
Abstract
Lip print recognition technology originated in the field of forensic medicine, and convolutional neural network has made breakthrough achievements in the field of pattern recognition and machine vision. Convolutional neural network (CNN) algorithm is rarely used in lip pattern recognition. Further exploration and research on the network model suitable for lip pattern recognition. Lip print recognition algorithm based on depth convolution neural network aims to solve the problems of complex image preprocessing, difficult feature extraction and low recognition efficiency in traditional lip print recognition algorithms. It includes collecting lip print images to establish data sets, selecting different CNN models to conduct performance evaluation experiments on low resolution lip print data sets, and analyzing the experimental results with model evaluation indicators.
Introduction
Image acquisition
The acquisition methods of lip print image mainly include contact and non-contact acquisition, and the lip print feature information and details obtained by different acquisition methods are different. Contact acquisition is achieved by direct contact of multiple lips with the acquisition equipment, or by leaving lip print information on some materials, and by some chemical methods, as shown in Fig. 1. The image obtained by observing the non-contact method has a large amount of lip print information, but the acquisition speed is slow. During acquisition, the lip print will also be deformed and distorted due to human factors, which can’t guarantee the integrity of the lip print and affect the final recognition effect [1].
Non-contact acquisition mainly adopts intelligent terminal devices with cameras, such as mobile phones, network cameras and computers. The camera directly captures and stores the image of an individual’s lips. This method is fast and highly acceptable to users. Based on the camera lip print image acquisition method of mobile phone and computer, and according to the characteristics of lips, the lip print location is carried out. The RGB color space of the lip print image is converted into YCbCr color space, and the lip print location is realized by combining Sobel algorithm and morphological transformation. Cut the redundant information of the image to reduce the complexity of subsequent processing. Combining the characteristics of the depth learning algorithm and the advantages of the non-contact acquisition method, this paper uses the network camera to capture the lip texture image [2]. In order to obtain lip print images from different angles, the method of video recording was adopted. The volunteers kept their lips at a distance of 30 cm from the camera lens, and then moved from left to right and from top to bottom in a normal closed state. A total of 60 volunteers were filmed in the data set, and finally the lip video files of each volunteer were obtained.
In response to the complexity of traditional recognition algorithms and the susceptibility of feature extraction to interference, etc. The algorithm proposed in the paper improves the effectiveness of convolutional neural networks and improves feature extraction performance.
Building the dataset
According to the video file obtained by the above acquisition method, considering the different definition of each person’s lip print in the video recording and the different position of each person’s lips in the image, the frame extraction method is used to obtain a clear RGB image by capturing an image every 5 frames. Because of acquiring multi-angle lip images, the position of the lips in the whole image is different. Set the rectangular frame of the region of interest through the machine vision processing library OpenCV to remove the redundant information in the image, and set 458
Data set division information
Data set division information
Lip obtained by contact acquisition method.
In order to avoid the over fitting phenomenon during the training of the depth convolution neural network model and improve the robustness of the network model to image noise, a simple image enhancement method is used to expand the data set, including rotating 45 degrees, adding gaussian fuzzy noise, adjusting the image brightness, and generating a horizontal mirror image, as shown in Fig. 2.
Data expansion effect.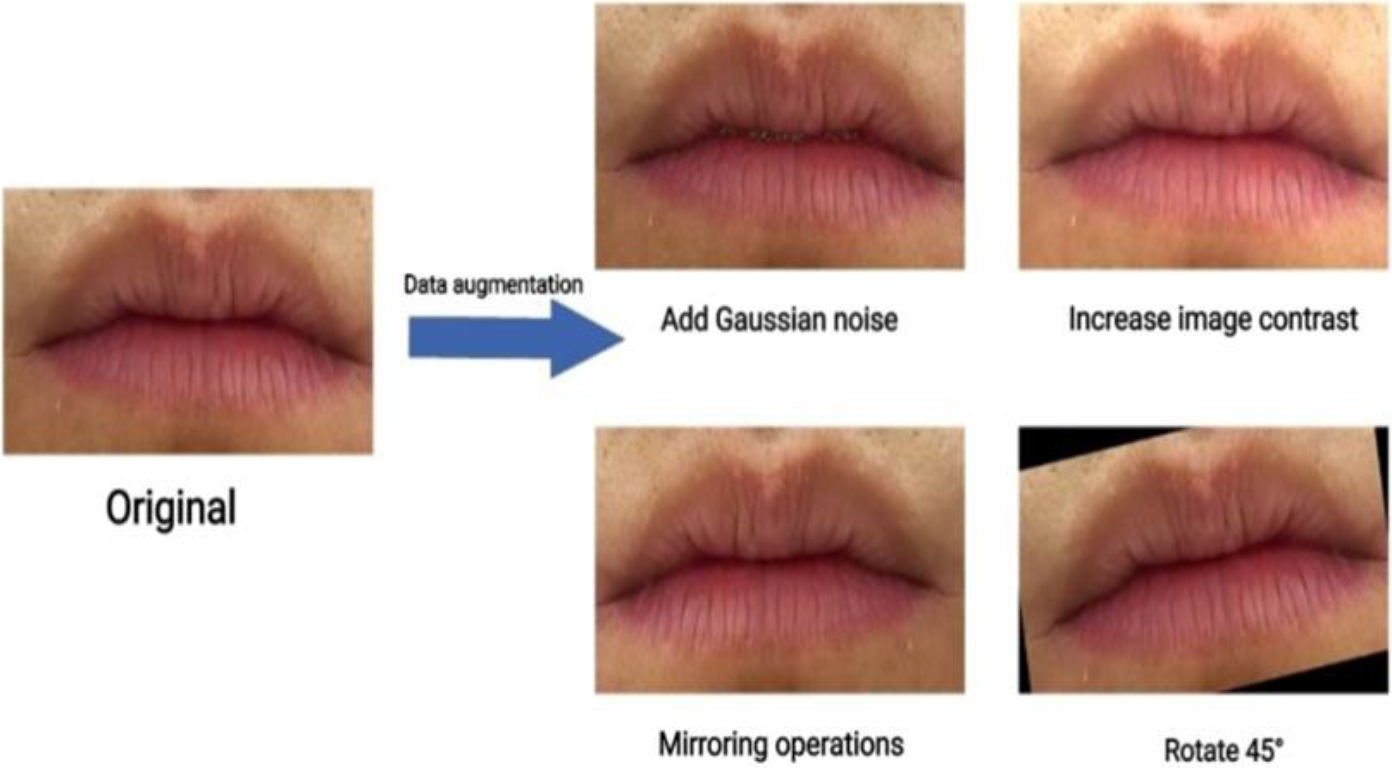
The data set consists of 18000 images for 60 people. It is divided into training set, verification set and test set according to the ratio of 7:2:1, as shown in Table 1. The training set is used to train the neural network model, and then the validation set is used to verify the validity of the model and select the model with the best effect. Finally, after the model passes the validation set, we use the test set to validate the final effect of the model and evaluate its accuracy [4].
Traditional lip recognition algorithm
The traditional lip pattern recognition algorithm mainly includes image acquisition, image preprocessing, feature extraction, feature matching and classification recognition. In the process of image acquisition, there are many human factors in the process of lip pressing direction, pressure and developing material, and the processing effect directly affects the final recognition effect. The image pre-processing needs to design pre-processing methods, using various image processing methods to highlight the feature information in the image, such as Hough transform, threshold algorithm, etc. This requires high quality of lip print image, and the processing effect directly affects the result of feature extraction. In the feature extraction stage, the extraction algorithm needs to be designed manually, resulting in long recognition cycle, complex preprocessing process and difficult feature extraction. Therefore, the overall recognition efficiency is relatively low. Therefore, we should focus on the research of automatic feature extraction algorithm to realize machine learning to reduce the interference of human factors and improve the recognition efficiency.
Lip recognition algorithm based on CNN
The core of convolution layer is to use convolution check images of different sizes for convolution operation, which is equivalent to filter operation in image processing. The convolution kernel is to slide the window according to a specific step size, and extract the feature information in the image by convolution with the pixel points in the image [5]. The size of the commonly used convolution kernel includes 3
Multi-channel convolution operation process.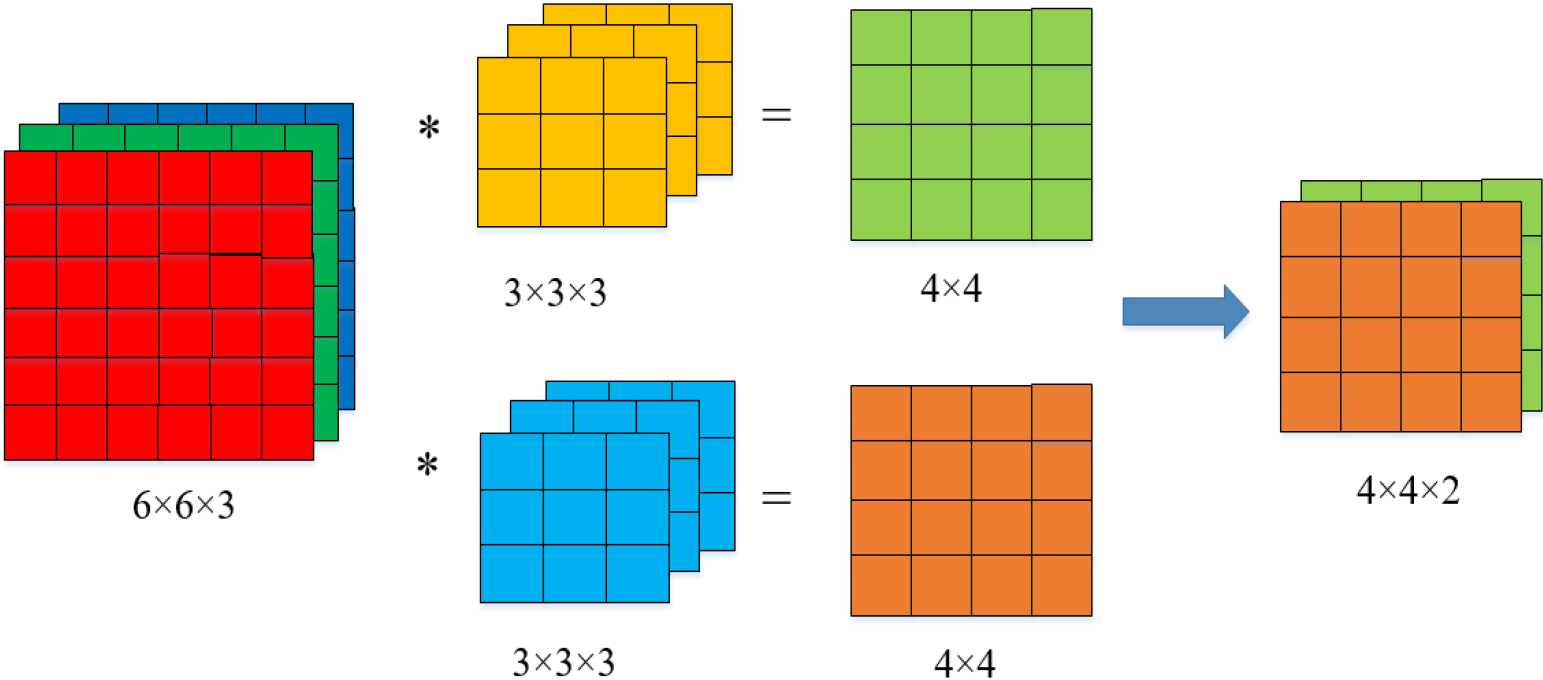
In the paper, a lip recognition method based on convolution neural network is proposed, which alternately connects the convolution layer and the pooling layer to form a feature extractor, and directly inputs the image for feature extraction and classification. Compared with the process of traditional recognition methods, the preprocessing process of lip image is simplified. The collected lip image is divided into training set, verification set and test set. CNN automatically extracts the color, texture and shape features by using a number of feature extractors, and then processes the feature information with a classifier and outputs the recognition results.
Lip pattern recognition is multi classification problem, so the selected classifier is Softmax, which is directly placed on the next layer of the full connection layer of the convolutional neural network. For the one dimensional vector
Where,
Influence of learning rate on recognition performance
As one of the important parameters for training convolutional neural network model, the learning rate not only affects the convergence state and learning ability of the model, but also determines the stability and generalization ability of the model. ResNet18 and MobileNetV2 proposed in ResNet are selected for model training experiments under different learning rates [6]. The results are shown in Table 2 and Fig. 4.
Recognition effect under different learning rates
Recognition effect under different learning rates
Loss value of training set and verification set under different learning rates.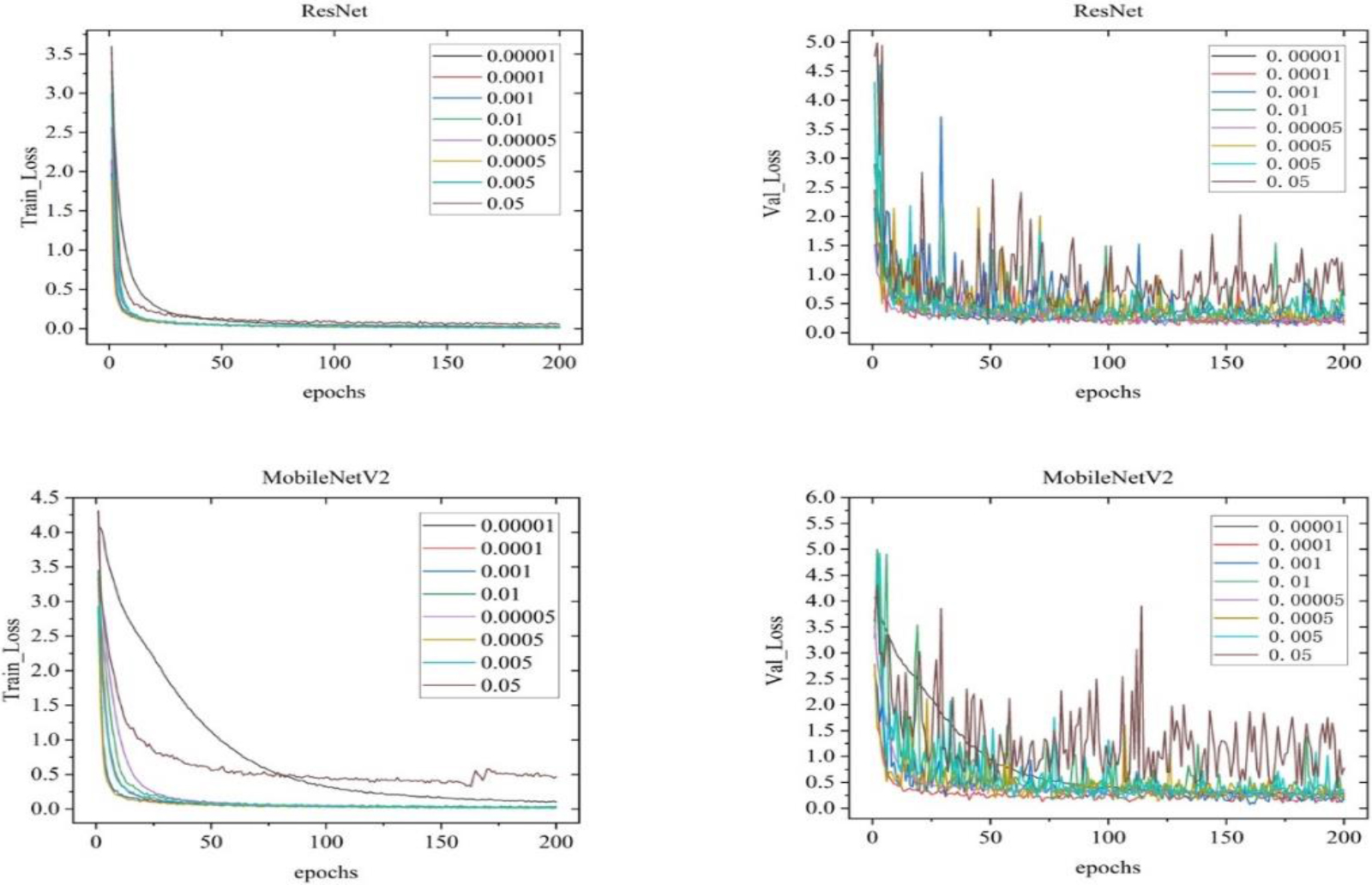
When the learning rate is 0.0001, the performance of ResNet18 and MobileNetV2 networks is the best, and the recognition accuracy is 96.63% and 96.91% respectively. When the learning rate is set between 0.0001–0.005, with the increase of the learning rate, the convergence speed is faster and faster, but the recognition accuracy is gradually reduced. When the learning rate is less than 0.0001, the convergence speed of the model becomes slow and the recognition accuracy is greatly reduced. In the same number of training iterations, the learning rate makes the model produce severe oscillation in the verification set, which is extremely unstable.
In order to explore the depth convolution neural network model suitable for lip line recognition algorithm and solve the problems of complex preprocessing, difficult feature extraction and low recognition rate in traditional recognition methods, 18 kinds of depth convolution neural networks were selected for recognition performance evaluation experiments [7]. Each network is an innovative research product from different time nodes. It is optimized and improved by solving the problems existing in the development process of the deep convolution neural network. Different design modules make different contributions to image classification, target detection, natural language processing and other research fields. Therefore, large-scale performance evaluation experiments are conducted to explore the network model suitable for lip print image classification tasks. The learning rate of the experiment is 0.0001, the batch size is 64. The experimental results are shown in Table 3.
Identification effect of different network models on test set
Identification effect of different network models on test set
It can be seen from the analysis of Table 3 that the parameters of VGG in the classical convolutional neural network reach 134.5 M, which not only increases the difficulty of network training, but also takes a relatively long time to train, requiring two GPUs to train in parallel [8]. MobileNetV2 network has the highest evaluation indicators, relatively few parameters of the model, and its accuracy rate is as high as 96.91%. Therefore, compared with other networks, this network is more suitable for lip image classification tasks. In lightweight networks, the parameters of squeezeNet and ShuffleNetV2 are relatively small, 0.77 M and 0.41 M respectively, but the accuracy is relatively low. That is, the identification accuracy is sacrificed to reduce the model parameters and model complexity, so as to better apply them to mobile devices with limited computing power. The recognition rate of ResNet, DenseNet, Xception, EfficientNet and EfficientNetV2 networks has reached 96%. For networks with many network parameters and difficult to train, migration pre training model is usually used for training.
In the development process of convolutional neural network, the network structure is constantly improved by increasing the network width, network depth and modular design methods, among which increasing the depth is one of the methods used relatively more in the early development. The number of network layers represents the depth of the network. The deeper the network is, the stronger its feature expression ability will be. Extracting more abstract features will also bring about problems such as large parameter quantities, gradient disappearance, gradient explosion and model degradation [9]. The memory size and computing performance of hardware devices are also increasingly required. In view of the impact of the number of network layers on the performance of network model recognition, ResNet proposes residual connection to build a deeper network structure, while DenseNet also implements dense connection and builds some deeper network structures, so ResNet18, 34, 50 and 101 and DenseNet121, 161, 169 and 201 are selected for lip pattern recognition model training experiments, and the learning rate is set to 0.0001. The experimental results are shown in Table 4.
Recognition results of ResNet and DenseNet series networks on test set
Recognition results of ResNet and DenseNet series networks on test set
Validation set accuracy and loss value of ResNet and DenseNet series networks.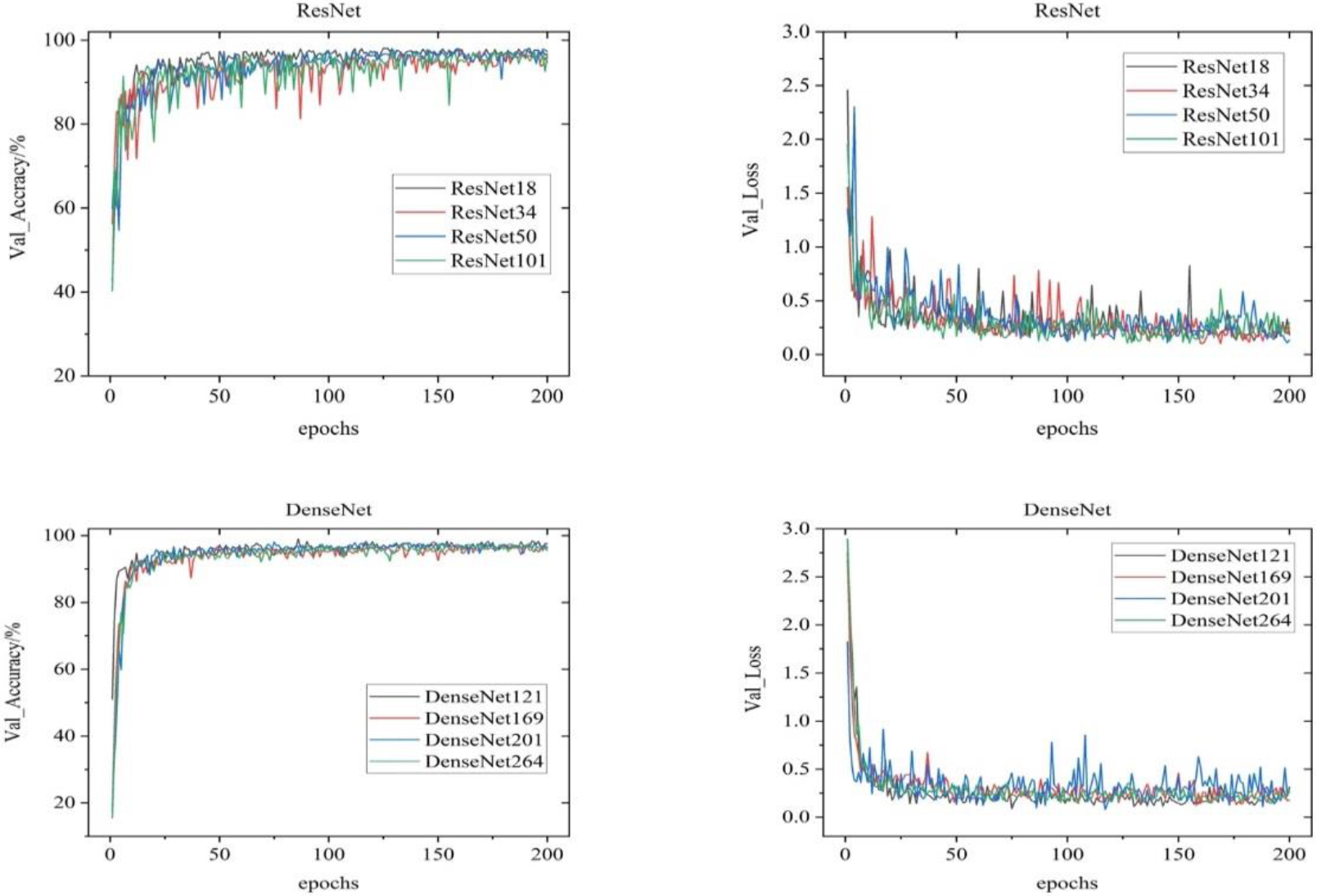
By analyzing the experimental results in Table 4, it can be concluded that (1) for ResNet, the recognition rate decreases gradually with the increase of network layers. The number of network layers increased by 101 from 18, and the recognition accuracy rate decreased from 96.63% to 95.39%. The main reason for the decrease is that the increase of network layers makes the model more complex, the model training time is longer, and the network degradation problem is suppressed. (2) For DenseNet, the number of network layers is more than 100. Compared with ResNet18, DenseNet121 has more network layers but fewer parameters. The reason for the slow training speed is that DenseNet has a large feature map and a large amount of convolution calculation, which leads to a longer training time. The number of DenseNet network layers increased from 121 to 264, and the recognition accuracy decreased by 1.78%. The main reason is that the increase in the number of network layers may lead to the degradation of the model. The deeper the network layers, the more samples are needed for model training.
Figure 5 shows the change curves of the accuracy and loss value of the verification set of the two networks. The accuracy curve of the ResNet series network will gradually oscillate with the increase of the number of network layers. In DenseNet, the change of accuracy curve is relatively stable, and the network model is relatively stable [10]. Compared with other network layer models, the 121 layers DenseNet is more suitable for low resolution lip print image recognition tasks.
Through different learning rates, different network models and different network depths, performance evaluation experiments were carried out respectively. The experimental results show that the recognition accuracy of the depth convolution neural network MobileNetV2 can reach 96.91%, which successfully verifies that the depth learning algorithm can be applied to lip pattern recognition tasks, but the recognition accuracy is 97% higher than that of the set component classifier in the machine learning classification algorithm proposed by Sandhya et al. in 2021, which needs further improvement.
Figure 6 shows the accuracy and loss value of the MobileNetV2 network in the verification set. Through the analysis of the convergence of its loss value, it can be seen that the network learning has encountered a bottleneck and cannot continue to converge. The lip pattern image of each person has the feature that the difference of texture details is small, and human eyes cannot distinguish and recognize, but the machine learning algorithm can learn the texture, color, shape and other feature information of the lip pattern, and the new breakthrough can be predicted and recognized through the learned feature information.
Validation set accuracy and loss value of MobileNetV2.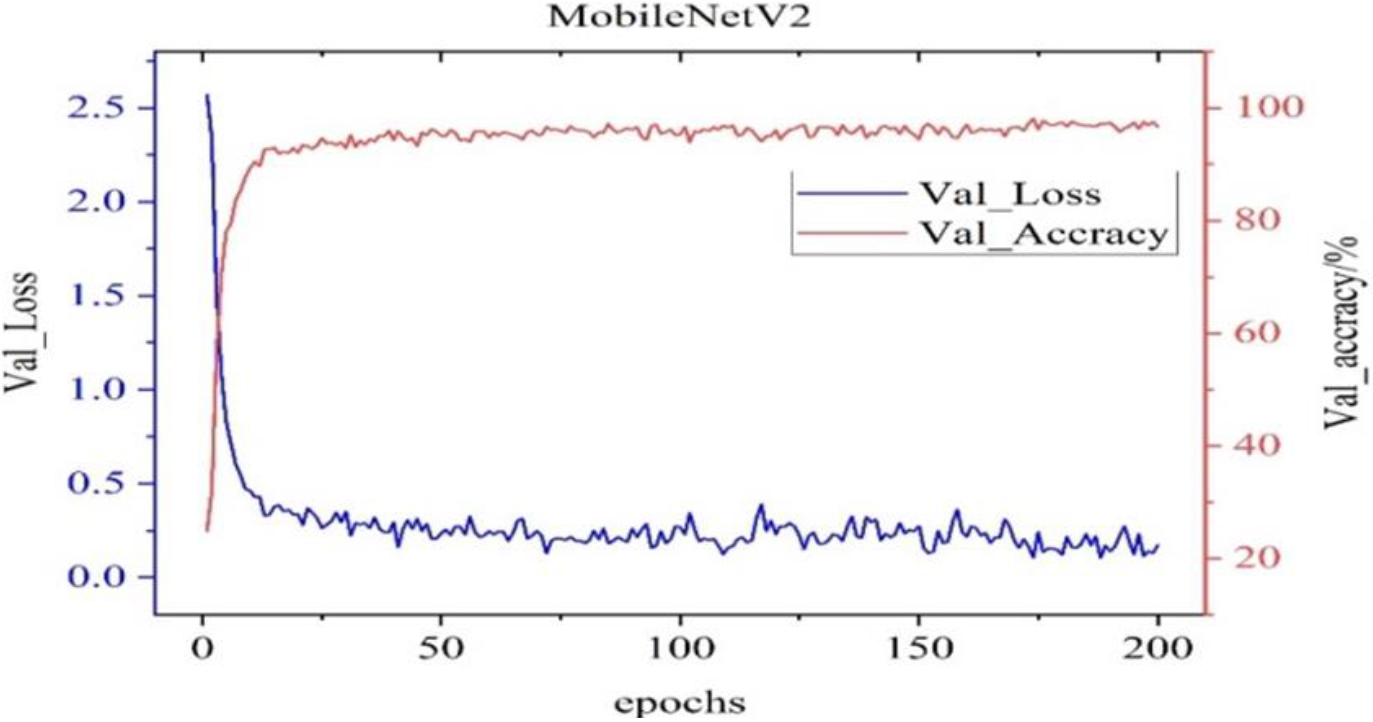
In this paper, a lip line recognition algorithm combined with depth learning algorithm is proposed. The goal is to solve the problem that the preprocessing process of traditional recognition algorithms is complex, and the artificially designed feature extraction algorithm is vulnerable to interference. The classic and lightweight CNN models were used to conduct large-scale performance evaluation experiments on low resolution lip print images to explore the best network suitable for low resolution lip print recognition tasks. The different networks, including AlexNet, GoogleNet and MobileNet, were selected to carry out performance evaluation experiments in terms of different models, learning rates and network depth on the established lip print dataset, and analyze the impact of various factors on the model recognition rate. Comprehensive comparative analysis of experimental results shows that the lightweight network MobileNetV2 is more suitable for lip print recognition tasks than other models, with a recognition rate of 96.91%, a model size of only 8.78 MB, and a more appropriate learning rate of 0.0001.
Footnotes
Acknowledgments
This work was supported by Cooperative Project of Jiangsu Province production, teaching and research (No. BY2021381), Jin Ling Institute of Technology Ph. D. Startup Fund (jit-b-202314).