
Abstract
To mine more semantic information between words, it is important to utilize the different semantic correlations between words. Focusing on the different degrees of modifying relations between words, this article provides a quantum-like text representation based on syntax tree for fuzzy semantic analysis. Firstly, a quantum-like text representation based on density matrix of individual words is generalized to represent the relationship of modification between words. Secondly, a fuzzy semantic membership function is constructed to discuss the different degrees of modifying relationships between words based on syntax tree. Thirdly, the tensor dot product is defined as the sentence semantic similarity by combining the operation rules of the tensor to effectively exploit the semantic information of all elements in the quantum-like sentence representation. Finally, extensive experiments on STS’12, STS’14, STS’15, STS’16 and SICK show that the provided model outperforms the baselines, especially for the data set containing multiple long-sentence pairs, which confirms there are fuzzy semantic associations between words.
Keywords
Introduction
Sentence embedding is an important topic in NLP study by passing knowledge to downstream tasks efficiently, such as cross-modal retrieval [1–3], emotion annotation [4, 5] and semantic analysis [6–11]. Different models have different mechanisms. Among the unsupervised methods, the models with better semantic expression are paraphrastic sentence embedding (PP) [12] and siamese continuous bag of words (SCBOW) [13] and their variants [14]. Using word2vec as the input vector of deep neural network has achieved very good experimental results in many downstream NLP tasks [12–15]. Quan et al. [15] established an association matrix between words based on the constituency parse and combined word embeddings with attention weight mechanisman to construct an attention constituency vector tree (ACVT) kernel for sentence similarity. The transformer-based model establishes the direct connection between any two words in a sentence through the self-attention mechanism, making long-distance dependent features easier to capture. Dissecting BERT-based word models were used to form a new sentence embedding, analyzing the word embedding spanned space [16].
Although the existing text representation models have achieved good experimental results in many NLP tasks, such as semantic analysis, two issues still need to be solved.
Firstly, the existing literature lacks the description of semantic association between words based on quantum density matrix. The tensor product of the word vector and its transposed conjugate vector was defined as the density matrix of the word, and the sum of the density matrices of the words in the sentence is defined as the semantic representation of the sentence [17–19]. The density matrix of the text is input into the neural network to extract features, thus realizing the deep neural network analysis based on quantum language. Therefore, the existing quantum-like text representation models based on density matrices treat words as independent individuals, ignoring the semantic associations between words.
Secondly, these existing text representation models regard words in text as individual, ignoring the different degrees of association between words, and can not reflect the grammatical modification structure of sentences. Moreover, words in different positions in the same grammar tree are closely related to each other, and the existing models do not consider the different degrees of association between words. The transformer-based model establishes the direct connection between any two words through the self-attention mechanism, but is not suitable for semantic similarity tasks [20].
Therefore, this article aims to construct a quantum-like text representation (QTR) based on syntax tree to discuss the influence of fuzzy associations between words on text semantics.
Firstly, from the perspective of quantum computing, the density matrix can not only represent the quantum states in an isolated system, but also describe the quantum states of subsystems in a composite system. Further, from the perspective of text representation, the expression of text semantics is not only related to the semantics of words, but also determined by the modified associations between words. Therefore, we can extend the density matrix representation based on independent words to the reduced density matrix representation that can reflect the semantic association between words.
Secondly, from the perspective of fuzzy set theory, in different contexts, the semantic information expressed by words needs to be measured according to the grammatical information between words. To reflect the influence of different degrees of association between words on text semantics, the fuzzy semantic membership function based on smallest subtree is defined as the semantic correlation coefficient, and combined with the reduced density matrix to form a weighted semantic association matrix between words. The linear superposition of all weighted semantic correlation matrices of the input sentence forms the sentence tensor representation. To utilize the semantic information of all elements of sentence tensor representation as much as possible, the dot product of the tensor representation of two input texts is defined as the semantic similarity matrix, and input into the convolutional neural network (CNN) to extract features. The flowchart of our model is shown in Fig. 1
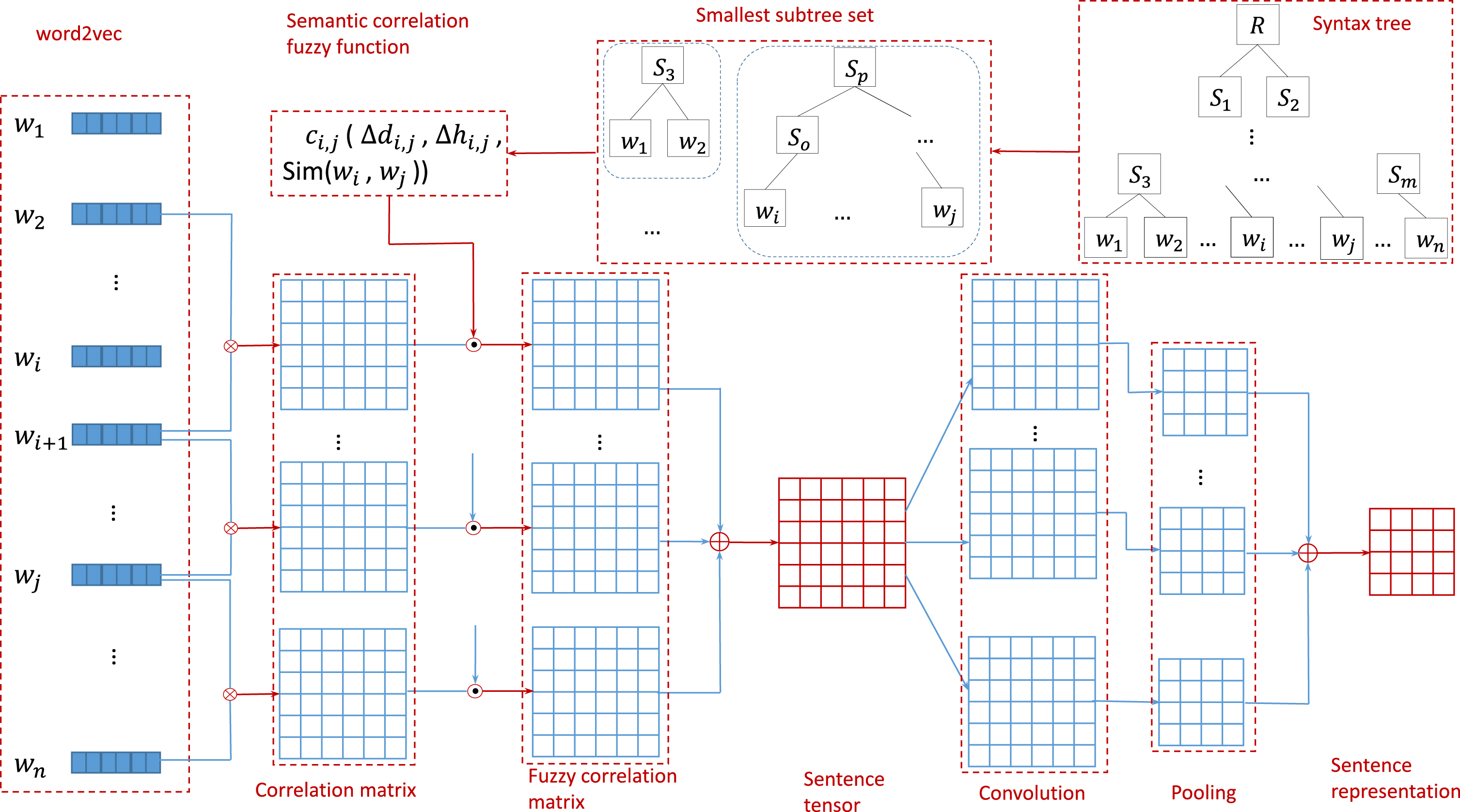
Framework of the provided model for sentence representation.
The rest of this paper is organized as follows. Section 2 summarizes some related literature on sentence embedding, the application of fuzzy rough set in NLP and the application of quantum computing in NLP. The proposed fuzzy semantic text representation model is constructed in Section 3. Section 4 demonstrates the experimental results and discussions. In Section 5, some conclusions are drawn.
Sentence embedding
How to effectively represent a text is a difficult problem that natural language processing (NLP) scholars have been exploring. In recent years, many researchers have proposed textual representations with different mechanisms to discuss the semantics of some continuous words. Sentence embedding is an important topic in NLP study by passing knowledge to downstream tasks efficiently, such as cross-modal retrieval [1–3], emotion annotation [4, 5] and semantic analysis [6–11]. Using word2vec as the input vector of deep neural network has achieved very good experimental results in many downstream NLP tasks [12–15]. The transformer-based model establishes the direct connection between any two words in a sentence through the self-attention mechanism, making long-distance dependent features easier to capture. Dissecting BERT-based word models were used to form a new sentence embedding, analyzing the word embedding spanned space [16]. BERT [20] and its variants [21–25] are regarded as effective models with outstanding performances in many NLP tasks [26–28]. However, BERT outputs and [CLS] token embedding were not suitable for semantic similarity tasks but appropriate for classification tasks through comparing the layer-wise evolution of word representations of deep contextualized models [16]. The transformer-based sentence representation considers all correlations between all words in a sentence through self-attention mechanism with a sharp rise of parameters for pre-training [29–31]. In brief, text representation based on deep learning depends on large-scale training set and huge parameter requirements. Accordingly, it is fundamental to use existing knowledge and certain parameters to establish a text representation model that can comprehensively discuss the semantic, grammatical and word order information between words.
Application of fuzzy rough set in NLP
The application of fuzzy sets in NLP attracts more and more attention, such as text representation [32–34], sentiment analysis [35, 36] and e-commerce logistics [37, 38]. According to the research objects, the existing text representation models based on fuzzy rough sets are mainly divided into two categories in semantic analysis. One is the study of words with fuzzy semantics [39–41], with the basic idea of measuring the similarity based on word embedding and the similarity between words according to the similarity of word vectors. To measure the semantic similarity between words, multiple semantic information of a word in WordNet was encoded into a vector space [42]. Standard similarity measures and new directives were implemented to generate the approximation degree by the proximity equations linking two words [43]. The other is fuzzy decision analysis for semantic overlap [44–46]. In query language tasks, a fuzzy decision mechanism was combined with the dependency graph to improve the model decision [47] and a fuzzy semantic representation was presented for rare words [48]. Top-k words as a selection technique was used to detect and return the k most similar words to a candidate set [49]. A fuzzy set representation was provided to measure the fuzzy words through the fuzzy set similarity [50]. In conclusion, existing NLP models based on fuzzy sets mainly study the semantic distributions of texts from the perspective of fuzzy sets, but lack researches on semantic enhancement caused by fuzzy modifications between words. Hence, it is necessary to study the different degrees of modifications between words in the text.
Application of quantum computing in NLP
Quantum-inspired text representations [51, 52] mainly use the mathematical framework of quantum theory to represent the semantics, syntax, and emotion of texts in NLP, so that text representations are better consistent with human cognitive information. In recent years, text representation models based on quantum excitation can be roughly divided into two categories: one is the theoretical study of text representation based on quantum language [53–58], and the other is deep neural network models based on density matrices and traces of matrices [17, 59–61]. The text representation based on density matrix is input into the neural network to extract features, thus realizing the deep neural network analysis based on quantum language [62–65]. As deep neural networks show much greater prominent advantages in various fields, more and more researchers combine the text representation model based on quantum density matrix with other basic knowledge of quantum theory to form a text representation that can better reflect human cognition model and apply it to different NLP tasks. With the excellent performance of the transformer in different NLP tasks, some scholars have input the density matrix of consecutive n words into the multi-head transformer to extract more semantic features [66–69]. In a word, the existing NLP models based on quantum computing mainly regard words as independent individuals, but lack of researches considering semantic and grammatical associations between words. Therefore, it is worth extending sentence representation based on density matrix of independent words to the semantic association between words.
In short, text representation models have different focuses as they are based on different frameworks. Consequently, it is essential to use the mathematical framework of quantum theory and fuzzy mathematics to study the modification relations among words, the degree of modification and the influence of word order on the semantics and syntax of text.
Fuzzy semantic quantum-like text representation
The general flowchart of the fuzzy semantic quantum-like text representation and the definition of the used parameter are respectively listed in Fig. 2 and in Table 1.
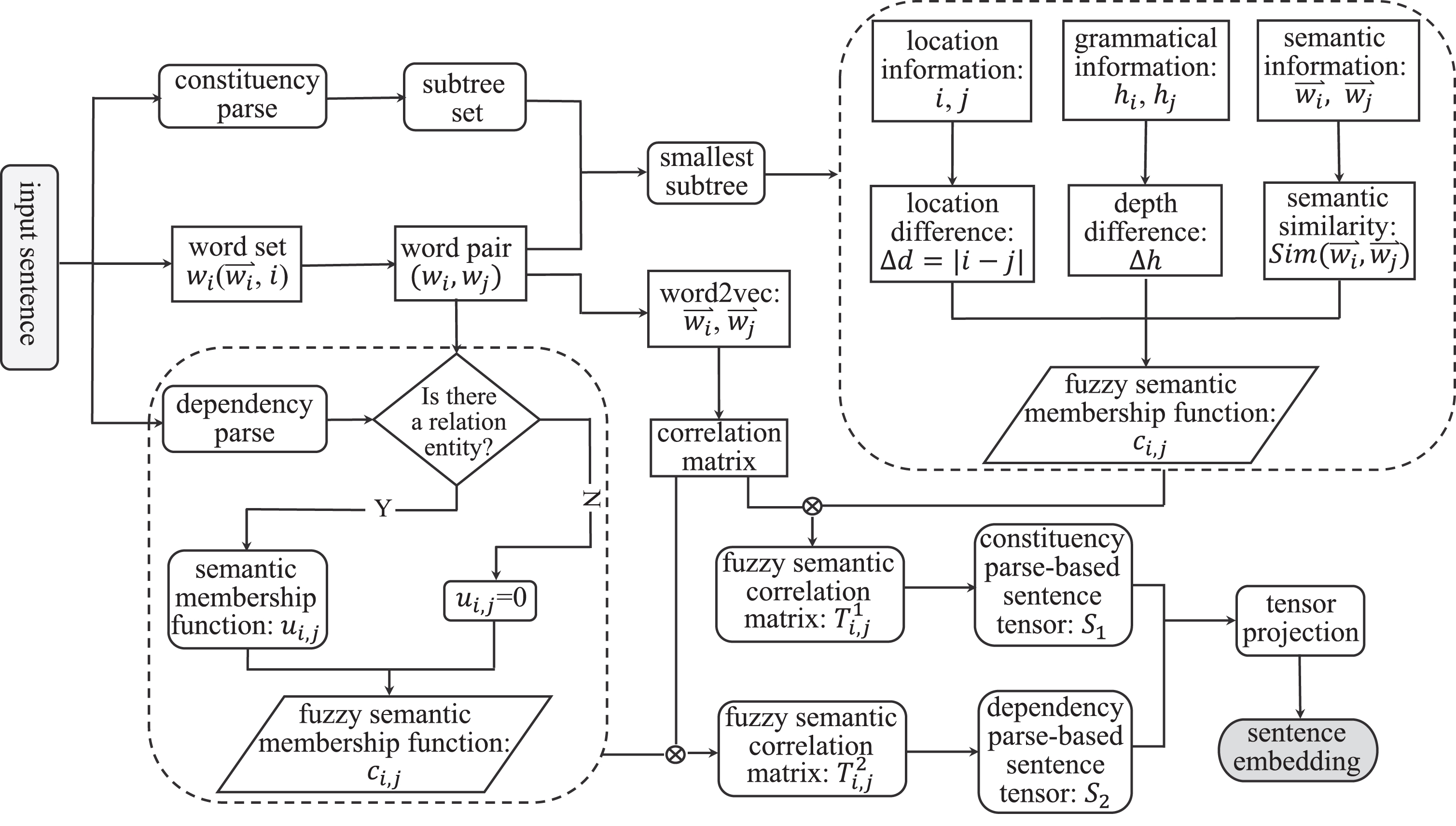
The general flowchart of the proposed method for preprocessing the sentence representation.
The definition of parameters
All words in the sentence T are stored in the word set
where w
i
is the normalized vector of the ith word embedding
The correlation matrix between w i and w j is defined as follows,
If the order of two associative words is exchanged, the correlation matrix is changed as follows,
where
According to
The constituency parse can reflect phrases with different modifications from different combinations of words 1 . Each subtree in a constituency parse saves the complete grammatical information, denoting a phrase with a certain modification. The size of the smallest subtree can reflect the different degrees between related words with different modifications.
Take a subtree of
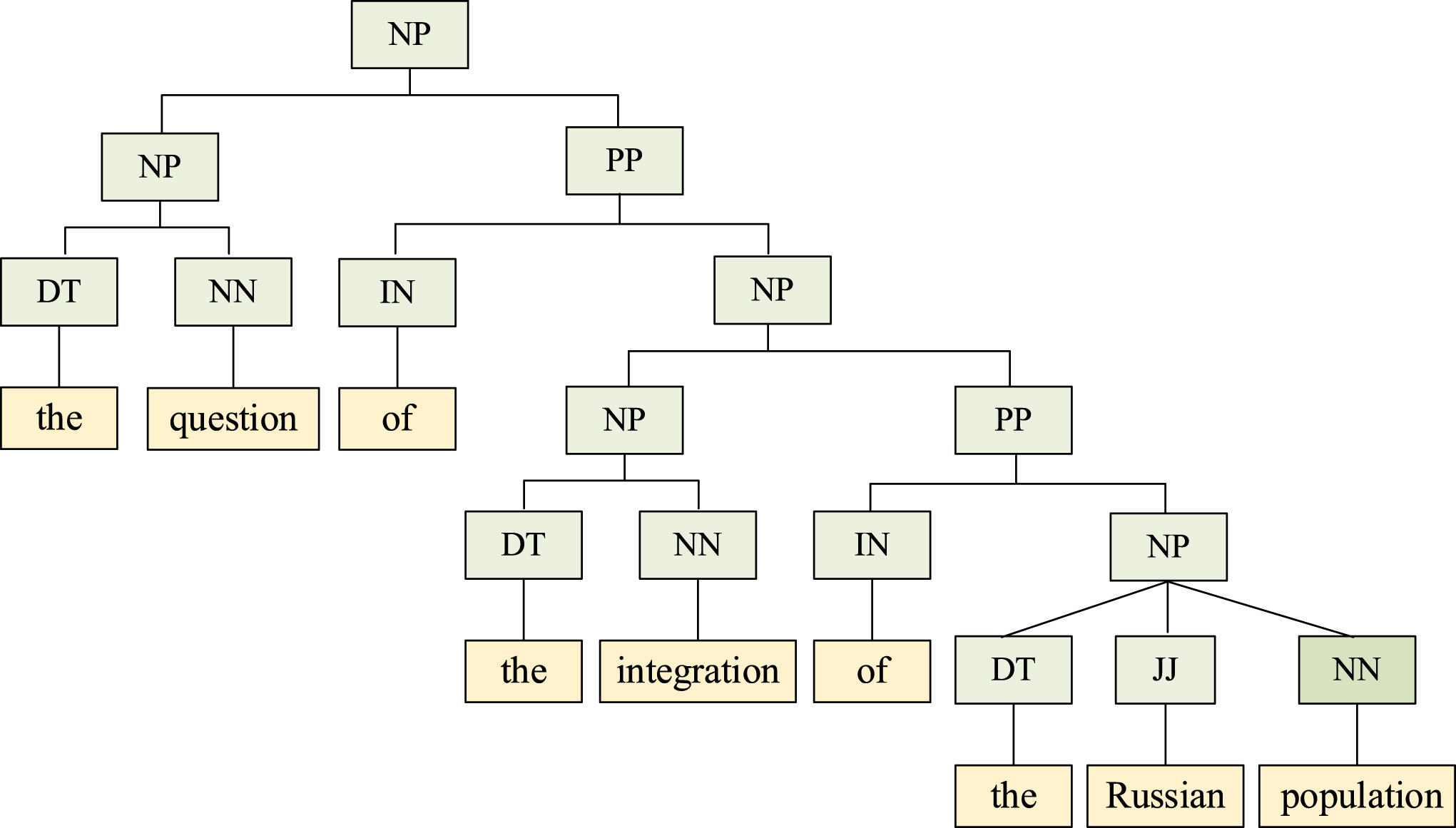
A subtree of the sentence constituency parse shown in Fig. 1.
There are five NPs with different phrase combinations listed in Table 2.
The sequences of NPs in
Apparently, Seq1 contains the other four NPs, that is, Seq2, Seq3, Seq4 and Seq5 are the descendants of Seq1. Seq3 is the smallest subtree of Seq4 and Seq5, not containing Seq2, which means that the semantic correlation between words in Seq4 and Seq5 is stronger than that in Seq2. Therefore, a membership function of semantic association between words based on a subtree is established to reflect the different degrees of the different correlations.
Input all the words of the sentence S to generate a constituency parse and construct a set of subtrees according to the constituency parse. The algorithm for generating the subtree set based on the constituency parse is listed in Alg. 1. Record the positions of all words in the sentence. For example, w i is the ith word of the sentence S and w j is the jth word.
Algorithm 1 Algorithm for generating the subtree set based on the constituency parser.
Smallest subtree
Find the smallest subtree ST
s
that contains leaf nodes w
i
and w
j
, and record the depths of leaf nodes w
i
and w
j
in the subtree, denoted respectively as
Algorithm 2 Algorithm for finding out the smallest subtree STs of word pair (wi,wj) from the subtree set ST.
Membership function of the semantic association
In fuzzy set theory, the membership degree equaling to 0.5 represents the least amount of information, which is, the most ambiguous. To reflect the most ambiguous semantic association between words, we define the membership function of semantic association between words as follows. if
Therefore, the difference of depths of the words w
i
and w
j
in the smallest subtree ST
s
is defined as the depth difference
The fuzzy membership function of the semantic association is regarded as the correlation coefficient between the related words. Therefore, the sentence representation is obtained by linear superposition of the correlation matrix of all the associated word pairs in the input sentence.
Algorithm 3 Framework of the constituency parse-based sentence embedding of fuzzy semantic association.
The components of a word embedding express the co-occurrence distribution of words in the training corpus. Since the co-occurring words of different words are different, the basis vectors are also different, so as the base vectors of the semantic association tensor obtained by the word2vec. To highlight the association semantics and reduce redundant information, the semantic association tensor is projected to a matrix core and then the maximum value is extracted to reduce the dimension of the semantic association tensor, as shown in Fig. 4. Considering that there are negative numbers in the elements of word2vecs, this model improves the pooling layer of the CNN to extract the value with the largest absolute value, and restores its original sign in the output layer.
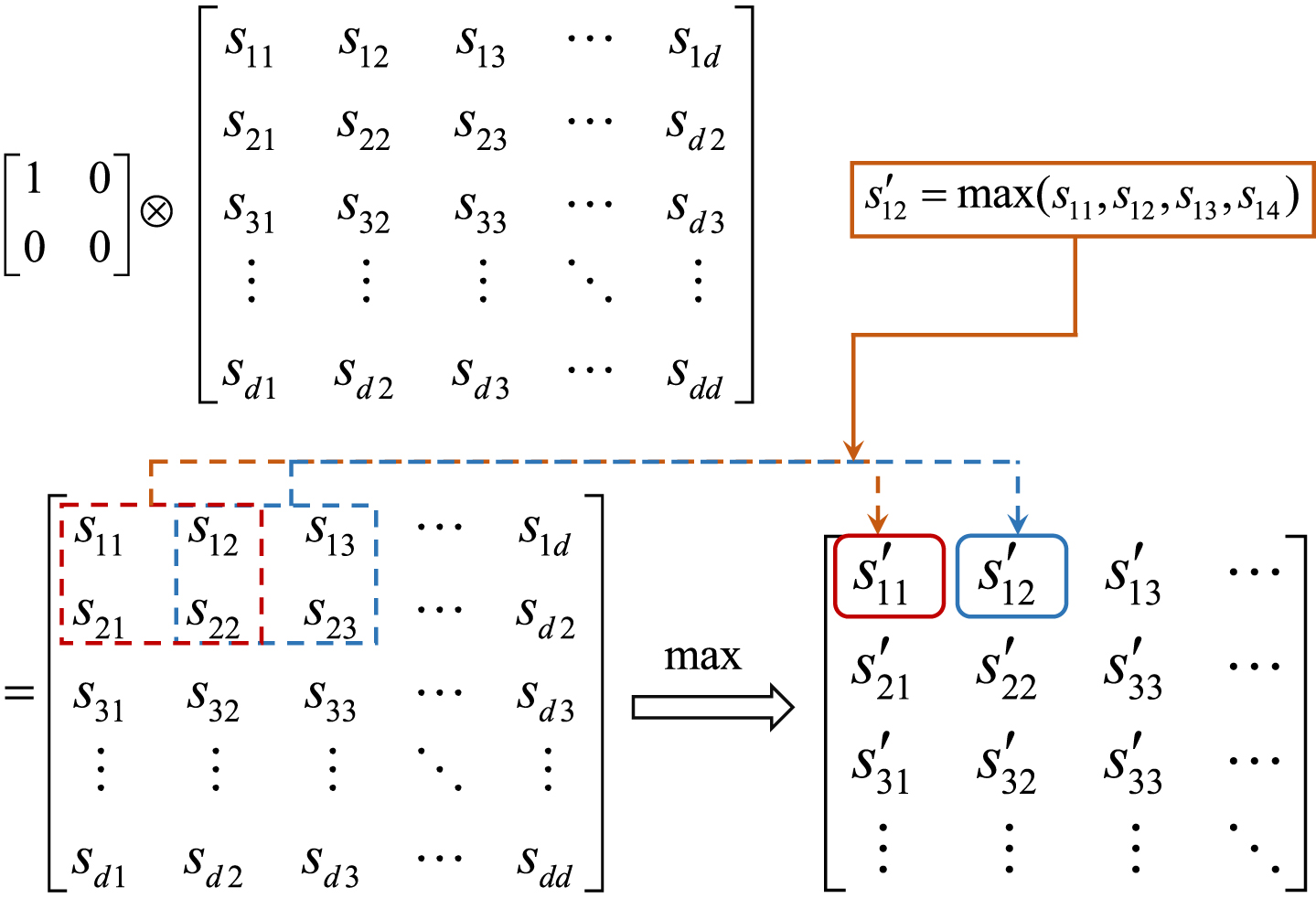
Flowchart of the dimension of sentence tensor representation reduced by tensor projection.
A sentence tensor of the provided model is taken as an example to list the processing of tensor projection, shown in Fig. 5. Figure 5 illustrates how to extract the maximum absolute value in sentence representation when the step size and kernel function are equal to 2. Among the four data in the blue box, the largest absolute value is -0.04576. If the maximum pooling in classical CNN is used to extract features, 0.02723 is obtained. Considering that the numbers and symbol in the word2vec can reflect the distribution characteristics of words co-occurring with them, -0.04576 has stronger semantic characteristics than 0.02723. Therefore, tensor projection can extract elements with stronger semantic features in sentence representation.
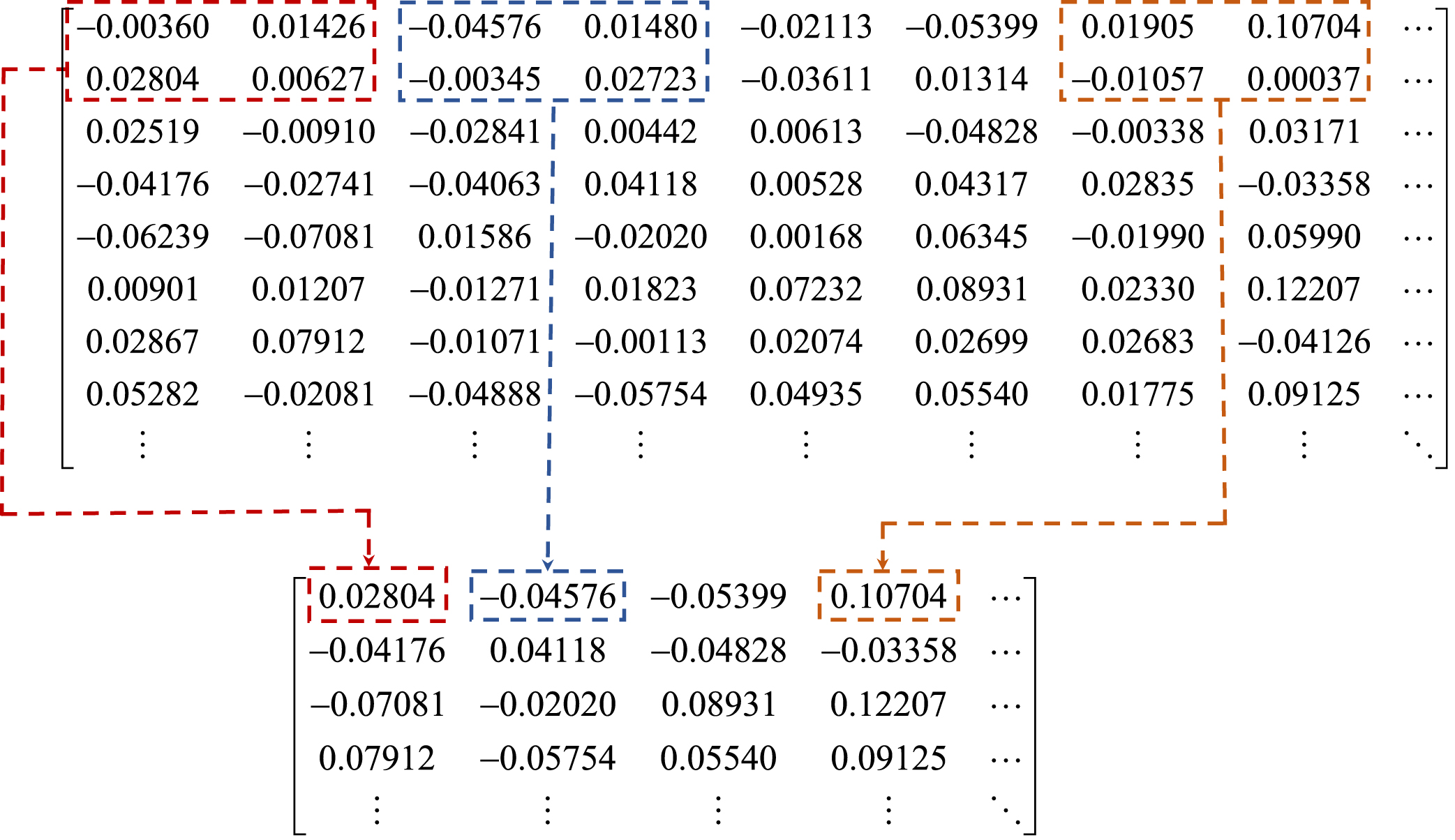
A sentence tensor to illustrate the tensor projection.
The dot product between the tensors of sentence embeddings S1 and S2 is seen as the correlation tensor of S1 and S2.
where
Similarly, the correlation tensor of S1 and S1 is
Experimental settings
Datasets and the total number of sentence pairs in each dataset
Datasets and the total number of sentence pairs in each dataset
For the same value of |x
i
- y
i
|, the relative errors of different y
i
are different. The larger y
i
, the smaller the relative error; the smaller y
i
, the larger the relative error. To have a unified expression for different y
i
, a constraint function is defined as follows,
Comparison of unsupervised models
Comparing the results listed in Table 4, except for SICK, QTR is higher than baselines, and the average of QTR on these five corpora is higher than that of all the baselines. The longer the sentence, the more complex the correlations between words, the more related phrases QTR obtains, which makes the semantic and grammatical expression of the sentence more accurate. Therefore, the semantic mining effect of QTR is more obvious for corpora with more long sentences. As an example, the result of QTR is much higher than the baselines in STS’12. However, in SICK, there are mostly short sentences and many sentence pairs with zero labeling value, and there are many identical words in the comparison sentence pairs, usually changing the synonym conversion of individual words, which makes QTR generate fewer discriminative associated word pairs, and leads to the calculation result that is larger than the labeled value, resulting in a lower Spearman’s rank correlation coefficient.
Comparison of some unsupervised models on Spearman rank correlation coefficient (Src) in each dataset
Comparison of some unsupervised models on Spearman rank correlation coefficient (Src) in each dataset
The comparson of the results listed in Table 5, shows that almost all calculation results of QTR are better than the results of the comparison models except STS’14.deft-news, accounting for 15/16, which indicates that QTR can effectively express the semantic and grammatical information of the text. If the logical language structures of most sentences in the corpus are obvious, and the coherence based on information is strong, especially the corpus containing more long sentences, the calculation result of QTR exceeds all the comparison models by absolute advantage, such as STS’12.MSRpar, STS’12.SMTeuroparl and STS’15. answers-forums. It shows that QTR based on constituency parse can effectively establish the correlation between words by combining the distance difference, the depth difference of grammatical trees and the cosine similarity between words as the influencing factors of the semantic membership function. In STS’14.deft-news, some texts are phrases with clauses as modifiers. The words in the clauses do not have much semantic relation to the subject of the phrase. However, all the words in the clauses are related to the subject with semantic association, which increases the semantic error and makes the calculated value smaller. Therefore, the Pcc of STS’14.deft-news is significantly lower than the comparison models.
Comparison of other methods based on word2vec on the Pearson correlation coefficient in each dataset
Comparison of other methods based on word2vec on the Pearson correlation coefficient in each dataset
All calculation results in Table 6 are computed by the sentence representation model based on constituency parse. As the distributions of the maximum Pcc and the minimum MSE are Compared, it is found that the semantic mining effect of the semantic association membership function between words that considers the depth difference Δh and ignores the distance difference Δd is significantly better than that of the other two while both considering the depth difference Δh and distance difference Δd, especially on the corpus containing a large number of long sentences, such as STS’15.belief. For a corpus of short text documents mainly composed of phrases or multiple short sentences, the effect of considering only Δh and ignoring Δd is better than considering Δd, and examples of this effect are STS’14.OnWN, STS’14.deft-forum, STS’15.belief and STS’15.answers-forums. However, for a corpus with diverse sentence structures, complete sentence patterns, and rhetorical accuracy between words in the text, it is better to consider both Δh and Δd comprehensively. For example, the Pccs of the five corpora of STS’12 all achieve the maximum values and MSE also reach the minimums.
Comparison of the influence of membership function ci,j in each dataset with λ = 1, where the ci,j of the smallest subtree are defined by Eqs. 4, 5, 6 and 7 with the condition of α1 = 4 and β1 = 2 and the other two ci,j are computed by Δhi,j, Δdi,j and Sim (w
i
, w
j
) directly without any other conditions attached
Comparison of the influence of membership function ci,j in each dataset with λ = 1, where the ci,j of the smallest subtree are defined by Eqs. 4, 5, 6 and 7 with the condition of α1 = 4 and β1 = 2 and the other two ci,j are computed by Δhi,j, Δdi,j and Sim (w i , w j ) directly without any other conditions attached
For sentence pairs satisfying 1 > y i > 0.8 and ɛ > 0.35, the dimension of the text representation is reduced by matrix projection. When the feature matrix is projected on the semantic relation matrix to extract the semantic features, the core of the feature matrix is set as the step size of the feature matrix movement. As the core of the feature matrix grows, the trend of the three corpora is the same, as illustrated in Fig. 6. Pcc first increases and then remains unchanged, and MSE first decreases and then remains stable. It shows that when the dimension of the association matrix is reduced to a certain value and then the dimension is reduced, there will be excessive dimension reduction, which may lead to the emergence of data sparseness.
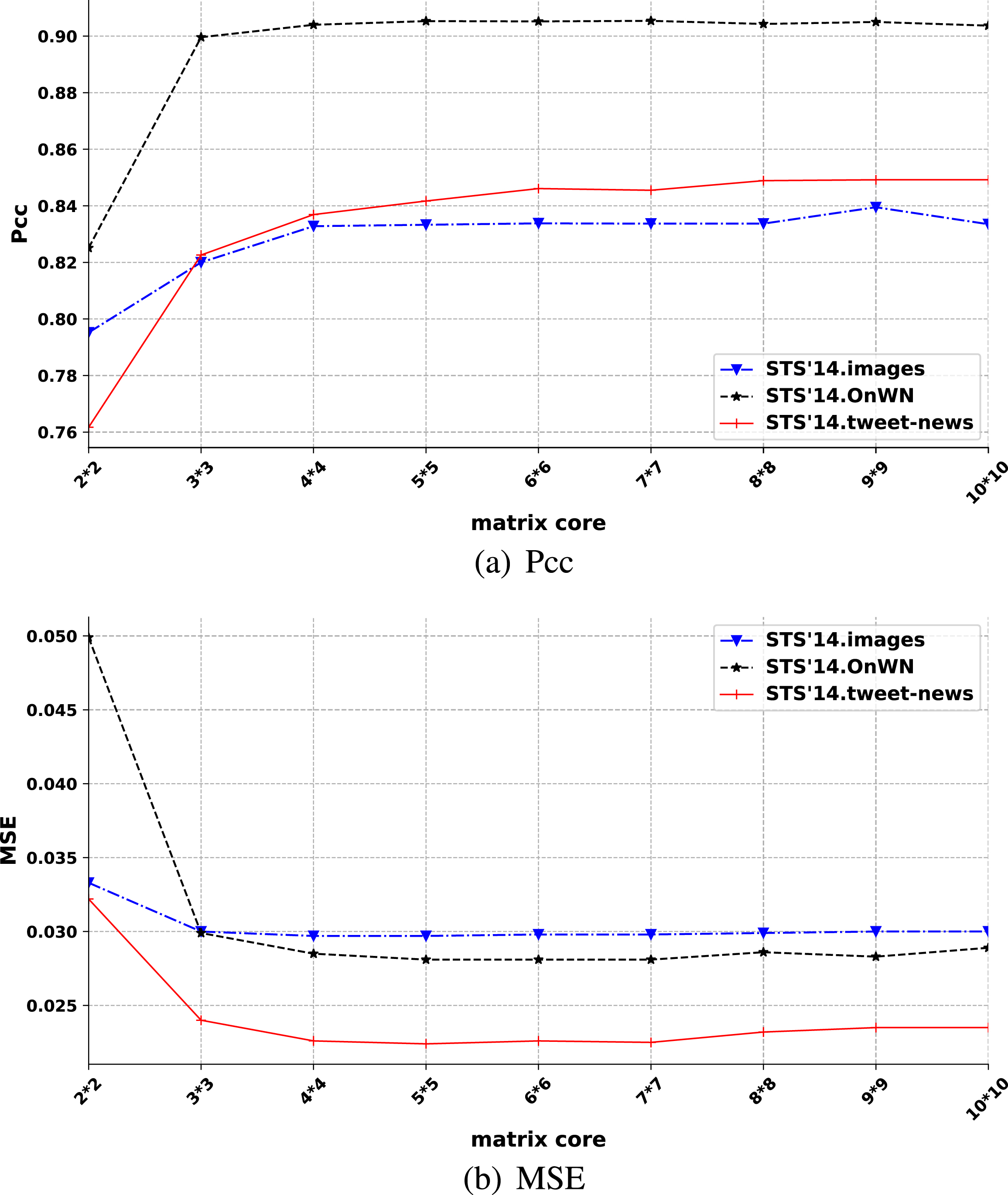
Influence of the tensor projection with the stride equaling to the matrix core.
This article provides a quantum-like text representation based on syntax tree to analyse the fuzzy modifying relationships between words for semantic similarity computing. The main advantages and differences compared to the existing models are summarized as follows. 1) To highlight the semantic relationship between words, the quantum-like text representation based on density matrix of individual words is generalized to represent the relationship of modification between words. 2) Combining the fuzzy mathematics theory, a fuzzy semantic membership function is constructed to discuss the different degrees of modifying relationships between words based on syntax tree. 3) To extract semantic information with larger absolute value in elements of the quantum-like sentence representation, we alter the pooling layers of CNN. 4) To effectively exploit the semantic information of all elements in the quantum-like sentence representation, the tensor dot product is defined as the sentence semantic similarity by combining the operation rules of the tensor.
Note that this study has certain limitations. This article mainly uses the computational method of quantum mechanics to preprocess the text representation to discuss the fuzzy semantic association between words. The dimension of sentence representation obtained by linear superposition of density matrix between words is expanded from d × N of word2vec to d2, thus increasing the computational complexity of the model. Future research will focus on reducing the computational complexity of this model and applying it to other natural language processing tasks such as fuzzy emotional association between words, multimodal fuzzy semantics and emotional associations.
Footnotes
https://nlp.stanford.edu/software/lex-parser.shtml
http://code.google.com/archive/p/word2vec
http://creativecommons.org/licenses/by-nc- sa/3.0/deed.en
http://groups.google.com/group/STS-semeval