
Abstract
Researches on using deep learning models to predict prices usually take magnitude-based error measurements (such as
In this study, we first find the parameter sets of LSTM and TCN models with low magnitude-based error and then use program trading to find out their profitability. The relationships between these profitability and error measurements are analyzed and studied on three commodities: gold, soybean, and crude oil (from GLOBEX).
Our findings are: with given parameter sets, if merchandise (gold and soybean) is of low averaged magnitude error, then its profitability is more stable. If it is of a more significant magnitude error (crude oil), then its profitability is unstable. A high positive correlation does not exist between the profitability and error measurement, and TCN outperforms LSTM in almost all our examples.
Our research indicates that, in assessing the performance of deep learning, how to use the predicted values in applications and the application results could also be part of the quality measurement for the model assessment in the learning.
Introduction
Forecasting future values of time series is the subject of research [1, 2, 3]. Deep learning provides better results for the prediction than linear models [1, 4]. Yet, few works offer guidelines on how to apply the forecasted values in actual trading, as well as whether the predicted values with lower error measurement (such as
Different merchandise may need different deep learning models. LSTM is suitable for merchandise with lower volatility [1, 5], and TCN may perform better on merchandise with higher volatility due to its pre-filtered local patterns [6]. Finding proper deep learning models and parameter sets for the commodities is the first step in studying their profitability.
Program trading can systematically and repeatedly explore the profitability of the target learning models. The utilized trading program should match the timing when target learning models generate predicted prices to reduce unnecessary logical errors, such as using unavailable future data in testing.
We explore the related works in Section 2. In Section 3, a three-stage process is proposed to evaluate errors in deep learning models with the trading program for assessing the profitability of predicted prices. Section 4 details the results of the experiments on three commodities. The conclusion comes in Section 5.
Related works
Time series
Variables inherently ordered by time are called time series, such as a stock or currency prices. They are usually not expressible as a linear function since the volatility and fluctuation may change as time progresses. With the right data mining technology and long enough data, a self-adaptive learning model may provide good prediction [7]. Deep learning models are one of this kind.
Neural networks as learning models
Neural networks use layers of neurons with adjustable weights to capture the non-linear relationship between input and production [8]. The neurons mimic the human brain to work as simple units, which are highly connected. Weights on the links may substantially affect the networks, and the overfitting problem occurs. The number of layers, the numbers of neurons in each layer, and parameters such as the dropout rate should be regulated to avoid the overfitting problem when utilizing the models.
Deep learning
In traditional data mining, features are usually manually specified by experts in advance, and this is called feature engineering. For data with inherently complex features, feature engineering is hard. Deep learning is a multi-layered neural network with sophisticated routing between both the interconnected neurons and layers. Deep learning has the effects of automatic feature engineering through those layers of neurons [8]. However, the quality of deep learning is profoundly affected by its training process. For example, the gradient should be managed appropriately to avoid gradient exploding or gradient vanishing problems.
Deep learning for time series
With cross-layered connectivity, recurrent neural network (RNN) accomplishes deep learning on time series [8]. By redirecting the output value back to the input, RNN acquires the “memory” effect. Nevertheless, its uncontrolled utilization of memory may lead to more noise. LSTM (Long-Short Term Memory) maintains the memory effect of RNN but keeps only the important one for future use. Pant [1] successfully applies LSTM to predict the currency fluctuation of the US dollar and the Russian Ruble.
CNN (Convolution Neural Networks) excels at image recognition but performs less robust in time series prediction. Bai [9] proposes TCN (Temporal Convolutional Networks) for time-series prediction and get better results than LSTM in many situations. TCN, similar to CNN, acquires signals simultaneously, where RNN acquires signals sequentially. TCN regulates the sliding windows of convolution to achieve the time series prediction. Thus, in this paper, TCN is also explored, in addition to LSTM.
Activation functions
In neural networks, the activation function ensures the input and output are not linearly related since the linear relationship between input and output significantly reduces the expressiveness of the networks. Commonly used non-linear functions are Sigmoid, tanh, and ReLu [10]. Sigmoid is best for classification problems as it maps inputs to values between 0 and 1. Tanh and ReLu are for non-classification problems where ReLu speeds up the training and avoids the gradient vanishing problem [11]. Hochreiter [12] provides another activation function, SeLu, for time series problems. SeLu can converge well, avoid gradient exploding or vanishing problems, and also perform well in deeper layered networks. Thus, we test both SeLu and ReLu in our TCN experiments. However, due to the limitation of Cudnn in our LSTM model, only Tanh can be used as the activation function in our LSTM experiments. For convenience, the definition of SeLu from [12] is listed here:
The loss function measures the difference between the predicted and actual values where absolute or squared distance may be the measurements. This distance also indicates regression errors. Minimizing loss function improves the quality of regression. Two commonly used loss functions, MAE and MSE, are shown as follows:
MAE tends to find a local optimum when the gradient increases. MSE could be affected by outliers, and normalization can ease the problem. Thus, MSE is more popular than MAE [13].
MSE or coefficient of determination (
When the number of samples increases,
Program trading uses a set of rules expressed as programs to buy and short merchandise. It can apply to merchandise with historical price data repeatedly to verify that the provided rules are indeed profitable [15]. We use Multicharts [16] in this research due to its broad user base and easy readability.
Predicted prices and trading profitability
Quality of the predicted prices from machine learning techniques (including deep learning) and how the predicted prices lead to trading profitability are, in fact, two different issues.
The quality of the predicted prices measures the difference between the actual value and predicted value where MSE, MAE, MASE, and coefficient of determination (
In addition to the quality of predicted value, how we use the predicted prices during the trading decision (e.g., buy, short, or liquidate the positions), usually called “trading strategy,” also determines the trading profitability significantly. A trading strategy can be better studied using program trading [15, 16]. Net profit, maximum drawdown, and annual growth rate are commonly used to measure the quality of a trading strategy [17]. Works in [1] used a simplified trading strategy with only net profit listed, and works in [1, 3] do not show trading results.
For completeness, measurements considering both the quality of predicted prices and trading profitability are compared and analyzed in our works.
System design and implementation
Our proposed system design and experiments are divided into three stages, as expressed in Fig. 1. The first stage focuses on finding better models and settings from LSTM and TCN based on traditional error measurements:
Three-staged system design and experiments.
Most works on deep learning models address their contribution by measuring the improvement based on
As shown in Fig. 2, we propose to enter the market five minutes before the close of today and liquidate the position before the end of the next trading day. A buy position is opened when the predicted close price for the next day is proportionally higher than today’s close price. A percentage-based stop-loss is used to liquidate the position if the position suffers certain percentage of loss in the coming trading day. The optimization mechanism of program trading will find the exact percentages for entry and stop-loss [17]. The exact opposite rules apply to the short position. If this simple trading program can profit, we can attribute most of the success to the precision of the anticipated next-day close value.
In existing researches, today’s close price is always used to predict the next-day close price [1, 4]. However, when today’s close price is available for the prediction, the market is already closed for trading. To avoid this problem, we use the price five minutes before the close as the actual input to predict the next-day close price of the proposed trading program. For the feasibility of this modification, we further analyze the fluctuation of the last five minutes before the market close for our studied merchandise. The average price fluctuation for these merchandise in the last five minutes is less than 0.01%, as shown in Table 1. We further use the actual close price and the price five minutes before the market close as two different inputs for the same LSTM models. The goal is to know how different the predicted next-day values are from the actual next-day close. As shown in Table 2, the
Price difference between today’s close and five minutes before the close
Price difference between today’s close and five minutes before the close
Trading model for utilizing the predicted next-day close price at around today’s close.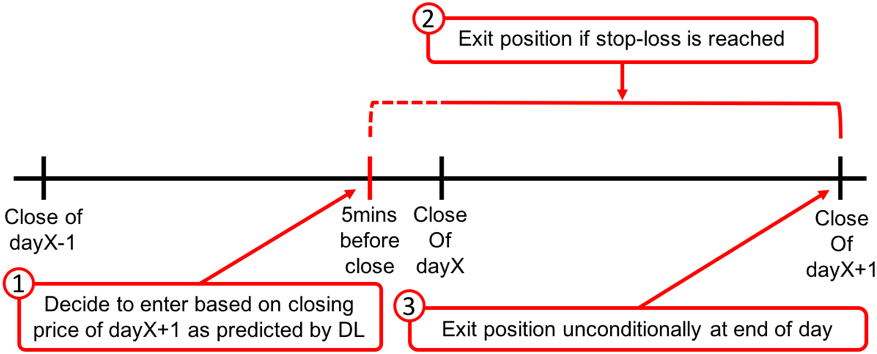
Based on Fig. 2, the corresponding trading program, in Multicharts’ Powerlanguage [16], is in Fig. 3. This next-day exit trading program has parameters SL and SS as the percentage of stop-loss for buy and short positions. When the difference between the current price and the predicted price exceeds numSD multiple of standard deviation, we initiate a new buy (or short) position. Length specifies the period to measure the standard deviation.
In the trading program, D2price is the predicted price from deep learning models and is input as the second data source (called “data2” in Multicharts).
Optimization in program trading is conducted to find the maximum profit as the profitability that a deep learning model (with specific parameters) can reach.
Data collection of the three traded merchandise
Based on Pant [1] and the data collected, three commonly traded commodities, gold, soybean, and crude oil, are used for the experiments in this paper with their exact trading specification provided in Table 3.
Data specification of three merchandises
Data specification of three merchandises
The code for the next-day exit trading program.
Both the daily close price and the price of five minutes before daily close are input for our deep learning models. All the collected price data is one-minute data since the program in Fig. 3 should be executed on one-minute data for correctness as required by Multicharts [16]. We use eighty percent of data for training and twenty percent for testing.
In this work, the CudnnLSTM in Cudnn library of GPU [18] is used as the LSTM model, where the ranges of parameter settings are in Table 4. Those for the TCN model are in Table 5.
Parameter setting for LSTM
Parameter setting for LSTM
Parameter setting for TCN
Based on the typical quality measures as discussed in Section 2.6 and the available open-source codes for further modification, we use the coefficient of determination (
Experiments and discussion
Using the parameter sets for LSTM in Section 3.3 and the error measurement of
When reading Fig. 4 for the results from test sets, the more points at the right lower corner the better for the merchandise since the more close to 1 the better for
Comparing results of LSTM
Comparing results of LSTM
Comparing results for activation functions of TCN
Error measurement for the test set from LSTM.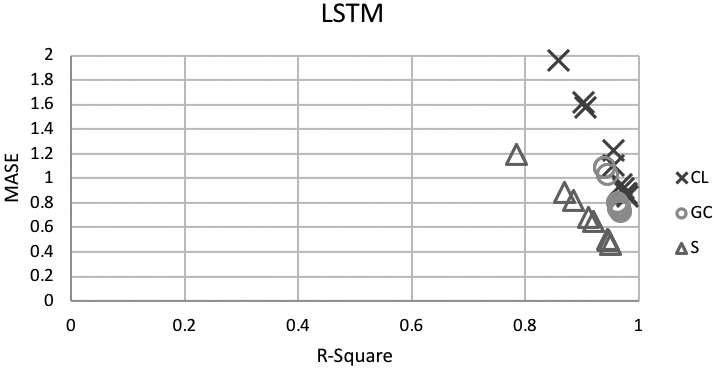
Parameter sets for the TCN models in Section 3.3 are also applied to the same three merchandises. TCN’s parameter setting includes activation function, filters, dilations, and dropout rate, which are evaluated individually.
Activation functions, SeLu and ReLu, are compared in Table 7. All three merchandise shows high
Filters for TCN are compared as in Table 8. For test sets, gold has good results on all Filter parameters, crude oil performs well at around 128 to 512, and soybean performs well at most values except 1024. MASE also reveals the same trend. Here the setting of other parameters is SeLu, Dilations: 32, and Dropour_rate: 0.2.
Dilations for TCN are compared as in Table 9. For test sets, gold has good results on all Dilations parameters, crude oil performs well at 16, 32, and 256, and soybean performs well at 8, 16, and 32. MASE also reveals the same trend. Here the setting of other parameters is SeLu, Filters: 256, and Dropour_rate: 0.2.
Dropout_rate for TCN is compared as in Table 10. For test sets, gold has good results at 0.2 and 0.5, and crude oil and soybean both perform well at 0.2. MASE also reveals the same trend. Here the setting of other parameters is SeLu, Filters: 256, and Dilations: 32.
All the parameter sets mentioned above are applied to the trading program to calculate its profitability. We can then examine the relationship between traditional error measurement (
Comparing results for parameter sets of Filters of TCN
Comparing results for parameter sets of Dilations of TCN
Comparing results for parameter sets of Dropout_rate of TCN
Performance summary of all models for three merchandises
From the previous results,
To evaluate the profitability of deep learning models, we use two years’ out-sample data with the trading program in Fig. 3 for initial capital of 100,000.0 US dollars to get the profitability of all the parameter sets of LSTM and TCN models in Tables 4 and 5. The average and maximum profitability for three merchandise in all models and parameter sets are in Table 11.
Relationship of profitability and error measurement on gold.
Relationship of profitability and error measurement on soybean.
Relationship of profitability and error measurement on crude oil.
As Compared to LSTM, TCN provides higher profitability for gold. The standard deviation of the profitability and the averaged maximum drawdown (MDD) for TCN are both better than those from LSTM. The relationship between profitability and error measurement for models on gold is in Fig. 5. The (orange-colored) circles represent LSTM, and the (blue) triangles are for TCN. More dots at upper right corners indicate their models are with a higher positive correlation between profitability and error measurement (i.e., lower error leads to higher profits). For gold, this correlation coefficient is
Soybean’s TCN models provide higher profitability than LSTM’s, and their standard deviation is also smaller. The relationship between profitability and error measurement for models of soybean is in Fig. 6. For soybean, the correlation coefficient is
The profitability patterns of Crude oil from LSTM models are quite unstable. TCN models of crude oil provide higher averaged profitability. The standard deviation for the profitability and the averaged maximum drawdown (MDD) for TCN are both better than those from LSTM. The relationship between profitability and error measurement of corresponding models of crude oil is in Fig. 7. For crude oil, the correlation coefficient is
From these analyses, we have the following findings: (1) TCN models provide a more positive correlation between profitability and error measurement (
In this work, a new validation approach is proposed to evaluate the quality of deep learning models. The proposed method explores the relationships between the profitability and error measurements of deep learning models. “More precise prediction leads to better profitability” is a common hidden assumption for price prediction from deep learning where usually only the error between the predicted and actual prices is used to measure the quality of learning results. We re-evaluate this common assumption through our proposed validation approach. Validation approaches similar to ours can be used by others to add a new dimension of quality measurements for deep learning models. Our approach emphasizes that the application results of the predicted values from deep learning are also one of the critical quality measurements.
A three-stage process of validation, as proposed in Section 3, is conducted on three commonly traded merchandise in this paper, with all experiment results displayed and analyzed in Section 4. Program trading measures the profitability of learning models. We use a next-day exit trading program in this paper to match the deep learning prediction model.
From these analyses, we have the following findings: (1) TCN models provide a more positive correlation between error measurement (
The focus of this work is to address the loose relationship between the error measurement of predicted values and the trading profitability. As for the absolute trading return of our proposed trading strategy, they are at around 7%–8% annual return based on Table 11, which is similar to those in [6]. The absolute return rate may further increase if domain experts are more involved during stages 2 and 3 for the proposed three-stage process. As it is not the focus of this work, we do not perform tasks that way.
A final note is that the quality of predicted prices from deep learning and how the predicted prices lead to profitability could be, in fact, two different issues. For example, we have conducted similar experiments on the 15 key Taiwan stocks with 30 years of data. Though the predicting quality (measured in MSE and