
Abstract
In this paper we explore to what extent text parameters, such as average number of words per sentence, syllables per word, nouns per sentence, frequency of content words, etc. can successfully rank Russian academic texts for different age and grade levels. We provide a brief overview of previous research on readability of Russian texts and describe the corpus of school textbooks on Social Studies (from 5-th to 11-th grade) compiled by the authors. We share our experience of using a variety of quantitative text complexity metrics and evaluate the measures of existing Russian text complexity formulas. Based on the tests of a set of extended text features, we propose one innovative metric for better prediction of Russian text complexity, i.e. the number of adjectives. As the results obtained compare favorably with the previously published results on the established complexity metrics for Russian texts, the study encourages the development of valid, reliable and transparent complexity tools for Russian texts.
Introduction
The modern scientific paradigm views readability formulas as tools to match texts and readers thus providing foundations for better comprehension [1]. They have extensively been applied over the world for about a century since 1923 [19], but their accuracy as well as the efficiency to rank readers’ cognitive abilities have been criticized since they were first developed [30]. One of the most frequent arguments against the existing readability formulas shared by experts is that they estimate only a limited number of text features, and such parameters as lexical variety, complexity of grammatical structures and/or general logic of textual information are neglected [11].
For over five decades scholars have been expanding the range of text complexity parameters trying to better identify a text complexity thus more precisely matching readers to reading materials. The new text features added to traditional readability notion of sentence and word length include the following: text information/propositional density [6], sentence structure (left/right-branching sentences) [27], narrativity [40], abstractness [26], the text structure clarity, etc. Though Russian history of text complexity started over 100 years ago (cf. the first research of Rubakin in 1898, Choldin, M.T. (1979), ‘Rubakin, Nikolai Aleksandrovic’, in Kent, Allen; Lancour, Harold), up to the beginning of the 21 century researchers in the field were mostly isolated and very much limited in their efforts due to the lack of computational tools able to store and process large datasets as well as absence of balanced and representative corpora. Since the mid-2000-s, work in psychology [2, 14], education [31], IT [36] and linguistics [16] have developed a solid foundation for Russian texts readability studies.
This paper describes the initial part of “Complexity of Academic Texts” (CAT) project initiated by Kazan Federal University team in 2017. We plan to design an automated tool able to rank Russian academic texts by their reading complexity and correlate them with students grade levels. The present study is aimed at sharing the authors’ experience of using the variety of quantitative text complexity metrics and encouraging the development of valid, reliable and transparent complexity tools for Russian texts. In the paper we aim at the following research questions (RQ). RQ.1: How well do the existing readability formulas work for Russian academic texts? RQ.2: Which linguistic text features better correlate with readability of Russian academic texts? RQ.3: What is the sufficient Russian sample size for text readability analysis?
Related work
Readability and text complexity in Russian
One of the first researchers to address the problem of reading texts complexity was the Russian writer Nikolai A. Rubakin who after examining over 10,000 texts determined the two main features of texts effecting readers’ comprehension, i.e. familiarity of words and sentence length [22]. By now the number of quantitative dimensions of text complexity has grown dramatically and includes over 100 text features [26], but familiarity of words and sentence length are still viewed as two of the three most significant metrics. The third parameter – length of words – introduced about a century ago [18] is a variable applied in all known readability formulas [10]. At the moment all these metrics are quite conveniently measured by computer tools developed for a number of languages 1 [35].
Russian readability formulas used in automated text analyzers are not original, but modifications of the formulas once designed for English texts 2 . One of the most popular readability formula was modified by Dr. I. V.Oborneva who conducted a contrastive English-Russian study of vocabulary of 100 English literary texts and two academic dictionaries, ‘Slovar russkogo yazyka pod redaktsyey Ozhegova’, 39174 words and ‘Muller English-Russian Dictionary’, 41977 words. The research showed distinctive differences in the mean length of English and Russian words: an English word pattern is formed of 2.97 syllables, while a Russian word pattern structure consists of 3.29 syllables. Another difference found by the researcher was the fact that English sentences of the academic texts studied are 1.5 longer than Russian sentences.
The Flesch Reading Ease (FRE), and the Flesch– Kincaid Grade Level (FKG) are two readability tests designed to indicate how difficult a passage in English is to understand. Based on the variations found, in 2006, I.Oborneva adapted the Flesch Reading Ease Readability Formula for Russian texts:
The formula takes into account two variables: ASL – words per sentence, and ASW – syllables per word [28]. The third metrics, i.e. word frequency, introduced in 1948 by E. Dale and J. S. Chall is strongly related to vocabulary difficulty, words familiarity and the percentage of rare words as it is generally assumed that more frequent words are acquired earlier in age [9]. The Dale-Chall formula defines text complexity or its readability level as a linear function of (1) the average number of words in a sentence and (2) the percentage of rare words (in the original version of the formula) or word familiarity/the average grade level of words (in the new version of the formula) [8].
In this respect, Russian is still treated as “under-resourced language since there were no free distributable gold standard corpora for various tasks” [37], though the last three decades have witnessed a rise in research on Russian texts readability [34]. Today researchers of the Russian language have free access to large annotated corpora, i.e. the Russian National Corpus(RNC) and Russian Web Corpus (RWC), available for extended quantitative studies 3 . The Corpora are provided with a reference system based on a collection of Russian original fiction and non-fiction texts representing standard Russian. The frequency dictionary based on RNC covering the core vocabulary of 5000 most frequently used words is a valuable reference for researchers of Russian.
At present a special attention is also given to studies of ‘subjective’ judgements of Russian texts difficulty by “expert” raters 4 and statistical analysis [15, 29, 31].
As for the type/genre of Russian texts used in text complexity/readability studies, the range is quite narrow: fiction (mostly for academic purposes), periodicals and textbooks (chemistry, philosophy, economics). Russian academic texts were quite excessively used in readability studies and the list of parameters evaluating the readability of text includes the following: number of syllables, number of words, number of sentences, number of abstract words, number of homonyms, number of polysemous words, number of technical terms etc. 5 [31]. Ivanov tested correlations of 49 factors, among which the strongest correlations are identified for “the percentage of short adjectives”, “the percentage of finite verb form”, “Flesch-Kincaid coefficient”, “Flesch coefficient”, “Coleman-Liau coefficient”, “average number of words per sentence”, “percentage of complex sentences”, “percentage of compound sentences”, “percentage of abstract words [15]. For the last two decades, readability of Russian acdemic texts has been actively discussed at conferences in Russia and abroad as well as in numerous publications [34] and the readability of educational materials used in Russian high school education has been measured [21].
Studies on corpus size
The modern views on size of corpora ample for statistical analysis vary and in some cases contradict each other, but many researchers admit that small, specialized corpora suffice to study specific metrics in texts of certain registers and genres [13]. Carter and McCarthy in [7] argue that high-frequency grammatical items, such as pronouns, can be reliably analyzed in a relatively small corpus. Vaughan et al. [39] characterize small corpora as better platforms to exemplify and define the range and frequency of grammatical features. The evidence for this is provided in a number of corpus case studies [20] and very well illustrated in [5].
The research shows that smaller, more specialised corpora have a distinct advantage: they allow insights into patterns of language used in particular settings. With a small corpus, the corpus compiler “has a high degree of familiarity with the context” thus providing correlations between “quantitative findings revealed by corpus analysis” [13, 24].
Though much depends on the content, i.e. type of text/discourse, and specific purposes for corpus compilation, the general agreement on the notion of ‘a ‘small’ written corpus’ implies that it contains up to 250,000 words [13]. This number of words provides a certain degree of representativeness which is defined by Biber [4] as ‘the extent to which a sample includes the full range of variability in a population’. Biber also discovered and proved relative stability of grammatical occurrence across 1,000-word samples of number of linguistic features in the English language (e.g. pronouns, contractions, past and present tense and prepositions). He confirmed that “linguistic tendencies are quite stable with ten (and to some extent even five) text samples per genre or register” [3].
Resources
Readability of Russian academic texts on Social Studies, to the best of our knowledge, has never been addressed, though as a compulsory subject in all high schools of the Russian Federation, the course is accomplished with a high stake matriculation exam after the 9th 6 and the 11th grades 7 . Therefore, the primary tasks of the present study is to measure and compare the readability levels of each textbook of the two sets from Recommended by the Ministry of Education of the Russian Federation Textbook List 8 . The choice of these particular sets of textbooks was caused by: (a) the fact that the texts under study were relatively free of non alphabetical symbols, graphs, figures etc., (b) the availability on Websites 9 . Based on the measurement conducted we select text parameters able to predict text complexity and rank them for different age and grade levels.
Data collection
The first step in evaluating complexity of Russian texts is collecting an adequate corpus of text documents with labels of their complexity. The collection of texts should be homogeneous with respect to the author style and the area of description. On the other hand the labels of the text complexity should represent a ground truth.
In order to comply these requirements, we selected two sets of school textbooks written independently by two groups of authors. One of the groups was headed by L.N. Bogolubov and the second one was headed A.F. Nikitin. The texts selected represent Russian academic texts on “Social Studies” ans are used to teach the subject in Russian schools in 5-th - 11-th grades. After Optical character recognition and cleaning, the books were saved as plain text files, available for further processing. We mark the corpus as RRC (Russian Readability Corpus); the two subcorpora written by independent groups of authors as BOG and NIK respectively. The sizes of BOG and NIK subcorpora are presented in Table 1.
Sizes of documents measured in tokens. Star sign (*) denotes advanced versions of books for the corresponding grade; sign “–” denotes absence of a textbook for the corresponding grade
Sizes of documents measured in tokens. Star sign (*) denotes advanced versions of books for the corresponding grade; sign “–” denotes absence of a textbook for the corresponding grade
Table 1 above also contains labels of readability derived in the following way. Firstly, we manually assigned the corresponding grade of a particular textbook to the FKG (Flesch-Kincaid) value. For instance value ‘8’ was assigned to the two texts (8 BOG, 8 NIK) intended for use in the 8-th year of Russian secondary schools. Secondly, based on the FKG value we assigned the FRE (Flesh Readability Ease) label to each text following the algorithm suggested by the authors of the formula [12].
For the sake of convenience, we have preprocessed all texts from the corpus in the same way. Common preprocessing included tokenization, splitting text into sentences and part-of-speech tagging (using the TreeTagger for Russian 10 ). During the preprocessing step we excluded all extremely long sentences (longer than 120 words) as well as too short sentences (shorter than 5 words) which we consider outliers. Clearly, such sentences can be not outliers at all in another domain, but for the case of school textbooks on Social Studies sentences shorter than 5 words are outliers. Sentence and word-level properties of the preprocessed dataset are presented in Table 2 below.
Properties of the preprocessed corpus
Properties of the preprocessed corpus
Extremely short sentences mostly appear as names of chapters and sections of the books or as a result of incorrect sentence splitting. We omit those sentences, because the average sentence length is a very important feature in text complexity assessment and hence should not be biased due to splitting errors. At the same time sentences with five to seven words in Russian can still be viewed as short sentences, because the average sentence length (in our corpus) is higher than ten.
The last two columns in Table 2 present well-known features that have been widely exploited for assessment of readability of English texts. Average sentence length (or average words per sentence) and average syllables per word are the parameters in Flesch and Flesch-Kincaid formulas [17]. Table 2 below demonstrates that values of ASL and ASW, as it is generally expected, increase with the grades. To ensure reproducibility of results, we uploaded the corpus on a website thus providing its availability online 11 .
Note, however, that the published texts contain shuffled order of sentences.
Application of linear models to academic texts
The FRE and FKG tests are represented by the following linear models (ASL – average sentence length in the text; ASW – average syllables per word in the text):
These two tests are not directly applicable to Russian texts. In order to apply them to Russian texts I. Oboroneva [28] proposed new values of coefficients. Oboroneva’s model has the same functional form with different weights:
Oboroneva’s model of readability has been derived based on differences between sentence length and words length in English and Russian. The model was validated on Russian translations of English fiction texts. Applied to the Russian academic texts from our corpus Oboroneva’s model retrieved the metrics presented in Table 3 below. Clearly, the FKG values calculated by the adapted Oboroneva’s model are inflated. The model systematically predicts a higher text complexity (based on the labels from the Corpus).
Aligning the corpus of school textbooks as ’a ground truth’ we used it to modify coefficients in I.Oboroneva’s models. The modified linear models were obtained based on the corpus of school textbooks as a result of adjustment of the existing linear model. The adjusted
12
parameters of the model are presented below (referred as Russian Readability Formulas, RRF-1 in Equation 1, and RRF-2 in Equation 1 respectively):
The juxtaposition of the two models metrics in Table 3 shows that the modified model provides a better adjustment of the corpus labels than Oboroneva’s model. The only reasonable explanation to this may be the fact that Oboroneva’s model was developed for fiction not academic texts. The last row of the table presents the mean squared error (MSE) which is calculated as follows (where N is the number of documents in corpus):
Oboroneva’s model (FRE
O
and FKG
O
) vs the modified model (FRE
mod
and FKG
mod
) of readability for Russian. Last row represents mean squared error values of metrics in the corresponding subcorpus
Oboroneva’s model (FRE O and FKG O ) vs the modified model (FRE mod and FKG mod ) of readability for Russian. Last row represents mean squared error values of metrics in the corresponding subcorpus
We have explored an extended feature set for text complexity modeling: frequency of content words (FREQ), average words per sentence (ASL), average syllables per word (ASW), and features based on POS-tags: number of nouns per sentence (NOUNS), number of verbs per sentence (VERBS), number of adjectives per sentence (ADJ), number of pronouns per sentence (PRONOUNS), number of personal pronouns per sentence (PERS. PRONOUNS), number of negations per sentence (NEG), number of connectives per sentence (CONN).
In order to calculate the ‘FREQ’ feature we first built a set of content words T. The set T is defined as a subset of all words from a given text (TextWords) that also appear in the Russian frequency dictionary collected by Sharov and Lyashevskaya [23] (FreqDict), but do not appear in the set of stop words (StopWords).
The relevance of these features for English text complexity modeling was studied by McNamara et al. in [25]. Correlation coefficients calculated between features and complexity values (Table 4) show that ADJ, NOUNS and FREQ features are closely related to the target variable of interest (complexity of a text) as well as ASL and ASW features. The feature of PERSONAL PRONOUNS also shows high correlation with the target variable. However, the values of correlation coefficients vary for different authors. Other features show low correlation (cf. Figs. 1 and 2) Clearly, this difference could be an evidence of the distinct author styles as well as the high variability of assignment of the complexity values.
Correlation between text complexity values of school textbooks and features of text
Correlation between text complexity values of school textbooks and features of text

Box-plots of features that show high correlation with a target variable (in the NIK subcorpus).
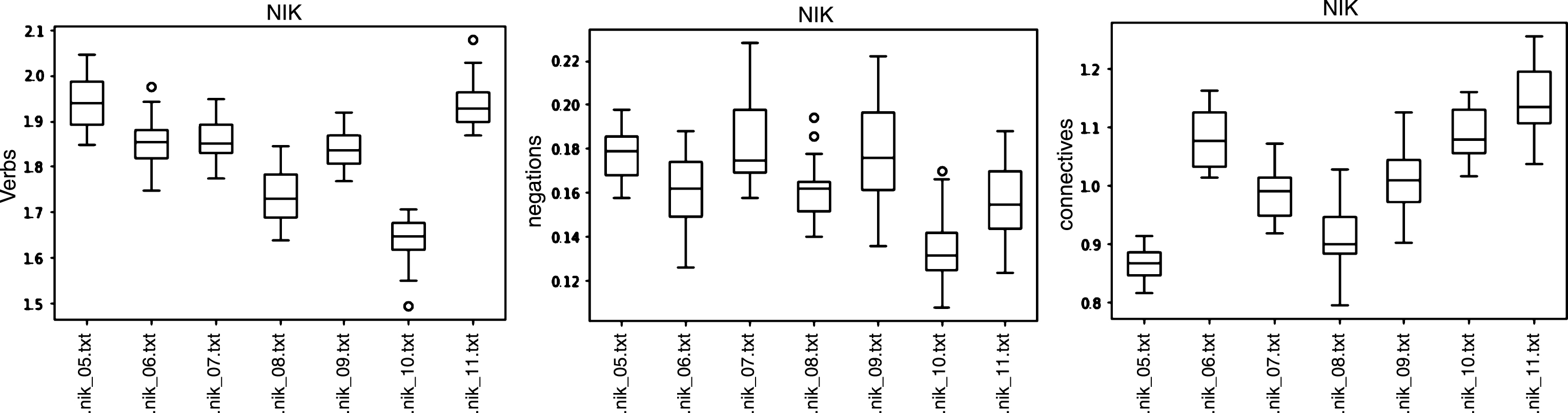
Box-plots of features that show low correlation with target variables (in the NIK subcorpus).
Analysis of the features shows that the following features could be very useful in extending existing linear models: ADJ, FREQ, NOUNS, and PERSONAL PRONOUNS. The extended feature set may serve to add new features in readability tests. In order to extend the linear model two features were tested: FREQ and ADJ. The functional forms of the models are presented below (for the FKG the same functional form is the same, I in the formula stands for the intercept):
To assess the quality of proposed models the mean squared error (MSE) and the coefficient of determination R2 were used. The perfect linear model has MSE = 0 and R2 = 1. For the results of fitting the parameter values in the corpus, see Table 5.
Results of fitting 3-parameter linear model on the RRC corpus
Evaluation of the linear model with three parameters was based on one sub-corpus of the RRC corpus (BOG or NIK) and tested it on the other (NIK or BOG). See Table 6 for the results. MSE values represented in the second column come from models trained on the NIK subcorpus, while MSE values in the last column come from the models trained on the BOG subcorpus. This evaluation shows that the performance of models with the three parameters to a great extend depends on the training corpus used. Thus, the appropriate size of corpus is highly important.
Results of evaluation of 3-parameter linear models. MSE values in the second column are received from models trained on NIK subcorpus; MSE values in the last column are received from the models trained on BOG subcorpus
The RRC contains 14 documents and thus by no means could be treated as a representative sample of the population of the school textbooks under study. Building a larger corpus is difficult, because it would violate some of the key properties: either new texts will come from other domains, or texts will come from different authors with different styles. Both cases of this kind may add noise to the dataset.
In order to overcome the issue of collection size it is suggested the following procedure of sampling from the corpus. In fact, a complexity value measured of a (significant) part of a text should be close to the complexity value of the whole text. This assumption means, that starting from a certain subset (or sample) of sentences, text complexity of the sample will be almost the same as text complexity of the whole document from corpus. The actual plots of the adjusted model is represented in Fig. 3. The sample corpus size was set to 500 sentences. Using the sampling technique, more texts from the original corpus can be generated. Even though the sampled texts will be not natural, they will carry the main features of the texts in the corpus.
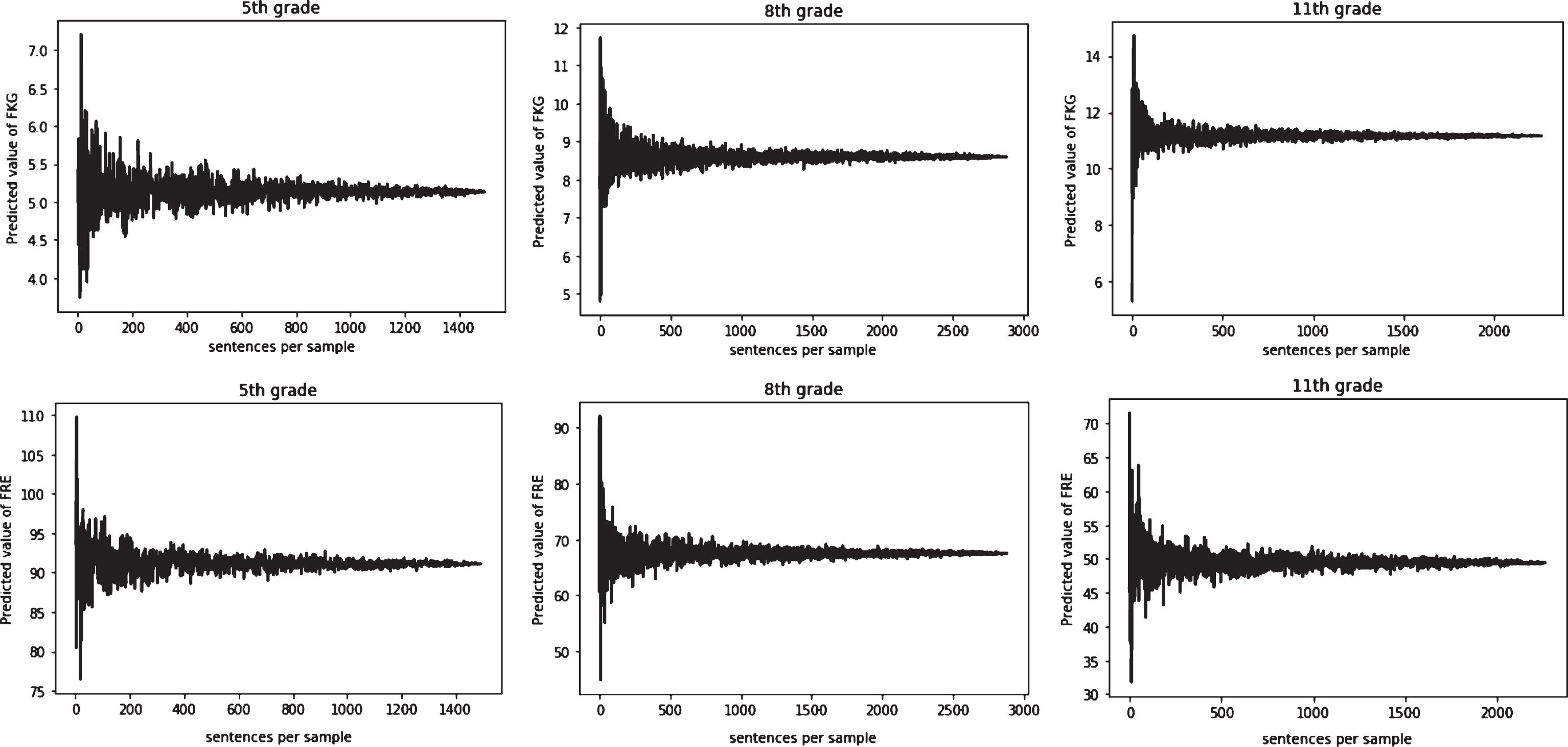
FKG mod and FRE mod values for different number of sentences sampled from a document.
The FKE and FKG formulas modified by the authors for Russian academic texts, i.e. 1 and 2, differ significantly from the formulas deduced by I.Oborneva. The latter, as the research shows, are applicable to a narrow class of fiction texts for schoolchildren only. The pilot research of academic texts readability with Oboroneva formulas computed false matches when the 6th grade textbook was ranked as having readability of the 11th grade (cf. Table 3). The discrepancy of the kind is caused by the fact that Oboroneva’s formulas were derived based on fiction texts, in which an average word is substantially shorter than in academic texts. Thus, readability formulas for fiction and academic texts must differ in the weight of at least this parameter. Admitting that Oboroneva formulas are not universal, we have to comply that the same is true about the formulas proposed by the authors of the article. Both RRF 1 and RRF 2 have not yet been tested outside the corpus of academic texts. It is logical to expect statistically different parameters for different text genres.
The authors also defined the range of metrics matching the text readability and the grade level (cf. Table 4). Except the standard metrics of ‘average words per sentence’ and ‘average syllables per word’, a statistically significant correlation, validated by Pearson coefficient, was proved for the following text features: ‘frequency of content words’, ‘number of nouns per sentence’; ‘number of adjectives per sentence’ and ‘number of personal pronouns per sentence’. At the same time, the research confirmed no correlation between text readability and the following parameters: ‘number of negations per sentence’, ‘number of connectives per sentence’, ‘number of verbs per sentence’, ‘number of pronouns per sentence’.
A sample text sufficient to accurately evaluate readability of the entire text is to be no longer than 500 sentences (cf. Fig. 3). The implications of this findings are mostly pragmatic as it significantly reduces the amount of the research to be conducted and the calculations to be performed. The methodology suggested can be used for assessing readability of texts in other languages. To perform the task it is suggested to design automated text processing tools for measuring the values of a range of selected text parameters.
Conclusion and future work
The article presents the results of the primary stage of the research project aimed at identifying Russian texts complexity parameters. The preliminary review of the published articles and conference proceedings on the topic over the period of 100 years elicited a number of research niches in the area. The study was simultaneously conducted on two sub-corpora of textbooks on Social Studies written by Bogolubov and Nikitin. The textbooks are recommended by the Ministry of Education of the Russian Federation for secondary and high school students of the 5th – 11th grades. We assume that their complexity level increases from Grade 5 to Grade 11 and use their metrics as standard for numerical experiments. To provide reliability of statistical results, we resorted to sampling techniques. The datasets are uploaded on website and are available for potential verification and validation of the research outcomes. Based on the world experience and defining characteristics of the Russian language we selected the following parameters which impact text complexity: frequency of content words, number of nouns per sentence; number of verbs per sentence; number of adjectives per sentence; number of pronouns per sentence; number of personal pronouns per sentence; number of negations per sentence; number of connectives per sentence; average words per sentence; average syllables per word.
We computed the correlation of each of the parameters for every separate textbook in the corpus. The highest correlation, as it was expected for informational texts, was registered for the parameter ‘number of adjectives per sentence’, which, to the best of our knowledge, was either neglected or understudied in the works on text complexity for the Russian language. We used the standard linear regression method to adjust the readability coefficients in English language readability formulas thus offering new versions of classical, most commonly used readability formulas of Flesch Reading Ease and Flesch-Kincaid Grade Level modified for Russian academic texts. As the research was conducted on academic texts only, though with the background of all the previous research in the area, it is unlikely to markedly discriminate text complexity parameters for different genres. Computing complexity parameters of texts of different genres is viewed by the authors as the near-term perspective of the research.
In future research we plan to apply more sophisticated semantic and syntactic features, such as generated by coreference recognizers [38] as well as features based on syntactic n-grams [32, 33].
Footnotes
1
12
To find parameters’ values we apply ordinary least squares lineal regression
Acknowledgments
This research was supported by the subsidy of the Russian Government to support the Program of Competitive Growth of Kazan Federal University and the state assignment in the sphere of scientific activities, agreement #34.5517.2017/6.7. Authors would like to thank Ivan Begtin (ANO “Infoculture”, http://infoculture.ru), who developed a web-service for readability metrics calculation (![]() ).
).