
Abstract
Human pose estimation is a challenging visual task that relies on spatial location information. To improve the performance of human pose estimation, it is important to accurately determine the constraint relationship among keypoints. To address this, we propose MfvPose, a novel hybrid model that leverages rich multi-scale information. The proposed model incorporates the HRFOV module, which uses cascaded atrous convolution to maintain high-resolution representations of the backbone extractor and enrich the multi-scale information. In addition, we introduce learnable scalar weights to the Transformer encoder. In detail, it involves a multiplication by a diagonal matrix with learnable scalar weights on output of each residual block, which improves the dynamics of model training and enhances the accuracy of human pose estimation. It is experimentally shown that our proposed MfvPose achieves promising results on various benchmarks.
Introduction
The goal of the 2D human pose estimation [1–4] task is to locate the position of human anatomical keypoints. It is a fundamental vision task in the field of computer vision and plays an important role in vision tasks such as motion recognition, human-computer interaction, and 3D human pose estimation [5, 6]. Currently, the existing solutions can be divided into heatmap-based methods [7, 8] and regression-based methods [1]. The heatmap-based approach locates keypoints by identifying the maximum response positions. Compared with regression-based methods, it can obtain better results by virtue of its spatial generalization capability.
In recent years, with the rapid development of deep learning, convolutional neural networks have achieved excellent results in human pose estimation tasks through their powerful visual characterization capabilities. In order to obtain a high-resolution representation, most of the existing methods recover high resolution representations from low-resolution representation [2, 9–11], or maintain a high-resolution representation throughout the process. HRNet [4] achieves high accuracy using parallel multi-resolution subnetworks, but the model always maintains high resolution, which can lead to high computational costs. Therefore, we introduce the atrous convolution module and appropriately reduce the network depth to increase the model’s receptive field, and then generate a multi-scale information fusion framework.
Recently, the Vision Transformer [12, 13] has demonstrated good performance in classification tasks. Its ability of modeling global dependencies is more powerful than convolutional neural network. As a result, it performs well on many vision tasks, such as object detection, semantic segmentation, and pose estimation. However, the design of Vision Transformer lacks the ability to utilize spatial information from visual signals, and therefore still needs to compensate for the loss of spatial information with the help of position embedding. To address this issue, We use a hybrid architecture and add learnable scalar weights [14] to the output position of each residual block in the Transformer encoder. This can further help the model converge and improve the accuracy of feature information.
We refer to the design of the atrous convolution module and the attention mechanism module to propose a new multi-scale network architecture for human pose estimation, named MfvPose. Examples of pose estimation obtained with the MfvPose framework are shown in Fig. 1.

The examples of pose estimation are obtained using the MfvPose framework.
In general, our work contributions are summarized as follows:
We propose the novel MfvPose framework, a hybrid model with rich multi-scale information for human pose estimation. We adopt the HRFOV module to improve the receptive field of the backbone and enrich the multi-scale information. We add learnable scalar weights to the Transformer encoder, which helps to makes the feature information more precise.
The remainder of this paper is structured as follows: We discuss related works in Section II of this paper, before providing a detailed description of the MfvPose framework in Section III. In Section IV, we introduce the two datasets used in the experiment, followed by a demonstration of the effectiveness of our approach in Section V. Finally, our work is concluded in Section VI.
Early human pose estimation tasks were performed by graphical structural models [15], which did not work well. As research continued, it was argued that some complex gestures, such as walking, running and jumping, could be estimated simply by locating the spatial positions of major joint points [16]. This human keypoint-based detection method sets the basic course for current human pose estimation tasks.
In recent years, deep learning methods based on convolutional neural networks [1, 18] have achieved better results than earlier work in human pose estimation. CPM [3] found the maximum response position in heatmap by learning image features and spatial information. Hourglass [2] proposed a stacked hourglass module to learn multi-scale features that improve the quality of heatmap. SimpleBaseline [11] designed a simple architecture based on ResNet [19] by stacking transposed convolutional layers to achieve good results. HRNet [4] used a parallel multi-resolution subnetworks to maintain high-resolution feature information. Therefore, how to enhance high-resolution features is important for 2D human pose estimation.
The large receptive field is conducive to the detection of large targets, and on the other hand the high resolution enables accurate target localization. However, blindly stacking atrous convolutions of the same dilation rate can create gridding problem. It causes a lack of correlation between long-distance information and results in local information loss. HDC [20] set different dilation rates to get information from a wider range of pixels and avoid gridding problems. In DeepLab [21], atrous convolution was used to increase the size of the receptive field in the network and avoid downsampling. The Atrous Spacial Pyramid Pooling(ASPP) [21] approach assembled atrous convolutions in four parallel branches with different rates, achieved good results in semantic segmentation tasks. Similarly, the increased resolution and receptive field provided by the ASPP module can facilitate the contextual detection of body parts.
To address the above issues, we propose a hybrid architecture design. Based on the ASPP approach, the HRFOV module enhances the feature maps of both the ResNet block and HRModule outputs, thereby increasing the receptive field. Additionally, we add a self-attention module to learn the spatial relationship among keypoints, which improves the model’s sensitivity to spatial information.
The proposed MfvPose framework, illustrated in Fig. 2, is a hybrid framework that leverages rich multi-scale information for human pose estimation. MfvPose framework combines multi-scale methods [4], transformer modules [12], and the HRFOV module proposed by us to make further improvements on the feature representation of human keypoints.
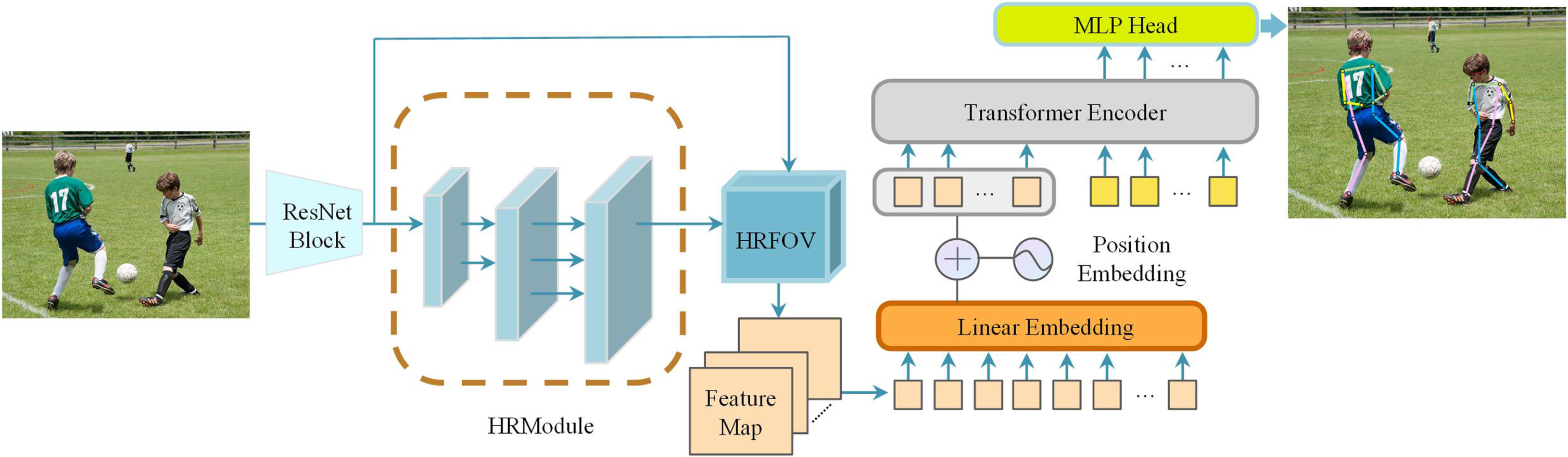
The schematic diagram of MfvPose is proposed. The feature maps extracted by the CNN backbone are fed into the HRFOV module for processing and then uniformly split into patches. After each patch is flattened into a one-dimensional vector, it is mapped into a 1D embedding by a linear projection function. Subsequently, the Transformer encoder learns the spatial relationships among keypoints.
The processing flow of MfvPose architecture with images is shown in Fig. 2. The structure uses HRNet [4] as the backbone network for feature extraction. The input image is first passed through the backbone. Afterwards, the high-resolution feature maps and low-level features are simultaneously processed by the HRFOV module. The integrated HRFOV module in our network further increases the receptive field of the backbone while maintaining the high-resolution of the images. Finally, the stacked Transformer encoders are used to learn the constraint relationships among keypoints. In the following, we describe the application of the HRFOV and transformer modules in detail.
High-resolution convolution algorithms have obtained remarkable results in pose estimation. It has been shown that increasing the receptive field and fusing multi-scale information are beneficial for human pose estimation. In this paper, in order to enhance the ability of the backbone network to extract multi-scale information, we propose to combine the Atrous Spatial Pyramid Pooling (ASPP) module [21] with high-resolution convolutional networks, named HRFOV module. It is shown in Fig. 3.
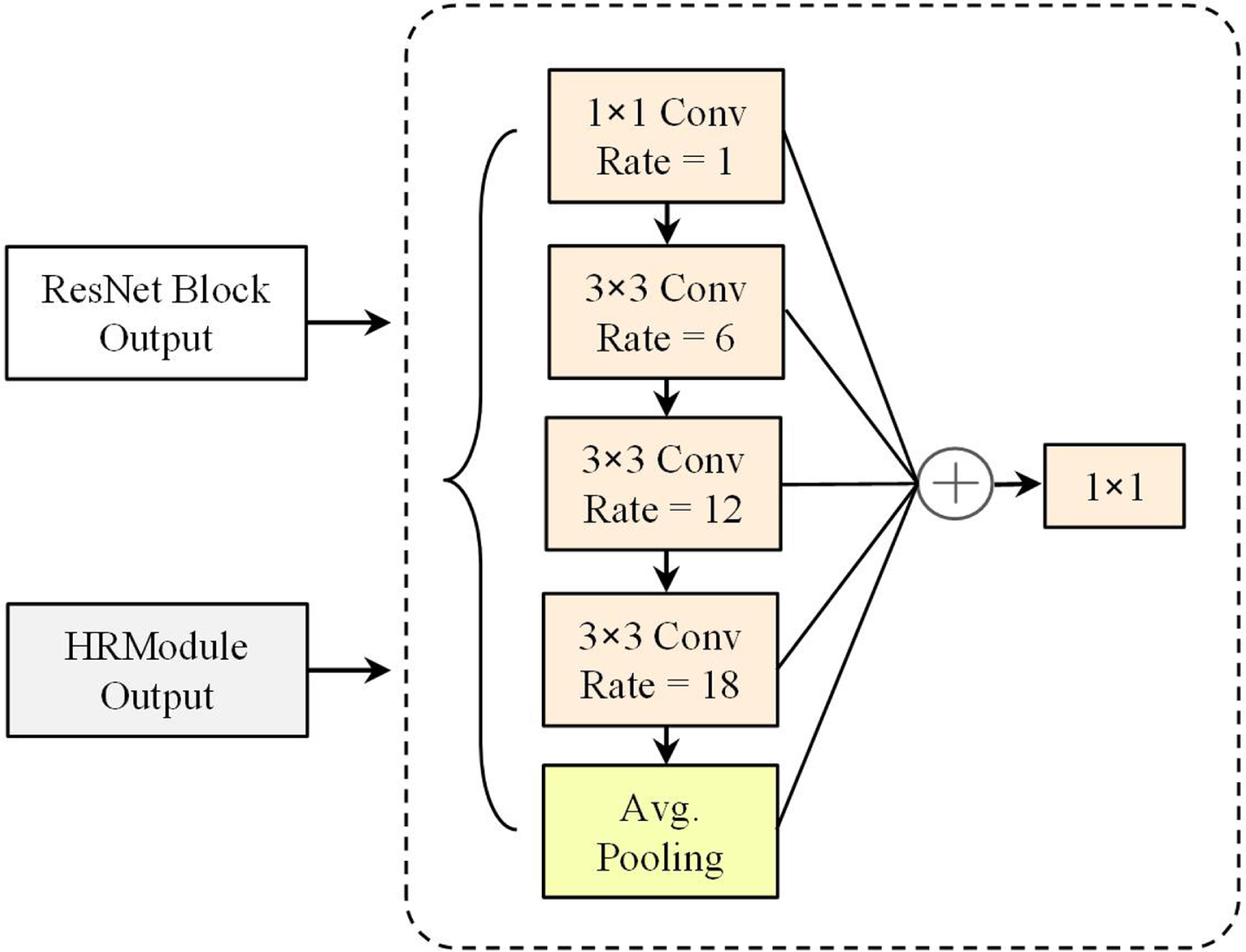
A schematic diagram of HRFOV is presented, which is designed to enhance the feature maps of both the ResNet Block and HRModule outputs, thereby increasing the receptive field.
The proposed method extends feature extraction with a multi-layer architecture in the HRFOV module. This module performs consistent high-resolution processing of feature maps in each branch to improve the model’s ability to obtain multi-scale information. By using HRNet-stage3 as a feature extractor instead of implementing the entire HRNet architecture, we significantly reduce the network parameters. The HRFOV module uniformly processes the feature maps outputted by the ResNet block and HRModule to increase their receptive field. In detail, utilizing different dilation rates in the atrous convolution allows the model to acquire multi-scale feature information without requiring a pooling operation. The four branches in the HRFOV module have different receptive field, and the dilation rates in the branches are arranged in an increasing form. The HRFOV module makes full use of the ASPP structure based on atrous convolution to maintain a large receptive field. Additionally, the module combines the advantages of ASPP and the WASP [25, 26] module to achieve promising results.
The output F
HRFOV
of the HRFOV module is described as follows:
CNN-based methods have inherent inductive biases, such as translation equivariance and locality, which allow CNN-based methods to have good generalization performance. However, the CNN-based approach lacks the ability to model global dependencies, which makes it difficult to capture the constraint relationships among keypoints. We are inspired by Vision Transformer [12] and TokenPose [27] to apply a multi-head self-attention module to capture the spatial relationships among keypoints.
In order to process 2D images, we take a sequence of vector embeddings as input. A feature map x ∈ RH×W×C is divided into a grid of P
n
patches, where
We refer to TokenPose and add K learnable d-dimensional vectors to the Transformer encoder to represent K human keypoints. The Transformer encoder takes the vectors of feature maps and keypoints as input to learn the constraint relationship among keypoints. According to Vision Transformer, each Transformer encoder consists of a multi-head self-attention module (MSA) and a feed-forward network (FFN). In addition, the LayerNorm (LN) is used prior to each module. The formulation of multi-head self-attention is given as:
In the Transformer encoder, the handling of the keypoint vectors is important. Therefore, we add learnable scalar weights to the output of each residual block, as shown in Fig. 4. In other terms, the output of each layer of the Transformer encoder can be expressed as:
To obtain K heatmaps, {H1, H2, . . . , Hk}, where H i represents the heatmap of the i-th human keypoint with size H′ × W′. The K d-dimensional vectors produced by the Transformer encoder undergo linear projection to be mapped into H′ × W′-dimensional vectors. Then, the resulting 1D vectors are reshaped into 2D heatmaps to obtain the final K heatmaps.
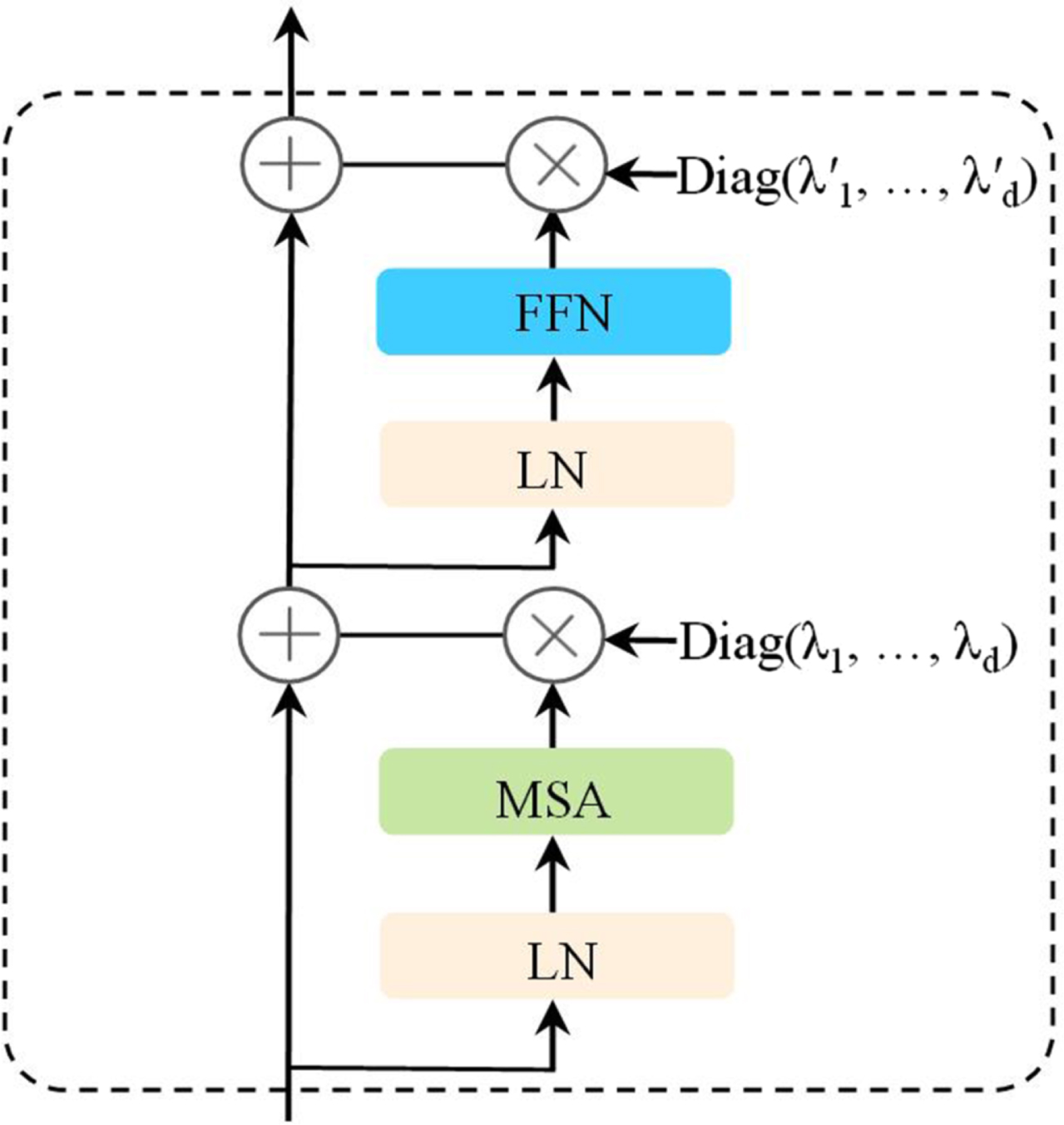
Transformer encoder with learnable scalar weights. We introduce a per-channel weighting method to improve the dynamics of model training.
Experiments are conducted on two datasets, which are the COCO [34] and MPII [35] datasets.
The COCO dataset, provided by Microsoft, is widely used for tasks such as object detection, human keypoints detection, and semantic segmentation. The COCO dataset is divided into three parts: training, validation, and testing, with a total of over 200,000 images and 250,000 person instances. Each image is annotated with information on the object class, bounding box location and visibility, and for the person instance, 17 keypoints are annotated. The COCO dataset is known for its complexity. There are many challenges such as object occlusion, complex backgrounds, and crowded environments among a large number of human instances in this dataset. These factors make it difficult to accurately extract human keypoints.
The MPII dataset is a widely-used resource for assessing the accuracy of human pose estimation. The dataset comprises approximately 25,000 images and over 40,000 instances of human body annotations, organized by human activity category. Each image is labeled with its corresponding activity, encompassing more than 400 human activities. Notably, these images are sourced from YouTube videos and provide a highly realistic depiction of everyday scenarios.
The performance of the MfvPose framework is compared with other approaches on the COCO test-dev set
The performance of the MfvPose framework is compared with other approaches on the COCO test-dev set
The experiments are conducted on the Ubuntu 20.04 operating system, using the PyTorch deep learning framework and Python as the development language. The CPU used for the experiments is the Intel E5-2680v3 2.50GHz, and the GPU used is the NVIDIA TITAN X (Pascal). We follow previous studies [25, 36] and set different dilation rates to effectively avoid the gridding problem. However, the difference in our approach is that we process the low-level features through the HRFOV module, which results in better prediction performance. For model training, we use the Adam optimizer. In the experiment, we use the original settings of HRNet [4] and SimpleBaseline [11], and adopt a top-down approach for human pose estimation [4, 11]. Initially, we detect human instances using a dedicated detector. Subsequently, we use a model to generate heatmaps for the keypoints. We calculate the learning rate based on the step method. In our work, the learning rate starts at 1e-3, and decreases at the 200th and 260th epochs.
COCO human pose estimation
In the COCO dataset, we evaluate MfvPose based on Object Keypoint Similarity (OKS).
The MfvPose is compared with state-of-the-art methods on the validation set of COCO dataset. As shown in Table 1, the proposed MfvPose obtains a competitive performance compared to previous methods. D8 and D24 represent Transformer encoder with 8 and 24 layers stacked respectively. With the same resolution, the accuracy is improved to 75.7% in combination with HRFOV module. Compared to the original HRNet-W32 and HRNet-W48, the proposed framework shows a notable improvement of 1.3% and 0.6%, respectively, while also demonstrating a considerable reduction in both parameters and GFLOPs. Compared to SimpleBaseline which uses ResNet-50, ResNet-101, and ResNet-152 as the backbone, our MfvPose achieves improvements of 5.3%, 4.3%, and 3.7%, respectively. In this study, we introduce learnable scalar weights to the Transformer encoder, enhancing the model’s ability to capture spatial information. We refer to the TokenPose [27] configuration and stack the same number of layers of Transformer encoder. The proposed method achieves a 0.2% improvement over TokenPose-B and a 0.2% improvement over TokenPose-L/24. Furthermore, the increase in parameters and GFLOPs is insignificant. Figure 5 demonstrates the visualization results of COCO set obtained using MfvPose.

The visualization results of COCO set obtained using the MfvPose framework.
The performance of the MfvPose framework is compared with other approaches on the COCO validation set
The MPII dataset contains images sourced from YouTube videos, offering a remarkably realistic portrayal of daily life scenes. In the MPII dataset, we evaluate MfvPose based on the Percentage of Correct Keypoints (PCK) [35]. This metric defines a keypoint prediction as correct if the detected joint is within a specified threshold distance of the ground truth. The MPII dataset commonly uses a PCKh@0.5 threshold, which corresponds to a threshold of 50% of the head diameter. The training strategy and data augmentation methods used are similar to those of the COCO dataset, except that the input size is cropped to 256 × 256 to enable a fair comparison with other techniques.
The results of PCKh@0.5 are shown in Table 3, and we follow the testing configuration in TokenPose. The experimental results show that the proposed MfvPose obtains a more competitive performance. Compared with other methods, our model is lighter, and despite having fewer parameters than TokenPose, it can still achieve better performance. Figure 6 demonstrates the visualization results of MPII set obtained using MfvPose.

The visualization results of MPII set obtained using the MfvPose framework.
The results of MfvPose on the MPII validation set (PCKh@0.5)
We conduct a series of ablation studies on the MPII dataset during our experiments, with the aim of analyzing the improvements resulting from various aspects of our approach. Table 4 shows the results of TokenPose, followed by the results obtained by combining the backbone with the proposed HRFOV module. The LSW represents the learnable scalar weights, and we use TokenPose-L/D6 as the baseline model. The performance of the proposed method gradually improves as innovative modules are added, resulting in a 0.41% improvement over TokenPose-L/D6. Moreover, our proposed method has a wider receptive field, which enables it to extract multi-scale features more effectively, and to achieve greater accuracy in predicting keypoints, even in complex backgrounds. While achieving better performance with MfvPose, the growth in parameters and GFLOPs can be ignored.
Ablations of various architectural design choices on the MPII set
Ablations of various architectural design choices on the MPII set
In this work, we present a new MfvPose architecture for human pose estimation. Specifically, our HRFOV module processes both the feature maps from the lower layers and the backbone. The HRFOV module stacks atrous convolutions with different dilation rates to improve the multi-scale information extraction capability of the backbone network. The cascaded atrous convolution structure increases the receptive field of the model, which helps to train a superior pose estimator. In addition, human pose estimation is sensitive to spatial information. Therefore, MfvPose includes an attention mechanism module to learn the spatial relationships among keypoints. With this design, MfvPose achieves encouraging results on various benchmarks.
Relying on the application of the self-attention module, it brings the ability to model global dependencies. However, this also incurs unnecessary computational and memory costs, which are already the main drawbacks of the Transformer. In future research, we will focus on solving this problem while also conducting further exploration to improve detection speed.
Footnotes
Acknowledgment
This work was supported in part by the National Natural Science Foundation of China (No. 62173285 and 62103345), the Fujian Provincial Natural Science Foundation of China (No. 2021J011181, 2020J02160 and 2022J011234) and Xiamen Youth Innovation Fund Project (No. 3502Z20206072 and 3502Z20206076).