
Abstract
The deployment of large-scale Convolutional Neural Networks (CNNs) in limited-power devices is hindered by their high computation cost and storage. In this paper, we propose a novel framework for CNNs to simultaneously achieve channel pruning and low-bit quantization by combining weight quantization with Sparse Group Lasso (SGL) regularization. We model this framework as a discretely constrained problem and solve it by Alternating Direction Method of Multipliers (ADMM). Different from previous approaches, the proposed method reduces not only model size but also computational operations. In experimental section, we evaluate the proposed framework on CIFAR datasets with several popular models such as VGG-7/16/19 and ResNet-18/34/50, which demonstrate that the proposed method can obtain low-bit networks and dramatically reduce redundant channels of the network with slight inference accuracy loss. Furthermore, we also visualize and analyze weight tensors, which showing the compact group-sparsity structure of them.
Keywords
Introduction
In recent years, the world has witnessed the success of a wide range of computer vision tasks, e.g., image classification [1], object detection [2], and video segmentation [3] owe to the development of deep neural networks (DNNs), especially convolutional neural networks (CNNs). However, with the refinement of vision tasks, large CNN model follows, which impose heavy storage burden on training devices. For example, the GoogleNet, ResNet101, AlexNet and VGG-Net involve 50, 200, 250 and 500 Mbytes of model parameters respectively [4]. It is unlikely to embed these large and high performance models into resource constrained platforms, which encourage CNNs models to have smaller memory and computation cost for fast inference without affecting the task performance. The deployment of CNNs in relative applications is mostly constrained by (a) model size, (b) run-time memory and (c) number of computing operations [6]. Since the computation cost of CNNs is mainly dominated by convolutional operation, which is exactly the dot-product between weights and activations [5]. Thus the number of parameters in the model is critical to above mentioned three factors. Considerable efforts have been proposed to compress large CNNs and speed up the inference. These works include weight pruning and sharing [7–10], low rank approximation [11–13], network quantization [14–20], special model architecture [21–27], and sparsity regularization constraints [28–30] etc. However, most of these techniques can only solve one constraint in real applications mentioned above while channel pruning could achieve all the aforementioned challenges to some extent.
In this paper, we propose a CNN channel pruning and low-bit framework, combining weight quantization with SGL regularization, which addresses both low-bit weight quantization and channel pruning when deploying CNNs under limited resources. For weight quantization, our approach introduces scaling factors in each output channel, and weights of the network are restricted to be either zero or powers of two so that the expensive floating-point multiplication operations can be replaced by cheaper shift operations. The opportunities for channel pruning occur when the scale factors equal to zero. Moreover, the SGL does not only yield sparsity within a group but also promotes group sparsity (identify insignificant channels) which facilitates channel pruning. In fact, pruning unimportant channels may sometimes lead to higher generation accuracy. Different from previous channel pruning work [6, 40], we also achieve low-bit networks using proposed weight quantization function. After using our framework in training process, the resulting network is much more compact than the initial model. Furthermore, iterative process of channel pruning can be conducted to obtain even more compact networks. The main contributions of this paper are summarized as follows: We propose a low-bit weight quantization method by introducing scaling factors which is the base for unified framework. Specially, we achieve channel pruning when the scaling factors equal to zero. We introduce the basic form of SGL, and model the low-bit network as discretely constrained optimization problem while adding SGL term. Considering the particularity of this problem, we use the alternating direction method of multipliers(ADMM) to decompose it into several subproblems and propose an iterative algorithm to make those problems can be efficiently solved. Experiments on several well-known neural network models and benchmark datasets show that the proposed framework can obtain compact and low-bit models with little accuracy loss.
Related work
In this section, we have a brief review of CNNs model compression and ADMM algorithm.
Model compression
On the whole, recent works about neural network compression and acceleration can be roughly divided into the following five categories. Weight pruning and sharing: [7–10] propose to find and prune the unimportant connections with small weights in the neural network model. Then the network is fine-tuned to obtain better accuracy. The resulting network size is reduced by special coding pattern like Huffman coding. However, compression ratio by these methods is very limited, and such simple parameter pruning often produce non-structured connectivity which may hurt inference accuracy drastically. Low rank approximation: In general training process, the weights are presented by high-order tensors. [11–13] approximate high-order tensors with the product of several low-order matrixes by using techniques such as Singular Value Decomposition (SVD), and maintain significant information of each layer. However, low rank approximation can indeed obtain compact structure but it needs more resources to decompose high-order tensors and without notable compression effects. Low-bit weight quantization: low-bit quantization methods mean that the weights and activations are represented by discrete values, which could replace the original floating-point operations by only accumulations or even binary logic operations [14]. [15] and [16] groundbreakingly constrain the weights to the binary and ternary space. It follows that both weights and activations are mapped into binary space or ternary space, i.e. binary neural networks (BNN) [17], XNOR-Net [18], and ternary neural networks (TNN) [19], which directly replace multiply-accumulate operations by logic operations. DoReFa-Net [20] not only quantizes weights and activations, but also quantizes gradients to low-bit width floating-point numbers with discrete states in the backward propagation. Our quantization method also fall into this category. Special model architecture: Simplifying the architecture of network model by using convolutional filters of small size, adopting depth-wise convolution operations, constraining convolution operations to specific input channels, related researches including Squeeze-Net [21], Mobile-Net [22, 23] and Shuffle-Net [24, 25]. Some recent works [26, 27] propose to learn suitable model architecture automatically using reinforcement learning. Sparsity regularization constraints: As we all know, Group Lasso is an efficient regularization to learn sparse structures in numerous studies. Kim [28] and [29] used group lasso to regularize the structure of filters in DNNs. Wen [30] applied group lasso to regularize multiple DNN structures (filters, channels, filter shapes and layer depth). Since these methods only sparsify part of model structures to achieve network compression. SGL is also the same effect with this kind of approach.
ADMM
ADMM is a useful algorithm [31, 32] for solving nonconvex optimization problems, potentially with combinatorial constraints, since it can converge to a solution that may not globally optimal but is good enough in many aspects [33]. ADMM solves problems in following form:
The proposed method
In this work, a regularization constraint of SGL is proposed to regulazire the convolutional layers. We also concentrate on training low-bit quantized neural networks. The diagram is shown in Figure 1. Assuming a general DNN with L layers can be summarized as the following forms [5]
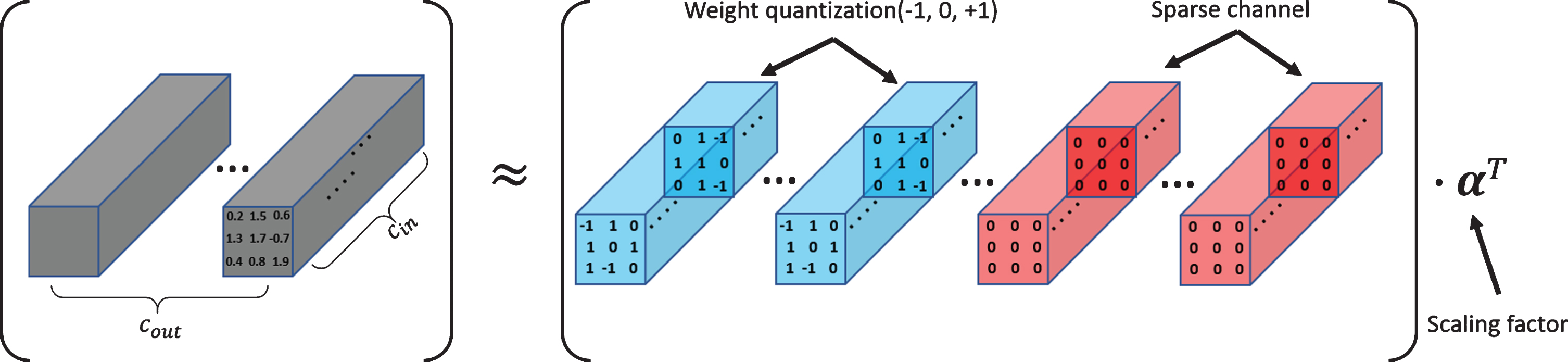
Proposed framework. We introduce a scaling factor with each channel in convolutional layers for weight quantization (Weight quantization). The SGL regularization is imposed on weights constraint. The channels with zero scaling factors will be pruned (Sparse channel).
Given f
In this section, we mainly concentrate on the relative model of Lasso, Group Lasso and Sparse Group Lasso. For general linear regression model:
We mainly concentrate on low-bit weight quantization for networks in this section. Assuming an L-layer CNN with [
In this paper, training neural networks with SGL can be modeled as discretely constrained optimization problems. According to above weight quantization method, the weight in networks are restricted to be {-20α i , 0, 20α i } when k = 1. It is worthy noting that there are different c out values of α in each layer. Generally, the objective function of our proposed framework can be formulated as
Referring to similar studies, we define an indicator function IC(constraining weights into prescribed quantized space) for whether
In this section, we mainly demonstrate the effectiveness of proposed channel pruning framework method on several benchmark datasets. We implement our method based on Pytorch for image classification. Moreover, most previous works do not quantize first and last layers of the network, and we follow the same strategy and report the averaged results over three runs for each experiment by SGD optimizer in this paper.
Datasets
In this paper, we empirically conduct experiments on CIFAR-10 and CIFAR-100 which contains 50,000 and 10,000 images in train and test sets respectively. These two datasets [38] consist of natural images with resolution 32 × 32. CIFAR-10 is selected from 10 classes while CIFAR-100 from 100 classes. We follow the data augmentation strategy in [39]: 4 pixels are padded on each side, and patch is randomly cropped. The input data is also normalized using channel means and standard deviations. The learning rate starts at 0.1 with a batch size of 128 and we use the learning rate decay equal to 0.2 at epochs number 60, 120 and 160 for the whole 200 epochs. Moreover, we use a weight decay of 5 × 10-4 and momentum of 0.9 for SGD optimizer.
Models
On CIFAR-10 datasets, we evaluate our framework method on two popular and simple network architectures: VGG7 and ResNet18. The network structure for “VGG7” is “2(128-C3)+MP2+2(256-C3)+MP2+2(512-C3)+MP2+2(1024-FC)+Softmax”, and “ResNet-18” is standard ResNet-18 which is shown in the official website of Pytorch. In order to show the effectiveness of proposed method, we also conduct more experiments on CIFAR-100. For VGGNet, we adopt VGG16 and VGG19. For ResNet, we use ResNet34 and ResNet50. All of those network architectures are original from the official website.
Because the limitation of our experimental conditions, we cannot evaluate our method on ImageNet and complex networks with more layers.
Relevant evaluation indicator
We define several evaluation terms that will be used in the following sections. Channel sparsity ratio = (number of zero channels) / (number of total channels). Parameter pruned = (parameter pruned) / (total parameter before pruned). FLOPs pruned = (FLOPs reduction) / (total FLOPs before pruned).
As we all know, FLOP is a commonly used indicator to compare the computation complexities of CNNs. To compute the number of FLOPs, we assume convolution is implemented as a sliding window and nonlinearity is computed for free. For convolutional layers we have [34]
Results
Performance on CIFAR-10 and CIFAR-100:
Noting in the whole experiments, we compare performance under the same conditions which only quantize weight not activations. In fact, our quantization method is a special XNOR network combined with SGL regularization constraint. Different from XNOR network, parameter sparsity and channel sparsity are ubiquitous in our network model. The comparison results with some classical method on CIFAR-10 are shown in Table 1, where ‘FWN’ represents full precision weight network without any quantization, ‘BWN’ represents binary weight networks which constrain the weights to the binary space {-1, + 1} (1 bit) [15], ‘TWN’ represents ternary weight networks which constrain the weights to the ternary space {-1, 0, + 1} (2 bits) [16] and ‘XNOR’ refers to XNOR-Net which constrain both the weights and the activations to the binary space (1 bit) which can directly replace the multiply-accumulate operations by binary logic operations [18], ‘OURS’ is by our framework with λ1 = λ2 = 0.001.
Test Error Comparison on CIFAR-10
Test Error Comparison on CIFAR-10
It could be seen that the proposed method achieves almost equal accuracy compared with full precision, and has outperform a little more than other several state-of-art algorithms. Moreover, our method achieve channel pruning while others not. On the other hand, considering the best performance on CIFAR-10 among several classical methods, we mainly compared ‘XNOR’ with ‘OURS’ on CIFAR-100 by different networks. The results on CIFAR-100 are shown in Table 2, which presents that our method is much better than ‘XNOR’ and closes to ‘FWN’. Obviously, our method is robust to some extent for complex data sets.
Effects of SGL regularization:
Test Error Comparison on CIFAR-100
We explore the effects of adding regularization in this section. It is clear that proposed quantization method could lead channel sparsity for channel pruning. Experimental results show that the ratio of channel sparsity becomes greater by adding SGL regularization while without accuracy loss as shown in Figure 3. Table 3 and Table 4 shows the network channel sparsity of each convolutional layer on ResNet18 and VGG7 for CIFAR-10, where Q is by our quantization only, Q+SGL is by proposed framework, "Q+SGL1" refers to λ1 = λ2 = 0.001 and “Q+SGL2” refers to λ1 = λ2 = 0.01.
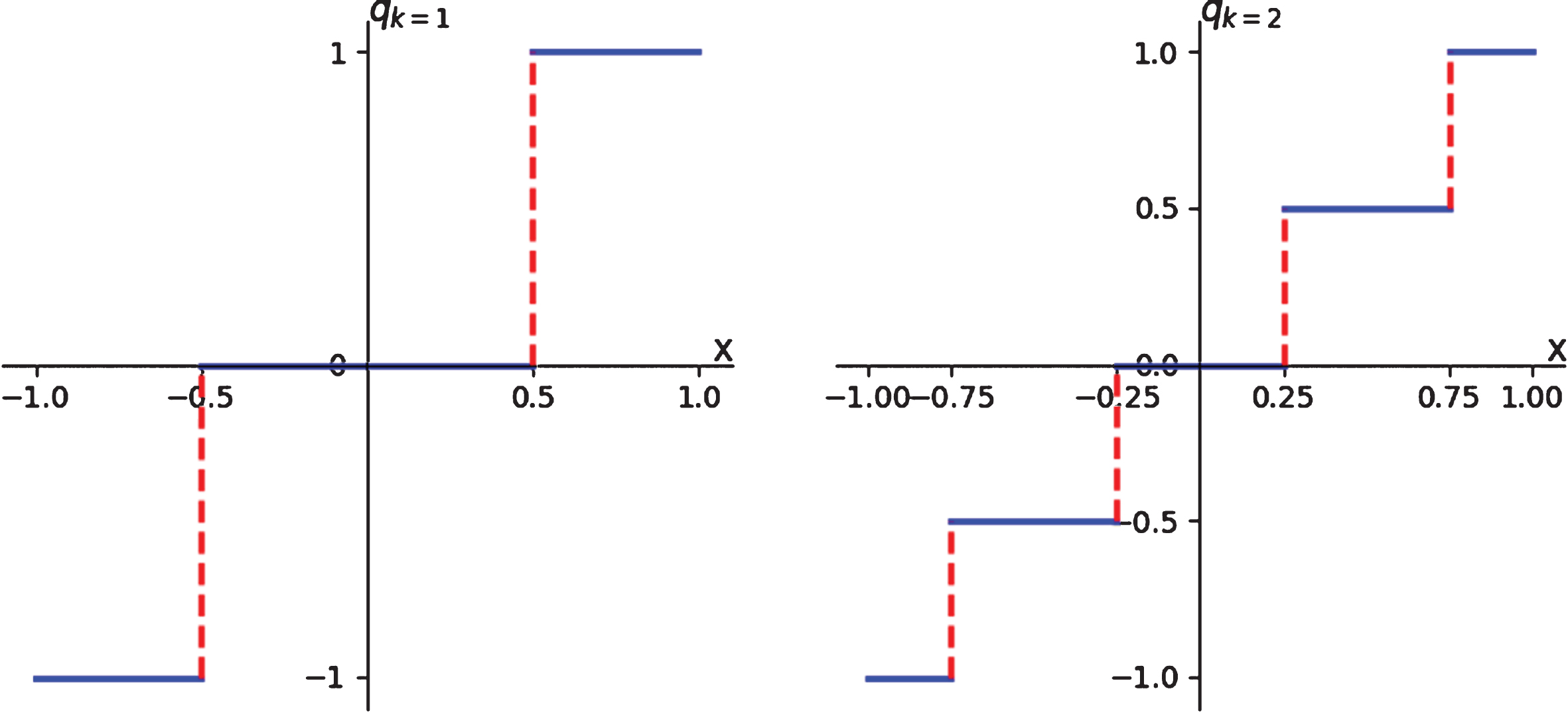
Quantization function q(x, k) with k = 1 and k = 2.
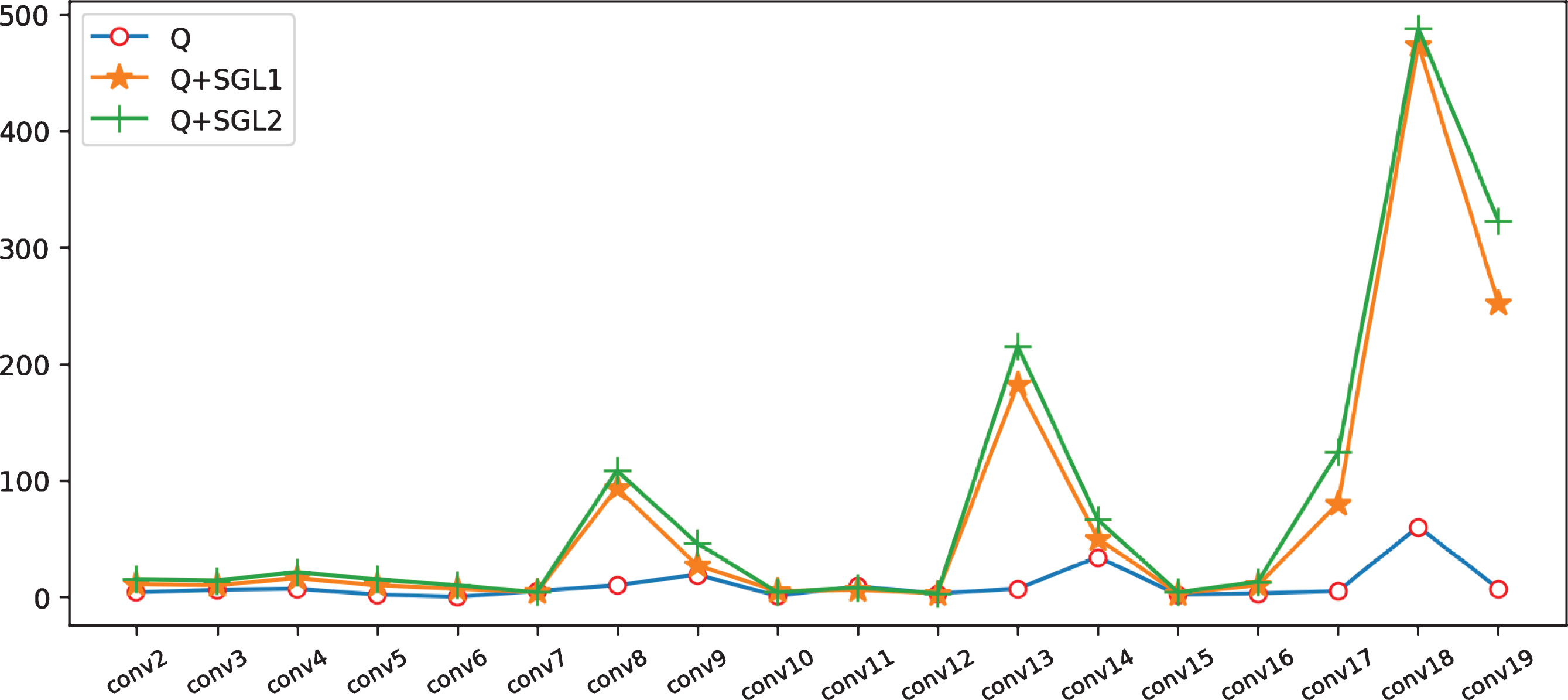
Sparse channel numbers(vertical axis) of each layer on ResNet-18.
Channel Sparsity on ResNet18
Channel Sparsity on VGG7
From Table 3 and 4 we can observe that, on ResNet18 (VGG7), typically 35% ( 8%) channels can be pruned, and achieve similar performance compared to original model. On the other hand, we obtain compact model by pruning many redundant channels obtained by proposed method. With larger values of λ1 and λ2, we obtain larger sparsity of each layer without accuracy loss. We also show the visualization result of convolutional kernel on ResNet18 in Figure 4 (the darker the color, the smaller the weight value. And black pixels mean that parameter value equals to zero). Moreover, the results of channel sparsity for CIFAR-100 are summarized in Table 5.
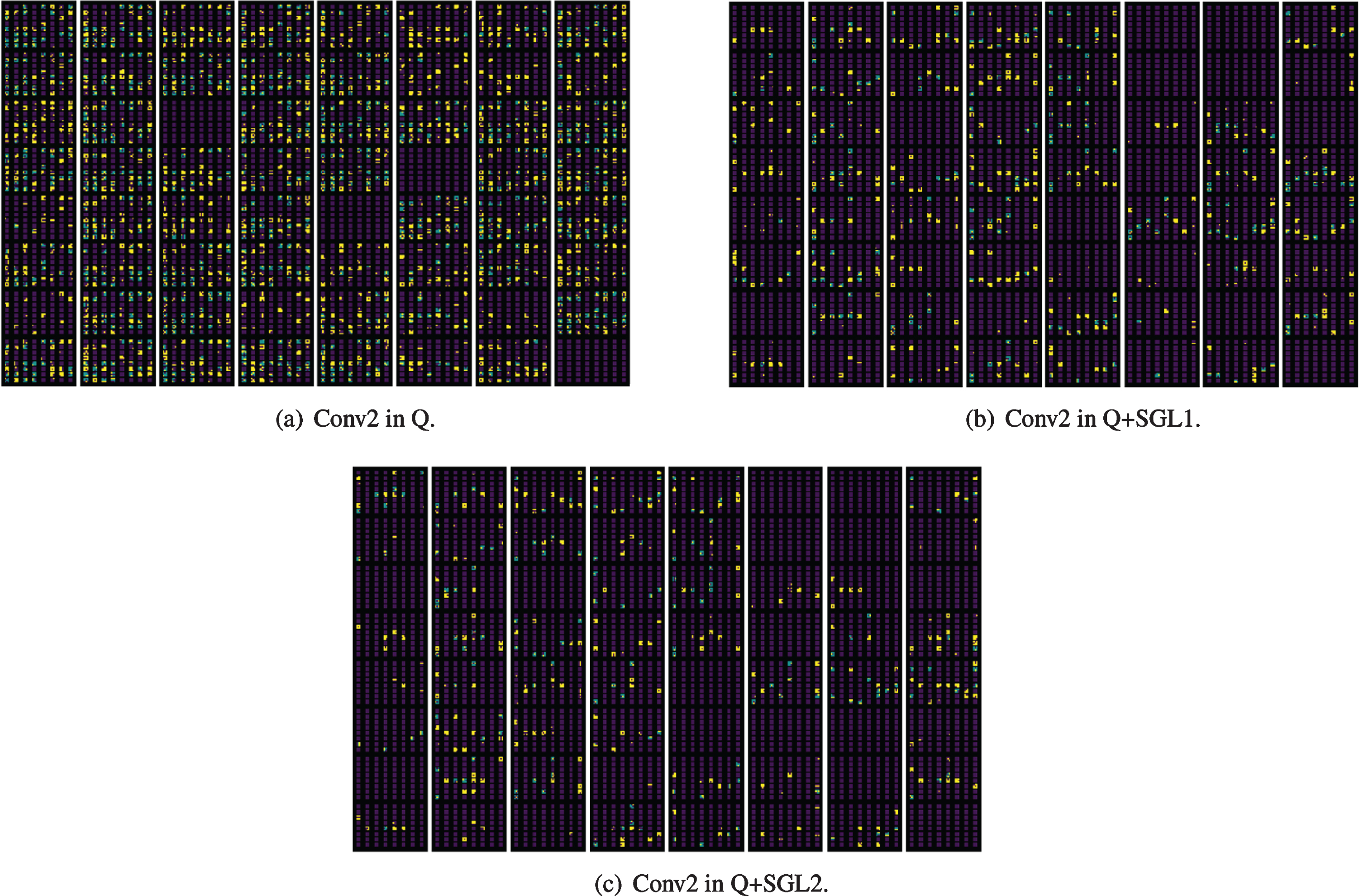
Visualization result of conv2 in Table 3.
Channel Sparsity Ratio on CIFAR-100
Obviously, experimental results in Figure 4 and Table 5 agree with the above discussion in more complex datasets. From Table 4 and Table 5, it can be concluded that the channel sparsity is more sensitive to the value of λ in simple network with less layers, and there are apparently more redundant channels in complex networks. Analysis of channel pruning:
By using proposed framework, we can obtain low-bit network in order to make floating-point multiplications be replaced by cheaper bit shift operations. Besides, plenty of redundant channels exist in each layer of the network. If we prune those sparse channels, the resource saving and computation saving can be very considerable. The results are shown on Table 6 and Table 7. It can be obviously concluded that much redundancy exists in ResNet than VGG-Net. Moreover, we could prune more parameters and FLOPs with larger λ (λSGL2> λSGL1) while almost no accuracy loss.
Channel Pruning Ratio on CIFAR-10
Channel Pruning Ratio on CIFAR-100
We also employ iterative channel pruning by using proposed method on CIFAR datasets. The test errors of models in each iteration are shown in Table 8. We count the number of pruned parameters and FLOPs in each iteration. As the pruning process goes, we obtain more compact quantized models. It is notable that we can prune near 80% parameters and 70% FLOPs without obvious accuracy loss on ResNet18. Run-time memory, wall-clock time and model size savings:
Iterative channel pruning on CIFAR-10(ResNet18)(%)
The experiments is conducted by using Pytorch with a batch size 128. We record the run-time memory and wall-clock time of VGG16 and ResNet34 on CIFAR-100 during inference time. We also compare model size of diffirent situation which are stored by Pytorch. The results are shown in Table 9, which roughly matches parameters pruned in Table 6 and Table 7. Note that run-time memory, wall-clock time and model size will be further reduced in special hardware due to our low-bit quantized network.
Run-time memory and wall-clock time savings on CIFAR-100
This paper focused on neural network compression with low-bit weights and channel pruning. We proposed a unified framework using weight quantization combined with SGL regularization, and transformed it into optimization problem with discrete constraints which could solved by ADMM. Unimportant channels can be identified by proposed framework during training process and then pruned. Experiments on different CNNs have shown that the proposed method is able to obtain low-bit networks and achieve channel pruning to learn more compact CNNs with little accuracy loss. Moreover, model size, computation cost and run-time memory could be reduced drastically by our method due to channel pruning. Because of our poor conditions, however, we cannot conduct more experiments on more complex datasets such as ImageNet, and networks such as ResNet101. In the future work, we wish to have more experiments on other datasets and networks to demonstrate to effectiveness of proposed framework. Furthermore, layer pruning is also possible for more complex networks in later research.
Footnotes
Acknowledgments
This work was partially supported by the National Natural Science Foundation(NSFC) of China (Grants No. 61602494, No. 61906206) and Natural Science Foundation of Hunan Province, China (Grant No.2019JJ50746).