
Abstract
Actionable Patterns are desired knowledge to be mined from large datasets. Action Rules are vital data mining method for gaining actionable knowledge from the datasets. They recommend actions which users can undertake to their advantage, or to accomplish their goal. Meta actions are the sub-actions to the Action Rules, which intends to change the attribute value of an object, under consideration, to attain the desirable value. The essence of this paper is to propose a new optimized and more promising system, in terms of speed and efficiency, for generating meta-actions by implementing Specific Action Rule discovery based on Grabbing strategy (SARGS) algorithm, and to apply that for Sentiment Analysis on Twitter data. We perform a comparative analysis of meta-actions generating algorithmic implementation in Apache Spark driven system, conventional Hadoop driven system and Single node machine using the Twitter social networking data and evaluate the results. We implement corpus based Sentimental Analysis of social networking data, and test the total time taken by the systems and their sub components for the data processing. Results show faster computational time for Spark system compared to Hadoop MapReduce and Single node machine for the meta-action generation methods.
Keywords
Introduction
Social interaction websites like Facebook, Flickr, and Twitter have added a new dimension to the social life of internet-aware people. This trend provides a huge amount of raw data that can be processed to generate useful or structured information. Data mining techniques are used to analyze huge volume of data, to identify the underlying data patterns and to reveal the hidden knowledge. Data digitization in social networking and the extensibility of the platform for social networking, from micro devices like watches and smart phones to macro devices like desktops and laptops, have greatly contributed to the huge amount of structured and unstructured data that can be processed to generate sensible and meaningful information. Action-ability extends the concept of data analysis to a level further, by which the user can attain his/her intended action through deducing the Action Rules from the dataset.
The attributes in a dataset are divided into flexible attributes, Flexible attributes are those for which the state can change and the stable attributes are those for which the state is always fixed [1]. The Action Rules are specific data patterns extracted from huge dataset which intends to change the current value of the flexible attribute, under consideration, to a desired value. An association rule is a rule extracted from an information system that describes a cascading effect of changes of attribute values listed in the left-hand side of a rule [6] on changes of attribute values listed in its right-hand side.
New algorithms have been proposed in the past decade to find some special actions based on the discovered patterns in the form of Action Rules. Action Rules propose an actionable knowledge that the user can undertake to his/her advantage. An Action Rule extracted from a decision system describes a possible transition of an object from one state to another state with respect to decision attribute [11]. Authors in [3, 11–14] proposed variety of algorithms to extract Action Rules from the given dataset. The eccentric exponential increase in the data in recent years, causes delay in computations on tasks that are dependent on Action Rules and thus causing applications relied on Action Rules to be slow. Hence, this mandate need to develop viable, scalable, time efficient and distributed methods to work on such huge volume of data for generating action.
Distributed database systems are the most appropriate system to handle huge data sets. They have substantiated the reliability and efficiency for storage and processing bulk data sets. Apache provides various open source like Hadoop [4], Spark [8, 21], Hive, and Pig to process and handle huge data in the distributed system [2]. Hadoop is a distributed computing framework, to work with large datasets, across multiple computers, using a single programming model in a parallel fashion. This parallel processing aspect of the distributed computing plays a vital role in the cost of the processing time. Hadoop aims to provide scalable and fault tolerant computations on the given data. The main components of Hadoop are HDFS [17], YARN [20] and MapReduce [4].
Hadoop Distributed File System – HDFS is the data storage unit of the MapReduce operations. HDFS also keeps track of machines holding the data for a job [17]. Yet another Resource Negotiator – YARN [20] is an extra feature to the upgraded version Apache Hadoop framework. YARN supports multiple applications like MapReduce, Spark [8, 21], Storm, etc.
MapReduce is an open source cluster computing framework which uses HDFS to save and process huge data sets. The MapReduce framework works in such a way that it divides the input data into size mutable input splits and cascades them to the clusters [Hadoop performance prediction]. By default, the input splits are 64MB individually. The MapReduce works in 2 phases, map and reduce. In the map phase, the input splits are processed in parallel fashion in the cluster and the intermediate results are stored on local disk. In the reduce phase the intermediate results are combined and saved in the HDFS. The frequent access to the HDFS system makes it less suitable for iterative algorithms.
Apache Spark addresses the issue with the concept of Resilient Distributed Dataset. Its in-memory data operations makes it well-suited for applications involving iterative machine learning and graph algorithms. In this paper, we present a system SARGS (Specific Action Rule discovery based on Grabbing Strategy) which is an alternative to ARoGS [13] and implement the system in Spark like our old system MR-Random Forest algorithm for Distributed Action rule Discovery [18] using Hadoop MapReduce, to extract Action Rules from the twitter data in the HDFS. The primary intent of the Action Rules generated is to provide viable suggestions to make a twitter user positive. Finally, we compare our current proposed system against our old Hadoop system of extracting and single node machine.
The rest of this paper is organized as follows. Section 2 gives the related works. In Section 3, we discuss about the algorithms and technologies we used for this system. Section 4 presents experiment and results in which the current system results are compared with the previous system. Section 5 concludes the paper.
Related work
The data mining algorithms can be divided into two well established categories: Supervised Learning and Unsupervised Learning.
Supervised learning algorithms, provide prior knowledge of the class attributes for datasets.
Unsupervised learning, the dataset has no class attribute and the task is to find similar instances and find significant patterns in dataset. For example, it can be used to identify events on Twitter data, because the frequency of tweeting is different for various events. Also by this method tweets can be grouped based on the times at which they appear and hence, identify the tweets’ corresponding real-world events. This section describes related research works with respect to social media data, Action Rules and performance of distributed frameworks.
Sentiment analysis and twitter data
The following research papers primarily performed sentimental analysis on twitter data.
Authors A. Balahur et al. [7] employs hybrid approach, using supervised learning with Support Vector Machines Sequential Minimal optimization (Platt, 1998) linear kernel, on unigram and bigram features, emotion lists, slang lists and other social media emotion features for a lexicon based sentimental analysis on the twitter data. The analysis involves two phases, preprocessing and then sentiment classifications. The processed tweets are then passed through the sentiment classification module. Training models were developed on the cluster of computers using Weka data software.
Authors A. Agarwal et al. [9] performed sentimental analysis on the twitter data. As part of the paper, they primarily experimented three types of models, unigram model, a feature based model and a tree kernel based model for two classification tasks, binary task which classifies the sentiment to positive and negative and 3-way task which classifies the sentiment to neutral along with the positive and negative category. The twitter data is first preprocessed using emotion dictionary, acronym dictionary and stop word dictionary. The comparative analysis on the models by experiment proved that tree kernel and feature based models outperform the unigram baseline.
Authors A. Chellal et al. [10] proposed multi-criterion real time tweet summarization based upon adaptive method. This method provides new relevant and non-redundant information about an event as soon as it occurs. The tweets selection is based on the following three criterions: informativeness, novelty and relevance with regards of the user’s interest which are combined as conjunctive condition. Experiments were carried out on TREC MB RTF-2015 data set.
Authors Yu. Xu et al. [15] proposed methods to infer a user’s expertise based on their posts on the popular micro-blogging site twitter. They proposed a sentiment-weighted and topic relation-regularized learning model. Sentiment intensity of a tweet is used to evaluate user’s expertise and the relatedness between expertise topics is exploited to model inference problem. The following four common metrics were used for evaluation: accuracy, precision, recall and F1- score.
Authors F. Marquez et al. [23] proposed a simple model for transferring sentiment labels from words to tweets and vice versa by representing both tweets and words using feature vectors residing in the same feature space. Tweet centroid model developed in this paper outperformed the classification performance of the popular emoticon-based method for data labelling and better results than a classifier trained from tweets labelled based on the polarity of their words.
Action rules mining
The following research papers deal with Action Rule mining.
Action Rules was first introduced in [11] by Z.W. Ras and A. Wieczorkowska. Action Rules have been extracted using two approaches for more than a decade. One approach is using rule-based approach which extracts intermediate classification rules using algorithms like LERS [5] (to extract classification rules from complete information system) or ERID [3] (to extract rules from incomplete information system) from which Action Rules can be extracted using system DEAR [11] (uses two classification rules to get Action Rules) or system ARoGS [13] (uses single classification rule to extract Action Rules). Second approach is object-based -approach to extract Action Rules directly from the information system, without pre-existing classification rules, using system ARED [6] or Association Action Rules [14]. In this paper, we focus on rule- based approach much like ARoGS [13] and to generate Action Rules.
Performance prediction on Hadoop based distribution systems are generally carried out in two ways. First approach is the machine learning approach, which is often used to predict system performance leveraging past system execution data [9] and can achieve reasonable prediction accuracy. But this requires training the dataset. Second approach is the modelling based approach. Unlike the machine learning approach, modeling based approaches predict performance through modeling system behavior [9], and often can provide a better understanding regarding internal execution of a program and resulting performance.
Performance prediction analysis for distributed framework
The following research papers deal with performance prediction analysis for distributed processing frameworks.
Authors G. Song et al. [25] propose a framework to predict the performance of a Hadoop MapReduce job. The framework comprises of two modules which are, a lightweight job analyzer module and prediction module. The job analyzer module analyzes the submitted job and collects features related to the jobs and parameters related to the clusters. The prediction module makes use of the collected parameters to train the developed local linear model using local weighted linear regression method. The experimental results vouch the accuracy of the method’s performance prediction.
Authors K. Wang et al. [24] propose a framework to predict the performance of Spark jobs. They apply analytical approaches to predict the performance of Apache Spark jobs. They leverage the multi-stage execution structure of Apache Spark jobs to develop hierarchical models that can effectively capture the execution behavior of different execution stages. They predict the job performance based on the limited scale execution job performance data on cluster. The experimental results show that the prediction accuracy evaluated for iterative and non- iterative algorithms is found to be high for execution time and memory, however the I/O cost prediction varied for different applications.
Authors A. Tzacheva et al. [1] have performed sentimental analysis on the twitter data via Action Rules generated. They implemented the ARoGS [14] algorithm proposed by Ras and Wyrzykowska, to generate the Action Rules. The real-time twitter data is extracted from the twitter API and then fed into the Hadoop Distributed File System – HDFS using MapReduce. Stanford core Natural Language Processing – NLP library was used to identify the polarity attribute through parts of speech (POS) of the tweets. MapReduce programs implementing the ARoGS algorithm was implemented on the twitter data. Experiments were conducted to generate Action Rules to make the user positive and increase the friends count.
In this work, we adapt the Action Rules mining algorithm [13] for twitter data processing. We follow model based approach to evaluate the existing single node machine model, MapReduce model [1] and our proposed Spark model for the Action Rule mining implementation on twitter data. We extend the work proposed by A. Tzacheva et al. [1] by incorporating Spark model for Action Rule mining and comparing performance with the MapReduce model. The proposed model involves simulation of the Action Rules generation by modifying the number of nodes in the cluster. Further, we perform sentiment analysis of twitter data based on discovering actionable patterns through Action Rules.
Methodology
The primary focus of this work is to evaluate the proposed Spark driven system implementing the Action Rule mining algorithm on twitter data, for making the users more positive, against the existing MapReduce driven system and single node machine. The Action Rule mining comprises of the six phases: data collection, pre-processing, classification, sentiment analysis, Action Rule generation, Summarization.
Pre-processing
In Pre-processing phase, we perform discretization on the following attributes, friends count, and followers count by placing their values into intervals. As part of this phase, we perform data cleaning for missing values, feature selection and remove unnecessary values. We retained the following attributes Retweet Count, Is Favorited, User ID, Tweet Text, User Language, User Friends Count, User Favorites Count, and User Followers Count.
Sentiment analysis
In this phase, we add two additional attributes to the existing attribute set, first is sentiment attribute which can take the following values: positive, negative, neutral, very positive, very negative and the second is action attribute with attribute verb for actionable pattern mining because verbs suggest actionable knowledge. The latter was taken from the extracted part of speech from the tweets.
Stanford core NLP powered by Java was used for sentiment analysis. The general sentiment analysis process is shown in Figs. 1 and 2. This NLP suite provides set of natural language analysis tools. The basic distribution provides model files for the analysis of well-edited english, but the engine is compatible with models for other languages [16]. This NLP suite provides various annotators making use of java’s Unicode support, by default UTF-8 encoding but also supports any character encoding. POS – Part of speech, Label tokens with their part-of-speech (POS) tag, using a maximum entropy POS tagger. Out of the annotators we are using tokenizer, part-of-speech, sentiment analysis in our work.
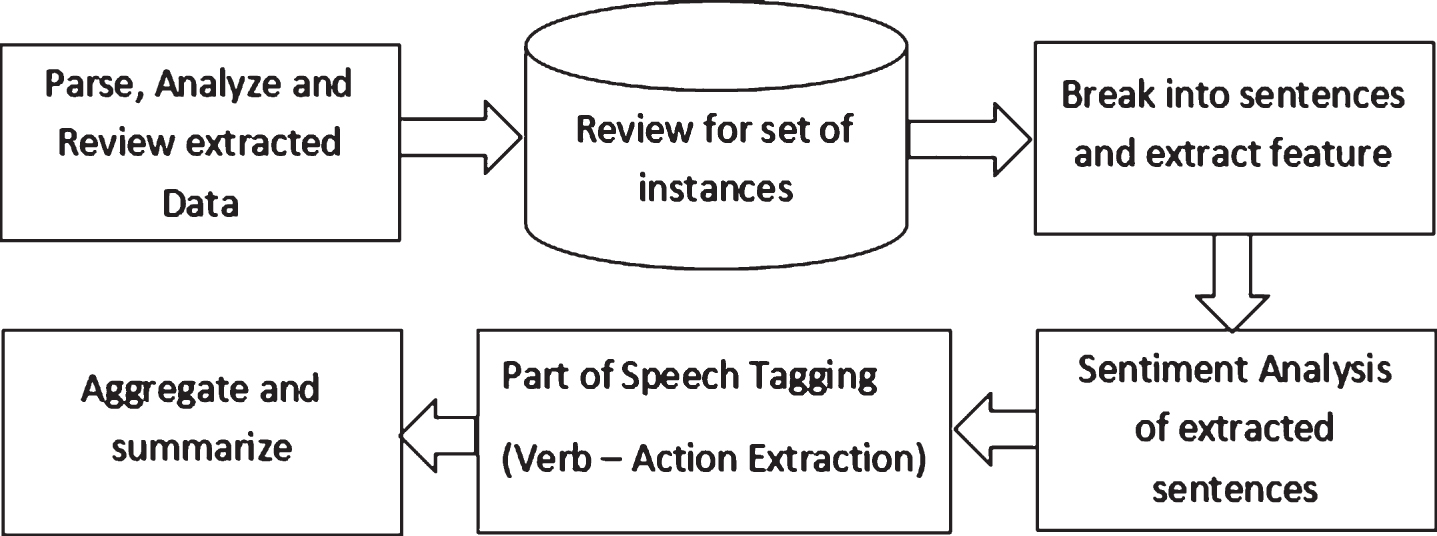
Actionable Pattern Mining system for Twitter Sentiment Analysis.

Sentiment Analysis.
We used LERS [26] algorithm to extract classification rules from twitter data. Classified each tweet as positive, negative, neutral, very positive, very negative. LERS [26] is a Learning from Examples based on Rough Sets which we use to extract classification rules from the information system. Our implementation follows distributed strategy of generating classification rules using LERS system. Figure 3 gives the LERS algorithm. Using the information system S from Table 1, LERS strategy can find all certain and possible rules describing decision attribute d in terms of attributes a, b, and c. LERS can be used as a data strategy to generate classification rules. LERS produces a set of certain and possible rules [26]. We consider only marked certain rules to construct the Action Rules. Since LERS follows bottom-up strategy, it constructs rules with a conditional part of length x, then it continues to construct rules with a conditional part of length x + 1 during the following iterations.

Part-Of-Speech Tagger – Verbs.
Sample Information System
For the information system given in Table 1, consider the following as decision support:
LERS module given in Fig. 4. For the given information system S, extracts certain and possible rules which are given in Table 2.

LERS Algorithm.
LERS Example for Information System S
ARoGS is Action Rules Discovery Based on Grabbing Strategy, which uses LERS. It was given by Ras and Wyrzykowska in paper [14] as an alternative to system DEAR [19] which extracts Action Rules from a pair of classification rules. The foremost advantage of using ARoGS is that it uses single classification rule to provoke Action Rules. ARoGS uses LERS kind of algorithm to extract Action Rules, without the need of verifying the validity of the certain relations. It just should check if these relations are marked previously by LERS. ARoGS presumes that system LERS construct classification rules describing target decision value. Figures 4 and 5. Together gives the algorithm of ARoGS Fig. 6. Algorithm AR takes each candidate classification rule and form an Action Rule schema which in turn is given to the algorithm ARoGS to build a cluster of Action Rules around each schema. For the classification rules in Table 2, algorithm AR generates following set of Action Rule schema:

AR (Action Rules) Algorithm in distributed environment using MapReduce.

ARoGs (Action Rules Discovery Based on Grabbing Strategy) in a distributed environment using MapReduce.
Algorithm ARoGS Fig. 6 takes each Action Rule schema and using their flexible and stable attributes, generates following Action Rules which imply d1 ⟶ d2. For the Action Rule schema ARs1, the algorithm ARoGS finds all missing flexible attributes AM: {a1, a3, b1}. Each missing flexible attribute is filled into appropriate action terms. In ARoGS, the maximum number of Action Rules generated = AM. For ARs1, ARoGS produces following Action Rules:
Let an action rule R takes a form of:
Y is the condition part of R
Z is the decision part of R
Y1 is a set of all left side of the all condition action terms
Y1 is a set of all right side of the all condition action terms
Z1 is the decision attribute value on left side
Z2 is the decision attribute value on right side
Let an Action Rule R takes a form of: (Y1 ⟶ Y2) ⟶ (Z1 ⟶ Z2) where, Y is the condition part of R, Z is the decision part of R.
Y1 is a set of all left side of the all condition action terms Y2 is a set of all right side of the all condition action terms Z1 is the decision attribute value on left side Z2 is the decision attribute value on right side.
In [13], the support and confidence of an Action Rule R is given as,
In this paper, we use the following support and confidence formula given by Tzacheva et al. [18] to reduce the complexity.
Overview of MR – Random-Forest algorithm for distributed Action Rules discovery using Apache Hadoop framework and Google MapReduce [4] is shown in Fig. 7. An overview of the proposed algorithm is shown on Fig. 8. We take as an input a set of files: the data, the attribute names, user specified parameters such as: minimum support, and confidence thresholds, stable attribute names, flexible attribute names, decision attribute choice, decision attribute value to change from, and decision attribute value to change to, which is the desired value of decision attribute (desired object state). We import these input files into the HDFS (Hadoop Distributed File System).

MR – Overview of MapReduce execution. The data partitions and results from Map and Reduce tasks reside in the distributed file system. The Map tasks and Reduce tasks are done in the distributed systems in a parallel fashion.
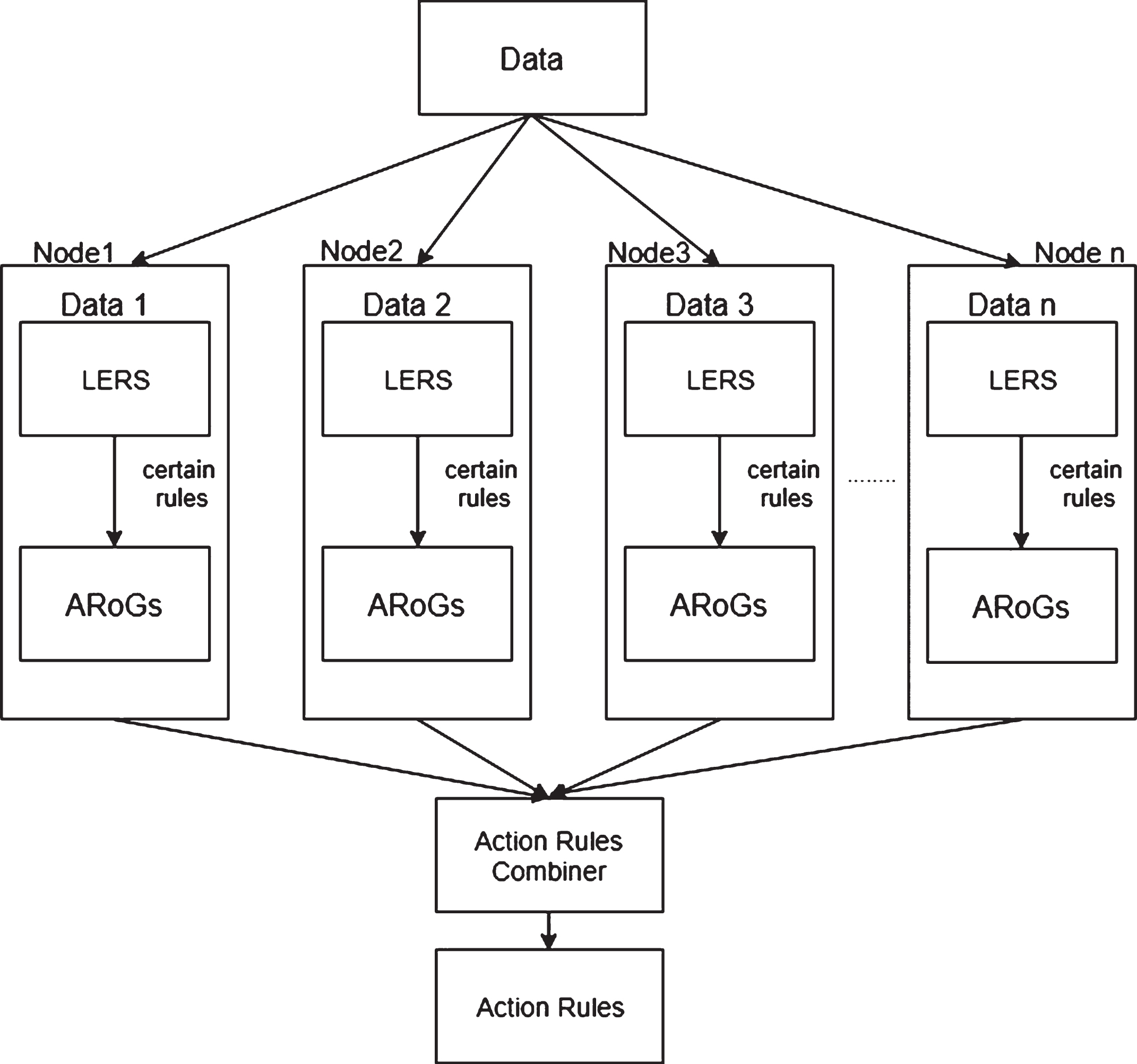
MR – Random Forest Algorithm for Distributed Action Rules Discovery.
The Action Rules generated in section B comprises only one specific action terms. The left side of other action terms are empty. These Action Rules can give only a limited knowledge to the user and leave the clueless due to the lack of specific action terms. In this paper, we propose a new algorithm Specific Action Rule discovery based on Grabbing Strategy (SARGS) as an alternative to the algorithm ARoGS to fill all missing values in the Action Rule schema in an efficient time.
Algorithm SARGS takes each Action Rule schema and finds all missing flexible attribute values. The algorithm then combines each missing value with other values giving a complete set of values that can fill all missing (left-side) of the conditional part of the Action Rule. For example, consider the Action Rule schema ARs1 shown in Section B. The algorithm SARGS finds all missing flexible attribute values AM: {{a1, a3}, {b1}}. Note that AM takes a form of main set containing a collection of multiple sets.
The algorithm then combines each element in the inner set with other elements in other inner sets. Thus, we get a combination of attribute values AC 1 = {a1, b1} and AC 2 = {a3, b1}. The algorithm puts each combination into corresponding Action Rule schema to generate following Action Rules:
New AR (Action Rules) Algorithm in a distributed environment using MapReduce
Unlike the algorithm ARoGS, algorithm SARGS does not produce any incomplete Action Rules. Instead it provides more specific Action Rules.
Spark [21] is a framework like MapReduce [4] to process large quantity of data in a short span of time. Spark introduces a distributed memory abstraction method called Resilient Distributed Datasets (RDD). Lineage graph utilized by RDD’s is shown in Fig. 11. Spark framework can outperform Hadoop MapReduce because of its in-memory capability, especially for iterative algorithms. Sparks performs as shown in Fig. 9. In [18], Hadoop manages data distribution over the nodes in a cluster and all algorithms ARoGS [13] and Association Action Rules [14], are implemented using MapReduce. When Hadoop manages data distribution, there are some possibilities that all records of single decision value move to a single Partition which can cause some loss of valuable Action Rules. In this paper, we propose a method similar to stratified sampling for data distribution to all partitions. We split the given data into groups where each group consists of records matching single decision value. We then measure how much proportion of data each decision value takes. According to this proportion, we take random samples of data from each group. By this way, each partition contains same proportion of data which is equal to the original dataset.

Overview of Spark execution using Resilient Distributed Datasets (RDD). Tasks such as transformations are given to the slave nodes. Slaves after performing the tasks, cache the result in RAM. Results can be given back to the Driver node.
Figure 10 Shows an example data partition for the information system S shown in Table 1. Our algorithms LERS and SARGS executes on each of these partitions and final Action Rules are grouped together. In Spark, reading each file: attributes, parameters and data creates three different RDDs. We manually split the data file into ‘d’ files, where d is a distinct number of decision values. Each file contains samples of records from the given data file. Spark on reading each of these files create ‘d’ RDDs. We also broadcast RDDs created from reading attributes and parameters file, so that all nodes can access them. Algorithms LERS and SARGS runs on each of d RDDs using Map Partition function, which is used to perform computations on each and every partition of data, and results in their own set of Action Rules with support and confidence. All Action Rules from the Map Partition function are sorted by the attribute name and returned as (Key, Value) pairs. We chose Action Rule to be a Key and support and confidence pair to be a Value. We then use groupByKey method to group all supports and confidences of a single Action Rule and aggregate them to calculate final support ‘fs’ and confidence ‘fc’ of an Action Rule. We output these Action Rules to a text file if fs > = minimumSupport and fc > = minimumConfidence. Now we describe the LERS, ARoGS algorithms and new SARGS method in detail. Consider an information system S:
X is a set of objects: X ={ x1, x2, x3, x4, x5 }
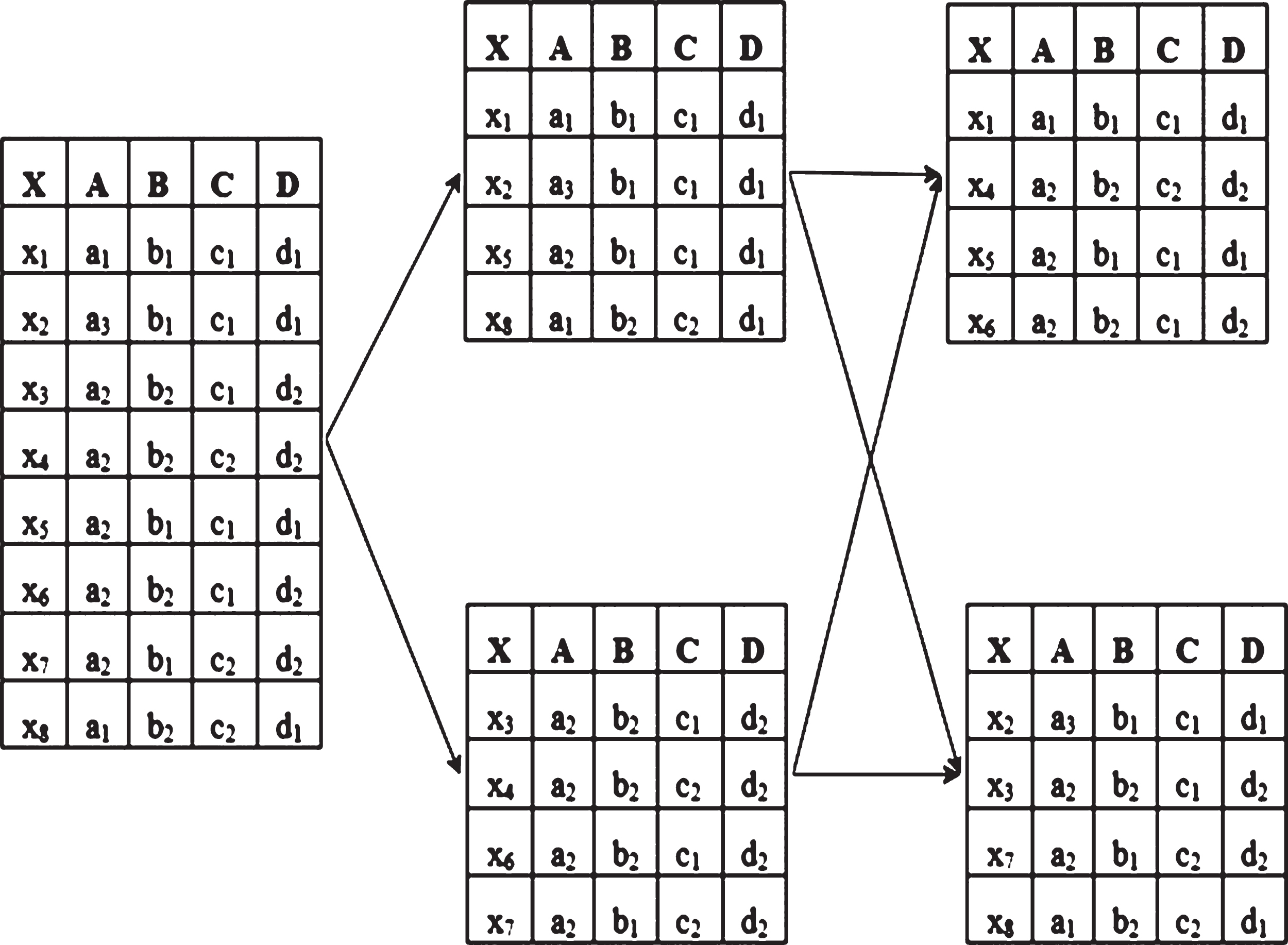
Data Distribution to partitions.
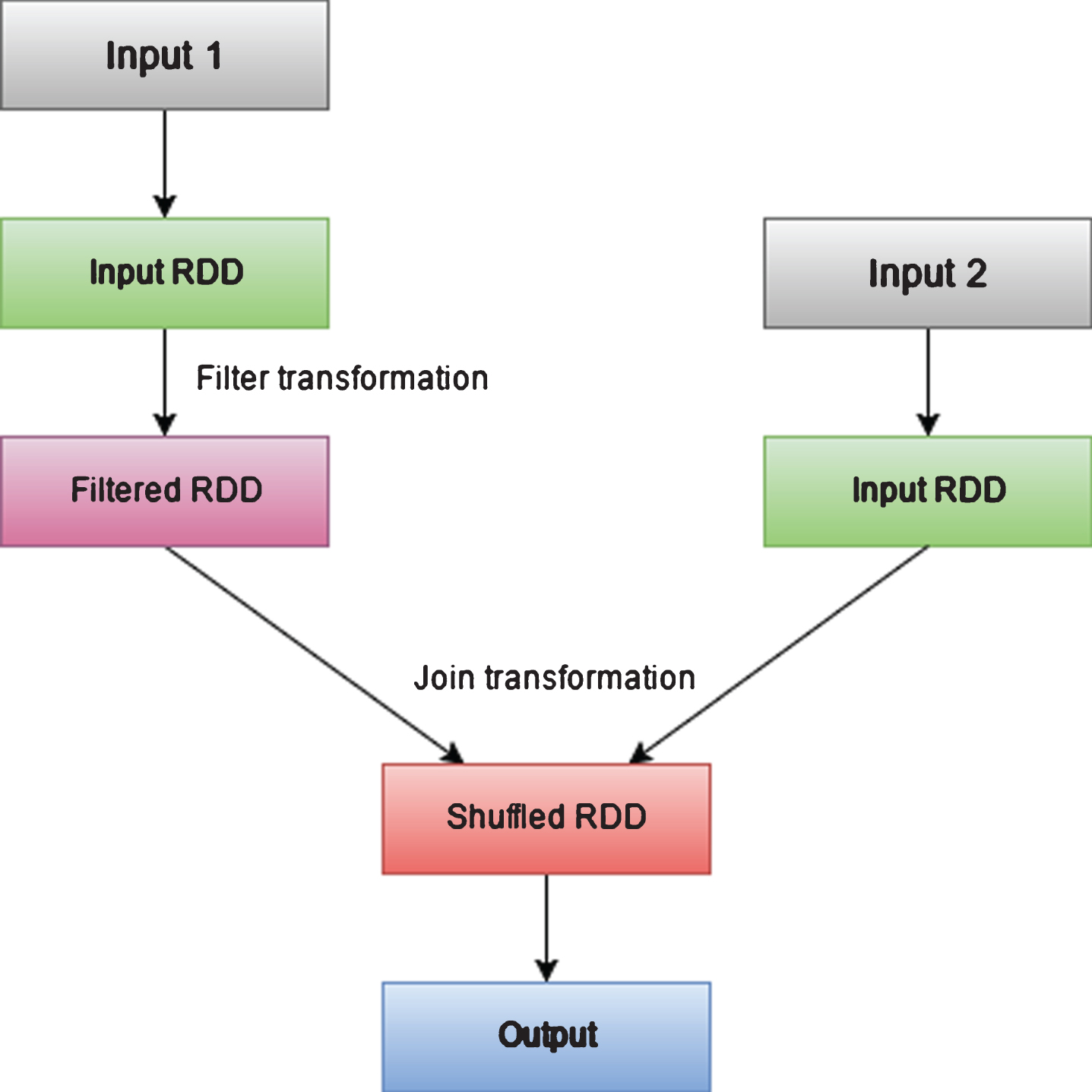
Spark Lineage Graph Example.
A is a set of attributes: A = A, B, C, D and
VA represents a set of values for each attribute in A. For Example, VB = b0, b2.
We use the sample information system S shown in Table 1 to demonstrate outputs from the above-mentioned algorithms. Consider attribute C to be a Stable Attribute, attributes A, B to be Flexible Attributes, attribute D to be the Decision Attribute, and that the user desires the decision value to change from d1 to d2. Also, consider that the user is interested in Action Rules with minimum support of 1 and minimum confidence of 80%. Instead of giving the data entirely to the Spark, we do some pre-processing step to make partitions of data to be given to Spark. All algorithms are then made to run on each partition of data. Following sub- sections talk about our implementation of these algorithms in a distributed environment.
The Action Rules generated as part of the experiment focuses on suggesting how to improve emotions from negative to positive, neutral to positive and to increase the friends count. For this experiment, we used live tweets extracted using Twitter Search API on the latest tweets. The Twitter Search API searches against a sampling of recent tweets published in the past 7 days. Our data contains the following attributes: Retweet count, IsFavorited, User ID, Friends count, Favorites count, Followers count, Tweet text, User language, Tweet sentiment, Tweet verb. We analyzed 40,000 instances with 9 attributes. Tables 3 and 4. gives the description about the dataset such as number of instances, attribute names, decision attribute values and data size. The Hadoop research cluster at University of North Carolina Charlotte was used to perform the experiments. This cluster has 6 nodes connected via 10 gigabits per second Ethernet network.
Properties of Datasets
Properties of Datasets
Sample Data with Sentiment Analysis Results
We used Action Rules to suggest how to change from positive to negative and neutral to negative sentiment. Also, to change from lower number of friends count to higher number of friends. Three experiments were conducted on both Hadoop and the Spark systems, for improving the emotions of the users from neutral to positive, negative to positive and to improve the friends and followers count. The results are tabulated, and the details of each experiments are debriefed below:
This experiment is focused in improving the user friends and followers count. The input attribute details are as follows: Stable Attributes are User Id and UserLanguage; Decision attribute is UserFriendsCount; Minimum support is 2 and confidence is 60%. The sample Action Rule generated for the experiment is recorded in the Tables 5 and 6.
Sample action rule for experiment 1 change from class UserFriendsCount: Low to Higher number of friends for single node and Hadoop system
Sample action rule for experiment 1 change from class UserFriendsCount: Low to Higher number of friends for single node and Hadoop system
Sample action rule for experiment 1change from class UserFriendsCount: Low to Higher number of friends for Hadoop and Spark System
This experiment is focused in transforming the tweet sentiment attribute value from negative to positive. The input attribute details are as follows: Stable Attribute is UserLanguage; Decision attribute is Tweet Sentiment; Minimum support is 2 and confidence is 60%. The sample Action Rule generated for the experiment is recorded in the Tables 7 and 8.
Sample action rule generated by the system for experiment 2 change class Tweet Sentiment from Negative to Positive for Hadoop and Spark System
Sample action rule generated by the system for experiment 2 change class Tweet Sentiment from Negative to Positive for Hadoop and Spark System
Sample action rule generated by the system for experiment 2 change class Tweet Sentiment from Negative to Positive for Single node and Hadoop System
This experiment is focused in transforming the tweet sentiment attribute value from negative to positive. The input attribute details are as follows: Stable Attribute is UserLanguage; Decision attribute is Tweet Sentiment; Minimum support is 2 and confidence is 60%. The sample Action Rule generated for the experiment is recorded in the Tables 9 and 10.
Sample action rule generated by the system for experiment 3 change class Tweet Sentiment from Neutral to Positive for Hadoop and Spark System
Sample action rule generated by the system for experiment 3 change class Tweet Sentiment from Neutral to Positive for Hadoop and Spark System
Sample action rule generated by the system for experiment 3 change class Tweet Sentiment from Neutral to Positive for Single node and Hadoop System
Our experiments show that with the volume of Twitter data, the processing of the proposed algorithm runs faster on distributed environment than on single machine. The experimental results explaining the time taken for the Hadoop and Spark system to generate the Action Rules and the number of Action Rules generated are tabulated in the Table 11.
Duration and Action Rules Count of both Systems
The Action Rules are assessed using the support and confidence metrics. User specified threshold of support 2, and confidence 60% were applied.
This work proposed a new approach to analyze sentiment of twitter data through mining actionable patterns via action rules. We suggest actions that can be undertaken to reclassify user sentiment from negative to positive and negative to neutral using comments. We also suggest action of how users can increase theirs friends, favorites, and followers count. We provide implementation on both single machine and a cloud distributed environment for scalability purpose. We compare the results with single machine implementation, distributed Hadoop MapReduce framework and Spark system. Our experiments show that with the volume of Twitter data, the processing of the proposed algorithm runs faster Spark system than on Hadoop system and single machine.
Also, the proposed Spark system implements the upgraded algorithm Specific Action Rule discovery based on Grabbing Strategy (SARGS) as an optimized alternative to system ARoGS [14] to extract complete Action Rules like system DEAR [11], ARED [5] and Association Action Rules [6]. The reduced time cost for our system in comparison with the conventional Hadoop system for distributed Action Rule mining attributes to the Apache Spark’s ability to perform in-memory computations and reduced communication cost compared to Hadoop MapReduce. We have also given more appropriate way of partitioning the data to be given to multiple nodes to extract Action Rules from them.
In future, we plan to introduce more robust and automated method of data sampling based not only on the decision attribute but also on stable and flexible attributes. We plan to test our system with more real-time large datasets to test and improve system’s scalability and feasibility. We also plan to expand our Sentiment Analysis to automatic detection of Emotions in Tweets, and mine actionable recommendations for altering the user emotions to more positive ones.