
Abstract
Graph convolutional networks (GCNs), which are capable of effectively processing graph-structural data, have been successfully applied in text classification task. Existing studies on GCN based text classification model largely concerns with the utilization of word co-occurrence and Term Frequency-Inverse Document Frequency (TF–IDF) information for graph construction, which to some extent ignore the context information of the texts. To solve this problem, we propose a gating context-aware text classification model with Bidirectional Encoder Representations from Transformers (BERT) and graph convolutional network, named as Gating Context GCN (GC-GCN). More specifically, we integrate the graph embedding with BERT embedding by using a GCN with gating mechanism to enable the acquisition of context coding. We carry out text classification experiments to show the effectiveness of the proposed model. Experimental results shown our model has respectively obtained 0.19%, 0.57%, 1.05% and 1.17% improvements over the Text-GCN baseline on the 20NG, R8, R52, and Ohsumed benchmark datasets. Furthermore, to overcome the problem that word co-occurrence and TF–IDF are not suitable for graph construction for short texts, Euclidean distance is used to combine with word co-occurrence and TF–IDF information. We obtain an improvement by 1.38% on the MR dataset compared to Text-GCN baseline.
Introduction
Text classification is a common and important Natural Language Processing (NLP) task, which aims to infer the most similar label for a given sentence or document. It has many applications in areas such as sentiment analysis, SPAM detection, topic classification, news filtering, and so on [1–3]. The main step in text classification is to build appropriate representation of the text [4]. Traditional methods for text classification, such as topic-based [5], kernel [6] based, and n-gram [7] based methods, represent text in terms of sparse features.
In recent years, artificial intelligence and hardware devices have been rapidly developed [8, 9], especially the successful application of deep learning [10], a multitude of neural network-based models, such as Recurrent Neural Networks (RNNs), Long Short-Term Memory (LSTM) [11] (a variant of RNN) and Convolutional Neural Networks (CNNs) [12] have been widely used for text representation. For the past few years, the application of graph neural networks (a new type of neural network) to NLP has caught the attention of a lot of researchers because it can solve the problem that other deep learning methods cannot perform relational reasoning. Graph Convolutional Network (GCN) is a kind of graph neural network and a variant of a convolutional neural network based on graph data. In [13], GCN was first introduced in citation network, achieving significant results. Inspired by this, Text-GCN [14] has been developed for text classification, which incorporate both word-to-word mutual information and word-to-document TF–IDF to build a text graph for a corpus and learns a graph embedding for text classification using a graph convolutional network. However, Text-GCN is one-hot initialized with representations of words and documents, such that the graph embedding of a text only contains information of related words and documents, which ignores the context information of the text itself.
Recently, gating mechanism has proved to be powerful in neural network-based models. LSTM is one of the RNN variants, in which the information flow is controlled by a gating mechanism, such that the gradient vanishing problem can be better handled. In [15], a new gating mechanism based on CNN was introduced, which was applied to language models and achieved competitive results on several benchmark datasets. In this study, we demonstrate that gating mechanism also have good effect on GCN.
In this paper, we propose a new architecture based on GCN and the BERT encoder for text classification. We combine the graph embedding learnt by GCN and BERT embedding, and then use a graph convolutional network (GCN) as gating mechanism to control the information flow. As BERT is used in our model, the information flow contains context information from the text, enabling the graph embedding to be more informative. Through the use of the novel gating mechanism, our proposed model outperforms the existing models on several text classification benchmark datasets. The main contributions of our work are as follows: This is a first time that a graph convolutional network has been successfully used as gating mechanism to control the propagation of information. And we also analyze and select the best gating mechanism from the mathematical point of view. We take full advantage of BERT embedding and gating mechanism to enable our model to capture context coding and shows competitive results with state-of-the-art models on several text classification datasets. We find the combination of Euclidean distance with word co-occurrence or TF–IDF in building the adjacency matrix is better to address the unsuitability of Point-wise Mutual Information (PMI) and TF–IDF information in building text graphs from short text data.
Related work
Traditional methods
Traditional text classification methods can be divide into two stages: the feature engineering stage and the classification stage. Feature engineering is the key step in constructing representation of the text. The most widely used methods for text representation are Bag-of-Words (BOW) [16] and TF–IDF [17]. To achieve improved text classification performance, more complex features were resorted, such as kernel methods [6], topic-based representation [5], and n-grams [7]. For the back-end classification stage, statistical machine learning based algorithms is often used, such as Naïve Bayes [18] or Support Vector Machine [19].
Deep learning methods
The main problems in constructing text representations by traditional approaches are high dimensionality, sparseness, and weak feature representation ability. With the development of deep neural networks, many new ideas for text representation have been proposed. The neural language model [20] (using Distributed Representations [21]) is capable of dealing with sparse data by representing original one-hot vectors as dense continuous vectors, and hence capturing meaningful syntactic and semantic information from the text. Furthermore, it can also map semantically similar words closely in a vector space. Word2vec [22, 23], a previously prevalent word representation method, has been successfully applied to text classification tasks. In [12], a CNN based text classification using pre-trained Word2vec vectors was used, which could fetch the local information from word embedding to generate more representative sentence features. In [24], an RNN-based model for paraphrase detection by using pre-trained word embedding was introduced. In [15], a convolutional-based gating mechanism for language models was proposed. Our experiments show that GCN has similar abilities in text classification task.
Recently, BERT [25] has been shown to achieve great success in many NLP tasks. There are three main innovations in BERT: masked language model, Transformer, and sentence-level coding. The masked language model randomly masks tokens in a proportion of an input sequence and then predicts them in pre-training, which allows the model to learn context information in both directions of a text. The transformer [26] is a new architecture which can replace the traditional RNN or CNN, and has outperformed many CNN- and RNN-based models in feature extraction. Finally, BERT is a sentence-level language model: Unlike the ELMo model [27], which needs to add weights to each layer for global pooling when it is concatenated with downstream-specific NLP tasks, BERT can directly obtain the unique vector representation of a whole sentence. Given the merits of BERT, we leverage BERT to obtain context information of a certain text and incorporate the BERT embedding into a GCN.
Graph-based neural networks
GNNs have been applied to many NLP tasks. In knowledge-based Question Answering (QA), Daniil Sorokin [28] tackled the problem of learning vector representations for complex semantic parses by using a gated graph neural network. In [29], a graph neural network and a LSTM were combined for sentence encoding in Semantic Role Labeling (SRL). In [30], an encoder based on graph convolution for Machine Translation was presented. GraphRel [31] is a relation extraction model based on graph convolutional neural networks. In [13], a local first-order approximation of spectral convolution was used to simplify a GCN for Semi-Supervised classification. Text-GCN [14], which builds a heterogeneous graph on an entire corpus, turning the text classification task into a node classification task, is based on a graph convolutional network. There also exist some attention-based graph network models, such as GATs [32], which leverage masked self-attention to calculate the contributions of different nodes to other nodes. In this way, the nodes with larger effects can be focus on and the nodes with smaller effects are ignored. In [33], the authors found a linear version of GCN by removing the non-linear activation function of each layer which obtained promising results and proposed an attention-based GCN, AGNN. In [34], the three architectures of GCN, Attention neural networks, and Relational neural networks were integrated to realize the node representation of a graph network for node classification and graph classification tasks. Based on the above, GNN and its variants can be considered as powerful tools and a good solution to relational reasoning for graph data.
Methodology
Graph convolutional networks (GCN)
Normally, a graph can be denoted as G = (N, E), with n nodes n
i
∈ N and edges e
ij
= (n
i
, n
j
) ∈ E with corresponding weights a
ij
. GCN works like a multilayer perceptron, by stacking layers to propagate information and representing the features x
i
of each node n
i
. The major difference between a GCN and a multilayer perceptron is that the GCN has an additional adjacency matrix to capture the local information of related nodes. In Figure 1, we consider H(k-1) to be the input of the kth graph convolutional layer and H
k
to be the output. The initial feature representation matrix is denoted as

Schematic layout of a GCN. The GCN transforms the node features repeatedly throughout K layers and then applies Logistic Regression as classifier on the final representation.
In detail, in the smoothing step for the representation of node n
i
, we average the feature vector of its related neighborhoods:
In this section, we present the proposed architecture based on GCN [13] and BERT [25]. We use BERT as the encoder to obtain context representation of the document and incorporate it into the graph embedding learnt by GCN. Then, the information flow is controlled by a gating mechanism. Finally, we use the controlled information as input to the second GCN layer for classification.
As shown in Figure 2, we first build a heterogeneous text graph based on Text-GCN [14] for a corpus {T = [t1, t2, . . . , t
m
], V = [w1, w2, . . . , w
q
]}, where T is a set of texts, V is the vocabulary of this corpus, m is the number of documents (or sentences), q is the number of unique words (i.e., vocabulary size) in the corpus, and m + q = n is the total number of nodes. Word co-occurrence typically employs the point-wise mutual information (PMI) to weigh the edge between two word nodes; details of PMI can be found in [14]. Similar to Text-GCN, we one-hot initialize the feature matrix (total node representation) X = I (I is identity matrix) to extract the graph embedding from the GCN. Following Eq. (6),
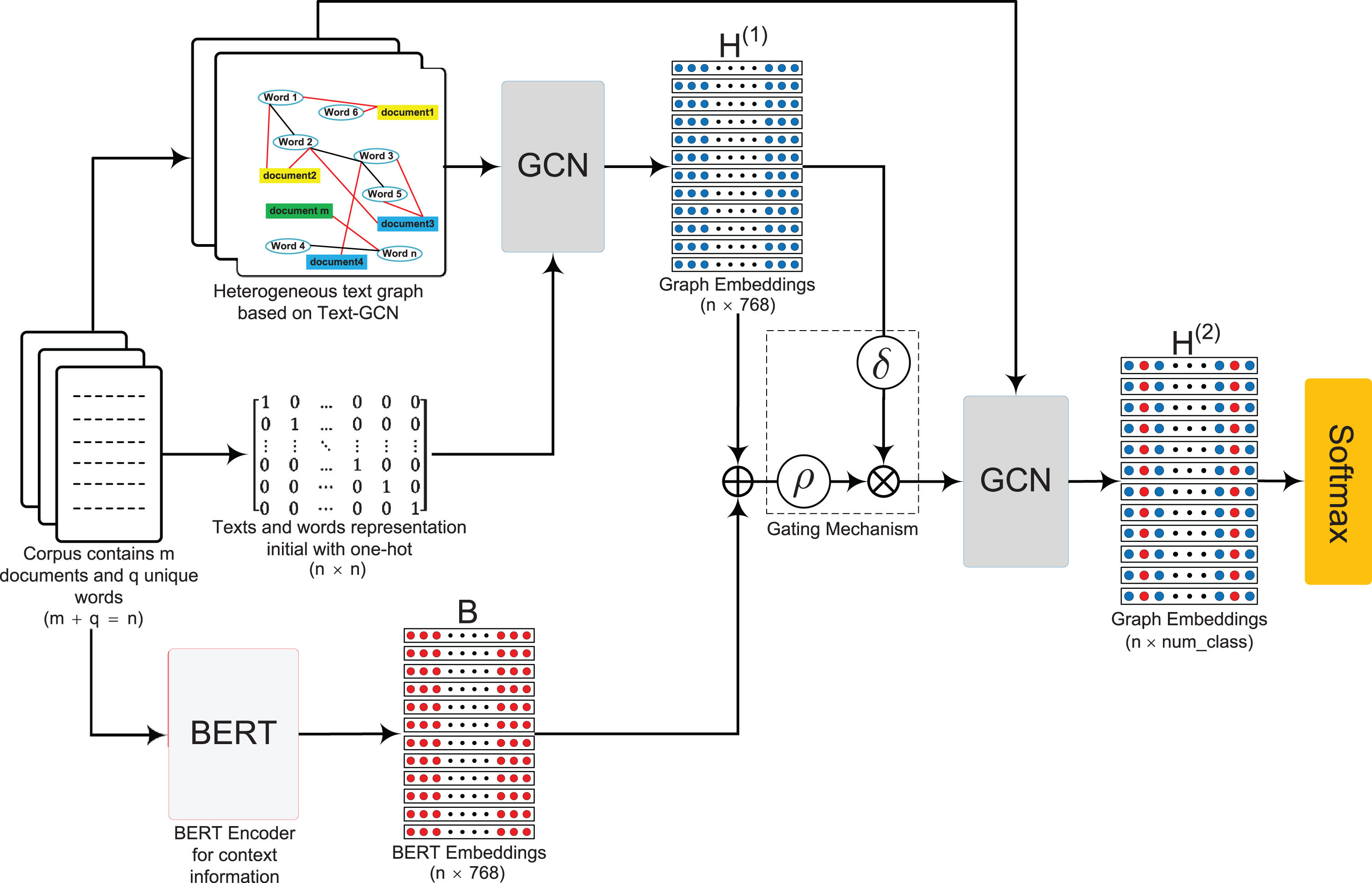
Schematic of GC-GCN. The heterogeneous text graph is based on Text-GCN [14], in which the circles represents q unique words (vocabulary size), the boxes stand for m documents (or sentences), where boxes of the same color represent those belonging to the same label, and q + m is the total number of nodes n. Red lines are document (sentence)–word edges and black lines are word–word edges. The original input feature is one-hot,
In this section, we compare our proposed model to Text-GCN on multiple datasets from various aspects, such as classification accuracy, visualization of learned features and changing the size of the training set. For GC-GCN, we use GloVe word embeddings [36] (http://nlp.stanford.edu/data/glove.6B.zip) for the document representation [37] for comparison with BERT embeddings, and mathematical analysis and experimental verification of a variety of gating mechanisms with different activation functions. Finally, we use Euclidean distance to construct the text graph of the MR dataset, and compare GC-GCN with Text-GCN on the new graph data.
Datasets
To make fair comparison with Text-GCN, we used the same benchmark corpora from [14]: 20-Newsgroups (20NG), Ohsumed, R52, R8, and binary Movie Review sentiment classification data (MR). We pre-processed these corpora according to [14]. All the datasets are available online (https://github.com/yao8839836/text_gcn/tree/master/data). The overview of the datasets were shown in Table 1.
Overview of the datasets. Sparsity describes the sparsity of data in a dataset
Overview of the datasets. Sparsity describes the sparsity of data in a dataset
We compared GC-GCN with several state-of-the-art text classification models. In this work, the comparisons are mainly made between GC-GCN and Text-GCN.
Implementation details
We implemented our models using PyTorch-1.3.0. For GC-GCN, we set the number of hidden units in the first graph convolutional layer to 768 in accordance with the dimensions of the BERT feature vectors. As for Eq. (10), we did not set the activation functions for F and H(1), which will be explained in Section 4.5. We set the window size to 20 when calculating the PMI, and randomly select 10% of the training set as the validation set. In the training step, we use gradient descent with the Adam [40] update rule. The initial learning rate is 0.04, and then, drops by 20% every five steps in the first 25 steps. The maximum number of epochs was 200 and training was stopped if the validation loss did not decrease for 10 consecutive epochs.
We also tested the effect of adding layers to our model, and found that our model achieved the best results with two layers; this is because deeper GCNs can suffer from over-smoothing problems [41].
Experimental results
Results in existing literature
Table 2 presents the test accuracy of from the models on the five benchmark datasets. We can see the results based on Text-GCN are better than those of the other traditional neural-based models, such as CNN, LSTM, and fastText, which is likely due to the graph network structure’s ability to transmit rich adjacency information in the graph data. Meanwhile, it also leads to indirect learning of label information between different nodes. These characteristics do not exist in other deep learning methods. In this paper, we mainly focus on comparing GC-GCN against Text-GCN; from Table 2, we can see that GC-GCN-BERT achieved state-of-the-art results on the 20NG, R8, R52 and Ohsumed. As for why GC-GCN-BERT did not outperform Text-GCN on MR, we consider that in more detail.
Test Accuracy on text classification. The results above the horizontal line in the table were taken from [14]. All models were run 10 times and report the mean ± standard deviation
Test Accuracy on text classification. The results above the horizontal line in the table were taken from [14]. All models were run 10 times and report the mean ± standard deviation
The results of Text-GCN are taken from the original paper [14], in which Text-GCN was implemented on Tensorflow with 200 dimensions of first graph convolutional layer. In order to make a fair comparison, we designed a series of new experiments, where Text-GCN-200, Text-GCN-300, and Text-GCN-768 were implemented in PyTorch (the numbers after Text-GCN stand for the dimensions of first graph convolutional layer: 200, 300, and 768, respectievly). All the parameters of Text-GCN were set according to [14]. We conducted the significant tests between GC-GCN-BERT and Text-GCN-768 on five datasets, and the p-values are 0.042, 0.012, 0.025, 0.005 and 0.008 respectively on the 20NG, R8, R52, Ohsumed and MR dataset, indicating the significance of the improvements from the proposed GC-GCN-BERT.
From Table 2, we can see the larger the dimensions of the first graph convolutional layer of Text-GCN, the better the results on 20NG, R8, R52, and Ohsumed; while a larger dimensions of first graph convolutional layer of Text-GCN is not good for the accuracy on MR. We think that this is due to the data itself. According to Eq. (8), when we one-hot initialize the node representations, the normalized symmetric adjacency matrix
Results by gating mechanism or context information
From G-GCN-768, we see the gating mechanism can effectively improve the classification accuracy on R8, R52, Ohsumed and MR compared with Text-GCN-768. In C-GCN-BERT, directly adding context information into the graph embedding can only get a slight improvement on R8 and R52, and even significantly decrease on 20NG, Ohsumed and MR compared with Text-GCN-768. As for the GC-GCN-BERT model, we find that GC-GCN-BERT combined the merits of the gating mechanism and BERT to boost its performance.
Results by different document representations
From Table 2, we can see that BERT+LR performs the best on the MR. From the above discussion we have learnt that MR is a short text dataset for binary sentiment classification, and contextual information is very important in the task of sentiment classification. Given BERT’s excellent performance on the MR, we know that BERT takes good account of the context information of words when encoding text. GloVe+LR achieves better results than BERT+LR on R8, R52, and Ohsumed, but does not outperform BERT+LR on MR; this is because, in the sentiment classification problem, the BERT encoder considers the context information in the text, which the document representation of GloVe embedding does not.
Text-GCN-300 is a comparison experiment of GC-GCN-GloVe, as the first convolutional layer of the two models all had dimension 300. The accuracy of GC-GCN-GloVe was about 1% higher than Text-GCN-300 on MR; GC-GCN-BERT obtained a relative poor result on MR, due to the sparsity of the data, but the gain of GC-GCN-BERT over Text-GCN-768 was about 1.89%, which greater than that of GC-GCN-GloVe over Text-GCN-300. We can also see that the accuracy of GC-GCN-GloVe on 20ng and Ohsumed were worse than those of GC-GCN-300; we also used Word2vec based embedding and the pretrained model GPT in GC-GCN, the results of GC-GCN-Word2vec and GC-GCN-GPT were poor, so the Word2vec based embeddings and GPT based embedding do not apply to GC-GCN; these suggest that, when we apply GC-GCN model, we need to select an appropriate context embedding.
Results by combine gating mechanism and context information
GC-GCN after choosing an appropriate document representation BERT, GC-GCN-BERT obtained the best results on four out of five datasets in Table 2. This is because the gating mechanism integrates the context information with graph embedding so that GC-GCN-BERT has the ability to process context information which is not available in Text-GCN. We can find that GC-GCN-BERT can mitigate the problem of sparse data on MR, making the result of GC-GCN-BERT on MR is close to that of Text-GCN-200.
Analysis of gating mechanism
Table 3 shows the accuracy of GC-GCN-BERT in R8, R52 and Ohsumed by using the gating mechanisms with different activation functions. Inspired by [15], we used different activation functions to verify the gating mechanism. By Eq. (10), we can define the gradient of the Gated Tanh Unit (GTU), where the activation function of F is tanh, as follows:
The accuracy of different activation mechanisms on the datasets R8, R52, and Ohsumed.
Sigmoid, Tanh, and ReLU are the different activation functions of the GLU. We tested all models 10 times and report the mean ± standard deviation
We can see that ∇F ⊗ δ (H(1) does not have a downscaling factor and, so, it suffers from less gradient vanishing than in the GTU. In a Bi-directional Gated Linear Unit (Bi-GLU), both the activation functions of F and H(1) are removed; we obtain the gradient of a Bi-GLU as
From Table 3, GTU with the Sigmoid activation function demonstrates poor results, due to the vanishing gradient problem. The different activation function used in the gated linear unit (GLU) achieves better results than Text-GCN-768. Bi-GLU obtained the best results on R52 and Ohsumed, and the gated linear unit with the ReLU activation function (GLU-ReLU) achieved best result on R8, it was about 0.55%, 0.55% and 1% higher than Text-GCN-768 in datasets R8, R52 and Ohsumed. Actually, the GLU with the ReLU activation function and Bi-GLU are gated linear units of the same type and, so, their results were similar. However, Bi-GLU has a higher computational efficiency than the former, as it does not have to compute the derivative of ReLU during gradient propagation. Therefore, we found Bi-GLU to be suitable for our model.
Figure 3 and Figure 4 use t-SNE tool [42] to show the Visual distribution of first and second layer embeddings learnt by Text-GCN-768, C-GCN-BERT and GC-GCN-BERT in the test set of R8 respectively. From Figure 3, We can intuitively see that GC-GCN-BERT and C-GCN-BERT had better clustering ability than Text-GCN-768, and that GC-GCN-BERT achieved the best performance. Figure 4 shows the Visual distribution of second layer embeddings in the test set of R8. It can be found that the document representation of each category learnt by GC-GCN-BERT is more effective than the clustering of Text-GCN-768 and C-GCN-BERT, especially the clustering of aca and earn, so GC-GCN-BERT achieved the best results in terms of classification accuracy. Secondly, the classification accuracy of C-GCN-BERT is higher than that of Text-GCN-768, so we can see that C-GCN-BERT was better than Text-GCN-768 at distinguishing between the classes "crude", "acq", and "trade".

The t-SNE visualization of test set document embeddings of the first layer learnt by Text-GCN-768, C-GCN-BERT, and GC-GCN-BERT in R8.

The t-SNE visualization of test set document embeddings of the second layer learnt by Text-GCN-768, C-GCN-BERT, and GC-GCN-BERT in R8.
Figure 5 shows the test accuracy when using 1%, 5%, 10%, and 20% of the original R8 and 20NG training sets. We can see that GC-GCN-BERT was better and more stable than Text-GCN-768, except for when the proportion of training set on 20NG was 1%; this was mainly related to the number of classes in the dataset. R8 had 8 classes and 20NG had 20 classes. When the training set was scaled down, for the dataset with a large number of classes, some classes may be eliminated from the training set altogether, which is more likely to happen than in datasets with a relatively small number of classes. Text-GCN-768 uses global word co-occurrence and TF–IDF information to generate the graph embedding but, in the case of GC-GCN-BERT, the learned graph embeddings add context information, so that the document representation learnt by GC-GCN-BERT is more targeted. Therefore, when the training set is scaled down significantly, GC-GCN-BERT cannot learn all the class information of a dataset with a large number of classes completely, as the information of the current text is added by BERT features, and as some classes may have been removed before training; therefore, the accuracy of the GC-GCN-BERT results may decrease significantly. However, for datasets with a small number of classes, GC-GCN-BERT is still better than Text-GCN when the training set is reduced significantly.

Test accuracy when altering the size of the training set. We used Text-GCN-768 and GC-GCN-BERT to test 10 times on R8 and 20NG, and report the mean ± standard deviation.
As has been discussed above, PMI or TF–IDF information alone is not sufficient to build a text graph on MR. So in this section, we use the Euclidean distance to build the adjacency matrix for the MR, in order to evaluate the influence of the adjacency matrix. It is found that a learning rate of 0.03 for our model is better for the new data. We directly use the BERT features to calculate the word–word E ww and word–document E wd Euclidean distances, due to its excellent performance in sentiment classification. Then, we set the PMI and TF–IDF values to W p and W t , respectively, and set α as the weight to calculate the new word–word and word–document information, where the new word–word information was α × E ww + (1 - α) × W p and the new word–document information was α × E wd + (1 - α) × W t .
Table 4 and Figure 6 show the accuracy of the GC-GCN and Text-GCN models when using different weights α. Text-GCN-200 and Text-GCN-768 denote that the hidden dimensions of first graph convolutional layer used in Text-GCN were 200 and 768 respectively, and their learning rate was set to 0.02, according to [14]. GC-GCN-CLR adopted the changing learning rate rule, GC-GCN-0.03 had a fixed learning rate of 0.03, and the context information used by GC-GCN was the BERT features. We can see that, when the value of α was set at 0.5 and 1, GC-GCN and Text-GCN achieved their best results, respectively. We note that, when the value of α was small (in other words, when the proportion of PMI and TF–IDF was large), the results of Text-GCN were relatively poor, This means that PMI and TF–IDF were not suitable for constructing an adjacency matrix for the MR. After incorporating Euclidean distance weighting, the accuracy of GC-GCN-0.03 was about 0.28% higher than LSTM (pre-trained) and very close to the result of Bi-LSTM, which handles context information well; this indicates that GC-GCN also has the ability to handle context information.
The accuracy after combining Euclidean distance with PMI and TF–IDF, using different weights α on the MR. We tested these new data on the GC-GCN-BERT and Text-GCN models 10 times repectively, and report the mean ± standard deviation
The accuracy after combining Euclidean distance with PMI and TF–IDF, using different weights α on the MR. We tested these new data on the GC-GCN-BERT and Text-GCN models 10 times repectively, and report the mean ± standard deviation

The accuracy after combining Euclidean distance with PMI and TF–IDF, using different weights α on the MR.
In this paper, we have proposed a simple and effective model for text classification named as GC-GCN. We use the graph convolutional network as a gating mechanism to integrate BERT’s context information with graph embedding, thus overcoming the problem of not considering context information in Text-GCN. We compared GC-GCN and Text-GCN on multiple datasets in terms of classification accuracy, visualization of learned features, and the accuracy of changing the size of the training set, and found that GC-GCN performed better than Text-GCN. Especially in classification accuracy, The GC-GCN has respectively obtained 0.19%, 0.57%, 1.05% and 1.17% improvements over the Text-GCN baseline on the 20NG, R8, R52, and Ohsumed benchmark datasets. We also used different document representations to illustrate BERT embedding’s suitability for GC-GCN. Further more, we used the Euclidean distance in a weighted sum with PMI and TF–IDF when constructing the adjacency matrix to address the problem that PMI and TF–IDF are not suitable for short data (i.e., the MR), and it was about 1.38% higher than Text-GCN on MR. In future research, we will consider the fine-tuning of the BERT Encoder during the GC-GCN training step, which can provide more precise context information for the current corpus.
Footnotes
Acknowledgments
This work is funded by National Key R&D Program of China (2017YFB1402101); Natural Science Foundation of China (61663044); Opening Project of Key Laboratory of Xinjiang Uyghur Autonomous Region, China.