
Abstract
Graph Convolutional Networks (GCN) are prevalent techniques in collaborative filtering recommendations. However, current GCN-based approaches for collaborative filtering recommendation have limitations in effectively embedding neighboring nodes during node and neighbor information aggregation. Furthermore, weight allocation for the user (or item) representations after convolution of each layer is too uniform. To resolve these limitations, we propose a new Graph Convolutional Collaborative Filtering recommendation method based on temporal information during the node aggregation process (TA-GCCF). The method aggregates and propagates information using Gated Recurrent Units, while dynamically updating features based on the timing and sequence of interactions between nodes and their neighbors. Concurrently, we have developed a convolution attention coefficient to ascertain the significance of embedding at distinct layers. Experiments on three benchmark datasets show that our method significantly outperforms the comparison methods in the accuracy of prediction.
Keywords
Introduction
In the era of the Internet, the amount of online data has grown so rapidly that users suffer from the dilemma of information overload. Personalized recommendations play a very important role in discovering user preferences and helping users make decisions. Collaborative filtering (CF) [1] is a common method for achieving personalized recommendations. It generates effective recommendations based on users’ historical interactions with items, such as conversations, purchases, clicks. Learning how users and items are represented is crucial to improving the effectiveness of collaborative filtering (CF). Therefore, the trend in research is to enhance the effectiveness of CF by learning the information representation of users and items. The development of graph neural networks (GNNs) [2] has recently advanced the effectiveness of CF, which models the interaction data as graphs (e.g., user-item interaction graphs) and then applies GNNs to learn effective node representations for recommendations, known as graph collaborative filtering.
While graph collaborative filtering has shown significant results in the recommendation domain, existing approaches still suffer from two shortcomings: Graph Convolutional Networks (GCN) [3] usually use interaction records of check-in datasets to construct user-item interaction graph (as shown in the left of Fig. 2) when implementing collaborative filtering recommendations. However, in the user-item interaction graph for CF, each node (user or item) is only described by a one-hot ID, which has no concrete semantics besides being an identifier. [4], this causes the weight distribution in aggregating neighbor embedding to be usually fixed in the current methods. The temporal data in the check-in dataset provides important information for a deeper understanding of user behavior. Without involving node semantics, existing methods have difficulty in using temporal features to capture the decay and deviation of user preferences. Meanwhile, current methods often rely on basic splicing or merging techniques to combine layers of convolved embeddings [4–6], which is ineffective in distinguishing between different layer embeddings.
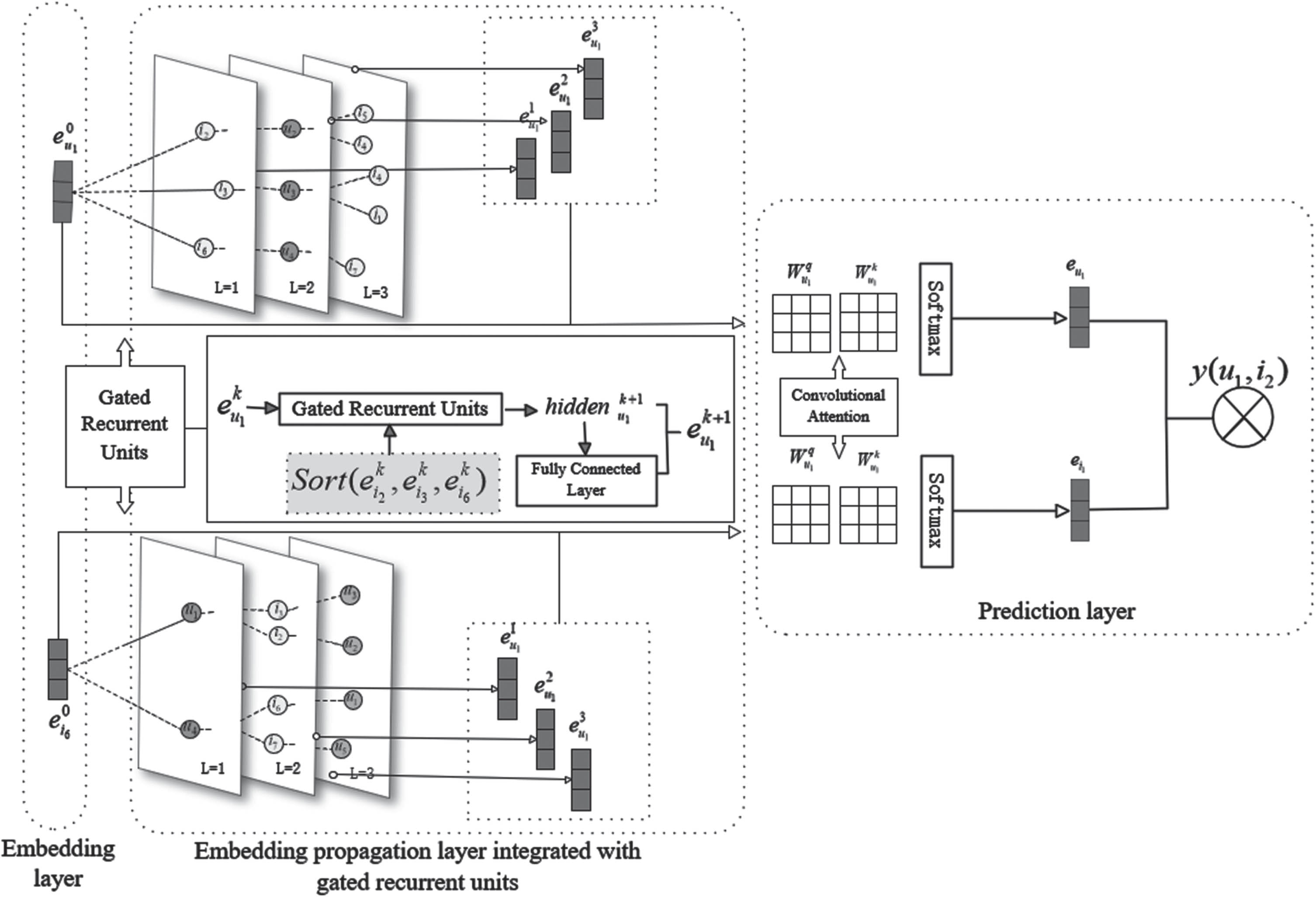
An illustration of TA-GCCF model architecture.
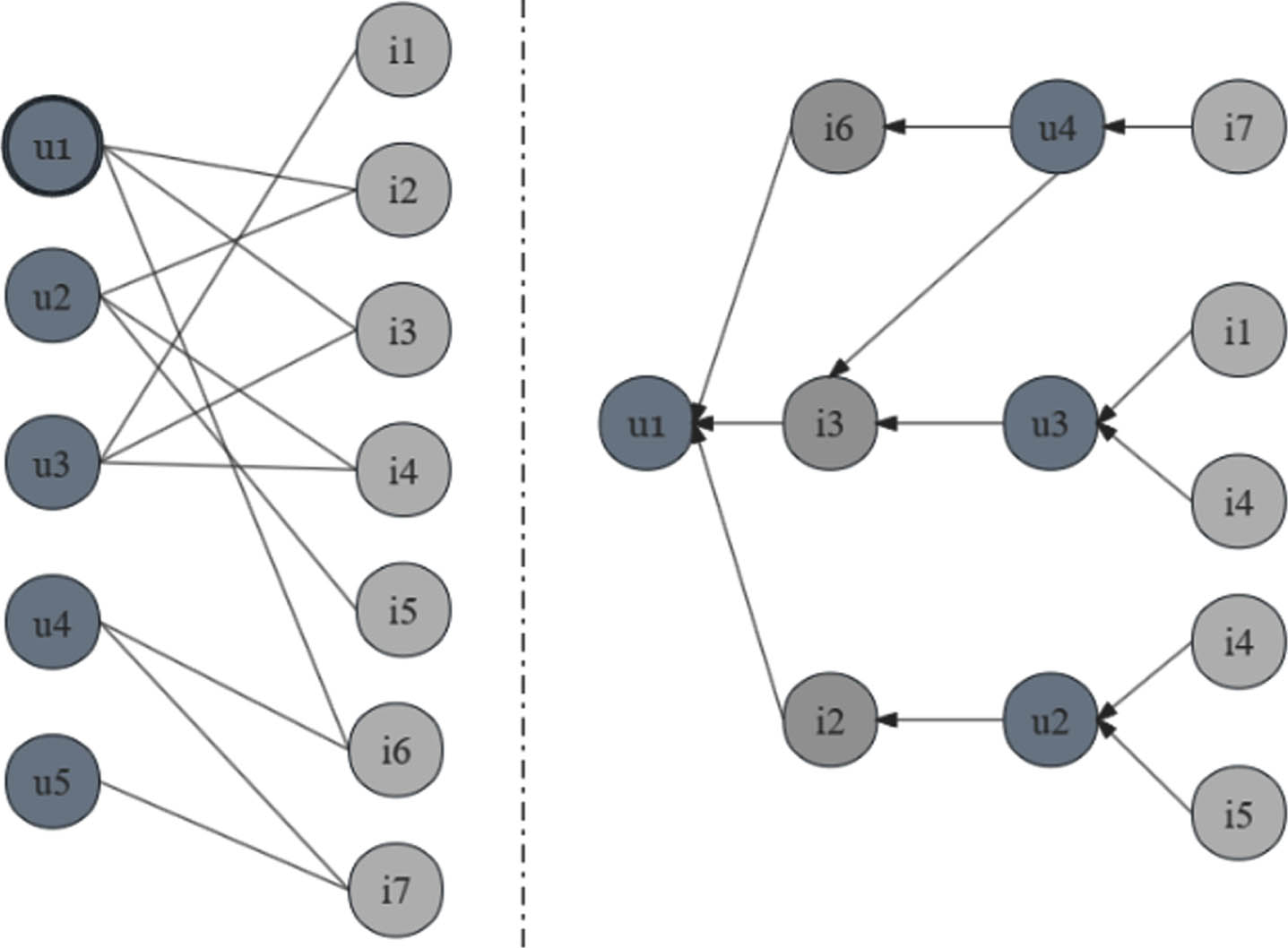
An illustration of the user-item interaction graph and the high-order connectivity incorporating temporal information. The node u1 is the target user to provide recommendations for.
To resolve these issues, we propose a new method of Graph Convolutional Network for collaborative filtering recommendation. We first introduce a temporal dimension in the user-item interaction graph and use the Gated Recurrent Unit (GRU) [7] to model feature changes at different interaction time nodes. The interaction sequence between users and items is considered as auxiliary information. At the same time, convolutional attention coefficients were devised to combine different embeddings within the graph convolution layer by learning the impact of each layer’s vector representations on the final representations.
Collaborative filtering infers the target user’s preference level for a specific product by utilizing behaviors (ratings, click counts) of users similar to the target user, and then makes relevant recommendations based on this inferred preference level [8, 9]. Matrix factorization [10] represents embedded user/item ID in the low-dimensional vector, predicting users’ ratings on items through the inner product of the user/item embedding. Other collaborative filtering methods have previously incorporated personal history as a pre-existing user embedding, along with embedding historical items to enhance its representation [1, 11]. Stai [12] presents a recommendation framework for personalized multimedia recommendation on an online platform that can recommend rich content accompanying videos to users while inferring their preferences based on interaction records.
The rapid progress of machine learning and deep learning technologies has led to their increasing use in the recommendation field to explore hidden associations between users and items. For instance, the neural collaborative filtering model combined with multilayer perceptron [13] (NCF) and the Collaborative Memory Network model [14] (CMN) are used. Nonetheless, these techniques still generate vector representations in the same way as matrix factorization, which considers the user-item pair as an independent individual and ignores the association between users and items.
In recent years, the natural compatibility of user-item interaction data with graph structures, along with advancements in computational capabilities, has directed increased attention toward recommendation models based on graph neural networks [15, 16]. Berg and others [17] proposed the GC-MC method, considering matrix completion of the recommendation system from the point of view of link prediction on graphs. Qu and others [18] proposed the concept of neighborhood interaction, expanding user-item interaction to neighborhood and neighborhood interaction through the graph. Wang and others [5] proposed the Neural Graph Collaborative Filtering model (NGCF), applied the method of graph convolution in recommendation, obtained higher-order collaborative information through the connectivity of graph network nodes, and incorporated it into the embedding of the target user/item. He and others [4] proposed a lightweight graph convolution model (LightGCN) to simplify the design of GCN and make it more concise and appropriate for recommendation. Liu and others [6] introduced the Gated Recurrent Unit in the graph neural network to solve the information loss problem between high-order connected nodes. Yang et al. [19] proposed STAM, which utilizes Scaled Dot-Product Attention to capture the temporal order of one-hop neighbors and joint attention for different latent subspaces using multi-head attention. Pareja et al. [20] proposed Evolved GCN, which focuses on dynamic graph data and models graphs at different time steps through the evolution of graph convolutional neural networks for recommendation. In their work, Wang [21] proposed LightGCAN. This approach captures static user preferences using a lightweight graph neural network with node aggregation only. Dynamic user preferences are captured using a time-aware graph attention network based on recent interaction terms. The two user preferences are then combined and fed into a dual-channel Deep Neural Network to learn feature interactions and predict matching scores.
While previous research has enhanced recommendation outcomes to an extent, it typically uses only rating information and hardly considers the influence of temporal information on node-aggregated neighbor features. Effective use of this information can further increase the accuracy of the recommendation algorithm.
TA-GCCF
Model architecture
Different from current collaborative filtering recommendation methods, the TA-GCCF approach proposed in this paper updates node features based on the temporal information of neighboring nodes and dynamically calculates the weights of the updated representation vectors, which ultimately improves the recommendation performance. Figure 1 illustrates the architecture of TA-GCCF. There are three components in the model:(1) Embedding layer: which constructs the adjacency matrix and initializes the embedding of users and items by using the user-item interaction graph. (2) Embedding propagation layer: which fuses the Gated Recurrent Unit and aggregates the high-order interaction information between users and items using graph convolution technology, capturing the temporal information of node interactions during the aggregation process. (3) The prediction layer is designed to create convolutional attention coefficients that learn the significance of the embedding vector following various convolution layers. It then uses the inner-product interaction function to determine the user’s preference for the recommended target item.
TA-GCCF detailed design
Definition of the problem
Embedding layer
The main role of the embedding layer is to construct an embedding representation of users and items, and the embedding vector contains information about users and items. Given user u and item i, their corresponding embedding representations are e
u
and e
i
, and the embedding vector lookup table initialized by users and items is as follows:
Where m represents the number of users, n is the number of items, and the superscript 0 indicates that the embedding is the initial zeroth-layer representation. The embedding lookup table serves as the initial state of user embedding and item embedding, it is processed and optimized in an end-to-end manner.
To capture the embedding of the user (item) and represent associative relationships between nodes, we aggregate nodes with interactive relationships. Normalized summation operations, which assign a static weight to all neighbors, have been used in many traditional models for node information aggregation. However, this has the limitation that equal aggregation does not distinguish the importance of neighbors, and in fact, the most recent interactive neighbors should have a higher weight during aggregation. Therefore, this paper presents a new aggregation method by adopting the Gated Recurrent Unit (GRU) to update the features of nodes in the convolution layer, and also adding a fully connected layer based on the GRU to assign different feature indices to different nodes, dynamically attenuating the weights of features with a larger time span.
The GRU uses the reset gate (r
t
) to control the amount of historical information it retains, the update gate (z
t
) to decide the amount of information to discard, and adds new state information (
W r , W z , W h represent the weight matrixes, σ(.) is the sigmoid activation function, ht-1 refers to the preceding moment’s output state, and x t is the current input. The symbols [·,·] denote the concatenation of two vectors, and ⊙ signifies the Hadamard product.
To simplify representation, the preceding function is formalized as:
Where f GRU () symbolizes the GRU network.
For each node u and i, we perform the following computations:
Where
Using the Laplace paradigm often used in graph convolutional networks, the coefficient indicates the measure of the contribution of the primary neighborhood nodes to the target node - the larger the first-order neighborhoods of the neighboring nodes, the lower the degree of contribution of the neighboring nodes to the target node, thereby preventing over-smoothing incidents. hiddenk+1 denotes the hidden state after the aggregation of the neighboring nodes by the GRU.
The Hadamard product of matrices A and T aims to integrate the two forms of information, the interaction relationship and the interaction time, into a novel graph structure matrix. Thus in the feature propagation process, not only the connectivity between nodes is considered, but also the time attributes of the interaction between nodes. The sort function sorts neighboring nodes according to time.
GRU output ‘hidden’ and corresponding timestamp input are processed by the fully connected layer for feature index calculation:
Where W α and W β represent trainable matrices, while “bias” stands for the bias term. The notation k ∈ Nu/i signifies all neighboring nodes of either the u or i node.
The final embeddings of the nodes are computed as the weighted sums of the outputs of all neighboring features:
This model further stacks multiple single-order propagation layers to explore higher-order interaction information and constructs high-order propagation of the model, as illustrated by the high-order connectivity graph in Fig. 2. The user of interest for recommendation is u1, labeled with the double circle in the left subfigure of the user-item interaction graph. The right of Fig. 2 expanded from u1 is illustrated by the subfigure on the right. For example, the path u1-i6/i3-u4 donates that stacking two convolutional layers can effectively capture the similarity in user behavior; through these two paths u1-i3-u3-i1, u1-i3-u4-i7 indicate that stacking three convolutional layers can explore potential recommendation priorities. In Fig. 2, neighboring nodes are sorted from top to bottom in order of interaction. For the two previous paths, following the use of GRU to aggregate the contributions of neighboring nodes, here it is assumed that the neighbor nodes that interacted first are more interesting, so i6, u4, and i7 are assigned greater weight by the update gate, thus predicting that i7 is more likely to arouse the interest of u1. In summary, the model uses the Z-layer stacking of the embedding propagation layer integrated with the Gated Recurrent Unit to capture the temporal information of user-item interaction for feature attenuation.
After the propagation of Z layers, multiple representations of user and item nodes are obtained. Following the concatenation operation, user/item representation matrices are obtained:
In the formula, W
q
and W
k
are trainable matrices, E is a representation matrix, and
The obtained γ represents the weight matrix for each layer of representation. The last layer of representation contains higher-order interactive information, therefore, the weight vector updated by the last layer Z is utilized:
Where β is the weight after comparing the representations of each layer with the final layer.
With the integration of the embeddings captured at each layer, the final user vector representation is constructed. The final embeddings for users and items take the following form:
In the model prediction section, we employ an inner product interaction function to estimate the user’s preference for the target item through an inner product operation.
To maximize the score difference between positive and negative samples. This paper uses the Bayesian Personalized Ranking (BPR)[22] loss function to train the model to increase the maximum margin probability. The objective function is as follows
Where P ={ (u, i, j) | (u, i) ∈ R+, (u, j) ∈ R- } represents the user’s interaction data set with the item, R+ is the observed user-item interaction, R- is the unobserved interaction, σ (.) represents the sigmoid function, λ ∥ Θ ∥ 2 is the L2 regularization term to prevent overfitting.
Dataset description
To evaluate the effectiveness of TA-GCCF, we use four publicly available benchmark datasets: Gowalla, Yelp2018, Amazon-Book, and MovieLens-1M. The Gowalla dataset is a check-in dataset from Gowalla collected from February 2009 to October 2010. Yelp2018 constitutes a part of the data released by Yelp from 2004 to 2018 as part of the Yelp Dataset Challenge. Amazon-Book contains information on 3 million book reviews for 212,404 books and the user information for these reviews. The MovieLens-1M dataset comprises 1 million ratings of 4,000 movies by 6,000 users, released in February 2003. Table 1 presents statistical information on the four datasets.
Statistics of the datasets
Statistics of the datasets
In this paper, we evaluate the performance of the recommendation method by using the commonly used evaluation metrics: Recall@k and Normalized Discounted Cumulative Gain (NDCG@k). We have set k = 20 as the default value.
These two evaluation protocols have also been widely applied in previous research [13, 14]. Recall@N is the proportion of the top-N recommended results that hit the items that the user will visit, while NDCG@N is an evaluation indicator based on sorting results, used to measure the quality of sorting.
To test the effectiveness of the TA-GCCF, this paper compares it to six state-of-the-art collaborative filtering algorithms.
GC-MC [17]: A matrix completion method based on graph convolutional neural networks. this method uses the interactive relationship and other auxiliary information between users and items and performs matrix filling by graph convolution operation to achieve recommendations.
NGCF [5]: This advanced recommendation method is based on graph convolutional neural networks, this model propagates the features of nodes in the user-item graph to fully consider the hidden information in high-order connections to improve recommendation performance.
LightGCN [4]: A collaborative filtering recommendation method based on graph structure, which learns embedding representation by linear propagation on interaction graph, and regards the weighted sum of embedding information from different propagation layers as the final embedding, removing feature transformation and non-linear activation and replacing self-connection with layer combination.
DGCF [23]: An advanced collaborative filtering approach that iteratively refines intent-aware interaction graphs and factor representations using graph disentangling module.
SGL [24]: Introduces a recommendation method for self-supervised learning and designs three types of data augmentation from different aspects to construct the auxiliary contrastive task.
SVD-GCN [25]: A simplified GCN that uses only the K-largest singular values and vectors for recommendation. A reformulation trick is employed to adjust the singular value gap, which helps alleviate the over-smoothing problem.
Implementation details
The models and baselines in this paper are implemented in Python 3.9, based on the RecBole framework. The machine runs on a CPU Xeon Gold 5117 2.50 GHz with a GPU NVIDIA Grid V100D-32Q and is operated under Windows 10. For each dataset, we randomly select 80% of the historical interactions of each user for the training set, 10% for the testing set, and 10% for the validation set.
The hyperparameters were optimized for all experiments using Adam [26] as the optimizer, and the parameters were initialized in the Xavier [27] manner. Each observed user-item interaction was treated as a positive instance, and a negative sampling strategy was performed to pair it with a negative item with which the user had no previous interaction. The data volume size for each processing is 4096, and the embedding size is 64. The DGCF is tuned in {2, 4, 8} and the SGL is instantiated using SGL-ED. The SVD-GCN is instantiated using the basic SVD-GCN-S. The optimal parameters are determined through grid search, with the L2 regularization coefficient λ adjusted in {10-5, 10-4 … 10-2} and the learning rate in {0.0001, 0.0005, 0.001, 0.005}. The number of model layers Z = 3 and η=γ3 are adjusted according to the experimental results. The model converged after 1000 iterations.
Performance comparison
Overall comparison
Five independent experiments were conducted on the same four datasets for the model presented in this paper and the comparison model. The average experimental results are shown in Table 2.
Overall performance comparison
Overall performance comparison
TA-GCCF is found to be improved in all comparisons with the baseline methods recommended above for collaborative filtering. It adequately captures the higher-order interactions between users and items, outperforming GC-MC. Due to the lack of node characterization in collaborative filtering scenarios, TA-GCCF achieves a significant improvement compared to NGCF. LightGCN uses only normalized summation to aggregate node information and the average distribution of representation weights. In contrast, TA-GCCF dynamically learns the weights and achieves significant results. DGCF has mediocre performance, and we speculate that the dimension of the disentangled cannot carry enough features in the case of limited overall dimensionality. SGL compares the original graph with the augmented graph for comparison, ignoring other potential relationships (e.g., user similarity) in the recommender system. SVD-GCN benefits from its replaced neighborhood aggregation and performs optimally in all baselines. However, TA-GCCF outperforms SVD-GCN by fully utilizing multidimensional features.
In terms of the overall comparison of recommendation effects among models, our proposed model significantly improves the two evaluations metrics across all four datasets compared to other methods This demonstrates the rationality of the model design and also proves the model’s efficiency and good generalization capacity.
To investigate the optimal number of embedding propagation layers, we varied the depth of the model. The experiment search L in the range of {1, 2, 3, 4} and summarize the empirical results in Table 3. As the number of layers in the graph convolutional layer increases, the recommendation effect of the model also improves significantly. Nonetheless, when the layer number increases to 4, the model shows overfitting. This is because the embedding propagation layer’s increased depth leads to an over-smoothing of the feature representation between nodes, which causes a lack of distinction in the node representation and reduces the model’s recommendation effectiveness. And, when the stacking of embedding propagation layers is too high, too much noise is introduced into the model training, which causes overfitting. This also indirectly verifies that the stacking of three embedding propagation layers is sufficient to capture effective collaborative filtering signals.
Effect of embedding propagation layer numbers
Effect of embedding propagation layer numbers
To further investigate the impact of different modules of TA-GCCF on model accuracy, we performed different transformations on TA-GCCF and obtained the following variant methods for compa-rative experiments. TA-GCCF-G: which removes convolutional attention coefficients to learn the weights of each representation vector, the default is the same weight, i.e. γ L = 1/(Z + 1). TA-GCCF-A: which removes GRU to capture temporal information, only using the convolutional attention coefficient. TA-GCCF-L: which removes both GRU and convolutional attention coefficients. Figure 3, show the performance differences between TA-GCCF and its different variants, using Recall and NDCG as two metrics to evaluate the effectiveness of each module. From the results of the experiment, it is apparent that the indicators for all variants decrease to varying degrees after the removal of the module across the three datasets. The decrease of TA-GCCF-A is larger than that of TA-GCCF-G, which indicates that temporal features are more effective than convolutional attention coefficients in improving model accuracy. The indicators reach the lowest level when two modules are deleted at the same time, which dem-onstrates the effectiveness of the model.
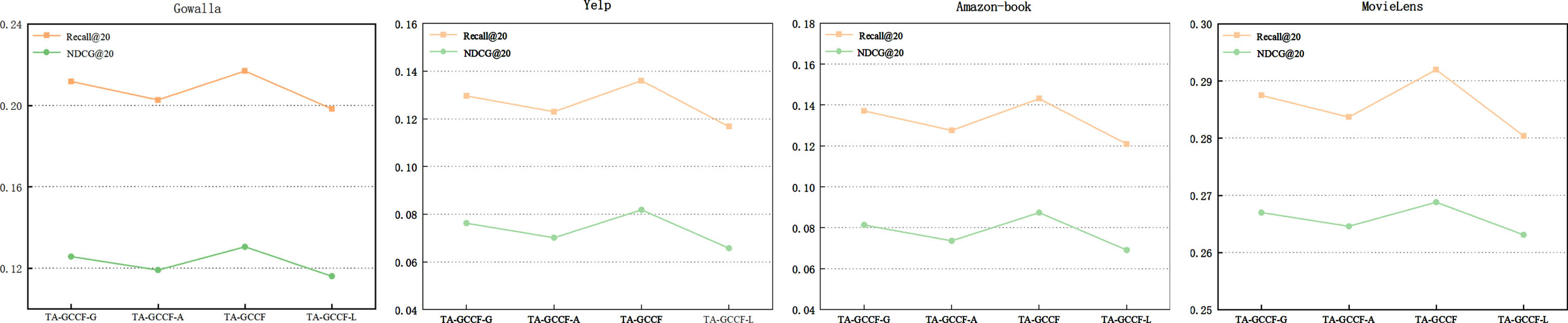
Ablation analyses.
As a whole, the accuracy of TA-GCCF’s recom-mendations is significantly improved from these variants. It has been demonstrated that the modules proposed in this paper do not conflict with each other and they all contribute to improving the recommendation performance of the model.
The TA-GCCF’s convolutional attention coefficient default calculation is based on the representation of the last layer when measuring similarity. To investigate whether the learning effect of the representation of the last layer is the best, we perform a comparative experiment in this section using the representation of different layers to compute similarity. The layers set for this experiment are γ1, γ2, and γ3, with the experi-mental results as shown in Table 4. When η=γ3, i.e. the representation of the last layer is used to compute the similarity, it can be seen that TA-GCCF has a performance improvement compared to the first two layers. Because, under the premise of reducing the effect of overfitting after the embedding propagation layer experiment, the representation of the last layer has higher-order connectivity and can capture higher-order interaction features between nodes. Therefore, the effect of using the last layer representation for computation is better.
Comparison of convolutional attention parameters conclusion
Comparison of convolutional attention parameters conclusion
In this work, we propose a new method named TA-GCCF., which considers the interaction information between the user and item at the embedding layer; the GRU and graph convolutional neural network are introduced in the embedding propagation layer, and a new aggregation method is proposed to capture the temporal features between nodes; the convolutional attention coefficient is used in the prediction layer to assign weights to different representation vectors, finally predicting the association score between the user and the item using the inner product operation. The experimental results show that compared with the existing mainstream collaborative filtering recommendation models, the model in this paper has achieved better recommendation results.
Footnotes
Acknowledgments
This work is supported by the University Collabo-rative Innovation Project (GXXT-2021-093-2) and Anhui Key R&D Programme Project –Top level Tackling Project (202004a07020050).