
Abstract
Joint spectral-spatial feature extraction has been proven to be the most effective part of hyperspectral image (HSI) classification. But, due to the mixing of informative and noisy bands in HSI, joint spectral-spatial feature extraction using convolutional neural network (CNN) may lead to information loss and high computational cost. More specifically, joint spectral-spatial feature extraction from excessive bands may cause loss of spectral information due to the involvement of convolution operation on non-informative spectral bands. Therefore, we propose a simple yet effective deep learning model, named deep hierarchical spectral-spatial feature fusion (DHSSFF), where spectral-spatial features are exploited separately to reduce the information loss and fuse the deep features to learn the semantic information. It makes use of abundant spectral bands and few informative bands of HSI for spectral and spatial feature extraction, respectively. The spectral and spatial features are extracted through 1D CNN and 3D CNN, respectively. To validate the effectiveness of our model, the experiments have been performed on five well-known HSI datasets. Experimental results demonstrate that the proposed method outperforms other state-of-the-art methods and achieved 99.17%, 98.84%, 98.70%, 99.18%, and 99.24% overall accuracy on Kennedy Space Center, Botswana, Indian Pines, University of Pavia, and Salinas datasets, respectively.
Keywords
Introduction
Hyperspectral images (HSIs) consist of several hundreds of continuous spectral bands across the entire electromagnetic spectrum, which provide wealth of information and helps in distinguishing objects or physical materials [1]. It has several applications such as environment observing [2], military purpose [3], agriculture [4]. On the other hand, HSIs also present inherent challenges, such as information redundancy, uncertainty, high dimensionality, varying spatial dimensions, interclass similarity, intraclass diversity, variations within the same class spectrum, and limited availability of labeled samples. However, one of the major task in the application of HSI is classification, which targets to assign a particular class to every image pixel. To classify the pixel, various HSI classification methods have been proposed such as support vector machine (SVM) [5, 6], sparse representation classifier [7]. Meanwhile, extreme learning machine (ELM), active learning [8], and other methods have been introduced and shown satisfactory performance. But, due to the presence of same spectrum of different objects and different spectrum of same objects, it was difficult for the methods to distinguish objects efficiently as they were relied only on spectral information [9, 10]. For this reason, poor classification accuracy has been reported by many methods. However, with the advancement of imaging technology, HSI sensors can exploit spatial information, which is another useful information resource. Early attempts for extracting spatial feature in HSI classification have shown improved classification performance [11, 12, 13]. But, it has been observed that depending only on spatial information also makes it hard to identify all types of objects due to complex distribution of spatial structure. Therefore, several studies in the past have suggested to consider both spectral and spatial features for improving the representation capability of HSIs.
During the past decades, various studies were carried out based on spectral-spatial features. But, the early spectral-spatial based classification approaches were relied on shallow features, which were unable to represent semantic information. Recently, various deep learning methods, such as stacked autoencoder (SAE) [9], deep belief network (DBN) [14] and convolutional neural network (CNN) [15, 16, 17, 18, 19], have shown excellent performance in various applications. These deep learning methods have been extensively used as powerful feature extraction methods. Compared with traditional methods, deep learning methods [20, 21, 22, 23, 24, 25] are much efficient for extracting abstract and semantic features. Therefore, HSI classification using these deep learning methods have shown great research interest in recent times.
For instance, in [9], a SAE based deep learning framework was proposed to extract joint spatial-spectral features. Chen et al. [14] presented DBN based model by training multiple layer’s through restricted Boltzmann machine network. To extract spatial information, SAE and DBN follows the same neighboring structure by converting image cube into 1D vectors. Therefore, it has limitation on spatial feature extraction. On the contrary, CNN can efficiently extract the spatial information through local connections and reduce the number of parameters by using shared weights [15]. Thus, CNN has attracted particular research interest in HSI classification [26, 27, 28, 29, 30, 31]. In [26], a CNN is adopted for spectral-spatial feature extraction of a pixel after applying the Randomized PCA and classification is done through multi-layer perceptron. Li et al. [27] presented a fully CNN based framework which enhances deep features via convolutional, deconvolutional and pooling layers. In [28], a HSI reconstruction model has been built by using deep CNN for improving the spatial feature, which follows ELM for classifying the image. Yu et al. [29] integrated hash features in a CNN framework which utilizes semantic information to enhance the classification performance. In [30], Chen et al. introduced 1D CNN, 2D CNN and 3D CNN to effectively learn the deep spectral and spatial features in the perspective of HSI classification. In 3D CNN, simultaneous extracting of spectral and spatial features may cause the loss of spectral information [31]. Therefore, to address this problem, we need to extract spectral and spatial features separately.
After spectral-spatial feature extraction, feature fusion is another important step for HSI classification [32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43]. In [32], a dual channel CNN method was proposed for extracting spectral and spatial features through 1D CNN, and 2D CNN, respectively and fused them together. Hao et al. [33] have proposed two channel framework with fusion scheme. The two channel framework includes stacked denoising autoencoder for encoding spectral information and CNN for spatial feature extraction. The extracted features from these two models were fused by adaptive-class specific weight. Xu et al. [34], presented a fusion scheme where the features from HSI and other sensor’s data (e.g. light detection and ranging) were extracted through CNN and cascade block CNN, respectively. Song et al. [35], proposed a fusion network where residual learning has been introduced to optimize the several convolutional layers and fused the output of different hierarchical layers to improve the classification accuracy. Cheng et al. [37] also improved the classification performance by adopting the off-the-shelf CNN models and unified metric learning based framework. In [38], the unsupervised cooperative sparse autoencoder was presented for fusing spatial context and raw spectral information. In [39], a novel fusion scheme was proposed. It utilized complimentary information of subpixel, pixel and superpixel for HSI classification. Li et al. [40] fused the spectral-spatial and texture features to complete the HSI classification. Recently, Zou et al. [41] adopted a fusion technique by utilizing fully 3D convolutional neural network to extract spectra-spatial and semantic information for HSI classification. From these fusion strategies, it can be concluded that fusion can be a effective choice to enhance the classification performance of HSI.
Nevertheless, optimal number of bands is an important criterion for visual recognition, especially when HSI is considered. The HSI classification models proposed in literature [30, 44] employed excessive number of bands for feature extraction, but these models were not fully able to extract the discriminative features due to mixing of informative and less informative (or noisy) bands. Further, the use of excessive bands may cause negative effects such as overfitting, performance degradation, and high computational cost.
To overcome the aforementioned drawbacks, we proposed a novel deep hierarchical spectral-spatial feature fusion (DHSSFF) method to classify HSIs. In DHSSFF, specific features were extracted separately through two different CNN based architectures, where 1D CNN is used to extract spectral features by considering entire spectral bands and 3D CNN is employed for extracting spatial features from few informative bands. Then, the extracted deep features from two architectures were fused to retain the discriminative feature followed by predicting the class level. This paper’s major contributions are summarized as follows.
Proposed a model named DHSSFF, where deep spectral and spatial features are extracted through 1D CNN and 3D CNN, respectively, to generate the accurate classification result. To make full use of spectral and spatial information, proposed model focuses on deep feature fusion which can merge the detailed information of shallow layers and semantic information of deep layers. Investigation of effect of number of bands on the performance of proposed model. Investigation of effect of number of training samples on the performance of proposed model. Extensive comparison of our model with the literature on five widely used HSI datasets.
The remaining part of this paper is organized as follows. Section 2 outlines our proposed method, which contains entire spectral band based 1D CNN, few informative band based 3D CNN, and fusion of deep spectral-spatial features for HSI classification. Section 3 demonstrates the experimental results and analysis followed by conclusion in Section 4.
Proposed methodology
In this section, we have presented a novel DHSSFF model for HSI classification. Here, the deep spectral features were extracted via 1D CNN by considering entire spectrum signatures. On the other hand, few informative bands were selected using principal component analysis (PCA) [45] to extract deep spatial features through 3D CNN. The reason for selection of PCA over other algorithms for hyperspectral image is its ability to effectively reduce dimensionality while preserving significant spectral information, its simplicity, interpretability and its widespread acceptance. At last, we have adopted a fusion technique to take full advantage of deep spectral-spatial features. In the following sections, a brief description has been provided of CNN model. Then, the details of entire spectral band based 1D CNN (ESB1DCNN) has been provided followed by few informative band based 3D CNN (FIB3DCNN). Finally, the proposed DHSSFF model has been presented.
CNN
In general, the CNN is constructed by alternate stacking of convolutional layers, pooling layers followed by fully connected (FC) layers. Let


After utilizing activation function, the pooling operation progressively downsizes the spatial dimension of the feature maps, which deals with minimizing the computation cost. The most common pooling method in HSI classification is max pooling [46] which picks strongest value from the pooling region to hold the discriminative features. Generally, after several convolutional and pooling operations, FC layers are considered at the top of the network. FC layer combines all the feature maps generated from its previous layer by converting them into a feature vector. Finally, the feature vector is transferred to the softmax layer to produce the probability distribution of each class.
In this paper, we have introduced a ESB1DCNN model as shown in Fig. 1 for spectral feature extraction. Here, normalized image in the range [

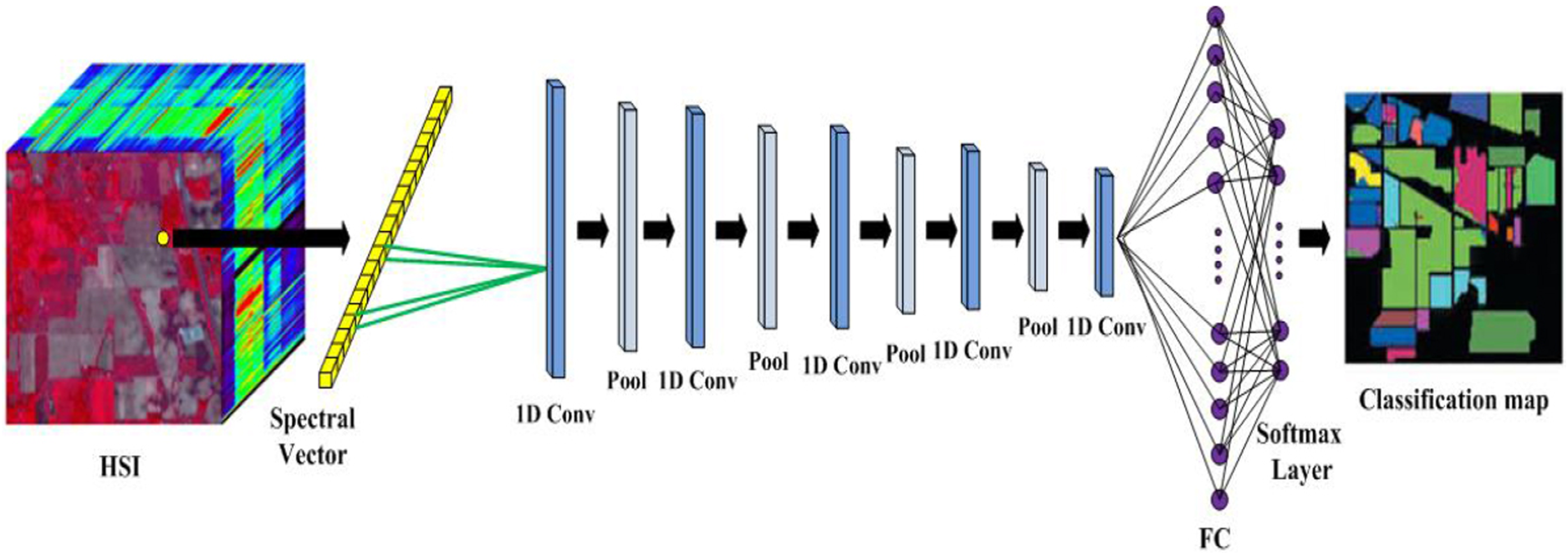
Architecture of ESB1DCNN model for spectral feture extraction.
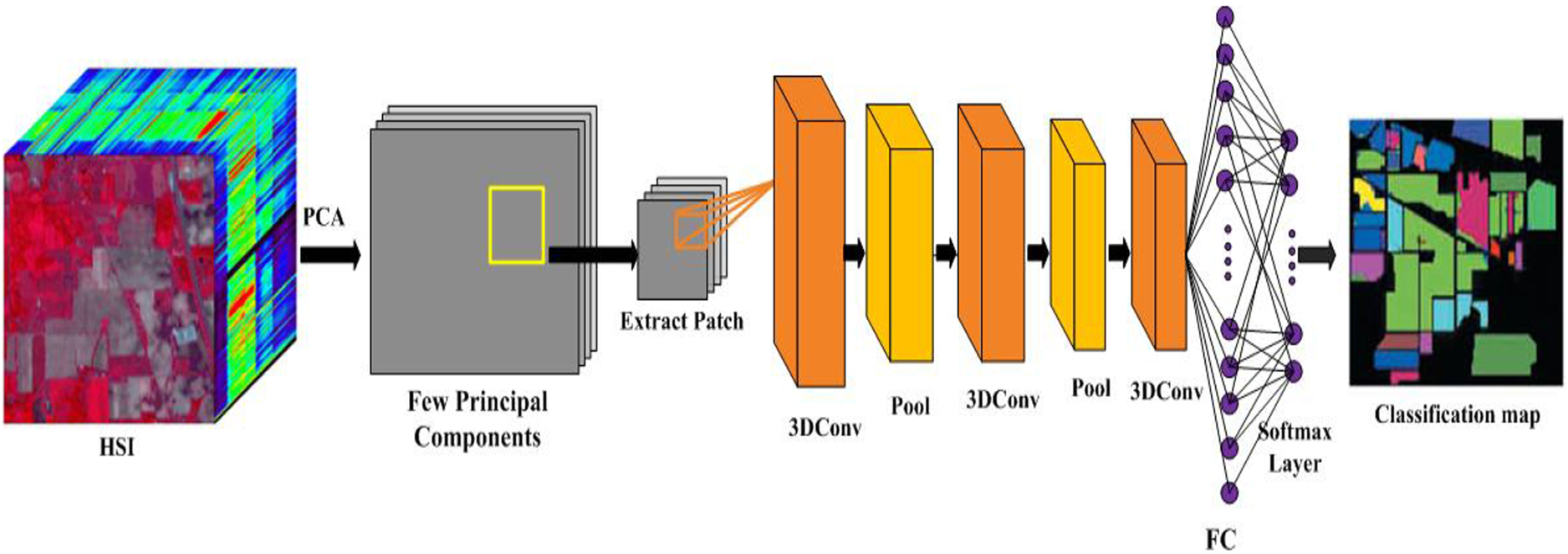
Architecture of FIB3DCNN model for spatial feture extraction.
To extract spatial features, another model FIB3DCNN has been developed in this paper. The Fig. 2 shows the FIB3DCNN architecture. As a preprocessing step of HSI classification, we have performed normalization in the range of [

Considering the complex structure of HSI, our FIB3DCNN model consists of four convolutional layers, two pooling layers, and one FC layer to process the image patches. But, after processing of several convolutional and pooling operations, sudden conversion of convolutional (or pooling) layer to FC may lead to spatial information loss. Due to this, we have adopted multiple convolutional layers before FC layer, where both spatial and semantics information were exploited properly.
In HSIs, the spectral bands of pixels of same class may vary due to the different imaging conditions, e.g., change in weather, environment, and temperature. Therefore, depending only on too few bands is critical for spectral-spatial feature extraction. On the contrary, spectral-spatial feature extraction requires several bands to be considered. However, excessive band may be associated with mixing of informative and non informative bands, which cannot provide desirable spectral and spatial features. For instance, when convolution operation is performed on HSI, any non informative band may lead to spectral information loss. Due to this, we have extracted spectral and spatial features separately using ESB1DCNN and FIB3DCNN, respectively and this dual channel model collectively called as DHSSFF model.
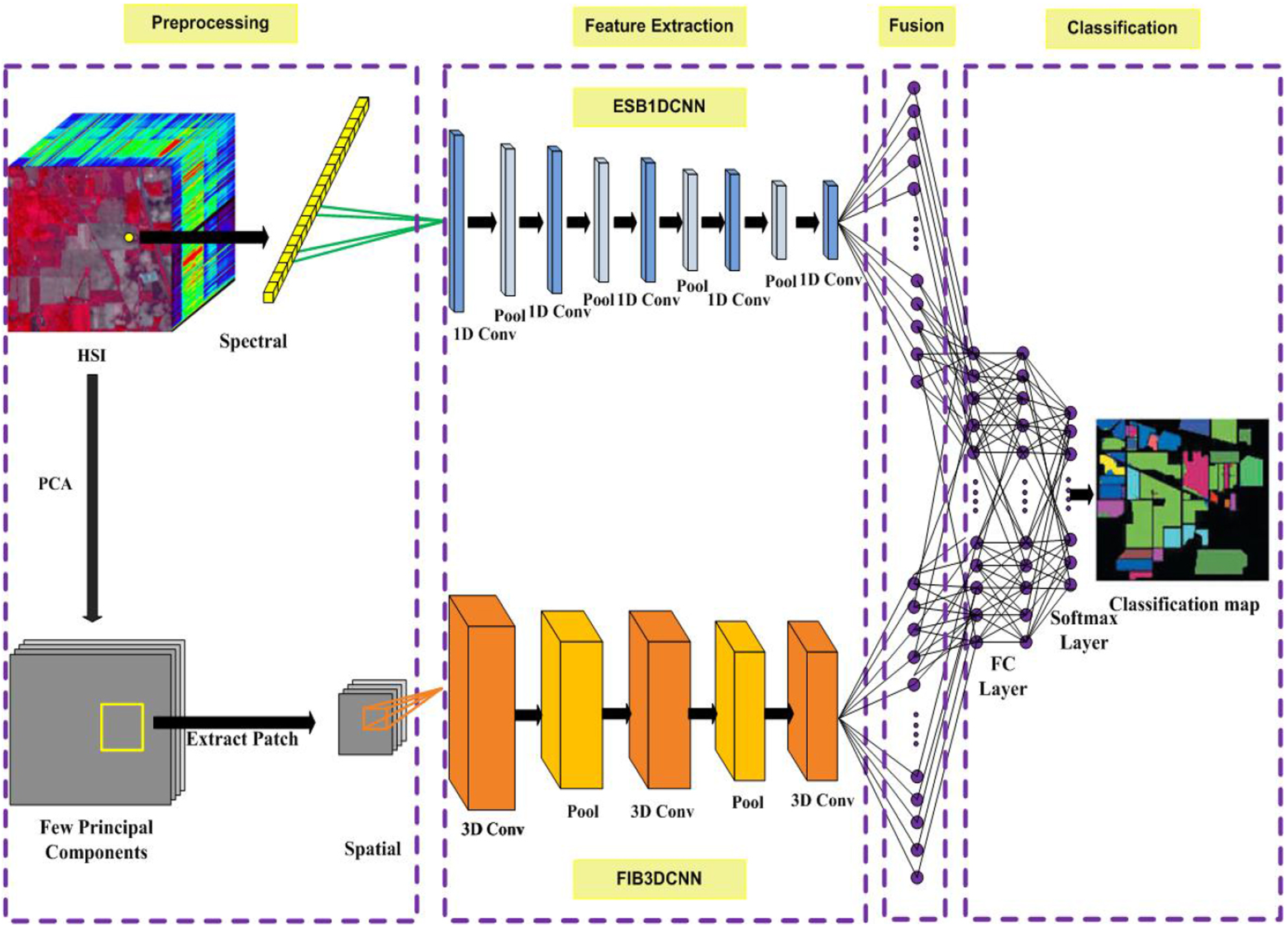
Architecture of the proposed DHSSFF model.
The architecture of DHSSFF model is shown in Fig. 3. The entire architecture is divided into four stages. In the first stage, preprocessing has been performed such as normalization and selection of informative bands using PCA for spatial feature extraction followed by patch extraction. The second stage is dedicated for feature extraction. The spectral features were extracted using ESB1DCNN and spatial features were extracted using FIB3DCNN. After that, a fusion scheme has been adopted to concatenate the deep features obtained from aforementioned two models which form a FC layer. In addition, we have considered two more FC layers for better representation of semantic information and lastly, a softmax classifier to predict the class label.
The pseudo code of DHSSFF model is represented in Algorithm 3. Let



Datasets
To show the effectiveness of our model, we have performed several experiments on five well known HSI datasets: Kennedy Space Center (KSC), Botswana (BOT), Indian Pines (IP), University of Pavia (UP) and Salinas (SA). The details of datasets are given below.
The KSC hyperspectral image was gathered by the Airborne Visible Infrared Imaging Spectrometer (AVIRIS) sensor over KSC, Florida, on March 23, 1996. This data set includes 176 bands after removing water absorption and noisy bands, which ranging from 0.4 to 2.5
The BOT dataset was captured by the NASA EO-1 satellite over the Okavango Delta, Botswana. It contains 242 spectral bands with 0.4 to 2.5

The IP hyperspectral image was acquired by the AVIRIS sensor in June 1992 over the Indian Pines test site in North-western Indiana. This image is comprising of 220 spectral reflectance bands in the wavelength range from 0.4 to 2.5
The UP image covers an urban area of the University of Pavia, Northern Italy. It was captured by the Reflective Optics System Imaging Spectrometer (ROSIS) sensor on July 8, 2002. This dataset has 115 spectral bands across the spectral range from 0.43 to 0.86
The SA dataset was also recorded by the AVIRIS sensor over the area of Salinas Valley, California, USA with a spectral range from 0.36 to 2.5
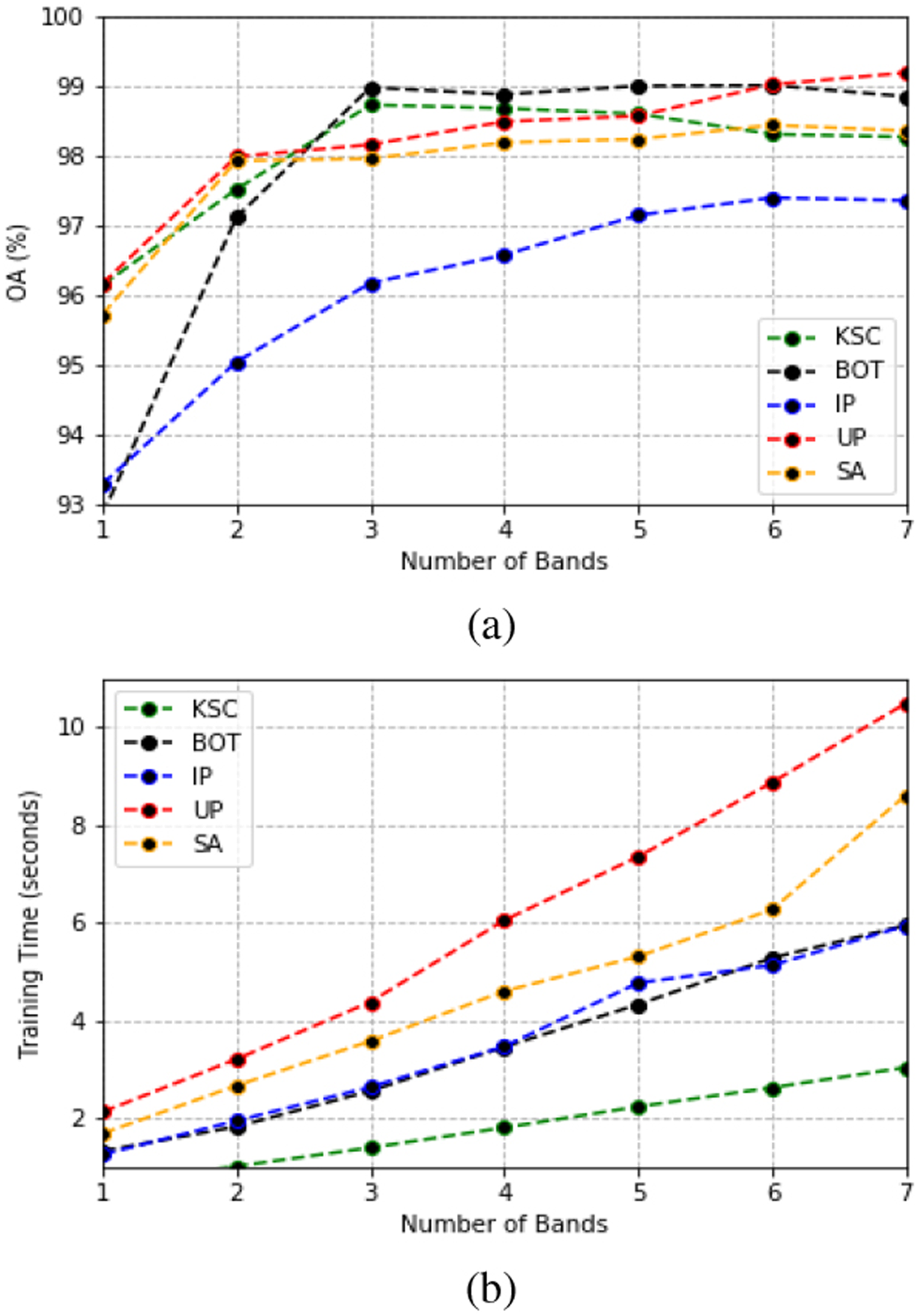
Sensitivity to the number of bands on FIB3DCNN for KSC, BOT, IP, UP, and SA datasets. (a) OA Vs number of bands. (b) Training time Vs number of bands.
In our experiments, we empirically selected the parameters of ESB1DCNN, and FIB3DCNN. Table 1 shows the details of the architecture adopted for each dataset. In Table 1, the convolutional, pooling, and fully connected layers have been represented with C, P, and FC, respectively. For convolutional layer, the kernel size is varied according to the datasets. The max pooling of size 1
Architectural details of ESB1DCNN and FIB3DCNN
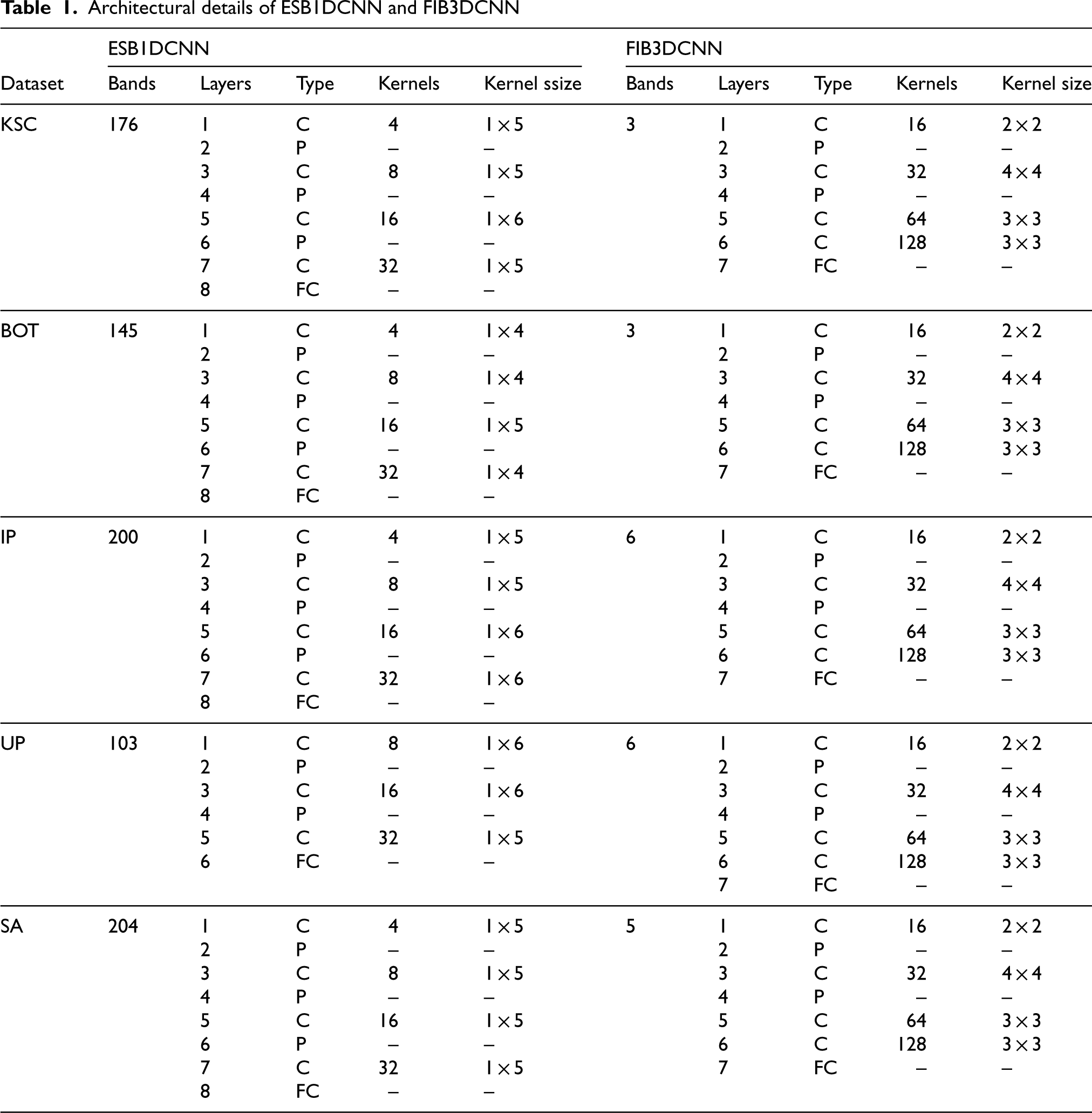
Architectural details of ESB1DCNN and FIB3DCNN
To measure the performance of classification methods, we have adopted three popular indexes: overall accuracy (OA), average accuracy (AA), and kappa coefficient (
In order to verify the effectiveness of the proposed model DHSSFF, we have compared it with four methods, SVM with radial basis function (RBF-SVM), ESB1DCNN, FIB3DCNN, and spectral spatial 3D CNN (SS3DCNN) [30]. For RBF-SVM and ESB1DCNN, spectral information alone is used in HSI classification whereas spatial features were extracted using image patches (27
Considering too few band for classification may lead to unsatisfactory performance due to the information loss. On the other hand, use of excessive number of bands results in reduction of classification accuracy due to non-informative bands with increase in computational time. Hence, an empirical investigation of trade-offs between classification accuracy and computational time has been done to get the number of optimum bands for each dataset in FIB3DCNN. We have selected the most informative bands using PCA by applying different number of principal components from 1 to 7 as shown in Fig. 4(a) and recorded the OA and training time. After analyzing, we have observed that the classification accuracy gets decreasing after third band with increase in computational time for KSC dataset as depicted in Fig. 4(b). Therefore, we have set the number of bands for KSC dataset as 3. Similarly, the classification accuracy gets saturated or start decreasing after 3rd, 6th, 6th, and 5th bands for BOT, IP, UP, and SA dataset, respectively. Hence, the number of bands has been set as 3, 6, 6 and 5 for BOT, IP, UP, and SA dataset, respectively.
Sensitivity to the number of training samples
To get the better performance, a deep learning model needs huge number of labeled training samples. On the contrary, remote sensing image has very less number of labeled training samples. Therefore, the objective in HSI classification is to achieve high classification accuracy with as less training samples as possible. In order to select the training samples, we have presented here an analysis with varying proportions of training and test samples for five methods on five datasets.
Figure 5(a)–(e) shows overall accuracy obtained using five methods with varying proportions of training samples. For KSC, BOT, and IP datasets, 4%, 6%, 8%, 10%, and 12% samples as training sets were haphazardly chosen from each class. As UP and SA datasets consist of huge number of samples compared with KSC, BOT, and IP datasets, less training samples were selected for these datasets. The proportions of training samples considered as 1%, 2%, 3%, 4%, 5% for UP dataset and 1%, 1.5%, 2%, 2.5%, 3% for SA dataset. We have observed from Fig. 5(a)–(e) that the classification performance gets improved when number of training sample is increased for all the methods and for all the datasets. In addition, our observation in DHFFSS method is that the OA reaches above 99%, 98%, and 98% for KSC, BOT, and IP dataset, respectively when 10% training samples were selected. There is marginal improvement in OA when more than 10% training samples were considered with increased computational time. Therefore, we have found 10% training samples to be an optimal choice for KSC, BOT, and IP datasets. With similar observations, 4% and 2.5% training samples have been found the optimal proportion for UP and SA datasets, respectively. Moreover, similar behavior can be observed in case of other methods on all five datasets. Hence, all the experiments performed in this paper are based on these selected proportions of training samples.
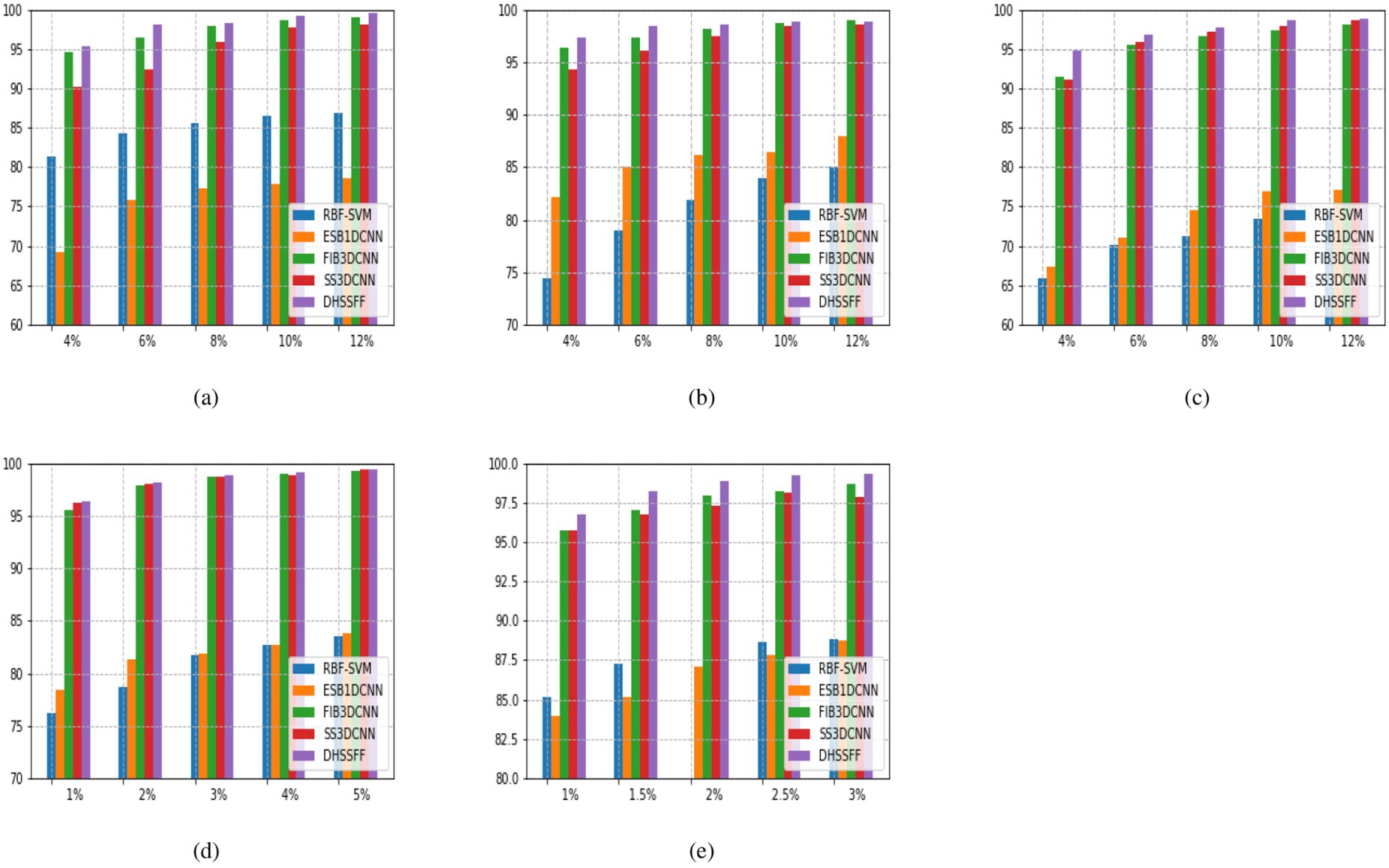
Sensitivity to the number of training samples using RBF-SVM, ESB1DCNN, FIB3DCNN, SS3DCNN, and DHSSFF methods. (a) KSC. (b) BOT. (c) IP. (d) UP. (e) SA.
Results on KSC dataset
The first experiment was performed on KSC dataset. All labeled samples were partitioned into training and test set. About 10% samples from each class were haphazardly selected to train the model, and rest samples were used as test set which is shown in Table 2.
Number of training and test samples used in the KSC dataset

Number of training and test samples used in the KSC dataset
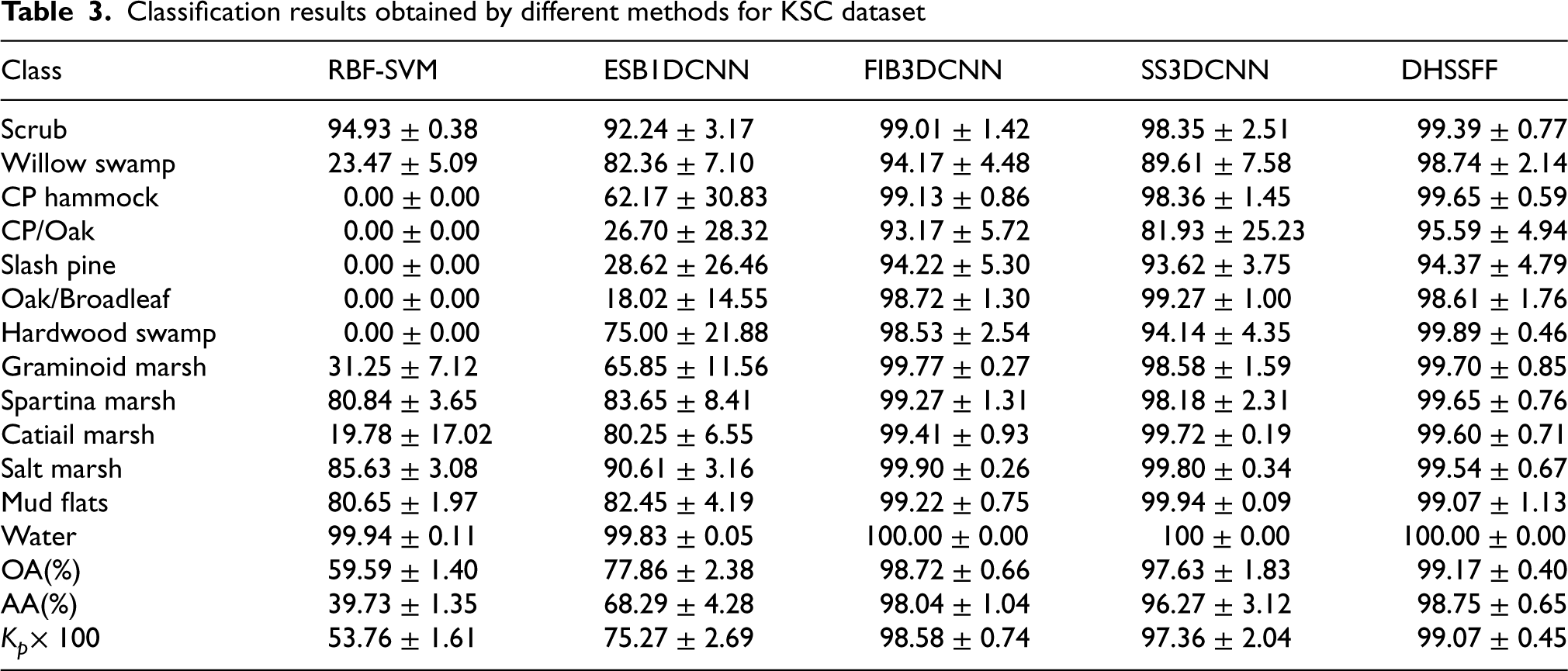
The classification results obtained through different methods for KSC dataset have been depicted in Table 3. We have reported the class-wise accuracy, OA, AA and Kp with standard deviation over 20 trials. The first 13 rows show the class wise accuracy and the last three rows represent OA, AA, and Kp. From the table, it can be observed that RBF-SVM performance is very poor for most of the classes. This is mainly happened due to the shallow learning nature of RBF-SVM. In particular, RBF-SVM fully misclassified few classes (CP hammock, CP/Oak, Slash pine, Oak/Broadleaf, Hardwood swamp) because of its inability in capturing the proper spectral information from limited training samples. Compared to RBF-SVM, EDB1DCNN shows better performance due to the deep feature extraction ability and has the support of spatial information. From the table, we can also see that all the spectral-spatial based methods such as FIB3DCNN, SS3DCNN, and DHSSFF have shown better classification results because of the combination of spectral and spatial information. Compared to FIB3DCNN and SS3DCNN, proposed DHSSFF has shown better classification result due to its deep feature fusion technique. With respect to class wise accuracy, DHSSFF obtained best classification accuracy in four classes (e.g. Scrub, Willow swamp, CP hammock and Spartina marsh) and marginally less in other classes among all the five methods. Moreover, DHSSFF has gained the improvement in OA by 0.45%, AA by 0.71% and Kp by 0.49% with its closest competitor FIB3DCNN.
Classification results obtained by different methods for KSC dataset
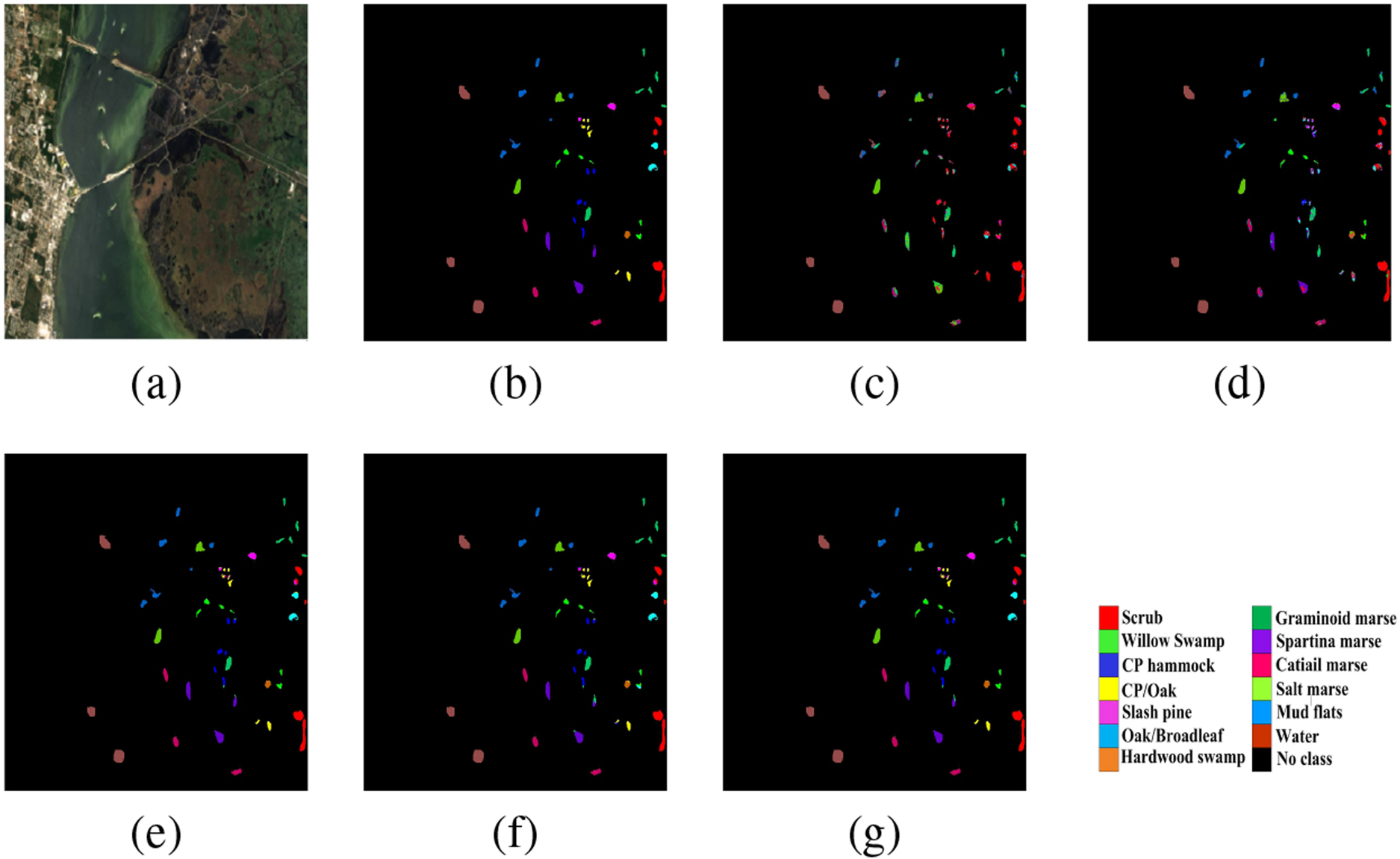
Classification maps for KSC dataset. (a) False color image (b) Ground truth. (c) RBF-SVM. (d) ESB1DCNN. (e) FIB3DCNN. (f) SS3DCNN. (g) DHSSFF.
Number of training and test samples used in the BOT dataset
Apart from the quantitative evaluation, the classification maps have been generated using five methods on KSC dataset as shown in Fig. 6(c)–(g). It can be observed that RFB-SVM and ESB1DCNN could not generate accurate classification map due to utilization of spectral information only. The remaining methods have shown satisfactory performance, since they considered both spectral and spatial information.
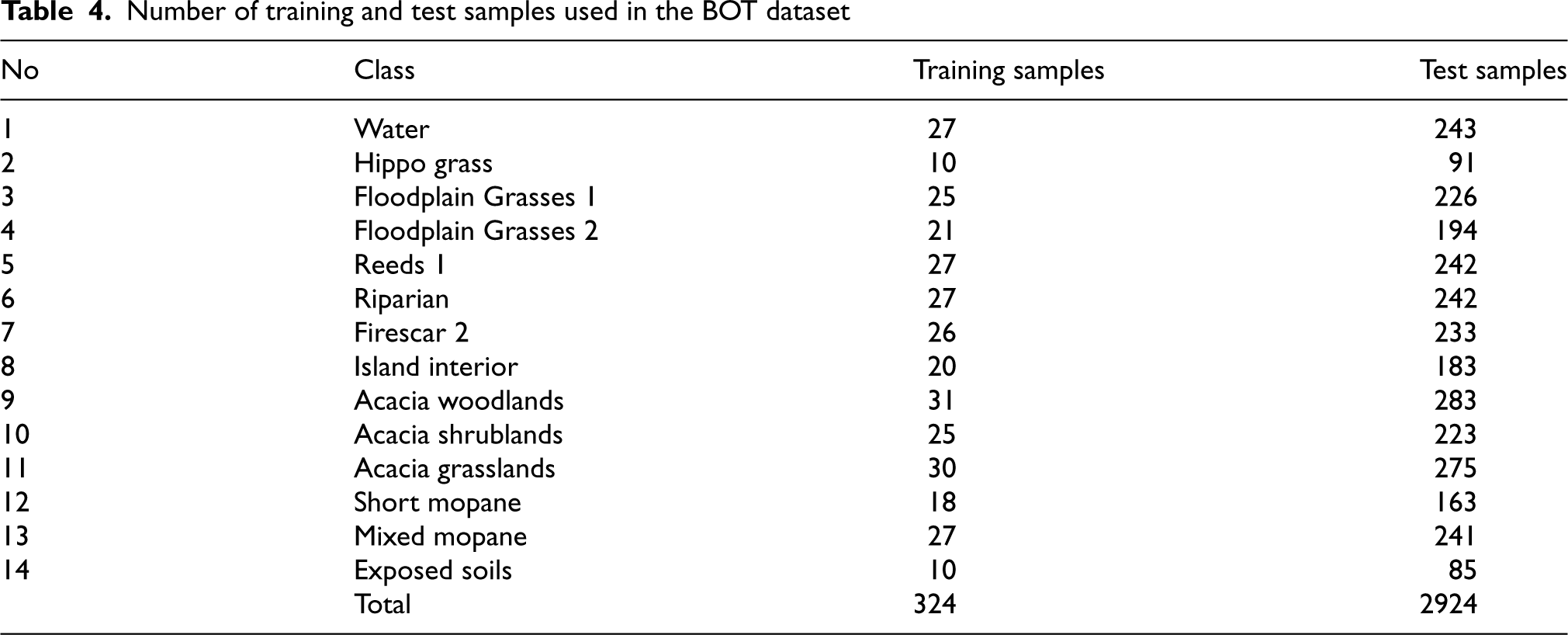
In the BOT dataset, 10% samples from each class were randomly selected as training set and the rest samples were considered as test set. The distribution of training and test samples from each class are shown in Table 4.
The classification results of five methods on BOT dataset have been shown in Table 5. From the table, we can see that all the spectral-spatial based methods including FIB3DCNN, SS3DCNN, and DHSSFF have shown better classification results than RBF-SVM and ESB1DCNN. In addition, the FIB3DCNN, SS3DCNN, and DHSSFF methods have achieved over 92% classification accuracy for all the classes and obtained absolutely correct classification results in the Firescar 2 class. However, many samples have been misclssified by RBF-SVM, ESB1DCNN, FIB3DCNN, and SS3DCNN in the Riparian class. Compared with these methods, DHSSFF has increased by 38.86%, 36.38%, 0.87%, and 1.91%, respectively. Beside this, DHSSFF has obtained high classification accuracy in most of the classes and achieved best statistical results in term of OA, AA, and
Classification results obtained by different methods for BOT dataset
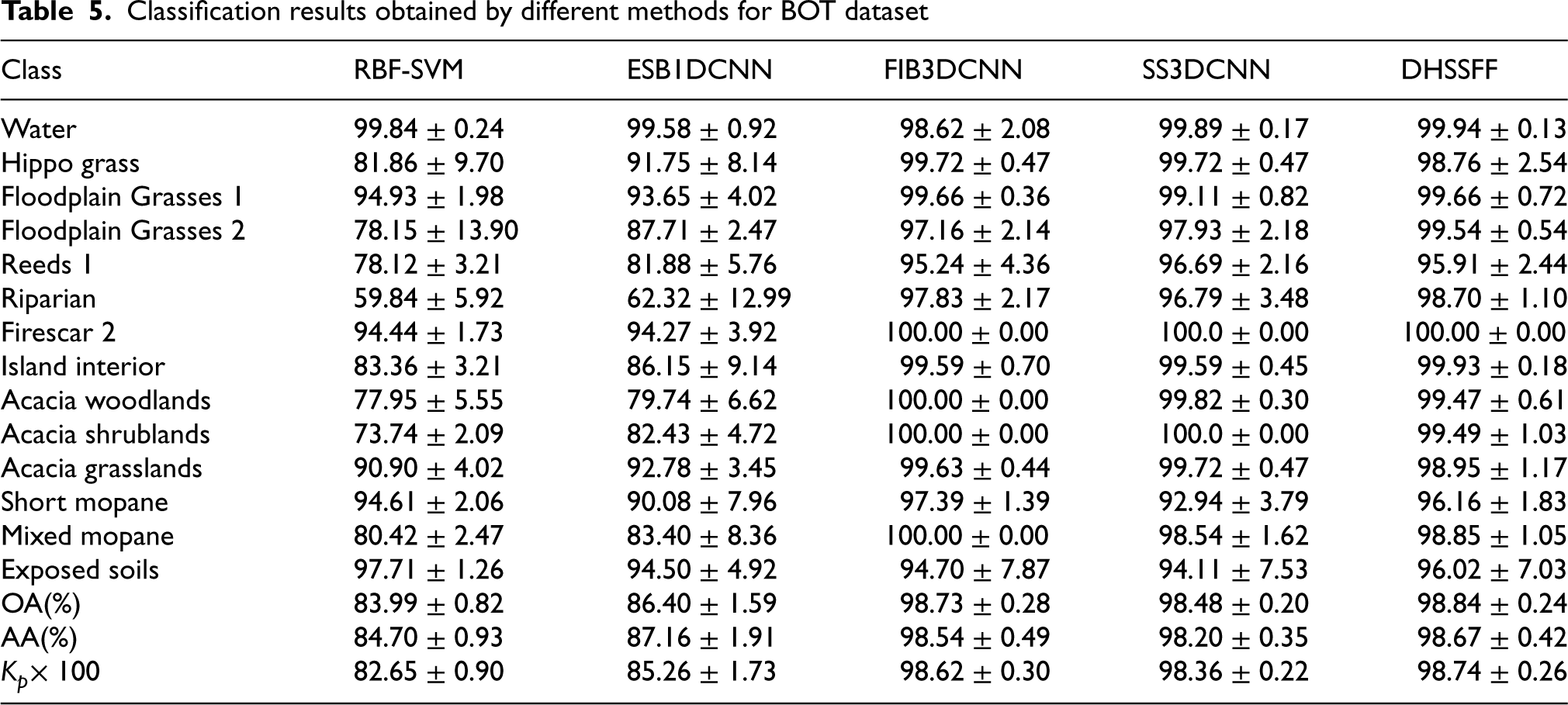
Classification results obtained by different methods for BOT dataset
Figure 7 shows the classification maps of five methods on BOT dataset. As shown in Fig. 7(c)–(g), many samples belonging to the Floodplain Grasses 2, Reeds 1, Acacia woodlands, Acacia shrublands and Mixed mopane classes are misclassified by RBF-SVM and ESB1DCNN. Compared with them, FIB3DCNN, SS3DCNN and DHSSFF offer a better distinction among these classes. Compared with FIB3DCNN and SS3DCNN, DHSSFF has achieved better boundary localization in the Riparian class.
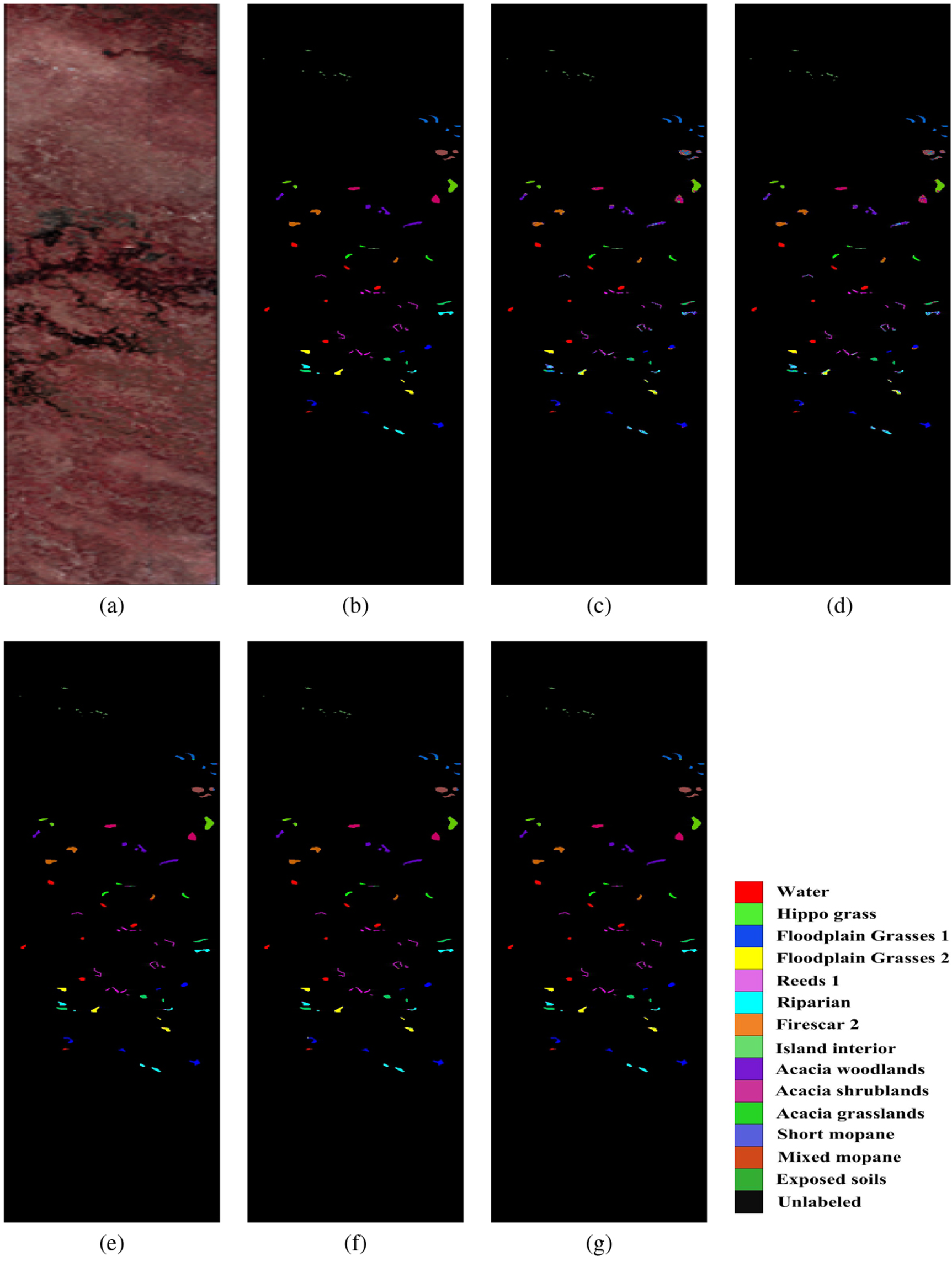
Classification maps for BOT dataset. (a) False color image. (b) Ground truth. (c) RBF-SVM. (d) ESB1DCNN. (e) FIB3DCNN. (f) SS3DCNN. (g) DHSSFF.
For IP dataset, 10% samples from each class were haphazardly selected as training set. The rest samples were considered as test set. The number of training and test samples from each class are listed in Table 6.
Number of training and test samples used in the IP dataset
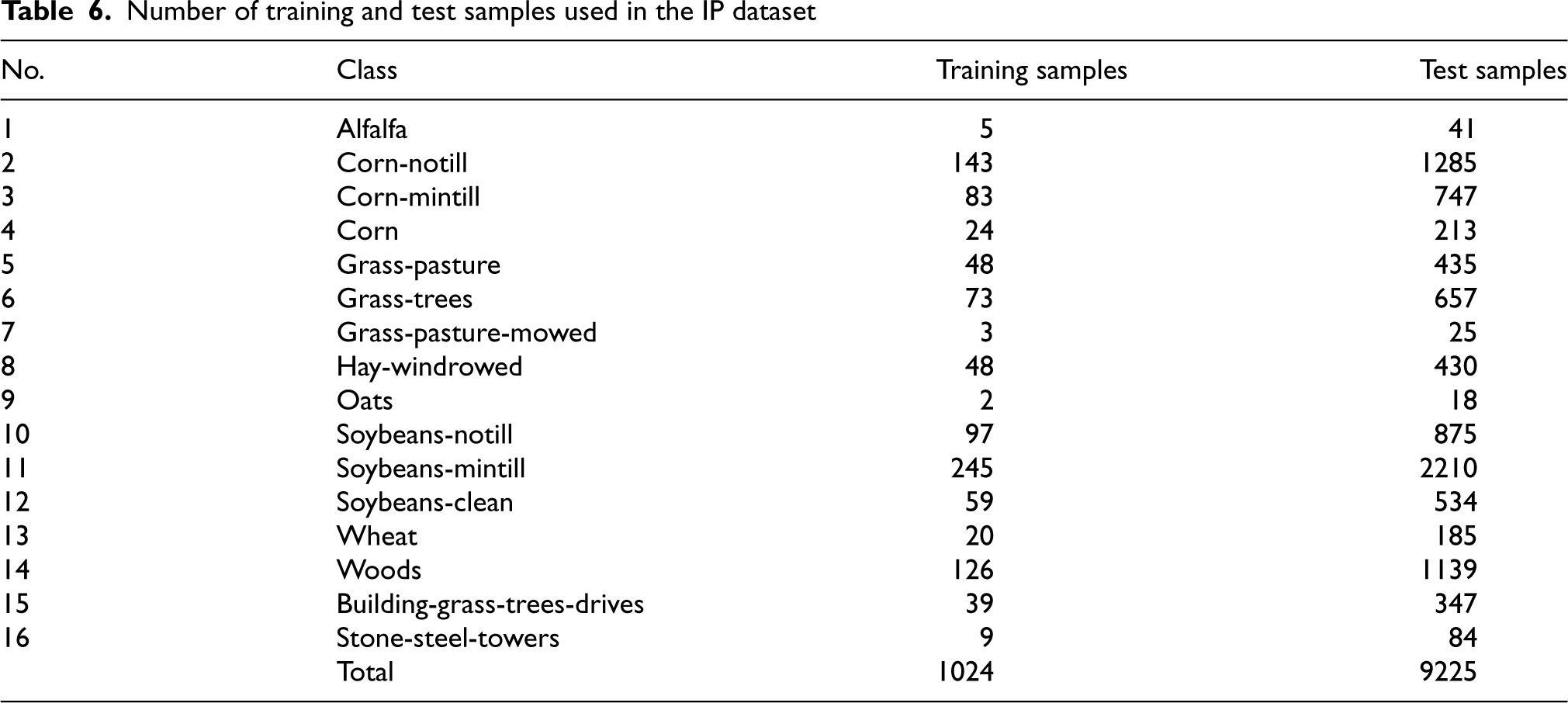
Number of training and test samples used in the IP dataset
The classification performance of five methods for IP dataset has been shown in Table 7. It has been observed that most of the classes has achieved over 90% classification accuracy except RBF-SVM and ESB1DCNN. RBF-SVM has shown poor performance for most of the classes and totally failed to identify few classes (Alfalfa, Grass-pasture-mowe, Oats). This is occurred mainly due to the shallow learning nature of RBF-SVM and unable to handle the complex scene. Compared to RBF-SVM, ESB1DCNN has shown better results because of deep feature extraction ability. However, proposed DHSSFF has achieved the best class specific accuracies with low standard deviation on ten classes (namely Corn-notill, Corn-mintill, Corn, Grass-trees, Soybeans-notill, Soybeans-mintill, Soybeans-clean, Wheat, Woods and BuildngGrassTrees). Further, there is an improvement of 33%, 21.81%, 1.31%, and 0.85% in OA by DHSSFF compared with RBF-SVM, ESB1DCNN, FIB3DCNN and SS3DCNN, respectively.
The classification maps of IP dataset generated using five methods have been depicted in Fig. 8(c)–(g). Due to the absence of spatial features, RBF-SVM and ESB1DCNN suffers from misclassification of objects. On the contrary, other three methods take the advantage of spectral-spatial based features and yields better classification maps. It is worth nothing that compared with FIB3DCNN and SS3DCNN, the DHSSFF has achieved better clarity on Soybeans-mintill class.
Classification results obtained by different methods for IP dataset

Classification maps for IP dataset. (a) False color image. (b) Ground truth. (c) RBF-SVM. (d) ESB1DCNN. (e) FIB3DCNN. (f) SS3DCNN. (g) DHSSFF.
As abundant samples are available in UP dataset, only 4% samples from each class were haphazardly selected for training set and rest samples were considered for test set. The distribution of training and test samples from each class are depicted in Table 8.
Number of training and test samples used in the UP dataset
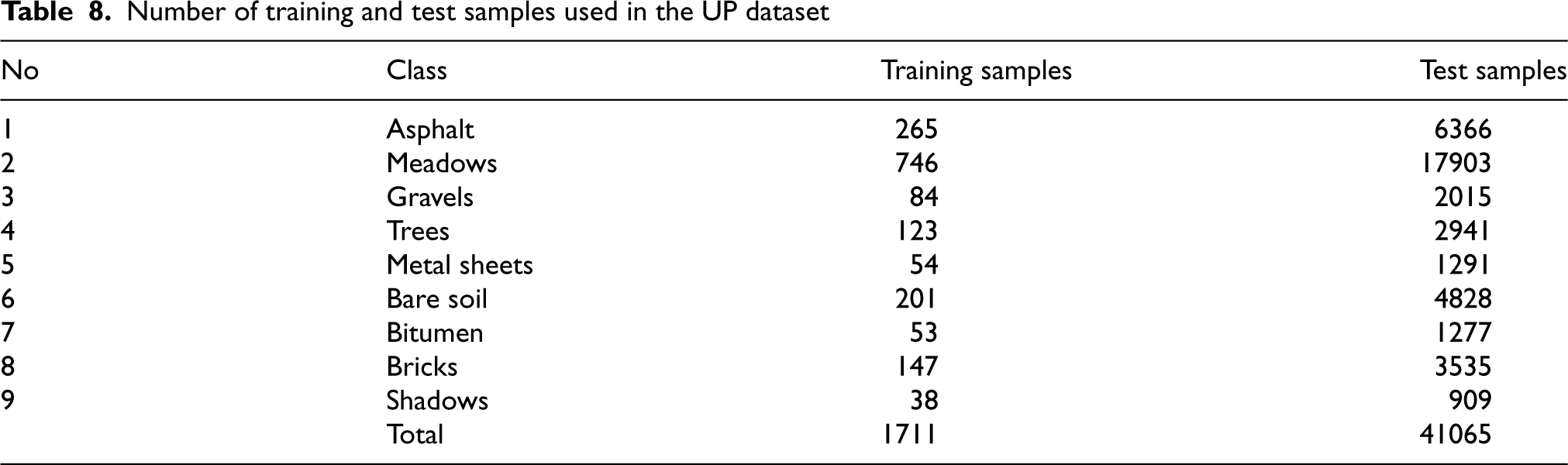
Number of training and test samples used in the UP dataset
Classification results obtained by different methods for UP dataset
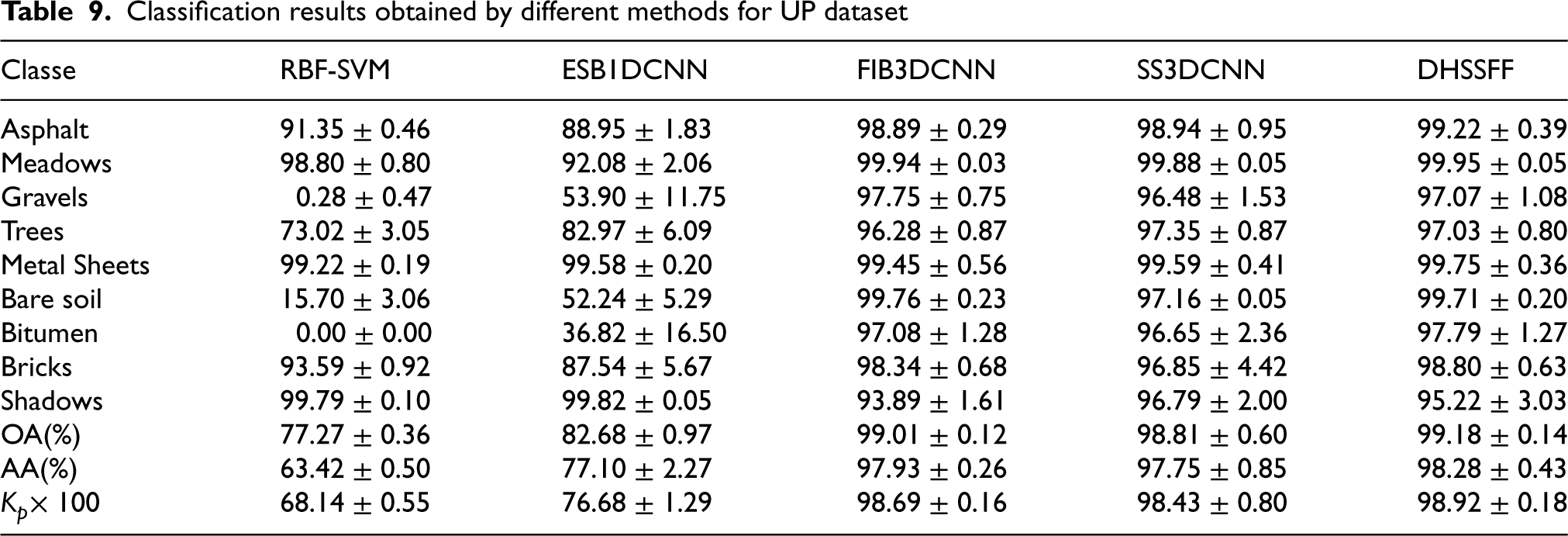
The classification performance using five methods on UP dataset have been presented in Table 9. From the table, we can observe that RBF-SVM has shown unsatisfactory results for Gravels and Bitumen classes. However, it is found that the quantitative assessment of FIB3DCNN, SS3DCNN and DHSSFF are superior than RBF-SVM, and ESB1DCNN by almost 16% on the basis of OA. Nevertheless, less than 1% difference was found in OA among spectral-spatial based methods. Further, the DHSSFF has achieved over 97% classification accuracy for all the classes except Shadows class. In addition, DHSSFF model is able to obtain almost correct classification results in asphalt, meadows, metal sheets, and bare soils classes.
Figure 9 shows the classification maps generated using five methods on UP dataset. As shown in Fig. 9(c) and 9(d), many samples belonging to the Bitumen class are misclassified as the Asphalt class by RBF-SVM and ESB1DCNN due to similar spectral characteristic. Similarly, RBF-SVM and ESB1DCNN misclassified many samples belonging to the Bare soil class due to the lack of spatial information. Compared with them, FIB3DCNN, SS3DCNN and DHSSFF have shown finer regional clarity in the bare soil class. Moreover, DHSSFF has gained improved boundary appearance in the Bitumen class.

Classification maps for UP dataset. (a) False color image. (b) Ground truth. (c) RBF-SVM. (d) ESB1DCNN. (e) FIB3DCNN. (f) SS3DCNN. (g) DHSSFF.
For SA dataset, only 2.5% samples from each class were randomly selected for training and rest samples were considered for testing. The number of training and test samples from each class are listed in Table 10.
Number of training and test samples used in the SA dataset
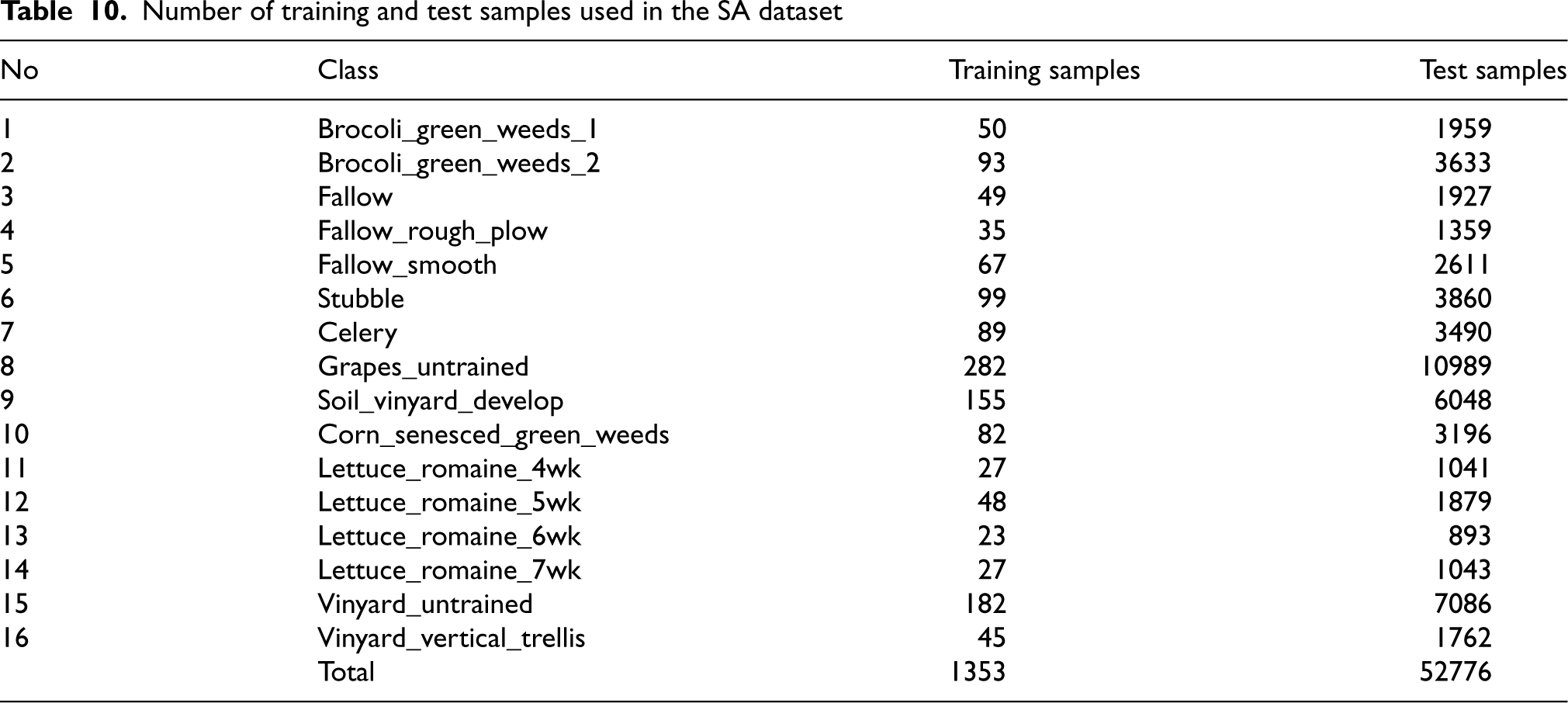
Number of training and test samples used in the SA dataset
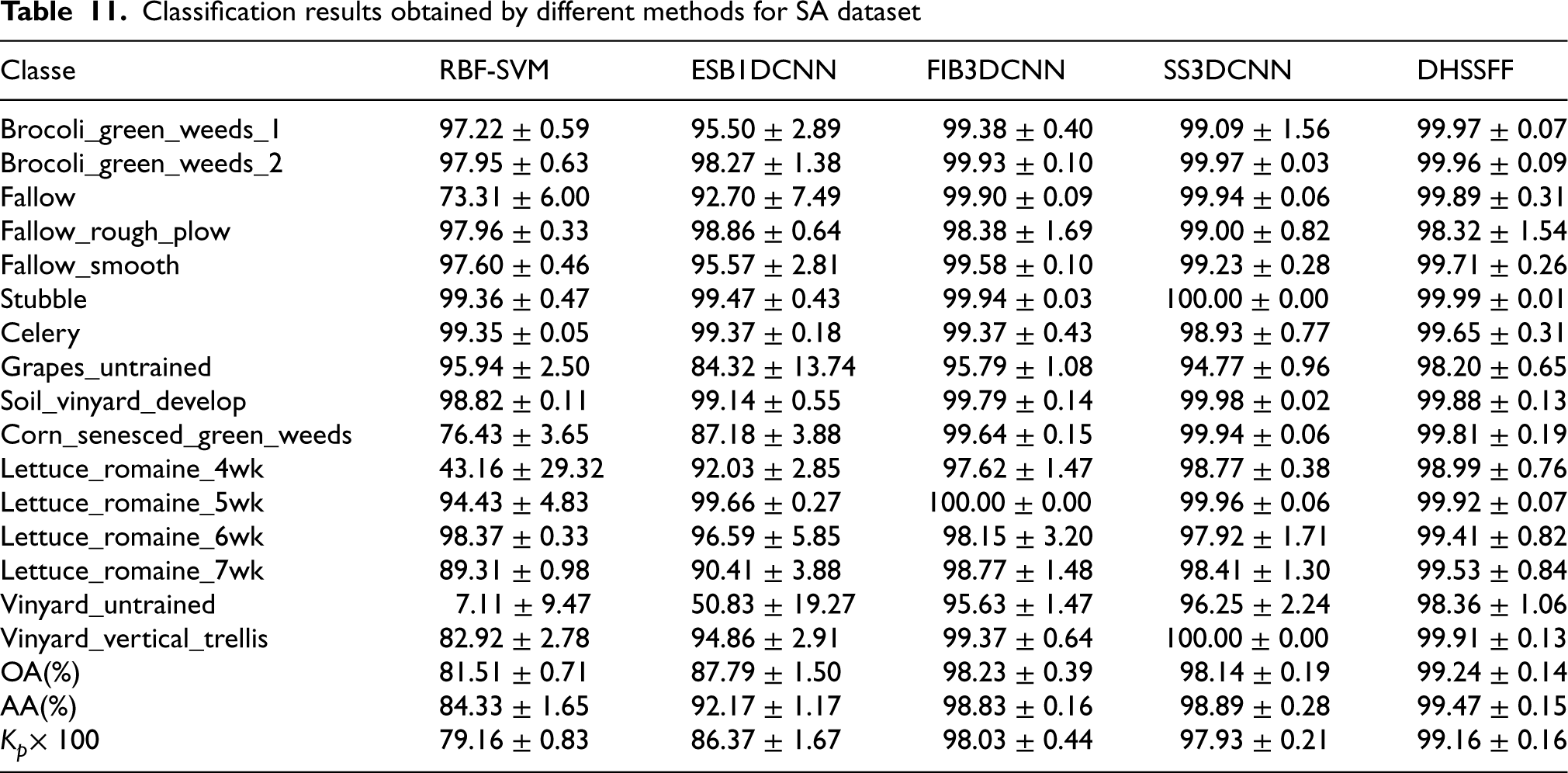
The classification results of five methods on SA dataset have been shown in Table 11. It can be seen that more than 92% classification accuracy has been obtained for most of the classes using all five methods. However, for grapes_untrained class, the classification results of FIB3DCNN and SS3DCNN are not satisfactory but DHSSFF has shown improvement in OA by 2.31% and 3.5%, respectively. Again, DHSSFF has increased 2.73% and 2.11%, respectively, for Vinyard_untrained class. Further, compared with FIB3DCNN and SS3DCNN, DHSSFF increases about 1.13% and 1.23%, respectively, in terms of
Figure 10(c)–(g) shows the classification maps generated using five methods on SA dataset. It can be observed that FIB3DCNN, SS3DCNN and DHSSFF provided better classification maps than RBF-SVM and ESB1DCNN. For instance, several samples of grapes_untrained and vinyard_untrained class have been misclassified by RBF-SVM and ESB1DCNN which leads to fuzzy classification maps. Comparing with FIB3DCNN, and SS3DCNN, our proposed model DHSSFF provided a better distinction between these two classes by removing noisy scatter points. In addition, DHSSFF has shown improved boundary localization in the Brocoli_green_weeds_1 class.
Classification results obtained by different methods for SA dataset

Classification maps for SA dataset. (a) False color image. (b) Ground truth. (c) RBF-SVM. (d) ESB1DCNN. (e) FIB3DCNN. (f) SS3DCNN. (g) DHSSFF.
Performance comparison of different fusion methods (dash (-) indicates data not available)

Computational performance comparison of different methods (

In this paper, we fused deep spectral and spatial features to explore the discriminative information existing in deep architecture. In literature, various fusion based deep learning models have been proposed for HSI classification. To show the effectiveness of our DHSSFF model, the classification results of different fusion based models on HSI datasets have been reported in Table 12.
The following methods have been considered for comparison: class-specific feature fusion (CSFF) [33], multilayer feature fusion and sample augmentation (MLFFSA) [47], feature fusion through unified network (FFUN) [31], and unsupervised method for fusion (UMF) [38]. CSFF utilized stacked denoising autoencoder, and CNN as a feature extraction tools for spectral, and spatial information, respectively before applying fusion scheme. MLFFFSA exploited multilayer feature fusion for extracting complementary information among sallow and deep layers. Further, a band grouping oriented long short-term memory and a CNN architecture has been applied in FFUN for spectral and spatial feature extraction, respectively. Another fusion model, UMF extracted multiscale deep spatial feature by utilizing pre-trained filter banks in VGG16 and fused spectral and spatial features through unsupervised cooperative sparse autoencoder.
From Table 12, we can observed that the FFUN and UMF methods have been reported OA as 97.71% and 97.79% respectively, which is 1.46% and 1.38% lower than our proposed model on KSC dataset. Compared with FFUN and UMF, DHSSFF shows better classification performance because of effective deep spectral-spatial feature fusion scheme. In case of IP dataset, the proposed model obtains marginally higher OA with 0.05%, 0.5%, 0.3%, and 1.46% improvement over CSFF, MLFFSA, FFUN, and UMF method, respectively. Here, compared with CSFF, MLFFSA, FFUN, and UMF models, DHSSFF has shown superior performance in term of OA for most of the cases on UP, and SA datasets.
Analysis of the computational complexity
In this section, we have explained the running time of various methods for HSI classification. The detailed information of training time (for 200 epochs) and test time of five methods on KSC, BOT, IP, UP, and SA datasets have been provided in Table 13. It can be seen that RBF-SVM and ESB1DCNN are much faster during training than FIB3DCNN, SS3DCNN, and DHSSFF but failed to show better classification results due to the simple architecture. As other three methods are based on 3D CNN architecture, they require more time to tune large number of parameters. Among these three methods, SS3DCNN consumed more time on training because of the involvement of regularization technique. In case of FIB3DCNN and DHFFSS methods, the training time is almost similar but DHFFSS method is able to achieve better classification accuracy for all aforementioned datasets.
Although, all the spectral-spatial based methods consume long time to train the model, the test time is much smaller compared with the training time. Moreover, the test time has a positive correlation with number of samples in a test set. The proposed method took an average of 6 seconds, 5 seconds, 21 seconds, 94 seconds, and 101 seconds for 4690, 2924, 9225, 41065, and 52776 test samples on KSC, BOT, IP, UP, and SA datasets, respectively. This demonstrates that our proposed method is capable to reach high classification accuracy with acceptable computational time.
Conclusion
In this paper, we have proposed a simple yet quite effective novel CNN based two-channel model with spectral-spatial feature fusion for HSI classification. In our model, the 1D CNN as first channel is adopted to exploit the spectral features by considering entire spectral bands of HSI whereas 3D CNN as second channel is employed to extract deep spatial features by selecting few informative bands of HSI. In the fusion stage, the deep features from two channels were concatenated, which learns the discriminative spectral and spatial information fully and effectively. In our experiments, five widely used HSI datasets were utilized to evaluate the effectiveness of separate feature extarction and fusion technique. Experimental results demonstrate that the standalone 3D CNN demonstrates high performance across all five datasets. However, DHSSFF, a fusion model incorporating both 1D CNN and 3D CNN, enhances performance with only a marginal rise in computational cost. Consequently, we can conclude that the proposed DHSSFF model can efficiently extract the deep features from two channels and fuse them properly. With the help of separate feature extraction and fusion technique, DHSSFF shown competitive performance compared with state-of-the-art methods.
In future, we intend to resolve the sample imbalance issue and misclassification problem at boundary regions. However, training time of the proposed model is slightly more. Therefore, further research will be conducted on more efficient computational scheme. Moreover, we will concentrate on improving the performance of the proposed model by incorporating fusion scheme at feature extraction stage.
Footnotes
Acknowledgements
The authors extend their appreciation to the Deanship of Research and Graduate Studies at King Khalid University for funding this work through the Large Research Project.
Availability statement
The data presented in this article are publicly available in github repository, [https://github.com/eecn/ Hyperspectral-Classification].