
Abstract
Researchers need to formulate their achievements as research papers. Representative references are essential to high-quality papers. Academic citation recommendation refers to providing the recommendation of citations for the author of papers when they write. With the help of citation recommendation, researchers can improve the efficiency of writing academic papers and reduce the omission of important related literature. To achieve this goal, some methods were proposed. Many of them used citation networks to learn the representation of papers and chose references, they tended to ignore the content properties of papers. There are also some methods used partial properties to recommend citation. But their performance can be further improved. In this paper, we propose a citation recommendation method based on context correlation. We use two neural network models to learn the representations of papers and their references, then calculate the context similarity of them. Besides, we also introduce the publishing time and authority of papers, two key properties of papers for citation evaluation. In the experiment section, we compare our method with other methods and evaluate the performance of different properties choice in our method, it shows that our method outperforms some baselines and the combination of the dimensions including time, authority and context performs better.
Introduction
Researchers often need to read large volumes of literature during conducting an academic study, and determine the overall research goals in project proposals and so on. Subsequent scientific research activities usually include two stages: carrying out scientific research and summing up fruits. In this paper, we focus on the latter stage. During this stage, a researcher needs to summarize the results of scientific research. When writing a paper, the researcher needs to cite suitable references from numerous papers that were read before. However, it is unnecessary to cite all the literature the researcher has read. When researchers want to pick suitable references accurately, citation recommendation will help. Citation recommendation is a major research direction. It can be divided into the following categories according to the recommended scenarios: global citation recommendation, local citation recommendation, potential citation recommendation, and cross-language citation recommendation. Global citation recommendation means recommending the citations that have high consistency with the paper according to the analysis of the whole article; local citation recommendation refers to recommending the citations with high consistency with some parts of the article; potential citation recommendation refers to the search for some citations with indirect citation relationship based on some literature already cited in the article; cross-language citation recommendation is also the recommendation of the citations with high consistency. The difference is that in this scenario, the recommended citations are written in different languages.
The concept of citation recommendation was first proposed by Strohman and others in 2007. This is the rudiment of global citation recommendation [29]. They use some features of papers to recommend. Their work performance is not satisfactory, but they attracted a great deal of interest from researchers. After that, plenty of citation recommendation approaches were proposed.
He et al. learned the closed-form estimate of density matrices, calculated the document similarity for global citation recommendation, and calculated the relevance of documents to context for local citation recommendation [11]. Ebesu et al. used a model trained by a neural network with context information and author information to score citations and then choose the top K documents [7]. They all chose the context of papers to recommend citations, but they hardly considered the structural features of citation networks other than directly connected edges in the network (i.e. first-order proximity). However, in a citation network, the edges are sparse, it is difficult to achieve good representations that can preserve the global network structures by only using first-order proximity. Tang et al. explored second-order proximity between the vertices to get more structural information [30]. Dong et al. further designed a heterogeneous network representation that could represent different types of vertices and links so that it can be used to calculate paper similarity [6], Jiang et al. used Relation Type Usefulness Distributions to construct hierarchical random walks and then learned a hierarchical representation on heterogeneous graphs to finish cross-language citation recommendation [14]. The heterogeneous graph contains different types of vertices and links, the extra amount of computation is generated for preserving the structural information as well as the context information.
We propose a novel citation recommendation method that can reduce computation while preserving the above information. In our method, we can preserve first-order proximity, second-order proximity, degree properties. We also use the paper context and the publishing time to improve the accuracy of computing similarity. We use a two-part neural network to score candidate papers. Two parts are used for training the weights and learning the context representation respectively. The latter combines first-order proximity, second-order proximity and the context. As our method is designed for local citation recommendation, this part trains two representation models for the input partial paper and candidate papers respectively. We also use degree centrality, betweenness centrality and closeness centrality to measure the authority of candidate papers so that the degree properties in the citation network can be preserved and utilized. We design experiments on the benchmark datasets used in [26, 32], compare our method with several citation recommendation methods and explore the effect of different properties selection on the performance of our method.
The main contributions of our work are summarized:
We propose a new neural network for citation recommendation that can perform much better than several baselines. This model can save much time by reducing calculation of different types of vertices and links. The model can also be used to recommend technical documentation of the computer field. Our method can preserve some common structural information of citation network. We use first-order proximity and second-order proximity to help train the context representation model, which has never been conducted before to our best knowledge, our experiments can prove the effectiveness of this method. We explore the effect of different properties combinations on our method and select the better properties for citation recommendation.
We organize the rest of the paper as follows. In Section 2, we discuss related work. In Section 3, we define the problems and concepts researched in this paper. In Section 4, we introduce the proposed method. In Section 5, we introduce the datasets and design the experiments to prove the effectiveness and efficiency of our method and the combination of time, authority, and context performs better in our method. At last, we conclude this paper and introduce future work in Section 6.
Citation recommendation
As for citation recommendation, some researchers tapped into the deep meaning of literature, they applied topic models to obtain the topic distribution, to perform citation recommendation depending on literature topics. If potential topics of a paper can be found, the topic model offers low-dimensional document representation. Tang et al. proposed the RBM-CS model for the paper versus citing relationship and employed the word term-topic-citation relationship to recommend citations [31]. Likewise, He et al. employed the topic model in citation recommendation, however, they divided recommendation units into global contexts based on abstracts and titles, and local contexts of specific paper texts, and extracted the topic models for the recommendation in cases of two different contexts, respectively [11]. Following this approach, Dai et al. proposed a novel probabilistic topic model to automatically recommend citations for researchers, they also calculated the community relevance among authors for effective citation recommendation [4].
It might be difficult to use only text topics for finding convincing citations. Therefore, researchers began to recommend citations using other methods. For example, McNee et al. recommended citations for users by leveraging the links between different literature [19]. Zhou et al. built a directed weightless graph to reflect the correspondence between literature and authors as well as the relation between literature and journals. By combining these relations, they assessed the similarity between literature and hence recommended citations [34]. Galke et al. utilized adversarial autoencoders to reconstruct the sparse item vectors, the autoencoders can be applied to citation recommendation. They focused on the problem of data sparsity but ignored the structure information of the citation network, which is considered in our method [9]. Further, based on the citation network, Shi et al. defined the co-authorship and co-citation rules to compute the strength of nodes and cluster citations, and depending on the clustering result, they looked for those candidate papers similar to the input paper and recommended them to the user [28]. Besides, Zarrinkalam and Mohsen used six types of relations between different literature, which along with literature text features constituted jointly semantic distance between different literature. By computing the semantic distance between input texts and the papers in references, this system recommended citations with smaller semantic distance to the user [33]. The methods mentioned above are mainly designed for global citation recommendation, while our method serves for local citation recommendation mainly. Our method can be adapted to global citation recommendation, and even cross-language citation recommendation. Another difference is that our method can use more structure information of the citation network than those methods, thus we can get higher accuracy.
Network embedding
Network embedding is used to learn the representation of the nodes in a network. This method can represent many types of networks. The citation network is one of them. In this field, the key point is to learn a representation that supports reconstructing the original network and inferences. Perozzi et al. learnt a latent representation through constructing short random walks which can extract the information in a network [23], the frequency of nodes appearing in random walks of a network is similar to that of words in natural languages so that they could borrow from natural language processing methods. While Tang et al. proposed a method related to DeepWalk, they learnt the representation by preserving the first-order proximity and the second-order proximity [30], our method also uses these two important properties to make representation of paper contexts which we learn can be used to restructure the original context. The ability of network inference can be proved by the experiments. We can use the latent representation of context to find context-related candidate papers.
Autoencoder
Autoencoder is an unsupervised neural network that can learn the representation of the input. The input can be various, Li et al. train an LSTM autoencoder for paragraphs and documents [16], while Pan et al. use it to learn a graph embedding [24], Hong et al. use it to capture the image features and map 2D images and 3D poses so that human pose can be recovered through monocular videos [12]. Inspired by these works, we use an autoencoder to learn the representation of paper context due to its representation ability.
Problem definition
We first introduce the notations used throughout the paper. In a local citation recommendation system (LCRS), all the documents constitute the document set
SUBPROBLEM1 How to design a standard to choose some
In our task, there are lots of candidate documents, we should choose some from them as the citations. This can be seen as a TopK problem or a classification problem. If it is a TopK problem, we should have a method that can score these documents and choose K documents as the result, the parameter K can be set according to the need. If we treat it as a classification problem, a document will be classified as related or unrelated, then the number of the recommended documents is not controlled. Thus we treat it as a TopK problem.
SUBPROBLEM2 In the representation model trained, how to preserve the structure of the citation network and the context relations of documents.
The structure of the citation network shows the relation of documents and document properties show the features of documents. We should find an efficient representation method to reduce the complexity of the heterogeneous network representation so that we can find the target documents accurately and efficiently.
Context-based citation recommendation method
As Section 3 mentions, we develop our work according to the order of the subproblems. The inputs of LCRS are a document set
Preprocessing and preparation
From AAN (ACL Anthology Network) and DBLP (DataBase systems and Logic Programming), we can get the text contents, the metadata and the citation relationship about a document. We firstly remove incomplete literature, including “No content”, “No abstract”, “No introduction” papers and those whose relevant references are not in the data set. According to the citation relationship and the publication time, we delete those documents that were published over 1 year and have not been cited, this is because we regard these documents as low-quality documents, and they should not be used as the guidelines of our method. If we learn the patterns of these papers when they choose citations, the papers written under the guidance of our trained model are likely to become low-quality papers. Also, there is another situation that should not appear in our data set as training data. Among the documents we download, there are documents published at different times and as we know, a document published in 2009 cannot cite a document published in 2010, so such non-reference documents should not be used as negative examples in our training set.
We create a word bag according to the high-quality documents filtered from
Score model
In our method, we use a forward neural network as the score model. The forward neural network receives input from three parts: the first part is the publication time used for searching for documents, the second is the document authority and the last is the context similarity between the input paragraph and the candidate document. The output is the score of the candidate document, documents are ranked according to the score obtained. The forward neural network consists of an input layer, an output layer and several hidden layers, the number of hidden layers and the number of neurons in each hidden layer are hyperparameters, in the experiment part, we will contrast the effects of different hyperparameters and select the best values.
Because the effect of three inputs on the score is non-linear, we use sigmoid function as the activation function to realize nonlinearization. To simplify the operation, we also map the output value of the output layer to the interval [0, 1]. In the training process, the expected output of positive samples is 1, while that of negative sample is 0. The loss function we use is the square loss function, we constantly adjust the weight of the network by minimizing the loss function.
In the following parts, we will introduce how to calculate the document time, document authority and document-paragraph similarity.
Time
When we search for papers in academic search engines, we find that search sites often have selection options about time. The default tabs include screening documents in the last year, the last two years or the last five years. This is because the relevance of a document is often dependent on its publication time, as time goes by, technology evolves, old documents are also less likely to be referenced. In the preprocessing and preparation part, we have explained that the paragraphs are all newer than their citations or their non-reference documents. As the effect of time is non-linear and the closer the publication time of the document is to the current time, the more obvious the difference is, so we use the reciprocal of the year gap as the time representation to input into the score model.
Authority
Among all the documents in
Degree centrality: In a directed graph, the centrality can be the indegree centrality or outdegree centrality. In the citation network, the indegree centrality of one node stands for the frequency of this document cited by others. The greater the indegree centrality is, the more important the document is. Each document has a similar outdegree, so we don’t use outdegree as a measurement of document importance. Betweenness centrality: It is measured by the number of the shortest paths crossing a node in the citation network. By connection density, the citation network can be divided into several communities, where a community represents a research group [15, 21]. If a node has high betweenness centrality, then it may link different knowledge communities, it may have the potential to be cited by these communities. Closeness centrality: It is a structural measure of the importance of a node in a network, which is based on the ensemble of its distances to all other nodes [3] and reflects how close a node is to other nodes in the network. If a node has higher closeness centrality, then it suggests that this node is at a more central position and can arrive at other nodes at ease. Eigenvector centrality: It is a measure of the importance of a node, depending on the number of its adjacent nodes as well as their importance. A node with higher eigenvector centrality has a greater influence in the citation network [2, 27].
In addition to these centrality attributes, our method also uses publisher information to calculate the authority of documents. This is because in the academic field, different academic conferences or journals often have different rankings or influencing factors, and the authority of these publishing media also has a certain impact on the authority of documents.
We propose a new method for computing document authority. A high authority document has the following features:
It is frequently cited by other documents, which is represented by higher indegree centrality in the citation network. A high authority document refers to a core representative document in several subfields, such a document can connect different subfields and thus can be cited by the documents in different subfields. This property can be represented by betweenness centrality in the citation network. It has some authoritative followers. If many authoritative documents cite the same document, then this document can be seen as an authoritative document. This property can be represented by eigenvector centrality in the citation network. It is often published in some prestigious publishers. As prestigious publishers have strict audits, their documents are more likely to have a high quality and be cited by other documents.
We use three kinds of centrality except for closeness centrality. This is because if we use closeness centrality, the distance from one node to all other nodes is calculated. When we calculate them, the distance between nodes with loss relationship is set a big value, as the citation network is very sparse, the total distance is the sum of many big values and few small values. The influence of big value is huge, so the difference between the results is small. Therefore, closeness centrality is abandoned from our method. Next, we introduce how these factors are calculated and how we can combine them to calculate the authority of documents:
The indegree centrality equals the citation frequency, which can be obtained through a scholar search engines. We get the citation frequency of a document from the datasets and use this number as the indegree centrality of a document in the citation network. Generally speaking, the betweenness centrality can be calculated using the shortest path method [1]. But in the sparse citation network, calculating the betweenness centrality by distance is not efficient enough for the geographical concept of far or near is not clear enough. So we use graph community detection method to cluster nodes in the citation network and calculate the betweenness centrality of nodes by counting the association between nodes and different clusters [8]. The algorithm to calculate the betweenness centrality is shown in Algorithm 1. [h] Calculating betweenness centrality[1] The eigenvector centrality is related to the adjacent nodes, we use the idea of PageRank algorithm to calculate it [22]. Every document in the citation network gets an initial
Herein, [h] Calculating eigenvector centrality[1] The publisher related authority depends on the quality of journal or conference, journals have impact factors (
Next, we train a model to calculate the authority of a document. The inputs are the indegree centrality, the betweenness centrality, the eigenvector centrality and the publisher related authority, the output is the authority. The authority consists of the citation frequency and the popularity of the document on the Internet. We count the popularity through a web spider, which can browse blog websites, forum websites, education websites of the related fields. We train the model instead to calculate the authority instead of getting it by the citation frequency and the popularity because the workload of getting the popularity especially the workload of the web spider is enormous. We just use the popularity to construct a dataset for training and testing and use the trained model. This model is also a forward neural network, the difference with the score model lies in the number of network layers and the number of neurons in each layer.
Context similarity in our paper is the context similarity between paragraphs and documents. We learn the representation of a paragraph as rp and the representation of a document as dp. rp and dp are located in the same vector space. The cosine distance between rp and dp can be calculated to show the similarity between paragraphs and documents. The smaller the cosine distance, the more similar they are. We use two different autoencoders to learn rp and dp respectively. As mentioned above, we use first-order proximity and second-order proximity when constructing positive samples.
In our method, first-order proximity denotes the relationship between a paragraph and its citations, second-order proximity denotes the relationship between a paragraph and the documents with one or more same references as it cites. We use Fig. 1 to explain first-order proximity and second-order proximity. This paragraph and four citations ([2, 6, 8, 16] in Fig. 1) are first-order proximity, while another document [25] which cites the third citation in Fig. 1 is not cited by this paragraph, this paragraph and [25] are second-order proximity.
Example of paragraphs citing documents.
Figure 2 shows a citation network, the arrows represent the citation relationship. As described in [30], the relation of (a, c), (a, b), (f, d), (d, c) and (e, c) in Fig. 2 belongs to first-order proximity, the relation of (a, f), (a, d) and (a, e) belongs to second-order proximity. But first-order proximity and second-order proximity in our paper are slightly different because the problem is to recommend citations for paragraphs.
An example of citation network.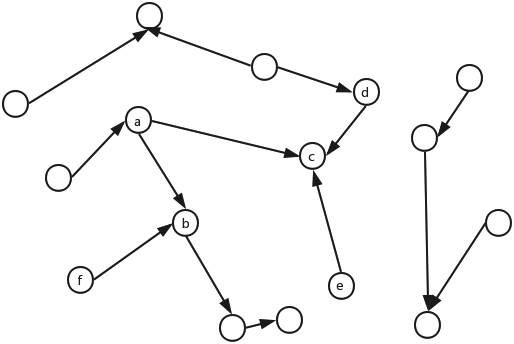
The model for calculating context similarity is shown in Fig. 3. The model contains two autoencoders: one is used to learn the representation of paragraphs, another is for documents. The representations learned are used to calculate the context similarity.
The model for calculating context similarity.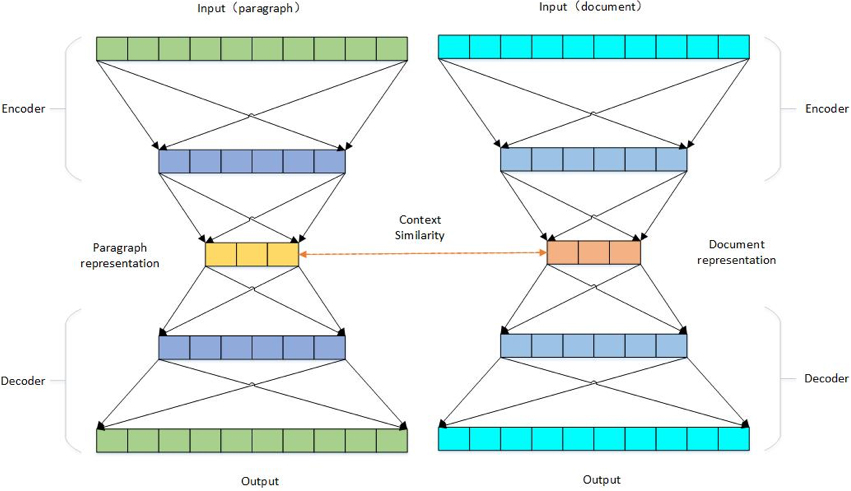
The input, output and learned representation of the left model in Fig. 3 are
We use Jaccard distance as the loss function of the autoencoders and the complement of the cosine distance between the paragraph representation and the document representation as the loss function of the context similarity calculation part. The Jaccard similarity coefficient in Eq. (2) is the ratio of the sum of the minimum values of each word term to the sum of the maximum values in two vectors. In the training step, we use SGD to minimize the loss function and update the weights in the model. The inputs of these two autoencoders are word terms, global word terms in all documents and word terms in a paragraph are both gained by the method in [18]. As a word term is mentioned in different documents, we use the TF-IDF (term frequency – inverse document frequency) value of a term as the input vector instead of the one-hot encoder to distinguish different documents and paragraphs [33]. After training, we use two encoders to represent a paragraph and a document and calculate the cosine distance between the two representations as the context similarity between the paragraph and the document.
Using the score model with the time score, authority score and context similarity score, we can gain a score for the documents in the candidate document set. Those documents with higher scores are recommended.
In the experimental section, we use the AAN (
After the clean work mentioned in the preprocessing and preparation part, we get a cleaned AAN dataset with 5642 documents and a cleaned DBLP dataset with 24672 documents. Paragraphs in documents are similar to the one shown in Fig. 3, with several citations for each paragraph. As the number of documents cited by a paragraph is far less than the number of documents not cited by this paragraph, so the number of positive and negative samples is unbalanced, we use the method of random under-sampling in sampling. We perform 10-fold cross-validation to evaluate the methods.
To evaluate our method – context correlation based method (CCB), we select four evaluation metrics: mean average precision (MAP), mean reciprocal rank (MRR), recall and normalized discounted cumulative gain (NDCG). The higher their value is, the better the results are. MAP is the average of experimental results. MRR measures the exact rank position of recommended documents. Recall@K is the ratio of the number of cited documents in the recommended TopK list to that of all cited documents. NDCG@K measures the performance of a method by the relevance score and the position of documents in the TopK list.
The formulas for the metrics are shown in Eqs (3)–(6).
In our method, the number of the hidden layers in the score model and the authority model are both set as 4, the representation layers in the autoencoders have 32 nodes. The learning rate is initially set as 0.01. As we recommend citations for paragraphs, the number of the citations is less than that for a document, so we set
In the experiments, we firstly contrast the performance of different combinations in our method. For convenience, we use T instead of time, A instead of authority, and C instead of context similarity. We contrast the performance of CCB-C, CCB-CA, CCB-CT, CCB-CAT. CCB-C uses context similarity only, CCB-CA uses context similarity and authority, the remaining two are similar. The experiment results are showed in Table 1. The recall and NDCG of combinations of different properties are shown in Figs 4 and 5 separately.
Experimental results of different properties combinations
From Table 1, we find that the combination of time, authority and context performs best, context alone performs poorest, the combination of authority and context performs better than the combination of time and context. So we use the combination of time, authority and context in our method.
To verify the effectiveness of our method and the correctness, we contrast our method with some baseline models. We choose five: [11] context-aware, [7] NCN, [30] LINE, [23] DeepWalk, [20] MMRQ.
Recall of different method properties combinations.
NDCG of different method properties combinations.
Recall of different methods.
NDCG of different methods.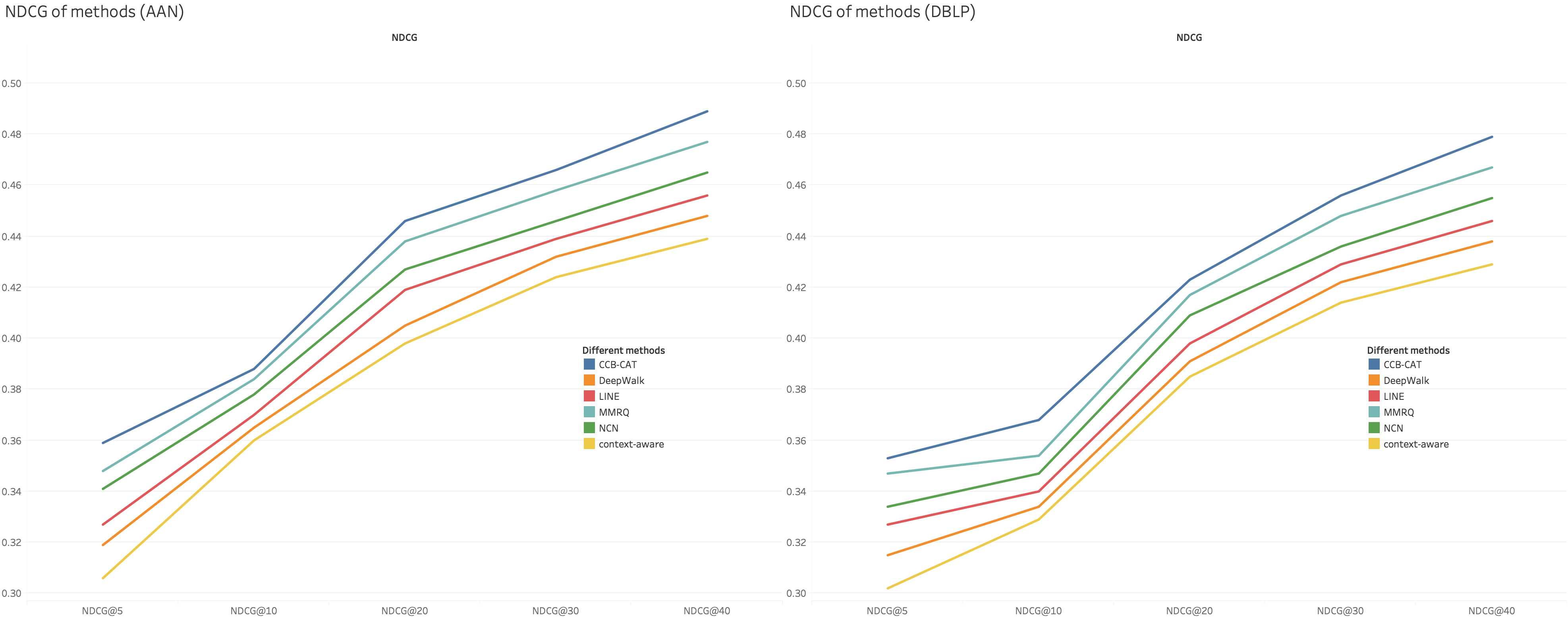
Experimental results are shown in Table 2. The recall and NDCG of different methods are shown in Figs 6 and 7 separately.
From Table 2, we find that our method outplays the others. The context-aware method has the worst performance, even CCB-C performs better than it because we calculate context similarity using some structural information (first-order proximity and second-order proximity). Both of DeepWalk and LINE are network embedding approaches, LINE has better performance due to its additional local network structure. NCN utilizes author information besides content information, thus, NCN is better than context-aware approach. MMRQ utilizes a three-layered graph including the author layer, the paper layer and the word layer, so MMRQ outperforms NCN. Compared with these approaches, our method use context information, publisher information, structural information and time information.
Experimental results of different recommendation approaches
When writing a research paper, a researcher has to screen suitable references from literature read before. However, the researcher normally has read a huge amount of literature over a long time. Therefore, it is prone to omission and improper citation of research achievements, thus citation recommendation is indispensable for writing papers.
To help the researcher spend less time selecting documents to be cited and improve the efficiency of writing academic papers, we propose a local citation recommendation problem and design a multi-unit score model combining citation network structure, context information, publishers and publish time to solve this problem. This model can utilize a variety of information to improve the accuracy of citation recommendation. To evaluate the performance of our method and find the best combination, we conduct some experiments, the results demonstrate that our method is effective and accurate.
In our future work, we plan to expand the score model to combine with author network information and test our model using more datasets.
Footnotes
Acknowledgments
The completion of the paper is attributed to many people who have offered selfless support to us.
First, we want to express my gratitude to The Association for Computational Linguistics for providing the open dataset. This has helped us save a lot of time in finding and organizing data.
Second, we want to thank professors and friends in our school, esp. Prof. Minbo Li, Shi Pu, Hongbo Zhao, Rongbin Zhu, Yuanwen Hu. They gave us technical and intellectual help.
Third, this work was supported by the National Nature Science Foundation of China [grant number 61671157], we want to give our heartiest thanks for the National Nature Science Foundation of China.
Last, we are extremely grateful to our family members, it is their understanding and support that help us finish this paper.