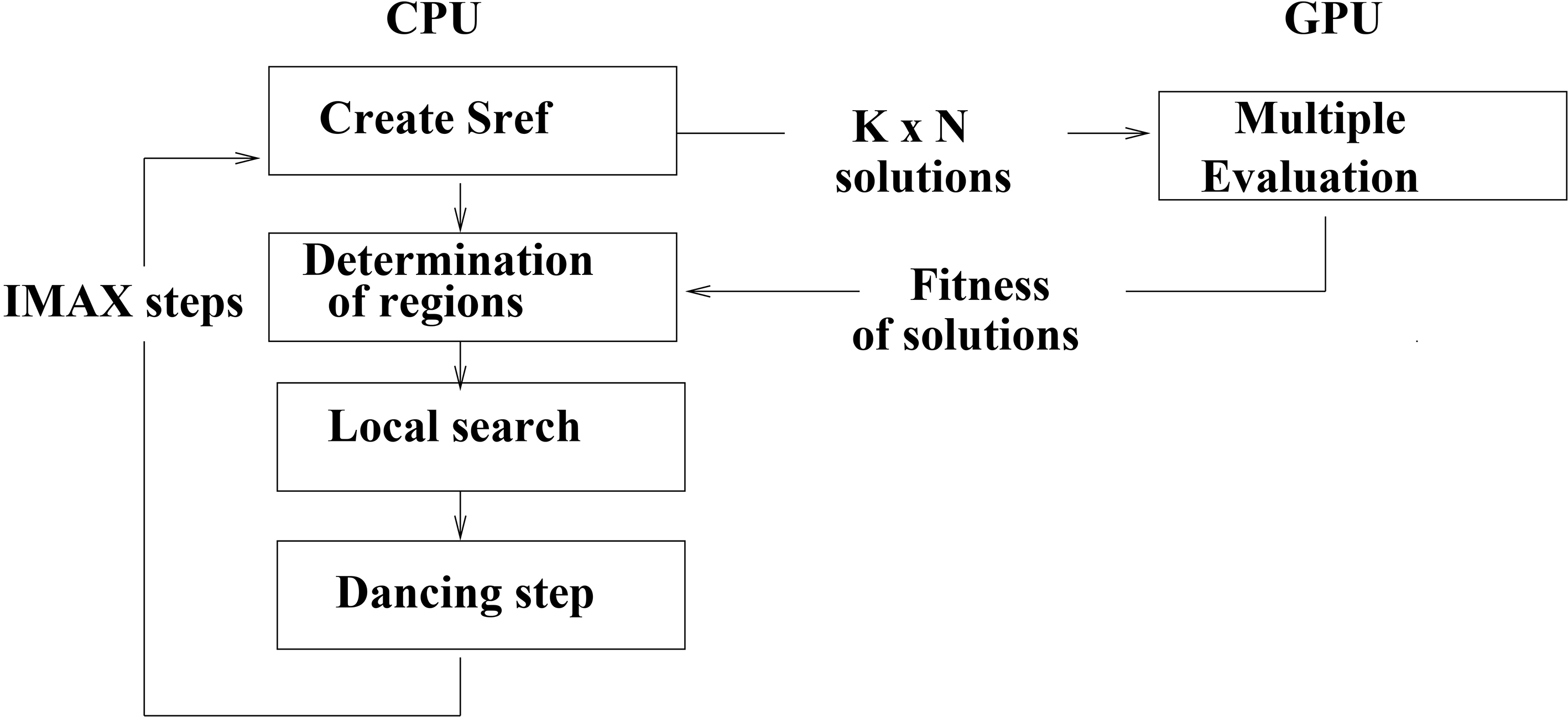
The fourth algorithm, named ALLGPU (All steps on GPU), performs solution creation on CPU and then send it to the GPU. The determination of regions and neighborhood computation are performed on GPU. After that, each block of threads sends the generated solutions to the global memory of the GPU. Afterwards, each block process one solution from the global memory and evaluates it in parallel. Each specified thread of each block obtains the best solution from the shared memory. The best solution of each block is sent to the global memory, where the specified thread obtains the best solution to be considered as the reference solution for the next iteration. This process is repeated on GPU until the maximum number of iterations is reached. Figure 6 shows the framework of the proposed approach.
ALLGPU framework.
Having presented the four versions of the proposed approach, the three next subsections asymptotically analyzes each algorithm in terms of (1) CPU/GPU communications, (2) threads synchronization costs and (3) thread divergence. Finally, the time complexity of each proposed algorithm is given and compared to the sequential version.
DRGPU. At each pass, the reference solution must be transmitted from CPU to GPU. Thus, if the number of iterations is set to IMAX, and the solution size is
SAGPU. At each pass,
MEGPU. First,
ALLGPU. For this algorithm, CPU/GPU communication only consists of transferring the Reference Solution to the GPU. Therefore, the CPU/GPU communication cost is
GPU-block synchronization
DRGPU. At each iteration, every GPU block generates one region. Region determination is completed when all blocks have determined their regions. The GPU-block synchronization of this approach is thus 1 at each pass. The total GPU-block synchronization of this approach is IMAX.
SAGPU. The local search of each region is established on GPU, where each block explores one region. The GPU-block synchronization of this approach is 1 at each iteration, which corresponds to the time where all blocks have explored their own regions. So the total GPU-block synchronization of this approach is IMAX points.
MEGPU. This strategy attempts to benefit from the massively parallel power of GPU by launching a large number of threads per rule to reduce CPU/GPU communication. Consequently, the threads of the same block must be synchronized after each iteration (to deal with the sum reduction operation). Thus,
ALLGPU. All tasks are implemented on GPU. Therefore, the total GPU-block synchronization is computed by summing the synchronization caused by the determination of regions (IMAX points), the local search (IMAX points), the evaluation process (
Thread divergence
Threads of the same block should execute the same instruction at the same time. Thread divergence occurs when distinct threads from the same warp execute different instructions at the same time.
DRGPU. Region determination is performed on the GPU, where each thread has to generate one region for a bee. All threads of a given block have to execute the same instruction. Consequently, there is no thread divergence between threads of the same block.
SAGPU. The local search is performed on GPU, where each thread of the given block generates one solution. All threads of such block have to execute the same instruction at the same time. Hence, there is no thread divergence between threads of the same block in this approach.
MEGPU. The transactions are usually different terms of number of items. To evaluate a single rule on GPU, the different threads have to scan all its items and compares them to the transaction it is mapped with. The comparison process of a thread is stopped when it does not find a given item of the considered rule in the transaction that it checks. Thread divergence (
where
In the worst case, transactions are highly different in size. Thus, it is possible to find on the same warp one transaction containing all items and another one containing only a single item. In this case, thread divergence can be approximated to the maximal number of items minus one for very large datasets (Eq. (4)).
The thread divergence count of this approach is thus
ALLGPU. All tasks are performed on a GPU, so the total GPU-block synchronization is computed by summing the thread divergence count caused by region determination (0), local search (0), the evaluation process (
The time complexity of any bioinspired-based approach depends on the empirical parameters used in the seaching process. As the proposed algorithms are based on BSO, their computation complexity depends on the following parameters:
IMAX is the maximum number of iterations to be performed by the algorithm.
The complexity cost of the sequential version is in
.
The complexity of DRGPU is
.
The complexity of SAGPU is
.
The complexity of MEGPU is:
.
The complexity of ALLGPU is
The comparison of the four approaches, presented in this section, is summarized in Table 1.
Summary of the analysis
Summary of the analysis
The table shows that every approach has advantages and disadvantages, when compared from a theoretical perspective. For instance, the two first approaches benefit from cluster computing challenges but have a high time complexity, while ALLGPU reduces the time complexity but has a high time divergence and synchronization cost.
Several experiments have been carried to evaluate the proposed solution. We first compare the proposed approaches with each other to select the best approach. Then, the best approach (ALLGPU) is compared with state-of-the-art GPU-based approaches. Finally, ALLGPU is extended for frequent graph mining to process big database instances. The proposed approaches have been implemented using the C-CUDA language. Experiments have been carried out on a CPU host coupled with a GPU device. The CPU host is a 64-bit quad-core Intel Xeon E5520 with a clock speed of 2.27 GHz. The GPU device is an Nvidia Tesla
where
The experiments have been performed on a set of benchmark datasets, described in Table 2). This includes large instances (
Description of the datasets
In the first experiment, performance of the four proposed algorithms is compared on the large instances (Connect and BMP-POS) described above. An initial parameter setting phase was done to find the best parameter settings for each algorithm. These settings have then been used for the rest of the experiment. The performance of DRGPU depends on the strategy used for region determination (Modulo, Next, and Syntactic). SAGPU depends on the strategy used for the neighborhood computation process (SLS: “Stochastic Local Search” [28] and TS: “Tabu Search” [29]). MEGPU depends on the strategy used for thread divergence (
the Next strategy for DRGPU, SLS method for SAGPU, and, TRMV for MEGPU.
Speed up of the proposed approaches on connect and BMP-POS using different number of iterations
The next experiment is to combine the previous best strategies in ALLGPU. Figures 7 and 8 show the speed up of the proposed approaches on the Connect and BMP-POS datasets, respectively. The results show that ALLGPU outperforms the three other approaches for all instances used. ALLGPU is thus only considered for the remaining experiments.
Comparison of the proposed apporaches in terms of speed up on connect.
Comparison of the proposed apporaches in terms of speed up on BMP-POS.
ALLGPU algorithm vs GPU-based ARM algorithms on the WebDocs instance (speed up).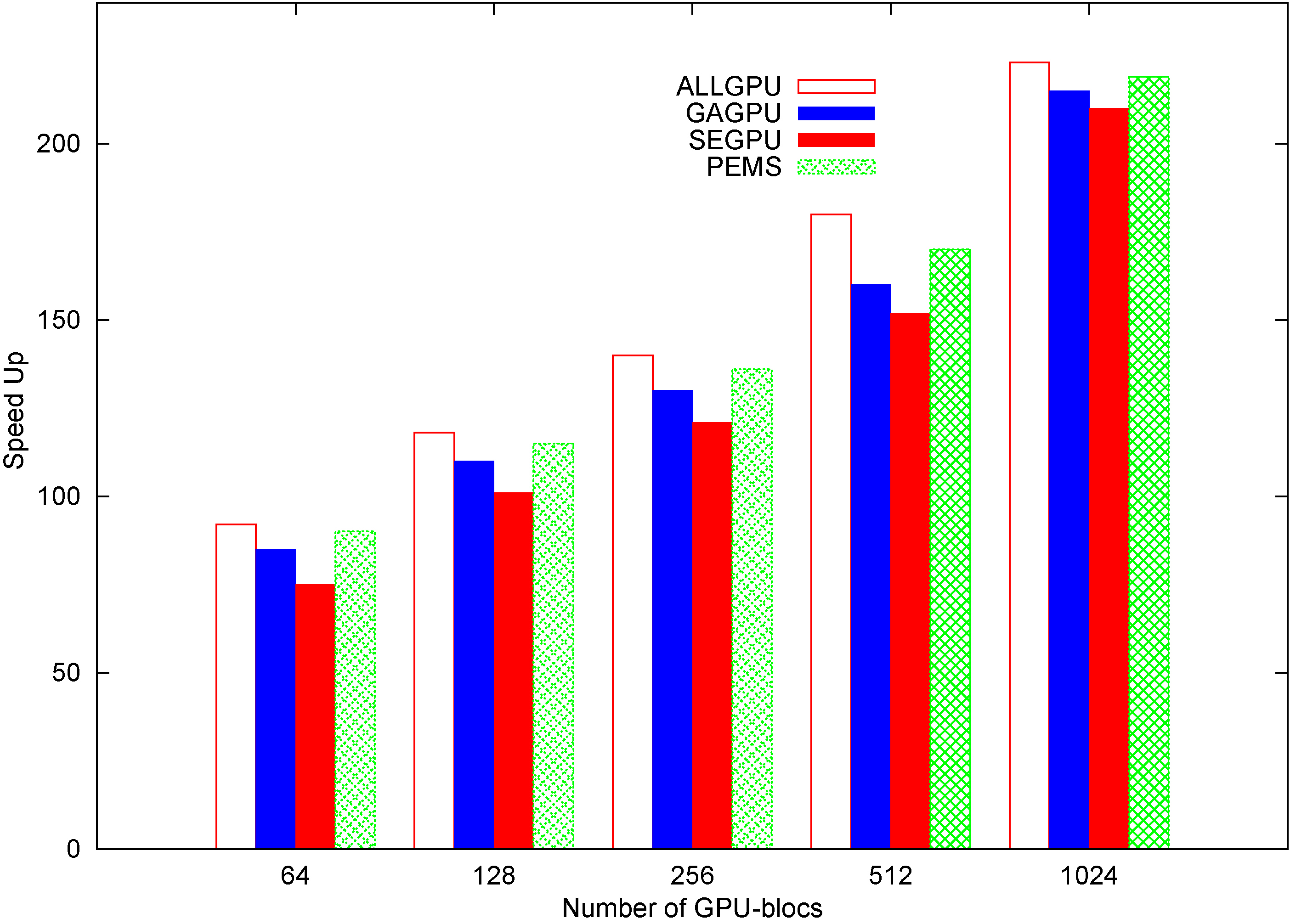
In the following, ALLGPU is compared to some state-of-the-art GPU-based ARM algorithms. Figure 9 presents the speed-up of the ALLGPU, SEGPU [30], GAGPU [35] and PEMS [31] approaches on the big Webdocs instance to generate 500000 association rules.
It is clear from that figure that our approach outperforms all GPU-based ARM approaches in terms of speed up. This is due to the higher GPU-parallelism compared to the existing GPU-based approaches, which evaluate only the generation of solutions on GPU.
Comparing ALLGPU and DMine
The last experiment aims to extend ALLGPU for dealing with big graph instances. For this, ALLGPU is adapted to mine frequent graphs. We compare ALLGPU and DMine [38], the most recent algorithm for mining frequent graphs. Figure 10 presents the runtime of both approaches (ALLGPU and DMine) for extracting association rules from the big graph instance Pokec that includes 1.63 million of nodes, and 269 different items.
ALLGPU algorithm vs DMine on pockec for different minimum support values (seconds).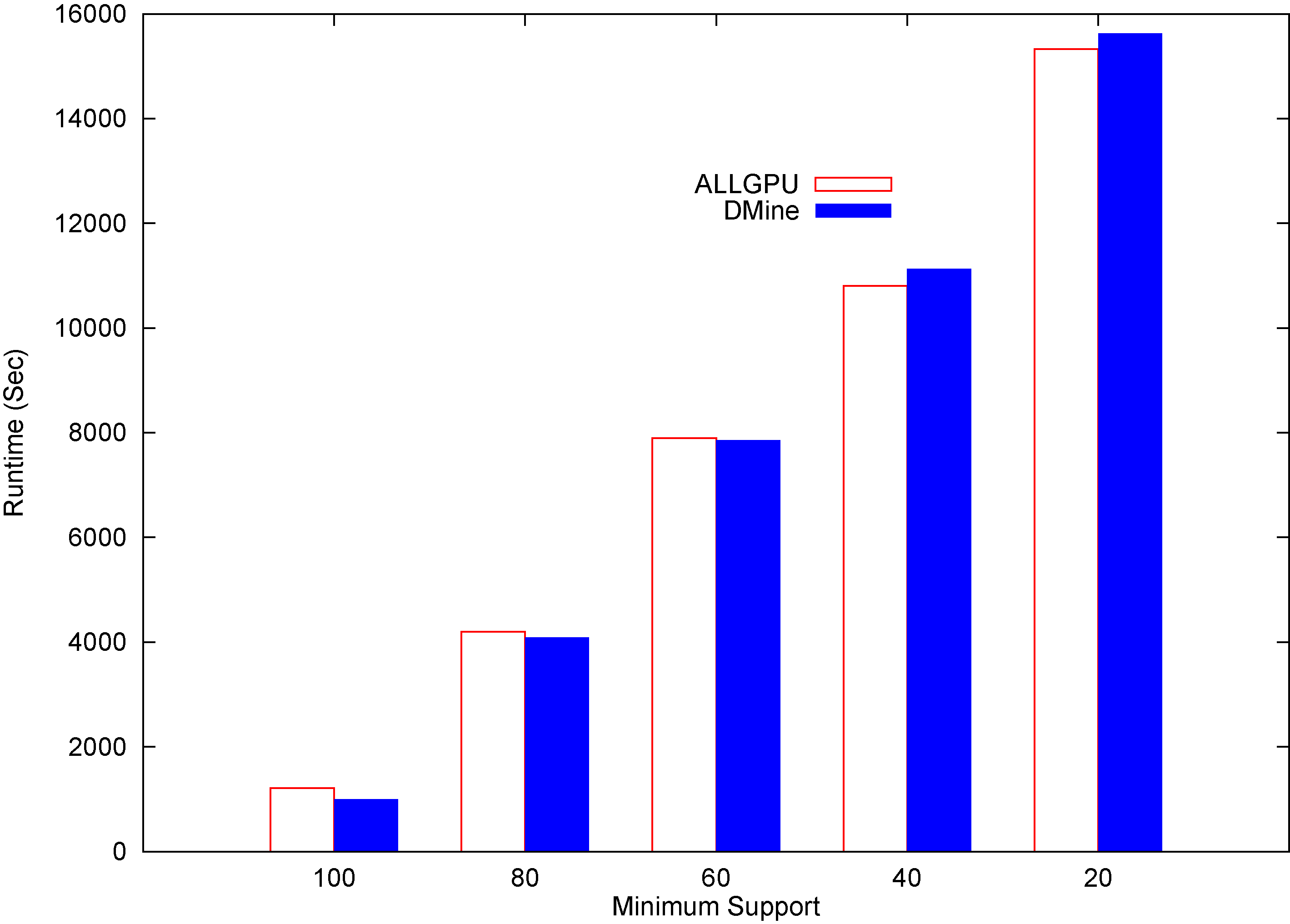
By varying the minimum support from 100% to 20%, it is observed that ALLGPU is more stable than DMine. The figure shows that the latter outperforms the former for high minimum support values, while ALLGPU becomes a bit faster for low values. These results are also due to the fact that ALLGPU exploits GPU-parallelism to explore the large rule space for low minimum support values.
This paper has proposed novel approaches for association rule mining that rely on GPU parallelism. Four versions of the proposed approach have been designed by considering, on the one hand, GPU computing challenges such as threads divergence, CPU/GPU communication and GPU-block synchronization, and on the other hand, the time complexity of the approach compared to the sequential version.
To numerically assess the contribution, several tests have been carried out on large and big datasets and a big graph dataset. Results show that the designed AllGPU approach outperforms the three other approaches in terms of speed up for large instances. For the big WebDocs instance, results confirm the usefulness of ALLGPU compared to state-of-the-art GPU-based ARM approaches. Moreover, when dealing with the big Pokec social graph dataset, results shows that using ALLGPU to mine frequent graphs outperforms the recent DMine algorithm. In future work, we plan to extend ALLGPU to be used with other swarm intelligence based approaches such as Particle Swarm Optimization, Bat Swarm Optimization, and Ant Colony Optimization.