
Abstract
Mining high utility itemsets (HUIs) is a basic task of frequent itemsets mining (FIM). In recent years, a trend in FIM has been to design algorithm for mining HUIs because FIM assumes that each item can not appear more than once in a transaction and all items have the same importance (weight, unit profit, price, etc.). However, in real-world, items appear more than once in a transaction and also have some importance. HUIs mining considers that items appear with some quantity and importance. Traditional HUIs mining algorithms assume that items have only positive unit profit. However, in real-world, items may appear with negative unit profit also. For example, it is common that a retail store sells items at a loss to stimulate the sale of other related items or simply to attract customers to their retail location. Therefore, items occur with negative unit profit or negative utility. To consider negative unit profit, HUIs with negative utility has been introduced. This paper surveys recent studies on HUIs mining with negative utility and their applications. The main goal is to provide a survey of recent advancements and research opportunities. This paper presents key concepts and terminology related to HUIs mining with negative utility. This presents a taxonomy of all the algorithms consider negative utility. To the best of our knowledge, this is the first survey on the mining task of HUIs with negative utility. The paper also presents research opportunities and the challenges in HUIs mining problems.
Introduction
Frequent itemsets mining (FIM) [1, 60] is one of the data mining technique that finds meaningful information from the raw data. FIM finds sets of items that often occur together. First and widely used application of FIM is market basket analysis. FIM mines important information, but it has two limitations. Firstly, it considers items as a binary occurrence, and secondly, it does not consider the relative importance such as unit profit or price of an item. To address these two issues, high utility itemsets (HUIs) mining has been actively studied [5, 56]. In utility mining, each item is associated with some utility (or unit profit). Each item in the transactions also contains the information about the purchase quantity of items. The utility is a measure of the importance of an itemset. It can be defined as the profit generated by the sale of items in a retail store.
High utility itemsets mining is the process of transforming raw transactional datasets into useful rules for effective strategic and decision-making purposes so that real business benefits can be yielded. HUIs mining is not an easy task because it does not satisfy anti-monotonic property
1 If a set can not pass a test, all the supersets will fail the same test as well.
All the above-discussed algorithms consider the positive utility only. However, in real-life, transactional datasets have negative utility. For example, a retail store sells items at a loss to stimulate the sale of other related items or simply to attract customers to their retail location. If we mine HUIs with negative items by using traditional algorithms, some candidate itemsets may be lost [7]. To address this issue of negative utility, in 2009 Chu et al. proposed an algorithm named HUINIV-Mine [7]. HUIs mining with negative items is difficult for newcomers to understand. Hence, in this paper, we present an up-to-date survey of HUIs mining with negative utility that can serve both as an introduction and as a guide to recent advancements and opportunities in the field. The major contributions of this paper are: The basic taxonomy of the most common approaches for HUIs mining with negative utility including data stream, transactional, on-shelf, sequential and uncertain datasets based mining as depicted in Fig. 1. We present a brief review and analysis of existing HUIs mining algorithms. We categorize HUIs mining with negative utility approaches into level-wise, tree-based and utility-list based mining. We analyze current HUIs mining with negative utility approaches and discuss their pros and cons in-depth. We also give future directions in negative utility based HUIs mining. Taxonomy of high utility itemsets mining with negative utility.
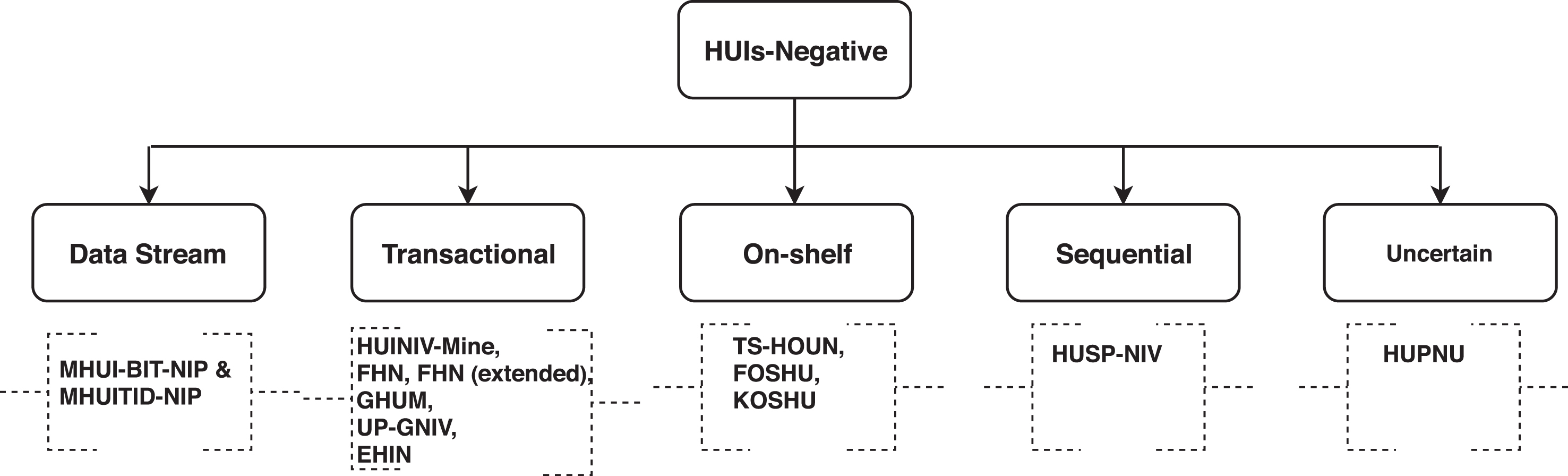
The rest of the paper is organized as follows. Section 2 describes preliminary definitions, properties to handle negative utility items and basic high utility itemsets mining algorithms. Section 3 discusses algorithms of high utility itemsets mining with negative items. Section 4 presents a summary and discussion on negative utility based high utility itemsets mining. Section 5 discusses research opportunities of high utility itemsets mining with negative items. Finally, Section 6 draws conclusions.
Preliminaries and definitions
Let I = {i1, i2, …, i n } be a set of distinct items. Each item i is associated with an external utility (price or unit profit, etc.), denoted as EU (i), which may be the unit profit or price of item i. Each item i is associated with internal utility (quantity) in transaction T j , denoted as IU (i, T j ).
Let us consider the transactional dataset shown in Table 1, which will be used as running example. This dataset contains seven transactions (T1, T2, …, T7). It contains five items A, B, C, D and E. The external utilities of items are presented in Table 2. For example, the transactional dataset, T1 contains four items A, B, D, E and has internal utility 2, 2, 1, 3 respectively. The external utilities of these items A, B, C, D and E are, respectively, 2, -3, 1, 4 and 1. Thus, item B is sold at a loss.
Transactional dataset
Transactional dataset
External utility of items
For example, the utility of an item A in transaction T1 is 2 × 2 =4. The utility of an itemset {A, D} in transaction T1 is 4 + 4 =8. Note that, U (X) may be negative, which means that itemset X has generated a loss (a negative profit). For example, if X is a single item with negative unit profit, then U (X) will always be negative.
For example, utility of an itemset {A, D} is U (AD, T1) +U (AD, T6) = 8 + 12 = 20.
For example, TU of T1 is U (A, T1)+ U (B, T1)+ U (D, T1) + U (E, T1) = 4+ (-6) + 4 + 3 =5. Third column of Table 3 shows TU for the running example.
TU and RTU for the running example
For example, TWU of item A is T1+ T5+ T6 = 23. TWU value of each item is shown in Table 4.
TWU and RTWU of each item
HUIs mining algorithms use TWU for fulfilling the anti-monotonic property.
Table 5 shows the HUIs for the running example where min _ util is 10.
HUIs of the running example
The traditional HUIs mining algorithms only can handle positive utility values and can utilize TWU based
For the running example, RTU of T1 is computed as RTU (T1)= U (A, T1) + U (D, T1) + U (E, T1) = 4 +4 + 3 = 11. We did not include utility of item B because we calculate RTU by only adding the positive items. RTU (X) ≥ TU (X), because, TU is the summation of all items in a transaction includes negative items whereas RTU is the summation of items have positive utility. Table 3 shows the TU and RTU value of each transaction.
For example, RTWU of T1 is RTU (T1)+ RTU (T5)+ RTU (T6) =11 + 4 +17 = 32. RTWU value of each item is shown in Table 4.
For example, RTWU of all the items is shown in Table 4.
Traditional high utility itemsets mining algorithms
Traditional HUIs mining algorithms generate rules from transactional datasets. Transactional datasets usually have a large number of distinct single items and their combinations is also a huge number of itemsets. Therefore, basic HUIs mining algorithms need some upper-bound or search space pruning strategies. In order to address this issue, Liu et al. proposed an algorithm Two-Phase algorithm [34] which proposed TWU based pruning strategy. Algorithms [25, 55] use two-phase model and TWU based pruning strategy. All these two-phase based algorithms suffer from multiple dataset scans and expensive joining operations. In order to overcome these limitations, in 2010, Tseng et al. proposed a tree-based algorithm named UP-Growth [50]. UP-Growth follows popular FIM algorithm FP-Growth [20]. Later on, some other tree-based algorithms are proposed such as [3, 59]. These algorithms are the improved versions of the basic UP-Growth algorithm. UP-Growth or UP-tree based algorithms still suffer from the generation of a lot of candidate itemsets and multiple dataset scans.
To overcome the limitations of tree-based algorithms, Liu et al. proposed HUI-Miner algorithms [32] which used utility-list based data structure. Later on, variations of utility-list and extension of HUI-Miner are proposed to improve the performance such as FHM [16] and HUP-Miner [21]. But utility-list algorithms suffer from generating the candidate itemsets which are not present in datasets. Utility-based algorithms perform worst when utility-list contains an entry for each transaction. To target these issues, Zida et al. proposed an algorithm EFIM [66]. It uses pattern-growth approach to mine HUIs. All the above-discussed algorithms do not work with negative utility value. In real-life, items may occur with negative utility value. To address this problem, HUIs with negative utility based algorithms have been presented. We discuss HUIs mining with negative utility algorithms in the next section.
High utility itemset mining with negative utility
HUIs mining is an important research area of data mining. HUIs mining gained the immense importance because of huge application areas. HUIs with negative item recently received much attention from the decision making community. It is quite useful in the marketing and retail communities as well as other more diverse fields.
This paper reviews three main types of HUIs mining algorithms as depicted in Fig. 2: level-wise (Apriori-based or Two-Phase based), tree-based (UP-tree like) and utility-list (vertical dataset format) based algorithms.

Taxonomy of high utility itemsets mining with negative utility according to mining approaches.
Level-wise algorithms follow Apriori-like approach for generating candidate such as joining. k-itemsets can generates (k + 1)-candidates. Level-wise approach generates itemsets of length k before length (k + 1)-itemsets. Only two (HUINIV-Mine and TS-HOUN) algorithms are available in the literature to mine HUIs with negative utility using level-wise approach.
Tree-based mining algorithms
Tree-based algorithms are based on set-enumeration tree-based concepts. The candidates can be explored with the use of the lexicographic tree or enumeration tree. The main characteristic of tree-based algorithms is that the enumeration tree (or lexicographic tree) provides a certain order of exploration that can be extremely useful in many scenarios. It is assumed that a lexicographic ordering exists among the items in the dataset. This lexicographic ordering is essential for efficient set enumeration without repetition.
Tree-based mining algorithms mines HUIs by starting from itemset length-1 (as an initial suffix itemset), constructing its UP-tree and performing mining recursively on such a tree. The pattern growth is achieved by the concatenation of the suffix itemset with HUIs from UP-tree. Tree-based algorithms transform the problem of finding long itemsets to search for shorter ones recursively and then concatenating the suffix. Four algorithms (MHUI-BIT-NIP, MHUI-TID-NIP, UP-GNIV and HUSP-NIV) are available in the literature to mine HUIs with negative utility using tree-based approach.
Utility-list based mining algorithms
Both the level-wise and tree-based algorithms mine HUIs from a set of transactions in a horizontal data format. Alternatively, mining can also be performed with data presented in a vertical data format like proposed in Eclat [61]. Vertical data format first scan of dataset builds the T ID set of every single item. The computation is done by intersection of the T ID sets of HUIs k-itemsets to compute the T ID sets of the corresponding (k + 1)-itemsets. This process repeats until itemsets fulfill min _ util threshold. In the generation of candidate (k + 1)-itemset from k-itemsets, the merit of this method is that there is no need to scan dataset to find the utility of (k + 1)-itemsets. This is because the T ID set of each k-itemset carries the complete information required for counting utility. Four algorithms (FHN, GHUM, HUPNU and FOSHU) are available that mine HUIs with negative utility items using utility-list based approach.
Summary and discussion
The previous section has reviewed three main types of HUIs with negative utility mining algorithms. The key differences between these algorithms can be described in terms of dataset scanning, data structure used, pruning strategies and base algorithm. Table 6 summarizes the characteristics of negative utility based HUIs algorithms which are discussed in section 3. It is noticed that there is no comprehensive study covering all of these algorithms in the literature.
An overview of High utility itemset mining algorithms with negative utility values
An overview of High utility itemset mining algorithms with negative utility values
aHigh on-shelf utility itemsets. bProbability-Utility list with Positive-and-Negative profits.
Table 6 depicts basic details of algorithms such as name of algorithms, publishing year of algorithms, name of the authors. The "Dataset scanning" column of this table gives the information about how many times a algorithm scans dataset; the "Data structure" shows the type of data structure used to store the information of items; the "Dataset" shows the type of inputted dataset used for experiments; the "Mining" represents output HUIs; the "Pruning strategy" column shows the strategies used to prune search space; the "State-of-the-art algorithms" shows the name the state-of-the-art algorithms and the "Base algorithm" represents the base algorithm for the presented algorithms. This table shows all the mining algorithms used to mine HUIs with negative utility value.
Negative utility based mining can also be used in other domains, such as market basket analysis [2, 56], website click-stream [27, 67], cross-marketing in retail stores [2, 57] biomedical applications [5] and mobile commerce applications [39, 47].
Both real and synthetic datasets having varied characteristics have been used for experimental results. Two synthetic datasets T10I4D100K and T40I10D100K also used for experiments by most of the algorithms. These datasets also used in the traditional HUIs mining. Table 7 shows the statistical characteristics of the datasets. The external utility or unit profit for items are generated between -1000 to 1000 by using a log-normal distribution [30, 40]. The internal utility or quantity of items are generated randomly between 1 and 5 [16, 49]. We categorize the datasets into two parts, dense and sparse. Dense datasets where all items appear in almost all transactions. Sparse datasets where a few items in the transaction appear. The datasets used in the studied paper can be found on the SPMF website [15].
Statistical information about datasets
Statistical information about datasets
Lot of research progresses have been carried out recently in high utility itemsets mining with negative utility values. However, there are more emerging issues to challenge the traditional methods. In this section, we identify the related opportunities in high utility itemsets mining with negative utility values.
Concise high utility itemsets mining with negative utility value
Closed HUIs are the itemsets that do not have superset having the same support count. Discovery of closed HUIs instead of all HUIs reduces the number of itemsets. Hence, closed HUIs are more interesting and actionable because they are a lossless representation of all HUIs. In other words, using closed HUIs, the information about all HUIs including their support can be recovered without scanning the dataset. Closed itemsets are more actionable because they represent the largest set of non repeated HUIs. Recently many closed algorithms for HUIs are proposed [18, 52]. But till now no algorithm has been proposed for mining closed HUIs with negative utility value. Therefore, closed HUIs with negative utility value is a good area to explore.
Constraint-based high utility itemsets mining with negative utility value
Although mining with negative utility uncovers thousands of HUIs, the user is particularly interested only in long and more actionable itemsets. Many algorithms have been proposed to reduce the total number of itemsets generated based on constraints on the resulting rules. Hence, the users are more interested in constrained HUIs mining. Pei and Han [36] presented many constraints for FIM. These presented constraints can also be pushed into HUIs mining.
Length-based HUIs mining plays an important role in constraint HUIs mining. Two upper bound (minimum length and maximum length) can be defined to mine length HUIs rules. In order to remove the tiny items, user can set the minimum length threshold. Length based HUIs can remove lots of small itemsets and produce more interesting and actionable HUIs. HUIs mining algorithm with length threshold has been presented by Fournier-Viger [14]. But, this work not considers negative utility value. Therefore, the length constraints can be utilized in HUIs mining with negative utility value. In order to find HUIs more efficiently, we need to push the constraint as deep as we can.
Top-k high utility itemsets mining with negative utility value
Mining HUIs using min _ util is difficult for user because specifying the appropriate min _ util is not an easy task. Hence, top-k HUIs mining problem were proposed. Many top-k HUIs mining algorithms are proposed such as [11, 53] but none of these algorithms can mine HUIs with negative utility value. Therefore, in future, top-k HUIs mining with negative utility can also be explored.
High utility itemsets mining with negative utility value from data stream
HUIs mining from data stream has many applications such as retail market analysis, wireless sensor networks, and stock market prediction. To handle the huge and dynamic dataset is a challenging task. To handle the data stream and negative utility value only MHUI-BIT-NIP & MHUI-TID-NIP [28] algorithms are proposed. These algorithms follow ordinary lexicographical tree structure. Hence, there are a lot of scope to improve and propose new algorithms for mining HUIs with negative utility from the data stream.
High utility itemsets mining on big data
The algorithms discussed in this paper do not scale with big data. In literature, no algorithm is available for mining HUIs with negative utility from big data. Big data can be dealt using Multi-core computing, Grid computing, Graphics processing units (GPUs), MapReduce, Apache Hadoop and Spark framework. Some works [4, 65] deal with big data and describe the basic data mining operations on big data. In future, itemsets mining can be done with big data also.
Other problems
Some other extensions of HUIs with negative utility value mine rich itemsets in various ways, such as fuzzy HUIs mining, periodic HUIs mining, episode HUIs mining, etc. We can be used latest prepossessing techniques to improve the accuracy, completeness, and consistency of the algorithms. Some works [37, 63] show the latest preprocessing techniques that can be utilized with HUIs mining.
Conclusion
HUIs mining have numerous applications such as market basket analysis [2, 56], website click-stream [27, 67], cross-marketing in retail stores [2, 57], business intelligence [9, 10] biomedical applications [5] and mobile commerce applications [39, 47]. In this paper, we introduce the fundamental methods to readers and let them choose the proper method for their applications. This work significantly reduces costs for finding the suitable algorithm for their applications and improves retailer satisfaction. The extracted HUIs help the corporate managers for a target customer and gain more profit. HUIs also help companies promptly to take the decision. In all, HUIs mining has a bright future and deserves the research attention.
In this survey, we presented an in-depth analysis of a number of existing algorithms which made a significant contribution to improve the efficiency of HUIs mining with negative utility.
Moreover, the paper presents important extensions of the HUIs mining with negative utility problems that address some shortcomings. In addition, the paper discusses other research problem related to HUIs mining with negative utility such as closed HUIs mining with negative utility, constraints HUIs mining with negative utility, HUIs mining with negative utility from data stream, top-k HUIs mining with negative utility and periodic HUIs mining with negative utility.
Compliance with ethical standards
The authors declare no conflicts of interest.This article does not contain any studies with human participants or animals performed by any of the authors. The article gives review of high utility itemsets mining with negative utility values.