
Abstract
Graph Convolution Networks (GCNs) have attracted significant attention and have become the most popular method for learning graph representations. In recent years, many efforts have focused on integrating GCNs into recommender tasks and have made remarkable progress. At its core is to explicitly capture the high-order connectivities between nodes in the user-item bipartite graph. However, we found some potential drawbacks existed in the traditional GCN-based recommendation models are that the excessive information redundancy yield by the nonlinear graph convolution operation reduces the expressiveness of the resultant embeddings, and the important popularity features that are effective in sparse recommendation scenarios are not encoded in the embedding generation process.
In this work, we develop a novel GCN-based recommendation model, named Refined Graph convolution Collaborative Filtering (RGCF), where a refined graph convolution structure is designed to match non-semantic ID inputs. In addition, a new fine-tuned symmetric normalization is proposed to mine node popularity characteristics and further incorporate the popularity features into the embedding learning process. Extensive experiments were conducted on three public million-size datasets, and the RGCF improved by an average of 13.45% over the state-of-the-art baseline. Further comparative experiments validated the effectiveness and rationality of each part of our proposed RGCF. We released our code at https://github.com/hfutmars/RGCF.
Keywords
Introduction
Modern recommendation systems have been widely applied to many online services such as video recommendation [4], music recommendation [5], e-commerce [8], and social network [28], etc. Collaborative Filtering (CF) is the mainstream algorithm in recommendation systems [19, 21], which vectorizes all users and items using only their ID features (user and item IDs, which are sequentially encoded features), and reconstructs their historical interactions with the inner product of them. Matrix Factorization (MF) [30] is the most classical CF method and can achieve good performance when sufficient interaction data is available. However, since the issue of sparsity is ubiquitous in modern recommendations, MF fails to learn expressive vector representations for users and items. In this case, how to make full use of the limited interaction data and how to dig out additional features from only these ID data become the key to improve the performance of CF models.
Why graph convolution networks?
In order to solve the performance bottleneck caused by sparsity of datasets, many efforts have been devoted to constructing complex embedding functions. Specifically, integrating all available useful information into the embedding representations can improve model performance. SVD
Why refined graph convolution networks?
It is worth mentioning that in some GCN-based machine learning tasks, such as image classification [34] and node classification [14], nonlinear network layers are necessary for feature extraction since the initial vector representations contain abundant and diverse information. In contrast, IDs of users (or items) used by most CF methods carry no complicated patterns or diverse semantic information that can be mined. Therefore, directly using nonlinear graph convolution layers to process ID features like [26, 32] will inevitably bring noise into the learned embeddings and further reduce the ability to capture high-order connectivities. To be specific, the network layers in the GCN fail to distill useful information and features from aggregated embedding inputs mapped by one-hot ID features only. Towards this end, LR-GCCF [35] designed a linear GCN structure by removing the nonlinear activation function from the network layers and achieved significant improvements. Additionally, too many parameters of the weight transformation matrices in the network layers are prone to the issue of overfitting and introduce redundant information into the embedding outputs. As discussed above, the nonlinear network layers in the traditional GCN structure are not suitable for the recommendation tasks. We elaborate on this in Section 3.2. The traditional graph convolution process can be seen as a weighted summation of neighbor nodes, which is then passed through a nonlinear network layer. Most GCN-based methods [26, 32] apply symmetric normalization to compute the weight for each neighbor node. Despite its effective for learning expressive embeddings, we argue that such symmetric normalization is insensitive to node popularity and fails to capture it. In Fig. 1, compared to item i4 with only one interaction, user u1 may prefer i3 with five interactions for that more interactions usually indicate potentially higher quality, illustrating that node popularity is an important distinguishing feature. However, considering only the popularity feature is insufficient for modeling cold user preferences. For example, in Fig. 1, we cannot tell whether user u1 prefers i5 or i4. From the perspective of popularity, u1 prefers i5 which has higher popularity, while from the perspective of collaborative filtering, u1 prefers i4 because there is a path between u1 and i4 but no path between u1 and i5. Such a phenomenon indicates that neither collaborative signal nor popularity feature alone can learn user preference well, but adding popularity features to the learning process of collaborative signals is clearly a feasible and effective strategy. Node popularity can be reflected by redits own degree in the user-item interaction graph. Therefore, using these degree data to fine-tune the symmetric normalization is capable of coordinating node popularity and collaborative signals to further improve the performance of the model. Section 4.3 verifies this assumption.
Illustration of the user-item bipartite interaction graph for target user u1, item i3 is interacted with {u2, u4, u5, u6, u7}, item i4 is interacted with {u3}, u1 is more interested in i3 than i4 because i3 and i4 are both the 3-order neighbor nodes of u1 but i3 is more popular than i4. Item i5 is more popular than item i4 but there is no path between i5 and u1, therefore we cannot distinguish which item is more in line with u1’s preference. 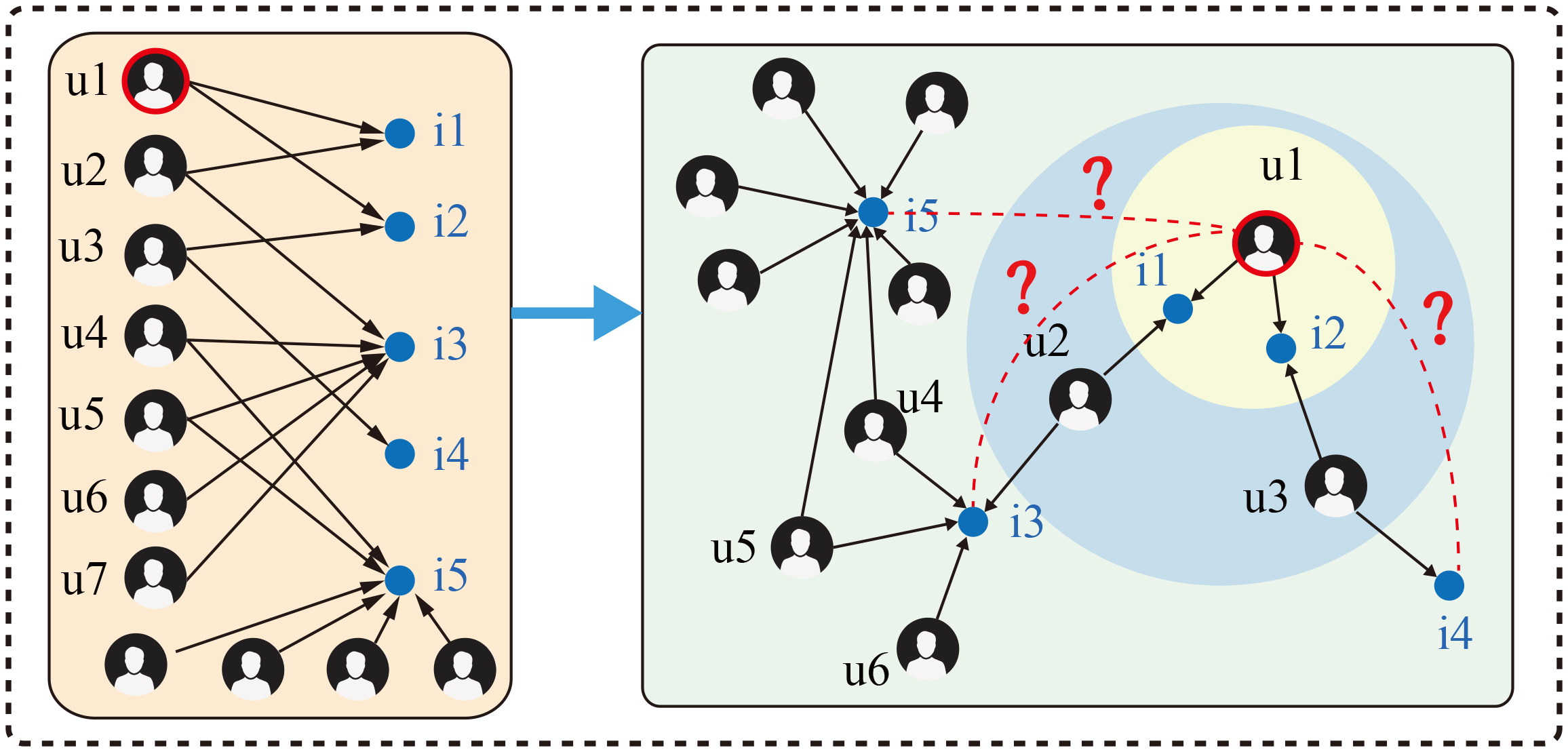
In some nonlinear GCN-based CF methods, such as NGCF [26] and LR-GCCF [35], the layer-aggregation mechanism [33] is applied to concatenate embeddings obtained at each convolution layer as the final embeddings. Despite its effectiveness, we argue that this layer-aggregation mechanism is unnecessary in CF scenarios when the negative impact of nonlinear network layers is eliminated. Specifically, when nonlinear network layers are not considered, the graph convolution can be seen as a linear aggregation process, that is, the embedding obtained at N-th convolution layer is equivalent to a linear combination of the embeddings of all neighbors within N hops, and the concatenation of embeddings obtained at each layer can also be seen as a similar linear combination. Therefore, using layer-aggregation mechanism in CF scenarios where no nonlinear units are used is redundant and meaningless. The reason why this layer-aggregation mechanism can work in nonlinear GCN-based models is that the information redundancy and noise generated by the network layers may be weakened by the embedding concatenation of each layer. However, in our research we actually found that the nonlinear network structure and the layer-aggregation mechanism limited the model’s learning process for high-order connectivities in CF scenarios. This assumption is detailed in Section 3.3 and verified in Section 4.3.
Our proposal and contributions
In this work, we discuss the limitations of traditional GCN structures for capturing the high-order relations among different entity nodes in recommendation tasks, and propose a new GCN-based CF model, RGCF, where the embeddings of entities are reconstructed through a refined graph convolution structure and some strategies are intuitively used to reduce noise and redundancy existed in GCN-based methods. First, a linear weighted average operation is used to instead the complex and nonlinear network layers in the embedding function of the GCN-based methods. Then, we simply use the embeddings obtained at the last layer as the final representations to avoid the information overlap caused by the embedding concatenation of each convolution layer (Layer-Aggregation Mechanism). Lastly, we propose a fine-tuned symmetric normalization to integrate popularity information into the collaborative signal learning process. In addition, we further improve the model performance by changing the weights of the self-loop nodes in the aggregation process on the user-item graph. We have conducted extensive experiments on three public datasets, and the results show RGCF achieves significant improvement against other state-of-the-art baselines. To be more specific, our model improves over LR-GCCF w.r.t Recall@20 by 7.2%, 11.8%, and 22.5% on Gowalla, Yelp2018, and Amazon-Book respectively.
The main contributions of this work are as follows:
We first propose that traditional nonlinear GCN-based methods suffer from information redundancy and highlight its negative impact on the model ability to capture high-order connectivities. We present a RGCF framework, which designs a refined graph convolution structure to reduce information redundancy and incorporate node popularity features into the learning process of collaborative signal. We have conducted extensive experiments on three public million-size datasets, empirically demonstrating the state-of-the-art performance of our proposed RGCF. To make it easier for subsequent researchers to reproduce our work, we have released our code at
The rest of this paper is organized as follows. We first give a brief review of related work in Section 2. And then we elaborate the proposed RGCF and discuss the information redundancy in Section 3. In Section 4, we report the experimental results and analyze the effectiveness and rationality of our proposed RGCF. Finally, we conclude this paper in Section 5.
This section introduces factorization-based CF methods and GCN-based CF methods, which are most related to our work.
Factorization-based CF methods
The core idea of the factorization-based methods is to parameterize all users and items and use the product of the user matrix and the item matrix to reconstruct the interaction matrix. For example, Matrix Factorization (MF) [30] obtains vector representations of users and items by mapping their IDs. In order to improve the expressiveness of the user embeddings, SVD
GCN-based CF methods
The GCN-based methods [14, 27, 6] are capable of capturing the high-order interaction between graph nodes, which is integrated into the node representations. In recent years, many works have applied GCN techniques to the research field of recommender systems. GC-MC [22] uses GCN to construct an encoder to aggregate the information of first-order neighbors into the embedding representations of the target nodes. Compared with GC-MC, PinSage [32] extends the message aggregation function to the higher-order cases and achieves better model performance. The Section 4.4.1 in NGCF [26] has proven that high-order neighborhood information aggregation can improve the expressiveness of the embeddings. NGCF [26] is a new work that combines GCN and MF to integrate high-order connectivities into the users and items embedding representations and predict the preference score with the inner product of them. LR-GCCF [35] is an improved version of NGCF that designs linear graph convolution structure by removing nonlinear activation function.
Despite their effectiveness, we theoretically and empirically find that they suffer from some redundancy problems discussed in Section 3.5 and the capability of capturing high-order connectivities is suboptimal. We design a refined graph convolution structure to avoid these information redundancy problems and achieve the significant performance improvements shown in Table 2.
Methodology
In this section, we first brief the basic concept of GCN [14] and NGCF [26], and then present the details of our model structure, as illustrated in Fig. 2. Last, we have a discussion about the negative impact of information redundancy on GCN-based method.
Preliminary
where
where
where
where
Illustration of our RGCF model which integrates high-order connectivities into the embeddings for user 
In this section, we present a detailed description of our RGCF model. As Fig. 2 shows, the embeddings of users and items are generated separately. User (item) embeddings are generated by propagating information from the first to the last layer. In each layer, the entity(user or item) is embedded by aggregating the information both from the neighbor nodes and the entity itself.
Embedding initialization
We first randomly initialize the embedding representations of all users and items. Considering that we are dealing with a collaborative filtering scenario where only ID information is available, that is, the input data is only the user IDs and the item IDs without any other additional information, thereby the initialization of the embedding can only be achieved by a simple ID mapping. The initialized user embeddings and item embeddings are as follows:
where
Inspired by the outstanding performance of GCN and SGCN in capturing high-order interactions, we design a refined graph convolution network structure to incorporate high-order neighborhood information into the embedding representations of users and items. The refined graph convolution can be seen as a linear aggregation process over the graph (the light blue part of the Fig. 2). We use the user embedding construction to detail the aggregation process, and the item embedding aggregation is similar.
The refined first-order GCN operation can be seen as a process of capturing messages from the node itself and from neighboring nodes, and incorporating this information into the node’s own embedding representation. We formulate these two messages as follows:
where
where
Next, we aggregate these two message
where
where
Algorithm 3.2.2 gives the specific iterative embedding generation process.
[t] : Embedding Generating
[1] Let
Generate embedding for item i.
where
Distinct from concatenating the multiple representations obtained at each convolution layers in NGCF [26], we use the embedding obtained at the last layer as the final representations in the RGCF framework, which is the same as the standard GCN [14]. The key reason is that concatenating representations at different layers leads to the issue of information redundancy. To be specific, the embeddings obtained at layer
where
Inner product is applied to predict the matching score of a user-item pair
where
where
Additionally, we recorded the training and inference time of MF, NGCF, LRGCCF, and RGCF as follows: MF, NGCF, LRGCCF, and RGCF cost around 7 s, 40 s, 36 s, and 22 s per training epoch on the Gowalla dataset, respectively; and the time costs of MF, NGCF, LRGCCF, and RGCF are 45 s, 143 s, 137 s, and 130 s for model inference on the test data.
where
In this section, we conduct experiments on three public datasets to evaluate the performance of our proposed model. We aim to answer the following research questions:
Statistics of the datasets
Statistics of the datasets
Overall performance comparison w.r.t. recall@20 and ndcg@20 on Gowalla, Yelp2018, and Amazon-Book datasets
We compared the performance of all methods in this section. Table 2 reports the performance of recall@20 and ndcg@20 for all compared methods. We have the following findings:
MF achieved poor performance on three datasets, indicating that simple inner product is insufficient to capture complex connectivities between users and items. NeuMF outperformed MF on all datasets, validating the effectiveness of applying neural networks to distill the nonlinear relations between users and items. Compared to MF and NeuMF, the performance of GC-MC demonstrates that integrating the first-order connectivities into the embedding process is helpful for improving the expressiveness of the embeddings. HOP-Rec generally outperformed GC-MC in all cases. The key reason is that HOP-Rec exploits high-order neighbors to enrich the training data while GC-MC considers the first-order neighbors only. PinSage slightly outperformed GC-MC on all datasets, which illustrates the necessity of stacking multiple graph convolution layers to capture higher-order interactions. SVD NGCF outperformed HOP-Rec on all datasets, which demonstrates that explicitly integrating high-order connectivities into the embedding process is more efficient than exploiting high-order interactions to enrich the training data. Meanwhile, NGCF performed slightly better than SVD LR-GCCF achieved better performance than NGCF in all cases, which is owning to the fact that LR-GCCF removes the nonlinear activation function from the graph convolution process, such result demonstrates that the nonlinear component in GCN is redundant for the recommendation scenarios. Our proposed RGCF achieved the best performance in all cases. Specifically, RGCF outperformed the state-of-the-art LR-GCCF w.r.t. Recall@20 by 7.2%, 11.8 %, and 22.5 % on Gowalla, Yelp2018, and Amazon-Book, respectively. To be more specific, RGCF can achieve better improvements on the Yelp2018 and Amazon-Book datasets compared to on the Gowalla dataset, which is correlated with the additional incorporation of node popularity features in RGCF. RGCF outperformed RGCF-sn in all cases, which demonstrates that capturing node popularity features and integrating them into the CF signal can significantly improve model performance.
Performance of RGCF w.r.t. Recall@20 and NDCG@20 on Gowalla, Yelp2018, and Amazon-book datasets under 5-fold cross validation
Considering that the use of hold-out 20% to test model performance may be affected by anomalies inside the dataset, a more rigorous 5-fold cross validation was additionally designed for the RGCF to eliminate this possible bias and to verify the model effectiveness. Table 3 records the Recall@20 and NDCG@20 per fold for RGCF on the Gowalla, Yelp2018, and Amazon-book datasets. According to Table 3, we found that the performance of the RGCF model under the 5-fold cross validation is quite similar to that using the hold-out 20%, which validates the effectiveness of our RGCF.
In this section, we first verified that the three components in GCN-based methods introduced in Section 3.5 are redundant. We then set the experimental comparison
Performance of RGCF variants with different information redundancies
Performance of RGCF variants with different information redundancies
We have analyzed the redundancy issues of some state-of-the-art GCN models in Section 3.5, namely (1) nonlinear network layers redundancy, (2) embedding concatenation redundancy, and (3) element-wise product redundancy.
For the sake of presentation, we divided the experiment into two parts: Part A with nonlinear network layers, and Part B without nonlinear network layers.
For experiments using the network layers (Part A), we have the following derived model from RGCF:
For experiments that did not use the nonlinear network layers (Part B), we have the following derived model from RGCF similarly:
Table 4 reports the experimental results. We have the following findings:
(1) The nonlinear network layers are redundant.
The variants (RGCF, RGCF
(2) The layer-aggregation mechanism is redundant, but it can alleviate the information redundancy caused by nonlinear network layers.
In Part B (without network layers), RGCF and RGCF In Part A (with network layers), RGCF RGCF of Part A outperformed RGCF
(3) The product terms are redundant.
The model variants of RGCF without the product terms achieved the better performance than the variant with the product terms. In all cases, RGCF outperformed RGCF
To illustrate the impact for RGCF
The performance of NGCF and RGCF As the layer depth increased, the performance of NGCF improved slightly, while RGCF showed an impressive improvement in all cases. This result is owning to that RGCF model can benefit much more from the growth of the layer depth than NGCF, again verifying that the refined structure in RGCF is capable of capturing high-order connectivities in the user-item interaction graph.
Performance of RGCF w.r.t. Recall@20 and NDCG@20 on Gowalla dataset with different cropping ratios
Performance of NGCF and RGCF with different number of convolution layers 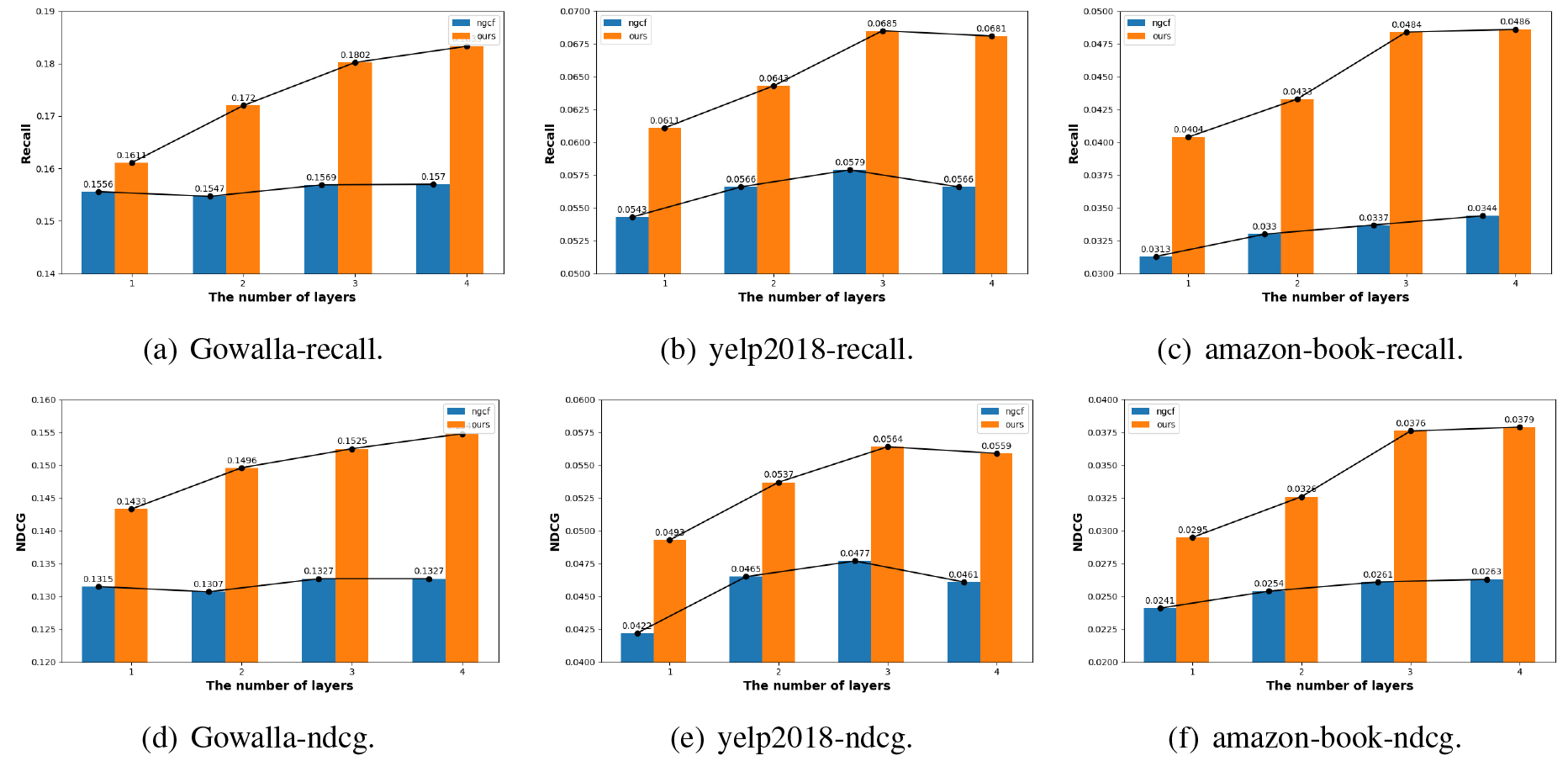
An additional experiment was carried out to investigate the model performance of RGCF in the scenario of sparse user interactions. In Table 5, we cropped Gowalla dataset by removing 20%, 40%, and 60% of the user interaction records, on which MF, NGCF, LR-GCCF, and RGCF were tested. Detailed results are reported in Table 5, showing that RGCF achieved significant improvements over the other baselines on the three cropped sparse datasets, further validating that RGCF is capable of alleviating the data sparsity problem.
Study of hyper-parameters (RQ3)
Performance of RGCF with different self-loop weights 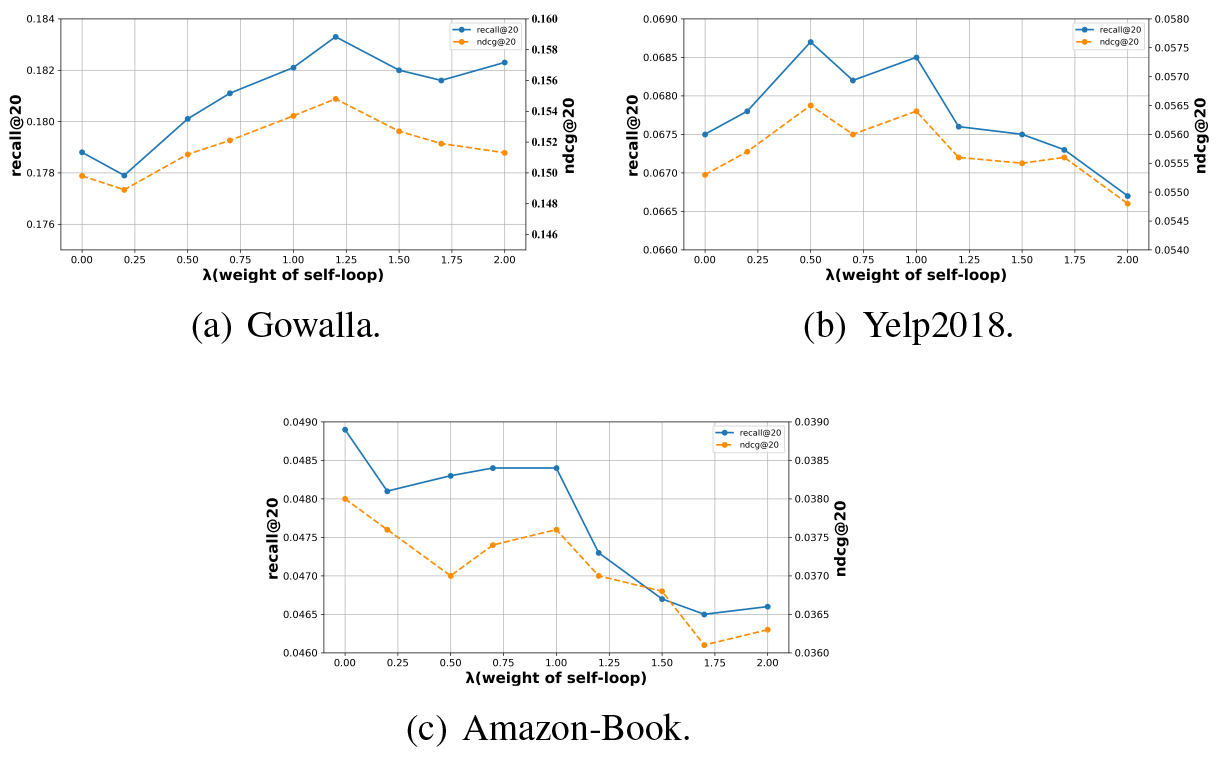
Performance of NGCF and RGCF with different 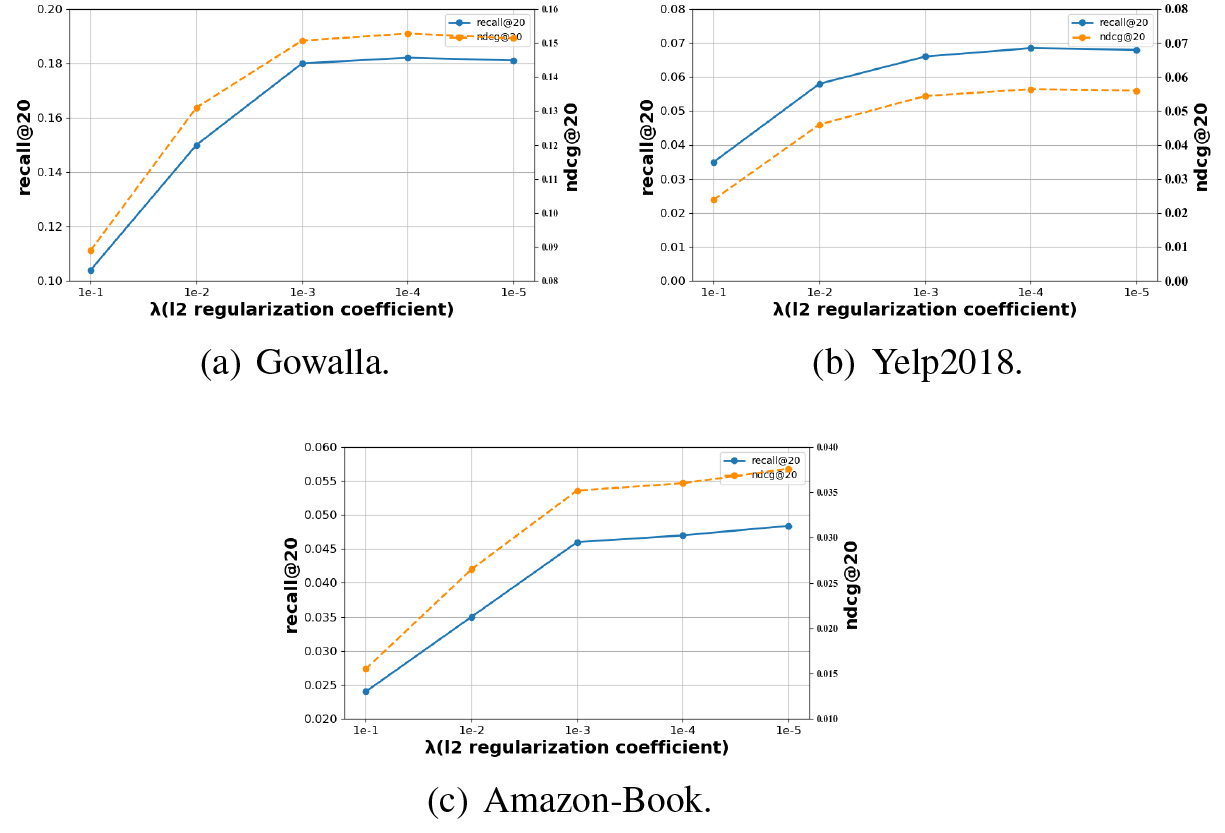
In this study, we investigated the effect of different self-loop weights
To investigate how self-loop weight affects model performance. We searched the
Effect of
regularization coefficient
Figure 5 shows the test performance
Conclusion
In this work, we highlighted the negative impact of information redundancy existed in traditional nonlinear GCN, and presented a novel GCN-based CF model, RGCF, which uses a refined graph convolution structure to eliminate this information redundancy. Additionally, RGCF integrates popularity features into the learning process of collaborative signal to achieve better recommendations for cold users (users with few interactions) and further alleviate the issue of data sparsity. Extensive experimental results demonstrate the state-of-the-art performance of our RGCF, and the further comparison experiments verify the effectiveness and rationality of our proposed RGCF.
In future work, we wish to further improve the performance of RGCF by using the attention mechanism [23, 2] to precisely assign the weight for neighboring nodes and control the granularity of node popularity feature for different recommendation scenarios. Meanwhile, we are interested in integrating causal inference [20] and knowledge graph [1, 25] into our RGCF to improve the interpretability of recommendations.
Footnotes
Acknowledgments
This work is supported by special support plan for innovation and entrepreneurship in Anhui Province.