
Abstract
In recent years, detection methods based on deep learning have received widespread attention in the field of concrete crack detection. In view of the shortcomings of traditional image detection methods, a concrete crack detection method based on feature fusion is proposed. The Fourier frequency domain processed image is used as the input of the deep learning neural network. The original time domain image and the frequency domain image are respectively input into two feature extraction modules to extract high-level features, and then the two features are fused to fully characterize the characteristics of the time domain and frequency domain, and finally the concrete crack detection results of the feature fusion are obtained. The performance of the proposed method is compared with VGG-16, AlexNet and DenseNet. Experiments show that the accuracy of the proposed method is higher than VGG-16, AlexNet and DenseNet. The proposed method has good results in concrete crack detection. To verify the generalization ability of the proposed model, the Concrete Crack Images for Classification data set was input into the proposed model for testing. The experimental results show that the proposed model has good generalization ability.
Introduction
Concrete is a commonly used building material, widely applied in the construction of houses, roads, bridges, and other structures. However, due to factors such as loading, temperature variations, volume shrinkage, and uneven settlement, concrete structures often develop cracks [1]. Cracking is an important indicator of concrete stress performance testing and is also the main manifestation of structural damages [2]. Cracks are characterized by complex causes of formation and significant harm. Failure to promptly detect and repair cracks may lead to building damage, endanger the safety of structures, and result in irreversible loss of life and property. Therefore, the monitoring of building quality through the detection of concrete cracks has always been a hot research topic [3].
Considering the high rate of missed detections and false alarms in traditional concrete crack detection methods, many researchers have turned to machine learning methods for crack detection in concrete. Feng C et al. [4] applied pixel-level deep model to detect cracks on dam surfaces. This method can accurately and quickly identify cracks on the concrete surface. Furthermore, Yu Y et al. [5] used an optimized deep convolutional neural network for concrete crack detection. Compared to traditional algorithms, automatic methods are more intelligent and yield more objective detection results [6, 7, 8]. Furthermore, Sun D et al. [9] proposed using wavelet transform for detecting dam cracks. Ye W et al. [10] proposed the application of convolutional neural networks for crack detection in asphalt pavements. Oliveira H et al. [11] developed a system for detecting and characterizing road cracks. Based on previous research, Shi Y et al. [12] used a random forest structure to obtain better performing crack detection devices that can identify more complex cracks. In the field of bridge and pavement crack detection, numerous scholars have conducted a lot of researches [13]. Su H et al. [14] proposed a bridge crack detection method based on the CBAM attention mechanism. Shi P et al. [15] developed a new method for identifying concrete crack using sonar images.
However, concrete crack images often have multi-modal characteristics, such as complex backgrounds, different shapes, and various interferences [16]. Visual detection of concrete cracks needs to overcome these difficulties. With the improvement of computer performance, deep learning is used by researchers for concrete crack detection. Flah M et al. [17] applied deep learning image techniques to crack detection. Using CNN as the basebone, they trained and learned from crack images to generate new models. This type of models can quickly detect concrete cracks [18]. Building on previous research, Bhowmick S et al. [19] went a step further by using deep learning to detect concrete cracks in drone images. This method is more accurate in detecting large cracks but has lower accuracy in detecting small and multiple cracks. In order to accurately detect small and multiple cracks, Chen C et al. [20] utilized improved R-CNN for crack detection. Similarly, to improve the accuracy of small defect detection, Teng S et al. [21] developed a model that can quickly identify crack locations. YOLOv3 was applied to crack surface detection in this model. Although the above methods have improved the detection accuracy compared to traditional methods, they still have limitations such as only being able to determine the possible locations of cracks or to classify cracks in a simple way. To solve this problem, Yang XC et al. [22] used a fully convolutional network to classify pixel-level cracks and determine their precise location. Furthermore, Fan X et al. [23] presented an algorithm called CrackLG based on local-global cluster analysis, which greatly improved the speed of detecting cracks. On this basis, they [24] also presented a concrete crack segmentation method named MA-AttUNet based on transfer learning and achieved higher accuracy. With the deepening of crack detection research, Qi ZL et al. [25] used algorithms such as detail enhancement to preprocess underwater images to eliminate interference effects and proposed a new crack detection algorithm. Meanwhile, Yang Q et al. [26] proposed an arithmet for automatic pixel set identification of cracks using Unet
Dataset
Partial collected images are shown in Fig. 1. In the captured image dataset, 218 cracked concrete images and 218 non-crack concrete images were manually selected. The selected images contain four main categories of images: cracked images with homogeneous backgrounds, cracked images with complex backgrounds, non-crack images with homogeneous backgrounds, and non-crack images with complex backgrounds. Cracked images with complex backgrounds have low contrast between the cracks and the background and contains interfering factors such as needle-like plants.
Partial collected images.
To expand the number of image samples, the data set was expanded through random rotation, mirroring, random cropping, brightness adjustment, contrast adjustment. 440 cracked concrete images and 440 non-crack concrete were obtained. The concrete texture around the crack mainly reflects as a high-frequency information, and the profile of the crack mainly reflects as a low-frequency information. In view of this, the Fourier transform is used to convert the original time image into a frequency domain image, and the original time domain image and frequency domain image are used as two-input for neural network learning. Input the original time domain image and frequency domain image into the proposed model to extract features respectively.
Fourier transform is the process of converting an image matrix into a series of periodic functions, which can transform the time domain function of the image into the frequency function of the image [27]. The result of perform a two-dimensional Fourier transform is actually the gradient map of the image. Figure 2 is the Fourier transform of concrete image. As shown in Fig. 2, Fourier transform is performed to obtain the frequency domain distribution map.
Fourier transform of concrete image.
The flow chart of the proposed method is shown in Fig. 3. The original time domain image and the obtained frequency domain image are input into the model for training. Finally, the concrete surfaces images are predicted as cracked and non-crack.
The flow chart of the proposed method.
The structure of the proposed model.
There are many interference factors in concrete images, such as surface stains, cement texture, lighting differences, companion plants, etc., and the traditional CNN model has poor crack classification performance. Kamnitsas et al. [28] proposed a two-path CNN. On this basis, a new two-input convolution classification model is proposed. The model contains two input channels, which input the time domain concrete image and the frequency domain concrete image, respectively. Since the two channels are in different domains, the weights are independent of each other. The structure of the proposed model is shown in Fig. 4. The figure below represents the Convolution operation, Batchnormalization operation, Maxpooling operation, Flatten operation, Dropout operation, Dense operation and Contact operation, respectively. In the model structure part of the figure above, the numbers below the cube indicate the size of the feature map. The black round cake indicates that the classification result is non-crack, and the white round cake indicates that the classification result is cracked.
Both input channels of the model are composed of 5 convolutional layers, 3 maximum pooling layers, 1 flat layer and 1 dense layer. To obtain more semantic information, a 3
Model training
The training of the proposed model includes forward and backward propagation. Forward propagation process inputs the concrete time and the frequency domain image of the concrete image into the model, and simultaneously calculates the features propagated through in each layer in the model. The backpropagation process first calculates the output loss based on the forward propagation output layer, then passes the loss back to each layer, and finally updates the weights. Figure 5 is the part of neuron structure inside the network, showing the layer i of the proposed model receiving input, calculating output and update the weights.
There are three commonly used activation functions in convolutional layers and pooling layers, namely Sigmoid, Tanh and ReLu. To obtain a fast convergence speed and avoid the problem of neuron death, Tanh function is selected as the activation functions for the convolution layer and pooling layer of the proposed model.
Partial network layers of the proposed model.
Visualization of some data features of the model.
The characteristics of the concrete time and frequency domain image learned by the proposed model in the 1st, 2nd, and 5th convolutional layers after sufficient training are shown in Fig. 6. The image is input into the proposed model in the form of three channels: R, G, and B. 32 convolution kernels are used by the first convolution layer uses, 64 convolution kernels are used by the second convolution layer, and 128 convolution kernels are used by the fifth layer convolution. The features of each layer in the model are mapped to the pixel space for visualization operations. Obviously, these features have good semantic consistency information. By visualizing the characteristics of the network layer, we can understand how the network detects and identifies effective content during the learning process, and then performs classification. This will help evaluate the role and sensitivity of each network layer to input data, and also reveal the impact of the weights of some parameters in the network layer on crack detection.
Concrete time distribution images and frequency domain distribution images reflect crack information in different forms. During the first layer of convolution processing, the network extracts shallow features from different locations in the image, and the differences between feature images are not obvious. After the second layer of convolution processing, more accurate shallow features are obtained. The model begins to extract pixels with rich texture in the image. After the fifth layer of convolution processing, the model only extracts the information of a small number of key pixels, while ignoring the information of other non-keypixels, eliminating the interference of non-important information. By visualizing the changes in images in each layer, the function of each layer of the proposed model in classifying concrete cracks was explored.
Experiments and analysis
All tests were performed on a computer with Intel (R) Core (TM) i9-11900K CPU@3.50 GHz, RAM: 128 GB and GPU (NVIDIA GeForce RTX 3080Ti).
As shown in Fig. 7, using only the time domain concrete crack images with one channel training, the classification accuracy is low. Using only the frequency domain concrete crack images with one channel training, the classification accuracy is slightly improved, but not significantly. The time domain concrete crack images and frequency domain images are input into the network together with two channel training, and the model classification accuracy has a significant improvement. The accuracy curve of images after Fourier transforms with one channel training, reaching a maximum of about 0.88. The accuracy of the two channels training with epoch stabilizes after 15 epochs, and eventually approaches 1.0.
Accuracy change curve with epoch for different input methods.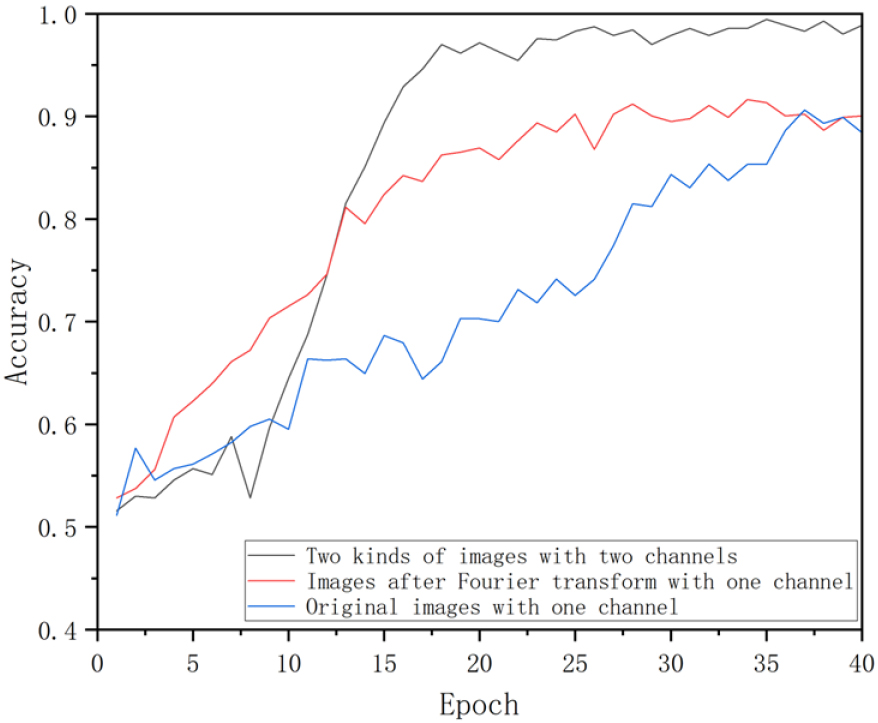
As shown in Fig. 8, the model gradually converged. The accuracy of train and accuracy of test increased in the first 20 epochs rapidly. The accuracy of the proposed model is stable at around 0.98 after 30 epochs.
Concrete image detection evaluation of the proposed model, VGG-16, AlexNet and DenseNet
Model accuracy change with epoch.
70% of the images was used for training and testing, and 30% was used for validation. A total of 880 images were used for experiments and analysis, of which 440 cracked images and 440 non-crack images. As shown in Table 1, the accuracy and training time of the proposed model are experimentally obtained, and compared with the commonly used VGG-16, AlexNet and DenseNet for crack detection in these two performance aspects. The accuracy of the proposed model is 97.82%, and the training time is 377 seconds. The accuracy of the proposed model is 97.82%, which is 14.3% higher than that of the VGG-16 model, 17.18% higher than that of the AlexNet model and 14.32% higher than that of the DenseNet model. The training time of the proposed model is 377 seconds, which is 106 seconds faster than VGG-16 and 83 seconds faster than DenseNet, but 310 seconds slower than AlexNet. Experiments show that the overall performance of the proposed model is better than the traditional VGG-16, AlexNet and DenseNet.
The confusion matrix results of the proposed model comparing VGG-16, AlexNet and DenseNet on the test set are shown in Fig. 9. The images number contained in the test set is 200. The number of correctly detected images by the proposed model is 195, and the number of incorrectly detected images is 5. The number of correctly detected images by the VGG-16 is 163, and the number of incorrectly detected images is 37. The number of correctly detected images by the AlexNet model is 161, and the number of incorrectly detected images is 39. The number of correctly detected images by the DenseNet model is 167, and the number of incorrectly detected images is 33. Obviously, under the same experimental environment, the detection accuracy of the proposed model is better than that of VGG-16, AlexNet and DenseNet networks.
Confusion matrix of 4 models.
As shown in Fig. 10, 200 images were taken from the Concrete Crack Images for classification as the test set, 191 images were correctly classified, and 9 images were classified incorrectly. The detection accuracy of the proposed model is 95.5%, which verifies that the proposed model has high generalization ability.
Confusion matrix tested on the Concrete Crack Images.
In view of the shortcomings of traditional algorithms in concrete crack detection, a two-input concrete image crack detection method based on feature fusion is proposed. This method detects cracks in concrete images with few samples by learning the characteristics of original time domain concrete images and frequency domain images. The conclusions are as follows:
The proposed model adopts a two-channel input method and takes the original time domain and frequency domain images as input data, which solves the problem of low classification accuracy with one channel training. The performance of the proposed model and the traditional classification model were compared on the data set. The proposed model has higher classification accuracy. The proposed model was tested on widely used data set-the Concrete Crack Images for Classification, which showed that it has good generalization ability.
Footnotes
Funding
This work was supported in part by the Science and Technology Project of Jiangxi Provincial Education Department (GJJ201910) and in part by Jiangxi Provincial Natural Science Foundation (20224BAB202033).