
Abstract
In daily life, English is increasingly used in various scenarios, and the technology of translation using machines and others is gradually maturing, but there are still cases of inaccurate translation. To enhance translation’s accuracy, this study optimizes the method of fuzzy semantic selection, and then optimizes the method of domain analysis combined with neural networks to improve the accuracy of machine translation in different domains. The accuracy of the optimized neural network tends to be stable when the number of iterations is 15, the accuracy is 0.96, the accuracy of the traditional neural network is 0.91, and RNN is 0.82. Compared with the benchmark system, the bilingual mapping model has increased by 0.67% in the news field and 0.56% in the education field. The precision, recall and
Keywords
Introduction
Ambiguity is one of the characteristics of language that is prevalent in life. Regardless of the language expressions, many words have fuzzy nature and there is semantic uncertainty, which leads to the accuracy of translation work being affected. In the process of machine translation, the selection of fuzzy semantics is particularly important. The translation needs to be combined with the semantic environment in which the phrase or sentence is located to give a translation result that fits the context, otherwise, it will be out of the meaning of the translation and reduce the accuracy of the translation. Using the visual information or prior knowledge related to the text and the text itself can improve the accuracy of translation [1]. Due to the late introduction of fuzzy semantics and the small content of related literature, there are scholars in the existing literature who have investigated fuzzy semantics in machine translation. For example, rare words are combined by hierarchical clustering method and integrated into the codec in the proposed fuzzy semantic representation (FSR). In neural machine translation, this structure can solve the problem of data sparsity, capture the semantics of rare words in the case of fuzzy context, and compensate the semantic information of the source and target [2]. Adjacency can introduce fuzzy information into the syntax layer to correctly express meaning. Julian-Iranzo [3] introduced a unified algorithm to establish a new model, which can manage adjacency and adapt to weak SLD resolution rules. Approximate reasoning in logic programming framework can be realized by combining unified algorithm and proximity relationship. In order to be able to improve the accuracy of translation, the selection of fuzzy semantics needs to be further optimized, and the combination of deep learning such as neural networks can be considered to improve the performance of the method, as well as the combination of domain information to improve the accuracy of machine translation.
Related work
More efficient algorithms have emerged in natural language processing, allowing the use of computer science and technology for detailed analysis and synthesis of different languages, and speech translation. Machine translation automates the translation process and reduces human dependence. The common translation methods included in machine translation classification are heavily dependent on parallel corpora [4]. The quality of translation depends on the language and the method used, and Dugonik et al. [5] proposed a standard approach based on the well-known statistical machine translation, which is proposed by a newly proposed method for optimizing the weights of translation system components. The results showed that the method used in the experiments improved the translation quality using better system component weights. With the revival of neural networks, for most language pairs, the translation quality exceeds that obtained using statistical techniques. Mahmoud and Mengash [6] introduced an algorithm for preprocessing a bilingual corpus by proposing a Corpus-Trie (CT) data structure to respond to translation requests using CT. The number of phrases in CT system is proportional to BLEU value. Deep learning techniques have driven the development of neural network machine translation (NMT), and the adequacy of translation can be improved by using new methods to transfer semantic knowledge [7]. The literature shows that the translation output quality of NMT is better in the mutual translation of multiple languages [8]. Some scholars also use rule-based methods to translate Tunisian dialect (TD) texts into modern standard Arabic (MSA) machine translation systems [9]. A new machine translation model in related literature can effectively enhance the precision of neural machine translation by fusing the attentional information of words and characters. This study also showed that bidirectional selective pass recursive unit (GRU) networks can be used to automatically construct word-level information from input character sequences [10].
In recent years, deep neural network models have shown excellent practicality in areas such as machine learning and thermal intelligence [11]. Translation program on the basis of neural network has become a mainstream approach in the field of machine translation, which means statistical machine translation is becoming to a faster and more reliable neural network translation. Comparing phrase-based SMT systems with NMT systems, Benkova et al. [12] evaluated the translation quality of English and Slovak using automatic metrics. The quality of neural machine translation was better regardless of the system used; based on all BLEU_n scores, SMT outperformed NMT with statistical significance. In Sanskrit translation work, the processing of initial data will affect the performance of the model and deep neural network was used to process Sanskrit raw data in a study. Better BLEU scores and word error rates were achieved with this model processing the Sanskrit text [13]. Researchers proposed a new DNN-based keyword recognition system that dynamically changes keywords and uses both trisyllabic and monophonic acoustic models. This model can effectively simplify the calculation difficulty and improve the generalization ability. The author tested on the FFMTIMIT corpus and found that the error rate of this model was more than 35% lower than that of the traditional model [14]. To extract text-related visual features, Kwon et al. [15] designed modulation networks based on visual information from a pre-trained CNN, applying a feature-based multiplicative transformation to obtain a modular trainable network model embedded in an existing multimodal translation model architecture. Through validation, it was confirmed that the model improves on text-based models and previous models. Liu and Chen [16] proposed a self-attention-based machine translation model. The model uses subword tokenization in corpus preprocessing to overcome rare words. In the encoder layer, a dual self-attention stack and fewer; In the decoder, the “decoder” stack is reduced to speed up training and inference while keeping the level of BLEU constant. Li et al. [17] proposed a deep learning model based on long-term and short-term memory (LSTM), which uses convolution neural network to deeply learn spatiotemporal features (DLSF-CNN) to measure the spatiotemporal correlation of time consuming on different routes, so as to accurately predict route travel time. Long short-term memory network has changed the machine learning and neural computing, and such models have improved Google’s speech recognition and greatly improved machine translation on Google [18]. In terms of recurrent neural network (RNN), Google neural machine translation (GNMT) is the most advanced language translation model using this network structure. Deep learning is applied to natural language processing, which can transform natural language description into source code to meet requirements [19]. A special RNN named as long short-term memory network (LSTM) is currently being used to analyze information from social media APPS for code-speaking and translating them phonetically into English [20].
In order to better study the research on the selection method of fuzzy semantics in machine translation, it is proposed in this research that the optimized neural network is used in the selection of fuzzy semantics, and the analysis is carried out in conjunction with the domain where the semantics are located to further improve the accuracy of translation, hoping to lay the foundation for further selection and optimization of fuzzy semantics under machine translation.
Optimization of selection method for fuzzy semantics in machine translation
Optimization method for fuzzy semantic best selection process
There are many problems that have not been solved in the daily translation process when using machines such as computers for translation [21]. For example, there are more meanings of the same textual content in Chinese or English, which can lead to semantic errors or contextual incompatibilities in the translation process, and it will reduce the accuracy and translation quality of the translation. To address these problems, a mathematical mapping method can be considered to label each semantic meaning in the fuzzy semantics, and then select the corresponding semantic labels according to the features of the text. In this study, a semantic model of citation translation in machine is constructed on this basis to optimize the selection of fuzzy semantics. First, the semantic content is characterized and extracted. A conceptual semantic constraint function
In Eq. (1),
In Eq. (2),
On the basis of the previous two steps, the semantic selection method is improved and optimized for design, and the topic word attribute table is established as shown in Fig. 1.
Fuzzy semantic subject word attribute table.
In Fig. 1, the semantic similarity is calculated by the gray correlation matching method, assuming that the translated semantic information of any direct superordinate word in the total evaluation set can be represented by the binary semantic group
The reliability factor is used to indicate the degree of reliability of the machine translation process using the search engine to translate adverbs based on ontologies, and the average reliability factor is defined as shown in Eq. (5).
A binary coordinate set
In Eq. (6),
In Eq. (7),
Domain-based translation models utilize neural networks to build models when processing information, and RNN, CNN, and R-CNN are often used for deep learning in existing studies. These deep learning neural networks have good performance and play an active role in different fields. For example, recurrent neural networks can be better adapted in modeling serialized information, training data autonomously and extracting image features, etc. [22]. Regional convolutional neural networks can combine expert prior knowledge into region definitions [23]. However, there are some limitations, such as recurrent neural networks cause inaccurate translation due to limited lexicon size and easy missing information. To address these problems, in this study, a bidirectional recurrent neural network (Bi RNN) is selected, which is a model widely used in machine translation, speech recognition and natural language processing [24]. Bi RNN can extract text features to complete word embedding, which can better understand contextual relationships and its word embedding effect is better. Using Bi RNN for deep learning of methods in machine translation, automatically extracted features can be obtained. On this basis, attention mechanism is used to enhance the effectiveness and precision of translation. Its structure schematic is shown in Fig. 2.
Bi RNN network detailed structure.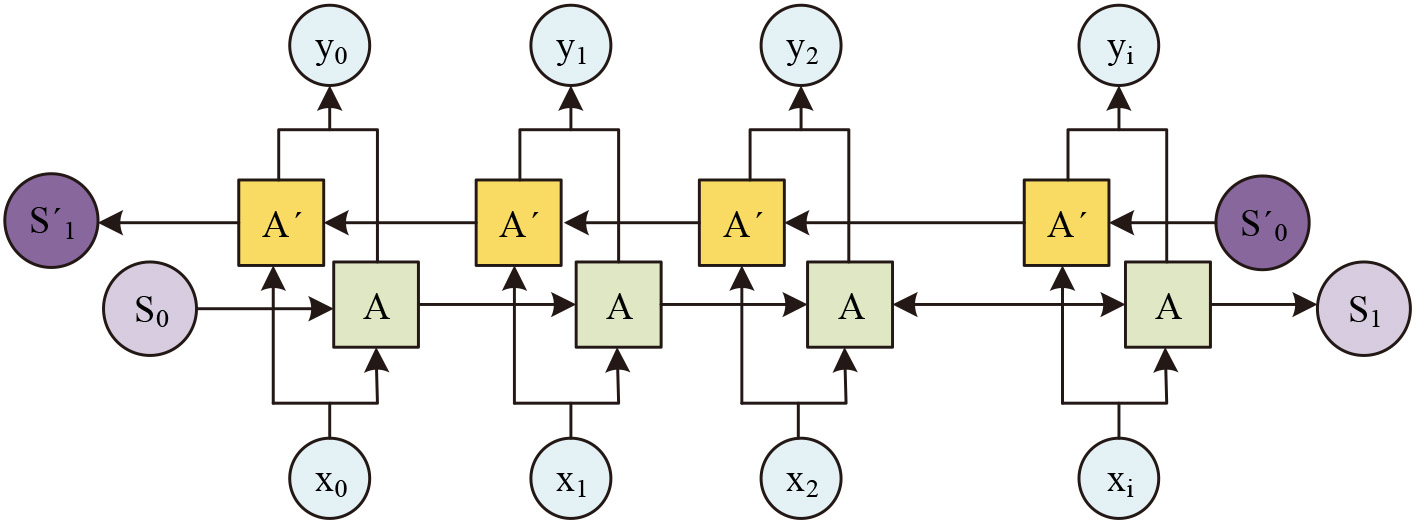
The specific steps of the bidirectional recurrent neural network are represented in Fig. 2. First, for the text
Text translation method based on Bi RNN and attention mechanism.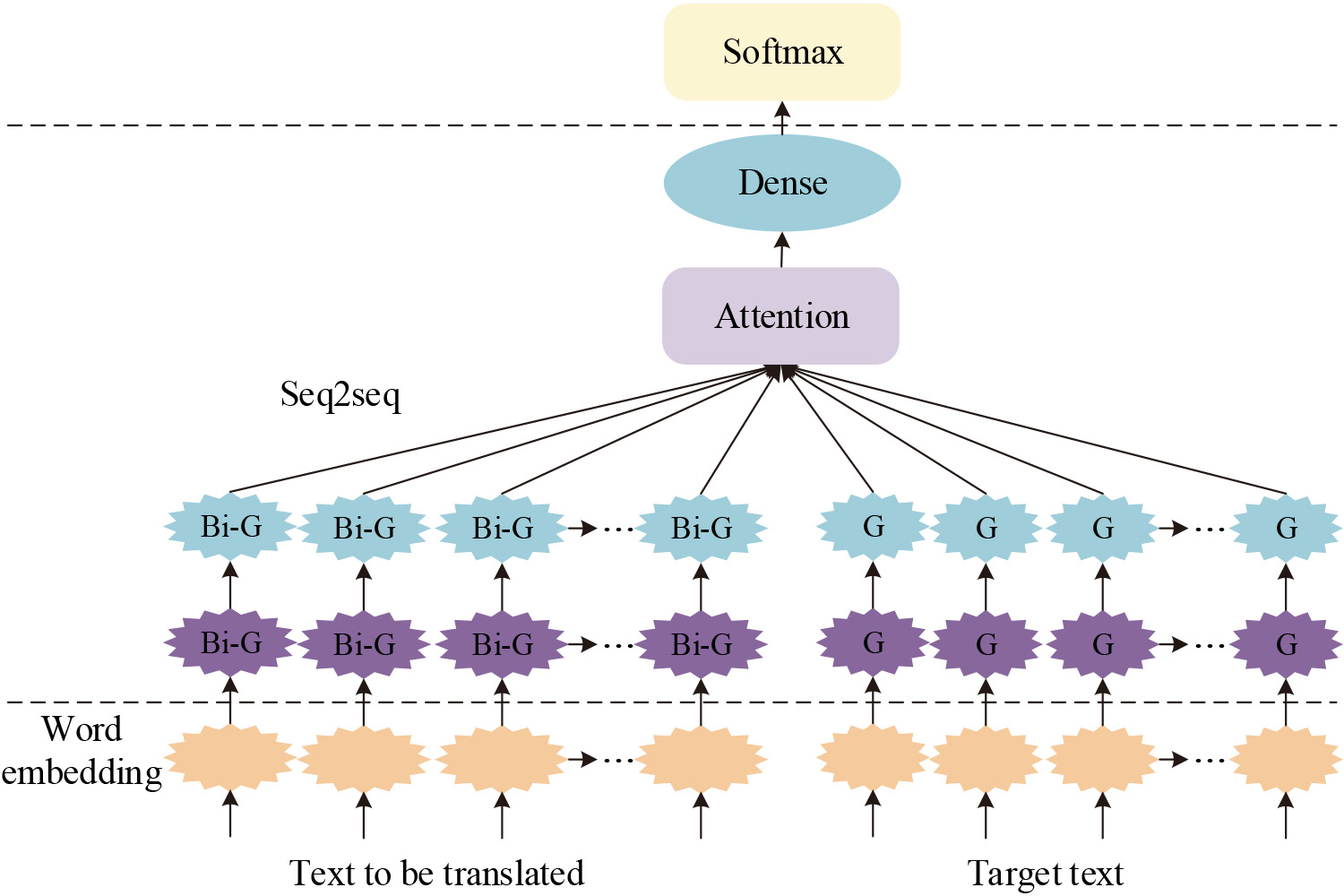
In Fig. 3, G stands fo GRU, and Bi-G stands fo Bi-GRU. The text translation is performed by first vectorizing the text entries and inputting the word vectors in the neural network. Then a word dictionary matrix is built, then a mapping relationship lookup table is built, and finally the words are converted into word embeddings by converting the ordinal numbers into word embeddings.
For fuzzy semantics, in addition to matching the features of semantics, translation can also be performed by combining the domain in which the semantic information is located with the linguistic environment in which the target vocabulary is located for a more accurate translation of the semantically fuzzy target. Therefore, this experiment proposes to build a domain translation model and optimize it on the basis of semantic similarity, which can assign high scores to domain-related candidates by calculating the domain intertranslation degree of phrase pairs. This optimization method mainly consists of 2 elements, firstly, obtaining the semantic
System framework diagram of domain translation model optimization method based on semantic similarity.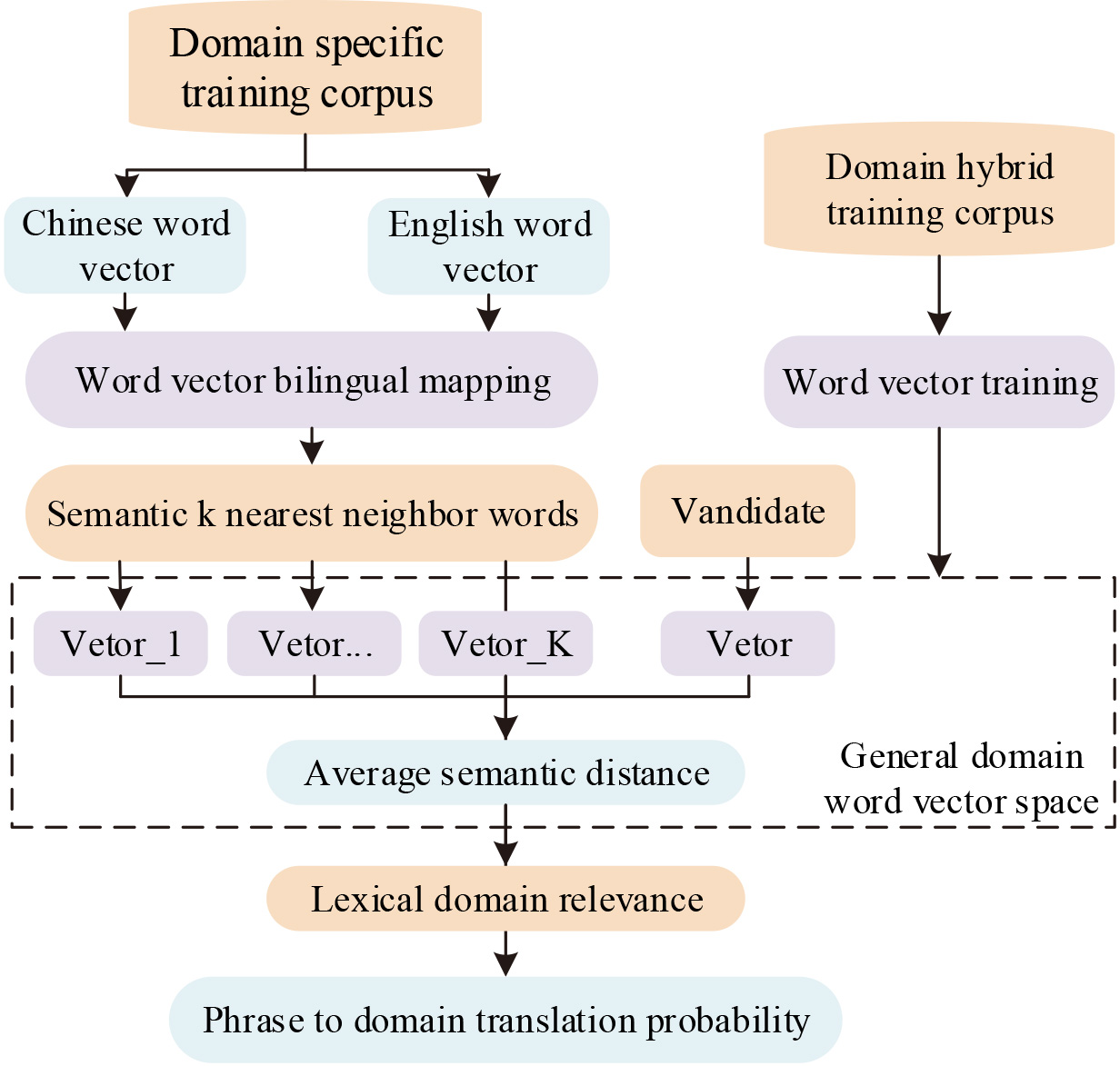
In Fig. 4, the source language and target language vector of the target domain are trained firstly, and the word vectors are mapped to the two-dimensional space after dimensionality reduction. Then, the source language is mapped to the target language vector space
Bilingual mapping model of domain word vector based on Neural Network.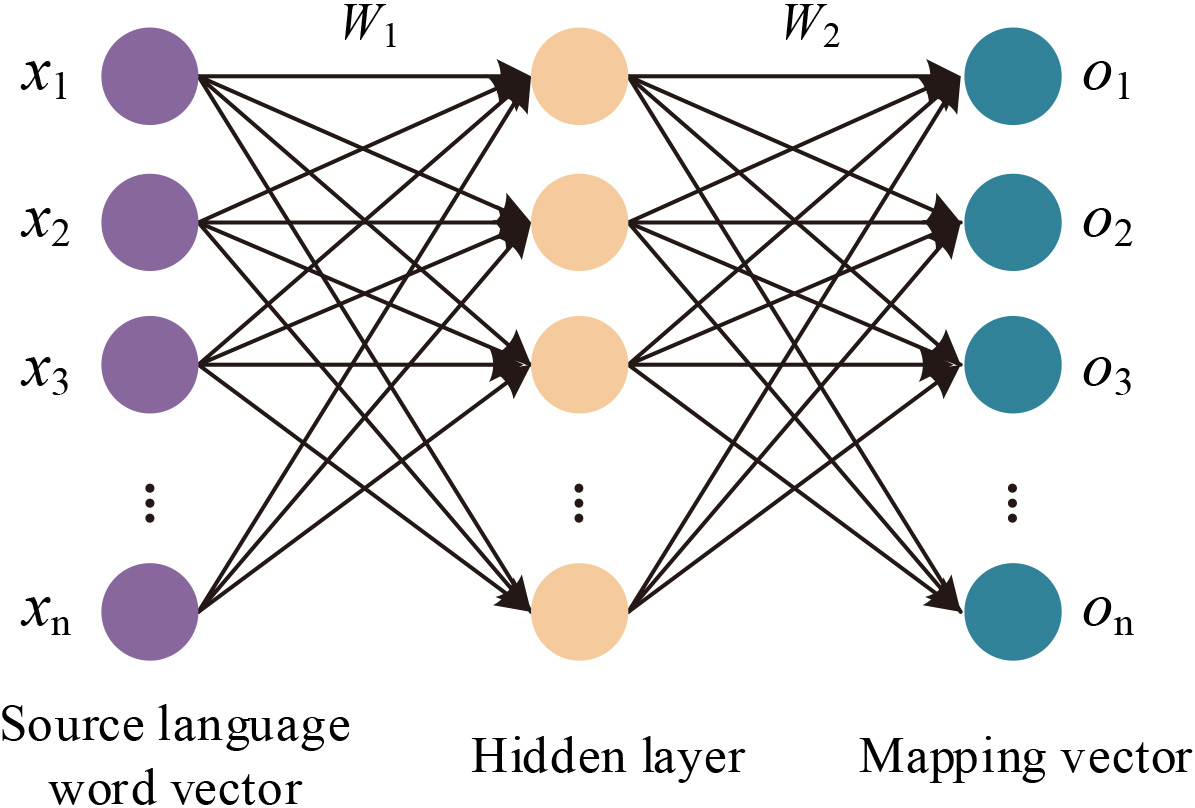
In Fig. 5, import the vector of the source language text in the input layer of the network model. After two nonlinear change, the mapping vector of the text enters the output layer. The error sum between the mapping result and the word vector can be reduced by training, and the formula of the input layer to the output layer and the loss function of the model are shown in Eqs (10) and (11).
In Eqs (10) and (11),
In Eq. (12),
Using the weighting formula, the phrase pair intertranslation probabilities were estimated as shown in Eq. (14).
To enable a better evaluation of the domain interpreter degree, the interpreter probability is calculated from the opposite direction, as shown in Eq. (15).
In Eq. (15),
To verify the rationality and accuracy of the selection optimization method of fuzzy semantics, this experiment is simulated and analyzed on MATLAB, and the data set used is CWMT09. Using the repetition rate and the accuracy checking rate as indicators, and the translation results of different methods are shown in Fig. 6.
Simulation analysis results of repetition rate and precision rate.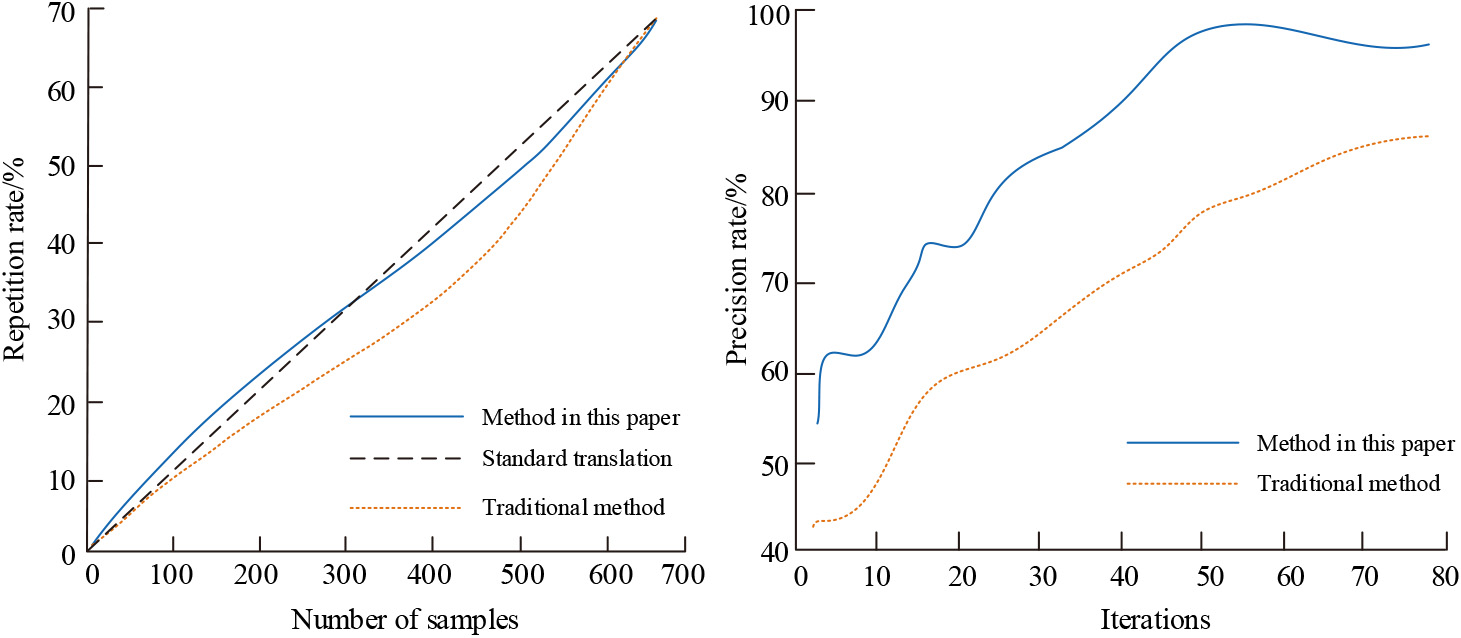
In Fig. 6 that the method used in this experiment matches better with the repetition rate of the standard method of manual translation when compared with the traditional translation method; and the accuracy checking rate of the method used in this experiment is better than the traditional method when compared with the traditional method.
To test the optimality and validity of the neural network optimization approach based on Bi RNN and attention mechanism, the traditional Bi RNN and the improved neural network are tested in the dataset. Before conducting the tests, both models are trained in the dataset to identify the best performance of RNN, traditional CRNN and improved CRNN methods until the end of convergence. The LOSS plots of these two methods are shown in Fig. 7.
Comparison diagram of loss curve of two models.
From Fig. 7, it can be seen that the optimized method gradually reaches a steady state with a value of 0.09 after 15 iterations, indicating that the number of iterations when the method starts to converge is 15. The number of iterations when the traditional Bi RNN method starts to converge is 18, and the loss function’s value is 0.1. The number of iterations of RNN method is 20, and its loss function value is 0.12. The comparison of the LOSS curves shows that the optimized neural network loss function value is smaller than the value of the traditional method and has better performance. The accuracy of these two methods was verified in the validation set during the iteration process, and Fig. 8 displayed the results.
In Fig. 8, the accuracy of the optimized neural network tends to stabilize at the number of iterations of 15 with an accuracy of 0.96, the accuracy of the traditional Bi RNN at the time of stabilization has a value of 0.91, and RNN is 0.82, which are lower than that of the improved method, indicating that the optimized neural network has higher performance.
In this study, six machine translation systems in the fields of journalism and education are constructed, including Baseline based on a generic domain parallel corpus, Mikolov_Sim based on matrix mapping, NN_Sim based on neural networks and calculating the probability of domain inter-translation, NN_Sim 1 based on neural networks and calculating the probability of forward translation, NN_Sim 2 based on neural networks and calculating the probability of reverse translation, and Sennrich_2012, which fuses text translation from different domains. The effectiveness and generality of the bilingual mapping models are verified by testing the performance of these six systems on the measurement set, and the BLEU metric is used for evaluation.
Machine translation system performance (BLEU%)
Comparison diagram of accuracy curve of two models.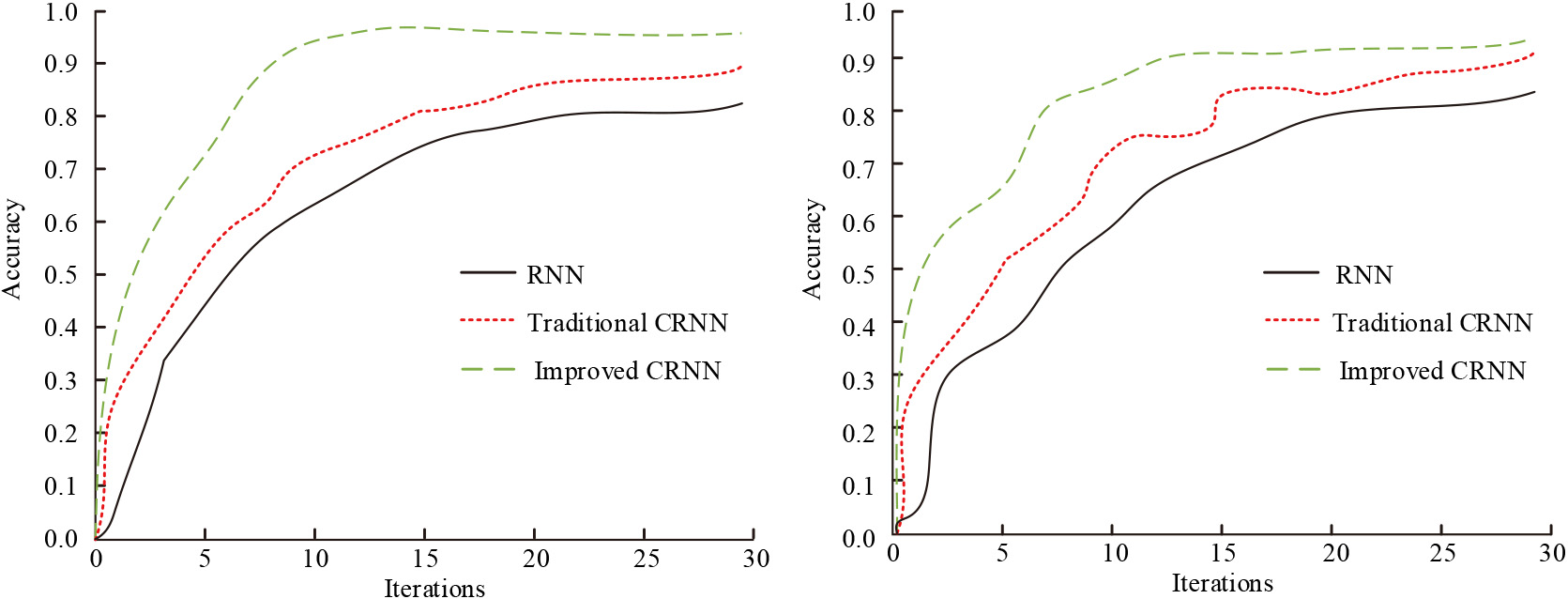
In Table 1, the bilingual mapping model improves the BLEU by 0.67% in the news domain and 0.56% in the education domain compared with the benchmark system, proving that the method proposed in this experiment can improve the translation performance in the news and education domains. Compared with Mikolov_Sim system, the Bleu index of NN_Sim system in the field of news and education has increased by 0.12% and 0.23% respectively, which proves that the translation performance of mapping methods in different fields is improved differently when testing, and the method based on neural network can obtain better performance. The NN_Sim system constructed by the bilingual mapping method improves its BLEU metrics by 0.21% in the news domain compared to Sennrich_2012, while the upper position in the education domain is significantly different. This may be because the size of the training corpus in the education domain is lower than that in the news domain, proving that the method in this experiment has a certain degree of dependence on the size of the corpus.
To evaluate more objectively the performance of the bilingual mapping model used in the method, training is performed in the dataset and algorithm’s overall performance is measured by the translation accuracy
In Fig. 9, the sample size is closely related to the new method’s performance, and the translation performance gradually improves as the sample size increases. When the sample size is small, the model used in this experiment has a weak learning ability in the training set, so there is a high accuracy rate and low recall and
Translation examples
The relationship between accuracy, recall, 
In ancient poems, “UTF8gbsn千…万…” means “many” and several translation software have correct translation. “UTF8gbsn梨花” means white snow, which is described in the translation method and not reflected in other translation software. This shows that the fuzzy semantic translation method combined with domain analysis has certain accuracy and superiority.
The verification results of the optimization of fuzzy semantic selection methods in machine translation show that the repetition rate of the method used in this experiment is more consistent with the standard method of human translation; the precision of the method used in this experiment is better. The accuracy of the optimized neural network tends to be stable when the number of iterations is 15, the accuracy is 0.96, and the accuracy of the traditional Bi RNN is 0.91. Compared with the benchmark system, the bilingual mapping model has increased by 0.67% in the news field and 0.56% in the education field. The precision, recall and value of machine translation are 93%, 86% and 0.8 respectively. The performance of the machine translation model optimized by the fuzzy semantic selection method has been effectively improved, and the performance of this model is closely related to the sample size. In this study, we innovatively build a bilingual mapping model based on the optimization of fuzzy semantic selection, combined with neural networks, to achieve semantic domain analysis, so as to improve the accuracy and effectiveness of machine translation. The disadvantage is that, when validating the domain analysis of bilingual mapping, it is found that the bilingual mapping model has a certain dependence on the corpus size, and further optimization of the method will be considered in the later research to improve the translation performance.
Footnotes
Funding
The research is supported by The First-class Major Construction of Business English in Xi’an Fanyi University (No. 2021-2025).